 Michael C. Hout
Michael C. Hout Jose Montelongo
Jose Montelongo Bryan L. White
Bryan L. White Anita Hernandez
Anita Hernandez Francisco Serrano-Wall
Francisco Serrano-Wall
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
BRIEF RESEARCH REPORT article
Front. Educ. , 14 September 2023
Sec. Language, Culture and Diversity
Volume 8 - 2023 | https://doi.org/10.3389/feduc.2023.1225169
Cognates are words that are orthographically and semantically identical (or similar) between languages. The purpose of Experiment 1 was to provide educators and researchers with orthographic similarity ratings for the English-Spanish cognate words that comprise the Academic Word List (Coxhead, 2000). To this end, similarity ratings for the 473 English-Spanish cognate pairs were collected from 42 students enrolled in literacy education courses at a southwestern university. Experiment 2 was conducted to validate the ratings from Experiment 1 using reaction time. We found that the orthographic similarity ratings were strongly correlated with reaction times during this task, lending support to the usefulness of the transparency ratings obtained in Experiment 1. Thus, educators and researchers can avail themselves of these ratings to create leveled educational materials for language instruction or to statistically calibrate experimental stimuli for learning and memory investigations. Additionally, we report an initial-letter effect, which describes the finding that the earlier an English word deviates from its Spanish cognate, the lower the similarity rating for the cognate pair, thus extending the generalizeability of the initial-letter effect observed in prior research.
The Academic Word List (AWL) is a listing of some of the most frequently used words in academic texts. Coxhead (2000) developed the Academic Word List by selecting the most frequently occurring nouns and verbs from 3.5 million running words in both long and short texts across four academic disciplines: the arts, commerce/business, law, and the sciences. The 570 words that comprise the AWL account for 10% of the total words in academic texts. Language educators use the list as a guide for teaching essential vocabulary to English-Learners (ELs). Students study the AWL to broaden their vocabulary and increase their chances for success in college. Additionally, researchers employ the list to calibrate materials for their empirical studies (e.g., Hyland and Tse, 2007; Durrant, 2014).
Lubliner and Hiebert (2011) found that more than 400 of the 570 family words listed in the Academic Word List (Coxhead, 2000) were English-Spanish cognates. Cognates are words in one language that share the same etymology as words in a second language. As a consequence of evolving from the same root, cognates are often orthographically identical (or similar), and possess the same (or nearly the same) meaning.
Cognates are especially prevalent in the English and Spanish languages as a result of a common Latinate origin. There are over 20,000 English-Spanish cognates (e.g., Nash, 1997) in the English Language. They represent an important segment of the language population because the majority of the English-Spanish cognates are academic vocabulary words. One reason for this is historical. A large number of cognates entered the English lexicon when the French-speaking Normans conquered the Anglo-Saxon inhabitants of England in 1066. Since the Normans established themselves in positions of power and privilege in government, the universities, and the churches, their Latin-based vocabulary words found their way into texts of the academic disciplines at all levels of learning.
Educators have long recommended the teaching of cognates to bolster the vocabularies of Latino English Learners because of their similarity to Spanish words (e.g., Corson, 1997). Teaching Latino ELs about cognates taps into their preexisting knowledge and enables them to engage with literacy more effectively than strategies that ignore or denigrate the linguistic knowledge EL students bring to the classroom (Cummins, 2005).
Experimental studies support these recommendations. In addition to being ubiquitous and important for reading academic texts, cognates have been shown to be easier to learn than non-cognates. For example, in a study of paired-associates learning, cognates were more easily learned and more often recalled after 1 week (compared to non-cognates; de Groot and Keijzer, 2000). Studies have also shown cognates to be superior to non-cognates in translation tasks. When bilinguals are asked to translate words from their first language (L1) to their second language (L2), they translated cognates faster and provided more correct responses than for non-cognates (De Groot and Poot, 1997).
In addition to these studies, numerous investigations into the organization and processing of cognates and non-cognates in semantic memory have been conducted. While these studies have proved fruitful endeavors, a review of these findings is beyond the scope of this paper.
In the language population of English-Spanish cognates, there exists different degrees of similarity with respect to orthography and phonology. Some cognates may by identical in spelling such as the English word, “animal,” and its Spanish cognate, “animal,” while others are less similar, as in the case of “phosphorous” and “fósforo.” Furthermore, cognates often differ in the way they are pronounced even if they are orthographically identical. Because of this variability, it seems logical that studies investigating cognate processing and learning for educational and theoretical purposes require rating systems to define the limits of generalizability for the cognate population.
In the past, cognitive psychologists relied on ratings of word frequency (e.g., Thorndike and Lorge, 1944), imagery (e.g., Paivio et al., 1968) and word association (e.g., Postman and Keppel, 1970) to study the effects of these variables on learning and forgetting. In analogous fashion, the collection of cognate similarity ratings could serve as a tool for investigating their effect on learning, recall, and reaction times by multilingual participants or by those learning a second language. For example, De Groot and Nas (1991) collected cognate similarity ratings for English-Dutch words by instructing their participants to base their ratings on both the overlapping appearance and sound between the pairs of words. Friel and Kennison (2001) gave their participants the same instructions for rating pairs of English-German words. Because these investigators used monolingual participants, however, Friel and Kennison suggested that their ratings were based mainly on the orthographic similarity between the word pairs.
