 Yasuko Okumura
Yasuko Okumura Yosuke Kita
Yosuke Kita Yuzuki Kitamura4
Yuzuki Kitamura4
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Educ., 28 February 2022
Sec. Language, Culture and Diversity
Volume 7 - 2022 | https://doi.org/10.3389/feduc.2022.758098
While letter-naming ability is a well-known preschool predictor of the later acquisition of literacy, little is known about an appropriate benchmark (i.e., how many letter names children must know at a given age) and how it may vary among different writing systems. The present study aimed to establish a letter-naming benchmark in Japanese Hiragana for pre-elementary children (age 5 to 6 years) and examined whether this benchmark predicts risk or success in later reading development via a one-year longitudinal survey. Children (N = 291) were assessed once in their pre-elementary year for Hiragana-naming accuracy and once in their first-grade year for oral reading fluency. As a result, the ability to name 40 of 45 letters was determined to be an optimal cut-off, and failure to meet it strongly predicted a risk of deficient reading fluency in first grade. These findings support the notion that Japanese children without near-perfect mastery of Hiragana-naming in their pre-elementary year are at great risk of reading difficulty in first grade. In addition, possible contrasts between Hiragana- and alphabet-naming indicated a need for further research in different languages and scripts to establish appropriate goals and policies for this foundational skill of reading in early education.
In alphabetic languages, letter-name knowledge is an important educational topic for preschool children, due to its strong ability to predict later literacy acquisition (Foulin, 2005; National Early Literacy Panel, 2008; Hjetland et al., 2017). Especially, a low level of letter-name knowledge has been shown to predict future reading disabilities (Gallagher et al., 2000; Catts et al., 2001; Torppa et al., 2006; Puolakanaho et al., 2007), which suggests that early childhood education must have explicit goals and rigorous ways to assess this specific skill (e.g., U.S. Department of Health and Human Services and Administration for Children and Families, 2003). Based on these notions, one study in the United States (Piasta et al., 2012) explored letter-naming benchmarks in preschoolers that define exactly how many letter-names a child should know at a given age, on the basis of its utility to predict future literacy outcomes. In that study, an English-speaking child who knew at least 18 uppercase or 15 lowercase alphabets at the end of preschool (52 months of age on average) was unlikely to meet at-risk criteria at the end of first grade, or 2 years later (Piasta et al., 2012). Since benchmark-type goals were reported to be more useful in educational settings (Powell et al., 2008), further exploration is expected to provide effective ways to monitor and support children at the beginning of reading development.
Given the large variation in reading development across writing systems (Seymour et al., 2003; Ziegler and Goswami, 2005; Daniels and Share, 2018), an important issue in this line of research may be to explore early letter-naming benchmarks in different languages and scripts. While there is no doubt that letter-naming is one of the foundational literacy skills in any written language, the contents of letter knowledge differ considerably across scripts. For example, letters in the Roman/Latin alphabet have both names and sounds (Foulin, 2005), and often correspond to more than one sound, especially in irregular orthographies like English (Borgwaldt et al., 2005; Perfetti and Harris, 2013). Thus, children must acquire multiple phonological identities for each letter that have different roles in reading. In addition, alphabet letters are case sensitive, which require children to correspond one phonological identity (i.e., letter-name) to different visual forms.
In other writing system like Japanese Hiragana, each letter basically has single phonological identity. More specifically, each Hiragana letter corresponds to one distinct syllable (or mora) in a one-to-one manner, with very few exceptions (Welty et al., 2014; Inoue et al., 2017). A sound of a Hiragana letter also serves as its name, and Hiragana is not case sensitive. Therefore, letter-knowledge in Hiragana involves very simple letter-sound/name associations, one sound/name for each letter, which is particularly the case for 45 fundamental Hiragana-letters called Sei-on. This simplicity of letter knowledge could ease the letter-naming acquisition in preschool children. In fact, previous Japanese studies have reported average naming accuracies of over 40 of 45 Hiragana Sei-on letters in pre-elementary1 children (Shimamura and Mikami, 1994; Ota et al., 2018).
Scripts also differ in the roles that letter-naming play in reading. In alphabetic scripts, the acquisition of letter-names has been considered to make letters familiar and identifiable (Evans et al., 2006), and to facilitate children’s access to letter-sounds because many letter-names contain their corresponding sounds (e.g., the/b/sound at the beginning of the letter-name B/b; Treiman et al., 1998; McBride-Chang, 1999). However, letter-names are not needed when it comes to read words, and could even disrupt reading (Walsh et al., 1988), so that children must switch their focus to letter-sounds and the ways in which they are synthesized (i.e., blending). In contrast, Hiragana words, in most cases, can be read by the simple addition of letter-names. Thus, the acquisition of letter-names immediately enables children to read words in Hiragana, and a major focus of reading development after the mastery of letter-names is to increase speed or fluency through the accumulation of reading experience. These implicit (alphabet) vs. immediate (Hiragana) roles of letter-naming in reading are likely to modulate the utility of a letter-naming benchmark in predicting later reading outcomes.
Therefore, the present study aimed to explore a pre-elementary letter-naming benchmark in Japanese Hiragana and to examine its ability to predict first-grade reading outcome based on one-year longitudinal data. The simplicity of letter knowledge in Hiragana should make letter-name acquisition fairly easy for many children, as reflected by the near-perfect average accuracies reported in previous studies (Shimamura and Mikami, 1994; Ota et al., 2018); thus, a high optimal benchmark was expected. Regarding the ability to predict future reading outcome, the immediate role of letter-naming in reading indicates that children with low knowledge are essentially unable to read, while a mastery of Hiragana-naming enables self-reading and an increase in reading fluency. Thus, passing/failing to meet the Hiragana-naming benchmark was expected to predict success/risk in future reading with balanced precision, respectively. Addressing these issues in Japanese Hiragana is expected to reveal commonality as well as variation in the development and significance of early letter-name knowledge among different languages and scripts.
