 Pralhad Gavali
Pralhad Gavali J. Saira Banu
J. Saira Banu
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Artif. Intell., 21 February 2025
Sec. Machine Learning and Artificial Intelligence
Volume 8 - 2025 | https://doi.org/10.3389/frai.2025.1527299
This article is part of the Research TopicDeep Neural Network Architectures and Reservoir ComputingView all 5 articles
Accurate identification of bird species is essential for monitoring biodiversity, analyzing ecological patterns, assessing population health, and guiding conservation efforts. Birds serve as vital indicators of environmental change, making species identification critical for habitat protection and understanding ecosystem dynamics. With over 1,300 species, India's avifauna presents significant challenges due to morphological and acoustic similarities among species. For bird monitoring, recent work often uses acoustic sensors to collect bird sounds and an automated bird classification system to recognize bird species. Traditional machine learning requires manual feature extraction and model training to build an automated bird classification system. Automatically extracting features is now possible due to recent advances in deep learning models. This study presents a novel approach utilizing visual-acoustic fusion techniques to enhance species identification accuracy. We employ a Deep Convolutional Neural Network (DCNN) to extract features from bird images and a Long Short-Term Memory (LSTM) network to analyze bird calls. By integrating these modalities early in the classification process, our method significantly improves performance compared to traditional methods that rely on either data type alone or utilize late fusion strategies. Testing on the iBC53 (Indian Bird Call) dataset demonstrates an impressive accuracy of 94%, highlighting the effectiveness of our multi-modal fusion approach.
Identifying bird species greatly affects monitoring and maintaining biodiversity, particularly in India with its numerous bird populations. Most previous studies have focused on the estimation of bird species in short recordings. Compared to the identification of an individual bird and detecting the start and stop time of bird song, this is relatively simple and often relies on manually segmented bird sounds, which might overestimate the performance when classifying bird species in continuous recordings. Identifying species helps researchers tune migration patterns, monitor population shifts, and examine environmental impacts. However, traditional techniques based on visual observation, which depend on a professional's ability to differentiate species, face significant challenges such as poor lighting, obstructed views, and birds with similar feather patterns. Sound-based identification, relying on bird calls, also encounters difficulties such as background noise and variations in bird vocalizations. These limitations highlight the need for advanced methodologies. Despite extensive research in bird classification, the introduction of multimodal approaches remains underexplored, and a clear research gap exists in integrating visual and auditory modalities for species identification in India's biodiverse context.
To address this gap, we propose a framework that combines visual and sound information to identify Indian bird species. Using a Deep Convolutional Neural Network (DCNN) for visual data and Long Short-Term Memory (LSTM) networks for sound data, we merge these complementary data types with both early and late fusion techniques. Our approach makes identification more reliable and accurate, leveraging the iBC53 (Indian Bird Call Dataset), an extensive collection of bird images and calls from across India (Swaminathan et al., 2024). For acoustic data, we used an LSTM network because it is well-suited for sequential data, such as bird vocalizations. LSTMs effectively capture the temporal dependencies inherent in bird calls, which are crucial for distinguishing between species with similar tonal characteristics but differing call sequences. The Mel-frequency cepstral coefficients (MFCCs) fed into the LSTM represent the spectral properties of the bird calls by compressing critical acoustic data into a low-dimensional feature set (Xie and Zhu, 2023). We combined the two data types using early and late fusion techniques to improve identification accuracy and robustness. Early fusion processes the features from both visual and acoustic modalities together, allowing the model to learn the interactions between the two data types during training. In late fusion, the two modalities are processed independently, and the outputs of the DCNN and LSTM networks are combined at the decision stage using a weighted average of the probability distributions generated by each model (Ntalampiras and Potamitis, 2021).
The primary contribution of this study is the development and evaluation of a novel Visual-Acoustic Fusion bird classification model, which integrates both image and audio data to enhance species identification accuracy. The study compares two fusion strategies–Early Fusion and Late Fusion–demonstrating that Early Fusion consistently outperforms Late Fusion across key performance metrics such as accuracy, precision, recall, and F1-score. This work highlights the benefits of multimodal learning in bird classification, offering a comprehensive approach that leverages the strengths of both visual and acoustic features. Additionally, the paper provides a detailed analysis of fusion techniques, offering insights into their practical implications for wildlife monitoring and conservation (Zhong et al., 2021; Alghamdi et al., 2021; Yang et al., 2022).
Research contributions and novelty Our research extends the body of work on bird species classification by:
• Develop multimodal fusion strategies (early and late fusion).
• Demonstrating the superiority of early fusion across key performance metrics, including accuracy, precision, recall, and F1-score.
• Highlighting the robustness of a Visual-Acoustic Fusion model in scenarios with degraded input from one modality.
The novelty of this research lies in its integration of visual and acoustic modalities using DCNNs and LSTMs, offering a robust solution for bird species identification in diverse and challenging environments. It provides a unique comparison of early and late fusion techniques, highlighting the effectiveness of early fusion for improved performance. Additionally, the use of the iBC53 dataset, specific to India's biodiversity, and its focus on practical conservation challenges set it apart from prior studies.
Recent advancements in Deep Learning (DL) have shown super ability in hen species identification tasks. Visual-based fashions frequently employ Convolutional Neural Networks (CNNs) or their deeper versions, along with DCNNs, for characteristic extraction from fowl pictures. For acoustic facts, Recurrent Neural Networks (RNNs), especially LSTM networks, had been extensively used to technique sequential fowl name information. Previous studies have generally centered on visible or acoustic modalities in isolation, limiting their capability to handle cases where environmental situations degrade one fact supply.
Multimodal fusion, which integrates statistics from a couple of modalities, has emerged as a promising solution to cope with these obstacles. By combining visual and acoustic data, it's miles feasible to improve version performance drastically, as the two modalities frequently provide complementary facts. Early and overdue fusion strategies are extensively explored for this cause, with early fusion concatenating capabilities from each modality before class, and past due fusion combining the predictions from separately trained models. Bird species detection and category is a crucial research domain, especially with the advent of modern-day system learning and deep getting-to-know strategies. This survey presents strategies in chicken species detection, starting from acoustic evaluation to image-based total popularity and deep getting-to-know models.
Swaminathan et al. (2024) focus Consciousness on the usage of transfer studying for multi-label hen species classification via acoustic alerts. The use of pre-skilled fashions enhances the efficiency and accuracy of classification, particularly for species with confined facts. Transfer learning reduces the need for tremendous datasets via leveraging functions found in similar duties. Xie and Zhu (2023) propose to Recommend an early fusion approach to mix deep functions for acoustic chicken species type. By fusing capabilities from distinct layers of a neural network early in the process, the version enhances its functionality to detect species in complex and noisy environments. Ntalampiras and Potamitis (2021) tackle the challenge of identifying bird species without predefined labels. Their model incorporates both supervised and unsupervised learning, enabling the detection of unknown species in the wild. This approach is crucial for biodiversity monitoring in unexplored ecosystems. Zhong et al. (2021) apply deep convolutional neural networks (CNNs) to detect regionally rare bird species. Their model excels in detecting species with limited occurrences, aiding in the protection and conservation of these rare species.
