 Eugene Pinsky
Eugene Pinsky- Department of Computer Science, Metropolitan College, Boston University, Boston, MA, United States
In recent years, there has been an increased interest in using the mean absolute deviation (MAD) around the mean and median (the L1 norm) as an alternative to standard deviation σ (the L2 norm). Till now, the MAD has been computed for some distributions. For other distributions, expressions for mean absolute deviations (MADs) are not available nor reported. Typically, MADs are derived using the probability density functions (PDFs). By contrast, we derive simple expressions in terms of the integrals of the cumulative distribution functions (CDFs). We show that MADs have simple geometric interpretations as areas under the appropriately folded CDF. As a result, MADs can be computed directly from CDFs by computing appropriate integrals or sums for both continuous and discrete distributions, respectively. For many distributions, these CDFs have a simpler form than PDFs. Moreover, the CDFs are often expressed in terms of special functions, and indefinite integrals and sums for these functions are well known. We compute MADs for many well-known continuous and discrete distributions. For some of these distributions, the expressions for MADs have not been reported. We hope this study will be useful for researchers and practitioners interested in MADs.
1 Introduction
Consider a real-valued random variable X on a sample space Ω ⊆ R with density f(x) and cumulative distribution function F(x) [1]. If X is a discrete random variable, then Ω is some countable sample space and f(x) is the probability mass function (discrete density function). Let μ denote the mean E(X) and M denote the median of X. For any real-value a, define the MAD of X from a as Bloomfield and Steiger [2]
This is defined in Lebesque–Stieltjes integration [3] and applies to continuous and discrete distributions. It is well known [2, 4–6] that for any distribution with finite variance, we have H(X, M) ≤ H(X, μ) ≤ σ. On the other hand, MADs require only the existence of the first-order moment.
MADs have been used for a long time, as early as the eighteenth century by Boscovitch and Laplace [7, 8]. For a historical survey, see Gorard [9] and Pham-Gia and Hung [10]. There is currently a renewed interest in using the L1 norm for robust statistical modeling and inference (e.g. [11–17], to name just a few). A MAD-based alternative to kurtosis based on H(X, M) was recently introduced in Pinsky and Klawansky [18].
Since the pioneering work of Fisher [19], standard deviation has been used as the primary metric for deviation. As noted in Gorard [9] and Pham-Gia and Hung [10], the convenience of differentiation and optimization, and the summation of variances for independent variables have contributed to the widespread use of the standard deviation in estimation and hypothesis testing.
On the other hand, using MAD offers a direct measure of deviation and is more resilient to outliers. In computing standard deviation, we square the differences between values and the central point such as mean or median. As a result, standard deviation emphasizes larger deviations. The computation of MAD offers a direct and easily interpretable measure of deviation.
As discussed in Gorard [9], difficulties associated with the absolute value operation are one of the main reasons for the lower use of the MAD. We address this by deriving the closed-form expressions for MADs directly from the cumulative distribution function of the underlying distribution. Moreover, the computation of MAD requires only the existence of the first-order moment, whereas the use of standard deviation requires the existence of the second moment as well. As an example, consider Pareto distribution with scale α [20] analyzed in Section 5. This distribution has a finite mean for α > 1 but the infinite variance for α < 2. As a result, we cannot use standard deviation to analyze cases 1 < α < 2 but can use MADs.
This study will primarily focus on computing the MAD about the mean. Such deviations have been derived for some distributions, primarily using density [21]. The most complete list (without derivations) is presented in Weisstein [22]. We significantly extend this list using a unified approach to computing these deviations as integrals and sums from cumulative distribution functions (CDFs) instead of probability density functions (PDFs). For many distributions, these CDFs have a simpler form than PDFs. Moreover, the CDFs are often expressed in terms of special functions, and indefinite integrals and sums for these functions are well known. When closed-form expressions for the median are available, we will compute MAD (about) median as well.
To our knowledge, the obtained results for some distributions, such as Pareto Type II, and logarithmic distributions, are presented for the first time. Our main contribution is a unified and simple computational approach to compute these deviations in closed form without absolute value operation from the cumulative distribution functions. This removes one of the main obstacles in using MADs [9]. We hope this article will be a useful reference for researchers and practitioners using MAD.
This article is organized as follows. In Section 2, we establish the expressions for H(X, μ) in terms of the integral of the CDF for the case of continuous distributions and in terms of sums of the CDFs for discrete distributions. In Section 3, we provide a simple geometric interpretation of our results in terms of appropriately folded CDF. In Section 4, we review definitions and some integrals for the special functions often appearing in CDFs for many distributions considered. In Section 5, we derive expressions for MAD for many continuous distributions. In Section 6, we derive expressions for many widely used discrete distributions.
