 Paloma Martínez
Paloma Martínez Alberto Ramos
Alberto Ramos Lourdes Moreno
Lourdes Moreno- Computer Science and Engineering Department, Universidad Carlos III de Madrid, Leganés, Spain
Ensuring text accessibility and understandability are essential goals, particularly for individuals with cognitive impairments and intellectual disabilities, who encounter problems accessing information across various mediums such as web pages, newspapers, online administrative tasks, or health documents. Initiatives like Easy to Read and Plain Language guidelines aim to simplify complex texts; however, standardizing these guidelines remains challenging and often involves manual processes. This work presents an exploratory investigation into leveraging Artificial Intelligence (AI) and Natural Language Processing (NLP) approaches to simplify Spanish texts into Easy to Read formats, with a focus on utilizing Large Language Models (LLMs) for creating accessible texts, especially in generating Easy to Read content. The study contributes a parallel corpus of Spanish adapted for Easy To Read format, which serves as a valuable resource for training and testing text simplification systems. Additionally, several text simplification experiments using LLMs and the collected corpus are conducted, involving fine-tuning and testing a Llama2 model to generate Easy to Read content. A qualitative evaluation, guided by an expert in text adaptation for Easy to Read content, is carried out to assess the automatically simplified texts. This research contributes to advancing text accessibility for individuals with cognitive impairments, highlighting promising strategies for leveraging LLMs while responsibly managing energy usage.
1 Introduction
In a society increasingly saturated with information, the ability to understand digital content has become a real challenge for many people. Despite the widespread access to information facilitated by Information and Communication Technologies (ICT), a considerable number of people encounter difficulties in understanding textual content because not everyone can read fluently, and the information written can exclude many people.
The challenge of understanding texts containing long sentences, unusual words, and complex linguistic structures can pose significant accessibility barriers. The groups of users directly affected include people with intellectual disabilities and individuals with cognitive impairments, but it also impacts those with literacy or comprehension problems, the elderly, the illiterate, and immigrants whose native language is different.
In Spain, more than 285,684 individuals with intellectual disabilities face challenges in understanding texts not tailored to their needs (Imserso, 2022). Additionally, over 435,400 individuals with acquired brain injury (ABI) encounter obstacles in reading comprehension, often as a result of strokes or traumatic brain injuries (INE, 2022). The aging population adds another layer to this issue. With nearly 20% of the Spanish population being over 65 years old and a global trend toward an aging population (WHO, 2021), the need to adapt textual content to the cognitive needs of older individuals is clear. These individuals may experience a natural decline in reading comprehension abilities. By 2050, the global population over 60 years is expected to almost double, emphasizing the urgency to address cognitive accessibility barriers. Also, according to WHO (2019), with ~50 million people affected by dementia worldwide, and a new case every three seconds, the number of people with dementia is expected to triple by 2050. Furthermore, individuals with low educational levels face more significant challenges. Despite over 86% of the world's population being able to read and write, disparities in reading comprehension remain profound. This is evident in the PIAAC results, which reveal that the Spanish population aged 16–65 scores below the OECD and EU average in reading comprehension. These statistics underscore the significant impact of cognitive accessibility barriers on various reader groups and the need to provide simplified adapted texts with relevant information to citizens.
To provide universal access to information and make texts more accessible, there are initiatives like the Easy to Read and Plain Language guidelines. However, standardizing these guidelines is challenging due to the absence of tools designed to systematically support the simplification processes. Websites that offer simpler versions of texts currently rely on manual processes. As a solution, there are methods of Artificial Intelligence (AI) and Natural Language Processing (NLP) using language resources and models.
This work presents an exploratory study on how approaches from these disciplines can be utilized to support the systematic fulfillment of simplifying the complexity of Spanish texts, with key premises being the use of easy reading guidelines and resources, and ensuring the participation of individuals with disabilities or experts in the field. Because of the high energy consumption of large generative AI models, which is not environmentally sustainable, and their associated costs that could increase social inequalities, this work aims to explore more cost-effective and energy-efficient solutions.
The article is organized as follows: Sections 1, 2 explain the motivation behind this research, as well as state-of-the-art NLP techniques applied to text simplification, with a special focus on creating Easy to Read content. Sections 3, 4 cover the proposed methodology, including the datasets used in training and testing, the technical architecture deployed to generate Easy to Read content, the LLMs explored, and the experimental configurations. Sections 5, 6 provide a preliminary analysis, as well as some insights.
2 Background
This section encompasses a discussion on strategies aimed at making text understanding and accessible, detailing their specific implementation in Spanish language and the alignment to Spanish standards, alongside a review of research in text simplification, especially within the realms of NLP and AI.
2.1 Understanding strategies: Easy to Read and Plain Language
Historically, Inclusion Europe crafted standards for those with intellectual disabilities, emphasizing simplicity and the importance of feedback to ensure clarity, a cornerstone of the Easy to Read method for making information understandable to this group (Freyhoff et al., 1998b). In contrast, the International Federation of Library Associations and Institutions (IFLA1) promoted broader, more adaptable guidelines, reflecting an understanding of accessibility for diverse reading levels. This approach broadened the scope of information accessibility. As time passed, the Easy to Read methodology evolved (Nomura et al., 2010), continually refining its strategies to serve the specific needs of individuals with intellectual disabilities.
Another approach is Plain Language, which historically predates Easy to Read and has been used in some fields, such as legal field (Wydick, 1979), but has experienced a resurgence in recent times. The revival of Plain Language underscores its growing significance in accessible communication, reflecting an expanded recognition of the need for clear, understandable information (Nomura et al., 2010; EC-DGT, 2011). Emphasizing direct, concise communication, Plain Language aims to be accessible to a wide audience, including those with cognitive impairments and the general public, like individuals with limited reading skills or non-native speakers. The goal of Plain Language is driven by an increased understanding of its role in promoting transparency. Various sectors such as government, healthcare, legal, and businesses are adopting Plain Language to improve communication with their stakeholders, highlighting its universal importance in creating an inclusive society where information is accessible to everyone, irrespective of their reading level or background.
The comparison between Easy to Read and Plain Language can be understood through several key aspects, each catering to different needs and audiences. Easy to Read is primarily designed for individuals with cognitive or intellectual disabilities, including those facing learning difficulties. This approach places a high emphasis on structural and linguistic simplicity, aiming to reduce cognitive load by using short and simple sentences, clear and direct language, and incorporating specific images and symbols to aid comprehension. A distinctive feature of Easy to Read is its practice of involving the target audience in testing and reviewing texts to ensure clarity and ease of understanding, directly obtaining feedback to refine the content. In contrast, Plain Language is directed toward a broader audience, including the general population, people with reading limitations, and non-native speakers, making it applicable across diverse groups. Its focus is on clarity, conciseness, and logical organization, employing techniques such as reader-centered organization, active voice, and the use of common and everyday words to eliminate ambiguity. This approach aims to make information accessible to as many readers as possible, with less emphasis on visual aids and a strong focus on avoiding jargon to promote general accessibility.
The advantages of each approach are notable. Easy to Read's tailored support for individuals with specific needs ensures that content is accessible to those who face significant challenges in reading and understanding standard texts. The use of visuals further enhances comprehension, making it a highly effective method for its target audience. On the other hand, Plain Language's broad applicability ensures that a wide range of readers, regardless of their reading abilities or linguistic backgrounds, can access and understand information easily. Its principles of clarity enhance understanding for all, making it a tool for promoting clear communication.
The application domains also differ, with Easy to Read commonly used in educational materials, and legal and government documents designed for people with intellectual disabilities, while Plain Language is widely used in government communications, legal, health, educational documents, business documents, and websites aimed at a general audience.