To our knowledge, there currently exist no other English-Spanish cognate ratings besides those collected by Montelongo et al. (2009) for the nouns and adjectives in the Juilland and Chang-Rodríguez (1964) frequency dictionary. Unlike De Groot and Nas (1991), Friel and Kennison (2001), and Montelongo et al. (2009) asked their participants to rate pairs of words only on their perceived orthographic similarity, not on both the overlapping orthographic appearance and sounds between the pairs of words. This was done in an effort to keep the ratings task as simple as possible for the participants. We continued this practice in Experiment 1.
The main purpose of this study is to provide educators and researchers with orthographic similarity ratings of the individual cognate words that comprise the AWL. Since the AWL is a compilation of many of the most important words needed for academic success, the resulting orthographic similarity ratings of English words and their Spanish cognates can be used to statistically calibrate experimental stimuli for processing, learning, and memory investigations.
Additionally, orthographic similarity ratings of English-Spanish cognates can be used to create leveled educational materials for language instruction. Educators can avail themselves of cognate orthographic similarity ratings to create more comprehensible teaching materials. For example, a teacher attempting to simplify a text for students not reading at their current grade level can substitute a problematic non-cognate word with a cognate synonym of high orthographic similarity to make the text easier to understand. Contradistinctively, the same teacher replacing a difficult non-cognate word with a cognate synonym of low orthographic similarity or with a non-cognate synonym would fail to make a text easier.
A final purpose of the present investigation is to test the generalizability of the “initial letter effect” reported by Montelongo et al. (2009). In that study, these investigators found that the point at which the cognate pairs began to differ was an important determinant of the orthographic transparency1 ratings for each pair. The earlier an English cognate deviated orthographically from its Spanish equivalent, the lower the transparency rating for that cognate pair. For example, the ratings of pairs which differed in their first letters, such as “svelte” and “esbelto,” averaged 3.2 (on a scale of 1–7). Contradistinctively, cognate equivalents where letters deviated on the ninth letter in pairs such as “indiscreet” and “indiscreto,” averaged 6.1. A Pearson correlation of 0.68 was obtained between the point at which the English-Spanish nouns began to differ orthographically and their transparency rating.
In Experiment 1, we collected similarity ratings for 473 English-Spanish cognate pairs. Then, in Experiment 2, we sought to validate these ratings. The purpose of Experiment 2 was specifically to validate the ratings obtained in Experiment 1, rather than to provide an additional (or proxy) measure of similarity. Our logical was simple: if the ratings obtained in Experiment 1 are valid, we should be able to use them to predict behavior or performance in another way.
We did so by giving a new group of participants a speeded cognate/no-cognate decision task. We found that similarity ratings were strongly correlated with reaction times during this task, and that reaction times were also strongly correlated with the point at which the word pairs became differentiated. These strong results lend support to the usefulness of the similarity ratings obtained in Experiment 1.
Forty-two college students enrolled in undergraduate and graduate literacy classes at a state university in New Mexico completed the ratings booklets for partial course credit. All of the participants were Spanish-English bilingual college students; all had listening, speaking, reading, and writing abilities in both English and Spanish. Of the 42 college students, 30 were graduate students in an MA literacy program and were between the ages of 27–40. These graduate students were also bilingual teachers certified by the state educational agency and had passed the Spanish Prueba exam. The 12 undergraduate students were also Spanish-English bilingual college students; all had listening, speaking, reading, and writing abilities in both English and Spanish. The 12 undergraduates were seniors between the ages of 21–30 and were former ELs who had completed the Spanish language course requirements and were preparing to take the Spanish Prueba exam to become certified bilingual education teachers.
To assess the degree of orthographic similarity, the procedures utilized by Montelongo et al. (2009) were followed. The ratings instrument was developed by first identifying the 473 English-Spanish cognates from the 570 words that comprise the Academic Word List (Coxhead, 2000). All of the cognates and the 97 non-cognates were then rated for orthographic similarity on a scale of 1–7. The non-cognates were randomly interspersed among the cognates.
The participants were given booklets containing 570 English-Spanish word pairs and were asked to complete the booklet within a 2-week time period. The participants were instructed to rate the stimulus words solely on the basis of orthographic similarity.
Prior to beginning the process, the participants were provided with the following definition of cognates: “cognate are words in English and Spanish which are spelled the same or nearly the same and which have the same or nearly the same meanings.” After the participants indicated they understood the definition of a cognate, they were told that the purpose of the ratings was to provide teachers, educational researchers, and textbook authors with calibrated language materials for Spanish-speaking English Learners and English-speaking Spanish Learners. To provide them with practice in rating the word pairs, the participants were given five examples of English-Spanish cognates and non-cognates to rate. The examples ranged from English-Spanish word pairs that were identical to non-cognates that were very dissimilar. None of the practice pairs were used in the study.
