 Andrea Avogaro
Andrea Avogaro Federico Cunico
Federico Cunico Bodo Rosenhahn2
Bodo Rosenhahn2 Francesco Setti
Francesco Setti
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
REVIEW article
Front. Comput. Sci., 06 July 2023
Sec. Computer Vision
Volume 5 - 2023 | https://doi.org/10.3389/fcomp.2023.1153160
This article is part of the Research TopicBody Talks: Advances in Passive Visual Automated Body Analysis for Biomedical PurposesView all 5 articles
Markerless Human Pose Estimation (HPE) proved its potential to support decision making and assessment in many fields of application. HPE is often preferred to traditional marker-based Motion Capture systems due to the ease of setup, portability, and affordable cost of the technology. However, the exploitation of HPE in biomedical applications is still under investigation. This review aims to provide an overview of current biomedical applications of HPE. In this paper, we examine the main features of HPE approaches and discuss whether or not those features are of interest to biomedical applications. We also identify those areas where HPE is already in use and present peculiarities and trends followed by researchers and practitioners. We include here 25 approaches to HPE and more than 40 studies of HPE applied to motor development assessment, neuromuscolar rehabilitation, and gait & posture analysis. We conclude that markerless HPE offers great potential for extending diagnosis and rehabilitation outside hospitals and clinics, toward the paradigm of remote medical care.
Movement data contain a huge amount of meaningful information about our body and brain status; so much that a dedicated research field named movement science was born. Humans are interested in analyzing their own or others' movement for the most varied reasons: humans track and forecast neighbors' movements for non-verbal communication as well as to avoid collisions in collaborative environments, a sport coach oversees athlete's movements to optimize performances and prevent injuries, and a physiotherapist analyzes patient's mobility to monitor the effectiveness of rehabilitation after a stroke or severe injury. Beyond medical applications, the understanding and reconstruction of human motion opened several commercial fields in the domains of games and movies, intelligent production, collaborative robotics, autonomous driving, home security (fall detections), and many more. Humans learn to move and to interpret others movements over many years of development from childhood on, so that it is becoming somehow “natural” for all of us. For this reason, translating this knowledge to machines is a complex task, that requires first accurately capturing human motion and subsequently making decisions or interpretations on top of it.
The interest in computer vision based capturing human motion dates back some centuries (Bregler and Malik, 1998; Moeslund and Granum, 2001; Mündermann et al., 2006). At this time, the core challenges have been in the hardware (capturing, storing, and transmitting synchronized multi-view images), the calibration of cameras, extraction of features, multi-view matching, and 3D reconstruction. A more historic overview is given in Klette and Tee (2008). The continuous commercial developments, e.g., driven by the games and movie industry, heavily boosted human pose estimation for biomedical applications. Thus, MoCap and HPE can be seen as different facets of the same field of research. Nowadays, a standard setting is to use computer vision, machine learning, and deep learning techniques to identify key landmarks on the body (e.g., knees, elbows, etc.) from visual inputs in the form of images/videos of RGB channels, depth, or a combination of the two. This input can be used for skeletal-based reconstruction of human motion and subsequent tasks.
Motion capture systems have been used in biomedical applications for a few decades, allowing the quantification and identification of complex movement patterns and impairments (Richards, 1999; Scott et al., 2022). Biomechanical information can be used to inform clinical decision-making, like the diagnosis of neurological diseases or assessing rehabilitation programs (Fogel and Kvedar, 2018). Systems used in clinical evaluations are predominantly 3D marker-based MoCap setups. These systems can provide accurate and reliable information to clinicians, and there are proven benefits in patients' outcomes as a result of better informed decisions. Significant demonstrable benefits are decreased number of unnecessary surgeries and more efficient diagnosis and treatments, both in terms of time and costs. Nevertheless, benefits come with high costs due to the complex infrastructure required (i.e., infrared cameras, powerful computers, etc.) and the need for technically experienced laboratory staff. These aspects de-facto prevent the adoption of these technologies on a vast scale, also producing barriers to the accessibility to such devices. Moreover, these systems are not widely used across multiple health conditions and tend to be focused on a few specific patient populations, like Parkinson's disease and Cerebral Palsy (Salami et al., 2019).
HPE, also referred to as markerless MoCap, may offer several advantages over marker-based solutions, mostly related to a simpler setup. Indeed, markerless HPE do not require to position reflective markers on the patient, resulting in reduced effort and more efficiency for clinicians and being less invasive on the patients. Hardware setups are often cheaper since input data can be acquired with standard RGB or depth sensors rather than IR cameras. These data can be easily acquired with common household devices (e.g., webcams, smartphones, videogames consoles) which offers the exciting potential for deploying such systems with minimal costs and effort (Stenum et al., 2021a). The drawback is a lower accuracy and robustness that often require to find a trade-off between usability and performances (Kanko et al., 2021).
In a recent study the authors observe that current HPE and tracking algorithms do not fit the needs of movement science due to the poor performances in estimating variables like joints velocity, acceleration, and forces which are crucial for movement science (Seethapathi et al., 2019). While this can be true for some specific problems, we argue that many real-world applications do not actually need such high precision and they do actually benefit from state-of-the-art HPE. Indeed, there are nowadays several approaches that can provide reliable skeletal reconstructions (Cao et al., 2017; Tu et al., 2020), ready to be adopted in real-world applications. Alternatively, HPE can be used as an assistive tool for clinicians rather than an automatic machine, allowing medical personnel to take advantage of automatic pose estimation, correct wrong estimates, and interpret quantitative data to make decisions. This approach can save lots of time since the alternative is to manually annotate videos, which is a tedious and error-prone operation.
A number of review papers appeared in the last years on this topic, but previous works either limit their analysis to specific approaches like 3D pose estimation (Desmarais et al., 2021), single camera (Scott et al., 2022), and deep learning models (Cronin, 2021), or they focus on specific clinical applications like motor development assessment (Silva et al., 2021; Leo et al., 2022), neuromuscolar rehabilitation (Arac, 2020; Cherry-Allen et al., 2023), and gait analysis (Wade et al., 2022).
In this paper, we focus on the biomedical applications of HPE. We examine the main features of HPE approaches, discussing whether or not those features are of interest to biomedical applications. Furthermore, this work will provide an overview of state-of-the-art methods and analyze their suitability for the medical context (Section 2). We will also identify applications in the biomedical field where such technologies are already studied or tested, presenting some peculiarities of these applications and the trends followed by researchers and practitioners (Section 3). We will also briefly present a few commercial products for HPE (Section 4). Finally, we will discuss the limitations of current approaches and opportunities for new research on this topic (Section 5).
Human Pose Estimation concerns the ability of a machine to identify the position of the joints of a human body in 3D space or in an image (Toshev and Szegedy, 2013). Several commercial systems have been developed to solve this problem with estimation errors up to less than a millimeter, but there are still a number of limitations. The currently established gold standard requires positioning of optical markers, i.e., spheres of reflective material close to the joints of the subject (following a predefined protocol for marker placement) and the illumination of the scene with ad-hoc light sources. This assumes a predefined recording volume and collaboration of the subject. Both is not always possible in healthcare applications (e.g., remote care or working with infants). The presence of marker can also affect the performances both physically and psychologically. Moreover, systems like Vicon1 and Optitrack2 are very expensive, making them not affordable for many applications. This explains the demand for HPE that can work with common devices like standard cameras or smartphones.
In the last decades many solutions have been proposed, each one with specific pros and cons. Please note, that this survey is limited to computer vision and deep learning based approaches with a core focus on biomedical applications. Thus, we have to omit impressive works from animation, games, or surveillance which make use of different sensors, special prior knowledge on the motions or multi-modal setups. In the following, we will discuss the main features of HPE methods for biomedical applications and provide a taxonomy of these approaches which is summarized in Table 1.
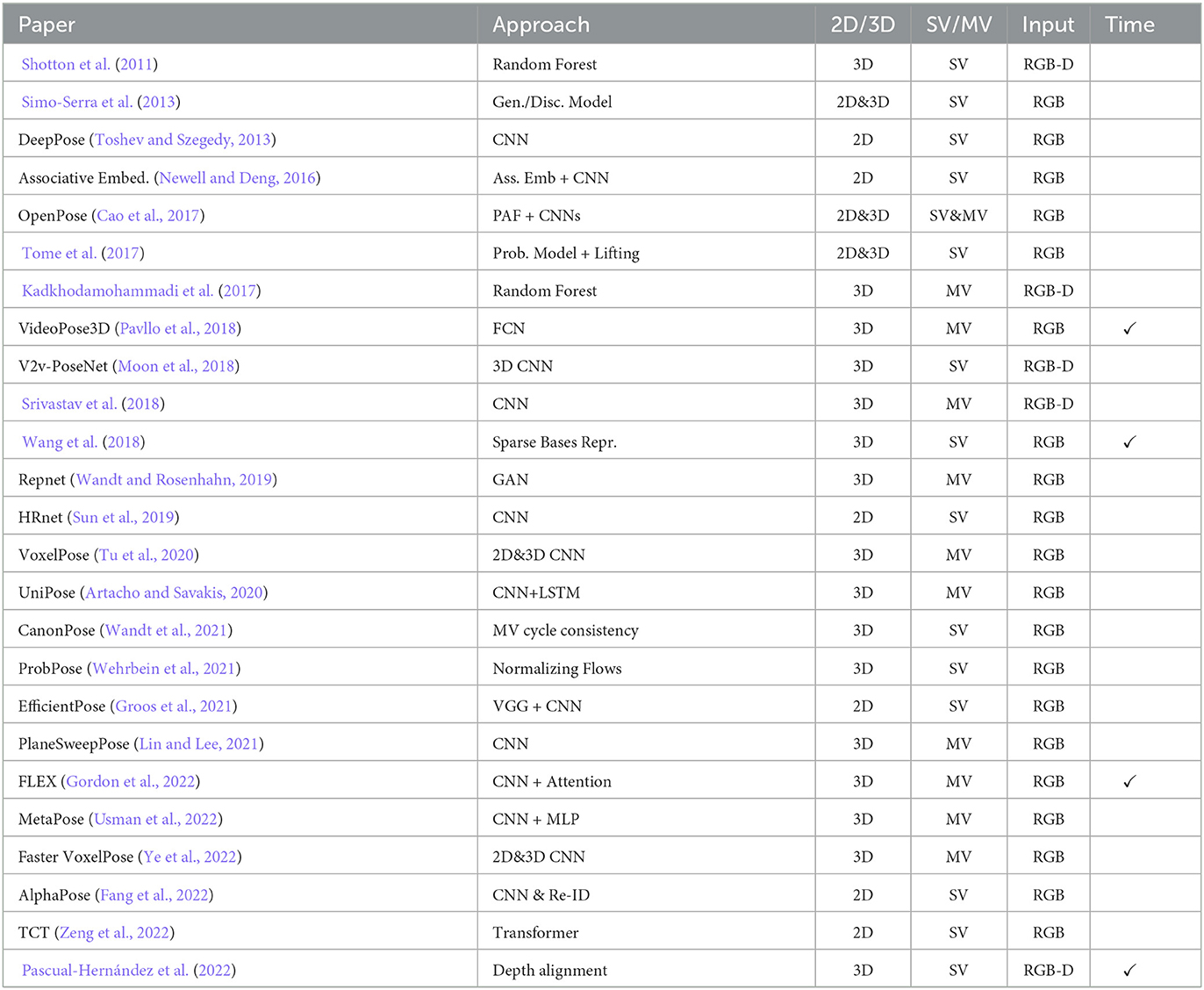
Table 1. Summary of HPE methods. The papers are associated by three main categories: Single-View (SV) or Multi-View (MV), RGB, or RGB-D.