Both approaches strive to make information accessible to all, highlighting the need for clear communication to foster a more inclusive society. However, it is important to note that simply applying some of their guidelines does not automatically qualify a text as Easy to Read or Plain Language. A text must adhere to all their respective guidelines to be truly considered as such.
2.2 Easy to Read in Spain
In Spain, the significant advancement in accessible communication was highlighted by the approval and publication of the world's first Easy Read standard (UNE, 2018). Based on this standard, the Easy to Read methodology is built upon three key principles: treating Easy to Read as a method for publishing documents that address both writing and design, involving the target group in the creation process to ensure the final product meets their needs, and defining Easy to Read as a tool for people with reading difficulties rather than for the general populace.
A literature review on text simplification in Spain shows limited research aimed specifically at producing Easy to Read texts following these principles. Relevant initiatives that utilize AI and NLP methods, such as the Simplext project (Saggion et al., 2015), which aimed to develop an automated Easy Language translator, and the Flexible Interactive Reading Support Tool (FIRST) (Barbu et al., 2015), focused on text simplification for improved accessibility, demonstrate some progress in this area. However, despite the exploration of Easy to Read best practices, the full implementation of writing guidelines for complete adaptation to Spanish standards is rare. Additionally, much of the research on text simplification tends to overlook the participation of individuals with disabilities (Alarcon et al., 2023). These efforts mainly concentrate on writing guidelines—spelling, grammar, vocabulary, and style—and less on document design and layout. It is worth mentioning previous work by the authors on a lexical simplification tool that did address enhancing simplification with visual elements like pictograms and provided simple definitions and synonyms in a glossary format (EASIER) (Alarcon et al., 2021; Moreno et al., 2023; Alarcon et al., 2022). Other works focus on supporting Easy to Read experts in their daily task of text adaptation (Suárez-Figueroa et al., 2022).
This research aims to bridge these gaps by following the principles outlined in the UNE15310: 20181 standard (UNE, 2018), explicitly focusing on rigorously involving people with intellectual disabilities and individuals with cognitive impairments, in addition to addressing the writing-related guidelines. Our goal is to provide comprehensive support for the practical application of Easy to Read in Spain, covering both the simplification processes and the professional needs of Easy to Read experts.
2.3 Related work
In the last years, the community of NLP and AI researchers addressed solutions to automatically translate texts into simpler ones but there are no approaches to automatically generate Easy to Read content from texts. Generation of this type of content is a complex task because the requirements of the target audience (people with intellectual disabilities) should be taken into account in this process.
Simplification can be approached as an all-in-one process or as a modular approach. In a modular approach, there is a pipeline composed of separated processes, for instance, replacing complex words with simpler ones, dividing coordinated or relative sentences into simple sentences, replacing passive sentences with active ones, etc. In an all-in-one approach, simplification is done in a single step, such as those based on generative models. First works were focused on rule-based simplification approaches to reduce syntactical complexity in subordinate or coordinated sentences once a morpho-syntactic analysis is done using a set of hand-crafted rules (Siddharthan, 2006). Additionally, other approaches used machine learning approaches to discover patterns in parallel corpora following statistical machine translation (Specia, 2010; Coster and Kauchak, 2011). See for a detailed survey on text simplification following these approaches. More recently, neural text simplification models such as transformed-based approaches have emerged. Research focus on encoder-based models, like BERT, that is pretrained to predict a word given left and right context using a high volume of text data. Other additional training methods can be done, for instance, next sentence prediction. These pretrained tasks can be leveraged to simplify words in a text or simplify complex sentences (Qiang et al., 2020; Martin et al., 2019).
Traditional machine learning approaches or fine-tuning of Large Language Models (LLM) require datasets of labeled texts, and easy dictionaries among others used in training and testing systems. Manual annotation is costly and time-consuming. In addressing the need for comprehensive resources, we conducted a survey of corpus resources in Spanish. This effort highlights different initiatives in the field of lexical simplification in Spanish. Parallel corpora, which include both original texts and their simplified versions, are extremely valuable tools for training text simplification algorithms, especially in languages with limited resources, such as Spanish. The most common corpora are those composed of a set of original sentences and their aligned simplified versions. As a result of this literature review, Table 1 compiles corpora and datasets for text simplification in Spanish describing the source, type, annotators, and size.

Table 1. Survey study of corpora for text simplification in Spanish.
Focusing on lexical simplification, three works on Spanish language are highlighted: (1) in Bott et al. (2012), an unsupervised system for lexical simplification, which utilizes an online dictionary and the web as a corpus is introduced. Three features (word vector model, word frequency, and word length) are calculated to identify the most suitable candidates for the substitution of complex words. The combination of a set of rules and dictionary lookup allows for finding an optimal substitute term. (2) Ferrés et al. (2017) describes the TUNER Candidate Ranking System, an adaptation of the TUNER Lexical Simplification architecture designed to work with Spanish, Portuguese, and English. This system simplifies words in context, omitting the complete simplification of sentences. The system proposes four phases: sentence analysis, disambiguation of word senses (WSD), synonym classification based on word form frequency using counts from Wikipedia in the respective language, and morphological generation. (3) Our previous work in Alarcon et al. (2021), a neural network-based system for lexical simplification in Spanish that uses pre-trained word embedding vectors and BERT models is described. These systems were evaluated in three tasks: complex word identification (CWI), Substitute Generation (SG), and Substitute Selection (SS). In the case of the CWI task, the Spanish dataset provided in CWI 2018 shared task was used (Yimam et al., 2017). For SG and SS tasks, the evaluation was carried out using the EASIER-500 corpus (Alarcon et al., 2023). The fourth task, substitute classification (SR), was not evaluated due to the absence of Spanish datasets for lexical simplification that could be used for that purpose.
After analyzing current Easy to Read guidelines, we present in Table 2 a set of Easy to Read guidelines based on the Spanish standards and European Guidelines (Freyhoff et al., 1998a). These guidelines drive the automated adaptation process, influencing the design of LLMs prompts and also serving as a benchmark for testing. This work aims to fine-tune decoder-based models such as Llama2 (Touvron et al., 2023) as a proof of concept in generating Easy to Read content using datasets composed of Easy to Read Spanish documents.
