 Saâd Soulaimani1,2*
Saâd Soulaimani1,2* Ayoub Soulaimani3
Ayoub Soulaimani3 Kamal Abdelrahman4*
Kamal Abdelrahman4* Abdelhalim Miftah5
Abdelhalim Miftah5 Mohammed S. Fnais4
Mohammed S. Fnais4 Biraj Kanti Mondal6
Biraj Kanti Mondal6- 1Resources Valorization, Environment and Sustainable Development Research Team (RVESD), Department of Mines, Mines School of Rabat, Rabat, Morocco
- 2Geology and Sustainable Mining Institute, Mohammed VI Polytechnic University, Ben Guerir, Morocco
- 3Natural Resources and Sustainable Development Laboratory, Department of Earth Sciences, Faculty of Sciences, Ibn Tofaïl University, Kénitra, Morocco
- 4Department of Geology and Geophysics, College of Science, King Saud University, Riyadh, Saudi Arabia
- 5Laboratory Physico-Chemistry of Processes and Materials, Faculty of Sciences and Techniques, Hassan First University of Settat, Settat, Morocco
- 6Department of Geography, Netaji Subhas Open University, Kolkata, India
Identifying lithology is crucial for geological exploration, and the adoption of artificial intelligence is progressively becoming a refined approach to automate this process. A key feature of this strategy is leveraging population search algorithms to fine-tune hyperparameters, thus boosting prediction accuracy. Notably, Bayesian optimization has been applied for the first time to select the most effective learning parameters for artificial neural network classifiers used for lithology identification. This technique utilizes the capability of Bayesian optimization to utilize past classification outcomes to enhance the lithology models performance based on physical parameters calculated from well log data. In a comparison of artificial neural network architectures, the Bayesian-optimized artificial neural network (BOANN) demonstrably achieved the superior classification accuracy in validation and significantly outperformed a non-optimized wide, bilayer, and tri-layer network configurations, indicating that incorporating Bayesian optimization can significantly advance lithofacies recognition, thus offering a more accurate and intelligent solution for identifying lithology.
1 Introduction
Identifying lithology is a critical operation in the oil and gas sector, providing essential insights for exploration and production processes. Lithology identification has historically relied on labor-intensive and error-prone manual analysis of geological data (Lui et al., 2022; McCormick and Heaven, 2023; Bonali et al., 2024). The recent surge in artificial intelligence (AI) technologies, particularly advancements in machine learning and neural networks (Alférez et al., 2021; Chen et al., 2024), offers a compelling solution for automating and streamlining lithology identification. However, accurately identifying lithological formations in complex subsurface environments is challenging due to the high-dimensional and non-linear nature of geological data. Traditional methods often struggle to handle the complexity and variability of such data, leading to suboptimal classification results. In recent years, machine learning, particularly Artificial Neural Networks (ANNs), has shown promise in lithology identification but still faces challenges related to model optimization and scalability.
Artificial neural networks (ANNs) demonstrate remarkable capability in replicating complex geological structures and identifying subtle lithological features from well log data. The successful application of ANNs in this domain hinges on the optimal configuration of their hyperparameters (Tilahun and Korus, 2023). The ANNs performance is highly dependent on the configuration of critical settings (hyperparameters). These hyperparameters encompass Network architecture, Learning rates (Dutta et al., 2010) and activation function (Hastie et al., 2009). The high computing cost and unpredictable nature of hyperparameter optimization (Houshmand et al., 2022; Djimadoumngar, 2023) have historically been associated with it. This iterative trial-and-error approach necessitates significant computational resources and lacks deterministic convergence towards the optimal network configuration. This approach often yielded suboptimal artificial neural network (ANN) configurations, hindering the model’s ability to achieve peak performance.
A strong substitute is provided by Bayesian optimization (Asante-Okyere et al., 2022), which guides the hyperparameter search using a probabilistic model. This method learns which regions of the hyperparameter space are most likely to produce good results by updating the probability model based on the findings of earlier assessments. By using this strategy, the networks’ predictive power is increased while the computational cost of doing comprehensive hyperparameter testing is decreased.
This paper introduces a novel approach that integrates Artificial Neural Networks (ANNs) with study to address the challenges of hyperparameter tuning in lithology identification. Unlike conventional methods, this approach leverages Bayesian optimization to efficiently explore the hyperparameter space, significantly improving classification accuracy and computational efficiency in high-dimensional geological data. The use of well log data from the Athabasca Oil Sands Area serves as a case study to demonstrate the effectiveness of the proposed method. The study highlights how Bayesian optimization, by constructing a probabilistic model of the objective function, outperforms traditional optimization techniques in terms of precision, scalability, and resource management. Additionally, this work offers a comprehensive comparison with state-of-the-art methods, illustrating its superiority in handling complex geological datasets, thus providing a scalable solution for various geophysical exploration settings.
Therefore, this work expand the employing Bayesian optimization (Asante-Okyere et al., 2022) to enhance the performance of artificial neural networks for lithology identification. To assess the effectiveness of Bayesian optimization in this domain, the BOANN’s performance is comparatively evaluated against established ANN architectures encompassing various layer configurations (single-hidden layer, double-hidden layer, and triple-hidden layer networks). This rigorous benchmarking aims to quantify the benefits of utilizing Bayesian optimization for hyperparameter tuning within the context of lithology identification. The BOANN model utilizes well log data (RW: water resistivity at formation temperature, Depth: depth of an interval in meters from the Kelly Bushing elevation, SW: water saturation, PHI: density, W_Tar: mass percent bitumen, and VSH: volume of shale) to deliver improved accuracy and dependability in lithofacies classification (Adeniran et al., 2019; Asante-Okyere et al., 2022; Ntibahanana et al., 2022; Albarrán-Ordás and Zosseder, 2023).
Our extensive testing and validation indicate that the Bayesian-optimized model substantially surpasses traditional approaches. This progress not only confirms that Bayesian optimization can refine neural network classifiers for geological applications but also indicates a significant shift towards smarter and more effective methodologies in the oil and gas industry.
2 Material and methods
2.1 Artificial neural networks
Artificial Neural Networks (ANNs) are fundamental to modern computational geoscience, particularly adept at analyzing complex datasets, like those obtained from well logs for lithology identification. These ANNs comprise interconnected processing elements, termed nodes or neurons, organized into distinct layers. Each neuron executes specific mathematical operations, and the collective activity across these layers empowers the network to learn intricate relationships within data (LeCun et al., 2015). This architecture allows them to capture and model the nonlinear and intricate relationships found in geological data, making them ideal for predictive tasks where conventional statistical approaches may struggle (Heaton, 2018) (Figure 1).
