 Radoslaw Niewiadomski
Radoslaw Niewiadomski Merijn Bruijnes
Merijn Bruijnes Gijs Huisman
Gijs Huisman Conor Patrick Gallagher4
Conor Patrick Gallagher4 Maurizio Mancini
Maurizio Mancini- 1Dipartimento di Psicologia e Scienze Cognitive, University of Trento, Rovereto, Italy
- 2School of Governance, Utrecht University, Utrecht, Netherlands
- 3Human-Centered Design, Delft University of Technology, Delft, Netherlands
- 4University College Cork, Cork, Ireland
- 5Department of Computer Science, Sapienza University of Rome, Rome, Italy
Previous research shows that eating together (i.e., commensality) impacts food choice, time spent eating, and enjoyment. Conversely, eating alone is considered a possible cause of unhappiness. In this paper, we conceptually explore how interactive technology might allow for the creation of artificial commensal companions: embodied agents providing company to humans during meals (e.g., a person living in isolation due to health reasons). We operationalize this with the design of our commensal companion: a system based on the MyKeepon robot, paired with a Kinect sensor, able to track the human commensal's activity (i.e., food picking and intake) and able to perform predefined nonverbal behavior in response. In this preliminary study with 10 participants, we investigate whether this autonomous social robot-based system can positively establish an interaction that humans perceive and whether it can influence their food choices. In this study, the participants are asked to taste some chocolates with and without the presence of an artificial commensal companion. The participants are made to believe that the study targets the food experience, whilst the presence of a robot is accidental. Next, we analyze their food choices and feedback regarding the role and social presence of the artificial commensal during the task performance. We conclude the paper by discussing the lessons we learned about the first interactions we observed between a human and a social robot in a commensality setting and by proposing future steps and more complex applications for this novel kind of technology.
1. Introduction
Eating together is a crucial social activity that is often referred to with the word “commensality”, which means “the practice of sharing food and eating together in a social group” (Ochs and Shohet, 2006). Social psychology has shown that being in a commensality setting has several positive impacts. For instance, social eating is more enjoyable than eating alone (Danesi, 2018), food choices are healthier (Fulkerson et al., 2014) and time spent while eating is longer (Bell and Pliner, 2003). Commensality may also strengthen social bonds, e.g., Giacoman (2016) shows that shared meals strengthen the cohesion among the members of a group. At the same time, studies (Yiengprugsawan et al., 2015; Sainsbury, 2018) realized in different parts of the world (UK, Thailand) show that eating meals alone is one of the most important causes of unhappiness. Moreover, it may cause several health consequences such as obesity (Hammons and Fiese, 2011). Despite these research results, current trends in industrialized societies are resulting in reduced commensality. People consciously choose (e.g., by eating in front of the TV) or are forced (e.g., by health reasons) to eat alone. Other examples include the elderly or people living away from family and friends due to work. It is expected that such social isolation may increase in the coming decades, bringing a further decline in commensality (Spence et al., 2019).
The role of interactive technologies in commensality settings is quite ambiguous. On the one hand, they are often seen as a cause of social distraction, for example, the stereotypical picture of a couple using smartphones while eating together. In this line, Dwyer et al. (2018) show that even the presence of the phone on the table during eating may negatively impact the benefits of social interactions. On the other hand, interactive technology (e.g., embodied agents) can also contribute positively to solving specific issues related to food consumption. For example, social robots can be used to motivate people to improve their eating habits or follow a diet (Baroni et al., 2014), or to assist people with physical disabilities in eating (Park et al., 2020). However, technology such as social robots, virtual agents, or chatbots can also be used for entertainment purposes to enable/enhance social interaction and conviviality, and, consequently, increase personal well-being. It can, for instance, become a part of an artistic performance (Breazeal et al., 2003) or a game buddy (Shahid et al., 2014). It is used to address social isolation (Toh et al., 2022), and humans may report a certain sense of attachment, especially to robot companions (Banks et al., 2008). Unfortunately, just a few works use these technologies in a commensality setting. Consequently, it remains unclear whether such technology may be used in an interaction rated positively by human partners, makes the eating experience more enjoyable, and increases the conviviality at the table. In order to address these questions, we introduce and explore a prototype of an interactive Artificial Commensal Companion (ACC): a system in which an embodied artificial agent becomes an active partner during eating, able to interact with a human partner and influence their eating experience. We aim to measure the user's experience with this technology and the ACC's ability to impact human behavior in a commensality scenario. Specifically, in this study, our ACC uses nonverbal behaviors to attempt to influence a person's food choice and perception of the food. By gaining insights into how people respond to such technology, we hope to learn how to develop more advanced artificial social agents in the future whose role at the dining table better fits with that of a human co-diner. Our long-term aims are to build ACCs that can create rated-positively interactions with humans while eating and to replicate with ACCs the benefits of human-human commensality, e.g., to impact on meal duration.
2. Commensality and technology
Nowadays, technology is widely present at the dining table. For instance, people texting with their smartphone while eating, sharing photos of their plates on social media (Ferdous et al., 2016), or even broadcasting themselves while consuming food (Choe, 2019; Anjani et al., 2020). While these technological activities impact social dynamics, other more sophisticated technologies are envisioned to better integrate social factors in food consumption. This is also one of the main interests of the Human-Food Interaction (HFI) research area. This emerging field looks at the intersection of human-technology interaction and (social) food practices (Altarriba Bertran et al., 2019). Niewiadomski et al. (2019) postulate that interactive technology may be used to replicate, emulate, or enable commensality. The idea behind this concept is that, by properly designing and implementing computer interfaces for allowing social interactions around eating activities, we could provide users with the beneficial effects characterizing human commensality in contexts that would otherwise force them to dine alone. While eating together with other people, in particular family members and friends, is something that is easily missed when situations prevent co-dining (e.g., during social distancing measures and lock-downs) and it is difficult to replace, technological solutions could potentially help reduce or mitigate the negative consequences of eating alone. However, Spence et al. (2019) highlight that there is still a “limited extent of research investigating how these approaches deliver the same health/well-being benefits associated with physically dining together with another person/other people.”
One up-and-coming technology in this regard is social robots. In general, social robots emulate human social behaviors to create natural interactions with humans. Such robots may have different physical appearances (humanoid or non-humanoid) and can use a variety of communication modalities (e.g., voice, touch, or movement). They have been applied in various settings and have been shown to affect perceived social presence (Pereira et al., 2014) positively. Moreover, the recent progress in automatic emotion and social signal detection (Hung and Gatica-Perez, 2010; Trigeorgis et al., 2016; Beyan et al., 2021) allow social robots to sense, recognize and adapt their behavior to a human's internal states and, as a consequence, to create a natural multimodal interaction (Belpaeme et al., 2013). However, it is currently not clear how social robots could, or should, fit in social eating settings. In this paper, we see whether social robots may become commensal companions.
3. Artificial commensal companions
An Artificial Commensal Companion (ACC) is a socially intelligent agent (Lugrin et al., 2021), e.g., a virtual agent or social robot designed to interact with humans during meal time. ACCs should be able to act autonomously, considering the social dynamics occurring during a meal in a commensality setting. Niewiadomski et al. (2019) propose a computational commensality scenario, in which “human(s) interact with an artificial companion during meal time. The companion uses sensors and computational models of commensality to guide its behavior toward the human interlocutor.” Ideally, ACC should be able to create interaction rated positively by their human interaction partners. It also means that agents must behave appropriately by considering human behavior and the context, e.g., when their human partners put food in their mouth or are chewing, they should avoid staring at them.
