 Theresa Wilkes
Theresa Wilkes Lisa Stark
Lisa Stark Kati Trempler
Kati Trempler Robin Stark
Robin Stark- 1Department of Education, Saarland University, Saarbrücken, Germany
- 2Institute for Educational Research, School of Education, University of Wuppertal, Wuppertal, Germany
Everyday teaching requires teachers to deal with a variety of pedagogical issues, such as classroom disruptions. Against the background of on-going calls for an evidence-informed practice, teachers should ground their pedagogical decisions not only on subjective theories or experience-based knowledge but also on educational theories and empirical findings. However, research suggests that pre- and in-service teachers rather refer to experiential knowledge than to educational knowledge when addressing practical, pedagogical issues. One reason for the infrequent use of educational knowledge is that acquired knowledge has remained inert and cannot be applied to complex situations in practice. Therefore, implementing learning with contrastive (i.e., functional and dysfunctional) video examples in teacher education seems promising to promote pre-service teachers’ acquisition of educational knowledge. The 2×2-intervention study (N = 220) investigated the effects of the video sequence (dysfunctional-functional/functional-dysfunctional) and of video analysis prompts (with/without) on learning outcomes (concept knowledge, application knowledge) and on learning processes (written video analyses). Results revealed that the sequence dysfunctional-functional led to higher application knowledge in the post-test. There was no sequencing effect on concept knowledge. Prompted groups showed higher concept knowledge and application knowledge in the post-test. Furthermore, both experimental factors affected learning processes, which resulted in higher learning outcomes. In conclusion, learning with contrastive video examples in teacher education seems to be more effective if the video examples are presented in the sequence dysfunctional-functional and if instructional prompts guide the video analysis. The results substantiate the relevance of instructional guidance in learning with video examples and broaden the scope of validity of the concept of learning from errors.
Introduction
Everyday teaching involves multiple complex situations in which teachers need to decide about how to act, such as classroom disruptions, learning difficulties, or students who do not engage in cooperative learning. With the aim of improving teaching practice, teachers are required to take decisions in their everyday teaching based not only on subjective theories or experiential knowledge but also on educational evidence, i.e., educational theories and empirical findings (Joyce and Cartwright, 2020; Ferguson, 2021; Slavin et al., 2021). The relevance of promoting evidence-informed practice in teacher education becomes particularly obvious in the light of studies showing that pre-service teachers and in-service teachers infrequently or inadequately draw on educational evidence in practical issues (e.g., Dagenais et al., 2012; Lysenko et al., 2015; Csanadi et al., 2021; Hartmann et al., 2021; Kiemer and Kollar, 2021). Reasons for such an infrequent or inadequate use of educational knowledge can be manifold: Research has revealed both cognitive and affective barriers of evidence-informed practice (Lysenko et al., 2014; Kiemer and Kollar, 2021; Thomm et al., 2021). In particular, for an evidence-informed teaching practice, knowledge about educational theories and empirical findings needs to be cognitively represented in such a way that it can be applied (Boshuizen et al., 2020). However, even if acquired knowledge was available, it could run the risk of remaining inert, i.e., not being used, when it comes to solving complex problems (Renkl et al., 1996). Inert knowledge does not necessarily have metacognitive or motivational causes. A low quality of available knowledge, especially a low level of elaboration depth, weak structuredness and/or a missing linkage to concrete (practical) situations during the phase of knowledge acquisition, can lead to inert knowledge (De Jong and Ferguson-Hessler, 1996; Renkl et al., 1996). To prevent teachers from inert knowledge, instructions in teacher education must be designed in a way that enables pre-service teachers to integrate educational and experiential knowledge (Hennissen et al., 2017; Lehmann et al., 2020). Therefore, it seems promising to encourage pre-service teachers to actively link educational knowledge with practice-oriented contexts of application already in the phase of knowledge acquisition.
Classroom videos have become a popular educational tool for situating learning and linking theory and practice in teacher education (Gaudin and Chaliès, 2015). Classroom videos can enhance cognitive, meta-cognitive, and motivational outcomes (e.g., Star and Strickland, 2008; Beitzel and Derry, 2009; Sherin and van Es, 2009; Barth et al., 2019; Thiel et al., 2020; for an overview cf. Hamel and Viau-Guay, 2019). To be authentic, classroom videos do not necessarily need to present real-world situations. So called “staged” videos, which present a teacher acting in an exemplary, pre-planned classroom situation with reduced complexity, enable learners to focus on the teachers’ and students’ key behaviors and their interrelations, e.g., the success of a teacher’s strategy to intervene in a classroom disruption (Piwowar et al., 2018; Codreanu et al., 2020; Thiel et al., 2020). Another advantage of staged videos is that they allow for constructing contrastive examples of functional and dysfunctional teacher behaviors in the same situational context (Piwowar et al., 2018).
However, it is unclear how contrastive video examples, i.e., functional and dysfunctional video examples, should be sequenced and whether instructional guidance should be included to promote pre-service teachers’ acquisition of educational application knowledge. To address this research desideratum, the present study investigates the effects of the video sequence (dysfunctional-functional vs. functional-dysfunctional) and of instructional support (with vs. without) on learning outcomes and learning processes when learning with contrastive video examples in teacher education.
Theoretical Framework
Instructional Challenges of Using Video Examples in Teacher Education
Although implementing video examples in teacher education can increase pre-service teachers’ knowledge integration, a video should not be regarded to be effective in itself. Simply presenting video examples does not necessarily induce deep learning processes (LeFevre, 2004; Seidel et al., 2013; Bates et al., 2016; Beilstein et al., 2017). Video-based learning brings several instructional challenges (for an overview cf. Derry et al., 2014). As with all learning materials, learners can deal with video examples less effectively so that they might not elaborate them deeply enough to benefit from them (Gerjets et al., 2008; Renkl, 2017). Since classroom videos are dynamical visualizations like other videos that are merely for entertainment, learners may underestimate the value of the learning task and the effort required to understand what is being taught (underwhelming effect; Lowe, 2004; Kant et al., 2017). This, in turn, might withdraw cognitive involvement (Lowe, 2004). Consuming video examples passively or underestimating their value and/or the effort required could also lead lead to learners overestimating their learning success (illusions of understanding; R. Stark et al., 2002).
Moreover, research on (pre-service) teachers’ ability to identify and to reason about relevant aspects in classroom situations based on theoretical concepts (also referred to as professional vision; Sherin and van Es, 2009) suggests that learners have difficulties to focus on relevant aspects (Star and Strickland, 2008; Goldsmith and Seago, 2011; Star et al., 2011; for a review cf. Amador et al., 2021). Learners’ selection of what is relevant and irrelevant can be biased (Derry et al., 2014). They might be distracted by irrelevant aspects that, on top, might cause cognitive overload (Mayer, 2001; Mayer and Moreno, 2003). Therefore, effective video-based learning requires an appropriate instructional design (Derry et al., 2014). In particular, research indicates the relevance of (1) the video content, (2) the sequence of learning objects, and of (3) the tasks guiding the learning process (e.g., Miller and Zhou, 2007; Borko et al., 2008; Brunvand, 2010; Derry et al., 2014; Hatch et al., 2016; Tekkumru-Kisa and Stein, 2017).
Video Content: Functional and Dysfunctional Teacher Behaviors
Classroom videos, for instance, can present a teacher handling students’ misbehavior, giving instructions, or dealing with complex materials, which can be reflected by pre-service teachers against the background of educational theories and empirical findings (Brunvand, 2010). In addition to presenting real-world classroom situations, it is often recommended to provide pre-service teachers with examples illustrating how to do something by the means of a teacher modeling “best practice” (Oonk et al., 2004; Rosaen et al., 2004; Sonmez and Hakverdi-Can, 2012). While enabling a vicarious experience of what works, functional examples contribute to building knowledge about what to do best (Oser et al., 2012). However, examples of how not to do something can also be beneficial for learning, as learners are encouraged to identify, comprehend, explain, and/or fix dysfunctional procedures by referring to underlying rules or principles (Große and Renkl, 2007; Durkin and Rittle-Johnson, 2012; Booth et al., 2013; Barbieri and Booth, 2020). By performing elaboration processes, learners acquire knowledge of what to do and what not to do in certain situations (negative knowledge; Oser et al., 2012). A cognitive conflict (Piaget, 1985) is assumed to be a key mechanism of why dysfunctional examples support learning (Melis, 2005; Tsovaltzi et al., 2012; Booth et al., 2013, 2015). During learning, cognitive conflicts occur when learners are confronted with situations in which the pre-knowledge-based expectation of what happens is inconsistent or in contradiction with the actual outcome of the situation; thus, learners are encouraged to resolve the inconsistency, and learning processes are fostered (Maharani and Subanji, 2018).
Thiel et al. (2020) investigated the effects of one functional vs. one dysfunctional video example on pre-service teachers’ professional vision and knowledge acquisition on the topic of classroom management. The video examples presented two contrasting courses of one classroom situation due to the teacher acting functionally or dysfunctionally, i.e., in accordance with educational evidence on classroom management or in contradiction with it. Working with the functional video led to a higher increase of knowledge than learning with the dysfunctional video. However, there were no significant effects on professional vision. The authors concluded that the model applying theoretical concepts in a functional way was more effective in anchoring these concepts. Nonetheless, Thiel et al. (2020) did not investigate the effects of learning with both the functional and the dysfunctional video examples.
Although their study was conducted in a different domain than teacher education, Durkin and Rittle-Johnson (2012) showed that comparing contrastive examples, i.e., respective functional and dysfunctional examples, was more likely to reduce misconceptions and to promote knowledge acquisition than comparing functional examples with each other. Applying these results to classroom videos, it seems promising to provide pre-service teachers with both a functional and a dysfunctional example to be compared against the background of evidence-based rules or principles. When reconstructing key relations of dysfunctional and functional procedures (e.g., its effects or consequences), learners must reflect on links between current and prior knowledge so that learners might elaborate the according rules or principles more deeply (Chi, 2000; Piwowar et al., 2018). From here, the question arises of how to sequence contrastive video examples.
Sequence: Dysfunctional-Functional or Functional-Dysfunctional?
When learning with multiple learning objects, such as contrastive video examples, the objects must be sequenced in a way of evoking cognitive processes that are beneficial for learning (Reigeluth et al., 1980; Renkl and Atkinson, 2007; Van Gog et al., 2008). Research on sequencing effects, when learning with video examples in teacher education, has primarily focused on the questions whether to present video examples or underlying rules and principles first (Beitzel and Derry, 2009; Seidel et al., 2013; Blomberg et al., 2014). In science education, Kant et al. (2017) investigated whether to present video examples on how to conduct scientific experiments before or after problem-solving activities. However, research on how to sequence multiple video examples is scarce. Some studies from different domains than teacher education indicated that a simultaneous presentation of written examples is more beneficial to learning and transfer than a sequential presentation of written examples (e.g., Gentner et al., 2003; Star and Rittle-Johnson, 2009). As it is impossible to present multiple video examples simultaneously, the only option left for contrastive video examples is to present them one after another, either in the order dysfunctional-functional or functional-dysfunctional. To our knowledge, the question of how to sequence contrastive video examples has not yet been resolved.
Considering the genuine logic of learning from errors, which is (1) noticing that an error was committed, (2) reconstructing the error by comparing it to one functional solution and (3) deriving error avoidance strategies (Oser and Spychiger, 2005; Oser et al., 2012; Tulis et al., 2016), it seems favorable to present the dysfunctional example first. The phenomenon of negative stimuli attracting more attention than positive ones (negativity bias; positive-negative asymmetry; Ohira et al., 1998) suggests that presenting a dysfunctional example before a functional example is more likely to guide learners’ attention to target incidents than the other way around (Große and Renkl, 2007; Booth et al., 2013; Barbieri and Booth, 2020).
Tasks Guiding the Learning Process: Need for Instructional Prompts?
To build up integrated and well-defined knowledge structures in video-based learning, learners need to process information deeply and reflect on the situation presented (Bransford et al., 2000). From a cognitive perspective, instructions should be designed in a way that does not overwhelm the learners and overload their working memory capacity (Kirschner et al., 2006). Thus, in order for students to link the practical situation presented in the video (i.e., the vicarious experience) with educational knowledge, balancing authenticity and cognitive demand is crucial when learning with classroom videos (Blomberg et al., 2013, 2014; Codreanu et al., 2020). In addition, task difficulty, which is strongly related to students’ prior knowledge base, must be considered (Codreanu et al., 2020).
Although contrastive video examples, in particular, suggest reflection processes on how and why the situations presented differ, the videos in themselves do not guarantee productive reflection: Not all learners might spontaneously identify key relations (i.e., key behaviors and their effects or consequences) in the situations presented, or, if they do so, they might not spontaneously reflect on them, although they would be able to do so (Cherrington and Loveridge, 2014). Beilstein et al. (2017), for instance, showed that pre-service teachers’ levels of video analysis varied in relation to the focus requested (i.e., unspecified, on teacher behavior, and on student behavior). To support learners’ knowledge construction, instructions on contrastive video examples must be designed in a way that requests clear objectives, draws learners’ attention to elements relevant to learning, and encourages them to engage in effective learning activities they would not engage in spontaneously (e.g., Brunvand, 2010; Blomberg et al., 2014).
When learning with contrastive video examples, superficial and fragmentary learning might be especially precarious, because failure to reflect on why certain behaviors are dysfunctional might lead learners to rehearse inappropriate behaviors (Bandura, 1977; Tsamir and Tirosh, 2005; Durkin and Rittle-Johnson, 2012; Metcalfe, 2017; Loibl and Leuders, 2019). Therefore, it seems promising to incorporate video analysis prompts that do not only aim at the integration of visual and written representations (Renkl and Scheiter, 2017) but also directly focus on teachers’ and students’ key behaviors and their interrelations. Such prompts could prevent learners from underestimating task value and from elaborating the examples superficially; further, they might optimize the use of working memory capacity, increase mental effort, and enhance germane learning processes (Chen and Bradshaw, 2007; Schworm and Renkl, 2007; Gerjets et al., 2008; Bannert, 2009; Van Merriënboer and Sweller, 2010; Wagner et al., 2016; Renkl, 2017). Especially, the sequence dysfunctional-functional might profit from video analysis prompts that encourage learners to scrutinize the dysfunctional model. Hence, the potential risk of internalizing dysfunctional procedures (Metcalfe, 2017) might be reduced.