After the short practice, the participants were each given a booklet containing all of the English-Spanish cognate and non-cognate stimuli to complete. They were instructed to rate the pairs of English-Spanish words on a 7-point Likert scale solely on the basis of orthographic similarity. A score of “7” indicated high orthographic similarity; a score of “1” indicated low orthographic similarity. The participants were told that their ratings should reflect only their assessment of the cognate pair’s orthographic similarity. They were informed that there were no “right” or “wrong” ratings and that they were to complete the ratings individually. The participants were advised not to rate all of the stimuli in one sitting, but to work on their ratings at different times and for no more than half an hour at a time. Once the participants understood the directions and purpose of the study, they were given the test booklet to complete on their own. The participants were given a 2-week time period to complete their ratings.
Each booklet contained 10 pages on which the 473 cognate and 97 non-cognate pairs were printed. Each page was divided into two columns. Each item in the instrument contained an English word and its Spanish equivalent. For the cognates, this meant that the English and Spanish cognates were presented side-by-side. For the English-Spanish non-cognate word pairs, the English word was paired with its Spanish translation. For example, the non-cognate English word, “seek,” was rated alongside its Spanish equivalent, “buscar.” In between all of the stimuli, a blank space on which the participants would rate the pair on cognate similarity was provided. The pages in each of the booklets were randomly assigned to reduce order effects.
All of the participants returned their ratings within the 2 weeks and received credit for their work. Each of the participant’s ratings was entered into a Microsoft Excel spreadsheet for analysis.
The alphabetized list of similarity ratings for each of the 473 English-Spanish cognate pairs are available on our page at the Open Science Foundation. The freely downloadable Excel sheet includes the mean orthographic similarity rating for each cognate pair (and the standard deviation of the ratings), as well as the point at which the English and Spanish words begin to differ.
The mean similarity rating for the English-Spanish cognates was 5.07 (sd. = 1.38). The mean rating for the non-cognate words was 1.67 (sd. = 1.39). An analysis of the distribution of the cognate nouns revealed that 54 of the 473 (11%) English-Spanish cognate pairs were rated as identical or nearly identical. Typically, these were cognate pairs that were exactly identical or those for which the Spanish equivalent possessed an accent mark as in the pair, “dimension” and “dimensión.” The largest percentage (49%) of words were those in the range between 5.01 and 6.00. These tended to be cognate pairs that were orthographically similar except for a single letter. The words, “paradigm” and “paradigma” exemplify such cognate pairs. The cognate pairs in the 4.01–5.00 range were those that showed slightly more prominent orthographic dissimilarities at the ends of words and comprised the second highest percentage (27%) of instances. Examples of pairs in this category were “expose” and “exponer.” Cognate pairs in the 3.01–4.00 range possessed more divergent spellings, as exemplified by the cognates “maintain” and “mantener.” These accounted for 8% of the cases. Four percent of the cognate pairs that tended to orthographically diverge early as in the pair, “style” and “estilo,” received ratings in the 2.1–3.00 range. Finally, there were only three instances (0.6%) of English-Spanish cognates with ratings less than 2.0: “aid” and “ayuda,” “ensure” and “asegurar,” and “enable” and “habilitar.” An analysis of the distribution is presented in Table 1.
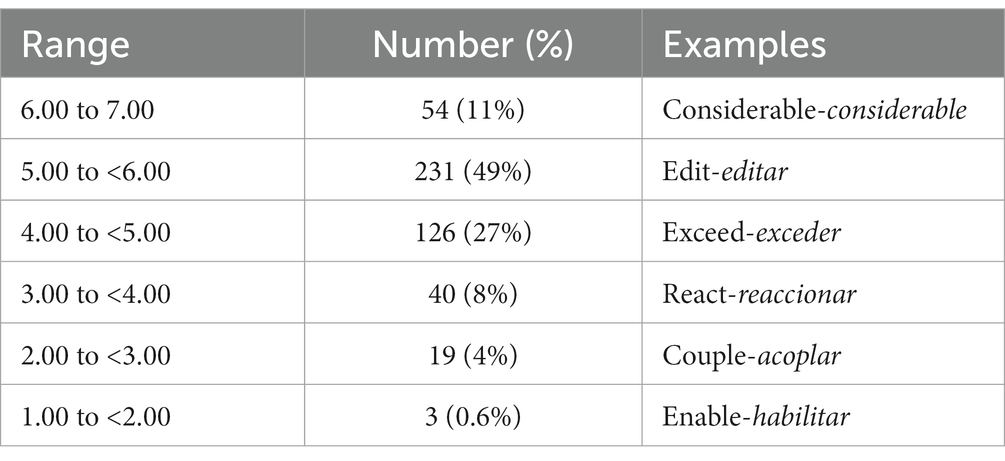
Table 1. Summary of orthographic ratings with examples from Experiment 1.
The distribution of the similarity ratings indicates that the earlier the cognate equivalents diverge orthographically from each other, the lower the rating tended to be. Raters attached more significance to differences occurring at the beginnings of words than those occurring later. Many of the cognate pairs which contained letter changes in the initial positions of the words tended to have lower ratings than those Spanish cognates which had letter changes at the ends of words. For instance, the word “hierarchy” and its cognate equivalent, “jerarquía” differ in their first letters. The cognate pair “foundation” and “fundación” differ in their second letters, “ethnic” and “étnico” in the third letter, etc. The Pearson product moment correlation between the position at which the first difference in letter occurs and the mean rating of the cognate equivalents was r (471) = 0.59 (p < 0.0001).
