 Sriram Ravichandran
Sriram Ravichandran Nandan Sudarsanam2,3
Nandan Sudarsanam2,3 Balaraman Ravindran
Balaraman Ravindran- 1Department of Management Studies, Indian Institute of Technology Madras, Chennai, Tamil Nadu, India
- 2Department of Data Science and AI, Indian Institute of Technology Madras, Chennai, Tamil Nadu, India
- 3Wadhwani School of Data Science and AI, Indian Institute of Technology Madras, Chennai, Tamil Nadu, India
- 4Department of Decision Analytics and Risk, University of Southampton Business School, Southampton, United Kingdom
Active learning enables prediction models to achieve better performance faster by adaptively querying an oracle for the labels of data points. Sometimes the oracle is a human, for example when a medical diagnosis is provided by a doctor. According to the behavioral sciences, people, because they employ heuristics, might sometimes exhibit biases in labeling. How does modeling the oracle as a human heuristic affect the performance of active learning algorithms? If there is a drop in performance, can one design active learning algorithms robust to labeling bias? The present article provides answers. We investigate two established human heuristics (fast-and-frugal tree, tallying model) combined with four active learning algorithms (entropy sampling, multi-view learning, conventional information density, and, our proposal, inverse information density) and three standard classifiers (logistic regression, random forests, support vector machines), and apply their combinations to 15 datasets where people routinely provide labels, such as health and other domains like marketing and transportation. There are two main results. First, we show that if a heuristic provides labels, the performance of active learning algorithms significantly drops, sometimes below random. Hence, it is key to design active learning algorithms that are robust to labeling bias. Our second contribution is to provide such a robust algorithm. The proposed inverse information density algorithm, which is inspired by human psychology, achieves an overall improvement of 87% over the best of the other algorithms. In conclusion, designing and benchmarking active learning algorithms can benefit from incorporating the modeling of human heuristics.
1 Introduction: active learning with human heuristics
Building prediction models is crucial for automating management decision processes because it enables organizations to make informed decisions based on data rather than relying solely on intuition or past experiences. There is an increasing need for training such models in conditions where obtaining labels is significantly more expensive than their attributes. For example, the safety of automobile designs is assessed by crash tests under carefully controlled conditions which is expensive. An active learning algorithm selects efficiently data points for training prediction models. This selection is made by adaptively querying an oracle for the labels of data points. That is, the training process starts from a small number of labeled data points and queries the oracle for further labels, wherein each query is a function of previously provided labels. Thus, prediction models can achieve better performance faster by employing active learning modules (Settles, 2009; Monarch, 2021).
Crucially, the oracle providing the labels is typically assumed to be unbiased (Wu et al., 2012; Cohn et al., 1994; Lan et al., 2024). This is sometimes a valid assumption when reliable and accurate data may be gathered through extensive, automated experimentation, such as the example provided earlier. But in many situations there is a need to consult a human oracle—a medical diagnosis must be provided by a doctor, a loan application must be decided on by a bank manager, and so on. In principle, such cases could also be approached by automated extensive experimentation, but there are ethical or business considerations that limit the extent to which this can be done.
The behavioral sciences, such as the psychology of judgment, decision-making, and behavioral economics, have found that people exhibit systematic biases in the sense of deviations from norms of logic and probability (Kahneman et al., 1982; Gilovich et al., 2002). Whereas such biases might be attributed to the structure of the decision environment or can be viewed as adaptive given a focus on accuracy or transparency (Todd et al., 1999; Katsikopoulos et al., 2020). This structured decision environment refers to the heuristics a human uses in decision-making, which may be biased. It remains a fact that human oracles sometimes provide biased labels, which challenges the common assumption in active learning literature.
This calls for an investigation into the impact of human heuristics used by human oracles on the performance of active learning algorithms(henceforth AL). Such a study would show whether AL algorithms are as effective as commonly assumed. Furthermore, this problem motivates the development of a novel AL algorithm specifically designed to be robust against human-induced biases in the labeling process. Our work successfully addresses both of these objectives.
This research is necessary because investigating the impact of biased oracles will prompt active learning researchers to consider human psychology when designing and evaluating algorithms. By addressing human-induced biases, the development of more robust AL algorithms can lead to more accurate prediction models with fewer labeled instances. This improvement will help practitioners optimize data labeling efforts, enhancing the overall efficiency and performance of AL systems in the presence of biased human inputs. The expected outcomes include more reliable models, reduced labeling costs, and improved algorithmic generalization.
The format of the paper is as follows: Literature pertinent to the investigation is discussed in Section 2. Section 3 provides a methodological overview, including information on the experimental design, AL algorithms, and human heuristic models. Section 4 presents the findings from rigorous investigations conducted in three phases, followed by the Conclusion.
2 Background literature
In this section, we provide some background on (i) AL algorithms, (ii) models of human heuristics, and (iii) literature addressing the research problem, which involves the intersection of active learning and biased oracles. We discuss the basic concepts; concrete examples with formal details are given in Section 3, which describes our methodology.
2.1 AL algorithms
In what follows, we consider a pool-based sampling scenario where a small number of labeled data points exist and the rest are unlabeled and available at once.
In the first family of AL algorithms, data points are ranked according to metrics such as each point's uncertainty or entropy (Shannon, 1948). The querying of labels is done based on the rank obtained over the pool of unlabeled data points. They might appear too simple, but such algorithms can be comparatively well-performing (Raj and Bach, 2022; Liu and Li, 2023). Recently, these methods have shown good performance when applied to convolutional auto-encoders for image classification (Roda and Geva, 2024).
The second family of AL algorithms also utilizes uncertainty, though not of data points per se, but rather uncertainty stemming from the predictions of classifiers. Each unlabeled data point is classified in multiple ways to measure this type of uncertainty. In an initial version of this approach (Mitchell, 1982), multiple classifiers are used (these classifiers perform well in the pool of labeled data points). Preference for querying is given to data points receiving contradicting labels from the classifiers. In a variant of this approach (Muslea et al., 2006), called multi-view learning, a classifier is trained with different sets of attributes —these are the multiple views—and again, preference is given to data points receiving contradicting labels based on these views.
The third family of AL algorithms considered here tends to outperform the first two families. The approach is to combine uncertainty with what is called information density. The aim of information density is to measure how representative an unlabeled data point is of the distribution of all unlabeled data points. The uncertainty and information density measures are typically multiplied to form the combined measure (Settles and Craven, 2008).
2.2 Models of human heuristics
Answering Herbert Simon's call for precise models of how people make decisions under realistic conditions of time, information, computation, and other resources (Simon, 1990), the fast-and-frugal heuristics approach has provided mathematical models that describe how people judge a quantity, choose one of several options, or classify objects into categories. These heuristics have been empirically validated (Gigerenzer et al., 2011). While fast-and-frugal heuristics can perform competitively to standard statistics and operations research benchmarks or even near-optimally or optimally (Baucells et al., 2008; Katsikopoulos, 2011) under certain conditions, they also commit systematic mistakes. For these reasons, fast-and-frugal heuristics constitute a viable possibility for modeling how human oracles provide labels.
A characteristic property of fast-and-frugal heuristics is that they use a few attributes and combine them in simple ways, for example, by ordering or summing attributes and relying on numerical thresholds. The spectrum of fast-and-frugal heuristics runs from the so-called non-compensatory to fully-compensatory models. Non-compensatory models make decisions without allowing for the values of some attributes to compensate for the values of other attributes. For example, in fast-and-frugal trees (Martignon et al., 2008), attributes encountered after an exit is reached cannot reverse the decision embodied in the exit. Of course, this is the case for all decision trees, but fast-and-frugal trees are special cases of decision trees (Section 3). In fully compensatory models, any attribute value can, in principle, compensate for the values of any other attribute. For instance, this is the case in tallying (Dawes, 1979), which is a linear model where all attribute weights equal one. Because these two extremes of the fast-and-frugal-heuristics spectrum can cover a large part of the behaviors produced by the heuristics (Katsikopoulos, 2013), thus we consider just fast-and-frugal trees and tallying as models of human heuristics. It must be noted that this work is based on the assumption that fast and frugal heuristics are good models for automating human labeling, which is based on the work of Gigerenzer et al. (2011) and this assumption is not validated in this study.
2.3 AL algorithms and biased oracles
A small part of the AL literature has considered biased oracles. Settles (2009) suggested the possibility of incorrect labeling because of the human oracle experiencing fatigue due to, for example, having to provide too many labels. Consistently, some AL algorithms modeling oracles that provide low-quality labels have been developed (Sheng et al., 2008; Groot et al., 2011). However, such algorithms model labeling error as random noise or uniformly distributed error, whereas, as discussed previously, the error is due to human bias and is systematic.
Agarwal et al. (2022) calculated that labeling biases would decrease the predictive accuracy of classifiers by at least 20%. In another approach, Du and Ling (2010) proposed an algorithm with an exploration and exploitation approach by relabeling data points that could be wrongly labeled. The oracle here was modeled based on the assumption that the probability of obtaining biased labels depends on the maximum posterior probability of an instance that is computed with the ground truth labels. We consider this idea promising because it models the effects of oracle behavior.
