 Li Wan1,2†
Li Wan1,2† Zhuang Ai
Zhuang Ai Liuqing Chen
Liuqing Chen
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Public Health , 20 October 2022
Sec. Digital Public Health
Volume 10 - 2022 | https://doi.org/10.3389/fpubh.2022.1034772
This article is part of the Research Topic Extracting Insights from Digital Public Health Data using Artificial Intelligence, Volume II View all 12 articles
Pigmented skin disease is caused by abnormal melanocyte and melanin production, which can be induced by genetic and environmental factors. It is also common among the various types of skin diseases. The timely and accurate diagnosis of pigmented skin disease is important for reducing mortality. Patients with pigmented dermatosis are generally diagnosed by a dermatologist through dermatoscopy. However, due to the current shortage of experts, this approach cannot meet the needs of the population, so a computer-aided system would help to diagnose skin lesions in remote areas containing insufficient experts. This paper proposes an algorithm based on a fusion network for the detection of pigmented skin disease. First, we preprocess the images in the acquired dataset, and then we perform image flipping and image style transfer to augment the images to alleviate the imbalance between the various categories in the dataset. Finally, two feature-level fusion optimization schemes based on deep features are compared with a classifier-level fusion scheme based on a classification layer to effectively determine the best fusion strategy for satisfying the pigmented skin disease detection requirements. Gradient-weighted Class Activation Mapping (Grad_CAM) and Grad_CAM++ are used for visualization purposes to verify the effectiveness of the proposed fusion network. The results show that compared with those of the traditional detection algorithm for pigmented skin disease, the accuracy and Area Under Curve (AUC) of the method in this paper reach 92.1 and 95.3%, respectively. The evaluation indices are greatly improved, proving the adaptability and accuracy of the proposed method. The proposed method can assist clinicians in screening and diagnosing pigmented skin disease and is suitable for real-world applications.
Skin, as the first layer of protection for the human body, has important physiological protection functions, such as excretion, regulating body temperature and feeling external stimuli. It is also the largest organ in the human body. However, the incidence of skin diseases is extremely high, and there are many types of skin diseases, among which pigmented skin lesions are common; most pathological areas are black, brown or other dark colors, which is mainly due to the increase or decrease in regional melanin caused by ultraviolet radiation or other external factors. In 2021, skin melanoma in pigmented skin disease accounts for 5.6% of all new cancers in the United States, and the number of skin melanoma patients has increased at an annual rate of ~1.4% over the past 10 years (1). However, melanoma that is detected early has a very high cure rate. Studies have shown that if abnormal skin melanocyte proliferation is found early, the survival rate is 96%. If late-stage melanoma is detected, the survival rate is reduced to only 5% (2), and its color is easily confused with that of other common skin pigmented diseases, leading to misdiagnosis. The diagnosis of pigmented skin lesions requires trained specialists, but the number of specialist doctors is grossly inadequate compared to the number of cases. Therefore, it is necessary to develop an algorithm for the automatic diagnosis of pigmented skin lesions.
In recent years, deep learning has been widely used in feature extraction, object classification and detection. Compared with machine learning, deep learning can automatically and efficiently extract features from medical images. Since 2012, various deep Convolutional Neural Network (CNN) models based on the “ImageNet” dataset have been proposed. AlexNet (ImageNet classification with deep convolutional neural networks), a network architecture proposed by Krizhevsky et al. (3), was the winner of the first ImageNet Challenge classification task in 2012; ZFNet (4) (Visualizing and understanding convolutional networks) is a large convolutional network based on AlexNet; VGGNET (5) (Very deep convolutional networks for large-scale image recognition) was proposed by Visual Geometry Group (VGG), a famous research group at Oxford University, and won the first place in localization and the second place in classification in that year's ImageNet competition. GoogleNet (6) (Going deeper with convolutions) was proposed by the Google team and won the first place in the ImageNet competition for the classification task; ResNet (7) (Deep residual learning for image recognition), proposed by Microsoft Research, won the first place in classification task and the first place in target detection in that year's ImageNet competition, and the first place in target detection and image segmentation in COCO dataset. ResNeXt (8) (Aggregated residual transformations for deep neural networks) is a new image classification network proposed by Kaiming He's team at CVPR 2017. ResNeXt is an upgraded version of ResNet; SENET (9) (Squeeze-and-Excitation Networks) is a new image recognition architecture announced by the self-driving company Momenta in 2017. This structure is the first place in the ImageNet competition in that year in the classification task; NASNet (Learning Transferable Architectures for Scalable) is a deep network model proposed by Zoph et al. (10) that can automatically generate network structures without manually designing network models; EfficientNet (11) (EfficientNet: Rethinking model scaling for convolutional neural networks) is proposed by Google team to obtain better performance by deepening the model, widening the model or increasing the resolution of the model input. These network models have ranked highly in competitions. The prediction effects of different network structures in various fields are inconsistent, so researchers cannot quickly find appropriate network models. Many scholars have thus conducted research to solve this problem. Researchers must test the outstanding network models one by one to find the most appropriate network model for their scenario (12–15). This strategy wastes time and resources. Therefore, an ensemble network can obtain an algorithmic model that is better than the model produced by the best individual network by setting the weights of different networks (16–18). However, at present, most network fusion approaches use majority voting, mean voting or the weights of the base classifiers to obtain the output of various networks through one-to-one testing, which cannot give full play to the various effects of different classifiers on different tasks. Therefore, this paper proposes a variety of fusion strategies and optimizes the weight of each classifier through the loss function of the network model to fully utilize the ability of each classifier for the detection of pigmented skin diseases.
Therefore, building a pigmented skin disease detection algorithm based on classifier-level and feature-level fusion encounters the following problems.
(1) How to handle unbalanced pigmented skin disease datasets.
(2) How to build an effective network fusion strategy.
In recent years, the applications of Artificial Intelligence (AI) in various fields have developed rapidly, especially in the fields of medical image analysis and bioinformatics. At present, AI is widely used in skin cancer diagnosis (19–21). From the point of view of whether features can be extracted automatically, the AI approaches in this area can be divided into skin cancer classification methods based on machine learning and skin cancer classification methods based on deep learning.
Skin cancer classification based on machine learning generally involves manually extracting image features and then inputting the extracted features into a machine learning algorithm to obtain classification results (22–25). Varalakshmi (26) first used an upsampling method called the Synthetic Minority Oversampling Technique (SMOTE) to balance his dataset, greatly improving the accuracy of various machine learning models. The accuracies of different machine learning algorithms were then analyzed. Support Vector Machine (SVM) algorithms with polynomial kernels provide better accuracy than other machine learning algorithms, such as decision trees using Gini indices and entropy, naive Bayes classifiers, extreme gradient boosting (XGBoost) classifiers, random forests, and logistic regression algorithms. Sabri (19) first extracted the shapes, colors, textures and skeletons of skin image lesions, then used the information gain method to determine the best combination of features, and finally input this feature combination into a commonly used machine learning algorithm to predict the categories of legions. Vidya (27) first extracted skin image asymmetry, border, color, and diameter information. A Histogram of Oriented Gradients (HOG) and a Gray Level Co-occurrence Matrix (GLCM) were used to extract texture features. The extracted features were passed directly to classifiers utilizing different machine learning techniques [such as an SVM, K-Nearest Neighbors (KNN) and a naive Bayes classifier] to classify skin lesions as benign or melanoma. Kalwa (28) presents a smartphone application that combines image capture capabilities with preprocessing and segmentation to extract the Asymmetry, Border irregularity, Color variegation, and Diameter (ABCD) features of a skin lesion. Using the feature sets, classification of malignancy is achieved through support vector machine classifiers.
Skin cancer classification approaches based on deep learning usually adopt a network model for automatic feature extraction, and thus feature extraction and classification can be completed in the same algorithm (20, 21, 29–31). Skin cancer detection algorithms based on deep learning can be divided into single-classifier detection methods and fusion detection methods based on multiple classifiers according to the number of utilized classifiers.
Based on single-classification detection, Sevli (32) proposed using a CNN model to classify seven different skin lesions in the HAM10000 dataset, and the model achieved 91.51% classification accuracy. The model linked its results to a web application and was assessed in two stages by seven dermatologists. Milton (12) first appropriately processed and enhanced skin images and then carried out experiments on various neural networks, including the progressive NASNet (PNASNet)-5-Large, InceptionResNet V2, SENet154, InceptionV4, etc. Finally, the PNASNet-5-Large model achieved the best validation result of 0.76.
Regarding detection based on multiple classifiers, Pal (33) solved the data imbalance problem in the training dataset by setting a propagation-weighted loss from the loss correspondence. For classifier model construction, the pretraining weights of these models were fine-tuned (by ResNet50, DenseNet-121, and MobileNet). Finally, the average category prediction probabilities obtained from these trained networks were used to determine the category labels of the test images. Xie (34) used four pretrained ResNet50 networks to characterize the multiscale information of skin lesions and combined them by using adaptive weighting schemes that could be learned during error propagation. The proposed model achieved an average Area Under Curve (AUC) value of 86.5% on the official ISIC-Skin 2018 validation database. Aldwgeri (35) aimed to solve the data imbalance problem in the training dataset and realized the equalization of each category through flipping, rotation, shifting, and scaling techniques. The equalized image data were then input into different pretraining models, including VGG-Net, ResNet50, Inception V3, Xception, and DenseNet-121. The outputs of the five pretraining models were averaged to produce the final prediction results.
Therefore, the innovations of this paper include the following aspects.
(1) An image style transfer algorithm is applied to the detection of pigmented skin diseases for the purpose of image augmentation.