2 Computing MADs by CDF
2.1 MAD formula for continuous distributions
We first start with continuous distributions. Let us define the left sample sub-space of Ω by ΩL(a) = {x ∈ Ω | x ≤ a} and the right sample sub-space of Ω by ΩR(a) = {x ∈ Ω | x > a}. Additionally, we will require the existence of the first-order moment,
To put it formally, let us consider the functional [23]
where a ∈ (−t, t) is finite and both integrals exist for any t. Then the first moment is defined as
It is well known that the integral in Equation 3 could be infinite when the support of X is unbounded. We will insist that the above integrals in the right-hand side of the above Equation 2 are finite and therefore μ < ∞. This can be shown to be equivalent:
and therefore, for distributions with possible negative values, we have
This condition will ensure that all terms in subsequent equations are finite.
We will find it convenient to introduce the following auxiliary integral:
This is a partial first moment of X computed over all x ≤ z. We can express H(X, a) in terms of the cumulative distribution function F(·) and auxiliary integral I(·) as follows:
Consider the function h(x) = xF(x). Then dh(x) = F(x) dx + x dF(x) and from the integration by parts formula, we can express I(a) as
Substituting this into Equation 8 we obtain
A geometric interpretation of H(X, a) for the case a ≤ μ is illustrated in Figure 1.
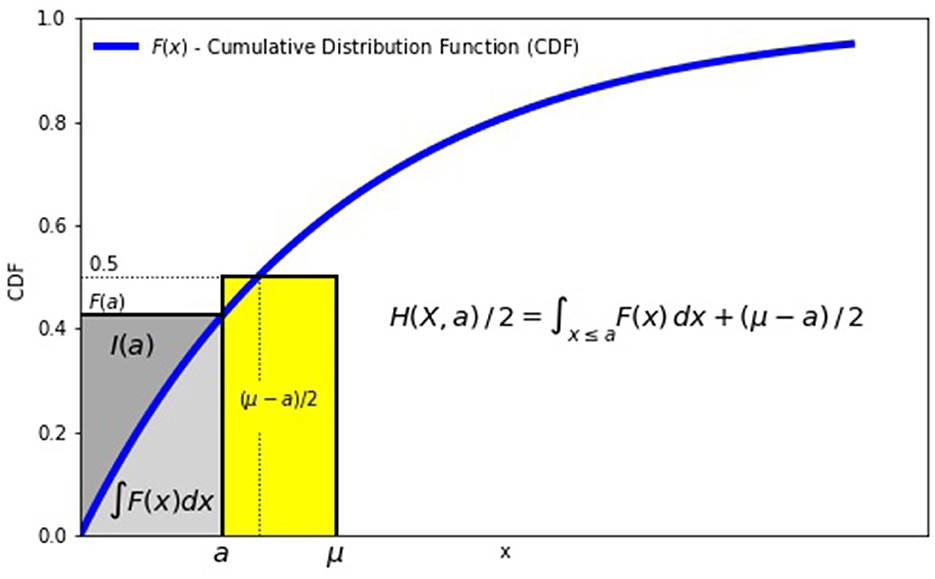
Figure 1. Geometric interpretation of H(X, a).
The MAD is twice the sum of two areas: the first area is the area under the cumulative distribution function for x ≤ a and the second area is (μ − a) · 0.5.
For MAD around the mean μ and the median M, we obtain
2.2 MAD formula for discrete distributions
We now derive an analogous formula for the discrete distribution. Let Ω = {x1, x2, …}. Without loss of generality, assume x1 < x2 < ⋯ . By analogy with the continuous case, define the auxiliary sum I(x) as
Then MAD of X from μ is
To compute I(a), we use the following summation by parts formula (analogous to integration by parts) [24]. If U = {u1, u2, …, un} and V = {v1, …, vn} are two sequences and Δ is the forward difference operator, then
To apply the formula, we let m = 1, vk = xk and uk = F(xk). Then we have
If we choose for a given a, then F(a) = F(xn(a)) and we have
in complete analogy for I(a) for the continuous case in Equation 9.
Substituting this expression for I(a) from Equation 16 into Equation 13, we obtain
The sum on the right of Equation 17 is the area under the cumulative distribution function for xi ≤ a and can be interpreted as the integral of the CDF computed for x ≤ a in direct analogy with the continuous case.
For MAD about mean μ and median M, the above equation gives us
The advantage of these formulas is that for many distributions, xi are consecutive integers, giving us Δxi = 1. In such cases, the above formulas for H(X, μ) and H(X, M) simplify to
with a direct analogy to the continuous case.
We will apply the above results to compute MADs of several well-known discrete distributions in Section 6.
