 Qingtian Geng
Qingtian Geng Yaning Wang
Yaning Wang Qingliang Li
Qingliang Li- Changchun Normal University, Changchun, Jilin, China
Currently, in Synthetic Aperture Radar Automatic Target Recognition (SAR ATR), few-shot methods can save cost and resources while enhancing adaptability. However, due to the limitations of SAR imaging environments and observation conditions, obtaining a large amount of high-value target data is challenging, leading to a severe shortage of datasets. This paper proposes the use of an Adaptive Dynamic Weight Hybrid Model (ADW-HM) meta-learning framework to address the problem of poor recognition accuracy for unknown classes caused by sample constraints. By dynamically weighting and learning model parameters independently, the framework dynamically integrates model results to improve recognition accuracy for unknown classes. Experiments conducted on the TASK-MSTAR and OpenSARShip datasets demonstrate that the ADW-HM framework can obtain more comprehensive and integrated feature representations, reduce overfitting, and enhance generalization capability for unknown classes. The accuracy is improved in both 1-shot and 5-shot scenarios, indicating that ADW-HM is feasible for addressing few-shot problems.
1 Introduction
Synthetic Aperture Radar (SAR) is an active radar system designed to produce high-resolution images of ground targets. It operates by emitting microwave pulses toward the ground and capturing the signals reflected by these targets. SAR’s ability to create detailed imagery, even in adverse weather conditions or low visibility, makes it highly effective for applications such as remote sensing and target classification. SAR systems achieve high-resolution imaging capabilities by accumulating radar signals during movement, simulating an antenna aperture much larger than its actual physical size (Moreira et al., 2013; Ma et al., 2020). Unlike traditional optical cameras, SAR can operate under all weather conditions and at all times of day, making it invaluable for applications in geological observation (Huang et al., 2020), port management (Zou et al., 2021), and various industrial applications (Dumitru et al., 2014). Influenced by the imaging mechanism, the occurrence of interference clutter in synthetic aperture radar (SAR) renders the identification of false alarms using detectors challenging. Polarimetric SAR has the potential to improve ship detection performance owing to its distinctive polarization characteristics. Gui Gao et al.proposes a dualistic cascade convolutional neural network (DCCNN) algorithm driven by polarization characteristics for ship detection with fully PolSAR data (Gao et al., 2023a). Xi Zhang et al. proposed an innovative approach in synthetic aperture radar (SAR) polarimetric measurements, introducing a new descriptor—polarization autocorrelation matrix. Different from polarimetric covariance and coherency matrices,the polarimetric autocorrelation matrix can capture hidden Doppler information in the frequency domain and encode it in the phase using higher order statistical methods. This matrix facilitates the joint extraction and analysis of polarization and Doppler information from fully polarimetric SAR (PolSAR) data through a matrix analysis (Zhang et al., 2024).
Automatic Target Recognition (ATR) refers to the process of automatically identifying and classifying targets in SAR images using computer algorithms and technologies. In SAR applications, ATR systems can automatically detect and recognize targets, facilitating effective surveillance and intelligence gathering over large areas. The advancement of ATR technology has expanded the application prospects of SAR systems in military intelligence, border security, disaster monitoring, and more. However, due to its complex characteristics, human recognition of SAR targets is challenging and inefficient. For example, speckle noise in SAR images increases the difficulty of feature extraction (Gao et al., 2017; Yue et al., 2020). In the field of automatic ship target recognition, synthetic aperture radar (SAR) technology has been widely used for ship detection and classification due to its all-weather, all-time imaging capabilities. In recent years, cross-modality domain adaptation methods have gained increasing attention. G. Gao et al. proposed the ADCG (Automatic Domain Cross-Modality Learning for Ships) approach, which enhances the accuracy of ship recognition in SAR images through cross-modality transfer learning (Gao et al., 2023b). Moreover, earlier research on SAR images presented a ship detection and classification method that simplifies the process while improving classification accuracy. The integration of these methods has significantly improved overall performance in ship target recognition, especially in complex environments. The application of cross-modality domain adaptation and lightweight adaptive models has further advanced technology in target detection and classification tasks (Gao et al., 2024).
With the progress of machine learning, algorithms capable of generating large-margin classifiers, such as SVM and AdaBoost, have been applied to SAR ATR (Zhao et al., 2001; Sun et al., 2007). Srinivas et al. (2014) proposed a two-stage ATR framework that combines SAR image features with learned graphical models. Traditional machine learning-based ATR methods (O'Sullivan et al., 2001) often rely on manually designed features, which limit recognition performance. However, Wagner (2014) combined convolutional features with SVM for SAR ATR, achieving better performance. Additionally, Morgan (2015) and Chen et al. (2016) applied convolutional neural networks (CNNs) to Synthetic Aperture Radar (SAR) automatic target recognition (ATR). Their work achieved state-of-the-art performance, attributed to the strong representational capacity of deep learning models, which excel in extracting and learning complex patterns from SAR data.
In the task of target classification, target detection is a crucial preliminary step, as its effectiveness directly impacts the accuracy and efficiency of subsequent classification. In recent years, significant progress has been made in addressing target detection challenges, particularly in ship detection using polarimetric synthetic aperture radar (PolSAR) imagery. The technique of simultaneous diagonalization of Hermitian matrices involves representing PolSAR data as Hermitian matrices and applying simultaneous diagonalization to effectively extract features from target regions. This method not only preserves the structural characteristics of polarimetric information but also reduces noise interference, thereby enhancing detection accuracy (Liu et al., 2023). The binary cascade convolutional neural network (CNN) approach introduces two cascaded CNN modules. The first module performs an initial screening of potential target regions, while the second module refines the detection in these regions. This cascaded structure effectively reduces false detection rates and improves target recognition accuracy. Compared to traditional methods, this deep learning approach leverages the multidimensional features of PolSAR data, demonstrating superior detection performance. The combination of these research methods not only improves target detection but also provides more precise input data for target classification. Therefore, incorporating relevant studies on target detection highlights its crucial role in enhancing the overall target classification process (Gao et al., 2023a).
Despite the notable success of current SAR target classification models, they rely heavily on extensive training with large-scale datasets. However, obtaining such datasets with fine annotations presents significant challenges. First, SAR data is more difficult to acquire than natural scene images. Second, the manual interpretation and labeling of SAR images require considerable time and effort, further complicating the process of building large, annotated datasets for SAR classification. Insufficient training samples limit the performance and development of SAR target classification. Expanding the training sample set (Balz et al., 2009; Hammer and Schulz, 2009; Auer, 2011; Ratner et al., 2017; Liu et al., 2018; Wang et al., 2018; Cao et al., 2019; Cubuk et al., 2019; Cui et al., 2019; Cao et al., 2023) is a direct method to address sample constraints from a data perspective, including traditional data augmentation, automatic data augmentation, and generating new samples through simulators or generative models. Transfer learning (Huang et al., 2017b; Malmgren-Hansen et al., 2017; Zhong et al., 2018; Huang et al., 2019; Rostami et al., 2019a; Rostami et al., 2019b; Wang et al., 2019) is another viable approach, leveraging prior knowledge learned in the source domain to address sample limitations in the target domain. Unsupervised learning effectively discovers information without supervision, primarily dealing with unlabeled data.
To reduce dependency on large training samples, few-shot learning has been proposed and is gaining attention in image classification, regression, and reinforcement learning. Meta-learning, a classic few-shot learning method, has driven the development of related research by learning update functions or learning rules from previous work (Schmidhuber, 1987; Bengio et al., 2013). A meta-learning model is designed to transition from learning with few examples to generalizing across many tasks, effectively addressing the few-shot learning problem (Wang and Hebert, 2016). Current meta-learning methods can be categorized into three types based on different learning mechanisms: optimization-based, model-based, and metric-based.
The semi-automatic image intelligent processing system developed by Lincoln Laboratory is a classic application of template matching technology. This system maintains a large template storage and uses template matching techniques to find the best match between potential targets and templates (Novak et al., 1997a; Novak et al., 1997b; Novak et al., 2000). However, extracting distinct features from SAR targets under varying imaging parameters, poses, and pitch angles poses significant challenges, which can negatively impact classification performance across different operational conditions. To overcome this challenge, model-based methods have been developed (Diemunsch and Wissinger, 1998; Hummel, 2000). Recent meta-learning models aim to achieve few-shot recognition and rapid adaptation to new targets, for instance, by using a few examples and iteratively updating the network. Model-Agnostic Meta-Learning (MAML) (Finn et al., 2017) learns a good initialization from which models can quickly converge on new few-shot tasks. Additionally, Meta-SGD (Li et al., 2017) not only learns a good initialization but also learns the appropriate learning rates for each parameter in the base learner. The Reptile algorithm is used to learn parameter initialization, allowing quick fine-tuning on new tasks with first-order gradient updates (Nichol, 2018). Fu et al. proposed a meta-learning framework MSAR, consisting of meta-learners and base learners, to address sample constraints by learning a good initialization and appropriate update strategies. Zeng et al. proposed a meta-adaptive stochastic gradient descent (Mada-SGD) method for inner-loop parameter updates. This approach employs meta-adaptive hyperparameter learning, which captures the weight distribution between previous and current update steps. Acting like a memory mechanism, it enhances the initialization of parameters, improving model adaptability across updates (Zeng et al., 2023). Zhou et al. designed a lightweight meta-feature extractor, DarknetS, enhancing SAR image features and improving detection efficiency (Zhou et al., 2022). Fan et al. proposed a meta-learning framework based on Sample and Embedding Adaptive Network (Sea-Net) for few-frame SAR image target classification (Fan et al., 2023). Wang et al. integrated a local feature classification module into meta-learning and proposed a multi-scale local classification network (MLC-Net) to enhance critical local detail features of targets (Wang et al., 2023). Yu et al. proposed a novel method called the Enhanced Prototype Network with Customized Region-Aware Convolution (CRCEPN). This network can adaptively adjust the convolutional kernels and their receptive fields based on the features of SAR images and the semantic similarities between spatial regions. As a result, it enhances the ability to extract more information and discriminative features (Yu et al., 2024). Qin et al. proposed a Scattering Attribute Embedded Network (SANet) for few-shot SAR Automatic Target Recognition (ATR). SANet embeds the inherent physical properties provided by the scattering centers of SAR targets, enabling effective generalization to new target categories that are unseen in training sets with very limited samples (Qin et al., 2024). The low resolution and high sample similarity of SAR images hinder instance recognition in contrastive learning. To address this, Liao et al. proposed Low Confidence Discriminative Contrastive Learning (LDCL), which combines group instance comparison with batch mix training (Liao et al., 2024). To enable SAR-ATR models to recognize subsequent target aspect domain SAR images online while minimizing forgetting, a Target-Aspect Hard Attention Continual Learning (THAT-CL) method is proposed. This approach applies a hard attention mechanism to retain information from different tasks by embedding the index of each target aspect recognition task as a vector in each network layer (Zhu et al., 2024).
