 Hongzhe Duan1*
Hongzhe Duan1* Konstantin Arbeev1
Konstantin Arbeev1 Rachel Holmes1
Rachel Holmes1 Olivia Bagley1
Olivia Bagley1 Deqing Wu1
Deqing Wu1 Igor Akushevich1
Igor Akushevich1 Nicole Schupf2
Nicole Schupf2 Anatoliy Yashin1
Anatoliy Yashin1 Svetlana Ukraintseva1*
Svetlana Ukraintseva1*- 1Biodemography of Aging Research Unit, Social Science Research Institute, Duke University, Durham, NC, United States
- 2Department of Epidemiology, Mailman School of Public Health, Columbia University, New York, United States
Overweight, defined by a body mass index (BMI) between 25 and 30, has been associated with enhanced survival among older adults in some studies. However, whether being overweight is causally linked to longevity remains unclear. To investigate this, we conducted a Mendelian randomization (MR) study of lifespan 85+ years, using overweight as an exposure variable and data from the Health and Retirement Study and the Long Life Family Study. An essential aspect of MR involves selecting appropriate single nucleotide polymorphisms (SNPs) as instrumental variables (IVs). This is challenging due to the limited number of SNP candidates within biologically relevant genes that can satisfy all necessary assumptions and criteria. To address this challenge, we employed a novel strategy of creating additional IVs by pairing SNPs between candidate genes. This strategy allowed us to expand the pool of IV candidates with new “composite” SNPs derived from eight candidate obesity genes. Our study found that being overweight between ages 75 and 85, compared to having a normal weight (BMI 18.5-24.9), significantly contributes to improved survival beyond age 85. Results of this MR study thus support a causal relationship between overweight and longevity in older adults.
1 Introduction
Overweight, defined by a body mass index (BMI) between 25 and 30, has been associated with certain health risks, as well as with reduced mortality in older adults (Carr et al., 2023; Chapman, 2010; Flegal et al., 2013; Hansel et al., 2015; Johnson and Bales, 2014; Lee et al., 2001; Pes et al., 2019; Porter Starr and Bales, 2015; Reaven, 2011; Zheng et al., 2021). This phenomenon, sometimes referred to as the “overweight/obesity paradox”, was reported mainly by observational studies; however, it remains unconfirmed whether overweight is causally linked to longevity. While observational studies are very valuable for revealing associations between various risk factors and health outcomes, they struggle with unmeasured confounding factors. As a result, uncovering causal relationships may prove challenging. An ideal solution would be well-designed randomized clinical trials (RCTs), where all confounders are evenly distributed between treatment and control groups. Such trials, however, are not readily available for longevity outcomes and are also ethically unsuitable. Fortunately, the wealth of information available in large observational studies can be leveraged by modern causal inference approaches to evaluate the underlying causal relationships between health-related risk factors and outcomes.
One such approach is Mendelian randomization (MR) (Plotnikov and Guggenheim, 2019; Wehby et al., 2008), a causal inference method, which capitalizes on the random distribution of genetic variants, allowing the separation of the study population into different groups. If specific alleles are significantly associated with a modifiable risk factor of interest and meet all necessary assumptions and criteria, they can serve as instrumental variables (IVs). These IVs create a setting akin to an RCT and enable researchers to explore causality more effectively. In this study, we applied the MR approach to explore causal relationships between overweight and longevity in participants of the Health and Retirement Study (HRS) and the Long Life Family Study (LLFS). The HRS data were used in primary analysis, and the LLFS data were used for replication purposes.
2 Materials and methods
2.1 Data
The HRS is a longitudinal panel study conducted by the University of Michigan and supported by the National Institute on Aging (grant number NIA U01AG009740) and the Social Security Administration. The data collection was launched in 1992. A representative sample of about 20,000 Americans aged 50 years and above is surveyed every 2 years. The original HRS cohort targeted the population of adults in the contiguous United States born during the years 1931–1941 with a 2:1 oversample of African-American and Hispanic populations. New birth cohorts were added every 6 years. Data collection includes a mixed mode design combining in-person, telephone, mail, and Internet. The RAND Center for the Study of Aging, with funding and support from the NIA and the Social Security Administration, created easy-to-use longitudinal files for researchers. We used version 2018 RAND data, which includes fourteen waves of core interview data across twenty-six survey years (1992-2018). Consent forms were read and signed by each respondent and collected by the interviewer. More details about the study can be found in Sonnega et al. (2014).
The LLFS is a longitudinal study of exceptional survival, longevity, and healthy aging, which is carried out in four field centers (Boston, New York, Pittsburgh, and Denmark). 4,953 individuals from 539 families of exceptional longevity that are determined by the criteria of Family Longevity Selection Score (FLOSS) ≥7 (Sebastiani et al., 2009) were enrolled into study. The first visit was between 2006 and 2009, and the willing participants completed a second in-person visit during 2014–2017 following the same protocols. Between the visits and after the second visit, participants were continuously contacted annually for telephone follow-up to update vital status, medical history, and general health. More details about LLFS can be found in Wojczynski et al. (2022). We used the 6 March 2023 release of LLFS data provided by the LLFS Data Management and Coordinating Center (DMCC).