In this study, a child’s letter-naming benchmark was examined with respect to accuracy. Although some alphabetic studies have indicated the importance of letter-naming fluency over accuracy (Walsh et al., 1988; Speece et al., 2003), we considered that mastery (i.e., how many letters a child can name) would be more important in Hiragana, due to the central role of letter-naming in reading. First-grade reading ability, on the other hand, was indexed by oral reading fluency because reading accuracy in transparent scripts is likely to hit a ceiling early in first grade (Seymour et al., 2003; Ziegler and Goswami, 2005), so that fluency was expected to reflect individual differences more reliably. In statistical analyses, we examined the association between pre-elementary letter-naming (passing or failing to meet the benchmark) and first-grade reading fluency (normal or deficient) by using binomial logistic regression and receiver operator characteristic (ROC) analyses, in which all possible cut-offs of Hiragana-naming (1 to 45 letters) were tested to determine an optimal benchmark. The predictive capability of the selected benchmark was examined by calculating a set of diagnostic efficiency indices, such as sensitivity and specificity, to examine whether the benchmark could predict success and/or failure in first-grade reading, respectively.
The study originally involved a total of 344 pre-elementary children at age 5 to 6 years. The assessment was conducted in two public and one private preschools, and two public elementary schools. None of the preschools included formal literacy instruction in their curricula. Of the original 344 children, 53 were either absent on the day of the first-grade assessment or had transferred to a different school, and thus were excluded from the final sample (15.4% drop-outs).
The final sample consisted of the remaining 291 children (154 boys). Their mean age was 70 months (SD = 3.70, range 63–79) and 81 months (SD = 3.42, range 75–87) on the days of the pre-elementary and first-grade assessments, respectively. Their mean age at elementary-school entrance was 78 months (SD = 3.42, range 72–83), which was 3 to 4 months prior to the first-grade assessment. No exclusion criterion was set so as to include children with a wide range of abilities. According to the Declaration of Helsinki, assent and informed consent were obtained from all participants and their parents or legal guardians, respectively, prior to their participation in the study. Before giving their consent and assent, they were given a full and appropriate explanation of the study protocol, which had been approved by a local ethics committee (#2020C006).
The participants were assessed once in their pre-elementary year and once in their first-grade year. The Japanese school year starts in April and ends in March. All children were assessed individually by trained researchers in a quiet room at the schools they attended.
Children were asked to name 45 letters of Hiragana Sei-on presented in random order on a single sheet, similar to the procedure used by Piasta et al. (2012). In accordance with the traditional Japanese text, they named the letters vertically and from right to left. The number of correctly named letters, including self-corrections, was recorded.
Children were tested with a standardized Hiragana-reading fluency test (Research Group for Formulation of Diagnostic Criteria and Medical Guideline for Specific Developmental Disorders, 2010), which consists of four tasks: letters (50 items including special syllables), words (30 items), non-words (30 items), and short sentences (3 items; see supplementary materials of Kita et al., 2013 for examples). In each task, children were asked to read aloud the items as fast and as accurately as possible, and reading times were recorded in seconds.
Reading times of the four tasks were transformed to z-values by using the means and standard deviation of the first-grade norm that was established based on data from healthy Japanese children (Research Group for Formulation of Diagnostic Criteria and Medical Guideline for Specific Developmental Disorders, 2010). According to the diagnostic criterion for a reading deficit based on this guideline, z-values over +2 (i.e., reading times longer than the first-grade mean + two standard deviations) were considered to indicate significant prolongations in each task. Finally, children who showed significant prolongation in 0–1 of the four tasks were classified as “normal” readers, and those with prolongation in 2 to 4 tasks were classified as “deficient” readers.
Using the data obtained at the two time points, we generated two-by-two contingency matrices of the children’s dichotomized performance (Table 1). The pre-elementary letter-naming performance was coded as “passed” when the child could name more than or equal to a given number of letters (i.e., benchmark) or “failed” when the number of correctly-named letters was less than the benchmark. First-grade reading fluency was coded as “normal” or “deficient” according to the criterion described above. Separate matrices were generated for all possible pre-elementary benchmarks (1 to 45 letters).
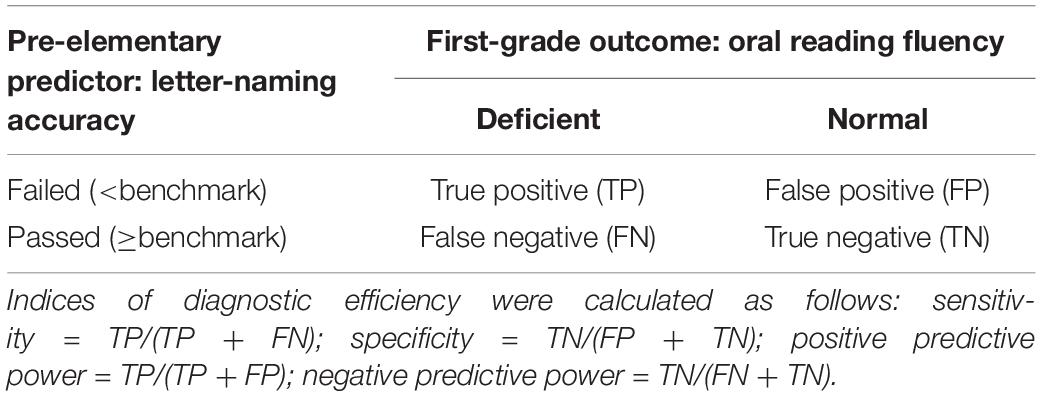
Table 1. Structure of contingency matrix based on longitudinal data.
Statistical analyses in the present study consisted of two parts: (1) selection of an optimal pre-elementary benchmark and (2) evaluation of its diagnostic precision with respect to first-grade reading fluency. For benchmark selection, we conducted a series of binomial logistic regressions, which were implemented with the glm function in R software (R Core Team, 2020), to examine changes in a predictor-outcome relationship with respect to all possible pre-elementary benchmarks. More specifically, the generated contingency matrices were subjected to binomial logistic regression one-by-one with age in first grade (in months) and gender (male or female) as control variables, and we tracked changes in the adjusted odds ratio (OR) of letter-naming performance and Akaike’s Information Criterion (AIC). A cut-off that gives a regression model with a minimum AIC was selected as a candidate for an optimal benchmark, because the lowest AIC indicates a model, and accordingly a letter-naming benchmark, with the best prediction precision (Bozdogan, 1987; Burnham and Anderson, 2004).
