 Houmem Slimi
Houmem Slimi Ala Balti
Ala Balti Sabeur Abid
Sabeur Abid- Research Laboratory SIME, ENSIT, University of Tunis, Tunis, Tunisia
Introduction: Alzheimer’s disease (AD) is a progressive neurodegenerative disorder characterized by cognitive decline, memory loss, and impaired daily functioning. Despite significant research, AD remains incurable, highlighting the critical need for early diagnosis and intervention to improve patient outcomes. Timely detection plays a crucial role in managing the disease more effectively. Pretrained convolutional neural networks (CNNs) trained on large-scale datasets, such as ImageNet, have been employed for AD classification, providing a head start for developing more accurate models.
Methods: This paper proposes a novel hybrid deep learning approach that combines the strengths of two specific pretrained architectures. The proposed model enhances the representation of AD-related patterns by leveraging the feature extraction capabilities of both networks. We validated this model using a large dataset of MRI images from AD patients. Performance was evaluated in terms of classification accuracy and robustness against noise, and the results were compared to several commonly used models in AD detection.
Results: The proposed hybrid model demonstrated significant performance improvements over individual models, achieving an accuracy classification rate of 99.85%. Comparative analysis with other models further revealed the superiority of the new architecture, particularly in terms of classification rate and resistance to noise interference.
Discussion; The high accuracy and robustness of the proposed hybrid model suggest its potential utility in early AD detection. By improving feature representation through the combination of two pretrained networks, this model could provide clinicians with a more reliable tool for early diagnosis and monitoring of AD progression. This approach holds promise for aiding in timely diagnoses and treatment decisions, contributing to better management of Alzheimer’s disease.
1 Introduction
Alzheimer’s disease (AD) is a degenerative neurological condition marked by cognitive decline, behavioral abnormalities, and memory loss. In order to manage the illness and enhance the patients’ quality of life, early diagnosis is essential. However, because the structural alterations in Alzheimer’s disease are subtle and complex, precisely identifying the condition using MRI scans remains a substantial issue. Brain MRI pictures show subtle structural differences that are difficult to interpret without sophisticated tools, and conventional diagnostic procedures frequently fail to capture these complex patterns. In order to support healthcare practitioners, more sophisticated, dependable, and automated classification systems are required. This is because early and accurate diagnosis might be challenging.
The complex patterns in MRI scans that differentiate between different stages of Alzheimer’s disease are difficult for traditional machine learning models and even some deep learning architectures to grasp. Issues including overfitting, computational efficiency, and cross-dataset generalization are not sufficiently addressed by many of the models that are currently in use. More advanced models are therefore required in order to efficiently learn and generalize these patterns, resulting in classifications that are more accurate. Though promising in other medical imaging tasks, advanced deep learning models are still limited in their ability to classify AD patients because of the particular difficulties presented by the disease’s course and its subtle impacts on brain structure. This justifies the exploration of novel model architectures and combinations to push the boundaries of what is currently achievable in AD diagnosis.
In this paper, we present a combinatorial deep learning method that combines DenseNet121 and Xception, two potent pretrained networks. DenseNet121’s dense connection makes feature reuse and gradient flow more effective. Because every layer in DenseNet121 is feed-forward coupled to every other layer, the vanishing gradient issue is lessened and feature reuse is encouraged, which enhances learning and performance. Conversely, Xception lowers model parameters and improves computational performance thanks to its depthwise separable convolutions. The convolution procedure is broken down into two parts in this architecture: a depthwise convolution and a pointwise convolution. This results in a significant reduction in computational cost without sacrificing performance. By combining these two networks, we aim to leverage the strengths of both architectures, resulting in a model that is both powerful and efficient.
Our strategy produced excellent results, with an average improvement in accuracy of 10% over the previous approaches. The effective fusion of Xception’s efficient convolutions and DenseNet121’s dense connectivity is responsible for this improvement. By using the Synthetic Minority Over-sampling Technique (SMOTE), which addressed the dataset’s class imbalance problem, this performance improvement was further improved. In order to balance the dataset without just copying existing samples, SMOTE creates synthetic samples for the minority class by interpolating between existing samples. The model can learn more efficiently thanks to this balanced dataset, particularly when some stages of Alzheimer’s disease are underrepresented in the training set.
Considerable progress has been made in the categorization of Alzheimer’s disease from MRI scans using the suggested combinatorial strategy. Utilizing the advantages of both Xception and DenseNet121, our model offers a reliable and effective solution. While Xception’s computational efficiency enables faster and more resource-efficient training and inference, DenseNet121’s dense connections enable a better and more thorough grasp of the subtle aspects of MRI images. SMOTE integration makes the model more robust in real-world applications by improving its generalization across imbalanced datasets. These developments open the door to earlier and more precise Alzheimer’s disease diagnosis, which may improve patient outcomes and facilitate the development of more potent disease management techniques. This study highlights the potential of combinatorial deep learning approaches in overcoming existing limitations and sets the stage for future research in this critical area.
This paper is structured as follows: we explain in section 2 some State-Of-the-Art Models, the dataset, preprocessing steps, followed by overviews. Some mathematical formulations of the proposed model are described in Section 3 as well as the proposed model architecture. In Same section, the proposed model’s architecture will be presented. Section 4 details the results achieved in this study. In Section 5, we discuss the results. Finally, the implications of our findings and future directions for research are exposed. Our approach demonstrates the potential of the proposed hybrid model in enhancing Alzheimer’s research, providing a framework that can be extended to other medical imaging applications.
2 Related work
In the domain of medical image analysis, transfer learning (TL) has received a lot of attention. One example of this is its use in the image classification of the Alzheimer’s Disease dataset. In a related study, You et al. (2020) Developed a cascade neural network that utilizes both gait and EEG data for AD classification, significantly outperforming other methods with a three-way AD classification accuracy of 91.07%. The next year, Mohammed et al. (2021) proposed many machine learning algorithms and deep learning models to classify images of OASIS and Alzheimer’s disease Datasets, they achieved an average accuracy equal to 94%. Furthermore, a recent study by Al Shehri (2022) proposed a deep learning-based solution using DenseNet-169 and ResNet-50 CNN architectures for the diagnosis and classification of Alzheimer’s disease. The DenseNet-169 architecture achieved training and testing accuracy values of 0.977 and 0.8382, respectively, while ResNet-50 had accuracy values of 0.8870 and 0.8192. One study by Thayumanasamy and Ramamurthy (2022) evaluated various machine learning and deep convolutional architectures for detecting Alzheimer’s disease (AD) from mild cognitive impairment (MCI), Accuracy equal to 82.2% was achieved by using DenseNet169. In a recent study by Bamber and Vishvakarma (2023) presents a model using a shallow convolution layer in a convolutional neural network for Alzheimer’s disease diagnosis in image patches, boasting a high accuracy rate of 98%. Another study by Mahmud et al. (2023) evaluate approach on a dataset of MRI scans from patients with AD and healthy controls, achieving an accuracy of 95% for combined ensemble models. Raza et al. (2023) focus on segmenting and classifying Magnetic Resonance Imaging (MRI) scans of Alzheimer’s disease, their approach involves leveraging transfer learning and customizing a convolutional neural network (CNN), accuracy achieved 97.84%. In same year, Balaji et al. (2023) create a hybrid deep learning model based on CNN and LSTM architectures, to classify images of two datasets, they also performed segmentation to improve results, accuracy of 98.5% is achieved. A recent study by Ching et al. (2024) focus on using EfficientNet-B0 to classify AD images and reached accuracy equal to 87.17%. In same year, Ali et al. (2024) uses Fuzzy C-means technique for image segmentation and merge LSTM architecture with CNN one to classify brain images, they reached an accuracy of 98.13%. In this study, we propose to integrate Xception and DenseNet121, two newly modified pretrained deep learning networks. At 99.85%, the suggested model has the highest accuracy. These works show how transfer learning can be used to improve the accuracy of image classification in the Alzheimer’s dataset and show how transfer learning can be used to further develop deep learning-based techniques.
3 Database study and preprocessing
The dataset of MRI images (link in Data Availability statement) initially consists of two parts: Training and Testing images, each with over 5000 images classified according to the severity of Alzheimer’s disease. Figure 1 shows some AD images categorized into four classes: Very Mild Demented, Mild Demented, Moderate Demented, and Non-Demented. Using the same methodologies as the proposed architecture, a comparison study with other pretrained networks has been conducted to assess the performance of the suggested model. All the dataset images were preprocessed as follows:
– Splitting data: the dataset contains two files: train and test. In this study, we merge the two parts and split obtained data into ratios of 80% for training and 20% for testing.
– Resizing Images: All images were resized to reduce computational power consumption and speed up application execution. By standardizing the image dimensions, we ensured that the model could process the data more efficiently, leading to faster training times without compromising accuracy.