When designing prompts used with contrastive video examples as an educational mean for promoting the acquisition of application knowledge of pre-service teachers, it seems appropriate to refer to the concept of professional vision (e.g., Sherin and van Es, 2009) and to link it with the genuine logic of learning from errors: Literature on professional vision (e.g., Seidel and Stürmer, 2014; Schäfer and Seidel, 2015; Gegenfurtner et al., 2020; Kramer et al., 2021) suggests a systematic process of (1) noticing and (2) reasoning to be relevant for dealing with different kinds of classroom events, such as classroom disruptions. While noticing refers to selecting relevant information in classroom situations, reasoning refers to interpreting the noticed information based on scientific knowledge by verbalizing a description, a possible explanation, and future-oriented consequences of what has been noticed. Learning from errors requires that learners are given the opportunity to realize a certain procedure to be dysfunctional, to understand why the procedure is dysfunctional, and to derive error avoidance strategies (Oser and Spychiger, 2005). Since reconstructing a dysfunctional procedure is relevant to yield the benefits of learning from errors, most work on dysfunctional examples includes tasks that require the learner to provide explanations (e.g., Barbieri and Booth, 2020). Findings from the study by Durkin and Rittle-Johnson (2012) indicate that comparison prompts asking learners to identify communalities and differences between multiple examples enhance learning. Furthermore, in the context of mathematics education, Loibl and Leuders (2019) showed that learners with comparison prompts outperformed the ones without when learning with functional and dysfunctional solutions after problem-solving. Mediation analyses hinted at elaboration processes mediating this effect.
Against this background, three decisive reflection prompts can be derived that are (1) recognizing key relations (between the teacher’s and pupils’ behaviors or the other way around in both the dysfunctional and functional video example), (2) comparing these key relations and (3) deriving error avoidance strategies as consequences for the own teaching practice. However, it is unclear to what extent such video analysis prompts promote pre-service teachers’ knowledge acquisition when learning with contrastive video examples.
Research Questions and Hypotheses
In the present study, pre-service teachers learned evidence-based classroom management rules and principles by analyzing two contrastive video examples in which the same teacher in the same context acted one time functionally (a functional video example) and one time dysfunctionally (a dysfunctional video example) in terms of classroom management (cf. Thiel et al., 2020). The study investigated to what extent the sequence of contrastive video examples (dysfunctional-functional vs. functional-dysfunctional) and video analysis prompts (with vs. without) affected different dimensions of learning outcomes, learning processes, and subjective dimensions.
(1) In terms of learning outcomes, it was investigated to what extent the factors sequence and prompts affected (a) declarative knowledge dimensions (i.e., concept knowledge about evidence-based classroom management principles) on the one hand, and (b) more complex procedural knowledge dimensions (i.e., application knowledge about evidence-based classroom management principles) on the other hand.
(2) Concerning the learning processes, the effects on the process of (a) recognizing key relations in the dysfunctional video example, (b) recognizing key relations in the functional video example, (c) comparing key relations, and (d) deriving error avoidance strategies were examined in the written video analyses.
(3) Above that, the study investigated the effects of the factors sequence and prompts on four subjective dimensions, namely, on (a) perceived mental effort and (b) perceived task difficulty, which serve as two indicators for cognitive load (Schmeck et al., 2015). Furthermore, in order to make statements about possible illusions of understanding (R. Stark et al., 2002; cf. Instructional challenges of using video examples in teacher education), effects on the (c) students’ perceived learning success were investigated. To detect potential underwhelming effects caused by the video-based learning environment (Kant et al., 2017; cf. Instructional challenges of using video examples in teacher education), it was also analyzed to what extent the factors sequence and prompts affected (d) students’ perceived task value.
(4) Moreover, it was analyzed to what extent the sequencing effect on learning outcomes was serially mediated by the learning processes for the conditions with and without video analysis prompts.
The following hypotheses were formulated:
Hypothesis 1. Regarding learning outcomes, i.e., (a) concept knowledge and (b) application knowledge, the sequence dysfunctional-functional and the prompts were expected to lead to higher learning outcomes, respectively. Furthermore, the group with the sequence dysfunctional-functional in combination with the prompts was assumed to show the highest learning outcomes.
Hypothesis 2. Similarly, the sequence dysfunctional-functional and the prompts were assumed to be more likely to promote the learning processes of (a) recognizing key relations in the dysfunctional video example, (b) recognizing key relations in the functional video example, (c) comparing key relations, and (d) deriving error avoidance strategies. In addition to this, it was expected that the group with the sequence dysfunctional-functional in combination with the prompts shows the deepest learning processes.
Hypothesis 3. The sequence dysfunctional-functional and the prompts were also assumed to lead to (a) higher ratings of perceived mental effort, (b) lower ratings of perceived task difficulty, (c) higher ratings of perceived learning success, and (d) higher ratings of perceived task value. The highest (for b lowest) ratings of each dependent measure were assumed with the sequence dysfunctional-functional combined with the prompts.
Hypothesis 4. The postulated sequencing effect on learning outcomes (i.e., concept knowledge, application knowledge) was assumed to be serially mediated by the learning processes (i.e., recognizing key relations in both video examples, comparing key relations, deriving error avoidance strategies) for the conditions with and without the prompts (cf. Figure 1).
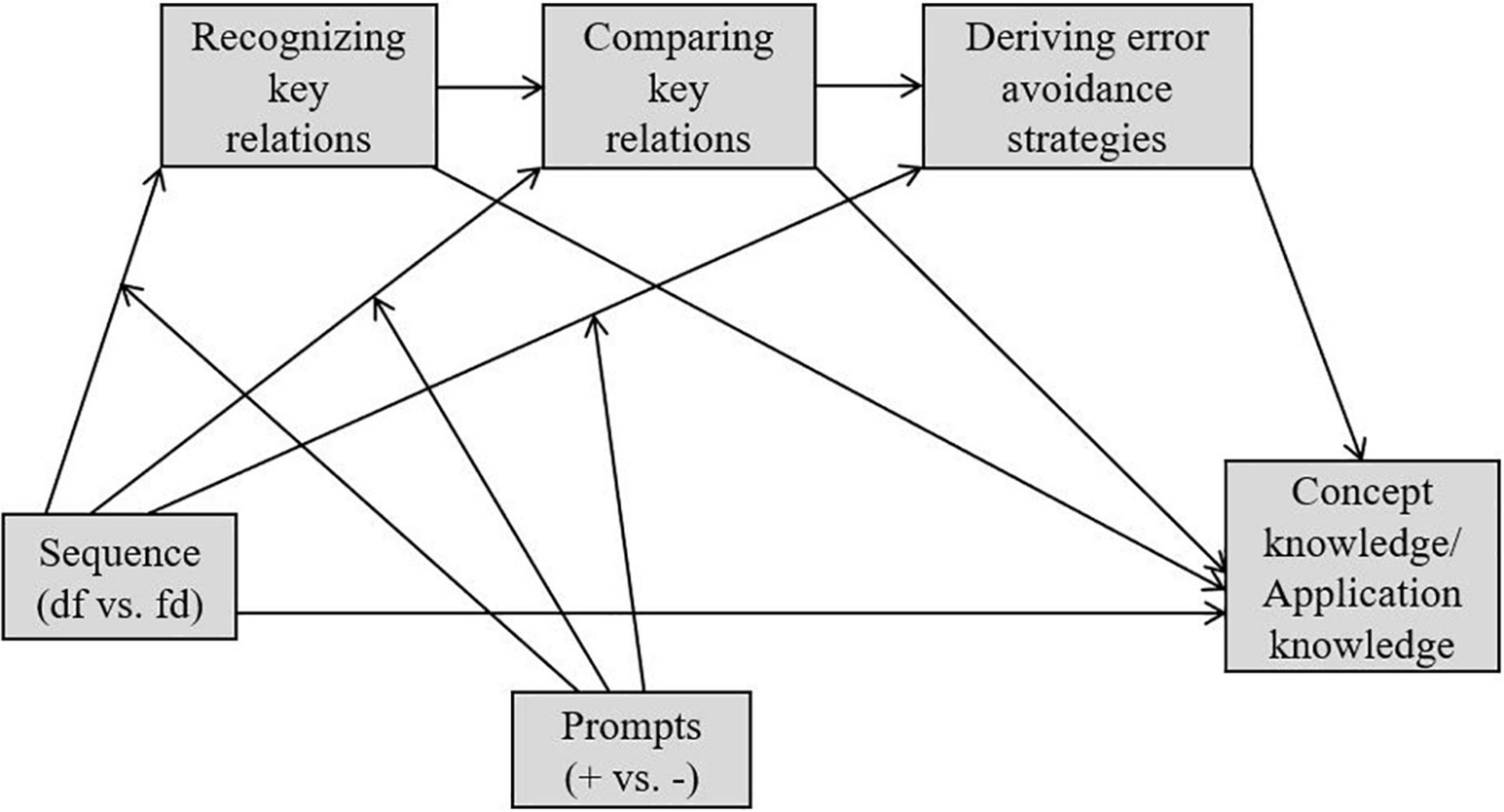
Figure 1. The conceptual regression model (Hypothesis 4). df, dysfunctional-functional; fd, functional-dysfunctional.
Materials and Methods
Participants and Design
In the present experimental intervention study, N = 220 pre-service teachers (age: M = 20.97, SD = 2.60; 60% female) participated during a regular teacher studies course at Saarland University in their first academic year. Since the data collection took place before their first internship at school, the students were novices concerning the treated topic of classroom management as well as in analyzing video examples. The factors sequence [dysfunctional-functional (df) vs. functional-dysfunctional (fd)] and prompts [with (+) vs. without (−)] were varied in a 2×2-factorial between-subjects design, resulting in four experimental groups with n = 55 participants each (cf. Table 1). To secure internal validity of the study, the participants were randomly assigned to the conditions (Goodwin and Goodwin, 2013). The groups df+ and df− were shown the dysfunctional video example first, which was followed by the functional video example. The group df+ received video analysis prompts, whereas df− did not. The functional video example was presented to fd+ and fd− before the dysfunctional video example, with fd+ receiving prompts and fd− not. A power analysis for 2×2-ANOVA with f = 0.20, α = 0.05, 1-β = 0.80 showed that a sample size of N = 199 would be sufficient to identify medium-sized effects.

Table 1. 2×2-factorial, experimental design.
Procedure and Material
The participants were tested in different rooms according to their assigned sequence (df or fd). To guarantee an identical procedure, the experimenters followed a detailed manual and were trained beforehand. At the start of the session, in a 15-min pre-test, all control measures were assessed. Then, in a 25-min pre-training, a handout of 1,900 words served as an instructional text on the content to be learned in the session, which was respective evidence on effective classroom management (e.g., Kounin, 1970; Ophardt and Thiel, 2013). At the beginning of the 90-min training phase, the participants briefly became acquainted with the individual worksheets to be used for the video analysis. With the worksheet, all the participants received the general instruction to analyze the two video examples to be followed behind the backdrop of classroom management evidence taught in the pre-training phase. The worksheets were irrespective of the sequence of the video examples, but they varied with the presence of additional video analysis prompts (cf. Prompts).
Dependent on the sequence (i.e., dysfunctional-functional vs. functional-dysfunctional; cf. Sequence), the dysfunctional or functional video example was presented one time from the front of the room. The video examples used in the training phase were taken from the video data base FOCUS Video Portal1 and were kindly made available to us by the Free University of Berlin (2018). The videos were produced at the Free University of Berlin for use in teacher training. For this purpose, a script was developed based on real classroom situations, evaluated by teachers, scientifically validated, and then implemented with actors and students from a theater group (cf. Thiel et al., 2017, 2020; Piwowar et al., 2018). Both video examples lasted about 8 min and started with the same initial situation in a ninth-grade class. Both video examples addressed typical classroom management situations (e.g., dealing with chatter, inattentiveness, or refusal to work)– with the difference that the teacher showed different pre- and intervention strategies that influenced the course of the lesson either in a negative or positive way. In other words, the video examples presented two contrasting courses of one classroom situation due to the teacher acting either in contradiction with evidence-based classroom management principles (e.g., Kounin, 1970; Ophardt and Thiel, 2013), or in accordance with it. In the dysfunctional video example, the teacher made typical novice errors, which resulted in an unfavorable course of action and increased disruptions in the lesson. In the functional video example, the teacher reacted appropriately to disruptions in the lesson, and thus positively influenced the course of action. The single interventions differed only in the degree of effectiveness (i.e., dysfunctional vs. functional), but were comparable regarding their context and the demands on the teacher (e.g., starting a lesson with a routine, structuring a lesson clearly and smoothy, monitoring, group mobilizing, reacting clearly to a certain misbehavior; cf. Kounin, 1970; Ophardt and Thiel, 2013). For instance, in the dysfunctional video example, the teacher involuntarily encouraged the pupils to talk, as she began the lesson without a routine, such as saying “good morning” (cf. Kounin, 1970; Ophardt and Thiel, 2013). In contrast, in the functional video example, the teacher signaled the start of the lesson by closing the door, interrupted the pupils’ conversation by walking around, and started with the routine of saying “good morning” (for further information on the video examples, cf. Piwowar et al., 2018 as well as Thiel et al., 2017, 2020). As the worksheets that were used with the videos in the present study differed from those that were used in the studies by Piwowar et al. (2018) and Thiel et al. (2020), the worksheets were piloted and evaluated in advance during another regular teacher studies course at Saarland University.
The participants could make notes while watching the video example and they were given 30 min afterward to analyze it in a written form, either guided by prompts (i.e., prompt 1; cf. Prompts) or not. Subsequently, the experimenter started the second video example (dysfunctional or functional) followed by another 30 min for the analysis (with prompts 2–4 or without). During the video analyses, the students were allowed to use the handout, but they had to put it away before the final phase started. In this final phase of 35 min, the subjective measures were assessed, and the performance test was administered (for an overview of the procedure, cf. Figure 2).