(2) To prevent image augmentation noise, the required upsampling image is applied to each class image.
(3) Attention mechanisms and common network architectures should be combined to achieve improved detection efficiency.
(4) Two feature-level fusion optimization schemes based on deep features and a classifier-level fusion method based on a classification layer are proposed.
(5) Two visualization algorithms, Grad_CAM and Grad_CAM++, are used to verify the validity of the fusion network.
This paper proposes a detection algorithm for pigmented skin diseases based on a fusion network (Figure 1). This approach can be divided into three modules: image preprocessing, image augmentation, and model building and prediction.
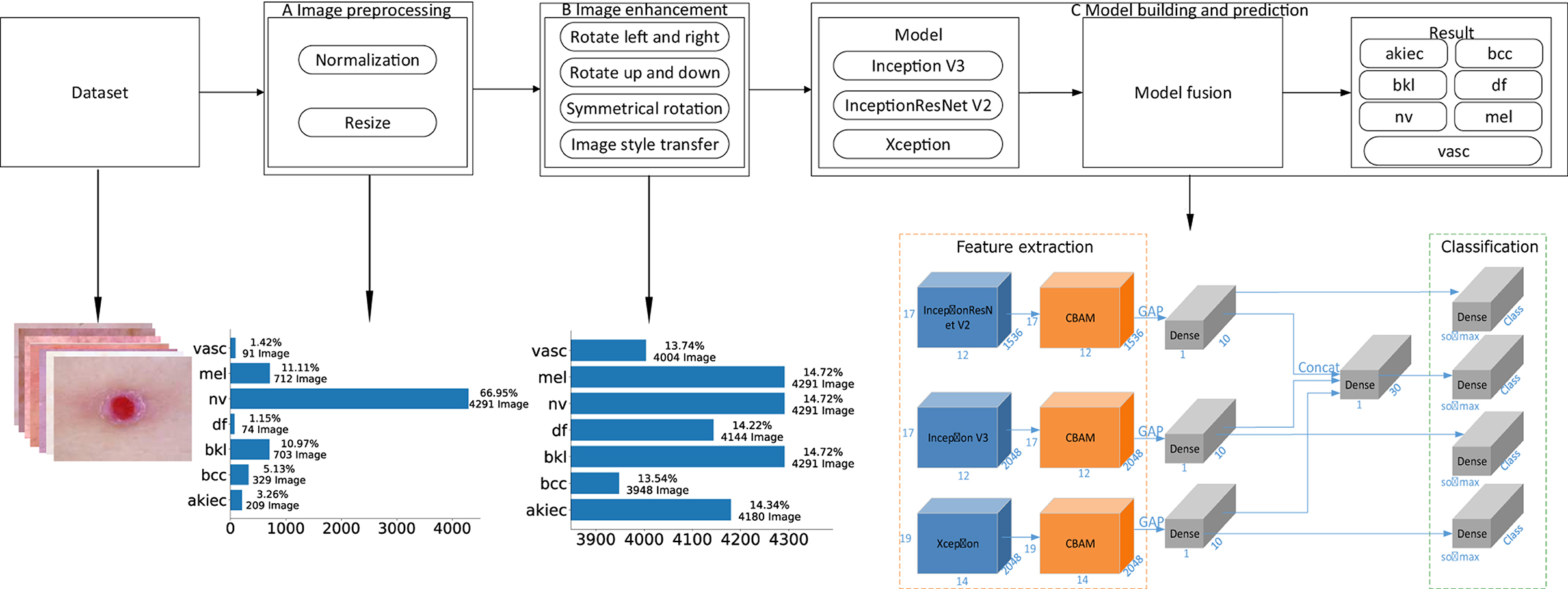
Figure 1. An overview of the proposed method. (A) “Image preprocessing,” including image normalization and image resizing, is performed on an input image before feature extraction. (B) “Image augmentation,” including operations such as image rotation and image style transfer, performs upsampling on the input image to keep the various categories in a balanced state. (C) “Model building and prediction” carries out model training and prediction on the input image, wherein the feature extraction part is the fusion of three base classifiers and an attention mechanism [the convolutional block attention module (“CBAM”)], “GAP” denotes global average pooling, “Dense” is a fully connected layer, “Concat” is the fusion of the output results of the three branches, and “Class” is the number of categories. In this article, Class is 7. “Softmax” is the activation function of the classification output layer, “Classification” is the prediction result output layer, and the number represents the change in the characteristic dimensionality at each stage.
Image preprocessing: First, the obtained pigmented skin disease images are normalized, and the pixel values of the images are limited to 0–1, which can effectively reduce the number of calculations required for the images in the neural network. Then, the height and width of each normalized image are unified to 450*600 (via nearest-neighbor interpolation). Finally, the preprocessed image dataset (three-channel color images with heights of 450 and widths of 600) for pigmented skin diseases can be obtained. As seen from Figure 1, the proportions of the different categories after image pretreatment are seriously unbalanced; among them, the “nv” category occupies 66.95% of the dataset. If no processing is performed, the neural network will seriously prefer this category in model training.
Image augmentation: As the nv category accounts for 66.95% of the dataset, if dataset balance needs to be achieved, other categories need to be upsampled. First, skin images (except those in the nv category) are preprocessed by turning them left and right, reversing up and down, symmetric rotation (the calculation process is shown in Algorithm 1) and performing image style transfer (the calculation process is shown in Algorithm 2) to achieve a balance between the various categories of images. As seen from Figure 1, the proportion of each category after image augmentation is relatively balanced, accounting for ~14% of the whole dataset of pigmentosa skin disease images.

Algorithm 1. Image augmentation—rotation.

Algorithm 2. Image augmentation—image style transfer.
Model building and prediction: The enhanced images of pigmented skin diseases are first input into three different base classifiers (i.e., Inception V3, InceptionResNet V2, and Xception), and the outputs of the three base classifiers are then fused. Finally, the fusion result is used as the pigmented skin disease prediction result.
The dataset used in this paper is provided by Tschandl et al. (36), and it contains 10,015 pictures of seven types of skin diseases. Cases include a representative collection of all import diagnostic categories in the realm of pigmented lesions. The seven types are melanocytic Nevi (nv), Melanoma (mel), Benign Keratosis-like Lesions (solar lentigines/seborrheic keratoses and lichen-planus-like keratoses) (bkl), Basal Cell Carcinoma (bcc), Actinic Keratoses and Intraepithelial Carcinoma/Bowen's disease (akiec), Vascular lesions (angiomas, angiokeratomas, pyogenic granulomas, and hemorrhage) (vasc), and Dermatofibroma (df). The corresponding amounts of image data are 6,705, 1,113, 1,099, 514, 327, 142, and 115, respectively. The proportion of each category is shown in Figure 2A. Typical images for each category are shown in Figure 2B. In Figure 2A, the selected dataset of pigmented skin diseases is severely imbalanced between categories, and the imbalance in the dataset causes the model to completely bias the prediction results to the side with a large sample size (18), and the model does not have any prediction effect on the other categories of sample classification, so a processing step for the imbalance in the dataset is necessary.
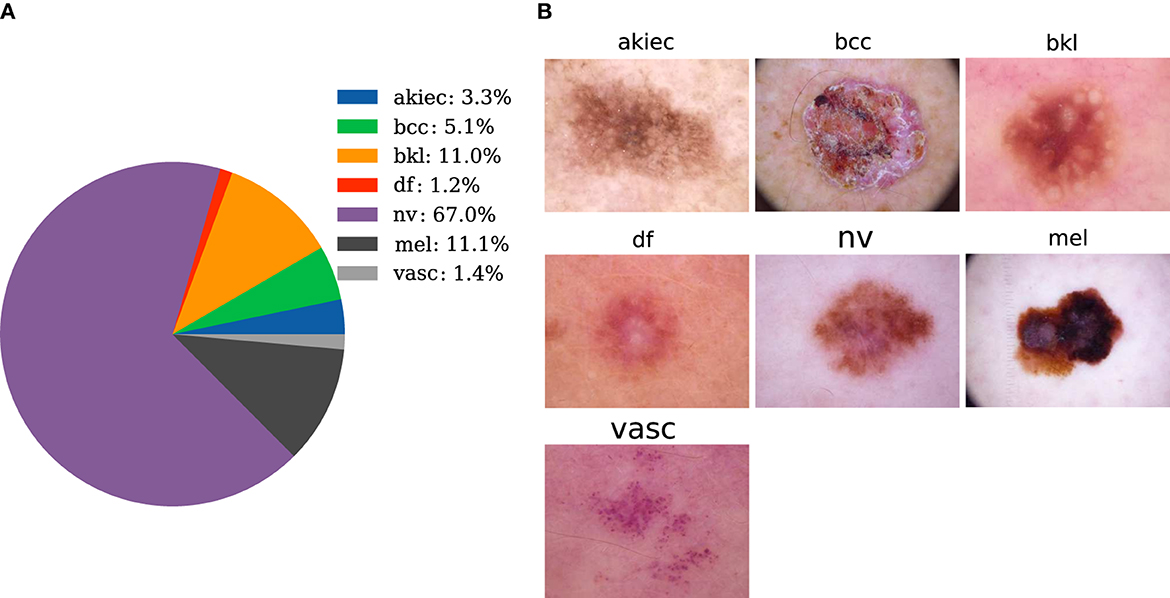
Figure 2. Data preparation. (A) The distribution of pigmented skin diseases in the specimens. (B) Photos of the representative pigmented skin diseases in each sampling category for clinical diagnosis.