– Data Augmentation: Data augmentation techniques were employed to create new training datasets that are variations of the original images. This process helps prevent overfitting by exposing the model to a wider variety of data. The augmentation methods used include:
• Rotation: Rotating images helps the model become invariant to the orientation of the MRI scans, allowing it to learn features regardless of image alignment.
• Flipping (Horizontal and Vertical): Flipping images increases data diversity by creating mirror images, which helps the model learn to recognize features from different perspectives.
• Shifting (Width and Height): Shifting images horizontally and vertically helps the model become invariant to small positional changes in the MRI scans.
• Zoom: Applying zoom augmentation ensures the model can handle variations in the size of brain structures, helping it focus on different levels of detail.
• Brightness Adjustment: Adjusting brightness variations makes the model robust to changes in lighting conditions, ensuring consistent performance across different MRI scans.
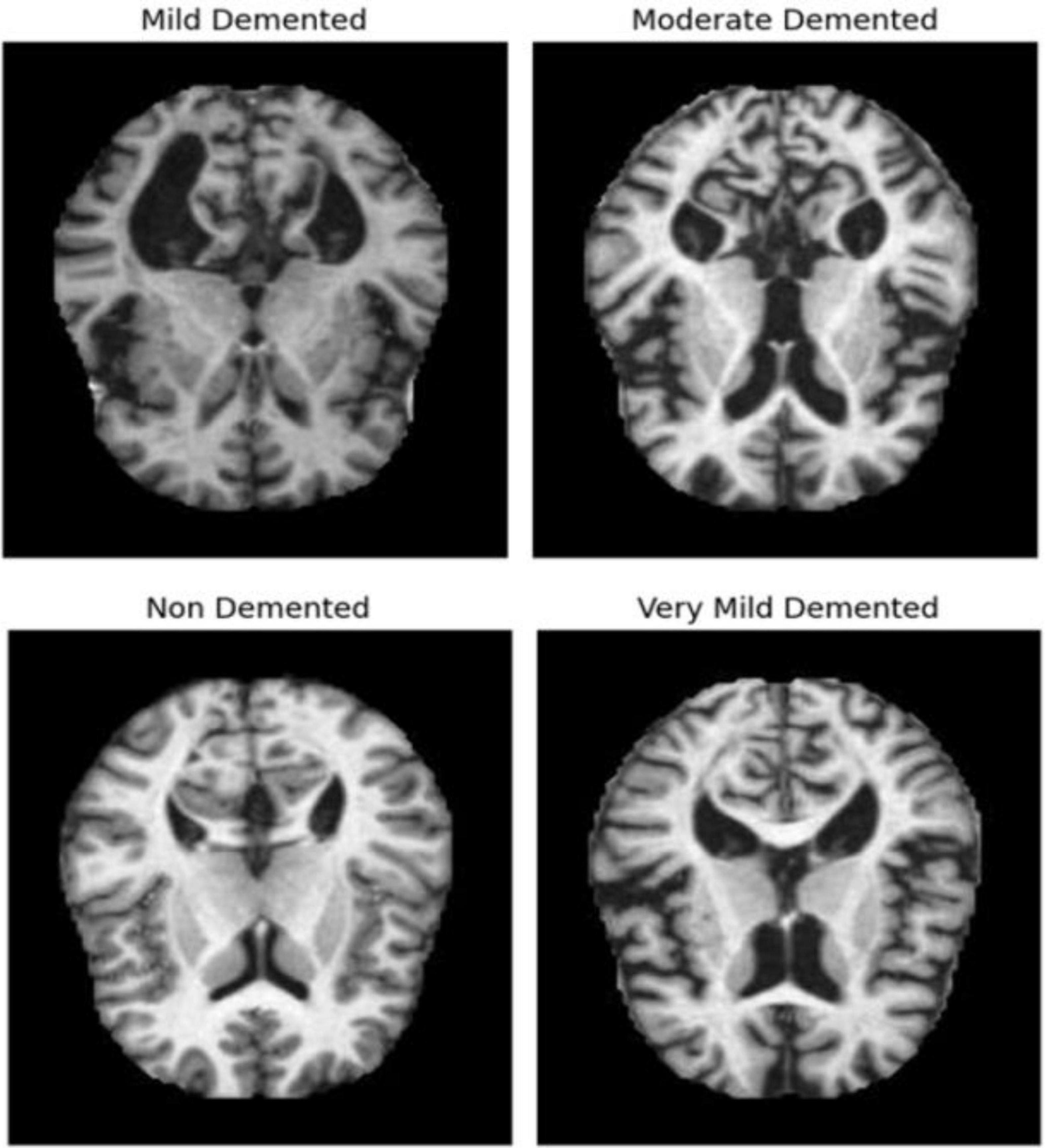
Figure 1. Example of images belongs to four classes from Alzheimer’s dataset.
These augmentation techniques not only increase the quantity of training data but also enhance the model’s ability to generalize by learning from a more diverse set of images. This diversity helps improve the model’s robustness and accuracy in identifying features relevant to different stages of Alzheimer’s Disease.
– Oversampling with SMOTE: The Synthetic Minority Oversampling Technique (SMOTE) was used by Chawla et al. (2002) and applied in this study to address the issue of unbalanced classes. SMOTE generates synthetic samples for the minority class by interpolating between existing samples.
3.1 Transfer learning technique
A powerful deep learning method called transfer learning (TL) uses model parameters that have previously been trained on a large dataset (such as the 1000-class ImageNet Dataset). Pretrained weights are also used in this strategy to speed up learning and improve accuracy in our model. It’s basically the same as imparting knowledge that one person has acquired to another. Instead than concentrating only on training the Fully Connected layers while maintaining the CNN layer unaltered, all layers are learned throughout the transfer learning process. Training just the CNN layers (either fully or partially) is one way to improve the model’s performance. This technique is used in this study by choosing two pretrained networks which are: DenseNet121 (Gupta and Mesram, 2022) and Xception (Chollet, 2017). The aim of this study is to merge these two PN, as will be described later, to improve the classification process.
3.2 Mathematical Formulations
• Performance metrics
TP: True Positives
TN: True Negatives
FP: False Positives
FN: False Negatives
For the hybrid model:
AccHybrid: Accuracy of the hybrid model
If AccHybrid is higher than AccDenseNet121 and AccXception, it indicates that the hybrid model is more accurate in its predictions. The hybrid model combines features from both DenseNet121 and Xception, potentially leveraging their complementary strengths, which can result in improved classification performance compared to each individual model. Thus, a higher accuracy for the hybrid model shows that it has a better overall performance in correctly identifying samples, proving its superiority over the individual models.
• Overall Performance Improvement
For the hybrid model:
ΔAccHybrid : Improvement in accuracy of the hybrid model
The improvement in ΔAccHybrid measures how much the accuracy of the hybrid model exceeds that of the best-performing individual model (either DenseNet121 or Xception). By subtracting the maximum accuracy of the individual models from the accuracy of the hybrid model, we can quantify the enhancement in performance provided by the hybrid approach. A positive value of indicates that the hybrid model offers superior accuracy compared to the single best model, demonstrating its effectiveness in improving classification results beyond what each individual model alone can achieve.
• Concatenation of Output Layers
O: Output layer
For the hybrid model:
OHybrid: Output layer of the hybrid model
ODenseNet121: Output layer of DenseNet121
OXception: Output layer of Xception
⊕: Concatenation operation
• Ensemble Performance Gain
For the hybrid model:
GAcc : Gain in accuracy
The ensemble performance gain GAcc calculates the average improvement in accuracy provided by the hybrid model compared to each individual model. It is determined by averaging the differences in accuracy between the hybrid model and DenseNet121, and between the hybrid model and Xception. This calculation helps quantify the extent to which the hybrid model outperforms both individual models. A positive GAcc value signifies that the hybrid model achieves better accuracy than either DenseNet121 or Xception, thereby demonstrating the advantages of combining the strengths of both models. This gain highlights the effectiveness of the hybrid approach in improving classification accuracy beyond what is achieved by each individual model alone.
• Error Reduction
E: Error rate
Acc: Accuracy
For the hybrid model:
ΔE: Error reduction
Error reduction ΔE measures how much the hybrid model’s error rate is reduced compared to the best-performing individual model. It is calculated by subtracting the error rate of the hybrid model from the minimum error rate of DenseNet121 and Xception. This metric helps to quantify the improvement in classification performance of the hybrid model by showing that it has a lower error rate than the best individual model. A lower error rate in the hybrid model indicates enhanced accuracy and effectiveness in classification, providing evidence that combining the two models leads to better overall performance compared to relying on either model alone. This reduction in error underscores the advantage of the hybrid approach in minimizing misclassifications.