To confirm the optimality of the benchmark indicated by the regression analysis, we also conducted a receiver operator characteristic (ROC) curve analysis to explore an optimal cut-off value for pre-elementary letter-naming. ROC analysis is a popular method for examining the discriminatory accuracy of a predictor (continuous variable) to make a binary classification, as well as to seek an optimal threshold (i.e., cut-off) that maximizes the precision of classification. A cut-off value can be determined by using the Youden Index [J = maximum (sensitivity + specificity −1), Fluss et al., 2005], and a point within a ROC curve that corresponds to this index is regarded as an optimal threshold. In other words, the Youden Index corresponds to the farthest point from the diagonal reference line that indicates random classification (Akobeng, 2007); thus, it serves as a criterion for selecting the optimal cut-off value. In addition, the area under the ROC curve (AUC) was also calculated as a global index of the accuracy of prediction based on pre-elementary Hiragana-naming.
After determination of the optimal benchmark, the final binomial logistic regression model was calculated and checked for the model fit. The model was used to examine the strength of the predictor-outcome relationship between pre-elementary letter-naming and first-grade reading fluency, based on the selected benchmark. Lastly, the final contingency table was used to calculate multiple diagnostic efficiency indices, including sensitivity, specificity, positive predictive value, and negative predictive value (see Table 1 for formulas). Based on these indices, the selected benchmark would be suggested to serve as both a success-predictor and a risk-screener when all indices are high and balanced, as a success-predictor with a high negative predictive value, and as a risk-screener with a high positive predictive value (Trevethan, 2017).
Table 2 shows descriptive statistics of Hiragana-naming and oral reading fluency measures. Pre-elementary children could name an average of 34 of 45 Hiragana Sei-on. There was a strong rightward distribution where most of the children showed near-perfect or perfect mastery (Figure 1; skewness = −1.18). Oral reading in the first grade was overall slow, since the mean z-values of reading time were near or above +2, which indicates significant prolongation (see Materials and Methods), in all four tasks. Consequently, nearly half of the children (45.4%) met the criterion for a deficient reader (Table 2). First-grade indices were negatively correlated with pre-elementary letter-naming performance (Table 2, all Holm-adjusted ps < 0.0001), which indicated that a child who could name more letters in the pre-elementary year tended to be faster in oral reading a year later.
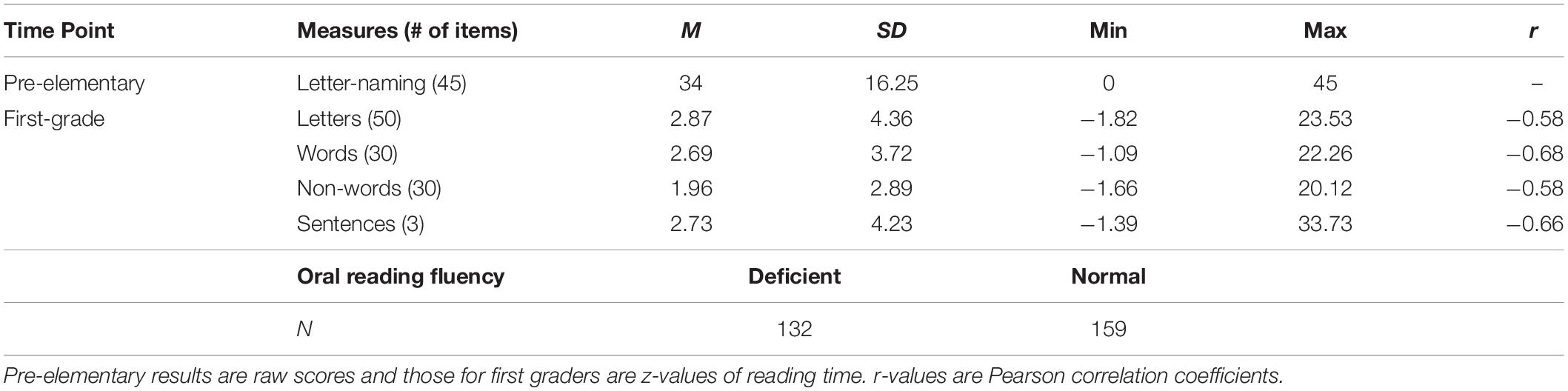
Table 2. Descriptive statistics of letter-naming and measures of oral reading fluency.
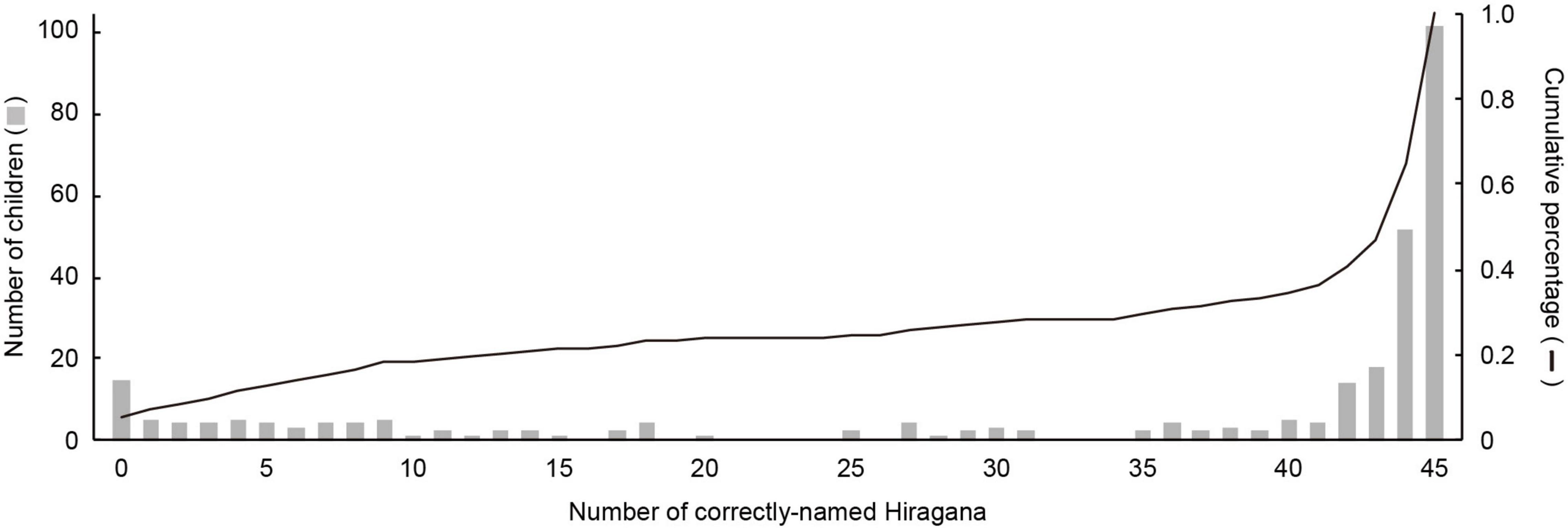
Figure 1. Distribution of Hiragana-naming performance in pre-elementary children. Gray bars indicate the number of children who named the given number of letters correctly (max score: 45, left y-axis). The line indicates the cumulative percentage of children up to a given number of letters (right y-axis).
