 Laurel L. Haak
Laurel L. Haak Alice Meadows
Alice Meadows Josh Brown
Josh Brown- ORCID, Bethesda, MD, United States
An evaluator's task is to connect the dots between program goals and its outcomes. This can be accomplished through surveys, research, and interviews, and is frequently performed post hoc. Research evaluation is hampered by a lack of data that clearly connect a research program with its outcomes and, in particular, by ambiguity about who has participated in the program and what contributions they have made. Manually making these connections is very labor-intensive, and algorithmic matching introduces errors and assumptions that can distort results. In this paper, we discuss the use of identifiers in research evaluation—for individuals, their contributions, and the organizations that sponsor them and fund their work. Global identifier systems are uniquely positioned to capture global mobility and collaboration. By leveraging connections between local infrastructures and global information resources, evaluators can map data sources that were previously either unavailable or prohibitively labor-intensive. We describe how identifiers, such as ORCID iDs and DOIs, are being embedded in research workflows across science, technology, engineering, arts, and mathematics; how this is affecting data availability for evaluation purposes: and provide examples of evaluations that are leveraging identifiers. We also discuss the importance of provenance and preservation in establishing confidence in the reliability and trustworthiness of data and relationships, and in the long-term availability of metadata describing objects and their inter-relationships. We conclude with a discussion on opportunities and risks for the use of identifiers in evaluation processes.
In evaluation studies, we try to understand cause and effect. As research evaluators, our goal is to determine whether programs are effective, what makes them effective, what adjustments would make them more effective, and whether these factors can be applied in other settings. We start off with lofty goals and quickly descend into the muck and mire: the data—or lack thereof. In many cases, programs do not have clearly stated goals. Even when goals are stated, frequently data were not collected to monitor progress or outcomes. From the perspective of a research scientist, this approach is backwards. Researchers start with a hypothesis, develop a study process with specific data collection and controls, and then analyze the data to test whether their hypothesis is supported.
Nevertheless we soldier on (one approach is described by Lawrence, 2017). Evaluators work with research program managers to develop frameworks to assess effectiveness. These frameworks, usually in the form of logic models, help establish program goals, and focus the questions to be addressed in the evaluation. Again, from lofty goals, we have to narrow and winnow our expectations based on the available data (Lane, 2016). Many program evaluations use journal article citations as the sole source of data, because citations are the only thing available. This is because one individual, Eugene Garfield, had the prescience and fortitude to create a publication citation index over 60 years ago (Garfield, 1955). This rich and well-curated index underlies much of the science, technology, engineering, arts, and mathematics (STEAM) research evaluation work, and underpins a number of metrics, indicators, and entire industries. However, by focusing on papers, it overlooks two important components of research: people and organizations. Its almost exclusive use for evaluation purposes has skewed how we think about research: as a factory for pumping out journal articles.
This emphasis on one contribution type has affected academic careers, since promotion and tenure review favor the subset of prolific publishers (the survivors in the “publish or perish” culture). It has also affected the nature of scholarly contributions. Work by Wang et al. (2017), has provided evidence that novel or blue skies thinking has been diminished as a presence in the literature by the emphasis on publication at all costs. Research is—and should be—about so much more than publications or journal articles.
We need to expand how we think about measuring research. We need to include people in our analyses (Zolas et al., 2015). We need to be thoughtful about the language we use to describe research contributions—as Kirsten Bell notes in her recent post on the topic, “outputs” is hardly the innocent bureaucratic synonym for “publications” or “knowledge” it might appear (Bell, 2018). We need to consider more “humanistic” measures of achievement, such as those proposed by the HuMetricsHSS initiative (Long, 2017). And we need to learn from Garfield and have the vision and fortitude to build infrastructure to support how we understand research and, through that, how we as a society support and encourage curiosity and innovation (Haak et al., 2012a).