• Statistical Significance
For the hybrid model:
DAcc,i : Difference in accuracy for the i-th sample
: Mean difference in accuracy
sD,Acc : Standard deviation of the differences in accuracy
tAcc : t-value for accuracy
To determine the statistical significance of the hybrid model’s performance improvement, we calculate several key metrics. First, DAcc,i measures the accuracy difference between the hybrid model and the best individual model for each sample, showing how much better the hybrid model performs on a sample-by-sample basis. The mean difference in accuracy averages these differences across all samples, indicating overall improvement. The standard deviation of these differences sD,Acc assesses the variability of the improvements, with a low value suggesting consistent superiority. Finally, the t-value tAcc assesses the statistical significance of the mean accuracy improvement by comparing to its standard error. A high t-value confirms that the observed improvement in accuracy is statistically significant, demonstrating the hybrid model’s robustness and superiority over the individual models.
3.3 The model structure
The architecture combines feature extraction from these pre-trained models with additional convolutional layers, upsampling, and fully connected layers to optimize the model’s performance. Below is a detailed explanation of each sub-module in the architecture presented by Figure 2:
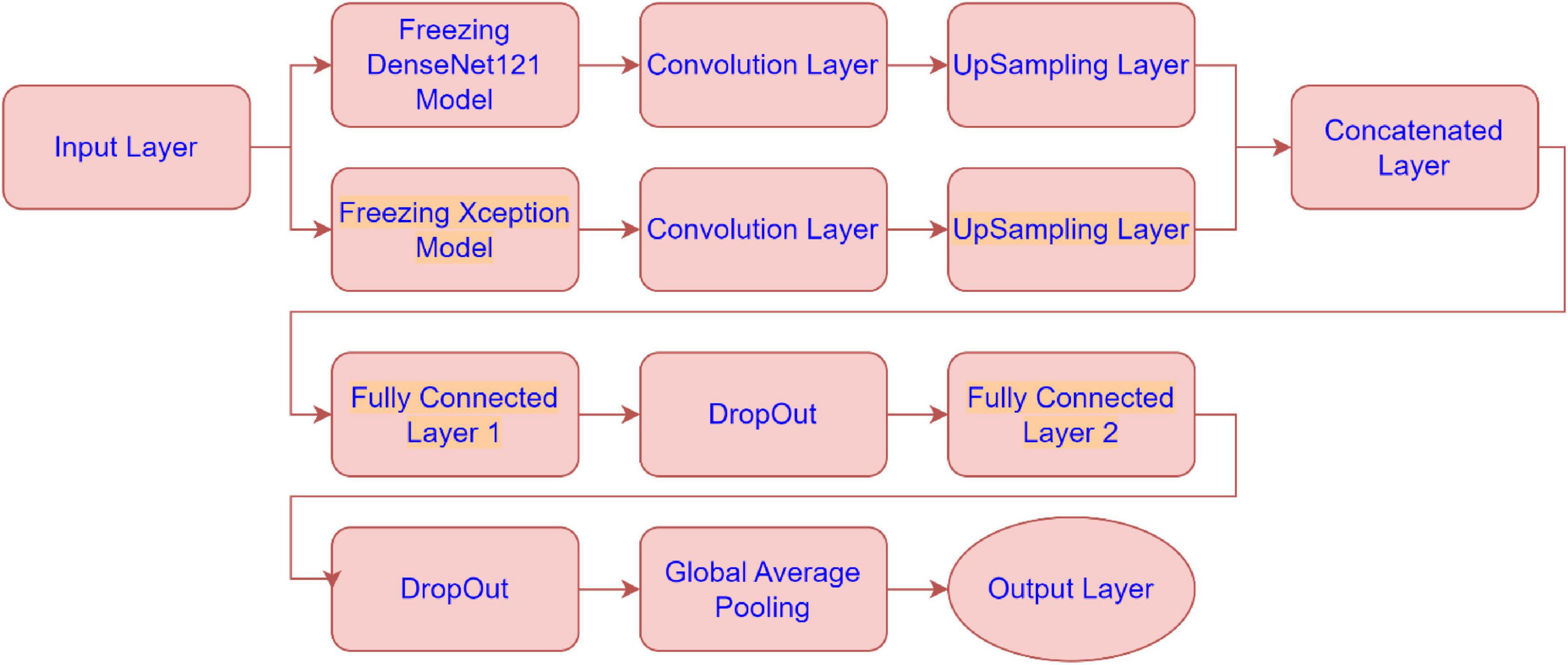
Figure 2. Architecture of the proposed model.
• Freezing DenseNet121 Model:
The DenseNet121 model is used as a feature extractor, but its weights are “frozen”, meaning they are not updated during training. This allows the model to leverage pre-trained weights without modifying them. The output of the frozen DenseNet121 model is passed to the next convolutional layer.
• Freezing Xception Model:
Similarly, the Xception model is also frozen and used as a feature extractor. The frozen model’s output is sent to a convolutional layer.
• Convolution Layer (for DenseNet121 and Xception):
After extracting features from both DenseNet121 and Xception, these features are further processed by convolutional layers. The convolution layers apply filters to extract spatial hierarchies from the feature maps. These layers help in refining the features obtained from the pre-trained models.
• UpSampling Layer (for DenseNet121 and Xception):
Once features are processed through the convolution layers, the UpSampling layers increase the resolution of the feature maps (essentially scaling them up). This is likely done to match the spatial dimensions of the two models’ feature maps before concatenating them.
• Concatenated Layer:
The outputs from the upsampled DenseNet121 and Xception models are concatenated along the channel dimension. This step fuses the feature representations from both models, combining their strengths to form a more comprehensive feature set for the next stage of the model.
• Fully Connected Layer 1:
After concatenation, the fused feature map is passed through a fully connected (dense) layer. This layer serves to learn and capture more abstract relationships in the combined features, transforming the spatial features into more compact, higher-level representations.
• DropOut:
Dropout is applied to prevent overfitting by randomly setting a fraction of the input units to 0 during training. This forces the model to not rely on any one specific feature and improves generalization.
• Fully Connected Layer 2:
Another fully connected layer follows the dropout. This layer further transforms the features, likely preparing them for the final classification. It’s part of the final layers that learn high-level representations to differentiate between the classes.
• Global Average Pooling:
Global average pooling reduces the spatial dimensions of the feature maps by averaging them across each channel. This reduces the dimensionality of the output, producing a single value per feature map (or channel). It replaces traditional fully connected layers before the output, promoting model generalization and reducing the risk of overfitting.
• Output Layer:
The final output layer produces the class probabilities for the input data. This layer takes the reduced representation from the global average pooling layer and outputs a prediction, likely using softmax activation for multi-class classification in Alzheimer’s disease MRI image classification.
4 Results
Several evaluation criteria, including accuracy, precision, recall, F1-score, and AUC, are used to assess how well deep learning architecture’s function.
Where the percentage of accurate predictions to all occurrences analyzed is measured by the Accuracy metric. The positive patterns that are accurately predicted from all of the projected patterns in a positive class are measured using the precision metric. The fraction of positive patterns that are correctly categorized is measured by recall, and the harmonic mean of recall and accuracy values is represented by the F1score metric. These evaluation metrics are more explained by Hossin and Sulaiman (2015).
The Area Under the Curve (AUC) is an effective metric having values in the interval [0, 1]. Since there is perfect discrimination between instances of the two classes, the AUC is equal to 1. Conversely, when all Benign cases are classified as Malignant, the AUC equals 0 and vice versa.
In this part, we use Kaggle platform with GPU P100 service for training and testing our proposed model to increase the running time of our code. The computer used for the experiments includes the following features: Windows 10 Professional, 64-bit operating system, Intel(R) Core(TM) i7-8750H CPU @ 2.20 GHz 2.21 GHz 8 GB Memory, x64-based processor. The specific approach is started by resizing images to 120x120 format. The next step consists of applying Data Augmentation on Alzheimer’s Dataset to get accurate results, this stage is followed by using the SMOTE Technique to solve the problem of imbalanced classes (The “Moderate Demented” class contains only 52 images). After that, we apply freezing on the first 40 layers of DenseNet121 and Xception models (freeze technique is used to make architecture more robust and to avoid overfitting), then merging them as explained in “The novel planned strategy” Part. The “Adam” optimization (Kingma and Jimmy, 2014) applied and learning rate parameter is fixed to 0.0001, the loss function is “categorical_crossentropy”, the activation function chosen is “RELU’ in hidden layers and “Softmax” is applied to the output layer. The first Fully Connected layer have 2048 nodes and the second one have 1048 nodes, each one is followed by dropout layers (with dropout rate equal to 0.3). We use EarlyStopping (with “patience” parameter equal to 7), and L2 Regularization (with waited decay equal to 0.001) to avoid overfitting problem. Note that the number of epochs for train was fixed to 20. The performance of the suggested model in comparison to the normal and hybrid pretrained models is displayed in Table 1. Figure 1 illustrated the different classes into the dataset, while Figure 2 show the proposed model’s architecture with details also explained in sub section 3.3. According to Figure 3, the Xception model outputs a tensor of shape (None, 4, 4, 2048), while DenseNet121 produces a tensor of shape (None, 3, 3, 1024). To harmonize these feature maps, each output is passed through a convolutional layer with 3 filters of size (3, 3), reducing the channel dimensions to 3, resulting in tensors of shape (None, 4, 4, 3) for Xception and (None, 3, 3, 3) for DenseNet121. These are then upsampled to (None, 12, 12, 3) using factors of (3, 3) and (4, 4) respectively, aligning their spatial dimensions. Finally, the upsampled feature maps are concatenated along the channel axis, resulting in a fused tensor of shape (None, 12, 12, 6). Figure 4 show respectively the confusion matrixes of DenseNet121, Xception, InceptionV3, InceptionV3&DenseNet121 and Xception&DenseNet121 of Alzheimer’s Dataset. Take note that there are fewer False Positive and False Negative cases in the confusion matrix of Xception&DenseNet121.