3 Interpretation of MADs via “folded” cumulative distribution functions
We can interpret H(x, a) as follows. Consider the function G(x) defined as follows:
We can interpret G(x) as the "folded" cumulative distribution function curve. Note that unless F(a) = 1/2 (i.e., a is the median M), the curve G(x) is discontinuous at x = a. The case a = μ is illustrated in Figure 2.
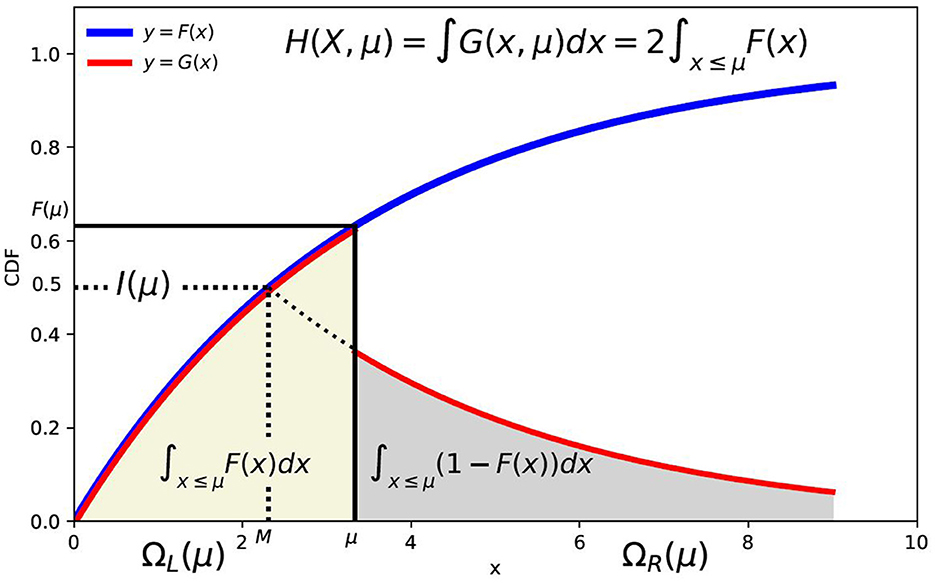
Figure 2. Illustration of folded cumulative distribution function (a = μ) and X ≥ 0.
For non-negative valued random variables X, we can interpret MAD H(X, a) in terms of G(x) as follows: let A(G) denote the area under this curve. For continuous case, we have
Comparing Equation 21 with Equation 8, we can interpret AL = aF(a) − I(a) as the area under left part of G(x, a) for x ≤ a and AR = (μ − I(a) − a(1 − F(a)) as the area under the right part of G(x, a) for x > a.
For the case a = μ, the areas under the curve for x ≤ a and x > a are equal. In this case, H(X, μ) = 2AL(G) is just twice the area under the "left" part of the folded CDF curve for x ≤ a. This is illustrated in Figure 2. From Equation 9, the auxiliary integral I(μ) is the area above cumulative distribution function F(x) for x ≤ μ and F(x) ≤ F(μ) (shown in yellow color).
For the case a = M, the folded cumulative distribution function G(x) is continuous as shown in Figure 3. The area under this curve is the MAD from the median [25]. It is interesting to compare the MAD H(X, M) around the median with the quartile deviation (QD) defined as half of the interquartile range semi-interquartile range QD = IQR/2 = (Q3 − Q1)/2 where Q1 and Q3 are the first and third quartile of X. The MAD around the median is the area under the folded CDF G(x) where the quartile deviation is the area spanned between the quartiles on the x-axis and between 0 and 1/2 on the y-axis.
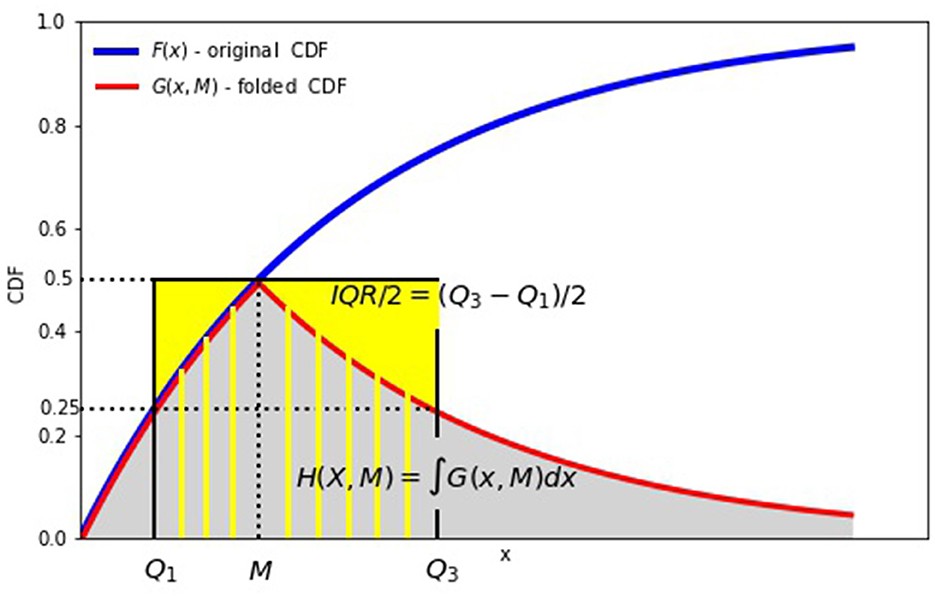
Figure 3. Mean absolute vs. quantile deviation (a = M and ≥ > 0.
