 Kevin Bui
Kevin Bui Fredrick Park2
Fredrick Park2 Shuai Zhang
Shuai Zhang Jack Xin
Jack Xin
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Appl. Math. Stat. , 24 February 2021
Sec. Mathematics of Computation and Data Science
Volume 6 - 2020 | https://doi.org/10.3389/fams.2020.529564
This article is part of the Research Topic Fundamental Mathematical Topics in Data Science View all 7 articles
Convolutional neural networks (CNN) have been hugely successful recently with superior accuracy and performance in various imaging applications, such as classification, object detection, and segmentation. However, a highly accurate CNN model requires millions of parameters to be trained and utilized. Even to increase its performance slightly would require significantly more parameters due to adding more layers and/or increasing the number of filters per layer. Apparently, many of these weight parameters turn out to be redundant and extraneous, so the original, dense model can be replaced by its compressed version attained by imposing inter- and intra-group sparsity onto the layer weights during training. In this paper, we propose a nonconvex family of sparse group lasso that blends nonconvex regularization (e.g., transformed
Deep neural networks (DNNs) have proven to be advantageous for numerous modern computer vision tasks involving image or video data. In particular, convolutional neural networks (CNNs) yield highly accurate models with applications in image classification [28, 39, 77, 95], semantic segmentation [13, 49], and object detection [30, 72, 73]. These large models often contain millions of weight parameters that often exceed the number of training data. This is a double-edged sword since on one hand, large models allow for high accuracy, while on the other, they contain many redundant parameters that lead to overparametrization. Overparametrization is a well-known phenomenon in DNN models [6, 17] that results in overfitting, learning useless random patterns in data [96], and having inferior generalization. Additionally, these models also possess exorbitant computational and memory demands during both training and inference. Consequently, they may not be applicable for devices with low computational power and memory.
Resolving these problems requires compressing the networks through sparsification and pruning. Although removing weights might affect the accuracy and generalization of the models, previous works [25, 54, 66, 81] demonstrated that many networks can be substantially pruned with negligible effect on accuracy. There are many systematic approaches to achieving sparsity in DNNs, as discussed extensively in Refs. 14 and 15.
Han et al. [26] proposed to first train a dense network, prune it afterward by setting the weights to zeroes if below a fixed threshold, and retrain the network with the remaining weights. Jin et al. [32] extended this method by restoring the pruned weights, training the network again, and repeating the process. Rather than pruning by thresholding, Aghasi et al. [1, 2] proposed Net-Trim, which prunes an already trained network layer by layer using convex optimization in order to ensure that the layer inputs and outputs remain consistent with the original network. For CNNs in particular, filter or channel pruning is preferred because it significantly reduces the amount of weight parameters required compared to individual weight pruning. Li et al. [43] calculated the sums of absolute weights of the filters of each layer and pruned the ones with the smallest sums. Hu et al. [29] proposed a metric called average percentage of zeroes for channels to measure their redundancies and pruned those with highest values for each layer. Zhuang et al. [105] developed discrimination-aware channel pruning that selects channels that contribute to the network’s discriminative power.
An alternative approach to pruning a dense network is learning a compressed structure from scratch. A conventional approach is to optimize the loss function equipped with either the
In this paper, we propose a family of group regularization methods that balances both group lasso for group-wise sparsity and nonconvex regularization for element-wise sparsity. The family extends sparse group lasso by replacing the
Given a training dataset consisting of N input-output pairs
where
W is the set of weight parameters of the DNN.
The most common regularizer used for DNNs is
To determine which filters or channels are relevant in each layer, group sparsity using the group lasso penalty [93] is considered. The group lasso penalty has been utilized in various applications, such as microarray data analysis [62], machine learning [7, 65], and EEG data [46]. Suppose a DNN has L layers, so the set of weight parameters W is divided into L sets of weights:
where
As an alternative to group lasso that encourages feature sharing, exclusive sparsity [104] enforces the model weight parameters to compete for features, making the features discriminative for each class in the context of classification. The regularization for exclusive sparsity is
Now, within each group, sparsity is enforced. Because exclusivity cannot guarantee the optimal features since some features do need to be shared, exclusive sparsity can be combined with group sparsity to form combined group and exclusive sparsity (CGES) [92]. CGES is formulated as
where
To obtain an even sparser network, element-wise sparsity and group sparsity can be combined and applied together to the training of DNNs. One regularizer that combines these two types of sparsity is the sparse group lasso penalty [76], which is formulated as
where
Sparse group lasso simultaneously enforces group sparsity by having the regularizer
Figure 1 demonstrates the differences between lasso, group lasso, and sparse group lasso applied to a weight matrix connecting a 5-dimensional input layer to a 10-dimensional output layer. In white, the entries are zero’ed out; in gray; the entries are not. Unlike lasso, group lasso results in a more structured method of pruning since three of the five neurons can be zero’ed out. Combined with
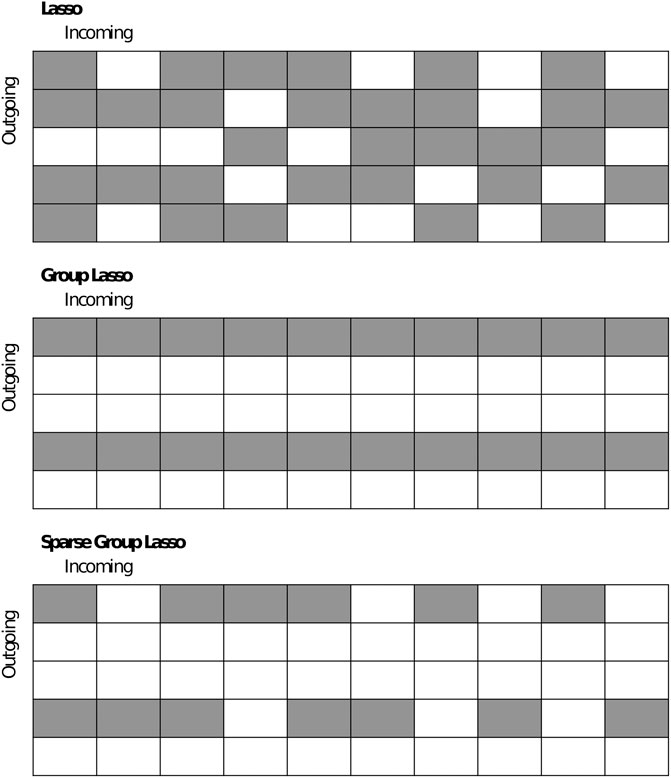
FIGURE 1. Comparison between lasso, group lasso, and sparse group lasso applied to a weight matrix. Entries in white are zero’ed out or removed; entries in gray remain.
We recall that the
where
when applied to the weight set
A continuous alternative to the
where
for
The transformed
where
In addition, it interpolates the
The transformed
Another Lipschitz continuous, nonconvex regularizer is the
where
Due to the advantages and recent successes of the aforementioned nonconvex regularizers, we propose to replace the
Using these regularizers, we expect to obtain a sparser and/or more accurate network than from using the original sparse group lasso. The
Before discussing the algorithm, we summarize notations that we will use to save space. They are the following:
If
for
We develop a general algorithm framework to solve
where
Assumption 1. The function
By introducing an auxiliary variable
The constraints can be relaxed by adding the quadratic penalty terms with
With β fixed, Eq. 16 can be solved by alternating minimization:
To solve Eq. 17a, we simultaneously update
where
To update V, we see that Eq. 17b can be rewritten as
The proximal operators for the considered regularizers are thresholding functions as their closed-form solutions, and as a result, the V update simplifies to thresholding W. The regularization functions and their corresponding proximal operators are summarized in Table 1.