Pose estimation has two very closely related variants: 2D (i.e., in images) and 3D (i.e., in the world). Although they have quite different solution methods, very often 3D pose estimation is directly consequential to 2D pose estimation (mostly in multi-camera systems).
In 2D pose estimation, the goal is to accurately identifying the location of body joints in an image. Over the past few years, several solutions based on deep learning models have been proposed. Early works used convolutional filters capable of learning the physical characteristics of each joint (Newell and Deng, 2016). The use of Convolutional Neural Networks (CNN) proved to be effective in that the appearance of keypoints can be learned, ensuring robustness and speed in inference, with a remarkable ability to generalize even in the wild. The substantial difference between several CNN-based models lies in the architectural design of the networks. In HRNet (Wang et al., 2019), residual connections were inserted between layers having equal resolution between encoders and decoders, ensuring the flow of information regardless of upscaling and downscaling performed in the bottleneck of the network. The most popular work based on CNNs is OpenPose (Cao et al., 2017), a multi-person approach that gained a high reputation due to its ease of integration and real-time performance. EfficientPose (Groos et al., 2021) is a lighter and more accurate model version of the OpenPose that represents a strong baseline for applications usable with mobile devices. More recent approaches have shifted the focus to the use of transformer (Vaswani et al., 2017) based models and attention-based mechanisms instead of convolutional filters. For instance, Zeng et al. (2022) exploits an image token-based approach, going to segment into image sub-portions (tokens) through the use of some CNN layers, alternating with transformer blocks in order to accurately select tokens that refer to body joints. A recent work (Xu L. et al., 2022) makes use of a particular version of Higher Resolution Net (HRNet W48) to extract the body components, aggregating the basic network with hand and face estimators in order to get a complete representation of the human skeleton. Besides providing a new baseline for 2D pose estimation, not only provides information about the body, but hands and face too.
Human Pose Estimation is not only related to joints identification, rather to represent a person with skeletal model. Thus, there are two approaches: bottom-up and top-down as can be seen in Figure 1. The bottom-up approach consists of localizing body joints within the image, and then identify which subsets of these keypoints belong to the same person. These approaches are very useful in images with strong occlusions (e.g., only the upper body) as they are able to identify joints without identifying the person first (Newell and Deng, 2016; Wang et al., 2019). Nonetheless, the main disadvantage of the bottom-up approaches is the number false positives that are usually found, especially in environments with strong noise due to reflections or “human-like” objects (e.g., robotic arms; Sampieri et al., 2022). Conversely, the top-down approach involves first identifying all the individuals in the scene and then estimating keypoints for each person. Methods based on this approach provide robustness to false positives, at the cost of weak person detection in case of high body occlusions (Xu L. et al., 2022).

Figure 1. Top-down and Bottom-up approaches: an example of a top-down approach, the robotic arms risks to generate false positives (left, reprinted from Sampieri et al., 2022); the bottom-up approach works very well with strong occlusion situation, the ideal environment excludes false positives risks (right, reprinted from Joo et al., 2016).
In multi-view camera systems, 3D pose estimation has a simple geometric solution (Hartley and Zisserman, 2003). Older works also proposed to make use of silhouettes which can be extracted reliable for a static background (Carranza et al., 2003; Balan et al., 2007). Given the position of a target point (i.e., a body joint) in multiple calibrated views, it is possible to compute 3D position of the target point via triangulation. Unfortunately this is not sufficient for developing performant 3D HPE systems. In fact, many errors related to system calibration and joint localization and matching concur in generating uncertainty in the 3D estimate. To partially overcome for this effect, VoxelPose (Tu et al., 2020) introduced a triangulation network that is able to approximate the triangulation function as well as compensate for small errors in 2D estimates and calibration. However, this generates problems at the application level: first, it easily overfits training data, and second, it is computationally expensive. PlanSweepPose (Lin and Lee, 2021) is a robust variant of VoxelPose where the 3D position of a point is estimated by minimizing the reprojection error in multiple views, while FasterVoxelPose (Ye et al., 2022) is an improved version of VoxelPose that reduces inference time maintaining high accuracy.
Given the limited access to annotated training data with high variability, numerous models have been studied to improve generalization capabilities to new environments. RepNet (Wandt and Rosenhahn, 2019) tries to estimate the human pose with a weakly supervised approach. Starting from the idea that for every view the corresponding 3D pose is the same, the training phase forces the latent space of the model for every view to be equal, that is the actual spatial position. More recent models like MetaPose (Usman et al., 2022) and FLEX (Guo et al., 2021) try to estimate 3D poses without any kind of reprojection operation and thus without the need for calibrated multi-view systems. The direction that this type of system wants to take HPE's research is increasingly toward plug-and-play systems that can generalize and be usable without the need for ground truth.
In summary, 3D pose estimators rely on robust 2D poses, but the lifting operation (i.e., from 2D to 3D) introduces uncertainty which has also been addressed in recent works (Wehrbein et al., 2021). On the other hand, in many real-world applications, one can use strong priors (e.g., planar motion, physical constraints) to improve reconstruction quality as in the case of gait analysis (see Section 3.3).
Marker-based MoCap are proved to be extremely accurate and robust, but still with strong limitations: (i) they require dedicated hardware and procedures that make them expensive to buy and use, (ii) retroflective markers can fall off, hamper the motions, and need to be placed very accurate, (iii) they are often limited to closed environments with controlled conditions, and (iv) they provide information on a limited (predetermined) number of points. Finally, trained staff is required for calibration, subject preparation, tracking, and the interactive correction of mismatches. An attempt to overcome these limitations was the GaMoCap system (Biasi et al., 2015), a multistereo marker based system where thousands of markers are printed on a special garment and 3D skeleton fitting is performed with structure from motion techniques.
In contrast, in HPE systems the point estimation is done by 2D estimators, which, however, struggle to estimate the same point between different views. An example might be the shoulder in front and lateral view. Even for a human, it is difficult to select a pair of points that provide accurate triangulation. Automatic approaches have to optimize an N-partite graph matching problem, which is known the be NP-hard. In commercial applications, approximate solutions, e.g., based on spectral clustering, are common. Still, identifying the same point in different views is a core limitation of 3D HPE systems. Markerless approaches, on the other side, are easier to set up and maintain (without any human intervention) and they work well on non-collaborative users, making them the most suitable technologies for clinical applications involving, for instance, infants.
The second main limitation of markerless HPE systems lies in the fact that the computational complexity for the two stages (first 2D estimation and then 3D estimation) is much higher than in MoCap systems. For this reason unlike MoCap, markerless systems often require numerous computations, making it very difficult to run in real-time on commonly used devices such as cell phones and mid-range laptops. Nevertheless, IoT solutions and knowledge distillation approaches have been proposed to reduce the computational costs and modern hardware and GPUs allow for very efficient inference times.
The identification of a point in 3D can be traced back to a geometric problem, based on at least two different views of the same point. Thus, the problem cannot be solved geometrically for all those setups that are formed by a single camera. However, several works have been proposed to estimate a 3D skeleton from single view by using heuristics and priors. This operation is usually called 3D lifting. The use of neural networks allows one to be able to estimate depth from a 2D HPE of the skeleton (Simo-Serra et al., 2013; Toshev and Szegedy, 2013; Tome et al., 2017; Wang et al., 2018; Artacho and Savakis, 2020; Wandt et al., 2021). The most popular technique is to use different CNN blocks to do lifting and refining the depth of the 2D pose in space. In other words, it estimates a direct mapping between the position and scale of the reprojected 2D pose with respect to the 3D pose that generated it. At the qualitative level, monocular estimations work very well; there are very versatile frameworks such as MMPose that implements VideoPose3D (Pavllo et al., 2018). Specifically, VideoPose3D is based on temporal convolutions to provide robustness and consistency between consecutive frames, with self-supervised learning paradigms to ensure reusability of the system without the need for ground truth. In the case of monocular systems, however, this is always an estimation and not a geometric projection. For this reason, multi-camera systems are generally more accurate, and mostly designed for performing 3D human pose estimation, but they require hardware and synchronization among different cameras. Thus, multi-camera setups are more expensive compared to monocular HPE systems, which can hold very low costs and be more usable in everyday life. In Figure 2, an examples of different setups, showing the complexity of a multiview setup compared to just a monocular one.

Figure 2. Examples of single-view and multi-view approaches. Single-view HPE on Human 3.6 M (left, reprinted from Xu et al., 2020) and an example of a multi-view HPE on CMU Panoptic (right, reprinted from Tu et al., 2020).