For the discrete case with non-negative valued X, we get a similar result. As before we assume that 0 ≤ x1 < x2 < ⋯ and let . Recall that F(xk) = f(x1) + ⋯ + f(xk). Therefore, we obtain
in exact analogy with the continuous case. Therefore, the MAD H(X, a) can also be interpreted as the area under the folded CDF curve G(x, a).
4 Some special functions and integrals
For many distributions, their cumulative distribution functions involve some special functions (for real arguments) such as Gamma and Beta functions [26, 27]. Indefinite integrals for many of these functions are readily available [28–30]. Some of these functions and their integrals are presented here for easy reference.
4.1 Some special functions and integrals
1. Error function ([30], Section 7.2 in Olver et al. [31]):
2. Density of the standard normal [31, 32]:
3. Cumulative distribution of the standard normal [31, 32]:
4. Lower and upper incomplete Gamma functions ([30], Section 8.6 in Olver et al. [31]):
5. Gamma function and regularized Gamma function ([30], Section 5.2 in Olver et al. [31]):
6. Beta function (Section 5.12 in Olver et al. [31] and Gupta and Nadarajah [33]):
7. Incomplete Beta function and regularized incomplete Beta functions ([33], Section 8.17 in Olver et al. [31]):
4.2 Some indefinite integrals
The following expressions will be used in many of the computations (C is a constant).
1. Integration of standard normal CDF (p. 396 in Owen [32]):
2. Integration of the product of standard normal density and x (integral #11, p. 393 in Owen [32]):
3. Integration of the product of error function and exponential (integral #1, Section 4.2 in Ng and Geller [30]):
4. Integration of incomplete gamma function (using integration by parts and Equation 24):
In particular, for b = 1 using the recurrence relation (chapter 8.6 in Olver et al. [31]),
we obtain
5. Integration of the incomplete beta function [33]
6. Integration of reciprocal functions with exponentials (integral 2.313 p. 92 in Gradshteyn and Ryzhik [29])
5 MAD computations for continuous distributions
We now illustrate the above formula for some well-known continuous distributions. We will focus on MAD around the mean μ. We will consider the following continuous distributions (in alphabetical order): Beta, chi-squared, exponential, Gamma, Gumbel type I, half-normal, Laplace, logistic, Maxwell, normal, Pareto type I and II, Rayleigh, Student-t, triangular, uniform, and Weibull. For some of these distributions, the expressions for MAD have been known. In contrast, to our knowledge, the expressions for MAD have not been published for some distributions like Pareto II and Weibull.
1. Beta distribution with parameters α, β > 0: The corresponding density f(x) and the cumulative distribution function F(x) are given by Johnson and Kotz [20] and Feller [34]:
where Ix(·) denotes the regularized incomplete beta function in Equation 27. The mean and standard deviation of this distribution are
Therefore, using Equation 33 we compute H(X, μ) as follows:
There is no closed-form formula for the median M. The MAD around the median M is
2. Exponential distribution with rate λ > 0 : The corresponding density f(x) and cumulative distribution function F(x) are given by Johnson and Kotz [20] and Feller [34]:
Its mean μ = 1/λ and standard deviation σ = 1/λ. We compute H(X, μ) as
In terms of σ, for this distribution H(X, μ) = (2/e)σ ≈ 0.74σ.
The median is M = (log2)/λ. The MAD about median is then
3. F (Fisher–Snedecor) distribution with α, β > 0 degrees of freedom: The corresponding density f(x) and cumulative distribution function F(x) are given by Johnson and Kotz [20] and Feller [34],
The mean μ and standard deviation σ are defined only for β > 2 and β > 5 respectively and are given by
To compute H(X, μ) we note that x = βz/(α(1 − z)) and therefore, dz = (β/α(1 − z)2)dz. Let μ* = αμ/(αμ + β) = α/(α + β − 2β). Therefore, for the MAD, we obtain
To compute the integral, we note that B′(z; α/2, β/2) = zα/2 − 1(1 − z)β/2 − 1. If we consider the function h(z) = B(z; α/2, β/2)/(1 − z) then
This immediately gives us the expression for the integral
We can now compute the MAD for the F distribution:
4. Gamma distribution with shape parameter α > 0 and rate β > 0: The corresponding density f(x) and cumulative distribution function F(x) are given by Johnson and Kotz [20] and Feller [34]:
where Γ(·) denotes the Gamma function (Equation 25 and ν(·) denotes the lower incomplete Gamma function (Equation 24). The mean of this distribution is μ = α/β and its standard deviation .
