 Kuo-Yang Huang
Kuo-Yang Huang Ching-Hsiung Lin
Ching-Hsiung Lin Shu-Hua Chi4
Shu-Hua Chi4 Ying-Lin Hsu
Ying-Lin Hsu Jia-Lang Xu
Jia-Lang Xu- 1Division of Chest Medicine, Department of Internal Medicine, Changhua Christian Hospital, Changhua, Taiwan
- 2Institute of Genomics and Bioinformatics, National Chung Hsing University, Taichung, Taiwan
- 3Ph.D. Program in Medical Biotechnology, National Chung Hsing University, Taichung, Taiwan
- 4Respiratory Therapy Section for Adult, Changhua Christian Hospital, Changhua, Taiwan
- 5Department of Applied Mathematics, Institute of Statistics, National Chung Hsing University, Taichung, Taiwan
- 6Department of Computer Science and Information Engineering, Chaoyang University of Technology, Taichung, Taiwan
Background: The success and failure of extubation of patients with acute respiratory failure is a very important issue for clinicians, and the failure of the ventilator often leads to possible complications, which in turn leads to a lot of doubts about the medical treatment in the minds of the people, so in order to increase the success of extubation success of the doctors to prevent the possible complications, the present study compared different time series algorithms and different activation functions for the training and prediction of extubation success or failure models.
Methods: This study compared different time series algorithms and different activation functions for training and predicting the success or failure of the extubation model.
Results: The results of this study using four validation methods show that the GRU model and Tanh’s model have a better predictive model for predicting the success or failure of the extubation and better predictive result of 94.44% can be obtained using Holdout cross-validation validation method.
Conclusion: This study proposes a prediction method using GRU on the topic of extubation, and it can provide the doctors with the clinical application of extubation to give advice for reference.
1 Introduction
With the aging of the population and the continuous improvement of medical technology, the number of patients requiring mechanical ventilation is gradually increasing (Criner, 2012). In the United States, there is an analysis of ICU occupancy and utilization and it was found that there is sufficient capacity to care for the patients (Wunsch et al., 2013), and the daily cost of patients requiring mechanical ventilation is as high as US$2,278 (Cooper and Linde-Zwirble, 2004).
In Taiwan, the number of patients requiring mechanical ventilation is increasing which will also lead to an increase in healthcare costs (Cheng et al., 2008). Therefore, the National Health Insurance Board (NHIB) has established a requirement for patients in respiratory care to be transferred to a respiratory care center after 21 days in the ICU and to a respiratory care unit after 42 days in the respiratory care center. Only a minority of patients admitted to a respiratory care unit can be extubated and discharged from the hospital (Hui et al., 2010), and only half of the patients in respiratory care centers can be extubated (Cheng et al., 2007), while one-third of patients in ICUs are mechanically ventilated (Cohen et al., 2019), and 10–20% of extubated patients may need to be reintubated, which is associated with a six-fold mortality rate (Tobin, 2001).
Rapid Shallow Breathing Index (RSBI) is an important indicator of extubation, and RSBI is usually measured at the beginning of the Spontaneous Breathing Trial (SBT), and RSBI at the completion of the SBT can be an effective predictor of extubation (Kuo et al., 2006), and the Convolutional Nerve Network (CNN) can be utilized in the off-respirator with clinical significance and appropriate features to achieve good results (Jia et al., 2021).
In this study, we used every second data available on the ventilator (including: Vte, RR, Ppeak, Pmean, PEEP, FiO2) to advise the doctor when the patient is ready to be extubated, and the LSTM can be used to effectively determine the patient’s advice on the success or failure of extubation.
The remainder of this article is as follows: Section 2 reviews the literature on deep learning about RNN, LSTM and GRU and. Section 3 introduces the proposed research framework and methods. Section 4 discusses research results and performance evaluation. Section 5 is discussion. Section 6 is conclusion.
2 Related work
2.1 Deep learning
2.1.1 Recurrent neural networks
Recurrent neural networks (RNN) is a way of cycling the state of the self through its own network, and the method allows the transmitted message to survive and be input in the structure of the time series, while RNNs are elusive in terms of long term memory effects, often due to gradient disappearance leading to the long term meaning to be affected by the short term memory. RNN models are often used in many medical fields such as snoring and non-snoring prediction (Arsenali et al., 2018), hemoglobin values in end-stage renal patients (Lobo et al., 2020), and septic symptoms prediction (Scherpf et al., 2019). All of them can be predicted using RNN modeling with good results. The main formulas of the model of RNN are shown in (1, 2), and the architecture is shown in Figure 1.
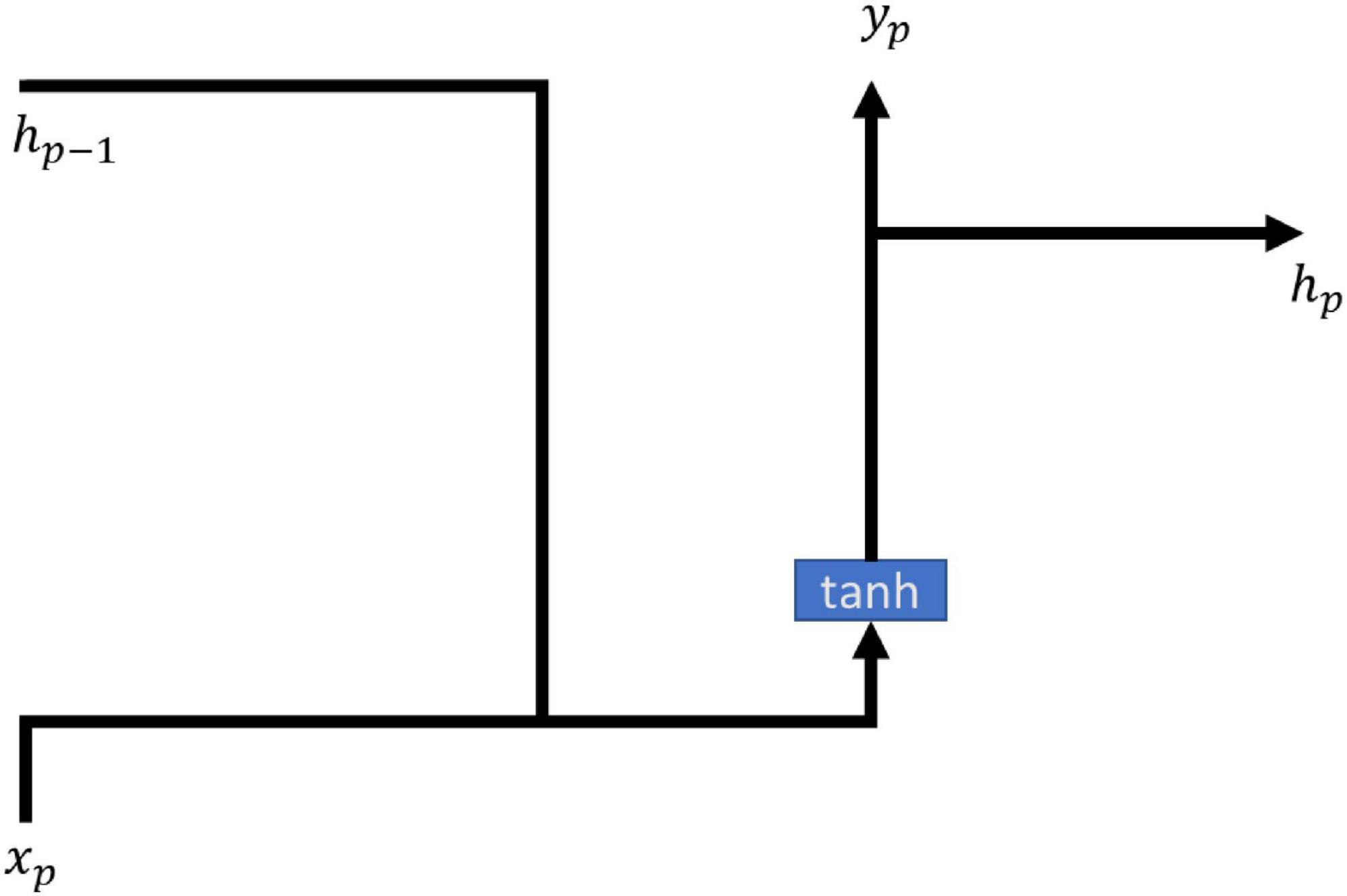
Figure 1. RNN architecture.