Several attempts have been made to make artificial companions present during meals. Khot et al. (2019) propose a speculative design prototype called FoBo, which aims to create playful and entertaining interactions around a meal. It may “consume” batteries, perform sounds related to eating (e.g., burping and purring), and mimic some human behaviors. Liu and Inoue (2014) propose a virtual eating companion being at the same time an active listener when consuming virtual food. The companion's role is to support the generation of new ideas during meals. Takahashi et al. (2017) develop a virtual co-eating system allowing small talks and conversations related to the food. A preliminary evaluation with five participants shows positive outcomes of using this technology. Weber et al. (2021) propose FoodChattAR—edible anthropomorphic virtual agents, i.e., virtual creatures displayed on top of food. A smartphone is used to scan a QR code and visualize an augmented version of the food, and the human may interact with this version of their food via text or voice. Fujii et al. (2020) propose a system composed of a humanoid robot and a Mixed Reality headset. Humans can see a robot putting food images into its mouth. The evaluation shows that users enjoy their meals more when the robot eats with them than when it only talks without eating. However, none of the previous attempts are specifically designed to study the social interaction between the ACC and the human during mealtime.
Other works exploit virtual agents and/or robots to support eating activity or food preparation, e.g., assistance for physically impaired people. In this line, McColl and Nejat (2013) propose an assistive robot to cognitively stimulate and engage the elderly while eating. Their robot can detect the amount of food intake while interacting with the user, both verbally and non-verbally. Some of the robot utterances are directly related to the eating itself (e.g., encouragements), while the others are aimed at enhancing the interaction (e.g., greetings, telling jokes, laughing). The robot described by Park et al. (2020) deliver food from a bowl to the user's mouth. It automatically estimates the location of food, scoops it and places it inside the user's mouth. More common are systems that monitor and support users in changing their eating habits. For example, in Gardiner et al. (2017), a virtual assistant provides personalized dietary suggestions and health information (e.g., food recipes) to the human user, asking them food-related questions. Pollak et al. (2010) use a mobile virtual pet to send daily reminders on eating habits. Baroni et al. (2014) use a humanoid robot to persuade children to eat more fruit and vegetables. Health-e-Eater by Randall et al. (2018) comprises a sensor-equipped plate and a simple robotic companion, which motivates and educates children during healthy meals. Again, it is essential to notice that the primary aim of all these systems is not related to social interaction but to support commitment to healthier eating.
Building an ACC is an exciting challenge. When designing the behavior of artificial companions to “replace” humans in complex interactive scenarios, the most common approach is replicating human behavior (Castellano et al., 2011). Usually, a large corpus of human-human interactions is collected. Machine learning or other techniques are used to model the companion's behavior using the data of human-human interactions. Such data can be used to generate specific nonverbal behaviors (e.g., to replicate sequences of facial actions or gestures) and appropriate social signals (e.g., for turn-taking, expressing attention, social attitudes, or interpersonal relations). Many examples exist in the literature, for example, laughing interactive virtual agents (Niewiadomski et al., 2013; Mancini et al., 2017) or actively listening virtual characters able to display back-channels to the human speakers (Bevacqua et al., 2010; op den Akker and Bruijnes, 2012).
A similar approach may not be appropriate for ACCs. Let us imagine two humans dining together: they continuously switch their attention between their meal and interlocutor, so their gaze constantly moves from the plate to the other person, and vice-versa. However, ACCs do not need to gaze at their plate (it is not clear yet whether they need one, see our discussion in Section 5.5), and they should neither continuously focus their attention on the (human) interlocutor's face (as looking at someone eating for too long will make the observed person feel uncomfortable) nor on their plate. So, in this case, instead of replicating the human behavior, e.g., by producing generative models using a data-driven approach, as it happens for other interaction types, e.g., Jin et al. (2019), we need to design carefully new interaction models (e.g., using procedural approach) that control behaviors of the agent in the commensal setting and test these models empirically. The user experience should be evaluated to see whether these new interaction models would be acceptable for humans while eating and would not be perceived as inappropriate, unusual, or disturbing during food consumption. In the following sections, we present a fundamental realization of this proposal: a simple ACC interacts nonverbally with an eating human. The interaction is not modeled on actual human data but based on the state machine model designed ad hoc. Next, the user experience and behavior are validated qualitatively and quantitatively.
4. System description
For this work, we utilize a myKeepon, a simple toy robot, which was already exploited for research purposes (Kozima et al., 2009). We decided to use a robot because, in our study, we explore gaze behavior, which is a significant nonverbal behavior in human-human interaction in general (Kleinke, 1986) and, as a consequence, in commensality settings. Usually, the impact of gaze behavior is more accessible to measure in human-robot interactions than, e.g., in human-virtual agent interactions, due to the robot's physical presence (Ruhland et al., 2015). Despite its simple design, the myKeepon robot can be programmed to mimic proper gaze behaviors (i.e., aiming gaze at specific locations in the real world). At the same time, we expect that using a toy robot will reduce users' expectations about what the robot can do and the interaction complexity in general. Consequently, even a limited repertoire of nonverbal behaviors might be acceptable to a human user (Thórisson and Cassell, 1996). Lastly, its pet-like design may elicit positive reactions in participants.
Figure 1 illustrates the system we developed. The user is sitting on a chair facing the robot, and the robot is placed on a dining table with 2 bowls containing food. The bowls are placed at 2 pre-defined positions in the scene: Object 0 is on the left, Object 1 is one the right of the user. As the positions of these two objects are predefined, the robot can “detect” the user's choice of eating from either bowl by tracking the user's hand position.

Figure 1. Technical setup: the participant is seated at a dining table with two bowls with identical chocolates; the robot is placed on the table at an equal distance from the bowls, performing nonverbal behaviors.
In the experimental scenario, both bowls contain the same amount of food. The robot interacts with a human and aims to get participants to eat more from the target bowl through gazing patterns and other nonverbal behavior.
4.1. Robot
The myKeepon robot is not equipped with any sensing ability. To track the human movement, we used a Kinect sensor placed behind the robot (see Section 4.2 for more details). The myKeepon's behavior is controlled via Python code and an Arduino board translating Python commands to I2C signals that the robot's controller can understand. The robot has three degrees of freedom (left/right rotation, front/back, and left/right leaning) and can perform stretching movements up and down. The list of commands for the robot's controller is available on GitHub1. Despite using this relatively simple hardware setup, the system is fully autonomous, and the human operator does not control it (e.g., through a Wizard-of-Oz).
4.2. User detection
The system utilizes a Kinect sensor through the Python pyKinect2 wrapper to track the user's position. Since the user is sitting in front of the robot and there are no other occlusions, tracking the user's head and hands with Kinect should provide good quality data. The wrapper returns a list of body joint names, locations, and confidence scores in [0, 1]. The system detects the 2D position of 3 joints: Head, HandRight and HandLeft.
The robot displays nonverbal feedback to the human (see Section 4.3 for details) whenever the latter picks up some food. These events are detected by determining the distance between the user's hand and the two bowls; for example, if this distance becomes less than a certain threshold, the user picks up food.
4.3. Robot synthesis
A signal planner determines the nonverbal signals to be displayed by the robot depending on the user's tracked behaviors. The planner is based on two components: a Gaze Model and an Emotion Model.
Gaze Model. Gaze is a nonverbal cue with several functions (Ruhland et al., 2015). In our system, the gaze is used to refer to regions, features, and values of interest in the visual field (Tsotsos et al., 1995). In particular, the robot can gaze at different regions of interest: each of the 2 bowls containing food, the user's head, and the user's hands. The gaze signals are generated by the state machine depicted in Figure 2.

