 Chi-Lan Yang1*†
Chi-Lan Yang1*† Keigo Matsumoto1*†
Keigo Matsumoto1*† Songping Yu1Leo Sawada1Kiyoaki Arakawa2Daisuke Yamada2
Songping Yu1Leo Sawada1Kiyoaki Arakawa2Daisuke Yamada2 Hideaki Kuzuoka1
Hideaki Kuzuoka1- 1Cyber Interface Lab, The University of Tokyo, Tokyo, Japan
- 2Michele Holdings Co., Ltd., Tokyo, Japan
Social VR enables people to join a remote discussion by keeping a high social presence and physical proximity using embodied avatars. However, the missing nonverbal cues, such as mutual eye contact and nuanced facial expression, make it challenging for distributed members to manage turn-taking, which could lead to unequal participation and affect trust building. Therefore, we propose a virtual moderator to make distributed members feel included by seeing their nonverbal behavior. The virtual moderator was designed with a “prompt Q&A″ feature to enable users to share feedback and an “attention guidance” feature to encourage participation. The preliminary result of a controlled experiment in social VR with 30 participants showed that seeing the virtual moderator’s body orientation enhanced participants’ psychological safety. In contrast, the prompt Q&A feature enhanced the perceived co-presence of their remote counterparts. We discussed how nonverbal behavior could be designed using a virtual moderator to shape human perception of the group discussion in social VR. We also pointed out challenges when providing multiple supports simultaneously in social VR.
1 Introduction
Social virtual reality (social VR), such as VRChat and Horizon Workrooms, has become an online space for distributed people to join discussions. People can have high engagement and social co-presence with their remote counterparts when embodied as an avatar in social virtual reality (Moustafa and Steed, 2018). The physical proximity and the embodiment of the avatar in social VR enable people to have a high social presence (Mennecke et al., 2011). Yet, the lack of nonverbal cues, such as correct gaze information and facial expression, in virtual reality affected remote discussion adversely (Garau et al., 2003; Tanenbaum et al., 2020), and could make it challenging for people to manage turn-taking and thus harm equal participation in remote discussion (Whittaker, 2003). Especially when all members were unacquainted with each other, the lack of mutual understanding and awareness about the nonverbal cues may make it even more difficult for people to find the right time to participate in the group discussion actively.
When discussing with unfamiliar group members remotely, such as holding a kick-off meeting online, the group dynamics people perceive may influence whether the collaborative relationship can be established (Maznevski and Chudoba, 2000). When having a discussion in social VR, where limited social cues can be perceived, the perceived psychological safety among distributed members to sense could determine the discussion outcome and trust building. Psychological safety is essential for people to feel included in a group discussion. Groups with high psychological safety encourage members to share their opinions without worrying about being evaluated. Psychological safety also enables members to participate equally in a forum, thus leading to productive collaboration outcome (DiMicco et al., 2004).
In addition, building rapport, which indicates a pleasant feeling among people, also plays a vital role in establishing a collaborative relationship. Although the past study showed that self-disclosure occurred when people started establishing trust with each other (Maloney et al., 2020), it can be challenging when building trust and rapport in a cueless environment. In the context of video-based communication, various existing approaches have been proposed to enable users to display nonverbal cues using their avatars for supporting relationship building, such as showing gaze (Pan et al., 2014) or changing the appearance or facial expression of one’s avatar (Hyde et al., 2015; Ichino et al., 2022). However, in the context of social VR, little has been explored about the effect of avatars’ nonverbal behavior on rapport building in group discussions.
Virtual agents, such as chatbots, have been found effective in moderating group discussion (Kim et al., 2020). Chatbots facilitate equal participation among online members using explicit and verbal guidance. However, when the virtual agents are embodied as avatars, we would like to know whether such embodiment enables virtual agents to moderate group discussion implicitly with their nonverbal behavior, such as gaze or head orientation. As gaze has been identified as an effective social cue to manage turn-taking (O’Conaill et al., 1993), we aim to highlight this information using an embodied virtual moderator in a social VR setting.
Therefore, in this study, we designed a virtual moderator, an agent embodied in a virtual human-like avatar, to moderate the remote discussion in virtual reality using VRChat. The virtual moderator is designed to implicitly influence distributed members’ awareness and perceptions through nonverbal behavior, such as orienting its head towards the least active person and displaying unspoken feedback from participants. This study aims to investigate how a virtual moderator could change distributed attendants’ perceptions toward their remote counterparts in social VR, which is the first step for supporting turn-taking in social VR. Hence, the research question we asked is, “How does the nonverbal behavior of a virtual moderator influence distribute members’ perceptions about the group discussion when discussing in social VR?”