Expanding our Universe
In the seventeenth century, there was a fundamental challenge to the way Europeans understood the world, from a long-held belief that the stars revolved around the earth to the discovery that, in fact, the stars were very distant and the earth was itself revolving around the sun. Galileo1 became a subject of the Inquisition for this discovery, which was seen as heretical. Looking back on this time, it is interesting to see the extent to which proponents of geocentrism used increasingly complex mathematics to bolster their worldview as data from more direct measurement techniques—telescopes!—became available. But, as these new methods were tested and accepted, the consensus was able to shift.
We need to start using more such direct measurement techniques in our evaluation processes. Garfield's citation index is an excellent foundation. It shows that building infrastructure is not only possible, but also has direct benefits. But it reflects only a part of the research world.
The citation index made it clear that identifiers—unique keys for articles—were essential to enable the coding of connections between articles and citing articles. In turn, this led to the understanding that these unique keys needed to follow some shared standard to be useful in a database of objects from many sources. Eventually, with advances in computing power, digitization, and the creation of the Internet, we saw the launch of the Handle system (Arms and Ely, 1995) to uniquely and persistently identify digital objects. This enabled organizations like Crossref (https://crossref.org) and DataCite (https://www.datacite.org) to provide an open infrastructure to uniquely identify research articles and datasets across multiple sources and domains.
The ability to uniquely identify and persistently access research articles transformed evaluation. Use of the publication citation index to study research blossomed. New, publication-derived metrics were developed and applied; entire national research evaluation frameworks were created that depended, wholly or in part, on these metrics2.
Increasingly, however, it is becoming clear that a new perspective is needed. We need to acknowledge our myopia. There is some progress in this direction, with tools that harvest research information and connections across multiple sources to enable real-time portfolio analysis (Haak et al., 2012c). Moher et al. (2018) identify and summarize 21 documents on the topic, including the Declaration on Research Assessment (DORA, https://sfdora.org)3, which calls for the recognition of the many and varied products of research, “including: research articles reporting new knowledge, data, reagents, and software; intellectual property; and highly trained young scientists.” Despite being signed by over 12,000 individuals and organizations, DORA has not yet resulted in significant changes to the evaluation process of most research.
Creating New Tools
To better understand research, we need to know not just about the publications, but also the people, organizations, and resources involved. Just as with publications, this means we need to establish unique keys—identifiers—for these entities. Discipline, workflow, and national-level registries have been developed and propagated along with the digital transformation of scholarly communications. However, research is not national or disciplinary; it is decidedly international and interdisciplinary. ORCID (https://orcid.org), which provides identifiers for researchers, was born when a number of organizations that had created their own researcher registries came together to create a global-scale open identifier registry for researchers (Haak et al., 2012b). Similar efforts are underway to create an open registry of research organization identifiers (Haak and Brown, 2018), and there are growing efforts to support registries for research resources, from rocks4 to antibodies5, protein structures and samples6, and the many types of facilities7 used to perform research studies.
These registries are all based on a simple concept: provision of a unique and persistent identifier and associated web services, to enable sharing of information about the people, organizations, resources, and products of research. Each registry is a basic and essential component of the infrastructure needed for the operation of the research enterprise. To be useful to the community, these infrastructures need to be open: governed by the community, sustainable, open source, and reliably implemented (Bilder et al., 2015). Openness ensures the identifiers and the connections made between them are available to the entire community, to use and reuse, develop analyses and platforms, and are responsive to community needs.
Persistent identifiers describe endpoints—digital manifestations of a (usually) physical entity. To be truly useful, these endpoints need to be connected to each other. These connections are called “assertions” and include information about the entities involved in making the connection. Understanding assertions is critical to our ability to evaluate research. We explore assertions more in the next section.
The Endpoints
At its most basic level, a persistent identifier (PID) is exactly as you'd imagine—a reference to a “thing” that can be used to uniquely identify it, in perpetuity8. There are several desirable characteristics which make some PIDs more useful for assertions than others.