Figure 2. Robot's nonverbal signals state machine. T is a time counter set to zero each time a new state is reached. Then, it is compared against 3 thresholds to determine state changes: TTA and TTB are the time thresholds for switching the robot's gaze between the user's dominant hand and the food bowl on which the robot would like to attract the user's attention; TTC is the time threshold for returning from the Happy or Sad state to the Gaze state. D0 is the distance between the user's dominant hand and the food bowl on which the robot would like to attract the user's attention, which is compared against 2 thresholds DTA and DTB, to know when the user has picked some food from the bowl (D0 < DTA) and starts bringing food back to mouth (D0 > DTB). Similarly, D1 is the distance between the user's dominant hand and the other food bowl, which is compared against the same 2 thresholds DTA and DTB, to know, again, when the user has picked some food from the bowl (D0 < DTA) and starts bringing food back to mouth (D0 > DTB). The dashed arrows in the Happy state indicate that one of the two nonverbal signals (jump, head nod) is randomly selected.
The goal of the robot's gaze behavior is to establish and maintain gaze contact with the user and to signal to the user that the robot is interested in the food that is contained in the 2 bowls placed on the table. More in detail, we implemented the command GazeAt(x,y), where (x, y) is the target location, in the robot's view space that must be gazed at by the robot. Assuming that a camera is placed in the same location as the robot's head, the point (0, 0) is the bottom-left corner of the camera field of view, while (1, 1) is the top-right corner. The x coordinate of the target location is reached by rotating the robot on the horizontal plane and by converting rotation values to linear values with the equation:
The same idea is applied to the vertical rotation:
Emotion Model. Emotional feedback can be expressed by robots, even by those with minimal degrees of freedom, as demonstrated by Beck et al. (2012). For our robot, this consists of the nonverbal signals produced by the robot to communicate its emotional state in response to the nonverbal actions of the user (e.g., picking some food from a bowl). Given the limited degrees of freedom of myKeepon, only 2 “broad” classes of emotional feedback are considered: positive feedback (e.g., joy, happiness) and negative feedback (e.g., sadness or disappointment). By producing emotional feedback after the user's action, the robot aims to “cheer on” the user or display disappointment. The emotional display depends on the user's choice of eating from one bowl (i.e., the target one) or another (i.e., the non-target bowl).
The emotion signals are:
• HeadNod- the robot produces a head nod by performing two tilt movements in a row (starting from the centered position), the first one of 25 degrees forward, the second one of 25 degrees backward (going back to the neutral starting position);
• Bow- the robot bows forward by performing one tilt movement, starting from the centered position of 45 degrees forward;
• Jump- the robot can “jump” by compressing and extending its body in the vertical direction, a movement called “pon” by the robot's makers. The jump signal is implemented by a sequence of “pon up” and “pon down” commands (repeated 3 times).
4.4. Interaction
At its core, the robot behavior decision module can be modeled as the state machine illustrated in Figure 2. The robot “gazes” at the user's dominant hand for a specific time, then it “gazes” at the target bowl and returns to gazing at the user's dominant hand. If the user takes one chocolate from the target bowl the robot randomly performs one of two positive emotional feedbacks. However, if the user takes one chocolate from the non-target bowl, the robot makes an “unhappy” sound and does a long “forward bow.”
4.4.1. States
While being in the Gaze state, the robot's gaze continuously shifts between the user's dominant hand, tracked by the Kinect, and the location of Object 0 in the scene, depending on 2 time thresholds TTA and TTB, that were empirically set to 8 and 2 s, respectively. The Happy state (see Figure 2) triggers the generation of two emotional signals of positive emotional feedback: one in which the robot performs some quick up/down movements, and another one in which it nods with its head, both accompanied by cheering sounds. The Sad state (see Figure 2) triggers the generation of an emotional signal of a negative emotional state: the robot bows forward, accompanying the movement with a low-frequency sound.
4.4.2. Transitions
Transitions between the states are conditioned by checking the value of variables T, D0 and D1. Variable T is a timer that is periodically reset to zero to make the robot's gaze shift between the user's hand and Object 0, and to make the robot return from the Happy and Sad states to the Gaze state. Variables D0 and D1 measure the distances between the user's dominant hand and Object 0 and Object 1, respectively. When D0 and D1 become smaller than threshold DTA, the robot changes its state to Happy and Sad, respectively. Since we want to produce emotional feedback only when the user's hand is retracting from one of the two objects, in both states, we keep comparing D0 and D1 with a different threshold DTB, this time to check weather they have become greater than that. The states labeled with emotional signals can be read as in the following example:
which means: “the value of D0 is continuously compared with threshold DTB and, whenever it becomes greater than the threshold, the jump signal is triggered, and the timer T is reset to zero to wait a certain amount of time before transitioning back to the state Gaze.”
5. Preliminary study
In this study, we investigate whether the presence of an interactive ACC is preferred over eating alone; and whether an ACC affects humans while eating, and more specifically, their food choice and food experience. Regarding the first question, according to our knowledge, while some interesting works exist (see Section 3), there are no previous studies evaluating the social acceptance of an artificial companion interacting with a human while eating. Additionally, by answering the second question, we can see whether the ACC's nonverbal behavior may have a tangible impact on its human interaction partner and whether the ACC is not ignored. For these reasons, we qualitatively and quantitatively explore the role of a simple interactive robot able to display certain nonverbal behavior in the context of food consumption. We learn about participants' impressions of the ACC and what directions for research those insights will direct us toward.
5.1. Participants
A convenience sample of participants recruited from the University College Cork was asked to participate in a chocolate testing study. According to the “cover story” presented in writing to the participants, a food company was to launch a new type of chocolate in the coming months. The participants were asked to try and rate the taste of four kinds of chocolates made with slightly different ingredients. They would compare two of these chocolate types at a time by picking chocolates from two bowls in front of them. They would have about 3 min to choose from any of the bowls any number of chocolates they wanted (all instructions are presented in Appendix 1). Before participating in the study, all participants signed the informed consent, allowing them to withdraw from the study at any time. They were also warned about possible food allergens. Importantly, the participants were not informed about the possible presence of a robot during the experiment.
The study took place in a University College Cork building.
5.2. Conditions
The study consists of 2 conditions: a Baseline condition and an Active condition (i.e., with a robot). In the cover story, we did not reference the robot's presence. In the Baseline condition, the robot is not present: the subject is seated alone at a dining table with two bowls in front of them, each containing 10 identical chocolates. The chocolates were a cheaper version of Nestle's Smarties, so they were all equal in shape and size but different in color. In the Active condition, the subject is seated at an identical table with two new bowls in front of them, each containing 10 chocolates of the same type as the ones in the other condition, but this time the robot is placed on the table in front of them, as illustrated in Figure 1. The robot interacts with the human and gives nonverbal feedback, as described in the previous section.
5.3. Data
First, we performed the qualitative evaluation through Interaction Questionnaire. For this purpose, we administered a survey with open-ended questions to determine the participants' impressions on this specific interaction with a robot (R1, R4), opinions on the chocolates (R2-R3), using robots as ACCs in general (R5, R7), possible improvements (R8), and applications of this technology (R9-R10). We also checked whether the cover story was believable and whether the participants suspected the study's real goal (R6). The questionnaire was composed of 10 questions, and participation was not obligatory. Participants filled it in online after the experiment. The open-ended questions were:
• R1. What did you think of the overall experience/setup?