A detailed discussion of the above literature, along with other notable studies, is presented in Table 1. It is important to highlight that none of the current research models the oracle based on human heuristics or designs AL algorithms with this consideration. This paper addresses this gap by explicitly modeling oracle behavior using well-established human heuristics.
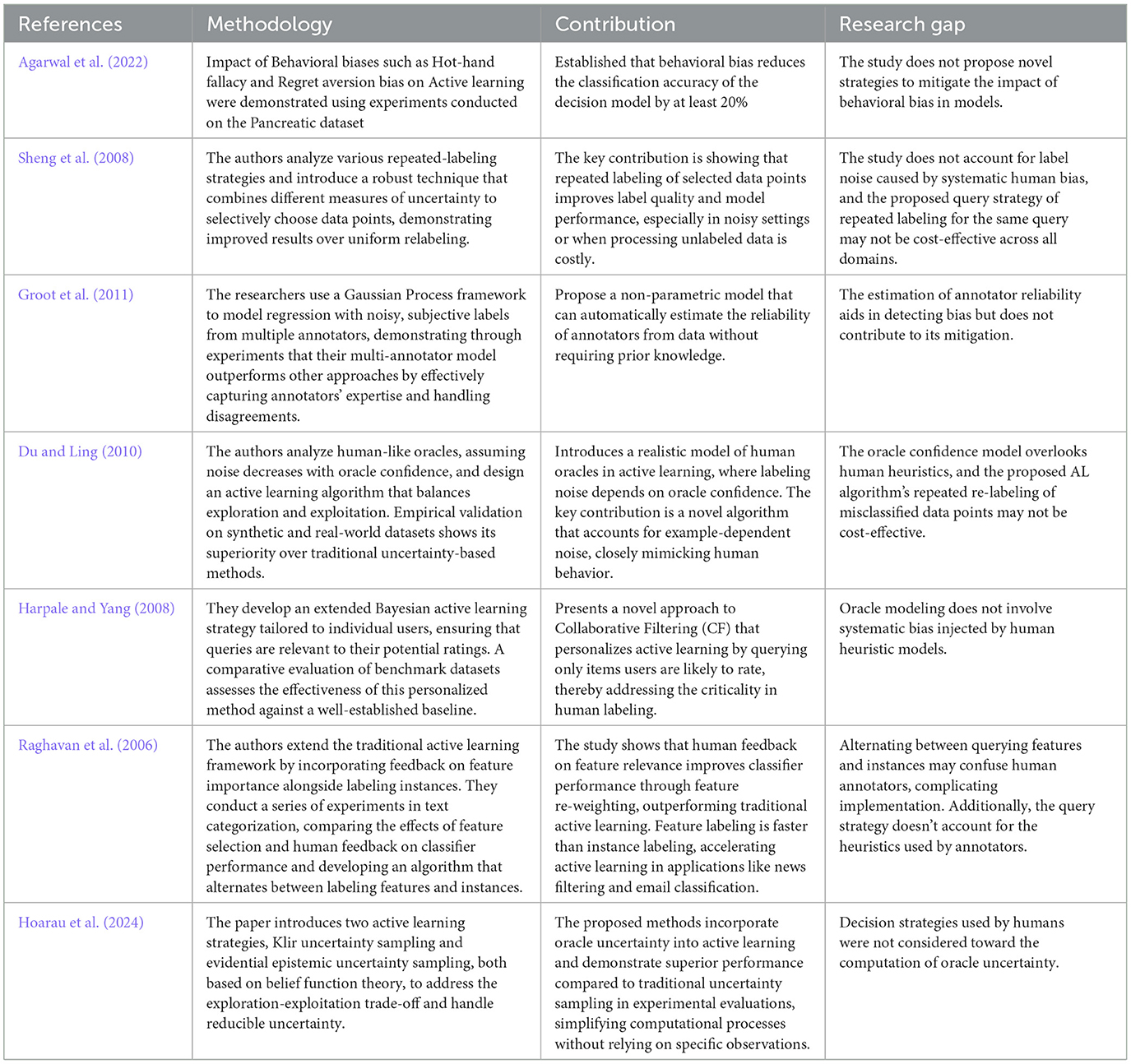
Table 1. Literature relevant to AL with biased oracles.
3 Methodology
The methodological framework is presented in Figure 1. Out of the dataset D(X, Y), where Y represents the ground truth labels for the set of data points X characterized by their attributes, a small fraction Xseed⊂X is used to train the classifier with the labels provided by the human heuristic. This operation is portrayed in the left part of the figure. On the other hand, as seen in the right part of the figure, the remaining large pool of data points Xpool⊂X is used by the AL algorithm to identify the next data point to query. The queried data point and its heuristic-provided label are used to retrain the classifier. The accuracy of the whole model M is recomputed after each query.

Figure 1. Methodological framework.
We use three standard classifiers, logistic regression (LR), random forest (RF), and support vector machines (SVM) that were predominantly used in AL literature (Yang and Loog, 2018; Gu et al., 2014; Kremer et al., 2014).
3.1 AL algorithms
This section includes a description of three well-known AL algorithms selected for this study (one from each AL family discussed in section 2.1), which are not only widely accepted and commonly used for benchmarking but also well-performing to date (Liapis et al., 2024; Tan et al., 2024; Moles et al., 2024). Following this, the novel inverse information density method is presented.
3.1.1 Entropy
The entropy E(x) of a data point x measures the information required to label this data point with certainty. The following equation calculates this value, where pM(yi/x) denotes the probability of a data point x belonging to class yi, ranging over K possible label assignments. This probability is derived from the model M, which is trained using the labels acquired up to the previous query.
The unlabeled data point with maximum E(x) is chosen to be queried:
3.1.2 Multi-view learning (MVL) with co-testing
The following pseudo-code describes an algorithm that incorporates uncertainty stemming from using different classification processes. There is a single classifier, trained with two different sets, called views, of attributes (Step 1). Unlabeled data points with different predicted labels in the two views form the co-testing set (Steps 2 and 3), where the point with maximum entropy is chosen to be queried (Step 4).
Input: Labeled set of data points (XL, YL), unlabeled pool of data points (XU)
1: The labeled data (XL) is split into two attribute sets (views), and , and trains two classifiers using these different views.
2: For each unlabeled data point x in XU, the predictions from the two classifiers are compared.
3: If the classifiers disagree on the label for x, this point is added to the co-testing set C. If no disagreements are found, all points in XU are added to C.
4: x* = argmaxx∈C[E(x)]
Output: Data point x* to query
It is important to emphasize that the labeled set (XL, YL) is updated with the newly acquired labels after each query. Similarly, the queried data point is removed from the pool of unlabeled data (Xpool) following every query, consistent with standard practices in other algorithms.
3.1.3 Conventional information density (CID)
This algorithm evaluates data points on two measures. The first measure captures the uncertainty of a data point's most probable label, as formulated below, where K represents the number of possible labels.
The second measure captures how representative a data point of the distribution of unlabeled data points xu by using the cosine similarity function sim (Settles and Craven, 2008), where U represents the size of the unlabeled set Xu as shown in the following.
The unlabeled data point with the maximum product of the two measures is chosen to be queried:
3.1.4 The proposed Inverse Information Density (IID)
The aim of this algorithm is to achieve robustness to labeling bias. We design an algorithm inspired by human psychology. Human heuristics are robust across a host of real-world situations, including prediction in classification tasks (Gigerenzer et al., 2011; Katsikopoulos et al., 2020).
The IID algorithm shares the basic concepts of the CID algorithm, but it employs them differently. There are two differences. First, IID does not use all available attributes but only the attributes that a statistical test (Pearson correlation test) has found to be significantly related to ground truth labels. People's fast-and-frugal heuristics routinely narrow down the set of available attributes, and this has been shown to, under some conditions, enhance their predictive accuracy (Baucells et al., 2008; Simşek, 2013). In IID, representativeness is computed using the narrowed set of attributes (N) significantly correlated with the previous set of labels obtained and the function sim stands for Euclidean distance.
The second difference between IID and CID is that, in IID, representativeness is seen as a reason to not query a data point. People have a natural tendency to explore uncharted territory, sometimes with good success, as in armed bandit problems (Stojić et al., 2015; Brown et al., 2022), and the IID tweak in using information density captures this tendency.
The following pseudo-code describes the IID algorithm.
Input: Labeled set of data points (XL, YL), unlabeled pool of data points (XU), attribute list (ATT),
1: For all att in ATT:
If Corratt(XL, YL) ≠0 (α = 0.001):
N ← att
2: For all x in XU:
3: x* = argmaxx∈XU[U(x)−R(x)]
Output: Data point x* to query
The IID algorithm begins by identifying the subset of attributes N that are significantly correlated with the labels in the labeled set (XL, YL), using a Pearson correlation test at a significance level α = 0.001 (Step 1). For each data point x in the unlabeled pool XU, the representativeness R(x) is computed based on its similarity to other points in XU, using the Euclidean distance sim(x, xu) specifically focusing on attributes contained in N (Step 2). Finally, the algorithm selects the data point x* that has the maximum difference between uncertainty U(x) and representativeness R(x).