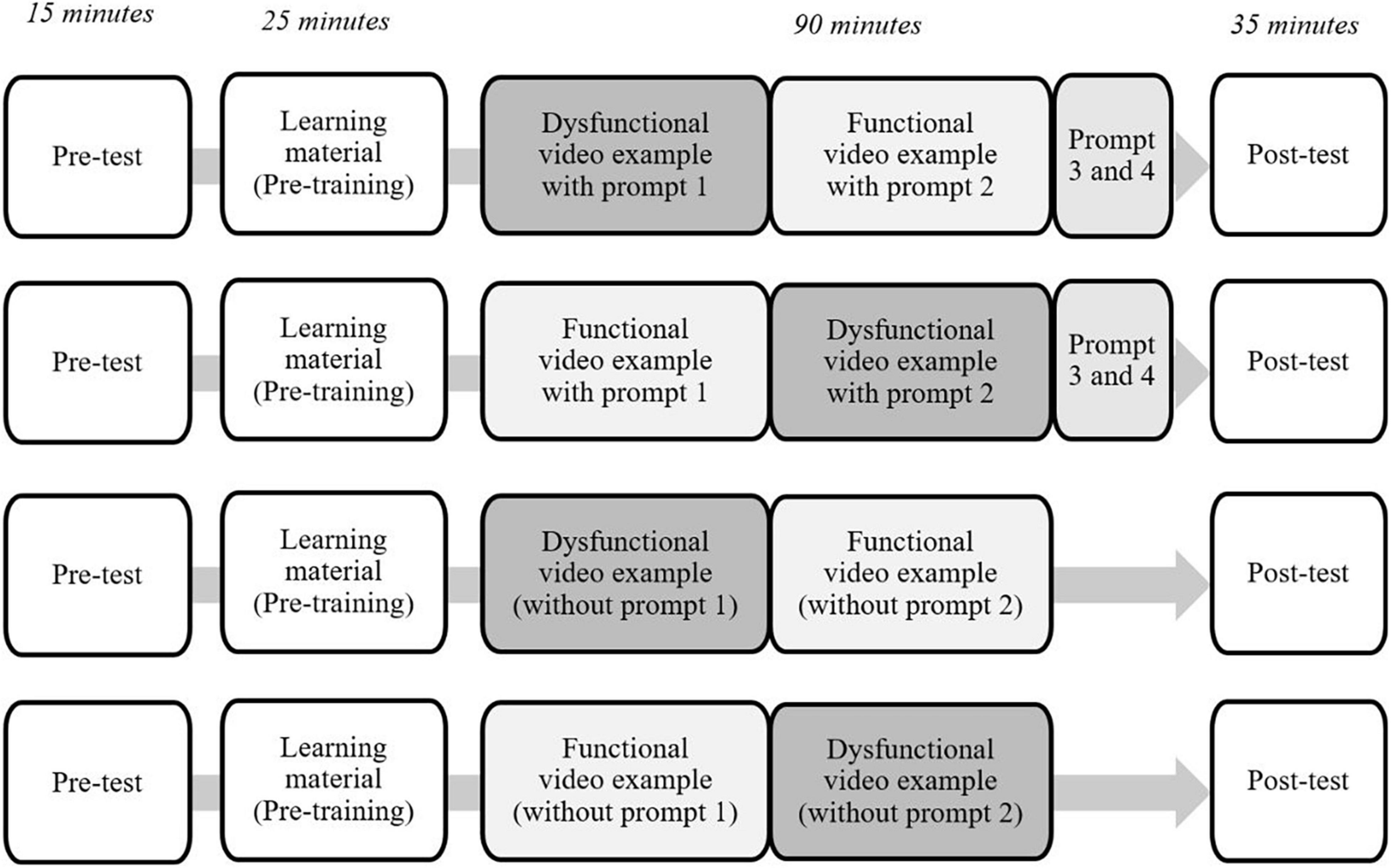
Figure 2. Procedure for the four experimental groups (df+; fd+; df−; fd−).
Sequence
During the training, the sequence of the video examples was experimentally varied. The groups with the sequence specification dysfunctional-functional (df+, df−) watched and analyzed the dysfunctional video example first. Subsequently, the functional video example was presented to be analyzed. In the other two groups (fd+, fd−), the sequence was changed, but the procedure remained the same.
Prompts
In addition to the general instruction to analyze the video examples against the background of classroom management evidence (cf. Procedure and Material), the worksheets for the supported groups (df+, fd+) provided four video analysis prompts, whereas the participants of the non-supported groups (df−, fd−) did not receive any video analysis prompts. The prompts were adapted from the concept of professional vision, which was transferred on the genuine logic of learning from errors (cf. Sequence: Dysfunctional-Functional or Functional-Dysfunctional? and Tasks Guiding the Learning Process: Need for Instructional Prompts?): Prompts 1 and 2 instructed the participants to recognize key relations in each video example, irrespective of the sequence of the video examples (“Recognizing key relations: Please explain which key behavior of the teacher you have noticed while watching the video caused certain key reactions of the students you have noticed – or the other way round.”). Prompt 3 asked the participants to explain the different courses of the action by comparing the key relations of both video examples with each other (“Comparing key relations: Please explain the different courses of the action by comparing the key relations of both videos with each other.”). Prompt 4 required them to derive suitable error avoidance strategies (“Deriving error avoidance strategies as consequences for own practice: Please describe how you would concretely avoid the teacher’s dysfunctional behaviors you have identified in terms of classroom management in your own school practice.”).
Measures
Learning Outcomes
A self-designed learning performance test on the topic of classroom management was administered to assess learning outcomes. The test included three recall tasks to measure concept knowledge (e.g., “Please explain what effective classroom management means referring to Kounin’s principles.”) and six application tasks to measure application knowledge. Five application tasks required evaluating the acting of teachers in a short scene, which was provided as a written text vignette (“The scenes below could be observed in everyday teaching. Please discuss whether the teacher acts functionally or dysfunctionally against the background of classroom management evidence.”). Each scene described behaviors of one pupil or a group of pupils and of the teacher in classroom (between 80 and 220 words per scene). The participants could score a maximum of four points per scene. The sixth application task asked the students to outline options to action to a students’ misbehavior described in a written vignette (two students continuously interrupting the lesson by talking and giggling; 50 words; “Please discuss how you would act as a teacher in the following scenario and justify your actions based on the phases of functional intervention you have just learned.”). The participants could score a maximum of eight points for this task. Like the worksheets, the learning performance test was also piloted and evaluated in advance during another regular teacher studies course at Saarland University.
Two raters were trained to evaluate the answers blind to conditions. To calculate inter-rater reliability, ten percent of the sample (n = 22) was double-coded. A mean Cohen’s kappa of κ = 0.93 for recall tasks and of κ = 0.85 for application tasks indicated a satisfactory inter-rater reliability. The total scores for concept knowledge and application knowledge were calculated by adding the scores achieved by the participants in each of the tasks (for concept knowledge: max., 16 points; Cronbach’s α = 0.60; for application knowledge: max., 28 points; Cronbach’s α = 0.65). All the tasks met satisfactory item parameters with a difficulty index 0.20 < pi < 0.80 and a discriminating power ri (t–i) > 0.20.
Learning Processes
To measure learning processes, two intensively trained raters coded the written video analyses. According to the concept of learning from errors (Oser and Spychiger, 2005), the following variables were computed by scoring the number of correctly mentioned aspects: (1) recognizing key relations in the dysfunctional video example (max., 15; e.g., “It is noticeable that the teacher tries to start the lesson without welcoming the students and waiting until they are quiet. This encourages the students to remain restless and not to listen to her.”), (2) recognizing key relations in the functional video example (max., 15; e.g., “In that video, the teacher closes the door before starting the lesson, and she walks around, which signals the students that they should now keep their voices down. Then, the lesson is officially started with a good morning.”), (3) comparing key relations (max., 15; e.g., “In summary, in the first video example, the pupils do not get quiet, because there is no routine that signals the beginning of the lesson; in the second video, in turn, the lessons start much more quiet due to this one routine of saying hello, I have just explained.”) and (4) deriving error avoidance strategies (max., 15; e.g., “For my own lessons, I take away that I should not just start the lesson without a clear signal, and that I should always wait until everyone is really quiet.”). The maximum numbers were deduced from an expert rating and related to 15 evidence-based classroom management principles that are represented in the video (e.g., starting a lesson with a routine, structuring a lesson clearly and smoothly, monitoring, group mobilizing, reacting clearly to a certain misbehavior; cf. Kounin, 1970; Ophardt and Thiel, 2013).
The analyses of the participants who did not receive the prompts (df−, fd−) were scored using the same categories. Again, ten percent of the sample (n = 22) was double-coded. A mean Cohen’s kappa of κ = 0.82 for recognizing key relations in the functional video example, κ = 0.80 for recognizing key relations in the dysfunctional video example, κ = 0.78 for comparing key relations and of κ = 0.85 for deriving error avoidance strategies indicated a satisfactory inter-rater reliability. In order to realize a serial mediation with the process measures, the scores of recognizing key relations in the functional and in the dysfunctional video example were summed.
Subjective Dimensions
As two indices for cognitive load, perceived mental effort (Paas, 1992; “How much mental effort did you invest in the learning unit?”; 1 = very little, 7 = very high) and perceived task difficulty (Kalyuga et al., 2000; “How easy or difficult was the learning unit to understand?”; 1 = very easy, 7 = very difficult) were assessed by single items. These subjective ratings were used in the current research as an economic method to measure cognitive load (cf. Schmeck et al., 2015). The ratings were supplemented by a single item (Park et al., 2015; “How low or high do you estimate your learning success?”; 1 = very low, 7 = very high) to measure perceived learning success. The participants’ perceived task value was assessed by twelve items (L. Stark et al., 2018; e.g., “Understanding the subject matter of this course is very important to me.”), which had to be rated on a 7-point Likert scale, ranging from 1 = not at all true to 7 = very much true (Cronbach’s α = 0.89).
Control Measures
Prior concept knowledge and prior application knowledge were assessed by a short version of the learning performance test (cf. Learning Outcomes) with one of the recall tasks (max., 8 points) and one of the application tasks that required evaluating the acting of teachers in a short scene (max., 4 points). Furthermore, attitudes toward the use of educational evidence were assessed by nine items adopted from Wagner et al. (2016; “Teachers should apply educational evidence when reflecting on their teaching.”; 1 = not at all true, 5 = very much true; Cronbach’s α = 0.90). The participants’ academic self-concept was assessed by five items (Dickhäuser et al., 2002; e.g., “I hold my talent for educational studies for 1 = low, 7 = high.”; Cronbach’s α = 0.79).
Analytic Strategy
For all global tests of significance, α = 0.05 was applied as a level of significance. For the interrelated measures of learning outcomes, learning processes and the two cognitive load measures, 2×2-factorial multivariate analyses of variance (MANOVAs) with the experimental factors sequence and prompts were calculated. For all other subjective measures, as well as subsequent to the MANOVAs, 2×2-factorial ANOVAs were computed. For significant interaction effects, planned contrast tests were performed. The Bonferroni–Holm correction was applied to account for potential alpha error inflation.
Hayes’s (2018) PROCESS macro for SPSS version 3.5 was used to examine the postulated mediation (Hypothesis 4). Two moderated serial mediation models were computed with three mediators in a row (i.e., recognizing key relations in both video examples, comparing key relations, deriving error avoidance strategies), with the factor sequence as predictor/as moderator (Figure 1). Concept knowledge was used as a dependent measure in Model 1 and application knowledge in Model 2. For regression-based analyses, all mediating and dependent variables were z-standardized and grouping variables were coded as contrasts with −1 and +1. The number of bootstrap samples was set at 10,000 to test indirect paths of mediation. Significant effects were interpreted referring to 95% confidence intervals not including zero.
Results
Table 2 displays the means and standard deviations of all variables for all experimental groups. One-way ANOVAs revealed no significant between-group differences regarding the control measures prior concept knowledge, prior application knowledge, attitudes toward the use of educational evidence, and academic self-concept, Fs < 1. Table 3 presents the results of the correlation analysis and Table 4 those of the contrast tests.
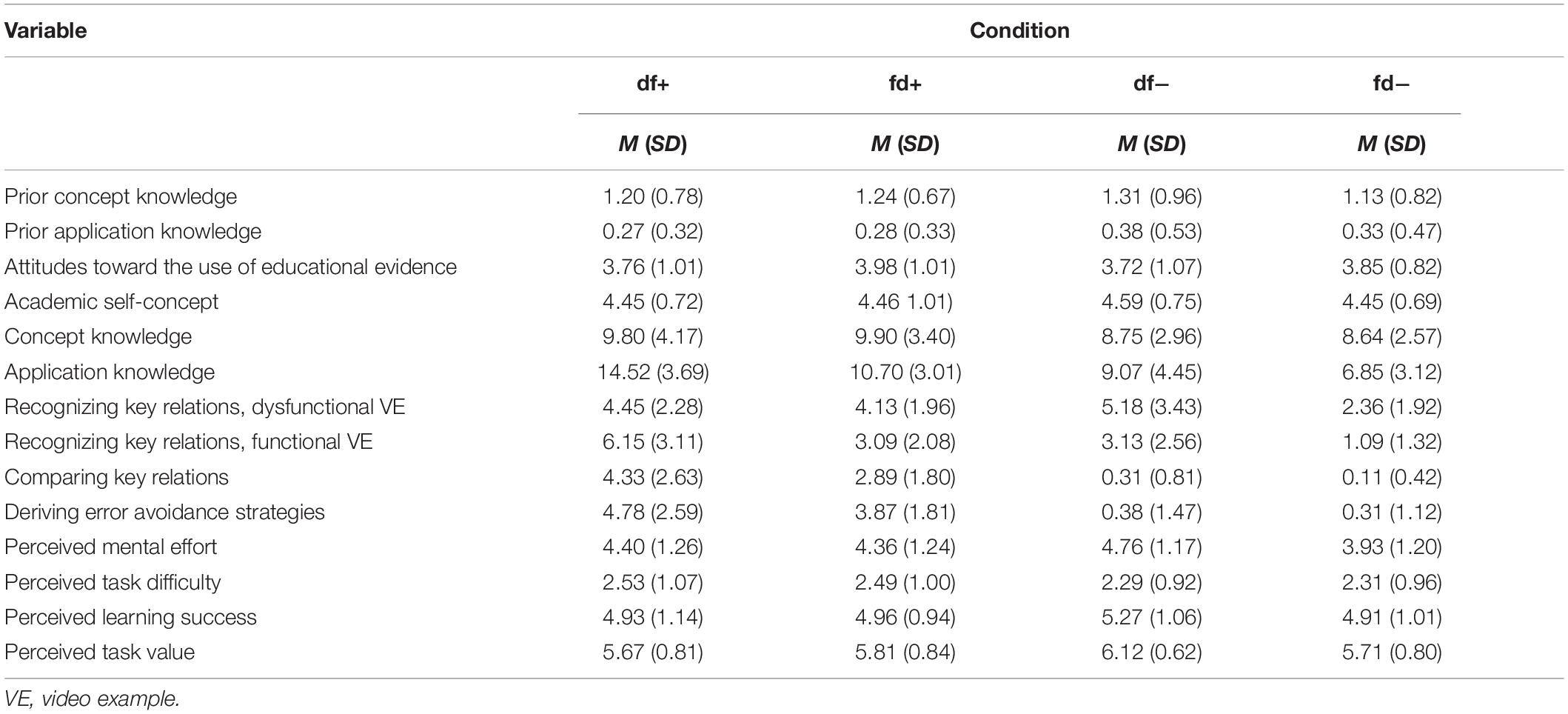
Table 2. Means and standard deviations for all variables, depending on the experimental condition.