For both data sets, ages at death were computed using dates of birth and death. For those who did not die within the follow-up period, ages at censoring were determined from dates of birth and the last follow-up: November 2022 in the LLFS and June 2019 in the HRS data. BMI values were determined by the average of BMI measurements between age 75 and 85. The main characteristics (mean, standard deviation, percentage) of variables for samples used in analyses are presented in Table 1.

Table 1. Characteristics of the HRS and LLFS samples used in analyses.
2.2 Genotyping and candidate genes
Genetic data on 15,620 HRS respondents were provided by the database of Genotypes and Phenotypes (dbGaP), dbGaP Study Accession: phs000428. v2. p2. Genotyping was performed by the National Institute of Health (NIH) Center for Inherited Disease Research (CIDR) (see details in Sonnega et al. (2014)). The HRS used Illumina’s Human Omni2.5-Quad (Omni2.5) BeadChip to genotype 2.4 million single nucleotide polymorphisms (SNPs). The LLFS used similar genotyping platform. 4692 LLFS participants have genotyping information in our data. Blood samples were processed at University of Minnesota and genotyping was performed by the CIDR. Details on genotyping in LLFS are provided in Lee et al. (2013).
Mendelian randomization can offer robust causal inferences provided that genetic variants used as IVs have plausible biological links with the risk factor (Burgess et al., 2018). We, therefore, selected SNPs in eight obesity/overweight related genes that were reported in the literature (Choquet and Meyre, 2011; Walley et al., 2009) as candidates for constructing the IVs in our MR study: ADIPOQ, FTO, LEP, LEPR, INSIG2, MC4R, PCSK1, and PPARG. We aimed to ensure a stronger association between SNPs and the exposure of interest, as SNPs in the obesity related genes tend to be correlated with increased BMI/weight. Table 1s (Supplementary Material) shows the numbers of SNPs available in each gene after Quality Control (QC) in HRS and LLFS data, as well as the locus and functional descriptions, according to National Center for Biotechnology Information Reference Sequence Database. QC procedures were performed based on published protocols (Anderson et al., 2010; Marees et al., 2018).
2.3 Instrumental variables
The validity of MR method depends heavily on several key assumptions (Greenland, 2020). This may result in a bottle neck scenario where a majority of the IV candidates are discarded due to their failure to satisfy all requirements. Due to limited number of individual genetic variants in candidate obesity genes, we introduced a novel method to create additional “composite” SNPs, and therefore substantially expanding the pool of candidate IVs (see details in Section 2.7 ““Composite” SNPs creation”). We then selected qualified IVs for further downstream MR analysis.
2.4 Assumptions
For a genetic variant to be eligible as an instrumental variable, it is critical that it satisfies three key assumptions (Greenland, 2020) (Figure 1).
(1) Relevance assumption: The SNP must be associated with the exposure of interest.
(2) Independence assumption: The SNP is not associated with any confounders.
(3) Exclusion assumption: The SNP should be independent of the outcome given the exposure and confounders.
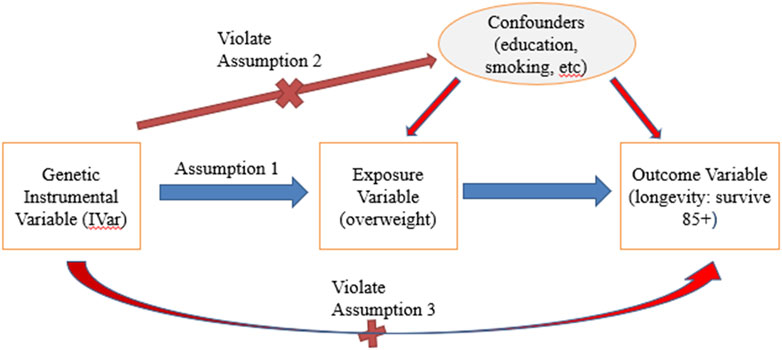
Figure 1. Instrumental variable assumptions in MR. Note: Red lines with crosses denote violations of assumptions if significant associations were identified. Blue line denotes that significant association should exist.
These assumptions can be expressed in the following Equations 1–3 respectively:
here coefficient
Since our exposure variable is dichotomized from a continuous variable, BMI, we also tested the continuous variable BMI measured during the same age period of interest (see description of variables below in Analysis), i.e., between age 75 and 85, for these assumptions (Burgess and Labrecque, 2018). All selected genetic variants passed both sets of tests, i.e., for both dichotomized and continuous BMI.
2.5 Independence between SNPs
The dependence between SNPs is a potential source of violation for assumption 3, as an IV could influence the outcome through its effect on another IV. To avoid this issue, we calculated the coefficient of determination (
2.6 Strength of instrumental variables
To ensure the strength of selected IVs, we applied criterion of
where
In unrelated samples, standard logistic regression is employed. The maximum rescaled R square (Nagelkerke, 1991) was calculated by dividing the regular R square by its upper bound to address when the upper bound less than 1.
2.7 “Composite” SNPs creation
When testing SNPs from candidate genes, few, if any of the original SNPs successfully pass all required tests. This issue becomes a significant bottleneck for reliable MR analysis, since the validity of the causal effect identified by MR analysis heavily depends on the qualified IVs that satisfy all assumptions. To address this issue, we tested the effect of SNP-SNP interaction on the exposure variable using SNPs from the same obesity/BMI related genes. We found that numerous SNP pairs are significantly associated with the exposure (Supplementary Figure 1s), which suggests that we can create a “composite” SNP by pairing the candidate SNPs to expand the candidate pool for IVs.