We first preprocess the acquired skin disease dataset (36) to obtain high-quality image data. In the preprocessing step, each image is first reduced to the specified size of 450*600, and then each pixel of the image is normalized according to Equation (1). In this way, the image is easy for the network to calculate. The image preprocessing part is transformed from Figure 3A to Figure 3B.
The dataset presents great disparities among the amounts of image data contained in various categories. Without performing certain processing steps, the prediction results will be greatly affected by this unbalanced dataset. Therefore, we must upsample the image data to obtain a balanced image dataset. First, we carry out the following basic operations on the images (except for those in the nv category): left and right mirror rotation, up and down mirror rotation, symmetric rotation, etc.; these operations can balance the images to a certain extent. The left and right mirror rotation operations mirror the original image with respect to its vertical centerline. The upper and lower mirror rotation operations mirror the original image with respect to its horizontal centerline. Symmetric rotation is an image transformation that flips the original image left and right before flipping them again in the up and down directions. After completing the basic image operations, the image data contained in different image categories are shown in Table 1. The basic image augmentation operation can be converted from Figure 3B to Figure 3C.

Table 1. Image number statistics during image preprocessing.
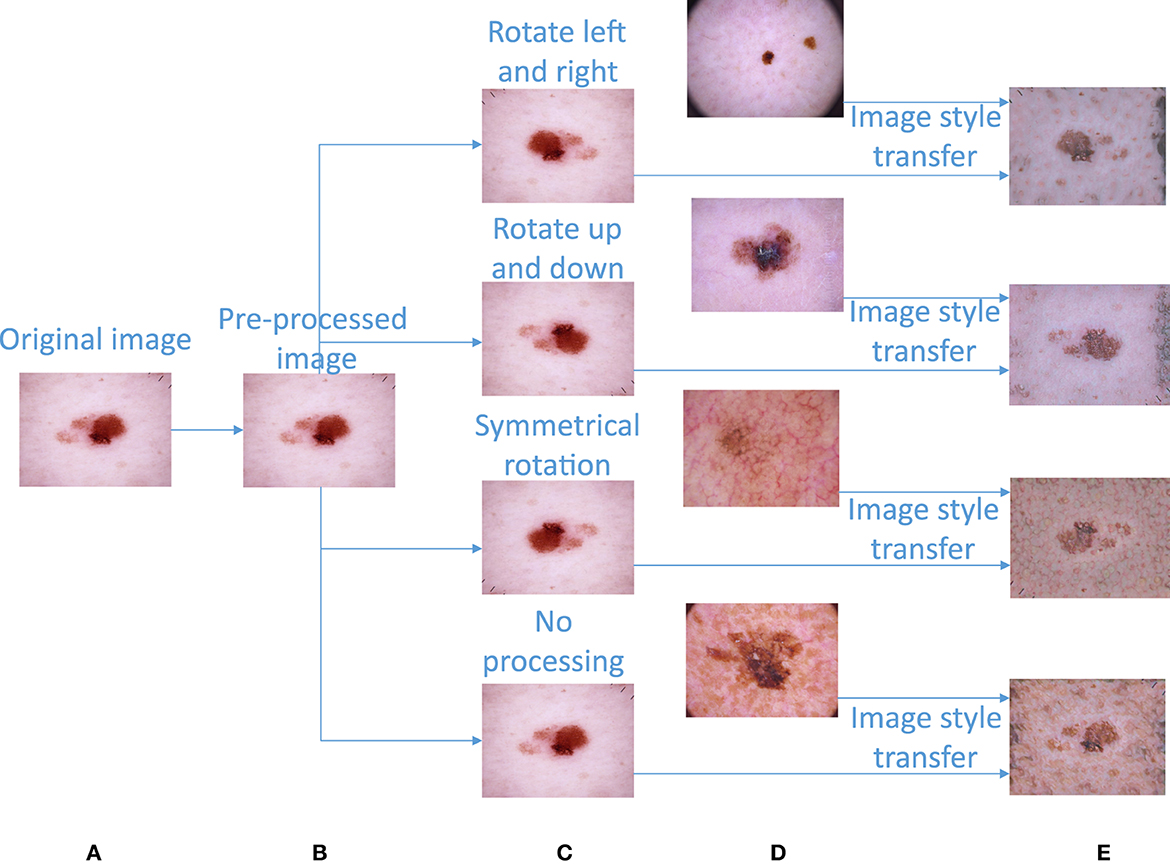
Figure 3. Image preprocessing and image augmentation. (A) Original image. (B) Preprocessed image. (C) Image obtained after a basic rotation operation. (D) Image randomly extracted from image category c for image style transfer. (E) Composite image obtained after image style transfer.
It can be seen from Table 1 that the numbers of images in various categories are still seriously imbalanced, so we adopt an image style transfer algorithm (37) to upsample the images. The image style transfer algorithm proposed by Ghiasi has been successfully trained on a corpus of ~80,000 paintings. In addition, it can be generalized to previously unobserved images.
First, this paper calculates the sample size differences between nv and the other categories in the image dataset according to Equation (2) and then divides each difference by the sample size of the corresponding category to obtain the sample size “n” that needs to be randomly added to the other categories. The image to be upsampled is selected as the “content image,” “n” images are randomly selected from the image samples of this category as the “style images,” and the “content image” and “n” “style images” are input into the image style transfer model in turn to obtain “n” upsampling images generated by the fusion of the “content image” and “style images” (the calculation process is shown in Algorithm 2). After performing image style transfer, the amount of data in each category is shown in Table 1. An example diagram of image style transfer is shown in Figures 3C–E.
In the equation, i represents the akiec, bcc, bkl, df, mel, and vasc categories; Num(Class_i) represents the data volume of the selected category. If Addn is <1, it indicates that the data volume of this category is not very different from that of nv. In this paper, the number of data differences is randomly extracted for image style transfer.
The base classifier of the fusion network used in this paper can consist of Inception V3, InceptionResNet V2, and Xception. The fusion part explores feature-level fusion based on deep features and classifier-level fusion based on a classification layer.
Feature-level fusion based on deep features has been proven to be an efficient fusion strategy (38–42) that can combine features extracted from N networks into a single feature vector containing more image information. Feature-level fusion techniques can be divided into parallel feature-level fusion and serial feature-level fusion based on whether the feature dimensions output by the networks are consistent. Three methods are available for realizing parallel feature fusion: summing up each feature (Equation 3); averaging each feature (Equation 4); and executing the max operation (Equation 5) for each feature. Serial feature fusion can only realize feature splicing (Equation 6) according to the channel dimension because of the inconsistency of the feature output dimensions. The classifier-level fusion method based on a classification layer can make the features extracted from N networks remain unchanged and perform feature splicing at the output of the classification layer.
When the input picture size is (Batch, 450, 600, 3), the output dimensions of Inception V3 are (Batch, 12, 17, 2048), the output dimensions of InceptionResNet V2 are (Batch, 12, 17, 1536), and the output dimensions of Xception are (Batch, 14, 19, 2048). In this paper, feature-level fusion based on deep features employs the output fusion results of three different networks, and the dimensions of the outputs of the three models are inconsistent. Therefore, we optimize the feature-level fusion strategy based on deep features. In the first method, the convolution layer is used to convert the feature map to achieve dimensional consistency. The dimension conversion method is shown in Equations (7) and (8), and the overall algorithm flow is shown in Figure 4A.
In the equation, Win and Hin are the width and height of the input, F is the size of the filter, P is the padding size, S is the step size, and Wout and Hout are the final width and height, respectively. Win and Hin are 14 and 19, and Wout and Hout are 12 and 17, respectively. Therefore, according to this equation, we set F as 3, P as 0, and S as 1. The output can realize the splicing of the three dimensions.