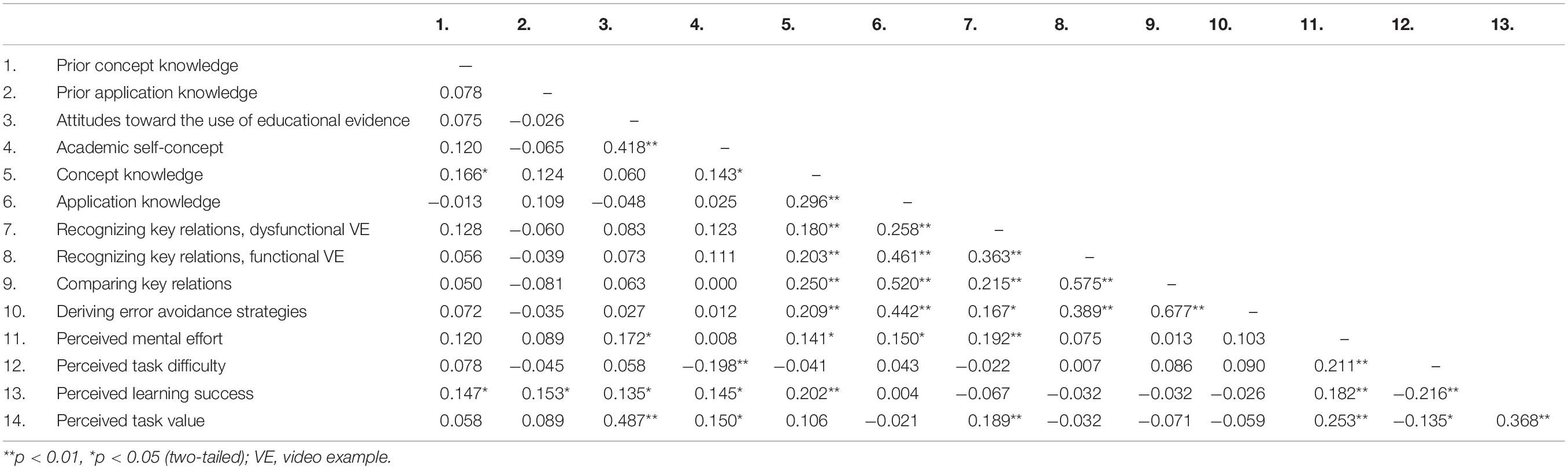
Table 3. Bivariate correlations between all variables: r-coefficients and p-levels.

Table 4. Results of contrast tests for those dependent variables with a significant interaction effect.
Learning Outcomes
The two measures of learning outcomes, i.e., concept knowledge and application knowledge, showed a weak to moderate positive correlation (Table 3). The 2×2-factorial MANOVA using the factors sequence and prompts as between-subject factors and both concept knowledge and application knowledge as dependent measures revealed significant main effects with large effect sizes of the video sequence, Λ = 0.84, F (2, 215) = 20.55, p < 0.001, ηp2 = 0.16, and of the prompts, Λ = 0.70, F (2, 215) = 45.21, p < 0.001, ηp2 = 0.296. The interaction between both factors was not significant, Λ = 0.99, F (2, 215) = 1.59, p = 0.207.
Regarding concept knowledge, the subsequent 2×2-ANOVA revealed no significant main effect of the video sequence, F < 1. There was only a small-sized main effect of the prompts, F (1, 216) = 6.67, p = 0.010, ηp2 = 0.030, indicating that learners with the prompts outperformed learners without the prompts in the post-test. In line with the results of the MANOVA, there was no interaction, F < 1.
Concerning application knowledge, however, ANOVA results revealed a significant main effect with large effect size of the video sequence, F (1, 216) = 38.34, p < 0.001, ηp2 = 0.151. The learners who watched the video examples in the sequence dysfunctional-functional outperformed the learners who watched the same video examples in the inverse sequence. In addition, there was a large-sized significant main effect of the prompts, F (1, 216) = 90.84, p < 0.001, ηp2 = 0.296, indicating that the prompts led to a higher level of application knowledge. The interaction effect was not significant, F (1, 216) = 2.69, p = 0.102.
Learning Processes
A 2×2-MANOVA using the learning process variables as dependent measures revealed a large-sized significant main effect of the video sequence, Λ = 0.75, F (4, 213) = 17.65, p < 0.001, ηp2 = 0.249 and of the prompts, Λ = 0.35, F (4, 213) = 99.03, p < 0.001, ηp2 = 0.650. Furthermore, there was a medium-sized significant interaction between both factors, Λ = 0.78, F (4, 213) = 7.89, p < 0.001, ηp2 = 0.129.
The 2×2-ANOVA with recognizing key relations in the dysfunctional video example as a dependent variable revealed a medium-sized main effect of the video sequence, F (1, 216) = 22.22, p < 0.001, ηp2 = 0.093. Analyzing the dysfunctional video example first was beneficial to recognizing key relations in this video. There was no significant main effect of the prompts, F (1, 216) = 2.41, p = 0.122. A significant hybrid interaction, F (1, 216) = 13.93, p < 0.001, ηp2 = 0.061, allows to interpret the main effect of the video sequence globally (Figure 3). Contrast tests showed that the learners analyzing the dysfunctional video example at the second position without prompts (fd−) recognized fewer key relations in this video than each of the other groups (ps < 0.001; Table 4).
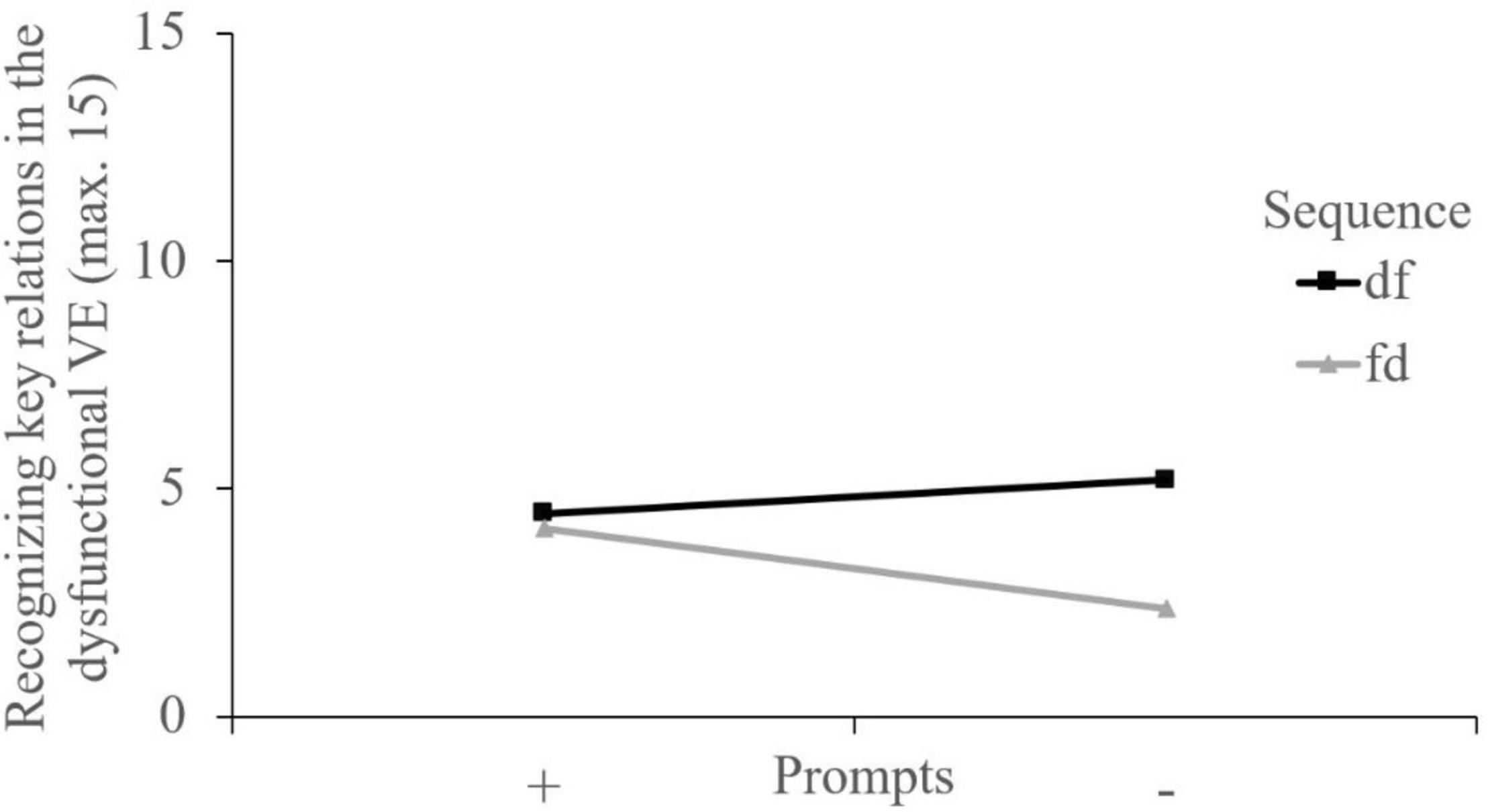
Figure 3. Interaction plot regarding recognizing key relations in the dysfunctional video example. VE, video example.
Regarding recognizing key relations in the functional video example, the subsequent 2×2-ANOVA revealed a significant main effect of the video sequence with large effect size, F (1, 216) = 63.93, p < 0.001, ηp2 = 0.228, indicating that the learners who studied the functional video example after the dysfunctional video example recognized more key relations than those who studied the functional video example first. In addition to this, there was a large significant effect of the prompts, F (1, 216) = 62.12, p < 0.001, ηp2 = 0.223, showing that the prompts enhanced recognizing key relations in the functional video example. The interaction between the factors sequence and prompts did not reach the level of statistical significance, F (1, 216) = 2.56, p = 0.111.
Concerning comparing key relations results revealed a small-sized significant main effect of the video sequence, F (1, 216) = 13.38, p < 0.001, ηp2 = 0.058. The learners who analyzed the dysfunctional video example first made more comparisons than those working the other way round. There was also a significant and large main effect of the prompts, F (1, 216) = 230.98, p < 0.001, ηp2 = 0.517, which indicated that the prompts increased the number of comparisons. Moreover, there was a significant ordinal interaction, F (1, 216) = 7.63, p = 0.006, ηp2 = 0.034. Thus, both main effects can be interpreted globally (Figure 4). Pairwise contrast tests showed that the group who analyzed the video examples in the sequence dysfunctional-functional with the help of the prompts reported most comparisons compared to each of the other groups (ps < 0.05; Table 4).
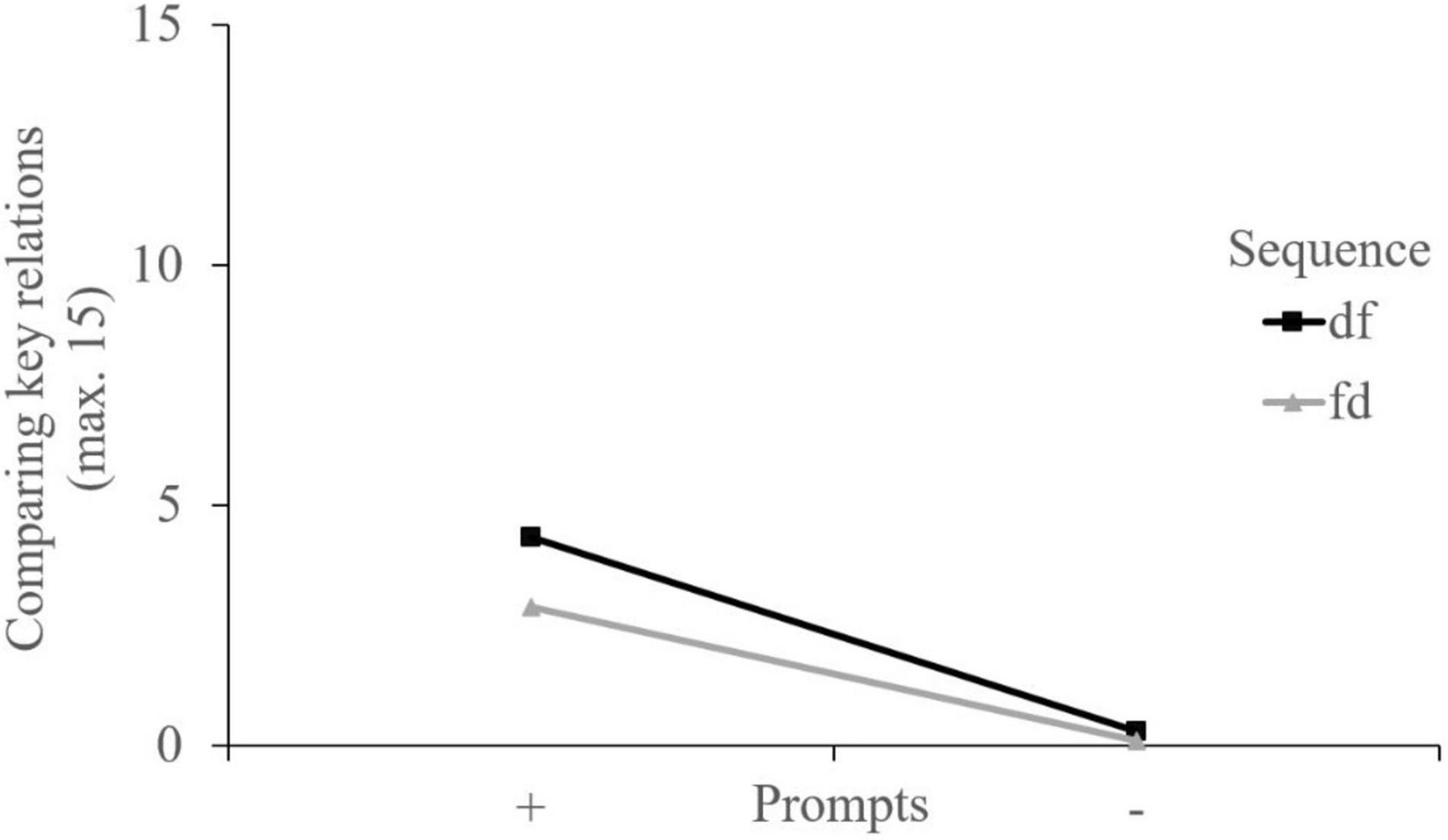
Figure 4. Interaction plot regarding comparing key relations.