The ODIN project defines a trusted PID (ODIN Consortium, 2013a,b), as unique, persistent, descriptive, interoperable, and governed. The definition states that PIDs must:
• Be unique on a global scale, allowing large numbers of unique identifiers
• Resolve as HTTP URI's with support for content negotiation; these HTTP URI's should be persistent9
• Come with metadata that describe their most relevant properties, including a minimum set of common metadata elements. A search of metadata elements across all trusted identifiers of that service should be possible
• Be interoperable with other identifiers, through metadata elements that describe their relationship
• Be issued and managed by an organization that focuses on this goal as its primary mission; has a sustainable business model and a critical mass of member organizations that have agreed to common procedures and policies; has a trusted governance structure; and is committed to using open technologies
The ODIN definition of a trusted PID relates to the European Commission's recommendation to its grantees that “Where possible, contributors should also be uniquely identifiable, and data uniquely attributable, through identifiers which are persistent, non-proprietary, open, and interoperable (e.g., through leveraging existing sustainable initiatives such as ORCID for contributor identifiers and DataCite for data identifiers, European Commission, Directorate General for Research and Innovation, 2017).” This, in turn, is similar to the definition of Findable, Accessible, Interoperable, and Re-usable (FAIR) data10. The FAIR principles relax the mechanism of interoperability, and so consider the technical requirement of having metadata available through http content negotiation to be overly prescriptive. They instead require that it be available from the same endpoint using a well-known process. Notably, they also expand the definition to include a requirement for provenance information, such as who created the metadata and when.
The Assertions
An assertion creates a vertex that connects endpoints in the research information graph. In evaluation, we strive for assertions that are created at the point of a formal transaction—when a researcher submits a paper, when a funder awards a grant, when a student submits their dissertation. The evidentiary basis of these assertions is traceable and defensible, similar to a citation listed in a paper.
For these assertions to be created, we need to agree as a community, not only that they are valuable but also that we will create them in our own workflows. The publishing community has been working with Crossref since 2001 to mint digital object identifiers for journal articles and book chapters, and are increasingly collecting ORCID iDs from authors. This combination of identifiers in a digital transaction creates a traceable Publication:Person assertion (Brown et al., 2016) as illustrated in Figure 1.

Figure 1. Assertion information enables traceability. From Brown (2017).
As stated earlier, we care about more than just papers: other forms of publication, employment history (Way et al., 2017), migration (Sugimoto et al., 2017), resource availability (Wagner and Jonkers, 2017), patents (Jefferson et al., 2015), and many other factors are critical components of the research graph. How can we surface this information to improve the richness of our understanding? Everyone in the community needs to be involved in using PIDs and making digital assertions. We are under no illusion that everything can—or should—be identified and quantified. Individuals and organizations should have choices about what information they share and with whom11, and there are existing PIDs and reliable processes that, with the proper controls and consent, can already be used for sharing research endpoints and making assertions about the relationships between them. One example is the use of ORCID, organization, and grant identifiers by research facilities and DOIs by publishers to connect use of these resources with the researchers who use them and the papers and datasets they create (Haak, 2018). Another is the use of ORCID, organization, and membership IDs to connect researchers with their affiliations (Demeranville, 2018).
An example of the contextual richness that can be achieved using these endpoints, even with a relatively constrained set of information types, is provided by the Research Graph initiative (Aryani et al., 2018) (see Figure 2). Research Graph is an open collaborative effort to connect scholarly records across global research repositories. This work is focused on linking research projects and research outcomes on the basis of co-authorship or other collaboration models such as joint funding and grants. Research Graph is enabled by adopting the interoperability model created by the Research Data Alliance DDRI working group (Data Description Registry Interoperability Working Group, 2018), and shows how multiple identifiers for one object type (such as, persons) can be accommodated without conflict in a single data model. Linking researchers, funding, datasets, and publications, using PIDs and mapping the relationships between these four types of entity, evaluators can follow webs of connections between people, projects, and contributions and fill significant gaps in their understanding of the research environment. The graph makes visible and comprehensible more of the antecedents and academic impacts of funded research projects.