TABLE 1. Regularization penalties and their corresponding proximal operators with

Algorithm 1:. Algorithm for Nonconvex Sparse Group Lasso RegularizationFAMS_fams-2020-529564_gs_fx1
Incorporating the algorithm that solves the quadratic penalty problem Eq. 16, we now develop a general algorithm to solve Eq. 14. We solve a sequence of quadratic penalty problems Eq. 16 with
An alternative algorithm to solve Eq. 14 is proximal gradient descent [70]. By this method, the update for
Using this algorithm results in weight parameters with some already zero’ed out.
However, the advantage of our proposed algorithm lies in Eq. 17a, written more specifically as
We see that this step performs exact weight decay or
To establish convergence for the proposed algorithm, the results below state that the accumulation point of the sequence generated by Eqs 17a and 17b is a block-coordinate minimizer, and an accumulation point generated by Algorithm 1 is a sparse feasible solution to (15). Proofs are provided in Section 5. Unfortunately, the feasible solution generated may not be a local minimizer of Eq. 15 because the loss function
Theorem 2. Let
Theorem 3. Let
Remark: To safely ensure that
If
We compare the proposed nonconvex sparse group lasso against four other methods as baselines: group lasso, sparse group lasso (
MNIST is trained on Lenet-5-Caffe, which has four layers with 1,370 total neurons and 431,080 total weight parameters. All layers of the network are applied with strictly the same type of regularization. No other regularization methods (e.g., dropout and batch normalization) are used. The network is optimized using Adam [37] with initial learning rate 0.001. For every 40 epochs, the learning rate decays by a factor of 0.1. We set the regularization parameter to the following values:
Table 2 reports the mean results for test error, weight sparsity, and neuron sparsity across five runs of Lenet-5-Caffe trained after 200 epochs. We see that although CGES has the lowest test errors at
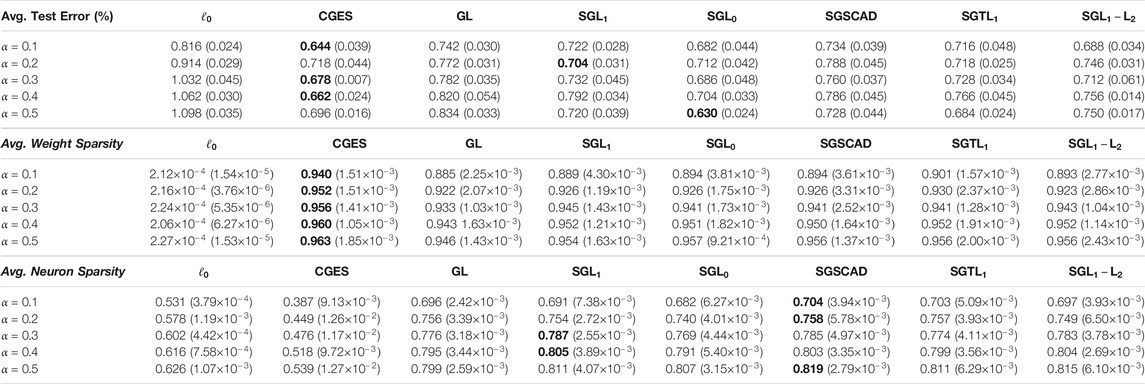
TABLE 2. Average test error, weight sparsity, and neuron sparsity of Lenet-5 models trained on MNIST after 200 epochs across 5 runs. Standard deviations are in parentheses.
Table 3 reports the mean results for test error, weight sparsity, and neuron sparsity of the Lenet-5-Caffe models with the lowest test errors from the five runs. According to the results, the best test errors are attained by
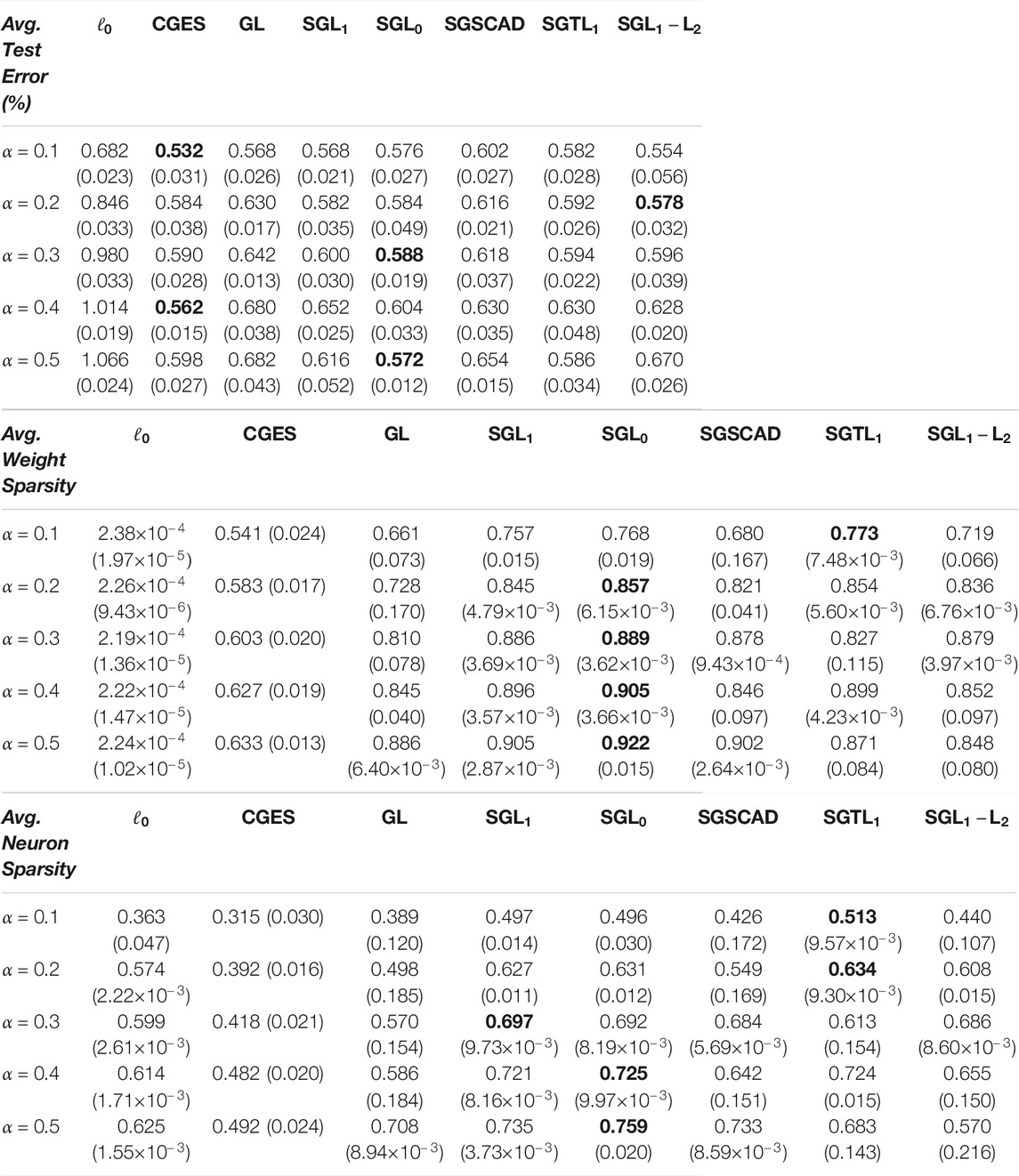
TABLE 3. Average test error, weight sparsity, and neuron sparsity of Lenet-5 models trained on MNIST with lowest test errors across 5 runs. Standard deviations are in parentheses.