Let us define z = βx. Then we have
There is no closed-form expression for the median M. The MAD (around median) is
5. χ2 Distribution with k degrees of freedom: The corresponding density f(x) and the cumulative distribution function F(x) are given by Johnson and Kotz [20] and Feller [34]:
where Γ(·) denotes the Gamma function (Equation 25 and ν(·) denotes the lower incomplete Gamma function (Equation 24. The mean of this distribution is μ = k and its standard deviation . This is a special case of Gamma distribution with shape α = k/2 and rate β = 1/2. This immediately gives us
6. Gumbel type I (extreme value distribution) with location μ and scale β > 0: The corresponding density and f(x) and cumulative distribution function F(x) are given by [20]):
Its mean is μ* = (μ + βγ) where γ is the Euler-Mascheroni constant. Its standard deviation . Let t = e−z. Then dt = (t/β)dx or dx = βt−1dt. Then for MAD (about mean) we obtain
where ν(·) denotes the incomplete lower gamma function in Equation 24.
The median for this distribution is M = μ − β log(log2). Therefore, for the MAD about the median we have
7. Half-normal distribution with scale parameter σ > 0: The corresponding density f(x) and cumulative distribution function F(x are given by Johnson and Kotz [20]):
The mean is and standard deviation . Let . Then and we have
The median is . Define c = erf−1(1/2). Then the MAD around the median M we have
8. Laplace distribution with location μ and scale b: The density f(x) and cumulative distribution function F(x) are given by Johnson and Kotz [20] and Feller [34]:
For this distribution, μ = M = b and . For the MAD, we obtain
In terms of σ, we have .
9. Logistic distribution with location μ and scale s > 0: The corresponding density function f(x) and cumulative distribution function F(x are given by Johnson and Kotz [20]:
The mean and the median are μ and the standard deviation is . Let z = (x − μ)/s. Since for this distribution M = μ, we have H(X, μ) = H(X, M). Using Equation 34 we obtain
In terms of σ we have
10. Log-normal distribution with parameters μ ∈ (∞, +∞) and σ2 (σ > 0): The density f(x) and cumulative distribution function F(x) are given by Johnson and Kotz [20] and Feller [34]:
We will use the notation μ* and σ* to denote the mean and standard deviation of X to distinguish it from the mean μ and standard deviation σ of the underlying normal distribution. The mean of the log-normal distribution is μ* = eμ+σ2/2 and its standard deviation .
To compute H(X, μ), define z = (log x − μ)/σ. Then, dx = σx dz = σeμ + σzdz and using Equation 30 with and b = σ, we obtain
The median M = eμ and therefore for the MAD around median, we obtain
11. Maxwell (or Maxwell-Boltzmann) distribution with scale parameter b > 0: The density function f(x) and the cumulative distribution function F(x) are given by Johnson and Kotz [20]
We can re-write these as
The mean is and standard deviation . We let z = x/b. Then dx = b dz and using Equations 28, 29, with a = 1/b, we obtain
There is no simple closed-form for the median M.
12. Normal distribution N(μ, σ): The density f(x) and cumulative distribution function F(x) are [20, 34]:
where Φ(·) denotes the cumulative distribution of the standard normal (Equation 23). Using Equation 28 with a = −μ/σ and b = 1/σ we obtain
In terms of σ, we have . Since this is a symmetric distribution H(X, M) = H(X, μ).
13. Pareto type I distribution with shape α > 0 and scale β > 0: The density f(x) and the cumulative distribution function F(x) are given by Johnson and Kotz [20]
the mean and standard deviation for this distribution are
This distribution has infinite mean μ for α ≤ 1 and infinite variance for α ≤ 2. We assume that α > 1. Then for MAD, we obtain
The median is . Therefore, for the MAD about the median, we obtain
14. Generalized Pareto (Type II) distribution with location μ ∈ R, scale σ > 0, and shape ξ ∈ R: We exclude the case ξ = μ = 0, that corresponds to the exponential distribution. The density f(x) and the cumulative distribution function F(x) are given by Johnson and Kotz [20]:
where the support of X is x ≥ μ for ξ ≥ 0 and μ ≤ x ≤ σ/ξ for ξ < 0. The mean μ* and standard deviation σ* of this distribution are defined only for ξ < 1 and ξ < 1/2 respectively and are
To compute H(X, μ*), we need to consider two cases
(a) ξ < 1 and ξ ≠ 0. We have
Note that the case ξ = −1 gives H(X, μ*) = σ/4 and corresponds to continuous uniform distribution U(0, σ). The case ξ > 0 and location μ = σ/ξ corresponds to the Pareto distribution with scale β = σ/ξ and shape α = 1/ξ.