Figure 1. Example of neural network architecture.
In the perspective of lithology recognition, a distinctive ANN (Xiong et al., 2020; Xiong et al., 2022; Liu et al., 2024) involves an input layer, numerous hidden layers, and an output layer. The input layer collects raw data like, depth of an interval in meters from the Kelly Bushing elevation, water saturation, density, mass percent bitumen, water resistivity at formation temperature, and volume of shale, which reflect various rock properties. The hidden layers, filled with numerous neurons that possess adjustable weights and biases, process this data. The activation functions like ReLU or sigmoid are used by These neurons to combine non-linearity, serving the network detect complex relationships and interactions indoors the data (Glorot et al., 2011).
Training an ANN implies adjusting the weights and biases to decrease variations between actual and predicted outputs through a method called backpropagation. During this method, the network reduces a predefined loss function (Ng and Jahanbani Ghahfarokhi, 2022) using optimization algorithms like stochastic gradient descent, refining the prediction accuracy (Manouchehrian et al., 2012) with each iteration (Diederik and Jimmy, 2014). Consequently, ANNs have become effective at distinguishing lithological units by detecting subtle differences and characteristics in well log data, serving as an essential resource for geologists and engineers in oil and gas exploration and development.
Featuring Bayesian optimization (Shahriari et al., 2016; Zhang et al., 2020; Asante-Okyere et al., 2022) into ANNs beyond enhances their performance by methodically adjusting hyperparameters (Asante-Okyere et al., 2022; Olmos-de-Aguilera et al., 2023; Nwaila et al., 2024) such as the number of hidden layers, neurons per layer, and learning rates, based on a feedback loop of performance data. This integration not only tailors the network architecture to the unique features of the geological data but also ensures it is optimized for the most accurate lithology predictions, significantly surpassing traditional, non-optimized methods (Snoek et al., 2012).
2.2 Bayesian optimization
The acquisition function is used in Bayesian optimization, for global minimum finding on behalf of HF function (hypothesis function)
•
•
•
The
•
•
2.3 Suitability of Bayesian optimization for lithology identification
Bayesian optimization is particularly effective in high-dimensional spaces, which is common in geological datasets where numerous features (F. Xiong et al., 2022) (e.g., well log measurements) must be considered. Traditional methods like grid search are inefficient and often impractical in such contexts, as they require exhaustive evaluations across all combinations of hyperparameters. It uses a probabilistic model to identify areas of the hyperparameter space that are more likely to yield better results. This approach allows it to focus on promising regions rather than blindly exploring the entire space, leading to faster convergence on optimal hyperparameters.
Unlike deterministic optimization methods, Bayesian optimization explicitly accounts for uncertainty in the model predictions. This is critical in lithology identification, where geological data can be noisy and complex. By modeling uncertainty, it allows for more informed decisions about which hyperparameters to test next. The balance between exploration (trying new hyperparameter values) and exploitation (refining known good values) is inherently managed in Bayesian optimization. This is crucial in lithology identification, where understanding the underlying geology often requires exploring various parameter combinations without committing to suboptimal settings.
Geological data often contains noise and outliers. Bayesian optimization’s ability to incorporate uncertainty helps mitigate the impact of such noise on the optimization process (F. Xiong et al., 2022). This resilience allows for more reliable model performance in identifying lithology, particularly in heterogeneous formations. The relationships between input features and lithology classes are often non-linear and complex. Bayesian optimization is well-suited to optimizing models like neural networks that can capture these complexities, allowing for a more nuanced understanding of lithological characteristics, and allows for the customization of the objective function, enabling the incorporation of specific metrics relevant to lithology identification (e.g., accuracy, precision, recall). This customization ensures that the optimization process aligns closely with the project goals, enhancing overall model performance.
2.4 Bayesian optimization of ANNs for advanced lithology identification
In addressing the multifaceted challenge of lithology identification, this study employs Bayesian optimization for neural networks (ANNs) hyperparameters fine-tuning, using its robust probabilistic outline to significantly enhance classification accuracy (Lozano et al., 2011). Well log data encompassing measurements such as depth of an interval in meters from the Kelly Bushing elevation, water saturation, density, mass percent bitumen, water resistivity at formation temperature, and volume of shale are critical inputs for this analysis, reflecting the diverse physical properties of subterranean materials (Jiang et al., 2021). Given the high dimensionality and variability inherent in such data, conventional neural network (Wu and Zhou, 1993) setups without optimization often struggle to achieve optimal performance, underscoring the need for sophisticated tuning methods (Lee et al., 2021).
Bayesian optimization serves as a pivotal advancement in this context, applying a Gaussian process to model the relationship between hyperparameter configurations and their corresponding predictive accuracies (Dutta et al., 2010). This probabilistic approach not only aids in identifying the most effective neural network architecture such as determining the ideal number of layers and neurons per layer but also in fine tuning other critical parameters like learning rates and batch sizes (Snoek et al., 2012). The chosen method utilizes the Expected Improvement (EI) acquisition function, which systematically guides the selection process towards hyperparameter values that are likely to yield improvements over previously tested configurations (Bischl et al., 2023).
Empirical validation of the optimized models on the test dataset discloses that Bayesian-optimized ANNs best traditional, non-optimized counterparts significantly, achieving up to a 96.69% (Validation)/97.21% (Test) accuracy in lithology classification (Asante-Okyere et al., 2022). This score not only underscores the efficacy of the Bayesian approach but also highlights its potential to refine predictive modelling in geoscience applications. Further, statistical analysis, using confusion matrix, confirms the significance of these improvements, reinforcing Bayesian optimization (Zhang et al., 2020) as a crucial tool for enhancing the reliability and accuracy of lithological predictions from well log data (Xie et al., 2023).
The implications of these findings are profound, suggesting that Bayesian optimization (Ng and Jahanbani Ghahfarokhi, 2022) can transform the landscape of geological data analysis by enabling more accurate, efficient, and reliable lithology identification. This advancement promises to reduce the costs and time associated with traditional geological surveys, offering a more streamlined approach that could revolutionize resource exploration and management practices (Nuzzo, 2017; van de Schoot et al., 2021).
2.5 Data description
The Geological Survey of Alberta started McMurray Formation mapping project, and the Wabiskaw Member overlying of the Clearwater Formation, in the Oil Sands Area of Athabasca. The Alberta Geological Survey data report is one of the most substantial results of the project and will expectantly assist future advancement of the oil sands. The main purpose was to provide a database with 2193 wells data, containing around 750 boreholes that include core analyses, of the Athabasca Oil Sands Area. The current investigation was operated on multiple probing wells (60) that is included in digital data bank that is depicted in a File Reports of Alberta Geological Survey.