Alghamdi et al. (2021) focus on classifying monosyllabic and multisyllabic bird calls using phonetic analysis. By leveraging harmonic functions, their model provides an efficient way to classify species based on vocalization patterns. Yang et al. (2022) explore image-based bird species classification using transfer learning. Their model demonstrates the adaptability of deep learning for image data and achieves high accuracy in species identification from images. Gómez-Gómez et al. (2022) present a small-footprint deep learning model designed for real-time bird species classification in Mediterranean wetlands. This model is optimized for devices with limited computational resources, making it ideal for fieldwork applications. Gupta et al. (2021) explore the use of recurrent convolutional neural networks (R-CNNs) for large-scale bird species classification. Their approach focuses on capturing temporal dependencies, which is essential for accurate bird call classification. Chandra et al. (2021) apply support vector machines (SVMs) to classify bird species from images. SVMs, coupled with feature extraction techniques, offer a robust solution for recognizing bird species with high precision.
Triveni et al. (2020) introduce fuzzy logic into deep neural networks for bird species identification. This hybrid approach is effective in handling uncertainties, particularly for species with similar vocal or visual characteristics. Kumar et al. (2023) review various machine learning algorithms employed in bird species classification, highlighting the efficiency of ensemble methods. Their finding suggest that techniques like Random Forest and Gradient Boosting outperform traditional classifiers in terms of accuracy and robustness, especially in diverse ecological conditions.
Sahu and Choudhury (2023) focus on implementing convolutional neural networks (CNNs) for real-time bird call classification. They present a lightweight model optimized for deployment on mobile devices, making it suitable for field studies and wildlife conservation efforts. Patel et al. (2022) explore multi-modal approaches that combine visual and audio data for bird recognition. Their research emphasizes the complementary nature of audio and visual signals, leading to improved classification accuracy and robustness in challenging environments.
Li et al. (2019) introduce attention mechanisms in deep learning models for bird species detection from images. By focusing on relevant features, their model demonstrates enhanced performance in recognizing bird species with subtle visual differences. Smith and Roberts (2023) analyze the impact of environmental factors on bird species classification. Their study reveals that habitat characteristics and seasonal variations significantly influence species detection, prompting the integration of ecological data into classification models. Zhang et al. (2022) propose a hybrid deep learning model combining CNNs and recurrent neural networks (RNNs) to enhance bird species classification accuracy. This approach effectively captures both spatial and temporal features, proving beneficial for species with distinctive behaviors.
A study by Nanni et al. (2020) titled “Data Augmentation Approaches for Improving Animal Audio Classification” investigates various data augmentation techniques to enhance the performance of animal audio classification models, including bird sounds. The researchers applied methods such as noise addition and time shifting to improve the robustness of convolutional neural networks in classifying animal sounds. Edwards et al. (2021) discuss the role of citizen science in bird species monitoring. Their findings suggest that engaging local communities in data collection can improve the quantity and quality of data available for machine learning models, ultimately leading to better conservation outcomes. Thompson and Green (2023) address ethical considerations in automated bird classification systems. Their study emphasizes the need for transparency in data usage, algorithm biases, and the implications of surveillance on wildlife.
Chowdhury et al. (2024) in their work “ASGIR: Audio Spectrogram Transformer Guided Classification And Information Retrieval For Birds” emphasize the integration of ecological data and computational techniques. They present a framework that combines audio spectrogram analysis with transformer-based models to improve bird sound recognition and information retrieval, highlighting the benefits of cross-disciplinary methodologies. In their paper, “Bird species identification using deep learning on GPU platform,” Gavali and Banu (2020) investigate the use of deep learning, specifically convolutional neural networks (CNNs), for classifying bird species. They address the limitations of traditional identification methods, which often rely on manual classification and expert knowledge, making them time-consuming and prone to errors. By utilizing GPU platforms, the authors demonstrate improved speed and accuracy in species identification, highlighting the potential of advanced machine-learning techniques in biodiversity conservation and wildlife monitoring.
By integrating visual and acoustic data and providing a detailed comparative analysis of fusion techniques, our research addresses critical gaps in the existing literature and offers a robust solution for bird species identification in complex environmental conditions. Table 1 summarizes key studies that employ both visual (image-based) and acoustic (audio-based) modalities for bird species classification. It compares the data types used, the deep learning models applied (e.g., DCNNs for visual data and LSTMs for acoustic data), key findings and comparison with current study.