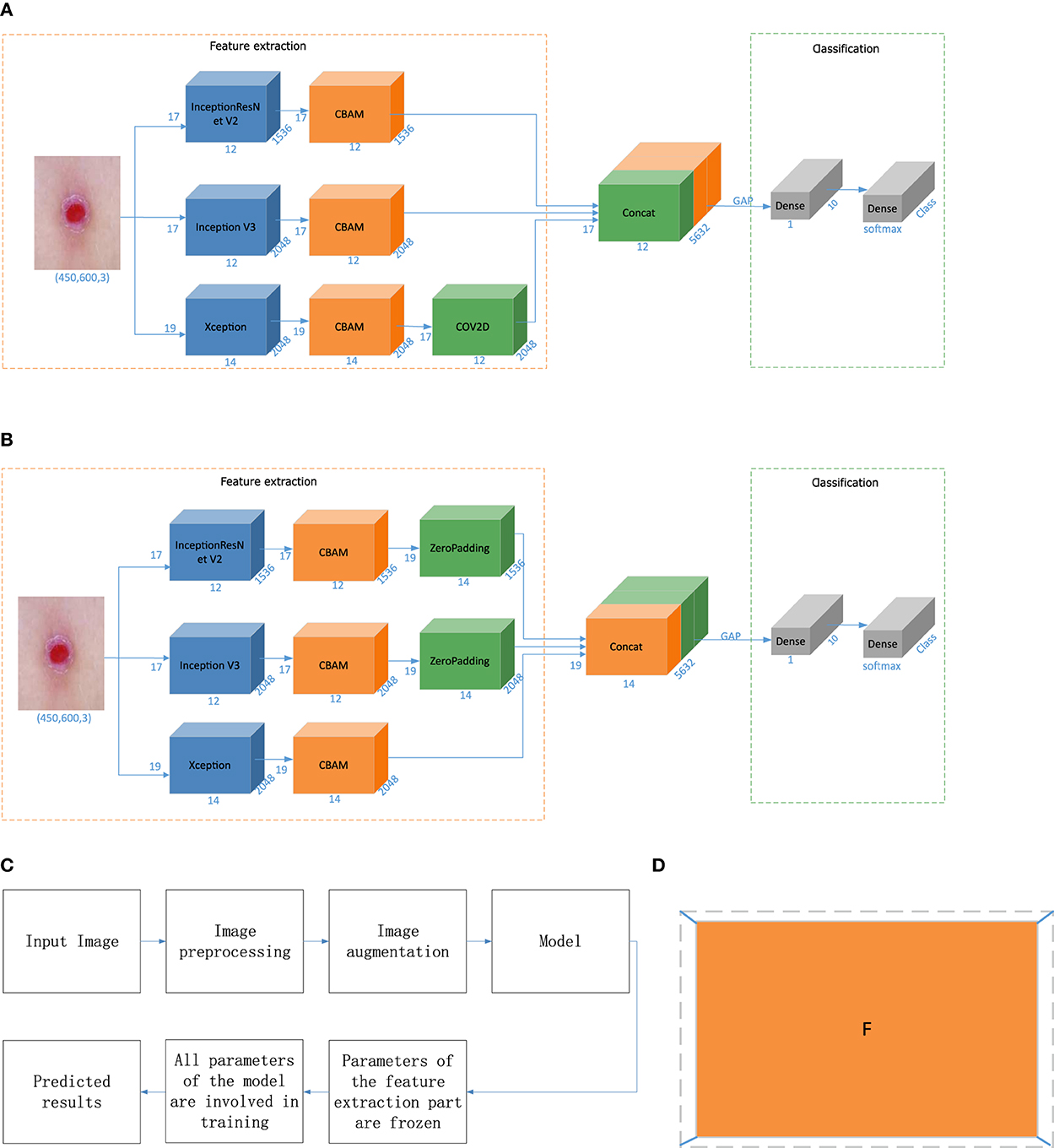
Figure 4. Model building and prediction. (A) Fusion based on the convolution operation. (B) Fusion based on the padding operation. (C) Model training process. (D) Zero-padding operation. “CBAM” is the attention mechanism, “zero padding” involves filling a circle of 0 s around the height and width of the feature vector, “Concat” denotes feature fusion, “GAP” is a global average pooling layer, “Dense” is a fully connected layer, “COV2D” is a convolution operation, and “Class” is the number of categories. In this article, Class is 7. “Softmax” is the activation function of the classification output layer, and the number represents the change in the dimensions in each stage.
In the second method, in this paper, the outputs of Inception V3 and InceptionResNet V2 are surrounded by a circle of 0s to achieve dimensionality consistency with Xception. The zero-padding operation is shown in Figure 4D. The fusion process is shown in Figure 4B.
Classifier-level fusion is performed based on the classification layer. This paper first fuses the last convolution layer of each of the three different networks with the Convolutional Block Attention Module (CBAM), then performs global average pooling on this basis, splices a fully connected layer to obtain the final feature vector, and performs a simple splicing operation on the three feature vectors. Finally, the splicing result is input into the classification layer to output the final predicted category value, as shown in Figure 1 in the model building stage. In this way, the network outputs four values corresponding to Inception V3, InceptionResNet V2, Xception, and a merged output. The loss value of the network is the sum of the loss values of the four parts, but the final output is the overall output of the network.
In Figures 1, 4, “CBAM” is an attention mechanism proposed by Woo (43) in 2018. Woo applied attention to both the channel and spatial dimensions. Similar to the SENet[10], a CBAM can be embedded in most mainstream networks at present. The feature extraction capability of a network model can be improved without significantly increasing its computational complexity and number of parameters. Therefore, this paper embeds a CBAM into the feature extraction part to improve the feature extraction ability of the model and facilitate the subsequent network classification ability improvement.
Transfer learning transfers knowledge learned from a source dataset to a target dataset. Fine-tuning is a common technique for transfer learning. The target model replicates all the model designs and their parameters on the source model except the output layer, and fine-tunes these parameters based on the target dataset. The output layer of the target model, on the other hand, needs to be trained from scratch. The whole process of model building and prediction is shown in Figure 4C. First, all the parameters of the base classifier are “frozen” to prevent large planned changes in these parameters during the initial network training. Subsequently all parameters of the network model are “unfrozen” and the parameters of the entire network are fine-tuned to achieve classification of skin diseases.
The experimental environment includes Linux X86_64, an Nvidia Tesla V100, and 16 GB of memory. This experiment is based on Python version 3.7.9, TensorFlow version 2.3.0, and Keras version 2.4.3.
In this study, the accuracy, recall, specificity, precision, F1, weighted AUC and AUC metrics are used to evaluate pigmented skin disease detection methods based on a fusion network. The model evaluation confusion matrix and calculation equations are shown in Table 2, respectively.

Table 2. Evaluation criteria.
True Negatives (TNs) represent the number of cases for which the real values are negative and the model thinks they are negative.
False Positives (FPs) represent the number of cases for which the real values are negative and the model thinks they are positive.
False Negatives (FNs) represent the number of cases for which the real values are positive and the model thinks they are negative.
True Positives (TPs) represent the number of cases for which the real values are positive and the model thinks they are positive.
In this paper, Inception V3 and cbam fusion are used to test three data augmentation methods. The first (column 4 of Table 3) class weights are calculated by adjusting the model to include a penalty for prediction error for classes with smaller sample sizes, and the weight parameters for each class are calculated as follows.
Where n_samples represents the total number of picture samples,n_classes represents the number of categories, and bincount(y) represents the sample size of each category in the training set. Weight is the weight corresponding to each category. The lower the sample size of the category, the higher its weight.
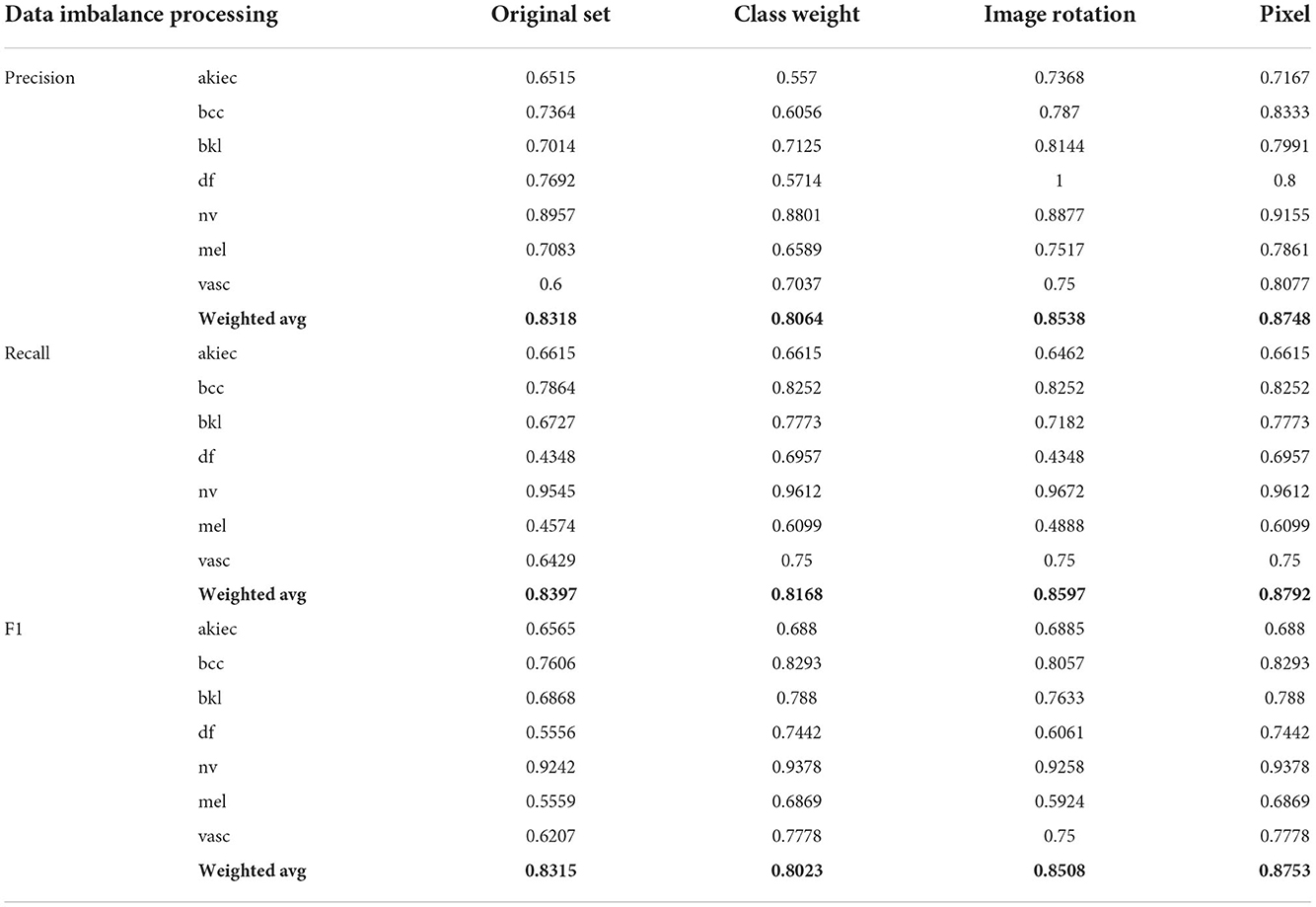
Table 3. The influence of the data imbalance treatment scheme on the results.