The study uses a comprehensive dataset comprised of well log data, sourced from multiple oil and gas fields known for their complex geological settings. This dataset includes several key geophysical logging measurements critical for lithology identification, SitID: A number used within AGS to identify wells, Depth: depth of an interval in meters from the Kelly Bushing elevation, SW: water saturation, PHI: density, W_Tar: mass percent bitumen, RW: water resistivity at formation temperature, and VSH: volume of shale. Each of these measurements provides insights into different rock properties that are indicative of specific lithological characteristics like water resistivity logs that help in identifying fluid content and porosity (Asquith et al., 2004; Ellis and Singer, 2007).
The dataset was carefully curated from a series of drilled wells, each providing a continuous depth-registered record of measured attributes. Preprocessing involved cleaning the data by removing outlier values, interpolating missing data points using statistical techniques, and normalizing the features to a consistent scale to ease effective machine learning analysis (Md Abul Ehsan et al., 2019). The final dataset includes over 18,847 individual log measurements, categorized into several lithological classes based on a combination of core sample analyses and expert geological interpretation. These classes involve Cemented Sand, Coal, Sand, Sandy Shale, Shale and Shaly Sand (Table 1).
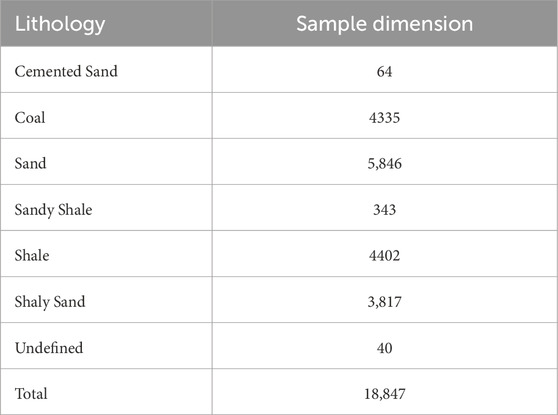
Table 1. Database Lithology outline category.
The database occurred randomly allotted into training (60%), validation (20%), and test sets (20%). This partitioning ensures that the model is exercised on a representative data sample, validated to tune the model settings without overfitting, and finally tested on unseen data to objectively assess its predictive performance. Such a structured approach to data handling is crucial for developing robust artificial neural network models capable of accurately classifying complex lithological formations (Bishop, 2006).
3 Results
3.1 Neural networks
The optimized and non-optimized artificial neural networks were elaborated for lithology prediction, employing described data on previous sections as inputs with MATLAB R2024a. The inclusive analysis of the ANNs models (2.0: optimized, 3.3: wide, 3.4: bilayer, and 3.5: tri-layer) (Wu and Zhou, 1993) offers a rich illustration of how ANNs architecture and optimization strategies shape the performance of machine learning models (Manouchehrian et al., 2012) in terms of accuracy, cost, and error rates across both validation and test datasets. This detailed exploration reveals the subtleties of model behavior, offering critical insights that can guide the selection of optimal configurations for specific applications, emphasizing the interplay between model complexity, learning strategies, and performance outcomes (Table 2).
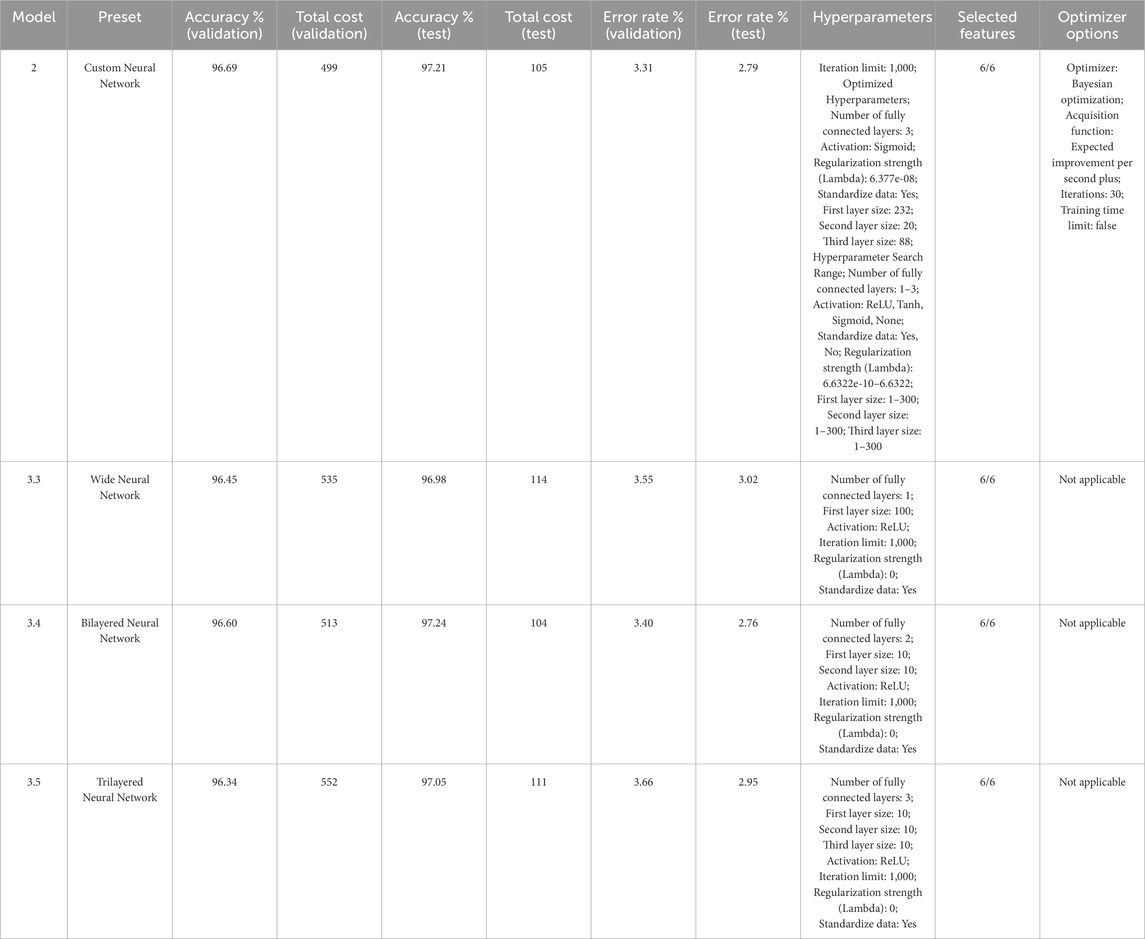
Table 2. Summary results table of the trained Neural Networks.
