 Mona Alshehri
Mona Alshehri Dongbo Zhang
Dongbo Zhang
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Educ., 16 September 2022
Sec. Language, Culture and Diversity
Volume 7 - 2022 | https://doi.org/10.3389/feduc.2022.926663
Recognition of individual words serves as an initial basis for comprehension of a written text; yet there are complex word-to-text (WTT) integration processes underlying the comprehension. This study focused on two components of WTT integration, that is, syntactic parsing and semantic association, and assessed how syntactic and semantic network knowledge differentially predicted two types of text comprehension (literal vs. inferential) in second language readers. Participants were 229 adult learners of English language as a foreign language at a Saudi University. A battery of tasks was administrated to measure their reading comprehension, syntactic knowledge (grammatical error correction), and semantic network knowledge (semantic association), together with working memory and vocabulary knowledge/size. Multiple regression analyses showed that both syntactic and semantic network knowledge significantly predicted reading comprehension (disregarding the type of comprehension), controlling for working memory and vocabulary knowledge. Syntactic knowledge, as opposed to semantic network knowledge, was a significant, unique predictor of literal comprehension, whereas a converse pattern was found for inferential comprehension.
Reading comprehension is a complex process which demands a number of processes to be properly and simultaneously executed (Perfetti et al., 2005; Grabe, 2009). It is “widely agreed to be not one, but many things,” and entails “cognitive processes that operate on many different kinds of knowledge to achieve many different kinds of reading tasks” (Perfetti and Adlof, 2012, p. 3). Reading comprehension involves interaction between lower-order and higher-order processes (Kintsch, 1998; Perfetti et al., 2005; Grabe, 2009). Lower-order processes include recognizing individual words and accessing their meanings. This initial basis is fundamental to yet insufficient for comprehension because words need to be integrated into the text (Fender, 2001; Grabe, 2009; Perfetti and Stafura, 2014, 2015).
Word-to-text (WTT) integration is an ongoing process where the meanings of individual words are continuously combined into larger units of meaning at the phrase, clause, and sentence levels and beyond (Fender, 2001; Perfetti and Stafura, 2014). Two key operations of WTT integration are underscored, that is, syntactic parsing and semantic association (Zwaan and Rapp, 2006; Grabe, 2009; Perfetti and Stafura, 2014). Different WTT integration operations may have differential effects on text comprehension, depending on the type of comprehension in question. Syntactic parsing is primarily important “locally” for establishing phrasal, clausal, and sentential meanings. On the other hand, semantic association, while crucial for constructing propositional meanings and establishing local coherence, can be additionally important for building and maintaining coherence beyond the clause and sentence levels, because semantic propositions need to be connected, as text reading unfolds, to form a larger network of information where inference is often essential (Perfetti and Stafura, 2014; Oakhill et al., 2015).
In the second language (L2) reading literature, although WTT integration is underscored for comprehension, compared to syntactic parsing (Fender, 2001; Grabe, 2005), less attention has been given to the semantic association, particularly in light of recent theoretical insights into its importance for inference generation and inferential comprehension (Perfetti and Stafura, 2014, 2015; Oakhill, 2020). Little research has aimed to test how the knowledge that underpins different WTT integration processes may be differentially important depending on the type of comprehension. This study sets out to fill this gap and test how syntactic and semantic network knowledge, controlling for vocabulary knowledge/size and working memory, differentially predict literal vs. inferential comprehension, focusing on adult Arabic-speaking learners of English as a Foreign Language (EFL).
Kintsch (1988) in his seminal Construction-Integration Model contends that text comprehension can be explained by an interactive combination of top-down (knowledge-driven) and bottom-up (word-based) processes. More specifically, the process of text comprehension starts with the reader accessing and integrating word meanings for establishing a text model, and then the reader building a situation model through activation of background knowledge and various inference processes. To understand a text, the reader draws upon a set of lower-order linguistic knowledge and skills to process letters/phonemes, words, clauses, sentences, and pragmatic and discourse structure information; in the meantime, they rely on knowledge about the world to generate higher-order inferences for integrating the text model to form a situation model (Perfetti et al., 2005; Grabe, 2009; see, however, Perfetti and Stafura, 2014, 2015).
One of the lower-order processes is word recognition (Perfetti, 1985; Nassaji, 2014). Although the definition of word recognition can differ slightly in its specific context of use, in written text comprehension it often refers to processing the orthographic and phonological form of a word and accessing its meaning. Comprehension of a text is impossible without learners recognizing the words that make up the text and knowing the meaning of those words (Perfetti and Adlof, 2012). Word recognition and vocabulary knowledge/size (i.e., knowledge of [partial] meaning of words) are important predictors of reading comprehension (Grabe, 2009; Melby-Lervåg and Lervåg, 2014; Nassaji, 2014). Vocabulary size, in particular, is a strong correlate of L2 reading comprehension as reported in recent research syntheses or meta-analyses (Jeon and Yamashita, 2014; Choi and Zhang, 2020; Zhang and Zhang, 2020).
Important as they are, recognizing words in a text and accessing their meanings are necessary but insufficient for understanding that text. In both L1 and L2 reading, WTT integration is important (Fender, 2001; Grabe, 2009; Perfetti and Stafura, 2014, 2015). Yet, its mechanism and underlying operations are not always clear in that the integration involves a range of mental processes for combining words into larger unit representations (phrase, clause, sentence, and beyond). The literature has underscored syntactic (Fender, 2001; Grabe, 2009; Raudszus et al., 2018) and semantic processing (Perfetti et al., 2005; Perfetti and Stafura, 2014) as two major processes of WTT integration, which interplay in comprehension (see Hagoort, 2013). Accordingly, readers need to possess both syntactic and semantic knowledge, over and beyond the knowledge that supports word recognition, for WTT integration and text comprehension. Yet, theoretical accounts of how the two types of integration or their knowledge underpinnings contribute to text comprehension do not always converge, particularly with respect to semantic integration and “intermediate-level” inference generation (Perfetti and Stafura, 2014, 2015; see also Oakhill et al., 2015), which is discussed in detail later.
Like other lower-order processes, WTT integration needs to be executed efficiently for mental model construction. The Memory, Unification, and Control framework emphasizes the role of control processes, such as working memory and inhibition, for the integration process to be achieved (Hagoort, 2013). Specifically, these control processes are necessary to guide the unification of elements retrieved from the long-term memory into larger units with new meaning. As words are recognized incrementally in a sentence, they have to be held in working memory for integration to happen. Both syntactic and semantic integration work within the constraints of working memory (Currie and Cain, 2015; Raudszus et al., 2018). In fact, working memory is a limited-capacity system that affects an individual’s ability to carry out many processes associated with text comprehension (Cain et al., 2004; Shin et al., 2019); and it can be particularly important for inferential comprehension (Alptekin and Erçetin, 2011).