2 Related work
Social VR enables distributed members to join the same virtual space by wearing head-mounted displays (HMD) to interact with each other. The embodiment of the avatar and simulated physical proximity makes remote interlocutors perceive the high social presence of each other, compared to other remote communication media, such as video conferencing or text messaging (Greenwald et al., 2017). However, its ability for people to express and sense nonverbal cues remains to be challenging. Nonverbal cues such as mutual eye contact, gesture, body orientation, or facial expression play important roles for people to infer the intention of each other and build trust (Tickle-Degnen and Rosenthal, 1990). During group discussions, these nonverbal cues also help distributed members recognize the appropriate timing for turn-taking, such as allowing others to interject or managing the flow of conversation topics (O’Conaill et al., 1993). When performing group discussions using social VR, the inability to display mutual eye contact, a tiny movement of the body orientation, and the movement of the mouth make it challenging for remote interlocutors to manage turn-taking, which could impede equal participation in group discussions.
Various approaches have been proposed to support equal participation in group discussions. For collocated group discussion, Shamekhi et al. (2018) revealed that an embodied conversational agent could facilitate discussion. The presence of the embodied conversational agent made each participant contribute equally to the group discussion regarding the number of turn-takings and the number of words. In cross-lingual communication, researchers also found that the gaze direction of a robot could mediate the turn-taking when the conversation was dominated by a native speaker (Gillet et al., 2021). Whereas for online discussion, the chatbot has been proposed to actively moderate group discussion by managing discussion time and facilitating equal participation (Kim et al., 2020). Moreover, the chatbot was also found effective in assisting human moderators to better moderate online discussion by showing the current discussion stage and suggesting moderating messages (Lee et al., 2020). In virtual reality, previous research has shown that an avatar could change group dynamics in cross-cultural conversation (Traum and Rickel, 2002). However, it remains unclear how a virtual moderator embodied in a human-like avatar influences group discussion in social VR.
Therefore, we proposed a virtual moderator in this study to enable distributed members to feel equally included in a remote discussion using social VR. First, limited social cues in social VR could prevent people from finding the right timing to cut in the conversation (O’Conaill et al., 1993), and extra channels for people to express their opinion are needed. Furthermore, a past study has revealed that people tend to share their opinion when seeing other people start disclosing themselves (Kou and Gray, 2018). Hence, based on this concept, we designed the virtual moderator as an information hub that could display unspoken words from every member. We expected to encourage people to share their idea in the discussion. Second, related work has shown that the body orientation of the human or a robot (Kuzuoka et al., 2010) could influence the perceived inclusiveness of their counterparts. Following this research, we designed the body orientation of the virtual moderator to be changed based on the engagement level of each member. We expected such nonverbal behavior of the virtual moderator could enable people to be aware of the non-dominant speaker implicitly and make people feel included in the remote discussion.
3 Proposed system
We introduced a virtual moderator to moderate group discussions in social VR to support equal participation by enhancing awareness about distributed participants. The system has two main features.
(1) Give the floor to people for cutting in the discussion: Past study has shown that people find it difficult to take the conversational floor during online group meeting due to the missing mutual eye contact (Vertegaal et al., 2003). To cope with this, we enabled participants to send textual feedback through the virtual moderator to indicate they intend to take the floor. In front of each participant, a panel will show sample questions and responses for participants to choose from during the discussion. In formal group discussions, we designed eight general sample questions and answers1 to prompt participants to share their thoughts and ask questions while listening to the ongoing discussion. We refer to this as prompt Q&A feature. For example, “I agree with this,” “What do you think?,“ etc. According to previous research (Kou and Gray, 2018), seeing other people disclose their opinion or expertise during online discussions encourages further self-disclosure from other online attendants. Hence, we expect that attendants in social VR would share their opinion after seeing the speech bubble displayed by the virtual moderator more than without this design feature. The embodied agent will display participants’ selection as Figure 1.