A summary of these means and standard deviations is presented in Table 2. The table shows that the ratings of cognates which diverged from their cognate equivalents in the first two letters received the lowest ratings. Those with changes occurring at the third, fourth, and fifth letter were moderately low, while those with later-occurring changes (letters 6 through 13) had the highest ratings. These results extend the generalizability of the findings reported by Montelongo et al. (2009) to another sample of English-Spanish cognates.
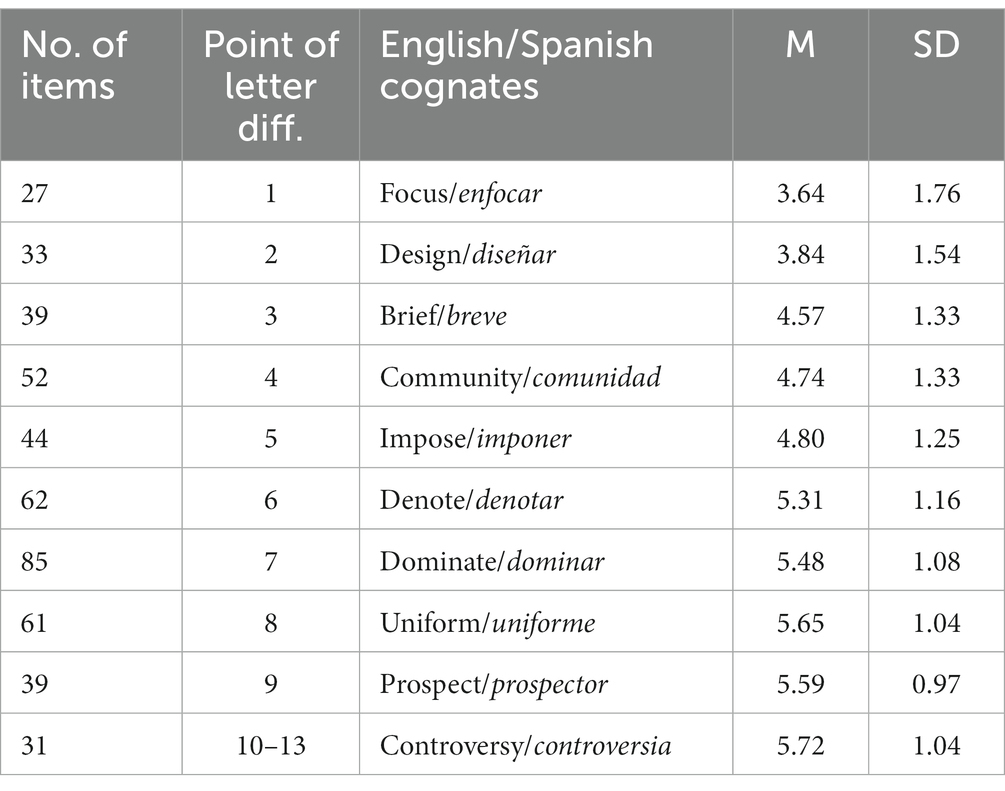
Table 2. Point at which English and Spanish cognates differ.
The importance of publishing ratings for cognates is for researchers to use them to create customized stimulus materials without having to rely on intuition, or to collect ratings themselves. Collecting cognate similarity ratings for the stimulus materials is time-consuming (Schepens, 2008), and this may have the effect of discouraging quantitative research on the study of cognates and their effect(s) on perception, learning, and memory. Our database is an attempt to circumvent these time constraints by providing researchers with a valuable (and validated) tool to use in their research.
More specifically, the purpose of Experiment 1 was to provide a set of orthographic similarity ratings for the 473 English-Spanish cognate pairs taken from the Academic Word List (Coxhead, 2000). A question that may arise from this study is the degree to which the obtained ratings are trustworthy. To validate the quality of our ratings, we therefore performed a second experiment that assessed similarity in a new way; that is, by using the ratings to predict the speed at which a pair of words are recognized to be cognates.
Specifically, a new group of participants were shown word pairs one at a time and were asked to make speeded decisions regarding whether or not the pair were cognates. It is common in studies of similarity to use speeded “same/different” responses as an index of similarity between a pair of stimuli (see, e.g., Hout et al., 2012, 2013, 2015). Typically, in such studies, the accuracy or speed of “different” decisions is used to index the perceived similarity of a pair of items. By contrast, in our investigation, the speed of “cognate” decisions (analogous to “same” decisions) was used to index perceived similarity of each word pair. By this logic, if the ratings obtained in Experiment 1 are valid, then word pairs given higher similarity ratings should be affirmed (i.e., responded to) more quickly (and vice versa). Additionally, the point of differentiation of the pair should predict reaction times such that later points of differentiation should result in shorter reaction times.
All participants (n = 47) were recruited via the New Mexico State University’s research information and scheduling tool, SONA, and were compensated with partial course credit awarded towards a course requirement.
Apparatus: Data collection was performed using E-Prime vs3 software (Psychology Software Tools, Pittsburgh, PA), run on identical desktop PCs with Intel Core i5 processors. Stimuli were displayed on 24″ monitors, and responses were made using standard keyboards.
