 Xue-Mei Dong
Xue-Mei Dong Xudong Kong
Xudong Kong- Collaborative Innovation Center of Statistical Data Engineering, Technology & Application, School of Statistics and Mathematics, Zhejiang Gongshang University, Hangzhou, China
When the human brain learns multiple related or continuous tasks, it will produce knowledge sharing and transfer. Thus, fast and effective task learning can be realized. This idea leads to multi-task learning. The key of multi-task learning is to find the correlation between tasks and establish a fast and effective model based on these relationship information. This paper proposes a multi-task learning framework based on stochastic configuration networks. It organically combines the idea of the classical parameter sharing multi-task learning with that of constraint sharing configuration in stochastic configuration networks. Moreover, it provides an efficient multi-kernel function selection mechanism. The convergence of the proposed algorithm is proved theoretically. The experiment results on one simulation data set and four real life data sets verify the effectiveness of the proposed algorithm.
1 Introduction
In supervised machine learning, we often encounter situations that establishing models for several related tasks, such as searching cancer sites, identifying cancer types, judging cancer stages and so on, based on cancer image data. Generally, these tasks are undertaken separately, which we refer to as single-task supervised learning (STSL) in traditional machine learning (Ben-David and Schuller, 2003). These models do not consider the correlation among multiple tasks so some common information in model parameters or data features is lost. In particular, when the training sample size of a single task is insufficient, it is difficult for STSL to capture enough information, which results in poor generalization performance. Multi-task supervised learning (MTSL) provides a solution for such a situation. It improves the performance of each task by setting shared representations among related tasks (Baxter, 2000; Argyriou et al., 2007; Liu et al., 2017). In a sense, a very important reason why human beings can learn based on a small number of samples is that human beings can make full use of various senses to obtain enough information and synthesize relevant information. MTSL is one of the ways to realize this idea.
Classical MTSL can be roughly divided into two categories, namely, MTSL based on constraint sharing and MTSL based on parameter sharing. In relation to the first method, Argyriou et al. (2008) proposed the MTL-L21 based on regularization strategies, that was achieved by adding a regularization term for all the tasks’ objective function coefficients on the cost function. But this method performs poorly when data features have the problem of collinearity. To reduce the impact of this problem, Chen et al. (2012) added a quadratic regularization term for all the tasks’ objective function coefficients based on MTL-L21. In 2015, Duong et al. (2015) used L2 distance to regularize the parameters in their multi-task neural networks, so that each task has similar but different model parameters. In 2017, Yang and Hospedales (2017) used the trace norm to implement Duong’s model. In 2019, Oliveira et al. (2019) attempted to conceive a group LASSO with asymmetric transference formulation in multi-task learning, looking for the best of both worlds in a framework that admits the overlap of groups. Since all of these MTSL methods need to learn sparse features, their performance is not ideal when the data has few features. The MTSL methods based on parameter sharing (Caruana, 1997; Jacob et al., 2009) are not affected by this problem. In 1997, Caruana (Caruana, 1997) proposed a MTSL method (MTL) based on backpropagation neural networks. He mirrored the correlation information by sharing the input and hidden layer neurons among different tasks. In 1998, Lecun et al. (1998) used convolutional neural networks, named as LeNet-5, for document recognition on the basis of MTL. Their results clearly demonstrated the advantages of training a recognizer at the word level, rather than training it on presegmented, hand-labeled, isolated characters. In 2018, Ma et al. (2018) proposed multi-gate mixture-of-experts (MMoE), which adapted the mixture-of-experts (MoE) structure to multi-task learning by sharing the expert submodels across all tasks, while also had a gating network trained to optimize each task. In 2021, Zhang et al. (Zhang et al., 2021) developed a programming framework, AutoMTL, which generates compact multi-task models given an arbitrary input backbone convolutional neural network model and a set of tasks. However, these methods have high computational complexity and poor learning performance when the training samples are insufficient.