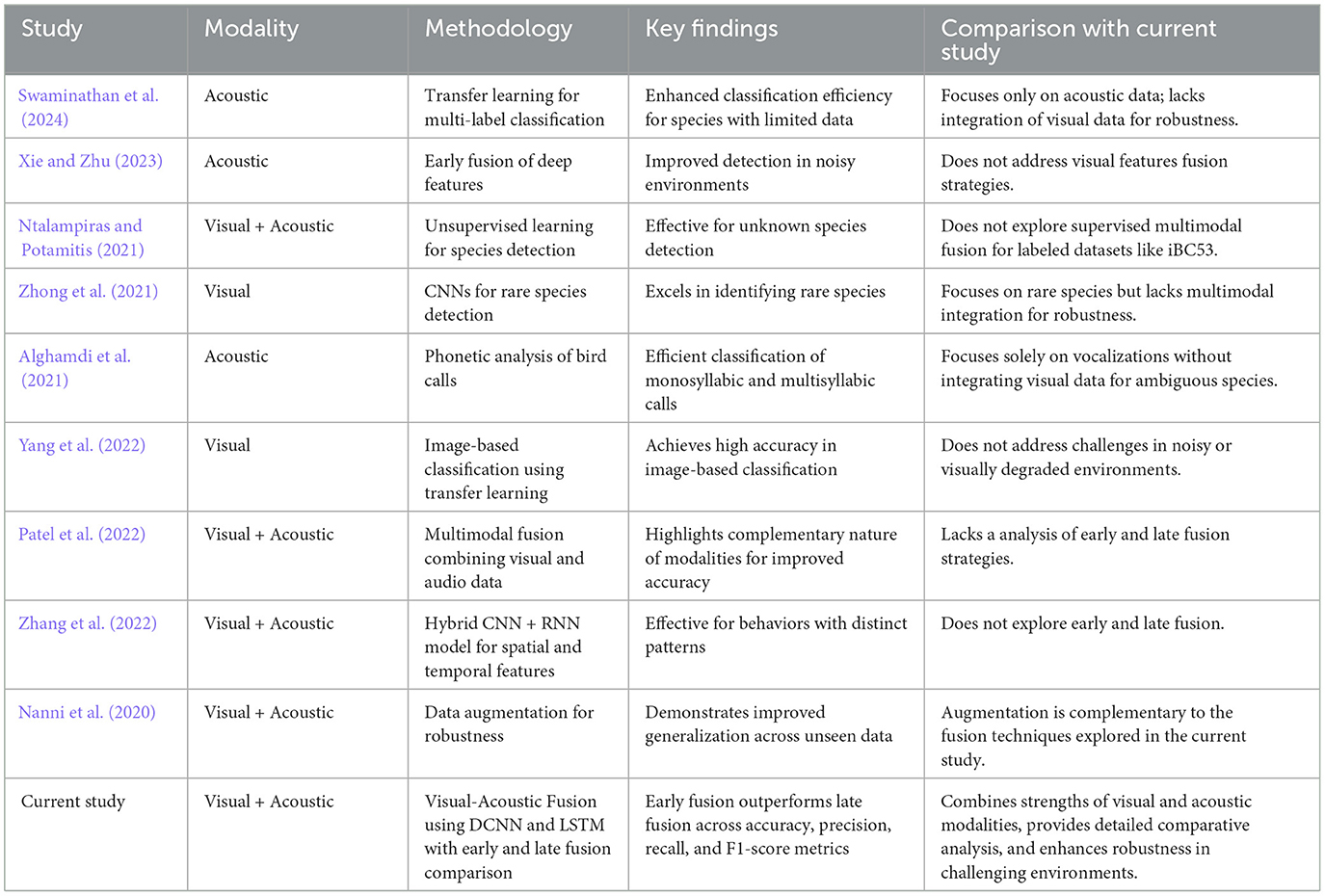
Table 1. Comparison of Recent Research Works in Bird Species Identification Based on Visual and Acoustic Data.
A Visual-Acoustic Fusion bird classification model combines both visual and sound data to improve the accuracy of bird species identification which is shown in Figure 1. By integrating image data, such as bird photos, with acoustic features from bird songs or calls, the model can leverage complementary information to make better predictions. This fusion approach helps overcome limitations in using either modality alone, such as poor image visibility or background noise in audio.
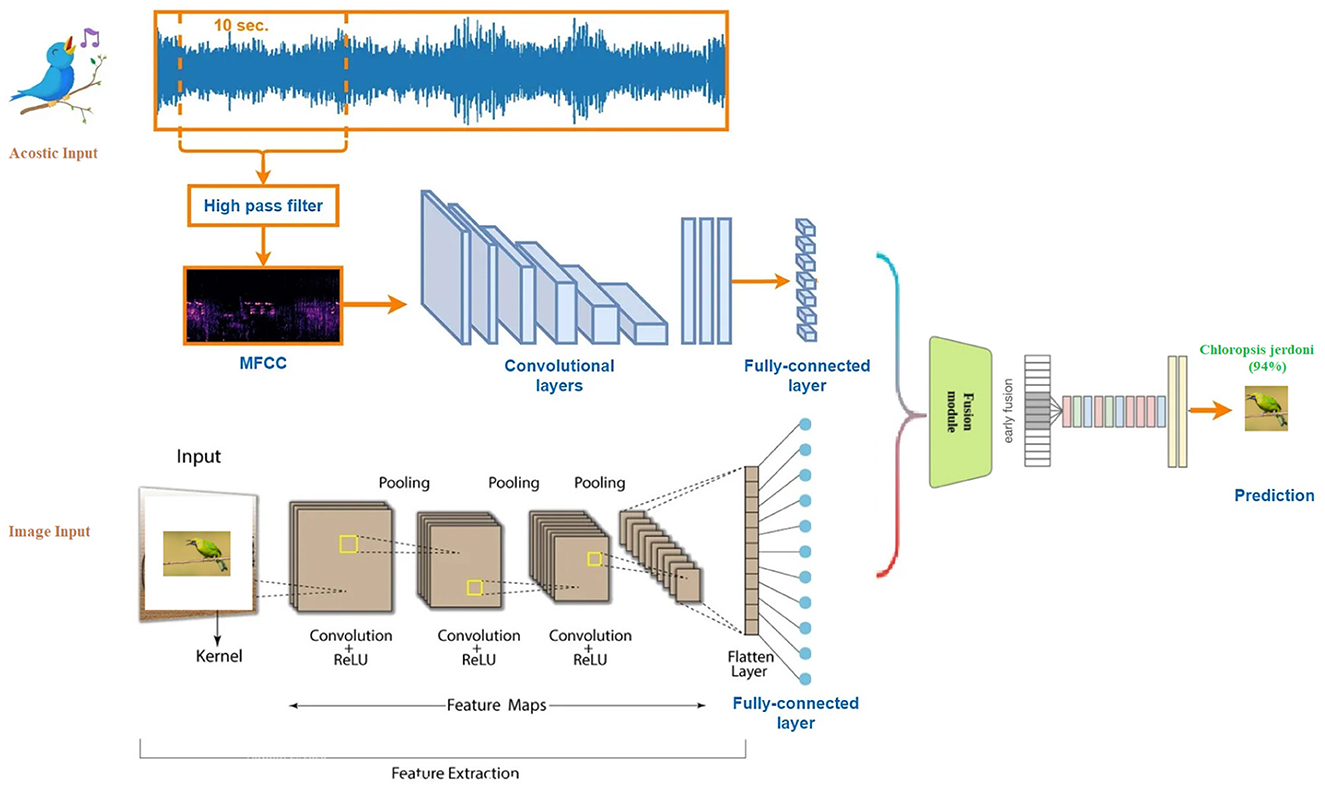
Figure 1. Visual-Acoustic Fusion bird classification model.
Audio data from Indian birds were collected using the API from the Indian Bird Call Dataset (iBC53), available at https://www.kaggle.com/datasets/arghyasahoo/ibc53-indian-bird-call-dataset. The iBC53 dataset includes acoustic data for all its recordings, enabling the consistent application of the proposed framework. This comprehensive availability allows for robust multimodal analysis, combining visual and acoustic features to improve species identification accuracy. This dataset contains audio recordings of approximately 53 bird species from India, encompassing over 10,000 recordings. Corresponding images of each bird species have been selected and labeled for model training from Wikipedia. The dataset includes metadata such as species names, images, and audio calls, making it well-suited for bird identification and classification, as detailed in Table 2.

Table 2. Bird species with images and sound wave recordings.