Model 2.0 stands out with its custom neural network architecture (Hallam et al., 2022; Ganerød et al., 2023; Neelakantan et al., 2024) and advanced Bayesian optimization (Pavlov et al., 2024). It achieves the highest validation accuracy of 96.69% and maintains substantial effectiveness in the test scenario with an accuracy of 97.21%. Particularly, this model also exhibits the lowest test costs and validation (105 and 499, respectively), as well as the lowest error rates, 3.31% in validation and 2.79% in testing. The greater performance of Model 2.0 can be attached to its advanced optimization technique, which efficiently balances the trade-offs between complexity and performance (Figures 2A, 3A).
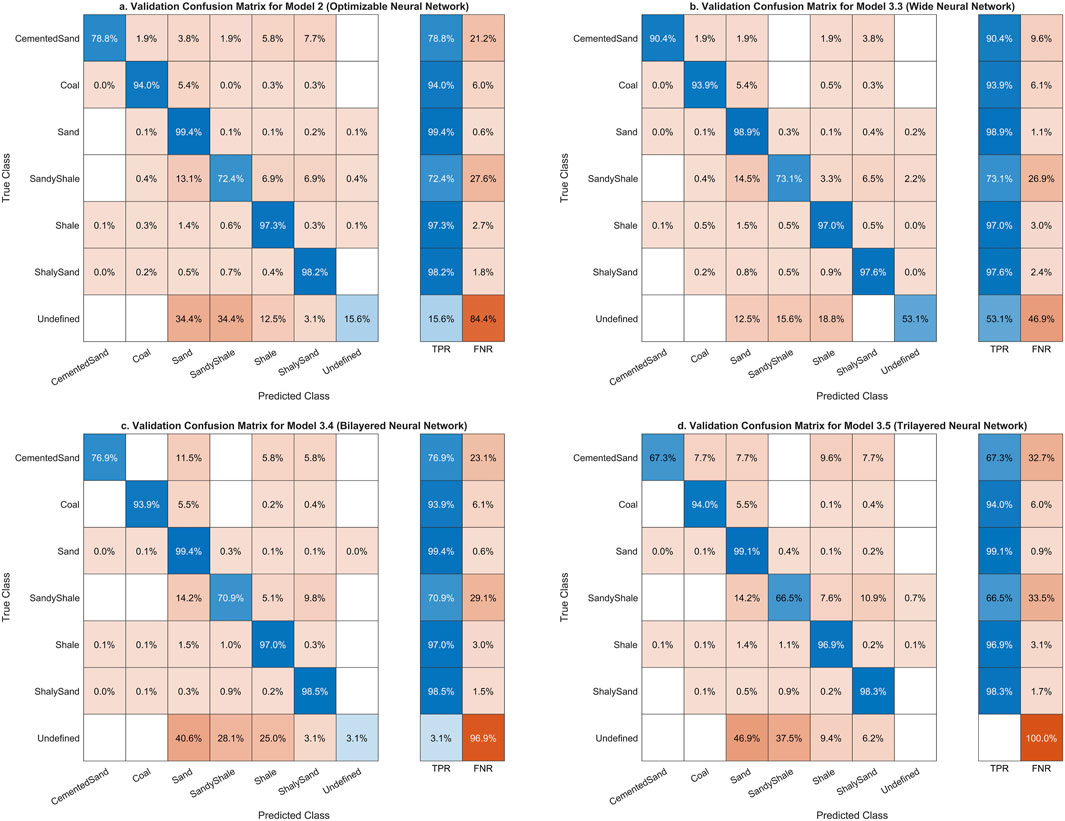
Figure 2. BOANN confusion matrices for: (A). Optimizable Neural Network (Model 2) (B). Wide Neural Network (Model 3.3) (C). Bilayered Neural Network (Model 3.4) (D). Trilayered Neural Network (Model 3.5).
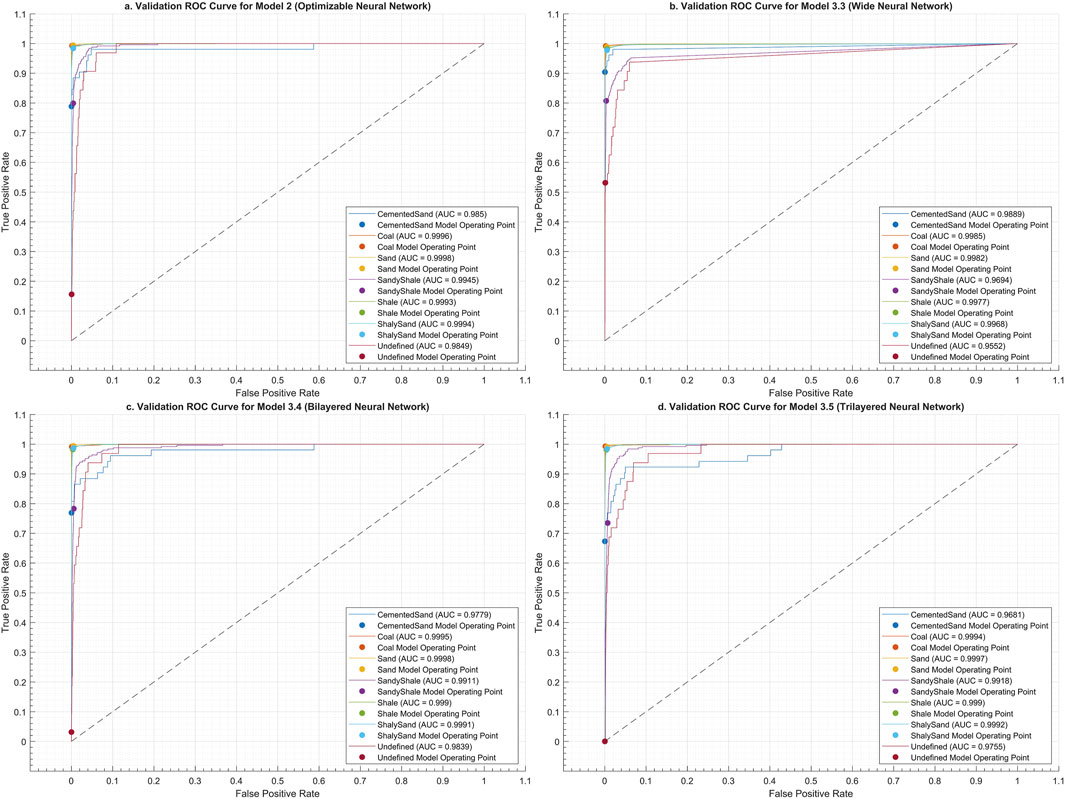
Figure 3. BOANN validation ROC Curves for: (A). Optimizable Neural Network (Model 2) (B). Wide Neural Network (Model 3.3). (C). Bilayered Neural Network (Model 3.4) (D). Trilayered Neural Network (Model 3.5).