2.1.2 Long short-term memory
Long short-term memory (LSTM) is a model derived from recurrent neural networks (RNN) mainly to improve the RNN memory problem, so LSTM is composed of three control valves: input valve, forgetting valve, and output valve (Hochreiter and Schmidhuber, 1997), and the LSTM model together with the dropout and l2 regularization techniques and Adam’s optimizer can achieve good diagnosis and grading in the diagnosis and severity of Parkinson’s disease (Balaji et al., 2021). The LSTM model with dropout and l2 normalization techniques and Adam’s optimizer can achieve good diagnosis and severity rating of Parkinson’s disease (Balaji et al., 2021). The number of cases and deaths in the current COVID epidemic can be predicted using LSTM model with migration learning and single or multi-step approach with good results in several countries (Gautam, 2021). Malaria is usually prevalent in subtropical countries and LSTM models can be applied to geographic location, satellite data and clinical data to achieve good prediction results (Santosh et al., 2020). Mechanical ventilation is one of the life-saving tools to help support the organs of patients with respiratory failure and improper delivery of tidal volume will lead to an increase in mortality, LSTM can achieve a level of accuracy in the prediction of tidal volume in the body (Hagan et al., 2020). The main formulas of the model of LSTM are shown in (3–8), and the architecture is shown in Figure 2.
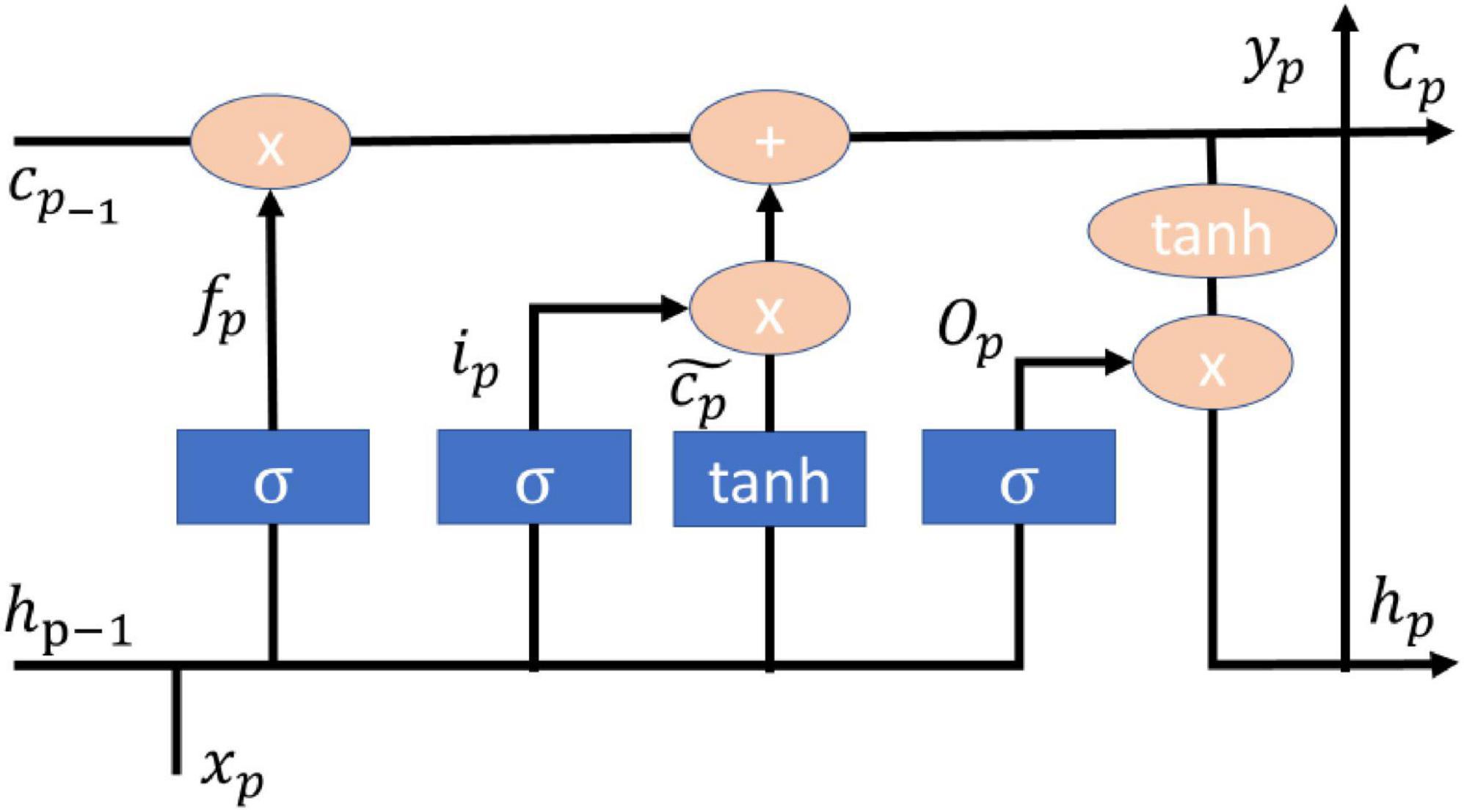
Figure 2. LSTM architecture.
fp is the forget valve, ip is the input valve, Op is the output valve, is the memory cell candidate. hp–1 is the current output value, xp is the input value. wi,wc,wo,wf and bi,bc,bo,bf are the weight matrix and bias vector, respectively. Cp is the storage unit. σ is Sigmoid activation function.
2.1.3 Gated recurrent unit
Gated recurrent unit (GRU) is a method proposed by Cho (2014), which can outperform the LSTM model in terms of CPU convergence time as well as parameter updating (Chung et al., 2014), and has been utilized by scholars in many fields such as heart failure (Gao et al., 2020), simulation of accidents at signalized intersections (Zhang et al., 2020), heartbeat detection of heartbeat signals (Hai et al., 2020). heartbeat detection with graphical signals (Hai et al., 2020) have been studied by scholars utilizing the GRU approach. GRU is an update gate used to replace the forget gate and input gate in LSTM, and then cell state and ht are merged, and the computation of GRU is also different than LSTM. The main formulas of GRU model are shown in (9–12), and the architecture is shown in Figure 3.