(b) Case ξ = 0. For this case, we obtain
Note that for ξ = 0, the case μ = 0 corresponds to an exponential distribution with parameter 1/σ.
For μ = 0 and ξ > 0, let α = 1/ξ and λ = ξσ. Then we obtain the Lomax distribution with shape α > 0 and scale λ > 0. Its mean μ* = λ/(α − 1) is defined only for α > 1 (corresponding to ξ < 1). Therefore, for α > 1 its MAD for the Lomax distribution is
15. Rayleigh distribution with scale parameter σ > 0: The density function f(x) and the cumulative distribution function F(x) are given by Johnson and Kotz [20]:
The mean is and standard deviation is . Let z = x/2σ. Then dx = 2σ dz and we have
For this distribution, the median . Therefore,
16. Student-t distribution with k > 1 degrees of freedom: Its probability density function f(x) and its cumulative distribution function F(x) are given by Johnson and Kotz [20] and Feller [34]:
The mean μ is μ = 0 for k > 1, otherwise it is undefined. The standard deviation is defined only for k > 2 and σ = k/(k − 2). From Equation 8 we have
Since this distribution is symmetric, M = μ and H(X, M) = H(X, μ).
17. Triangular distribution with lower limit a, upper limit b and mode c ∈ [0, 1]: The density function f(x) and the cumulative distribution function F(x) is given by [20, 34, 35]:
For this distribution, μ = (a + b + c)/3 and . It is easy to show that for 0 ≤ c ≤ (a + b)/2, we have μ ≥ c and for (a + b)/2 ≤ c ≤ b, we have μ ≤ c. Therefore,
The median M of this distribution is
Therefore, the MAD about the median is then
18. Uniform continuous distribution in [a, b]: The density function f(x) and the cumulative distribution function F(x) are given by Johnson and Kotz [20] and Feller [34]:
Mean is μ = (a + b)/2 and standard deviation . The MAD is
19. Weibull distribution with scale α > 0 and shape k > 0: The density f(x) and the cumulative distribution function F(x) are given by Johnson and Kotz [20].
Its mean is μ = αΓ(1 + 1/k) and its standard deviation is σ = α(Γ(1 + 2/k) − Γ2(1 + 1/k)), If we let z = x/α then dx = α dz and using Equation 24 we obtain
For k = 1 we have Γ(1 + 1/k) = 1, μ = 2α, and Γ(1, 1) = 1/e. Therefore, H(X, μ) = 2α/e. This case with k = 1 corresponds to exponential distribution with λ = 1/α.
The median . Therefore for MAD about median, we obtain
6 MAD computations for discrete distributions
In this section, we compute MADs for the following discrete distributions (in alphabetical order): binomial, geometric, logarithmic, negative binomial, Poisson, uniform, Zipf, and zeta distributions. For some of these distributions, the expressions for MAD have been known, whereas for some distributions like logarithmic, the formulae for MAD have not been published, to our knowledge.
1. Binomial distribution with parameters n ∈ N and success probability 0 < p < 1: Let q = 1 − p. Its density f(x) and umulative distribution function F(x) are [20, 34]:
where Iq(·) is the regularized incomplete beta function defined in equation 27.
The mean μ = Np and standard deviation is . Let n = ⌊Np⌋. Then we have
The last step in the above equation can be established by induction on N.
2. Geometric distribution with success probability 0 < p < 1: The density f(x) and cumulative distribution function are [20, 34]:
The mean μ = (1−p)/p and standard deviation is . Let n = ⌊μ⌋ = ⌊1/p⌋ − 1. Therefore, we obtain
3. Logarithmic distribution with parameter 0 < p < 1: The density f(x) and cumulative distribution function are [20]:
where B(·) is the incomplete beta function. Its mean μ = −p/((1 − p)log(1 − p)).
Let n = ⌊μ⌋. Therefore, for the MAD, we obtain
To evaluate the integral in the above equation, we note that log′(1 − t) = −1/(1 − t) and (1/(1−t))′ = −1/(1 − t)2. Therefore, for this integral, we have
Substituting this into the above equation for H(X, μ), we obtain
4. Negative binomial distribution with number of successes parameter r > 0 and success probability 0 < p < 1: The density f(x) and cumulative distribution function are [20, 34]:
where Ip(·) denotes the regularized incomplete beta function.