To address the aforementioned problems, this paper proposes a MTSL method based on a constraint sharing framework of stochastic configuration networks (SCNs) proposed by Wang et al. (Wang and Li, 2017a; Wang and Li, 2017b) Instead of the complex gradient descent method for solving the weight parameters of hidden layer nodes in general neural networks, SCNs use a supervision mechanism to stochastically configure these parameters. This stochastic configuration mechanism greatly reduces the computational complexity. Inspired by this idea, we establish a multi-task supervised learning algorithm based on stochastic configuration radial basis networks (MTSL-SCRBN). The main contributions of this study are as follows.
1. We combine constraint sharing of SCNs and parameter sharing of MTSL organically. The shared parameters are stochastically configured under certain constraint, which has low computational complexity. At the same time, to improve learning performance, the radial basis functions (Powell, 1987; Broomhead and Lowe, 1988) with different scale parameters are used as the basis functions to replace the original sigmoid functions of SCNs.
2. Two types of difficult to choice hyper parameters of the proposed model, the scale parameters and the centers of the radial basis functions, are stochastically configured during the learning process.
The rest of the paper is organized as follows. In Section 2, we briefly review MTL-L21, MTEN, MTL, and SCNs. Section 3 details our proposed algorithm MTSL-SCRBN and proves its convergence. The experimental results of these algorithms on one simulation data set and five real data sets are detailed in Section 4. Section 5 summarizes this paper.
2 Related Work
Firstly, we introduce some notations. Suppose that there are M supervised learning tasks. The samples of the m-th task are given by,
where
2.1 Multi-Task Learning Methods Based on Constraint Sharing
Inspired by group sparsity, Argyrios et al. (Argyriou et al., 2008) proposed the MTL-L21 method to learn the correlation among multiple tasks under a regularization strategy. It can be described as the following optimization problem,
where
When data features have the problem of collinearity, MTL-L21 will have an unstable prediction performance. Xi Chen et al. (Chen et al., 2012) proposed the MTEN method by adding another quadratic regularization term for the objective function coefficients of all tasks on the basis of MTL-L21. It can be described as the following optimization problem,
where ρ ∈ [0, 1] represents the elastic net mixing parameter. For the input
In the case of insufficient data features and data size, the two algorithms MTL-L21 and MTEN cannot obtain enough information by learning sparse features, which leads to poor prediction performance.
2.2 Multi-Task Learning Methods Based on Parameter Sharing
Caruana (1997) implemented MTSL on backpropagation nets by sharing input and hidden layer neurons among different tasks. Essentially, this method optimizes the choice of function space by the correlation among tasks and obtains better internal weight parameters.
Figure 1 shows the process of traditional backpropagation nets to deal with four related tasks. This method ignores the information among related tasks. Especially in the case of insufficient data samples, these models may have problems such as over-fitting.
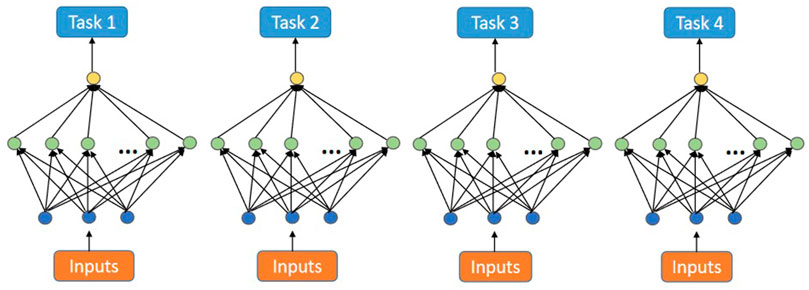
FIGURE 1. Single-task backpropagation nets.
Figure 2 shows the multi-task backpropagation net (MTL) conceived by Caruana. In MTL, each task shares input and hidden layer neurons.