As words are recognized, they need to be combined into phrasal and clausal units of meaning based on structural information, a process often known as syntactic parsing (Fender, 2001; Grabe, 2005). The importance of syntactic processing in comprehension can be easily seen in a situation where grammatically important information such as word order is missing. Compare, for example, “Broke antique washing night the all the be man will vase dishes who” with “The man who broke the antique vase will be washing dishes all night” (Grabe, 2009, p. 29). This example highlights how the word order is important to comprehend a text. In the first sentence, word order was missing which could lead to a miscomprehension of the meaning, while the other sentence was easily understood. Other than word order, a number of other types of syntactic information can affect WTT integration and text comprehension, including, for example, argument structure of verbs, tense, aspect, subject–verb agreement, case markings, and articles. These types of information constitute “a network of cueing systems” in text comprehension that provide “a continuous lower-level stream of information that anchors comprehension processing” (Grabe, 2009, p. 203). Syntactic integration serves as a stepping-stone between word recognition and text comprehension (Raudszus et al., 2018). To combine words into larger units of meaning or construct semantic propositions using the cueing systems (Fender, 2001), the reader needs to possess various aspects of syntactic knowledge, in addition to the knowledge that supports word recognition and knowledge of word meanings (Grabe, 2005; Jeon and Yamashita, 2014).
In L2 reading research, there has long been an interest in syntactic involvement in reading comprehension (Grabe, 2005). Syntax was found to affect text readability (Crossley et al., 2008); and syntactic modification improved text comprehension (Oh, 2001). Syntactic knowledge also distinguishes skilled L2 readers from less skilled ones (Nassaji, 2003). Some studies on both young and adult L2 learners also found that syntactic knowledge explained individual differences in reading comprehension. Raudszus et al. (2018), for example, found young L2 (and L1 as well) Dutch readers’ syntactic integration (grammar judgement) significantly predicted reading comprehension, controlling for vocabulary knowledge and decoding. Likewise, Shiotsu and Weir (2007) found syntactic knowledge significantly predicted reading comprehension, over and beyond vocabulary knowledge, in university learners of English in Japan. In fact, recent meta-analyses or research syntheses showed that grammatical knowledge is one of the strongest correlates of L2 reading comprehension (Choi and Zhang, 2020; Jeon and Yamashita, 2014).
What remains to be explored, though, is how syntactic integration and other processes of integration (such as semantic integration discussed in the next section) or their respective knowledge underpinnings may differentially contribute to reading comprehension. Given that syntactic integration is primarily concerned with constructing phrasal, clausal, and sentential meaning or local cohesion and coherence (Fender, 2001), syntactic knowledge may be primarily important for generating an understanding of the literal meaning or what is explicit in a text (i.e., literal comprehension), as opposed to inferential comprehension, which is a deeper level of comprehension where the reader needs to rely on additional processes, such as semantic association discussed below, to read “between the lines.” This issue has rarely been tested in the L2 literature where there was a heavy reliance on more global measures of comprehension for assessing the contribution of different processes (see Choi and Zhang, 2020).
WTT integration also involves semantic processing where comprehenders draw upon their knowledge of semantic relations between words in the mental lexicon to integrate word meanings and fill any semantic gaps for coherence building (Perfetti and Stafura, 2014, 2015; Oakhill, 2020). In native speakers as well as L2 learners, whenever words are picked up and enter the mental lexicon, they are integrated into a lexical network where associative links are established with existing words in the network through various types of semantic relations (Read, 2004; Meara, 2009; Aitchison, 2012). These word associations or the semantic network serves as an important basis for language comprehension.
In explaining how coherence is built and maintained in text comprehension, the Reading Systems Framework highlights that inference generation is not solely a top-down knowledge-driven process (e.g., background knowledge; cf. Anderson and Pearson, 1984) but involves some lexically-driven processes initiated by lower-level recognition and integration of words (Perfetti and Stafura, 2014; see also Oakhill et al., 2015). Perfetti and Stafura (2015) distinguished between “the linguistically constrained implicit meaning” and “the linguistically independent, reader-constructed implicit meaning” to underscore the distinction between the two processes. As words are recognized and their meaning activated (i.e., the word identification system), they need to be integrated into the ongoing context such as a sentence or a larger discourse unit across sentences (i.e., the comprehension system). This process is characterized by selecting context-specific word meanings and integrating incoming words into the current situation model and updating the model. This semantic association process was observed in a number of ERP studies by Perfetti and colleagues (e.g., Yang et al., 2007; Perfetti et al., 2008).
The execution of the semantic process necessarily draws upon the reader’s knowledge about semantic relations between words or their semantic network knowledge. To construct coherence between “A few bombs fell on the town” and “Luckily, little damage was caused to property” through the integration of the word “damage” to the previous situation model on bombing, the “damaging” sense associated with bombing will need to be activated (and held in the working memory), which means the reader needs to know the associative link between bomb and damage. Semantic association or network knowledge of this kind is hence crucial for inference generation, construction and maintenance of local as well as global coherence as text reading unfolds. As Oakhill (2020) pointed out, “rich and well-connected semantic representations of words will permit the rapid activation not only of a word’s meaning but also the meanings of related concepts;” and “many of the local cohesion and global coherence inferences in the text depend on semantic links between words in the text” (pp. 413–414).
The contribution of semantic network knowledge to comprehension is sometimes studied under the name of vocabulary depth (Ouellette, 2006; Cain and Oakhill, 2014; Oakhill et al., 2015), which is distinct from vocabulary breadth/size or the number of words with a (partial) meaning known (Read, 2004; Schmitt, 2014). The semantic association is also conceptualized as an important underlying component of lexical quality (Richter et al., 2013; Oakhill, 2020). The Lexical Quality Hypothesis (Perfetti, 2007) contends that high-quality representations of lexical and sub-lexical features are fundamental for comprehension. While lower-level skills that support word recognition (e.g., phonological and orthographic processing) and vocabulary knowledge/size are important for comprehension, the “semantic constituent of lexical quality” or vocabulary depth should also play a crucial role (Perfetti and Stafura, 2014, 2015; Oakhill et al., 2015; Oakhill, 2020).
Empirically, a small but increasing body of research has focused on semantic network knowledge (or however else it is called such as vocabulary depth) as a predictor of reading comprehension over and beyond word recognition skills in monolinguals (e.g., Cain et al., 2004; Ouellette, 2006; Tannenbaum et al., 2006; Cain and Oakhill, 2014) as well as bilingual readers (e.g., Cremer and Schoonen, 2013; Spätgens and Schoonen, 2018). In the L2 literature, there has been an interest in how vocabulary size is important yet insufficient for explaining individual differences in reading comprehension and how vocabulary size and depth relatively predict reading comprehension (e.g., Qian, 1999, 2002). Read’s (1998) Word Associates Test (WAT), which incorporates syntagmatic and paradigmatic associations between words, has been a popular tool for measuring L2 learners’ vocabulary depth and studying its contribution to reading comprehension (see Zhang and Koda, 2017). In those studies, although the relative strength of vocabulary size versus depth did not always converge (e.g., Qian, 1999; Zhang, 2012), semantic network knowledge measured with the WAT or a similar measure usually significantly predicted reading comprehension (e.g., Zhang, 2012; Cremer and Schoonen, 2013; Zhang and Yang, 2016).
As noted earlier, what remains to be understood, however, is how the knowledge underpinnings of different WTT integration processes may be differentially important depending on the type of comprehension. The Reading Systems Framework (Perfetti and Stafura, 2014, 2015) underscores that at least some inference is generated through the semantic integration process for which lexical association or semantic network knowledge is essential. In this respect, semantic integration, while necessary for comprehension in general, may be particularly important for inferential comprehension compared to syntactic integration.