With respect to deriving error avoidance strategies, there was a small-sized significant main effect of the video sequence, F (1, 216) = 3.96, p = 0.048, ηp2 = 0.018. The sequence dysfunctional-functional led the participants to derive more error avoidance strategies than the inverse sequence. Moreover, there was a large-sized significant main effect of the prompts, F (1, 216) = 260.80, p < 0.001, ηp2 = 0.547. The learners with the prompts derived more strategies than those without. There was no significant interaction between the two factors, F (1, 216) = 2.88, p = 0.091.
As Table 3 displays, all correlations between learning processes and learning outcomes were significant and positive, reaching from weak correlations in the case of concept knowledge to moderate and high correlations in the case of application knowledge.
Subjective Dimensions
The 2×2-factorial MANOVA with the cognitive load indicators (i.e., perceived mental effort and task difficulty) as dependent variables showed a significant main effect of the video sequence, Λ = 0.97, F (2, 215) = 3.66, p = 0.027, ηp2 = 0.033, but none of the prompts, Λ = 0.99, F (2, 215) = 1.24, p = 0.293. The interaction effect was significant, too, Λ = 0.97, F (2, 215) = 3.24, p = 0.041, ηp2 = 0.029.
A subsequent 2×2 ANOVA with perceived mental effort as a dependent variable showed a small-sized significant sequencing effect, F (1, 216) = 7.80, p = 0.008, ηp2 = 0.032. In line with the MANOVA, there was no significant main effect of the prompts, F < 1. Due to a small-sized significant hybrid interaction, F (1, 216) = 5.95, p < 0.016, ηp2 = 0.027, the main effect of the video sequence can be interpreted globally (Figure 5). The sequencing effect occurred particularly in the absence of the prompts, since contrast tests revealed only significant differences between the groups without the prompts (df– and fd–): In these groups, the participants working with the dysfunctional video example first reported higher perceived mental effort than those working with the functional video example first (ps < 0.001; Table 4).
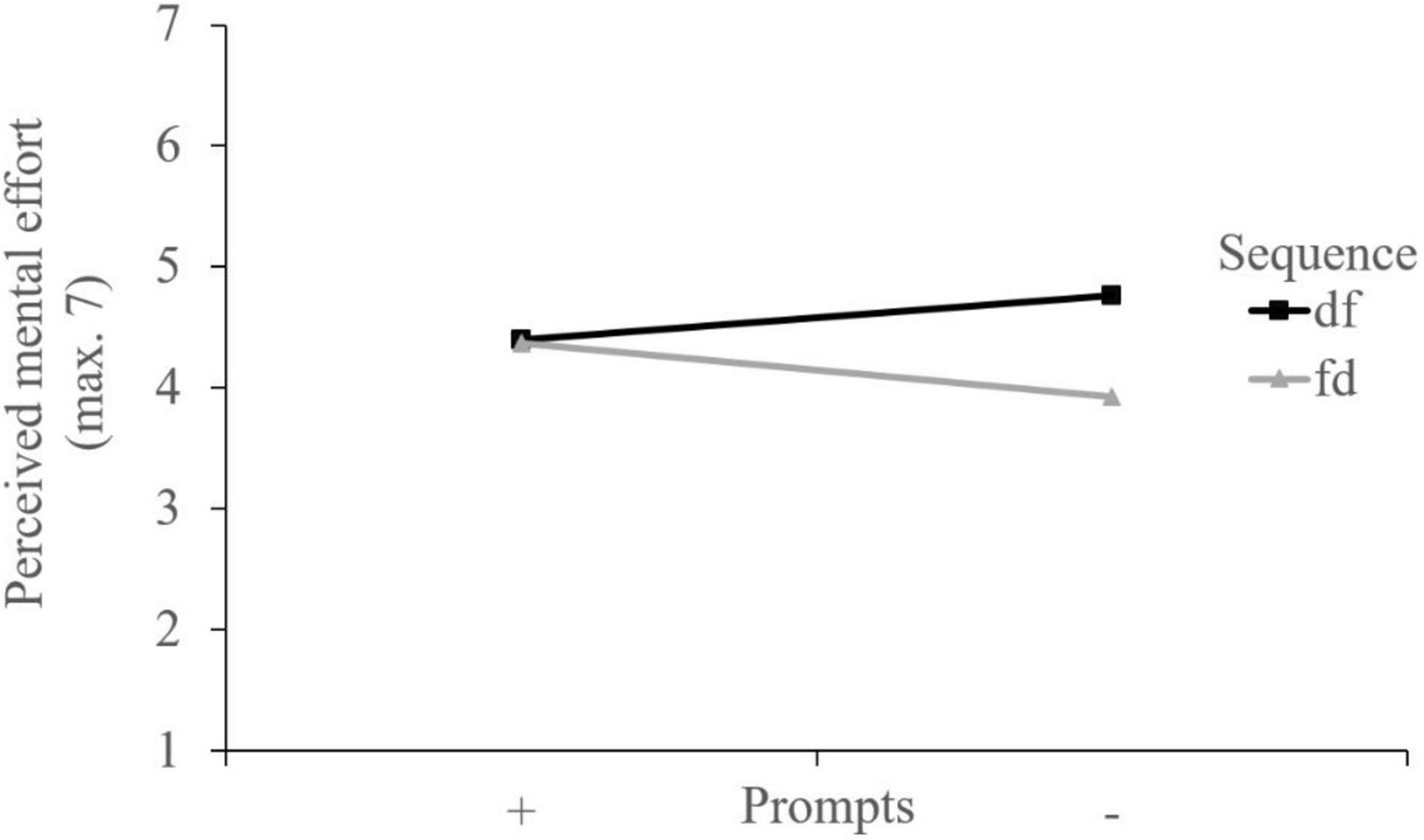
Figure 5. Interaction plot regarding perceived mental effort.
Concerning perceived task difficulty, there was neither a significant main effect of the video sequence, F < 1, a significant main effect of the prompts, F (1, 216) = 2.47, p = 0.118, nor a significant interaction, F < 1.
With respect to perceived learning success, results did not reveal significant main effects of the video sequence, F (1, 216) = 1.37, p = 0.244, or of the prompts, F (1, 216) = 1.08, p = 0.300. The interaction was not significant either, F (1, 216) = 2.03, p = 0.155.
The 2×2 ANOVA with perceived task value as a dependent variable revealed neither a significant main effect of the video sequence, F (1, 216) = 1.70, p = 0.193 nor one of the prompts, F (1, 216) = 2.79, p = 0.096. However, there was a significant disordinal interaction with small effect size, F (1, 216) = 6.90, p = 0.009, ηp2 = 0.031 (Figure 6). The group watching the dysfunctional video example first and having no prompts reported the highest perceived task value. The difference was significant in comparison to the group with the same sequence but with the prompts and in comparison to the group without the prompts and with the reversed (ps < 0.05; Table 4).
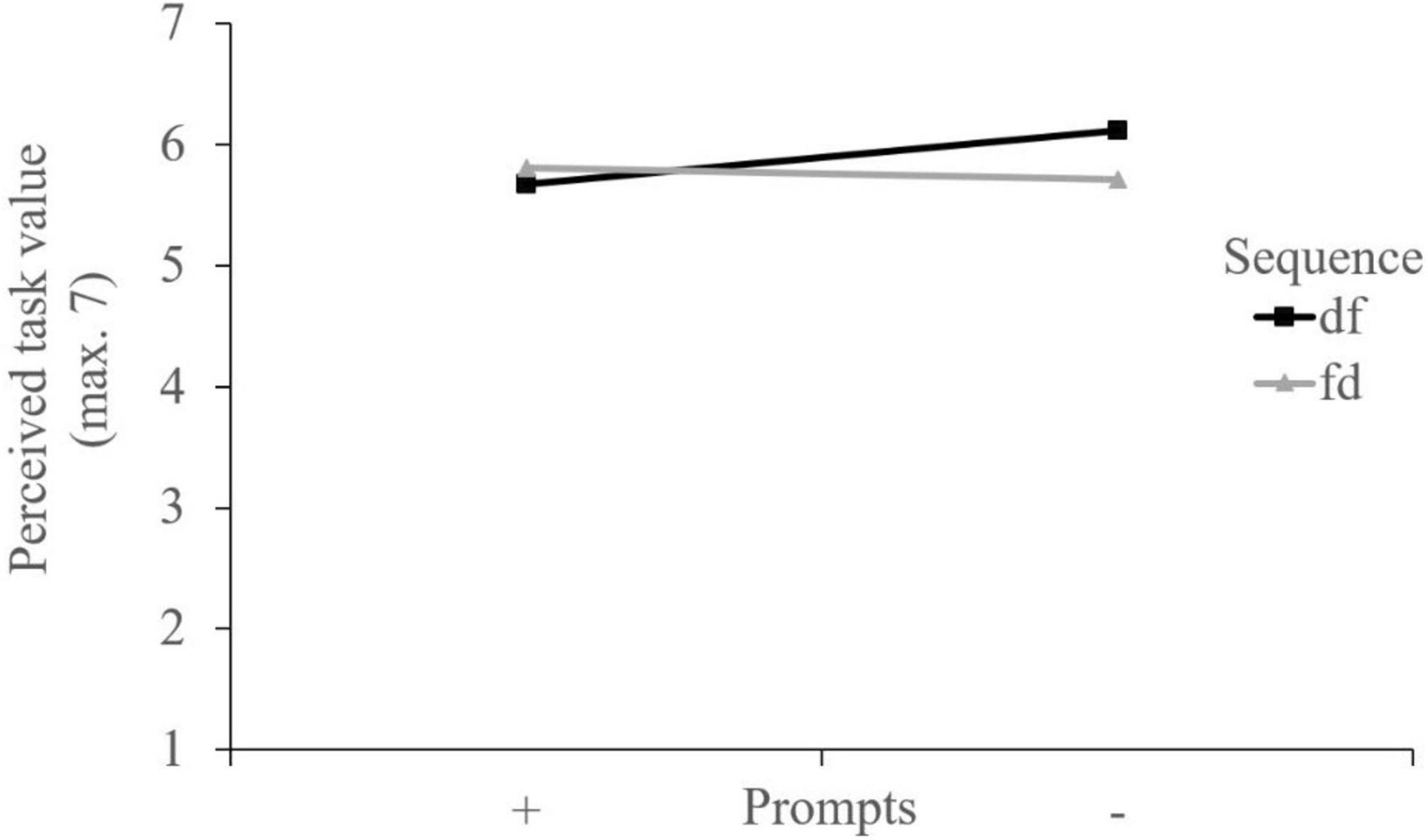
Figure 6. Interaction plot regarding perceived task value.
Correlation analyses revealed significant but weak positive relations between perceived mental effort and learning outcomes. Neither the relation between learning outcomes and perceived task difficulty nor the relation between learning outcomes and perceived task value was significant. Perceived learning success showed a weak, positive correlation with concept knowledge but not with application knowledge (Table 3).
Serial Mediation
Two moderated serial mediation analyses were computed to examine whether the sequencing effect on concept knowledge (Model 1) and on application knowledge (Model 2) was serially mediated by the learning processes (i.e., recognizing key relations in both video examples as the first-stage mediator, comparing key relations as the second-stage mediator and deriving error avoidance strategies as the third-stage mediator) for both conditions with and without prompts (Hypothesis 4, Figure 1). The results of comprised regressions are displayed in Tables 5, 6, those of the indirect paths in Table 7.
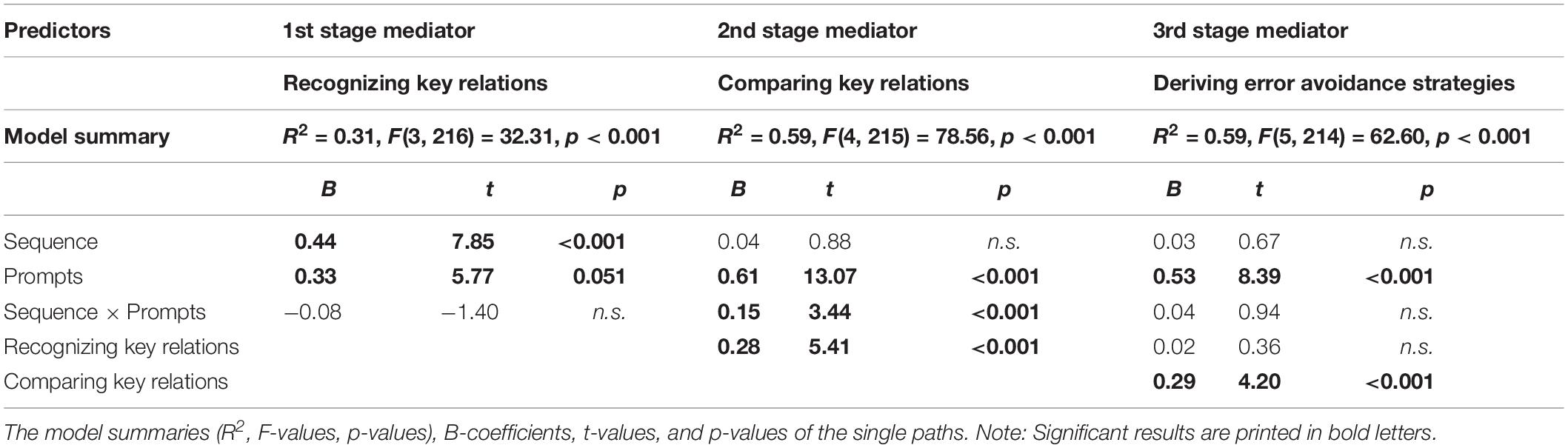
Table 5. Results of moderated serial mediation analyses with the mediators as dependent variables.
