
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
METHODS article
Front. Psychol. , 18 March 2025
Sec. Quantitative Psychology and Measurement
Volume 16 - 2025 | https://doi.org/10.3389/fpsyg.2025.1549767
This article is part of the Research Topic Promoting Replicability: Empowering Method and Applied Researchers in Driving Reliable Results View all articles
 María Paula Fernández-García1*†
María Paula Fernández-García1*† Guillermo Vallejo-Seco1†
Guillermo Vallejo-Seco1† Pablo Livácic-Rojas2†
Pablo Livácic-Rojas2† Francisco Javier Herrero-Díez1†
Francisco Javier Herrero-Díez1†Introduction: Monte Carlo simulation studies allow testing multiple experimental conditions, whose results are often difficult to communicate and visualize to their full extent. Some researchers have proposed alternatives to address this issue, highlighting its relevance. This article develops a new way of observing, analyzing, and presenting the results of simulation experiments and is explained step by step with an example.
Methods: A criterion is proposed to decide which results could be averaged and which results should not be averaged. It is also indicated how to construct Traceability Tables. These tables will show the behavior of the different analytical approaches studied under the chosen conditions and their variability under the averaged conditions. A way of observing the influence of the manipulated variables on the performance of the set of analysis approaches studied is also developed, Variability Set. Finally, a way of exposing the procedures that have the best performance in a particular condition is suggested.
Results and discussion: This Analysis Plan for reporting the results of simulation studies provides more information than existing alternative procedures, provides valuable information for method researchers, and specifies to applied researchers which statistic they should use in a particular condition. An R Shiny application is provided.
Monte Carlo simulation experimentation is the usual way in which methodological researchers empirically evaluate the properties of statistical estimators of different analytical approaches (Morris et al., 2019; Siepe et al., 2024). The reliability and validity of these results are of vital importance, both for the applied researcher who needs to make an informed choice as to the best statistic to test their hypothesis, and for the method researcher who wants to continue to dig deeper and find better solutions. Both aspects are essential for dealing with the lack of replicability of results (Boulesteix et al., 2020a; Boulesteix et al., 2020b; Kelter, 2024; Lohmann et al., 2022; Luijken et al., 2024; Seibold et al., 2021; Zivich et al., 2023), probably one of the most debated topics in current science, and undoubtedly the topic that brings together the greatest diversity of experts (applied researchers in all sciences, methodologists, philosophers, journalists, etc.).
The interest in good practices in conducting comparative simulation studies (Pawel et al., 2023) is noteworthy, and there are excellent tutorials, guidelines, and standards on how to design, implement, report, present, and check empirical Monte Carlo simulation investigations (Burton et al., 2006; Morris et al., 2019; Pawel et al., 2023; Paxton et al., 2001; Siepe et al., 2024; White et al., 2024). Moreover, seeking to ensure the replicability of the results, and in order not to make mistakes in their design and implementation, several authors have developed programs and applications to perform these investigations flawlessly (Chalmers and Adkins, 2020; Duncan et al., 2024; Kelter, 2024; Kenny and Wolock, 2024). Other researchers have worked on developing applications to organize the presentation of results in tabular and graphical form (Chang et al., 2023; Gasparini et al., 2021; Meyer et al., 2023), meeting the ideal requirements for presentation in scientific journals.
This research focuses on the exploration, analysis, visualization, reporting, and presentation of the results found in the comparative simulation study in relation to the performance of measures used for evaluating different methods (e.g., Type I error rate, Power, Bias, etc.).
Ideally, the results should be reported narratively and also presented in full in different tables and graphs. This is possible when the number of experimental conditions examined is not excessive (e.g., Bell and Rabe, 2020; Blanca et al., 2023; Debelak, 2019). But when the design is complex and the volume of results is high, methodologists look for alternatives to communicate the results in the best possible way because scientific journals have length restrictions for articles (to differing degrees).
To this end, sometimes authors choose to display all results using multiple graphs (e.g., Adams, 2024; Austin et al., 2015; Finch et al., 2018; Haverkamp and Beauducel, 2017; Michiels et al., 2019). Graphs make the article more readable, and they make it possible to identify general trends, but they also make it difficult to identify and interpret the results precisely and accurately (Luijken et al., 2024; Morris et al., 2019; Siepe et al., 2024). In other cases, authors decide to show only the results they consider most salient (e.g., Fingleton et al., 2017; Tibbe and Montoya, 2022; Tofighi, 2020; Wei and Zhan, 2023), which can create the risk and suspicion that perhaps the authors chose to present only the most convenient results in favor of their hypotheses (Nießl et al., 2021). And in other cases, the authors opt to average the results of various experimental conditions. In a review conducted in three highly relevant scientific journals —Psychological Methods, Behavior Research Methods, and Multivariate Behavioral Research—Siepe et al. (2024) identified this behavior in at least 17% of the investigations evaluated (other examples are De and Onghena, 2022; Livacic-Rojas et al., 2020; Michiels et al., 2019; Svetina et al., 2018). Averaged results allow the identification of dominant behaviors; however, they may unintentionally convey the misleading idea that the results extend to all averaged conditions.
When results are reported in these three ways, usually all the original tabulated results are shown in Supplementary material or at a web address, or the authors state their commitment to provide this information to interested readers. However, reading multiple results in multiple tables makes it difficult to identify exceptional results or behaviors, difficult to identify general trends (even more difficult to identify the strength of those trends), and very difficult to identify which statistical procedure has the optimal behavior in each experimental condition examined. Thus, reporting the results of these very voluminous investigations, providing as much information as possible without omitting relevant information, is not an easy task.
Several investigations have addressed this issue and the solutions proposed can be categorized into two groups: one analytical and the other graphical. The former have explored the possibility of summarizing the complete set of results found in the comparative simulation study. To do so, they have sought to express the relationship between the manipulated variables (the supposed cause, e.g., sample size, variable distribution, autocorrelation, etc.) and the observed variables (the effect to be observed, e.g., Type I error rate, Power, Bias, etc.), thus adding complementary information as well. This has been done in four main ways: using regression techniques (Harwell, 1992; Zumbo and Jennings, 2002), using ANOVA (Chipman and Bingham, 2022), using meta-analytical methods (Harwell, 2003; Harwell et al., 1992), and using response surface methodology (Zumbo and Harwell, 1999). The second group have tried to find a way to graphically represent the results, present them in their entirety, and display them better (Rücker and Schwarzer, 2014).
Despite all these efforts, experts in Monte Carlo simulation research state that “There is no one correct way to present results” (see Section 6.2 in Morris et al., 2019) and that “Figures should therefore ideally be combined with quantitative summaries of results, such as tables” (see Siepe et al., 2024, p.17). In the spirit of giving another chance to the possibility of resolving this issue, we have conducted this research, which we now present.
In this research we develop an alternative way to explore and present the results found in the comparative simulation study in relation to the performance execution of the measures (considered appropriate and necessary by the researcher) for evaluating different methods. This approach allows us to obtain relevant information, different and complementary to the information provided by the analytical and graphical solutions previously mentioned, and also to the information provided by the usual way of presenting simulation results (presenting all results, presenting only a set of selected results, or presenting averaged results). Our proposal involves the exploration and visualization of the results in three phases as follows:
Phase 1: Presentation and analysis of the global and specific results related to the analytical procedures under study.
Phase 2: Exposure and evaluation of the influence of the manipulated conditions on the variability observed in the execution of the set of procedures under study.
The results found in Phase 1 and Phase 2 will be of great interest and useful for the purposes of method researchers. They may be difficult to understand, however, for applied researchers, who are generally not experts in methodology. To address this issue, some researchers have proposed substantive and practical solutions to communicate simulation research results in a user-friendly and straightforward way, and thus provide clear guidelines for applied researchers to make informed decisions (Bandalos and Gagné, 2012; Maxwell and Cole, 1995). Still, the complaints and pleas continue (Boulesteix et al., 2020b). In the spirit of aiming to delve into this issue thoroughly and to bridge the gap between method researchers and applied researchers, Phase 3 is proposed.
Phase 3: Evaluation and recommendation for use. Presentation of the analytical procedure(s) of choice and representation of the conditions in which they present optimum performance.
Thus, after contextualizing, justifying, and presenting the objective of this research, in this paper we exemplify step by step the procedure we propose, and we do so with a selection of results from the simulation study carried out by Livacic-Rojas et al. (2020). We have structured this paper as follows: Section 2 (Materials and methods) is divided into three sections. In Section 2.1, we describe in detail each of the three phases involved in the analysis and presentation of the results of the comparative simulation studies. In Section 2.2, we briefly present the simulation study carried out by Livacic-Rojas et al. (2020) and explain the motivation for this paper. In Section 2.3, we replicate a subset of experimental conditions performed by Livacic-Rojas et al. (2020), the results of which remained hidden in the averaged results of the first table of their paper. With these results, in Section 3 (Results), we exemplify step-by-step the process and development involved in each of the three phases (Sections 3.1, 3.2, and 3.3), and highlight the added value of each of them. We have developed a Shiny application that allows us to obtain some of the most relevant results of this procedure and to visualize the result as a function of the variables manipulated. Section 3.4 explains how it works. Finally, Section 4 of the paper is devoted to the discussion and conclusion of this procedure.
The content of the three phases in which the results analysis process will be carried out is described, and a diagram of the process is shown.
Phase 1: Presentation and analysis of the global and specific results related to the analytical procedures under study. This involves three activities.
First activity: Analysis of the average performance of each analytical procedure (AP) and its variability. Taking as the unit of analysis the performance of each of the analytical approaches tested, we will explore the behavior of each of them in the set of all the experimental conditions examined, and also at each level of each of the variables manipulated in the simulation experiment. The variability statistic we use is the coefficient of variation.
The coefficient of variation ] expresses the standard deviation (S) as a percentage of the arithmetic mean (Kelley, 2007), thus providing a relative interpretation of the degree of variability independent of the scale of the variable and being a suitable statistic to compare the variability of the same variable in different samples, or of different variables in the same sample (see a detailed explanation in Ospina and Marmolejo-Ramos, 2019). For this reason, it is possible to use it to observe and compare the relative behavior of each of the APs, each one with respect to the others, and to compare the efficacy of each of them under the different conditions investigated (all conditions, only some conditions, and when the results of some of the conditions examined have been averaged).
The CV has been used in methodological research for different purposes, among others, to calculate sample size by controlling sampling error (Chattopadhyay and Kelley, 2016), for assessing variability of quantitative assays (Reed et al., 2002), for detecting outliers in time series data (Nkechi et al., 2022), for sensitivity analysis in Monte Carlo investigations (Menz et al., 2020), etc. We propose to use the coefficient of variation to observe and to compare the vulnerability or instability of the performance of each AP with respect to the other APs in the set of conditions that have been averaged, and thus obtain even more information from the results found in the simulation study, as shown below.
Both calculations, the averages and the CVs, will be highlighted by symbols that will allow us to display the exceptionality of each of the procedures (each one compared to the others), and the distribution of variability in their behavior at each level of each manipulated variable.
Second activity: Analysis of the influence of the manipulated variables on the performance of the set of procedures under study. Considering the set of analytical procedures under evaluation as sample units, the influence of all the variables manipulated in the simulation study on the observed effect of interest (Type I error, Power, Bias, etc.) will be analyzed by means of ANOVA (or by regression). This information is very relevant since it will allow us to observe if the observed performance is dominated by an interaction between variables, if any manipulated variable has no influence on the observed performance, or if only some levels of some variable have differential influence on the observed result.
Third activity: Presentation and analysis of the specific results. The results shown in the paper will be conditioned to the number of experimental conditions contained in the simulation study. If the number of experimental conditions examined is not excessive, all results will be shown in tabular form (as well as graphically if possible).
If space is not available, the researcher must decide which results to show. The researcher may decide to show a subset of results, or they may decide to average the results of some experimental conditions. We propose to form a useful and non-arbitrary criterion based on the results found in the two previous activities to decide which results to present (and which not to present in the main text of the paper), and to decide which results can be averaged and which cannot. If averaging is chosen, the usual tables of results will become Traceability Tables, showing the performance of each of the analysis approaches studied under the desired experimental conditions, and the variability in their behavior under the particular conditions under which they were averaged. As before, the averages and CVs will be highlighted with symbols that will allow easy identification of the performance of the APs.
Phase 2: Presentation and evaluation of the influence of the manipulated conditions on the variability observed in the performance of the set of procedures under evaluation. Presentation of the Variability Set.