Stimuli: Cognate word pairs were identical to those of Experiment 1. Additionally, there were many non-cognate word pairs. All stimuli can be found in the Excel spreadsheet on our OSF page (see Experiment 1 Results for the link); there are two tabs for the cognate stimuli and non-cognate word pairs.
Procedure: Participants viewed one pair of words at a time, and conducted as many trials as they could in two blocks of 10-min duration (separated by a short break). The computers collected millisecond accurate response times (RTs) and all responses were coded for accuracy. The procedure began by asking participants to fill out informed consent, after which the experiment began. The experiment started with the collection of demographic data. Then, participants were given the following instructions for the task.
The general instructions given to participants were as follows:
“You are being tested for how similar words are in English and Spanish with regard to the way they are spelled. During the experiment, you may be shown words that possess the same meaning but are not spelled similarly. For instance, perro/dog, sol/sun, and libro/book.
For the purposes of this study, a cognate can be defined as words in English and Spanish that are the same/similar orthographically (i.e., cognates normally share a common etymology too (usually Latin, Greek, and Arabic)). Etymology is the origin of a word and the historical development of its meaning.
For example, the English word ‘experiment’ and its Spanish cognate ‘experimento’ are cognates because they are spelled similarly AND they mean the same thing. However, the English word ‘sugar’ and its Spanish equivalent ‘azúcar’ are cognates even though they are spelled very differently.
Cognate transparency refers to this relationship; specifically, how orthographically similar the pair of words is.”
Specific instructions were then provided on how to complete the task, as follows:
“In the following, you will be shown a pair of words, one in English and one in Spanish. Sometimes the words will be cognates and sometimes they will not. Your task is simple. If you think the word pair are cognates, press the ‘F’ key to indicate that they are. If you think they are NOT cognates, press the ‘J’ key.
It is important that you respond as quickly and as accurately as possible. Please keep your left and right index fingers on the ‘F’ and ‘J’ keys, respectively, so that you can respond easily.”
Each trial began with a prompt asking the participant to press any key when ready to begin. Upon initiation, a fixation cross—an enlarged “+” symbol centered in the computer screen—would appear to center the participant’s gaze, with two randomly selected word stimuli appearing directly above and below the fixation cross. In the bottom corners of the display were the response choices: “Cognate: Press F” in green text, and “Not a Cognate: Press J” in red text. All trial pairs consisted of one Spanish and one English word; stimuli were selected at random (without replacement) in equal proportions from the cognate and non-cognate word lists (to avoid any response biases). The pair of stimuli persisted on screen until a response was made. After responses were made, feedback was provided. For incorrect responses, participants were shown “Incorrect” in red text and given a reminder of what cognates are, as follows:
“Remember … cognates are words in English and Spanish that are the same/similar orthographically (i.e. how they are spelled) AND semantically (i.e., what they mean). For example: experiment/experimento and sugar/azúcar.”
For correct responses, participants were given the display “Correct!” in green text. Both types of feedback were displayed until the participant pressed any key, thus terminating the trial. Participants continued in this manner, working at their own pace, for a total of 50 min. Upon termination of the experiment, all participants were thanked, debriefed, given credit for participation in the SONA system, and released.
We examined the time it took for participants to render their responses as a function of the word pair’s mean similarity rating (from Experiment 1), and the pair’s point of differentiation. We predicted that higher similarity ratings between the word pairs would result in shorter RTs, and that later points of differentiation would also result in shorter RTs. We examined RTs only for accurate responses; overall accuracy on this task was high: participants responded accurately to 91% of cognate pairs, and 89% of non-cognate pairs. The accuracy of responses to each pair of cognates is reported in our full data sheets, available at our OSF page.
Prior to data analysis, the data were cleaned to remove participants who were not completing the task as instructed (or who were otherwise inattentive), and to remove outlier RTs on trials in which the participant may have had an attentional lapse or erroneously responded too quickly. Two participants were removed for having response times that were more than 2.5 standard deviations longer than the group mean, and one participant was removed for having accuracy more than 2.5 standard deviations below the group mean. These participants were clearly not attending properly to the task or following instructions. This resulted in removal of only 6% of participants, leaving a total sample of 44 participants.
Individual trial RTs (from the remaining set of participants, on trials with correct responses) were then cleaned to remove RTs less than 200 msec (which would indicate an erroneous early button-press) or more than 2.5 standard deviations beyond the group mean (i.e., those longer than 3,085 msec, which would indicate a clear attentional lapse). This resulted in the loss of only 6.18% of remaining RTs, leaving 25,037 total usable trials.
Because word pairs were randomly selected across trials, there were an unequal number of observations across pairs. Figure 1 presents a histogram of the number of observations (after data cleaning) obtained. As can be seen, each pair received at least 3 ratings, and up to as many as 37. The mean number of observations was 27.01, indicating that most pairs received a large amount of data from which average RTs were computed; the majority of pairs received more than 20 observations each. Our full data sheet reports the number of correct responses to each cognate word pair.