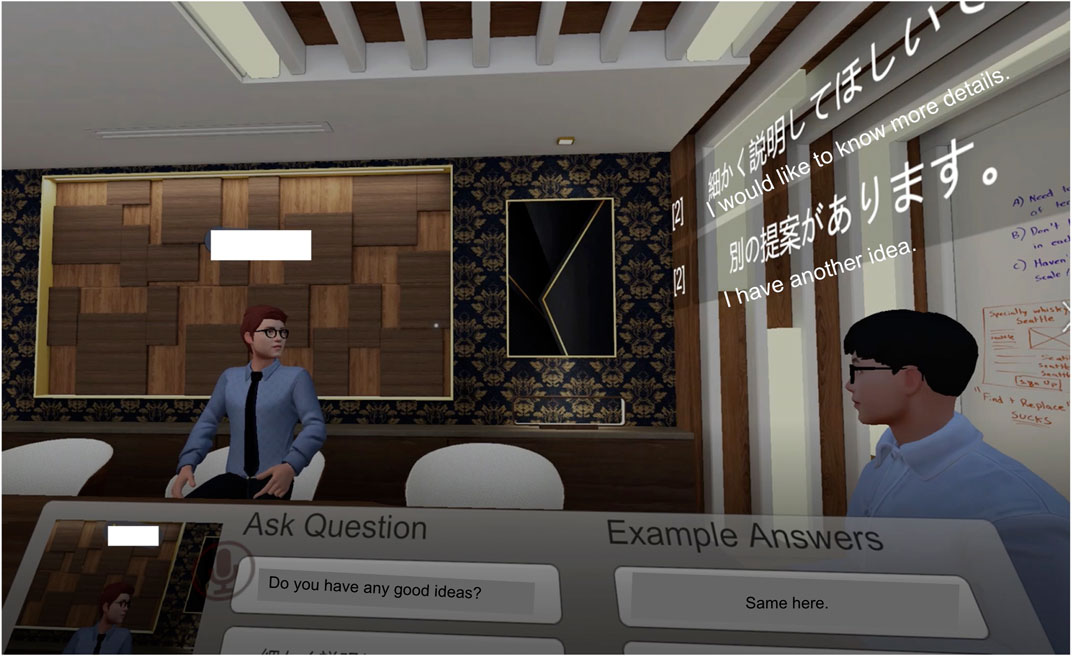
FIGURE 1. The avatar on the right is the virtual moderator, whereas the avatar on the left is one of the participants. This figure shows the attention guidance feature where the virtual moderator turns its head and body toward the least talkative person in the meeting. Moreover, regarding the prompt Q&A feature, when the participant clicks the sample questions and sentences shown in Figure 2, the selected prompt will be displayed above the virtual moderator on the right side.
(2) Enhance awareness of the least talkative person: Related work has shown that gaze, head, and body orientation are helpful social cues for managing turn-taking in multiparty conversation (Duncan, 1972; Kuzuoka et al., 2010). Furthermore, previous work has shown that visualizing every attendant’s participation enhanced equal participation (Samrose et al., 2018). Based on these related works, we implemented the virtual moderator to orient its head and body toward the least talkative person to engage them in the discussion by encouraging them to take turns or reminding others to include them in the debate (Figure 1). This nonverbal movement of the virtual moderator was intended to implicitly shift people’s attention in social VR as in face-to-face interaction, where gaze orientation was an indicator to give the floor to their interlocutor. The system will detect every participant’s audio input and display the least talkative person in a small window in front of everyone’s panel (Figure 2). We called it as attention guidance feature. Note that we did not tell participants that the movement of the virtual moderator was moved based on their conversation.
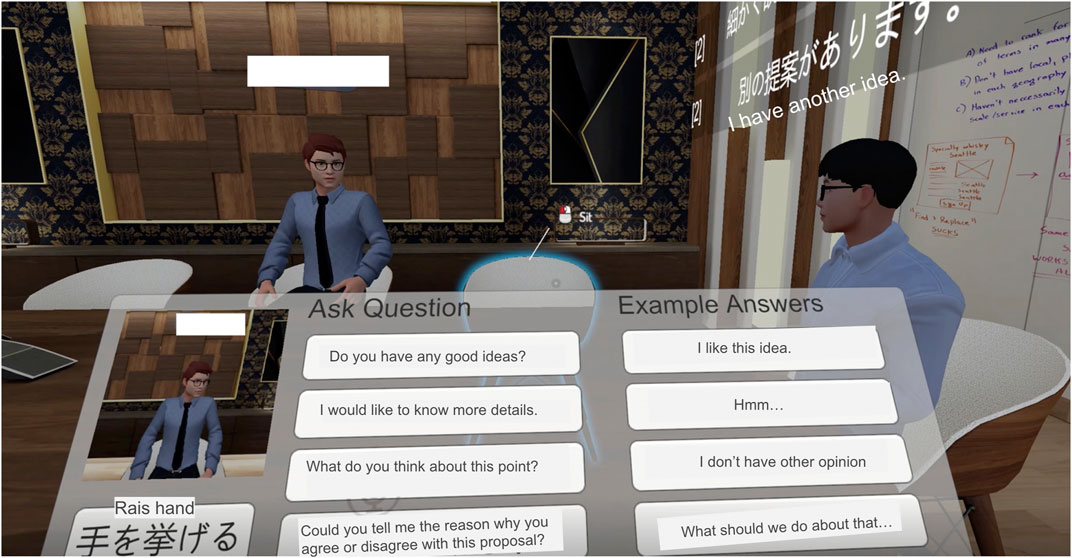
FIGURE 2. The panel display in front of the participants shows how the prompt Q&A and attention guidance work. The prompt Q&A feature is on the right side of the panel. Several short responses are displayed to participants for them to select and provide feedback while listening to the discussion. For attention guidance feature, the small window on the left side of the panel shows the participant who spoke the least in the discussion in the past 1 min.