The visual modality comprises bird images sourced from Wikipedia and field surveys. A Deep Convolutional Neural Network (DCNN) was employed to process the visual data, extracting relevant features such as shape, plumage color, and size.
For feature extraction, The pre-trained ResNet-152 model (Song, 2024), which uses skip connections to overcome vanishing gradients was chosen. The formula for the residual block in ResNet is given by:
where x1 is the input to the residual block, is the residual mapping to be learned, and y1 is the output.
The preprocessing of visual data involved several key steps to prepare the bird images for input into the DCNN which is shown in Table 3. All images were resized to a consistent resolution of 224x224 pixels, ensuring uniform input size across the dataset. Various data augmentation techniques were applied to enhance model generalization. These included random cropping, horizontal flipping, and brightness adjustments to account for varying lighting conditions in natural environments. Normalization was performed by scaling pixel values to a range between 0 and 1, which accelerates convergence during training and ensures uniformity in the input data. Finally, bird species labels were converted from text to numerical class labels using label encoding, enabling efficient processing and classification by the DCNN model.

Table 3. Summary of preprocessing steps for visual.
Feature extraction in visual data processing involves identifying and learning significant patterns from images using deep learning techniques. Specifically, the ResNet-50 model is utilized to extract hierarchical features from bird images.
The selection of Mel-frequency cepstral coefficients (MFCCs) as a key feature in this research is driven by their ability to effectively capture the spectral properties of bird vocalizations in a compact and meaningful manner, closely mimicking human auditory perception. MFCCs reduce high-dimensional spectral data into a low-dimensional feature set, preserving essential information while minimizing computational complexity, which is crucial for real-time bird call analysis. Their proven effectiveness in bioacoustic studies and compatibility with LSTMs make them an ideal choice for learning temporal dependencies in bird calls. Additionally, MFCCs are relatively robust to background noise, ensuring reliable performance even in noisy environments which is shown in Table 4. These qualities make MFCCs a natural and practical choice for the acoustic modality in the proposed framework.

Table 4. Summary of preprocessing steps for acoustic data.
To examine the audio indicators of different hen species, waveforms were examined to study the versions in their shapes and patterns, thinking about environmental elements where each species became recorded to decide their capacity effect at the acoustic traits of the bird calls (Shipeng Hu, 2023). A spectrogram plot visually represented the frequency distribution through the years, with the x-axis indicating time, the y-axis displaying frequency in hertz (Hz), and the color depth reflecting the value of the frequencies. This plot revealed how frequency content numerous through the years. The functions extracted blanketed 0-crossing price, spectral centroid, chroma capabilities, Mel-Frequency Cepstral Coefficients (MFCCs), and Gain-Frequency Cepstral Coefficients (GFCCs). Each function changed into selected for its ability to seize particular aspects of the audio alerts critical for classifying different bird species. The zero-crossing charge measures how regularly a signal shifts from positive to negative, reflecting the spectral traits of hen vocalizations. The spectral centroid indicates the common frequency content, assisting inside the differentiation between species with varying frequency tiers. Additionally, spectral roll-off provides insights into the spectral shape of the sound, at the same time as spectral flux captures modifications in spectral content over the years. Chroma features constitute individual musical notes, and MFCCs are computed to identify spectral and temporal styles relevant for category. GFCCs, less typically used in hen species category literature, offer greater robust representations of hen calls, especially in noisy environments.
Feature selection is an essential step in device getting to know, minimizing the number of capabilities at the same time as maintaining those that significantly impact version overall performance. In this examination, Correlation-Based Feature Selection (CBFS) was employed to investigate the connection between the extracted audio functions and the target species. A statistical description of the dataset was performed, mainly due to the choice of 21 extraordinarily correlated features for addition analysis. The correlation coefficients were calculated to perceive capabilities with the most powerful relationships to species class.
This method is now not the handiest streamlined version of computations however additionally superior overall performance through decreasing overfitting and enhancing generalization. The function choice procedure efficiently recognized the most applicable developments for the audio dataset, optimizing version performance. Four distinct characteristic sets were created, as unique in Table 5.
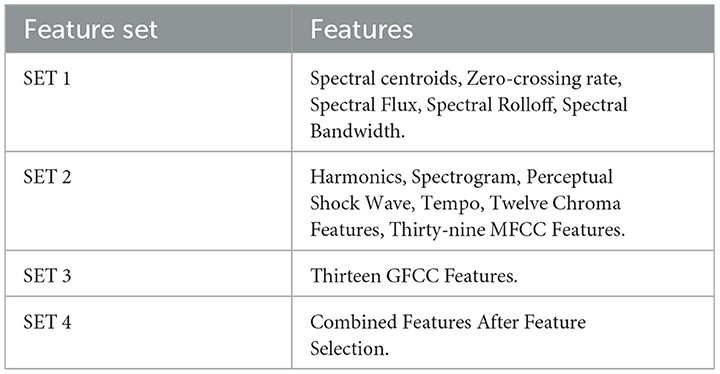
Table 5. Different feature sets.
Model architecture: a pre-trained CNN (e.g., ResNet, VGG, or EfficientNet) is used with transfer learning. These architectures, initially trained on large image datasets, are fine-tuned to classify bird species.
Mathematical representation:
- Convolutional layer:
where:
- Pooling layer:
Pooling reduces the spatial dimensions while retaining essential features.
Transfer learning strategy: features are extracted using the CNN's backbone, followed by fine-tuning or adding layers specifically to classify bird species.
Acoustic data is represented as a spectrogram–a time-frequency representation obtained through Short-Time Fourier Transform (STFT).
- Spectrogram conversion:
where:
Temporal feature extraction:
- GRU (Gated recurrent unit):
where σ is the sigmoid function, ⊙ denotes element-wise multiplication, and W and U are weight matrices.
- Transformer encoder:
- Self-attention mechanism:
where Q, K, and V represent the query, key, and value matrices, and dk is the dimensionality of the keys.
- Positional encoding:
where pos is the position in the sequence and i is the dimension index.
Feature fusion:
Classification layer: the combined feature vector Fcombined is passed through a dense layer with softmax to predict species probabilities:
where Wc and b are the weights and biases of the classification layer, and y gives the probability distribution over the bird species classes.
The first set comprises cepstral features, the second set includes spectral features, the third set contains GFCC features, and the fourth set is a composite of the most relevant features determined during selection.
With the optimal features identified and four feature sets established, the next phase involved utilizing these features for species classification. A neural network-based approach was implemented, employing a fully connected neural network with four hidden layers and a sigmoid output layer. The model received a set of 21 audio features extracted via the aforementioned techniques.