Bayesian optimization, acknowledged for its efficiency in exploring parameter spaces, and optimizing performance objectives, improves the model’s capability to generalize across different datasets, thus minimizing overfitting and ensuring robustness. This model reveals how advanced optimization strategies can considerably boost the efficiency of neural networks, making it an ideal choice for applications requiring high accuracy with constrained resource usage.
Model 3.3, described as a Wide Neural Network (Soltanmohammadi and Faroughi, 2023), exhibits somewhat lower performance metrics compared to the other models. With validation and test accuracies of 96.45% and 96.98%, respectively, and higher costs in both scenarios (535 in validation and 114 in testing), it reflects potential limitations in its architectural design and the absence of a specialized optimization approach. The higher error rates of 3.55% in validation and 3.02% in testing further suggest that this model may struggle with efficiency and generalization, potentially due to its wide structure not being complemented by an effective learning strategy. This emphasizes the importance of incorporating advanced optimization techniques for performance improvement of the neural networks, particularly in complex predictive tasks, where precision and cost-efficiency are crucial (Figures 2B, 3B).
Model 3.4, with its Bilayered Neural Network structure, excels particularly in the test dataset, showcasing the highest accuracy of 97.24% and the lowest test cost of 104. This model’s configuration appears to offer an optimal balance, providing sufficient complexity to effectively capture and model intricate data patterns without incurring excessive computational overhead. The low-test error rate of 2.76% underscores its capacity for excellent generalization, suggesting that the bilayered approach is particularly effective in environments where predictive accuracy is paramount, the performance outcomes indicate a potentially well-tuned setup that maximizes efficiency and minimizes costs in operational settings (Figures 2C, 3C).
Model 3.5 represents the most complex network (Ozkaya and Al-Fahmi, 2022; Ommi and Hashemi, 2024) in this analysis, featuring a Trilayered Neural Network. It shows the lowest validation accuracy (96.34%) and the highest validation cost (552), which might indicate a tendency towards overfitting on the validation set due to its deeper network architecture. Nevertheless, it performs well in the test stage, succeeding an accuracy of 97.05% with a relative cost of 111. This suggests that while deeper networks can effectively handle complex datasets, they require careful tuning and possibly more sophisticated optimization strategies to prevent overfitting and manage computational costs effectively. The higher validation error rate (3.66%) further points to the challenges associated with managing more complex models, emphasizing the need for precise model calibration and optimization (Figures 2D, 3D).
In summary, this analysis and comparison delves deep into how different neural network architectures and their associated optimization strategies (Alyaev et al., 2021; Thomas et al., 2023) can dramatically affect machine learning outcomes (Nwaila et al., 2024). The comparison between these models elucidates a spectrum of behaviors and outcomes, from the highly efficient and robust performance of Model 2.0 with its advanced Bayesian optimization to the nuanced challenges faced by the deeper, more complex Model 3.5. Models 2.0 and 3.4 emerge as particularly effective, suggesting that a balanced approach to network design and optimization can yield superior results. This analysis not only grants a described understanding of each model’s strengths and weaknesses, but also extends useful advice for designing neural networks that are tailored to meet specific operational needs and performance criteria (Lawley et al., 2022; Nakamura, 2023). It offers a comprehensive blueprint for leveraging architectural and strategic optimizations to enhance the predictability, efficiency, and cost-effectiveness of neural network models in varied application scenarios.
4 Discussion
Artificial intelligence (AI), particularly using machine learning algorithms like artificial neural networks (ANNs) and optimization techniques such as Bayesian optimization, has transformed various industries, including geological exploration. This part explores the inferences drawn from recent research on AI-driven lithology identification, examines the limitations encountered, and proposes future directions to advance this field of study.
4.1 Inferences drawn from research
The application of AI in lithology identification has yielded several key inferences.
4.1.1 Effectiveness of AI in lithology identification
Recent studies, including those utilizing Bayesian optimization to optimize ANN architectures, have consistently demonstrated the effectiveness of AI in accurately identifying lithological formations. Models enhanced with Bayesian optimization (e.g., Model 2.0), have proven substantial advances in predictive accuracy compared to traditional methods. This underscores the potential of AI to automate and enhance the efficiency of geological exploration processes.
4.1.2 Optimization strategies and model performance
The conducted research features the crucial role of optimization strategies, such as Bayesian optimization, in enhancing model performance. By iteratively fine-tuning hyperparameters based on past performance, Bayesian optimization enables ANNs to achieve higher accuracy levels while mitigating overfitting risks. Models like the bilayered neural network (Model 3.4) exemplify how a balanced approach to architecture design and optimization can optimize predictive capabilities without compromising computational efficiency.
4.1.3 Generalization and transferability
AI models trained on specific datasets have shown varying degrees of generalization across different geological settings. While models like Model 2.0 demonstrated robust performance in validation and test datasets within the study’s scope, challenges remain in extrapolating these findings to diverse geological terrains with unique lithological characteristics. Upcoming research should focus on improving model generalization through multi-modal data incorporation and transfer learning techniques.
4.1.4 Impact of computational resources
The study also underscores the impact of computational resources on AI model deployment and scalability. Deeper neural network architectures (e.g., Model 3.5) exhibited potential for higher accuracy but required significant computational power and time-intensive training processes. This limitation highlights the need for optimizing computational efficiency while maintaining model robustness, particularly in real-time or resource-constrained exploration environments.
4.2 Limits encountered
Despite the promising findings, several limitations were encountered during the research.
4.2.1 Dataset specificity and bias
The analysis relied on specific lithological datasets, potentially limiting the generalizability of findings to broader geological contexts. Dataset bias, inherent in geological data collection processes, can impact model performance and validity across different geological formations and exploration scenarios. Addressing dataset variety and predisposition could be essential for improving the pertinence, robustness and applicability of AI models in real-world applications.
4.2.2 Computational complexity and resource constraints
Complex neural network architectures, although beneficial for capturing intricate lithological patterns, posed challenges in terms of computational complexity and resource-intensive training requirements. Balancing model complexity with computational efficiency remains a significant hurdle in deploying AI solutions for large-scale geological exploration and resource management tasks.