In remote sensing image analysis, the use of meta-learning for Automatic Target Recognition (ATR) remains limited, especially in the context of SAR ATR. Relying on a single model with updated parameters typically fails to deliver strong recognition performance for unseen target classes. Hence, an Adaptive Dynamic Weight Hybrid Model (ADW-HM) meta-learning structure is introduced, capable of dynamically learning model parameters and integrating model predictions to achieve good recognition results for unknown classes. Experiments demonstrate that ADW-HM improves recognition accuracy compared to existing benchmark models. The contributions can be summarized as follows:
(1) By combining meta-learning and ensemble learning, a hybrid model can be constructed to enhance performance in SAR-ATR tasks. The meta-learning framework enables the model to learn optimal initial parameters, allowing it to quickly adapt and update when recognizing new classes. This rapid adaptability is crucial for addressing the challenges of few-shot classification. Additionally, the integration of ensemble learning improves recognition accuracy and stability, particularly for unknown classes. Unlike traditional fixed-weight or simple linear combination models, the ADW-HM framework incorporates a task-specific dynamic weight adjustment mechanism. This mechanism adaptively adjusts the weights of different model components in real-time, responding to the data distribution and feature complexity of each task. As a result, the framework ensures optimal performance across a wide range of tasks. This hybrid approach effectively mitigates the issues of limited sample size and inadequate feature representation, which are common in SAR-ATR tasks.
(2) The proposed ADW-HM framework introduces a dynamic weighting mechanism that adjusts the contributions of individual models based on task-specific requirements. By dynamically updating both the model parameters and the prediction results, the framework effectively improves recognition accuracy for unseen target classes. This adaptive mechanism enables the model to capture the varying importance of different models across tasks, leading to better generalization and performance.
(3) We partitioned the MSTAR dataset to facilitate effective training and evaluation of our meta-learning approach. The ADW-HM framework demonstrated strong performance on the TASK-MSTAR and OpenSARShip datasets, validating its potential in real-world SAR-ATR scenarios. Through task-specific partitioning, the model can better generalize across different target categories, further supporting the robustness of the proposed method in practical applications.
2 Related works
In SAR target classification, the lack of target sample data is a common phenomenon, making it imperative to improve SAR target recognition methods with limited samples. Traditional supervised learning methods require a large number of target training samples to acquire the learned knowledge for recognition on validation and test set targets. SAR few-shot learning methods address recognition tasks with a limited number of samples. Given the scarcity of SAR images, directly training networks to extract sufficient discriminative features for accurate target recognition is often unfeasible. Hence, few-shot learning is proposed to address this issue. Few-shot learning (FSL) initially trains on a large set of category targets to extract discriminative features. It then uses a small number of target samples—typically one or five shots—to extend the model’s discriminative ability to novel targets in the test set. Figure 1 illustrates the difference between traditional supervised learning and FSL. As shown in the figure, in supervised learning, the training set and the test set belong to the same category but different individuals. However, in FSL, the training set and the test set belong to independent entities of different categories. Additionally, it should be noted that the FSL training set includes support set and query set components, which help facilitate learning about the training targets.
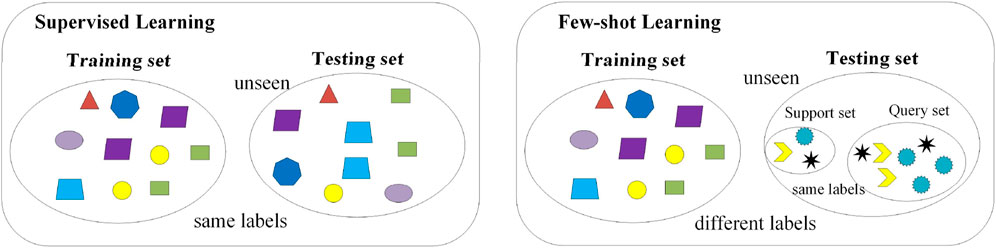
Figure 1. The difference between traditional supervised learning and few-shot learning: Left:Supervised learning; Right:Few-Shot learning.
Meta-learning in the context of few-shot learning is a machine learning paradigm designed to equip models with the ability to quickly adapt to new tasks or domains. This enables them to learn efficiently from only a few samples when presented with novel tasks. The core principle of meta-learning is that, during the meta-training phase, the model acquires generalizable knowledge or strategies from a limited set of training tasks. This equips the model to generalize more effectively when faced with new, unseen tasks. Meta-learning has wide-ranging applications, including few-shot learning, transfer learning, and fast adaptation to novel tasks. By leveraging these capabilities, meta-learning offers a powerful solution for overcoming sample constraints in various learning scenarios. Meta-learning generally comprises two stages: outer learning and inner learning. In outer learning, the model acquires general knowledge from various tasks, which it applies to new task categories during inner learning. Inner learning, in turn, manages the process and outcomes of outer learning, enhancing its effectiveness for quick adaptation to novel tasks or environments. As illustrated in Figure 2, meta-learning typically includes two key components: the meta-learner and the base learner. The meta-learner extracts broad knowledge or learning strategies from meta-training tasks, enabling the base learner to adapt swiftly to new tasks, achieving strong performance with minimal sample fine-tuning. The base learner, often a deep learning model such as a convolutional neural network, focuses on learning task-specific patterns.
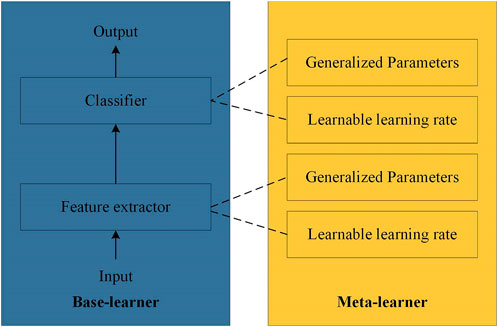
Figure 2. Meta-learning framework.
Unlike traditional supervised learning methods, meta-learning is a few-shot learning approach that takes learning tasks as basic units of input. Generally, a meta-learning dataset comprises a meta-training set and a meta-testing set. Tasks in the meta-training set are used to train the model and extract useful prior knowledge. Meanwhile, tasks in the meta-testing set, which are drawn from categories different from those in the meta-training set, are used to validate and assess the performance of the meta-learning model. Tasks extracted from the meta-training set are called meta-training tasks, while new tasks from new categories form the meta-testing set. Each task consists of a support set and a query set, analogous to the training set and test set in supervised learning. Tasks in meta-learning can be described as an N-way, K-shot problem, where N represents the number of target categories, and K represents the number of target samples per category. Figure 3 shows an example of a meta-dataset consisting of three tasks from the MSTAR dataset. Each task in the support set comprises three target categories, each with only one target sample, and the query set’s targets are derived from these target categories, containing a total of two targets. In SAR-FSL, N and K are usually determined based on specific situations and task requirements. In this paper, for training and testing purposes, we adopt combinations of N = 3 and K = 1 or 5, which further enables the model to learn more thoroughly during meta-training.