The components of word-to-text integration (i.e., syntactic parsing and semantic association), based on the corresponding aspects of linguistic knowledge, could contribute differently to various reading tasks that are literal or inferential in nature. As noted earlier, what remains to be understood, however, is how the knowledge underpinnings of different word-to-text integration processes may be differentially important depending on the type of comprehension. The Reading Systems Framework (Perfetti and Stafura, 2014, 2015; see also Oakhill et al., 2015) underscores that at least some inference is generated through the semantic integration process for which lexical association or semantic network knowledge (or vocabulary depth) is essential. In this respect, semantic integration, while necessary for comprehension in general, may be particularly important for inferential comprehension compared to syntactic integration.
Syntactic and semantic integration are both important for L2 reading comprehension. The two operations are executed simultaneously and interact in reading comprehension. Yet, to our knowledge, no published studies seemed to have aimed to explore how their knowledge underpinnings may have differential contributions depending on the type of comprehension in question. The current study aimed to address this gap and to generate new understandings concerning the complex linguistic processes underlying L2 reading comprehension. Furthermore, the findings would inform the construction of a more comprehensive and accurate reading comprehension model for L2 readers. Thus, the current study assesses how syntactic and semantic network knowledge may differentially predict literal and inferential comprehension, over and beyond working memory and vocabulary knowledge/size in adult EFL readers. It aimed to answer the following two questions:
1. To what extent do syntactic knowledge and semantic network knowledge, which respectively underpin the syntactic and semantic process of WTT integration, uniquely predict reading comprehension in adult L2 readers of English?
2. How do the two types of knowledge differentially predict literal vs. inferential comprehension?
Data were collected from 268 Arabic-speaking first-year students in a female university in Saudi Arabia. Their age ranged from 17 and 22 years old (M = 20 years). Thirty-nine of them were excluded from the analyses reported later because they missed one or more of the tests described below due to random absence at testing sessions. At the time of the study, the students, as per the university requirement, were having a whole year of intensive English instruction to further develop their proficiency, particularly English for academic purposes, before they proceeded with disciplinary learning through English-medium instruction from the second year. They had learned English for at least six years through school instruction before they entered the university, and represented a range of undergraduate majors (Chemistry, Computer Science, and Nutrition).
The quality of the findings of a study and the possibility of generalizing results depend on the quality of the data. In this research, to ensure data quality, a number of validity and reliability aspects were considered. For example, the clarity of instructions is fundamental for data quality and the validity of the research findings. To ensure the clarity of instructions, various procedures were followed, such as providing verbal explanations of the tasks. In addition, the instructions were given in both English and Arabic (the participants’ native language) to ensure a full understanding of the questions. Furthermore, a pilot study was conducted to refine some tasks before they were administered to the participants, i.e., before the actual data collection.
To fulfill the validity criterion, the internal content validity of each method was evaluated to ensure that it adequately covered the intended domain. The research adopted well-known instruments that are firmly established and widely used in the literature, making some adjustments to ensure they were suitable for the study participants. Furthermore, the completed versions of the data collection instruments were reviewed by five native speakers of English and English instructors to check the clarity of items. They were also reviewed by the research supervisor, who is a professor in the field of language learning, to check whether the measures adequately covered the areas to be investigated with careful consideration of each item in the measures. Subsequently, several suggested amendments were made to different versions of each instrument.
The reliability of the measures was accomplished by estimating the Cronbach’s alpha coefficient for each instrument, with the acceptable value being no less than 0.6. Estimating the Cronbach’s alpha coefficient values of each instrument in the pilot study made it possible to ensure that the final versions of the data collection instruments achieved reliability. The precise Cronbach’s alpha values for each instrument are provided as follows.
To ensure the professional appearance of the tests and the clarity and suitability of the items for the purpose for which they were developed, as well as the smoothness of the procedures, it was essential to pilot the data collection methods and procedures before starting actual data collection. In other words, piloting would assure the validity, reliability, and feasibility of the data collection methods and procedures. Moreover, piloting the methods made it possible to estimate the average time needed to complete each test. Therefore, a pilot study was conducted with 30 participants from the same target population but who did not participate later in the study.
This phase was completed over four weeks for all instruments. Following the completion of data collection in the pilot study, the first author had a quick informal chat with some of the participants, enquiring about the clarity of the methods and any related issues. In response to the participants’ suggestions and answers, modifications were subsequently made to the wording of some questions to improve their clarity, and some items were added or deleted.
The participants completed a battery of paper-based tests on a group basis that measured their vocabulary knowledge/size, syntactic knowledge, semantic network knowledge, and passage comprehension. Group testing was divided into several short sessions of 20–25 minu during an 8-week testing period. A computerized test was also administered individually to measure working memory. The instruments were piloted on 30 other first-year students who studied at the same university but did not participate later in this study.
Gates-MacGinitie Reading Tests, Fourth Edition (Form S) (MacGinitie et al., 2000) was used to measure reading comprehension. This test was selected because it includes different types of texts with separate questions for measuring literal and inferential comprehension. Four reading passages were selected from Level 5 of the test, based on our expert knowledge of local students’ reading proficiency and the pilot study. Of the four passages selected, two were informational and the other were two narrative texts so as to have a balanced representation of text types. Each passage was accompanied by five or six multiple-choice questions, with a total of 21 questions (10 for literal comprehension and 11 for inferential comprehension). This test was administered in two class sessions, two passages in each session and each session for about 25 min. Participants received one point for a correct choice and zero points for an incorrect or missing response. The Cronbach’s α was 0.630. This could be relatively a low value of reliability which could reflect the moderate level of English language proficiency of the participants.
Syntactic knowledge was measured with a researcher-developed grammatical error correction task. This measure consisted of 15 lexically simple sentences where there was a grammatical error in each sentence. Participants were asked to first identify the part of the sentence, from three underlined choices, that made the sentence ungrammatical and then correct the identified part. For example, in This is the man which house is on fire, which is the erroneous part, which can be corrected to whose to make the sentence grammatical. This measure covered various aspects of grammar such as subject-verb agreement, verb tenses, irregular verbs, passive, relative clauses, pronouns, prepositions, and word order. Following Zhang (2012), participants received one point for a correct error identification and an additional point for an appropriate error correction, and zero points for incorrect answers and for missing responses. The maximum score was 30. An example was given, and instructions were given in both English and Arabic. It took roughly 20 min for all students to complete this test. The Cronbach’s α was 0.875.
Semantic network knowledge was measured with a multiple choices task that tapped various semantic relations. Read’s (1998) WAT is a well-known task to measure L2 semantic network knowledge or vocabulary depth. Learners are basically asked to identify the paradigmatic (i.e., synonyms) and syntagmatic associates (i.e., collocates) of an adjective from a list of adjectives and nouns. The original WAT, however, was not used for this study, because many target words and choices were unfamiliar to the participants, which would threaten the validity of measuring knowledge of semantic relationships between (known) words (see Zhang and Koda, 2017).