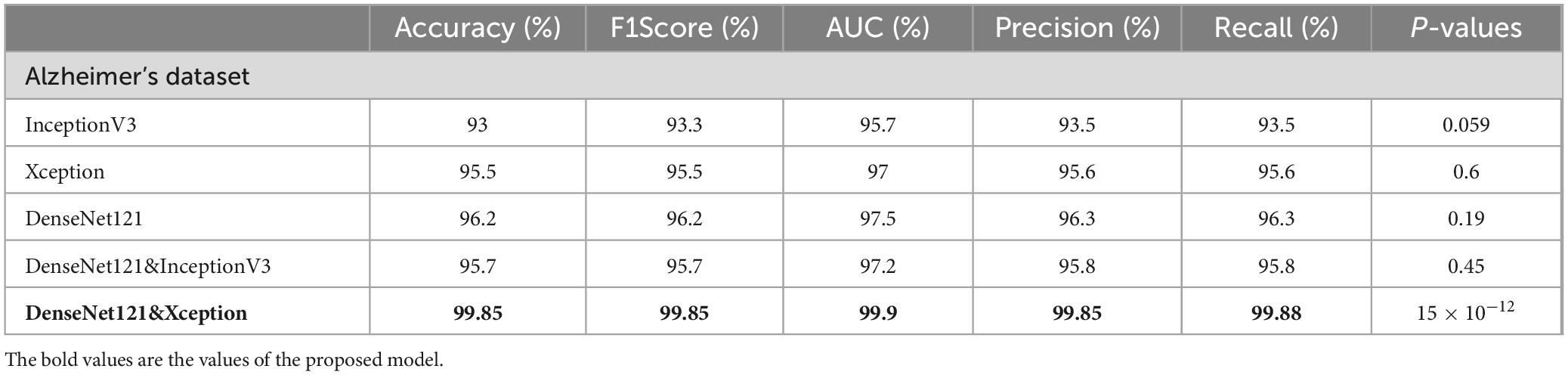
Table 1. Evaluation metrics of different models.
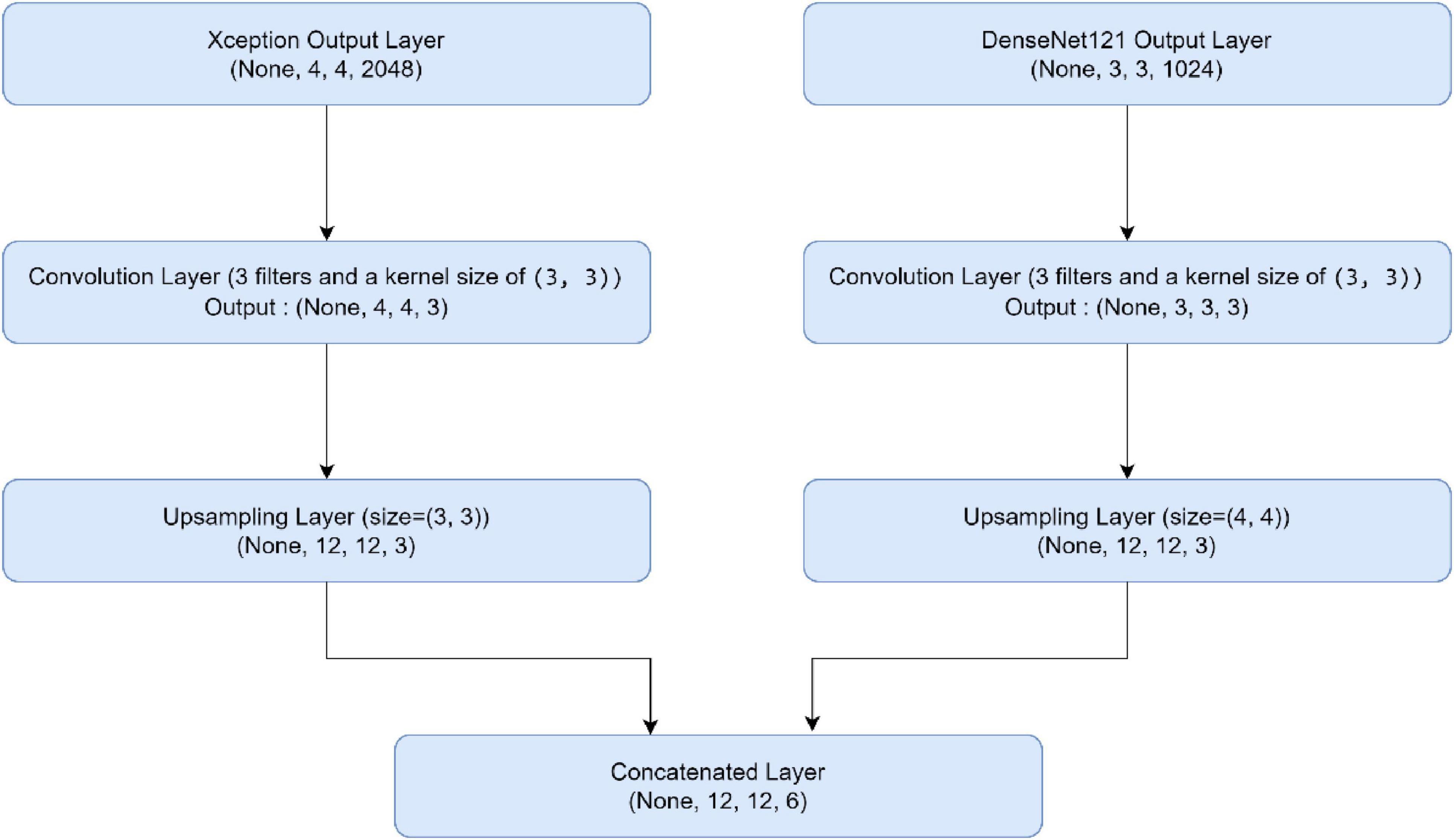
Figure 3. Feature fusion architecture.