3.2 Models of human heuristics
3.2.1 Fast-and-frugal trees
A fast-and-frugal tree (FFT) is a tree for making classifications such that it (i) always has an exit after it queries an attribute (two exits after it queries the last attribute), (ii) has only a ‘few' attributes (a common default value is three attributes) and (iii) queries each attribute once and does not query multiple attributes together.
These three conditions jointly imply that fast-and-frugal trees are, all else being equal, sparser than standard classification trees. In general, trees are made sparser by using fewer attributes or by using each attribute fewer times; methods of statistical induction of trees include pruning modules that pursue these goals (Bertsimas and Dunn, 2017; Breiman et al., 1984). Fast-and-frugal trees further increase sparsity by using each attribute at most once.
There are several statistical and qualitative methods for inducing fast-and-frugal trees from data (Katsikopoulos et al., 2020). Here, we build fast-and-frugal trees via the fan algorithm (Phillips et al., 2017), where attributes were binarized using a median split. Additionally, the maximum depth of the tree is set to three. An example fast-and-frugal tree induced in the 'Raisin' dataset (Cinar et al., 2020), where the task is to predict the type of raisin (Kecimen or Besni) based on two morphological features of raisins, is shown in Figure 2.
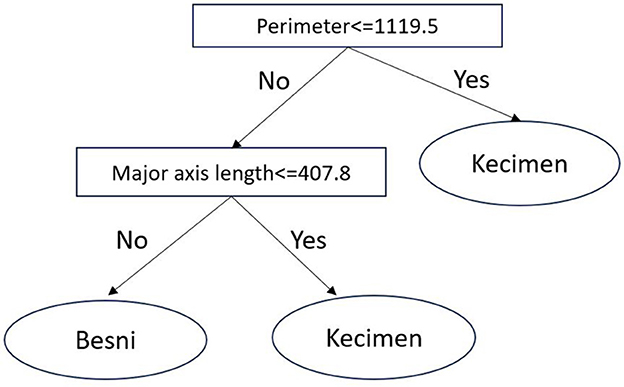
Figure 2. A fast-and-frugal tree for predicting raisin type.
3.2.2 Tallying
According to (Martignon et al., 2008), a tallying model is a unit-weight linear model for making classifications, with the number of its parameters equalling the number of possible classes minus one.
For example, assume that there are two classes, C1, C2, and one wishes to classify a data point x with binary attribute values xi, i = 1, ..., n to one class. Tallying can be described by the following, where the parameter k can take any integer value from 1 to n.
4 Results
We use 15 datasets from the UCI ML Repository (Kelly et al., n.d.), where people routinely provide labels. Datasets come mostly from health but other domains too, such as marketing and transportation. For brief descriptions of the datasets, see Supplementary material A. We chose datasets with two possible classes because there is more empirical evidence for people's use of fast-and-frugal heuristics in such classification tasks (Katsikopoulos et al., 2020) It must be noted that all the datasets used for the study were used and cited by multiple published works (Jalali et al., 2017; Xie et al., 2019).
Our investigations were carried out in three phases. In the first phase, a hypothesis on the nature of human heuristics is proposed, and its validity is empirically explored to comprehend the points susceptible to labeling bias. The second phase aims to establish that our algorithm has the characteristics that make it robust toward such bias. An evaluation of the performance of Active learning algorithms is provided in the final section.
4.1 Phase 1: experimental validation on the hypothesized nature of human heuristics
To understand the nature of human heuristics, we develop a hypothesis. We hypothesize that data points farther away from the data points with median values for the most important attributes are more likely to be accurately labeled by human heuristics.
We report an empirical test that supports the hypothesis. Figures 3, 4 illustrate the distribution of correctly/incorrectly labeled data points with respect to important attribute values used by heuristics in the decision-making process. Notably, the correctly classified points, represented in purple, tend to lie farther from the median attribute values, marked by the dotted lines. This pattern holds overall for all 30 scenarios ( 15 datasets x 2 heuristics), as shown in Supplementary material B. These results support our assertion that data points with attribute values deviating from their population median are more likely to be labeled correctly by the heuristics.
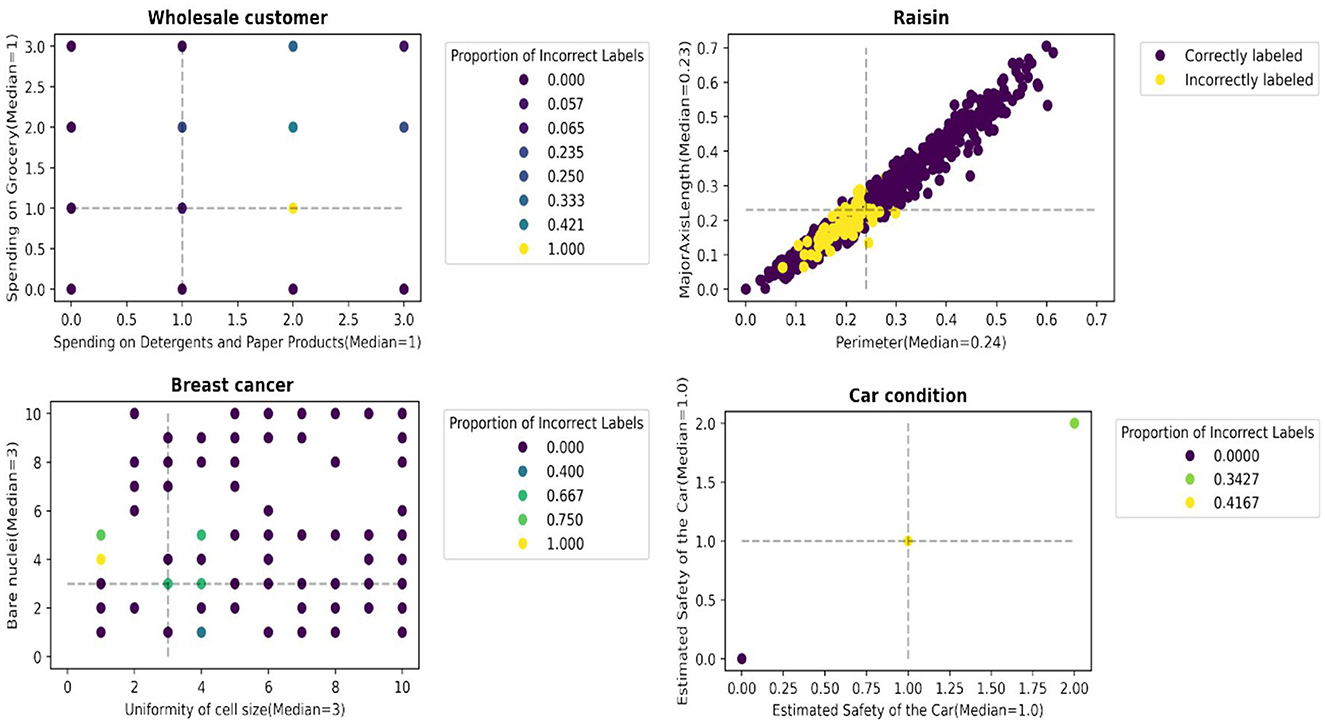
Figure 3. Data points farther away from the data points with median values for the most important attributes are more likely to be accurately labeled by the fast-and-frugal tree.
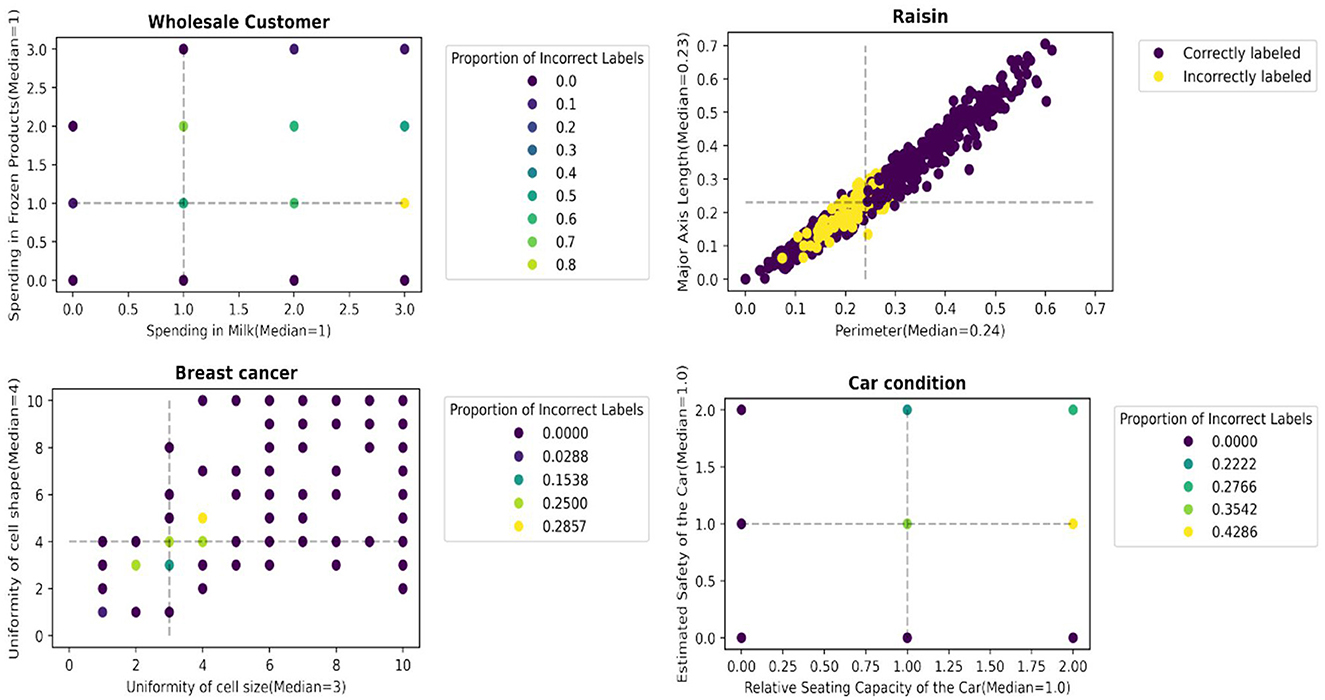
Figure 4. Data points farther away from the data points with median values for the most important attributes are more likely to be accurately labeled by tallying.