Figure 2 shows changes in the results of binomial logistic regression (Figure 2A) and ROC (Figures 2B,C) analyses for the possible cut-offs for the Hiragana-naming benchmark. Of all the possible cut-offs (1 to 45 letters), a benchmark of 1 to 9 letters resulted in unreasonably large and unstable odds ratios in the binomial logistic regression; thus, these results are not shown in Figure 2 and were excluded from further consideration.
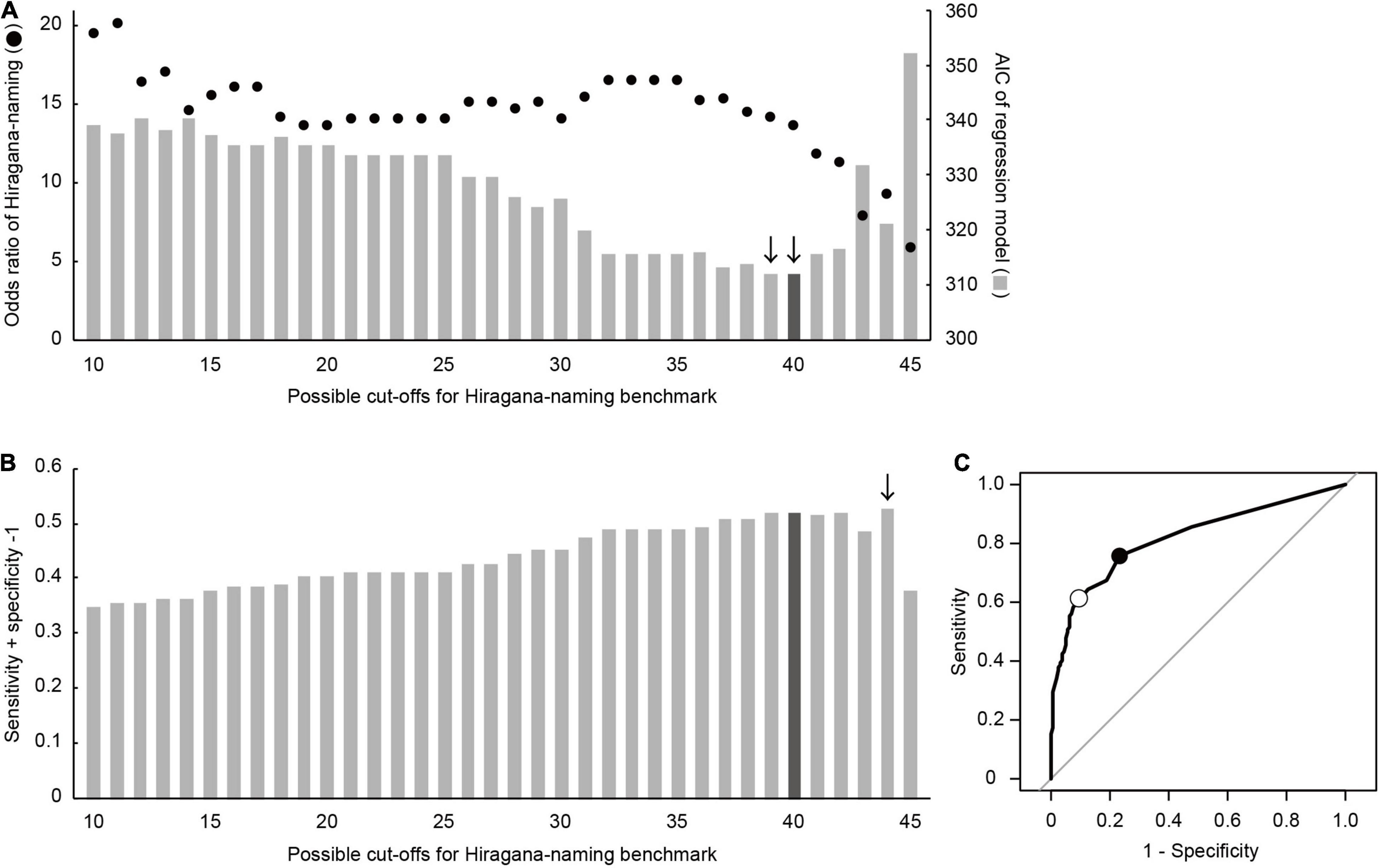
Figure 2. (A) Changes in the results of binomial logistic regression analysis with respect to Hiragana-naming cut-offs from 10 to 45. Black dots indicate adjusted odds ratio of Hiragana naming and gray bars indicate AIC of the regression model at a given cut-off. (B) Changes in the distance between the diagonal reference line and ROC curve over possible Hiragana-naming cut-offs. For both panels (A,B), arrows indicate recommended cut-off(s) based on each analysis, while a black bar at 40 letters indicates a selected optimal benchmark. (C) ROC curve with thresholds indicated at 40 (white circle) and 44 (black circle) letters.
The results of the regression analysis (Figure 2A) showed that the adjusted odds ratio of Hiragana-naming performance remained stable at around 15, except for the lower and higher ends. This result indicated that children who failed to meet a given benchmark were far more likely to be deficient readers in first grade. Regarding the precision of regression models, AIC reached a minimum when the benchmark was set at 39 letters (311.97) and increased only slightly at 40 letters (312.01, Figure 2A). Thus, the binomial regression analysis indicated that 39 and 40 letters were good candidates for an optimal benchmark. On the other hand, the ROC analysis indicated that 44 letters was an optimal cut-off, at which the distance between the ROC curve and a diagonal reference line became maximum (i.e., Youden Index; Figures 2B,C). The prediction accuracy of Hiragana-naming performance with respect to first-grade reading fluency was overall good, with an AUC of 0.817 (95% confidence interval: 0.768–0.867).