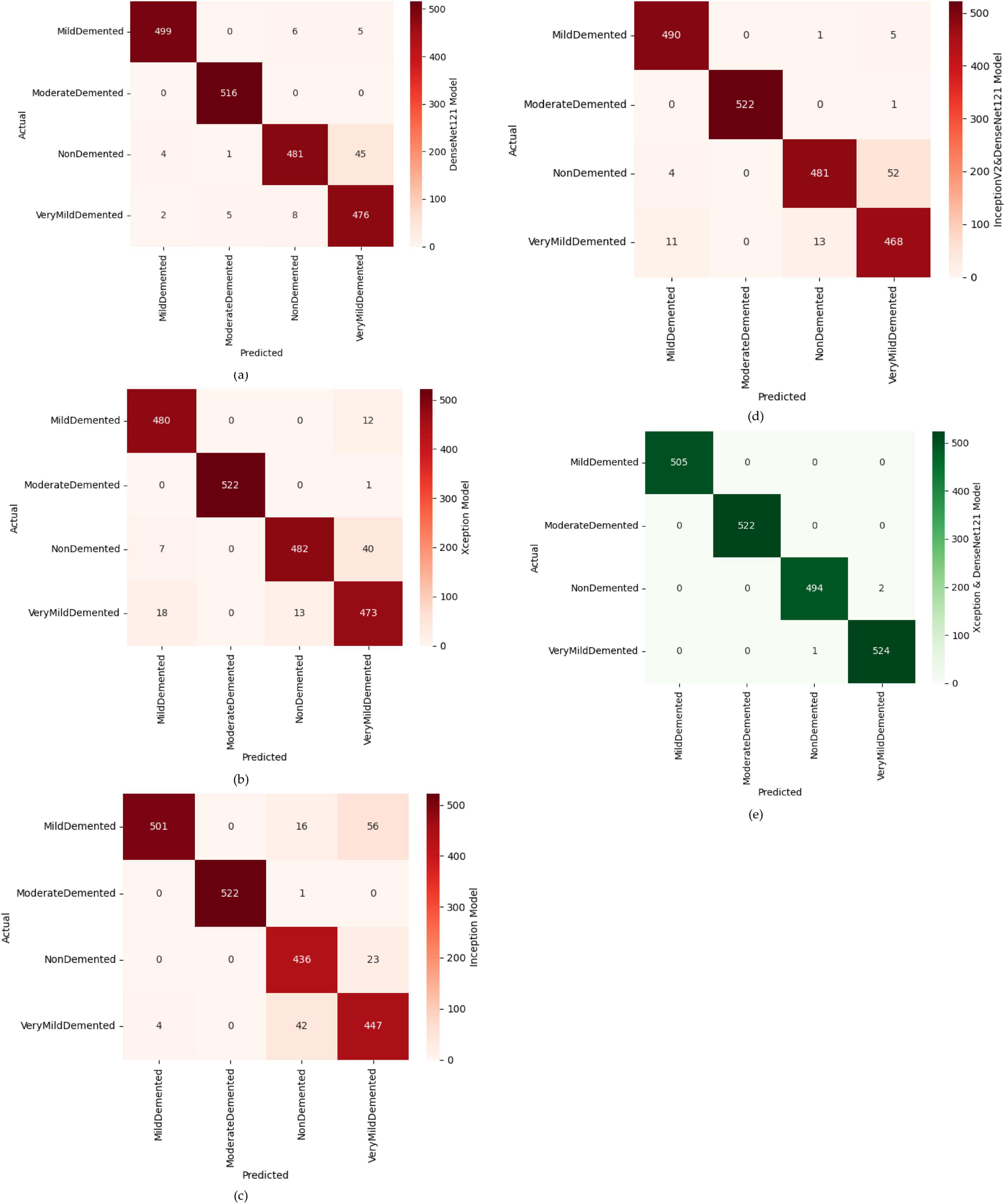
Figure 4. Confusion matrices of different models, where (a) confusion matrix of DenseNet121 model, (b) confusion matrix of Xception model, (c) confusion matrix of inception model, (d) confusion matrix of InceptionV2&DenseNet121 model, (e) confusion matrix of Xception&DenseNet121 model.
The performance of various models is greatly impacted by the critical usage of data augmentation strategies in this study. Figure 5 illustrated different curves of respectively accuracy and loss of each model in case of train and validation cases. Table 1 shows a comparison, in term of evaluation metrics, between different models: DenseNet121, Xception, InceptionV3, DenseNet121&InceptionV3 and DenseNet121&Xception. In Table 2, We offer an additional comparison in the AD Dataset between EM with and without the SMOTE approach. We compare results of the proposed model with some state-of-the-art ones in Table 3. In Table 4, we also make a comparison between our proposed model and some other models using the same dataset (MRI images from ADNI dataset). In Figure 6 and Table 5, we investigate the robustness of our Alzheimer’s dataset image classification model through the injection of various types of noise. The goal is to understand how different types and levels of noise affect the performance of the model across different classes. We applied three types of noise to the original images: Gaussian Blur with standard deviations (σ) of 0.2, 0.4, and 0.6 to simulate different levels of blurring, Salt-and-Pepper Noise with probabilities (p) of 0.05, 0.1, and 0.15 to mimic pixel corruption, and Speckle Noise with standard deviations (σ) of 0.1, 0.2, and 0.3 to simulate multiplicative noise. By experimenting with multiple parameter values for each type of noise, we aimed to observe their effects on the classification performance of our model. Our findings highlight the importance of evaluating model robustness against various types and levels of noise. Understanding the impact of noise on classification accuracy is crucial for developing more robust and reliable deep learning models for Alzheimer’s disease diagnosis. To ensure the robustness and generalizability of the proposed model, a 5-fold cross-validation approach was employed in Table 6. The dataset was randomly split into five subsets, and the model was trained and evaluated five times, each time using a different subset as the test set while the remaining four subsets were used for training. This process was implemented with shuffling enabled to ensure randomness and a fixed seed for reproducibility. After each fold, the accuracy was recorded, and the final performance was assessed by calculating the mean and standard deviation of the accuracy across all folds. The cross-validation yielded a mean accuracy of 99.72% and a standard deviation of 0.0141. To gain deeper insights into the discriminative power of the features extracted by the proposed model, dimensionality reduction techniques such as UMAP was applied. Specifically, features were extracted from the penultimate layer of the suggested model and then projected into a 2-dimensional space using UMAP (Uniform Manifold Approximation and Projection). UMAP was configured with 5 neighbors and a minimum distance of 0.3 to balance local and global structure in the data, while preserving the cluster structure. Figure 7 shows the resulting 2D scatter plot in the proposed model, in DenseNet121 model and the Xception model.
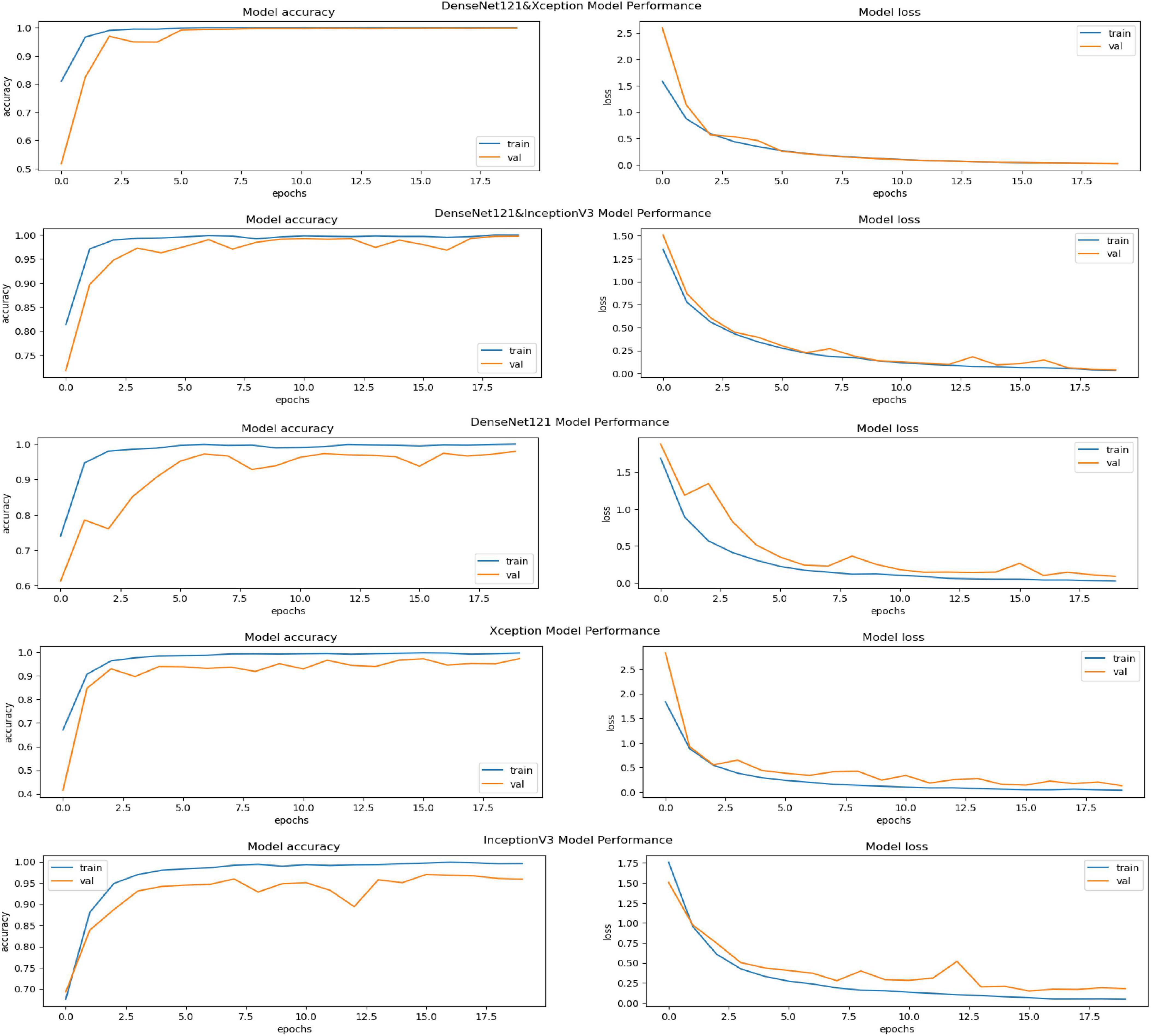
Figure 5. Accuracy and loss curves for different models.

Table 2. Comparison between two proposed approaches (with and without SMOTE Technique).