The mean is μ = r(1 − p)/p and standard deviation is . Let n = ⌊μ⌋. Then from Equation 26 we have . On the other hand, we have
From this, we obtain
Using Equation 26 for B·), we obtain for the MAD
5. Poisson distribution with rate λ > 0: The density f(x) and cumulative distribution function F(x) are [20, 34]:
where Q(·) is the regularized Gamma function in Equation 25.
The mean is μ = λ and standard deviation is . Let n = ⌊λ⌋. For this distribution, we have
On the other hand, from Equation 24, we have F′(n) = Q′(n + 1, λ) = −e − λλn/n!. Therefore, I(n) = λF(n) − e − λλn+1/n! and we obtain for the MAD
6. Uniform (discrete) distribution on interval [1, N]: The density f(x) and cumulative distribution function F(x) are [20, 34]:
Its mean μ = N/2 and its standard deviation is . Let n = ⌊μ⌋. Then, for the MAD, we obtain
There are two cases to consider:
(a) N is odd. Then N = (2m + 1) for some m and μ = (m + 1). Then n = (m + 1) and H(X, μ) = (m + 1)(m + 2)/N = (N − 1)(N + 1)/4N.
(b) N is even. Then N = 2m for some m and μ = (m + 1/2). Then n = m and H(X, μ) = m(m + 1)/N = N/4
We summarize both cases as follows:
For odd N we can express MAD in terms of σ as H(X, μ) = 12σ2/N
7. Zipf and zeta distributions We start with generalized Zipf distribution [20, 34]. Assume X is distributed according to zeta distribution with parameters s > 1 and integer N. Its density f(x) and cumulative distribution functions are
where hk, s is the generalized harmonic number defined as . The mean and standard deviation of this distribution are
Let n = ⌊μ⌋. Then, using the following equation for the sum of harmonic numbers
we obtain the MAD of the Zipf's distribution with N elements
For s > 1, we can extend to N = ∞. In this case, we have the Zeta distribution, with its density f(x) and cumulative distribution function given by
where ζ(s) is the Riemann zeta function . The mean μ is defined for s > 2 and standard deviation σ is defined for s > 3 and are
Let n = ⌊ζ(s − 1)/ζ(s)⌋. Then, using the above equation for the sum of harmonic numbers we obtain for the MAD of Zeta distribution:
7 Concluding remarks
This article presented a unified approach to compute MADs from cumulative distribution functions. The computation involves computing integrals of these functions often expressed in closed form in terms of special functions such as beta, gamma, or error functions. For many distributions, the integrals of these functions are well known and the resulting expressions for MADs can be easily obtained. For some of these distributions, the obtained results have not been reported elsewhere. We hope that this study will be useful for researchers and practitioners interested in using mean absolute deviations.
Data availability statement
The original contributions presented in the study are included in the article/Supplementary material, further inquiries can be directed to the corresponding author/s.
Author contributions
EP: Writing – original draft, Writing – review & editing.
Funding
The author(s) declare that no financial support was received for the research, authorship, and/or publication of this article.
Acknowledgments
The author would like to thank Metropolitan College of Boston University for their support.
Conflict of interest
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fams.2025.1487331/full#supplementary-material
References
1. Papoulis A. Probability, Random variable, and Stochastic Processes, 2nd Edn. New York, NY: McGraw-Hill (1984).
2. Bloomfield P, Steiger WL. Least Absolute Deviations: Theory, Applications and Algorithms. Boston, MA: Birkhauser. (1983). doi: 10.1007/978-1-4684-8574-5
4. Elsayed EA. On uses of mean absolute deviation: shape exploring and distribution function estimation. arXiv. (2022) [Preprint]. doi: 10.48550/arXiv.2206.09196
5. Schwertman NC, Gilks AJ, Cameron J. A simple noncalculus proof that the median minimizes the sum of the absolute deviations. Am Stat. (1990) 44:38–41. doi: 10.2307/2684955
6. Shad SM. On the minimum property of the first absolute moment. Am Stat. (1969) 23:27. doi: 10.2307/2682577
7. Farebrother RW. The historical development of the L_1 and L_∞ estimation methods. In:Dodge Y, , editor. Statistical data Analysis Based on the L_1-norm and Related Topics. Amsterdam: North-Holland (1987), p. 37–63.