The architecture consisted of an input layer with 21 nodes (one for each audio feature), four fully connected hidden layers with 256, 128, and 32 nodes respectively, utilizing the Rectified Linear Unit (ReLU) activation function to model complex nonlinear interactions. The output layer contained nine nodes, corresponding to the species, with the softmax function applied to produce a probability distribution across the classes.
The Adam optimizer, with a learning rate of 1 × 10−4 and a categorical cross-entropy loss function, was employed during training. To mitigate overfitting, L2 regularization (coefficient = 0.01) was applied to the output layer. The model was trained for 75 epochs with a batch size of 16.
The proposed methodology effectively integrated audio data collection and preprocessing, signal analysis, feature extraction, and selection, culminating in the development of a deep learning model for the accurate classification of Indian bird species. While previous studies (Sharma et al., 2022) have demonstrated that combining audio and visual features can increase computation time, this approach solely utilizes audio features, achieving commendable accuracy and showing promise as a valuable tool for species identification based on audio signals.
The convolutional layers in a DCNN apply a series of convolution operations to detect patterns such as edges, textures, and shapes. The convolution operation can be mathematically described as:
where:
Multiple convolutional filters extract different types of features from the image. The deeper the network, the more complex the features become.
After the convolution operation, a non-linear activation function is applied to introduce non-linearity into the model. The Rectified Linear Unit (ReLU) function is defined as:
ReLU replaces negative values in the feature map with zeros, retaining only the positive activations, which helps to capture important features.
Pooling layers reduce the spatial dimensions of the feature maps, making the representation more compact while preserving salient information. The max pooling operation is defined as:
This operation selects the maximum value from a region of the feature map, reducing its size and computational complexity.
ResNet-50 uses residual connections to mitigate the vanishing gradient problem and enable deeper learning. The residual learning function can be written as:
where:
These connections allow the network to pass information directly to deeper layers, making it easier to train very deep networks.
After multiple convolutional and pooling operations, the high-level features are flattened and passed through a fully connected layer. The output of the fully connected layer is computed as:
where:
Finally, the softmax function converts the logits into probabilities for each bird species class:
where:
Where yj is the true label and is the predicted probability for the j-th class.
The acoustic data consists of bird calls and songs from the iBC53 dataset, which includes recordings from diverse Indian habitats.
Audio recordings were cleaned using spectral subtraction to reduce background noise. Mel-Frequency Cepstral Coefficients (MFCCs) were extracted from the audio samples, representing the timbre and pitch of the bird calls. The MFCCs are computed as:
Where Xn is the magnitude of the signal at frame n, and m is the MFCC coefficient.
The LSTM network processes the MFCC features by utilizing memory cells, which operate according to the following set of equations:
In this structure, f1t refers to the forget gate, i1t is the input gate, and o1t represents the output gate. The cell state is denoted by C1t, which is updated by combining the previous state and new candidate information based on the operations of the forget and input gates.
This architecture enables the LSTM to efficiently retain important information over extended sequences, mitigating issues that arise in standard RNNs like the vanishing gradient problem.
The LSTM model was trained using RMSprop optimizer with categorical cross-entropy loss. A fixed learning rate of 0.001 and batch size of 64 were used.
Table 6 compares the deep learning architectures applied to visual and acoustic data. For the visual modality (ResNet-50), there are 49 convolutional layers, 2 pooling layers (1 max pooling and 1 global average pooling), and 1 fully connected layer, resulting in a feature vector size of 2048. In contrast, the acoustic modality, based on LSTM networks, does not include convolutional layers as MFCC features are directly extracted from the audio input. It has no pooling layers and 1 fully connected layer after the LSTM, producing feature vectors of size 128 or 256. Finally, the fused modality combines the visual and acoustic features into a single fully connected fusion layer, producing a feature vector size of 2304, capturing the integrated information from both data sources."

Table 6. Summary of layers.
We explored two primary strategies for integrating visual and acoustic modalities in species identification: early fusion and late fusion. Both strategies leverage the strengths of each modality to enhance classification performance.
• Visual features: advanced deep learning models, particularly Deep Convolutional Neural Networks (DCNNs), are employed to extract intricate visual features from bird images. These features encompass aspects like shape, color patterns, and other distinguishing visual characteristics.
• Acoustic features: to analyze audio data, models such as Long Short-Term Memory (LSTM) networks are utilized. Acoustic features are extracted through techniques like Mel-frequency cepstral coefficients (MFCCs), which capture the spectral properties of bird calls and other audio patterns relevant to species identification.
Early and late fusion techniques are methods used to combine visual and acoustic information for bird species identification. In early fusion, features from both types of data–such as images and sounds–are merged early in the process, allowing the model to analyze them together and learn interactions between the two. This approach helps the model to utilize complementary information from both modalities simultaneously. Late fusion, on the other hand, involves processing visual and acoustic data separately through their respective models and then combining their predictions at the end, using methods like weighted averages. While early fusion emphasizes understanding the relationships between the two data types during training, late fusion focuses on combining their individual strengths after independent analysis.
• Early fusion: In this approach, visual and acoustic features are concatenated into a single feature vector before being fed into the classifier. This allows the model to jointly learn from both modalities simultaneously.
• Late Fusion: Here, separate classifiers are trained for each modality (visual and acoustic), and their respective outputs are fused post-classification, typically through a weighted combination of their predictions.
• Visual data is processed through a DCNN to extract features, resulting in a feature vector fvisual.
• Acoustic data is preprocessed, and relevant features are extracted, generating a feature vector facoustic.
The visual and acoustic features are concatenated into a single vector. This fused feature vector is then passed through a fully connected neural network for classification, allowing the model to learn from both modalities in tandem.
Separate classifiers are trained for the visual and acoustic features, producing probabilities pvisual and pacoustic for each modality. The final prediction pfinal_late is obtained by combining the outputs through a weighted sum, where α is a hyperparameter that is optimized during the validation phase.
The algorithm 1 classifies Chloropsis jerdoni using a multimodal approach by integrating image, audio, and location data. First, the input data is preprocessed–images are normalized, audio is converted into spectrograms, and location metadata is standardized. Features are then extracted from each modality: a CNN is used for image features, an RNN or transformer model for audio spectrograms, and a dense network for location data. These features are fused into a single vector, optionally reduced in dimensionality. A multimodal deep learning model is trained on these fused features using a suitable loss function and optimizer. For testing, the model processes the features from unseen samples to predict class probabilities, identifying Chloropsis jerdoni if the probability exceeds a defined threshold. Finally, the model's performance is validated using metrics such as accuracy, precision, recall, F1-score, and AUC-ROC, ensuring reliable classification. the overall step by step explaination is shown in Figure 2.

Algorithm 1. Bird Classification for Chloropsis jerdoni bird using a multimodal approach.