4 User study
4.1 Experiment design and procedure
To examine the effect of prompt Q&A and attention guidance on the discussion in social VR, we designed a between-subject in-lab controlled study, which was with/without prompt Q&A × with/without attention guidance. In total, four conditions were compared.
We simulate a small group discussion in social VR by creating a triad discussion. We experimented with two trained confederates with one participant to control the potential influence of confounding factors in a small group discussion. We trained one male confederate to act like the most talkative person in the discussion, whereas the other female confederate acted as the quietest person. This design enabled us to control the group dynamics at a certain level for every participant. Two confederates joined the virtual discussion room with a male and a female human-like avatar. Participants were unaware that two other attendees in the virtual meeting room were confederates. They were instructed to join a group discussion with two online strangers. Two confederates joined the VR room using desktop mode from their home, and participants joined by wearing an HTC VIVE Pro2 in the lab. See Figure 3.
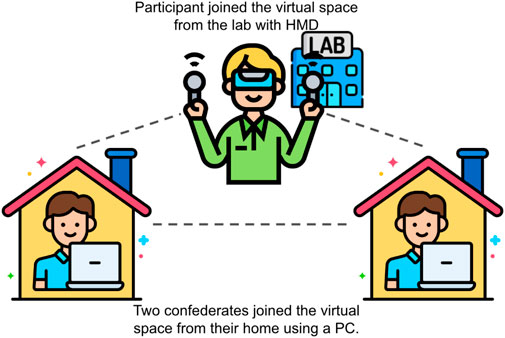
FIGURE 3. Experimental setup. The images were modified from Flaticon.com.
First, participants were informed about their rights to participate in the experiment. Next, after receiving the introduction to the study, participants proceeded to the first small talk task for 7 minutes. The purpose is to get familiar with the other attendees, which were the two confederates, in virtual reality. We prepared several examples of conversational topics for participants to chat with each other. For example, “what is your major or interests,” “what do you usually do in the weekend?“ Next, they were asked to complete the survey about their perception of the previous small talk. The survey details will be described in Section 4.3. Subsequently, they started a 20-min negotiation task modified from (Abdullah et al., 2021). The goal of this simulated negotiation task requires the triad to achieve a consensus in allocating the budget for completing a project for game development. Each attendant represented one of three business units, including the manager of finance (participants), development (confederate A), and public relationship (confederate B). They were instructed to have agreement on four topics, which were 1) how many engineers we should hire to develop the game, 2) how many salespeople we should hire to promote the game, 3) how much we should pay for each engineer, and 4) how much should we pay for each salesperson. In each role, the manager was assigned a goal for these four topics to persuade others to accept his/her proposal. For instance, the goal of the financial manager was to hire two engineers and two salespeople and pay six thousand USD monthly for each of them. Finally, participants answered the same survey again after finishing the 20-min discussion. In total, the study lasted less than 1 hour (Figure 4).

FIGURE 4. Procedure of the controlled experiment.
4.2 Participant
Thirty participants (16 female and 14 male) were recruited from social media in the university of the authors3. To participate in the 1-h study, they were paid 15 USD. This amount was decided based on the hourly wage in the country where the study was performed.
4.3 Measurement
We focused on psychological safety, self-disclosure, and co-presence to investigate whether and how two proposed features affected participants’ perceptions and behavior.