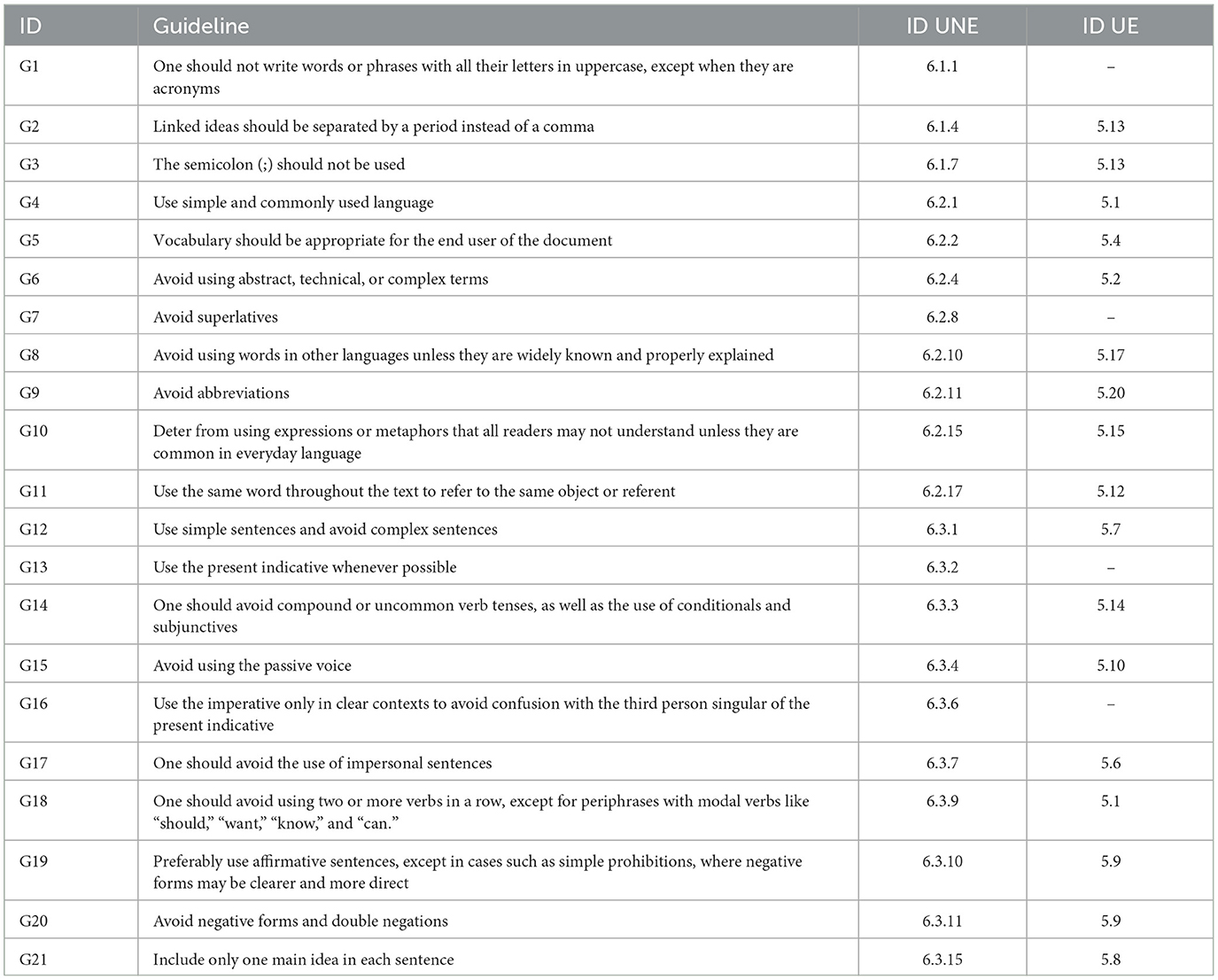
Table 2. Easy to Read guidelines.
3 Method
In this section, the methodology of this research is described, including the dataset used to train and test the generative LLMs to simplify texts in Easy to Read formats, the method used to align the original sentences with the corresponding simplification (if exists), the LLM architecture chosen and finally the evaluation procedure. The use of an open-source generative model is proposed, highlighting its capacity to address complex language-related tasks. This approach involves fine-tuning the model using a corpus containing texts adapted for easy reading, to achieve specific adaptation to readability requirements, primarily targeting individuals with intellectual disabilities and difficulties in reading comprehension. The contributions of this work are highlighted in this section, including the creation of a parallel corpus resulting from an alignment process, which serves as a resource of immense value for future research in text simplification in Easy to Read formats. The use of an open-source generative model is emphasized, which is adapted through a fine-tuning process to generate Easy to Read content.
3.1 Dataset
The Amas Fácil Foundation2 is an organization that supports, promotes and defends the rights of people with intellectual disabilities located in the Region of Madrid (Spain); it offers a specific service of text adaptation for easy reading in addition to other cognitive accessibility services for individuals with intellectual disabilities, and in the context of this research has provided various sets of general domain documents. These documents are pairs of original text and its corresponding adaptation for easy reading, tailored for users with intellectual disabilities that hinder reading comprehension. This dataset emerges as a significant source of data in the simplification. From these texts, a subset of 13 documents related to sports guides, literature, competitive examinations, and exhibitions has been selected to be used in training and testing LLMs.
The corpus has a total of 1,941 sentences, 56,212 words of the original text and 40,372 words of adapted texts, with an average of 27 words in the source sentence and 20 words in an adapted sentence. The original texts contain terms and expressions that impede comprehension for individuals with intellectual disabilities.
The original source texts and their respective adaptations follow a different grammar and style depending on the topic of the text. For instance, the language used in literature texts is entirely different from that employed in a sports guide. We have employed texts from different themes because there is a limitation regarding the number of texts adapted for easy reading in Spanish. Conversely, more resources are available for texts with lexical simplification and adapted to Plain Language, but this deviates from the focus on accessibility and inclusion for individuals with intellectual disabilities who requires to consider the text as a whole.
3.2 Text selection
Pairs of original-adapted texts have to be preprocessed before using them in LLM fine-tuning. Any sentence from the original texts that did not have an easy reading adaptation were excluded. This exclusion ensures that only texts with both the original and adapted versions are considered for analysis. In our approach, each original sentence is uniquely identified and paired with its potential adaptations. These pairs are then evaluated based on the cosine similarity between the original sentence and its adaptation. As part of the cosine similarity evaluation process, any original sentences lacking a corresponding candidate adaptation are removed.
Subsequently, from the pool of candidate adaptations for each original sentence, we select the adaptation with the highest cosine similarity score. This process guarantees that for each original sentence, we identify the most closely aligned adapted version for easy reading. This selection strategy results in a curated set of sentence pairs, each consisting of an original sentence and its optimal easy reading adaptation. Table 3 provides an overview of the distribution of texts and sentences across various topics, illustrating the breadth of content considered in our analysis.
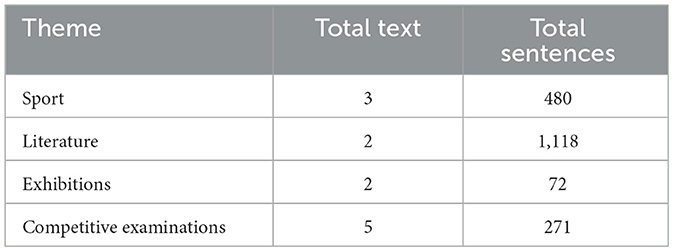
Table 3. Distribution of texts by theme.
Adapting texts to enhance readability often involves significant simplification, including the omission of words, entire sentences, or parts thereof. This process introduces challenges in accurately identifying corresponding sentences between the original and adapted versions. To overcome this challenge and facilitate the collection of parallel data, we have developed a specialized sentence aligner which is presented in the following section.
3.3 Sentence alignment process
The main function of this aligner is to process sentences from the texts, aligning them between the original text and its Easy to Read adapted version. Initially, the texts are segmented into individual sentences to generate sentence embeddings. These embeddings are vector representations that encapsulate semantic information about the sentences, enabling the comparison and measurement of semantic similarity between sentences. For generating these embeddings, we utilize the Sentence Transformers framework (Reimers and Gurevych, 2019), which offers a suite of pre-trained models specifically optimized for the task of sentence alignment.
Upon generating the sentence embeddings, we determine the semantic similarity between them by computing the cosine similarity. The Language-agnostic BERT Sentence Embedding (LaBSE) model (Feng et al., 2020), a BERT modification (Devlin et al., 2018), is employed for this purpose. Optimized to produce analogous representations for pairs of sentences, this model assesses the cosine similarity across all sentence pairs, selecting the most similar sentence among potential candidates as the correct alignment.
It is important to highlight that the development of this sentence aligner and the subsequent creation of a parallel corpus represent significant contributions to this research. The parallel corpus, which is in the process of being published, will offer a valuable resource to the scientific community, aiming to enhance text simplification efforts.
3.4 Generating Easy to Read texts
In line with our initial commitment to address the environmental and economic impacts of large generative AI models, this section shows an application that meets sustainability and inclusivity. The reliance on energy-intensive models poses significant environmental challenges and exacerbates social inequalities through their substantial monetary costs. To mitigate these issues, we have selected Llama2 (Llama-2-7b-hf) (Touvron et al., 2023), an open-source model provided by Hugging Face to generate Easy to Read content in an efficient and adaptable way. Also, it has shown considerable promise in executing complex reasoning tasks across a broad spectrum of domains, from general to highly specialized fields, including text generation based on specific instructions and commands.