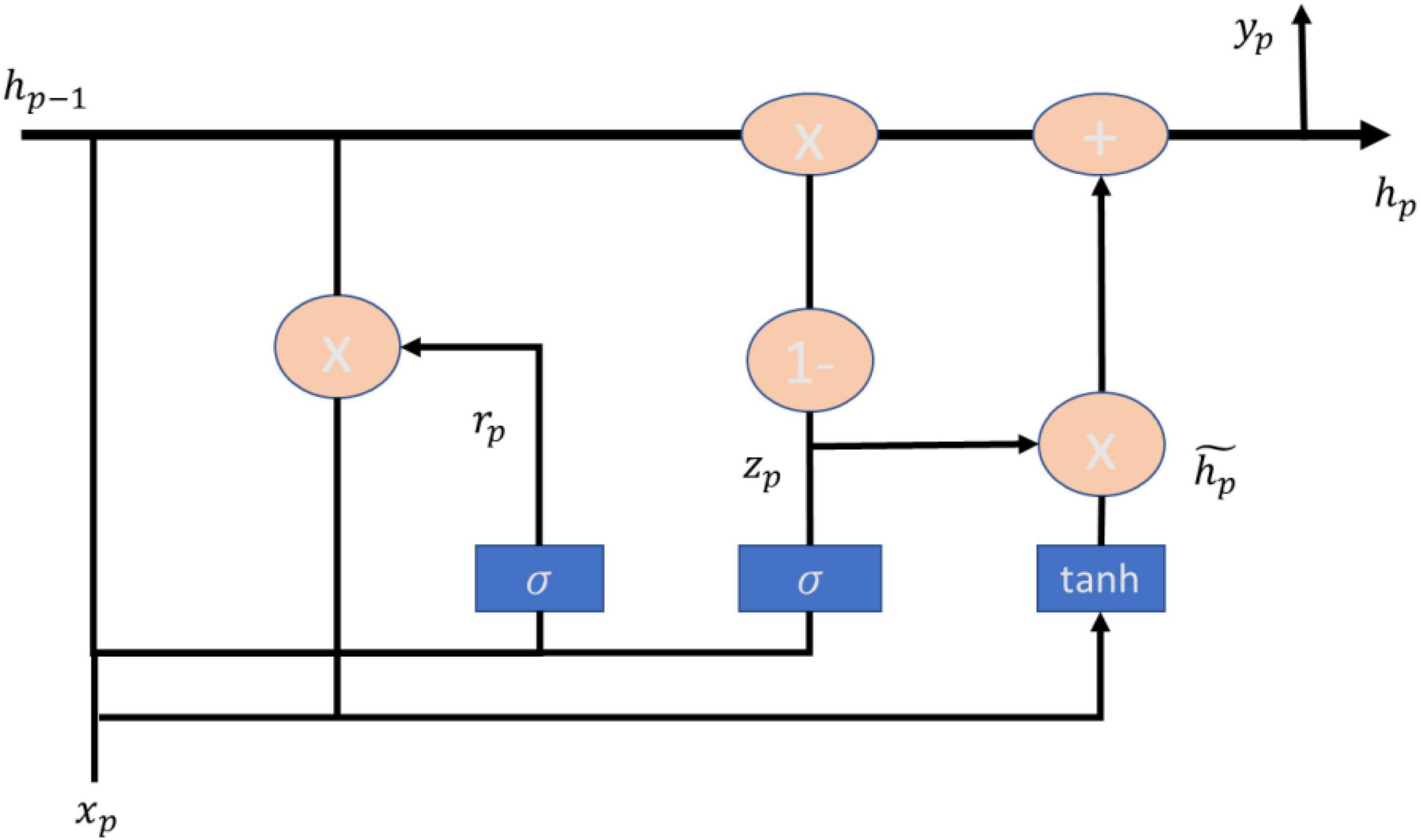
Figure 3. GRU architecture.
2.2 Activation functions
2.2.1 Hyperbolic tangent function
Hyperbolic tangent function is a smooth and zero-centered function with the range between −1 and 1 (Nwankpa et al., 2018), and its convergence is faster and the application is similar to the Sigmoid function, so it is easier to learn slower, Figure 4 shows the Tanh activation function and derivatives, the equation is shown in (13).
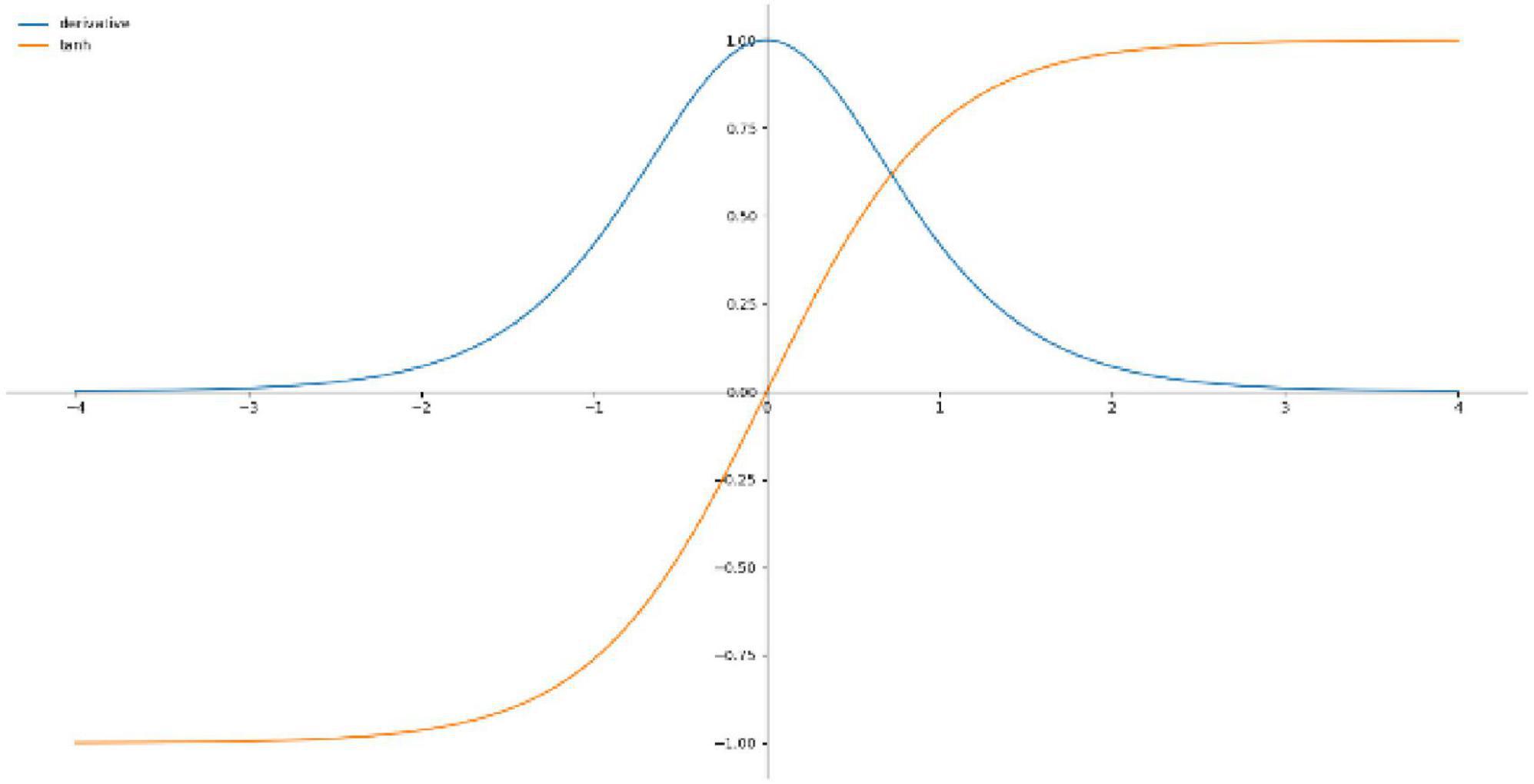
Figure 4. Tanh activation functions and derivatives.
2.2.2 Softsign function
Softsign Function is an alternative to the hyperbolic tangent function for the reason that this model can achieve flatter curves and the derivative decreases slower and achieves a better learning method, whereas Softsign Function is decentered, differentiable and anti-symmetric and returns values between −1 and 1. Figure 5 shows the Softsign activation function and the derivative and the equation is shown in (14).