4.3.1 Psychological safety
Psychological safety indicates how well each group member is comfortable sharing their opinion or proposing different viewpoints to the team (Nembhard and Edmondson, 2006). Previous research has shown that high psychological safety predicts team performance (Bradley et al., 2012). Hence, we were interested in examining whether prompt Q&A and attention guidance features changed group dynamics that could be inferred by increased psychological safety. The psychological safety survey was adopted from (Edmondson, 1999). The survey was conducted with a seven-point Likert scale, where one indicates “absolutely disagree,” whereas seven indicates “strongly agree.” There were seven questions, three of which were reversed items. For example, “if you make a mistake in this group, it is often held against you”; “Group members can bring up problems and tough issues”. After transforming the reversed items, we averaged all seven items to indicate the participant’s psychological safety during the discussion.
4.3.2 Self-disclosure
When people establish rapport, they tend to disclose themselves to each other (Arroll and Allen, 2015). Hence, we measured participants’ perceived degree of self-disclosure as an index to understand how prompt Q&A and attention guidance features influenced social relationships among distributed members. We adopted the survey from (Sprecher, 2021). The survey was conducted with a seven-point Likert scale, where one indicates “not at all,” whereas seven indicates “a great deal.” There were four questions. For example, “How much did you tell the group about yourself?“. We averaged the scores from four questions to get the level of self-disclosure.
4.3.3 Co-presence
Prompt Q&A and attention guidance features were designed to enhance awareness of the inactive member, so we evaluated participants’ perceived co-presence, which indicates how much awareness people have toward their distributed counterparts. We adopted the survey from (Biocca and Harms, 2003), conducted with a seven-point Likert scale, where one indicates “absolutely disagree,” whereas seven indicates “strongly agree.” There were four questions, and two of them were reversed items. Example question includes “I often felt as if the group and I were in the same room together”. After transforming the reversed items, we averaged all four questions to represent each participant’s sense of co-presence during the discussion.
All survey items were delivered to participants using online Google Forms. Please refer to the supplementary material for the full list.
5 Result
Here, we report our analysis of the effect of two proposed features on psychological safety, self-disclosure, and co-presence. The Shapiro-Wilk tests showed that three dependent variables in each comparison were not significantly different from the normal distribution. Therefore, we performed a two-way ANOVA for each dependent variable.
A two-way ANOVA was performed to analyze the effect of “prompt Q&A” and “attention guidance” on psychological safety. The result revealed that there was a statistically significant interaction between the effects of “prompt Q&A″ and “attention guidance” on psychological safety (F [1, 26] = 7.58, p < 0.01, Figure 5, left). This result shows that participants’ psychological safety could be increased if one of the features, either when “prompt Q&A″ or “attention guidance,” was provided to participants. Psychological safety would not improve if both features were presented to the participants.
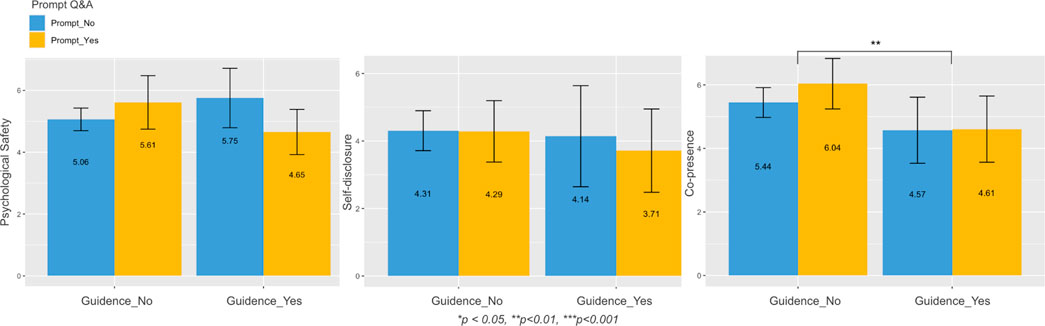
FIGURE 5. Barcharts for psychological safety (left), self-disclosure (middle), and co-presence (right). The numbers in each bar show the mean score of each condition. The error bar shows a 95% confidence interval of the data. X-axis shows the factor of attention guidance (without and with guidance). Y-axis shows the averaged score from the three corresponding surveys we measured in subsection 4.3 The color coding shows the factor of prompt Q&A (without and with Q&A).
Unexpectedly, we did not find any effect of two features on self-disclosure from a two-way ANOVA (F [1, 26] = 0.22, p = 0.65, Figure 5, middle). Simple main effects analysis also showed that “prompt Q&A” (p = 0.59) and “attention guidance” (p = 0.42) did not have a statistically significant effect on self-disclosure, respectively. One possible reason might be that the negotiation task in the current design did not require participants to disclose much about themselves, so we did not observe a significant difference in this dimension across conditions.