MNIST is also trained on a 4-layer CNN with two convolutional layers with 32 and 64 channels, respectively, and an intermediate layer with 1000 neurons. Each convolutional layer has a
Table 4 reports the mean results for test error, weight sparsity, and neuron sparsity across five runs of the 4-layer CNN models trained after 200 epochs. Although CGES consistently has the highest weight sparsity, it does not yield the most accurate models until when
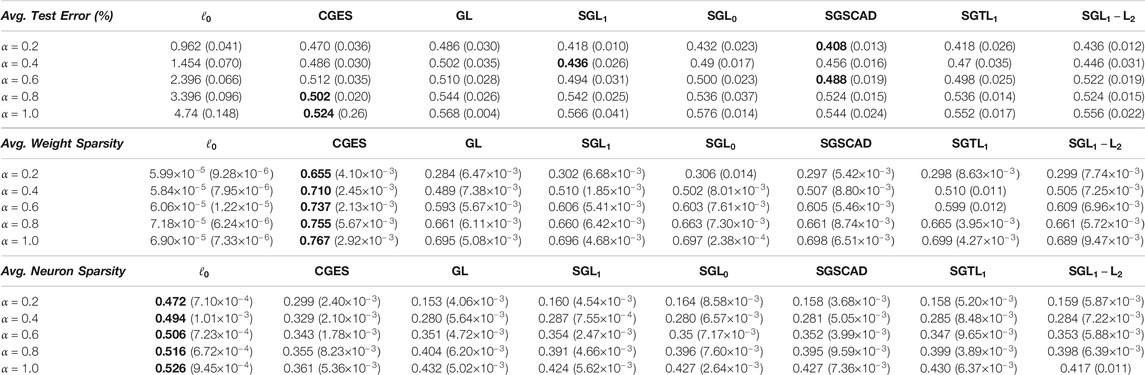
TABLE 4. Average test error, weight sparsity, and neuron sparsity of 4-layer CNN models trained on MNIST after 200 epochs across 5 runs. Standard deviations are in parentheses.
Table 5 reports the mean results for test error, weight sparsity, and neuron sparsity of the 4-layer CNN models with the lowest test errors from the five runs. At
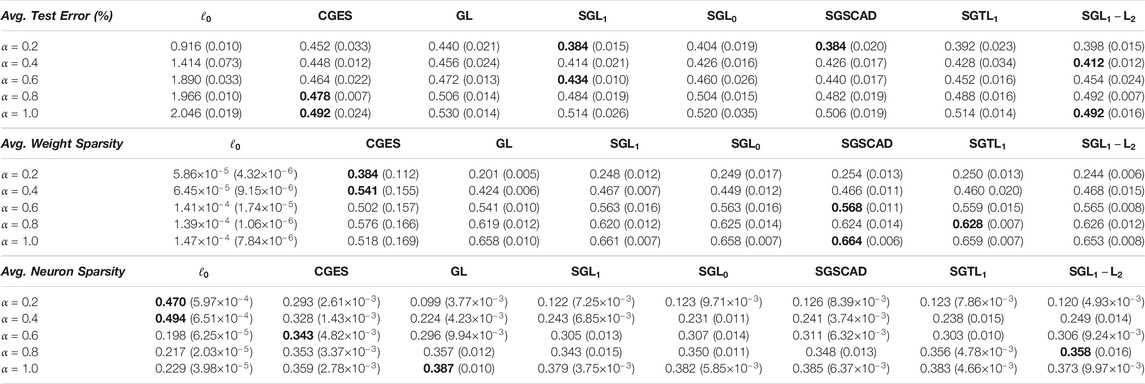
TABLE 5. Average test error, weight sparsity, and neuron sparsity of 4-layer CNN models trained on MNIST with lowest test errors across 5 runs. Standard deviations are in parentheses.
CIFAR 10/100 is trained on Resnet-40 and wide Resnet with depth 28 and width 10 (WRN-28-10). Resnet-40 has approximately 570,000 weight parameters and 1520 neurons while WRN-28-10 has approximately 36,500,000 weight parameters and 10,736 neurons. The networks are optimized using stochastic gradient descent with initial learning rate 0.1. After every 60 epochs, learning rate decays by a factor of 0.2. Strictly the same type of regularization is applied to the weights of the hidden layer where dropout is utilized in the residual block. We vary the regularization parameter
Table 6 reports mean test error, weight sparsity, and neuron sparsity across the Resnet-40 models trained on CIFAR 10 with the lowest test errors from the five runs. Group lasso has the lowest test errors for all α’s provided while CGES,
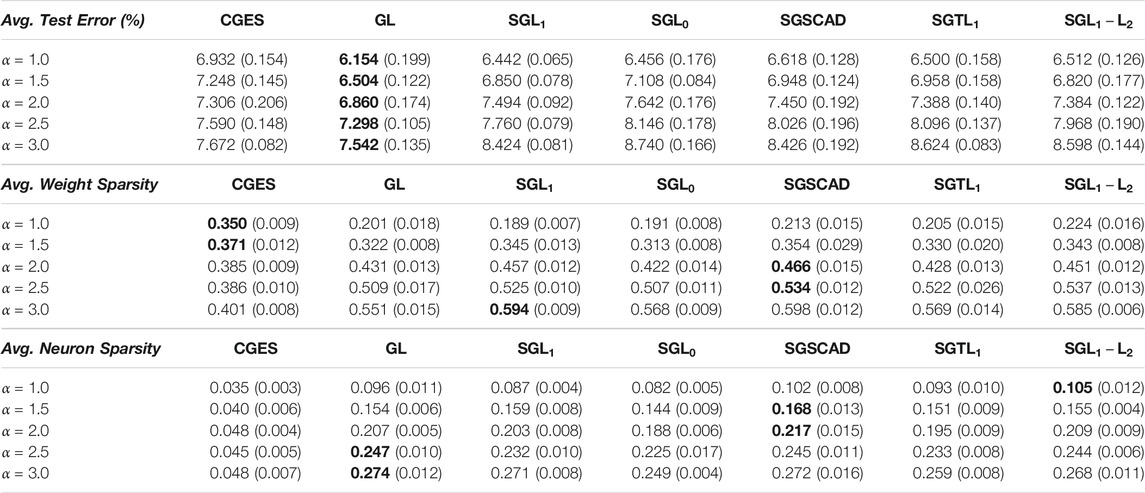
TABLE 6. Average test error, weight sparsity, and neuron sparsity of Resnet-40 models trained on CIFAR 10 with lowest test errors across 5 runs. Standard deviations are in parentheses.