Our approach involved first selecting all original SNPs that passed quality control from candidate genes and pairing them with each other. Then we summed the dosages of minor alleles (MA) of the two original SNPs and used it to denote the new MA count of the paired SNPs (see Figure 2).

Figure 2. Determination of MA number of “composite” SNP.
For each new pair of SNPs, we denote its MA as follows: 0 if the sum is 0 or 1, 1 if the sum is 2, and 2 if the sum is 3 or 4. In the subsequent analysis, we treated these “composite” SNPs as “original” SNPs with newly denoted minor allele numbers. We then created new binary Plink genetic data incorporating these new “SNP”s, and tested all three key assumptions, as well as
2.8 Analysis
Table 1 describes the key characteristics of study populations of HRS and LLFS data. Our study adhered to the STROBE-MR (Skrivankova et al., 2021) reporting guidelines (checklist is provided in the Supplementary Table 2s). For each dataset, we created survival outcome variable (group 1: survived age 85 or above; group 0: died before age 85), and exposure variable (group 1: average BMI ≥25 and <30 (“overweight”) at ages [75, 85]; group 0: average BMI ≥18.5 and <25 (“normal weight”) at ages [75, 85]). Covariates used include sex (1 – male, 2 – female), race (1 – white, 2 – black, 3 - others), education (0 – below high school, 1 – high school, 2 – above high school), smoking status (1 – ever smoked, 0 – never smoked), first two principal components, and comorbidity (presence of cancer, diabetes or cardiovascular disease (CVD), 1 – yes, 0 - no). For LLFS data, we also included field center (1 – US, 2 – Denmark) as a covariate. Individuals with any missing value(s) were excluded from the study. We did not use covariates in calculating statistics from composite SNP-risk factor and composite SNP-outcome associations for downstream MR analysis (Hartwig et al., 2021).
Coefficients,
SAS 9.4 was used to calculate these statistics, which were then delivered to R package (“MendelianRandomization”) for downstream MR analysis adjusted for association between outcome and risk factor to address the fact that we applied one-sample MR analysis in this study.
The Inverse-Variance Weighted (IVW) method, widely used in health studies, was used to evaluate causal estimates (Burgess and Thompson, 2017). It benefits from an explicit expression, averaging the ratio estimates from each IV using an inverse-variance weighted formula and provides an overall causal estimate. The causal estimate of IVW is averaged
IVW is a commonly used approach, but suffers from bias if all IVs are not valid. To address this issue, we employed a weighted median approach (Bowden et al., 2016) as a complementary analysis. Ratio estimates of each SNP are ordered and weighted by the inverse of variance. The median MR estimate is considered unbiased if at least 50% of the total weight comes from valid IVs, therefore, it is rather robust. This approach assumes no single IV can contribute more than 50% of the weight.
Additionally, we computed the Kaplan-Meier estimates of survival curves (Supplementary Figure 2s) to visually illustrate the survival difference between the overweight and normal weight groups. Age at baseline or age 75 years (whichever was the largest) was used as the left truncation variable.
2.9 Sensitivity analysis
Sensitivity analyses were performed to assess the sensitivity of specific IVs sets using SNPs obtained from genome-wide association study (GWAS) conducted on LLFS data. We performed a GWAS using the same dichotomized exposure variable (group 1: overweight, at ages [75, 85]; group 0: normal weight, at ages [75, 85]) as the trait, and the same covariates described in Analysis section. All SNPs with p-value <0.05 from the GWAS were considered as IV candidates. Then, those that satisfied all key assumptions and passed LD and
To address the concern that residual unmeasured confounding may compromise causal induction in this observational study, E-values were computed. The E-value is defined as the minimum strength of association on the risk ratio (RR) scale that an unmeasured confounder would need to have with both the exposure and the outcome, conditional on the measured covariates, to completely explain away an observed exposure–outcome association. This helps rule out spurious association even with statistically significant results. For each IV, we used the following formula to calculate the E-value (Swanson and VanderWeele, 2020).
2.10 Pleiotropy assessment
In addition to assumptions test described above, we also employed MR-Egger regression (Bowden et al., 2015) to address the issue of potential pleiotropy. SNPs from obesity/BMI related genes often involve different mechanisms, and in turn impact longevity in various ways. These pleiotropy effects are difficult to assess directly. Despite using a predefined small LD to remove SNPs that are correlated with others, residual correlation may still exist to some extent. The intercept of MR-Egger regression offers unbiased evidence for pleiotropy effect. If the regression intercept is observed as non-distinct from the origin, it provides confidence that pleiotropy does not bias the causal effect.
3 Results
3.1 Descriptive Analyses
Table 1 shows the characteristics of the HRS and LLFS samples at the baseline visit and follow-up. The number of missing values for each variable can be found in the notes under the table. The numbers shown in the table are derived from the participants that were selected in this analysis. Participants need to have a valid value for exposure and outcome variables, as well as all other covariates, to be included in the study. Furthermore, they must have mean BMI measurements ranging from 18.5 to 30 (including normal and over-weight) during the age of between 75 and 85 years old.