4.2 Phase 2: assessment on AL algorithm's robustness for human heuristics
The robustness of an AL algorithm toward labeling bias depends on (i) the independence of the algorithm on labeling accuracy and (ii) the ability of the algorithm to identify and query data points that are more likely to be accurately labeled. In this section, we find that the IID algorithm is well-suited for the aforementioned factors. Therefore, we hypothesize that the IID algorithm would perform better than the existing ones.
Factor (i) favors the information density algorithms, CID and IID. This is so because Entropy and MVL only rely on E(x) and U(x) that are dependent on labeling accuracy, whereas the information density algorithms also use R(x).
When the experimentally validated hypothesis is combined with the fact that IID prefers querying such points more than CID (because only in IID R(x) measures how close a data point is to the data points with median values for the most important attributes), They jointly imply that IID has a higher ability than CID to identify and query data points more likely to be accurately labeled.
In Figure 5, evidence is provided for the Raisin dataset (one run, the fast-and-frugal tree provided labels) that IID is the only algorithm that prefers querying the data points farther away from the data points with median values for the most important attributes. This pattern holds overall for the 30 scenarios (see Supplementary material B).
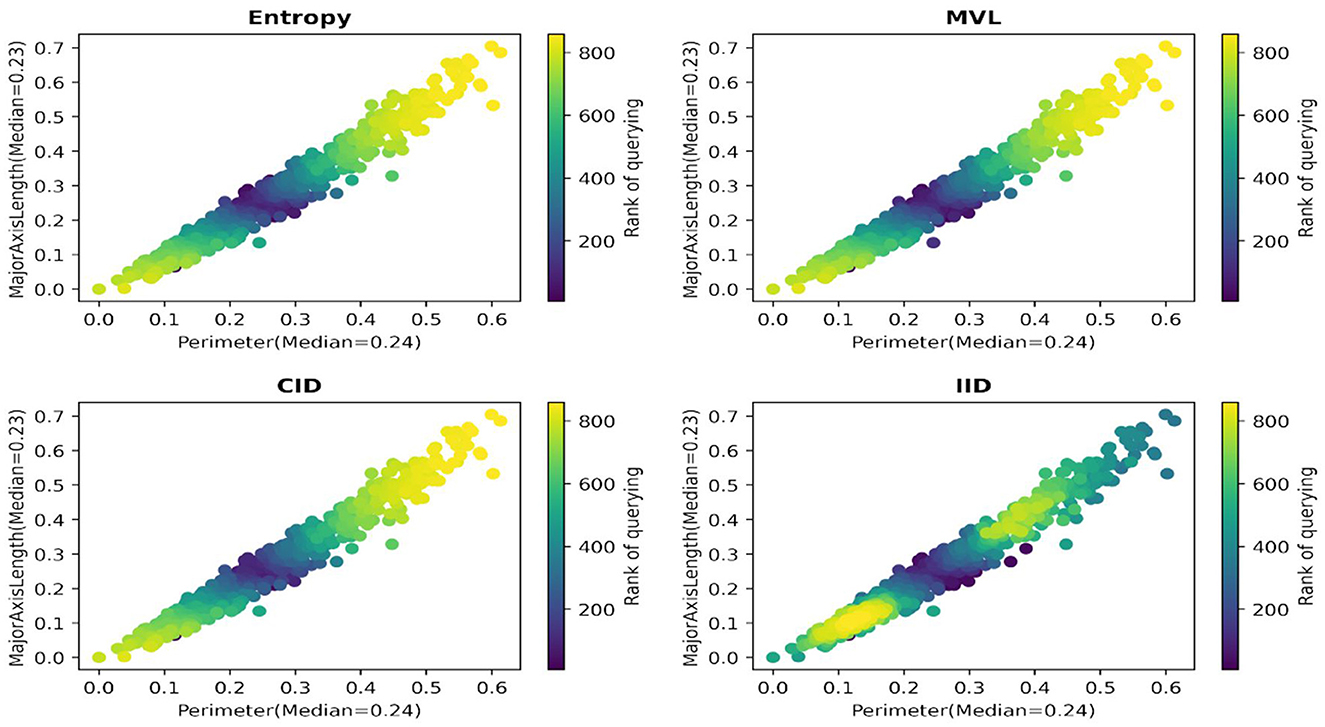
Figure 5. Rank of querying for the Raisin dataset.
4.3 Phase 3: performance of AL algorithms
Experiments were carried out on datasets using human heuristics and AL query methods. In every iteration, a randomly chosen seed set (Xseed) labeled with the human heuristic was used to train a classifier, and the remaining pool (Xpool) was used by the AL query strategies to choose the data points to query. The classifier was re-trained to predict the entire dataset after every query. The above process was pursued for 30 iterations by varying the Xseed and Xpool chosen from X after each iteration.
Figure 6 provides learning curves (accuracy as a function of the number of data points queried) for the four AL algorithms(averaged over all iterations), including random sampling as a benchmark for two datasets and both human heuristics. The IID algorithm has superior performance in these cases.
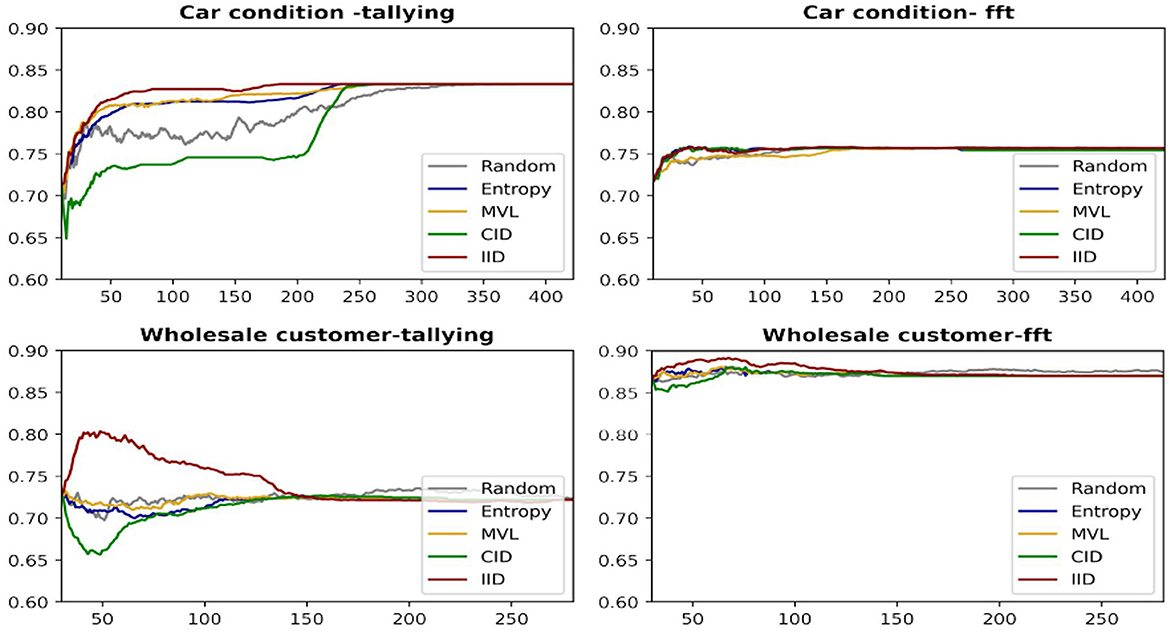
Figure 6. Learning curves for two datasets using the LR classifier.
Tables 2–5 report the area under the learning curve for both human heuristics for the LR classifier. Bold font denotes the algorithm with the best performance, and underlined font denotes that an algorithm performed worse than random. It can be inferred that irrespective of the performance metric, entropy sampling consistently outperforms other methods in most scenarios when ground truth labels are available. Additionally, the proposed IID algorithm demonstrates superior performance when heuristics are employed for labeling. Table 6 summarizes these findings by illustrating the frequency of algorithms that exhibit optimal performance. Similar results were obtained for the RF and SVM classifiers (see Supplementary material C).