The auto-regressive Llama2 transformer is initially trained on an extensive corpus of self-generated data and then fine-tuned to human preferences using Reinforcement Learning with Human Feedback (RLHF) (Touvron et al., 2023). Although the training methodology is simple, the high computational cost have constrained the development of LLMs. Llama2 is trained on 2 billion tokens of text data from various sources and has models ranging from 7 to 70B parameters. Additionally, they have increased the size of the pretraining corpus by 40%, doubled the model context length to 4,096 tokens, and adopted clustered query attention to enhance the scalability of inference in the larger 70B model.
Since Llama2 is open-source and has a commercial license, it can be used for many tasks such as lexical simplification. However, to achieve better performance in the task, it is necessary to fine-tune it with the specific data and adapt it to the readability needs of individuals with intellectual disabilities. Therefore, the weights and parameters of the pre-trained model will be adjusted, resulting in increased precision in task outcomes, as well as a reduction in the likelihood of inappropriate content.
A key contribution of this work is the demonstration of the adaptability of Llama2 for the generation of Easy to Read texts, marking a significant step toward customizing advanced language models for enhanced accessibility.
3.5 Evaluation procedure
In validating our model, we diverge from using traditional performance metrics common in text simplification tasks, such as BLEU (Papineni et al., 2002), SARI (Xu et al., 2016), and the Flesch-Kincaid readability index (Kincaid et al., 1975), among others. Instead, we prioritize a qualitative human evaluation conducted by professional easy reading adapters and individuals with intellectual disabilities. While traditional metrics can gauge a model's effectiveness to some extent, they do not adequately capture the nuances of language understanding, simplicity, and the preservation of meaning in practical contexts.
Engaging professionals in the evaluation process is critical to ensuring the results are genuinely accessible and beneficial for people with intellectual disabilities. This human-centric approach is vital in the context of easy reading, where adherence to specific guidelines is necessary to enhance readability and understanding.
For the evaluation, we have chosen documents concerning sports, specifically focusing on the competition regulations for indoor soccer and the sports guidelines related to the Organic Law for Comprehensive Protection of Children and Adolescents against Violence (LOPIVI). These documents provide a suitable basis for assessing if the model's outputs align with Easy to Read standards.
The qualitative evaluation conducted by experts is based on their expertise in adapting texts in easy reading and the standards outlined in Table 2, which summarizes the easy to read guidelines for adapting texts as introduced in Freyhoff et al. (1998a) and AENOR (2018). This table is the result of a comprehensive analysis of easy reading guidelines, drawn from standards and best practices.
4 Experimental setup
The architecture of the overall system is depicted in Figure 1 outlining the four key processes: (1) sentence alignment, (2) low-rank adaptation, (3) LLM fine-tuning for the smaller 7B parameter Llama2 model, and (4) testing utilizing both Llama2 7B and Llama2 70B models.
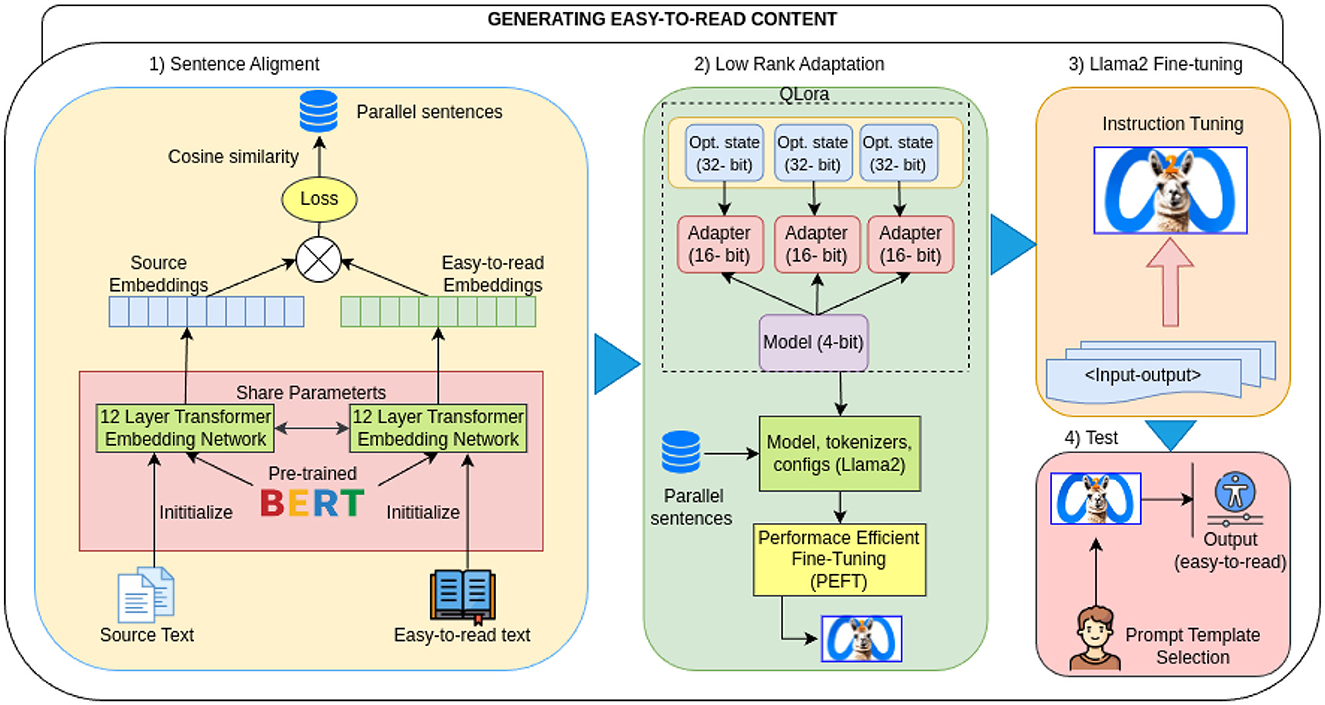
Figure 1. Diagram of the system architecture.
Sentence alignment is the process required to match sentences from source texts to the corresponding sentences of Easy to Read adaptation preserving the meaning across the texts used as is explained in Section 3. To achieve this goal, we employ the LaBSE encoder model (Feng et al., 2020), pre-trained to support 109 languages. The model has been trained with both Masked Language Modeling (MLM) and Translation Language Modeling (TLM), allowing it not to depend on parallel datasets for training heavily. The model transforms sentences into vector representations, which are used to calculate the similarity between sentences.
Once the aligned corpus is obtained, the LLama2 model is used to perform the task of text simplification into Easy to Read text. There are some available Spanish LLMs at the Barcelona Supercomputing Center, but the available Spanish decoder-based GPT-2 (Gutiérrez-Fandiño et al., 2021), is older than the new LLama 2 (Touvron et al., 2023), that has emerged showing better results across a variety of tasks.
To fine-tune the Llama2 model with 70B parameters, significant computing resources are required. We have utilized the smaller Llama2 model with 7B parameters. Yet, it still requires 30 GB of GPU memory, so we employed the QLoRa (Quantitative Low-Rank Adaptation) technique to reduce the model size and expedite the process, achieving greater efficiency (Dettmers et al., 2023). QLoRA technique is employed using the PEFT library (Mangrulkar et al., 2022), to fine-tune LLMs with higher memory requirements combining quantization and LoRA, where quantization is the process of reducing the precision of 32-bit floating-point numbers to 4 bits. Precision reduction is applied to the model's parameters, layer weights, and layer activation values. This results in agility in calculations and improvement in the model's storage size in GPU memory. While achieving greater efficiency, there is a slight loss of precision in the model. The LoRa technique includes a parameter matrix in the model that helps it learn specific information more efficiently, leading to faster convergence.