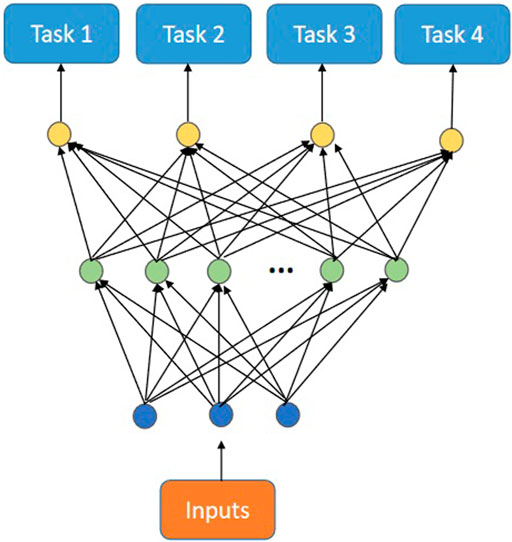
FIGURE 2. The multi-task backpropagation net.
Compared with the data form given in Eq. 1, the data form suitable for MTL is that different tasks have the same input,
and the output is,
MTL can be described as follows
where S is the number of hidden layer nodes,
From a mathematical point of view, the essence of the backpropagation net is the gradient descent algorithm. In single-task supervised learning, the backpropagation net may fall into local optimum. However, in multi-task supervised learning, the local optimum of different tasks is in different positions, and the interaction among tasks can help the hidden layer to escape from local optimums (Caruana, 1997).
2.3 Stochastic Configuration Networks
Wang and Li (Wang and Li, 2017a; Wang and Li, 2017b) proposed supervised stochastic configuration networks, and implemented SCNs using three algorithms SC-i (i=I,II,III). SC-i starts with a small network structure (Tin-Yan Kwok and Dit-Yan Yeung, 1997), and uses a supervision mechanism to add hidden layer neurons until the model meets a predetermined error criterion. Since SC-III performs the best of the three algorithms, we next describe the implementation of the SC-III algorithm.
Suppose a SC-III with L − 1 hidden layer nodes has already been constructed, that is,
where
For training data set
if
The leading model
3 Multi-Task Supervised Learning Based on Stochastic Configuration Radial Basis Networks
In this section, we introduce the proposed MTSL-SCRBN algorithm.
3.1 Model Introduction
In order to combine SCNs and MTL organically, we need to change the data form given in Eq. 1. In MTSL-SCRBN, first, we require each task to have a same number of samples, namely, N1 =…= NM =: N. (If the number of samples for each task is different, this requirement can be achieved by random sampling.) Then we merge the input data of different tasks into a new input data, that is, the i-th new input data is
In order to obtain good learning performance, we use the following radial basis function kσ(x, x′) as model’s basis function,
where x is the input, x′ represents the center and σ is the scale parameter.
Suppose f0 = [0, 0, …, 0] ∈ RM, for L = 2, 3, …, it is assumed that a MTSL-SCRBN with L − 1 hidden layer nodes has already been constructed as follows,
where
Denote
Similar to that in SCNs, we introduce a variable ξm,L in our multi-task learning case as follows,
Here
If
The leading model,
will have an improved residual error. Repeat the above steps to add hidden layer nodes until the residual error meets the predetermined error criteria.
The above implementation process of the proposed MTSL-SCRBN algorithm is described as follows.
Algorithm 1. The MTSL-SCRBN algorithm

Notice that in step 19, we calculate the parameter matrix based on the standard least squares method,
where
3.2 The Convergence Theorem of the MTSL-SCRBN Algorithm
We extend the method in (Wang and Li, 2017a) to the multi-task learning framework of this paper and prove the convergence of the proposed algorithm.
Theorem 1. Assume that there are some pk ∈ R+, satisfying
If the basis function
and the external weight parameter vector is evaluated by,
Then, we have limL→+∞‖Y − fL‖F = 0.
Proof of Theorem 1. Define intermediate values
and
Then, the following inequality holds,
Since limL→+∞μL = 0, and 0 < r < 1, we have
Remark 1. Unlike SC-III, we relax the condition for the configuration parameters in the formula (∗). SC-III requires each task to meet the inequality conditions, but MTSL-SCRBN only requires the sum of all tasks to satisfy the inequality condition. The rationality of this condition will also be verified in the experiment results of next section.