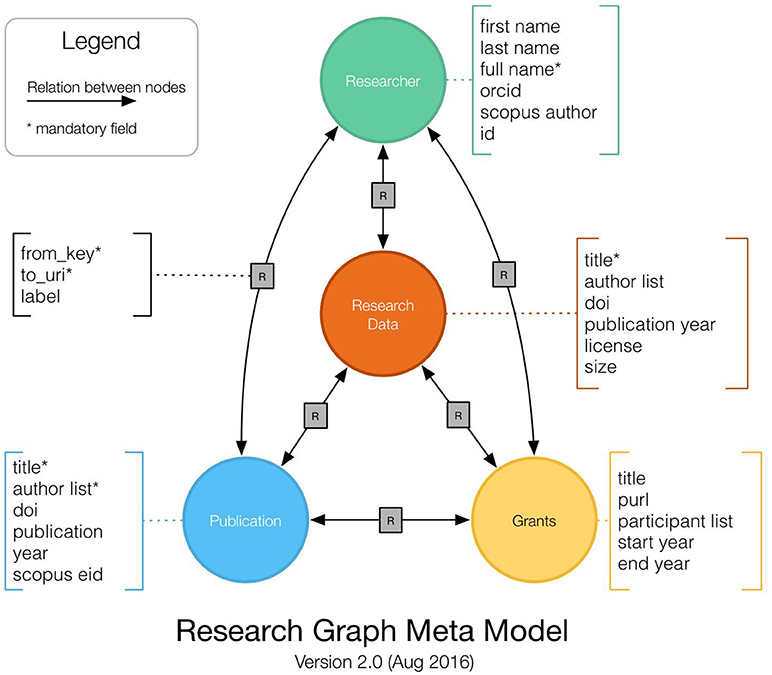
Figure 2. The research graph meta model (Aryani et al., 2018).
Community Roles and Responsibilities
For each sector in the research community there is a role, responsibility, and benefit in contributing to the research graph. Researchers need to register and use their ORCID iD (Figure 3). This creates the person endpoint. Research organizations need to use identifiers for organizations and objects (publication, grant, patent, service, affiliation, etc.), create transaction points where researchers can provide their ORCID iD, and create digital assertions between these endpoints. We are already seeing publishers (for example, see ORCID, 2018), funders (for example, see Lauer, 2017), and research institutions12 embedding ORCID iDs and other PIDs into standard research workflows and creating open, digital, and traceable connections that everyone in the community benefits from. Indeed, entire nations are starting to use this open infrastructure to develop comprehensive sources of research information, to “simplify administration for researchers and research organizations, and improve the quality of data. This helps researchers focus on their work, fosters innovation, and enables funders to make smart investments (Ministry of Business, Innovation and Employment Hikina Whakatutuki, 2016).”
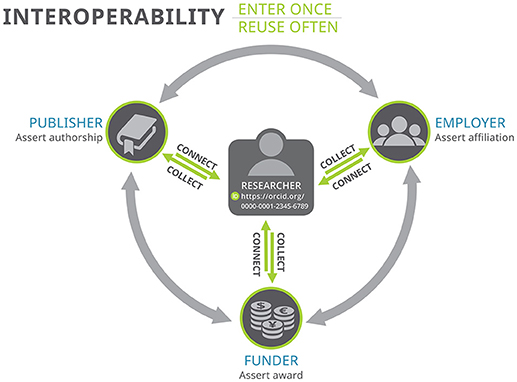
Figure 3. The virtuous circle of interoperability (ORCID CC0 image).
The Research Graph: Discrete Examples of Endpoints and Vertices
Peer Review
From the time of Boyle, presentation of research findings for review by one's colleagues has been a fundamental component of research (Shapin and Schaffer, 2017). As journals flourished, peer review became de rigeur in the publication process, although in many cases the names of the peers and the content of the reviews were not made publicly available. One consequence of this is that reviewers have gone largely unacknowledged for their important contribution to their discipline. And, the role of peer review has been largely invisible in the research graph. This has started to change with the use of the PID infrastructure to support citation of peer review activity (Hanson et al., 2016). Publishers are collecting ORCID iDs for reviewers as assignments are accepted and, after the review is completed, connecting that iD to information about the review activity. For blind reviews, this recognition involves an assertion of the reviewer (ORCID iD), the organization requesting the review (organization ID), an identifier for the review assignment, and the year of the review; there is no disclosure of the review report or the paper reviewed. Open review acknowledgments also include information about the review report (DOI) and paper reviewed (DOI). Over 500,000 review assertions have been created using this workflow since its launch in 2016, providing information to support a richer understanding of the full range of research contributions made by researchers. So far, journal publishers have used this functionality, but book publishers, associations, funders, and research institutions are now also starting to express an interest.