Finally, two-way ANOVA showed that there was no statistically significant interaction between the effects of “prompt Q&A″ and “attention guidance” on co-presence (F [1, 26] = 0.66, p = 0.42, Figure 5, right). We did not observe any statistically simple main effects of the “Prompt Q&A″ feature (p = 0.45) on co-presence. However, simple main effects analysis showed that the “attention guidance” feature (p = 0.003) statistically significantly affected co-presence. This result revealed that providing attention guidance would give participants lower perceived co-presence than no attention guidance.
6 Discussion
The result showed that making the virtual moderator move toward the quietest person (the feature of attention guidance) or providing Q&A examples (the feature of Prompt Q&A) can give people psychological safety, but only when one of these two features was presented alone without the co-occurrence with another feature. The attention guidance feature led participants to have the highest psychological safety among four conditions (Figure 5, left). It may be because this nonverbal behavior indicates a welcoming gesture to include everyone to participate in the discussion. Consistent with previous works showing that gaze information helps people to manage turn-taking in the collocated discussion (Vertegaal and Ding, 2002), our result revealed that this nonverbal information could be designed using a virtual moderator to mediate remote group discussion.
Interestingly, when combining two features (with attention guidance and prompt Q&A), participants’ ratings on psychological safety, self-disclosure, and co-presence were the lowest compared to the other three conditions. Using both two features at the same time did not improve communication in any dimension. One possible interpretation is that the cognitive load and experience may be negatively affected by too much information users received during the discussion. Although we tried to reduce cognitive workload by displaying two features on one virtual moderator instead of in multiple spaces, monitoring the conversation while paying attention to every virtual moderator’s movement may cost users too many attentional resources.
Another unexpected result is the finding that providing attention guidance led to lower perceived co-presence than without attention guidance (Figure 5, right). One possible explanation is that the design of gazing at the quietest person does not fit the usual behavior people perform. When attending a group discussion, people usually look at the person talking rather than the least talkative person, thus making people feel less co-presence. If the virtual moderator looked away from the speaker to the least talkative person, it might give other members an incorrect impression that someone was not paying attention. The current result suggests that turning the virtual moderator’s body toward the quietest person might not be the best design to keep a social presence in social VR. Other design features need to be explored. For instance, adjusting the virtual moderator’s behavior to more closely resemble human behavior, such as looking at the speaker but occasionally shifting gaze to the least talkative person, might foster co-presence and psychological safety.
7 Conclusion
We designed and investigated a virtual moderator to mediate group discussion in social VR to support distributed members’ psychological safety in a cueless environment. This short paper demonstrated the preliminary finding showing that a virtual moderator’s nonverbal behavior could influence distributed members’ psychological safety and perceived co-presence. In addition, we learned that information overload must be handled when introducing multiple conversational supports in social VR. Our future work is to design a field experiment without using confederates so that we can examine how turn-taking behavior will be changed after seeing the nonverbal behavior of a virtual moderator.
Data availability statement
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding authors.
Ethics statement
The studies involving human participants were reviewed and approved by the Research Ethics Review Committee, Graduate School of Information Science and Technology, The University of Tokyo. The patients/participants provided their written informed consent to participate in this study.
Author contributions
C-LY and KM designed the study. SY and LS experimented. C-LY and KM performed the statistical analyses. C-LY and KM designed the features of the prototype. C-LY wrote the first draft of the paper. C-LY, KM, KA, DY, and HK contributed to the whole research project from ideation until the paper writing process and approved the submitted version. All authors contributed to the article and approved the submitted version.
Funding
This work was supported by Michele Holdings Co., Ltd. and Michele Properties Co., Ltd.
Acknowledgments
Natsuki Hakomori cooperated in the experiment as a trained confederate. Toshiyuki Numata helped implement the experimental system. The authors thank them for their cooperation.
Conflict of interest
The authors declare that this study received funding from Michele Holdings Co., Ltd.
The funder had the following involvement in the study: topic ideation of the research topic, planning the schedule of the research, checking the manuscript, and approving the submission.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/frvir.2023.1198024/full#supplementary-material
SUPPLEMENTARY DATA SHEET S1 | The dataset of the study.
SUPPLEMENTARY DATA SHEET S2 | All survey items in the study.