The second uses image flipping (column 5 of Table 3) to flip the category with a small sample size to flip the image left and right, invert it up and down, and flip it systematically so that the imbalance between its various categories is somewhat mitigated.
For the network model, a change in a pixel value of an image represents that this image will then change. Therefore, the third one (column 6 of Table 3) is based on the second one to achieve a complete balance between its various categories. The interval of increasing and decreasing pixel values is first calculated by the equation, and then a random value is randomly drawn from the interval without put-back as the increasing or decreasing pixel value.
Where n_classes represents the number of categories, and differences represents the difference between this category and the category “nv.” Therefore, the interval of image increase and decrease is from 1 to Pixel.
From Table 3, it can be seen that the effect of solving the data imbalance by changing the calculation method of the model loss values decreases the correct prediction rate compared to the dataset without any change, mainly because the change of the loss values causes the model to have some bias between the categories during training. By changing the image flip compared to not making any changes, the imbalance between categories is somewhat alleviated, so the prediction accuracy is somewhat improved, but there is still some imbalance between categories. Based on the image flip, each image is randomly added or subtracted a certain pixel value to get a brand new image, thus achieving a balance between each category of the image and a certain improvement in prediction.
Therefore, in this paper, we use the image style transfer upsampling scheme to equalize the dataset. After completing dataset equalization, in the single-classifier experiment, we successively change the model module in Figure 4C into three algorithm models: “Inception V3+CBAM,” “InceptionResNet V2+CBAM,” “Xception,” and “Xception+CBAM.” The algorithm test results are shown in Table 4. It can be seen from the third to the sixth column of Table 3 and the third column of Table 4 that the effects of the original dataset, image preprocessing, pixel change and image style transfer on the detection of pigmented skin lesions based on Inception V3 are improved in order, and the accuracy of image style transfer regarding the detection of pigmented skin lesions is 4% higher than that of image preprocessing. It is proven that image style transfer is effective for the detection of pigmented skin lesions. From column 5 and column 6 of Table 4, it can be seen that the presence or absence of the attention mechanism makes some difference to the classification effect (Acc, F1, Specificity), thus proving the contribution of the attention mechanism in the classification of pigmented skin diseases. However, it can be seen from the Acc and F1 values in the table that the detection rate of the “nv” category is much higher than that of the other categories, indicating that a single model has certain anti-interference ability limitations with respect to the images generated by the algorithm.
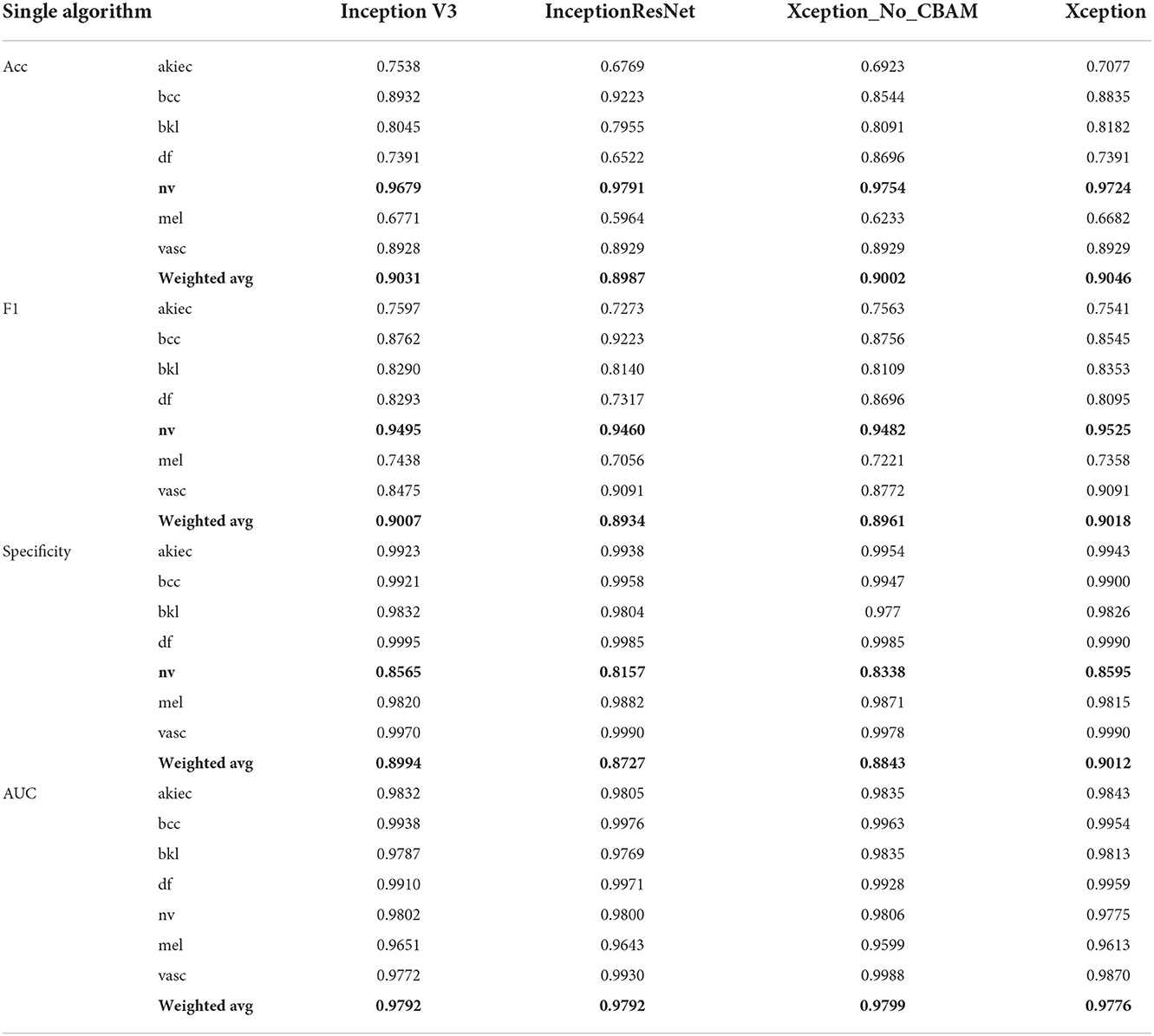
Table 4. The influence of a single network model on evaluation metrics.
The detection effect of multinetwork fusion can generally strengthen the generalization ability of a model, thereby improving its detection ability. After performing dataset equalization, we first compare different fusion methods in terms of their final classification effects in multiple classifier experiments, and we test the feature-level fusion approach based on deep features and the classifier-level fusion method based on the classification layer. All three fusion strategies use Inception V3, InceptionResNet V2, and Xception as the three base classifiers. The first feature-level fusion method based on deep features reduces the dimensionality of a feature graph with a larger output through the convolution layer to realize the splicing of dimensions. The second feature-level fusion method based on deep features adds feature graphs with smaller output dimensions to larger feature graphs with the zero-padding operation. The third classifier-level fusion method based on the classification layer splices the outputs of the fully connected layers of the three base classifiers.
Three kinds of fusion strategy evaluation indices are shown in Table 5. According to the data supplied by the convolution layer, the first one-dimensional characteristic figure of dimensionality reduction is generally low. The main reason for this is that adding a convolution layer results in many parameters that need to be trained. The first network loss value is large and can lead to difficult network training for reaching a more appropriate stage. As a result, the overall parameters of the network cannot achieve good results. If zero padding is used, the small-dimensional feature graph is extended, and no redundant parameter training requirement is imposed. Therefore, the output result will be consistent with the transfer learning result. The third method is to splice the output of the fully connected layer, and the final prediction index is the best option. First, the feature extraction part of the network contains the network parameters trained by ImageNet, and the features are relatively appropriate. Finally, only the parameters of the fully connected layer are added; thus, the feature extraction process of the network model does not change, and the final prediction effect is also the best.

Table 5. The influence of different fusion strategies on evaluation metrics.
From the weighted average of the Acc and F1 values in Tables 4, 5, it can be seen that the model training and prediction steps performed by a single classifier are better than those of the two fusion strategies based on feature-level fusion. The main reason for this involves the changes in the extracted image features during feature-level fusion. Compared with the better network feature extraction ability of “ImageNet” training, the feature extraction ability of the modified network exhibits a certain decline, resulting in a decrease in the classification index based on feature-level fusion. During feature extraction, the classifier-based fusion scheme does not change the feature extraction capability of the original network based on “ImageNet.” Features are learned separately through the convolution layer of each base classifier, and the results of the fully connected network (i.e., the classifier) of the base classifier are fused to obtain the final predicted category value. Based on classifier-level fusion, the output results of multiple base classifiers are fused. The generalization ability and anti-interference ability of the network are enhanced, and the model classification ability is enhanced.