Table 7 reports mean test error, weight sparsity, and neuron sparsity across the Resnet-40 models trained on CIFAR 100 with the lowest test errors from the five runs. Group lasso has the lowest test errors for
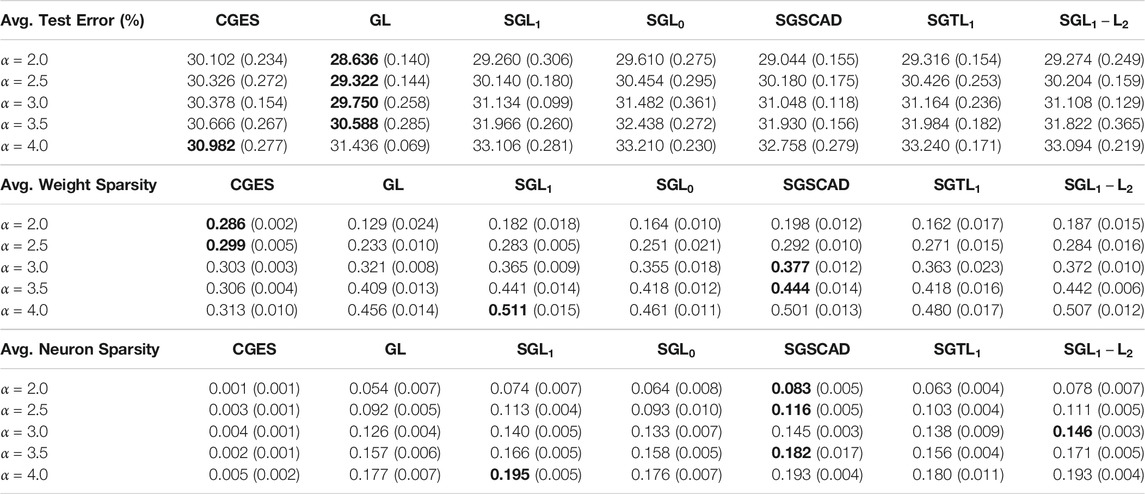
TABLE 7. Average test error, weight sparsity, and neuron sparsity of Resnet-40 models trained on CIFAR 100 with lowest test errors across 5 runs. Standard deviations are in parentheses.
Table 8 reports mean test error, weight sparsity, and neuron sparsity across the WRN-28-10 models trained on CIFAR 10 with the lowest test errors from the five runs. The best test errors are attained by
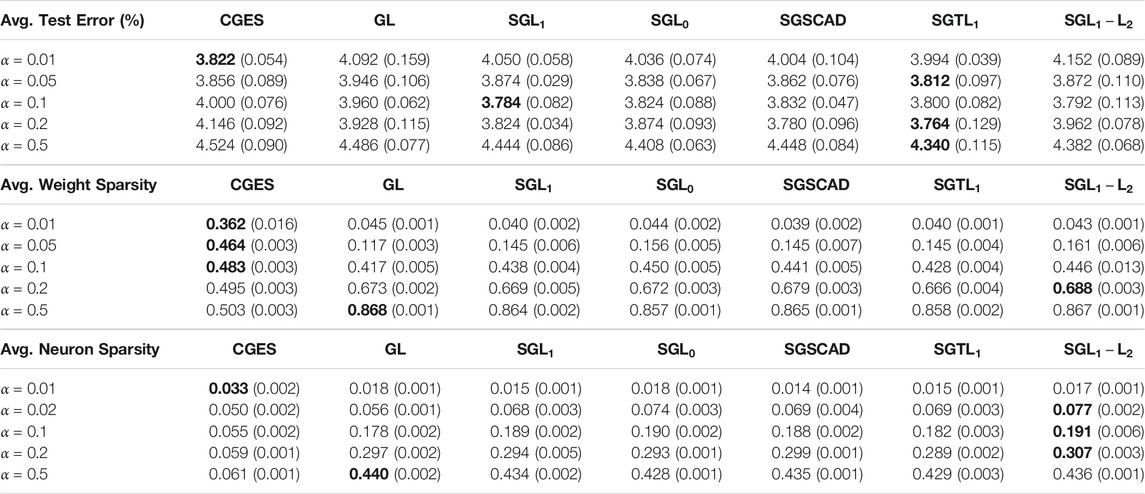
TABLE 8. Average test error, weight sparsity, and neuron sparsity of WRN-28-10 models trained on CIFAR 10 with lowest test errors across 5 runs. Standard deviations are in parentheses.
Table 9 reports mean test error, weight sparsity, and neuron sparsity across the WRN-28-10 models trained on CIFAR 100 with the lowest test errors from the five runs. According to the results, the best test errors are attained by CGES when
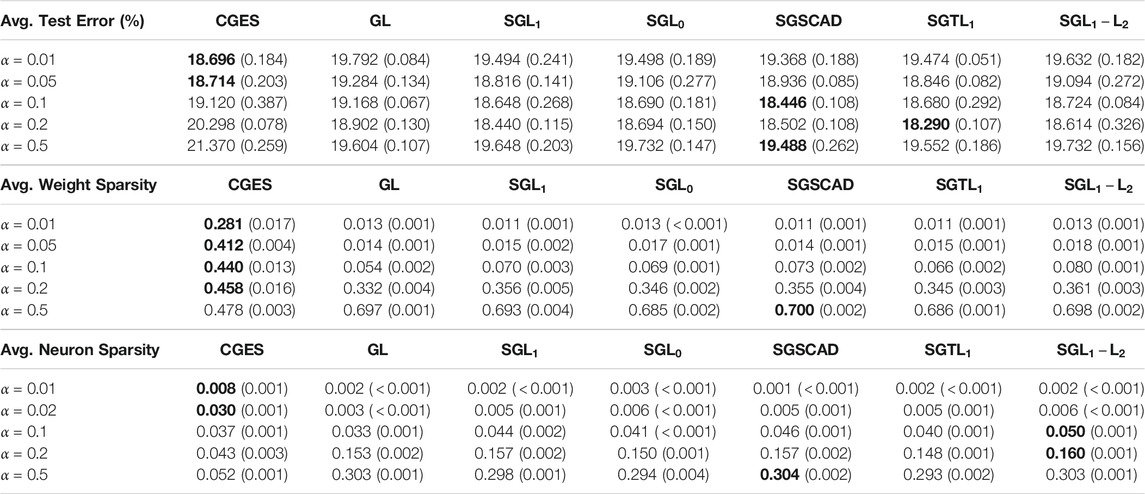
TABLE 9. Average test error, weight sparsity, and neuron sparsity of WRN-28-10 models trained on CIFAR 100 with lowest test errors across 5 runs. Standard deviations are in parentheses.