Taken together, these results show that, although the ROC result indicated 44 letters, setting a benchmark above 40 letters was considered to be not optimal, due to a decrease in the prediction precision. More specifically, the binomial logistic regression analysis involved an apparent increase in AIC and a drop in the odds ratio, which was associated with an increase in the number of false positives as indicated by the ROC curve (Figure 2C). Therefore, we sought a benchmark of (1) 40 letters of less, where (2) the AIC of the regression model reaches a minimum or close to a minimum, and (3) the distance between the ROC curve and a diagonal reference line reaches a maximum. As a result, all three of these criteria were met when we set a benchmark at 40 letters (Figure 2). Therefore, in the present study, 40 or more of 45 Hiragana Sei-on letters was considered to be a sufficient level of letter-naming for Japanese pre-elementary children.
Table 3 shows the final binomial logistic regression model with the selected benchmark. A model fit was indicated to be appropriate with non-significant χ2 in the Hosmer-Lemeshow goodness of fit test (χ2 = 10.15, df = 8, p = 0.25) and a sufficiently large estimate of determination coefficient (McFadden’s pseudo R2 = 0.242; McFadden, 1997). The adjusted odds ratio indicated that a child who failed to meet the pre-elementary benchmark was at high risk of becoming a deficient reader in the first grade, while the age in first grade and gender were not significantly associated with the first-grade reading status (Table 3).

Table 3. Final model of binomial logistic regression.
Lastly, Table 4 shows the final contingency table of pre-elementary Hiragana-naming performance and first-grade reading fluency. Diagnostic efficiency indices based on Table 4 were moderate sensitivity (0.614) and negative predictive value (0.738), high specificity (0.906) and positive predictive value (0.844), and an overall correct classification rate of 0.773. As shown in Table 4, while some deficient first graders had passed the pre-elementary benchmark (i.e., false negatives; 51/291 = 17.5% of the final sample), children who failed to meet the benchmark rarely became normal readers (i.e., false positives; 15/291 = 5.15% of the final sample). Therefore, the present benchmark was considered to more strongly predict a risk, rather than a successful outcome, with respect to reading ability in the first grade.

Table 4. Contingency table for the optimal Hiragana-naming benchmark.
The goal of the present study was to establish an optimal benchmark for Hiragana Sei-on naming in Japanese pre-elementary children and to examine its ability to predict oral reading fluency in the first grade. Our data supported the conclusion that Hiragana-naming accuracy should reach 40 of 45 letters or more in the pre-elementary year, which is at a level of near-perfect mastery. The selected benchmark was shown to have good overall ability to predict first-grade reading fluency. However, more specifically, failure to meet the pre-elementary benchmark predicted deficient reading fluency (i.e., risk) more reliably than reaching the benchmark predicted normal reading (i.e., success). Therefore, the present study revealed that pre-elementary children without near-perfect mastery of Hiragana Sei-on letters are very likely to exhibit reading difficulties after entering elementary school.
As expected, the present benchmark required the acquisition of nearly 90% of Hiragana Sei-on letters (40/45 letters = 88.9%). In this study, 67.0% of the Japanese pre-elementary children without formal literacy instruction met this criterion (see Table 4). Although direct comparison of this result with previously reported benchmarks in an alphabet is difficult, due to a difference in age (52 vs. 70 months in the present study; Piasta et al., 2012), the average letter-name knowledge reported in similar-aged children may serve as a reference. For example, kindergarteners in Canada (English-speaking) showed mean letter-naming accuracies of 89.1% for uppercase and 74.9% for lowercase letters, and half of them scored 80.8% (21 of 26 letters) or less for lowercase letters (Evans et al., 2006). In grande-section preschoolers in France (French-speaking), the mean accuracy for uppercase letters has been reported to be 75.0% (19.5 of 26 letters; Bouchière et al., 2010). Since early education in these countries typically involves formal alphabet instruction at this age, the imperfect acquisition suggests that learning letter-names in alphabet is generally more demanding than learning Hiragana. More strikingly, Greek kindergarteners without literacy instruction showed even lower letter-name knowledge for uppercase letters (8.47 of 24 letters, 35.3% at the end of a school year), although Greek is more transparent than English or French (Manolitsis and Tafa, 2011). Accordingly, optimal benchmarks are expected to be lower for an alphabet at this age (5 to 6 years), especially for lowercase letters.
The high level of the Hiragana-naming benchmark should be due, at least partially, to the simplicity of the letter-knowledge, as mentioned earlier. Moreover, since Hiragana words can be read by the simple addition of letter-names, reading experience after the initial acquisition can reciprocally strengthen the letter-naming ability. In many Japanese children, a higher chance of mastering letter-names without formal instruction should owe much to these characteristics. In contrast, the alphabet comprises more complex letter knowledge, and a child’s natural exposure to print (e.g., book reading) does not always or necessarily include letter names. This may account for the possibility that the acquisition of alphabet-names takes more time and relies more heavily on formal instruction, so that a smaller proportion of children can reach a mastery level at the same age. These notions suggest that the nature of letter knowledge greatly affects the course and level of letter-name acquisition in a given script, which should be further clarified by taking the difference in the education systems into consideration.
Based on the present Hiragana-naming benchmark, a high proportion (over 80%) of children who failed to meet it became deficient readers, which is in line with previous findings that poor preschool alphabet-knowledge strongly predicts later reading difficulty (Gallagher et al., 2000; Catts et al., 2001; Torppa et al., 2006; Puolakanaho et al., 2007). On the other hand, meeting the benchmark did not strongly predict normal reading fluency, as opposed to the alphabet-naming benchmarks in younger English-speaking children that predominantly predicted successful outcomes (Piasta et al., 2012). Theoretically, the acquisition of Hiragana-names immediately enables children to read words and to increase fluency, so that mastering them by a certain point in the pre-elementary year could strongly predict sufficient first-grade reading fluency; however, the present result did not fully support this hypothesis.
There are two possible accounts for this result. The first is the well-known dissociation between reading accuracy and fluency in transparent scripts. While children with reading difficulties in regular orthography can attain a normal level of reading accuracy, poor reading fluency tends to persist (e.g., Katzir et al., 2004; Lallier et al., 2014; Diamanti et al., 2018), even into adulthood (Oren and Breznitz, 2005; Re et al., 2011). Given the extremely transparent nature of Hiragana Sei-on, it is highly possible that at least some of the children with false-negative results (see Tables 1, 4) had a pure fluency deficit, which had little impact on the acquisition of letter-names. Secondly, the first-grade reading assessment in the present study contained so-called “special moras” that require additional orthographic knowledge in Hiragana, such as voiced and semi-voiced letters (Daku-on and Han-daku-on) and two-letter syllables (You-on; Welty et al., 2014; Inoue et al., 2017). In general, scripts with more complex orthography are associated with a higher prevalence of developmental dyslexia (Habib and Giraud, 2013; Peterson and Pennington, 2015; Daniels and Share, 2018), which is also the case for multiple Japanese scripts (Hiragana: 0.2–1.6% vs. Kanji: 6.1–6.9%; Uno et al., 2009). Therefore, it is possible that a child can acquire Hiragana Sei-on names normally but then struggles with “special moras” and later meets the criterion of deficient reader.