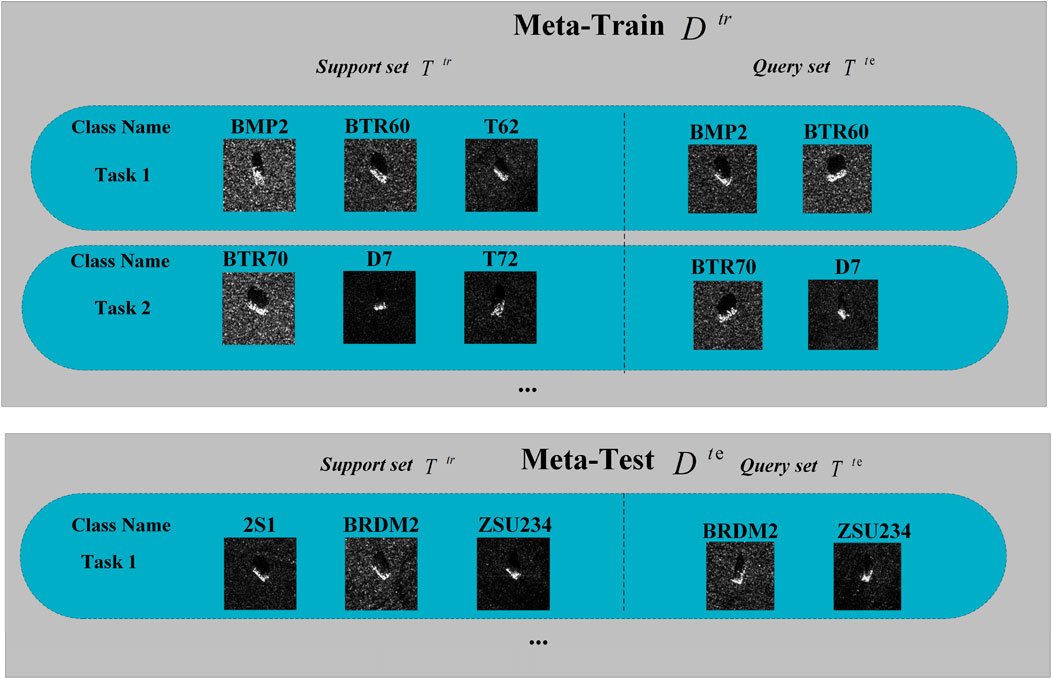
Figure 3. Task allocation diagram for the SAR meta-dataset in a 3-way, 1-shot setting.
3 Methods
3.1 Hybrid model meta-learning framework
Few-shot learning, a specialized form of meta-learning within supervised learning, focuses on extracting relevant information from various tasks to inform and accelerate the learning process for new tasks. This achieves strong generalization across tasks and rapid adaptation to new tasks. Additionally, “episode” training is used to learn and update meta-parameters. In the hybrid model, multiple models’ performances on tasks are considered. The hybrid model meta-learning architecture, as shown in Figure 4, illustrates its execution process in the meta-training and meta-testing phases.
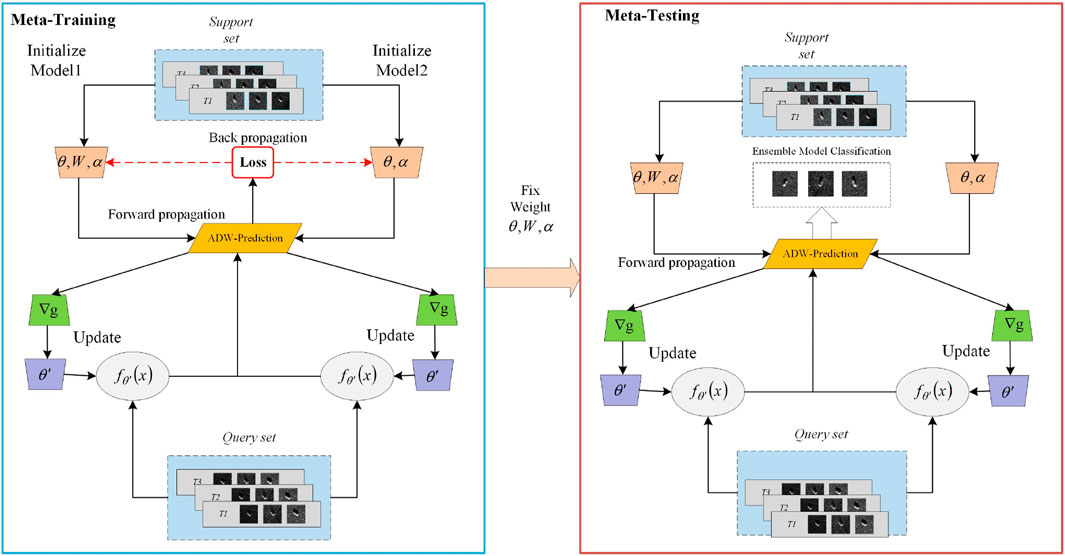
Figure 4. Hybrid model meta-learning architecture.
In the meta-training phase, two models with identical structures but different general parameters are initialized, along with learnable learning rates and weight proportions allocated to each model. This paper introduces the ADW-HM (Adaptive Dynamic Weighting Hybrid Model) framework, which integrates multiple sub-models within a meta-learning structure and employs an adaptive dynamic weighting mechanism to enhance predictive performance in few-shot learning tasks. During the meta-training phase, the hybrid model first performs forward propagation on the support set, where the combined predictions from the sub-models are aggregated using adaptive dynamic weights. Each sub-model generates independent parameter gradients based on specific task characteristics, allowing their parameters to be updated in parallel. Unlike previous models, ADW-HM introduces a novel adaptive weight update mechanism for each sub-model. This feature enables dynamic adjustments of the model’s parameters during training, increasing its adaptability to diverse tasks. Specifically, ADW-HM calculates the adaptive dynamic weight predictions on the query set during meta-training to generate a meta-loss, which informs a parameter update strategy applicable to all meta-tasks. This strategy not only updates the initial parameters and learning rates but also optimizes them using the adaptive weight W, allowing the hybrid model to swiftly and accurately adapt to new tasks.
In the meta-testing phase, the initialized parameters, learning rates, and adaptive weight W are fixed, allowing the meta-learner to adapt swiftly to new tasks without further updates, ensuring rapid adaptation to novel categories within the meta-testing set. The key innovation of ADW-HM lies in its dynamic weight allocation strategy, which combines predictions from multiple sub-models, applying a weighted integration approach. This ensemble learning method mitigates potential performance fluctuations that can occur in single-model frameworks. If one sub-model underperforms, the others can compensate through weighted adjustments, thereby enhancing the overall stability and robustness of the hybrid model. The ADW-HM framework introduces a novel hybrid model structure that goes beyond merely adjusting and combining model weights. It leverages advanced strategies like dynamic weighting and ensemble learning to tackle the challenges of few-shot learning. Key innovations in this framework include:
Enhancing Model Stability: In few-shot learning, individual models are susceptible to data noise, leading to unstable performance. The ADW-HM framework addresses this by integrating multiple models, each capturing different features or patterns. Unlike existing methods, it utilizes a dynamic weighting mechanism, allowing models to compensate for one another when some underperform, thus ensuring stable overall performance. This approach is particularly effective for handling complex and noisy data.
Improving Adaptability with Dynamic Weighting: Traditional few-shot learning models often lack flexibility. The ADW-HM framework introduces a task- or data-feature-based dynamic weighting system, adjusting model weights based on the specific needs of the task or characteristics of the data. This adaptive mechanism enables the framework to quickly respond to diverse scenarios, enhancing its ability to generalize, particularly when faced with new or unseen data.
Reducing Reliance on a Single Model Through Hybrid Models Fusion: The ADW-HM framework maximizes the strengths of multiple models while minimizing their individual weaknesses. Unlike single-model or static-weight approaches, this dynamic fusion of model predictions prevents over-reliance on any single model. By balancing performance across models, the framework significantly improves overall performance in few-shot learning situations, capitalizing on the complementary strengths of each model.
3.2 Meta-learning pipeline
In the hybrid model meta-learning framework, the parameter updating process depicted in Figure 4 involves computing the loss on the support set during meta-training, as shown in Equation 1. Here, x and y represent the input image and the category label, respectively.
The loss function in the hybrid model architecture is calculated by combining the loss functions of multiple models. As shown in Equation 2, it represents the overall loss on the support set, where W denotes the adaptive dynamic weights that are adjusted to suit the specific requirements of each task.
The loss on the support set,
Subsequently, based on the meta-training query set, the query set loss
As shown in Equation 5, the loss function for the query set is also dynamically calculated, depending on the loss functions of the two models.
The parameters
In the model, the values of the generalized parameters and adaptive dynamic weights are updated using the standard gradient descent method as described in Equation 8, W represents the adaptive weight values of the Hybrid model. During the meta-testing phase, for each task, the meta-learning model initially fine-tunes the well-learned generalized parameters on the support set to adapt them to the current task. Subsequently, the model evaluates accuracy on the query set under meta-testing. To ensure more effective evaluation, the query set in the meta-testing phase should contain more test examples compared to the meta-training phase.
3.3 Meta-learning architecture
The base learner framework is constructed using a 4-layer convolutional structure based on CNN to extract features. Each convolutional module contains a 3 × 3 convolution with 64 filters, batch normalization (BN), and the ReLU non-linear activation function. As shown in Figure 5, the model structure includes a 2 × 2 max-pooling operation after each convolutional layer to extract features containing more target information. Before training the dataset images, all images in the dataset are preprocessed to a uniform format. The original image pixel dimensions are transformed to a uniform size of 84 × 84 pixels, resulting in the input image size for the base meta-learning framework being 84 × 84 pixel grayscale images.

Figure 5. Model structure.
In the hybrid model, various forms of loss functions can be selected for differentiated learning based on task requirements. In this paper, cross-entropy loss (CEL) is primarily used to quantify the differences between different tasks. The formula for the cross-entropy loss function is shown in Equation 9:
Here, f and y represent the predicted labels and the true labels, respectively. n denotes the number of SAR targets in the meta-task.