Consequently, we developed our own test, which consisted of two separate sections focusing on the paradigmatic and syntagmatic association, respectively. The first section consisted of three groups of five items (a total of 15 items), which focused on synonymy, antonymy, and hyponymy, respectively. In each item, a target word (adjective, noun, or verb) was followed by four candidate associates, one of which was a synonym, antonym, or hyponym of the target word. For example option: choice, unit, answer, chance. The second section also consisted of 15 items. For each item, participants were asked to select a word that best collocates with the word in the prompt. For example, __ line: high, long, tall, large. Each correct choice received one point; an incorrect or missing response received zero points. Examples were given and instructions were in both English and Arabic. The maximum score possible was 30. The task was completed by the participants in approximately 20 minutes. The Cronbach’s α was 0.898.
To statistically model the contribution of syntactic and semantic network knowledge to reading comprehension, it is important to control for readers’ knowledge of individual words, as vocabulary knowledge/size is a strong correlate of reading comprehension (Jeon and Yamashita, 2014). Vocabulary knowledge was measured with an abridged version of the Vocabulary Levels Test (VLT) (Schmitt et al., 2001). The test for this study covered only four levels of word frequency: 1,000, 2,000, 3,000, and 5,000. For each frequency level, six items were randomly sampled. Each item consisted of a list of six words and three meaning choices. Different from the original VLT, the three meaning choices were translated and presented in Arabic. Participants were asked to select a word to match each meaning choice. The maximum score possible was 72. This test was administered in one class session. Participants were given 20 min to complete it. The Cronbach’s α was 0.949.
Working memory was measured with a computer-based digital span task and later included as a covariate in regression analysis. The test was administered individually to participants on a laptop computer in a quiet space on the university campus and run on PsychoPy 3.0 (Peirce et al., 2019). It consisted of 20 numerical sequences: 10 for forward span and 10 for backward span. For the forward span items, participants were asked to decide, as quickly as possible, whether a digit sequence presented on the computer screen was the one they saw earlier and in the given order. Likewise, for the backward span items, they were to decide whether a digit sequence was the one that they saw earlier but had the order reversed. Responses were made by pressing “Yes” or “No” marked on the keyboard. For both types of span, there were five sets of random numerical digits increasing in length of the sequence. It started with two-digit sequences and ended with six-digit sequences. Each set consisted of two items: one with the order matched and the other with the wrong order. Both reaction times (RTs) and Yes/No responses were recorded. The Cronbach’s α was 0.754 based on response accuracy.
RT was calculated as the interval between the onset of an item appearing on the computer screen and the time of Yes/No being pressed. Participants began the test by seeing a digit sequence appear in the center of the computer screen for a fixed rate of 1.000 ms. Upon the offset of the stimulus sequence, a question, together with a digit sequence, appeared on the screen that asked the participants whether the current digit sequence matches, in order or reserve order, the stimulus sequence they saw earlier. The pressing of a Yes/No key automatically activated the next item. If no key was pressed for an item after a certain period of time (which was tailored for each item based on the pilot, but generally ranged from 1,000 to 2,000 ms), the item would automatically disappear, and the next item would appear.
To calculate the right RTs for analysis, we relied on the RTs of correctly answered items. We recorded the RT of a missed or wrong decision as missing. Then we calculated the mean RT for each item. An RT that was above or below the item mean by two or more standard deviations was considered to be an outlier and further recoded as missing. This was followed by computing the mean RT of correctly answered items for each participant. Finally, to accommodate the rate of correct responses, a raw RT was replaced by an Inverse Efficiency Score (IES), which was calculated for each participant by having the raw mean RT divided by the percentage of correct responses (Townsend and Ashby, 1983). In other words, participants with a low RT but a low accuracy rate were penalized for the low accuracy.
The data were analyzed primarily through bivariate correlation hierarchical regression. The analysis was completed using the IBM SPSS Statistics 26 program. A separate SPSS data file was created that included all the focal variables of the study. The focal variables were reading comprehension, lexical knowledge, sub-lexical/morphological knowledge, lexical processing efficiency, sub-lexical/morphological processing efficiency, and working memory. In each data file, cases with missing values were excluded from the analysis. In other words, only cases that had a score for all focal variables were retained in the dataset for analysis.
Some descriptive analysis, including the estimate of means, standard deviations, skewness, and kurtosis was conducted. Then, the bivariate correlations were calculated, followed by a set of hierarchical regression analyses. In all regression analyses, working memory was entered first into the regression equation as a covariate because this was one of the core aspects of data collection employed in the study. This was followed by the predictors in different orders. To explore the unique effects of the predictors, the orders of the linguistic processing predictors were adjusted.
As shown in Table 1, overall, the measures were all normally distributed as the skewness and kurtosis estimates were below the rule-of-thumb values (i.e., ±2) for univariate normality. Their reliability was also good or acceptable. The accuracy rate and raw RT are both presented for working memory, but it was the IES RT that was used for subsequent analyses. Based on the percentage of correct answers, the participants, perhaps unsurprisingly, performed significantly better on literal comprehension than inferential comprehension (t = 5.240, p < 0.001).
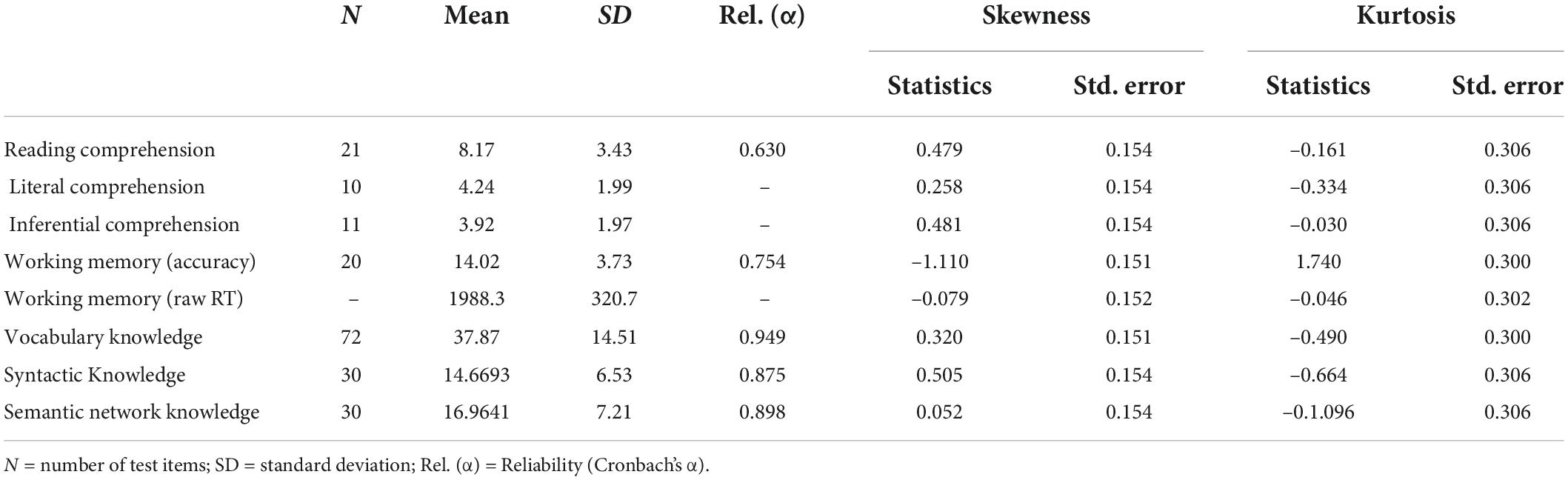
Table 1. Measures and descriptive statistics.