A consideration of these additional requirements in Hiragana reading leads to at least two types of developmental trajectories that are associated with the prediction characteristic of the present benchmark. First, because Sei-on letter-naming is fairly easy, even within Hiragana, children who struggle at this level will continue to be challenged by fluency acquisition and adaptation to exceptional rules. These children rarely catch up to their grade level, as reflected by the small number of false positives (see Tables 1, 4), so that the benchmark could identify at-risk children with high precision. Conversely, children with potentially normal reading ability rarely fail at this level, as reflected by the high specificity. Second, children with milder reading deficit may have little problem with Sei-on naming but start to struggle when additional requirements are introduced. It is difficult for the present benchmark to detect these children; thus, meeting the benchmark does not necessarily assure a successful reading outcome, as reflected by the lower sensitivity and negative predictive value. Given this second trajectory, the ability of present pre-elementary Hiragana-naming benchmark to predict reading outcome beyond first grade, including kanji acquisition, is a topic for future studies.
Regarding alphabet-naming, while the utility of a similar benchmark will need to be determined in future studies, differences in letter-naming with Hiragana may provide some clue. Given that the acquisition of alphabet-naming is presumably more time-consuming and demanding (Evans et al., 2006; Bouchière et al., 2010), it might be difficult for the benchmark to precisely screen for high-risk children at age 5 to 6 years. In fact, a previous study reported a high precision of predicting success, but not risk, throughout the possible range of cut-offs (i.e., 1 to 26 letters) in younger preschoolers (Piasta et al., 2012). As a speculation, the attainment of certain alphabet-naming knowledge by a given age, especially without formal instruction, might reflect a child’s potential advantage in reading acquisition, such as higher cognitive abilities (Evans et al., 2006), and thus could predict a successful outcome more reliably. While it is well-established that early alphabet-name knowledge correlates with later reading abilities (Foulin, 2005; National Early Literacy Panel, 2008; Hjetland et al., 2017), the identification of appropriate benchmark-settings for this skill will require further studies that carefully consider the nature and roles of letter-names in reading.
The present study has several limitations. First, since the present longitudinal data were obtained from a limited number of children at few schools, the benchmark and its ability to predict reading fluency should be verified in larger and different samples of children in Japan to increase a practical value. Second, we only measured the speed of oral reading in the first grade as an outcome measure. Although oral reading fluency is one of the fundamental reading abilities, especially in younger readers and/or transparent scripts (Florit and Cain, 2011; Park et al., 2015), associations between pre-school/pre-elementary letter knowledge and higher-order reading abilities such as comprehension have also been reported (National Early Literacy Panel, 2008; Piasta et al., 2012). Since the ultimate goal of reading is to comprehend the text, the significance of the present benchmark should also be examined from this perspective. Third, since the present study did not include control variables, taking potentially confounding measures (e.g., general cognitive abilities) into account should be important to verify the significance of the benchmark.
Fourth, a substantial influence of environmental and genetic factors, such socio-economic status (SES), home literacy environment, and familial background, on early reading development has been reported, even in transparent scripts (Strang and Piasta, 2016; Lohvansuu et al., 2021). Thus, lack of these measures also limits our conclusions, although letter-naming in Hiragana could be less affected by environmental factors (Inomata et al., 2016). While an interest and engagement in reading might influence Hiragana-naming acquisition to a lesser extent, due to its simplicity, their influence on further literacy development, such as reading fluency, must be examined further. Finally, variations in the level of benchmarks and the significance of early letter-name knowledge among writing systems require similar types of studies, particularly in transparent alphabetic scripts (e.g., Spanish, Italian, Finnish, Korean Hangeul) and those with unique letter-name knowledge (e.g., Hebrew, Levin et al., 2002).
Nonetheless, the present findings and presumable differences between Hiragana and alphabet scripts have important educational implications. First, an appropriate goal of the letter-naming ability and relevant educational policies, such as the starting age and the necessary amount of instruction, should vary greatly among scripts. Thus, each country and region must develop empirically-defined standards, assessments, and curricula for this foundational skill of reading in preschool to early elementary children. Second, the prediction characteristics of a letter-naming benchmark tells educators what should be a focus of monitoring at different stages. For example, Japanese preschool/pre-elementary teachers should pay close attention to and immediately start interventions with children who are, or who may be, failing to meet the Hiragana-naming benchmark. At the same time, teachers of early elementary grades must be aware of the later-onset reading deficits in children who have passed the pre-elementary benchmark. On the other hand, for an alphabet script, careful growth monitoring through formal instruction may be more suitable for identifying at-risk children on the basis of letter-naming ability. Further studies on these issues can be expected to promote various aspects of early reading acquisition and education across languages, countries, and regions.
In conclusion, the present study revealed that Japanese pre-elementary children without near-perfect mastery of Hiragana Sei-on are at great risk of having reading difficulty in the first grade. Since an empirically-determined goal of letter-naming ability is not necessarily part of the official curriculum for preschoolers (Piasta et al., 2012), the present findings and those of future studies must be considered in the development of policies for early education, especially for facilitating the identification of at-risk children. While letter-name knowledge may be the strongest predictor of reading development in any scripts, including the most transparent ones (e.g., Lohvansuu et al., 2021), cross-linguistic and cross-script differences in letter-naming should be carefully considered upon the establishment of particular benchmarks to monitor children’s early reading acquisition more effectively.
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
The studies involving human participants were reviewed and approved by Hitotsubashi University. Written informed consent to participate in this study was provided by the participants’ legal guardian/next of kin.
YO and YoK conceptualized and designed the study. YO performed the analysis and wrote first draft of the manuscript. All authors performed material preparation and data collection, commented on previous versions of the manuscript, and read and approved the content of the work and final manuscript.