Taking as a unit of analysis a performance measure of the set of procedures under test, we will explore the variability of the performance of the set of procedures in each of the experimental simulation conditions performed. The Variability Set will make it possible to display the influence that the variables manipulated in the simulation study have on the execution of the set of analysis approaches under study.
The exploration, presentation, and writing up of the results found in Phase 1 and Phase 2 is of great interest and usefulness for the purposes of method researchers. But for applied researchers, who are generally not experts in methodology, this information is of little use. In the spirit of bridging the gap between method researchers and applied researchers, Phase 3 is proposed.
Phase 3: Evaluation and recommendation of use. Presentation of the AP(s) of choice, and representation of the conditions in which they present optimum performance.
Taking into account the information contained in the full results tables, in the specific results tables, or in the Traceability Tables (depending on which option has been chosen), the methodologist will determine which would be the statistical procedure(s) of choice, i.e., the procedure that performs best under the conditions examined, and he or she will represent how it performs in them. The purpose of Phase 3 is to provide the relevant information to which the applied researchers must pay attention, and thus avoid making decisions on the basis of general criteria that may be incorrect.
This procedure that we propose will allow method researchers to know the traceability of each of the analytical approaches studied and also to understand how the manipulated conditions determine their influence on the set of analytical approaches studied. It will also allow applied researchers to easily locate the appropriate procedure to use in their particular case, and to understand the risk they are exposed to in making this decision. Overall, we believe that this procedure will contribute to making comparative simulation studies “neutral comparison studies” (Boulesteix et al., 2017; Kelter, 2024) and thereby boost scientific replicability (Boulesteix et al., 2020a; Seibold et al., 2021). To our knowledge, this is the first time that something similar is proposed in order to explore, analyze, display, report, and present the results found in the comparative simulation study in relation to the performance of measures used for evaluating different methods (e.g., Type I error rate, Power, Bias, etc.). Figure 1 schematically illustrates the plan for analyzing the results across the three phases.
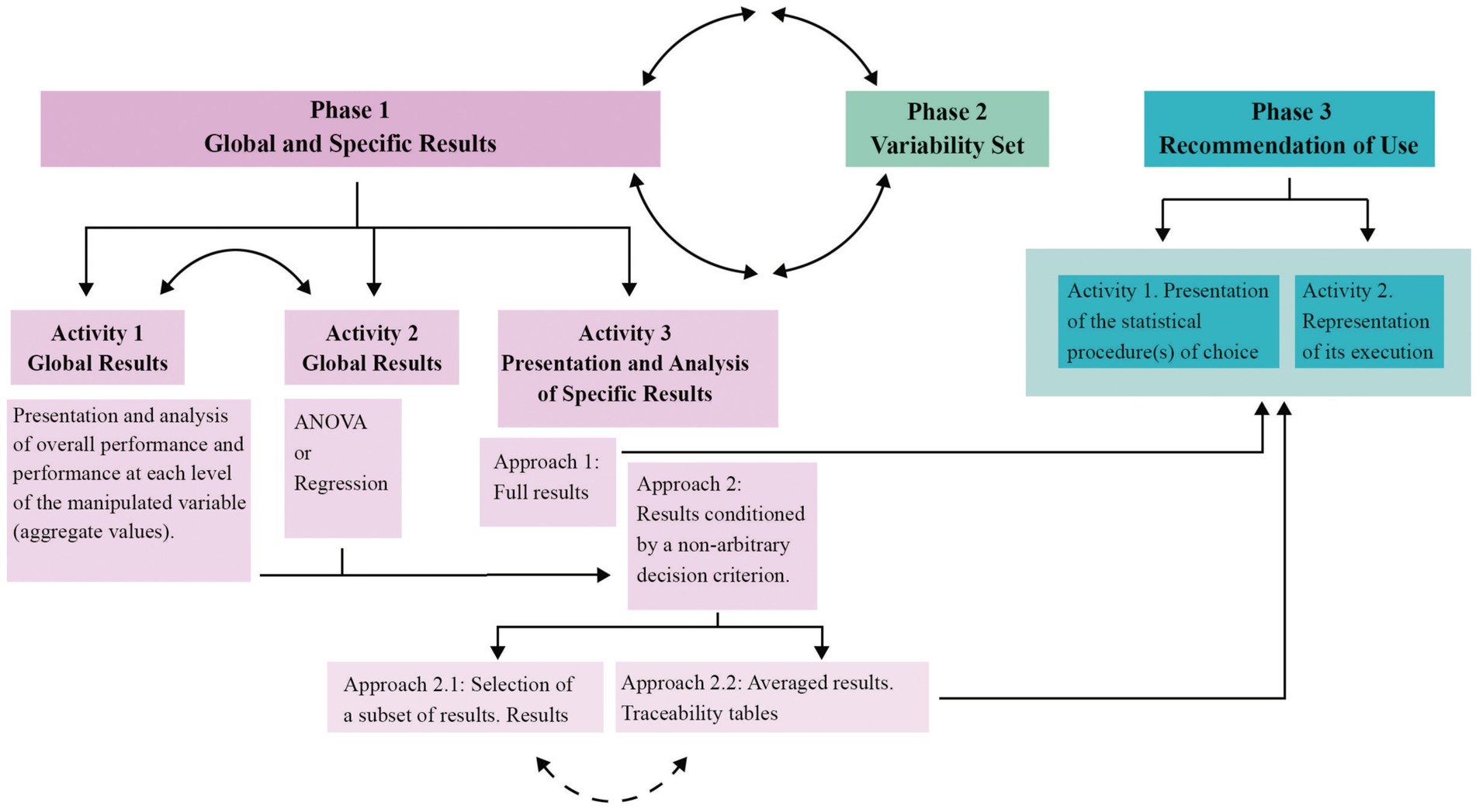
Figure 1. Circle formed by continuous double-arrow arcs = Together, Phase 1 and Phase 2 provide a comprehensive view of the results and integrate everything that has occurred in the simulation research. All of this represents different, distinct, and complementary information; Continuous double-arrow arc = The outcome of both activities, Activity 1 and Activity 2, shapes the objective and non-arbitrary criterion on which the methodologist bases their decision; Discontinuous double-arrow arc = Only one of the two result options is displayed (unless the number of experimental conditions is very large, in which case part of the results might need to be presented in one way, and another part in a different way).
Contextualization: When the dependent variable is quantitative, the Linear Mixed Model (LMM) is the best option for analyzing repeated measures designs, as it allows modeling both the fixed effects of the model (i.e., treatment, time, and interaction) and the variance–covariance structure of the data. The combination of the means model and the covariance matrix structure represents the true data-generating process (DGP). If the DGP is correctly identified, the quality of statistical inferences is ensured (see Vallejo et al., 2011). However, the DGP may be partially or entirely unknown.
The LMM enables model selection using the likelihood ratio test (LRT) and/or information criteria (ICs). The LRT is restricted to comparing nested models and can only evaluate two models at a time, requiring a hierarchical approach when more than two models are considered. In contrast, ICs allow for the simultaneous comparison and selection of multiple models, whether nested or not. Due to this flexibility, ICs are widely used and are the focus of extensive methodological research (e.g., Vallejo et al., 2010; Vallejo et al., 2011). One such study is Livacic-Rojas et al. (2020), which examines the behavior of ICs in identifying the DGP across three different scenarios.
Livacic-Rojas et al. (2020) conducted a comparative simulation study to evaluate the performance of five ICs to identify the DGP underlying in a partially repeated measures design (2×5) when the interaction is the term of interest in the model. This was carried out in three scenarios (S). The ICs evaluated were AIC (Akaike IC), AICC (AIC Corrected), HQIC (Hannan-Quinn IC), BIC (Bayesian IC), and CAIC (Consistent AIC) as offered by the SAS PROC MIXED program. In Scenario 1, Means Model, and in Scenario 2, Covariance Structure, the DGP is partially known, whereas in Scenario 3, named Means Model and Covariance Structure, the DGP is completely unknown. The authors manipulated 7 variables, as follows. The data missingness mechanism (MM) [4 levels: Complete Data (CD), Missing Completely at Random (MCAR), Missing at Random (MAR), and Missing Not at Random (MNAR)], the total sample size (N) [3 levels: N = 50, 100, and 120], the ratio between the size of the groups (R:nj) [5 levels: equal size (1), and 4 levels of different size], the homogeneity between the covariance matrices of the groups [3 levels: 1:1, 1:3, and 1:5], the pairing of covariance matrices and group size [3 levels: null, positive, and negative relationship], and the distribution of the measurement variable [5 levels: normal distribution and 4 levels of non-normal distribution]. They also manipulated the covariance matrix (CM) underlying the data. In the first scenario (S1), only the linear random coefficients matrix (RCL) was used, and in the two remaining scenarios (S2 and S3), three CM [heterogeneous first-order autoregressive ARH(1), heterogeneous Toeplitz covariance pattern (TOEPH), and unstructured (UN)] were used.
The combination of the levels of the manipulated variables formed 4,500 experimental conditions whose results would occupy a very large number of tables. It is not possible to present the full set of results in any scientific article due to its length. Thus, the authors chose to average the results. Finally, they presented them in 6 tables, and each of the data points contained therein is the mean of 15 experimental conditions. The average was performed with the set of experimental conditions defined by the interaction of the levels of the manipulated variables [NxR:nj].
The results derived from this research are valid and very important, but the content hidden in the average may also be important. In addition, it is impossible to know whether the exposed results can be generalized to all or some of the 15 experimental conditions that have been averaged.
The motivation for developing this alternative approach to presenting the results of comparative simulation studies originates from this investigation and many others like it, where numerous experimental conditions are manipulated and the authors decided to use averages to present their results. Initially, the intention was to explore a way to estimate how much information is lost when the results are averaged. However, the proposed method will allow us to obtain all the information that was highlighted in paragraph 2.1.
Starting point: As a starting point for the explanation of the procedure we propose, we will focus on the first table of results shown by Livacic-Rojas et al. (2020), which has been adapted and is shown in Table 1.
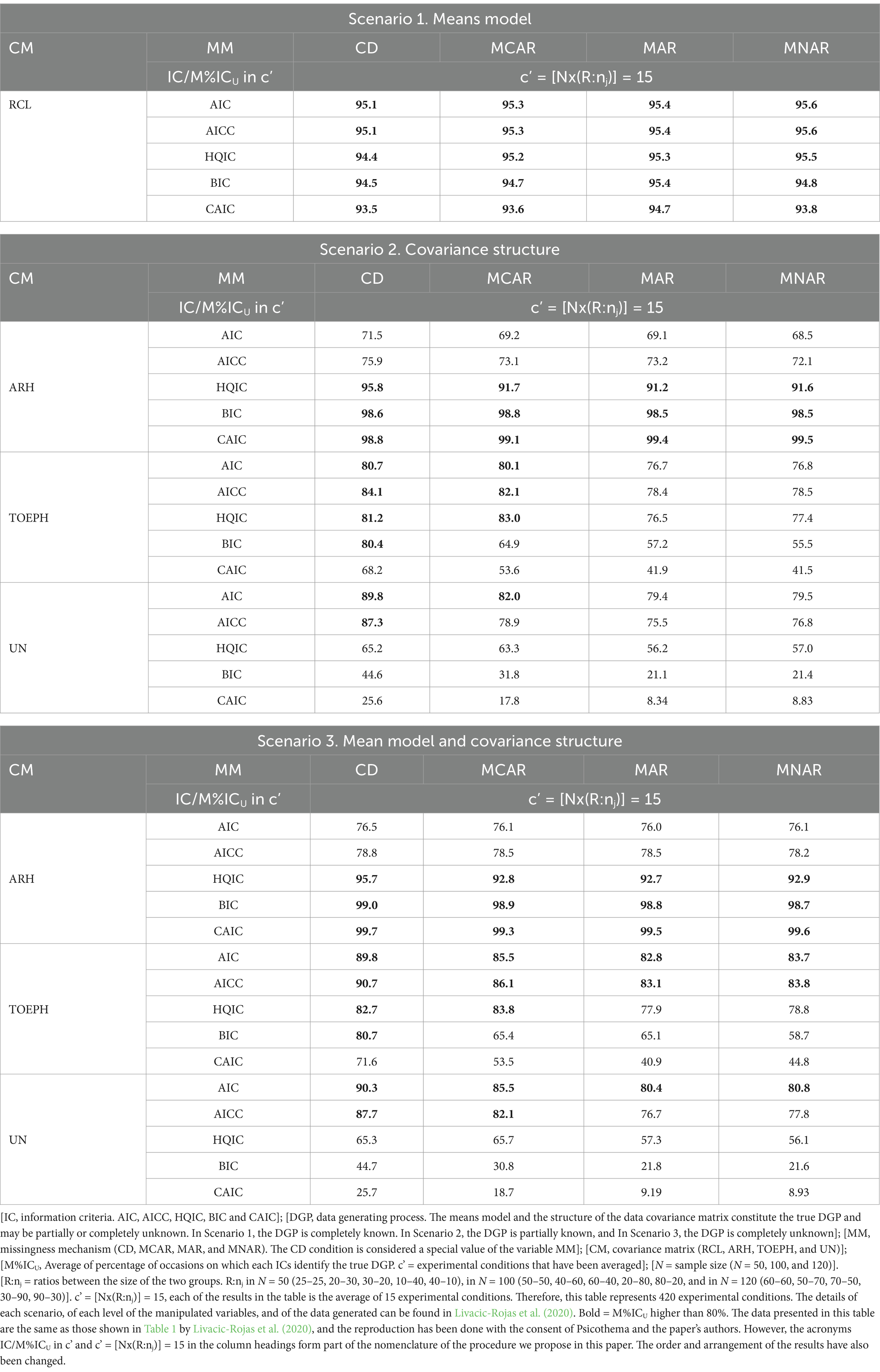
Table 1. Results shown in Livacic-Rojas et al. (2020). Average of percentage of occasions on which the ICs identify the true DGP in three Scenarios. Normal distribution and homogeneous covariance matrices.