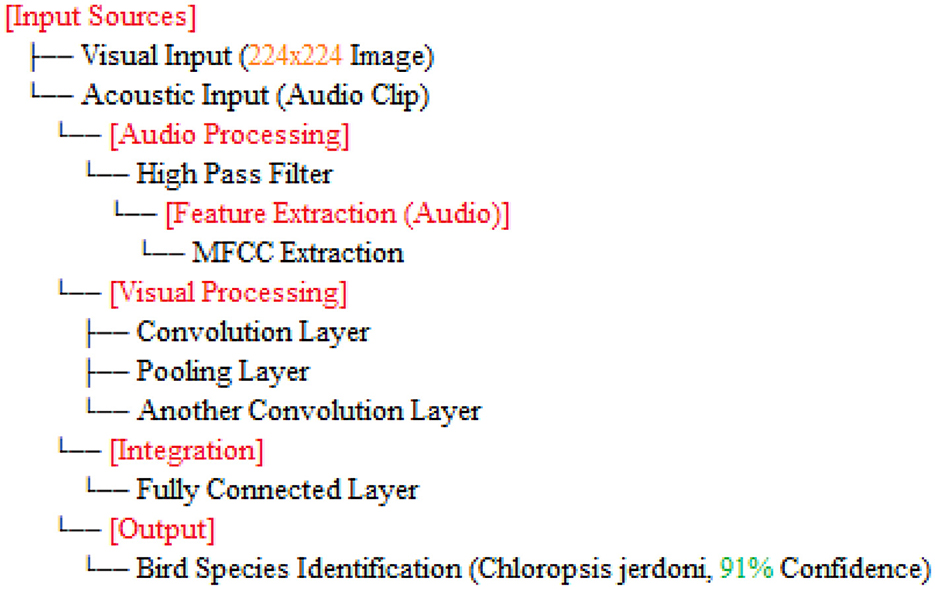
Figure 2. Steps design for bird species identification using visual and acoustic inputs (Chloropsis_jerdoni).
• Enhanced classification accuracy: by combining both fusion strategies, the system benefits from the strengths of each, leading to more accurate species classification.
• Robustness to noise: the independent processing of visual and acoustic modalities helps mitigate the impact of noise in one modality, improving the system's overall robustness.
• Comprehensive feature representation: hybrid fusion allows the model to capture complex relationships between modalities while maintaining the uniqueness of the features from each source.
This approach significantly advances ecological monitoring and species identification, leveraging visual and acoustic data for more accurate and reliable classification. The model offers a comprehensive solution for identifying bird species in diverse environments by effectively integrating multimodal inputs.
The models were trained and evaluated on the iBC53 dataset, which contains 10,000 images and 5,000 audio recordings representing 53 bird species from across India. The dataset was split into 70% training, 15% validation, and 15% test sets.
This section presents the experimental evaluation of the proposed Visual-acoustic fusion techniques for Indian bird species identification. We assess the model performance using both visual and acoustic data, and further analyze the improvements brought by multimodal fusion techniques in terms of classification accuracy, robustness, and modality contributions.
For the visual modality, we fine-tuned a pre-trained Inception-ResNet-152 model using bird images, extracting deep visual features. For the acoustic modality, audio features were extracted using Mel-frequency cepstral coefficients (MFCCs), and a Long Short-Term Memory (LSTM) network was employed to analyze sequential audio data. The two fusion techniques, early and late fusion, were implemented and tested to evaluate their effectiveness.
To establish baseline results, we first evaluated the performance of individual modalities shown in Table 7. The fine-tuned visual model (DCNN) achieved an accuracy of 87.2%, while the acoustic model (LSTM with MFCCs) attained an accuracy of 84.3%. These results highlight the classification potential of each modality, though both exhibit certain limitations when used independently.
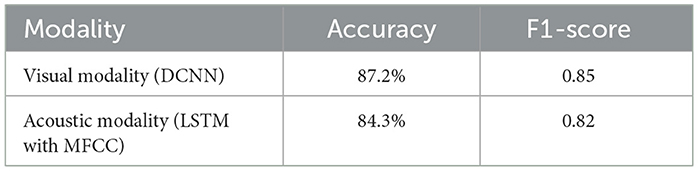
Table 7. Performance of individual modalities.
Table 8 comprises Performance comparison of early fusion and late fusion approaches for multi modal bird species identification. In the early fusion approach, visual and acoustic features are concatenated into a single feature vector before classification, leading to a significant accuracy improvement of 95.2%. This method allows the model to capture complementary features from both modalities, resulting in superior classification performance shown in the Figure 3. In contrast, the late fusion approach trains independent classifiers for visual and acoustic data, with their final predictions combined using a weighted sum. This method achieved an accuracy of 93.8%, demonstrating slightly lower performance than early fusion but offering greater robustness in situations with noisy or incomplete data which is shown in the Figure 4. The comparison underscores the strengths of each fusion strategy, with early fusion excelling in accuracy and late fusion providing greater resilience to data imperfections.
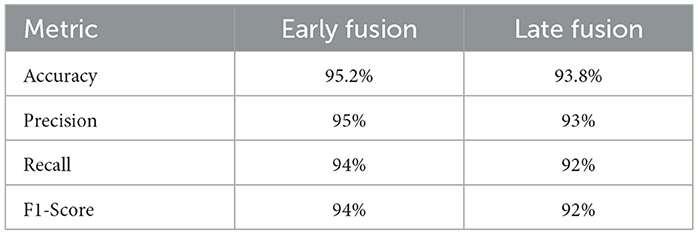
Table 8. Performance comparison between early fusion and late fusion techniques for bird species identification.
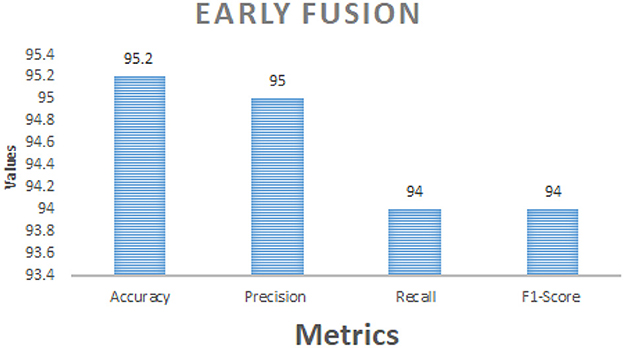
Figure 3. Performance metrics of early fusion strategy.