Footnotes
1The eight pairs of questions and answers were derived based on one of the authors’ anecdotal observations of workplace discussion. Two co-authors discussed and revised the final list.
2https://www.vive.com/us/product/#pro%20series.
3We failed to collect the exact age of the participants. But 90% of participants were undergraduate and graduate students, whereas three participants decided not to disclose this information.
References
Abdullah, A., Kolkmeier, J., Lo, V., and Neff, M. (2021). Videoconference and embodied vr: Communication patterns across task and medium. Proc. ACM Human-Computer Interact. 5, 1–29. doi:10.1145/3479597
Arroll, B., and Allen, E.-C. F. (2015). To self-disclose or not self-disclose? A systematic review of clinical self-disclosure in primary care. Br. J. general Pract. 65, e609–e616. doi:10.3399/bjgp15x686533
Biocca, F., and Harms, C. (2003). Networked minds social presence inventory:—- (scales only, version 1.2)measures of co-presence, social presence,subjective symmetry, and intersubjective symmetry
Bradley, B. H., Postlethwaite, B. E., Klotz, A. C., Hamdani, M. R., and Brown, K. G. (2012). Reaping the benefits of task conflict in teams: The critical role of team psychological safety climate. J. Appl. Psychol. 97, 151–158. doi:10.1037/a0024200
DiMicco, J. M., Pandolfo, A., and Bender, W. (2004). “Influencing group participation with a shared display,” in Proceedings of the 2004 ACM conference on Computer supported cooperative work, 614–623.
Duncan, S. (1972). Some signals and rules for taking speaking turns in conversations. J. Personality Soc. Psychol. 23, 283–292. doi:10.1037/h0033031
Edmondson, A. C. (1999). Psychological safety and learning behavior in work teams. Adm. Sci. Q. 44, 350–383. doi:10.2307/2666999
Garau, M., Slater, M., Vinayagamoorthy, V., Brogni, A., Steed, A., and Sasse, M. A. (2003). “The impact of avatar realism and eye gaze control on perceived quality of communication in a shared immersive virtual environment,” in CHI ’03.
Gillet, S., Cumbal, R., Pereira, A., Lopes, J., Engwall, O., and Leite, I. (2021). Robot gaze can mediate participation imbalance in groups with different skill levels. Proc. 2021 ACM/IEEE Int. Conf. Human-Robot Interact., 303–311.
Greenwald, S. W., Wang, Z., Funk, M., and Maes, P. (2017). “Investigating social presence and communication with embodied avatars in room-scale virtual reality,” in Immersive learning research network: Third international conference, iLRN 2017, coimbra, Portugal (Springer), 3, 75–90. June 26–29, 2017.
Hyde, J., Carter, E. J., Kiesler, S., and Hodgins, J. K. (2015). “Using an interactive avatar’s facial expressiveness to increase persuasiveness and socialness,” in Proceedings of the 33rd annual ACM conference on human factors in computing systems, 1719–1728.
Ichino, J., Ide, M., Yokoyama, H., Asano, H., Miyachi, H., and Okabe, D. (2022). “i’ve talked without intending to”: Self-disclosure and reciprocity via embodied avatar. Proc. ACM Human-Computer Interact. 6, 1–23. doi:10.1145/3555583
Kim, S., Eun, J., Oh, C., Suh, B., and Lee, J. (2020). “Bot in the bunch: Facilitating group chat discussion by improving efficiency and participation with a chatbot,” in Proceedings of the 2020 CHI conference on human factors in computing systems.
Kou, Y., and Gray, C. M. (2018). “what do you recommend a complete beginner like me to practice?” professional self-disclosure in an online community. Proc. ACM Human-Computer Interact. 2, 1–24. doi:10.1145/3274363
Kuzuoka, H., Suzuki, Y., Yamashita, J., and Yamazaki, K. (2010). “Reconfiguring spatial formation arrangement by robot body orientation,” in 2010 5th ACM/IEEE international conference on human-robot interaction (HRI), 285–292.
Lee, S.-C., Song, J.-H., Ko, E.-Y., Park, S., Kim, J., and Kim, J. (2020). “Solutionchat: Real-time moderator support for chat-based structured discussion,” in Proceedings of the 2020 CHI conference on human factors in computing systems.
Maloney, D., Zamanifard, S., and Freeman, G. (2020). “Anonymity vs. familiarity: Self-disclosure and privacy in social virtual reality,” in Proceedings of the 26th ACM symposium on virtual reality software and Technology, 1–9.