4 Experiment Results
In order to show the effectiveness of the proposed algorithm, this section uses the classical STSL algorithms SVM (Cortes and Vapnik, 1995), SC-III (Wang and Li, 2017a) and seven MTSL algorithms MTSL-SCRBN, MTL (Caruana, 1997), MTEN (Chen et al., 2012), DMTRL (Yang and Hospedales, 2017), MMoE (Ma et al., 2018), GAMTL (Oliveira et al., 2019), AUTOMTL (Zhang et al., 2021) to perform comparative experiments. All calculations are conducted using Python 3.6.5 on a computer with 2.60 GHz CPU and 8 GB RAM. The input features are scaled into [ − 1, 1] and the output remains unchanged. All the results reported in this paper take averages over 20 independent trials, except for the SVM and MTEN algorithms, which have fixed experiment results. The accuracy (ACC) and root mean square error (RMSE) are chosen as the classification and regression evaluation indicators, where
with
For different data sets, some algorithms used in the following experiments can stochastically configure hyperparameters within specified ranges or determine parameters by cross-validation. Table 1 gives the specific selection range of each parameter.

TABLE 1. Parameter description.
4.1 Experimental Results and Analysis on Simulated Data
The simulation data set selected in this paper is generated by the following five functions, which we refer as five tasks,
Figure 3 depicts the distributions of five functions on [0, 1]. As we can see, when the independent variables of the five functions are the same, the function values follow similar trends. Therefore, learning the function values of five functions with the same independent variable can be regarded as a multi-task learning. Here, we independently extract 100 one-dimensional input data from the same uniform distribution, then calculate the corresponding function values according to these five functions, and add white Gaussian noise with a standard deviation of 0.01 to form 100 five-dimensional output data. In the following experiments, we randomly select 70% of the data as training data and 30% of the data as test data. From the figures of the five functions, it can be seen that only 70 training samples are not enough to achieve good single-task learning results. We verify this point by experimenting with single-task and multi-task algorithms.
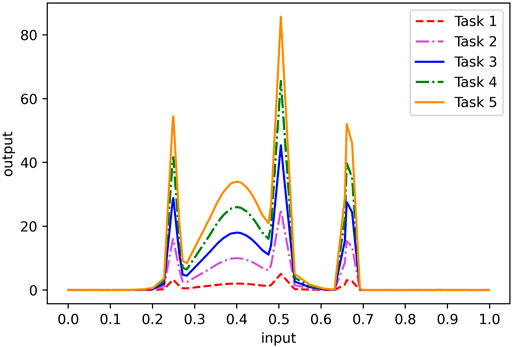
FIGURE 3. Distribution of the simulation data set.
Firstly, we compare the learning performance of the proposed MTSL-SCRBN with other two STSL algorithms, SVM and SC-III, on five tasks. For MTSL-SCRBN, these five tasks are combined to learn together. The training and test RMSEs on five tasks for these three methods are given in Table 2. Clearly, the proposed multi-task learning model can product better performance on each task than the two STSL models, which only use 70 samples to learn each task independently. Furthermore, we show the learning effects of the three algorithms on Task 1 in Figure 4. It is can be seen that the proposed MTSL-SCRBN has good learning performance where the data changes dramatically.

TABLE 2. The results of MTSL-SCRBN, SC-III and SVM on the simulation data set.
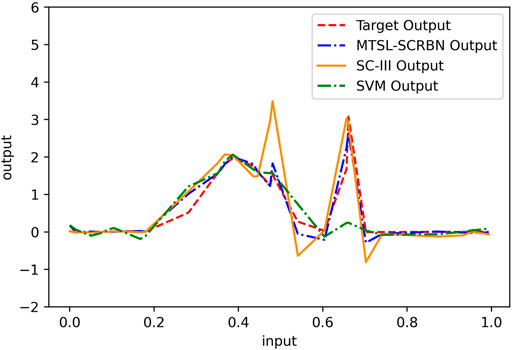
FIGURE 4. Prediction performance of MTSL-SCRBN, SC-III and SVM on Task 1 of simulation data set.