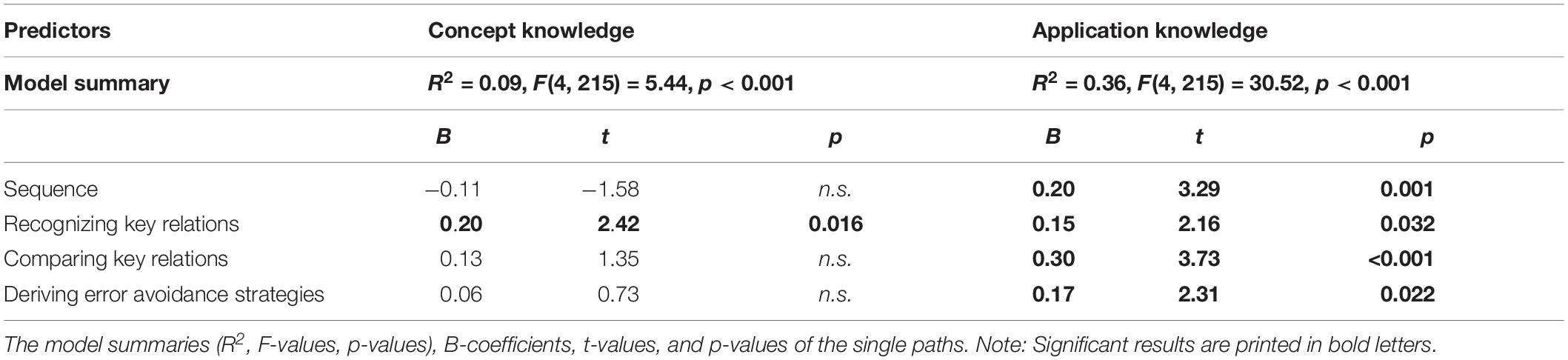
Table 6. Results of regression models with concept knowledge and application knowledge as dependent variables.
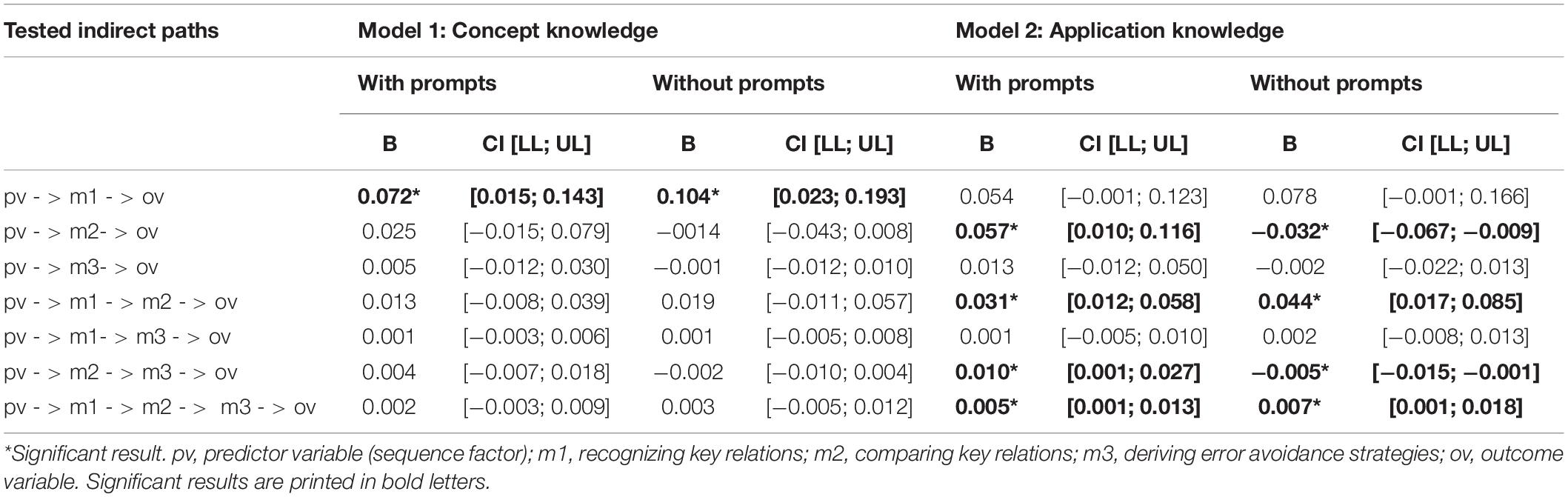
Table 7. Indirect effects for the moderated serial mediation models regarding learning outcomes for the groups with and without prompts: B-coefficients and 95% confidence intervals (CI).
Regarding concept knowledge (Model 1), the learning process variables did not serve as serial mediators. Here, only the indirect path with recognizing key relations as a single mediator was significant for both conditions with the prompts and without (Table 7). In Model 2, however, results revealed that the sequencing effect on application knowledge was serially mediated by the processes of recognizing key relations, comparing key relations and deriving error avoidance strategies for both conditions with the prompts and without (Table 7). All indirect paths of the model that included comparing key relations as a mediator turned out to be significant, too (Table 7).
Discussion
The present study focused on the effects of sequencing contrastive video examples and incorporating video analysis prompts in the context of an error-based approach in the domain of teacher education. The internal validity of the study can be regarded as secured, as the four experimental groups did not differ significantly with respect to potential confounding variables.
Effects of the Factors Sequence and Prompts on Learning Outcomes
Concerning learning outcomes, basic declarative knowledge dimensions (i.e., concept knowledge) and complex procedural knowledge dimensions (i.e., application knowledge) were assessed. Theoretical considerations, as well as the low correlation between concept and application knowledge, suggested that both constructs should be analyzed separately. However, Hypothesis 1 was only partly confirmed. As expected, the acquisition of concept knowledge was supported by prompts, whereas the effect on application knowledge was even more pronounced. Presenting the video examples in the order dysfunctional-functional fostered the acquisition of application knowledge but not of concept knowledge, which contrasts with our assumptions. The postulated superiority of the condition with the sequence dysfunctional-functional and with the prompts was confirmed only descriptively for application knowledge, which might be caused by power restrictions. The video sequence did not affect the acquisition of concept knowledge. Thiel et al. (2020) showed that the functional video example enhanced the acquisition of declarative knowledge facets. In the present study, providing both video examples might have had a compensatory function irrespective of the video sequence. The sequence following the genuine logic of learning from errors and the processes triggered by it (Oser and Spychiger, 2005) seemed to be particularly decisive for the acquisition of more complex and procedural knowledge facets.
Relating Results of Learning Processes and of Learning Outcomes
Most of our assumptions regarding Hypothesis 2 were confirmed. As expected, learning processes were supported by presenting the dysfunctional video example first and by providing prompts afterward. The postulated effects of the prompts were even stronger than those of the video sequence, except for recognizing key relations in the dysfunctional video example, for which an interaction effect was detected. An interaction effect was confirmed for comparing key relations, too. As expected, the group who analyzed the videos in the sequence dysfunctional-functional with the help of prompts made the most comparisons. The findings converge with the significant positive correlations of the learning processes with the learning outcomes (especially application knowledge) and with the results of the moderated serial mediation analyses.
The acquisition of application knowledge and learning processes was enhanced by presenting the dysfunctional video example first. The sequence dysfunctional-functional may have induced a cognitive conflict that, in turn, enhanced learning with the functional video example (Piaget, 1985; cf. Booth et al., 2015). Furthermore, negative stimuli attract more attention than positive ones (negativity bias; positive-negative asymmetry; Ohira et al., 1998). The dysfunctional example seems to have guided learners’ attention to target incidents (Große and Renkl, 2007; Booth et al., 2013; Barbieri and Booth, 2020) and stimulated them to find corresponding incidents in the subsequent functional example, even without being requested by the second prompt. In contrast to this, the learners who analyzed the functional video example first were initially presented to classroom interactions that were conformed to the instructional text presented before. They might have recognized fewer key relations in both video examples, as the relations in the initial, functional video example were too self-evident to them to be classified as relevant (Miller, 2011; Scheiner, 2021), especially if no guidance was provided.
Adequate instructional guidance seemed to be essential to trigger comparison processes and, especially, the reflection of these processes by deriving error avoidance strategies. The groups who were not supported by the video analysis prompts did rarely engage themselves in the processes of comparing key relations and deriving error avoidance strategies. The findings replicate the findings of other studies in the context of teacher education, in which prompts supported problem-solving activities and the acquisition of educational knowledge (e.g., Chen and Bradshaw, 2007; Wagner et al., 2016). Furthermore, they substantiate the relevance of instructional guidance in the context of example-based learning (Schworm and Renkl, 2007; Renkl, 2017; Mayer, 2020).
Hypothesis 4 was completely confirmed regarding application knowledge and, partly, for concept knowledge. While the sequencing effect on application knowledge was mediated by all postulated process variables in a row for both conditions with and without the prompts, only recognizing key relations turned out to be a significant mediator for the acquisition of concept knowledge. Integrating the theoretical concepts, which were provided during the pre-training, and corresponding behaviors, presented in the video example, proved to be particularly crucial for knowledge consolidation (Thiel et al., 2020). However, the processes following the genuine logic of learning from errors (Oser and Spychiger, 2005) did not seem to be important for the acquisition of concept knowledge but of more complex knowledge facets. Nevertheless, according to both the correlation and the mediation analyses, especially comparing processes appeared to be decisive for the acquisition of complex knowledge dimensions. Comparing key relations turned out as the most important mediating variable, as all indirect paths, including this variable, were significant. Furthermore, it seemed to have built the source for the final process of deriving error avoidance strategies, as these variables were highly related. The findings are in line with the evidence on the benefits of comparisons for learning and transfer (Rittle-Johnson and Star, 2009; Star and Rittle-Johnson, 2009; Durkin and Rittle-Johnson, 2012; Loibl and Leuders, 2019; Rittle-Johnson et al., 2019). However, mediation results were independent of the prompting procedure. That might hint at a potential internal script (Fischer et al., 2013) that corresponds with the rationale of learning from errors, and that is particularly activated by the sequence dysfunctional-functional. Finally, these results of the present study have broadened the scope of validity of the concept of learning from errors by supporting its process-related assumptions.
Impact of the Factors Sequence and Prompts on Subjective Dimensions
Most assumptions of Hypothesis 3 could not be confirmed. The participants’ perceived mental effort was influenced by the video sequence, but not by the prompts. A small interaction between both experimental factors showed that the participants working with the functional video example first reported lower mental effort than those in the dysfunctional-functional conditions if they were not provided with the prompts. As perceived mental effort can be cautiously interpreted as an indicator of germane cognitive load (for an overview on the discourse about cognitive load indicators, cf. Korbach et al., 2018), the investment of germane resources in the functional-dysfunctional condition without the prompts was comparably low. This result is also consistent with the fact that the learners in that group recognized and compared fewer key relations than the learners in all other conditions. The second indicator of cognitive load, task difficulty (Schmeck et al., 2015), was influenced neither by the video sequence nor by instructional guidance, which might be due to a floor effect limiting the variance. This floor effect might also be an explanation for the low correlation between task difficulty and prior knowledge.
Similarly, concerning the ratings of perceived learning success, the variance seemed to be limited by a ceiling effect, which might have caused the non-significant results regarding this variable. All groups rated the task difficulty equally low and their learning success equally high, which might also be explained by illusions of understanding (Stark et al., 2002). Nonetheless, as the learners’ success in the complex application tasks did not correlate either with their evaluation of task difficulty or with their perceived learning success, these findings might also result from the complexity of the knowledge acquisition process under consideration; the complexity makes self-evaluations of learning outcomes difficult and can result in various biases influencing the subjective ratings.
Concerning the learners’ perceptions of the task value, the interaction effect and subsequent comparisons showed that the learners who studied the dysfunctional video example first, without the prompts, reported the highest task value. Perceived task value correlated highly with both the perceived learning success and with attitudes toward the use of educational evidence used as a control variable in the present study. These attitudes, as well as the perceived learning success, seem to be more important predictors of perceived task value than specific aspects of the learning environment. From a pedagogical perspective, it is important to experience a task as effective and valuable for sustainable learning (e.g., Lawanto et al., 2014). The latter findings regarding subjective dimensions support the pedagogical relevance of the approach using staged contrastive video examples, as it compensated for potential underwhelming effects (Lowe, 2004).
Limitations
Concerning methodical limitations, the sample size was too small to detect potential small-sized effects and to use more refined statistical procedures like structural equation modeling. The regression-based approach applied in the present study did not account for potential variable reciprocity or autoregressive effects. All subjective measures, including the cognitive load measures, were assessed after and not during the training itself. Therefore, they might not have provided reliable information about the learning process (Korbach et al., 2018).
Other limitations result from the procedure and the design of the learning environment. It must be noted that, although all groups seemed to have profited from the approach, nobody reached the theoretical maximum of the outcome tasks. The entire procedure was completed in one session to avoid sample failures and between-group communication. However, the session lasting about 3 h was, perhaps, too strenuous for some of the participants, which might have influenced their learning success negatively. Perhaps, more key relations would have been recognized by the learners if they had been able to watch the video examples multiple times and to stop the video in a self-paced learning environment, or to analyze the videos collaboratively (Derry et al., 2014; Thiel et al., 2020).
The external validity of the study is another limitation. The participants in our study were at the beginning of their university courses and rather novices concerning both the treated topic and the learning approach. Hence, it is unclear whether students who are at the end of their studies profit from instructional prompts, too (cf. expertise-reversal effect; Kalyuga et al., 2003). More generally, there is a need of understanding how much prior knowledge is needed to use contrastive examples with instructional prompts effectively, which points at the question of the benefits of pre-training materials. Besides this, we tested our approach in the context of a specific learning topic (classroom management) for which a set of evidence-based rules and principles exists so that the topic can be regarded as rather well-structured. Further research must clarify whether the results can be generalized for less-structured topics, which would complicate evidence-based decision-making.