Table 2 shows the bivariate correlations between all the variables. To highlight, reading comprehension correlated significantly with all other variables, including both syntactic knowledge (r = 0.476) and semantic network knowledge (r = 0.605), both ps < 0.001. Literal and inferential comprehension correlated significantly (r = 0.498, p < 0.001); and the correlations of both with other variables were significant as well, except that between working memory and inferential comprehension (r = -0.104). Syntactic knowledge correlated significantly with both types of comprehension: rs = 0.422 and 0.402 for literal and inferential comprehension, respectively (both ps < 0.001). Semantic network knowledge also correlated significantly with literal (r = 0.517) as well as inferential comprehension (r = 0.530), both ps < 0.001. Overall, while semantic network knowledge had slightly stronger correlations with both types of reading comprehension than did syntactic knowledge, the pattern seemed more salient for inferential comprehension.
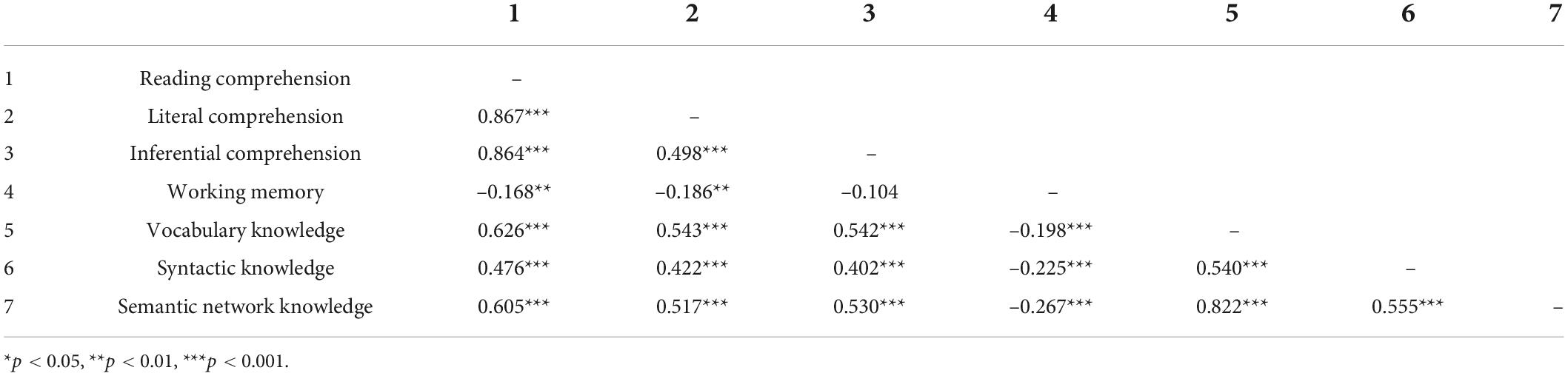
Table 2. Bivariate correlations between all measured competences.
Three sets of hierarchical regression analyses were performed to examine the unique contribution of WTT integration components to reading comprehension and its sub-levels (literal and inferential). In each set of analyses, a baseline model was first created to control for the effects of working memory and vocabulary knowledge. Syntactic knowledge and semantic network knowledge were then added to the model consecutively. To determine any distinct contribution of the two knowledge components for WTT integration, the order of entry for semantic network knowledge and syntactic knowledge was switched.
As shown in Table 3, working memory significantly predicted reading comprehension (p = 0.011). Controlling for working memory, vocabulary knowledge explained a substantial amount of variance in reading comprehension (p < 0.001). Together, these two control variables accounted for about 38.9% of the variance in reading comprehension. Over and beyond the two control variables, syntactic knowledge significantly predicted reading comprehension (p = 0.002), adding about 2.5% to the variance explained. As the last variable added to the regression equation, syntactic knowledge contributed an extra 1.5% of the variance in reading comprehension (p < 0.016). A similar pattern was observed when the order of entry for syntactic and semantic network knowledge was switched. Syntactic knowledge entered as the last step significantly explained an additional 1.7% of the variance in reading comprehension (p = 0.010) after accounting for the effects of working memory, vocabulary knowledge, and semantic network knowledge. Altogether the four predictors explained over 42% of the variance in reading comprehension. Overall, it can be concluded that both WTT integration components were a significant, unique predictor of reading comprehension, although the effect size for both appeared small after the effects of vocabulary knowledge and working memory were concurrently considered.

Table 3. Unique contribution of each WTT integration component to reading comprehension.
As shown in Table 4, the effect of both working memory and vocabulary knowledge on literal comprehension was significant. These two covariates in total explained about 29.5% of the variance in the criterion variable. Over and beyond these covariates and syntactic knowledge, a significant, unique effect of semantic network knowledge did not surface (p = 0.130). It only explained about 0.7% of the variance in literal comprehension. On the other hand, controlling for all the other three variables, syntactic knowledge explained a small but significant amount of variance (about 1.5%) in literal comprehension (p = 0.026).

Table 4. Unique contribution of each WTT integration component to literal comprehension.
Table 5 shows the result of the regression analysis for inferential comprehension. Working memory was not a significant predictor. The effect of vocabulary knowledge, however, was significant; it explained about 28.3% of the variance in inferential comprehension. Unlike when literal comprehension was the criterion variable, semantic network knowledge explained a small but significant additional amount of variance (about 1.6%) in inferential comprehension (p = 0.021), over and above the two covariates and syntactic knowledge. When syntactic knowledge was the last predictor entered into the regression model, a significant, unique effect did not surface (p = 0.065); and the proportion of additional variance explained was very little.

Table 5. Unique contribution of each WTT integration component to inferential comprehension.
To answer the first research question, disregarding the type of comprehension, both syntactic and semantic network knowledge were significant, unique predictors of reading comprehension. Their unique effect was assessed with the control of vocabulary knowledge/size and working memory, particularly the former, which has been found to be a strong correlate of L2 reading comprehension (Jeon and Yamashita, 2014; Zhang and Zhang, 2020) and also explained a substantial amount of variance in reading comprehension in this study. Both syntactic and semantic network knowledge explained a small but significant amount of unique variance in reading comprehension. This finding was not a surprise, given that the two types of knowledge underpinned distinct WTT integration processes, both of which are theoretically essential, and thus need to be simultaneously in place, for constructing the meaning of larger units (clausal, sentential, and beyond), over and beyond word recognition and knowledge of word meanings (Fender, 2001; Grabe, 2009; Nassaji, 2014; Perfetti and Stafura, 2014).