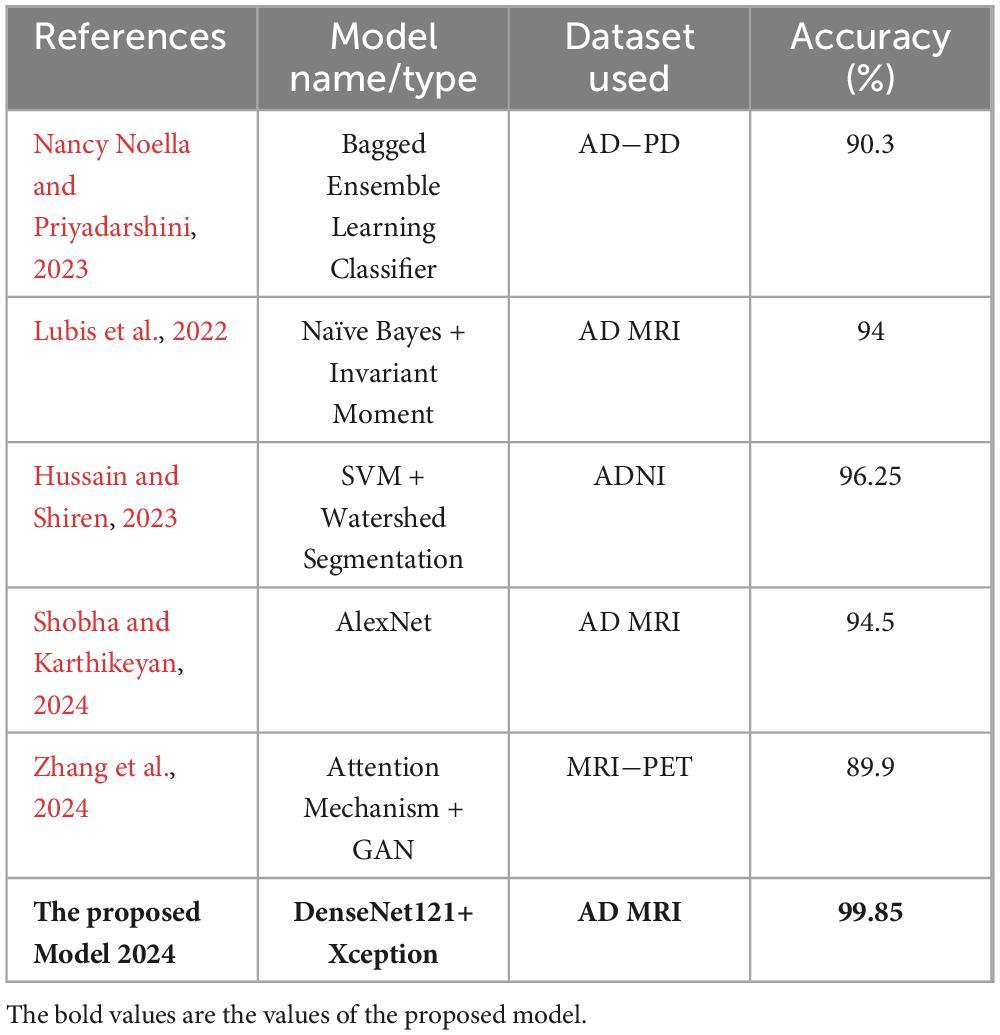
Table 3. Comparison between the proposed model and state of the art models.
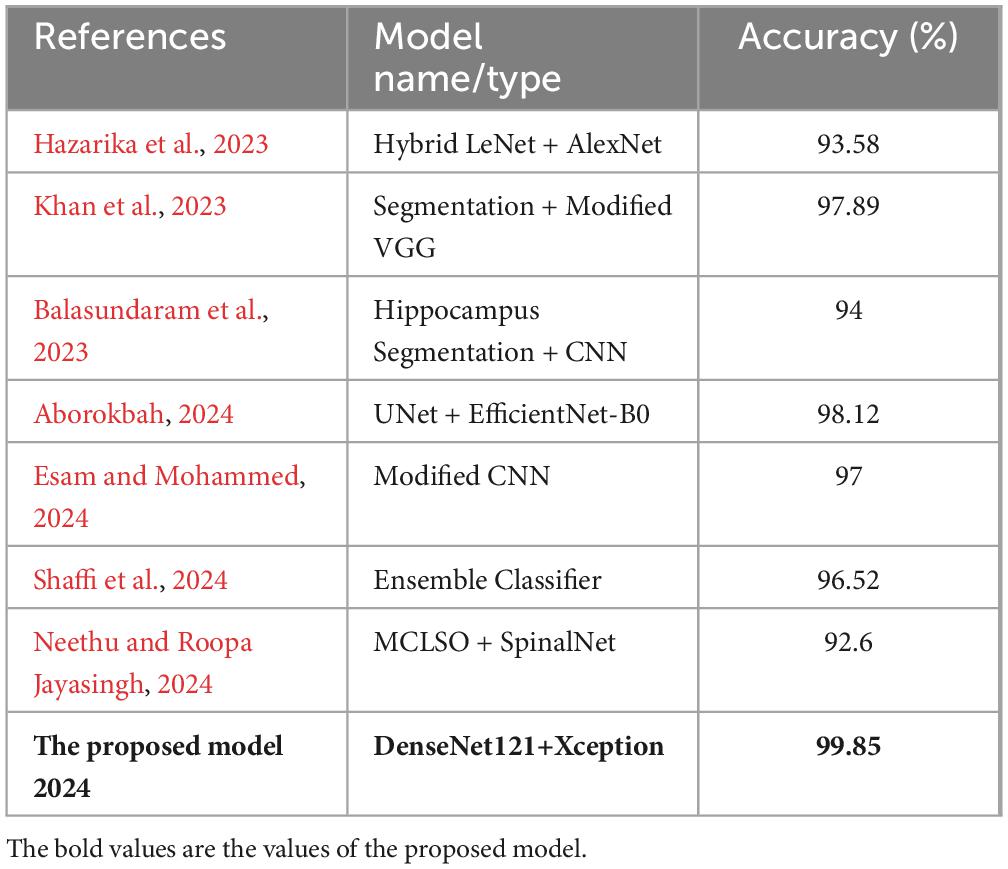
Table 4. Comparison between the proposed model and state of the art models applied on MRI images from ADNI dataset.
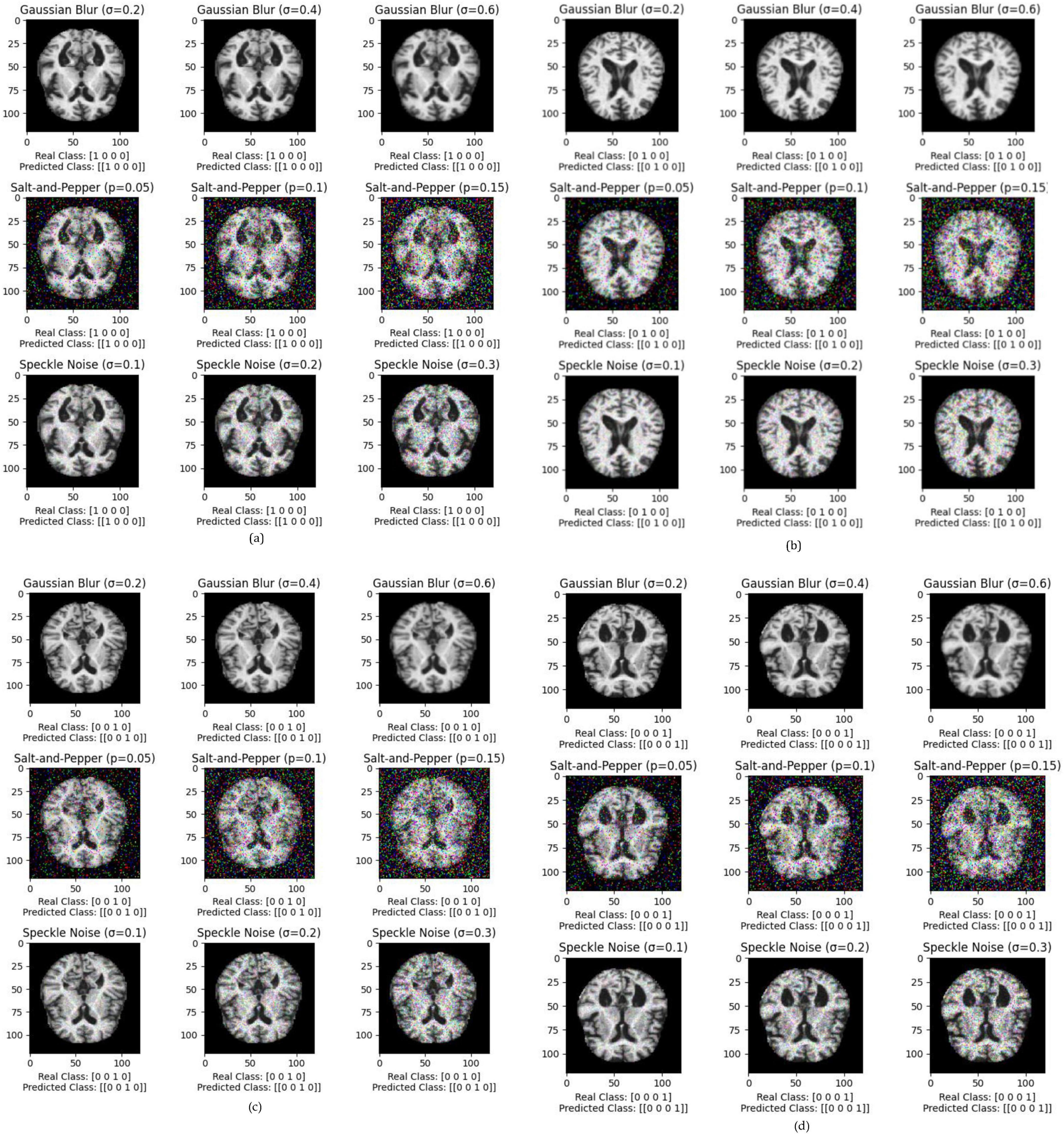
Figure 6. Exploring the impact of Gaussian Blur (σ = 0.2, 0.4, 0.6), salt-and-pepper noise (p = 0.05, 0.1, 0.15), and speckle noise (σ = 0.1, 0.2, 0.3) on Alzheimer’s dataset image classification for each class, where (a) impact of noises in Class 1, (b) impact of noises in Class 2, (c) impact of noises in Class 3, (d) impact of noises in Class 4.