• R2. What did you think about the chocolates?
• R3. Overall, which chocolate was your favorite?
• R4. What was your impression of the robot? (Like/Dislike)
• R5. Did you prefer having a robot companion over no companion at all?
• R6. Did you think the robot had a specific purpose, if so, what did you think it was?
• R7. Would you ever consider a robot as a dinner table companion? Why/Why not?
• R8. What else should the robot be able to do to be more useful for you?
• R9. (Optional) Who could benefit from such a robot companion?
• R10. (Optional) Do you have any other comments to share with us?
Second, the participants were asked to provide detailed impressions of the chocolates and whether they would recommend them or not (Chocolate Evaluation). This questionnaire was used to give credibility to the cover story and check whether the robot influences the participants' perception of the consumed food. The previous works show that other types of interactive technology can, in fact, influence taste and flavor perceptions, e.g., Bruijnes et al. (2016) and Huisman et al. (2016). More specifically, participants were asked to express their opinions about the tasted chocolates in terms of texture (C1 - from soft to hard), taste (C2 - from bad to good), texture in the mouth (C3 - from sticky to smooth, and C4 - solid to melted) as well as the residual sensation (C5 - from “sticky after swallowing” to “not sticky after swallowing”) using 9-point scales. The chocolate evaluation questionnaire was inspired by Lenfant et al. (2013). Additionally, we asked participants whether or not they would recommend the chocolates from each cup (binary answer Yes/No). The participants filled this questionnaire immediately after each condition.
Third, we measured the Chocolate Intake in both conditions by counting, after each trial, the number of remaining chocolates in each bowl. At the beginning of each trial, the same number of chocolates, i.e., ten, was in each bowl.
5.4. Results
5.4.1. Qualitative analysis
Ten students (8 males, 2 females) participated in the study. All of them performed both conditions. Due to external factors (i.e., the COVID-19 outbreak), we could not complete the study, which was initially planned to involve 40 participants testing the two conditions in a different order.
Six persons filled out the questionnaires. Their general impressions were positive (question R1). The participants reported that they enjoyed the experience. Regarding R2, the participants reported that they liked all proposed chocolates. Some of the participants explicitly remarked having difficulties in finding any difference between them, e.g.:
“The chocolates were tasty. In the first round, I thought they tasted similar, but in the second round with the robot, I thought they tasted the same.”
However, when they were asked to express their preference by picking one bowl out of four (question R3), four out of six participants indicated to prefer the chocolates in the target bowl (i.e., the one suggested by the robot).
When responding to question R4, all participants indicated to like the robot. One participant commented on the nature of the robot's behavior:
“I thought it was fun playing with gestures and seeing the robot's reactions, both physically and verbally. The robot also seemed really curious about my actions.”
Two participants mentioned that they appreciated the robot's presence while they were tasting the chocolates, remarking that it was enjoyable and made them feel less alone:
“I liked the robot, made it comfortable to eat as I didn't feel I was all by myself.”
“I liked the robot. He made eating the chocolate more enjoyable.”
When asked whether participants preferred tasting the chocolates alone or with the robot companion (question R5), all participants indicated preferring the tasting in the presence of the robot companion. One participant remarked:
“I preferred the robot companion, it made it less awkward than being alone and eating in public.”
Regarding question R7, a majority of participants (four out of six) responded that they would consider the robot an alternative to eating alone. Participant remarked:
“Yeah, I think it would be a fun experience if the robot was part of a group, but if it was a one-on-one situation I'm not sure if I would enjoy it.”
The other two said:
“I would consider it instead of eating on your own.”
and
“Yes, it made eating alone a lot more enjoyable.”
Participants could also suggest (question R8) how to make the robot more useful. Adding verbal communication was the main suggestion made by participants. For example:
“On the subject of conscious eating it would be cool for the robot to tell you how much you ate, like how many chocolates or how many portions of a meal. It would make people more responsible with regards to over-eating.”
The robot's potential to reduce loneliness was underlined when participants were asked who could benefit from the robot's presence (question R9). Half of the participants suggested that people living alone could benefit from such a companion (the elderly were given as an example). We also asked participants what they thought the robot's purpose was (question R6). Interestingly, only one participant out of six commented that the robot attempted to “force you to pick a certain cup of chocolate.” Half of the participants indicated they thought the robot was their purely for entertainment, e.g.;
“Rough idea about making people laugh while eating was my initial thought.”
Interestingly, one participant thought the robot tried to encourage more mindful eating:
“[...]with someone staring at me it caused me to eat fewer chocolates because I felt like I was being judged or something.”
Finally, one participant thought the robot was there to make participants feel more at ease when eating alone.
To estimate the overall users' impression, we applied a sentiment analysis tool called Vader2 (Hutto and Gilbert, 2014) to the participants' answers. The tool evaluates the emotional valence of the text and provides, for each sentence, positive, neutral, and negative scores. In Figure 3 average scores are reported for questions that focus on the robot (we skipped questions R2 and R3 as they are about chocolate, and R9 and R10 as they were optional). This Figure shows strong numerical supremacy of non-negative scores over negative ones. It means that the comments tend to be positive or neutral. In particular, the highest positive score was obtained for the question R4, which directly evaluates the robot.
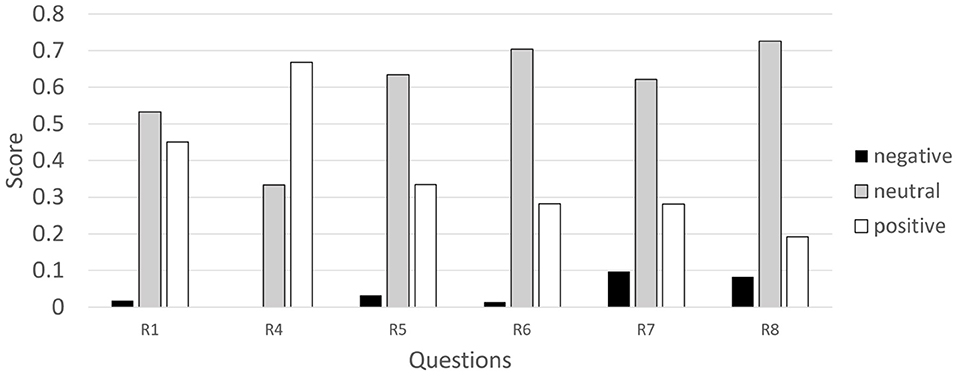
Figure 3. Average values of positive, neutral, and negative scores obtained with sentiment analysis tool for robot-related questions. The scores represent probabilities, so the positive, neutral and negative scores per question always sum to 1. For each question, we report the probability that the corresponding answers have a positive, neutral, or negative affective content.
5.4.2. Quantitative analysis
The Chocolate Evaluation questionnaire was filled by all ten participants. No significant differences were observed in the chocolate evaluation between the four bowls computed with repeated measures ANOVA: F(3, 27) = 0.399, p = 0.76 for C1, F(3, 27) = 0.234, p = 0.87 for C2, F(3, 27) = 1.667, p = 0.72 for C3, F(3, 27) = 0.856, p = 0.48 for C4, and F(3, 27) = 0.683, p = 0.57 for C5. Next, we computed the absolute difference of the C1–C5 scores between the left and right bowls in Baseline and Active conditions, and the results are in Figure 4. The more significant differences would be expected in the Active condition than in the Baseline condition if the robot influenced the perception of some chocolates' features, such as texture. All the results are non significant measured with paired 1-tailed T-test: t(9) = −0.643, p = 0.27 for C1, t(9) = −0.418, p = 0.34 for C2, t(9) = 0.231, p = 0.41 for C3, t(9) = 1.060, p = 0.16 for C4, and t(9) = −0.287, p = 0.39 for C5.