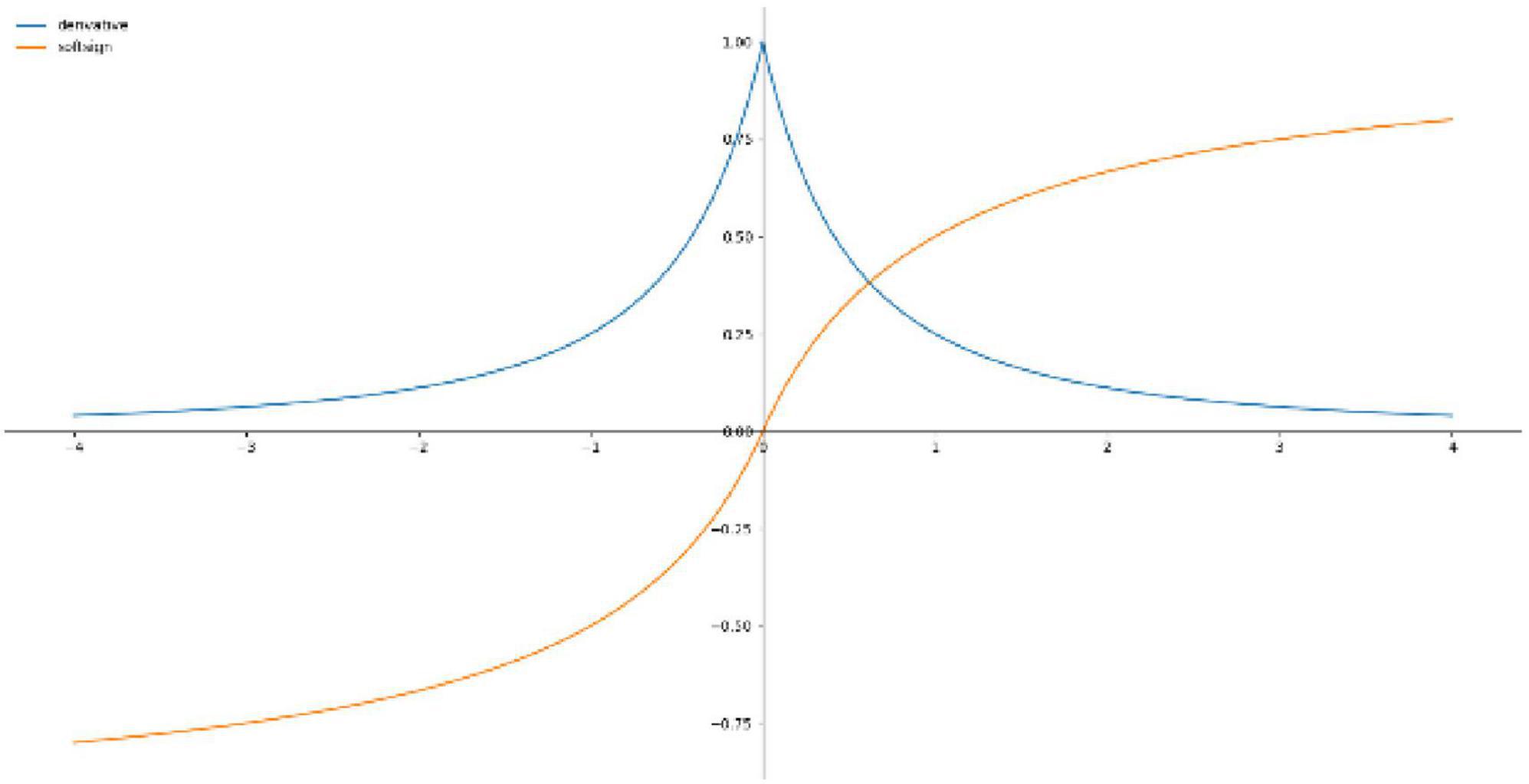
Figure 5. Softsign activation function and derivatives.
3 Materials and methods
The hardware operating system for this study is Win10 64-bit, CPU: i7, RAM: 2 4G, GPU: RTX 2070, and the software is written in Python, including Pandas, Numpy, Tensorflow, and Keras.
The research process is divided into four steps: Dataset, Data Preprocessing and Model Training and Evaluate.
3.1 Dataset
This study was conducted in a hospital in Taiwan from 1 August 2015 to 30 November 2020. The dataset containing the following data: extubation success or failure, Vte, RR, Ppeak, Pmean, PEEP, FiO2, and some of the collected respiratory data contained missing values. To ensure the completeness of the data, patients with missing values were excluded from this study. There were 289 sets of data for three and a half hours. In this study, there were 28 data for failed extubation and 205 data for successful extubation. There were 147 males and 86 females. The mean age was 73 years (61.8–81.3).
3.2 Data preprocessing
In this study, the data are first pre-processed by averaging the data every second, every 30 s, every 60 s, every 120 s, every 180 s, and every 300 s, and it can be seen in Figure 6 that using different averaging methods can reduce the interval between the data and also reduce the range of outliers. This study will add the original data input data with a total of 6 feature attributes, and this study will compress the input data in the range of −1 to 1 by performing the absolute maximum standardization of the input data. Since the activation functions tanh and Softsign used in this study are in the range of −1 to 1, the data compression method chosen is absolute maximum standardization instead of min-max scaling. the absolute maximum standardization formula is shown in (15).
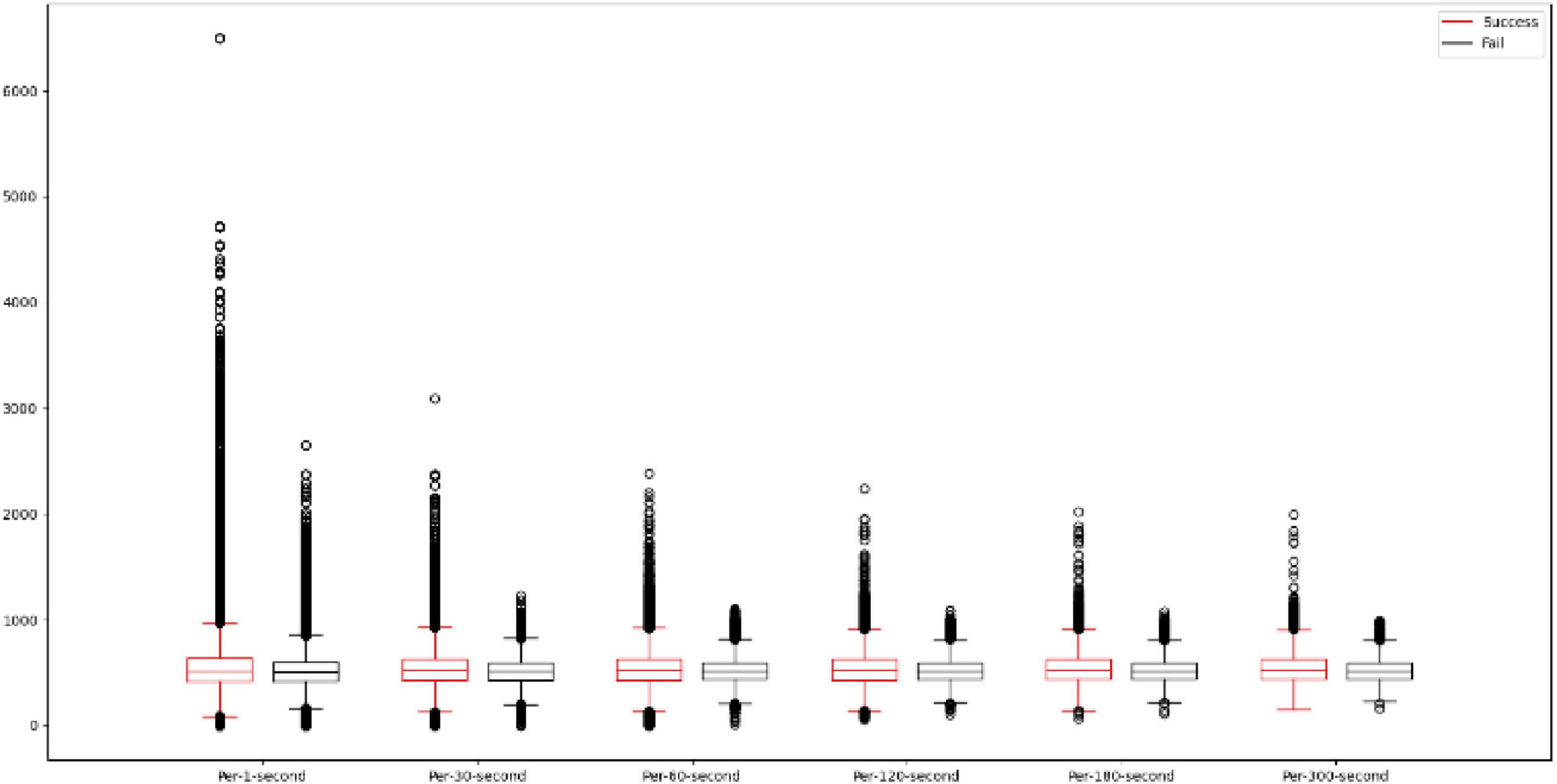
Figure 6. Difference in data between different averaging methods.