4 Dataset and experiments
4.1 Dataset and experimental setup
MSTAR Dataset: Unlike the rapid development in natural image recognition research, obtaining a sufficient number of publicly available datasets in the field of remote sensing SAR image recognition is challenging due to the difficulty of target detection methods. Among the few available datasets, the publicly accessible MSTAR dataset from the United States is notable for vehicle target recognition. MSTAR images were provided in the mid-1990s by the Defense Advanced Research Projects Agency (DARPA) and the Air Force Research Laboratory. The dataset utilizes HH polarization, X-band frequency, with a resolution of 0.3 m × 0.3 m, capturing images at 1° intervals over a 360° range. The dataset includes ten categories of targets, primarily consisting of SAR slice images of stationary vehicles, capturing various vehicle targets at different azimuth angles. As illustrated in Figure 6, it contains some SAR images and their corresponding optical images from the dataset. Specifically, the MSTAR dataset includes slice images of ten different types of military targets, namely, 2S1 (self-propelled howitzer), BRDM2 (armored reconnaissance vehicle), BTR60 (armored personnel carrier), BTR70 (armored personnel carrier), D7 (bulldozer), T62 (tank), ZIL131 (cargo truck), ZSU234 (self-propelled anti-aircraft gun), T72 (tank), and BMP2 (infantry fighting vehicle).

Figure 6. SAR partial images and their corresponding optical images on the MSTAR dataset.
TASK-MSTAR Dataset:To facilitate experimental testing and analysis based on specific models and requirements, this section introduces a specialized MSTAR few-shot target recognition task dataset, referred to as the TASK-MSTAR dataset. The TASK-MSTAR dataset is composed of individual tasks, defined as N-way K-shot tasks. An N-way K-shot task consists of N categories and K samples. First, N categories are selected, and then K samples are randomly chosen from each of these categories to form the support set, resulting in a total of N×K samples. Additionally, some random samples from the same N categories are used to create the query set. Detailed information on the SAR images of each category is presented in Table 1. The MSTAR dataset is divided into a meta-training set with 7 categories and a meta-testing set with 3 categories. The categories BMP2, BTR60, T62, ZIL131, BTR70, D7, and T72 are used as the meta-training set, while the categories 2S1, BRDM2, and ZSU234 are used as the meta-testing set to construct the TASK-MSTAR dataset, ensuring that the target categories in the meta-training and meta-testing sets are non-overlapping.
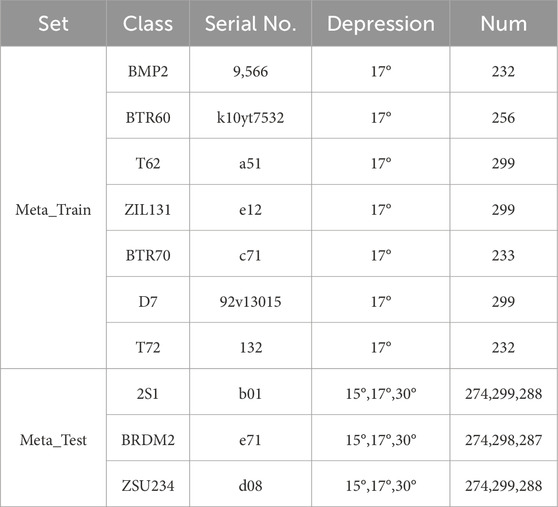
Table 1. Configuration information of the TASK-MSTAR dataset.
OpenSARShip Dataset: The OpenSARShip dataset (Huang et al., 2017a), released by Shanghai Jiao Tong University, is widely used as a benchmark for evaluating SAR target detection and recognition algorithms. It is publicly available on the OpenSAR platform. The dataset contains 11,346 SAR images of 17 types of ship targets, all derived from 41 Sentinel-1 images and featuring four polarization modes. Each SAR image has an original size of 128 × 128 pixels, with a resolution of 10 m × 10 m. In this paper, we conduct experiments using SAR images with vertical polarization (VV) and vertical-horizontal polarization (VH). To mitigate the impact of class imbalance, we follow the method outlined in the literature (Wang et al., 2020), ensuring an equal number of meta-training and meta-testing samples for each class. Figure 7 shows several optical images and corresponding SAR images of six ship targets from the OpenSARShip dataset. Based on previous studies (Zhang et al., 2021; Wang et al., 2022), we use SAR images of dredgers, fishing boats, and tugboats as meta-training data, while bulk carriers, container ships, and oil tankers serve as meta-testing data. Table 2 lists the number of targets in both the meta-training and meta-testing sets for each category.

Figure 7. SAR partial images and their corresponding optical images on the OpenSARShip dataset.
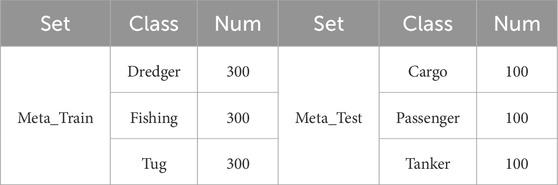
Table 2. Configuration information of the OpenSARShip dataset.
This paper primarily utilizes 3-way, K-shot tasks for training and testing. In this setup, the meta-training set consists of samples from seven target classes, while the meta-test set includes samples from three different target classes (2S1, BRDM2, and ZSU234). This division offers advantages because the MSTAR dataset contains only ten target classes. By maximizing the size of the meta-training task space, overfitting can be prevented, and the meta-test model’s adaptability across different tasks is enhanced. Using 3-way K-shot tasks expands the meta-training task space to

Table 3. 3-Way, K-shot task Configuration information.
4.2 Experimental results and analysis
The performance evaluation of the experiments primarily uses two metrics: Accuracy and Standard Deviation (Std). The definition of the accuracy metric is given by Equation 10:
The standard deviation metric is defined by Equation 11, where
The loss is computed using the cross-entropy loss function, as described in Equation 9. For the meta-training set, 4,000 meta-tasks are randomly selected for training. For the meta-test set, SAR few-shot experiments are conducted under different depression angle conditions. As shown in Table 4, 200 meta-tasks are randomly selected for testing to evaluate the target performance of the few-shot samples in new categories, ensuring an equal probability of selecting each target. The notation 17°D/15°D indicates that the depression angle of the target samples selected for meta-training is 17°, while for the meta-test, it is 15°.The experimental setup for both the OpenSARShip dataset and the TASK-MSTAR dataset is the same, with 4, 000 tasks for meta-training and 200 tasks for meta-testing.

Table 4. Experimental setup for the TASK-MSTAR dataset.
4.2.1 Analysis of model recognition results
This section evaluates the recognition performance of ADW-HM on unknown new classes and the impact of different elevation angle image experimental settings on SAR-FSL recognition. The testing is conducted using 200 new meta-testing tasks for quantitative analysis. The detailed results are shown in Table 5.
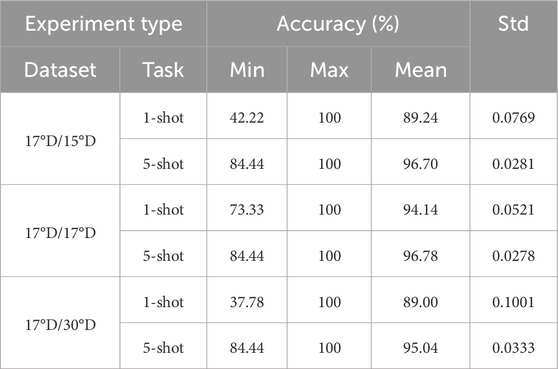
Table 5. Quantitative testing results of ADW-HM target recognition.
Based on the results shown in Table 5, it can be observed that ADW-HM achieves outstanding SAR-FSL recognition results across three different depression angle test groups. Specifically, in the 1-shot tests at 15°, 17°, and 30°, the average target recognition accuracies are 89.24%, 94.14%, and 89.00%, respectively. Additionally, in the 5-shot tests, as the number of target images in the training tasks increases, the model learns better knowledge, resulting in improved accuracy, with average target recognition accuracies of 96.70%, 96.78%, and 95.04%, respectively. When using images trained at a 17 depression angle, the testing accuracy is slightly higher when the test images are also at 17° compared to 15° and 30°, due to the higher similarity of image features at the same depression angle. Moreover, Table 6 shows the average confusion matrix for 200 tasks tested under different experimental configurations using ADW-HM. It can be observed that ADW-HM demonstrates satisfactory recognition performance across three different SAR test unknown classes (2S1, BRDM2, and ZSU234), rather than just high performance on a single class. The recall and precision rates of the average confusion matrix for different unknown classes in Table 6 indicate that our proposed model maintains both high recall and high precision, achieving more stable and comprehensive target recognition performance.
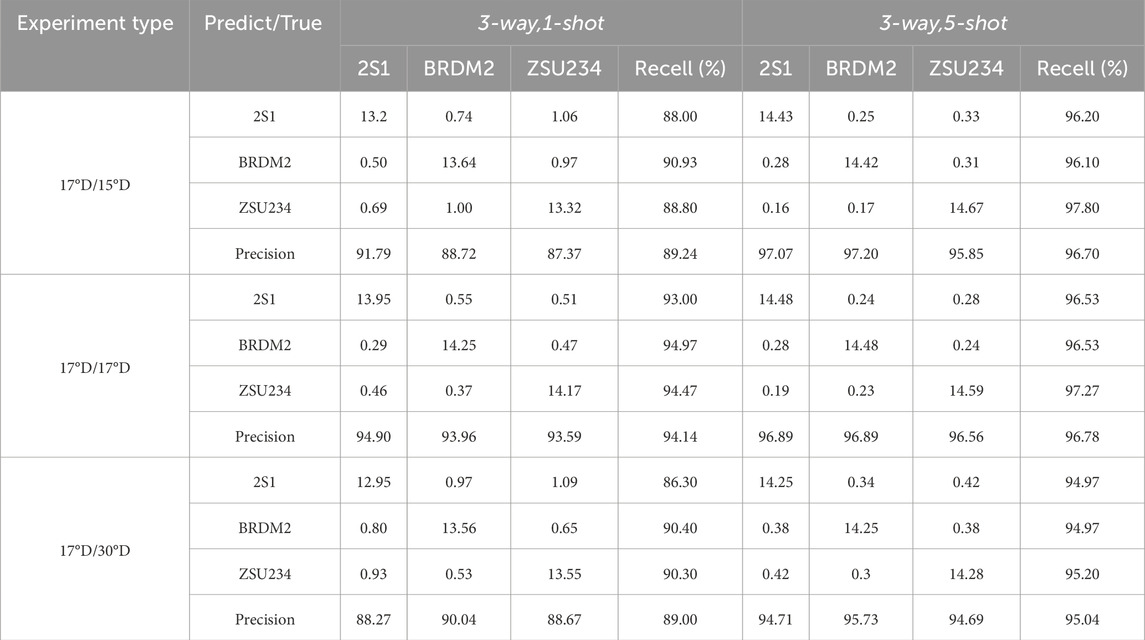
Table 6. Average confusion matrix for ADW-HM.