By definition, images are a projection of the 3D environment into 2D, mixing up a third dimension. Hence, systems that rely on RGB only, often struggle to infer the depth and try to get insights of it in some way, directly or indirectly. An alternative technology are depth cameras, either based on structured light or time-of-flight. More common nowadays are devices integrating both channels (RGB and depth) to produce so called RGB-D images. Unlike traditional RGB cameras, RGB-D devices output two distinct images, one color image and a depth map where each pixel returns the distance between the camera lens and the corresponding point in the 3D world. Since sensors often have different frame rate, sensing ranges and resolution, interpolation is often performed to align the RGB-D sensors for follow up tasks. This can also induce inaccuracies into the overall system. Similar results can be obtained, with less accuracy, using (small baseline) stereocameras and disparity map computation. The most popular cameras on the market include Zed, Microsoft Kinect, and RealSense. Using RGB-D cameras it is relatively easy to combine 2D estimator with depth maps to derive 3D poses. Early approaches to pose estimation using RGB-D cameras exploit splitting the problem in two tasks (Shotton et al., 2011): a body keypoint localization is made for each pixel in the image and then the final joint position is inferred. Similarly, other attempts have been made by analyzing probabilistic inference by optimizing the pose of kinematic models (Zhu et al., 2008). More recent techniques based on CNN employ two different methodologies: the first (Moon et al., 2018) consists of using 3D Convolutions to identify the joint in the three-dimensional space provided by the acquired depth. The second method (Pascual-Hernández et al., 2022) on the other hand aims to estimate the skeleton using a 2D estimator in the image, moving on to retrieve the spatial information from the depth camera to estimate the distance. The accuracy that can be achieved with systems of this type, however, turns out to be lower than the performance of a multi-view system. This performance gap is mostly due to self-occlusions. Especially in systems such as Moon et al. (2018) and Pascual-Hernández et al. (2022), if the arms are estimated correctly behind the torso the detected distance will be the same, resulting in a flat pose. This problem, however, has been solved by systems that make use of multi-view RGB-D cameras (Kadkhodamohammadi et al., 2017; Srivastav et al., 2018), where 3D pose is computed for each view, then skeletons are aligned and recorded for increased spatial rigor and consistency.
Until now, the problem of pose estimation has been discussed only referring to frames that were intended atomically. However, when we are faced with applying HPE algorithms to sequences of frames, we often encounter problems in that the slightest variations in pixels from frame to frame can cause chattering. To solve this problem, temporal filtering methodologies, such as Kalman filters (Pascual-Hernández et al., 2022), have been incorporated within the models. Other methodologies such as VideoPose3D (Pavllo et al., 2018) make use of 3D lifting convolutions that process poses sequentially, providing results with temporal consistency. The use of filters to make the pose sequences smooth tend to reduce what is the range of motion of the person, affecting the spatial coherence of the system. In addition, the use of effective filters is not possible in the case of real-time models without introducing latency in the system.
It is widely recognized that there is a need for new technologies for human motion analysis. Current methods are either subjective (e.g., clinical scales), expensive, potentially inaccessible to most clinicians (e.g., MoCap systems), or provide only limited information about specific, predefined features of movement (Cherry-Allen et al., 2023). HPE offers clear and significant potential for applications in biomedical field, as it enables quantitative measurement of human movement kinematics in virtually any setting with minimal cost, time investment, and technological requirements.
Based on an accurate analysis of recent literature in the field, we identified four main areas where HPE can be effectively applied as an assistive tool for clinicians or an automatic support for patients. In the following, we will analyse each field, summarizing recent works and discussing potentialities of HPE to further expand.
Motor development is a process aimed at achieving full mobility and independence by an infant. In healthy developing infants, the sequence of movements is the same and repetitive. The detection of abnormalities in an infant's motor development is crucial for the early diagnosis of neurological disorders, thus allowing to start the therapeutic process, reducing the likelihood of sensory disorders, coordination problems, and postural problems. Table 2 shows the methods for motor development assesment detailed in this section.
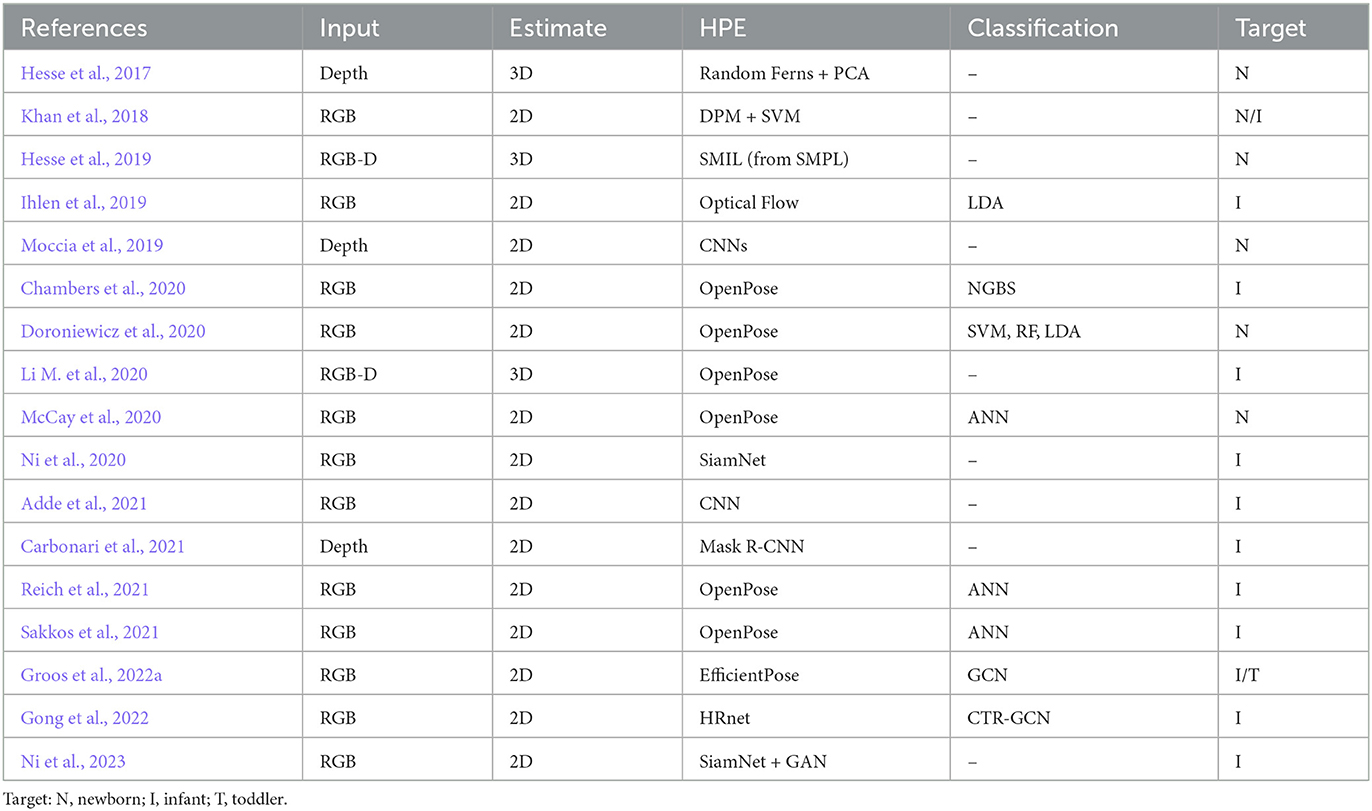
Table 2. Summary of papers addressing motor development assessment with HPE techniques (in chronological order).
Current video-based approaches suffer from the time-intensive but necessary process of manually coding child behaviors of interest by clinicians. Pose estimation technologies offer the opportunity to accelerate video coding to capture specific behaviors of interest in such developmental investigations. Such approaches could further help offering a cost-effective and scalable way to distinguish between typical and atypical development (Stenum et al., 2021a).
The main issue in the adoption of automatic HPE models in motor development assessment is related to the age of the subjects, typically in the range 0–4 years. Kids have different anatomical proportions with respect to adults, that represent the majority of training data for HPE systems. A challenging task in this context is to transfer knowledge acquired from large datasets of adult people to infants by using only a limited amount of task specific data. For this reason, the majority of studies involving newborns (0–2 months of age) and infants (2–12 months of age) exploit traditional geometry based approaches, while for toddlers (1–4 years of age) we witness an effort in transferring knowledge of deep learning models. Figure 3 shows the typical acquisition setup for newborns and infants.
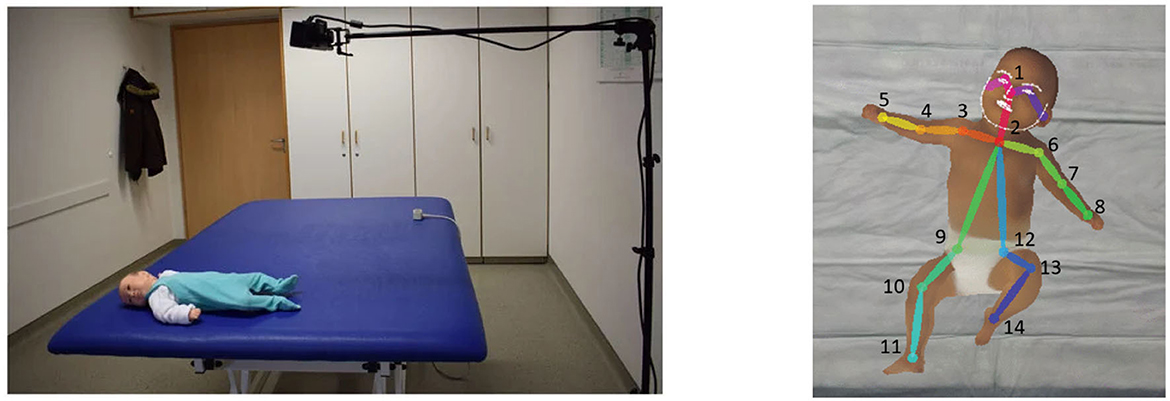
Figure 3. Typical acquisition setup for general movement assessment (GMA) on newborns and infants with the subject lying on a uniform colored bed and a camera above it in perpendicular direction (left, reprinted from Khan et al., 2018), and an example of skeletal reconstruction of an infant with a simplified 14-joints model (right, reprinted from McCay et al., 2020).