The Llama2 7B model is fine tuned with the entire corpus dataset, a total of 1,941 sentences. We implement it in PyTorch using the Transformers and QLoRa libraries. The entire implementation is completed using Jupyter Notebook, and an NVIDIA GeForce RTX 3,060 12GB is used to train the text simplification model. The GPU facilitates asynchronous data loading and multiprocessing.
The Llama2 model is pre-trained with 32 layers and 7B parameters. The pre-trained model shows significant improvements over the previous version Llama1. It has been trained with 40% more tokens and a context length of 4,096 tokens. We train it for four epochs with a maximum length of 512 tokens for input to the transformer model. Table 4 shows the hyperparameters of the model. After fine-tuning, a set of instruction templates is used to guide the system on the desired output.
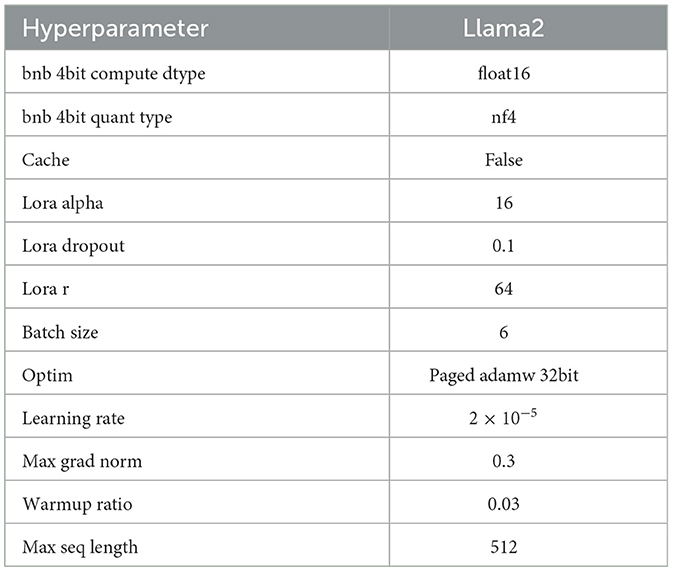
Table 4. Hyperparameters of the LLM tested.
The prompt used is: Transform the sentence to make it easier to understand for people with intellectual disabilities and difficulties in reading comprehension. Use very simple, short, direct sentences in the active voice, and avoid complicated words.
To complement our main findings, additional experiments were conducted using various approaches to text simplification. Specifically, the ollama library was employed to test the Llama2 model with 70B parameters without fine-tuning, contrasting it with our primary method that involves fine-tuning a smaller Llama2 model. This approach facilitates local model testing, leveraging 4-bit quantization and packaging model weights, configurations, and datasets into a unified Modelfile. Table 5 outlines these experiments, providing insights into the efficacy of different configurations and prompts in generating accessible texts.
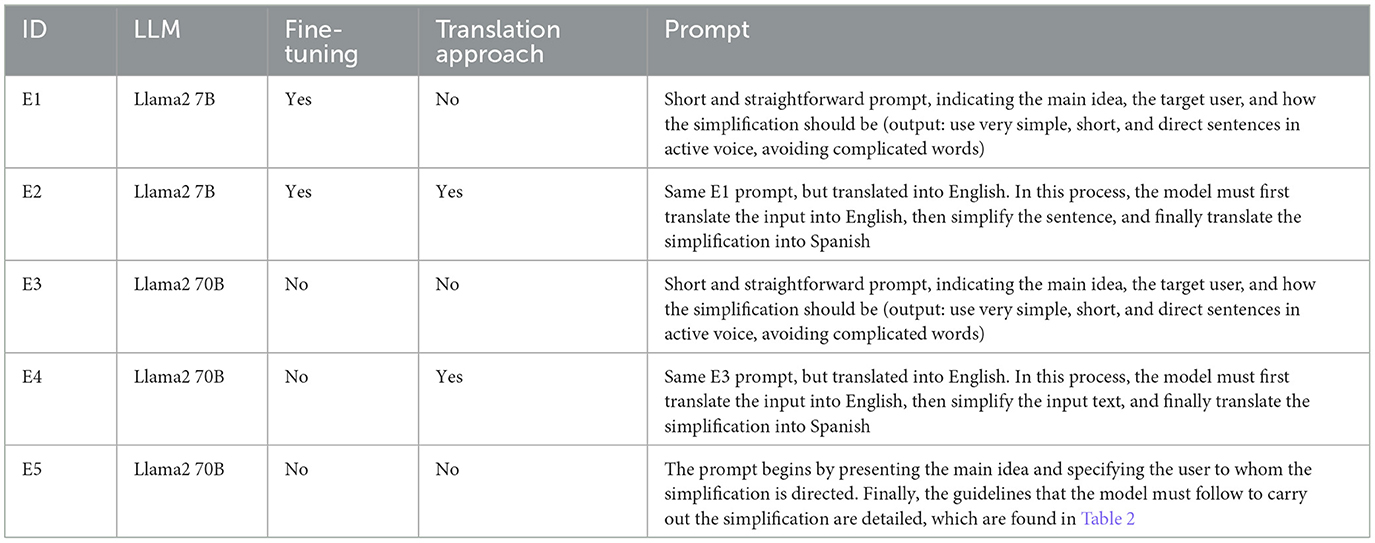
Table 5. Experiments performed using Llama2 70B and Llama2 7B, different prompts and with/without prompt and output translations.
A particular focus of these experiments was the translation approach, where the original text is translated into English, simplified, and then the simplified text is translated back into Spanish. This method evaluates the impact of translations on the coherence and accessibility of the final simplified text. This aspect is crucial because it directly addresses the challenges posed by the limited presence of the Spanish language in the resources of existing LLMs.
This comparative analyses aims to identify optimal strategies for simplifying texts into Easy to Read formats, taking into account available resources and the under-representation of the Spanish language in current LLMs resources.
5 Results and discussion
We present an exploratory evaluation of our simplification system using documents on sports regulations and guidelines. Table 6 displays examples of sentences input into the system and their corresponding simplifications according to Easy to Read guidelines performed by an expert human adapter in Easy to Read.
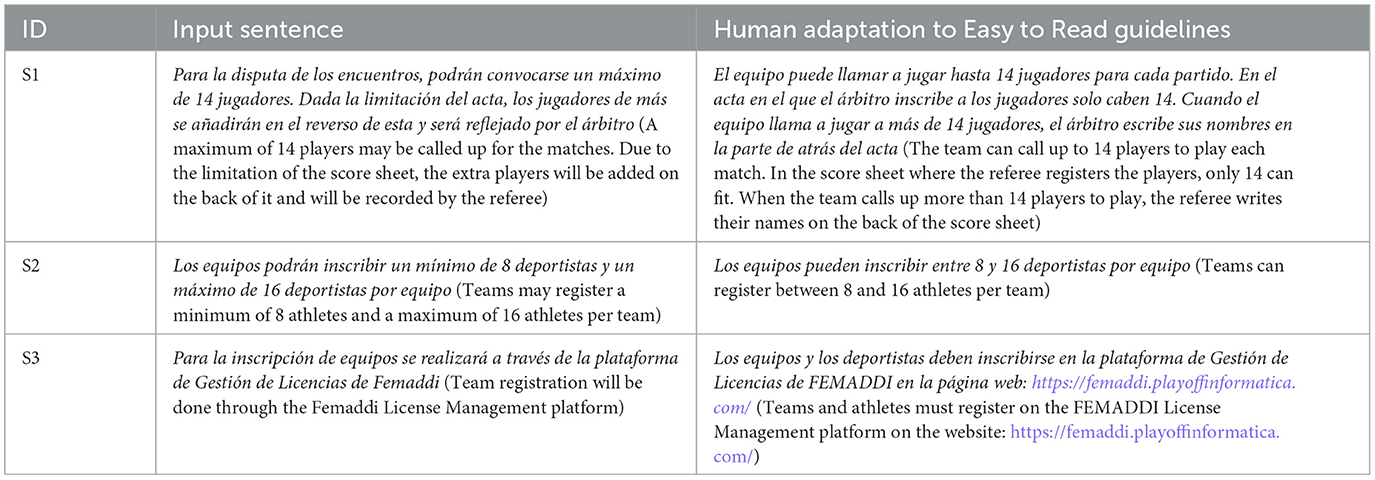
Table 6. Examples of sentences used as LLMs input and corresponding human-adapted versions.