3.3 Model training and evaluation
Since it is difficult to collect patient data on respiratory parameters per second, this study compared three different time series deep learning models: RNN, LSTM, GRU, and four different validation methods such as: Resubstitution validation, 8:Holdout validation, 10-fold cross-validation and Leave-one-out cross-validation. Resubstitution validation, 8:2Holdout validation, 10-fold cross-validation and Leave-one-out cross-validation. Resubstitution take the first three hours of data from 250 sets of data as training samples, and the first three hours of data from 250 sets of data as validation samples, Holdout, and Cross-validation is to split the data from the first three hours of 250 sets of data into 8:2 using the Holdout method. Cross-validation is to split the data from the first 3 h of the 250 sets of data into 8:2 by using the Holdout method, the first 2 h and 24 min of the data will be used as the training sample, and the remaining 36 min will be used as the validation sample. 10-fold cross-validation is to split the data from the first 3 h of the 250 sets of data into 10-fold by using the 10-fold method, and to split the data into 10-fold by using the 10-fold method. 10-fold cross-validation is to divide the data from the first 3 h of the 250 sets of data into 10 sets of data by using the 10-fold method, one set of data is used as the validation sample and the remaining set of data is used as the training sample, and finally the 250 sets of data are divided into the first 3 h of each set of data by using the Leave-one-out method as the validation sample, and the remaining set of data is used as the first 3 h of data as the training sample. For the external validation dataset in this study, the data of each patient half an hour before extubation was used as a separate dataset. The part of the model that connects the hidden layer to the output layer uses a dropout method to prevent data over-simulation. Utilizing Accuracy in Model Evaluation for Model Evaluation. In this study, a sliding window is used to segment the time series data, and the size of the sliding window is based on every five time periods and the data are obtained in Step 1 each time, and Table 1 shows the parameter settings of the model.
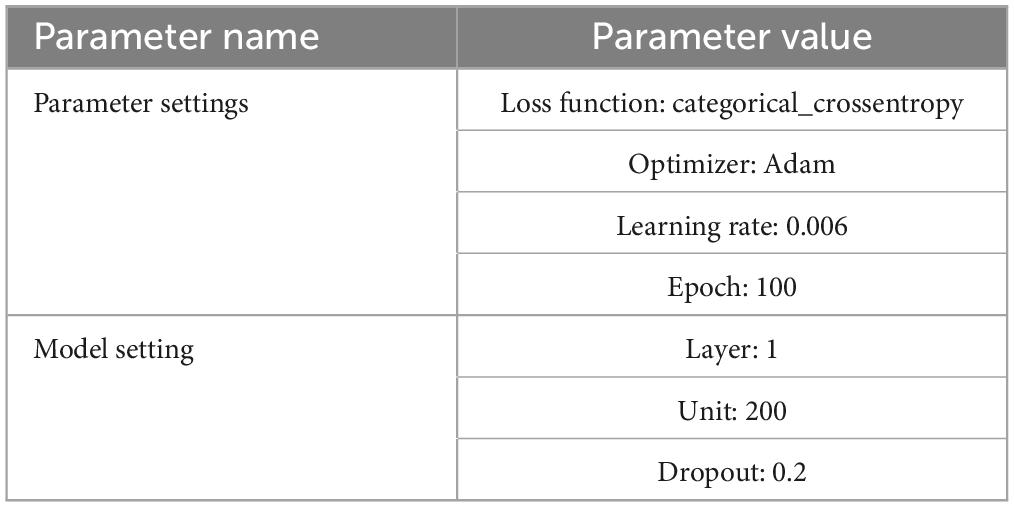
Table 1. Model reference settings.
4 Results
The results of this study are firstly shown in Table 2, where the Resubstitution method is utilized and then the data are averaged and pre-processed on a per-second, per-30-s, per-60-s, per-120-s, per-180-s. The results of this study are compared to the results of the model training with every 2 steps, every 3 steps, every 4 steps, and every 5 steps for training in the RNN model. Comparing the results of every 5 steps, every 3 steps, every 4 steps, and every 5 steps in the RNN model for training, the results of the study show that the training of the model with every 5 steps can get better prediction results in each average method with 76.57, 94.57, 96.59, 95.28, 91.20, and 77.67%, respectively. In per-1-s, the result of every 5 steps is slightly worse than the result of every 3 steps.
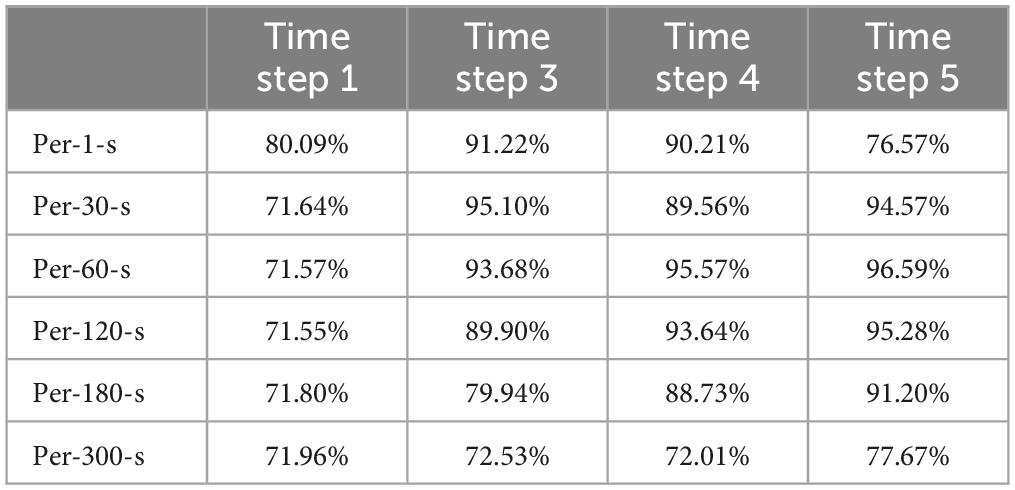
Table 2. Time step verification results.
Table 3 shows the validation of the model using the activation function of tanh and different models and different validation methods for each average method, and the results show that LSTM has good prediction results in different validation methods for Per-1-s: 93.09, 91.41, 83.21, and 79.04%, and the prediction results for Per-30-s: 98.82, 94.44, 84.75, and 84.83%, for per-120-s: 10-fold. Per-30-s shows the best prediction results for GRU: 98.82, 94.44, 84.75, and 84.83%, where the 10-fold validation method is slightly inferior to LSTM, and per-60-s shows the better prediction results for LSTM: 97.75, 94.08, 84.91, and 82.30%, where the Resubstitution validation method has good prediction results, 93.09, 91.41, 83.21, and 79.04%. For per-120-s, the predictions of LSTM are 97.21, 93.16, 84.79, and 82.36%, respectively. Per-180-s has better prediction results for LSTM: 95.65, 87.35, 80.43, and 79.75%. Among them, Holdout’s validation method GRU model has better prediction results. Per-300-s comes to LSTM with better prediction results: 94.85, 88.58, 80.04, and 75.54%, respectively. Among them, Leave-one-out of the validation approach GRU model has better prediction result 79.36%, in total, the results of this study concluded that Tanh activation function performs better in the model of LSTM, while the part of average method considered that Holdout of per-30-s has better prediction result.