This work was supported by the Japan Society for the Promotion of Science (JSPS) under Grants 19J01121 to YO, FY2019 (Researcher Exchange Program) and 19K02944 to YoK; and by the Ministry of Health, Labour and Welfare under Grant H28-Kankaku-Ippan-001 to YoK.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Akobeng, A. K. (2007). Understanding diagnostic tests 3: receiver operating characteristic curves. Acta Paediatr. 96, 644–647. doi: 10.1111/j.1651-2227.2006.00178.x
Borgwaldt, S. R., Hellwig, F. M., and De Groot, A. M. B. (2005). Onset entropy matters: letter-to-phoneme mappings in seven languages. Read. Writ. 18, 211–229. doi: 10.1007/s11145-005-3001-9
Bouchière, B., Ponce, C., and Foulin, J. N. (2010). Développement de la connaissance des lettres capitales. Étude transversale chez les enfants français de trois à six ans. Psychol. Française 55, 65–89. doi: 10.1016/j.psfr.2009.12.001
Bozdogan, H. (1987). Model selection and Akaike’s Information Criterion (AIC): the general theory and its analytical extensions. Psychometrika 52, 345–370. doi: 10.1007/BF02294361
Burnham, K. P., and Anderson, D. R. (2004). Multimodel inference: understanding AIC and BIC in model selection. Sociol. Methods Res. 33, 261–304. doi: 10.1177/0049124104268644
Catts, H. W., Fey, M. E., Zhang, X., and Tomblin, J. B. (2001). Estimating the risk of future reading difficulties in kindergarten children: a research-based model and its clinical implementation. Lang. Speech. Hear. Serv. Sch. 32, 38–50. doi: 10.1044/0161-1461(2001/004)
Daniels, P. T., and Share, D. L. (2018). Writing system variation and its consequences for reading and dyslexia. Sci. Stud. Read. 22, 101–116. doi: 10.1080/10888438.2017.1379082
Diamanti, V., Goulandris, N., Campbell, R., and Protopapas, A. (2018). Dyslexia profiles across orthographies differing in transparency: an evaluation of theoretical predictions contrasting English and Greek. Sci. Stud. Read. 22, 55–69. doi: 10.1080/10888438.2017.1338291
Evans, M. A., Bell, M., Shaw, D., Moretti, S., and Page, J. (2006). Letter names, letter sounds and phonological awareness: an examination of kindergarten children across letters and of letters across children. Read. Writ. 19, 959–989. doi: 10.1007/s11145-006-9026-x
Florit, E., and Cain, K. (2011). The simple view of reading: is it valid for different types of alphabetic orthographies? Educ. Psychol. Rev. 23, 553–576. doi: 10.1007/s10648-011-9175-6
Fluss, R., Faraggi, D., and Reiser, B. (2005). Estimation of the Youden Index and its associated cutoff point. Biom. J. 47, 458–472. doi: 10.1002/bimj.200410135
Foulin, J. N. (2005). Why is letter-name knowledge such a good predictor of learning to read? Read. Writ. 18, 129–155. doi: 10.1007/s11145-004-5892-2
Gallagher, A., Frith, U., and Snowling, M. J. (2000). Precursors of literacy delay among children at genetic risk of dyslexia. J. Child Psychol. Psychiatry 41, 203–213. doi: 10.1111/1469-7610.00601
Habib, M., and Giraud, K. (2013). Dyslexia. Handb. Clin. Neurol. 111, 229–235. doi: 10.1016/B978-0-444-52891-9.00023-3
Hjetland, H. N., Brinchmann, E. I, Scherer, R., and Melby-Lervåg, M. (2017). Preschool predictors of later reading comprehension ability: a systematic review. Campbell Syst. Rev. 14, 1–156. doi: 10.4073/csr.2017.14
Inomata, T., Uno, A., Sakai, A., and Haruhara, N. (2016). Contribution of cognitive abilities and home literacy activities to hiragana reading and spelling skills in kindergarten children. Japan J. Logop. Phoniatr. 57, 208–216. doi: 10.5112/jjlp.57.208
Inoue, T., Georgiou, G. K., Muroya, N., Maekawa, H., and Parrila, R. (2017). Cognitive predictors of literacy acquisition in syllabic Hiragana and morphographic Kanji. Read. Writ. 30, 1335–1360. doi: 10.1007/s11145-017-9726-4
Katzir, T., Shaul, S., Breznitz, Z., and Wolf, M. (2004). The universal and the unique in dyslexia: a cross-linguistic investigation of reading and reading fluency in Hebrew-and English-speaking children with reading disorders. Read. Writ. 17, 739–768. doi: 10.1007/s11145-004-2655-z
Kita, Y., Yamamoto, H., Oba, K., Terasawa, Y., Moriguchi, Y., Uchiyama, H., et al. (2013). Altered brain activity for phonological manipulation in dyslexic Japanese children. Brain 136, 3696–3708. doi: 10.1093/brain/awt248
Lallier, M., Valdois, S., Lassus-Sangosse, D., Prado, C., and Kandel, S. (2014). Impact of orthographic transparency on typical and atypical reading development: evidence in French-Spanish bilingual children. Res. Dev. Disabil. 35, 1177–1190. doi: 10.1016/j.ridd.2014.01.021
Levin, I., Patel, S., Margalit, T., and Barad, N. (2002). Letter names: effect on letter saying, spelling, and word recognition in Hebrew. Appl. Psycholinguist. 23, 269–300. doi: 10.1017/S0142716402002060
Lohvansuu, K., Torppa, M., Ahonen, T., Eklund, K., Hämäläinen, J. A., Leppänen, P. H. T., et al. (2021). Unveiling the mysteries of dyslexia—lessons learned from the prospective Jyväskylä longitudinal study of dyslexia. Brain Sci. 11:427. doi: 10.3390/brainsci11040427
Manolitsis, G., and Tafa, E. (2011). Letter-name letter-sound and phonological awareness: evidence from Greek-speaking kindergarten children. Read. Writ. 24, 27–53. doi: 10.1007/s11145-009-9200-z
McBride-Chang, C. (1999). The ABCs of the ABCs?: the development of letter-name and letter-sound knowledge. Merrill. Palmer. Q. 45, 285–308.
McFadden, D. (1997). Quantitative Methods for Analyzing Travel Behaviour of Individuals: Some Recent Developments Cowles Foundation Discussion Papers 474. New Haven, CT: Yale University.