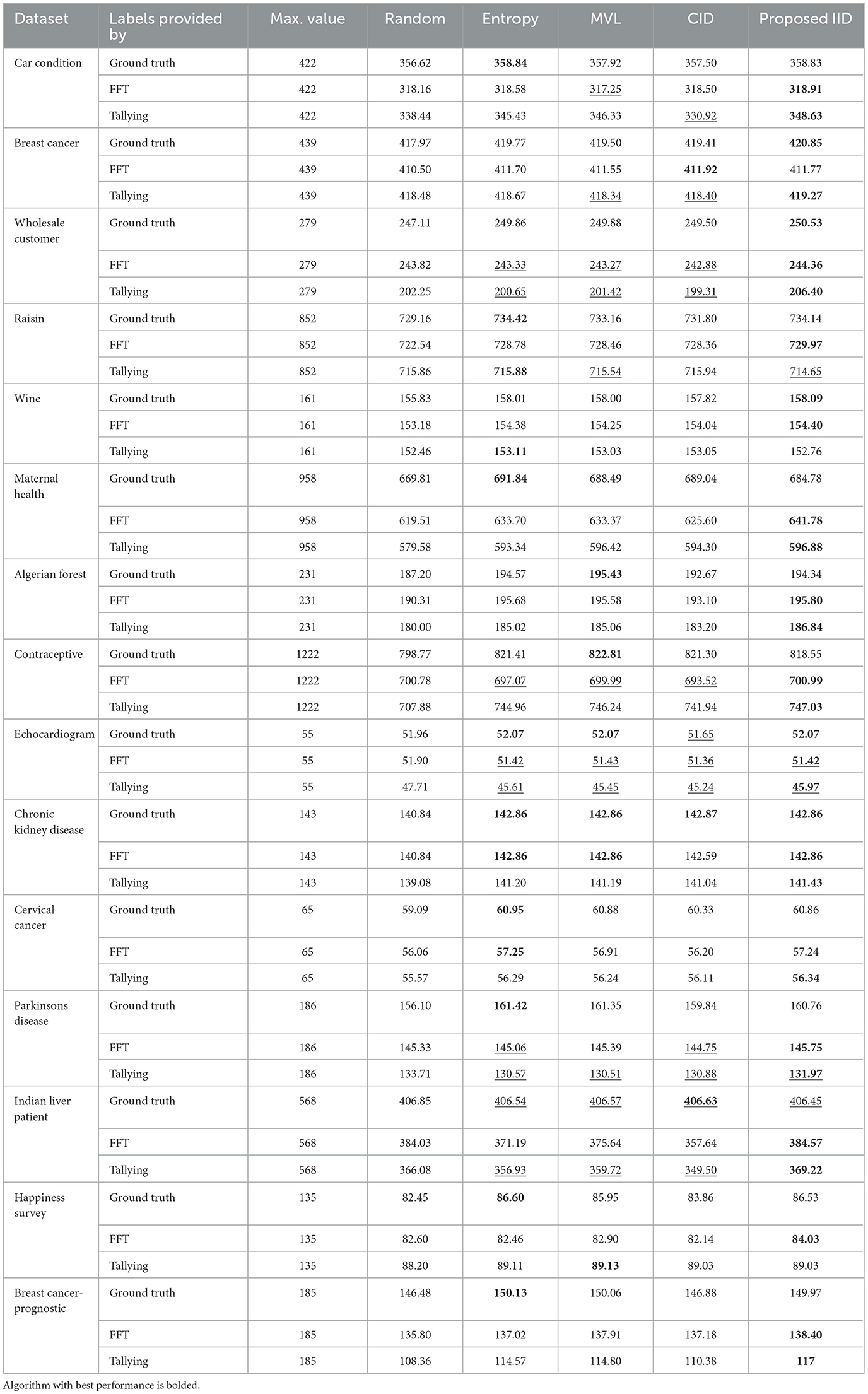
Table 2. Area under the learning curve (accuracy) for all 15 datasets and the LR classifier.
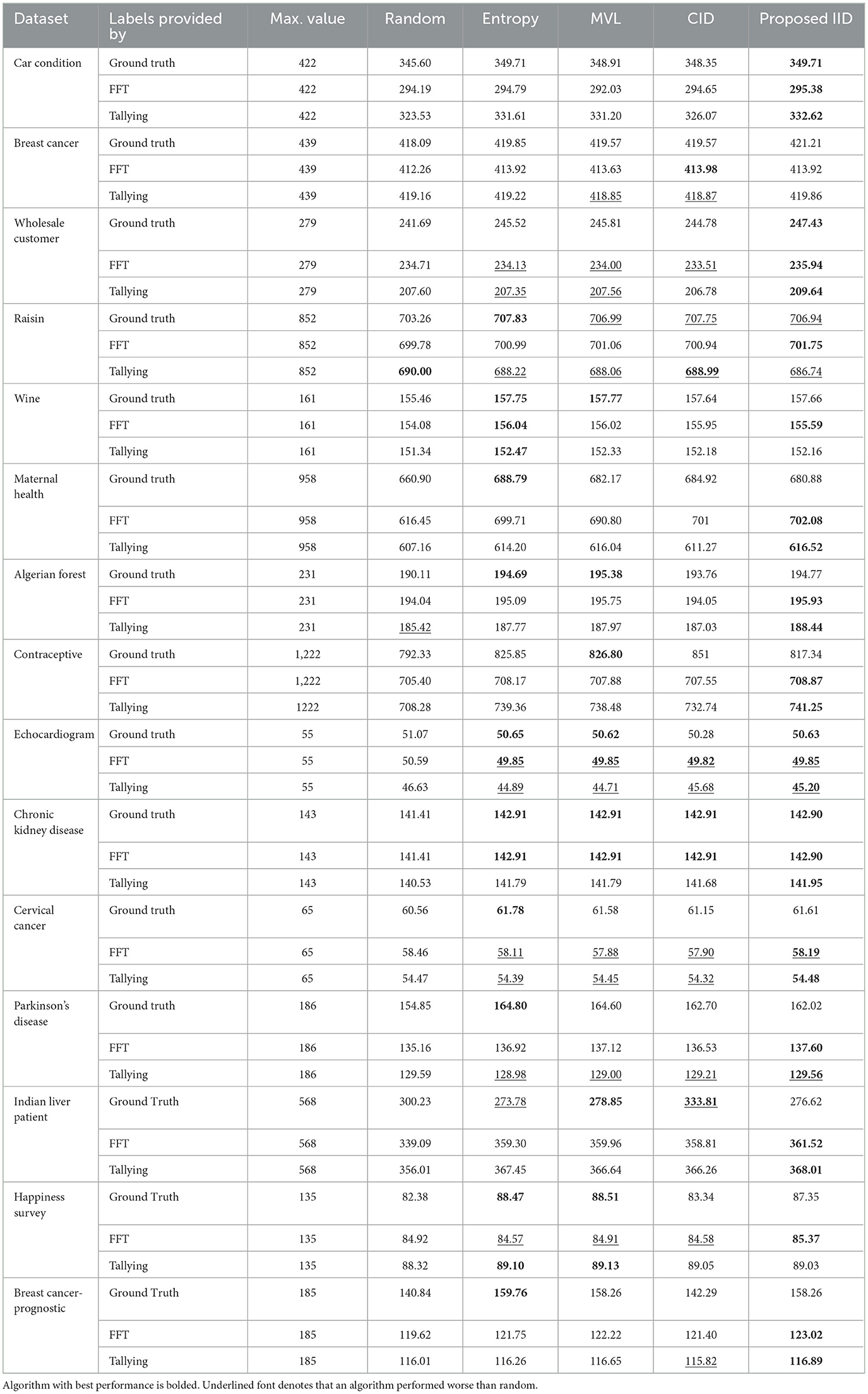
Table 3. Area under the learning curve (Precision) for all 15 datasets and the LR classifier.