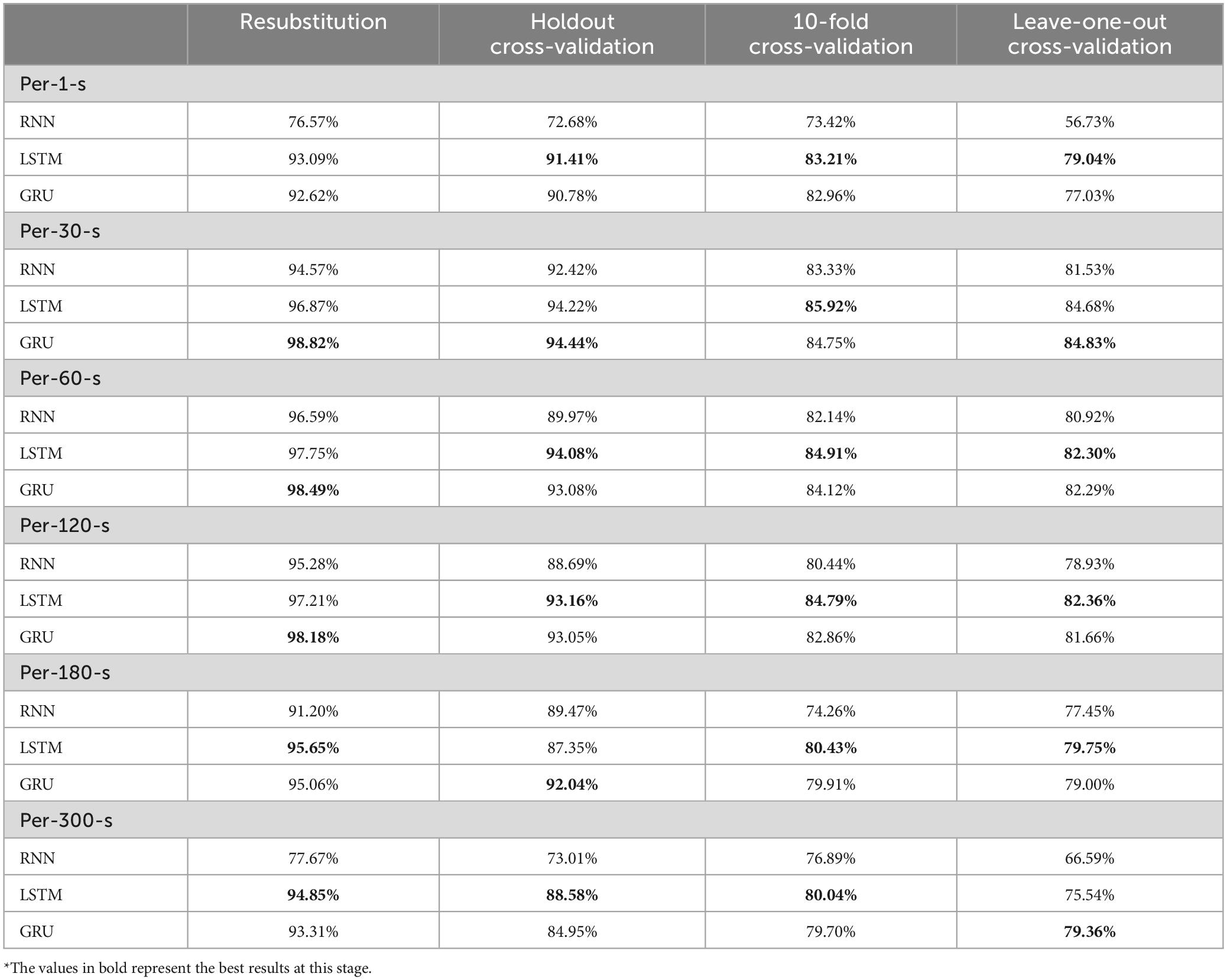
Table 3. Results of Tanh validation model.
Table 4 shows the validation of the model using the activation function as softsign and different models and different validation methods for each average method. The results show that the LSTM and GRU for per-1-s have different prediction results in different validation methods, among which Resubstitution and 10-fold have better prediction results for the LSTM model: 93.73 and 83.21%, respectively, and GRU for Holdout and Leave-one-out have better prediction results: 91.58 and 79.51% respectively. Resubstitution and 10-fold have better prediction results for LSTM model, which are 93.73 and 83.21%, respectively, and GRU has better prediction results for Holdout and Leave-one-out, which are 91.58 and 79.51%, respectively. per-30-s shows that GRU has the best prediction results for LSTM model, which are 96.71, 94.25, 86.43, and 83.46%, respectively. Resubstitution’s validation method is slightly inferior to LSTM, while per-60-s shows better prediction results for GRU: 97.97, 94.27, 84.80, and 82.16%, respectively. Per-120-s has different prediction results for different validation methods, among which Resubstitution and 10-fold validation methods have better prediction results for LSTM: 96.67 and 84.79%, respectively, and Holdout has better prediction results for RNN: 93.37%. Holdout for RNN has a better prediction result of 93.37%, Leave-one-out for GRU has a better prediction result of 81.65%, Per-180-s has different prediction results for different validation methods, among which Resubstitution and Leave-one-out for LSTM have a better prediction result of 96.82 and 80.83%, respectively. Holdout and 10-fold validation methods have better prediction results for GRU model: 92.24 and 80.96%, respectively, while Per-300-s has better prediction results for GRU: 94.59, 86.51, 81.11, and 77.85%, respectively. Among them, Holdout’s validation method LSTM model has better prediction results, and in sum, the results of this study concluded that Softsign activation function performs better in GRU’s model, and Plant’s part considered that Holdout of Plant B has better prediction results.