Table 5. Impact of various noise types on Alzheimer’s dataset image classification: all predicted classes match real classes.

Table 6. Cross-validation technique.
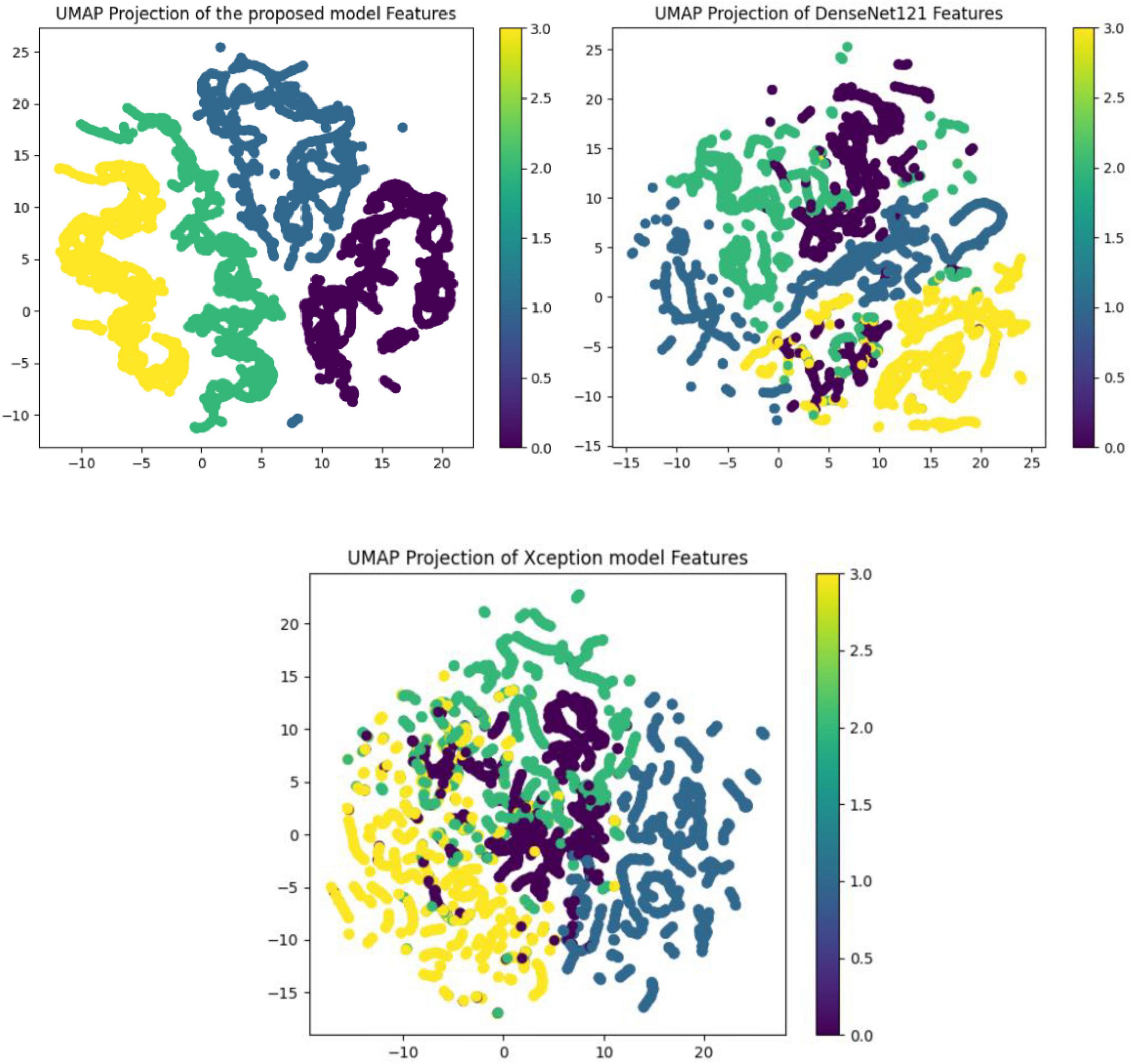
Figure 7. UMAP projection of extracted features: visualization of class separation in each model.
5 Discussion
The proposed hybrid model integrates DenseNet121 and Xception architectures, leveraging their unique strengths to improve the classification of Alzheimer’s disease using MRI images. The approach centers on freezing the pre-trained layers of these models to retain their pre-learned features while preventing the model from becoming overly complex or prone to overfitting. This combination of architectures is particularly appropriate for medical imaging tasks due to their proven success in domains such as breast and brain image classification. By freezing the pre-trained layers, the model benefits from the robust feature extraction capabilities of DenseNet121 and Xception while still allowing the new layers to adapt specifically to Alzheimer’s MRI data.
An essential enhancement to this approach is the application of SMOTE (Synthetic Minority Over-sampling Technique), which addresses class imbalance by generating synthetic examples for underrepresented classes. This results in a more balanced training dataset, allowing the model to better generalize across all classes. The model’s performance improvement, especially in correctly classifying minority classes, demonstrates the effectiveness of SMOTE in reducing bias and improving overall accuracy. This method enhances the model’s ability to identify complex features in the minority classes, which is crucial for a more equitable classification performance. Moreover, the model’s ability to remain robust under noisy conditions, such as Gaussian blur and salt-and-pepper noise, showcases its reliability for real-world medical imaging applications. Noise is an inherent challenge in medical images due to factors like equipment limitations or patient movement, and a model that can maintain high accuracy under these conditions is vital for clinical deployment. The robustness observed across various noise types highlights the model’s resilience, underscoring its potential for reliable clinical use. The hybrid model’s architecture, which balances DenseNet121’s dense connections and Xception’s computational efficiency through depthwise separable convolutions, contributes to an effective extraction and processing of features from MRI images. This synergy between the two models results in a powerful classifier that captures complex patterns while maintaining reasonable computational costs. Nevertheless, the increased complexity and resource demands present challenges, particularly in terms of training time and memory requirements. Future research could explore optimization techniques like pruning and quantization to reduce model size and improve efficiency without sacrificing performance.
In conclusion, the proposed hybrid model effectively capitalizes on the strengths of both DenseNet121 and Xception while addressing key challenges like class imbalance and noise robustness. While the model exhibits improved performance and robustness, future work should focus on further optimization and exploration of complementary architectures to enhance computational efficiency and scalability for broader clinical application.
6 Conclusion and recommendations
6.1 Conclusion
In this long work, we used a large Alzheimer’s disease (AD) dataset to carefully assess the performance of five different models: DenseNet121, Xception, InceptionV3, DenseNet121&InceptionV3, and DenseNet121&Xception. Beyond a simple evaluation, we also suggested new, altered architectures for DenseNet121, InceptionV3, MobileNetV2, and InceptionV3. The most notable accomplishment is the exceptional accuracy of our model, which achieved an astounding 99.85% inside the AD dataset. This notable enhancement marks a major advancement in our newly suggested architecture’s ability to classify and detect things. By utilizing these cutting-edge neural networks, we support the continuous endeavors to improve patient care and early AD diagnosis. Our results highlight the potential utility of transfer learning techniques in medical imaging, underscoring the significance of ongoing innovation in the battle against Alzheimer’s.
6.2 Recommendations
– Further Validation on External Datasets: Although the model performs remarkably well on the current AD dataset, it is essential to validate its generalizability by testing it on external and more diverse datasets, particularly those from different populations or imaging sources.