The expert adapter conducts an evaluation of the adaptation by both Llama2 models. In an initial review, a significant achievement in lexical simplification was evident. Afterward, Easy to Read guidelines have been analyzed in detail to identify those that have been implemented and those that have not.
5.1 Limitations of the experimental study
In this experimentation, certain guidelines will not be evaluated due to non-applicability to the texts under consideration. Specifically, guidelines G1, G3, G7, G9, and G16 cannot be assessed. G1 is irrelevant because the texts do not contain words or phrases entirely in uppercase letters, except for acronyms. G3 is not applicable as none of the input sentences include semicolons. G7, concerning the avoidance of superlatives, does not apply because the original texts do not use superlative forms. G9, which advises against abbreviations, is not relevant here as the texts do not contain any abbreviations. Lastly, G16, pertaining to the use of the imperative mood, is not applicable because the imperative is not used in any of the input sentences, making it impossible to assess the guideline's adherence in this context. Of the 21 guidelines provided, 16 will be applicable in the experimental study.
5.2 Experimental results
Table 7 shows the results of the experiments detailed in Table 5 along with the corresponding input sentence provided in Table 6. The experiments explored different approaches to simplification, with a focus on assessing the effectiveness of text simplification for easy reading in specific knowledge areas where the model has been fine-tuned, the impact of translations on simplification quality, and the performance of simplification without domain-specific fine-tuning.
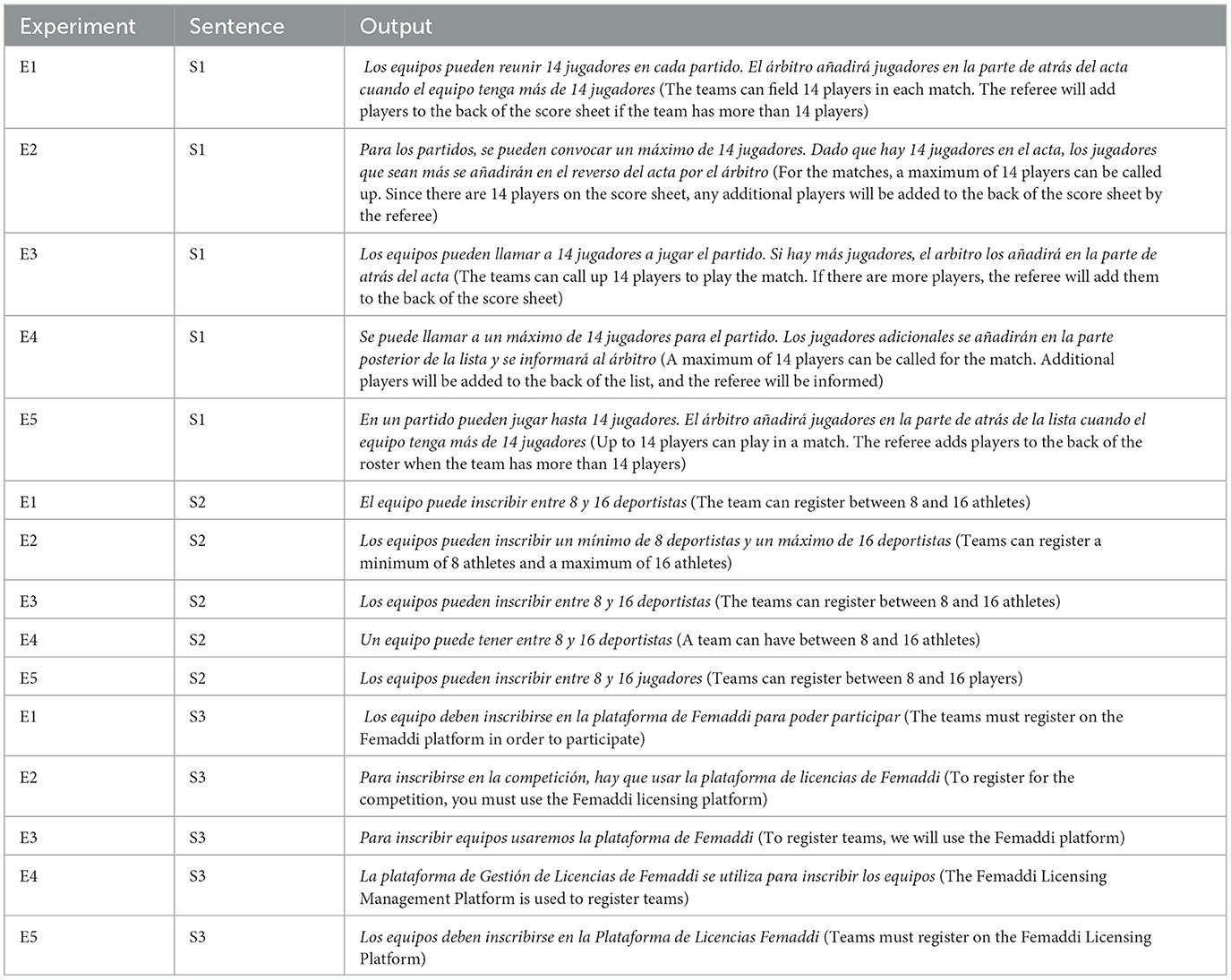
Table 7. Output of the experiments.
5.3 Discussion
The results of the experiments with different approaches are presented below, and detailed in Table 5.
• The objective of Experiment E1 is to confirm the effectiveness of text simplification for easy reading in specific knowledge areas where the model has been fine-tuned. In this case, the focus was on the sports domain, using sports regulations and guidelines as references. It was observed that the performance of simplification is notably better when the model is familiar with the domain.
• In experiment E2, the default Llama2 7B parameter model achieves accurate translations from Spanish to English. However, after fine-tuning for easy reading simplification, the model does not accurately translate. In most cases, the outputs remain in Spanish, and some show simplifications, even though the original prompt only requests translation into English. This discrepancy may stem from the layer selection during the fine-tuning process, where weight modifications enable the model to adapt to the new task. In this specific process, all layers were modified since it is recommended to use the complete set of layers for more complex and demanding tasks in natural language processing. However, it is possible that using fine-tuning with 8 or fewer layers could achieve correct translation into English. Then, the option of employing the method of (1) translating into English, (2) simplifying the text, and (3) translating it back into Spanish for the fine-tuned model is rejected. As shown in Table 7, this approach yields the most deficient results.
• The results of experiment E3 are less satisfactory compared to model 7B with fine-tuning. This is because it is limited solely to replacing terms with simpler synonyms, without achieving shorter or more direct sentences. The reason is that the model lacks familiarity with examples of easy reading because it has not been previously trained in this domain, and does not possess the necessary guidelines to carry out proper simplification in easy reading.
• In experiment E4, the results are superior to those obtained in experiment E3. The model effectively simplifies by using short and direct sentences, with a clear main idea and avoiding using complex words. Although not specified in the request, the model often separates sentences using periods instead of commas. The Llama2 7B model with fine-tuning yields better results in domains where it is familiar compared to the results obtained using this approach.