Comparatively, the age at enrollment is about 22 years older in LLFS than in HRS, which represents the specific selection of exceptional longevity families in LLFS. HRS participants exhibit a higher proportion of highly educated people and a history of smoking, but a lower incidence of major diseases, including diabetes, cancer, and cardiovascular diseases. Notably, this difference can be explained by different age ranges in the two samples. When we compare the two cohorts at specific age range 75–85, 56.18% of LLFS participants have the above major diseases, compared with 60.16% in HRS data. Moreover, LLFS has a relatively late onset of the above major diseases (67.95 vs. 65.33 in HRS) at the same age range. The ages at death or last follow-up are similar in the two data sets. Furthermore, we observed a higher percentage of participants survived beyond 85 years old in LLFS, along with a higher percentage of overweight between ages 75 and 85, as expected.
3.2 Mendelian randomization
Associations between genetic variants and exposure, as well as between genetic variants and outcome are reported (Supplementary Table 3s 1-6 for HRS, 7-8 for LLFS). Stratified and non-stratified MR results including causal effect estimates, 95% confidence intervals and P-values using HRS and LLFS data, are reported in Tables 2, 3, respectively. In general, a positive IVW effect estimate suggests that an increase in the exposure is associated with an increase in the outcome. In our study, this means overweight at age 75-85 increase the chance of surviving above age 85. The larger estimate implies that the exposure has a more substantial impact on the outcome, assuming all other factors remain constant.
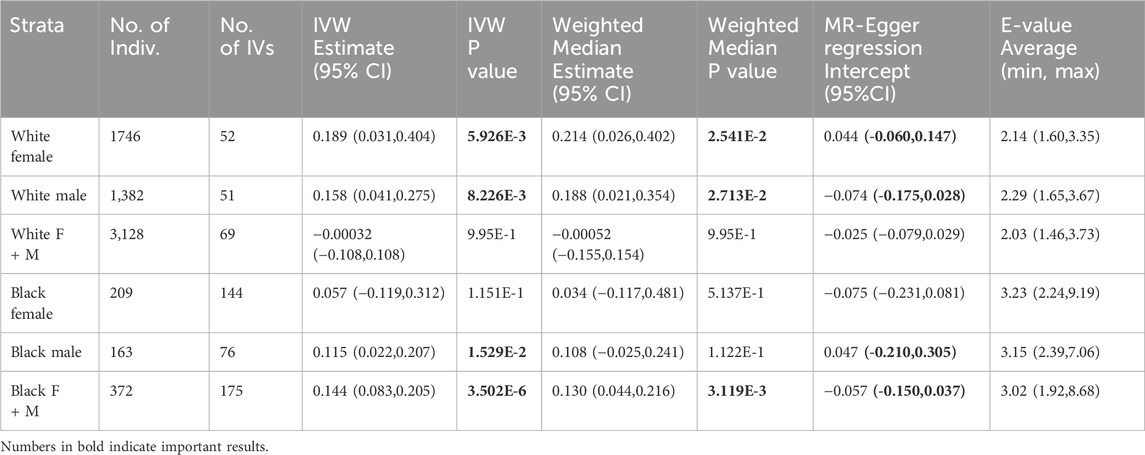
Table 2. MR analysis results in HRS data using composite SNP from obesity/BMI related genes as IV.
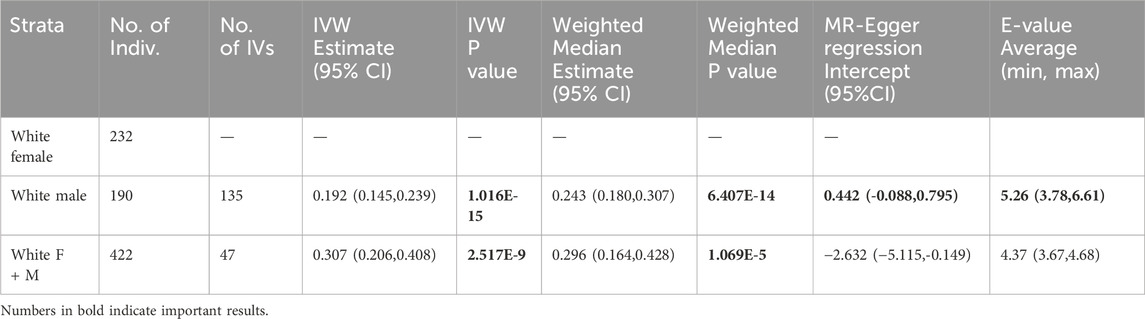
Table 3. MR analysis results in LLFS data using composite SNP from obesity/BMI related genes as IV.
In HRS data, MR analysis revealed that being overweight at ages 75–85 had a significant causal effect on improved survival above age 85, compared with normal weight at this age range, in white female (IVW p-value = 5.926E-3), white male (IVW effect estimate = 0.189, p-value = 8.226E-3), black male (IVW effect estimate = 0.115, p-value = 1.529E-2), and non-stratified black subsamples (IVW effect estimate = 0.144, p-value = 3.502E-6). The most significant results were observed in non-stratified black samples (Table 2). However, the same significant level of causal effect was not seen in black females, warranting further evaluation. All significant results are supported by a significant weighted median test (except for black males) and have survived the MR-Egger regression intercept test.