National Early Literacy Panel (2008). Developing Early Literacy: Report of the National Early Literacy Panel. Available online at: http://lincs.ed.gov/publications/pdf/NELPReport09.pdf (accessed January 18, 2020).
Oren, R., and Breznitz, Z. (2005). Reading processes in L1 and L2 among dyslexic as compared to regular bilingual readers: behavioral and electrophysiological evidence. J. Neurolinguistics 18, 127–151. doi: 10.1016/j.jneuroling.2004.11.003
Ota, S., Uno, A., and Inomata, T. (2018). Attainment level of Hiragana reading/spelling in kindergarten children. Japan J. Logop. Phoniatr. 59, 9–15. doi: 10.5112/jjlp.59.9
Park, Y., Chaparro, E. A., Preciado, J., and Cummings, K. D. (2015). Is earlier better? Mastery of reading fluency in early schooling. Early Educ. Dev. 26, 1187–1209. doi: 10.1080/10409289.2015.1015855
Perfetti, C. A., and Harris, L. N. (2013). Universal reading processes are modulated by language and writing system. Lang. Learn. Dev. 9, 296–316. doi: 10.1080/15475441.2013.813828
Peterson, R. L., and Pennington, B. F. (2015). Developmental dyslexia. Annu. Rev. Clin. Psychol. 11, 283–307. doi: 10.1146/annurev-clinpsy-032814-112842
Piasta, S. B., Petscher, Y., and Justice, L. M. (2012). How many letters should preschoolers in public programs know? The diagnostic efficiency of various preschool letter-naming benchmarks for predicting first-grade literacy achievement. J. Educ. Psychol. 104, 945–958. doi: 10.1037/a0027757
Powell, D. R., Diamond, K. E., Bojczyk, K. E., and Gerde, H. K. (2008). Head start teachers’ perspectives on early literacy. J. Lit. Res. 40, 422–460. doi: 10.1080/10862960802637612
Puolakanaho, A., Ahonen, T., Aro, M., Eklund, K., Leppanen, P. H. T., Poikkeus, A.-M., et al. (2007). Very early phonological and language skills: estimating individual risk of reading disability. J. Child Psychol. Psychiatry 48, 923–931. doi: 10.1111/j.1469-7610.2007.01763.x
R Core Team (2020). R: A Language and Environment for Statistical Computing. Available online at: https://www.r-project.org/ (accessed January 25, 2021).
Re, A. M., Tressoldi, P. E., Cornoldi, C., and Lucangeli, D. (2011). Which tasks best discriminate between dyslexic university students and controls in a transparent language? Dyslexia 17, 227–241. doi: 10.1002/dys.431
Research Group for Formulation of Diagnostic Criteria and Medical Guideline for Specific Developmental Disorders (2010). Diagnostic Criteria and Medical Guideline for Specific Developmental Disorders. Tokyo: Shindan to Chiryosha.
Seymour, P. H. K., Aro, M., and Erskine, J. M. (2003). Foundation literacy acquisition in European orthographies. Br. J. Psychol. 94, 143–174. doi: 10.1348/000712603321661859
Shimamura, N., and Mikami, H. (1994). Acquisition of Hiragana letters by pre-school children: in comparison with the 1967 investigation of the National Language Research Institute. Japanese J. Educ. Psychol. 42, 70–75. doi: 10.5926/jjep1953.42.1_70
Speece, D. L., Mills, C., Ritchey, K. D., and Hillman, E. (2003). Initial evidence that letter fluency tasks are valid indicators of early reading skill. J. Spec. Educ. 36, 223–233. doi: 10.1177/002246690303600403
Strang, T. M., and Piasta, S. B. (2016). Socioeconomic differences in code-focused emergent literacy skills. Read. Writ. 29, 1337–1362. doi: 10.1007/s11145-016-9639-7
Torppa, M., Poikkeus, A. M., Laakso, M. L., Eklund, K., and Lyytinen, H. (2006). Predicting delayed letter knowledge development and its relation to grade 1 reading achievement among children with and without familial risk for dyslexia. Dev. Psychol. 42, 1128–1142. doi: 10.1037/0012-1649.42.6.1128
Treiman, R., Tincoff, R., Rodriguez, K., Mouzaki, A., and Francis, D. J. (1998). The foundations of literacy: learning the sounds of letters. Child Dev. 69, 1524–1540. doi: 10.1111/j.1467-8624.1998.tb06175.x
Trevethan, R. (2017). Sensitivity, specificity, and predictive values: foundations, pliabilities, and pitfalls in research and practice. Front. Public Heal. 5:307. doi: 10.3389/fpubh.2017.00307
U.S. Department of Health and Human Services and Administration for Children and Families (2003). The Head Start Path to Positive Child Outcomes. Available online at: https://www.lakeshorelearning.com/assets/media/images/pdfs/HeadStartPositiveOutcomes.pdf (accessed March 24, 2021).
Uno, A., Wydell, T. N., Haruhara, N., Kaneko, M., and Shinya, N. (2009). Relationship between reading/writing skills and cognitive abilities among Japanese primary-school children: normal readers versus poor readers (dyslexics). Read. Writ. 22, 755–789. doi: 10.1007/s11145-008-9128-8
Walsh, D. J., Price, G. G., and Gillingham, M. G. (1988). The critical but yransitory importance of letter naming. Read. Res. Q. 23:108. doi: 10.2307/747907
Welty, Y. T., Menn, L., and Oishi, N. (2014). Developmental reading disorders in Japan: prevalence, profiles, and possible mechanisms. Top. Lang. Disord. 34, 121–132. doi: 10.1097/TLD.0000000000000014
Keywords: reading development, letter knowledge, pre-elementary, Hiragana, longitudinal, oral reading fluency
Citation: Okumura Y, Kita Y, Kitamura Y and Oyama H (2022) Pre-elementary Children With Imperfect Letter-Name Knowledge Are at Great Risk of Reading Difficulty in First Grade: One-Year Longitudinal Study in Japanese Hiragana. Front. Educ. 7:758098. doi: 10.3389/feduc.2022.758098
Received: 13 August 2021; Accepted: 25 January 2022;
Published: 28 February 2022.
Edited by:
Adriana Bus, University of Stavanger, NorwayReviewed by:
Heikki Juhani Lyytinen, Niilo Mäki Institute, FinlandCopyright © 2022 Okumura, Kita, Kitamura and Oyama. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yasuko Okumura, eWFzdWtvdGNoQG1hYy5jb20=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.