Early works focused on fitting a skeletal model starting from body joints localization or body parts segmentation. The testing setup is common for all these studies, i.e., a Microsoft Kinect camera positioned on top of a testing bed to acquire newborns motion. Depth channel is used in Hesse et al. (2017) to extract Random Ferns features trained on synthetic data and process them to localize body joints. RGB channel is employed in Khan et al. (2018) instead, where Deformable Part Models (DPM) are used to segment body parts and then a structured SVM classifier assigns labels to each segment. Multimodal data analysis is introduced in Hesse et al. (2019), where for the first time both RGB and depth channels are exploited to directly fit a 3D virtual model of a baby generated as an extension of SMPL (Loper et al., 2015) model to infants. All these works are designed as assistive tools for clinicians: they provide a visualization and quantitative reconstruction of the skeletal model of the baby. Some works also provide indication of the joint angles. Anyway, a common point is that they do not aim at recognizing atypical subjects or providing measures on how the observation differs from typical data. A step forward is presented in Ihlen et al. (2019) that performs body parts segmentation based on optical flow and particle matching; then motion features are extracted and an LDA model is trained to predict high/low risk of cerebral palsy in infants. While early work rely on relatively simple traditional computer vision methods for pose estimation, more accurate HPE approaches can boost performances.
OpenPose (Cao et al., 2017) library has been proved as a solid asset for estimating the risk of neurological disorders in newborns and infants. Doroniewicz et al. (2020) attempts to automatically detect writhing movements on newborns within three days of life. Movement features are automatically extracted from baby poses and used to distinguish between newborns with good level of writhing movements against those showing a poor repertoir, i.e., a lower quality of movement in relation to the norm. In McCay et al. (2020), reconstructed poses are used to extract normalized pose-based feature sets, namely Histograms of Joint Orientation 2D (HOJO2D) and Histograms of Joint Displacement 2D (HOJD2D). These features are then fed to five different deep learning models was aim is to predict if observed movements are indicative of typically developing infants (Normal) or that may be of concern to clinicians (Abnormal). A Naïve Gaussian Bayesian Surprise (NGBS) is applied in Chambers et al. (2020) to calculate how much infant's movements deviate from a group of typically developing infants and output an indicator of risk for atypical motor development. In Li M. et al. (2020), 3D pose estimation is achieved starting from 2D body poses by using the mapping function between pixels in the RGB and depth channels of the RGB-D scan with a Kinect sensor. All previous works use a simplified OpenPose model with 14 body joints. A more complete model with 25 body joints is used in Reich et al. (2021) instead. Poses represent input vectors for a shallow multilayer neural network to discriminate fidgety from non-fidgety movements in infants. More sophisticated models like EfficientPose (Groos et al., 2021) are also applied to MDA in combination with Graph Neural Networks to predict cerebral palsy in infants at high risk (Groos et al., 2022a).
In the last 4 of years, there has been an increased interest in developing dedicated deep learning based approaches for baby pose estimation. In Moccia et al. (2019), limb-pose estimation is performed using a deep-learning framework consisting of a detection and a regression convolutional neural networks (CNN) for rough and precise joint localization, respectively. The CNNs are implemented to encode connectivity in the temporal direction through 3D convolution. As an extension of this work, Carbonari et al. (2021) proposes an end-to-end learnable convolutional neural network architecture based on Mask R-CNN model for limb-pose estimation in NICUs facilities. More recently, a new infant pose estimation method has been proposed in Wu et al. (2022). The main contribution is represented by a novel keypoint encoding method, called joint feature coding (JFC), to produce high-resolution heatmaps with a CNN model. The system presented in Gong et al. (2022) first extracts trajectories of the body joints with HRNet (Wang et al., 2019) to learn the representations that are most relevant to the movement while avoiding the irrelevant appearance-related features, and then returns a normal/abnormal movement binary classification with CTR-GCN (Chen et al., 2021). Finally, to overcome the limited availability of labeled training data in infant pose estimation, a semi-supervised body parsing model, called SiamParseNet (SPN), to jointly learn single frame body parsing and label propagation throughout time is proposed in Ni et al. (2020). SPN consists of a shared feature encoder, followed by two separate branches: one for intra-frame body parts segmentation, and one for inter-frame label propagation. In Ni et al. (2023), the same authors complement SPN with a training data augmentation module, named Factorized Video Generative Adversarial Network (FVGAN), to synthesize novel labeled frames by decoupling foreground and background generation.
In line with the general trends of digital medicine, some recent works tried to simplify the acquisition setup, opening to remote diagnosis. In Adde et al. (2021), videos of infants were taken at home using handheld smartphones and the In-Motion-App; a simplified skeletal model with only seven joints (head, chest, pelvis, wrists, and ankles) is fit and tracked by a convolutional neural network trained on about 15 k video frames of high-risk infants. Fidgety movements were then classified as continuous (FM++), intermittent (FM+), sporadic (FM+/-), abnormal (Fa), or absent (FM-), according to Prechtl's method (Ferrari et al., 2004). This was the first automatic system tested on video recordings from handheld smartphones.
Despite being proved to perform as well as an experienced clinician in identifying babies with high risk of neurological disorders (Groos et al., 2022b), the adoption of such systems in the clinical practice is slow because of the lack in interpretability of results, i.e., doctors can hardly understand the reasons why a machine makes some predictions in case of disagreement. A big step forward in this sense is represented by Sakkos et al. (2021). This work introduces a framework that provides both prediction and visualization of those movements that are relevant for predicting a high-risk score. First the 2D skeletal pose is detected on a per-frame basis using OpenPose, hence, for each pose body parts are segmented and processed by a specific branch to learn a part-specific spatiotemporal representation using an LSTM. Finally, the output is passed to a shallow fully connected network for classification as well as to a visualization tool.
Human motion analysis for rehabilitation has been an active research topic for more then 30 years now. Markerless motion capture technologies offer clear and significant potential for applications in rehabilitation, as they enable quantitative measurement of human movement kinematics in virtually any setting with minimal cost, time investment, and technological requirements (Cherry-Allen et al., 2023). Such systems represent valuable tools for many use cases. In clinical work, accurate reconstruction allows physiotherapists to monitor the progress of patients in their rehabilitation journey. In telerehabilitation setups, patients can perform their workout autonomously with supervision of an AI. Accurate estimates of skeletal models are also necessary for a safe and effective implementation of robotic assisted rehabilitation protocols. Table 3 shows a summary of the techniques of this section.
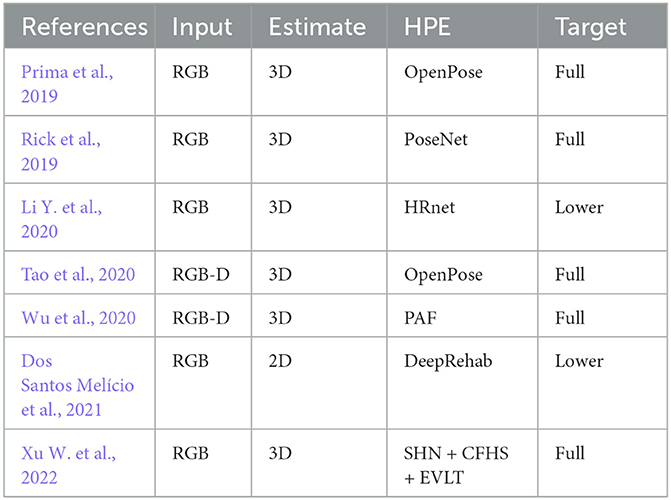
Table 3. Summary of papers addressing neuromuscolar rehabilitation with HPE techniques (in chronological order).
A supporting system for managing therapeutic exercises should consist of two central tools: capturing human motion in real-time, and quantitatively evaluate the performance. In order to be effective an HPE based platform used in rehabilitation must ensure correct exercise performance of the client and automatic detection of wrong executing.
Assessment studies like Sarsfield et al. (2019) observed that current (at that time) markerless HPE systems were mostly inadequate for correctly assessing rehabilitation exercises due to poor accuracy and inability to handle self occlusions. Nevertheless, newer approaches were presented in the last years and researchers proposed variations of standard HPE models that are specifically designed to perform well in rehabilitation scenarios. We should also consider that in this context patients could have appearance significantly different from the typical distributions used in publicly available annotated training datasets. Consider the fact that patients are usually recovering from surgeries where arts could be amputee, or they could be following therapies for obesity related postural problems. In these cases, pre-trained HPE models can easily fail in tracking joints or fitting the skeletal model. For this reason annotated datasets have been provided for the specific domain.
In Xu W. et al. (2022), a framework for accurate 3-D pose estimation using multiview videos is presented. The pipeline is divided in two steps: First, a Stacked Hourglass Network (Newell et al., 2016) associated with a coarse-to-fine heatmap shrinking (CFHS) strategy generates localizes joints on each image; Second, a spatial-temporal perception network fuses 2D results from multiple views and multiple moments (i.e., leverages temporal information) to generate 3D pose estimation. A combination of RGB and depth channels captured by a Microsoft Kinect device are used in Wu et al. (2020). 2D poses are extracted from RGB images using Part Affinity Fields (Cao et al., 2017) and then exploit mapping between the two channels to estimate 3D body joints locations. Such models perform very well in their specific contexts, but it is also computationally demanding, making it only suitable for usage in clinic.
For telerehabilitation scenarios instead, effort was made to design a neural network model that is both accurate and lightweight in computation. Li Y. et al. (2020) adopts HRNet as the backbone and leverage the modules in MobileNetv1 (Howard et al., 2017) to simplify the original network. Meanwhile they also leverage dilated convolution (Mehta et al., 2019) for its spatial features extraction capability. The resulting network, called Extremely Efficient Spatial Pyramid (EESD), is further enriched with an attention module and can run smoothly on a mid level smartphone. A web based application called NeuroPose is presented in Rick et al. (2019). The backbone of pose estimation is PoseNet (Moon et al., 2018) model deployed using tensorflow.js framework, a browser based implementation that uses common libraries like WebGL to access local GPU resources when available, and otherwise can scale back parameters to support a wider range of hardware. Alternative solutions are represented by the two opposite directions of cloud and edge computing. In Prima et al. (2019), 2D poses are provided by OpenPose library, 3D lifting exploits heuristics and prior information, and joint angles are computed from skeleton model. Here the IoT paradigm is exploited to allow the application to work on a smartphone, while computationally expensive parts are running on a cloud service. Conversely, Dos Santos Meĺıcio et al. (2021) introduces DeepRehab, a bottom up model inspired by PoseNet that estimates joints' positions with a fully convolutional architecture with ResNet101 as a backbone for feature extraction. The code runs on an Edge TPU device that is dedicated to this computation, while the patient can interact with a smartphone app.