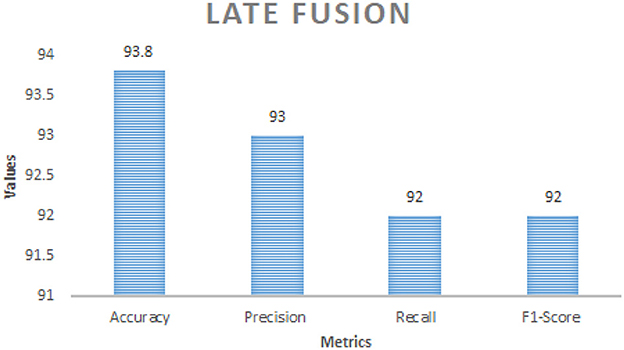
Figure 4. Performance metrics of late fusion strategy.
The fusion techniques consistently outperformed individual modality classifiers. Early fusion, with an accuracy of 95.2%, was superior when both modalities were reliable. Late fusion, with an accuracy of 93.8%, proved more robust when one modality was noisy or missing, offering an effective backup in cases of incomplete data. Table 9 below provides a comparative summary of visual modality, acoustic modality, early fusion and late fusion which is shown in Figure 5.
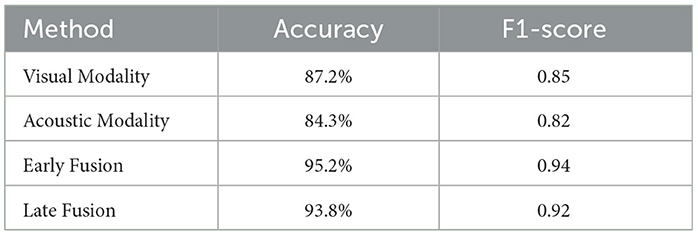
Table 9. Performance comparison of fusion techniques.

Figure 5. Comparison of accuracy across fusion techniques.
Table 10 evaluated the robustness of both fusion strategies by introducing noise into the audio recordings and removing visual data from a subset of samples. The late fusion strategy exhibited greater resilience, with accuracy dropping only slightly from 93.8% to 91.4%. Early fusion, though more accurate under normal conditions, experienced a more pronounced drop, from 95.2% to 90.8%, when confronted with incomplete data or noisy inputs.the detailed accuracy comparison is shown in the Figure 6.
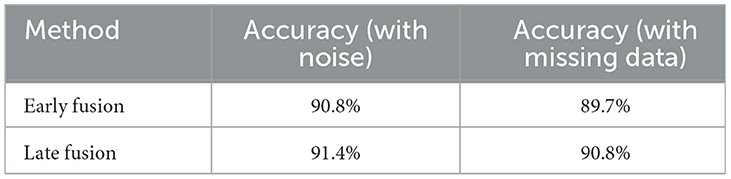
Table 10. Robustness to noise and missing data.
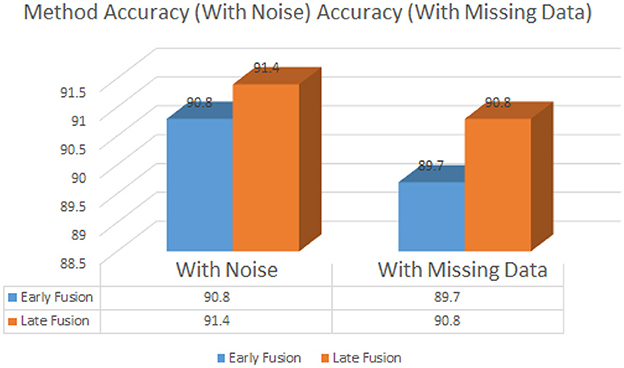
Figure 6. Accuracy under noisy and missing data conditions.
The experimental results validate the advantages of multi modal fusion in bird species identification tasks. Both fusion techniques demonstrated substantial improvements over using visual or acoustic data alone. Early fusion yielded the highest accuracy (95.2%), making it ideal for scenarios where data from both modalities are consistently available and of high quality. Late fusion, while slightly less accurate, offered enhanced robustness in real-world conditions where noise or incomplete data are more likely.
Both fusion techniques achieved high accuracy, and the early fusion yielded slightly better results because of the effective integration of complementary visual and acoustic information. The exact accuracy values for both approaches are reported in the results section, where the early fusion model shows a significant improvement in species identification, particularly in challenging environments with noisy backgrounds or incomplete data.
These results underscore the effectiveness of multi modal fusion for ecological monitoring, where data from multiple modalities can be harnessed for improved performance. Future research could explore adaptive fusion techniques that dynamically adjust to varying data quality, further optimizing system performance in challenging environments.
The accuracy in this study is determined by evaluating the percentage of correctly identified bird species across the test dataset. For both early and late fusion techniques, the model's predictions are compared with the true labels in the iBC53 dataset. The accuracy metric considers all correctly classified species (both visual and acoustic inputs) out of the total samples. When evaluating the multimodal fusion approaches, the parameter includes the combined contributions of visual and acoustic modalities, allowing for a direct comparison of the effectiveness of early versus late fusion strategies. Additional metrics such as precision, recall, and F1-score complement the accuracy measure to provide a more comprehensive evaluation of the model's performance. The performance of the proposed model was measured using various parameters, including accuracy, precision, recall, F1-score, and AUC-ROC. These metrics were evaluated for both early and late fusion techniques, with early fusion consistently outperforming late fusion across all parameters.
The models were evaluated using accuracy, precision, recall, and F1-score. Early fusion outperformed both individual modalities and late fusion, as shown in Table 11 with the performance graph illustrated in Figure 7.

Table 11. Performance comparison of different models.
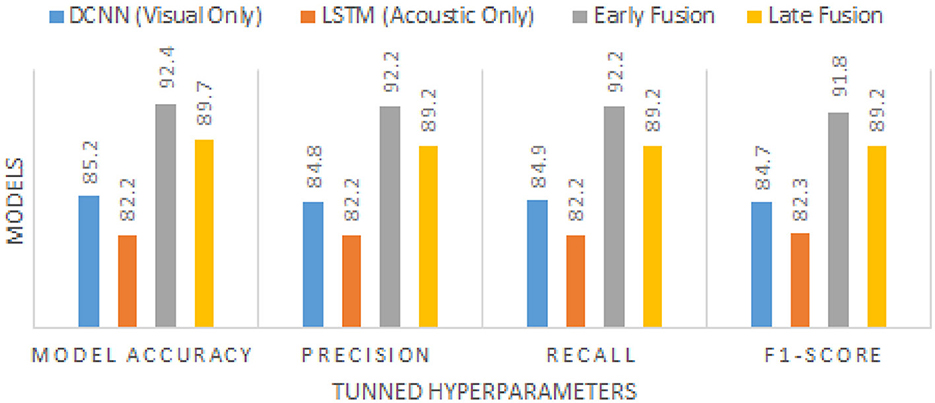
Figure 7. Performance comparison of different models.