Table 1 shows the performance of each IC in 28 experimental conditions (in S1 [1 CM x 4 MM = 4c] and in each scenario S2 and S3, [3 CM x 4 MM = 12c]) when the distribution is normal, and the covariance matrices are homogeneous. However, each result is the average of the performance in 15 experimental conditions (c’ = [NxR:nj] = 3×5 = 15). Therefore, Table 1 condenses the result of 420 experimental conditions. A description of these results can be found in Livacic-Rojas et al. (2020), and they are also described in detail in the Supplementary material. To interpret the results it should be noted that the authors consider that the behavior of the ICs is adequate when the identification of the true DGP ≥80%.
The initial premise from which we start is the following. In order for Table 1 to report as much information as possible about the influence of the manipulated variables on the performance of the ICs, the average should represent the set of conditions that have been averaged. If this is so, a subset of the experimental conditions contained in the average should replicate the results shown in Table 1. In this case, for example, the result at the three manipulated sample size levels should be similar.
To check this issue, we asked the authors for the result of 84 experimental conditions contained in Table 1, which result from manipulating the following variables (in S1 [1 CM x 4 MM x 3 N = 12c] and in each scenario S2 and S3, [3 CM x 4 MM x 3 N = 36c]), and only in the condition R:nj = 1. The result is shown in Table 2. This result should be compared with the results shown in Table 1.
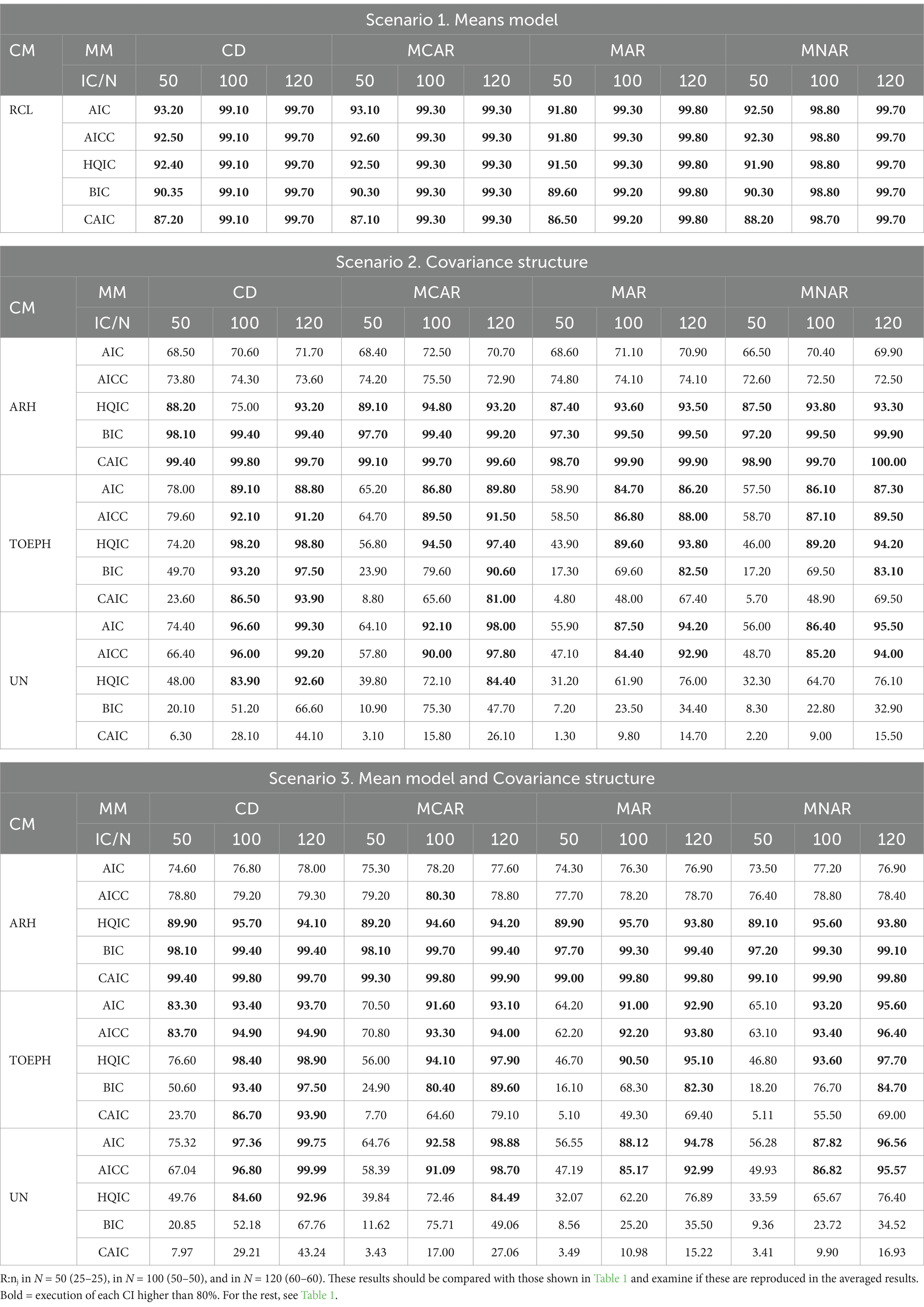
Table 2. Results provided by Livacic-Rojas et al. (2020). Percentage of occasions on which the ICs identify the true DGP in 84 experimental conditions (c) contained in Table 1 (in S1 [1 CM x 4 MM x 3 N = 12c] and in each scenario S2 and S3, [3 CM x 4 MM x 3 N = 36c]). Normal distribution, homogeneous covariance matrices, and R:nj= 1.
It is quickly observed that in some experimental conditions the averaged results (see Table 1) are substantially underestimated with respect to the non-averaged results (see Table 2). This is noticeable when the CM is TOEPH and UN, and when the MM is MAR and MNAR, to a greater extent in S2 than in S3. Table 2 shows that when N = 50, only on two occasions is the result ≥80%, and the performance of all ICs differs significantly from the performance observed at N = 100 and N = 120. It can be concluded, therefore, that the averaged results cannot be generalized to the three levels of sample size, and the impact of the other levels of the variable R:nj on the result is unknown.
To test how important sample size is, we decided to replicate the 84 experimental conditions contained in Table 2, but with a slight variation. Instead of considering N = 50, 100, and 120, this time it was N = 60, 90, and 120. This was done for two reasons. Firstly, if the simulation study is replicated correctly, the result in N = 120 should be the same (with slight variations due to chance), and it would be possible to know to what extent 5 more or 5 less subjects in both groups has an impact on the performance of the ICs. Secondly, Vallejo et al. (2010) used N = 30 and 60, and Vallejo et al. (2011) used N = 30, 60, and 120 in some conditions identical to these, and our results should converge with theirs in the manipulated conditions that are identical. The results are shown in Table 3.
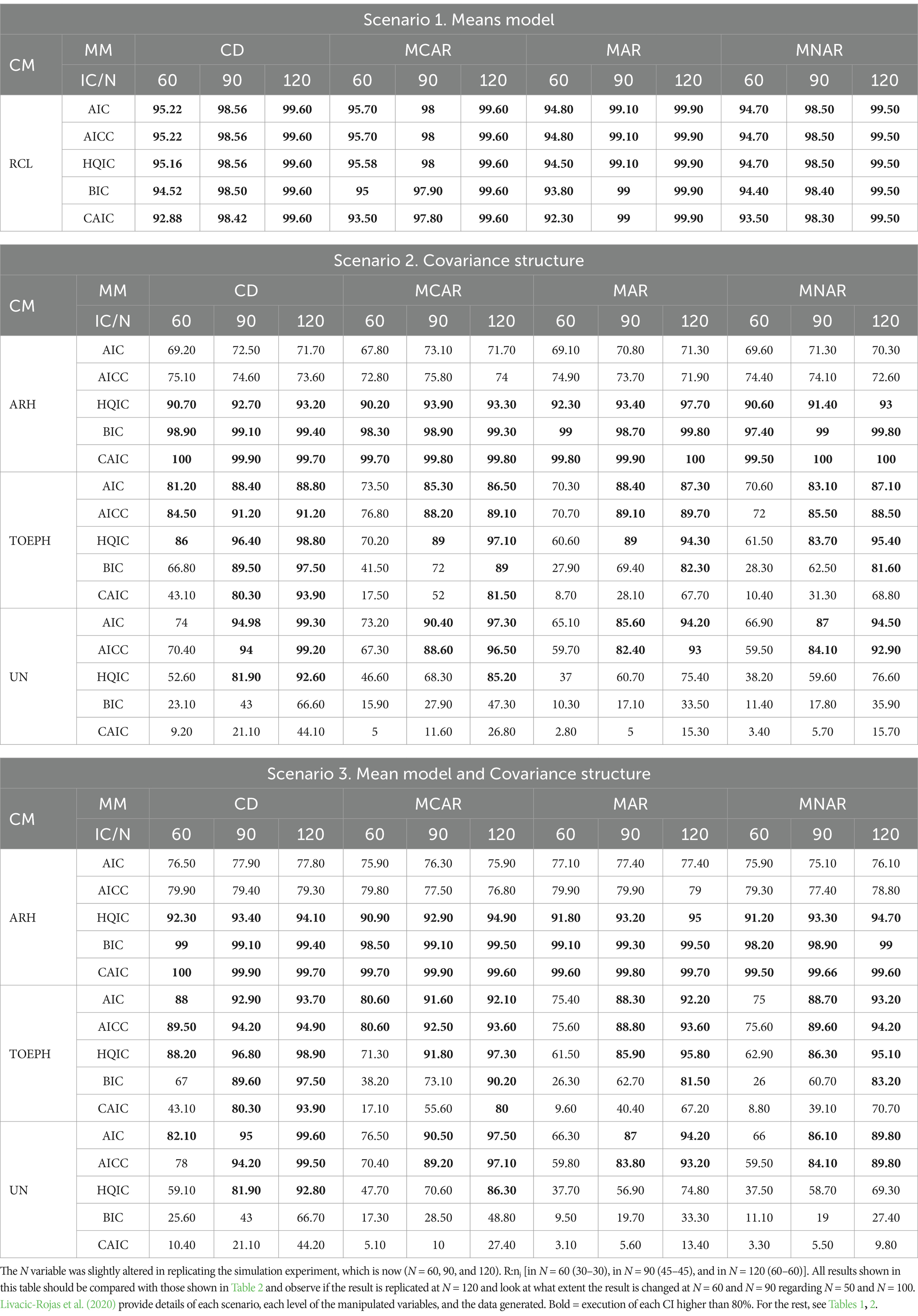
Table 3. Replication of the same 84 experimental conditions carried out by Livacic-Rojas et al. (2020), whose results are presented in Table 2. In this case, N = 60, 90, and 100. Percentage of occasions on which the ICs identify the true DGP. Normal distribution, homogeneous covariance matrices, and R:nj=1.
A detailed description of these results and the corresponding discussion is shown in the Supplementary material. What we are interested in highlighting here is that, indeed, when the sample size is N = 60 (nj = 30) the performance of all ICs improves appreciably with respect to N = 50 (nj = 25) (significantly, in Table 3 the performance highlighted in bold in S2 and S3 appears 9 times versus only 2 times in Table 2). And when N = 90 (nj = 45), the performance of all ICs is only slightly worse than when N = 100 (nj = 50). These results converge with the trend found in Vallejo et al. (2010) and Vallejo et al. (2011).