A new trend is represented by robotic assisted rehabilitation, particularly useful for patients with motor disorders caused by stroke or spinal cord disease since rehab robots can deliver high-dosage and high-intensity training. In this case the focus is on guaranteeing safety during execution of exercises. A comparison of two popular HPE models, namely OpenPose and Detectron2, for angles estimation in upper body joints is provided in Hernández et al. (2021). This study concludes that OpenPose has accuracy compared with expert therapists and a frame rate of about 10 fps, making it suitable for real world applications. Thus, OpenPose is used in Tao et al. (2020) to track human poses when executing an exercise supported by an expert; then a robot plans trajectories to substitute the physiotherapist in assisting patients while replicating the same movement. Again, 3D poses are obtained from depth channel.
Gait analysis is the systematic study of body movements that are responsible for locomotion in human beings, i.e., walk, run, jump, etc. It is widely used to identify gait abnormalities and to propose appropriate treatments. It is an essential functional evaluation in clinical applications for recognizing health problems related to posture and movement and monitoring patients' status. Successful applications of HPE in this field are mostly employing either OpenPose (Cao et al., 2017) or DeepLabCut (Mathis et al., 2018), while a wider comparison among different HPE methods is provided in Kanko et al. (2021) and Washabaugh et al. (2022).
Gait is most often a planar task, i.e., patients are asked to walk on a straight line, two planes are of particular interest in these analysis: sagittal and coronal. Thus, two cameras are needed to accurately monitor 3D poses: one placed in front of the user and one laterally. Moreover, the goal of gait analysis is not to accurately monitor the whole body, rather to extract quantitative evaluation of specific movement features, i.e., statistics on joint angles. Several studies focused on the lateral view since it can provide more relevant information in many scenarios. Three studies have examined 2D monocular applications of DeepLabCut against manual labeling or marker-based methods in sagittal view in different conditions: underwater running (Cronin et al., 2019), countermovement jumping (Drazan et al., 2021), and walking in stroke survivors (Moro et al., 2020). These studies consistently conclude that, despite having a higher average error with respect to marker based approaches, markerless HPE can be effectively used in gait and posture analysis. Similar results are obtained by Viswakumar et al. (2022) using OpenPose to estimate knee angles. The main issue with single camera setups is represented by self-occlusions. To overcome this problem, Serrancoĺı et al. (2020) and Stenum et al. (2021b) used two cameras placed on either side of the sagittal plane, each one only monitoring the closest limbs and ignoring the rest. Nevertheless, both studies showed poor results in terms of accuracy and robustness, requiring frequent intervention of a user.
Temporal information has been examined in two separate studies using 2D monocular HPE combined with projection mapping (Shin et al., 2021) and with 3D musculoskeletal model (Azhand et al., 2021) to subsequently extract gait parameters measures, finding strong correlations when compared to the GAITRite pressure walkway3. An end-to-end model is presented in Sokolova and Konushin (2019). Starting from 2D pose estimation from OpenPose, authors crop patches around the joints and compute optical flow in these regions; finally a convolutional neural network is trained to directly output gait descriptors.
Gait analysis in biomedical applications often requires the computation of the inverse dynamics. It implies methods for computing forces and the torques based on 3D motion of a body and the body's inertial properties (e.g., masses of each limb). It usually requires additional information, e.g., ground reaction forces, stemming from force plates. Brubaker et al. (2007, 2009) use an articulated body model to infer joint torques and contact dynamics from motion data. They accelerate the optimization procedure by introducing additional root forces and effectively decoupling the problem at different time frames. Researchers also proposed to learn a direct mapping from a motion parametrization (joint angles) to the acting forces (joint torques) on the basis of MoCap data: Johnson and Ballard (2014) investigate sparse coding for inverse dynamics regression and Zell and Rosenhahn (2015) introduced a two dimensional statistical model for human gait analysis and extended it later to a 3D model and a neural network based inference (Zell et al., 2020). While most approaches solely focus on walking motions, further works (Vondrak et al., 2008; Duff et al., 2011) consider a wider range of motion types. A physical driven prior is also suitable to support statistical approaches, e.g., Wei et al. (2011) use a maximum a posteriori approach to synthesize a wide range of physically realistic motions and motion interactions. Many human pose estimation methods further rely either on anthropometric constraints (Wang et al., 2014; Akhter and Black, 2015) to stabilize the computations.
As Parkinson's disease represents a major field of investigation with gait analysis, several works focused on these class of patients. For instance, Shin et al. (2021) processed monocular frontal videos for providing temporospatial outcome measures (i.e., step length, walking velocity, and turning time). Martinez et al. (2018) used OpenPose to examine walking cadence and automate calculation of an anomaly score for monitoring progression of the disease. Connie et al. (2022) uses a two cameras setup (frontal and lateral) and extracts eight spatio-temporal features from 2D trajectories of body joints estimated with AlphaPose (Fang et al., 2022). These features are then used in a random forest classifier to distinguish between classes of disease severity. Similarly, Sato et al. (2019) proposed an unsupervised approach to quantify gait features and extract cadence from gait video by applying OpenPose.
Several solutions based on HPE systems have been developed commercially for the analysis of person movement and pose. The most popular (Captury, 2023; Contemplas, 2023; Indatalabs, 2023; Theiamarkerless, 2023) are systems all based on markerless technology. Of these systems, most are purely designed to be able to do motion analysis in the medical/sports field. All of the proposed systems make use of multiview models, with the exception of Indatalabs (2023) which also allow pose estimation in single view. In addition, Captury (2023) and Indatalabs (2023) provide software capable of using non-proprietary camera setups, allowing a wide range of setup choices based on end-user needs. Each solution offers dedicated frameworks and suites with integrations with Unity and Blender, so that motion can be obtained and analyzed not only based on the skeleton but also with body mesh. Actual performance in terms of error is not reported by the site developers.
Clinical application of markerless HPE is precluded by some technical and practical limitations. First, there is a need for extensive evaluation studies like Carrasco-Plaza and Cerda (2022) that will allow to better understand how well these methods, designed and trained on healthy population, can be transferred to clinical population with antropometric models that can significantly differ from average adults, e.g., infants or obese people. Hence, there is a need of accessible annotated data for retraining models on these typologies of subjects that are of particular interests in medical applications. Second, there is a need for accessible software that can be used out-of-the-box from non technical users with minimal effort. This is witnessed by the fact that, despite being no more state-of-the-art, OpenPose is still the most used approach in medical field. Third, despite being low demanding in terms of acquisition setups, markerless HPE systems are relatively expensive in terms of computational power, raising barriers to the deployment on mobile devices.
All the limitations listed above, are actually opening new opportunities for researchers and technicians. Indeed, while for HPE in-the-wild the generalization capability of a method is an important feature, for many medical applications it is actually not so relevant. Considering the case of a patient that needs for a long rehabilitation program, spending a few sessions to overfit the model to the specific user can represent an acceptable cost in the face of improved accuracy. A study in this direction is the patient-specific approach of Chen et al. (2018), and we argue that other strategies like continual (i.e., incremental) learning or domain adaptation can be effectively applied in this context. As for the lack of annotated data, there is a range of studies that try to transfer learning from synthetic data to real-world data. While this is not trivial, it would allow for generating data with high variability, as well as controlling characteristics of the specific subject categories. Data can be effectively generated with Generative Adversarial Networks and used to fine-tune pre-trained general-purpose models. Finally, we believe that computational issues will be soon overcome by technological advancement. Nevertheless, recent studies developed solutions that can leverage either computing on dedicated edge devices, using cloud computing under the paradigm of Internet-of-Things, or mixing the two as proposed, for a different scenario, in Cunico et al. (2022) and Capogrosso et al. (2023).
In this paper, we reviewed the state of the art in markerless Human Pose Estimation with applications to the biomedical field. First, we examined the main features of HPE approaches generating a taxonomy that allows to map proposed methods and discriminate those approaches that are not suitable for specific applications. Then we identified three areas of medicine and healthcare where HPE is already in use (or under investigation): namely motor development analysis, neuromuscular rehabilitation and gait & posture analysis. For each of these fields we presented an overview of the state-of-the-art considering peculiarities and trends followed by researchers and practitioners. In our analysis, we included 25 different approaches for Human Pose Estimation and more than 40 studies of HPE applied to the three areas identified above. We can draw the conclusion that markerless HPE offers great potential for extending diagnosis and rehabilitation outside hospitals and clinics, toward the paradigm of remote medical care. Current approaches are limited in accuracy with respect to the gold standard in clinical practice, i.e., marker-based motion capture systems, still, they can complement video analysis with lots of useful information that allow clinicians to make more informed decisions, saving a huge amount of time.
Writing abstracts and the introduction by BR. Section 2 regarding pose estimation was edited by AA, while the applications of HPE in the medical field (section 3) were written by FS. Finally, sections 4, 5, and 6 were written by FC. The work was organized and supervised by FS. All authors contributed to the article and approved the submitted version.
This study was carried out within the PNRR research activities of the consortium iNEST (Interconnected North-Est Innovation Ecosystem) funded by the European Union Next-GenerationEU (Piano Nazionale di Ripresa e Resilienza (PNRR) - Missione 4 Componente 2, Investimento 1.5 - D.D. 1058 23/06/2022, ECS_00000043).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
FG in the role of senior member overviewing a junior reviewer, declared a past co-authorship with the authors AA, FS, and FC to the handling editor.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
This manuscript reflects only the Authors' views and opinions, neither the European Union nor the European Commission can be considered responsible for them.