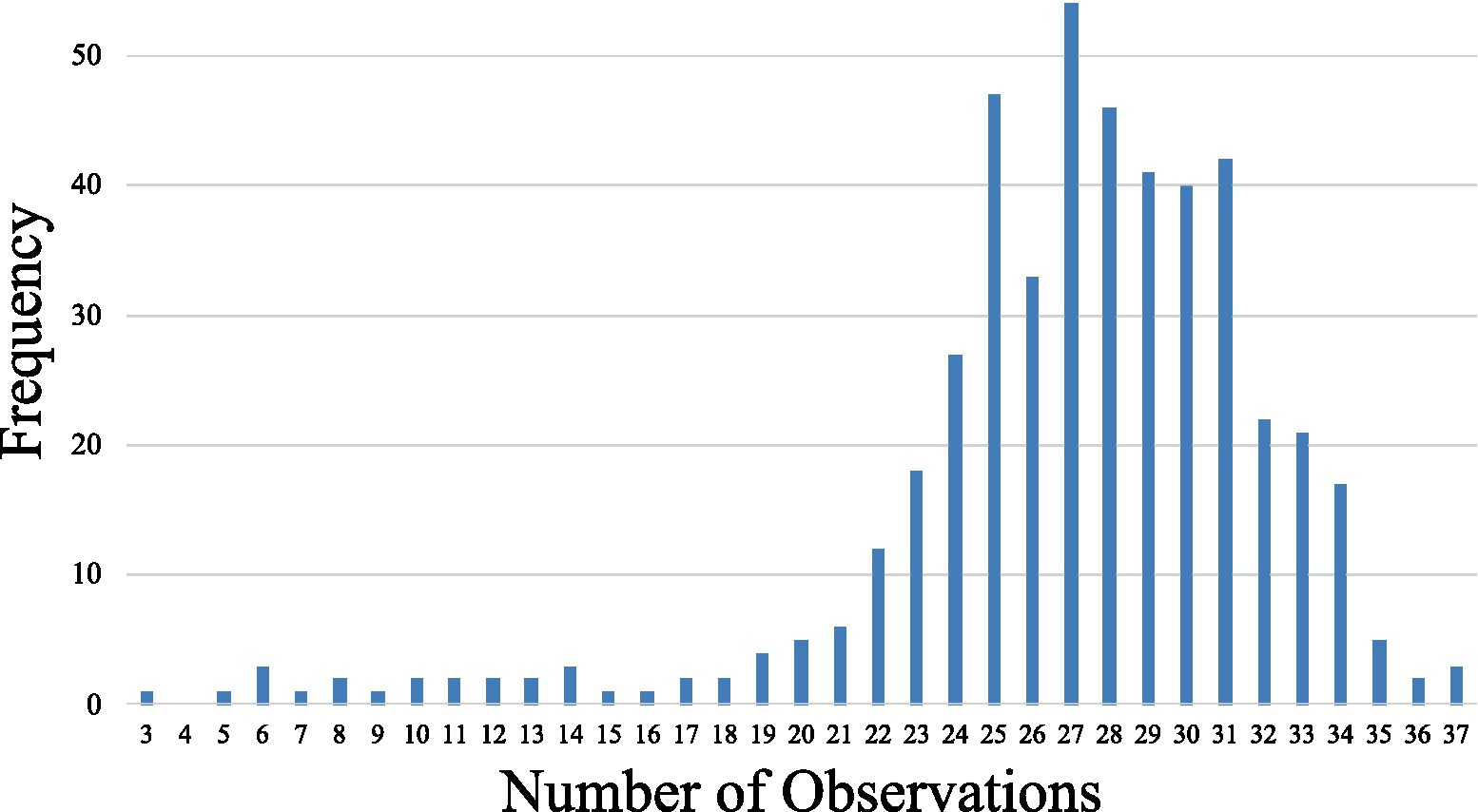
Figure 1. Histogram of the number of observations received by word pairs following data cleaning.
We next performed a pair of correlational analyses (on cleaned data) examining the relationship between mean similarity ratings (obtained in Experiment 1) and RT, and between point of differentiation and RT. We found a strong negative correlation between mean similarity rating and RT—r(469) = −0.610, p < 0.001—indicating that word pairs with high similarity ratings tended to be responded to more quickly. We also found a strong negative correlation between point of differentiation and RT—r(469) = −0.585, p < 0.001—indicating that words with later points of differentiation were responded to more quickly. Both of these analyses confirmed our a priori hypotheses. Figure 2 presents these correlations.