Thus, once it has been confirmed that the impact of the sample size (and presumably also the impact of R:nj) is dissolved in the average, we proceed in the following section to explain step by step the procedure we propose, which, among other issues, will allow us not to ignore the impact that the variables that have been averaged have on the calculation of the average.
In this section we exemplify step by step the process and the development involved in each of the three phases contained in the results Analysis Plan, and highlight the added value of each of them. The procedure is explained with the results of the comparative simulation study shown in Table 3.
It should be noted that the researcher has all the results in tabular form. They have all the tables on their desk and are predisposed to write their contents in the best possible way. In this case all the possible results are in Table 3, but there could be multiple tables of results.
In this case, the performance of five ICs to identify the true DGP with a partially repeated measures design (2×5) when the interaction is the term of interest in the model. The reference used (control condition) to evaluate the performance of the 5 ICs is the performance observed in the DC condition, as this condition allows for comparing the results based on the uncertainty associated with each experimental condition. Phase 1 involves three activities.
Table 4 shows, on the left, the averages of the percentages of identification of the true DGP of each of the ICs (M%ICU) in all the conditions examined (OP), and according to each level of each of the variables manipulated, S, CM, MM, and N. On the right, Table 4 shows the respective coefficients of variation (CVU). Both calculations, the M%ICU and the CVU are highlighted by symbols that allow us to visualize the exceptionality of each of the ICs (each one versus the others), and the distribution of variability in their behavior at each level of each manipulated variable (aggregated values).
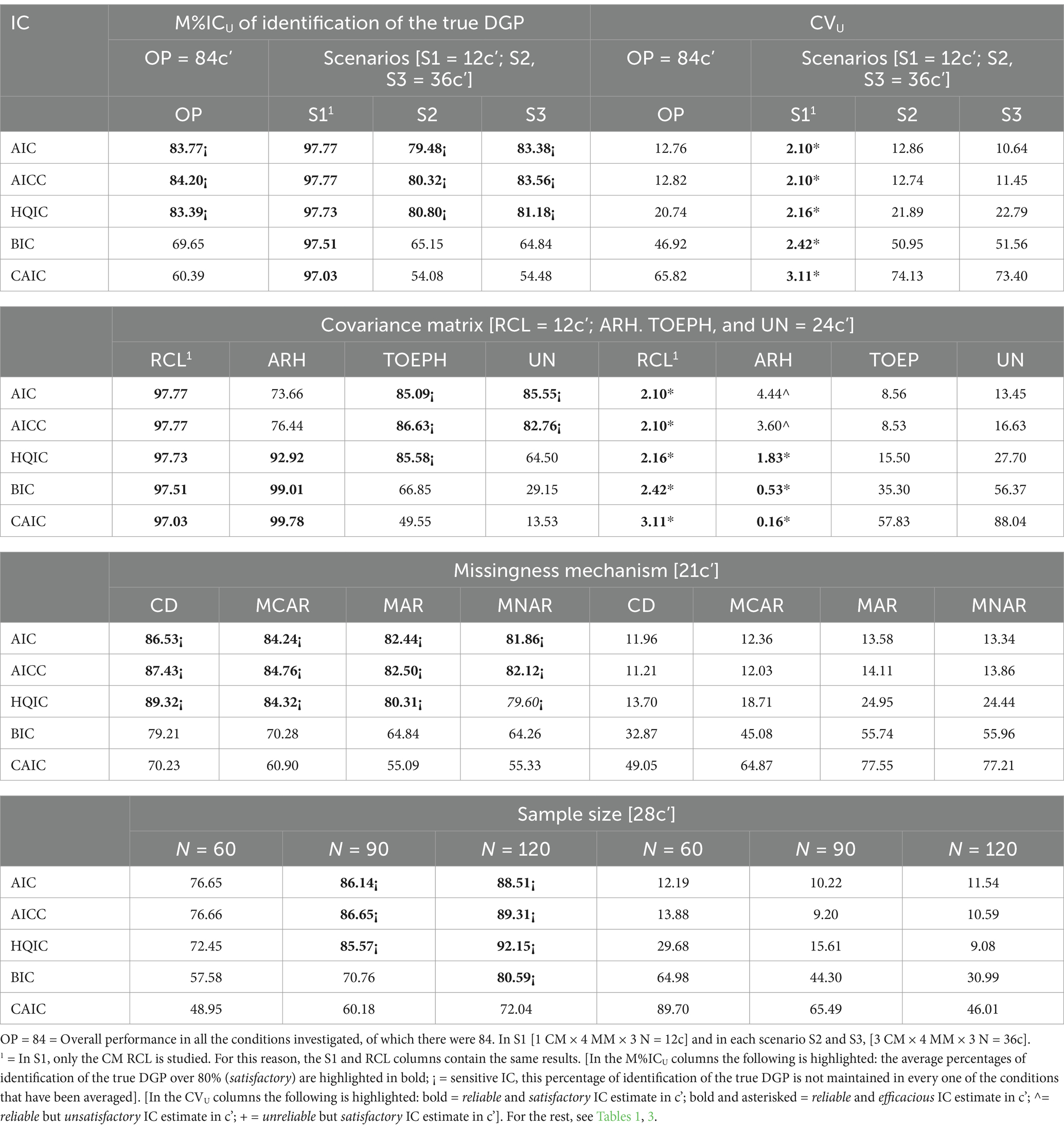
Table 4. Results of the performance (aggregated values) of each of the ICs in the set of all examined experimental conditions (OP), as well as at each level of each manipulated variable (S, CM, MM, and N) in the comparative simulation study. The left and right columns respectively show the mean percentages of identification of the true DGP of each IC (M%ICU) and the respective coefficient of variation (CVU).
To interpret the results of Table 4, and also the results of the successive tables, we establish the following criteria a priori:
With respect to the performance averages: We consider that an IC has a satisfactory average performance in the identification of the true DGP when it is ≥80% (Livacic-Rojas et al., 2020 used the same criteria). We consider it to be efficacious when it is ≥90%. In addition, we arbitrarily consider that the behavior of an IC is reliable when M%ICU represents the whole of the results on the basis of which it has been calculated, and we consider this to be the case when the difference between the highest and lowest result is not greater than 0.109. When M%ICU ≥ 80% but this condition does not hold in all the averaged experimental conditions, we say that the average estimate of the IC is sensitive. These aspects are highlighted in the table as follows. All performance averages ≥80% are highlighted in bold. Now, if this behavior does not hold for all conditions contained in that estimate, the performance is defined as sensitive and is highlighted by also adding the symbol [¡].
Regarding the coefficients of variation: There is no cut-off point beyond which a CV is considered to indicate strong or weak variability, except the observer’s judgment. The absolute magnitude of the CV is not of interest in the Analysis Plan. What we are interested in is observing the magnitude of the CV corresponding to each performance average in terms of the distribution, arrangement, and location of those magnitudes. The interest lies in showing the relative distribution of the CV magnitudes across the different analytical approaches and experimental conditions, and in this way, identifying patterns of variability. That is, in Phase 1,we propose to use the CV to observe and to compare the vulnerability or inconsistency, and therefore also the stability and robustness, of the performance of each IC with respect to the other ICs in the set of conditions that have been averaged, and thus provide added important information to the performance behavior of the ICs in the simulation study.
The information contained in the CVs will be conditional on the corresponding performance averages, and this information is also highlighted in Table 4 in four ways. One, the CV is highlighted in bold when the performance average of an IC is reliable and satisfactory. Two, it is highlighted in bold and asterisked [*], when the average performance of an IC is reliable and efficacious. Three, it is highlighted by the symbol [^] when the average is reliable but unsatisfactory, and four, it is highlighted by the symbol [+] when the average is unreliable but satisfactory.
Table 4 contains 70 different results for M%ICU (note that columns S1 and RCL contain the same results). The same is true for the results referring to the CVU. Table 4 allows us to appreciate the following:
A. On 40 occasions (57.14%), an IC shows satisfactory behavior in the set of averaged conditions (M%ICU highlighted in bold). However, on 32 occasions (80% of them), the M%ICU is highlighted with the ¡ sign, which means that we have qualified them as sensitive. In other words, on these 32 occasions, the M%ICU does not represent the set of averaged conditions, and therefore, in no case can it serve as a reference for use. That is, the result cannot be generalized to the set of conditions that have been averaged (c’). As can be seen, no IC is satisfactory in all the conditions evaluated (see column OP).
B. The performance of all of the ICs in conditions S1 (CM RCL) and [ARH(1)], is reliable (see CVs highlighted in bold, with and without the symbol * and CVs highlighted with the symbol ^). In these conditions, only in these (10 occasions, 14.28%), the maximum difference between the highest and lowest percentages of identification of the true DGP of all the conditions manipulated is ≤0.109. In this case, we consider that the mean percentage is representative of the set of percentages involved in the calculation.
However, in ARH(1), AIC and AICC meet the reliability condition, but they have neither a satisfactory performance (i.e., its execution is not ≥80%; they are 73.66 and 76.44% respectively) nor an efficacious one (i.e., its execution is not ≥90%). Thus, the M%ICU and CV are not highlighted in bold. However, the CV is highlighted with the symbol [^]. Therefore, they have no practical use under this condition.
On the other hand, all of the ICs in the S1 condition (CM RCL), and consistent ICs (BIC, CAIC, and HQIC) in the ARH(1) condition meet the reliability condition and estimate with maximum efficacy on all occasions, with more and fewer subjects, with and without loss of data. Therefore, the M%ICU are highlighted in bold (without any added symbol), and the respective CVU are highlighted in bold and with the [*] symbol. There are 8 occasions (11.42%).
That is, in conditions S1 (CM RCL) and [ARH(1)], the result M%ICU in all of the ICs is maintained in all the conditions involved in the calculation of the average, which in this case are the levels of variables N and MM, and therefore, it can be said that the behavior of the ICs is insensitive to the variation studied in variables N and MM in those conditions.
C. The CVUs allow us to appreciate three clusters of behavior, AIC-AICC, HQIC, and BIC-CAIC (with the dash we wish to indicate that the difference in the performance of these ICs is minimal). In Table 4 it can be easily seen that the consistent ICs (BIC, CAIC, and HQIC), to a greater extent BIC and CAIC, are the most sensitive and vulnerable in all the experimental conditions examined (OP) and in scenarios S2 and S3. Also the ICs are the most sensitive and vulnerable to data loss and sample size. In all conditions where the ICs are vulnerable, the CV is not highlighted in bold, and in addition, its corresponding M%ICU is either not highlighted in bold, or it is highlighted with the symbol ¡ (sensitive). Therefore, this information containing the average value is misleading and can lead to errors if it is generalized and used as a valid criterion for all situations.
D. Other surprising patterns are also identified in Table 4.
First: It is clear that the larger the sample size, the greater the efficacy of the ICs, and the more similar the performance of all of them is to each other.
It is common to find higher test power in any analytical procedure when the sample size is higher. In this case this does not seem to be the case, at least not for all ICs in all conditions (recall what was discussed in point B). Table 4 shows a significant change between N = 60 and N = 90, however, the change experienced at N = 90 with respect to N = 120 is very small. Moreover, the magnitude of the change is uneven among the ICs. A clear asymmetry can be seen between the performance of AIC-AICC-HQIC and that of BIC-CAIC. In other words, to improve the performance of an IC, increasing the sample size will not always be a practical solution for all of them in all the conditions studied here. In other words, this generalization cannot be made.
Second: The similarity of the CVU in MAR and MNAR is noteworthy. Also noteworthy is the equidistance of the magnitude of the CVUs in MCAR with respect to CD and with respect to MAR-MNAR.
It has been shown that when the loss mechanism is MNAR, the impact on the performance of analytic approaches is much larger than when it is MAR. It has also been shown that the consequences are not significant (generally) when the loss mechanism is MCAR (see Fernández-García et al., 2018). That is, the impact of data loss on the performance of ICs seems to follow a different pattern from that observed in other analytical approaches. Moreover, here too, an important asymmetry in the performance of ICs is also apparent, and that is that in the performance of AIC-AICC, the MM seems to have very little impact, certainly much less than in the execution of BIC and CAICC.
Third: The similarity of the CVUs of S2 and S3 is noteworthy.