We compare the proposed Algorithm 1 with direct stochastic gradient descent, where the gradient of the regularizer is approximated by backpropagation, and proximal gradient descent, discussed in Section 2.4, by applying them to
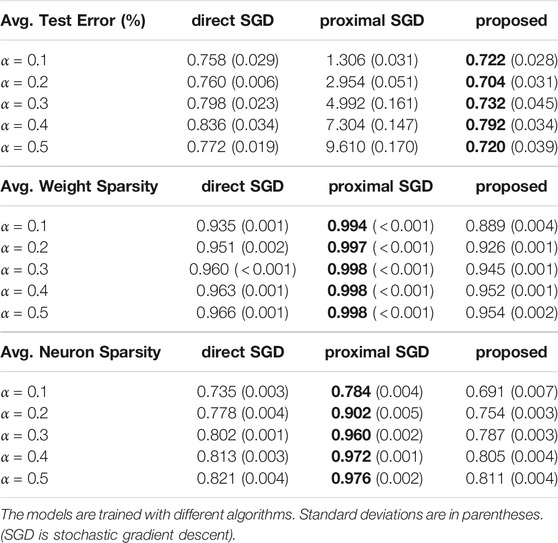
TABLE 10. Average test error, weight sparsity, and neuron sparsity of
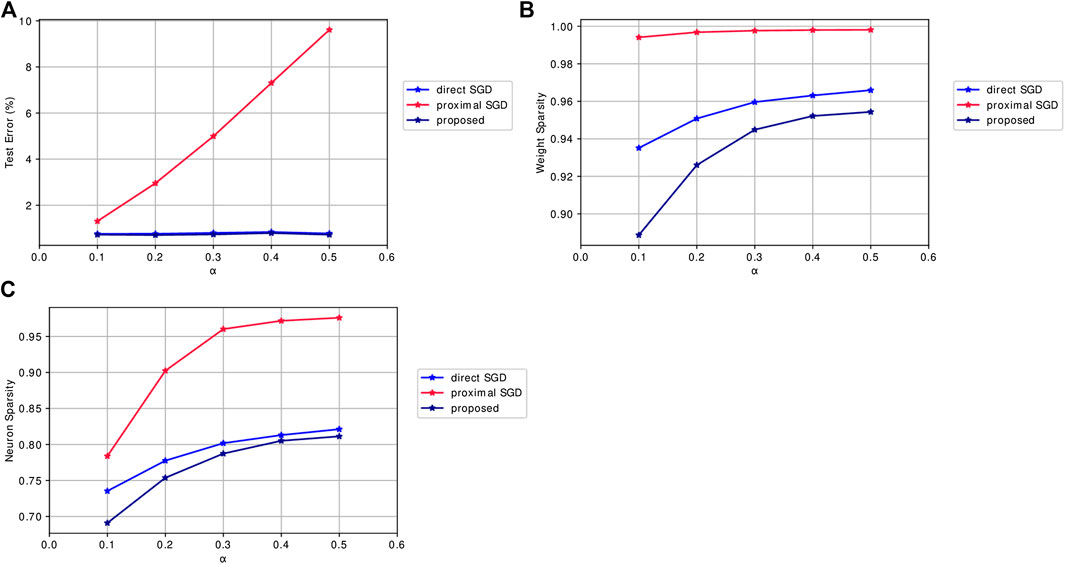
FIGURE 2. Mean results of algorithms applied to SGL1 for Lenet-5 models trained on MNIST for 200 epochs across 5 runs when varying the regularization parameter
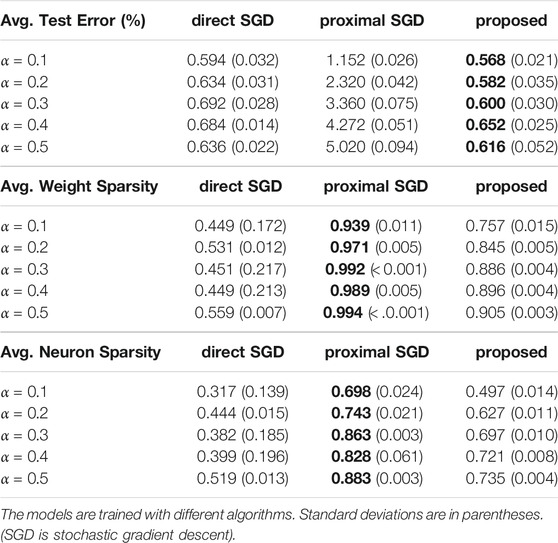
TABLE 11. Average test error, weight sparsity, and neuron sparsity of
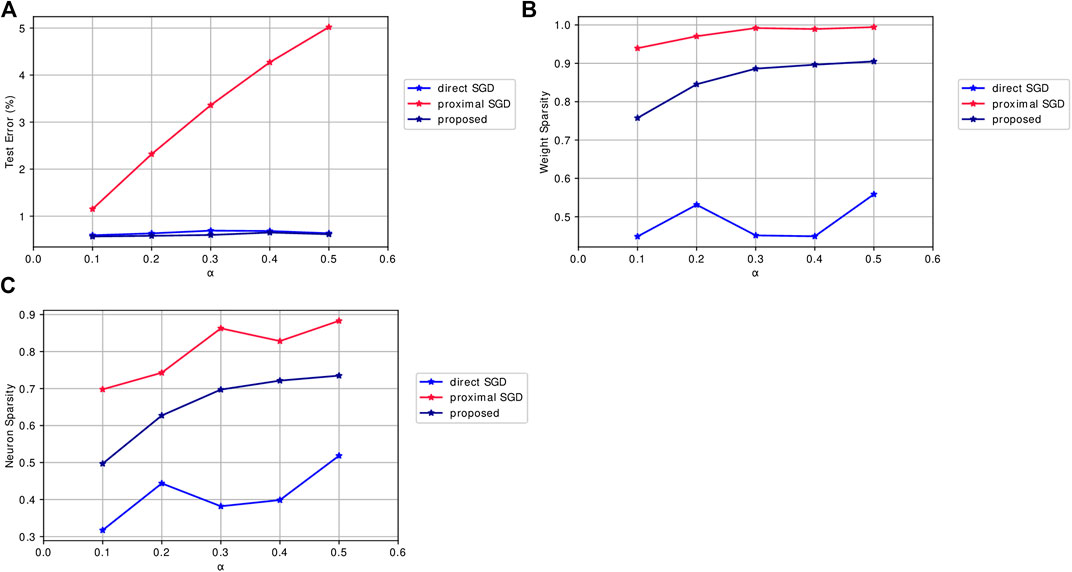
FIGURE 3. Mean results of algorithms applied to SGL1 for Lenet-5 models trained on MNIST with lowest test errors across 5 runs when varying the regularization parameter
In this work, we propose nonconvex sparse group lasso, a nonconvex extension of sparse group lasso. The
According to the numerical results, there is no single sparse regularizer that outperforms all other on any CNN trained on a given dataset. One regularizer may perform well in one case while it may perform worse on a different case. Due to the myriad of sparse regularizers to select from and the various parameters to tune, especially for one CNN trained on a given dataset, one direction is to develop an automatic machine learning framework that efficiently selects the right regularizer and parameters. In recent works, automatic machine learning can be represented as a matrix completion problem [88] and a statistical learning problem [24]. These frameworks can be adapted for selecting the best sparse regularizer, thus saving time for users who are training sparse CNNs.
We provide proofs for the results discussed in Section 2.5.
By Eqs 17a and 17b, for each
for all W, and
for all V. By Eq. 23, we have
for each
for each
Taking the limit gives us
Since
Because
for
by continuity, so it follows that
For notational convenience, let
By Eq. 22, we have
Because
after applying Eq. 26 in the third inequality and by continuity in the last equality.
Taking the limit over the subsequence
by continuity. Adding
which follows that
Because
As a result,
Taking the limit over
which follows that
The datasets MNIST and CIFAR 10/100 for this study are available through the Pytorch package in Python. Codes for the numerical experiments in Section 3 are available at https://github.com/kbui1993/Official_Nonconvex_SGL.
KB and FP performed the experiments and analysis. All authors contributed to the design, evaluation, discussions and production of the manuscript.
The work was partially supported by NSF grants IIS-1632935, DMS-1854434, DMS-1924548, DMS-1952644 and the Qualcomm Faculty Award.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The authors would like to thank Thu Dinh for helpful conversations. They also thank Christos Louizos for answering our questions we had regarding his work in [54]. Lastly, the authors thank AWS Cloud Credits for Research and Google Cloud Platform (GCP) for providing cloud based computational resources for this work.
1. Aghasi, A, Abdi, A, Nguyen, N, and Romberg, J. Net-trim: convex pruning of deep neural networks with performance guarantee. In: Advances in Neural Information Processing Systems; 2017 Nov 23; Long Beach, CA. Pasadena, CA: NeurIPS (2017). p. 3177–86. doi:10.5555/3294996.3295077
2. Aghasi, A, Abdi, A, and Romberg, J. Fast convex pruning of deep neural networks. SIAM J Math Data Sci (2020). 2:158–188. doi:10.1137/19m1246468
3. Ahn, M, Pang, J-S, and Xin, J. Difference-of-convex learning: directional stationarity, optimality, and sparsity. SIAM J Optim. (2017). 27:1637–1665. doi:10.1137/16m1084754
4. Alvarez, JM, and Salzmann, M. Learning the number of neurons in deep networks In: Advances in Neural Information Processing Systems; 2018 Oct 11; Barcelona, Spain. Pasadena, CA: NeurIPS (2016). p. 2270–8.