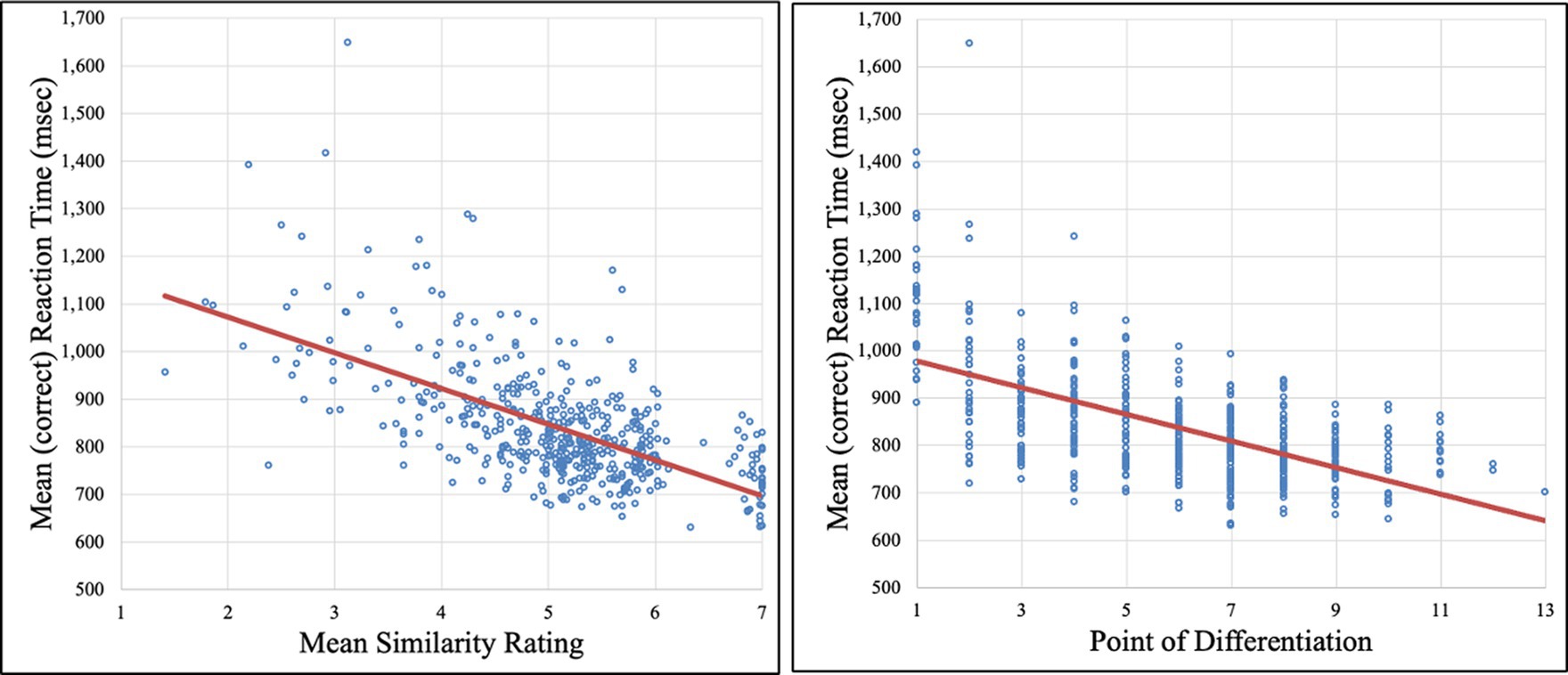
Figure 2. The correlations between RT and mean similarity rating (left plot) and between RT and point of differentiation (right plot). Each point represents a single word pair, and solid red lines indicate the best fitting linear trendline.
The purpose of the present study was to produce a set of orthographic similarity ratings for the 473 English-Spanish cognate words that comprise the Academic Word List (Coxhead, 2000). These ratings of English-Spanish cognate nouns can be used by educators wishing to create educational materials such as vocabulary exercises for English Learners. Educational researchers in the areas of learning and memory can use the ratings to calibrate their stimulus materials for their investigations.
Interestingly, the results of Experiment 1 involved an initial-letter effect. Simply put, the initial-letter effect describes the finding that the earlier an English word orthographically deviates from its Spanish equivalent, the lower is the similarity rating for the pair. This suggests that the participant raters weight the similarity of the initial letters of the word more heavily than later deviations. These results serve to generalize the similar findings reported by Montelongo et al. (2009).
In Experiment 2, we cross-validated these similarity ratings by asking a new group of participants to provide speeded judgments regarding whether or not a pair of words were cognates. We found that reaction times were strongly correlated with similarity ratings and with the point of differentiation for the pairs. These findings validate the similarity ratings obtained in Experiment 1 by showing that they can be used to predict behavior in another domain.
A limitation of the present study is that participants (in Experiment 1) were given the stimulus worksheets to complete on their own and at their chosen pace. Therefore, students probably worked on the stimuli at several different times and for different amounts of time. On the one hand, this broadens the generalizability of the results to different boundary conditions such as the numbers of words rated at a single time and the amount of time dedicated to the rating of each English-Spanish cognate pair. For those investigators desiring greater control over the rating process, this study may serve as a comparison. The study might also be replicated with a larger participant sample as a check on stability across samples, including persons other than college students.
A second limitation of the present study is that there is no comparison of these objective ratings with other methods for measuring orthographic similarity, such as the use of the Levenshtein distance, which objectively measures the differences between two strings of letters. While this computational technique seems promising in the study of cognates in linguistic settings (e.g., Greenhill, 2011; Schepens et al., 2012) further studies comparing this objective technique with phenomenological ratings need to be conducted. It must also be noted that this computational approach, while clearly useful, does not necessarily align with the subjective impression of human raters, and thus our more person-centric approach to quantifying orthographic similarity should be viewed as a useful complement to computational approaches, rather than a replacement for them.
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found at: https://osf.io/b8kvs/?view_only=a3adc32189444f69847b1327df13eebb.
The studies involving humans were approved by New Mexico State University IRB. The studies were conducted in accordance with the local legislation and institutional requirements. The participants provided their written informed consent to participate in this study.