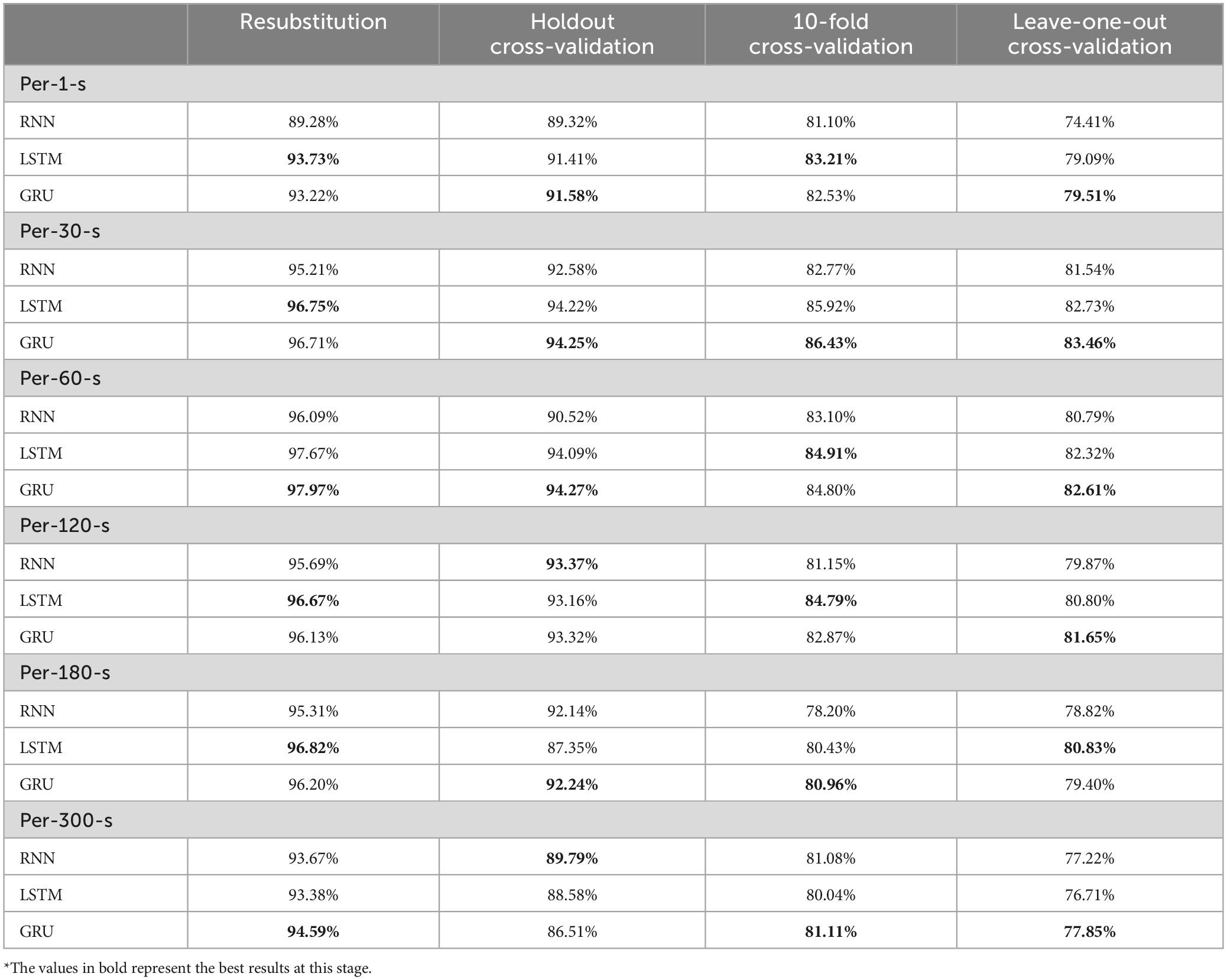
Table 4. Softsign validation model results.
5 Discussion
In this study, different averaging methods and different models were applied to compare with different activation functions, and the results of averaging every 30 s were better, and the GRU model was considered to have better predictive results in the overall assessment, and finally, Tanh’s activation function was considered to have better predictive results in terms of activation functions. In this study, Tanh’s GRU model can be effective in achieving good results regardless of success or failure and can give good advice to doctors.
In this study, different activation functions are applied for the comparison of Tanh and Softsign, in the results of this study, it can be seen that there is not much difference in the accuracy of the two activation functions and the Tanh activation function has a better predictive effect in each model.
AI extubation decision system can be used to help the medical team to analyze whether or not to perform an extubation action before extubation. As shown in Figure 7. In this study, a trend is generated every three minutes in the clinical decision support system. If there are missing values in the data, the study will utilize the previous data to ensure that the data is complete. Therefore, the model can increase the confidence of the healthcare team in extubation. It can also reduce the burden of the patient and the family’s confidence in the medical treatment. At this stage, different countries have different laws and regulations on clinical decision-making by AI. Therefore, AIs need to strictly comply with the relevant laws in order to avoid legal disputes. The trends generated in this study can be viewed by clinicians at this time, but the right decision still needs to be made by the healthcare team.
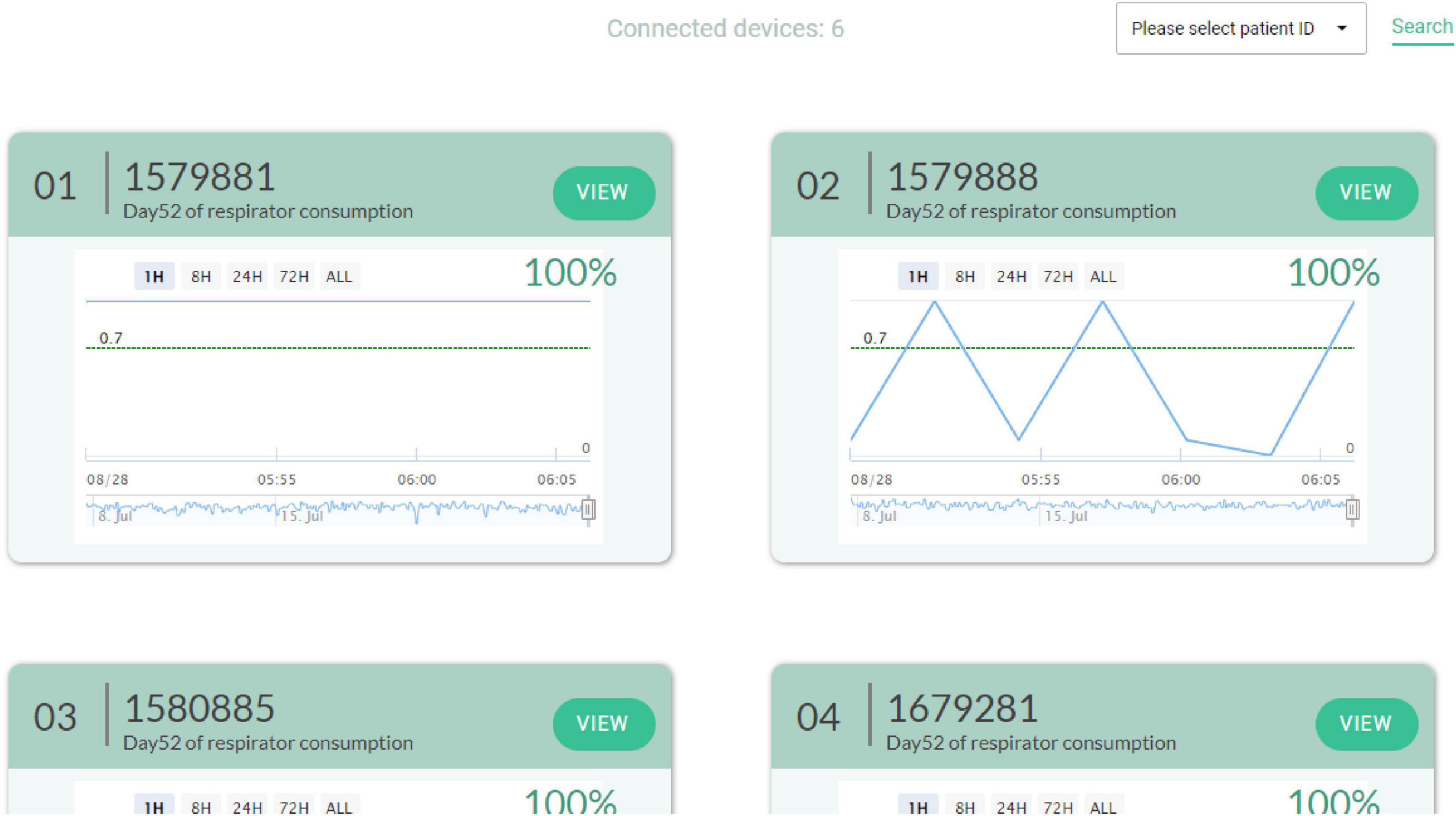
Figure 7. Clinical decision aids.