5. Antoniadis, A, and Fan, J. Regularization of wavelet approximations. J Am Stat Assoc. (2001). 96:939–67. doi:10.1198/016214501753208942
6. Ba, J, and Caruana, R. Do deep nets really need to be deep? Adv Neural Inf Process Syst. (2014). 2:2654–62. doi:10.5555/2969033.2969123
7. Bach, FR. Consistency of the group lasso and multiple kernel learning. J Mach Learn Res. (2008). 9:1179–225. doi:10.5555/1390681.1390721
8. Bao, C, Dong, B, Hou, L, Shen, Z, Zhang, X, and Zhang, X. Image restoration by minimizing zero norm of wavelet frame coefficients. Inverse Problems. (2016). 32:115004. doi:10.1088/0266-5611/32/11/115004
9. Breheny, P, and Huang, J. Coordinate descent algorithms for nonconvex penalized regression, with applications to biological feature selection. Ann Appl Stat. (2011). 5:232. doi:10.1214/10-aoas388
10. Candès, EJ, Li, X, Ma, Y, and Wright, J. Robust principal component analysis? J ACM. (2011). 58:1–37. doi:10.1145/1970392.1970395
11. Candès, EJ, Romberg, JK, and Tao, T. Stable signal recovery from incomplete and inaccurate measurements. Commun Pure Appl Math. (2006). 59:1207–23. doi:10.1002/cpa.20124
12. Chan, RH, Chan, TF, Shen, L, and Shen, Z. Wavelet algorithms for high-resolution image reconstruction. SIAM J Sci Comput. (2003). 24:1408–32. doi:10.1137/s1064827500383123
13. Chen, LC, Papandreou, G, Kokkinos, I, Murphy, K, and Yuille, AL (2018). Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans Pattern Anal Mach Intell. 40, 834–848doi:10.1109/TPAMI.2017.2699184
14. Cheng, Y, Wang, D, Zhou, P, and Zhang, T. A survey of model compression and acceleration for deep neural networks. Preprint repository name [Preprint] (2017). Available from: https://arxiv.org/abs/1710.09282.
15. Cheng, Y, Wang, D, Zhou, P, and Zhang, T. Model compression and acceleration for deep neural networks: The principles, progress, and challenges. IEEE Signal Process Mag. (2018). 35:126–36. doi:10.1109/msp.2017.2765695
16. Cohen, A, Dahmen, W, and DeVore, R. Compressed sensing and best k-term approximation. J Am Math Soc. (2009). 22:211–31. doi:10.1090/S0894-0347-08-00610-3
17. Denton, EL, Zaremba, W, Bruna, J, LeCun, Y, and Fergus, R. Exploiting linear structure within convolutional networks for efficient evaluation. Adv Neural Inf Process Syst. (2014). 1:1269–77. doi:10.5555/2968826.2968968
18. Dinh, T, and Xin, J. Convergence of a relaxed variable splitting method for learning sparse neural networks via ℓ1,ℓ0, and transformed-ℓ1 penalties. In: Proceedings of SAI Intelligent Systems Conference. Springer International Publishing (2020). p. 360–374.
19. Dong, B, and Zhang, Y. An efficient algorithm for ℓ0 minimization in wavelet frame based image restoration. J Sci Comput. (2013). 54:350–68. doi:10.1007/s10915-012-9597-4
20. Donoho, DL, and Elad, M. Optimally sparse representation in general (nonorthogonal) dictionaries via ℓ1 minimization. Proc Natl Acad Sci USA. (2003). 100:2197–202. doi:10.1073/pnas.0437847100
21. Esser, E, Lou, Y, and Xin, J. A method for finding structured sparse solutions to nonnegative least squares problems with applications. SIAM J Imag Sci (2013). 6:2010–46. doi:10.1137/13090540x
22. Fan, J, and Li, R. Variable selection via nonconcave penalized likelihood and its oracle properties. J Am Stat Assoc. (2001). 96:1348–60. doi:10.1198/016214501753382273
23. Foucart, S, and Rauhut, H. An invitation to compressive sensing. A mathematical introduction to compressive sensing. New York, NY: Birkhäuser (2013). p. 1–39.
24. Gupta, R, and Roughgarden, T. A pac approach to application-specific algorithm selection. SIAM J Comput. (2017). 46:992–1017. doi:10.1137/15m1050276
25. Han, S, Mao, H, and Dally, WJ. Deep compression: compressing deep neural networks with pruning, trained quantization and Huffman coding (2015). Available from: https://arxiv.org/abs/1510.00149.
26. Han, S, Pool, J, Tran, J, and Dally, W. Learning both weights and connections for efficient neural network. Adv Neural Inf Process Syst. (2015). 1:1135–43. doi:10.5555/2969239.2969366
27. Hastie, T, Tibshirani, R, and Friedman, J. The elements of statistical learning: data mining, inference, and prediction. New York, NY: Springer Science & Business Media (2009). 745 p.
28. He, K, Zhang, X, Ren, S, and Sun, J. Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition; 2016 Jun 27–30; Las Vegas, NV. New York, NY: IEEE (2016). p 770–8.
29. Hu, H, Peng, R, Tai, Y-W, and Tang, C-K. Network trimming: A data-driven neuron pruning approach towards efficient deep architectures (2016). Available from: https://arxiv.org/abs/1607.03250.
30. Huang, J, Rathod, V, Sun, C, Zhu, M, Korattikara, A, Fathi, A, et al. Speed/accuracy trade-offs for modern convolutional object detectors. In: Proceedings of the IEEE conference on computer vision and pattern recognition; 2017 Jul 21–26; Honolulu, HI. New York, NY: IEEE (2017). p. 7310–1.
31. Jia, Y, Shelhamer, E, Donahue, J, Karayev, S, Long, J, Girshick, R, et al. Caffe: convolutional architecture for fast feature embedding. In: Proceedings of the 22nd ACM international conference on multimedia (ACM); 2014 Jul 20; Berkeley, CA. Berkeley, CA: UC Berkeley EECS (2014). p. 675–8.
32. Jin, X, Yuan, X, Feng, J, and Yan, S. Training skinny deep neural networks with iterative hard thresholding methods (2016). Available from: https://arxiv.org/abs/1607.05423.
33. Jung, H, Ye, JC, and Kim, EY. Improvedk-tBLAST and k-t SENSE using FOCUSS. Phys Med Biol. (2007). 52:3201. doi:10.1088/0031-9155/52/11/018
34. Jung, M. Piecewise-Smooth image Segmentation models with L1 data-fidelity Terms. J Sci Comput. (2017). 70:1229–61. doi:10.1007/s10915-016-0280-z
35. Jung, M, Kang, M, and Kang, M. Variational image segmentation models involving non-smooth data-fidelity terms. J Sci Comput. (2014). 59:277–308. doi:10.1007/s10915-013-9766-0
36. Kim, C, and Klabjan, D. A simple and fast algorithm for L1-norm kernel PCA. IEEE Trans Patt Anal Mach Intell. (2019). 42:1842–55. doi:10.1109/TPAMI.2019.2903505
37. Kingma, DP, and Ba, J. Adam: a method for stochastic optimization. (2014). Available from: https://arxiv.org/abs/1412.6980.