4.2.3 Model interpretability and transparency
The essential complexity of AI models, often results in limited interpretability and transparency in decision-making processes. Understanding how AI-derived predictions align with geological domain knowledge and expert insights is essential for building trust and confidence in AI-driven solutions within the geosciences community. Future research should prioritize developing interpretable AI models that facilitate meaningful collaboration between AI algorithms and domain experts.
4.3 Future directions
Building upon the insights gained and addressing the identified limitations, several promising future directions for research in AI-driven lithology identification include.
4.3.1 Advanced optimization techniques
Further exploration of advanced optimization techniques beyond Bayesian methods, such as evolutionary algorithms, reinforcement learning, or hybrid approaches, to enhance the efficiency and adaptability of AI models in geological exploration and resource management. These techniques can optimize not only hyperparameters but also model architectures and training strategies to improve performance across diverse geological settings.
4.3.2 Integration of multi-modal data sources
Integration of varied data sources, comprising remote sensing data, geological images and geochemical analyses, to supplement the feature space and advance the robustness of AI models for lithology identification. Multi-modal integration can enhance predictive accuracy, facilitate comprehensive geological insights, and mitigate the impact of dataset bias on model performance.
4.3.3 Transfer learning and domain adaptation
Application of transfer learning strategies to leverage pre-trained models for lithology identification tasks across different geological terrains. By transferring knowledge and models learned from one dataset to anothers, transfer learning can enhance generalization capabilities, speed up model training, and enhance the scalability of AI solutions in diverse exploration scenarios.
4.3.4 Real-time application and deployment strategies
Development of real-time AI applications and deployment strategies tailored for operational use in geological exploration and resource management. Highlighting scalability, adaptability and reliability to dynamic environmental conditions will be critical in incorporating AI-driven technologies into decision-making processes and operational systems within the geosciences.
4.3.5 Collaborative research initiatives
Cooperation with academic institutions, industry partners and government agencies to validate AI model performance in real-world exploration situations. Integrating domain expertise and feedback from geological professionals can enhance model robustness, address practical challenges, and foster innovation in AI-driven technologies for sustainable resource exploration and management.
4.4 Summary
The inferences drawn from recent research in AI-driven lithology identification underscore the transformative potential of AI technologies in revolutionizing geological exploration and resource management practices. Despite encountered limitations related to dataset specificity, computational complexity, and model interpretability, the field continues to evolve with promising advancements in optimization techniques, data integration strategies, and real-time deployment solutions. By adopting these challenges and tracking innovative research paths, the geosciences society can employ the full potential of AI to realize more sustainable, efficient and accurate exploration outcomes in the future.
5 Conclusion
In this study, we have led a thorough assessment of four distinct neural network models (2.0, 3.3, 3.4, and 3.5) analyzing their performance, across critical metrics such as accuracy, cost, and error rates within validation and test scenarios. This comparative study has not only illuminated the influence of varying neural network architectures and optimization strategies on model efficiency but also underscored the importance of strategic optimization in achieving superior machine learning outcomes (Costa et al., 2023).
Model 2.0, featuring a custom neural network architecture optimized through Bayesian techniques, emerged as the most efficient model, showcasing high accuracy and minimal operational costs, coupled with the lowest error rates across both datasets. This model’s success highlighted the effectiveness of sophisticated optimization strategies, which fine-tune model parameters to enhance generalization capabilities and prevent overfitting. In contrast, Model 3.3, a Wide Neural Network without specific optimization enhancements, demonstrated the limitations of increasing network size without commensurate advancements in learning strategies, resulting in higher costs and reduced performance. Model 3.4, a Bilayered Neural Network, excelled in test conditions, affirming that an optimal balance of model complexity and computational efficiency can yield significant benefits, particularly in predictive accuracy and cost management. Finally, Model 3.5, with its Trilayered Neural Network, illustrated the challenges and potential of deeper networks, which, despite their complexity, can be effective with proper tuning and optimization, especially in handling complex datasets.
Overall, this study reinforces the critical role of matching network architecture with robust optimization techniques to maximize the performance of neural networks. The conclusions from this study give valuable perceptions for both specialists and researchers, offering support on designing neural networks that are not only powerful but also efficient and adaptable to various applications. This work contributes significantly on machine learning in geosciences, highlighting the need for incessant innovation in network design and optimization strategies to enhance the predictability, efficiency, and practical utility of neural network models.
Data availability statement
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found below: https://drive.google.com/drive/folders/16hTgxLc7SygD9IjnjK5IvWuP_oZXP8d9?usp=sharing.
Author contributions
SS: Conceptualization, Data curation, Formal Analysis, Funding acquisition, Investigation, Methodology, Project administration, Software, Resources, Supervision, Validation, Visualization, Writing - original draft, Writing - review and editing. AS: Conceptualization, Data curation, Formal Analysis, Funding acquisition, Investigation, Methodology, Project administration, Resources, Software, Supervision, Validation, Visualization, Writing–original draft, Writing–review and editing. KA: Conceptualization, Data curation, Formal Analysis, Funding acquisition, Investigation, Methodology, Project administration, Resources, Software, Supervision, Validation, Visualization, Writing–original draft, Writing–review and editing. AM: Conceptualization, Data curation, Formal Analysis, Funding acquisition, Investigation, Methodology, Project administration, Resources, Software, Supervision, Validation, Visualization, Writing–review and editing. MF: Conceptualization, Data curation, Formal Analysis, Funding acquisition, Investigation, Methodology, Project administration, Resources, Software, Supervision, Validation, Visualization, Writing–review and editing. BM: Conceptualization, Data curation, Formal Analysis, Funding acquisition, Investigation, Methodology, Project administration, Resources, Software, Supervision, Validation, Visualization, Writing–review and editing.
Funding
The author(s) declares that financial support was received for the research, authorship, and/or publication of this article. This research was funded by the Researchers Supporting Project Number (RSP2024R249), King Saud University, Riyadh, Saudi Arabia.