In summary: The overall results examined in this way, using the criteria established a priori with respect to M%ICU and CV, and being highlighted in the way shown in Table 4, have enabled us to extract very valuable information. Some of this information is definitive and firm (that referring to the reliable behavior of the ICs in S1 conditions and in ARH in S2 and S3). This information can certainly be generalized to all levels of the rest of the manipulated variables. Moreover, it predisposes us and warns us about where we have to focus or direct our attention in the interpretation, reading, and explanation of the specific results, and thus we are able to explain the causes of the surprising patterns we have observed. But before we do so, it will help us, together with the result of the second activity, to form the non-arbitrary decision criteria on the basis of which to decide which specific results to show in the paper.
This information can be obtained by regression or by analysis of variance (These are the analytical solutions referred to in the introduction). We recommend performing the ANOVA instead of the regression because it is easier to study the simple effects in the ANOVA, but everyone has a preferred way of proceeding. In any case, we recommend emphasizing the effect size more than p, especially of the interactions, and we recommend being careful when interpreting interactions of more than 2 variables that are statistically significant.
Table 5 shows the results of the ANOVA [(2x3x4x3) SxCMxMMxN] (excluding S1 because only one CM is examined). The ANOVA shows that all the variables, except S, explain differences in executing the set of ICs (Set-ICs). However, only the sources of variation referring to MM and the interaction CMxN are interpretable.
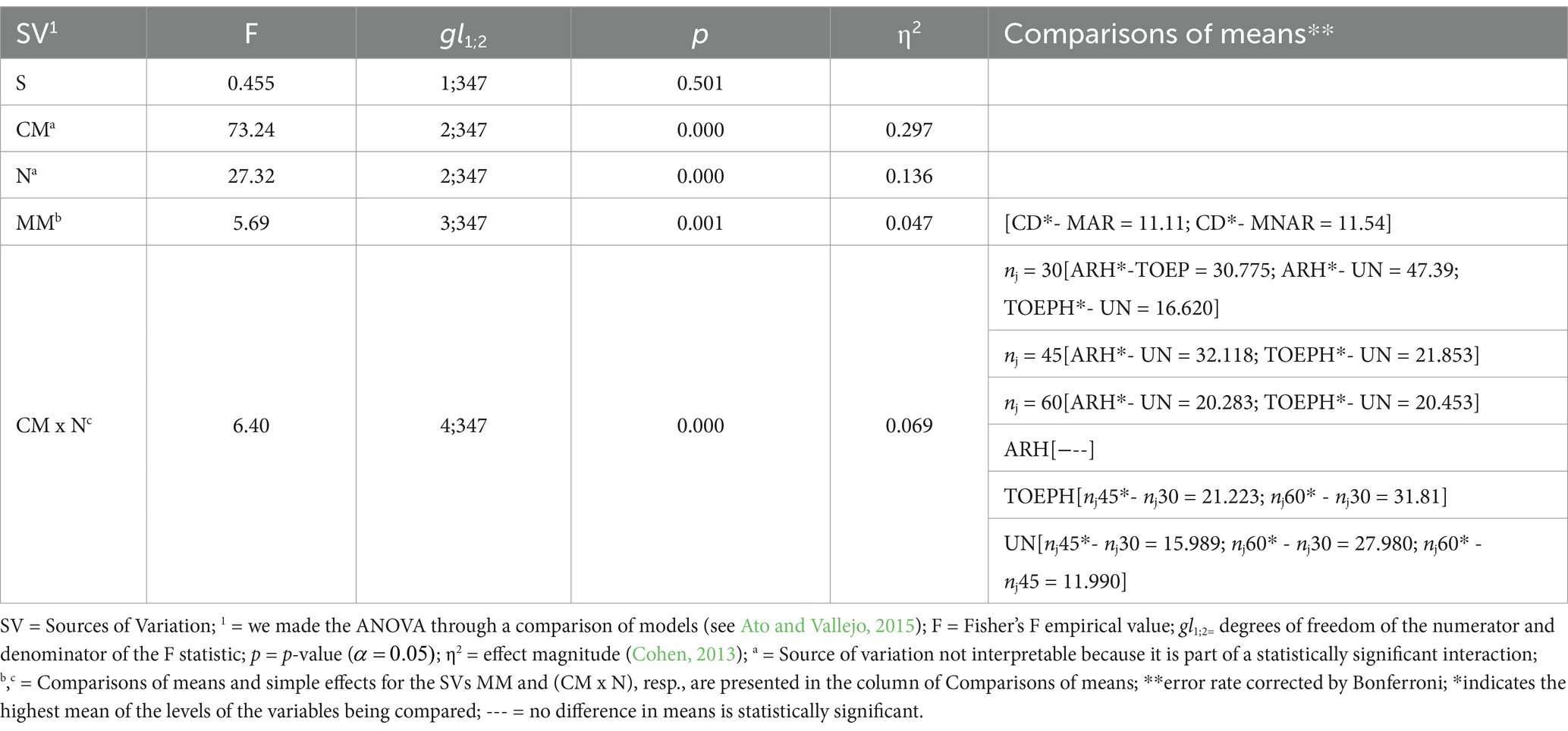
Table 5. ANOVA results [(2x3x4x3) S x CM x MM x N] (excluding S1 because only one CM is examined).
Regarding MM, the comparisons of means highlight differences in the performance of the Set-ICs between CD and MAR, and CD and MNAR.
Regarding the CMxN interaction, the simple effects show that when the N = 60 (nj = 30), the Set-ICs behave differently in the three CMs studied. However, when N ≥ 90 (nj ≥ 45), the statistically significant differences in performance in the Set-ICs are between ARH and UN and between TOEPH and UN.
On the other hand, when the CM underlying the data is ARH, the efficacy of the Set-ICs is the same in all the Ns investigated; when it is TOEPH, the performance in the Set-ICs is similar when nj ≥ 45, and in these cases, they are different from nj = 30. Finally, when the CM is UN, the estimate in the Set-ICs in the three Ns studied is very different.
These results are very illustrative, but nothing tells us to which IC they apply. Nevertheless, it can be seen that these results converge with the results described in the previous section, and therefore, they also predispose us and warn us about where we have to focus or direct our attention in the interpretation, reading, and explanation of the specific results. Prior to that, these results together with the ones in the previous section will allow us to form the non-arbitrary decision criteria on the basis of which to decide which specific results to show in the paper.
The information provided by the two previous Activities is very rich, and it is impossible to display and detect in the tables of results that the researcher has on their desk (Table 3, but there could be many tables). Moreover, separately, neither of them allows us to make an accurate judgment about each IC in each of the experimental conditions studied, with the exception, in this case, of the exceptional results revealed in Table 4.
However, we have been able to verify that the result of the ANOVA converges with the patterns that we have observed in Table 4. Thus, together, both activities will allow method researchers to make an informed and non-arbitrary decision about which results to present in the main text of the article when it is not possible to present all results due to space constraints (Note that all results should be made available to readers in some form, on a web page, in the Supplementary material, or available on request from the authors).
The results shown in Table 3 take up little space and could be presented in full. But let us imagine that there is not room for all of them. We would have two options:
First: The researcher could choose to present a subset of results.
In this particular case, the author could present the results of S1, and either S2 or S3. This would be justified because the ANOVA did not detect statistically significant differences between S2 and S3, and because M%ICU and CVU (see Table 4) are very similar for the five ICs in S2 and S3 (see point D in section 3.1.1).
The number of results could be reduced even further. One could present the results of S1, S2 (or S3), but as for the MM variable, include only the results in CD, MCAR and MAR (or MNAR), for the same reason as above. That is, because of the similarity of M%ICU and CVU in MAR-MNAR, and because the performance of the ICs at the studied levels of the MM variable is not moderated by the presence of other variables (i.e., they are not part of an interaction, and mean comparisons support this aspect).
Second: The researcher may choose to average some results.
Our criterion is that the results of variables that are part of an interaction should never be averaged, and neither should the results of different scenarios. Thus, we can make the decision to average the results of each IC in the set of MM levels.
The averages and respective CVs should be presented together as shown in Table 6. We call this table the Traceability Table. In this case, the CV will show the variability experienced by the performance of each IC in the set of MM levels. If each detail observed in Table 3 (in the tables of the specific results that the researcher has on their desk; see the description of said results in the Supplementary material) can be observed in the Traceability Table (observing both, M%ICU and CVU), the purpose of this resource would be justified and the criterion used for averaging will have been the correct one.
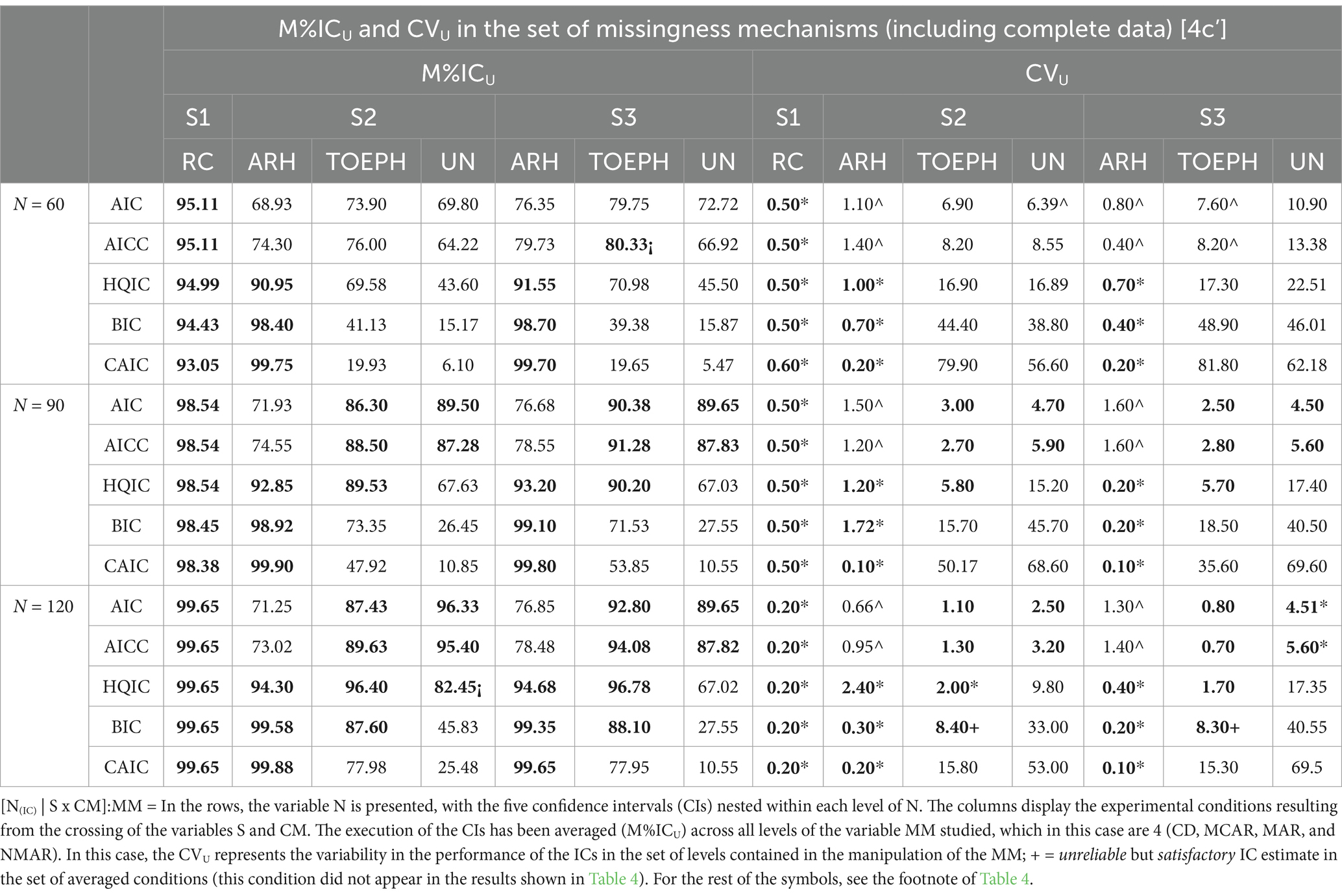
Table 6. Traceability of each IC submitted to evaluation in the comparative simulation study. Mean percentages of identification of the true DGP of each IC in [N(IC) | S x CM]:MM, and your respective coefficient of variation.
The Traceability Table should replicate the results revealed in Table 4, i.e., the results rated as reliable, the 3 clusters of ICs that were observed based on their behavior, and one should find therein the explanation for and delimitation of the surprising patterns that were observed. It should also reflect the results found in the ANOVA (difference of measures and simple effects). If that is achieved, averaging is justified, and therefore, it will be justified to replace results tables with Traceability Tables. In Section 3.1.1 and 3.1.2, we wrote “… Moreover, it predisposes us, warns us, about where we have to focus or direct our attention in the interpretation, reading, and explanation of the specific results.” This is what we meant.