38. Krizhevsky, A, and Hinton, G. Learning multiple layers of features from tiny images (2009). p. 60. Available from: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.222.9220&rep=rep1&type=pdf.
39. Krizhevsky, A, Sutskever, I, and Hinton, GE. Imagenet classification with deep convolutional neural networks. Commun ACM. (2012). 60:1097–105. doi:10.1145/3065386
40. Krogh, A, and Hertz, JA. A simple weight decay can improve generalization. Adv Neural Inf Process Syst. (1992). 4:950–957. doi:10.5555/2986916.2987033
41. LeCun, Y, Bottou, L, Bengio, Y, and Haffner, P. Gradient-based learning applied to document recognition. Proc IEEE. (1998). 86:2278–324. doi:10.1109/5.726791
42. Li, F, Osher, S, Qin, J, and Yan, M. A multiphase image segmentation based on fuzzy membership functions and l1-norm fidelity. J Sci Comput. (2016). 69:82–106. doi:10.1007/s10915-016-0183-z
43. Li, H, Kadav, A, Durdanovic, I, Samet, H, and Graf, HP. Pruning filters for efficient convnets (2016). Available from: https://arxiv.org/abs/1608.08710.
44. Li, P, Chen, W, Ge, H, and Ng, MK. ℓ1−αℓ2 minimization methods for signal and image reconstruction with impulsive noise removal. Inv Problems. (2020). 36:055009. doi:10.1088/1361-6420/ab750c
45. Li, Z, Luo, X, Wang, B, Bertozzi, AL, and Xin, J. A study on graph-structured recurrent neural networks and sparsification with application to epidemic forecasting. World congress on global optimization. Cham, Switzerland: Springer (2019). p. 730–9.
46. Lim, M, Ales, JM, Cottereau, BR, Hastie, T, and Norcia, AM. Sparse EEG/MEG source estimation via a group lasso. PloS One. (2017). 12:e0176835. doi:10.1371/journal.pone.0176835
47. Lin, D, Calhoun, VD, and Wang, Y-P. Correspondence between fMRI and SNP data by group sparse canonical correlation analysis. Med Image Anal. (2014). 18:891–902. doi:10.1016/j.media.2013.10.010
48. Lin, D, Zhang, J, Li, J, Calhoun, VD, Deng, H-W, and Wang, Y-P. Group sparse canonical correlation analysis for genomic data integration. BMC bioinf. (2013). 14:1–16. doi:10.1186/1471-2105-14-245
49. Long, J, Shelhamer, E, and Darrell, T. Fully convolutional networks for semantic segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition; 2015 Jun 7–15; Boston, MA. New York, NY: IEEE (2015). p. 3431–40.
50. Lou, Y, Osher, S, and Xin, J. Computational aspects of constrained minimization for compressive sensing. Modelling, computation and optimization in information systems and management sciences. Cham, Switzerland: Springer (2015). p. 169–80.
51. Lou, Y, and Yan, M. Fast L1-L2 minimization via a proximal operator. J Sci Comput. (2018). 74:767–85. doi:10.1007/s10915-017-0463-2
52. Lou, Y, Yin, P, He, Q, and Xin, J. Computing sparse representation in a highly coherent dictionary based on difference of L1 and L2. J Sci Comput. (2015). 64:178–96. doi:10.1007/s10915-014-9930-1
53. Lou, Y, Zeng, T, Osher, S, and Xin, J. A weighted difference of anisotropic and isotropic total variation model for image processing. SIAM J Imag Sci. (2015). 8:1798–823. doi:10.1137/14098435x
54. Louizos, C, Welling, M, and Kingma, DP. Learning sparse neural networks through regularization (2017). Available from: https://arxiv.org/abs/1712.01312.
55. Lu, J, Qiao, K, Li, X, Lu, Z, and Zou, Y. ℓ0-minimization methods for image restoration problems based on wavelet frames. Inverse Probl. (2019). 35:064001. doi:10.1088/1361-6420/ab08de
56. Lu, Z, and Zhang, Y. Sparse approximation via penalty decomposition methods. SIAM J Optim. (2013). 23:2448–78. doi:10.1137/100808071
57. Lustig, M, Donoho, D, and Pauly, JM. Sparse MRI: the application of compressed sensing for rapid MR imaging. Magn Reson Med. (2007). 58:1182–95. doi:10.1002/mrm.21391
58. Lv, J, and Fan, Y. A unified approach to model selection and sparse recovery using regularized least squares. Ann Stat. (2009). 37:3498–528. doi:10.1214/09-aos683
59. Lyu, J, Zhang, S, Qi, Y, and Xin, J. Autoshufflenet: learning permutation matrices via an exact Lipschitz continuous penalty in deep convolutional neural networks. In: Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining. New York, NY: Association for Computing Machinery (2020). p. 608–16.
60. Ma, N, Zhang, X, Zheng, H-T, and Sun, J. “Shufflenet v2: practical guidelines for efficient CNN architecture design”. Computer Vision – ECCV 2018. Cham: Springer International Publishing (2018). p. 122–38.
61. Ma, R, Miao, J, Niu, L, and Zhang, P. Transformed ℓ1 regularization for learning sparse deep neural networks. Neur Netw (2019). 119:286–98 doi:10.1016/j.neunet.2019.08.01
62. Ma, S, Song, X, and Huang, J. Supervised group lasso with applications to microarray data analysis. BMC bioinf. (2007). 8:60. doi:10.1186/1471-2105-8-60
63. Ma, T-H, Lou, Y, Huang, T-Z, and Zhao, X-L. Group-based truncated model for image inpainting. In: IEEE international conference on image processing (ICIP); 2018 Feb 22; Beijing, China. New York, NY: IEEE (2017). p. 2079–83.
64. Mehranian, A, Rad, HS, Rahmim, A, Ay, MR, and Zaidi, H. Smoothly clipped absolute deviation (SCAD) regularization for compressed sensing MRI using an augmented Lagrangian scheme. Magn Reson Imag. (2013). 31:1399–411. doi:10.1016/j.mri.2013.05.010
65. Meier, L, Van De Geer, S, and Bühlmann, P. The group lasso for logistic regression. J Roy Stat Soc B. (2008). 70:53–71. doi:10.1111/j.1467-9868.2007.00627.x
66. Molchanov, D, Ashukha, A, and Vetrov, D (2017). Variational dropout sparsifies deep neural networks. In Proceedings of the 34th International Conference on Machine Learning; Sydney, Australia. Sydney, NSW, Australia: JMLR. 2498–507.
67. Nie, F, Wang, H, Huang, H, and Ding, C. Unsupervised and semi-supervised learning via ℓ1-norm graph. In: 2011 international conference on computer vision (IEEE) (2011). 2268–73.
68. Nikolova, M. Local strong homogeneity of a regularized estimator. SIAM J Appl Math. (2000). 61:633–58. doi:10.1137/s0036139997327794
69. Nocedal, J, and Wright, S. Numerical optimization. New York, NY: Springer Science & Business Media (2006). 651 p.
70. Parikh, N, and Boyd, S. Proximal algorithms. FNT Optimization. (2014). 1:127–239. doi:10.1561/2400000003
71. Park, F, Lou, Y, and Xin, J. A weighted difference of anisotropic and isotropic total variation for relaxed mumford-shah image segmentation. In: 2016 IEEE International Conference on Image Processing (ICIP); 2016 Sep 25–28; Phoenix, AZ. New York, NY: IEEE (2016). 4314 p.
72. Parkhi, OM, Vedaldi, A, and Zisserman, A. Deep face recognition. In: Proceedings of the british machine vision conference. Cambridge, UK: BMVA Press (2015). p. 41.1–41.12.