Career Information
Funders and other agencies collect a significant volume of information about researchers and their contributions at the point of project applications or proposals. The apparent weight given to different kinds of information in such data-gathering processes gives a powerful indication of the value accorded to specific activities. Given that this data can then indicate potential strengths beyond publication, it is an ideal source of insight that could then be used to extend the scope and diversity of evaluation data points, and thus career trajectories. As part of the ORBIT (ORCID Reducing Burden and Improving Transparency) project13, a team from ORCID compared the lists of data fields that participating funders14 collect in the career profile or curriculum vitae section of the application. They found that <30% of the funders collected data about society memberships or other professional activities, and even fewer collected data about mentoring or similar activities. Collecting data about these types of contribution to the strength of research, especially if linked to a global graph of connections between outputs (articles, data, samples, etc.), activities, funding, people, and organizations, would bring the whole picture of a researcher's “good citizenship” into view, including activities such as training of new researchers, peer review of contributions, and establishing and maintaining best practices in the discipline through participation in learned societies. In so doing, funders and evaluators could reward and incentivize more than just authorship, thereby supporting more diverse research careers, and enriching the scientific enterprise with the broadest possible pool of minds and insights.
Research Facilities
Researchers use instruments, equipment, special collections, and other resources to perform their work. Some of these resources are included in methods sections, while others go unacknowledged. Not only does this make research harder to reproduce, it also means that some resource providers have a difficult time demonstrating their impact on research. This can have an impact on continued support for these facilities, which in turn affects availability. Even when researchers do cite these resources, it is done without use of a standard assertion framework, making it very difficult, if not impossible, to gather the information into an evaluation dataset. This is changing with the growing use of persistent identifiers for resources, and the embedding of identifiers into resource use workflows, such as large neutron spallation facilities used to study structure of materials. ORCID iDs and organization IDs are being collected as researchers request time at the facility and, when the request is granted, an assertion is created connecting the researcher, the facility, and the request proposal. In turn, publishers are currently defining processes to easily collect this assertion information when researchers submit articles describing work using these facilities (Haak et al., 2017).
Use by Evaluators: Opportunities and Challenges
The identifier infrastructure has been leveraged by evaluators to study researcher mobility (Bohannon, 2017; Orazbayev, 2017), peer review (Lerback and Hanson, 2017), and increasingly is being used to locate scholarly orphans (Klein and van de Sompel, 2017) and augment algorithmic-based disambiguation in publication and patent datasets (Jefferson et al., 2018). However, there is a risk that early studies utilizing the infrastructure, which demonstrate promise but also gaps in coverage (Youtie et al., 2017), may dissuade others from following in their steps.
The original citation index created by Garfield took several years to reach critical functionality. And that was just one contribution endpoint: publications. The identifier infrastructure covers endpoints from multiple domains. In addition, the identifier infrastructure requires action on the part of the entire community to build it—and we still don't (quite) have a registry for organization identifiers.
This does not mean that, as evaluators, we should not use the infrastructure. Evaluators, by communicating what questions they are asking about programs, can help the community to set priorities on what information to connect, and where to encourage adoption and use of identifiers. Evaluators can help form and test new metrics, derived by use of identifiers. Evaluators, by using the identifier infrastructure, can demonstrate the value and utility of open research information, and also help pave the way toward open research practices by the organizations they evaluate and the researchers themselves. Indeed, one key role of evaluators can be to explain the value of an open identifier infrastructure, and to encourage researchers and programs to start using identifiers in research workflows. Evaluators can also provide valuable feedback to registries to help prioritize our engagement activities and to focus attention on underserved communities. Together we can build a resilient framework to enable visualization of the research graph, using a hypothesis-based approach, traceable assertions, and assisted by qualitative analysis. One that will encompass the many forms of research contributions made across the whole spectrum of disciplines and organization types, and ultimately enable fairer and more representative evaluation of all those contributions.