8. Portnoy S, Koenker R. The Gaussian hare and the Laplacian tortoise: computability of square-error versus abolute-error estimators. Stat Sci. (1997) 2:279–300. doi: 10.1214/ss/1030037960
9. Gorard S. Revisiting a 90-year-old debate: the advantages of the mean deviation. Br J Educ Stud. (2005) 53:417–30. doi: 10.1111/j.1467-8527.2005.00304.x
10. Pham-Gia T, Hung TL. The mean and median absolute deviations. J Math Comput Modell. (2001) 34:921–36. doi: 10.1016/S0895-7177(01)00109-1
11. Dodge Y. Statistical Data Analysis Based on the L_1 Norm and Related Topics. Amsterdam: North-Holland (1987).
12. Elsayed KMT. Mean absolute deviation: analysis and applications. Int J Bus Stat Anal. (2015) 2:63–74. doi: 10.12785/ijbsa/020201
13. Gorard S. An absolute deviation approach to assessing correlation. Br J Educ Soc Behav Sci. (2015) 53:73–81. doi: 10.9734/BJESBS/2015/11381
14. Gorard S. Introducing the mean deviation “effect" size. Int J Res Method Educ. (2015) 38:105–14. doi: 10.1080/1743727X.2014.920810
15. Habib E. Mean absolute deviation about median as a tool of exploratory data analysis. Int J Res Rev Appl Sci. (2012) 11:517–23.
16. Leys C, Klein O, Bernard P, Licata L. Detecting outliers: do not use standard deviation around the mean, use absolute deviation around the median. J Exp Soc Psychol. (2013) 49:764–6. doi: 10.1016/j.jesp.2013.03.013
17. Yager RR, Alajilan N. A note on mean absolute deviation. Inf Sci. (2014) 279:632–41. doi: 10.1016/j.ins.2014.04.016
18. Pinsky E, Klawansky S. MAD (about median) vs. quantile-based alternatives for classical standard deviation, skew, and kurtosis. Front Appl Math Stat. (2023) 9:1206537. doi: 10.3389/fams.2023.1206537
19. Fisher RA. A mathematical examination of the methods of determining the accuracy of observation by the mean error, and by the mean square error. Mon Not R Astron Soc. (1920) 80:758–70. doi: 10.1093/mnras/80.8.758
22. Weisstein E. Mean Deviation (Wolfram Mathworld). (2011). Available at: https://mathworld.wolfram.com/MeanDeviation.htm (accessed February 1, 2025).
23. Trapani L. Testing for (in)finite moments. J Econom. (2016) 191:57–68. doi: 10.1016/j.jeconom.2015.08.006
24. Chu W. Abel's lemma on summation by parts and basic hypergeometric series. Adv Appl Math. (2007) 39:490–514. doi: 10.1016/j.aam.2007.02.001
25. Xue JH, Titterington DM. The p-folded cumulative distribution function and the mean absolute deviation from the p-quantile. Stat Probab Lett. (2011) 81:1179–82. doi: 10.1016/j.spl.2011.03.014
26. Andrews GE, Askey R, Roy R. Special Functions. Cambridge, MA: Cambridge University Press. (2000). doi: 10.1017/CBO9781107325937
27. Olver FW. Introduction to Asymptotics and Special Functions, 1st Edn. New York, NY: Academic Press. (1974). doi: 10.1016/B978-0-12-525856-2.50005-X
28. Conway JT. Indefinite integrals of products of special functions. Integer Transforms Spec Funct. (2017) 28:166–80. doi: 10.1080/10652469.2016.1259619
29. Gradshteyn IS, Ryzhik IM. Table of Integrals, Series, and products. New York, NY: Academic Press. (1980).
30. Ng E, Geller M. A table of integrals of the error function. J Res Natl Bureau Stand B Math Sc. (1969) 738:1–20. doi: 10.6028/jres.073B.001
31. Olver FW, Lozier DW, Boisvert RF, Clark CW. NIST Handbook of Mathematical Functions. New York, NY: Cambridge University Press (2010).
32. Owen DB. A table of normal integrals. Commun Stat Simul Comput. (1980) 9:389–419. doi: 10.1080/03610918008812164
33. Gupta AK, Nadarajah S. Handbook of Beta Distributions and its Applications. New York, NY: CRC Press, Taylor & Francis (2018).
Keywords: mean absolute deviations, probability distributions, cumulative distribution functions, central absolute moments, folded CDFs
Citation: Pinsky E (2025) Computation and interpretation of mean absolute deviations by cumulative distribution functions. Front. Appl. Math. Stat. 11:1487331. doi: 10.3389/fams.2025.1487331
Received: 27 August 2024; Accepted: 20 January 2025;
Published: 12 February 2025.
Edited by:
George Michailidis, University of Florida, United StatesCopyright © 2025 Pinsky. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Eugene Pinsky, ZXBpbnNreUBidS5lZHU=
†ORCID: Eugene Pinsky orcid.org/0000-0002-3836-1851