In LLFS data (Table 3), being overweight at ages 75–85 showed protective effect on living beyond age 85 in white males (IVW effect estimate = 0.192, p-value = 1.016E-15), but the same effect was not seen in white females as none of the composite SNPs met all criteria. However, a similar effect was observed in white non-stratified samples (IVW effect estimate = 0.307, p-value = 2.517E-9); weighted median tests are also significant for these two tests. Non-stratified samples did not pass MR-Egger regression intercept test though.
In a sensitivity analysis using LLFS data, we selected the single SNPs significantly associated with exposure variable (p< 0.05) from GWAS results. All SNPs satisfied each assumption and criteria as IVs. We observed significant causal effect on life span over 85 years old in penalized IVW method and weighted median test in male (penalized IVW effect estimate = 0.156, p-value = 7.905E-3, weighted median p-value = 6.203E-3) and non-stratified participants (penalized IVW effect estimate = −0.2, p-value = 2.142E-3, weighted median p-value = 3.401E-3). The standard IVW did not show significance. Both results (Supplementary Table 4s) and statistics (Supplementary Table 3s 9-11) are reported.
In another sensitivity analysis, we calculated E-values to test the robustness of our causal effect estimation to residual confounding (Tables 2, 3). Although there were no universally accepted or standardized ad-hoc thresholds for the E-value in the context of Mendelian randomization, an E-value of 2 or 3 is considered large enough to reasonably conclude that any residual confounding is unlikely to explain away the causal effect.
4 Discussion
Our MR study found that being overweight between the ages 75–85 years significantly contributes to a better survival at ages 85 and beyond in both HRS and LLFS participants. An earlier MR analysis utilizing the UK Biobank data found that the significance of a high BMI as a risk factor in coronary artery disease (CAD) declines in older age (Jansen et al., 2022). Other studies suggested that being moderately overweight could be a marker of a healthy aging that may also protect, at least in part, against comorbidities (Chapman, 2010; Lee et al., 2001; Pes et al., 2019; Porter Starr and Bales, 2015; Zheng et al., 2021). Our MR findings are broadly in line with these earlier studies and strongly support the idea that being overweight is a causal factor for longevity. This can have an important implication for clinical practice.
Physicians often consider overweight, defined by BMI between 25 and 30, as detrimental to health, and commonly recommend lifestyle changes to decrease BMI. While some major conditions, such as cardiovascular diseases and type II diabetes, have been associated with high BMI, our study found that BMI that is moderately higher than “normal” (18.5-24.9) could be beneficial for lowering all-cause mortality risk in the very old. Potential mechanisms may involve improved resilience of overweight individuals to late-life stressors (Cho et al., 2018; de Miguel-Diez et al., 2022; Nie et al., 2014; Prescott and Chang, 2018). Indeed, larger energy reserves in overweight individuals may be essential for recovery after adverse health events (e.g., pneumonia, fractures), treatments, or surgeries, commonly experienced at the oldest old ages. Conversely, lower energy reserves may adversely affect the capacity of the immune system to fight infections and address harmful exposures. Additional amounts of fat may also better protect older individuals from fall-related fractures, which is a leading factor contributing to mortality in advanced years of life.
One should note that “overweight” may not always equate to “over-fat” because BMI does not directly measure body composition. Such situations could be especially relevant to elite athletes and body-builders with increased muscle mass. In such individuals, an elevated BMI may not always reflect fatness. Our study, however, focuses on older individuals. Recent research found that older individuals tend to have higher fat percentage than younger people, so BMI may even underrepresent ‘fatness’ in this population (Di Renzo et al., 2022). Still, the interpretation of causal effect in this study might be limited by the use of BMI as an indicator of “overweight”, so we recognize this potential limitation.
Our results also imply that being overweight may differentially influence longevity in males and females, indicating that they should be analyzed separately. Analyses of combined and unstratified samples yielded less significant and consistent results. For instance, in LLFS, sensitivity analysis found an adverse effect of overweight on survival, while in HRS it showed protective effect, without statistical significance. This discrepancy between the data might result from different study designs. E.g., LLFS cohort has a shorter follow-up period with only two visits, while HRS has fourteen waves of core interviews. This fact could potentially affect calculated mean weight. The observed male-female differences in outcomes may also be due to variations in the composition of weight. Males typically have more muscle mass compared to females, which might contribute to the differing impacts of BMI on mortality between sexes.
Several other factors may also contribute to the discrepant results between the HRS and LLFS data. For example, although BMI is widely used as a criterion of obesity, it is difficult to differentiate between the amount of fat and the amount of muscle. Additionally, studies have shown a significant pattern of assortative mating for BMI (Conley et al., 2016), resulting in the clustering of body weight. These factors are likely more significant in the LLFS data and could act as effective confounders. It is worth noting that SNPs from the eight candidate genes may have different biological effects on obesity and overweight, despite the fact that these genes are all significantly correlated with these traits. In this paper, we introduced a novel method for constructing and selecting instrumental variables for MR studies. According to our search of up-to-date literature, this is the first time this method has been applied for such purpose. Our approach offers several advantages. Firstly, it uses a straightforward computation and can be easily performed by other researchers. Secondly, it greatly increases the number of the IV candidates and is more likely to lead to a successful selection of qualified IVs. We used all the qualified “composite” SNPs as multiple IVs for the downstream analysis. Alternatively, these IVs can be combined into a ‘polygenic risk score’ by summing their weighted effect alleles, and using this score as a single IV in downstream MR analysis (Dudbridge, 2021). However, careful consideration of assumptions and potential biases is crucial when making the decision to apply such score as single IV. Our strategy of leveraging the SNPxSNP interactions to construct IVs from the single SNPs selected from biologically relevant genes was successful and we plan to expand the list of the candidate genes in future analyses.