A multi-modal framework for identifying bird species was introduced, utilizing deep learning techniques to combine visual and audio data. The method demonstrated exceptional performance through the use of early fusion techniques, making it particularly beneficial for ecological research and biodiversity preservation in India. The findings highlight that accuracy and robustness are significantly enhanced by combining the complementary strengths of DCNNs and LSTMs, offering a reliable approach to addressing the challenges of multi-modal data and environmental variability.
Future work will focus on exploring adaptive fusion strategies that dynamically adjust modality weights based on data quality. In addition, our goal is to incorporate environmental data as an additional modality and develop real-time bird species identification capabilities for broader applications, including conservation efforts and citizen science projects.
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found below: https://www.kaggle.com/datasets/arghyasahoo/ibc53-indian-bird-call-dataset.
PG: Conceptualization, Data curation, Methodology, Resources, Writing – original draft. JS: Investigation, Software, Supervision, Writing – review & editing.
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This work is supported by the School of Computer Science and Engineering, Vellore Institute of Technology, Vellore, Tamil Nadu, India.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The author(s) declare that no Gen AI was used in the creation of this manuscript.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Alghamdi, A., Mehtab, T., Iqbal, R., Leeza, M., Islam, N., Hamdi, M., et al. (2021). Automatic classification of monosyllabic and multisyllabic birds using PDHF. Electronics 10:624. doi: 10.3390/electronics10050624
Chandra, B., Raja, S., Gujjar, R., Varunkumar, J., and Sudharsan, A. (2021). Automated bird species recognition system based on image processing and SVM classifier. Turk. J. Comp. Mathem. Educ. 12, 351–356. doi: 10.17762/turcomat.v12i2.813
Chaudhuri, Y., Mundra, P., Batra, A., Phukan, O. C., and Buduru, A. B. (2024). ASGIR: Audio spectrogram transformer guided classification and information retrieval for birds. arXiv preprint arXiv:2407.18927.
Edwards, T., Jones, C. B., Perkins, S. E., and Corcoran, P. (2021). Passive citizen science: The role of social media in wildlife observations. PLoS ONE 16:e0255416. doi: 10.1371/journal.pone.0255416
Gavali, P., and Banu, J. S. (2020). “Bird species identification using deep learning on GPU platform,” in 2020 International Conference on Emerging Trends in Information Technology and Engineering (ic-ETITE) (Vellore: IEEE), 1–6. doi: 10.1109/ic-ETITE47903.2020.85
Gómez-Gómez, J., Vidaña-Vila, E., and Sevillano, X. (2022). Western mediterranean wetlands bird species classification: evaluating small-footprint deep learning approaches on a new annotated dataset. arXiv preprint arXiv:2207.05393. doi: 10.48550/arXiv.2207.05393
Gupta, G., Kshirsagar, M., Zhong, M., Gholami, S., and Ferres, J. (2021). “Recurrent convolutional neural networks for large scale bird species classification. Sci. Rep. 11:17085. doi: 10.1038/s41598-021-96446-w
Kumar, R. (2023). A comprehensive review on machine learning techniques for bird species classification. Int. J. Environm. Sci. Technol. 20, 3751–3765.
Li, N., Sun, Y., Chu, H., Qi, Y., Zhu, L., Ping, X., et al. (2019). Bird species diversity in altai riparian landscapes: wood cover plays a key role for avian abundance. Ecol. Evol. 9, 9634–9643. doi: 10.1002/ece3.5493
Nanni, L., Maguolo, G., and Paci, M. (2020). Data augmentation approaches for improving animal audio classification. Ecol. Inform. 57:101084.
Ntalampiras, S., and Potamitis, I. (2021). Acoustic detection of unknown bird species and individuals. CAAI Trans. Intellig. Technol. 6, 291–300. doi: 10.1049/cit2.12007
Patel, H. (2022). Multi-modal bird recognition using audio and visual signals. Artificial Intellig. Rev. 55, 521–540.
Sahu, A., and Choudhury, S. (2023). Real-time bird call classification using lightweight cnns. Comp. Environm. Urban Syst. 92:101775.
Sharma, N., Vijayeendra, A., Gopakumar, V., Patni, P., and Bhat, A. (2022). “Automatic identification of bird species using audio/video processing,” in 2022 International Conference for Advancement in Technology (ICONAT) (IEEE), 1–6.
Shipeng, H.u, and Yihang Chu, Z. W. G. Z. Y. S. (2023). Deep learning bird song recognition based on mff-scsenet. Ecol. Indicat. 154:110844. doi: 10.1016/j.ecolind.2023.110844
Smith, M., and Roberts, L. (2023). The impact of environmental factors on bird species classification. Ecol. Evol. 13:e10762.
Song, H. (2024). Bird image classification based on improved resnet-152 image classification model. Appl. Comp. Eng. 54, 206–212. doi: 10.54254/2755-2721/54/20241530
Swaminathan, B., Jagadeesh, M., and Vairavasundaram, S. (2024). Multi-label classification for acoustic bird species detection using transfer learning approach. Ecol. Inform. 80:102471. doi: 10.1016/j.ecoinf.2024.102471
Thompson, A., and Green, J. (2023). Ethical considerations in automated bird classification systems. Ethics Inform. Technol. 25, 285–297.
Triveni, G., Malleswari, G., Sree, K., and Ramya, M. (2020). Bird species identification using deep fuzzy neural network. Int. J. Res. Appl. Sci. Eng. Technol. 8, 1214–1219. doi: 10.22214/ijraset.2020.5193
Xie, J., and Zhu, M. (2023). Acoustic classification of bird species using an early fusion of deep features. Birds 4, 138–147. doi: 10.3390/birds4010011
Yang, C., Harjoseputro, Y., Hu, Y., and Chen, Y. (2022). An improved transfer-learning for image-based species classification of protected indonesian birds. CMC-Comp. Mater. Continua 73, 4577–4593. doi: 10.32604/cmc.2022.031305
Zhang, Y. (2022). A hybrid deep learning approach for bird species classification. Neural Netw. 145, 61–70.
Keywords: birds identification, species classification, visual-acoustic data, fusion technique, deep CNN
Citation: Gavali P and Banu JS (2025) A novel approach to Indian bird species identification: employing visual-acoustic fusion techniques for improved classification accuracy. Front. Artif. Intell. 8:1527299. doi: 10.3389/frai.2025.1527299
Received: 13 November 2024; Accepted: 29 January 2025;
Published: 21 February 2025.
Edited by:
Sou Nobukawa, Chiba Institute of Technology, JapanReviewed by:
Khondekar Lutful Hassan, Aliah University, IndiaCopyright © 2025 Gavali and Banu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: J. Saira Banu, anNhaXJhYmFudUB2aXQuYWMuaW4=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.