Adde, L., Brown, A., Van Den Broeck, C., DeCoen, K., Eriksen, B. H., Fjørtoft, T., et al. (2021). In-motion-app for remote general movement assessment: a multi-site observational study. BMJ Open 11:e042147. doi: 10.1136/bmjopen-2020-042147
Akhter, I., and Black, M. J. (2015). “Pose-conditioned joint angle limits for 3d human pose reconstruction,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (Boston, MA), 1446–1455. doi: 10.1109/CVPR.2015.7298751
Arac, A. (2020). Machine learning for 3d kinematic analysis of movements in neurorehabilitation. Curr. Neurol. Neurosci. Rep. 20:8. doi: 10.1007/s11910-020-01049-z
Artacho, B., and Savakis, A. (2020). “Unipose: unified human pose estimation in single images and videos,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (Seattle, WA), 7035–7044. doi: 10.1109/CVPR42600.2020.00706
Azhand, A., Rabe, S., Müller, S., Sattler, I., and Heimann-Steinert, A. (2021). Algorithm based on one monocular video delivers highly valid and reliable gait parameters. Sci. Rep. 11, 1–10. doi: 10.1038/s41598-021-93530-z
Balan, A., Black, M. J., Haussecker, H., and Sigal, L. (2007). “Shining a light on human pose: on shadows, shading and the estimation of pose and shape,” in International Conference on Computer Vision, ICCV (Rio de Janeiro, Brazil), 1–8. doi: 10.1109/ICCV.2007.4409005
Biasi, N., Setti, F., Del Bue, A., Tavernini, M., Lunardelli, M., Fornaser, A., et al. (2015). Garment-based motion capture (gamocap): high-density capture of human shape in motion. Mach. Vis. Appl. 26, 955–973. doi: 10.1007/s00138-015-0701-2
Bregler, C., and Malik, J. (1998). “Tracking people with twists and exponential maps,” in Proceedings of Computer Vision and Pattern Recognition (Santa Barbara, CA), 8–15. doi: 10.1109/CVPR.1998.698581
Brubaker, M., Fleet, D. J., and Hertzmann, A. (2007). “Physics-based person tracking using simplified lower-body dynamics,” in Conference of Computer Vision and Pattern Recognition (CVPR) (Minnesota: IEEE Computer Society Press). doi: 10.1109/CVPR.2007.383342
Brubaker, M. A., Sigal, L., and Fleet, D. J. (2009). “Estimating contact dynamics,” in International Conference on Computer Vision (ICCV) (Kyoto). doi: 10.1109/ICCV.2009.5459407
Cao, Z., Simon, T., Wei, S.-E., and Sheikh, Y. (2017). “Realtime multi-person 2d pose estimation using part affinity fields,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 7291–7299. doi: 10.1109/CVPR.2017.143
Capogrosso, L., Cunico, F., Lora, M., Cristani, M., Fummi, F., and Quaglia, D. (2023). Split-et-impera: a framework for the design of distributed deep learning applications. arXiv preprint arXiv:2303.12524. doi: 10.48550/arXiv.2303.12524
Captury (2023). Available online at: https://captury.com/ (accessed January 28, 2023).
Carbonari, M., Vallasciani, G., Migliorelli, L., Frontoni, E., and Moccia, S. (2021). “End-to-end semantic joint detection and limb-pose estimation from depth images of preterm infants in NICUs,” in IEEE Symposium on Computers and Communications (ISCC) (Athens). doi: 10.1109/ISCC53001.2021.9631261
Carranza, J., Theobalt, C., Magnor, M. A., and Seidel, H.-P. (2003). “Free-viewpoint video of human actors,” in Proceedings of SIGGRAPH 2003 (New York, NY), 569–577. doi: 10.1145/1201775.882309
Carrasco-Plaza, J., and Cerda, M. (2022). “Evaluation of human pose estimation in 3D with monocular camera for clinical application,” in International Symposium on Intelligent Computing Systems (Santiago: Springer), 121–134. doi: 10.1007/978-3-030-98457-1_10
Chambers, C., Seethapathi, N., Saluja, R., Loeb, H., Pierce, S. R., Bogen, D. K., et al. (2020). Computer vision to automatically assess infant neuromotor risk. IEEE Trans. Neural Syst. Rehabil. Eng. 28, 2431–2442. doi: 10.1109/TNSRE.2020.3029121
Chen, K., Gabriel, P., Alasfour, A., Gong, C., Doyle, W. K., Devinsky, O., et al. (2018). Patient-specific pose estimation in clinical environments. IEEE J. Transl. Eng. Health Med. 6, 1–11. doi: 10.1109/JTEHM.2018.2875464
Chen, Y., Zhang, Z., Yuan, C., Li, B., Deng, Y., and Hu, W. (2021). “Channel-wise topology refinement graph convolution for skeleton-based action recognition,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (Montréal, QC), 13359–13368. doi: 10.1109/ICCV48922.2021.01311
Cherry-Allen, K. M., French, M. A., Stenum, J., Xu, J., and Roemmich, R. T. (2023). Opportunities for improving motor assessment and rehabilitation after stroke by leveraging video-based pose estimation. Am. J. Phys. Med. Rehabil. 102, S68–S74. doi: 10.1097/PHM.0000000000002131
Connie, T., Aderinola, T. B., Ong, T. S., Goh, M. K. O., Erfianto, B., and Purnama, B. (2022). Pose-based gait analysis for diagnosis of Parkinson's disease. Algorithms 15:474. doi: 10.3390/a15120474
Contemplas (2023). Available online at: https://contemplas.com/en/motion-analysis/gait-analysis/ (accessed January 28, 2023).
Cronin, N. J. (2021). Using deep neural networks for kinematic analysis: challenges and opportunities. J. Biomech. 123:110460. doi: 10.1016/j.jbiomech.2021.110460
Cronin, N. J., Rantalainen, T., Ahtiainen, J. P., Hynynen, E., and Waller, B. (2019). Markerless 2d kinematic analysis of underwater running: a deep learning approach. J. Biomech. 87, 75–82. doi: 10.1016/j.jbiomech.2019.02.021
Cunico, F., Capogrosso, L., Setti, F., Carra, D., Fummi, F., and Cristani, M. (2022). “I-split: deep network interpretability for split computing,” in 2022 26th International Conference on Pattern Recognition (ICPR) (Montréal, QC), 2575–2581. doi: 10.1109/ICPR56361.2022.9956625
Desmarais, Y., Mottet, D., Slangen, P., and Montesinos, P. (2021). A review of 3D human pose estimation algorithms for markerless motion capture. Comput. Vis. Image Understand. 212:103275. doi: 10.1016/j.cviu.2021.103275
Doroniewicz, I., Ledwoń, D. J., Affanasowicz, A., Kieszczyńska, K., Latos, D., Matyja, M., et al. (2020). Writhing movement detection in newborns on the second and third day of life using pose-based feature machine learning classification. Sensors 20:5986. doi: 10.3390/s20215986
Dos Santos Melìcio, B. C., Baranyi, G., Gaál, Z., Zidan, S., and Lőrincz, A. (2021). “Deeprehab: real time pose estimation on the edge for knee injury rehabilitation,” in International Conference on Artificial Neural Networks (Cham: Springer), 380–391. doi: 10.1007/978-3-030-86365-4_31
Drazan, J. F., Phillips, W. T., Seethapathi, N., Hullfish, T. J., and Baxter, J. R. (2021). Moving outside the lab: markerless motion capture accurately quantifies sagittal plane kinematics during the vertical jump. J. Biomech. 125:110547. doi: 10.1016/j.jbiomech.2021.110547
Duff, D., Mörwald, T., Stolkin, R., and Wyatt, J. (2011). Physical simulation for monocular 3d model based tracking, 5218–5225. doi: 10.1109/ICRA.2011.5980535
Fang, H.-S., Li, J., Tang, H., Xu, C., Zhu, H., Xiu, Y., et al. (2022). Alphapose: Whole-body regional multi-person pose estimation and tracking in real-time. IEEE Trans. Pattern Anal. Mach. Intell. 45:1–17. doi: 10.1109/TPAMI.2022.3222784
Ferrari, F., Einspieler, C., Prechtl, H. F. R., Bos, A. F., and Cioni, G. (2004). Prechtl's Method on the Qualitative Assessment of General Movements in Preterm, Term and Young Infants. London: Mac Keith Press.
Fogel, A. L., and Kvedar, J. C. (2018). Artificial intelligence powers digital medicine. NPJ Digit. Med. 1:5. doi: 10.1038/s41746-017-0012-2
Gong, X., Li, X., Ma, L., Tong, W., Shi, F., Hu, M., et al. (2022). Preterm infant general movements assessment via representation learning. Displays 75:102308. doi: 10.1016/j.displa.2022.102308
Gordon, B., Raab, S., Azov, G., Giryes, R., and Cohen-Or, D. (2022). “FLEX: extrinsic parameters-free multi-view 3d human motion reconstruction,” in Computer Vision-ECCV 2022: 17th European Conference (Tel Aviv: Springer), 176–196. doi: 10.1007/978-3-031-19827-4_11
Groos, D., Adde, L., Aubert, S., Boswell, L., De Regnier, R.-A., Fjørtoft, T., et al. (2022a). Development and validation of a deep learning method to predict cerebral palsy from spontaneous movements in infants at high risk. JAMA Netw. Open 5:e2221325. doi: 10.1001/jamanetworkopen.2022.21325
Groos, D., Adde, L., Stòen, R., Ramampiaro, H., and Ihlen, E. A. (2022b). Towards human-level performance on automatic pose estimation of infant spontaneous movements. Comput. Med. Imaging Graph. 95:102012. doi: 10.1016/j.compmedimag.2021.102012
Groos, D., Ramampiaro, H., and Ihlen, E. A. (2021). Efficientpose: scalable single-person pose estimation. Appl. intell. 51, 2518–2533. doi: 10.1007/s10489-020-01918-7
Guo, Y., Liu, J., Li, G., Mai, L., and Dong, H. (2021). “Fast and flexible human pose estimation with HyperPose,” in Proceedings of the 29th ACM International Conference on Multimedia (Chengdu). doi: 10.1145/3474085.3478325
Hartley, R., and Zisserman, A. (2003). Multiple View Geometry in Computer Vision. Cambride, UK: Cambridge University Press. doi: 10.1017/CBO9780511811685
Hernández, Ó. G., Morell, V., Ramon, J. L., and Jara, C. A. (2021). Human pose detection for robotic-assisted and rehabilitation environments. Appl. Sci. 11:4183. doi: 10.3390/app11094183
Hesse, N., Pujades, S., Black, M. J., Arens, M., Hofmann, U. G., and Schroeder, A. S. (2019). Learning and tracking the 3d body shape of freely moving infants from RGB-d sequences. IEEE Trans. Pattern Anal. Mach. Intell. 42, 2540–2551. doi: 10.1109/TPAMI.2019.2917908
Hesse, N., Schröder, A. S., Müller-Felber, W., Bodensteiner, C., Arens, M., and Hofmann, U. G. (2017). “Body pose estimation in depth images for infant motion analysis,” in Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), 1909–1912. doi: 10.1109/EMBC.2017.8037221
Howard, A. G., Zhu, M., Chen, B., Kalenichenko, D., Wang, W., Weyand, T., et al. (2017). Mobilenets: efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861. doi: 10.48550/arXiv.1704.04861
Ihlen, E. A., Støen, R., Boswell, L., de Regnier, R.-A., Fjørtoft, T., Gaebler-Spira, D., et al. (2019). Machine learning of infant spontaneous movements for the early prediction of cerebral palsy: a multi-site cohort study. J. Clin. Med. 9:5. doi: 10.3390/jcm9010005
Indatalabs (2023). Available online at: https://indatalabs.com/resources/human-activity-recognition-fitness-app (accessed January 28, 2023).