Acknowledgments
We would like to thank MathWorks and Datamine software for their assistance during the development of the work. Deep thanks and gratitude to the Researchers Supporting Project Number (RSP2024R249), King Saud University, Riyadh, Saudi Arabia, for funding this research article.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Adeniran, A. A., Adebayo, A. R., Salami, H. O., Yahaya, M. O., and Abdulraheem, A. (2019). A competitive ensemble model for permeability prediction in heterogeneous oil and gas reservoirs. Appl. Comput. Geosciences 1, 100004. doi:10.1016/j.acags.2019.100004
Albarrán-Ordás, A., and Zosseder, K. (2023). Uncertainties in 3-D stochastic geological modeling of fictive grain size distributions in detrital systems. Appl. Comput. Geosciences 19, 100127. doi:10.1016/j.acags.2023.100127
Alférez, G. H., Vázquez, E. L., Martínez Ardila, A. M., and Clausen, B. L. (2021). Automatic classification of plutonic rocks with deep learning. Appl. Comput. Geosciences 10, 100061. doi:10.1016/j.acags.2021.100061
Alyaev, S., Ivanova, S., Holsaeter, A., Bratvold, R. B., and Bendiksen, M. (2021). An interactive sequential-decision benchmark from geosteering. Appl. Comput. Geosciences 12, 100072. doi:10.1016/j.acags.2021.100072
Asante-Okyere, S., Shen, C., and Osei, H. (2022). Enhanced machine learning tree classifiers for lithology identification using Bayesian optimization. Appl. Comput. Geosciences 16, 100100. doi:10.1016/j.acags.2022.100100
Asquith, G., Krygowski, D., Henderson, S., and Hurley, N. (2004). Basic well log analysis. American Association of Petroleum Geologists. doi:10.1306/Mth16823
Bischl, B., Binder, M., Lang, M., Pielok, T., Richter, J., Coors, S., et al. (2023). Hyperparameter optimization: foundations, algorithms, best practices, and open challenges. WIREs Data Min. Knowl. Discov. 13, e1484. doi:10.1002/widm.1484
Bishop, C. M. (2006). Pattern recognition and machine learning. New York: Springer. Available at: http://archive.org/details/patternrecogniti0000bish (Accessed April 18, 2024).
Bonali, F. L., Vitello, F., Kearl, M., Tibaldi, A., Whitworth, M., Antoniou, V., et al. (2024). GeaVR: an open-source tools package for geological-structural exploration and data collection using immersive virtual reality. Appl. Comput. Geosciences 21, 100156. doi:10.1016/j.acags.2024.100156
Chen, Z., Yuan, F., Li, X., Zhang, M., and Zheng, C. (2024). A novel few-shot learning framework for rock images dually driven by data and knowledge. Appl. Comput. Geosciences 21, 100155. doi:10.1016/j.acags.2024.100155
Costa, F. R., Carneiro, C. de C., and Ulsen, C. (2023). Imputation of gold recovery data from low grade gold ore using artificial neural network. Minerals 13, 340. doi:10.3390/min13030340
Diederik, P. K., and Jimmy, Ba (2014). Adam: a method for stochastic optimization. Available at: http://archive.org/details/arxiv-1412.6980 (Accessed April 18, 2024).
Djimadoumngar, K.-N. (2023). Parallel investigations of remote sensing and ground-truth Lake Chad’s level data using statistical and machine learning methods. Appl. Comput. Geosciences 20, 100135. doi:10.1016/j.acags.2023.100135
Dutta, S., Bandopadhyay, S., Ganguli, R., and Misra, D. (2010). Machine learning algorithms and their application to ore reserve estimation of sparse and imprecise data. J. Intelligent Learn. Syst. Appl. 02 02, 86–96. doi:10.4236/jilsa.2010.22012
D. V. Ellis, and J. M. Singer (2007). Well logging for earth scientists (Dordrecht: Springer Netherlands). doi:10.1007/978-1-4020-4602-5
Ganerød, A. J., Bakkestuen, V., Calovi, M., Fredin, O., and Rød, J. K. (2023). Where are the outcrops? Automatic delineation of bedrock from sediments using Deep-Learning techniques. Appl. Comput. Geosciences 18, 100119. doi:10.1016/j.acags.2023.100119
Glorot, X., Bordes, A., and Bengio, Y. (2011). “Deep sparse rectifier neural networks,” in Proceedings of the fourteenth international conference on artificial intelligence and statistics (JMLR Workshop and Conference Proceedings), 315–323. Available at: https://proceedings.mlr.press/v15/glorot11a.html (Accessed April 18, 2024).
Hallam, A., Mukherjee, D., and Chassagne, R. (2022). Multivariate imputation via chained equations for elastic well log imputation and prediction. Appl. Comput. Geosciences 14, 100083. doi:10.1016/j.acags.2022.100083
Hastie, T., Tibshirani, R., and Friedman, J. (2009). The elements of statistical learning. doi:10.1007/978-0-387-84858-7
Heaton, J. (2018). Ian goodfellow, yoshua bengio, and aaron courville: deep learning. Genet. Program Evolvable Mach. 19, 305–307. doi:10.1007/s10710-017-9314-z
Houshmand, N., GoodFellow, S., Esmaeili, K., and Ordóñez Calderón, J. C. (2022). Rock type classification based on petrophysical, geochemical, and core imaging data using machine and deep learning techniques. Appl. Comput. Geosciences 16, 100104. doi:10.1016/j.acags.2022.100104
Jiang, C., Zhang, D., and Chen, S. (2021). Lithology identification from well-log curves via neural networks with additional geologic constraint. GEOPHYSICS 86, IM85–IM100. doi:10.1190/geo2020-0676.1
Lawley, C. J. M., Raimondo, S., Chen, T., Brin, L., Zakharov, A., Kur, D., et al. (2022). Geoscience language models and their intrinsic evaluation. Appl. Comput. Geosciences 14, 100084. doi:10.1016/j.acags.2022.100084
LeCun, Y., Bengio, Y., and Hinton, G. (2015). Deep learning. Nature 521, 436–444. doi:10.1038/nature14539
Lee, J. H., Han, M.-K., Ko, D. W., and Suh, I. H. (2021). From big to small: multi-scale local planar guidance for monocular depth estimation. doi:10.48550/arXiv.1907.10326
Liu, F., Chen, D., Guan, Z., Zhou, X., Zhu, J., Ye, Q., et al. (2024). RemoteCLIP: a vision language foundation model for remote sensing. IEEE Trans. Geosci. Remote Sens. 62, 1–16. doi:10.1109/tgrs.2024.3390838
Lozano, A. C., Świrszcz, G., and Abe, N. (2011). Group orthogonal matching pursuit for logistic regression. J. Mach. Learn. Res. 15, 452–460.