6 Conclusion
The success or failure of extubation is a very important issue in medicine, and the research topic of AI is getting more and more attention. Therefore, this study compares whether the time series model can effectively predict the success or failure of extubation, and the results show that the GRU model with Tanh activation function has a better prediction result of 94.44% at the average of every 30 s, so this study proposes a prediction method using GRU on the topic of extubation, and it can provide the doctors with the clinical application of extubation to give advice for reference. In the future, this study will be possible to validate this model with several different hospitals to collect mergers from different ethnic groups to increase the credibility of the model. This model will be validated with many different hospitals to collect different groups to increase the confidence of the model. The model will also be applied to many different clinical settings for use. The data will provide by the respirator was used, and in the future, we can add more variables such as patient’s data or different expansion dimensions, and this study will use more deep learning models to verify whether they can help to achieve the prediction effect, so as to reduce the failure rate of extubation. This study will add more algorithm such as: XGBoost, LightGBM, and Transformer models for model training and comparison.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Ethics statement
The studies involving humans were approved by the Institutional Review Board of Changhua Christian Hospital (approval no.: 210716). The studies were conducted in accordance with the local legislation and institutional requirements. Written informed consent for participation was not required from the participants or the participants’ legal guardians/next of kin because the Institutional Review Board waived the need for informed consent considering the retrospective nature of data collected.
Author contributions
K-YH: Writing – original draft. C-HL: Writing – review & editing. S-HC: Writing – review & editing. Y-LH: Writing – review & editing. J-LX: Writing – original draft.
Funding
The authors declare financial support was received for the research, authorship, and/or publication of this article. This research was funded by Changhua Christian Hospital Research Program (No. 112-NCHU-CCH-012).
Acknowledgments
We would like to thank the referees and the editors for their comments and valuable suggestions.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Arsenali, B., van Dijk, J., Ouweltjes, O., den Brinker, B., Pevernagie, D., Krijn, R., et al. (2018). “Recurrent neural network for classification of snoring and non-snoring sound events,” in Proceedings of the 2018 40th annual international conference of the IEEE engineering in medicine and biology society (EMBC), (New York, NY: IEEE), 328–331. doi: 10.1109/EMBC.2018.8512251
Balaji, E., Brindha, D., Elumalai, V. K., and Vikrama, R. (2021). Automatic and non-invasive Parkinson’s disease diagnosis and severity rating using LSTM network. Appl. Soft Comput. 108:107463. doi: 10.1016/j.asoc.2021.107463
Cheng, K. H., Peng, M. J., and Wu, C. L. (2007). Outcomes of very elderly patients admitted to a respiratory care center in Taiwan. Int. J. Gerontol. 1, 157–163. doi: 10.1016/S1873-9598(08)70040-1
Cheng, S. H., Jan, I. S., and Liu, P. C. (2008). The soaring mechanic ventilator utilization under a universal health insurance in Taiwan. Health Policy 86, 288–294. doi: 10.1016/j.healthpol.2007.11.002
Cho, K. (2014). Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv [Preprint]. arXiv:1406.1078.
Chung, J., Gulcehre, C., Cho, K., and Bengio, Y. (2014). Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv [Preprint]. arXiv:1412.3555.
Cohen, J. N., Gopal, A., Roberts, K. J., Anderson, E., and Siegel, A. M. (2019). Ventilator-dependent patients successfully weaned with cognitive-behavioral therapy: A case series. Psychosomatics 60, 612–619. doi: 10.1016/j.psym.2019.02.003
Cooper, L. M., and Linde-Zwirble, W. T. (2004). Medicare intensive care unit use: Analysis of incidence, cost, and payment. Crit. Care Med. 32, 2247–2253. doi: 10.1097/01.CCM.0000146301.47334.BD
Criner, G. (2012). Long-term ventilator-dependent patients: New facilities and new models of care. The American perspective. Rev. Portuguesa Pneumol. 18, 214–216. doi: 10.1016/j.rppneu.2012.04.004
Gao, S., Zheng, Y., and Guo, X. (2020). Gated recurrent unit-based heart sound analysis for heart failure screening. Biomed. Eng. Online 19, 1–17. doi: 10.1186/s12938-020-0747-x
Gautam, Y. (2021). Transfer learning for COVID-19 cases and deaths forecast using LSTM network. ISA Trans. 124, 41–56. doi: 10.1016/j.isatra.2020.12.057
Hagan, R., Gillan, C. J., Spence, I., McAuley, D., and Shyamsundar, M. (2020). Comparing regression and neural network techniques for personalized predictive analytics to promote lung protective ventilation in intensive care units. Comput. Biol. Med. 126:104030. doi: 10.1016/j.compbiomed.2020.104030
Hai, D., Chen, C., Yi, R., Gou, S., Su, B. Y., Jiao, C., et al. (2020). “Heartbeat detection and rate estimation from ballistocardiograms using the gated recurrent unit network,” in Proceedings of the 2020 42nd annual international conference of the IEEE engineering in medicine & biology society (EMBC) (pp. 451-454), (Montreal, QC: IEEE). doi: 10.1109/EMBC44109.2020.9176726
Hochreiter, S., and Schmidhuber, J. (1997). Long short-term memory. Neural Comput. 9, 1735–1780. doi: 10.1162/neco.1997.9.8.1735
Hui, C., Lin, M. C., Liu, T. C., and Wu, R. G. (2010). Mortality and readmission among ventilator-dependent patients after successful weaned discharge from a respiratory care ward. J. Formosan Med. Assoc. 109, 446–455. doi: 10.1016/S0929-6646(10)60076-9
Jia, Y., Kaul, C., Lawton, T., Murray-Smith, R., and Habli, I. (2021). Prediction of weaning from mechanical ventilation using convolutional neural networks. Artif. Intell. Med. 117:102087. doi: 10.1016/j.artmed.2021.102087
Kuo, P. H., Kuo, S. H., Yang, P. C., Wu, H. D., Lu, B. Y., and Chen, M. T. (2006). Predictive value of rapid shallow breathing index measured at initiation and termination of a 2-hour spontaneous breathing trial for weaning outcome in ICU patients. J. Formosan Med. Assoc. 105, 390–398. doi: 10.1016/S0929-6646(09)60135-2
Lobo, B., Abdel-Rahman, E., Brown, D., Dunn, L., and Bowman, B. (2020). A recurrent neural network approach to predicting hemoglobin trajectories in patients with end-stage renal disease. Artif. Intell. Med. 104:101823. doi: 10.1016/j.artmed.2020.101823
Nwankpa, C., Ijomah, W., Gachagan, A., and Marshall, S. (2018). Activation functions: Comparison of trends in practice and research for deep learning. arXiv [Preprint]. arXiv:1811.03378.
Santosh, T., Ramesh, D., and Reddy, D. (2020). LSTM based prediction of malaria abundances using big data. Comput. Biol. Med. 124:103859. doi: 10.1016/j.compbiomed.2020.103859
Scherpf, M., Gräßer, F., Malberg, H., and Zaunseder, S. (2019). Predicting sepsis with a recurrent neural network using the MIMIC III database. Comput. Biol. Med. 113:103395. doi: 10.1016/j.compbiomed.2019.103395
Tobin, M. J. (2001). Advances in mechanical ventilation. N. Engl. J. Med. 344, 1986–1996. doi: 10.1056/NEJM200106283442606
Wunsch, H., Wagner, J., Herlim, M., Chong, D., Kramer, A., and Halpern, S. D. (2013). ICU occupancy and mechanical ventilator use in the United States. Crit. Care Med. 41, 2712–2719. doi: 10.1097/CCM.0b013e318298a139
Keywords: time series, deep learning, extubation, weaning, smart healthcare
Citation: Huang K-Y, Lin C-H, Chi S-H, Hsu Y-L and Xu J-L (2024) Optimizing extubation success: a comparative analysis of time series algorithms and activation functions. Front. Comput. Neurosci. 18:1456771. doi: 10.3389/fncom.2024.1456771
Received: 29 June 2024; Accepted: 06 September 2024;
Published: 04 October 2024.
Edited by:
Pengfei Wang, University of Science and Technology of China, ChinaReviewed by:
Chandan Kumar Behera, University of Texas Health Science Center at Houston, United StatesMahmoud Elbattah, University of the West of England, United Kingdom
Copyright © 2024 Huang, Lin, Chi, Hsu and Xu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jia-Lang Xu, amx4dUBjeXV0LmVkdS50dw==