This section mainly studies how to combine base classifiers in fusion networks to achieve the best effect for the detection of pigmented skin lesions. This paper mainly tests the effectiveness of combinations including three basic classifiers: Inception V3, InceptionResNet V2, and Xception. The fusion effects of two networks, three networks, four networks, etc. are tested. The best fusion scheme (classifier-level fusion based on the classification layer in Section 4.3.2) is adopted. Six scenarios are available regarding the fusion of two networks, as shown in the table: fusing Inception V3 with Inception V3, InceptionResNet V2 with InceptionResNet V2, Xception with Xception, Inception V3 with InceptionResNet V2, Inception V3 with Xception, and InceptionResNet V2 with Xception. Four scenarios are considered regarding the fusion of three networks, as shown in the table: the fusion of Inception V3, Inception V3, and Inception V3; the fusion of InceptionResNet V2, InceptionResNet V2, and InceptionResNet V2; the fusion of Xception, Xception, and Xception; and the fusion of Inception-V3, Inception-ResNet-V2, and Xception. The four-network case is a fusion of Inception V3, InceptionResNet V2, Xception, and ResNet50. It can be seen from Table 6 and Figure 5 that if two base classifiers are consistent in the fusion process of two networks, the classification effect will be worse than that of using one base classifier alone. In a fusion network, there must be some difference between the base classifiers; otherwise, the network easily falls into local minima during the training process. It can be seen from Table 6 that when two different base classifiers are used, the classification accuracy is greatly improved compared with that of a network containing two identical classifiers. From the values listed in Table 6, the monitoring indices of Inception V3_InceptionResNet, Inception V3_Xception, and Inception V3_InceptionResNet are better than those of single Inception V3, InceptionResNet, Xception models; It can be seen from the data in Table 7 that the fusion effect of four networks is not as good as that of three networks, thus proving that the network fusion does not guarantee that a greater number of base classifiers leads to better results. Therefore, the fusion method based on Inception V3, InceptionResNet V2, and Xception is finally selected as the network model in this paper.
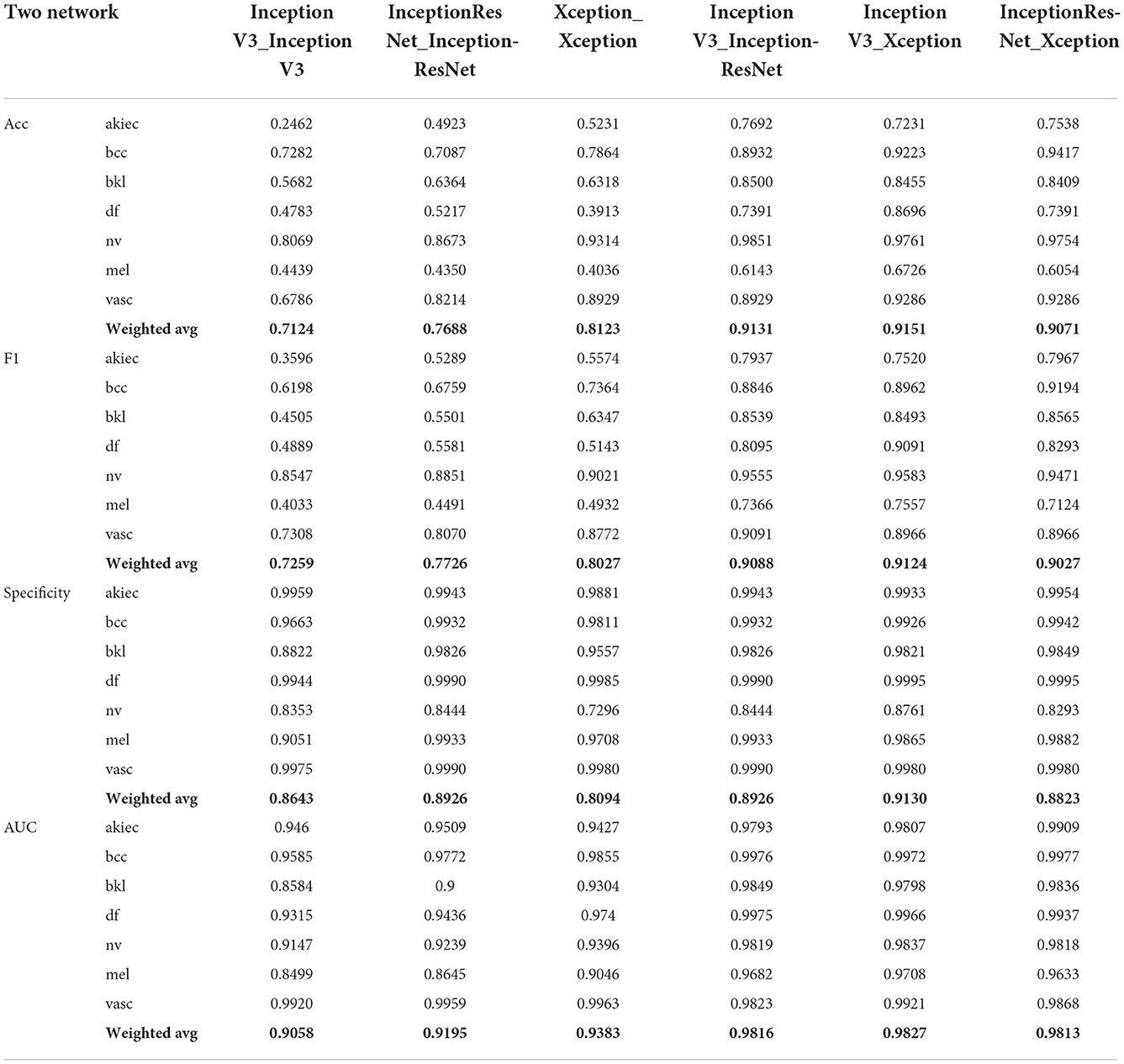
Table 6. The influence of fusion of two base classifiers on evaluation metrics.

Figure 5. Effect of the number of classifiers on the resulting network.
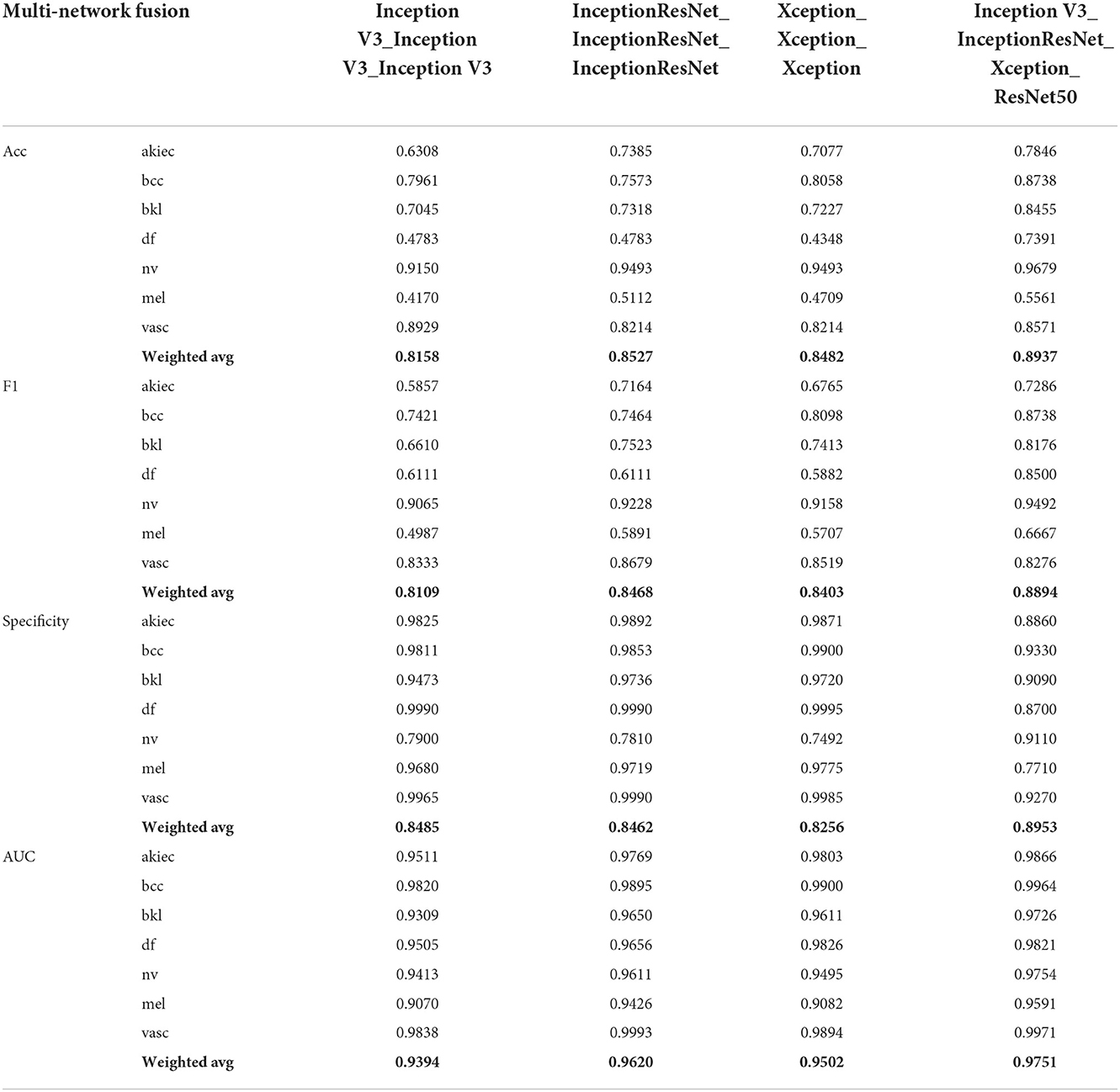
Table 7. The influence of fusion of multiple base classifiers on evaluation metrics.