73. Ren, S, He, K, Girshick, R, and Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv Neural Inf Process Syst (2015). 39:91–99. doi:10.1109/TPAMI.2016.2577031
74. Santosa, F, and Symes, WW. Linear inversion of band-limited reflection seismograms. SIAM J Sci Stat Comput. (1986). 7:1307–30. doi:10.1137/0907087
75. Scardapane, S, Comminiello, D, Hussain, A, and Uncini, A. Group sparse regularization for deep neural networks. Neurocomputing. (2017). 241:81–9. doi:10.1016/j.neucom.2017.02.029
76. Simon, N, Friedman, J, Hastie, T, and Tibshirani, R. A sparse-group lasso. J Comput Graph Stat. (2013). 22:231–45. doi:10.1080/10618600.2012.681250
77. Simonyan, K, and Zisserman, A. Very deep convolutional networks for large-scale image recognition (2015). Available from: https://arxiv.org/abs/1409.1556.
78. Tibshirani, R. Regression shrinkage and selection via the lasso. J Roy Stat Soc B. (1996). 58:267–88. doi:10.1111/j.2517-6161.1996.tb02080.x
79. Tran, H, and Webster, C. A class of null space conditions for sparse recovery via nonconvex, non-separable minimizations. Res Appl Math. (2019). 3:100011. doi:10.1016/j.rinam.2019.100011
80. Trzasko, J, Manduca, A, and Borisch, E. Sparse MRI reconstruction via multiscale L0-continuation. In: 2007 IEEE/SP 14th workshop on statistical signal processing. New York, NY: IEEE (2007). p. 176–80.
81. Ullrich, K, Meeds, E, and Welling, M. Soft weight-sharing for neural network compression. Stat. (2017). 1050:9.
82. Vershynin, R. High-dimensional probability: An introduction with applications in data science. Cambridge, UK: Cambridge University Press (2018). 296 p.
83. Vincent, M, and Hansen, NR. Sparse group lasso and high dimensional multinomial classification. Comput Stat Data Anal. (2014). 71:771–86. doi:10.1016/j.csda.2013.06.004
84. Wang, L, Chen, G, and Li, H. Group scad regression analysis for microarray time course gene expression data. Bioinformatics. (2007). 23:1486–94. doi:10.1093/bioinformatics/btm125
85. Wen, F, Chu, L, Liu, P, and Qiu, RC. A survey on nonconvex regularization-based sparse and low-rank recovery in signal processing, statistics, and machine learning. IEEE Access. (2018). 6:69883–906. doi:10.1109/access.2018.2880454
86. Wen, W, Wu, C, Wang, Y, Chen, Y, and Li, H. Learning structured sparsity in deep neural networks. In: Advances in Neural Information Processing Systems; 2016 Aug 12; Barcelona, Spain. NeurIPS. Red Hook, NY: Curran Associates Inc. (2016). p. 2074–82.
87. Xue, F, and Xin, J. Learning sparse neural networks via ℓ0 and Tℓ1 by a relaxed variable splitting method with application to multi-scale curve classification. World congress on global optimization. Cham, Switzerland: Springer (2019). p. 800–809.
88. Yang, C, Akimoto, Y, Kim, DW, and Udell, M. Oboe: Collaborative filtering for automl model selection. In: Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining. New York, NY: ACM (2019). p. 1173–183.
89. Ye, Q, Zhao, H, Li, Z, Yang, X, Gao, S, Yin, T, et al. L1-Norm Distance minimization-based fast robust twin support vector κ-plane Clustering. IEEE Trans Neural Netw Learn Syst. (2018). 29:4494–503. doi:10.1109/TNNLS.2017.2749428
90. Yin, P, Lou, Y, He, Q, and Xin, J. Minimization of ℓ1-2 for Compressed Sensing. SIAM J Sci Comput. (2015). 37:A536–63. doi:10.1137/140952363
91. Yin, P, Sun, Z, Jin, W-L, and Xin, J. ℓ1-minimization method for link flow correction. Transp Res Part B Methodol. (2017). 104:398–408. doi:10.1016/j.trb.2017.08.006
92. Yoon, J, and Hwang, SJ. Combined group and exclusive sparsity for deep neural networks. In: Proceedings of the 34th international conference on machine learning; Sydney, Australia. JMLR (2017). 3958–66.
93. Yuan, M, and Lin, Y. Model selection and estimation in regression with grouped variables. J Roy Stat Soc B. (2006). 68:49–67. doi:10.1111/j.1467-9868.2005.00532.x
94. Yuan, X-T, Li, P, and Zhang, T. Gradient hard thresholding pursuit. J Mach Learn Res. (2017). 18:166–1. doi:10.5555/3122009.3242023
95. Zagoruyko, S, and Komodakis, N. Wide residual networks (2016). Available from: https://arxiv.org/abs/1605.07146.
96. Zhang, C, Bengio, S, Hardt, M, Recht, B, and Vinyals, O. Understanding deep learning requires rethinking generalization (2016). Available from: https://arxiv.org/abs/1611.03530.
97. Zhang, S, and Xin, J. Minimization of transformed L-1 penalty: Closed form representation and iterative thresholding algorithms. Commun Math Sci. (2017). 15:511–37. doi:10.4310/cms.2017.v15.n2.a9
98. Zhang, S, and Xin, J. Minimization of transformed L1 penalty: theory, difference of convex function algorithm, and robust application in compressed sensing. Math Program. (2018). 169:307–36. doi:10.1007/s10107-018-1236-x
99. Zhang, S, Yin, P, and Xin, J. Transformed schatten-1 iterative thresholding algorithms for low rank matrix completion. Commun Math Sci. (2017). 15:839–62. doi:10.4310/cms.2017.v15.n3.a12
100. Zhang, X, Lu, Y, and Chan, T. A novel sparsity reconstruction method from Poisson data for 3d bioluminescence tomography. J Sci Comput. (2012). 50:519–35. doi:10.1007/s10915-011-9533-z
101. Zhang, X, Zhou, X, Lin, M, and Sun, J. Shufflenet: an extremely efficient convolutional neural network for mobile devices. In: Proceedings of the IEEE conference on computer vision and pattern recognition. IEEE (2018). p. 6848–56.
102. Zhang, Y, Dong, B, and Lu, Z. ℓ0 minimization for wavelet frame based image restoration. Math Comput. (2013). 82:995–1015. doi:10.1090/S0025-5718-2012-02631-7
103. Zhou, H, Sehl, ME, Sinsheimer, JS, and Lange, K. Association screening of common and rare genetic variants by penalized regression. Bioinformatics. (2010). 26:2375. doi:10.1093/bioinformatics/btq448
104. Zhou, Y, Jin, R, and Hoi, S. Exclusive lasso for multi-task feature selection. In: Proceedings of the thirteenth international conference on artificial intelligence and statistics; Montreal, Canada. JMLR: W&CP (2010). p. 988–95.
Keywords: deep learning, sparsity, nonconvex optimization, sparse group lasso, feature selection
Citation: Bui K, Park F, Zhang S, Qi Y and Xin J (2021) Structured Sparsity of Convolutional Neural Networks via Nonconvex Sparse Group Regularization. Front. Appl. Math. Stat. 6:529564. doi: 10.3389/fams.2020.529564
Received: 25 January 2020; Accepted: 16 October 2020;
Published: 24 February 2021.
Edited by:
Lucia Tabacu, Old Dominion University, United StatesCopyright © 2021 Bui, Park, Zhang, Qi and Xin. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jack Xin, amFjay54aW5AdWNpLmVkdQ==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.