This finding also corroborates previous studies that showed the importance of syntactic knowledge (e.g., Shiotsu and Weir, 2007; Raudszus et al., 2018) as well as vocabulary depth knowledge (Qian, 2002; Zhang and Yang, 2016) in L2 reading comprehension. Additionally and more importantly, it extends the literature where there was a particular interest in comparing the contribution of vocabulary (size) vs. grammatical knowledge on the one hand (e.g., Shiotsu and Weir, 2007; Zhang, 2012; see Choi and Zhang, 2020 for a review), and that of vocabulary size vs. depth on the other in L2 reading comprehension (e.g., Qian, 1999, 2002; Zhang, 2012; see also Zhang and Zhang, 2020). The present study contributed to that body of literature through a distinct perspective. We distinguished between word recognition and word-to-text integration processes in text comprehension. We acknowledged that word recognition and knowledge of individual word meanings (i.e., vocabulary size) are fundamental to propositional meaning construction and text model construction, yet also pointed out the insufficiency of these lower-order processes in text comprehension (Kintsch, 1998; Perfetti et al., 2005; Grabe, 2009). The comparison between syntactic and semantic WTT integration or syntactic vs. semantic network knowledge has provided a new perspective on studying the contribution of linguistic processes to larger unit meaning construction and L2 reading comprehension beyond the basic process that concerns individual words (see also Nassaji, 2003).
In addition to the aforementioned distinct perspective, the present study addressed another notable niche, that is, we distinguished between literal and inferential comprehension and explored how the knowledge underpinnings distinct WTT integration processes differentially contributed to reading comprehension depending on the type of comprehension. To answer the second research question, controlling for working memory and vocabulary knowledge, syntactic knowledge, as opposed to semantic network knowledge, significantly predicted literal comprehension, whereas, for inferential comprehension, a converse pattern was found.
As noted in the review of literature, previous studies relied heavily on global measures of L2 reading comprehension (see Alptekin and Erçetin, 2011; Li and Kirby, 2014; Zhang and Yang, 2016 for a few exceptions), which has restricted understanding of the complexity of component processes that interplay in text comprehension. The unique contribution of syntactic knowledge for literal comprehension, which concerns the understanding of messages explicitly presented in a text, seems quite reasonable because structural information is essential for word integration (Grabe, 2005, 2009). The fact that semantic network knowledge did not surface as a significant predictor of literal comprehension, after controlling for vocabulary knowledge/size and syntactic knowledge, seems to match exactly recent new perspectives on how semantic association functions in text comprehension (Perfetti and Stafura, 2014, 2015; Oakhill, 2020). That is, the process of integrating words into ongoing context plays an important role in inference generation and continuous construction of coherence as text reading unfolds.
This is exactly what the finding of the present study showed for inferential comprehension, that is, semantic network knowledge, as opposed to syntactic knowledge, uniquely and significantly predicted inferential comprehension. Models of text comprehension generally underscore high-order inference as a knowledge-driven process. For example, in the Construction-Integration model (Kintsch, 1998), word-level processes are for text model construction, and world knowledge is integrated to generate inferences and construct the situation model. Based on neurocognitive evidence, Perfetti and Stafura, 2014, 2015 proposed that there is some lexically-driven process (i.e., words being continuously integrated into ongoing context and modifying, updating, or “fine-tuning” the situation model for construction and maintenance of coherence) that possibly interacts with the knowledge-driven process for inference generation and situation model building. In this respect, the unique contribution of the “semantic constituent of lexical quality” (Perfetti and Stafura, 2014, 2015), which was measured in the form of semantic network knowledge in the present study, to inferential comprehension was not unexpected.
One may argue that, as semantic network knowledge measures vocabulary depth and some studies in the L2 literature have shown the importance of vocabulary depth to reading comprehension (e.g., Qian, 1999; Zhang and Yang, 2016), the findings reported in this study may not be particularly interesting, despite the new perspective through the lens of WTT integration. However, we would emphasize that it was exactly the lens of WTT integration and the focus on inferential comprehension that made the present study important and the findings interesting. Although a small but increasing number of studies have confirmed the importance of vocabulary depth (or semantic network knowledge such as measured with the WAT; Read, 1998) in L2 reading comprehension (see Zhang and Koda, 2017), what remains puzzling is how this depth knowledge is uniquely important, over and beyond vocabulary size (what the VLT intended to measure in the present study). Oftentimes, a study that aimed to compare vocabulary size vs. depth in reading comprehension was framed primarily through differentiating the different dimensions of vocabulary knowledge (e.g., Zhang, 2012; Zhang and Yang, 2016) rather than aiming to first and foremost theoretically delineate how (distinct) lexical processes drive text comprehension. In this respect, Perfetti and colleagues’ Reading Systems Framework (Perfetti and Stafura, 2014) as well as their emphasis on lexical quality and comprehension (Perfetti, 2007), although contextualized in L1 reading, have much to inform understandings about L2 reading comprehension, particularly semantic association/vocabulary depth and inferential comprehension. These important theoretical insights have underpinned some recent empirical work on L1 reading (e.g., Richter et al., 2013; Cain and Oakhill, 2014; Segers and Verhoeven, 2016); yet their influence in L2 reading comprehension research is only beginning to be visible (e.g., Raudszus et al., 2018). The present study thus extends the current body of research in light of its focus on WTT integration and different types of comprehension, particularly the significance of semantic integration and inference generation for explaining any empirical relationship between vocabulary depth and L2 reading comprehension.
This study was a modest effort to explore WTT integration processes and their differential contribution to literal and inferential comprehension, hence not without limitations. For example, we only focused on the knowledge that underpins WTT integration without also considering integration efficiency or the facility with which the participants accessed that knowledge. In this respect, Schoonen and colleagues’ studies (Cremer and Schoonen, 2013; Spätgens and Schoonen, 2018) are particularly noteworthy, despite their distinct focus from this study’s. In those studies, knowledge availability and accessibility were differentiated; and participants’ access to semantic network knowledge was measured with time-sensitive tasks. Their approach and that of the present study can be integrated into future research to study WTT integration and reading comprehension (see also Oakhill et al., 2015 on lexical facility or speed of access; and Zhang, 2012 on explicit vs. implicit grammatical knowledge).
It was a surprise that working memory did not significantly predict inferential comprehension. Theoretically, working memory is particularly important for inference generation and comprehension, because propositional meaning or text model information needs to be maintained there for knowledge to participate in situation model building or model integration (Kintsch, 1998; Zwaan and Rapp, 2006). In light of a lexically framed explanation of WTT integration and inference generation, words also need to be held in the working memory for lexical associates to be integrated for modifying and fine-tuning the situation model (Perfetti and Stafura, 2014; see also Hagoort, 2013). We conjecture that this might be related to the narrow focus of the digit span test on storage as opposed to processing (and storage). In Alptekin and Erçetin (2011), where working memory differentiated between readers with distinct levels of inferential comprehension, the reading span test required participants to not only recall sentence-final words but also make grammaticality judgments. The latter task requirement apparently involved a processing demand, not to mention the task’s potential involvement of lexical and syntactic processes. Future research may include different working memory components to study linguistic processes in inferential comprehension.
This study focused on two major components of WTT integration, that is, syntactic parsing and semantic association, and L2 reading comprehension; and assessed how syntactic and semantic network knowledge differentially predicted literal and inferential comprehension in adult EFL readers. Both types of knowledge were a significant, unique predictor of reading comprehension (disregarding the type of comprehension), after controlling for working memory and vocabulary knowledge/size. Yet, for literal comprehension, controlling for all other predictors, syntactic knowledge, as opposed to semantic network knowledge, was a significant predictor, whereas for inferential comprehension, a converse pattern was found.