• Finally, in experiment E5, the results can be considered superior to the 7B model with fine-tuning. This model follows the instructions and guidelines of Table 2 to perform Easy to Read simplification. Additionally, the 70B model with this prompt does not need to be familiarized with the domain like the 7B model with fine-tuning to achieve good results.
Table 8 introduces the classification of errors identified during the evaluation of results by the Easy to Read adapter. It details the types of errors along with their corresponding descriptions and their alignment with the Easy to Read guidelines. Only errors found in the Llama2 7B model with fine-tuning and the Llama2 70B model using the prompt that includes easy reading guidelines are presented. These approaches have been demonstrated to yield the most competitive results.

Table 8. Classification of errors detected by the human evaluator.
One of the errors is that the models use the plural article with singular nouns, and vice versa. For example, in the sentence Los equipo de nueva creación que quieran acceder a las ligas deberán disputar un partido amistoso (The newly formed teams that wish to access the leagues must play a friendly match.), the determinant is in plural and the noun in singular. The language used in Llama2 is mostly English and not so much Spanish.
A common mistake related to Easy to Read generation is to use different terms to refer to the same thing. For example, the futsal regulations document sometimes refers to team members as “players” and other times as “athletes”.
The easy-reading adapter highlighted the importance of providing explanations or including certain terms in a glossary when working in a field with technical terminology. For example, the word acta (score sheet) is defined in the glossary of the Gold Standard document, while the model output presents it without explanation or replaces it with the synonym lista (roster).
The adaptations have improved the Llama2 model through fine-tuning to simplify language for people with intellectual disabilities. It has been shown that good results are achieved by using a training dataset focused on the domain of simplification. Creating a dataset that encompasses different domains adapted for easy reading could represent a valuable resource to achieve even more competitive results in other areas. This task can also be applied to English, a language with a poorer morphology comparing to Spanish and fewer inflectional verb forms. The texts in Spanish are characterized by the presence of numerous subordinate clauses and extensive phrases, which can exhibit a wide variation in word order.
5.4 Implications and future directions
The conducted study opens new possibilities for future research in lexical simplification and adaptation to easy reading in Spanish, highlighting the versatility of the employed methodology, which can be applied across various fields and domains. It was observed that the Llama2 7B model provides adequate results in an initial evaluation. However, it should be tested that a greater number of texts adapted for easy reading could significantly enhance the obtained results. On the other hand, more advanced models such as the Llama2 70B offer even more competitive outcomes. To optimize accuracy, it is suggested to utilize the Llama2 70B model without quantization and fine-tuning using a broad set of adaptations for easy reading, potentially leading to exceptional performance with high-quality results. It is worth noting that this approach would require considerably high computational resources for implementation.
6 Conclusion
The research described in this article represents the first study on simplifying to Spanish Easy to Read language for people with intellectual disabilities, through the use of decoder-based LLMs. We have outlined the procedure for creating a parallel corpus of Easy to Read texts composed of a collection of 1941 sentences that is a valuable resource to train machine learning approaches to simplify content. In the near future, it would be beneficial to explore other strategies to group pieces of information (sentences, paragraphs, or even entire texts) to obtain a broader context in this type of corpus. Increasing the size of these resources is an open challenge because adapting LLM to new tasks requires larger corpora. Some tests have been conducted with texts from domains that the model is unfamiliar with, and the results are not as good as when the model is familiar with the domain in question.
We suggest that future research should consider incorporating training with a domain terminology dictionary in which researchers are currently working. This is because some documents contain complex or uncommon terminology depending on the domain being worked on. This way, when an unfamiliar term appears, it can be accurately described, facilitating reader comprehension.
The experiments presented illustrate a use case and show that the corpus has allowed the evaluation of lexical simplification approaches based on language models. The methodology used could be applied to other languages, such as English, for which linguistic models with more training data are available.
In summary, this first approach significantly improves the accessibility of documents in Spanish for people with intellectual disabilities. In addition, the development of corpora plays a crucial role in the development of simplification systems for people with reading comprehension difficulties. However, it is essential to emphasize that documents simplified through an automated system must always be reviewed and validated by a professional.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Author contributions
PM: Conceptualization, Investigation, Methodology, Writing – original draft. AR: Data curation, Software, Validation, Writing – original draft. LM: Conceptualization, Funding acquisition, Methodology, Resources, Writing – original draft.
Funding
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This work was supported by ACCESS2MEET project (PID2020-116527RB-I0) supported by MCIN AEI/10.13039/501100011033/.
Acknowledgments
We would like to thank the adapter of the AMAS foundation for supporting the user evaluation.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Footnotes
References
AENOR (2018). Norma 153101 EX Lectura fácil: pautas y recomendaciones para la elaboración de documentos. Madrid: Asociación Española de Normalización, AENOR.
Alarcon, R., Moreno, L., and Martínez, P. (2021). Lexical simplification system to improve web accessibility. IEEE Access 9, 58755–58767. doi: 10.1109/ACCESS.2021.3072697
Alarcon, R., Moreno, L., and Martínez, P. (2023). Easier corpus: a lexical simplification resource for people with cognitive impairments. PLoS ONE 18:e0283622. doi: 10.1371/journal.pone.0283622
Alarcon, R., Moreno, L., Martínez, P., and Macías, J. A. (2022). Easier system. evaluating a spanish lexical simplification proposal with people with cognitive impairments. Int. J. Hum. Comp. Interact. 40, 1195–1209. doi: 10.1080/10447318.2022.2134074
Barbu, E., Martín-Valdivia, M. T., Martinez-Camara, E., and Urena-López, L. A. (2015). Language technologies applied to document simplification for helping autistic people. Expert Syst. Appl. 42, 5076–5086. doi: 10.1016/j.eswa.2015.02.044
Bott, S., Rello, L., Drndarević, B., and Saggion, H. (2012). “Can spanish be simpler? lexsis: lexical simplification for spanish,” in Proceedings of COLING 2012 (Association for Computational Linguistics), 357–374.
Campillos-Llanos, L., Terroba Reinares, A. R., Zakhir Puig, S., Valverde Mateos, A., and Capllonch Carrión, A. (2022). Clara-Med Corpus. Madrid: DIGITAL.CSIC.
Coster, W., and Kauchak, D. (2011). “Simple english wikipedia: a new text simplification task,” in Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies (Association for Computational Linguistics), 665–669.
Dettmers, T., Pagnoni, A., Holtzman, A., and Zettlemoyer, L. (2023). QLORA: Efficient finetuning of quantized LLMs. arXiv [preprint]. doi: 10.48550/arXiv.2305.14314
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. (2018). BERT: pre-training of deep bidirectional transformers for language understanding. arXiv [preprint]. doi: 10.48550/arXiv.1810.04805
EC-DGT (2011). How to Write Clearly. European Commission-Directorate General for Translation, Publications Office.
Feng, F., Yang, Y., Cer, D., Arivazhagan, N., and Wang, W. (2020). Language-agnostic bert sentence embedding. arXiv [preprint]. doi: 10.48550/arXiv.2007.01852
Ferrés, D., AbuRa'ed, A. G. T., and Saggion, H. (2017). Spanish morphological generation with wide-coverage lexicons and decision trees. Procesamiento Lenguaje Nat. 58, 109–116.
Ferrés, D., and Saggion, H. (2022). “Alexsis: a dataset for lexical simplification in Spanish,” in Proceedings of the Thirteenth Language Resources and Evaluation Conference (European Language Resources Association), 3582–3594.