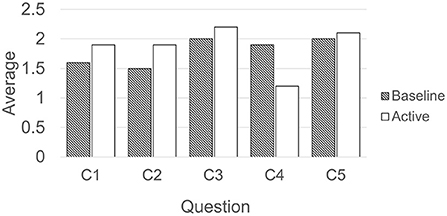
Figure 4. Absolute average differences of the scores C1–C5 given to chocolates places in two bowls per condition.
Regarding the last question of the Chocolate Evaluation questionnaire, in the Active Condition, the same number of participants recommended the chocolates from the target and non-target bowl. These results suggest that the robot behavior did not influence the perception of the chocolates' features. In the first questionnaire, 4 out of 6 participants indicated the target bowl by answering question R3 (which chocolate was your favorite). This may suggest that their preferences do not depend on the specific features of the chocolates (all the chocolates were identical in taste).
Last but not least, we counted the number of chocolates remaining in each of the four bowls (two bowls in the Baseline and two in the Active condition). Next, we computed the averages of the participants. We performed two different statistical analyses of these data. First, the repeated measures ANOVA did not show differences between 4 bowls [F(3, 27) = 0.587, p = 0.629]. Additionally, we counted, per participant and condition, the difference between the number of chocolates that were left in the right and left bowl. Using paired 1-tailed T-test we conclude that there was no significant difference between Baseline and Active conditions [t(9) = 1.049, p = 0.16]. While there is no statistically significant difference between the bowls and conditions, in Baseline Condition, the participants left nearly the same quantity of chocolates in each bowl (left bowl: M = 5.8, SD = 1.31, right bowl: M = 5.9, SD = 0.99). In the Active condition, however, they left fewer chocolates in the target bowl, i.e., the bowl on which the ACC was directing the attention of the user by providing positive feedback; M = 5.3, SD = 2.21), and more in the non-target bowl (M = 6.1, SD = 1.73). The standard deviations are higher in the Active condition, and a few participants left only 1–2 chocolates in the target bowl. The reason for these substantial differences between the participants in the Active condition needs to be better explored in future studies. In total, slightly more chocolates were eaten in the Active condition. Even if this result is not statistically significant, it suggests that the social and interactive artificial companions might affect the intake quantity (similarly to how human commensal companions affect the intake quantity).
5.5. Discussion
Results from our qualitative survey indicate that the presence of an interactive and social robot is preferred over eating alone. At the same time, the subjects would like to have a robot displaying more active social behaviors. They also expressed the desire to have a more interactive, emotive, and expressive robot companion in the future. According to the participants, the robot's presence resulted in a more enjoyable eating experience, indicating that this technology can be helpful to create commensality. The subjects identified the groups of people who would benefit the most from the development of such ACC: the elderly and people who live alone, two of the groups we expect to be most at risk of social isolation, lacking the experience of commensality.
We speculate that the ACC may influence food choices and intake. While previous research showed that artificial agents could, in general, be persuasive (Poggi et al., 2008; Chidambaram et al., 2012), in the particular context of changing the eating habits using robots, they focused mainly on verbal communication, e.g., Baroni et al. (2014), while our work used on the nonverbal communication only. Interestingly, while the participants could not find differences, e.g., in taste or texture, they still showed some preference toward the chocolates suggested by a robot companion. They also ate more chocolates from that bowl.
This study inspires several questions relating to commensality and ACCs. For example, the current implementation uses a toy robot, but it is unknown what is the most appropriate embodiment for an ACC. Does an ACC need to have a human-like appearance or not? On the one hand, a human-like appearance might raise human expectations regarding the communicative and social skills of the robot, eventually evoking the Uncanny valley effect. On the other hand, measuring preferences in the health care context between 1) anthropomorphic, 2) zoomorphic, and 3) mechanomorphic robots, 4) able to speak, 5) generate no-speech sounds, or 6) communicate by written text only, anthropomorphic, and speaking robots were preferred (Klüber and Onnasch, 2022). Importantly, in that study, the robots were not only performing social but also functional tasks, e.g., providing medications, assisting with serving meals, etc. ACCs are mainly social partners; thus, the expectations regarding their embodiment might be different.
Independently from the fact whether the ACCs are human-like or not, it is not clear whether they should simulate the food intake during the interaction. Some preliminary works, in this line, exist that use both virtual agents (Liu and Inoue, 2014) and robots (Fujii et al., 2020), and report interesting results (see Section 3 for details). Unfortunately, the solution proposed in the latter paper requires additional technology (a headset), which makes the experience less natural. However, we believe that to become positively rated social partners, artificial companions do not need to replicate all human behaviors at the table, including food intake.
The other open question related to the “human-likeness” issue, is the use of verbal communication. From our questionnaires, it seems that our participants would prefer to be able to communicate verbally with the artificial companions. Adding the possibility of verbal communication may, however, again potentially raise the participants' expectations regarding this type of technology. The topics of the discussions at the table may vary a lot, which can be a challenge even for the most advanced existing AI systems. Additionally, conversations at the table usually do not have predefined leaders; the partners exchange the roles of speakers and active listeners, and this task is not trivial for AI. Other issues need to be addressed to build more complex and natural interactions. The automatic recognition of commensal activities, i.e., the activities commensal partners perform at the table (such as food intake, speaking, chewing, etc.), is another open challenge. The first datasets (Ceccaldi et al., 2022) and computational models detecting, e.g., chewing and speaking in a video data were only recently proposed (Hossain et al., 2020; Rouast and Adam, 2020). Such models are, however, indispensable to building human-robot verbal interaction in the commensal setting. The robot needs to know when to take the conversation turn and not to interrupt the human speaking, etc. The inappropriate modeling of turn-taking make bring rather negative consequences (ter Maat et al., 2010).
Another question is related to the interaction's aim. When we invite, e.g., a friend at home to eat dinner together, our motivations are, probably, to experience conviviality and make the activity (i.e., eating) more enjoyable (Phull et al., 2015). Even being aware of the health benefits of the commensality (see Section 1 for some examples), we would not prepare dinner for a friend for these reasons. By analogy, we believe the ACCs should, first of all, make the experience more enjoyable and convivial. One of the means to obtain this is to introduce the playfulness (Altarriba Bertran et al., 2019) and humor (Mancini et al., 2017; Shani et al., 2022) to the behavior of the ACCs. In this line, the previous works, e.g., Khot et al. (2019) and Weber et al. (2021), focus on entertainment and new forms of interactions with human partners at the table.
Last but not least, the question of whether a robot or virtual agent provides a more appropriate ACC is relevant. The same interaction scenario discussed in the paper could be applied to a virtual agent (e.g., in an augmented reality setup). The advantage of the interaction model proposed in Figure 2 is that it can be easily implemented on different platforms, permitting cross-platform comparison. Using virtual agents makes it easier to eventually simulate the food intake; on the other hand, physical robots are more persuasive and perceived more positively (Li, 2015). They can enter into physical contact with food, plates, e.g., by passing or taking away food, which creates a possibility for social but also playful interactions.