Johnson, L., and Ballard, D. (2014). “Efficient codes for inverse dynamics during walking,” in Proceedings of the AAAI Conference on Artificial Intelligence (Québec), 28. doi: 10.1609/aaai.v28i1.8747
Joo, H., Simon, T., Li, X., Liu, H., Tan, L., Gui, L., et al. (2016). “Panoptic studio: a massively multiview system for social interaction capture, in 2015 IEEE International Conference on Computer Vision (ICCV). doi: 10.1109/ICCV.2015.381
Kadkhodamohammadi, A., Gangi, A., de Mathelin, M., and Padoy, N. (2017). A multi-view RGB-D approach for human pose estimation in operating rooms. CoRR abs/1701.07372. 363–372. doi: 10.1109/WACV.2017.47
Kanko, R. M., Laende, E. K., Davis, E. M., Selbie, W. S., and Deluzio, K. J. (2021). Concurrent assessment of gait kinematics using marker-based and markerless motion capture. J. Biomech. 127:110665. doi: 10.1016/j.jbiomech.2021.110665
Khan, M. H., Schneider, M., Farid, M. S., and Grzegorzek, M. (2018). Detection of infantile movement disorders in video data using deformable part-based model. Sensors 18:3202. doi: 10.3390/s18103202
Klette, R., and Tee, G. (2008). Understanding Human Motion: A Historic Review. Dordrecht: Springer Netherlands, 1–22. doi: 10.1007/978-1-4020-6693-1_1
Leo, M., Bernava, G. M., Carcagnì, P., and Distante, C. (2022). Video-based automatic baby motion analysis for early neurological disorder diagnosis: State of the art and future directions. Sensors 22:866. doi: 10.3390/s22030866
Li, M., Wei, F., Li, Y., Zhang, S., and Xu, G. (2020). Three-dimensional pose estimation of infants lying supine using data from a kinect sensor with low training cost. IEEE Sensors J. 21, 6904–6913. doi: 10.1109/JSEN.2020.3037121
Li, Y., Wang, C., Cao, Y., Liu, B., Tan, J., and Luo, Y. (2020). “Human pose estimation based in-home lower body rehabilitation system,” in 2020 International Joint Conference on Neural Networks (IJCNN) (Glasgow), 1–8. doi: 10.1109/IJCNN48605.2020.9207296
Lin, J., and Lee, G. H. (2021). “Multi-view multi-person 3d pose estimation with plane sweep stereo,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 11886–11895. doi: 10.1109/CVPR46437.2021.01171
Loper, M., Mahmood, N., Romero, J., Pons-Moll, G., and Black, M. J. (2015). SMPL: a skinned multi-person linear model. ACM Trans. Graph. 34, 1–16. doi: 10.1145/2816795.2818013
Martinez, H. R., Garcia-Sarreon, A., Camara-Lemarroy, C., Salazar, F., and Guerrero-González, M. L. (2018). Accuracy of markerless 3d motion capture evaluation to differentiate between on/off status in parkinson's disease after deep brain stimulation. Parkinson's Dis. 2018:5830364. doi: 10.1155/2018/5830364
Mathis, A., Mamidanna, P., Cury, K. M., Abe, T., Murthy, V. N., Mathis, M. W., et al. (2018). DeepLabCut: markerless pose estimation of user-defined body parts with deep learning. Nat. Neurosci. 21, 1281–1289. doi: 10.1038/s41593-018-0209-y
McCay, K. D., Ho, E. S., Shum, H. P., Fehringer, G., Marcroft, C., and Embleton, N. D. (2020). Abnormal infant movements classification with deep learning on pose-based features. IEEE Access 8, 51582–51592. doi: 10.1109/ACCESS.2020.2980269
Mehta, S., Rastegari, M., Shapiro, L., and Hajishirzi, H. (2019). “Espnetv2: a light-weight, power efficient, and general purpose convolutional neural network,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (Long Beach, CA), 9190–9200. doi: 10.1109/CVPR.2019.00941
Moccia, S., Migliorelli, L., Carnielli, V., and Frontoni, E. (2019). Preterm infants' pose estimation with spatio-temporal features. IEEE Trans. Biomed. Eng. 67, 2370–2380. doi: 10.1109/TBME.2019.2961448
Moeslund, T., and Granum, E. (2001). A survey of computer vision based human motion capture. Comput. Vis. Image Understand. 81, 231–268. doi: 10.1006/cviu.2000.0897
Moon, G., Chang, J. Y., and Lee, K. M. (2018). “V2v-posenet: voxel-to-voxel prediction network for accurate 3d hand and human pose estimation from a single depth map,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (Salt Lake City), 5079–5088.
Moro, M., Marchesi, G., Odone, F., and Casadio, M. (2020). “Markerless gait analysis in stroke survivors based on computer vision and deep learning: a pilot study,” in Proceedings of the 35th Annual ACM Symposium on Applied Computing, 2097–2104. doi: 10.1145/3341105.3373963
Mündermann, L., Corazza, S., and Andriacchi, T. P. (2006). The evolution of methods for the capture of human movement leading to markerless motion capture for biomechanical applications. J. Neuroeng. Rehabil. 3, 1–11. doi: 10.1186/1743-0003-3-6
Newell, A., and Deng, J. (2016). Associative embedding: end-to-end learning for joint detection and grouping. CoRR, abs/1611.05424. doi: 10.48550/arXiv.1611.05424
Newell, A., Yang, K., and Deng, J. (2016). “Stacked hourglass networks for human pose estimation,” in Computer Vision-ECCV 2016: 14th European Conference (Amsterdam: Springer), 483–499. doi: 10.1007/978-3-319-46484-8_29
Ni, H., Xue, Y., Ma, L., Zhang, Q., Li, X., and Huang, S. X. (2023). Semi-supervised body parsing and pose estimation for enhancing infant general movement assessment. Med. Image Anal. 83:102654. doi: 10.1016/j.media.2022.102654
Ni, H., Xue, Y., Zhang, Q., and Huang, X. (2020). “Siamparsenet: joint body parsing and label propagation in infant movement videos,” in Medical Image Computing and Computer Assisted Intervention-MICCAI 2020: 23rd International Conference (Lima: Springer), 396–405. doi: 10.1007/978-3-030-59719-1_39
Pascual-Hernández, D., Oyaga de Frutos, N., Mora-Jiménez, I., and Cañas-Plaza, J. M. (2022). Efficient 3d human pose estimation from RGBD sensors. Displays 74:102225. doi: 10.1016/j.displa.2022.102225
Pavllo, D., Feichtenhofer, C., Grangier, D., and Auli, M. (2018). “3D human pose estimation in video with temporal convolutions and semi-supervised training,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. doi: 10.1109/CVPR.2019.00794
Prima, O. D. A., Imabuchi, T., Ono, Y., Murata, Y., Ito, H., and Nishimura, Y. (2019). “Single camera 3d human pose estimation for tele-rehabilitation,” in International Conference on eHealth, Telemedicine, and Social Medicine (eTELEMED) (Athens).