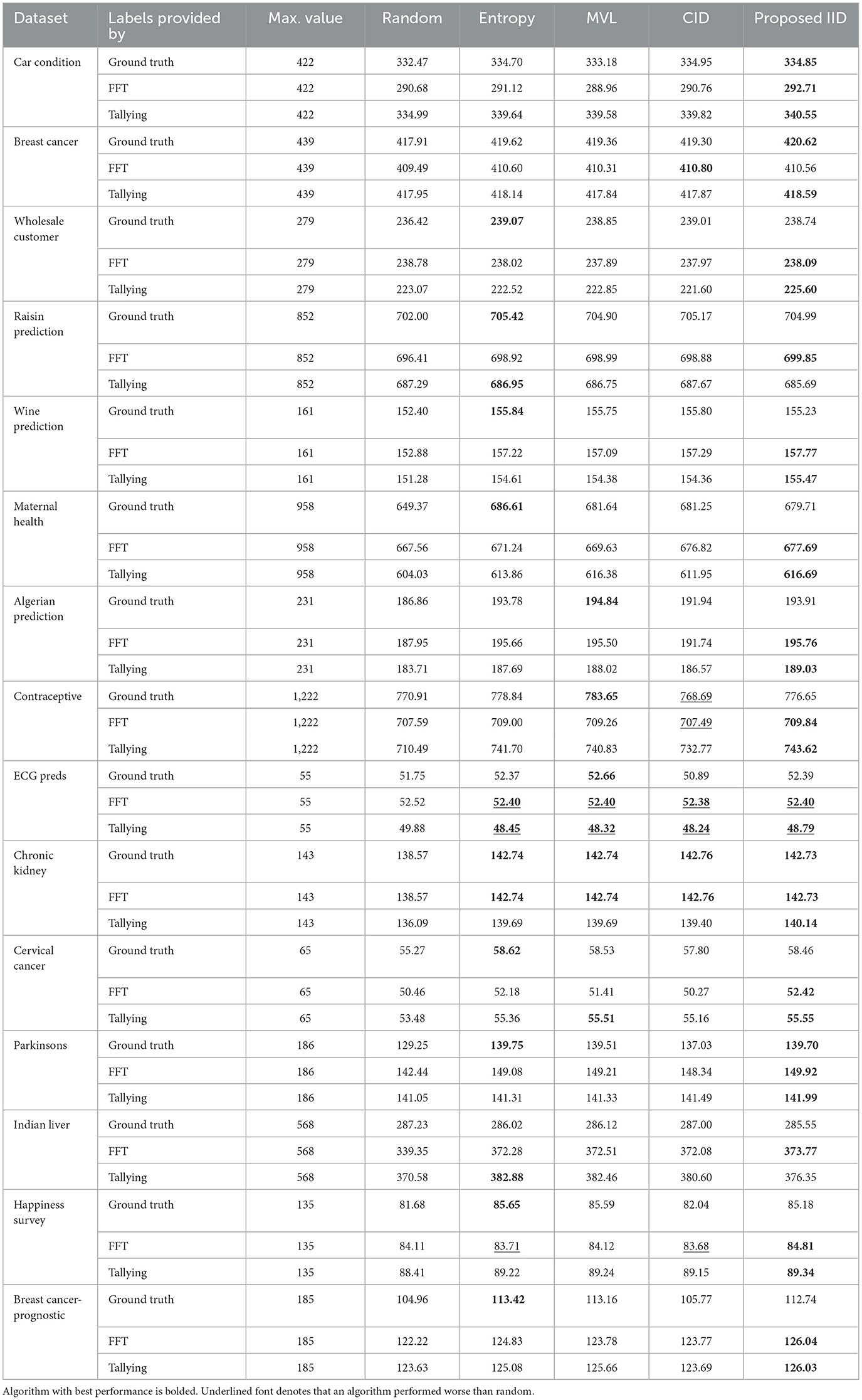
Table 4. Area under the learning curve (Recall) for all 15 datasets and the LR classifier.
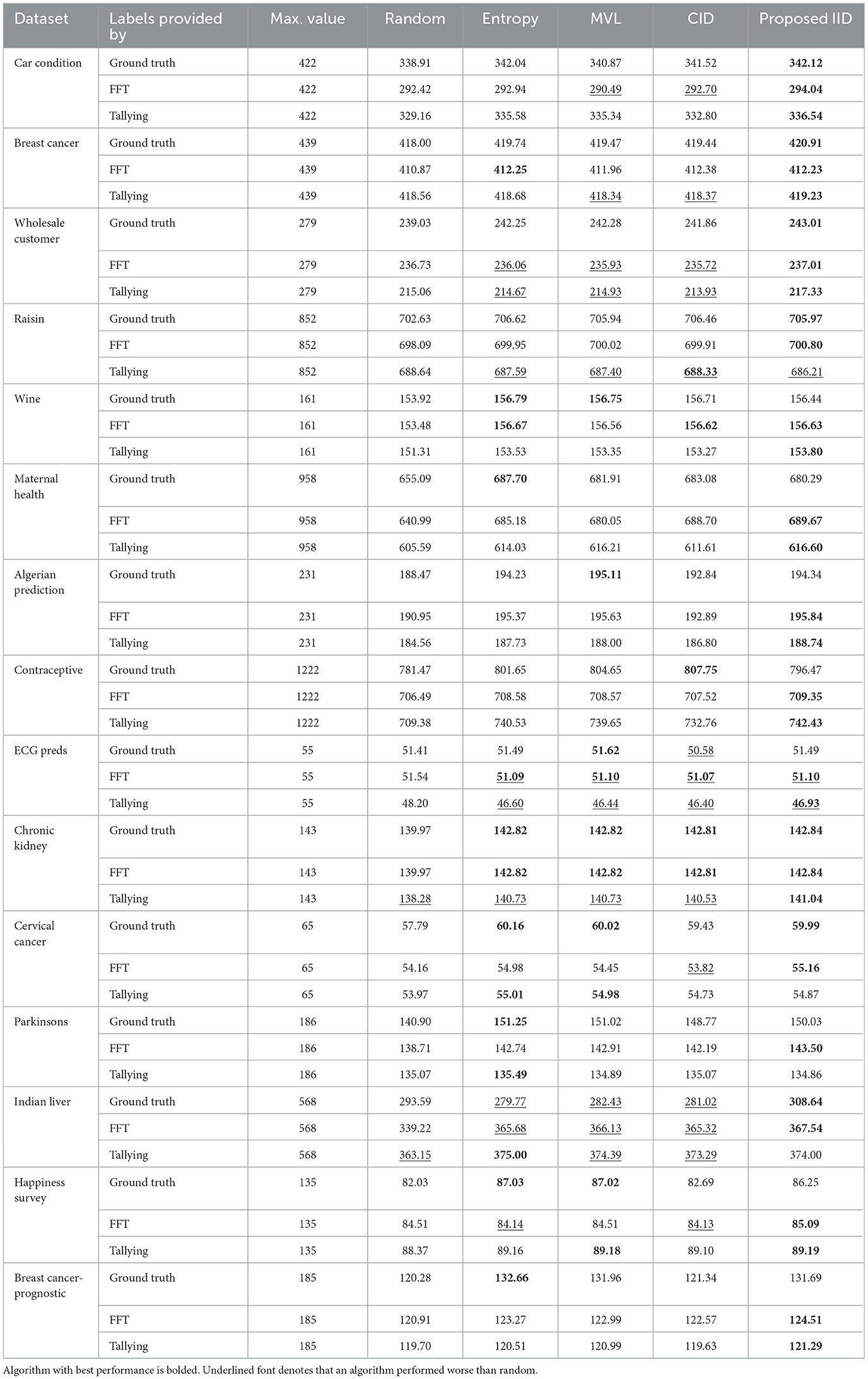
Table 5. Area under the learning curve (F1 score) for all 15 datasets and the LR classifier.
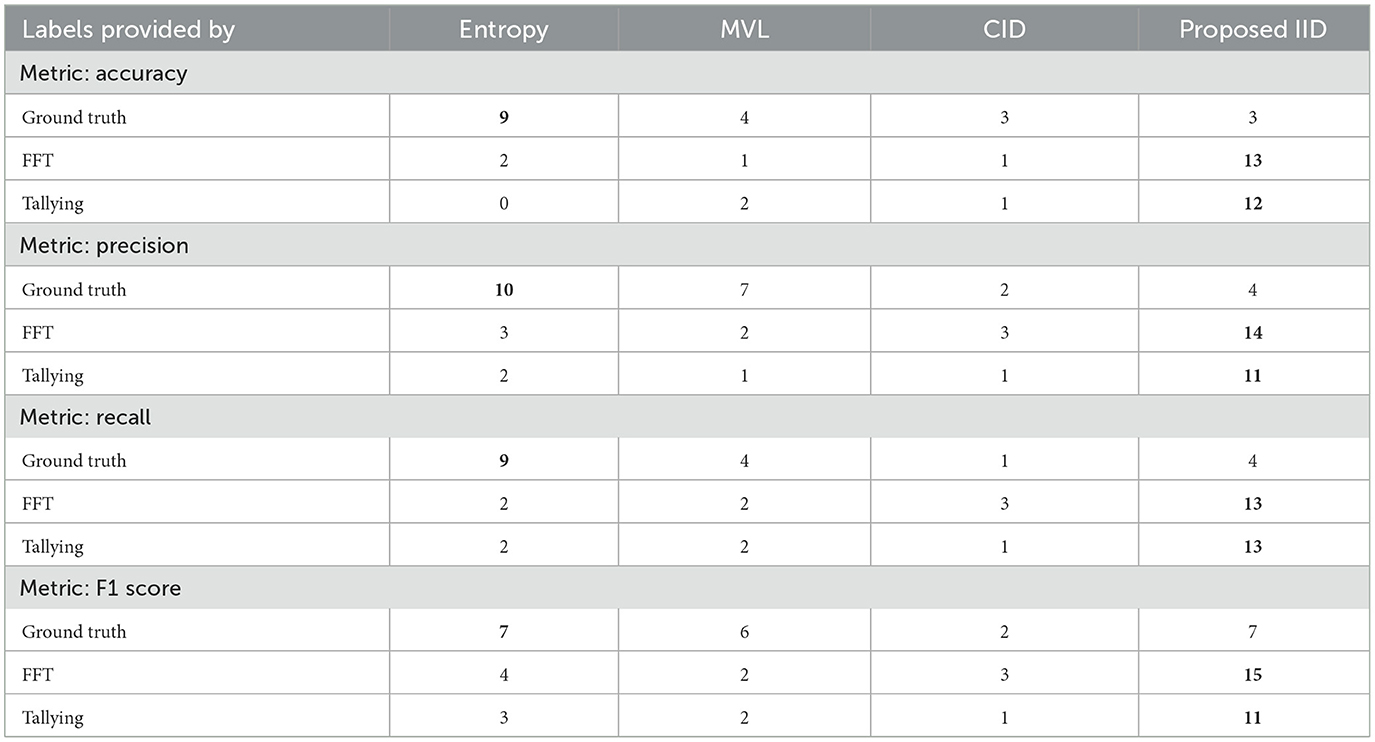
To provide insights into the overall trends in the behavior of active learning (AL) algorithms, irrespective of the specific prediction tasks, we utilize Table 7. This table presents the average performance of all classifiers across all datasets, using accuracy as the primary metric. The best performances within 0.05 are highlighted in bold. The proposed IID method showed an overall effectiveness improvement of 19.8% compared to Entropy sampling, which was the best-performing alternative. This boost in performance is primarily due to the Inverse Information Density (IID) metric, which complements the uncertainty measure captured by entropy sampling. Notably, the improvement increases to 87% when labels are generated by human heuristic models, further demonstrating the suitability of the proposed method in such environments, as anticipated. However, this summary masks data-specific variations in performance, which serves as a notable caveat.