5.6. Limitations and future works
Several limitations of this work should also be mentioned. The number of participants and the duration of the interaction were limited, and the novelty of the experience could have a positive effect on our participants. It would be essential to repeat the interaction after some time with the same participants (that was impossible due to pandemia). The number of nonverbal behavior displayed by this robot is also limited, which might negatively impact the user's experience if the interaction was longer. The number of “positive” Vs. “negative” behaviors was not balanced, and they were not validated in terms of perceived meaning. Another factor that might influence the agent's perception, which was not considered in this experiment, is the type of food consumed. Some types of food may require more attention (e.g., fish, some sauces), and in such cases, the robot's behavior might be perceived as distractive. Moreover, the type of food used in this experiment, i.e., chocolates, could create a bias and positively influence the perception of the interaction and robot, as chocolates are usually liked by most humans. Thus, other-taste food (e.g., sour, acid) or food of neutral taste should added in a form of additional experimental conditions in the future. Finally, the within-subject design used in this study also has some limitations. The participants performed two conditions on the same day. Even if the task in both conditions was the same, after consuming some chocolates in the first condition, the participants might not be willing to consume as many chocolates in the second condition, e.g., because they believed that they ate them too much at once. Thus, we recommend splitting the conditions into two or more days.
In future works, alternative interaction models should be tested using the same robot platform and questionnaires to see whether the model described in Figure 2 is optimal or can be improved. The other extensions of the current setup regard the interaction with food. A more advanced robot could be used to perform social signals, e.g., by passing (or refusing to pass) the food to the human interaction partners. Last but not least, our participants agree that this technology could benefit the elderly and lonely people. Thus, future validations could be performed directly on these sub-populations. It might be fascinating to test it with a specific category of older adults keen to use new technologies.
6. Conclusions
In this paper, we advocate for the creation of Artificial Commensal Companions, i.e., embodied systems able to create positively-perceived social interactions with eating humans. Such agents should be, first of all, social actors that make the eating experience more enjoyable and convivial. Their role is not assistance (e.g., feeding) or therapy (e.g., diet control). In other words, the ACCs are, instead, convivial partners than digital nurses or virtual coaches. We also proposed implementing this idea—a system composed of a programmable toy robot and a Kinect camera that can communicate nonverbally with the human partner. Our ACC can simulate gaze and produce emotional feedback responses based on the user's actions.
We analyzed the impressions of first users of this technology and drew several interesting conclusions. The positive reaction of the participants to the Active condition indicates that most individuals are comfortable with the idea of eating with an ACC in place of or in addition to eating with others in a commensality setting. At the same time, we cannot show that the robot has a significant impact on the food intake, and experiments with more participants are needed to address this issue. The limitations of the current setup were also indicated, including the limited communicative skills of the robot. Finally, the idea of using a food tasting scenario as a cover story to study the human attitudes toward ACC seems successful. Thus we plan to reuse it in future experiments.
We believe that there is excellent potential for ACC technology. For example, soon, such systems could make repetitive meals (e.g., in a hospital setting) more enjoyable or used by persons who, due to some social phobias, e.g., Ruch et al. (2014), avoid social interactions. However, some risks may also be associated with introducing ACCs at the dining table. Like other media, ACCs might distract eating humans, contributing to mindless eating and increasing unwanted calorie intake. ACCs, especially when poorly designed, could disrupt social interactions that already exist during commensal settings, reducing any positive effects in such settings. All these factors should be carefully analyzed in future works.
We see the work presented in this paper as a first step toward ACCs. Our work provides some suggestions on how to build better ACCs. We hope it will foster further research into the potential benefits and risks of ACCs.
Data availability statement
The data supporting this study's findings are available from the author, Maurizio Mancini, upon request.
Ethics statement
Ethical review and approval was not required for the study on human participants in accordance with the local legislation and institutional requirements. The patients/participants provided their written informed consent to participate in this study.
Author contributions
MM and CPG built the system and performed the data collection. RN conducted the data analysis and discussion of the results. All authors participated in the system design, study design, and paper writing. All authors contributed to the article and approved the submitted version.
Funding
This study was supported by a grant from the Italian Ministry of University and Research (Excellence Department Grant awarded to the Department of Psychology and Cognitive Science, University of Trento, Italy).
Acknowledgments
The content of this manuscript has been presented in part at the 4th Workshop on Multisensory Approaches to Human-Food Interaction (MFHI'20) organized in conjunction with the 22nd ACM International Conference on Multimodal Interaction, and in Extended Abstracts of the 2020 CHI Conference on Human Factors in Computing Systems (CHI'20) (Gallagher et al., 2020; Mancini et al., 2020).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fcomp.2022.909844/full#supplementary-material
Footnotes
References
Altarriba Bertran, F., Jhaveri, S., Lutz, R., Isbister, K., and Wilde, D. (2019). “Making sense of human-food interaction,” in Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems (Glasglow), 1–13.
Altarriba Bertran, F., Wilde, D., Berezvay, E., and Isbister, K. (2019). “Playful human-food interaction research: state of the art and future directions,” in Proceedings of the Annual Symposium on Computer-Human Interaction in Play, CHI PLAY '19 (New York, NY: Association for Computing Machinery), 225–237.
Anjani, L., Mok, T., Tang, A., Oehlberg, L., and Goh, W. B. (2020). Why Do People Watch Others Eat Food? An Empirical Study on the Motivations and Practices of Mukbang Viewers. New York, NY: Association for Computing Machinery.
Banks, M. R., Willoughby, L. M., and Banks, W. A. (2008). Animal-assisted therapy and loneliness in nursing homes: use of robotic versus living dogs. J. Am. Med. Dir. Assoc. 9, 173–177. doi: 10.1016/j.jamda.2007.11.007
Baroni, I., Nalin, M., Zelati, M. C., Oleari, E., and Sanna, A. (2014). “Designing motivational robot: how robots might motivate children to eat fruits and vegetables,” in The 23rd IEEE International Symposium on Robot and Human Interactive Communication (Edinburgh, UK: IEEE), 796–801.
Beck, A., Stevens, B., Bard, K. A., and Ca namero, L. (2012). Emotional body language displayed by artificial agents. ACM Trans. Interact. Intell. Syst. 2, 2. doi: 10.1145/2133366.2133368
Bell, R., and Pliner, P. L. (2003). Time to eat: the relationship between the number of people eating and meal duration in three lunch settings. Appetite 41, 215–218. doi: 10.1016/S0195-6663(03)00109-0
Belpaeme, T., Baxter, P., Read, R., Wood, R., Cuayáhuitl, H., Kiefer, B., et al. (2013). Multimodal child-robot interaction: building social bonds. J. Hum. Robot Interact. 1, 33–53. doi: 10.5898/JHRI.1.2.Belpaeme
Bevacqua, E., Pammi, S., Hyniewska, S. J., Schröder, M., and Pelachaud, C. (2010). “Multimodal backchannels for embodied conversational agents,” in Intelligent Virtual Agents, eds J. Allbeck, N. Badler, T. Bickmore, C. Pelachaud, and A. Safonova (Berlin; Heidelberg: Springer Berlin Heidelberg), 194–200.
Beyan, C., Karumuri, S., Volpe, G., Camurri, A., and Niewiadomski, R. (2021). Modeling multiple temporal scales of full-body movements for emotion classification. IEEE Trans. Affect. Comput. doi: 10.1109/TAFFC.2021.3095425
Breazeal, C., Brooks, A., Gray, J., Hancher, M., Kidd, C., McBean, J., et al. (2003). “Interactive robot theatre,” in Proceedings 2003 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2003) (Cat. No.03CH37453), Vol. 4 (Las Vegas, NV: IEEE), 3648–3655.