Author Contributions
All authors listed have made a substantial, direct and intellectual contribution to the work, and approved it for publication.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Footnotes
1. ^Galileo Galilei. Available online at: https://en.wikipedia.org/wiki/Galileo_Galilei (Accessed April 7, 2018).
2. ^Examples include the Research Excellence Framework (REF) in the United Kingdom (https://www.ref.ac.uk/about/) and the Excellence in Research for Australia (ERA) framework (http://www.arc.gov.au/excellence-research-australia) (accessed April 7, 2018).
3. ^DORA was first published in 2012. The full text of the declaration is available online at. https://sfdora.org/read/ (accessed April 7, 2018).
4. ^International Geosample Number (IGSN) is a unique identifier for samples and specimens collected from our natural environment. Available online at: http://www.igsn.org
5. ^Research Resource Identifiers (RRID) to cite key biomedical resources used to produce scientific findings. Available online at: https://www.force11.org/group/resource-identification-initiative/
6. ^BioSamples database stores and supplies descriptions and metadata about biological samples used in research and development by academia and industry. Available online at: https://www.ebi.ac.uk/biosamples/
7. ^Mapping of the European Research Infrastructure Landscape (MERIL) is a database of openly accessible European facilities (see https://portal.meril.eu/meril/); Eagle-I models research resources and provides a searchable database for the translational research community (see https://www.eagle-i.net/about/).
8. ^Note that while this model does include HTTP URIs to identify and resolve things, it does not require RDF or SPARQL endpoints. As such it is not formally “Linked Open Data” although data can be transformed to an LOD framework.
9. ^We have relaxed this requirement to: “must be possible to transform into URLs, be machine actionable and resolve to metadata in a well-defined manner.”
10. ^The FAIR Data Principles. Available online at: https://www.force11.org/group/fairgroup/fairprinciples
11. ^For example, see the ORCID Trust Program (https://orcid.org/about/trust/home), which articulates the rights and responsibilities of individuals in contributing to and participating in durable research information infrastructure.
12. ^For example, see ORCID at Oxford, Available online at: https://libguides.bodleian.ox.ac.uk/ORCID (accessed April 7, 2018).
13. ^https://orcid.org/organizations/funders/orbit (accessed April 11, 2018).
14. ^https://orcid.org/content/funder-working-group (accessed April 11, 2018).
References
Arms, W., and Ely, D. (1995). The Handle System: A Technical Overview. The Corporation for Research Initiatives. Available online at: http://www.cnri.reston.va.us/home/cstr/handle-overview.html (Accessed April 7, 2018).
Aryani, A., Poblet, M., Unsworth, K., Wang, J., Evans, B., Devaraju, A., et al. (2018). A research graph dataset for connecting research data repositories using RD-Switchboard. Sci. Data 5:180099. doi: 10.1038/sdata.2018.99
Bell, K. (2018). Does not compute: Why I'm proposing a moratorium on academics' use of the term “outputs.” LSE Impact Blog. Available online at: http://blogs.lse.ac.uk/impactofsocialsciences/2018/04/11/does-not-compute-why-im-proposing-a-moratorium-on-academics-use-of-the-term-outputs/ (Accessed April 13, 2018).
Bilder, G., Lin, J., and Neylon, C. (2015). Principles for Open Scholarly Infrastructure-v1. doi: 10.6084/m9.figshare.1314859. (Accessed April 11, 2018).
Bohannon, J. (2017). Vast set of public CVs reveals the world's most migratory scientists. Science 356, 690–692. doi: 10.1126/science.356.6339.690
Brown, J., Demeranville, T., and Meadows, A. (2016). Open access in context: connecting authors, publications, and workflows using ORCID identifiers. Publications 4, 1–8. doi: 10.3390/publications4040030
Data Description Registry Interoperability Working Group (2018). Research Data Alliance. Available online at: https://rd-alliance.org/groups/data-description-registry-interoperability.html (Accessed April 11, 2018).