We acknowledge several other study limitations. We did not take advantage of HRS sample weights, limiting us from making inferences at the population-level. This is due to the use of a subsample of HRS data, and binary variables based on the continuous measurement of BMI. Additionally, we analyzed a unique sample (LLFS) selected for exceptional longevity (which was the goal of LLFS); the LLFS participants also have better health and function in several domains compared to other cohorts. Therefore, the results are not generalizable to the general population. Furthermore, limited number of participants in LLFS data decreased the power of this analysis to detect the underlying causal relationship. The relatively small number of LLFS participants increased the difficulty of identifying appropriate SNPs as IVs as the F value changes almost linearly with sample size. We also assumed that the genetic variants exhibit consistent associations with the outcome across various strata, such as different age groups and ethnicities, which could affect result interpretation, especially in unstratified analysis. We did not investigate other potential confounders (such as gait speed, or other physical activity measures) beyond the ones listed as covariate. The potential issues of pleiotropy were addressed by intercept testing of MR-Egger regression.
Altogether, results of our study suggest that attempts to lose weight (e.g., via diet or meds) in excess to its natural aging-related decline may reduce physical resilience and increase vulnerability to death in the very old. Additional MR studies conducted in different datasets may help further clarify these mechanisms.
Data availability statement
This study used existing data from the Health and Retirement Study (HRS) and the Long Life Family Study (LLFS). These data are subject to the following licenses/restrictions: The HRS data are provided by the RAND Center for the Study of Aging and are available to registered users. Specific policies governing the process to access the HRS RAND data can be found online at https://hrsdata.isr.umich.edu/data-products/rand. The HRS genetic data are provided by dbGaP and are subject to the restrictions of the Data Use Certification Agreement. Requests to access the dbGaP data should be directed to https://www.ncbi.nlm.nih.gov/gap/. The LLFS data are not freely available to the public. Questions about the LLFS data can be submitted online at https://longlifefamilystudy.com/contact/.
Ethics statement
The studies involving human subjects were approved by the Duke University Health System Institutional Review Board. This publication includes only secondary analyses of existing data. Written informed consent from participants of the original studies was obtained by the data holders in accordance with local legislation and institutional requirements.
Author contributions
HD: Data curation, Formal Analysis, Investigation, Methodology, Software, Validation, Visualization, Writing–original draft, Writing–review and editing. KA: Funding acquisition, Investigation, Methodology, Resources, Supervision, Validation, Writing–review and editing. RH: Investigation, Methodology, Software, Writing–original draft, Writing–review and editing. OB: Data curation, Writing–review and editing. DW: Writing–review and editing. IA: Funding acquisition, Writing–review and editing. NS: Writing–review and editing. AY: Funding acquisition, Project administration, Resources, Supervision, Writing–review and editing. SU: Conceptualization, Funding acquisition, Investigation, Project administration, Resources, Supervision, Writing–original draft, Writing–review and editing.
Funding
The author(s) declare that financial support was received for the research, authorship, and/or publication of this article. The Research work described in this paper were supported by the National Institute on Aging of the National Institutes of Health (NIA/NIH) under Award Numbers U19AG063893 and R01AG062623. This content is solely the responsibility of the authors and does not necessarily represent the official views of the NIA/NIH.
Acknowledgments
This study was conducted using data provided by the LLFS, HRS, and dbGaP. We acknowledge researchers and staff who collected these data and made them available for the secondary analyses. The LLFS is sponsored by the National Institute on Aging and carried out in four field centers. The HRS is sponsored by the National Institute on Aging and conducted by the University of Michigan. Access to the HRS genetic data is provided by the database of Genotypes and Phenotypes, dbGaP.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fragi.2024.1442017/full#supplementary-material
References
Anderson, C. A., Pettersson, F. H., Clarke, G. M., Cardon, L. R., Morris, A. P., and Zondervan, K. T. (2010). Data quality control in genetic case-control association studies. Nat. Protoc. 5 (9), 1564–1573. doi:10.1038/nprot.2010.116