Next, the comparison results of three MTSL algorithms, MTSL-SCRBN, MTL, MTEN, on the simulation data set are recorded in Table 3 and Figure 5. In Table 3, the values in parentheses represent the standard deviations of 20 experiments’ results. According to these results, compared with MTEN and MTL, the proposed MTSL-SCRBN has better approximation ability.

TABLE 3. The results of MTSL-SCRBN, MTL, MTEN on the simulation data set.
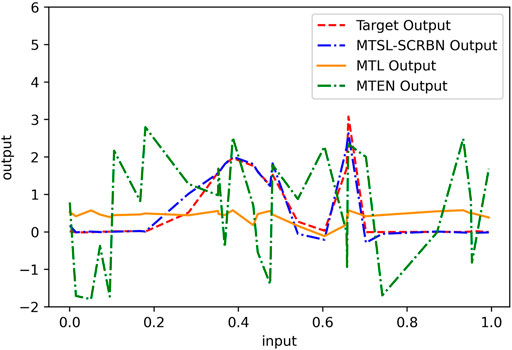
FIGURE 5. Prediction performance of MTSL-SCRBN, MTL, MTEN on Task 1 of simulation data set.
4.2 Experimental Results and Analysis on Benchmark Datasets
This subsection further compares seven MTSL algorithms on four benchmark datasets. They are MTL, MTEN, DMTRL, MMoE, GAMTL, AUTOMTL and the proposed MTSL-SCRBN. According to the characteristics of data sets and algorithms, different algorithms will be selected for comparative analysis on different data sets. The four benchmark datasets include three regression problems on the stock portfolio performance data set, the bionic robot data set SARCOS and the School data set, one classification problem on the Mnist data set from Yann LeCun1 The basic information of the four datasets are summarized in Table 4.

TABLE 4. Descriptions of benchmark datasets.
Firstly, we compare the performance of MTL, MTEN, DMTRL, MMoE, GAMTL and MTSL-SCRBN on different sizes of three regression data sets. For the three data sets, we randomly choose 15/30/3,500 samples outside the training set as test set, respectively. At the same time, we select 5 tasks, all of which have more than 230 samples, from 139 tasks in School data set. Table 5 below shows the specific experiment results. As we can see, the performance of each algorithm tends to be better and more stable with an increasing number of training samples. Furthermore, the proposed MTSL-SCRBN algorithm exhibits good performance even with a small number of training observations.
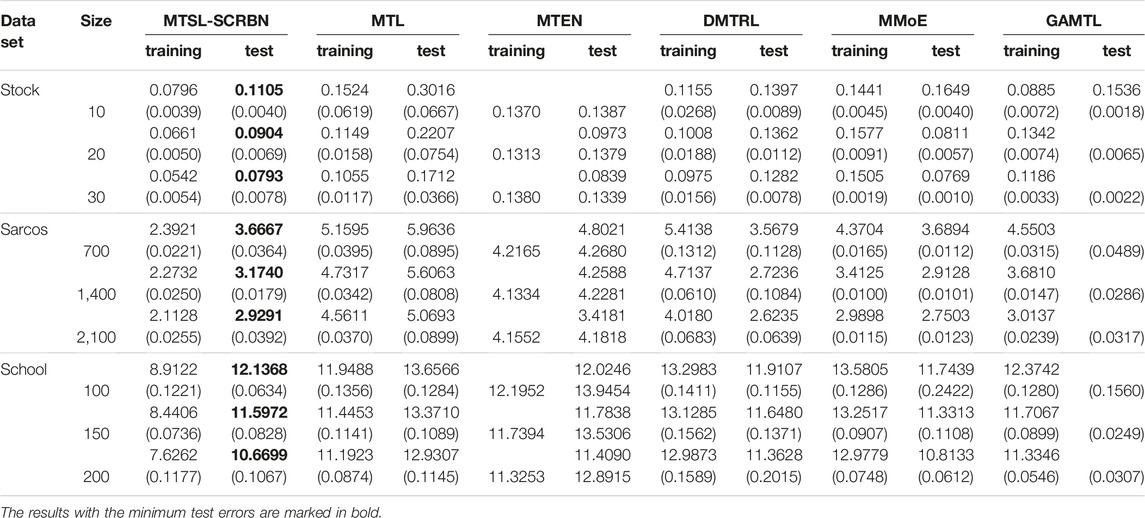
TABLE 5. The comparison results of six MSTL algorithms on three data sets.