Demeranville, D. (2018). Expanding Affiliations in ORCID: An Update. ORCID Blog. Available online at: https://orcid.org/blog/2018/03/01/expanding-affiliations-orcid-update (Accessed August 7, 2018).
European Commission, Directorate General for Research and Innovation. (2017). Guidelines to the Rules on Open Access to Scientific Publications and Open Access to Research Data in Horizon 2020. Available online at: https://ec.europa.eu/research/participants/data/ref/h2020/grants_manual/hi/oa_pilot/h2020-hi-oa-pilot-guide_en.pdf (Accessed April 10, 2018).
Garfield, E. (1955). Citation indexes for science: a new dimension in documentation through association of ideas. Sci. Magazine 122, 108–111. doi: 10.1126/science.122.3159.108
Haak, L. (2018). Acknowledging Research Resources: New ORCID Data Model. ORCID Blog. Available online at: https://orcid.org/blog/2018/04/10/acknowledging-research-resources-new-orcid-data-model (Accessed August 7, 2018).
Haak, L., and Brown, J. (2018). Beneficiaries of organization IDs must be willing to invest in them. Res. Fortnight. 4:8.
Haak, L. L., Arndt, E., Brown, B., Doyle, M. D., Elsayed, M., Garvey, P., et al. (2017). User Facilities and Publications Working Group: Findings and Opportunities. ORCID. doi: 10.23640/07243.5623750.v1
Haak, L. L., Baker, D., Ginther, D. K., Gordon, G. J., Probus, M. A., Kannankutty, N., et al. (2012a). Standards and infrastructure for innovation data exchange. Science 338, 196–197. doi: 10.1126/science.1221840
Haak, L. L., Fenner, M., Paglione, L., Pentz, E., and Ratner, H. (2012b). ORCID: a system to uniquely identify researchers. Learned Publishing 25, 259–264. doi: 10.1087/20120404
Haak, L. L., Ferriss, W., Wright, K., Pollard, M. E., Barden, K., Probus, M. A., et al. (2012c). The electronic Scientific Portfolio Assistant: integrating scientific knowledge databases to support program impact assessment. Sci. Public Policy 39, 464–475. doi: 10.1093/scipol/scs030
Hanson, B., Lawrence, R., Meadows, A., and Paglione, L. (2016). Early adopters of ORCID functionality enabling recognition of peer review: two brief case studies. Learn Publish. 29, 60–63. doi: 10.1002/leap.1004
Jefferson, O. A., Jaffe, A., Ashton, D., Warren, B., Koehlhoffer, D., Dulleck, U., et al. (2018). A Mapping the global influence of published research on industry and innovation. Nat. Biotechnol. 36, 31–39. doi: 10.1038/nbt.4049
Jefferson, O. A., Köllhofer, D., Ehrich, T. H., and Jefferson, R. A. (2015). The ownership question of plant gene and genome intellectual properties. Nat Biotechnol. 33, 1138–1143. doi: 10.1038/nbt.3393
Klein, M., and Van de Sompel, H. (2017). Discovering scholarly orphans using ORCID. Proceedings of the 2017 ACM/IEEE Joint Conference on Digital Libraries. Arxiv [Preprint]. arXiv:1703.09343. Available online at: https://arxiv.org/abs/1703.09343
Lauer (2017). Teaming with ORCID to Reduce Burden and Improve Transparency. NIH Nexus. Available online at: https://nexus.od.nih.gov/all/2017/11/15/teaming-with-orcid-to-reduce-burden-and-improve-transparency/ (Accessed April 7, 2018).
Lawrence, N. (2017). Data Readiness Levels: Turning Data from Pallid to Vivid. Available online at: http://inverseprobability.com/2017/01/12/data-readiness-levels (Accessed April 7, 2018).