Taken together, these findings suggest that, while syntactic and semantic processes of WTT integration interplay and are both needed for successful text comprehension, different types of comprehension may place differential demands on these processes and their corresponding knowledge underpinnings. The findings also extend the current body of research on cognitive and linguistic processes of L2 reading comprehension, which tended to rely heavily on global measures of reading comprehension and thus have obscured an understanding of how these processes can and should be orchestrated in differential ways by the reader to cope with different levels of comprehension or tasks of reading.
The findings obviously have important pedagogical implications. They have confirmed the importance we have long been cognizant of vocabulary size for reading comprehension and also suggested that knowing the (partial) meaning of a large number of words is important but insufficient. Syntactic knowledge for word integration and structure building is arguably important. More importantly, explicit instructional attention needs to be given to building and consolidating learners’ semantic network knowledge or vocabulary depth. This implication is perhaps not new as this type of knowledge has been emphasized in L2 vocabulary teaching (and assessment) (Read, 2000; Nation, 2001). Yet, the theoretical basis on which the importance was empirically confirmed in the present study, that is, semantic integration and inference generation, has provided new insights into why this knowledge is important and how it is to be promoted in L2 learners. In a recent study, Raudszus et al. (2019) adopted a “pathfinder networks” approach to measuring L1 and L2 readers’ textbase memory and situation model building ability. Basically, participants were asked to read a text and work on the computer to drag around words/concepts from the text to show how they thought those words were more or less closely related. Although this network-building approach was a research paradigm there, we believe it has valuable pedagogical benefits as well, as the approach is notably contextualized in an actual text reading situation. It can bridge goals for L2 vocabulary learning and reading instruction (esp. instruction to promote inferential comprehension development) (see Grabe, 2009; Grabe and Stoller, 2019).
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
The studies involving human participants were reviewed and approved by University of Exeter. The patients/participants provided their written informed consent to participate in this study.
MA performed the research. DZ supervised the work and edited the manuscript. Both authors contributed to the article and approved the submitted version.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Aitchison, J. (2012). Words In The Mind: An Introduction To The Mental Lexicon, 4th Edn. Oxford: Wiley-Blackwell.
Alptekin, C., and Erçetin, G. (2011). The effects of working memory capacity and content familiarity on literal and inferential comprehension in L2 reading. TESOL Q. 45, 235–265. doi: 10.5054/tq.2011.247705
Anderson, R. C., and Pearson, P. D. (1984). “A schema-theoretic view of basic processes in reading,” in Handbook Of Reading Research, ed. P. D. Pearson (New York, NY: Longman), 255–291.
Cain, K., and Oakhill, J. (2014). Reading comprehension and vocabulary: Is vocabulary more important for some aspects of comprehension? L’Anneìe Psychol. 114, 647–662. doi: 10.4074/S0003503314004035
Cain, K., Oakhill, J., and Bryant, P. (2004). Children’s reading comprehension ability: Concurrent prediction by working memory, verbal ability, and component skills. J. Educ. Psychol. 96, 31–42. doi: 10.1037/0022-0663.96.1.31
Choi, Y., and Zhang, D. (2020). The relative role of vocabulary and grammatical knowledge in L2 reading comprehension: A systematic review of literature. Int. Rev. Appl. Linguist. Lang. Teach. 59, 1–30. doi: 10.1515/iral-2017-0033
Cremer, M., and Schoonen, R. (2013). The role of accessibility of semantic word knowledge in monolingual and bilingual fifth-grade reading. Appl. Psycholinguist. 34, 1195–1217. doi: 10.1017/S0142716412000203
Crossley, S. A., Greenfield, J., and McNamara, D. S. (2008). Assessing text readability using cognitively based indices. TESOL Q. 42, 475–493. doi: 10.2307/40264479
Currie, N. K., and Cain, K. (2015). Children’s inference generation: The role of vocabulary and working memory. J. Exp. Child Psychol. 137, 57–75. doi: 10.1016/j.jecp.2015.03.005
Fender, M. (2001). A review of L1 and L2/ESL word integration skills and the nature of L2/ESL word integration development involved in lower-level text processing. Lang. Learn. 51, 319–396. doi: 10.1111/0023-8333.00157
Grabe, W. (2005). “The role of grammar in reading comprehension,” in The Power Of Context In Language Teaching And Learning, eds J. Frodesen and C. Holton (Boston, MA: Heinle & Heinle), 268–282.
Grabe, W. (2009). Reading In A Second Language: Moving From Theory To Practice. Cambridge, MA: Cambridge University Press.
Grabe, W., and Stoller, F. L. (2019). Teaching And Researching Reading, 3rd Edn. New York, NY: Routledge.
Hagoort, P. (2013). MUC (memory, unification, control) and beyond. Front. Psychol. 4:416. doi: 10.3389/fpsyg.2013.00416
Jeon, E. H., and Yamashita, J. (2014). L2 reading comprehension and its correlates: A meta-analysis. Lang. Learn. 64, 160–212. doi: 10.1111/lang.12034
Kintsch, W. (1988). The construction-integration model of text comprehension. Psychol. Rev. 95, 163–182.
Kintsch, W. (1998). Comprehension: A Paradigm For Cognition. Cambridge, MA: Cambridge University Press.
Li, M., and Kirby, J. R. (2014). The effects of vocabulary breadth and depth on English reading. Appl. Linguist. 36, 611–634. doi: 10.1093/applin/amu007
MacGinitie, W., MacGinitie, R., Maria, R. K., and Dreyer, L. G. (2000). gates-Macginitie Reading Tests, 4th Edn. Chicago, IL: Riverside Publishing Co.
Meara, P. M. (2009). Connected Words: Word Associations And Second Language Vocabulary Acquisition. Amsterdam: John Benjamins.
Melby-Lervåg, M., and Lervåg, A. (2014). Reading comprehension and its underlying components in second-language learners: A meta-analysis of studies comparing first-and second-language learners. Psychol. Bull. 140, 409–433. doi: 10.1037/a0033890
Nassaji, H. (2003). Higher-level and lower-level text processing skills in advanced ESL reading comprehension. Mod. Lang. J. 87, 261–276. doi: 10.1111/1540-4781.00189
Nassaji, H. (2014). The role and importance of lower-level processes in second language reading. Lang. Teach. 47, 1–37. doi: 10.1017/S0261444813000396
Nation, I. S. P. (2001). Learning Vocabulary In Another Language. Cambridge, MA: Cambridge Universiy Press.
Oakhill, J. (2020). Four decades of research into children’s reading comprehension: A personal review. Discourse Process. 57, 402–419. doi: 10.1080/0163853X.2020.1740875
Oakhill, J., Cain, K., and McCarthy, D. (2015). “Inference processing in children: The contributions of depth and breadth of vocabulary knowledge,” in Inferences During Reading, eds E. J. O’Brien, A. E. Cook, and R. F. Lorch Jr. (Cambridge, MA: Cambridge University Press), 140–159.