The study was designed by all co-authors, and also contributed to data collection. Primary data analysis was conducted and primary writing was performed by JM and MH. All authors contributed to the article and approved the submitted version.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
1. ^Note that Montelongo et al. (2009) refer to orthographic “transparency” whereas we currently refer to this construct as orthographic “similarity.” We have instituted this change because prior literature has used the term “transparency” to refer specifically to the correspondence between graphemes and phonemes in a language.
Corson, D. (1997). The learning and use of academic English words. Lang. Learn. 47, 671–718. doi: 10.1111/0023-8333.00025
Cummins, J. (2005). Teaching for cross-language transfer in dual language education: possibilities and pitfalls. Available at: https://www.tesol.org/docs/default-source/new-resource-library/symposium-on-dual-language-education-3.pdf
de Groot, A. M. B., and Keijzer, R. (2000). What is hard to learn is easy to forget: the roles of word concreteness, cognate status, and word frequency in foreign language learning and forgetting. Lang. Learn. 50, 1–56. doi: 10.1111/0023-8333.00110
de Groot, A. M. B., and Nas, G. L. J. (1991). Lexical representation of cognates and noncognates in compound bilinguals. J. Mem. Lang. 30, 90–123. doi: 10.1016/0749-596X(91)90012-9
De Groot, A. M., and Poot, R. (1997). Word translation at three levels of proficiency in a second language: the ubiquitous involvement of conceptual memory. Lang. Learn. 47, 215–264. doi: 10.1111/0023-8333.71997007
Durrant, P. (2014). Discipline and level specificity in university students’ written vocabulary. Appl. Linguis. 35, 328–356. doi: 10.1093/applin/amt016
Friel, B. M., and Kennison, S. M. (2001). Identifying German-English cognates, false cognates, and non-cognates: methodological issues and descriptive norms. Biling. Lang. Congn. 4, 249–274. doi: 10.1017/S1366728901000438
Greenhill, S. J. (2011). Levenshtein distances fail to identify language relationships accurately. Comput. Linguist. 37, 689–698. doi: 10.1162/COLI_a_00073
Hout, M. C., Godwin, H. J., Fitzsimmons, G., Robbins, A., Menneer, T., and Goldinger, S. D. (2015). Using multidimensional scaling to quantify similarity in visual search and beyond. Atten. Percept. Psychophys. 78, 3–20. doi: 10.3758/s13414-015-1010-6
Hout, M. C., Goldinger, S. D., and Ferguson, R. W. (2013). The versatility of SpAM: a fast, efficient spatial method of data collection for multidimensional scaling. J. Exp. Psychol. Gen. 142, 256–281. doi: 10.1037/a0028860
Hout, M. C., Papesh, M. H., and Goldinger, S. D. (2012). Multidimensional scaling. Wiley interdisciplinary reviews (WIREs). Cogn. Sci. 4, 93–103. doi: 10.1002/wcs.1203
Hyland, K., and Tse, P. (2007). Is there an “academic vocabulary”? TESOL Q. 41, 235–253. doi: 10.1002/j.1545-7249.2007.tb00058.x
Juilland, A. J., and Chang-Rodríguez, E. (1964). Frequency dictionary of Spanish words. Berlin: De Gruyter Mouton.
Lubliner, S., and Hiebert, E. H. (2011). An analysis of English–Spanish cognates as a source of general academic language. Biling. Res. J. 34, 76–93. doi: 10.1080/15235882.2011.568589
Montelongo, J. A., Hernández, A. C., Herter, R. J., and Hernández, C. (2009). Orthographic transparency and morphology of Spanish-English cognate adjectives. Psychol. Rep. 105, 970–974. doi: 10.2466/PR0.105.3.970-974
Nash, R. (1997). NTC's dictionary of Spanish cognates thematically organized. Lincolnwood (Chicago), IL: NTC/Contemporary Publishing Group.
Paivio, A., Yuille, J. C., and Madigan, S. A. (1968). Concreteness, imagery, and meaningfulness values for 925 nouns. J. Exp. Psychol. 76, 1–25. doi: 10.1037/h0025327
Schepens, J., (2008). Distributions of cognates in Europe based on the Levenshtein distance. (B.A. Thesis, Radboud University Nijmegen, Netherlands).
Schepens, J., Dijkstra, T., and Grootjen, F. (2012). Distributions of cognates in Europe as based on Levenshtein distance. Biling. Lang. Congn. 15, 157–166. doi: 10.1017/S1366728910000623
Keywords: cognates, academic word list, orthographic similarity, reading, education, bilingualism
Citation: Hout MC, Montelongo J, White BL, Hernandez A and Serrano-Wall F (2023) Orthographic similarity ratings for English-Spanish cognates from the academic word list. Front. Educ. 8:1225169. doi: 10.3389/feduc.2023.1225169
Edited by:
Marco A. Bravo, Santa Clara University, United StatesReviewed by:
Claudia Rodriguez-Mojica, Santa Clara University, United StatesCopyright © 2023 Hout, Montelongo, White, Hernandez and Serrano-Wall. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Michael C. Hout, bWhvdXRAbm1zdS5lZHU=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.