Lerback, J., and Hanson, B. (2017). Journals invite too few women to referee. Nature 541, 455–457. doi: 10.1038/541455a
Long, C. P. (2017). Reshaping the tenure and promotion process so that it becomes a catalyst for innovative and invigorating scholarship. LSE Impact Blog. Available online at: http://blogs.lse.ac.uk/impactofsocialsciences/2017/11/01/reshaping-the-tenure-and-promotion-process-so-that-it-becomes-a-catalyst-for-innovative-and-invigorating-scholarship/ (Accessed April 13, 2018).
Ministry of Business, Innovation and Employment Hikina Whakatutuki (2016). 2016 Research, Science, and Innovation Domain Plan. Available online at: http://www.mbie.govt.nz/info-services/science-innovation/research-and-data/pdf-library/research-science-and-innovation-domain-plan.pdf (Accessed April 7, 2018).
Moher, D., Naudet, F., Cristea, I. A., Miedema, F., Ioannidis, J. P. A., and Goodman, S. N. (2018). Assessing scientists for hiring, promotion, and tenure. PLoS Biol. 16:e2004089. doi: 10.1371/journal.pbio.2004089
ODIN Consortium (2013a). Conceptual Model of Interoperability. Available online at: https://zenodo.org/record/18976/files/D4.1_Conceptual_Model_of_Interoperability.pdf
ODIN Consortium (2013b). Workflow for Interoperability. Available online at: https://zenodo.org/record/…/ODIN_WP4_WorkflowInteroperability_0002_1_0.pdf
Orazbayev, S. (2017). Immigration Policy and Net Brain Gain. EconPapers. Available online at: https://EconPapers.repec.org/RePEc:pra:mprapa:78058
ORCID (2018). Requiring ORCID in Publication Workflows: Open Letter. Available online at: https://orcid.org/content/requiring-orcid-publication-workflows-open-letter (Accessed April 7, 2018).
Shapin, S., and Schaffer, S. (2017). Leviathan and the Air-Pump: Hobbes, Boyle, and The Experimental Life. Princeton, NJ: Princeton University Press.
Sugimoto, C. R., Robinson-Garcia, N., Murray, D. S., Yegros-Yegros, A., Costas, R., and Lariviére, V. (2017). Scientists have most impact when they're free to move. Nature 550, 29–31. doi: 10.1038/550029a
Wagner, C. S., and Jonkers, K. (2017). Open countries have strong science. Nature 550, 32–33. doi: 10.1038/550032a
Wang, J., Veugelers, R., and Stephan, P. (2017). Bias against novelty in science: a cautionary tale for users of bibliometric indicators. Res. Policy 46, 1416–1436. doi: 10.1016/j.respol.2017.06.006
Way, S. F., Morgan, A. C., Clauset, A., and Larremore, D. B. (2017). The misleading narrative of the canonical faculty productivity trajectory. Proc. Natl. Acad. Sci. U.S.A. 114, E9216–E9223. doi: 10.1073/pnas.1702121114
Youtie, J., Carley, S., Porter, A. L., and Shapira, P. (2017). Tracking researchers and their outputs: new insights from ORCID. Scientometrics 113, 437–453. doi: 10.1007/s11192-017-2473-0
Keywords: persistent identifier, ORCID, evaluation, research infrastructure, information integration, information systems, researcher mobility, research policy
Citation: Haak LL, Meadows A and Brown J (2018) Using ORCID, DOI, and Other Open Identifiers in Research Evaluation. Front. Res. Metr. Anal. 3:28. doi: 10.3389/frma.2018.00028
Received: 13 April 2018; Accepted: 27 August 2018;
Published: 04 October 2018.
Edited by:
Kristi Holmes, Northwestern University, United StatesReviewed by:
Raf Guns, University of Antwerp, BelgiumJulie A. McMurry, Oregon Health & Science University, United States
Heather L. Coates, Indiana University, Purdue University Indianapolis, United States
Copyright © 2018 Haak, Meadows and Brown. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Laurel L. Haak, bC5oYWFrQG9yY2lkLm9yZw==