Then, in order to further verify the performance of MTSL-SCRBN for classification cases, we compare the results of MTSL-SCRBN, DMTRL, MMoE, GAMTL and AUTOMTL on the Mnist data set. We randomly choose 50/100/150 samples from each task in the Mnist data set as training set, and 10000 samples in the remaining samples as test set. Considering that this is a high dimensional small sample problem, we firstly reduce the dimensionality of the data set, and then use MTSL-SCRBN for training and prediction. There are many dimensionality reduction methods, such as Principal Component Analysis(PCA) (Pearson, 1901), Latent Dirichlet Allocation(LDA) (Blei et al., 2003), Sequential Markov Blanket Criterion (SMBC) (Pratama et al., 2017), Auto Encoder (Hinton and Salakhutdinov, 2006) and so on. Here, we use the performance of the dimensionality-reduced data in the MTSL-SCRBN as the selection criterion, and choose Auto Encoder to reduce the dimension of original data set into 30 dimensions. It can be seen from Table 6 that the performance of MTSL-SCRBN which uses dimensionality reduction data set is a little bit better than that of other Multi-task deep learning algorithms, but as the sample size increases, the performance of the two algorithms gradually approaches.
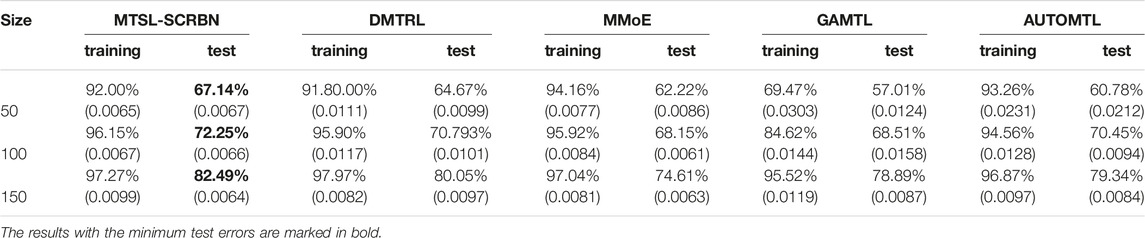
TABLE 6. The accuracy of MTSL-SCRBN, DMTRL, MMoE, GAMTL and AUTOMTL on Mnist data set.
4.3 Comparison Experiment Results for Different Activation Functions
The previous results show that the proposed MTSL-SCRBN algorithm is effective for multi-task learning in the case of small samples. This subsection mainly discusses the impact of selecting different activation functions on algorithm performance. Here we select other three usually used activation functions. They are sigmoid function, Tanh function and ReLU function. After replacing the radial basis functions in MTSL-SCRBN with these three functions respectively, the model names are respectively called MTSL-SCSGM, MTSL-SCTANH and MTSL-SCReLU. We choose to conduct comparative experiments on the Stock and SARCOS data sets.
For different data sets, the parameters contained in each algorithm need to be randomly set or cross verified within a certain range. The specific selection range of each parameter is given in Table 7.

TABLE 7. Parameter description for the four models.
Table 8 depicts the RMSE results of stochastic configuration multi-task learning models based on four different activation functions. Under the training samples with different sample sizes in the two data sets, the MTSL-SCRBN, which based on radial basis functions, has certain advantages over other three models in terms of performance.