Oh, S.-Y. (2001). Two types of input modification and EFL reading comprehension: Simplification versus elaboration. TESOL Q. 35, 69–96. doi: 10.2307/3587860
Ouellette, G. P. (2006). What’s meaning got to do with it: The role of vocabulary in word reading and reading comprehension. J. Educ. Psychol. 98, 554–566. doi: 10.1037/0022-0663.98.3.554
Peirce, J. W., Gray, J. R., Simpson, S., MacAskill, M. R., Höchenberger, R., Sogo, H., et al. (2019). PsychoPy2: Experiments in behavior made easy. Behav. Res. Methods 51, 195–203. doi: 10.3758/s13428-018-01193-y
Perfetti, C. A. (2007). Reading ability: Lexical quality to comprehension. Sci. Stud. Read. 11, 357–383. doi: 10.1080/10888430701530730
Perfetti, C. A., and Adlof, S. M. (2012). “Reading comprehension: A conceptual framework from word meaning to text meaning,” in Measuring Up: Advances In How We Assess Reading Ability, eds J. P. Sabatini, E. R. Albro, and T. O’Reilly (New York, NY: Rowman & Littlefield Education), 3–20.
Perfetti, C. A., and Stafura, J. Z. (2015). “Comprehending implicit meanings in text without making inferences,” in Inferences During Reading, eds E. J. O’Brien, A. E. Cook, and R. F. Lorch Jr. (Cambridge, MA: Cambridge University Press), 1–18.
Perfetti, C. A., Landi, N., and Oakhill, J. (2005). “The acquisition of reading comprehension skill,” in The Science Of Reading: A Handbook, eds M. J. Snowling and C. Hulme (Oxford: Blackwell), 227–247. doi: 10.1002/9780470757642.ch13
Perfetti, C., and Stafura, J. (2014). Word knowledge in a theory of reading comprehension. Sci. Stud. Read. 18, 22–37. doi: 10.1080/10888438.2013.827687
Perfetti, C., Yang, C. L., and Schmalhofer, F. (2008). Comprehension skill and word-to-text integration processes. Appl. Cogn. Psychol. 22, 303–318. doi: 10.1002/acp.1419
Qian, D. D. (1999). Assessing the roles of depth and breadth of vocabulary knowledge in reading comprehension. Can. Mod. Lang. Rev. 56, 282–308. doi: 10.3138/cmlr.56.2.282
Qian, D. D. (2002). Investigating the relationship between vocabulary knowledge and academic reading performance: An assessment perspective. Lang. Learn. 52, 513–536. doi: 10.1111/1467-9922.00193
Raudszus, H., Segers, E., and Verhoeven, L. (2018). Lexical quality and executive control predict children’s first and second language reading comprehension. Read. Writ. 31, 405–424. doi: 10.1007/s11145-017-9791-8
Raudszus, H., Segers, E., and Verhoeven, L. (2019). Situation model building ability uniquely predicts first and second language reading comprehension. J. Neurolinguist. 50, 106–119. doi: 10.1016/j.jneuroling.2018.11.003
Read, J. (1998). “Validating a test to measure depth of vocabulary knowledge,” in Validation In Language Assessment, ed. A. J. Kunnan (Mahwah, NJ: Lawrence Erlbaum Associates), 41–60.
Read, J. (2004). “Plumbing the depths: How should the construct of vocabulary knowledge be defined,” in Vocabulary In A Second Language: Selection, Acquisition And Testing, eds B. Laufer and P. Bogaards (Amsterdam: John Benjamins), 209–227.
Richter, T., Isberner, M.-B., Naumann, J., and Neeb, Y. (2013). Lexical quality and reading comprehension in primary school children. Sci. Stud. Read. 17, 415–434. doi: 10.1080/10888438.2013.764879
Schmitt, N. (2014). Size and depth of vocabulary knowledge: What the research shows. Lang. Learn. 64, 913–951. doi: 10.1111/lang.12077
Schmitt, N., Schmitt, D., and Clapham, C. (2001). Developing and exploring the behaviour of two new versions of the Vocabulary Levels Test. Lang. Test. 18, 55–88. doi: 10.1177/026553220101800103
Segers, E., and Verhoeven, L. (2016). How logical reasoning mediates the relation between lexical quality and reading comprehension. Read. Writ. 29, 577–590. doi: 10.1007/s11145-015-9613-9
Shin, J., Dronjic, V., and Park, B. (2019). The interplay between working memory and background knowledge in L2 reading comprehension. TESOL Q. 53, 320–347. doi: 10.1002/tesq.482
Shiotsu, T., and Weir, C. J. (2007). The relative significance of syntactic knowledge and vocabulary breadth in the prediction of reading comprehension test performance. Lang. Test. 24, 99–128. doi: 10.1177/0265532207071513
Spätgens, T., and Schoonen, R. (2018). The semantic network, lexical access and reading comprehension in monolingual and bilingual children: An individual differences study. Appl. Psycholinguist. 39, 225–256. doi: 10.1017/S0142716417000224
Tannenbaum, K. R., Torgesen, J. K., and Wagner, R. K. (2006). Relationships between word knowledge and reading comprehension in third-grade children. Sci. Stud. Read. 10, 381–398. doi: 10.1207/s1532799xssr1004_3
Townsend, J. T., and Ashby, F. G. (1983). Stochastic Modeling Of Elementary Psychological Processes. Cambridge, MA: Cambridge University Press.
Yang, C. L., Perfetti, C. A., and Schmalhofer, F. (2007). Event-related potential indicators of text integration across sentence boundaries. J. Exp. Psychol. Learn. Mem. Cogn. 33, 55–89. doi: 10.1037/0278-7393.33.1.55
Zhang, D. (2012). Vocabulary and grammar knowledge in second language reading comprehension: A structural equation modeling study. Mod. Lang. J. 96, 558–575. doi: 10.1111/j.1540-4781.2012.01398.x
Zhang, D., and Koda, K. (2017). Assessing L2 learners’ vocabulary depth with Word Associates Format tests: Issues, findings, and suggestions. Asian-Pac. J. Second Foreign Lang. Educ. 2:1. doi: 10.1186/s40862-017-0024-0
Zhang, D., and Yang, X. (2016). Chinese L2 learners’ depth of vocabulary knowledge and its role in reading comprehension. Foreign Lang. Ann. 49, 699–715. doi: 10.1111/flan.12225
Zhang, S., and Zhang, X. (2020). The relationship between vocabulary knowledge and L2 reading/listening comprehension: A meta-analysis. Lang. Teach. Res. 26, 696–725. doi: 10.1177/1362168820913998
Keywords: second-language reading, reading comprehension, literal comprehension, inferential comprehension, word-to-text integration, syntactic parsing, semantic association
Citation: Alshehri M and Zhang D (2022) Word-to-text integration components in second language (L2) reading comprehension. Front. Educ. 7:926663. doi: 10.3389/feduc.2022.926663
Received: 22 April 2022; Accepted: 19 August 2022;
Published: 16 September 2022.
Edited by:
Zhengdong Gan, University of Macau, Macao SAR, ChinaReviewed by:
Aydin Durgunoglu, University of Minnesota Duluth, United StatesCopyright © 2022 Alshehri and Zhang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Mona Alshehri, bW9uYS1hbHNoZWhyaTFAaG90bWFpbC5jb20=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.