Maznevski, M. L., and Chudoba, K. M. (2000). Bridging space over time: Global virtual team dynamics and effectiveness. Organ. Sci. 11, 473–492. doi:10.1287/orsc.11.5.473.15200
Mennecke, B. E., Triplett, J. L., Hassall, L. M., Conde, Z. J., and Heer, R. (2011). An examination of a theory of embodied social presence in virtual worlds. Decis. Sci. 42, 413–450. doi:10.1111/j.1540-5915.2011.00317.x
Moustafa, F., and Steed, A. (2018). “A longitudinal study of small group interaction in social virtual reality,” in Proceedings of the 24th ACM symposium on virtual reality software and Technology.
Nembhard, I. M., and Edmondson, A. C. (2006). Making it safe: The effects of leader inclusiveness and professional status on psychological safety and improvement efforts in health care teams. J. Organ. Behav. Int. J. Industrial, Occup. Organ. Psychol. Behav. 27, 941–966. doi:10.1002/job.413
O’Conaill, B., Whittaker, S., and Wilbur, S. (1993). Conversations over video conferences: An evaluation of the spoken aspects of video-mediated communication. Human-computer Interact. 8, 389–428. doi:10.1207/s15327051hci0804_4
Pan, Y., Steptoe, W., and Steed, A. (2014). “Comparing flat and spherical displays in a trust scenario in avatar-mediated interaction,” in Proceedings of the SIGCHI conference on human factors in computing systems, 1397–1406.
Samrose, S., Zhao, R., White, J., Li, V., Nova, L., Lu, Y., et al. (2018). Coco: Collaboration coach for understanding team dynamics during video conferencing. Proc. ACM Interact. Mob. wearable ubiquitous Technol. 1, 1–24. doi:10.1145/3161186
Shamekhi, A., Liao, Q. V., Wang, D., Bellamy, R. K. E., and Erickson, T. (2018). “Face value? Exploring the effects of embodiment for a group facilitation agent,” in Proceedings of the 2018 CHI conference on human factors in computing systems.
Sprecher, S. (2021). Closeness and other affiliative outcomes generated from the fast friends procedure: A comparison with a small-talk task and unstructured self-disclosure and the moderating role of mode of communication. J. Soc. Personal Relat. 38, 1452–1471. doi:10.1177/0265407521996055
Tanenbaum, T. J., Hartoonian, N., and Bryan, J. S. (2020). ““how do i make this thing smile?”: An inventory of expressive nonverbal communication in commercial social virtual reality platforms,” in Proceedings of the 2020 CHI conference on human factors in computing systems.
Tickle-Degnen, L., and Rosenthal, R. (1990). The nature of rapport and its nonverbal correlates. Psychol. Inq. 1, 285–293. doi:10.1207/s15327965pli0104_1
Traum, D. R., and Rickel, J. (2002). “Embodied agents for multi-party dialogue in immersive virtual worlds,” in Aamas ’02.
Vertegaal, R., and Ding, Y. (2002). “Explaining effects of eye gaze on mediated group conversations: Amount or synchronization?,” in Proceedings of the 2002 ACM conference on Computer supported cooperative work, 41–48.
Vertegaal, R., Weevers, I., Sohn, C., and Cheung, C. (2003). “Gaze-2: Conveying eye contact in group video conferencing using eye-controlled camera direction,” in Proceedings of the SIGCHI conference on Human factors in computing systems, 521–528.
Keywords: social VR, communication, virtual moderator, nonverbal cues, online discussion
Citation: Yang C-L, Matsumoto K, Yu S, Sawada L, Arakawa K, Yamada D and Kuzuoka H (2023) Understanding the effect of a virtual moderator on people’s perception in remote discussion using social VR. Front. Virtual Real. 4:1198024. doi: 10.3389/frvir.2023.1198024
Received: 31 March 2023; Accepted: 26 June 2023;
Published: 18 July 2023.
Edited by:
Thuong Hoang, Deakin University, AustraliaReviewed by:
Hasan Ferdous, The University of Melbourne, AustraliaDeepti Aggarwal, Deakin University, Australia
Copyright © 2023 Yang, Matsumoto, Yu, Sawada, Arakawa, Yamada and Kuzuoka. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Chi-Lan Yang, Y2hpbGFuLnlhbmdAY3liZXIudC51LXRva3lvLmFjLmpw; Keigo Matsumoto, bWF0c3Vtb3RvQGN5YmVyLnQudS10b2t5by5hYy5qcA==
†These authors have contributed equally to this work and share first authorship