4.2.2 Comparative analysis of results
Most current SAR few-shot learning methods rely on metric-based meta-learning algorithms, while optimization-based SAR-FSL methods have been less explored, and model-based approaches are even rarer. The proposed method is compared with the most stable optimization-based SAR-FSL target recognition models: MAML, MSGD, and Reptile. A series of comparative experiments and discussions were conducted. Table 7 presents the test results of ADW-HM compared with other SAR-FSL methods on the TASK-MSTAR dataset. The results indicate that all models achieve the highest recognition accuracy at 17° depression angle, with decreased accuracy at 15° and 30°. Moreover, our model outperforms other SAR-FSL methods in both 1-shot and 5-shot test tasks at all depression angles, demonstrating its effectiveness and reliability.Figures 8, 9 show the recognition accuracy and loss error curves for the 1-shot and 5-shot tasks at 17° D/17° D, respectively. The figures reveal that as the training progresses, the model’s test accuracy gradually increases and the loss decreases. Additionally, ADW-HM reaches high recognition accuracy faster than other models, indicating its rapid adaptation capability. MAML and Reptile focus only on optimizing well-initialized parameters, while MSGD not only learns initialization parameters but also optimizes the learning rate in its update strategy. Unlike previous methods, our approach not only optimizes initialization parameters and adjusts the learning rate in the update process but also combines model outputs to dynamically predict results, while automatically determining the contribution of each model. The recognition results of ADW-HM in 1-shot and 5-shot test tasks demonstrate better performance improvement compared to other SAR-FSL methods, with increases of 4.53%, 1.52%, and 0.71% in 1-shot tasks, and 3.34%, 1.65%, and 2.91% in 5-shot tasks. This highlights the superiority of our model over others.
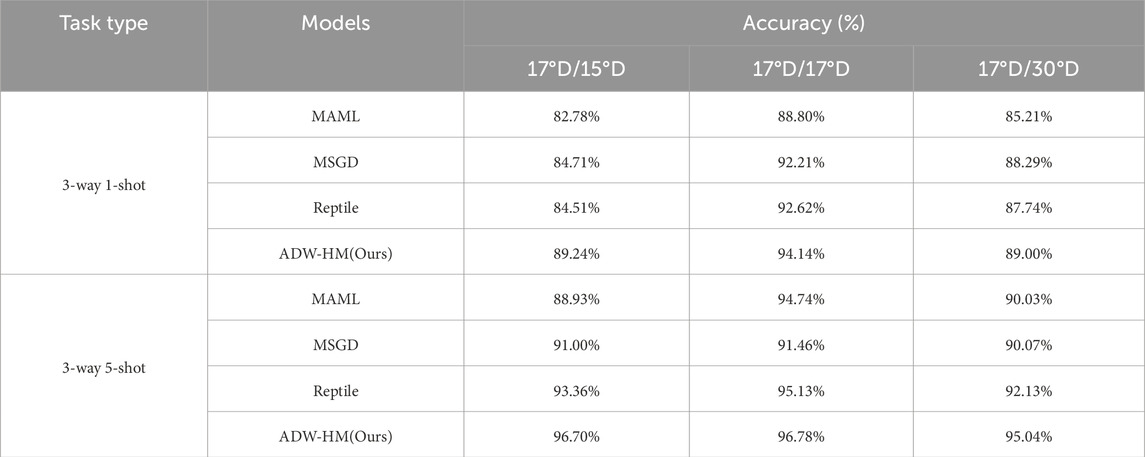
Table 7. Comparative results of testing accuracy between ADW-HM and other SAR-FSL methods on the TASK-MSTAR dataset.
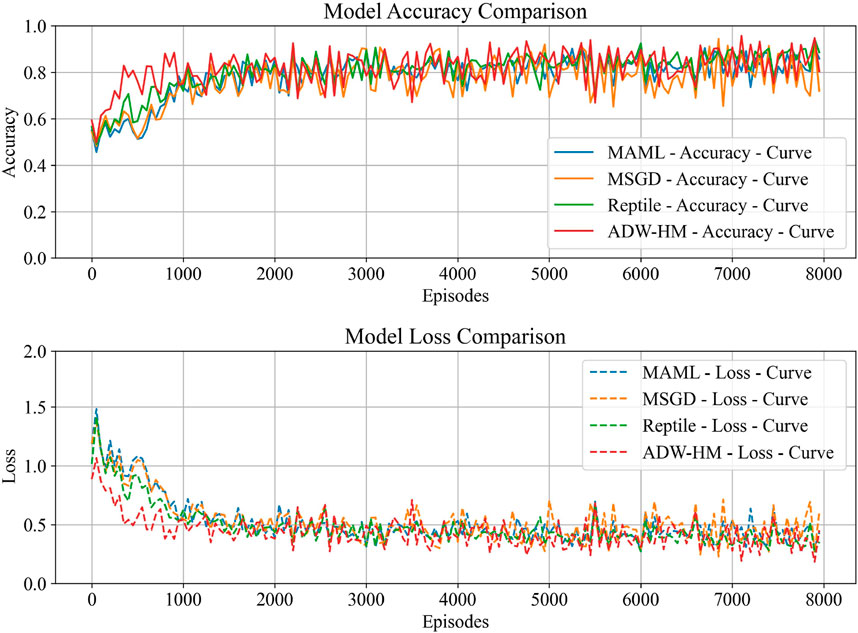
Figure 8. 1-Shot testing accuracy and loss curve (17°D/17°D).
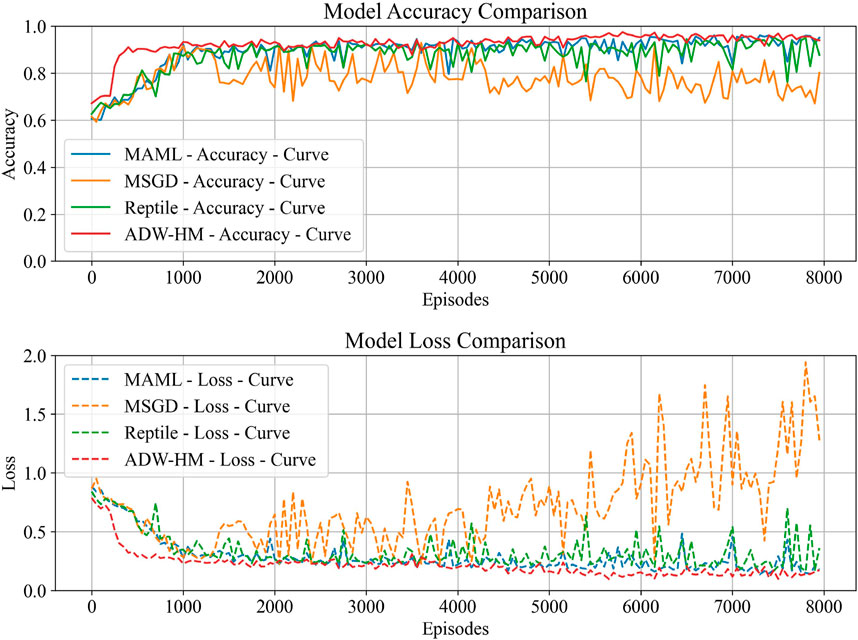
Figure 9. 5-Shot testing accuracy and loss curve (17°D/17°D).
Evaluation experiments were conducted on the OpenSARShip dataset to further verify the recognition performance of the proposed method for few-shot SAR ATR tasks. Table 8 lists the recognition results of each method for the 1-shot and 5-shot tasks on the OpenSARShip dataset. From the experimental results in Table 8, it can be observed that on the more challenging few-shot OpenSARShip dataset, the proposed ADW-HM method still demonstrates the best performance in both the 1-shot and 5-shot tasks. Specifically, in the 1-shot and 5-shot settings, the recognition rates of the ADW-HM method are 43.20% and 50.88%, respectively, outperforming the second-best method by approximately 0.51% and 2.48%.