Reich, S., Zhang, D., Kulvicius, T., Bölte, S., Nielsen-Saines, K., Pokorny, F. B., et al. (2021). Novel AI driven approach to classify infant motor functions. Sci. Rep. 11:9888. doi: 10.1038/s41598-021-89347-5
Richards, J. (1999). The measurement of human motion: a comparison of commercially available systems. Hum. Mov. Sci. 18, 589–602. doi: 10.1016/S0167-9457(99)00023-8
Rick, S. R., Bhaskaran, S., Sun, Y., McEwen, S., and Weibel, N. (2019). “Neuropose: geriatric rehabilitation in the home using a webcam and pose estimation,” in Proceedings of the 24th International Conference on Intelligent User Interfaces: Companion (Marina del Ray, CA), 105–106. doi: 10.1145/3308557.3308682
Sakkos, D., Mccay, K. D., Marcroft, C., Embleton, N. D., Chattopadhyay, S., and Ho, E. S. (2021). Identification of abnormal movements in infants: a deep neural network for body part-based prediction of cerebral palsy. IEEE Access 9, 94281–94292. doi: 10.1109/ACCESS.2021.3093469
Salami, F., Brosa, J., Van Drongelen, S., Klotz, M. C., Dreher, T., Wolf, S. I., et al. (2019). Long-term muscle changes after hamstring lengthening in children with bilateral cerebral palsy. Dev. Med. Child Neurol. 61, 791–797. doi: 10.1111/dmcn.14097
Sampieri, A., D'Amely di Melendugno, G. M., Avogaro, A., Cunico, F., Setti, F., Skenderi, G., et al. (2022). “Pose forecasting in industrial human-robot collaboration,” in Computer Vision-ECCV 2022 (Cham: Springer Nature Switzerland), 51–69. doi: 10.1007/978-3-031-19839-7_4
Sarsfield, J., Brown, D., Sherkat, N., Langensiepen, C., Lewis, J., Taheri, M., et al. (2019). Clinical assessment of depth sensor based pose estimation algorithms for technology supervised rehabilitation applications. Int. J. Med. Inform. 121, 30–38. doi: 10.1016/j.ijmedinf.2018.11.001
Sato, K., Nagashima, Y., Mano, T., Iwata, A., and Toda, T. (2019). Quantifying normal and parkinsonian gait features from home movies: practical application of a deep learning-based 2D pose estimator. PLoS One 14:e0223549. doi: 10.1371/journal.pone.0223549
Scott, B., Seyres, M., Philp, F., Chadwick, E. K., and Blana, D. (2022). Healthcare applications of single camera markerless motion capture: a scoping review. PeerJ 10:e13517. doi: 10.7717/peerj.13517
Seethapathi, N., Wang, S., Saluja, R., Blohm, G., and Kording, K. P. (2019). Movement science needs different pose tracking algorithms. arXiv preprint arXiv:1907.10226. doi: 10.48550/arXiv.1907.10226
Serrancolí, G., Bogatikov, P., Huix, J. P., Barberà, A. F., Egea, A. J. S., Ribé, J. T., et al. (2020). Marker-less monitoring protocol to analyze biomechanical joint metrics during pedaling. IEEE Access 8, 122782–122790. doi: 10.1109/ACCESS.2020.3006423
Shin, J. H., Yu, R., Ong, J. N., Lee, C. Y., Jeon, S. H., Park, H., et al. (2021). Quantitative gait analysis using a pose-estimation algorithm with a single 2d-video of Parkinson's disease patients. J. Parkinson's Dis. 11, 1271–1283. doi: 10.3233/JPD-212544
Shotton, J., Fitzgibbon, A., Cook, M., Sharp, T., Finocchio, M., Moore, R., et al. (2011). “Real-time human pose recognition in parts from single depth images,” in CVPR 2011 (Colorado Springs, CO), 1297–1304. doi: 10.1109/CVPR.2011.5995316
Silva, N., Zhang, D., Kulvicius, T., Gail, A., Barreiros, C., Lindstaedt, S., et al. (2021). The future of general movement assessment: the role of computer vision and machine learning-a scoping review. Res. Dev. Disabil. 110:103854. doi: 10.1016/j.ridd.2021.103854
Simo-Serra, E., Quattoni, A., Torras, C., and Moreno-Noguer, F. (2013). “A joint model for 2d and 3d pose estimation from a single image,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (Portland, OR), 3634–3641. doi: 10.1109/CVPR.2013.466
Sokolova, A., and Konushin, A. (2019). Pose-based deep gait recognition. IET Biometr. 8, 134–143. doi: 10.1049/iet-bmt.2018.5046
Srivastav, V., Issenhuth, T., Kadkhodamohammadi, A., de Mathelin, M., Gangi, A., and Padoy, N. (2018). MVOR: a multi-view RGB-D operating room dataset for 2d and 3d human pose estimation. CoRR, abs/1808.08180. doi: 10.48550/arXiv.1808.08180
Stenum, J., Cherry-Allen, K. M., Pyles, C. O., Reetzke, R. D., Vignos, M. F., and Roemmich, R. T. (2021a). Applications of pose estimation in human health and performance across the lifespan. Sensors 21:7315. doi: 10.3390/s21217315
Stenum, J., Rossi, C., and Roemmich, R. T. (2021b). Two-dimensional video-based analysis of human gait using pose estimation. PLoS Comput. Biol. 17:e1008935. doi: 10.1371/journal.pcbi.1008935
Sun, K., Xiao, B., Liu, D., and Wang, J. (2019). “Deep high-resolution representation learning for human pose estimation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (Long Beach, CA), 5693–5703. doi: 10.1109/CVPR.2019.00584
Tao, T., Yang, X., Xu, J., Wang, W., Zhang, S., Li, M., et al. (2020). “Trajectory planning of upper limb rehabilitation robot based on human pose estimation,” in 2020 17th International Conference on Ubiquitous Robots (UR) (Kyoto), 333–338. doi: 10.1109/UR49135.2020.9144771
Theiamarkerless (2023). Available online at: https://www.theiamarkerless.ca/ (accessed January 28, 2023).
Tome, D., Russell, C., and Agapito, L. (2017). “Lifting from the deep: convolutional 3d pose estimation from a single image,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (Honolulu, HI), 2500–2509. doi: 10.1109/CVPR.2017.603
Toshev, A., and Szegedy, C. (2013). Deeppose: human pose estimation via deep neural networks. CoRR, abs/1312.4659. 1653–1660. doi: 10.1109/CVPR.2014.214
Tu, H., Wang, C., and Zeng, W. (2020). “Voxelpose: towards multi-camera 3d human pose estimation in wild environment,” in European Conference on Computer Vision (Glasgow: Springer), 197–212. doi: 10.1007/978-3-030-58452-8_12
Usman, B., Tagliasacchi, A., Saenko, K., and Sud, A. (2022). “Metapose: fast 3d pose from multiple views without 3d supervision,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 6759–6770. doi: 10.1109/CVPR52688.2022.00664
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., et al. (2017). Attention is all you need. CoRR, abs/1706.03762. doi: 10.48550/arXiv.1706.03762
Viswakumar, A., Rajagopalan, V., Ray, T., Gottipati, P., and Parimi, C. (2022). Development of a robust, simple, and affordable human gait analysis system using bottom-up pose estimation with a smartphone camera. Front. Physiol. 12:784865. doi: 10.3389/fphys.2021.784865
Vondrak, M., Sigal, L., and Jenkins, O. C. (2008). “Physical simulation for probabilistic motion tracking,” in 2008 IEEE Conference on Computer Vision and Pattern Recognition (Anchorage, AK), 1–8. doi: 10.1109/CVPR.2008.4587580
Wade, L., Needham, L., McGuigan, P., and Bilzon, J. (2022). Applications and limitations of current markerless motion capture methods for clinical gait biomechanics. PeerJ 10:e12995. doi: 10.7717/peerj.12995
Wandt, B., and Rosenhahn, B. (2019). “RepNet: weakly supervised training of an adversarial reprojection network for 3d human pose estimation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (Anchorage, AK), 7782–7791. doi: 10.1109/CVPR.2019.00797
Wandt, B., Rudolph, M., Zell, P., Rhodin, H., and Rosenhahn, B. (2021). “Canonpose: self-supervised monocular 3D human pose estimation in the wild,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 13294–13304. doi: 10.1109/CVPR46437.2021.01309
Wang, C., Wang, Y., Lin, Z., and Yuille, A. L. (2018). Robust 3D human pose estimation from single images or video sequences. IEEE Trans. Pattern Anal. Mach. Intell. 41, 1227–1241. doi: 10.1109/TPAMI.2018.2828427
Wang, C., Wang, Y., Lin, Z., Yuille, A. L., and Gao, W. (2014). “Robust estimation of 3d human poses from a single image,” in 2014 IEEE Conference on Computer Vision and Pattern Recognition (Columbus, OH), 2369–2376. doi: 10.1109/CVPR.2014.303
Wang, J., Sun, K., Cheng, T., Jiang, B., Deng, C., Zhao, Y., et al. (2019). Deep high-resolution representation learning for visual recognition. CoRR, abs/1908.07919. doi: 10.48550/arXiv.1908.07919
Washabaugh, E. P., Shanmugam, T. A., Ranganathan, R., and Krishnan, C. (2022). Comparing the accuracy of open-source pose estimation methods for measuring gait kinematics. Gait Posture 97, 188–195. doi: 10.1016/j.gaitpost.2022.08.008
Wehrbein, T., Rudolph, M., Rosenhahn, B., and Wandt, B. (2021). “Probabilistic monocular 3D human pose estimation with normalizing flows,” in International Conference on Computer Vision (ICCV) (Montréal, QC). doi: 10.1109/ICCV48922.2021.01101
Wei, X., Min, J., and Chai, J. (2011). Physically valid statistical models for human motion generation. ACM Trans. Graph. 30, 1–10. doi: 10.1145/1966394.1966398
Wu, Q., Xu, G., Wei, F., Kuang, J., Qin, P., Li, Z., and Zhang, S. (2022). Supine infant pose estimation via single depth image. IEEE Trans. Instrument. Measure. 71, 1–11. doi: 10.1109/TIM.2022.3178693
Wu, Q., Xu, G., Zhang, S., Li, Y., and Wei, F. (2020). “Human 3D pose estimation in a lying position by RGB-D images for medical diagnosis and rehabilitation,” in International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC). doi: 10.1109/EMBC44109.2020.9176407
Xu, J., Yu, Z., Ni, B., Yang, J., Yang, X., and Zhang, W. (2020). “Deep kinematics analysis for monocular 3d human pose estimation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). doi: 10.1109/CVPR42600.2020.00098
Xu, L., Jin, S., Liu, W., Qian, C., Ouyang, W., Luo, P., et al. (2022). ZoomNAS: searching for whole-body human pose estimation in the wild. IEEE Trans. Pattern Anal. Mach. Intell. 45, 5296–5313. doi: 10.1109/TPAMI.2022.3197352
Xu, W., Xiang, D., Wang, G., Liao, R., Shao, M., and Li, K. (2022). Multiview video-based 3-d pose estimation of patients in computer-assisted rehabilitation environment (CAREN). IEEE Trans. Hum. Mach. Syst. 52, 196–206. doi: 10.1109/THMS.2022.3142108
Ye, H., Zhu, W., Wang, C., Wu, R., and Wang, Y. (2022). “Faster voxelpose: real-time 3d human pose estimation by orthographic projection,” in Computer Vision-ECCV 2022: 17th European Conference (Tel Aviv: Springer), 142–159. doi: 10.1007/978-3-031-20068-7_9
Zell, P., and Rosenhahn, B. (2015). “A physics-based statistical model for human gait analysis,” in Pattern Recognition, eds J. Gall, P. Gehler, and B. Leibe (Cham: Springer International Publishing), 169–180. doi: 10.1007/978-3-319-24947-6_14
Zell, P., Rosenhahn, B., and Wandt, B. (2020). “Weakly-supervised learning of human dynamics,” in European Conference on Computer Vision (ECCV). doi: 10.1007/978-3-030-58574-7_5
Zeng, W., Jin, S., Liu, W., Qian, C., Luo, P., Ouyang, W., et al. (2022). Not all tokens are equal: human-centric visual analysis via token clustering transformer. New Orleans, LA. doi: 10.1109/CVPR52688.2022.01082
Keywords: human pose estimation (HPE), general movement assessment (GMA), gait analysis, rehabilitation, markerless motion capture, biomedical application, survey
Citation: Avogaro A, Cunico F, Rosenhahn B and Setti F (2023) Markerless human pose estimation for biomedical applications: a survey. Front. Comput. Sci. 5:1153160. doi: 10.3389/fcomp.2023.1153160
Received: 29 January 2023; Accepted: 03 May 2023;
Published: 06 July 2023.
Edited by:
Mohamed Chetouani, Sorbonne Université, FranceReviewed by:
Giacinto Barresi, Italian Institute of Technology (IIT), ItalyCopyright © 2023 Avogaro, Cunico, Rosenhahn and Setti. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Francesco Setti, ZnJhbmNlc2NvLnNldHRpQHVuaXZyLml0
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.