To explore the performance of different network combinations in the feature extraction framework, we perform ablation experiments for each image classification configuration. The first case utilizes combinations with the same subnetwork. With the increase in the number of networks (columns 3, 4, 6 in Table 4, 3–5 in Table 6, and 3–5 in Table 7), the classification performance declines. Therefore, it is not better to increase the number of subnetwork when they are the same. The possible reason for this finding is that overfitting easily occurs in overly complex networks, which leads to performance degradation. However, the classification performance shown in Table 7 is higher than that in Table 6. The main reason for this is that in ensemble learning, the number of general base classifiers cannot appear to be even; otherwise, the same predicted value is likely to occur, and random judgment may occur during model classification. The second was for different subnetworks. With the increase in the number of networks (columns 3, 4, 6 in Table 4, columns 6–8 in Table 6, and columns 6 in Table 7), the classification performance increases first and then decreases, indicating that increasing the number of subnetworks can improve the accuracy of pigmented skin lesion detection, but more is not always better. The overfitting of complex networks may also occur. Third, it can be seen from Table 6 that when the number of networks is the same, the performance obtained when using different subnetworks as feature extractors is better than that achieved with identical subnetworks. These results prove the feasibility of the proposed network.
According to the test results, the comparison between this study and similar recent studies is shown in Table 8. The dataset listed in Table 8 is HAM10000, which was presented in the ISIC 2018 Challenge and is used in this study. From the evaluation indices obtained on the test set, it can be seen that the data upsampling scheme based on image flipping and image style transfer proposed in this paper can produce the same amount of data in each category; In addition, network fusion schemes based on available data can achieve higher detection efficiency for pigmented skin lesions than hard voting fusion schemes.

Table 8. Comparison of the results obtained in this study with those in the literature.
In order to validate the impact of the developed fusion network on external test data, the UCSD common retinal OCT dataset (45) was collected with a total sample size of 108,309 images in four categories: Normal, Drusen, CNV, and DME. The sample sizes of the four categories are 51,140, 8,616, 37,205, and 11,348, respectively, and this paper focuses on the “limited model,” i.e., 1,000 randomly selected images in each category, to compare the performance using the fusion strategies. Table 9 shows that the overall accuracies of the three fusion strategies are 97.4, 97.5, and 98.7%, respectively. Compared with the model proposed by Kermany (46), the accuracy is 93.4%, which is an average improvement of 4% points. Overall, the three fusion strategies proposed in this paper are effective.

Table 9. Comparison of different methods on external datasets.
To verify the interpretable and explainable of the classifier-level fusion network based on the classification layer proposed in this paper, the visualization effect of the sample with the highest prediction probability for each category among the test set samples is shown in Figure 6. In this paper, Grad_CAM (48) and Grad_CAM++ (49) are used as visualization algorithms, and the prediction probability value of the final output category of the test model is used to visualize the fusion of the three base classifiers and the CBAM. To compare the visualization effects of the Grad_CAM and Grad_CAM++ visualization algorithms on the results of this paper and to determine the visualization effect of the final predicted probability value of the model in this paper for the fusion of each base classifier and the attention mechanism, each row in Figure 6 shows that the pictures are all derived from the same sample image. It can be seen from the results that the visualization effects of Grad_CAM++ on the three base classifiers are better than those of Grad_CAM. Grad_CAM++ can display the lesion areas of pigmented skin lesions in a good thermal map. After the image is checked by professional clinicians, the visual part of the image can show that the locations focused on by the model are similar to those yielded by human experience. The visualization effect of Xception shows that the localization area is small and that all results are contained in the lesion area, which is superior to the effects of the other two classifiers (Inception V3 and InceptionResNet V2), thus proving the more interpretable and explainable of the proposed algorithm.

Figure 6. Model visualization.
A fusion network-based detection algorithm for pigmented skin lesions is proposed in this paper. Image preprocessing and image augmentation are carried out before inputting the given dataset into the network, which can solve the problem of low classification accuracy caused by the unbalanced distribution of the original data to a large extent. In this paper, various fusion strategies are used to verify the applicability of the algorithm for pigmented skin lesions. Based on a network performance comparison, we empirically find that the classification effects of the two fusion strategies based on feature-level fusion are not good according to their pigmented skin lesion results. However, the proposed fusion scheme can be applied in other application scenarios and can provide experience guidance for the corresponding model design process. Second, our algorithmic architecture (containing three fusion strategies) only covers single-modal, categorization-oriented methods. However, we also note that multimodal input data are present in medical image analyses, and the corresponding fusion schemes can be studied by extending the current framework (50–52). At the same time, two visualization algorithms are used to apply the color visualization method to make the proposed deep learning model more interpretable and explainable, and the accuracy of the developed algorithm was confirmed by comparing the results with those of related papers. In the future, we plan to test the robustness of the proposed algorithm using a hospital database of actual high definition images of pigmented skin diseases, deploy the algorithm model on servers for physicians in remote areas to diagnose pigmented skin diseases, and apply the three fusion strategies to other more medical application scenarios to validate the advantages of the algorithm.
The datasets generated and analysed during the current study are available from the corresponding author upon reasonable request. All deep learning methods are implemented by using TensorFlow (https://tensorflow.google.cn/). The custom script for this study will be available at https://github.com/YHHAZ/NetworkFusion. Correspondence and requests for data materials should be addressed to LC (Y2hscTM1QDEyNi5jb20=).
LW and ZA: conceptualization and writing—original draft preparation. LW, ZA, and YL: methodology. ZA, JC, QJ, HC, and QL: writing—review and editing. YL and LC: project administration. JC and QJ: data collection. LW, LC, and YL: funding acquisition. All authors read and agreed to the published version of the manuscript.
This work was supported in part by a Wuhan Medical Scientific Research Project grant to LC (WX20B25), in part by a Science and Technology Planning Project of Wuhan grant to LC (2019010701011418), in part by a Research Innovation Fund Project of Jianghan University grant to LW (211051003), and in part by Sinopharm Genomics Technology Co., Ltd. The funders were not involved with the study design; the collection, analysis, or interpretation of data; the writing of this article; or the decision to submit it for publication.
The numerical calculations in this paper were performed on the supercomputing system in the Supercomputing Center of Wuhan University.
ZA, QL, and YL are employees of Sinopharm Genomics Technology Co., Ltd.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as potential conflicts of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
1. National Cancer Institute Surveillance Epidemiology Program ER. Cancer Stat Facts: Melanoma of the Skin (2021). Available online at: https://seer.cancer.gov/statfacts/html/melan.html
2. Freedberg KA, Geller AC, Miller DR, Lew RA, Koh HK. Screening for malignant melanoma: a cost-effectiveness analysis. J Am Acad Dermatol. (1999) 41:738–45.
3. Krizhevsky A, Sutskever I, Hinton GE. ImageNet classification with deep convolutional neural networks. In:Pereira F, Burges CJ, Bottou L, Weinberger KQ, , editors. Advances in Neural Information Processing Systems. Vol. 25. Curran Associates, Inc. (2017).
4. Zeiler MD, Fergus R. Visualizing and understanding convolutional networks. In:Fleet D, Pajdla T, Schiele B, Tuytelaars T, , editors. European Conference on Computer Vision. Part 1. Zurich: Springer International Publishing (2014). p. 818–33.
5. Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:14091556 (2014). doi: 10.48550/arXiv.1409.1556
6. Szegedy C, Liu W, Jia Y, Sermanet P, Reed S, Anguelov D, et al. Going deeper with convolutions. In: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR). Boston, MA (2015). p. 1–9.
7. He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV (2016). p. 770–8.
8. Xie S, Girshick R, Dollár P, Tu Z, He K. Aggregated residual transformations for deep neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Honolulu, HI (2017). p. 1492–500.
9. Hu J, Shen L, Albanie S, Sun G, Wu E. Squeeze-and-excitation networks. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT (2020). doi: 10.1109/CVPR.2018.00745
10. Zoph B, Vasudevan V, Shlens J, Le QV. Learning transferable architectures for scalable image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Salt Lake City, UT (2018). p. 8697–710.
11. Tan M, Le QV. EfficientNet: Rethinking model scaling for convolutional neural networks. In: Chaudhuri K, Salakhutdinov R, editors. Proceedings of the 36th International Conference on Machine Learning (ICML) Long Beach, CA (2019). p. 6105–14.
12. Milton MAA. Automated skin lesion classification using Ensemble of deep neural networks in ISIC 2018: skin lesion analysis towards melanoma detection challenge. arXiv preprint arXiv:190110802 (2019). doi: 10.48550/arXiv.1901.10802
13. Ardakani AA, Kanafi AR, Acharya UR, Khadem N, Mohammadi A. Application of deep learning technique to manage COVID-19 in routine clinical practice using CT images: results of 10 convolutional neural networks. Comput Biol Med. (2020) 121:103795. doi: 10.1016/j.compbiomed.2020.103795
14. Chowdhury MEH, Rahman T, Khandakar A, Mazhar R, Kadir MA, Mahbub ZB, et al. Can AI help in screening viral and COVID-19 pneumonia? IEEE Access. (2020) 8:132665–76. doi: 10.1109/ACCESS.2020.3010287
15. Narin A, Kaya C, Pamuk Z. Automatic detection of coronavirus disease (COVID-19) using X-ray images and deep convolutional neural networks. Pattern Anal Appl. (2021) 24:1207–20. doi: 10.48550/arXiv.2003.10849
16. Qjidaa M, Mechbal Y, Ben-Fares A, Amakdouf H, Maaroufi M, Alami B, et al. Early detection of COVID19 by deep learning transfer Model for populations in isolated rural areas. In: 2020 International Conference on Intelligent Systems and Computer Vision (ISCV) Fez (2020). p. 1–5.
17. Tammina S. CovidSORT: detection of novel COVID-19 in chest X-ray images by leveraging deep transfer learning models. In:Kumar A, Senatore S, Gunjan VK, , editors. Proceedings of the 2nd International Conference on Data Science, Machine Learning and Applications (ICDSMLA). Lecture Notes in Electrical Engineering. Vol. 783. Pune: Springer (2022). p. 431–47.