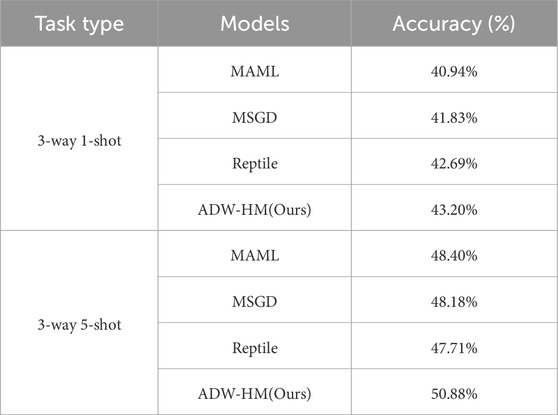
Table 8. Comparative results of testing accuracy between ADW-HM and other SAR-FSL methods on the OpenSARShip dataset.
4.2.3 Analysis of dynamic weight parameters
In ADW-HM, an adaptive parameter update strategy is employed to improve the representation and recognition of few-shot target features. This strategy works by learning the correlation between two model parameters and integrating the output predictions for enhanced performance. This is achieved by combining different model weights, where the adaptive dynamic weight factor dynamically scales the update of model parameters during iterative updates, facilitating multi-model learning and preserving relevant data information. Figure 10 shows the weight variation process of adaptive weights during training under the 3-way 1-shot condition at 17°D/17°D. As the training progresses, the weight W deviates from its initial value to adapt to different learning tasks. This indicates that the contribution of weight W to the model is not fixed and should be learned through training rather than predefined. ADW-HM dynamically allocates weights to each model during each training session, ensuring that each model’s contribution is reflected in the final recognition result. Considering adaptive weights further improves SAR few-shot recognition performance because it helps to learn the correlation between them. This fully validates the advancement and effectiveness brought by our proposed ADW-HM.
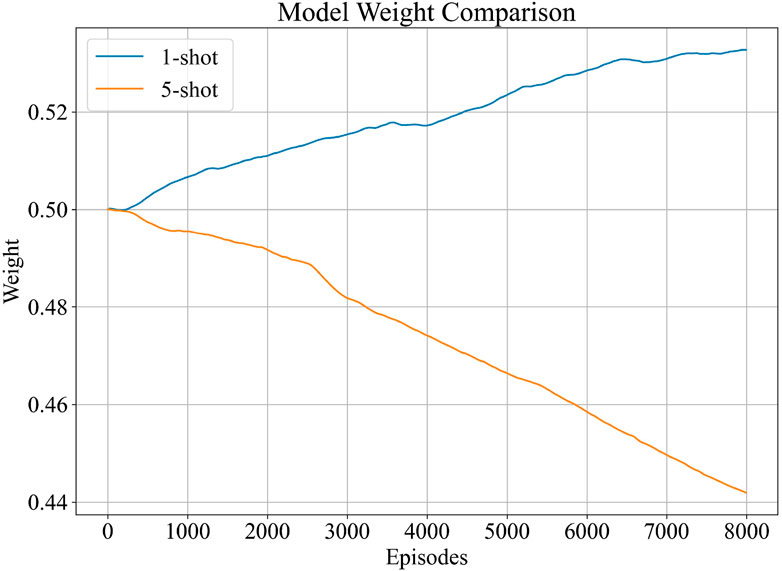
Figure 10. Adaptive dynamic weight variation curve.
To determine the contribution of each model to the prediction outcomes, dynamic weight adaptation is applied. This enables ADW-HM to automatically adjust and learn the weight W for each model’s contribution, eliminating the need for manual optimization of W. Figure 11 illustrates the impact of different weight values on the recognition accuracy of SAR-FSL meta-test classes under 3-way 1-shot and 3-way 5-shot conditions. It is evident that the best recognition results are achieved at 94.14% and 96.78% for 1-shot and 5-shot tasks, respectively, indicating that the contribution of the required models varies. This suggests that in different experimental configurations, the weight factor contributing to the models in ADW-HM is a variable value rather than a fixed one, and it should be determined through training and learning to achieve the optimal value.
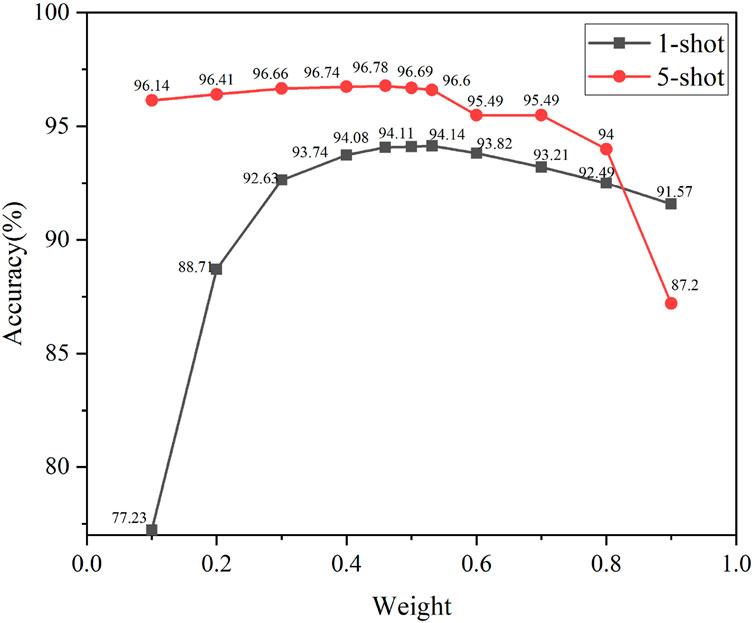
Figure 11. Influence of different weights on testing accuracy.
Table 9 displays the results of ablation experiments on SAR-FSL conducted under the experimental configuration of 17° D/17° D for the 3-way 1-shot task using hybrid model and adaptive dynamic weight parameters. From the experimental data, it can be observed that when neither the hybrid model nor the adaptive dynamic weights are used, the model’s recognition accuracy is 90.67%. When using only the hybrid model without applying adaptively learned weight factors, the recognition accuracy reaches 94.08%. Then, when both the hybrid model and adaptive dynamic weight factors are used simultaneously, the highest SAR target recognition performance is achieved at 94.14%.The results indicate that even without using adaptive dynamic weight factors, good recognition results can be obtained. However, the initial choice of weight factors significantly affects the model’s recognition performance. For convenience and effectiveness, employing adaptive dynamic weight factor learning to determine the model’s contribution value is crucial. This approach not only improves the model’s recognition accuracy but also eliminates the need for manually adjusting weight parameters.

Table 9. Ablation experiment of hybrid model and adaptive dynamic weight parameters.
4.2.4 Analysis of model convolution kernel size
This section explores the impact of different convolution kernel sizes in the base learner on the performance of ADW-HM in few-shot recognition tasks. As shown in the results in Table 10, the convolution kernel sizes of the base learner were set to 3 × 3, 5 × 5, 7 × 7, and 9 × 9, with other experimental configurations remaining unchanged. According to the experimental results, the recognition accuracies for few-shot target recognition with different convolution kernel sizes are 94.14%, 90.63%, 92.81%, and 92.63%, respectively. It can be observed that the model’s recognition performance is optimal and the parameter size is the smallest when the convolution kernel size is 3 × 3. Larger convolution kernels result in lower recognition accuracy. This is because smaller convolution kernel sizes can effectively capture local texture features of the targets, while larger kernel sizes focus more on macro features at a larger scale. For few-shot target recognition, smaller convolution kernels can better extract target features and improve SAR target recognition compared to larger kernels.
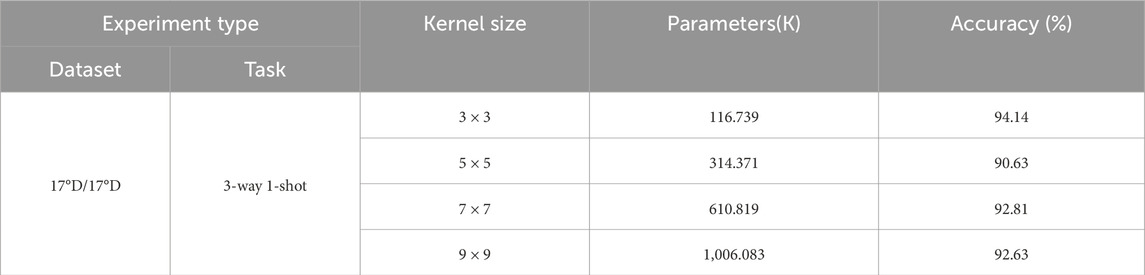
Table 10. Testing results with different kernel sizes in the base learner.
Additionally, Figure 12 presents the t-distributed stochastic neighbor embedding (t-SNE) visualization of target sample recognition for 2S1, BRDM2, and ZSU234 in the meta-test tasks, using varying convolution kernel sizes. It can be seen that with a convolution kernel size of 3 × 3, the test targets exhibit a more compact and distinguishable feature space distribution. In contrast, larger convolution kernel sizes result in a sparse distribution with significant overlap, leading to decreased stability in recognition performance. As a result, ADW-HM utilizes a base learner model with a 3 × 3 convolution kernel to enhance intra-class similarity and inter-class differentiation while reducing the number of model parameters. This approach improves the stability and reliability of SAR-FSL target recognition.