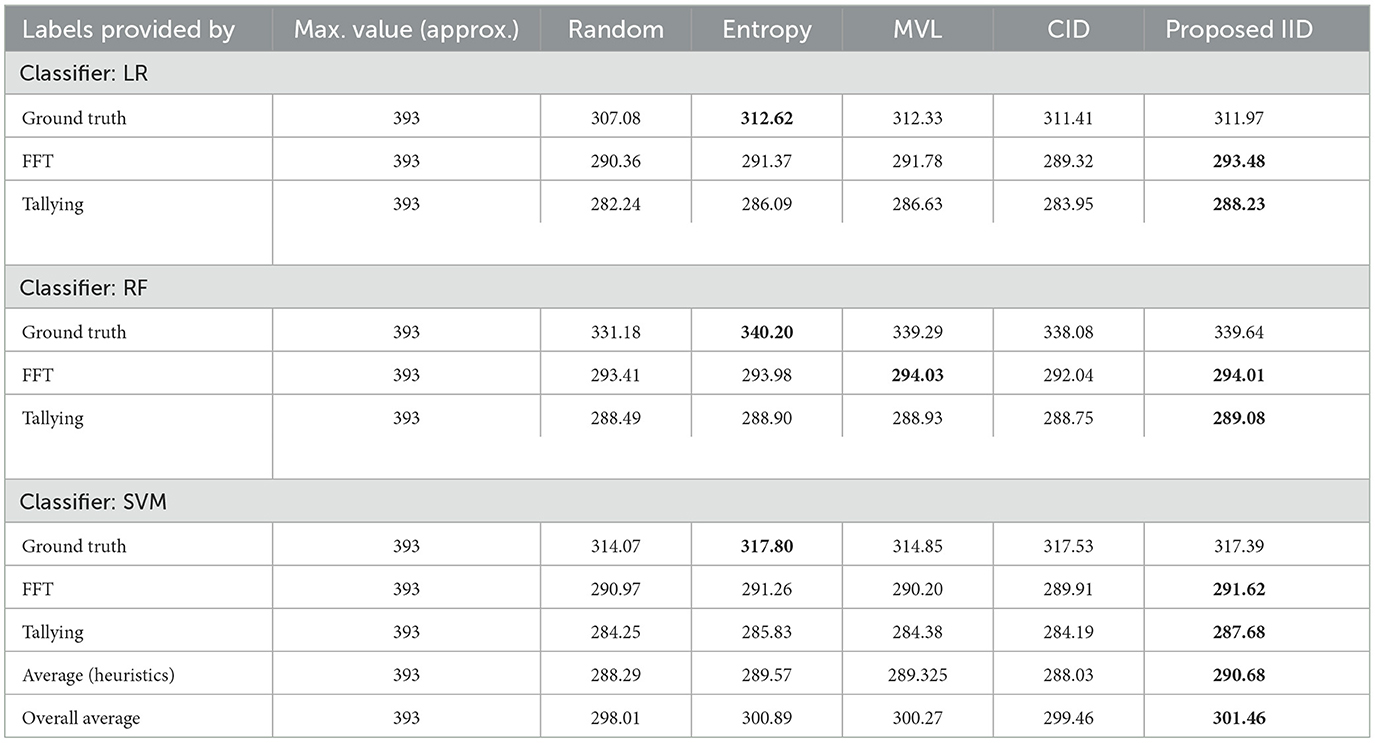
Table 7. Average area under the learning curves, based on accuracy, across all datasets, presented for each classifier.
Despite the significant performance improvements demonstrated by the proposed model, it lacks a specific mechanism for handling adversarial samples. Adversarial examples are generated by introducing small perturbations to normal data points, which remain correctly recognizable to humans but are misclassified by prediction models (Kwon, 2023; Kwon and Kim, 2023). Given the potential application of this model for automating critical human decisions, such as detecting diseases or forest fires, it is crucial for the model to be resilient to adversarial attacks. Several mitigation strategies, including adversarial training and transfer learning, have been developed to address this issue (Kwon and Lee, 2022; Kwon et al., 2022). Incorporating such mitigation strategies into the proposed model presents a promising direction for future work.
5 Conclusion: active learning and oracle uncertainty
AL algorithms hold tremendous potential but should be based on realistic assumptions. Starting from the commonsense observation that sometimes the labels necessary for AL must be provided by a human, who might be biased, we model the oracle by fast-and-frugal heuristics. In other words, we also modeled the labeling strategy used by an oracle beyond the known modeling of data and prediction uncertainty in active learning. Our study showed the need to design AL algorithms robust to labeling bias, and this was pursued by taking inspiration from heuristics research. More generally, this exercise shows that it may be beneficial to consider human psychology in the design of active learning algorithms.
Data availability statement
The original contributions presented in the study are included in the article/Supplementary material. The codeset required to replicate this study is available at https://github.com/SriramML/AL-with-Human-Heuristics.git. Further inquiries can be directed to the corresponding author.
Author contributions
SR: Formal analysis, Methodology, Validation, Visualization, Writing – original draft, Writing – review & editing. NS: Conceptualization, Formal analysis, Funding acquisition, Investigation, Methodology, Validation, Writing – original draft, Writing – review & editing. BR: Investigation, Methodology, Supervision, Writing – original draft, Writing – review & editing. KK: Methodology, Supervision, Validation, Writing – original draft, Writing – review & editing.
Funding
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. A project “Improving active learning performance in the context of human heuristics and biases—SB20210345CPAMEXAMEHOC was funded internally by the Amex DART Lab (Data Analytics, Risk and Technology lab). A laboratory within IIT Madras (which is the affiliation of the three of the co-authors).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The author(s) declared that they were an editorial board member of Frontiers, at the time of submission. This had no impact on the peer review process and the final decision.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/frai.2024.1491932/full#supplementary-material
References
Agarwal, D., Covarrubias, Z. O., Bossmann, S., and Natarajan, B. (2022). “Impacts of behavioral biases on active learning strategies,” in International Conference On Artificial Intelligence in Information And Communication (ICAIIC), 256–261.
Baucells, M., Carrasco, J., and Hogarth, R. (2008). Cumulative dominance and heuristic performance in binary multiattribute choice. Oper. Res. 56, 1289–1304. doi: 10.1287/opre.1070.0485
Bertsimas, D., and Dunn, J. (2017). Optimal classification trees. Mach. Learn. 106, 1039–1082. doi: 10.1007/s10994-017-5633-9
Breiman, L., Friedman, J., Stone, C., and Olshen, R. (1984). Classification and Regression Trees. Orange, CA: Chapman.
Brown, V., Hallquist, M., Frank, M., and Dombrovski, A. (2022). Humans adaptively resolve the explore-exploit dilemma under cognitive constraints: evidence from a multi-armed bandit task. Cognition 229:105233. doi: 10.1016/j.cognition.2022.105233
Cinar, I., Koklu, M., and Tasdemir, S. (2020). Classification of raisin grains using machine vision and artificial intelligence methods. Comp. Sci. Agricult. Food Sci. 6(3): 200-209. doi: 10.30855/gmbd.2020.03.03
Cohn, D., Atlas, L., and Ladner, R. (1994). Improving generalization with active learning. Mach. Learn. 15:201–221.