Conclusion, Implications, and Future Directions
In conclusion, the findings of the present study indicate that analyzing contrastive video examples following the order dysfunctional-functional combined with specific instructional prompts that focus on the processes of error-based learning proved to be a promising approach to foster the acquisition of educational knowledge in the context of teacher education. Thus, the results provide valuable support for designers of learning environments in the context of teacher education that aim at fostering pre-service teachers’ acquisition of concept knowledge in terms of classroom management, and the ability to apply it in classroom situations. Above that, the findings suggest that contrastive video examples should be implemented as a concrete educational tool in teacher educational courses to demonstrate future teachers the potentials of using educational evidence in practice, as well as to prepare them for evidence-informed practice. Error-based learning approaches are often criticized because of the potential risk of internalizing dysfunctional procedures (cf. Metcalfe, 2017). Our findings do not support this critique. The quality of implementing an error-based learning approach and inducing the specific processes of recognizing key relations of a dysfunctional procedure, comparing these key relations with a functional solution, and deriving error-avoidance strategies, seems to be the crucial point in order to support the acquisition of functional knowledge. Given the amount of research on video-based learning in teacher education and on dysfunctional examples, presented in the outset of this article, the field might benefit from an integrative view, combining these so far rather unconnected strands of research. Thus, it is of importance for future research to accumulate evidence on how to combine different scaffolds to effectively support pre-service teachers (and in-service teachers) in the acquisition of applicable scientific knowledge. Applying such an integrative perspective, teacher educators should also design teacher trainings for areas other than classroom management, from which both pre-service teachers and in-service teachers could benefit.
Data Availability Statement
The datasets presented in this article are not readily available because of legal reasons. Participants gave their consent to store, process and analyze the data as well as to the publication of the analysis results. Participants were assured that the data will not be distributed. Requests to access the datasets should be directed to TW, dGhlcmVzYS53aWxrZXNAdW5pLXNhYXJsYW5kLmRlLg==
Ethics Statement
Ethical review and approval was not required for the study on human participants in accordance with the local legislation and institutional requirements. The patients/participants provided their written informed consent to participate in this study.
Author Contributions
TW and RS conceived of the presented idea. TW, LS, and KT planned the experiment. TW and KT carried out the experiment. TW developed the theory and performed the computations. RS and LS verified the analytical methods. All authors provided critical feedback and helped shape the research, analysis, and manuscript. TW took the lead in writing the manuscript with support and input from RS, LS, and KT. RS supervised the project.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
We thank Hannah Laass for her help in the preparation of the manuscript.
Footnotes
- ^ The FOCUS Video Portal is part of the K2 teach project at the Freie Universität Berlin under the direction of Prof. Dr. Felicitas Thiel.
References
Amador, J. M., Bragelman, J., and Superfine, A. C. (2021). Prospective teachers’ noticing: a literature review of methodological approaches to support and analyze noticing. Teach. Teach. Educ. 99:103256. doi: 10.1016/j.tate.2020.103256
Bannert, M. (2009). Promoting self-regulated learning through prompts. Z. Pädagog. Psychol. 23, 139–145. doi: 10.1024/1010-0652.23.2.139
Barbieri, C. A., and Booth, J. L. (2020). Mistakes on display: incorrect examples refine equation solving and algebraic feature knowledge. Appl. Cogn. Psychol. 34, 862–878. doi: 10.1002/acp.3663
Barth, V. L., Piwowar, V., Kumschick, I. R., Ophardt, D., and Thiel, F. (2019). The impact of direct instruction in a problem-based learning setting. Effects of a video-based training program to foster preservice teachers’ professional vision of critical incidents in the classroom. Int. J. Educ. Res. 95, 1–12. doi: 10.1016/j.ijer.2019.03.002
Bates, M. S., Phalen, L., and Moran, C. G. (2016). If you build it, will they reflect? Examining teachers’ use of an online video-based learning website. Teach. Teach. Educ. 58, 17–27. doi: 10.1016/j.tate.2016.04.004
Beilstein, S. O., Perry, M., and Bates, M. S. (2017). Prompting meaningful analysis from pre-service teachers using elementary mathematics video vignettes. Teach. Teach. Educ. 63, 285–295. doi: 10.1016/j.tate.2017.01.005
Beitzel, B. D., and Derry, S. J. (2009). When the book is better than the movie: how contrasting video cases influence text learning. J. Educ. Comput. Res. 40, 337–355. doi: 10.2190/EC.40.3.e
Blomberg, G., Renkl, A., Sherin, M. G., Borko, H., and Seidel, T. (2013). Five research-based heuristics for using video in pre-service teacher education. J. Educ. Res. Online 5, 90–114.
Blomberg, G., Sherin, M. G., Renkl, A., Glogger, I., and Seidel, T. (2014). Understanding video as a tool for teacher education: investigating instructional strategies to promote reflection. Instr. Sci. 42, 443–463. doi: 10.1007/s11251-013-9281-6
Booth, J. L., Cooper, L. A., Donovan, M. S., Huyghe, A., Koedinger, K. R., and Paré-Blagoev, E. J. (2015). Design-based research within the constraints of practice: algebrabyexample. J. Educ. Stud. Placed Risk 20, 79–100. doi: 10.1080/10824669.2014.986674
Booth, J. L., Lange, K. E., Koedinger, K. R., and Newton, K. J. (2013). Using example problems to improve student learning in algebra: differentiating between correct and incorrect examples. Learn. Instr. 25, 24–34. doi: 10.1016/j.learninstruc.2012.11.002
Borko, H., Jacobs, J., Eiteljorg, E., and Pittman, M. E. (2008). Video as a tool for fostering productive discussions in mathematics professional development. Teach. Teach. Educ. 24, 417–436. doi: 10.1016/j.tate.2006.11.012
Boshuizen, H. P. A., Gruber, H., and Strasser, J. (2020). Knowledge restructuring through case processing: the key to generalise expertise development theory across domains? Educ. Res. Rev. 29:100310. doi: 10.1016/j.edurev.2020.100310
Bransford, J. D., Brown, A. L., and Cocking, R. R. (2000). How People Learn: Brain, Mind, Experience and School: Expanded Edition. Washington, DC: National Academy Press, doi: 10.17226/9853
Brunvand, S. (2010). Best practices for producing video content for teacher education. Contemp. Issues Technol. Teach.Educ. 10, 247–256.
Chen, C. −H., and Bradshaw, A. C. (2007). The effect of web-based question prompts on scaffolding knowledge integration and ill-structured problem solving. J. Res. Technol. Educ. 39, 359–375. doi: 10.1080/15391523.2007.10782487
Cherrington, S., and Loveridge, J. (2014). Using video to promote early childhood teachers’ thinking and reflection. Teach. Teach. Educ. 41, 42–51. doi: 10.1016/j.tate.2014.03.004
Chi, M. T. H. (2000). “Self-explaining expository texts: the dual processes of generating inferences and repairing mental models,” in Advances in Instructional Psychology: Educational Design and Cognitive Science, Vol. 5, ed. R. Glaser (Hillsdale, NJ: Lawrence Erlbaum Associates, Inc), 161–238.
Codreanu, E., Sommerhoff, D., Huber, S., Ufer, S., and Seidel, T. (2020). Between authenticity and cognitive demand: finding a balance in designing a video-based simulation in the context of mathematics teacher education. Teach. Teach. Educ. 95:103146. doi: 10.1016/j.tate.2020.103146
Csanadi, A., Kollar, I., and Fischer, F. (2021). Pre-service teachers’ evidence-based reasoning during pedagogical problem-solving: better together? Eur. J. Psychol. Educ. 36, 147–168. doi: 10.1007/s10212-020-00467-4
Dagenais, C., Lysenko, L., Abrami, P. C., Bernard, R. M., Ramde, J., and Janosz, M. (2012). Use of research-based information by school practitioners and determinants of use: a review of empirical research. Evid. Policy 8, 285–309. doi: 10.1332/174426412X654031
De Jong, T., and Ferguson-Hessler, M. G. (1996). Types and qualities of knowledge. Educ. Psychol. 31, 105–113. doi: 10.1207/s15326985ep3102_2
Derry, S. J., Sherin, M. G., and Sherin, B. L. (2014). “Multimedia learning with video,” in The Cambridge Handbook of Multimedia Learning, 2nd Edn, ed. R. E. Mayer (New York, NY: Cambridge University Press), 785–812. doi: 10.1017/cbo9781139547369.038
Dickhäuser, O., Schöne, C., Spinath, B., and Stiensmeier-Pelster, J. (2002). Die Skalen zum akademischen Selbstkonzept [The academic self-concept scales]. Z. Differentielle Diagnostische Psychol. 23, 393–405. doi: 10.1024//0170-1789.23.4.393
Durkin, K., and Rittle-Johnson, B. (2012). The effectiveness of using incorrect examples to support learning about decimal magnitude. Learn. Instr. 22, 206–214. doi: 10.1016/j.learninstruc.2011.11.001
Ferguson, L. E. (2021). Evidence-informed teaching and practice-informed research. Z. Pädagog. Psychol. 35, 199–208. doi: 10.1024/1010-0652/a000310
Fischer, F., Kollar, I., Stegmann, K., and Wecker, C. (2013). Toward a script theory of guidance in computer-supported collaborative learning. Educ. Psychol. 48, 56–66. doi: 10.1080/00461520.2012.748005
Free University of Berlin (2018). Umgang mit Störungen im Unterricht [Dealing With Classroom Disruptions]. FOCUS-Videoportal. Berlin: Free University of Berlin.
Gaudin, C., and Chaliès, S. (2015). Video viewing in teacher education and professional development: a literature review. Educ. Res. Rev. 16, 41–67. doi: 10.1016/j.edurev.2015.06.001
Gegenfurtner, A., Lewalter, D., Lehtinen, E., Schmidt, M., and Gruber, H. (2020). Teacher expertise and professional vision: examining knowledge-based reasoning of pre-service teachers, in-service teachers, and school principals. Front. Educ. 5:59. doi: 10.3389/feduc.2020.00059
Gentner, D., Loewenstein, J., and Thompson, L. (2003). Learning and transfer: a general role for analogical encoding. J. Educ. Psychol. 95, 393–408. doi: 10.1037/0022-0663.95.2.393
Gerjets, P., Scheiter, K., and Schuh, J. (2008). Information comparisons in example-based hypermedia environments: supporting learners with processing prompts and an interactive comparison tool.Educ. Technol. Res. Dev. 56, 73–92. doi: 10.1007/s11423-007-9068-z
Goldsmith, L. T., and Seago, N. (2011). “Using classroom artifacts to focus teachers’ noticing: affordances and opportunities,” in Mathematics Teacher Noticing: Seeing Through Teachers’ Eyes, eds M. G. Sherin, V. R. Jacobs, and R. A. Philipp (New York, NY: Routledge), 169–187.
Goodwin, K., and Goodwin, C. J. (2013). Research in Psychology: Methods and Design, 7th Edn. New York, NY: John Wiley & Sons Inc.
Große, C. S., and Renkl, A. (2007). Finding and fixing errors in worked examples: can this foster learning outcomes? Learn. Instr. 17, 612–634. doi: 10.1016/j.learninstruc.2007.09.008
Hamel, C., and Viau-Guay, A. (2019). Using video to support teachers’ reflective practice: a literature review. Cogent Educ. 6, 1–14. doi: 10.1080/2331186X.2019.1673689
Hartmann, U., Kindlinger, M., and Trempler, K. (2021). Integrating information from multiple texts relates to pre-service teachers’ epistemic products for reflective teaching practice. Teach. Teach. Educ. 97:103205. doi: 10.1016/j.tate.2020.103205
Hatch, T., Shuttleworth, J., Jaffee, A. T., and Marri, A. (2016). Videos, pairs, and peers: what connects theory and practice in teacher education? Teach. Teach. Educ. 59, 274–284. doi: 10.1016/j.tate.2016.04.011
Hayes, A. F. (2018). Introduction to Mediation, Moderation, and Conditional Process Analysis: A Regression-Based Approach, 2nd Edn. New York, NY: The Guilford Press.
Hennissen, P., Beckers, H., and Moerkerke, G. (2017). Linking practice to theory in teacher education: a growth in cognitive structures. Teach. Teach. Educ. 63, 314–325. doi: 10.1016/j.tate.2017.01.008
Joyce, K. E., and Cartwright, N. (2020). Bridging the gap between research and practice: predicting what will work locally. Am. Educ. Res. J. 57, 1045–1082. doi: 10.3102/0002831219866687
Kalyuga, S., Ayres, P., Chandler, P., and Sweller, J. (2003). The expertise reversal effect. Educ. Psychol. 38, 23–31. doi: 10.1207/s15326985ep3801_4
Kalyuga, S., Chandler, P., and Sweller, J. (2000). Incorporating learner experience into the design of multimedia instruction. J. Educ. Psychol. 92, 126–136. doi: 10.1037/0022-0663.92.1.126
Kant, J. M., Scheiter, K., and Oschatz, K. (2017). How to sequence video modeling examples and inquiry tasks to foster scientific reasoning. Learn. Instr. 52, 46–58. doi: 10.1016/j.learninstruc.2017.04.005
Kiemer, K., and Kollar, I. (2021). Source selection and source use as a basis for evidence-informed teaching. Z. Pädag. Psychol. 35, 127–141. doi: 10.1024/1010-0652/a000302
Kirschner, P. A., Sweller, J., and Clark, R. E. (2006). Why Minimal guidance during instruction does not work: an analysis of the failure of constructivist, discovery, problem-based, experiential, and inquiry-based teaching. Educ. Psychol. 41, 75–86. doi: 10.1207/s15326985ep4102_1
Korbach, A., Brünken, R., and Park, B. (2018). Differentiating different types of cognitive load: a comparison of different measures. Educ. Psychol. Rev. 30, 503–529. doi: 10.1007/s10648-017-9404-8
Kounin, J. S. (1970). Discipline and Group Management in Classrooms. New York, NY: Holt, Rinehart and Winston.
Kramer, M., Förtsch, C., Seidel, T., and Neuhaus, B. J. (2021). Comparing two constructs for describing and analyzing teachers’ diagnostic processes. Stud. Educ. Eval. 68:100973. doi: 10.1016/j.stueduc.2020.100973
Lawanto, O., Santoso, H. B., Goodridge, W., and Lawanto, K. N. (2014). Task-value, self-regulated learning, and performance in a web-intensive undergraduate engineering course: how are they Related? J. Online Learn. Teach. 10, 97–111.