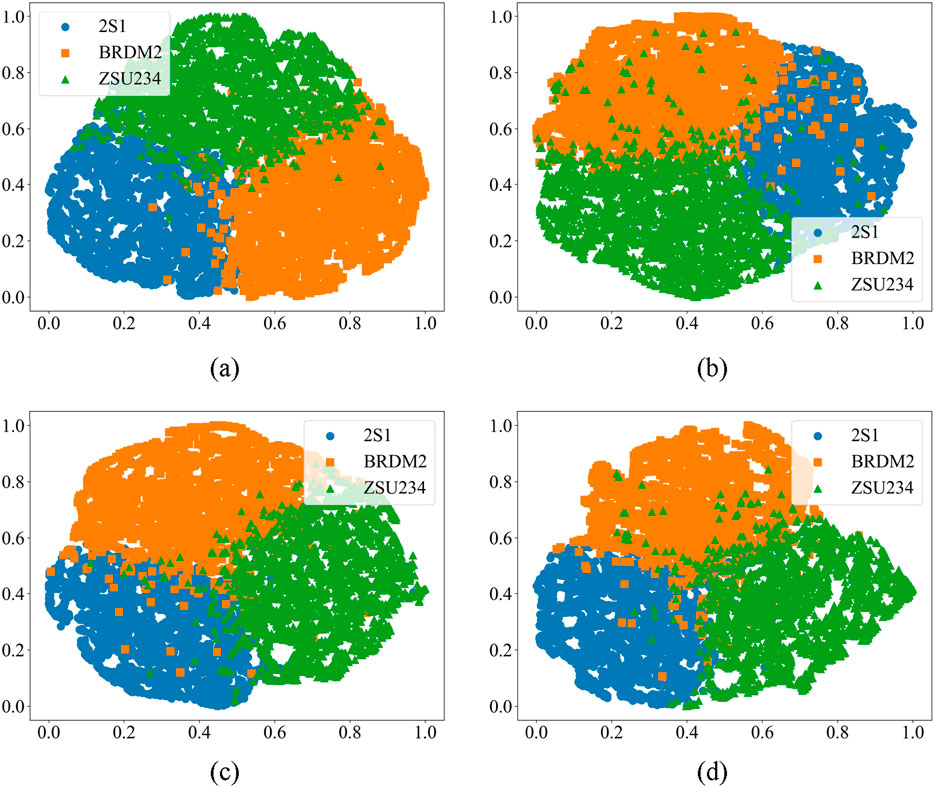
Figure 12. Visualization of the Targets 2S1, BRDM2, and ZSU234 Using t-SNE Dimensionality Reduction Method with Different Kernel Sizes. (A) Kernel size = 3. (B) Kernel size = 5. (C) Kernel size = 7. (D) Kernel size = 9.
5 Conclusion
To tackle the challenge of small sample target recognition under severely limited sample conditions in SAR-ATR, an adaptive dynamic weight hybrid model is proposed. This method updates model parameters and integrates model results to solve the problems caused by small samples in model parameter updates and unknown class recognition. By using meta-learning and ensemble learning to construct the hybrid model, the stability and accuracy of unknown class recognition are enhanced. The TASK-MSTAR and OpenSARShip datasets are designed to effectively train and evaluate the model, consistently outperforming the baseline models in terms of accuracy and stability.
While much attention has been given to SAR-based vehicle target classification, ship-based SAR research is equally active and promising. However, the complexities of the maritime environment, such as irregular weather patterns, ocean waves, and other sea-related disturbances, introduce additional challenges to target detection and classification. Maritime target classification differs significantly from land-based tasks due to the intricate nature of the background environment. The dynamic sea surface, strong waves, and the presence of sea ice can adversely affect the quality and accuracy of SAR images. For example, adverse weather conditions at sea may reduce the contrast between the target and its background, impacting detection performance. This necessitates more advanced image preprocessing techniques or the incorporation of additional features to enhance classification accuracy. Future research could benefit from integrating the latest advancements in oceanography to improve target classification in complex maritime environments. For instance, combining meteorological models with deep learning may offer valuable insights for modeling environmental backgrounds in SAR images, thereby improving recognition and classification accuracy. By merging advancements in oceanography with deep learning, more precise target identification and classification under these challenging conditions can be achieved, ultimately supporting maritime surveillance and security efforts. In conclusion, while radar-based deep learning has made significant strides, there remain many challenges. Continuous innovation is required to enhance the performance and robustness of radar systems, tailored to the specific needs of real-world applications.
Data availability statement
Publicly available datasets were analyzed in this study. This data can be found here: https://www.sdms.afrl.af.mil/.
Author contributions
QG: Data curation, Formal Analysis, Funding acquisition, Methodology, Software, Validation, Visualization, Writing–original draft. YW: Conceptualization, Data curation, Formal Analysis, Methodology, Software, Validation, Writing–review and editing. QL: Project administration, Resources, Software, Supervision, Writing–review and editing.
Funding
The author(s) declare that financial support was received for the research, authorship, and/or publication of this article. This research was funded by the Jilin Provincial Science and Technology Development Program (No. 20230201070GX).
Acknowledgments
The authors express their gratitude to the reviewers for their valuable comments.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Auer, S. J. (2011). 3D synthetic aperture radar simulation for interpreting complex urban reflection scenarios. Munich, Germany: Technische Universität München.
Balz, T., Stilla, U. J. I. T. o.G., and Sensing, R. (2009). Hybrid GPU-based single-and double-bounce SAR simulation. IEEE 47(10), 3519–3529. doi:10.1109/TGRS.2009.2022326
Bengio, S., Bengio, Y., Cloutier, J., and Gecsei, J. (2013). “On the optimization of a synaptic learning rule,” in Optimality in biological and artificial networks? (London, United Kingdom: Routledge), 265–287.
Cao, C., Cao, Z., Cui, Z. J. I. T. o.G., and Sensing, R. (2019). LDGAN: a synthetic aperture radar image generation method for automatic target recognition. IEEE Trans. Geosci. Remote Sens. 58 (5), 3495–3508. doi:10.1109/tgrs.2019.2957453
Cao, Z., Fang, L., Li, R., Yang, X., Li, J., Li, Z., et al. (2023). Research on image classification of coal and gangue based on a lightweight convolution neural network. 11(9), 3042–3054. doi:10.1002/ese3.1501
Chen, S., Wang, H., Xu, F., Jin, Y., and sensing, R. (2016). Target classification using the deep convolutional networks for SAR images. IEEE Trans. Geosci. Remote Sens. 54 (8), 4806–4817. doi:10.1109/tgrs.2016.2551720
Cubuk, E. D., Zoph, B., Mane, D., Vasudevan, V., and Le, Q. V. (2019). “Autoaugment: learning augmentation strategies from data,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 113–123.
Cui, Z., Zhang, M., Cao, Z., and Cao, C. J. I. A. (2019). Image data augmentation for SAR sensor via generative adversarial nets, IEEE 7, 42255–42268. doi:10.1109/ACCESS.2019.2907728
Diemunsch, J. R., and Wissinger, J. (1998). “Moving and stationary target acquisition and recognition (MSTAR) model-based automatic target recognition: search technology for a robust ATR,” in Algorithms for synthetic aperture radar Imagery V: spie, 481–492.
Dumitru, C., Cui, S., Schwarz, G., Datcu, M., and Sensing, R. (2014). Information content of very-high-resolution SAR images: semantics, geospatial context, and ontologies. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 8 (4), 1635–1650. doi:10.1109/jstars.2014.2363595
Fan, L., Zeng, C., Liu, H., Liu, J., Li, Y., and Cao, D. (2023). Sea-net: visual cognition-enabled sample and embedding adaptive network for sar image object classification.
Finn, C., Abbeel, P., and Levine, S. (2017). “Model-agnostic meta-learning for fast adaptation of deep networks,” in International conference on machine learning (Sydney, Australia: PMLR), 1126–1135.
Gao, F., Ma, F., Wang, J., Sun, J., Yang, E., and Zhou, H. J. I. A. (2017). Visual saliency modeling for river detection in high-resolution SAR imagery, 6, 1000–1014.
Gao, G., Bai, Q., Zhang, C., Zhang, L., Yao, L. J. I. J. o.P., and Sensing, R. (2023a). Dualistic cascade convolutional neural network dedicated to fully PolSAR image ship detection. ISPRS J. Photogramm. Remote Sens. 202, 663–681. doi:10.1016/j.isprsjprs.2023.07.006
Gao, G., Chen, Y., Feng, Z., Zhang, C., Duan, D., Li, H., et al. (2024). R-LRBPNet: a lightweight SAR image oriented ship detection and classification method. Remote Sens. (Basel). 16 (9), 1533. doi:10.3390/rs16091533
Gao, G., Dai, Y., Zhang, X., Duan, D., Guo, F. J. I. T. o.G., and Sensing, R. (2023b). “ADCG: a cross-modality domain transfer learning method for synthetic aperture radar,” in Ship automatic target recognition.
Hammer, H., and Schulz, K. (2009). “Coherent simulation of SAR images,” in Image and signal Processing for remote sensing XV: spie, 406–414.
Huang, L., Liu, B., Li, B., Guo, W., Yu, W., Zhang, Z., et al. (2017a). OpenSARShip: a dataset dedicated to Sentinel-1 ship interpretation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 11 (1), 195–208. doi:10.1109/jstars.2017.2755672
Huang, Z., Datcu, M., Pan, Z., Lei, B., and Sensing, R. (2020). Deep SAR-Net: learning objects from signals, 161, 179–193.
Huang, Z., Pan, Z., Lei, B., and Sensing, R. (2019). What, where, and how to transfer in SAR target recognition based on deep CNNs. IEEE Trans. Geosci. Remote Sens. 58 (4), 2324–2336. doi:10.1109/tgrs.2019.2947634
Huang, Z., Pan, Z., and Lei, B. (2017b). Transfer learning with deep convolutional neural network for SAR target classification with limited labeled data. Remote Sens. (Basel). 9 (9), 907. doi:10.3390/rs9090907
Hummel, R. (2000). “Model-based ATR using synthetic aperture radar,” in Record of the IEEE 2000 international radar conference [cat. No. 00CH37037]: IEEE, 856–861.