Item extra: The Traceability table shows that BIC and CAIC are the worst performing ICs when the CM is UN and TOEPH. Moreover, they are very sensitive to data loss, i.e., their behavior is “scourged” by the data loss mechanism (higher CVUs). However, this scourge, which is due to the MM, benefits from an increase in sample size in TOEPH but not in UN. That is, when the covariance matrix is UN, BIC and CAIC are collapsed; they do not react to an increase in sample size. This aspect cannot be clearly seen in Table 3 (in the results tables that the researcher has on their desk), although it can be detected in the Traceability Table.
Thus, although it may be possible to present all the results in the paper, when the results are averaged on the basis of a manipulated variable that does not interact with other variables and the result is observed together with the CVUs, we can find information that is impossible to see in the results tables (in this case, in Table 3, or in the tables that the researcher has on their desk), and that is also impossible to find in Table 4. At least, the aforementioned detail had gone unnoticed by us.
We recommend identifying the Traceability Table. We have done it this way, [N(IC) | SxCM]:MM. What is contained in the table is shown in square brackets. Rows and columns are separated by [|]. In the rows, the variable N is presented, and the five ICs are nested at each level of N. In the columns, the experimental conditions resulting from crossing the variables S and CM are shown. The performance of the ICs has been averaged (M%ICU) over all levels of the variable MM, which in this case are 4 (CD, MCAR, MAR, and NMAR). This is represented by [:].
The corollary of the results derived from the three activities of Phase 1 could be the following: the result of the three previous activities has allowed us to verify that the variance and covariance matrix strongly determines the behavior of the ICs. That is, there are ICs suitable for each CM, at least, when the data of a repeated measures design can be explained with a non-additive model such as this one. In other words, there is an IC for each matrix. This aspect is also supported by the fact that the ICs that perform better in each situation are much more robust to variation in the levels of the variables MM and N, and the ICs that are less appropriate in each condition are much more vulnerable to variation in the levels of the variables MM and N (always, of course, taking into account the context of the variables manipulated in this comparative simulation study).
For this, we calculate the CV of the set of five ICs (Set-ICs) in each of the 84 conditions resulting from manipulating the variables in the comparative simulation study, and we construct Table 7. We call the information contained in Table 7 the Variability Set.
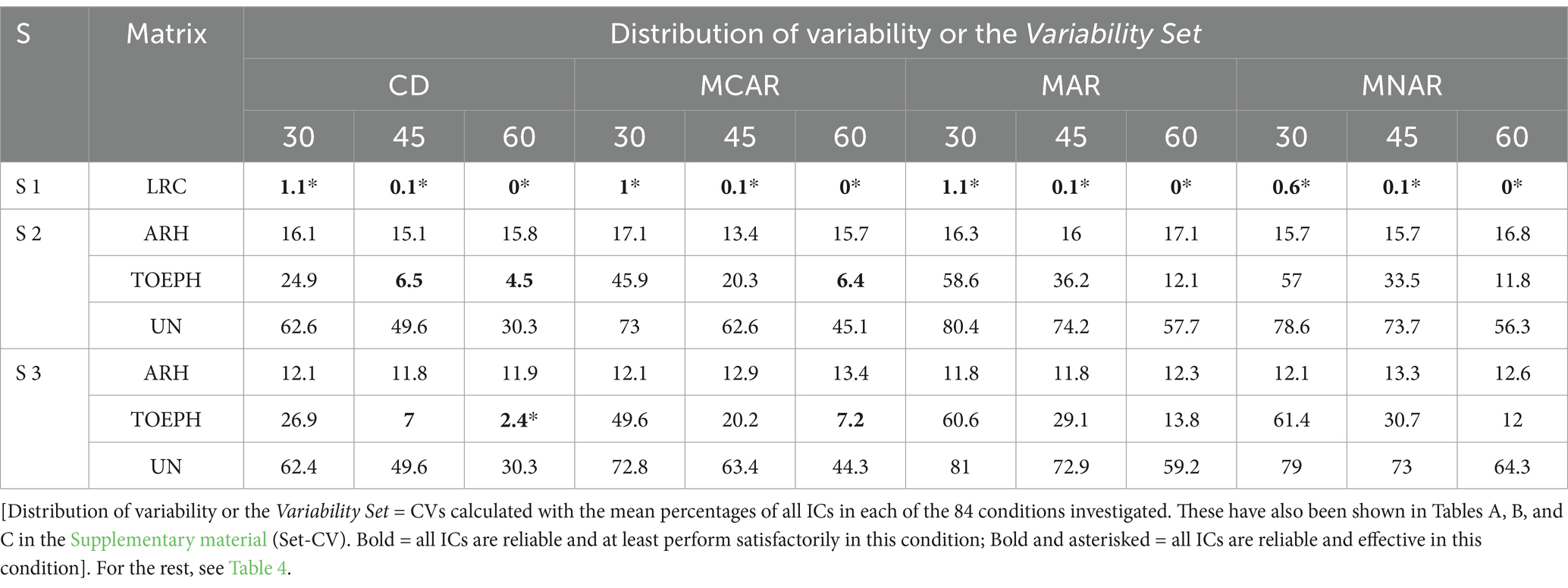
Table 7. Distribution of variability in terms of CV in the estimation of the percentage in identifying the true DGP of the set of ICs (Set-ICs) in each of the 84 conditions investigated. Variability Set.
In the Supplementary material, we present the results of Table 3 segmented by scenarios. These are Tables A, B, and C, which contain the results of S1, S2, and S3, respectively. These tables also contain the rows headed by Set-M%IC and Set-CV. The M%IC values have no substantive interpretation; they are of no use. The important information is what we can extract from the CVs. The presentation of all of the CVs makes up the Variability Set.
The distribution of the magnitude of the CVs in the Variability Set will allow us to observe how, in the LMM, the combination of the variables MM (considering the complete data a special value of the variable) and N, condition the behavior of the Set-ICs in identifying the true DGP established by the means model and by the covariance matrix that underlies the data in each one of the three scenarios. This information is implicit in the results shown in Table 3 (in all the tables that the researcher has on their desk), and also in the results shown in Table 6 (Traceability Table), but it is impossible to see it. The overall results displayed in Tables 4, 5, similar to how they predispose us to observe the specific results (whether they are all displayed, only some are displayed, or averaged results are displayed in the Traceability Tables), also predispose us to observe the information displayed in the Variability Set in Table 7. However, they do not allow us to extract the information provided by the Variability Set. This additional information, which is not readily apparent, could be captured metrically in this way.
We interpret the CVs in the same way as they were interpreted in Table 4 and in the Traceability Table. The results that can be extracted from the Variability Set are as follows:
At first glance, what strikes us most are the CVs that are highlighted in bold. In those conditions, and only in those, all five ICs identify the true DGP at least 80% of the time. Now let us examine this in more detail.
In S1 the efficacy of all ICs is always above 90%. We have seen that the ICs do not behave exactly the same in all experimental conditions of S1, however, the difference between them is so small in each condition, and the influence that the MM and N variables have is so small as well, that at no time is the identification of the true DGP less than 90%. For this reason, we qualify S1 in the Variability Set as a safety zone.
In S2 and S3, when the CM is TOEPH, there are also conditions where it can be recommended to use all five ICs. We note that in CD condition, when nj ≥ 45 all the ICs have a satisfactory performance (Even in S3 when nj = 60, the efficacy of all the ICs is above 90%, and it is therefore another safety zone). The loss of MCAR data penalizes the Set-ICs result, but this satisfactory performance is maintained, although only when nj = 60. The conditions observed in the Variability Set where we can recommend all the ICs, because all of them identify the true DGP at least 80% of the time, are called confidence zones.
At first glance, another very unique aspect that occurs only when the CM is ARH(1) is also striking.
When the ARH(1) matrix intervenes in the true DGP, only in this condition, the Set-ICs do not experience significant change either as a function of MM or as a function of N, and it is the same in both scenarios. We had already observed in Tables 4, 6 that in this condition no IC experiences significant change either as a function of MM or as a function of N. We are not surprised by this aspect; therefore, because this unique behavior occurs in this condition, and it is clearly seen in the Variability Set; we call it the protected zone.
What we do find surprising now is the following: When the CM is ARH(1), the magnitude of the CVs in S3 with respect to the magnitude of the CVs in S2 drops in all conditions (MMxN) to the same extent (we could say it drops en bloc). To explain this issue, we had to examine Table 3, and we observe that the identity of ARH(1) in S3 impacts significantly on the AIC and AICC ICs. AIC and AICC do not have the best behavior ever in ARH(1); however, they improve their performance in S3, getting closer to the performance of the consistent criteria, which in this situation show maximum efficacy. For this reason, the CVs are lower in S3. This observation led us to identify other unique phenomena, such as the following, which surprised us even more:
We noticed that this change in behavior is not experienced by the other three ICs, at least not in a significant way. Moreover, AIC and AICC also experience a better performance in TOEPH and UN in S3; however, it does not have an impact on the CVs as in ARH(1), and that is because in TOEPH and UN, AIC and AICC are the best performing ICs, and the margin of improvement they experience is smaller.
Again, at first glance, another very unique aspect is also striking when we focus on the TOEPH and UN CMs, and this issue is in line with what was described above:
If we look at the TOEPH and UN CMs, we observe that the CVs are much higher in UN (likewise in S2 and S3). The results found in Phase 1 showed that when the CM is TOEPH and UN, the AIC and AICC ICs perform best, and the performance in both CMs is similar. Again we go back to Table 3, and also to the Traceability Table, and in them we find the explanation. What is happening is that the more complex the CM is (UN is more complex than TOEPH), the more the performance of the ICs differs (those with the best performance from those with the worst). And in the cases of the ICs that perform the worst, the more complex the matrix, the more they are affected by data loss and by N. This is the reason for the difference in CVs between the TOEPH and UN matrices.
We believe that we would not have noticed this if we had not constructed the Variability Set. Furthermore, we believe that we would not have found an explanation for it if we had not analyzed the results as was done in the three activities of Phase 1.
In the Variability Set, we can also identify two other aspects that have already been observed. These are as follows:
One: The CVs show that the whole set of ICs is sensitive to data loss. The most notable reaction occurs when the MM is MCAR concerning CD. Between MCAR and MAR-MNAR, the difference is much smaller. This occurs in all three scenarios and in the four covariance matrices underlying the data.
Two: In both Scenarios, S2 and S3, in both CMs, TOEPH and UN, the CV shows that the increase in the sample size has a systematic effect on Set-ICs, causing a tendency to homogenize behavior. This can be seen by observing how the CV decreases in each condition as the N increases. However, we know that this issue cannot be generalized to the five ICs, as already discussed in the previous section.
In summary: From our point of view, the Variability Set provides us with information that is very relevant and different from the information provided by the results found in Phase 1. This information is impossible to obtain by looking at the multiple tables of specific results that the researcher might have on their desk or by looking at the Traceability Table. We believe that multiple graphs could not provide this information either.
Before moving on to Phase 3, we’d like to present a metaphor of something that is shown in Figure 1 when the Analysis Plan is plotted. Let us imagine that we are about to walk the Camino de Santiago, specifically, the French Camino de Santiago. We would say that Phase 1 would be the equivalent of doing the Camino on foot or by bicycle, and the Variability Set in Phase 2 would be like doing the Camino in a balloon or in a light aircraft. When we outlined the Analysis Plan, we wrote that the Variability Set will allow us to visualize the streams of influence that the variables manipulated in the simulation study have on the performance of the set of analysis approaches under study. We were referring to these results observed by means of the Variability Set.
In the next section, we will only provide the information that applied researchers need to make a decision. We will spare the applied researchers, if they wish, this long route, which from our point of view is of great interest, but only the method researchers will appreciate its magnitude.
Now the researcher will determine which are the analytical procedures of choice (in this case, the ICs of Choice), and he or she will present the schematization of their performance. The ICs of Choice are easily chosen by looking at the full results tables (if it has been possible to show the results in the paper) or by looking at the Traceability Table results (when it has been possible to form a non-arbitrary decision criterion). If the volume of results is very large, the researcher might consider presenting some results one way and other results another way. This information is shown in Table 8.