Freyhoff, G., Hess, G., Kerr, L., Menzel, E., Tronbacke, B., and Van Der Veken, K. (1998a). El camino más fácil: directrices europeas para generar información de fácil lectura. Bruselas: ILSMH European Association.
Freyhoff, G., Hess, G., Kerr, L., Tronbacke, B., and Veken, K. (1998b). Make it Simple. European Guidelines for the Production of Easyto-Read Information for People with Learning Difficulties. ILSMH European Association. Available at: https://www.inclusion-europe.eu/ (accessed September 29, 2024).
Gutiérrez-Fandiño, A., Armengol-Estapé, J., Pàmies, M., Llop-Palao, J., Silveira-Ocampo, J., Carrino, C. P., et al. (2021). Maria: Spanish language models. arXiv [preprint] arXiv:2107.07253.
Imserso (2022). Base estatal de datos de personas con valoración del grado de discapacidad. Available at: https://imserso.es/documents/20123/146998/bdepcd_2022.pdf/390b54fe-e541-3f22-ba1a-8991c5efc88f (accessed September 29, 2024).
INE (2022). Encuesta de discapacidad, autonomía personal y situaciones de dependencia. Instituto Nacional de Estadística. Available at: https://www.ine.es/prensa/edad_2020_p.pdf (accessed September 29, 2024).
Kang, J., Azzi, A. A., Bellato, S., Carbajo-Coronado, B., El-Haj, M., El Maarouf, I., et al. (2022). “The financial document structure extraction shared task (FinTOC 2022),” in Proceedings of the 4th Financial Narrative Processing Workshop@ LREC2022 83–88.
Kincaid, J. P., Fishburne Jr, R. P., Rogers, R. L., and Chissom, B. S. (1975). Derivation Of New Readability Formulas (Automated Readability Index, Fog Count And Flesch Reading Ease Formula) For Navy Enlisted Personnel. Institute for Simulation and Training. Available at: https://stars.library.ucf.edu/istlibrary/56
Mangrulkar, S., Gugger, S., Debut, L., Belkada, Y., Paul, S., and Bossan, B. (2022). PEFT: STATE-of-the-Art Parameter-Efficient Fine-Tuning Methods. Available at: https://github.com/huggingface/peft
Martin, L., Sagot, B., de la Clergerie, É., and Bordes, A. (2019). “Controllable sentence simplification,” in Proceedings of the Twelfth Language Resources and Evaluation Conference, eds. N. Calzolari, F. Béchet, P. Blache, K. Choukri, C. Cieri, T. Declerck, S. Goggi, H. Isahara, B. Maegaard, J. Mariani, H. Mazo, A. Moreno, J. Odijk, and S. Piperidis (European Language Resources Association), 4689–4698. Available at: https://aclanthology.org/2020.lrec-1.577
Moreno, L., Petrie, H., Martínez, P., and Alarcon, R. (2023). Designing user interfaces for content simplification aimed at people with cognitive impairments. Univers. Access. Inf. Soc. 23, 99–117.
Nomura, M., Skat Nielsen, G., and Tronbacke, B. (2010). Guidelines for Easy-to-Read Materials. International Federation of Library Associations and Institutions (IFLA).
Ortiz-Zambranoa, J. A., and Montejo-Ráezb, A. (2020). “Overview of alexs 2020: first workshop on lexical analysis at SEPLN,” in Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2020), Vol. 2664 (CEUR Workshop Proceedings), 1–6.
Papineni, K., Roukos, S., Ward, T., and Zhu, W.-J. (2002). “BLEU: a method for automatic evaluation of machine translation,” in Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (Association for Computational Linguistics), 311–318.
Qiang, J., Li, Y., Zhu, Y., Yuan, Y., and Wu, X. (2020). “Lexical simplification with pretrained encoders,” in Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 34 (Association for the Advancement of Artificial Intelligence), 8649–8656.
Reimers, N., and Gurevych, I. (2019). “Sentence-BERT: sentence embeddings using siamese BERT-networks,” in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (Association for Computational Linguistics), 3982–3992.
Saggion, H., Štajner, S., Bott, S., Mille, S., Rello, L., and Drndarevic, B. (2015). Making it simplext: implementation and evaluation of a text simplification system for spanish. ACM Transact. Access. Comp. 6, 1–36. doi: 10.1145/2738046
Siddharthan, A. (2006). Syntactic simplification and text cohesion. Res. Lang. Comp. 4, 77–109. doi: 10.1007/s11168-006-9011-1
Specia, L. (2010). “Translating from complex to simplified sentences,” in Computational Processing of the Portuguese Language: 9th International Conference, PROPOR 2010, Porto Alegre, RS, Brazil, April 27-30, 2010. Proceedings 9 (Springer), 30–39.
Štajner, S., Calixto, I., and Saggion, H. (2015). “Automatic text simplification for spanish: comparative evaluation of various simplification strategies,” in Proceedings of the International Conference Recent Advances in Natural Language Processing (Association for Computational Linguistics), 618–626.
Štajner, S., Ferrés, D., Shardlow, M., North, K., Zampieri, M., and Saggion, H. (2022). Lexical simplification benchmarks for english, portuguese, and spanish. Front. Artif. Intell. 5:991242. doi: 10.3389/frai.2022.991242
Štajner, S., Saggion, H., and Ponzetto, S. P. (2019). Improving lexical coverage of text simplification systems for spanish. Expert Syst. Appl. 118, 80–91. doi: 10.1016/j.eswa.2018.08.034
Suárez-Figueroa, M., Diab, I., and Ruckhaus, E. (2022). First Steps in the Development of a Support Application for Easy-to-Read Adaptation. Universal Access in the Information Society, Springer.
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., et al. (2023). Llama 2: Open foundation and fine-tuned chat models. arXiv [preprint]. doi: 10.48550/arXiv.2307.09288
UNE (2018). UNE 153101:2018: Easy-to-Read Standards. Spanish Association for Standardization (UNE). Available at: https://www.une.org/ (accessed September 29, 2024).
WHO (2019). Risk Reduction of Cognitive Decline and Dementia: WHO Guidelines. World Health Organization.
Xu, W., Callison-Burch, C., and Napoles, C. (2015). Problems in current text simplification research: new data can help. Transact. Assoc. Comp. Linguist. 3, 283–297. doi: 10.1162/tacl_a_00139
Xu, W., Napoles, C., Pavlick, E., Chen, Q., and Callison-Burch, C. (2016). Optimizing statistical machine translation for text simplification. Transact. Assoc. Comp. Linguist. 4, 401–415. doi: 10.1162/tacl_a_00107
Yimam, S. M., Biemann, C., Malmasi, S., Paetzold, G., Specia, L., Štajner, S., et al. (2018). “A report on the complex word identification shared task 2018”, in Proceedings of the Thirteenth Workshop on Innovative Use of NLP for Building Educational Applications, eds. J. Tetreault, J. Burstein, E. Kochmar, C. Leacock, and H. Yannakoudakis (New Orleans, LA: Association for Computational Linguistics), 66–78. doi: 10.18653/v1/W18-0507
Keywords: Large Language Model, text simplification, Plain Language, Easy to Read, digital accessibility, Natural Language Processing
Citation: Martínez P, Ramos A and Moreno L (2024) Exploring Large Language Models to generate Easy to Read content. Front. Comput. Sci. 6:1394705. doi: 10.3389/fcomp.2024.1394705
Received: 02 March 2024; Accepted: 16 September 2024;
Published: 08 October 2024.
Edited by:
Carlos Duarte, University of Lisbon, PortugalReviewed by:
Marcela Alina Farcasiu, Politehnica University of Timişoara, RomaniaSandra Sanchez-Gordon, Escuela Politécnica Nacional, Ecuador
Copyright © 2024 Martínez, Ramos and Moreno. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Paloma Martínez, cG1mQGluZi51YzNtLmVz