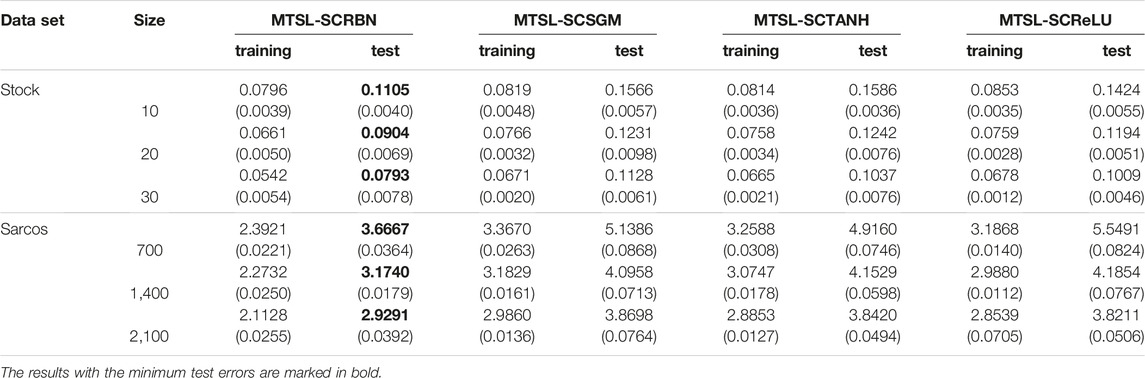
TABLE 8. The comparison results of different activation functions based models on two data sets.
5 Conclusion
In this paper, we propose a multi-task supervised learning framework based on stochastic configuration radial basis network. It can be effectively used in classification and regression problems when a single task has a small number of samples. The series experiment results on the four data sets show the proposed MTSL-SCRBN achieves a good performance compared with some existing methods.
Interesting areas for further directions include using the proposed algorithm in hyperspectral remote sensing image classification and other related research areas, considering the impact of using different activation functions in the network, and trying to explore the range of the sample size of the data set to use the multi-task learning method.
Data Availability Statement
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author.
Author Contributions
X-MD: Conceptualization, Methodology, Formal analysis, Supervision, Project administration. XK: Writing-original draft, Software, Investigation. XZ: Validation, Writing—review and editing.
Funding
This work was supported in part by the Characteristic and Preponderant Discipline of Key Construction Universities in Zhejiang Province (Zhejiang Gongshang University- Statistics) and the special fund for basic business expenses of colleges and universities in Zhejiang Province.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Footnotes
1These four datasets can be obtained from http://archive.ics.uci.edu/ml/datasets/Stock+portfolio+performance, http://gaussianprocess.org/gpml/data, http://bristol.ac.uk/cmm/learning/support/datasets and http://yann.lecun.com/exdb/mnist/, respectively.
References
Argyriou, A., Evgeniou, T., and Pontil, M. (2008). Convex Multi-Task Feature Learning. Mach. Learn 73, 243–272. doi:10.1007/s10994-007-5040-8
Argyriou, A., Evgeniou, T., and Pontil, M. (2007). “Multi-task Feature Learning,” in Advances in Neural Information Processing Systems, 41–48. doi:10.7551/mitpress/7503.003.0010
Ben-David, S., and Schuller, R. (2003). “Exploiting Task Relatedness for Multiple Task Learning,” in Learning Theory and Kernel Machines (Springer), 567–580. doi:10.1007/978-3-540-45167-9_41
Blei, D. M., Ng, A. Y., and Jordan, M. I. (2003). Latent Dirichlet Allocation. J. Mach. Learn. Res. 3, 993–1022. doi:10.1162/jmlr.2003.3.4-5.993
Broomhead, D., and Lowe, D. (1988). Radial Basis Functions, Multi-Variable Functional Interpolation and Adaptive Networks. Malvern, United Kingdom: Royal Signals and Radar Establishment Malvern United Kingdom. Tech. rep.