Dawes, R. (1979). The robust beauty of improper linear models in decision making. Am. Psychol. 34, 571–582. doi: 10.1037/0003-066X.34.7.571
Du, J., and Ling, C. (2010). “Active learning with human-like noisy oracle,” in IEEE International Conference On Data Mining (Sydney, NSW: IEEE), 797–802.
Gigerenzer, G., Hertwig, R., and Pachur, T. (2011). Heuristics: The Foundations of Adaptive Behavior. Oxford: Oxford University Press.
Gilovich, T., Griffin, D., and Kahneman, D. (2002). Heuristics and Biases: The Psychology of Intuitive Judgment. Cambridge: Cambridge University Press.
Groot, P., Birlutiu, A., and Heskes, T. (2011). “Learning from multiple annotators with Gaussian processes,” in Artificial Neural Networks And Machine Learning - ICANN, 159–164. doi: 10.1007/978-3-642-21738-8_21
Gu, Y., Zydek, D., and Jin, Z. (2014). “Active learning based on random forest and its application to terrain classification,” in Progress in Systems Engineering. Advances in Intelligent Systems and Computing, Vol. 366, eds. H. Selvaraj, D. Zydek, G. Chmaj (Cham: Springer International Publishing). doi: 10.1007/978-3-319-08422-0_41
Harpale, A. S., and Yang, Y. (2008). “Personalized active learning for collaborative filtering,” in ACM SIGIR 2008 - 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Proceedings, 91–97.
Hoarau, A., Lemaire, V., Le Gall, Y., Dubois, J.-C., and Martin, A. (2024). Evidential uncertainty sampling strategies for active learning. Mach. Learn. 113, 6453–6474. doi: 10.1007/s10994-024-06567-2
Jalali, V., Leake, D. B., and Forouzandehmehr, N. (2017). “Learning and applying case adaptation rules for classification: an ensemble approach,” in International Joint Conference on Artificial Intelligence. Available at: https://api.semanticscholar.org/CorpusID:39250916
Kahneman, D., Slovic, P., and Tversky, A. (1982). Judgment under Uncertainty: Heuristics and Biases. Cambridge: Cambridge University Press.
Katsikopoulos, K. (2011). Psychological heuristics for making inferences: definition, performance, and the emerging theory and practice. Deci. Analy. 8, 10–29. doi: 10.1287/deca.1100.0191
Katsikopoulos, K. (2013). Why Do Simple Heuristics Perform Well in Choices with Binary Attributes? Deci. Analy. 10, 327–340. doi: 10.1287/deca.2013.0281
Katsikopoulos, K., Simşek, Ö., Buckmann, M., and Gigerenzer, G. (2020). Classification in the Wild: The Science and Art of Transparent Decision Making. Cambridge, MA: The MIT Press.
Kelly, M., Longjohn, R., and Nottingham, K. (n.d.). The UCI Machine Learning Repository. Available at: https://archive.ics.uci.edu
Kremer, J., Pedersen, K., and Igel, C. (2014). Active learning with support vector machines. Wiley Interdisc. Rev.: Data Mining Knowl. Discov. 4:1132. doi: 10.1002/widm.1132
Kwon, H. (2023). Adversarial image perturbations with distortions weighted by color on deep neural networks. Multimed. Tools Appl. 82, 13779–13795. doi: 10.1007/s11042-022-12941-w
Kwon, H., and Kim, S. (2023). Dual-mode method for generating adversarial examples to attack deep neural networks. IEEE Access 1:1. doi: 10.1109/ACCESS.2023.3245632
Kwon, H., Lee, K., Ryu, J., and Lee, J. (2022). Audio adversarial example detection using the audio style transfer learning method. IEEE Access. 2022:1. doi: 10.1109/ACCESS.2022.3216075
Kwon, H., and Lee, S. (2022). Textual adversarial training of machine learning model for resistance to adversarial examples. Secur. Commun. Networ. (2022) 12:4511510. doi: 10.1155/2022/4511510
Lan, G., Xiao, S., Yang, J., Wen, J., Lu, W., and Gao, X. (2024). Active learning inspired method in generative models. Expert Syst. Appl. 249:123582. doi: 10.1016/j.eswa.2024.123582
Liapis, C. M., Karanikola, A., and Kotsiantis, S. (2024). Data-efficient software defect prediction: a comparative analysis of active learning-enhanced models and voting ensembles. Inf. Sci. 676:120786. doi: 10.1016/j.ins.2024.120786
Liu, S., and Li, X. (2023). Understanding uncertainty sampling. arXiv [preprint] arXiv:2307.02719. doi: 10.48550/arXiv.2307.02719
Martignon, L., Katsikopoulos, K., and Woike, J. (2008). Categorization with limited resources: a family of simple heuristics. J. Math. Psychol. 52, 352–361. doi: 10.1016/j.jmp.2008.04.003
Mitchell, T. (1982). Generalization as search. Artif. Intell. 18, 203–226. doi: 10.1016/0004-3702(82)90040-6
Moles, L., Andres, A., Echegaray, G., and Boto, F. (2024). Exploring data augmentation and active learning benefits in imbalanced datasets. Mathematics 12:1898. doi: 10.3390/math12121898
Monarch, R. (2021). Human-in-the-Loop Machine Learning: Active Learning and Annotation for Human-Centered AI. Shelter Island, NY: Manning Publications.
Muslea, I., Minton, S., and Knoblock, C. (2006). Active learning with multiple views. J. Artif. Intellig. Res. 27, 203–233. doi: 10.1613/jair.2005
Phillips, N., Neth, H., Woike, J., and Gaissmaier, W. (2017). FFTrees: a toolbox to create, visualize, and evaluate fast-and-frugal decision trees. Judgm. Decis. Mak. 12, 344–368. doi: 10.1017/S1930297500006239
Raghavan, H., Madani, O., and Jones, R. (2006). Active Learning with Feedback on Features and Instances. J. Mach. Learn. Res. 7, 1655–1686.
Raj, A., and Bach, F. (2022). “Convergence of uncertainty sampling for active learning,” in Proceedings of the 39th International Conference on Machine Learning, Proceedings of Machine Learning Research, Vol. 162 (MLResearchPress), 18310–18331.
Roda, H., and Geva, A. (2024). Semi-supervised active learning using convolutional auto-encoder and contrastive learning. Front. Artif. Intellig. 7:1398844. doi: 10.3389/frai.2024.1398844
Settles, B. (2009). Active Learning Literature Survey. Madison, WI: University of Wisconsin-Madison.
Settles, B., and Craven, M. (2008). “An analysis of active learning strategies for sequence labeling tasks,” in Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing (ACL Press), 1070–1079.
Shannon, C. (1948). Mathematical theory of communication. Bell Syst. Tech. J. 27, 379–423. doi: 10.1002/j.1538-7305.1948.tb01338.x
Sheng, V., Provost, F., and Ipeirotis, P. (2008). “Get another label? improving data quality and data mining using multiple, noisy labelers,” in Proceedings Of The 14th ACM SIGKDD International Conference On Knowledge Discovery And Data Mining, 614–622.
Simon, H. (1990). Invariants of human behavior. Annu. Rev. Psychol. 41, 1–20. doi: 10.1146/annurev.ps.41.020190.000245
Simşek, Ö. (2013). “Linear decision rule as aspiration for simple decision heuristics,” in Part of Advances in Neural Information Processing Systems 26 (NIPS 2013 ).
Tan, H. S., Wang, K., and Mcbeth, R. (2024). Exploring UMAP in hybrid models of entropy-based and representativeness sampling for active learning in biomedical segmentation. Comput. Biol. Med. 176:108605. doi: 10.1016/j.compbiomed.2024.108605
Todd, P., Ortega, J., Davis, J., Gigerenzer, G., Goldstein, D., Goodie, A., et al. (1999). Simple Heuristics That Make Us Smart. Oxford: Oxford University Press.
Wu, W., Liu, Y., Guo, M., and Liu, X. (2012). Advances in active learning algorithms based on sampling strategy. Jisuanji Yanjiu Yu Fazhan/Computer Res. Dev. 49, 1162–1173.
Xie, S., and Braga-Neto, U. M. (2019). On the bias of precision estimation under separate sampling. Cancer Inform. Available at: https://api.semanticscholar.org/CorpusID:198962973
Keywords: active learning, human in the loop, human behavior, biases, robustness, fast-and-frugal heuristics
Citation: Ravichandran S, Sudarsanam N, Ravindran B and Katsikopoulos KV (2024) Active learning with human heuristics: an algorithm robust to labeling bias. Front. Artif. Intell. 7:1491932. doi: 10.3389/frai.2024.1491932
Received: 05 September 2024; Accepted: 31 October 2024;
Published: 19 November 2024.
Edited by:
Cornelio Yáñez-Márquez, National Polytechnic Institute (IPN), MexicoReviewed by:
Hyun Kwon, Korea Military Academy, Republic of KoreaLuis Rato, University of Evora, Portugal
Copyright © 2024 Ravichandran, Sudarsanam, Ravindran and Katsikopoulos. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Sriram Ravichandran, bXMyMGQyMDBAc21haWwuaWl0bS5hYy5pbg==