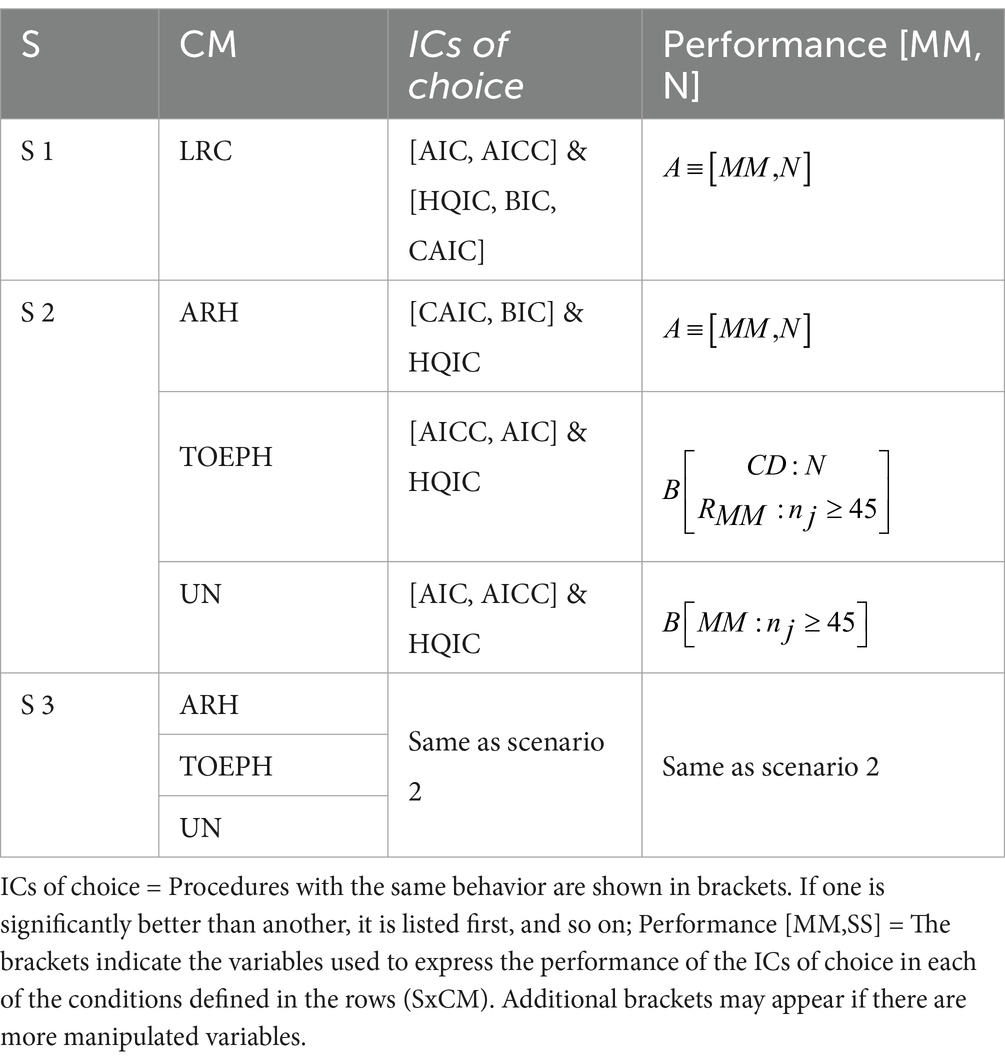
Table 8. Presentation of analytical procedure(s) of choice and representation of the conditions in which they present optimum performance.
The ICs of Choice are the ICs that have demonstrated, at least, a satisfactory performance (≥80% of identification of the true DGP) in the set of conditions (or in a subset of conditions) defined by the manipulated variables, in this case, MM and N in each condition defined by the true DGP. It could be the case that no IC was effective.
In the description of the performance of the ICs of Choice, first appears the qualification reached according to the empirical efficacy demonstrated. It is highlighted by means of the letters A, B, and C. A indicates that all the ICs of Choice achieve an efficacy greater than 90% under the conditions specified (indicated in square brackets). B indicates that the ICs of Choice only achieve an efficacy greater than 90% under some of the specified conditions. C indicates that in no case do the ICs of Choice reach an efficacy of 90%, but in all or some of the manipulated conditions (the conditions specified in square brackets), the performance is satisfactory; that is, the percentage of identification is ≥80%.
Regarding performance, ≡ indicates that the performance is the same in all conditions expressed in brackets [in this case for example, it is in MM and N (in S1), and then, in S2 and S3 (in CM ARH)]. If the performance is not the same, the conditions under which the ICs have an optimum performance are indicated. For example, the row corresponding to the TOEPH covariance matrix shown in brackets [CD: N, and RMM:nj ≥ 45]. This indicates that in the condition of Complete Data, the rating B occurs in all sample sizes, and in the rest of the MMs (RMM), only when nj ≥ 45.
This is the information that applied researchers, if they so desire, need to locate to make an informed decision.
A proof-of-concept Shiny application that can be run locally and demonstrates the main functionalities proposed in this study.
We have developed three Shiny applications in R, designed to facilitate the flexible evaluation and interpretation of the results obtained. These applications allow the use of both the data presented in this article and data from another research paper. The algorithms implemented in R (RStudio release 2024.04.2: Build 764), along with the databases and supplementary documentation (pdf format), are available at the following address (see index):
https://drive.google.com/drive/folders/17WecxmWw2ZsngMGtACN0EYF08jGsOFke?usp=drive_link.
Figures 2, 3 graphically represent some results of Tables 4, 7, respectively. This is just an example of how the results presented in the tables can be visualized to aid in their interpretation. These are some of the visualizations that can be obtained using the Shiny application.
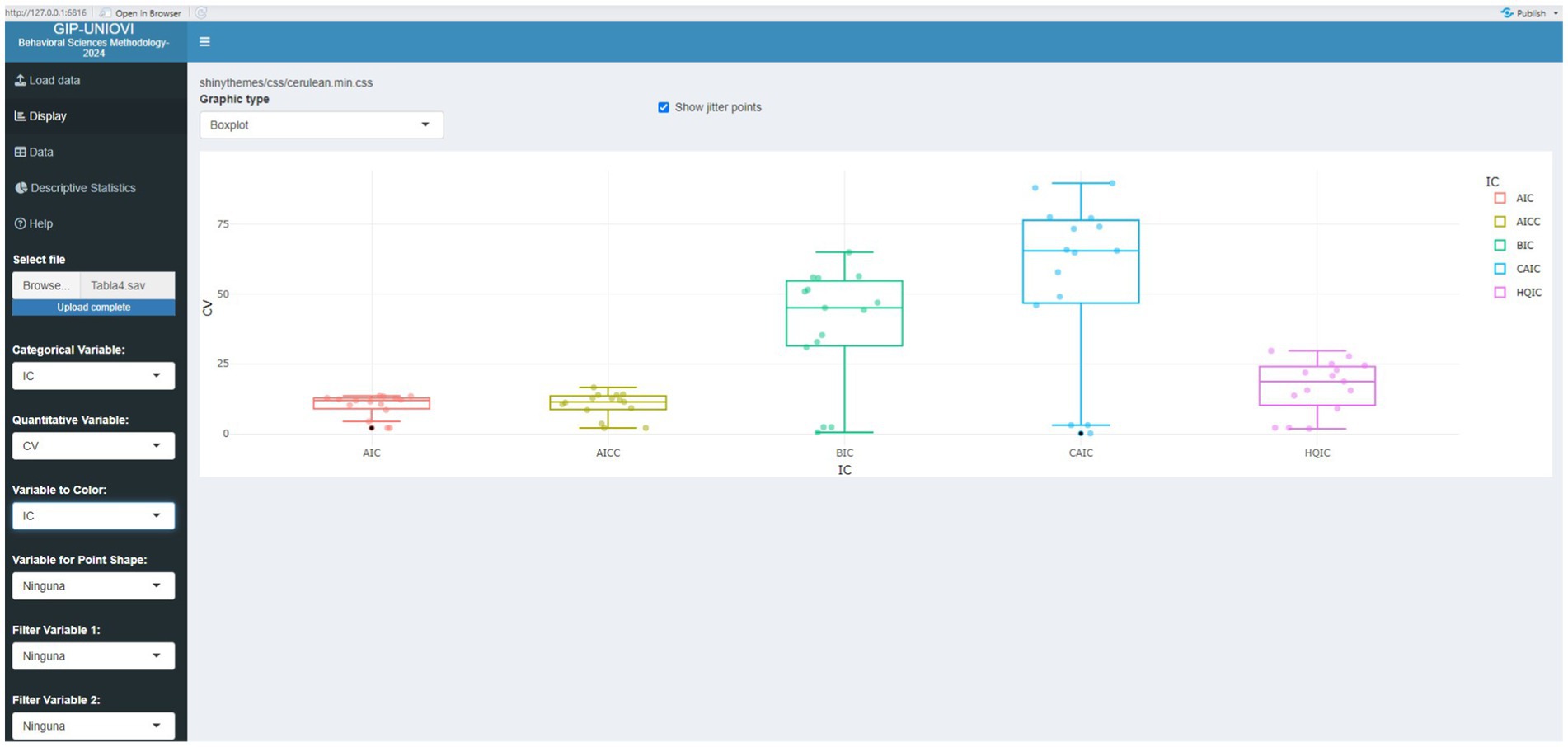
Figure 2. Visualization of selected results from Table 4 using the Shiny application.

Figure 3. Visualization of selected results from Table 7 using the Shiny application.
The main objective of this research was to develop an alternative way of analyzing, presenting, and communicating the results derived from the comparative simulation studies. A three-phase results Analysis Plan is proposed, which is especially useful and necessary when a large number of variables are manipulated in the simulation experiment, which inevitably generates a large number of results.
The contributions and benefits of this Analysis Plan can be summarized in four points:
First: In order to report as much information as possible without omitting relevant information, we propose a way of forming a useful and non-arbitrary criterion that allows us to know two things: (1) whether the set of all the results found could be sufficiently represented by a subset of results, and (2) whether some or all of them could be presented in an averaged way without losing the possibility of knowing to what extent and in what way the variables (or levels of variables) on the basis of which the average has been made have an influence.
Second: The Analysis Plan makes it possible to extract relevant and novel information that cannot be obtained in other ways of presenting the results. It is the first time that the construction of Traceability Tables is proposed when deciding to average some results, and it is the first time that the construction of the Variability Set is proposed. The Traceability Tables show the performance of each of the analysis approaches studied under the desired experimental conditions, as well as the variability in their behavior under the particular conditions under which they were averaged. The Variability Set will make it possible to display the influence that the variables manipulated in the simulation study have on the execution of the set of analysis approaches under study.
Third: The examination of the CV provides very valuable information with a different meaning depending on whether it is calculated in the overall average results, in the Traceability Tables or in the Variability Set. Since the CV must always be accompanied by the corresponding mean values, the symbology proposed for both results allows us to quickly grasp three aspects: the peculiarities of the different analytical approaches under study, the differences between them, and the influence of the manipulated variables both on each analytical approach and on the set of all of them.
Fourth: An R Shiny application is provided (still under development) that enables the visualization of some of the most outstanding results of the example presented and that can be used by any researcher who wishes to observe his or her results from this point of view.
The Analysis Plan has been exemplified by the results of the replication of a subset of the experimental conditions of the research conducted by Livacic-Rojas et al. (2020). The purpose of this study was to examine the performance of the AIC, AICC, HQIC, BIC, and CAIC information criteria as provided by the SAS PROC MIXED program to identify the true DGP in a partially repeated measures design when interaction is the term of interest in the model.
Through the example it has been shown that averaging the results without a justified empirical criterion leads to hiding information that may be very relevant, and it also leads to the generalizing of erroneous information to the conditions that have been part of the average. It has also been shown that the proposed Analysis Plan allows us to extract and visualize a great amount of information about the behavior of the CIs, of each one individually, and of the set of CIs as well, including information that was unknown until now. This is because the CV provides a relative measure of variability, making it particularly useful for comparing the stability and performance of different analytical approaches across various experimental conditions.
Beyond the specific results obtained in the simulation experiment for each of the analytical approaches studied, methodologists will be able to identify through the Variability Set the safe zones and the most vulnerable zones, the latter being where the need to advance the research is more imperative due to the higher risk (and potential uncertainty) when choosing the appropriate statistic (such as an IC, in the case of the example shown). Zones where no analytical approach is effective may even be identified.