– Incorporate Explainability Methods: For clinical adoption, incorporating explainability techniques (e.g., Grad-CAM, SHAP) would help provide insights into the decision-making process of the model, ensuring transparency and fostering trust among healthcare professionals.
– Optimization for Real-Time Deployment: Investigating lightweight versions of the hybrid model could make it more suitable for real-time deployment in clinical settings where computational resources may be limited. This could involve pruning, quantization, or the integration of more efficient architectures like MobileNetV2.
– Broader Clinical Applications: Given the success in Alzheimer’s classification, the hybrid architecture could be adapted and tested for other neurodegenerative diseases, such as Parkinson’s and Huntington’s disease, thereby broadening its impact on early diagnosis across a range of conditions.
– Ongoing Research in Transfer Learning: Continuous refinement of transfer learning approaches should be pursued to stay ahead in the rapidly evolving field of medical imaging. Exploration of novel pre-training strategies on larger, more diverse medical datasets could further boost performance in specialized tasks.
Data availability statement
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found below: https://www.kaggle.com/datasets/tourist55/alzheimers-dataset-4-class-of-images.
Author contributions
HS: Conceptualization, Data curation, Formal analysis, Funding acquisition, Investigation, Methodology, Project administration, Resources, Software, Visualization, Writing – original draft, Writing – review and editing. AB: Conceptualization, Formal analysis, Methodology, Writing – review and editing. SA: Formal analysis, Investigation, Methodology, Project administration, Software, Supervision, Validation, Visualization, Writing – original draft, Writing – review and editing. MS: Investigation, Project administration, Resources, Supervision, Validation, Visualization, Writing – original draft, Writing – review and editing.
Funding
The author(s) declare that no financial support was received for the research, authorship, and/or publication of this article.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The reviewer [ZM] declared a shared affiliation with the authors to the handling editor at the time of review.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Aborokbah, M. (2024). “Alzheimer’s disease MRI classification using EfficientNet: A deep learning model,” in Proceedings of the 2024 4th international conference on applied artificial intelligence (ICAPAI), (New York, NY: IEEE), 1–8.
Al Shehri, W. (2022). Alzheimer’s disease diagnosis and classification using deep learning techniques. PeerJ Comput. Sci. 8:e1177. doi: 10.7717/peerj-cs.1177
Ali, E., Sadek, S., and El Nashef, G. (2024). Advanced integration of machine learning techniques for accurate segmentation and detection of Alzheimer’s disease. Algorithms 17:207.
Balaji, P., Chaurasia, M., Bilfaqih, S., Muniasamy, A., and Alsid, L. (2023). Hybridized deep learning approach for detecting Alzheimer’s disease. Biomedicines 11:149. doi: 10.3390/biomedicines11010149
Balasundaram, A., Srinivasan, S., Prasad, A., Malik, J., and Kumar, A. (2023). Hippocampus segmentation-based Alzheimer’s disease diagnosis and classification of MRI images. Arab. J. Sci. Eng. 58, 1–17. doi: 10.1007/s13369-022-07538-2
Bamber, S. S., and Vishvakarma, T. (2023). Medical image classification for Alzheimer’s using a deep learning approach. J. Eng. Appl. Sci. 70:54. doi: 10.1186/s44147-023-00211-x2
Chawla, N., Bowyer, K., Hall, L., and Kegelmeyer, W. (2002). SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 16, 321–357.
Ching, W. P., Abdullah, S., and Shapiai, M. I. (2024). Transfer learning for Alzheimer’s disease diagnosis using efficientnet-B0 convolutional neural network. J. Adv. Res. Appl. Sci. Eng. Technol. 35, 181–191.
Chollet, F. (2017). “Xception: Deep learning with depthwise separable convolutions,” in Proceedings of the IEEE conference on computer vision and pattern recognition, (Berlin), 1251–1258.
Esam, S., and Mohammed, A. (2024). “Alzheimer’s disease classification for MRI images using convolutional neural networks,” in Proceedings of the 2024 6th International Conference on Computing and Informatics (ICCI), (Berlin: IEEE), 01–05.
Gupta, P., and Mesram, S. (2022). AlexNet and DenseNet-121-based hybrid CNN architecture for skin cancer prediction from dermoscopic images. Int. J. Res. Appl. Sci. Eng. Technol. 10, 540–548.
Hazarika, R., Maji, A. K., Kandar, D., Jasinska, E., Krejci, P., Leonowicz, Z., et al. (2023). An approach for classification of Alzheimer’s disease using deep neural network and brain magnetic resonance imaging (MRI). Electronics 12:676.
Hossin, M., and Sulaiman, M. N. (2015). A review on evaluation metrics for data classification evaluations. Int. J. Data Min. Knowl. Manag. Process 5:2859.
Hussain, G., and Shiren, Y. (2023). Identifying Alzheimer disease dementia levels using machine learning methods. arXiv [Preprint]. arXiv:2311.01428.
Khan, R., Akbar, S., Mehmood, A., Shahid, F., Munir, K., Ilyas, N., et al. (2023). A transfer learning approach for multiclass classification of Alzheimer’s disease using MRI images. Front. Neurosci. 16:1050777. doi: 10.3389/fnins.2022.1050777
Kingma, D. P., and Jimmy, B. (2014). Adam: A method for stochastic optimization. arXiv [Preprint] 1–15. arXiv:1412.6980.
Lubis, A. I., Sibagariang, S., and Ardi, N. (2022). “Classification of Alzheimer disease from MRI image using combination naïve bayes and invariant moment,” in Proceedings of the 5th international conference on applied engineering, ICAE 2022, (Batam: European Alliance for Innovation), 100.
Mahmud, T., Barua, K., Barua, A., Das, S., Basnin, N., Shahadat, M., et al. (2023). “Exploring deep transfer learning ensemble for improved diagnosis and classification of alzheimer’s disease,” in Proceedings of the international conference on brain informatics, (Cham: Springer Nature Switzerland), 109–120.
Mohammed, B. A., Senan, E. M., Rassem, T., Makbol, N. M., Alanazi, A. A., Al-Mekhlafi, Z. G., et al. (2021). Multi-method analysis of medical records and MRI images for early diagnosis of dementia and Alzheimer’s disease based on deep learning and hybrid methods. Electronics 10:2860.
Nancy Noella, R., and Priyadarshini, J. (2023). Machine learning algorithms for the diagnosis of Alzheimer and Parkinson disease. J. Med. Eng. Technol. 47, 35–43. doi: 10.1080/03091902.2022.2097326
Neethu, M., and Roopa Jayasingh, J. (2024). K-Net based segmentation and manta crow light spectrum optimization enabled DNFN for classification of Alzheimer’s disease using MRI images. Multimedia Tools Appl. 86, 1–38.
Raza, N., Naseer, A., Tamoor, M., and Zafar, K. (2023). Alzheimer disease classification through transfer learning approach. Diagnostics (Basel) 13:801. doi: 10.3390/diagnostics13040801
Shaffi, N., Subramanian, K., Vimbi, V., Hajamohideen, F., Abdesselam, A., and Mahmud, M. (2024). Performance evaluation of deep, shallow and ensemble machine learning methods for the automated classification of Alzheimer’s disease. Int. J. Neural Syst. 34:2450029. doi: 10.1142/S0129065724500291
Shobha, S., and Karthikeyan, B. R. (2024). Classification of Alzheimer’s disease using transfer learning and support vector machine. Int. J. Intell. Syst. Appl. Eng. 12, 498–508.
Thayumanasamy, I., and Ramamurthy, K. (2022). Performance analysis of machine learning and deep learning models for classification of Alzheimer’s disease from brain MRI. Traitement. Signal 39:58.
You, Z., Zeng, R., Lan, X., Ren, H., You, Z., Shi, X., et al. (2020). Alzheimer’s disease classification with a cascade neural network. Front. Public Health 8:584387. doi: 10.3389/fpubh.2020.584387
Keywords: Alzheimer’s disease (AD), pretrained networks (PN), evaluation metrics (EM), SMOTE, data augmentation (DA)
Citation: Slimi H, Balti A, Abid S and Sayadi M (2024) A combinatorial deep learning method for Alzheimer’s disease classification-based merging pretrained networks. Front. Comput. Neurosci. 18:1444019. doi: 10.3389/fncom.2024.1444019
Received: 04 June 2024; Accepted: 23 September 2024;
Published: 17 October 2024.
Edited by:
Jinwei Xing, Google, United StatesReviewed by:
Moez Bouchouicha, Université de Toulon, FranceZouhair Mbarki, Tunis University, Tunisia
Hao Jia, University of Vic - Central University of Catalonia, Spain
Copyright © 2024 Slimi, Balti, Abid and Sayadi. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Houmem Slimi, cy5ob3VtZW1AZ21haWwuY29t