Li, Z., Zhou, F., Chen, F., and Li, H. (2017). Meta-sgd: learning to learn quickly for few-shot learning.
Liao, J., Zhai, Y., Wang, Q., Sun, B., Piuri, V. J. I. T. o.G., and Sensing, R. (2024). LDCL: low-confidence discriminant contrastive learning for small-sample SAR ATR. IEEE Trans. Geosci. Remote Sens. 62, 1–17. doi:10.1109/tgrs.2024.3350196
Liu, L., Pan, Z., Qiu, X., and Peng, L. (2018). “SAR target classification with CycleGAN transferred simulated samples,” in IGARSS 2018-2018 IEEE international Geoscience and remote sensing symposium: IEEE, 4411–4414.
Liu, T., Yang, Z., Gao, G., Marino, A., Chen, S., and Sensing, R. (2023). Simultaneous diagonalization of Hermitian matrices and its application in PolSAR ship detection. IEEE Trans. Geosci. Remote Sens. 61, 1–18. doi:10.1109/tgrs.2023.3330063
Ma, F., Gao, F., Wang, J., Hussain, A., and Zhou, H. (2020). A novel biologically-inspired target detection method based on saliency analysis for synthetic aperture radar (SAR) imagery. Sar. Imag. 402, 66–79. doi:10.1016/j.neucom.2019.12.009
Malmgren-Hansen, D., Kusk, A., Dall, J., Nielsen, A. A., Engholm, R., Skriver, H., et al. (2017). Improving SAR automatic target recognition models with transfer learning from simulated data. IEEE Geosci. Remote Sens. Lett. 14 (9), 1484–1488. doi:10.1109/lgrs.2017.2717486
Moreira, A., Prats-Iraola, P., Younis, M., Krieger, G., Hajnsek, I., Papathanassiou, K., et al. (2013). A tutorial on synthetic aperture radar. IEEE Geosci. Remote Sens. Mag. 1 (1), 6–43. doi:10.1109/mgrs.2013.2248301
Morgan, D. A. (2015). “Deep convolutional neural networks for ATR from SAR imagery,” in Algorithms for synthetic aperture radar imagery XXII: SPIE, 116–128.
Novak, L. M., Halversen, S. D., Owirka, G., Hiett, M., and Systems, E. (1997a). Effects of polarization and resolution on SAR ATR. IEEE Trans. Aerosp. Electron. Syst. 33 (1), 102–116. doi:10.1109/7.570713
Novak, L. M., Owirka, G. J., Brower, W. S., and Weaver, A. (1997b). The automatic target-recognition system in SAIP. 10(2).
Novak, L. M., Owirka, G. J., Brower, W., and Systems, E. (2000). Performance of 10-and 20-target MSE classifiers. IEEE Trans. Aerosp. Electron. Syst. 36 (4), 1279–1289. doi:10.1109/7.892675
O'Sullivan, J. A., DeVore, M. D., Kedia, V., Miller, M., and Systems, E. (2001). SAR ATR performance using a conditionally Gaussian model. 37(1), 91–108.
Qin, J., Zou, B., Chen, Y., Li, H., Zhang, L., and Systems, E. (2024). Scattering Attribute embedded network for few-shot SAR ATR. IEEE Trans. Aerosp. Electron. Syst. 60, 4182–4197. doi:10.1109/taes.2024.3373379
Ratner, A. J., Ehrenberg, H., Hussain, Z., Dunnmon, J., and Ré, C. (2017). Learning to compose domain-specific transformations for data augmentation. Adv. Neural Inf. Process. Syst. 30, 3239, 3249. doi:10.48550/arXiv.1709.01643
Rostami, M., Kolouri, S., Eaton, E., and Kim, K. (2019a). “Sar image classification using few-shot cross-domain transfer learning,” in Proceedings of the IEEE/CVF Conference on computer Vision and pattern recognition workshops.
Rostami, M., Kolouri, S., Eaton, E., and Kim, K. J. R. S. (2019b). Deep transfer learning for few-shot SAR image classification. Remote Sens. (Basel). 11 (11), 1374. doi:10.3390/rs11111374
Schmidhuber, J. (1987). Evolutionary principles in self-referential learning, or on learning how to learn: the meta-meta-hook. Munich, Germany: Technische Universität München.
Srinivas, U., Monga, V., Raj, R., and Systems, E. (2014). SAR automatic target recognition using discriminative graphical models. IEEE Trans. Aerosp. Electron. Syst. 50 (1), 591–606. doi:10.1109/taes.2013.120340
Sun, Y., Liu, Z., Todorovic, S., Li, J., and Systems, E. (2007). Adaptive boosting for SAR automatic target recognition. IEEE Trans. Aerosp. Electron. Syst. 43 (1), 112–125. doi:10.1109/taes.2007.357120
Wagner, S. (2014). “Combination of convolutional feature extraction and support vector machines for radar ATR,” in 17th international conference on information Fusion (FUSION): ieee, 1–6.
Wang, C., Pei, J., Yang, J., Liu, X., Huang, Y., Mao, D., et al. (2022). Recognition in label and discrimination in feature: a hierarchically designed lightweight method for limited data in sar atr, 60, 1–13.
Wang, C., Shi, J., Zhou, Y., Yang, X., Zhou, Z., Wei, S., et al. (2020). Semisupervised learning-based SAR ATR via self-consistent augmentation. IEEE Trans. Geosci. Remote Sens. 59 (6), 4862–4873. doi:10.1109/tgrs.2020.3013968
Wang, K., Zhang, G., Leng, Y., Leung, H. J. I. G., and Letters, R. S. (2018). Synthetic aperture radar image generation with deep generative models. IEEE Geosci. Remote Sens. Lett. 16 (6), 912–916. doi:10.1109/lgrs.2018.2884898
Wang, K., Zhang, G., and Leung, H. (2019). SAR target recognition based on cross-domain and cross-task transfer learning, 7, 153391–153399.
Wang, S., Wang, Y., Liu, H., Sun, Y., Zhang, C., and Sensing, R. (2023). A few-shot SAR target recognition method by unifying local classification with feature generation and calibration, 62, 1–19.
Wang, Y.-X., and Hebert, M. (2016). “Learning to learn: model regression networks for easy small sample learning,” in Computer vision–ECCV 2016: 14th European conference, Amsterdam, The Netherlands, october 11-14, 2016, Proceedings, Part VI 14 (Springer), 616–634.
Yu, X., Yu, H., Liu, Y., and Ren, H. J. R. S. (2024). Enhanced Prototypical network with customized region-aware convolution for few-shot SAR ATR. Remote Sens. (Basel). 16 (19), 3563. doi:10.3390/rs16193563
Yue, Z., Gao, F., Xiong, Q., Wang, J., Hussain, A., Zhou, H., et al. (2020). A novel attention fully convolutional network method for synthetic aperture radar image segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 13, 4585–4598. doi:10.1109/jstars.2020.3016064
Zeng, Z., Sun, J., Wang, Y., Gu, D., Han, Z., Hong, W. J. I. T. o.G., et al. (2023). Few-shot SAR target recognition through meta adaptive hyper-parameters learning for fast adaptation. IEEE Trans. Geosci. Remote Sens. 61, 1–17. doi:10.1109/tgrs.2023.3325988
Zhang, X., Gao, G., Chen, S., and Sensing, R. (2024). Polarimetric autocorrelation matrix: a new tool for joint characterizing of target polarization and Doppler scattering mechanism. IEEE Trans. Geosci. Remote Sens. 62, 1–22. doi:10.1109/tgrs.2024.3398632
Zhang, Y., Guo, X., Ren, H., and Li, L. J. S. P. (2021). Multi-view classification with semi-supervised learning for SAR target recognition, 183. 108030.
Zhao, Q., Principe, J., and Systems, E. (2001). Support vector machines for SAR automatic target recognition. 37(2), 643–654.
Zhong, C., Mu, X., He, X., Wang, J., Zhu, M. J. I. G., and Letters, R. S. (2018). SAR target image classification based on transfer learning and model compression. IEEE Geosci. Remote Sens. Lett. 16 (3), 412–416. doi:10.1109/lgrs.2018.2876378
Zhou, Z., Chen, J., Huang, Z., Wan, H., Chang, P., Li, Z., et al. (2022). FSODS: a lightweight metalearning method for few-shot object detection on SAR images, 60, 1–17.
Zhu, J., Du, C., Guo, D. J. I. G., and Letters, R. S. (2024). Target-aspect domain continual SAR-ATR based on task hard attention mechanism. IEEE Geosci. Remote Sens. Lett. 21, 1–5. doi:10.1109/lgrs.2024.3449289
Keywords: few-shot learning (FSL), adaptive dynamic weight hybrid model, synthetic aperture radar, automatic target recognition, meta-learning
Citation: Geng Q, Wang Y and Li Q (2024) Few-shot SAR target classification via meta-learning with hybrid models. Front. Earth Sci. 12:1469032. doi: 10.3389/feart.2024.1469032
Received: 23 July 2024; Accepted: 06 November 2024;
Published: 19 November 2024.
Edited by:
Yikui Zhai, Wuyi University, ChinaCopyright © 2024 Geng, Wang and Li. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Qingliang Li, bGlxaW5nbGlhbmdAY2NzZnUuZWR1LmNu