Chen, X., He, J., Lawrence, R., and Carbonell, J. (2012). “Adaptive Multi-Task Sparse Learning with an Application to Fmri Study,” in Proceedings of the 2012 SIAM International Conference on Data Mining, 212–223. doi:10.1137/1.9781611972825.19
Cortes, C., and Vapnik, V. (1995). Support-vector Networks. Mach. Learn 20, 273–297. doi:10.1007/BF00994018
Duong, L., Cohn, T., Bird, S., and Cook, P. (2015). “Low Resource Dependency Parsing: Cross-Lingual Parameter Sharing in a Neural Network Parser,” in Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, 2, 845–850. Short Papers. doi:10.3115/v1/p15-2139
Hinton, G. E., and Salakhutdinov, R. R. (2006). Reducing the Dimensionality of Data with Neural Networks. Science 313, 504–507. doi:10.1126/science.1127647
Jacob, L., Vert, J., and Bach, F. (2009). “Clustered Multi-Task Learning: A Convex Formulation,” in Advances in Neural Information Processing Systems, 745–752.
Lecun, Y., Bottou, L., Bengio, Y., and Haffner, P. (1998). Gradient-based Learning Applied to Document Recognition. Proc. IEEE 86, 2278–2324. doi:10.1109/5.726791
Liu, T., Tao, D., Song, M., and Maybank, S. J. (2017). Algorithm-dependent Generalization Bounds for Multi-Task Learning. IEEE Trans. Pattern Anal. Mach. Intell. 39, 227–241. doi:10.1109/TPAMI.2016.2544314
Ma, J., Zhao, Z., Yi, X., Chen, J., Hong, L., and Chi, E. (2018). “Modeling Task Relationships in Multi-Task Learning with Multi-Gate Mixture-Of-Experts,” in Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (London, United Kingdom: Association for Computing Machinery), 1930–1939. doi:10.1145/3219819.3220007
Oliveira, S. H. G., Gonçalves, A. R., and Von Zuben, F. J. (2019). “Group Lasso with Asymmetric Structure Estimation for Multi-Task Learning,” in Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI-19 (Macao, China: International Joint Conferences on Artificial Intelligence Organization), 3202–3208. doi:10.24963/ijcai.2019/444
Pearson, K. (1901). Liii. on lines and planes of closest fit to systems of points in space. Lond. Edinb. Dublin Philosophical Mag. J. Sci. 2, 559–572. doi:10.1080/14786440109462720
Powell, M. (1987). Radial Basis Functions for Multivariable Interpolation: A Review. Oxford, United Kingdom: Algorithms for approximation, 143–167.
Pratama, M., Lu, J., Lughofer, E., Zhang, G., and Er, M. J. (2017). An incremental learning of concept drifts using evolving type-2 recurrent fuzzy neural networks. IEEE Trans. Fuzzy Syst. 25, 1175–1192. doi:10.1109/tfuzz.2016.2599855
Tin-Yan Kwok, T., and Dit-Yan Yeung, D. (1997). Objective functions for training new hidden units in constructive neural networks. IEEE Trans. Neural Netw. 8, 1131–1148. doi:10.1109/72.623214
Wang, D., and Li, M. (2017). Robust stochastic configuration networks with kernel density estimation for uncertain data regression. Inf. Sci. 412-413, 210–222. doi:10.1016/j.ins.2017.05.047
Wang, D., and Li, M. (2017). Stochastic configuration networks: Fundamentals and algorithms. IEEE Trans. Cybern. 47, 3466–3479. doi:10.1109/tcyb.2017.2734043
Yang, Y., and Hospedales, T. (2017). “Deep multi-task representation learning: A tensor factorisation approach,” In International Conference on Learning Representations.
Keywords: multi-task learning, neural networks, stochastic configuration, knowledge sharing and transfer, supervised mechanism
Citation: Dong X-M, Kong X and Zhang X (2022) Multi-Task Learning Based on Stochastic Configuration Networks. Front. Bioeng. Biotechnol. 10:890132. doi: 10.3389/fbioe.2022.890132
Received: 05 March 2022; Accepted: 16 June 2022;
Published: 04 August 2022.
Edited by:
Gongfa Li, Wuhan University of Science and Technology, ChinaReviewed by:
Inci M Baytas, Boğaziçi University, TurkeyTiantian He, Agency for Science, Technology and Research (A∗STAR), Singapore
Copyright © 2022 Dong, Kong and Zhang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Xudong Kong, c2ltb25fa29uZ0AxNjMuY29t