Bowden, J., Davey Smith, G., and Burgess, S. (2015). Mendelian randomization with invalid instruments: effect estimation and bias detection through Egger regression. Int. J. Epidemiol. 44 (2), 512–525. doi:10.1093/ije/dyv080
Bowden, J., Davey Smith, G., Haycock, P. C., and Burgess, S. (2016). Consistent estimation in mendelian randomization with some invalid instruments using a weighted median estimator. Genet. Epidemiol. 40 (4), 304–314. doi:10.1002/gepi.21965
Burgess, S., Butterworth, A., and Thompson, S. G. (2013). Mendelian randomization analysis with multiple genetic variants using summarized data. Genet. Epidemiol. 37 (7), 658–665. doi:10.1002/gepi.21758
Burgess, S., Foley, C. N., and Zuber, V. (2018). Inferring causal relationships between risk factors and outcomes from genome-wide association study data. Annu. Rev. Genomics Hum. Genet. 19, 303–327. doi:10.1146/annurev-genom-083117-021731
Burgess, S., and Labrecque, J. A. (2018). Mendelian randomization with a binary exposure variable: interpretation and presentation of causal estimates. Eur. J. Epidemiol. 33 (10), 947–952. doi:10.1007/s10654-018-0424-6
Burgess, S., and Thompson, S. G. (2017). Interpreting findings from Mendelian randomization using the MR-Egger method. Eur. J. Epidemiol. 32 (5), 377–389. doi:10.1007/s10654-017-0255-x
Carr, P. R., Webb, K. L., Neumann, J. T., Thao, L. T. P., Beilin, L. J., Ernst, M. E., et al. (2023). Associations of body size with all-cause and cause-specific mortality in healthy older adults. Sci. Rep. 13 (1), 3799. doi:10.1038/s41598-023-29586-w
Chapman, I. M. (2010). Obesity paradox during aging. Interdiscip. Top. Gerontol. 37, 20–36. doi:10.1159/000319992
Cho, W. H., Oh, J. Y., Yeo, H. J., Han, J., Kim, J., Hong, S. B., et al. (2018). Obesity survival paradox in pneumonia supported with extracorporeal membrane oxygenation: analysis of the national registry. J. Crit. Care 48, 453–457. doi:10.1016/j.jcrc.2018.08.003
Choquet, H., and Meyre, D. (2011). Genetics of obesity: what have we learned? Curr. Genomics 12 (3), 169–179. doi:10.2174/138920211795677895
Conley, D., Laidley, T., Belsky, D. W., Fletcher, J. M., Boardman, J. D., and Domingue, B. W. (2016). Assortative mating and differential fertility by phenotype and genotype across the 20th century. Proc. Natl. Acad. Sci. U. S. A. 113 (24), 6647–6652. doi:10.1073/pnas.1523592113
de Miguel-Diez, J., Jimenez-Garcia, R., Hernandez-Barrera, V., de Miguel-Yanes, J. M., Carabantes-Alarcon, D., Zamorano-Leon, J. J., et al. (2022). Obesity survival paradox in patients hospitalized with community-acquired pneumonia. Assessing sex-differences in a population-based cohort study. Eur. J. Intern Med. 98, 98–104. doi:10.1016/j.ejim.2022.01.027
Di Renzo, L., Itani, L., Gualtieri, P., Pellegrini, M., El Ghoch, M., and De Lorenzo, A. (2022). 'New BMI cut-off points for obesity in middle-aged and older adults in clinical nutrition settings in Italy: a cross-sectional study. Nutrients 14 (22), 4848. doi:10.3390/nu14224848
Dudbridge, F. (2021). Polygenic mendelian randomization. Cold Spring Harb. Perspect. Med. 11 (2), a039586. doi:10.1101/cshperspect.a039586
Flegal, K. M., Kit, B. K., and Graubard, B. I. (2013). Overweight, obesity, and all-cause mortality--reply. Jama 309 (16), 1681–1682. doi:10.1001/jama.2013.3101
Greenland, S. (2000). An introduction to instrumental variables for epidemiologists. Int. J. Epidemiol. 47 (1), 358. doi:10.1093/ije/dyx275
Hansel, B., Roussel, R., Elbez, Y., Marre, M., Krempf, M., Ikeda, Y., et al. (2015). Cardiovascular risk in relation to body mass index and use of evidence-based preventive medications in patients with or at risk of atherothrombosis. Eur. Heart J. 36 (40), 2716–2728. doi:10.1093/eurheartj/ehv347
Hartwig, F. P., Tilling, K., Davey Smith, G., Lawlor, D. A., and Borges, M. C. (2021). Bias in two-sample Mendelian randomization when using heritable covariable-adjusted summary associations. Int. J. Epidemiol. 50 (5), 1639–1650. doi:10.1093/ije/dyaa266
Jansen, S. A., Huiskens, B., Trompet, S., Jukema, J., Mooijaart, S. P., Willems van Dijk, K., et al. (2022). Classical risk factors for primary coronary artery disease from an aging perspective through Mendelian Randomization. Geroscience 44 (3), 1703–1713. doi:10.1007/s11357-021-00498-9
Johnson, M. A., and Bales, C. W. (2014). 'Is there a best body mass index for older adults? Moving closer to evidence-based recommendations regarding “overweight,” health, and mortality. J. Nutr. Gerontol. Geriatr. 33 (1), 1–9. doi:10.1080/21551197.2014.875817
Lee, I. M., Blair, S. N., Allison, D. B., Folsom, A. R., Harris, T. B., Manson, J. E., et al. (2001). Epidemiologic data on the relationships of caloric intake, energy balance, and weight gain over the life span with longevity and morbidity. J. Gerontol. A Biol. Sci. Med. Sci. 56 (Spec No 1), 7–19. doi:10.1093/gerona/56.suppl_1.7