18. Ai Z, Huang X, Fan Y, Feng J, Zeng F, Lu Y. DR-IIXRN : detection algorithm of diabetic retinopathy based on deep ensemble learning and attention mechanism. Front Neuroinformatics. (2021) 15:778552. doi: 10.3389/fninf.2021.778552
19. Sabri MA, Filali Y, El Khoukhi H, Aarab A. Skin cancer diagnosis using an improved ensemble machine learning model. In: 2020 International Conference on Intelligent Systems and Computer Vision (ISCV). Fez (2020). p. 1–5.
20. Sae-Lim W, Wettayaprasit W, Aiyarak P. Convolutional neural networks using mobileNet for skin lesion classification. In: 2019 16th International Joint Conference on Computer Science and Software Engineering (JCSSE): Knowledge Evolution Towards Singularity of Man-Machine Intelligence Chonburi (2019). p. 242–7.
21. Mohamed EH, El-Behaidy WH. Enhanced skin lesions classification using deep convolutional networks. In: 2019 Ninth International Conference on Intelligent Computing and Information Systems (ICICIS) Cario (2019). p. 180–8.
22. Hegde PR, Shenoy MM, Shekar BH. Comparison of machine learning algorithms for skin disease classification using color and texture features. In: 2018 International Conference on Advances in Computing, Communications and Informatics (ICACCI) Bangalore (2018). p. 1825–8.
23. Hameed N, Shabut A, Hossain MA. A Computer-Aided diagnosis system for classifying prominent skin lesions using machine learning. In: 2018 10th Computer Science and Electronic Engineering (CEEC) Colchester (2019). p. 186–91.
24. Barata C, Ruela M, Francisco M, Mendonça T, Marques JS. Two systems for the detection of melanomas in dermoscopy images using texture and color features. IEEE Syst J. (2013) 8:965–79. doi: 10.1109/JSYST.2013.2271540
25. Seidenari S, Pellacani G, Grana C. Pigment distribution in melanocytic lesion images: a digital parameter to be employed for computer-aided diagnosis. Skin Res Technol. (2005) 11:236–41. doi: 10.1111/j.0909-725X.2005.00123.x
26. Varalakshmi P, Aruna Devi V, Ezhilarasi M, Sandhiya N. Enhanced dermatoscopic skin lesion classification using machine learning techniques. In: 2021 Sixth International Conference on Wireless Communications, Signal Processing and Networking (WiSPNET) Chennai (2021). p. 68–71.
27. Ma V, Karki MV. Skin cancer detection using machine learning techniques. In: 2020 IEEE International Conference on Electronics, Computing and Communication Technologies (CONECCT) Bangalore (2020). p. 1–5.
28. Kalwa U, Legner C, Kong T, Pandey S. Skin cancer diagnostics with an all-inclusive smartphone application. Symmetry. (2019) 11:790. doi: 10.3390/sym11060790
29. Gupta S, Panwar A, Mishra K. Skin disease classification using dermoscopy images through deep feature learning models and machine learning classifiers. In: IEEE EUROCON 2021 - 19th International Conference on Smart Technologies Lviv (2021). p. 170–4.
30. Rahman Z, Ami AM. A transfer learning based approach for skin lesion classification from imbalanced data. In: 2020 11th International Conference on Electrical and Computer Engineering (ICECE) Dhaka (2020). p. 65–8.
31. Chaturvedi SS, Gupta K, Prasad PS. Skin lesion analyser: an efficient seven-way multi-class skin cancer classification using mobilenet. In:Hassanien AE, Bhatnagar R, Darwish A, , editors. Advanced Machine Learning Technologies and Applications. Vol. 1141. Cairo: Springer (2021). p. 165–76.
32. Sevli O. A deep convolutional neural network-based pigmented skin lesion classification application and experts evaluation. Neural Comput Appl. (2021) 33:12039–50. doi: 10.1007/s00521-021-05929-4
33. Pal A, Ray S, Garain U. Skin disease identification from dermoscopy images using deep convolutional neural network. arXiv preprint arXiv:180709163 (2018). doi: 10.48550/arXiv.1807.09163
34. Xie Y, Zhang J, Xia Y. A multi-level deep ensemble model for skin lesion classification in dermoscopy images. arXiv preprint arXiv:180708488 (2018). doi: 10.48550/arXiv.1807.08488
35. Aldwgeri A, Abubacker NF. Ensemble of deep convolutional neural network for skin lesion classification in dermoscopy images. In:Badioze Zaman H, Smeaton AF, Shih TK, Velastin S, Terutoshi T, Mohamad Ali N, et al., , editors. Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). Vol. 11870. Bangi (2019). p. 214–26.
36. Tschandl P, Rosendahl C, Hararld K. The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. Sci Data. (2018) 5:1–9. doi: 10.1038/sdata.2018.161
37. Ghiasi G, Lee H, Kudlur M, Dumoulin V, Shlens J. Exploring the structure of a real-time, arbitrary neural artistic stylization network. arXiv preprint arXiv:170506830 (2017). doi: 10.48550/arXiv.1705.06830
38. Wang C, Peng G, De Baets B. Deep feature fusion through adaptive discriminative metric learning for scene recognition. Inform Fusion. (2020) 63:1–12. doi: 10.1016/j.inffus.2020.05.005
39. Chaib S, Liu H, Gu Y, Yao H. Deep feature fusion for VHR remote sensing scene classification. IEEE Trans Geosci Remote Sens. (2017) 55:4775–84. doi: 10.1109/TGRS.2017.2700322
40. Song W, Li S, Fang L, Lu T. Hyperspectral image classification with deep feature fusion network. IEEE Trans Geosci Remote Sens. (2018) 56:3173–84. doi: 10.1109/TGRS.2018.2794326
41. Bian X, Chen C, Sheng Y, Xu Y, Du Q. Fusing two convolutional neural networks for high-resolution scene classification. In: 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS). Fort Worth, TX (2017). p. 3242–5.
42. Xue W, Dai X, Liu L. Remote sensing scene classification based on multi-structure deep features fusion. IEEE Access. (2020) 8:28746–55. doi: 10.1109/ACCESS.2020.2968771
43. Woo S, Park J, Lee JY, Kweon IS. CBAM: Convolutional block attention module. In: Proceedings of the European Conference on Computer Vision (ECCV). Munich Vol. 11211 (2018). p. 3–19.
44. Salian AC, Vaze S, Singh P, Shaikh GN, Chapaneri S, Jayaswal D. Skin lesion classification using deep learning architectures. In: 2020 3rd International Conference on Communication Systems, Computing and IT Applications, CSCITA 2020 - Proceedings Mumbai (2020).
45. Kermany D, Zhang K, Goldbaum M. Large dataset of labeled optical coherence tomography (oct) and chest x-ray images. Mendeley Data. (2018) 3:10–17632. doi: 10.17632/rscbjbr9sj.3
46. Kermany DS, Goldbaum M, Cai W, Valentim CC, Liang H, Baxter SL, et al. Identifying medical diagnoses and treatable diseases by image-based deep learning. Cell. (2018) 172:1122–31. doi: 10.1016/j.cell.2018.02.010
47. Kaymak S, Serener A. Automated age-related macular degeneration and diabetic macular edema detection on oct images using deep learning. In: 2018 IEEE 14th international conference on intelligent computer communication and processing (ICCP). Cluj-napoca (2018). p. 265–9.
48. Selvaraju RR, Cogswell M, Das A, Vedantam R, Parikh D, Batra D. Grad-CAM: visual explanations from deep networks via gradient-based localization. In: Proceedings of the IEEE International Conference on Computer Vision. Venice (2017). p. 618–26.
49. Chattopadhay A, Sarkar A, Howlader P, Balasubramanian VN. Grad-CAM++: generalized gradient-based visual explanations for deep convolutional networks. In: 2018 IEEE Winter Conference on Applications of Computer Vision (WACV). Lake Tahoe, NV (2018). p. 839–47.
50. Qian X, Pei J, Zheng H, Xie X, Yan L, Zhang H, et al. Prospective assessment of breast cancer risk from multimodal multiview ultrasound images via clinically applicable deep learning. Nat Biomed Eng. (2021) 5:522–32. doi: 10.1038/s41551-021-00711-2
51. Ning W, Lei S, Yang J, Cao Y, Jiang P, Yang Q, et al. Open resource of clinical data from patients with pneumonia for the prediction of COVID-19 outcomes via deep learning. Nat Biomed Eng. (2020) 4:1197–207. doi: 10.1038/s41551-020-00633-5
Keywords: fusion network, pigmented skin disease, attention mechanism, image style transfer, model interpretability
Citation: Wan L, Ai Z, Chen J, Jiang Q, Chen H, Li Q, Lu Y and Chen L (2022) Detection algorithm for pigmented skin disease based on classifier-level and feature-level fusion. Front. Public Health 10:1034772. doi: 10.3389/fpubh.2022.1034772
Received: 02 September 2022; Accepted: 30 September 2022;
Published: 20 October 2022.
Edited by:
Yu-Dong Zhang, University of Leicester, United KingdomReviewed by:
Jatinderkumar R. Saini, Symbiosis Institute of Computer Studies and Research (SICSR), IndiaCopyright © 2022 Wan, Ai, Chen, Jiang, Chen, Li, Lu and Chen. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yaping Lu, bHV5YXBpbmdAc2lub3BoYXJtLmNvbQ==; Liuqing Chen, Y2hscTM1QDEyNi5jb20=
†These authors have contributed equally to this work and share first authorship
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.