Bruijnes, M., Huisman, G., and Heylen, D. (2016). “Tasty tech: human-food interaction and multimodal interfaces,” in Proceedings of the 1st Workshop on Multi-sensorial Approaches to Human-Food Interaction, (Tokyo), 1–6.
Castellano, G., Mancini, M., Peters, C., and McOwan, P. W. (2011). Expressive copying behavior for social agents: a perceptual analysis. IEEE Trans. Syst. Man Cybern. A Syst. Hum. 42, 776–783. doi: 10.1109/TSMCA.2011.2172415
Ceccaldi, E., De Lucia, G., Niewiadomski, R., Volpe, G., and Mancini, M. (2022). “Social interaction data-sets in the age of covid-19: A case study on digital commensality,” in Proceedings of the 2022 International Conference on Advanced Visual Interfaces (AVI 2022) (New York, NY: Association for Computing Machinery), 1–5. doi: 10.1145/3531073.3531176
Chidambaram, V., Chiang, Y., and Mutlu, B. (2012). “Designing persuasive robots: how robots might persuade people using vocal and nonverbal cues,” in 2012 7th ACM/IEEE International Conference on Human-Robot Interaction (HRI) (Boston, MA: IEEE), 293–300.
Choe, H. (2019). Eating together multimodally: collaborative eating in mukbang, a korean livestream of eating. Lang. Soc. 48, 171–208. doi: 10.1017/S0047404518001355
Danesi, G. (2018). A cross-cultural approach to eating together: practices of commensality among french, german and spanish young adults. Soc. Sci. Inf. 57, 99–120. doi: 10.1177/0539018417744680
Dwyer, R. J., Kushlev, K., and Dunn, E. W. (2018). Smartphone use undermines enjoyment of face-to-face social interactions. J. Exp. Soc. Psychol. 78:233–239. doi: 10.1016/j.jesp.2017.10.007
Ferdous, H. S., Ploderer, B., Davis, H., Vetere, F., and O'hara, K. (2016). Commensality and the social use of technology during family mealtime. ACM Trans. Comput. Hum. Interact. 23, 1–26. doi: 10.1145/2994146
Fujii, A., Kochigami, K., Kitagawa, S., Okada, K., and Inaba, M. (2020). “Development and evaluation of mixed reality co-eating system: Sharing the behavior of eating food with a robot could improve our dining experience,” in 2020 29th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN) (Naples: IEEE), 357–362.
Fulkerson, J. A., Larson, N., Horning, M., and Neumark-Sztainer, D. (2014). A review of associations between family or shared meal frequency and dietary and weight status outcomes across the lifespan. J. Nutr. Educ. Behav. 46, 2–19. doi: 10.1016/j.jneb.2013.07.012
Gallagher, C. P., Niewiadomski, R., Bruijnes, V., Huisman, G., and Mancini, M. (2020). “Eating with an Artificial Commensal Companion,” in Companion Publication of the 2020 International Conference on Multimodal Interaction (ICMI '20 Companion) (New York, NY: Association for Computing Machinery), 312–316. doi: 10.1145/3395035.3425648
Gardiner, P. M., McCue, K. D., Negash, L. M., Cheng, T., White, L. F., Yinusa-Nyahkoon, L., et al. (2017). Engaging women with an embodied conversational agent to deliver mindfulness and lifestyle recommendations: a feasibility randomized control trial. Patient Educ. Couns. 100, 1720–1729. doi: 10.1016/j.pec.2017.04.015
Giacoman, C. (2016). The dimensions and role of commensality: a theoretical model drawn from the significance of communal eating among adults in santiago, chile. Appetite 107, 460–470. doi: 10.1016/j.appet.2016.08.116
Hammons, A. J., and Fiese, B. H. (2011). Is frequency of shared family meals related to the nutritional health of children and adolescents? Pediatrics 127, e1565-e1574. doi: 10.1542/peds.2010-1440
Hossain, D., Ghosh, T., and Sazonov, E. (2020). Automatic count of bites and chews from videos of eating episodes. IEEE Access 8, 101934–101945. doi: 10.1109/ACCESS.2020.2998716
Huisman, G., Bruijnes, M., and Heylen, D. K. (2016). “A moving feast: effects of color, shape and animation on taste associations and taste perceptions,” in Proceedings of the 13th International Conference on Advances in Computer Entertainment Technology, (Osaka), 1–12.
Hung, H., and Gatica-Perez, D. (2010). Estimating cohesion in small groups using audio-visual nonverbal behavior. IEEE Trans. Multimedia 12, 563–575. doi: 10.1109/TMM.2010.2055233
Hutto, C., and Gilbert, E. (2014). Vader: a parsimonious rule-based model for sentiment analysis of social media text. Proc. Int. AAAI Conf. Web Soc. Media 8, 216–225.
Jin, A., Deng, Q., Zhang, Y., and Deng, Z. (2019). “A deep learning-based model for head and eye motion generation in three-party conversations,” in Proceedings of the ACM in Computer Graphics and Interactive Techniques, Vol. 2.
Khot, R. A., Arza, E. S., Kurra, H., and Wang, Y. (2019). “Fobo: towards designing a robotic companion for solo dining,” in Extended Abstracts of the 2019 CHI Conference on Human Factors in Computing Systems, CHI EA '19 (New York, NY: ACM), LBW1617:1-LBW1617:6.
Kleinke, C. L. (1986). Gaze and eye contact: a research review. Psychol. Bull. 100, 78. doi: 10.1037/0033-2909.100.1.78
Klüber, K., and Onnasch, L. (2022). Appearance is not everything - preferred feature combinations for care robots. Comput. Human Behav. 128, 107128. doi: 10.1016/j.chb.2021.107128
Kozima, H., Michalowski, M. P., and Nakagawa, C. (2009). Keepon. Int. J. Soc. Robot. 1, 3–18. doi: 10.1007/s12369-008-0009-8
Lenfant, F., Hartmann, C., Watzke, B., Breton, O., Loret, C., and Martin, N. (2013). Impact of the shape on sensory properties of individual dark chocolate pieces. LWT Food Sci. Technol. 51, 545–552. doi: 10.1016/j.lwt.2012.11.001
Li, J. (2015). The benefit of being physically present: a survey of experimental works comparing copresent robots, telepresent robots and virtual agents. Int. J. Hum. Comput. Stud. 77, 23–37. doi: 10.1016/j.ijhcs.2015.01.001
Liu, R., and Inoue, T. (2014). “Application of an anthropomorphic dining agent to idea generation,” in Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing: Adjunct Publication, UbiComp '14 Adjunct (New York, NY: ACM), 607–612.
Lugrin, B., Pelachaud, C., and Traum, D. (Eds.). (2021). The Handbook on Socially Interactive Agents: 20 Years of Research on Embodied Conversational Agents, Intelligent Virtual Agents, and Social Robotics Volume 1: Methods, Behavior, Cognition, Vol. 37, 1st Edn. New York, NY: Association for Computing Machinery.