Lee, J. H., Cheng, R., Honig, L. S., Feitosa, M., Kammerer, C. M., Kang, M. S., et al. (2013). 'Genome wide association and linkage analyses identified three loci-4q25, 17q23.2, and 10q11.21-associated with variation in leukocyte telomere length: the Long Life Family Study. Front. Genet. 4, 310. doi:10.3389/fgene.2013.00310
Marees, A. T., de Kluiver, H., Stringer, S., Vorspan, F., Curis, E., Marie-Claire, C., et al. (2018). 'A tutorial on conducting genome-wide association studies: quality control and statistical analysis. Int. J. Methods Psychiatric Res. 27 (2), e1608. doi:10.1002/mpr.1608
Nagelkerke, N. J. D. (1991). A note on a general definition of the coefficient of determination. Biometrika 78 (3), 691–692. doi:10.2307/2337038
Nie, W., Zhang, Y., Jee, S. H., Jung, K. J., Li, B., and Xiu, Q. (2014). Obesity survival paradox in pneumonia: a meta-analysis. BMC Med. 12, 61. doi:10.1186/1741-7015-12-61
Palmer, T. M., Lawlor, D. A., Harbord, R. M., Sheehan, N. A., Tobias, J. H., Timpson, N. J., et al. (2012). Using multiple genetic variants as instrumental variables for modifiable risk factors. Stat. Methods Med. Res. 21 (3), 223–242. doi:10.1177/0962280210394459
Pes, G. M., Licheri, G., Soro, S., Longo, N. P., Salis, R., Tomassini, G., et al. (2019). Overweight: a protective factor against comorbidity in the elderly. Int. J. Environ. Res. Public Health 16 (19), 3656. doi:10.3390/ijerph16193656
Plotnikov, D., and Guggenheim, J. A. (2019). Mendelian randomisation and the goal of inferring causation from observational studies in the vision sciences. Ophthalmic Physiol. Opt. 39 (1), 11–25. doi:10.1111/opo.12596
Porter Starr, K. N., and Bales, C. W. (2015). Excessive body weight in older adults. Clin. Geriatr. Med. 31 (3), 311–326. doi:10.1016/j.cger.2015.04.001
Prescott, H. C., and Chang, V. W. (2018). Overweight or obese BMI is associated with earlier, but not later survival after common acute illnesses. BMC Geriatr. 18 (1), 42. doi:10.1186/s12877-018-0726-2
Reaven, G. M. (2011). Insulin resistance: the link between obesity and cardiovascular disease. Med. Clin. North Am. 95 (5), 875–892. doi:10.1016/j.mcna.2011.06.002
Sebastiani, P., Hadley, E. C., Province, M., Christensen, K., Rossi, W., Perls, T. T., et al. (2009). A family longevity selection score: ranking sibships by their longevity, size, and availability for study. Am. J. Epidemiol. 170 (12), 1555–1562. doi:10.1093/aje/kwp309
Skrivankova, V. W., Richmond, R. C., Woolf, B. A. R., Davies, N. M., Swanson, S. A., VanderWeele, T. J., et al. (2021). Strengthening the reporting of observational studies in epidemiology using mendelian randomisation (STROBE-MR): explanation and elaboration. BMJ 375, n2233. doi:10.1136/bmj.n2233
Sonnega, A., Faul, J. D., Ofstedal, M. B., Langa, K. M., Phillips, J. W. R., and Weir, D. R. (2014). Cohort profile: the health and retirement study (HRS). Int. J. Epidemiol. 43 (2), 576–585. doi:10.1093/ije/dyu067
Swanson, S. A., and VanderWeele, T. J. (2020). 'E-Values for mendelian randomization. Epidemiology 31 (3), e23–e24. doi:10.1097/EDE.0000000000001164
Walley, A. J., Asher, J. E., and Froguel, P. (2009). The genetic contribution to non-syndromic human obesity. Nat. Rev. Genet. 10 (7), 431–442. doi:10.1038/nrg2594
Wehby, G. L., Ohsfeldt, R. L., and Murray, J. C. (2008). Mendelian randomization' equals instrumental variable analysis with genetic instruments. Stat. Med. 27 (15), 2745–2749. doi:10.1002/sim.3255
Wojczynski, M. K., Jiuan Lin, S., Sebastiani, P., Perls, T. T., Lee, J., Kulminski, A., et al. (2022). NIA long life family study: objectives, design, and heritability of cross-sectional and longitudinal Phenotypes. J. Gerontol. A Biol. Sci. Med. Sci. 77 (4), 717–727. doi:10.1093/gerona/glab333
Xu, S., Wang, P., Fung, W. K., and Liu, Z. (2023). A novel penalized inverse-variance weighted estimator for Mendelian randomization with applications to COVID-19 outcomes. Biometrics 79 (3), 2184–2195. doi:10.1111/biom.13732
Keywords: overweight, longevity, Mendelian randomization, instrumental variable, health and retirement study, long life family study, aging
Citation: Duan H, Arbeev K, Holmes R, Bagley O, Wu D, Akushevich I, Schupf N, Yashin A and Ukraintseva S (2024) Is being overweight a causal factor in better survival among the oldest old? a Mendelian randomization study. Front. Aging 5:1442017. doi: 10.3389/fragi.2024.1442017
Received: 01 June 2024; Accepted: 02 September 2024;
Published: 20 September 2024.
Edited by:
Lawrence D. Hayes, Lancaster University, United KingdomReviewed by:
Bradley Elliott, University of Westminster, United KingdomZerbu Yasar, Synfuse Exercise Science, United Kingdom
Copyright © 2024 Duan, Arbeev, Holmes, Bagley, Wu, Akushevich, Schupf, Yashin and Ukraintseva. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Svetlana Ukraintseva, c3ZvQGR1a2UuZWR1; Hongzhe Duan, bWF0dC5kdWFuQGR1a2UuZWR1