LeFevre, D. M. (2004). “Designing for teacher learning: video-based curriculum design,” in Advances in Research on Teaching, Volume 10: Using Video in Teacher Education, ed. J. E. Brophy (Amsterdam: Elsevier, Inc), 235–258. doi: 10.1016/S1479-3687(03)10009-0
Lehmann, T., Pirnay-Dummer, P., and Schmidt-Borcherding, F. (2020). Fostering integrated mental models of different professional knowledge domains: instructional approaches and model-based analyses. Educ. Technol. Res. Dev. 68, 905–927. doi: 10.1007/s11423-019-09704-0
Loibl, K., and Leuders, T. (2019). How to make failure productive: fostering learning from errors through elaboration prompts. Learn. Instr. 62, 1–10. doi: 10.1016/j.learninstruc.2019.03.002
Lowe, R. (2004). Interrogation of a dynamic visualization during learning. Learn. Instr. 14, 257–274. doi: 10.1016/j.learninstruc.2004.06.003
Lysenko, L. V., Abrami, P. C., Dagenais, C., and Janosz, M. (2014). Educational research in educational practice: predictors of use. Can. J. Educ. 37, 1–26. doi: 10.2190/mhur-4fc9-b187-t8h4
Lysenko, L. V., Abrami, P. C., Bernard, R. M., and Dagenais, C. (2015). Research use in education: an online survey of Canadian teachers. Brock Educ. J. 25, 1–20. doi: 10.26522/brocked.v25i1.431
Maharani, I. P., and Subanji, S. (2018). Scaffolding based on cognitive conflict in correcting the students’ algebra errors. Int. Electron. J. Math. Educ. 13, 67–74. doi: 10.12973/iejme/2697
Mayer, R. E. (2001). Multimedia Learning. New York, NY: Cambridge University Press, doi: 10.1017/9781316941355
Mayer, R. E. (2020). Advances in designing instruction based on examples. Appl. Cogn. Psychol. 34, 912–915. doi: 10.1002/acp.3701
Mayer, R. E., and Moreno, R. (2003). Nine ways to reduce cognitive load in multimedia learning. Educ. Psychol. 38, 43–52. doi: 10.1207/s15326985ep3801_6
Melis, E. (2005). “Design of erroneous examples for ActiveMath,” in Artificial Intelligence in Education. Supporting Learning Through Intelligent and Socially Informed Technology, eds B. Bredeweg, C.-K. Looi, G. McCalla, and J. Breuker (Amsterdam: IOS Press), 451–458.
Metcalfe, J. (2017). Learning from errors. Annu. Rev. Psychol. 68, 465–489. doi: 10.1146/annurev-psych-010416-044022
Miller, K., and Zhou, X. (2007). “Learning from classroom video: what makes it compelling and what makes it hard,” in Video Research in the Learning Science, eds R. Goldmann, R. Pea, B. Barron, and S. J. Derry (Mahwah, NJ: Lawrence Erlbaum), 335–348.
Miller, K. F. (2011). “Situation awareness in teaching: what educators can learn from video-based research in other fields,” in Mathematics Teacher Noticing: Seeing Through Teachers’ Eyes, eds M. G. Sherin, V. R. Jacobs, and R. A. Philipp (New York, NY: Routledge), 51–65.
Ohira, H., Winton, W. M., and Oyama, M. (1998). Effects of stimulus valence on recognition memory and endogenous eyeblinks: further evidence for positive-negative asymmetry. Pers. Soc. Psychol. Bull. 24, 986–993. doi: 10.1177/0146167298249006
Oonk, W., Goffree, F., and Verloop, N. (2004). ““For the enrichment of practical knowledge: good practice and useful theory for future primary teachers,” in Advances in Research on Teaching, Volume 10: Using Video in Teacher Education, ed. J. E. Brophy (Amsterdam: Elsevier, Inc), 131–168. doi: 10.1016/s1479-3687(03)10006-5
Ophardt, D., and Thiel, F. (2013). Klassenmanagement: Ein Handbuch für Studium und Praxis. [Classroom Management: A handbook for study and practice]. Stuttgart: Kohlhammer.
Oser, F., Näpflin, C., Hofer, C., and Aerni, P. (2012). “Towards a theory of Negative Knowledge (NK): almost-mistakes as drivers of episodic memory amplification,” in professional and Practice-Based Learning: Vol. 6. Human Fallibility: The Ambiguity of Errors for Work and Learning, eds J. Bauer and C. Harteis (Dordrecht: Springer), 53–70. doi: 10.1007/978-90-481-3941-5_4
Oser, F., and Spychiger, M. (2005). Lernen ist schmerzhaft. Zur Theorie des Negativen Wissens und zur Praxis der Fehlerkultur [Learning is painful. On the Theory of Negative Knowledge and the Practice of Error Culture]. Weinheim: Beltz.
Paas, F. G. W. C. (1992). Training strategies for attaining transfer of problem-solving skill in statistics: a cognitive-load approach. J. Educ. Psychol. 84, 429–434. doi: 10.1037/0022-0663.84.4.429
Park, B., Knörzer, L., Plass, J. L., and Brünken, R. (2015). Emotional design and positive emotions in multimedia learning: an eyetracking study on the use of anthropomorphisms. Comput. Educ. 86, 30–42. doi: 10.1016/j.compedu.2015.02.016
Piaget, J. (1985). The Equilibration of Cognitive Structures: The Central Problem of Intellectual Development. New York, NY: The University of Chicago Press.
Piwowar, V., Barth, V. L., Ophardt, D., and Thiel, F. (2018). Evidence-based scripted videos on handling student misbehavior: the development and evaluation of video cases for teacher education. Prof. Dev. Educ. 44, 369–384. doi: 10.1080/19415257.2017.1316299
Reigeluth, C. M., Merrill, M. D., Wilson, B. G., and Spiller, R. T. (1980). The elaboration theory of instruction: a model for sequencing and synthesizing instruction. Instr. Sci. 9, 195–219. doi: 10.1007/BF00177327
Renkl, A. (2017). “Instruction based on examples,” in Educational Psychology Handbook Series. Handbook of Research on Learning and Instruction, eds R. E. Mayer and P. A. Alexander (New York, NY: Routledge), 325–348.
Renkl, A., and Atkinson, R. K. (2007). “An example order for cognitive skill acquisition,” in Oxford Series on Cognitive Models and Architectures. In Order to Learn: How the Sequence of Topics Influences Learning, eds F. E. Ritter, J. Nerb, E. Lehtinen, and T. O’Shea (New York, NY: Oxford: Oxford University Press), 95–105. doi: 10.1093/acprof:oso/9780195178845.003.0007
Renkl, A., Mandl, H., and Gruber, H. (1996). Inert knowledge: analyses and remedies. Educ. Psychol. 31, 115–121. doi: 10.1207/s15326985ep3102_3
Renkl, A., and Scheiter, K. (2017). Studying visual displays: how to instructionally support learning. Educ. Psychol. Rev. 29, 599–621. doi: 10.1007/s10648-015-9340-4
Rittle-Johnson, B., and Star, J. R. (2009). Compared with what? The effects of different comparisons on conceptual knowledge and procedural flexibility for equation solving. J. Educ. Psychol. 101, 529–544. doi: 10.1037/a0014224
Rittle-Johnson, B., Star, J. R., Durkin, K., and Loehr, A. (2019). “Compare and discuss to promote deeper learning,” in Deeper Learning, Dialogic Learning, and Critical Thinking, ed. E. Manalo (New York, NY: Routledge), 48–64. doi: 10.4324/9780429323058-4
Rosaen, C. L., Degnan, D., VanStratt, T., and Zietlow, K. (2004). “Designing a virtual K-2 classroom literacy tour: learning together as teachers explore “best practice,” in Advances in Research on Teaching, Volume 10: Using Video in Teacher Education, ed. J. Brophy (Amsterdam: Elsevier, Inc), 169–199. doi: 10.1016/s1479-3687(03)10007-7
Schäfer, S., and Seidel, T. (2015). Noticing and reasoning of teaching and learning components by pre-service teachers. J. for Educ. Res. Online 7, 34–58. doi: 10.25656/01:11489
Scheiner, T. (2021). Towards a more comprehensive model of teacher noticing. ZDM Math. Educ. 53, 85–94. doi: 10.1007/s11858-020-01202-5
Schmeck, A., Opfermann, M., van Gog, T., Paas, F., and Leutner, D. (2015). Measuring cognitive load with subjective rating scales during problem solving: differences between immediate and delayed ratings. Instr. Sci. 43, 93–114. doi: 10.1007/s11251-014-9328-3
Schworm, S., and Renkl, A. (2007). Learning argumentation skills through the use of prompts for self-explaining examples. J. Educ. Psychol. 99, 285–296. doi: 10.1037/0022-0663.99.2.285
Seidel, T., Blomberg, G., and Renkl, A. (2013). Instructional strategies for using video in teacher education. Teach. Teach. Educ. 34, 56–65. doi: 10.1016/j.tate.2013.03.004
Seidel, T., and Stürmer, K. (2014). Modeling and measuring the structure of professional vision in preservice teachers. Am. Educ. Res. J. 51, 739–771. doi: 10.3102/0002831214531321
Sherin, M. G., and van Es, E. A. (2009). Effects of video club participation on teachers’ professional vision. J. Teach. Educ. 60, 20–37. doi: 10.1177/0022487108328155
Slavin, R. E., Cheung, A. C. K., and Zhuang, T. (2021). How could evidence-based reform advance education? ECNU Rev. of Educ. 4, 7–24. doi: 10.1177/2096531120976060
Sonmez, D., and Hakverdi-Can, M. (2012). Videos as an instructional tool in pre-service science teacher education. Eurasian J. Educ. Res. 46, 141–158.
Star, J. R., Lynch, K., and Perova, N. (2011). “Using video to improve mathematics’ teachers’ abilities to attend to classroom features: a replication study,” in Mathematics Teacher Noticing: Seeing Through Teachers’ Eyes, eds M. G. Sherin, V. R. Jacobs, and R. A. Philipp (New York, NY: Routledge), 117–133.
Star, J. R., and Rittle-Johnson, B. (2009). It pays to compare: an experimental study on computational estimation. J. Exp. Child Psychol. 102, 408–426. doi: 10.1016/j.jecp.2008.11.004
Star, J. R., and Strickland, S. K. (2008). Learning to observe: using video to improve preservice mathematics teachers’ ability to notice. J. Math. Teach. Educ. 11, 107–125. doi: 10.1007/s10857-007-9063-7
Stark, L., Malkmus, E., Stark, R., Brünken, R., and Park, B. (2018). Learning-related emotions in multimedia learning: an application of control-value theory. Learn. Instr. 58, 42–52. doi: 10.1016/j.learninstruc.2018.05.003
Stark, R., Mandl, H., Gruber, H., and Renkl, A. (2002). Conditions and effects of example elaboration. Learn. Instr. 12, 39–60. doi: 10.1016/S0959-4752(01)00015-9
Tekkumru-Kisa, M., and Stein, M. K. (2017). A framework for planning and facilitating video-based professional development. Int. J. STEM Educ. 4:28. doi: 10.1186/s40594-017-0086-z
Thiel, F., Böhnke, A., Barth, V. L., and Ophardt, D. (2020). How to prepare preservice teachers to deal with disruptions in the classroom? Differential effects of learning with functional and dysfunctional video scenarios. Prof. Dev. Educ. 1–15. doi: 10.1080/19415257.2020.1763433
Thiel, F., Ophardt, D., and Barth, V. (2017). Staged Videos zur Störungsprävention und -intervention in der Lehrerbildung - Potenziale und Entwicklung. [Staged videos for disruption prevention and intervention in teacher education - potentials and development]. J. LehrerInnenbildung 17, 57–62.
Thomm, E., Sälzer, C., Prenzel, M., and Bauer, J. (2021). Predictors of teachers’ appreciation of evidence-based practice and educational research findings. Z. Pädagog. Psychol. 35, 173–184. doi: 10.1024/1010-0652/a000301
Tsamir, P., and Tirosh, D. (2005). In-service elementary mathematics teachers’ views of errors in the classroom. Focus Learn. Probl.Math. 27, 30–42.
Tsovaltzi, D., McLaren, B. M., Melis, E., and Meyer, A.-K. (2012). Erroneous examples: effects on learning fractions in a web-based setting. Int. J. Technol. Enhanc. Learn. 4, 191–230. doi: 10.1504/IJTEL.2012.051583
Tulis, M., Steuer, G., and Dresel, M. (2016). Learning from errors: a model of individual processes. Frontline Learn. Res. 4:12–26. doi: 10.14786/flr.v4i2.168
Van Gog, T., Paas, F., and van Merriënboer, J. J. G. (2008). Effects of studying sequences of process-oriented and product-oriented worked examples on troubleshooting transfer efficiency. Learn. Instr. 18, 211–222. doi: 10.1016/j.learninstruc.2007.03.003
Van Merriënboer, J. J. G., and Sweller, J. (2010). Cognitive load theory in health professional education: design principles and strategies. Med. Educ. 44, 85–93. doi: 10.1111/j.1365-2923.2009.03498.x
Wagner, K., Klein, M., Klopp, E., and Stark, R. (2016). Förderung anwendbaren bildungswissenschaftlichen Wissens anhand kollaborativem Lernen aus Fehlern [Facilitation of applicable knowledge in teacher education by collaborative learning from instructional errors]. Unterrichtswissenschaft 44, 373–390.
Keywords: teacher education, video examples, erroneous examples, sequencing effects, instructional prompts, evidence-informed practice
Citation: Wilkes T, Stark L, Trempler K and Stark R (2022) Contrastive Video Examples in Teacher Education: A Matter of Sequence and Prompts. Front. Educ. 7:869664. doi: 10.3389/feduc.2022.869664
Received: 04 February 2022; Accepted: 19 April 2022;
Published: 31 May 2022.
Edited by:
Dominik E. Froehlich, University of Vienna, AustriaReviewed by:
Ilona Södervik, University of Helsinki, FinlandBijen Filiz, Afyon Kocatepe University, Turkey
Copyright © 2022 Wilkes, Stark, Trempler and Stark. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Theresa Wilkes, dGhlcmVzYS53aWxrZXNAdW5pLXNhYXJsYW5kLmRl