Mancini, M., Biancardi, B., Pecune, F., Varni, G., Ding, Y., Pelachaud, C., et al. (2017). Implementing and evaluating a laughing virtual character. ACM Trans. Internet Technol. 17, 3. doi: 10.1145/2998571
Mancini, M., Niewiadomski, R., Huisman, G., Bruijnes, M., and Gallagher, C. P. (2020). “Room for one more? - Introducing Artificial Commensal Companions,” in Extended Abstracts of the 2020 CHI Conference on Human Factors in Computing Systems (CHI EA '20) (New York, NY: Association for Computing Machinery), 1–8. doi: 10.1145/3334480.3383027
McColl, D., and Nejat, G. (2013). Meal-time with a socially assistive robot and older adults at a long-term care facility. J. Hum. Robot Interact. 2, 152–171. doi: 10.5898/JHRI.2.1.McColl
Niewiadomski, R., Ceccaldi, E., Huisman, G., Volpe, G., and Mancini, M. (2019). Computational commensality: from theories to computational models for social food preparation and consumption in hci. Front. Robot. AI 6, 1–19. doi: 10.3389/frobt.2019.00119
Niewiadomski, R., Hofmann, J., Urbain, J., Platt, T., Wagner, J., Piot, B., et al. (2013). “Laugh-aware virtual agent and its impact on user amusement,” in Proceedings of the 2013 International Conference on Autonomous Agents and Multi-agent Systems, (St. Paul, MN), 619–626.
Ochs, E., and Shohet, M. (2006). The cultural structuring of mealtime socialization. New Dir. Child Adolesc. Dev. 2006, 35–49. doi: 10.1002/cd.154
op den Akker, R., and Bruijnes, M. (2012). “Computational models of social and emotional turn-taking for embodied conversational agents: a review,” in University of Twente, Centre for Telematics and Information Technology (Enschede: CTIT). TR-CTIT-12–13.
Park, D., Hoshi, Y., Mahajan, H. P., Kim, H. K., Erickson, Z., Rogers, W. A., et al. (2020). Active robot-assisted feeding with a general-purpose mobile manipulator: design, evaluation, and lessons learned. Rob. Auton. Syst. 124:103344. doi: 10.1016/j.robot.2019.103344
Pereira, A., Prada, R., and Paiva, A. (2014). “Improving social presence in human-agent interaction,” in Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (Toronto, ON). 1449–1458.
Phull, S., Wills, W., and Dickinson, A. (2015). Is it a pleasure to eat together? theoretical reflections on conviviality and the mediterranean diet. Sociol. Compass 9, 977–986. doi: 10.1111/soc4.12307
Poggi, I., Niewiadomski, R., and Pelachaud, C. (2008). “Facial deception in humans and ecas,” in Modeling Communication with Robots and Virtual Humans, volume 4930 of Lecture Notes in Computer Science, eds I. Wachsmuth and G. Knoblich (Berlin; Heidelberg: Springer Berlin Heidelberg), 198–221.
Pollak, J., Gay, G., Byrne, S., Wagner, E., Retelny, D., and Humphreys, L. (2010). It's time to eat! Using mobile games to promote healthy eating. IEEE Pervasive Comput. 9, 21–27. doi: 10.1109/MPRV.2010.41
Randall, N., Joshi, S., and Liu, X. (2018). “Health-e-eater: dinnertime companion robot and magic plate for improving eating habits in children from low-income families,” in Companion of the 2018 ACM/IEEE International Conference on Human-Robot Interaction (New York, NY: Association for Computing Machinery), 361–362.
Rouast, P. V., and Adam, M. T. P. (2020). Learning deep representations for video-based intake gesture detection. IEEE J. Biomed. Health Inform. 24, 1727–1737. doi: 10.1109/JBHI.2019.2942845
Ruch, W. F., Platt, T., Hofmann, J., Niewiadomski, R., Urbain, J., Mancini, M., et al. (2014). Gelotophobia and the challenges of implementing laughter into virtual agents interactions. Front. Human Neurosci. 8, 928. doi: 10.3389/fnhum.2014.00928
Ruhland, K., Peters, C. E., Andrist, S., Badler, J. B., Badler, N. I., Gleicher, M., et al. (2015). A review of eye gaze in virtual agents, social robotics and hci: behaviour generation, user interaction and perception. Comput. Graph. Forum 34, 299–326. doi: 10.1111/cgf.12603
Sainsbury (2018). The Sainsbury's Living Well Index. Available online at: https://www.about.sainsburys.co.uk//media/Files/S/Sainsburys/living-well-index/sainsburys-living-well-index-may-2018.pdf (accessed January 26, 2022).
Shahid, S., Krahmer, E., and Swerts, M. (2014). Child-robot interaction across cultures: How does playing a game with a social robot compare to playing a game alone or with a friend? Comput. Human Behav. 40:86–100. doi: 10.1016/j.chb.2014.07.043
Shani, C., Libov, A., Tolmach, S., Lewin-Eytan, L., Maarek, Y., and Shahaf, D. (2022). “alexa, do you want to build a snowman?” characterizing playful requests to conversational agents,” in CHI Conference on Human Factors in Computing Systems Extended Abstracts, CHI EA '22 (New York, NY: Association for Computing Machinery).
Spence, C., Mancini, M., and Huisman, G. (2019). Digital commensality: eating and drinking in the company of technology. Front. Psychol. 10, 2252. doi: 10.3389/fpsyg.2019.02252
Takahashi, M., Tanaka, H., Yamana, H., and Nakajima, T. (2017). “Virtual co-eating: making solitary eating experience more enjoyable,” in Entertainment Computing-ICEC 2017, eds N. Munekata, I. Kunita, and J. Hoshino (Cham: Springer International Publishing), 460–464.
ter Maat, M., Truong, K. P., and Heylen, D. (2010). “How turn-taking strategies influence users' impressions of an agent,” in Intelligent Virtual Agents, eds J. Allbeck, N. Badler, T. Bickmore, C. Pelachaud, and A. Safonova (Berlin; Heidelberg: Springer Berlin Heidelberg), 441–453.
Thórisson, K. R., and Cassell, J. (1996). Why put an agent in a human body: the importance of communicative feedback in human-humanoid dialogue. Proc. Lifelike Comput. Charact. 96, 44–45.
Toh, G., Pearce, E., Vines, J., Ikhtabi, S., Birken, M., Pitman, A., et al. (2022). Digital interventions for subjective and objective social isolation among individuals with mental health conditions: a scoping review. BMC Psychiatry 22, 331. doi: 10.1186/s12888-022-03889-0
Trigeorgis, G., Ringeval, F., Brueckner, R., Marchi, E., Nicolaou, M. A., Schuller, B., et al. (2016). “Adieu features? end-to-end speech emotion recognition using a deep convolutional recurrent network,” in 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (Shanghai: IEEE), 5200–5204.
Tsotsos, J. K., Culhane, S. M., Wai, W. Y. K., Lai, Y., Davis, N., and Nuflo, F. (1995). Modeling visual attention via selective tuning. Artif. Intell. 78, 507–545. doi: 10.1016/0004-3702(95)00025-9
Weber, P., Krings, K., Nießner, J., Brodesser, S., and Ludwig, T. (2021). Foodchattar: Exploring the Design Space of Edible Virtual Agents for Human-Food Interaction. DIS '21. New York, NY: Association for Computing Machinery.
Keywords: computational commensality, social robot, artificial companion, nonverbal interaction, commensality
Citation: Niewiadomski R, Bruijnes M, Huisman G, Gallagher CP and Mancini M (2022) Social robots as eating companions. Front. Comput. Sci. 4:909844. doi: 10.3389/fcomp.2022.909844
Received: 31 March 2022; Accepted: 22 July 2022;
Published: 31 August 2022.
Edited by:
Elvira Popescu, University of Craiova, RomaniaReviewed by:
Luigi Laura, Università Telematica Internazionale Uninettuno, ItalyFrancisco Barbosa Escobar, Aarhus University, Denmark
Copyright © 2022 Niewiadomski, Bruijnes, Huisman, Gallagher and Mancini. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Radoslaw Niewiadomski, ci5uaWV3aWFkb21za2lAdW5pdG4uaXQ=