Lui, T. C. C., Gregory, D. D., Anderson, M., Lee, W.-S., and Cowling, S. A. (2022). Applying machine learning methods to predict geology using soil sample geochemistry. Appl. Comput. Geosciences 16, 100094. doi:10.1016/j.acags.2022.100094
Manouchehrian, A., Sharifzadeh, M., and Moghadam, R. H. (2012). Application of artificial neural networks and multivariate statistics to estimate UCS using textural characteristics. Int. J. Min. Sci. Technol. 22, 229–236. doi:10.1016/j.ijmst.2011.08.013
McCormick, T., and Heaven, R. E. (2023). The British Geological Survey Rock Classification Scheme, its representation as linked data, and a comparison with some other lithology vocabularies. Appl. Comput. Geosciences 20, 100140. doi:10.1016/j.acags.2023.100140
Md Abul Ehsan, B., Begum, F., Ilham, S. J., and Khan, R. S. (2019). Advanced wind speed prediction using convective weather variables through machine learning application. Appl. Comput. Geosciences 1, 100002. doi:10.1016/j.acags.2019.100002
Nakamura, K. (2023). A practical approach for discriminating tectonic settings of basaltic rocks using machine learning. Appl. Comput. Geosciences 19, 100132. doi:10.1016/j.acags.2023.100132
Neelakantan, S., Norell, J., Hansson, A., Längkvist, M., and Loutfi, A. (2024). Neural network approach for shape-based euhedral pyrite identification in X-ray CT data with adversarial unsupervised domain adaptation. Appl. Comput. Geosciences 21, 100153. doi:10.1016/j.acags.2023.100153
Ng, C. S. W., and Jahanbani Ghahfarokhi, A. (2022). Adaptive proxy-based robust production optimization with multilayer perceptron. Appl. Comput. Geosciences 16, 100103. doi:10.1016/j.acags.2022.100103
Ntibahanana, M., Luemba, M., and Tondozi, K. (2022). Enhancing reservoir porosity prediction from acoustic impedance and lithofacies using a weighted ensemble deep learning approach. Appl. Comput. Geosciences 16, 100106. doi:10.1016/j.acags.2022.100106
Nuzzo, R. L. (2017). An introduction to bayesian data analysis for correlations. PM&R 9, 1278–1282. doi:10.1016/j.pmrj.2017.11.003
Nwaila, G. T., Zhang, S. E., Bourdeau, J. E., Frimmel, H. E., and Ghorbani, Y. (2024). Spatial interpolation using machine learning: from patterns and regularities to block models. Springer US. doi:10.1007/s11053-023-10280-7
Olmos-de-Aguilera, C., Campos, P. G., and Risso, N. (2023). Error reduction in long-term mine planning estimates using deep learning models. Expert Syst. Appl. 217, 119487. doi:10.1016/j.eswa.2022.119487
Ommi, S., and Hashemi, M. (2024). Machine learning technique in the north zagros earthquake prediction. Appl. Comput. Geosciences 22, 100163. doi:10.1016/j.acags.2024.100163
Ozkaya, S. I., and Al-Fahmi, M. M. (2022). Estimating size of finite fracture networks in layered reservoirs. Appl. Comput. Geosciences 15, 100089. doi:10.1016/j.acags.2022.100089
Pavlov, M., Peshkov, G., Katterbauer, K., and Alshehri, A. (2024). Geosteering based on resistivity data and evolutionary optimization algorithm. Appl. Comput. Geosciences 22, 100162. doi:10.1016/j.acags.2024.100162
Shahriari, B., Swersky, K., Wang, Z., Adams, R. P., and de Freitas, N. (2016). Taking the human out of the loop: a review of bayesian optimization. Proc. IEEE 104, 148–175. doi:10.1109/JPROC.2015.2494218
Snoek, J., Larochelle, H., and Adams, R. P. (2012). Practical bayesian optimization of machine learning algorithms. doi:10.48550/arXiv.1206.2944
Soltanmohammadi, R., and Faroughi, S. A. (2023). A comparative analysis of super-resolution techniques for enhancing micro-CT images of carbonate rocks. Appl. Comput. Geosciences 20, 100143. doi:10.1016/j.acags.2023.100143
Thomas, T., Sharma, P., and Kumar Gupta, D. (2023). Use of AI tools to understand and model surface-interaction based EOR processes. Appl. Comput. Geosciences 17, 100111. doi:10.1016/j.acags.2022.100111
Tilahun, T., and Korus, J. (2023). 3D hydrostratigraphic and hydraulic conductivity modelling using supervised machine learning. Appl. Comput. Geosciences 19, 100122. doi:10.1016/j.acags.2023.100122
van de Schoot, R., Depaoli, S., King, R., Kramer, B., Märtens, K., Tadesse, M. G., et al. (2021). Bayesian statistics and modelling. Nat. Rev. Methods Prim. 1, 1–26. doi:10.1038/s43586-020-00001-2
Wu, X., and Zhou, Y. (1993). Reserve estimation using neural network techniques. Comput. Geosciences 19, 567–575. doi:10.1016/0098-3004(93)90082-G
Xie, Y., Jin, L., Zhu, C., and Wu, S. (2023). A semi-supervised coarse-to-fine approach with bayesian optimization for lithology identification. Earth Sci. Inf. 16, 2285–2305. doi:10.1007/s12145-023-01014-7
Xiong, F., Zhou, J., and Qian, Y. (2020). Material based object tracking in hyperspectral videos. Trans. Img. Proc. 29, 3719–3733. doi:10.1109/TIP.2020.2965302
Xiong, F., Zhou, J., Zhao, Q., Lu, J., and Qian, Y. (2022). MAC-net: model-aided nonlocal neural network for hyperspectral image denoising. IEEE Trans. Geoscience Remote Sens. 60, 1–14. doi:10.1109/TGRS.2021.3131878
Keywords: geology, lithology identification, machine learning, neural network, Bayesian optimization
Citation: Soulaimani S, Soulaimani A, Abdelrahman K, Miftah A, Fnais MS and Mondal BK (2024) Advanced machine learning artificial neural network classifier for lithology identification using Bayesian optimization. Front. Earth Sci. 12:1473325. doi: 10.3389/feart.2024.1473325
Received: 30 July 2024; Accepted: 25 October 2024;
Published: 20 November 2024.
Edited by:
Sheng Nie, Chinese Academy of Sciences (CAS), ChinaReviewed by:
Fengchao Xiong, Nanjing University of Science and Technology, ChinaZhiwen Xue, University of Chinese Academy of Sciences, China
Copyright © 2024 Soulaimani, Soulaimani, Abdelrahman, Miftah, Fnais and Mondal. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Saâd Soulaimani, c291bGFpbWFuaUBlbmltLmFjLm1h; Kamal Abdelrahman, a2hhc3NhbmVpbkBrc3UuZWR1LnNh