We believe that this Analysis Plan of the results constitutes a novel approach for examining the performance of any analytical approach in the comparative simulation studies, using any relevant measure that the methodologist considers appropriate (Power, Type I error, Bias, etc.). However, we find it necessary to clarify that when the mean of a performance measure is close to zero (e.g., bias), the CV may yield disproportionately high values, which could lead to misleading conclusions if interpreted directly. Therefore, this issue warrants further analysis and should be addressed in future research. Additionally, we have observed that the same CI may perform exceptionally well under certain manipulated conditions while exhibiting poor performance under others. Similarly, within a single experimental condition, substantial variability can be found in the performance of the five CIs under study. This pattern may arise in any analytical method evaluated through simulation studies. In both cases, the CV could also be very high, which is likely attributable to a highly skewed distribution of means. Although the validity of this procedure does not depend on the absolute CV values, in such cases, employing a robust CV instead of the classical CV used here may be warranted (see Ospina and Marmolejo-Ramos, 2019). In other words, it is crucial to determine whether the information provided by a robust CV differs from that offered by the classical CV. Thus, this matter warrants further investigation and should be addressed in future research.
Despite the aforementioned concerns, the example developed demonstrates that the classical CV facilitates a systematic and comparative assessment of variability patterns across multiple conditions, supporting its adequacy for the intended purpose. Therefore, we believe that this Analysis Plan can be applied in all Monte Carlo simulation investigations, regardless of the object of study, and regardless of the set of statistical procedures being studied. For this reason, the Analysis Plan constitutes a new tool that also allows us to reanalyze the results of published simulation experiments to extract additional and complementary information to that already obtained. It will also allow us to map the effectiveness of analytical approaches under multiple experimental conditions, integrating research carried out by different methodologists.
Thus, in line with the previous considerations and the new information obtained during the exemplification of the Analysis Plan, we deem it essential to continue exploring whether relevant new findings are concealed within the remaining averaged results presented in the research by Livacic-Rojas et al. (2020). This issue will be evaluated in two stages. First, we will examine the impact of the unbalanced design on the CIs’ performance and the effect of different relationships between group sizes and covariance sizes. In the second stage, we will apply the Analysis Plan to conditions involving non-normal distributions. Throughout both analyses, we will continue developing the Shiny application to implement a beta version that is accessible online through an appropriate platform.
Finally, we emphasize that Phases 1, 2, and 3 are independent. Therefore, simulation studies may report the results of all three phases (the most comprehensive approach), the first two phases, or only the first phase. In this regard, we recommend that, regardless of whether all findings are reported, only a subset is presented, or averaged results are shown, the Variability Set (Phase 2) should also be conducted for two key reasons. First, this is the first time such an analysis has been proposed. Just as in the exemplification of the Analysis Plan, the Variability Set allowed us to extract previously unobserved information, this approach may uncover novel and highly relevant insights in other research contexts. Second, beyond its previously highlighted advantages, this analysis could also help identify factors contributing to the lack of result replicability, particularly when certain data analysis approaches are employed.”
Lastly, we argue that applied researchers should have access to essential findings from simulation studies to make well-informed decisions when analyzing their data. This would spare them the challenge of deciphering the complexities of simulation research and the statistical formulations underlying their methods. More importantly, providing clear and structured methodological insights is crucial for fostering rigorous data analysis practices and, ultimately, for ensuring the replicability of scientific findings. To this end, in Phase 3, we propose a structured approach for reporting simulation results in a way that is both accessible and informative. However, our framework is not the only possible solution. What matters is not the specific approach adopted, but rather that methodological findings are effectively communicated to applied researchers. Our Analysis Plan represents one possible strategy to bridge the gap between methodological advancements and their practical application, strengthening both the reliability of statistical analyses and the reproducibility of empirical research.
The original contributions presented in the study are included in the article/Supplementary material, further inquiries can be directed to the corresponding author. The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation. Additionally, they can be accessed through the Shiny application link.
MF-G: Conceptualization, Data curation, Formal analysis, Funding acquisition, Investigation, Methodology, Writing – original draft, Writing – review & editing. GV-S: Conceptualization, Data curation, Formal analysis, Investigation, Methodology, Writing – original draft, Writing – review & editing. PL-R: Data curation, Formal analysis, Investigation, Supervision, Validation, Writing – review & editing. FH-D: Data curation, Formal analysis, Methodology, Software, Supervision, Validation, Writing – review & editing.
The author(s) declare that financial support was received for the research and/or publication of this article. This work was supported by the grant PID2021-129100NB-I00 funded by the Ministerio de Ciencia e Innovación, Government of Spain.
We appreciate the input of María Teresa Anguera and Marcelino Cuesta, expert researchers in methodology, for reviewing and verifying the usefulness of the proposed procedure for methodologists and its ease of calculation. We also thank Carmen González González-Mesa and Ana María González Menéndez, researchers in substantive areas of Psychology who conduct data analysis in their applied research, for confirming that this method of presenting results is both very useful and practical for easily identifying the most appropriate statistic for a particular condition.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The authors declare that no Gen AI was used in the creation of this manuscript.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpsyg.2025.1549767/full#supplementary-material
Adams, I. T. (2024). Power simulations of rare event counts and introduction to the ‘power lift’ metric. CrimRxiv. doi: 10.21428/cb6ab371.dfc6b8fa
Austin, P. C., Schuster, T., and Platt, R. W. (2015). Statistical power in parallel group point exposure studies with time-to-event outcomes: an empirical comparison of the performance of randomized controlled trials and the inverse probability of treatment weighting (IPTW) approach. BMC Med. Res. Methodol. 15:87. doi: 10.1186/s12874-015-0081-3
Bandalos, D. L., and Gagné, P. (2012). “Simulation methods in structural equation modeling” in Handbook of structural equation modeling. ed. R. H. Hoyle (New York, NY: The Guilford Press), 92–108.
Bell, M. L., and Rabe, B. A. (2020). The mixed model for repeated measures for cluster randomized trials: a simulation study investigating bias and type I error with missing continuous data. Trials 21:148. doi: 10.1186/s13063-020-4114-9
Blanca, M. J., Arnau, J., García-Castro, F. J., Alarcón, R., and Bono, R. (2023). Repeated measures ANOVA and adjusted F-tests when sphericity is violated: which procedure is best? Front. Psychol. 14:1192453. doi: 10.3389/fpsyg.2023.1192453
Boulesteix, A.-L., Groenwold, R. H., Abrahamowicz, M., Binder, H., Briel, M., Hornung, R., et al. (2020a). Introduction to statistical simulations in health research. BMJ Open 10:e039921. doi: 10.1136/bmjopen-2020-039921
Boulesteix, A.-L., Hoffmann, S., Charlton, A., and Seibold, H. (2020b). A replication crisis in methodological research? Significance 17, 18–21. doi: 10.1111/1740-9713.01444
Boulesteix, A.-L., Wilson, R., and Hapfelmeier, A. (2017). Towards evidence-based computational statistics: lessons from clinical research on the role and design of real-data benchmark studies. BMC Med. Res. Methodol. 17:138. doi: 10.1186/s12874-017-0417-2
Burton, A., Altman, D. G., Royston, P., and Holder, R. L. (2006). The design of simulation studies in medical statistics. Stat. Med. 25, 4279–4292. doi: 10.1002/sim.2673
Chalmers, R. P., and Adkins, M. C. (2020). Writing effective and reliable Monte Carlo simulations with the SimDesign package. Quant. Methods Psychol. 16, 248–280. doi: 10.20982/tqmp.16.4.p248
Chang, W., Cheng, J., Allaire, J., Sievert, C., Schloerke, B., Xie, Y., et al. (2023). Shiny: Web application framework for R [Computer software manual] (R package version 1.7.5). Available online at: https://CRAN.R-project.org/package=shiny
Chattopadhyay, B., and Kelley, K. (2016). Estimation of the coefficient of variation with minimum risk: a sequential method for minimizing sampling error and study cost. Multivar. Behav. Res. 51, 627–648. doi: 10.1080/00273171.2016.1203279
Chipman, H., and Bingham, D. (2022). Let’s practice what we preach: planning and interpreting simulation studies with design and analysis of experiments. Canadian J. Stat. 50, 1228–1249. doi: 10.1002/cjs.11719
Cohen, J. (2013). Statistical power analysis for the behavioral sciences. 2nd ed. Nueva York: Routledge Academic.
De, T. K., and Onghena, P. (2022). The randomized marker method for single-case randomization tests: handling data missing at random and data missing not at random. Behav. Res. Methods 54, 2905–2938. doi: 10.3758/s13428-021-01781-5
Debelak, R. (2019). An evaluation of overall goodness-of-fit tests for the Rasch model. Front. Psychol. 9:2710. doi: 10.3389/fpsyg.2018.02710
Duncan, J., Tang, T., Elliott, C. F., Boileau, P., and Yu, B. (2024). simChef: high-quality data science simulations in R. J. Open Source Softw. 9:6156. doi: 10.21105/joss.06156
Fernández-García, M. P., Vallejo-Seco, G., Livácic-Rojas, P., and Tuero-Herrero, E. (2018). The (Ir)responsibility of (under)estimating missing data. Front. Psychol. 9:556. doi: 10.3389/fpsyg.2018.00556
Finch, H. W., French, B. F., and Finch, M. E. H. (2018). Comparison of methods for factor invariance testing of a 1-factor model with small samples and skewed latent traits. Front. Psychol. 9:332. doi: 10.3389/fpsyg.2018.00332
Fingleton, B., Gallo, J. L., and Pirotte, A. (2017). A multidimensional spatial lag panel data model with spatial moving average nested random effects errors. Empir. Econ. 55, 113–146. doi: 10.1007/s00181-017-1410-7
Gasparini, A., Morris, T. P., and Crowther, M. J. (2021). INTEREST: INteractive tool for exploring REsults from simulation sTudies. J. Data Sci. Stat. Visual. 1:9. doi: 10.52933/jdssv.v1i4.9
Harwell, M. R. (1992). Summarizing Monte Carlo results in methodological research. J. Educ. Stat. 17, 297–313. doi: 10.3102/10769986017004297
Harwell, M. (2003). Summarizing Monte Carlo results in methodological research: the single-factor, fixed-effects ANCOVA case. J. Educ. Behav. Stat. 28, 45–70. doi: 10.3102/10769986028001045
Harwell, M. R., Rubinstein, E. N., Hayes, W. S., and Olds, C. C. (1992). Summarizing Monte Carlo results in methodological research: the one- and two-factor fixed effects ANOVA cases. J. Educ. Stat. 17, 315–339. doi: 10.3102/10769986017004315
Haverkamp, N., and Beauducel, A. (2017). Violation of the Sphericity assumption and its effect on type-I error rates in repeated measures ANOVA and multi-level linear models (MLM). Front. Psychol. 8:1841. doi: 10.3389/fpsyg.2017.01841
Kelley, K. (2007). Sample size planning for the coefficient of variation from the accuracy in parameter estimation approach. Behav. Res. Methods 39, 755–766. doi: 10.3758/bf03192966
Kelter, R. (2024). The Bayesian simulation study (BASIS) framework for simulation studies in statistical and methodological research. Biom. J. 66:e2200095. doi: 10.1002/bimj.202200095
Kenny, A., and Wolock, C. J. (2024). SimEngine: a modular framework for statistical simulations in R. arXiv. doi: 10.48550/arxiv.2403.05698
Livacic-Rojas, P., Fernández, P., Vallejo, G., Tuero-Herrero, E., and Ordóñez, F. (2020). Sensitivity of five information criteria to discriminate covariance structures with missing data in repeated measures designs. Psicothema 3, 399–409. doi: 10.7334/psicothema2020.63
Lohmann, A., Astivia, O. L. O., Morris, T. P., and Groenwold, R. H. H. (2022). It’s time! Ten reasons to start replicating simulation studies. Front. Epidemiol. 2:973470. doi: 10.3389/fepid.2022.973470
Luijken, K., Lohmann, A., Alter, U., Claramunt Gonzalez, J., Clouth, F. J., Fossum, J. L., et al. (2024). Replicability of simulation studies for the investigation of statistical methods: the RepliSims project. R. Soc. Open Sci. 11:231003. doi: 10.1098/rsos.231003
Maxwell, S. E., and Cole, D. A. (1995). Tips for writing (and reading) methodological articles. Psychol. Bull. 118, 193–198. doi: 10.1037/0033-2909.118.2.193
Menz, M., Dubreuil, S., Morio, J., Gogu, C., Bartoli, N., and Chiron, M. (2020). Variance based sensitivity analysis for Monte Carlo and importance sampling reliability assessment with Gaussian processes. arXiv. doi: 10.48550/arXiv.2011.15001
Meyer, E. L., Kumaus, C., Majka, M., and Koenig, F. (2023). An interactive R-shiny app for quickly visualizing a tidy, long dataset with multiple dimensions with an application in clinical trial simulations for platform trials. SoftwareX 22:101347. doi: 10.1016/j.softx.2023.101347
Michiels, B., Tanious, R., De, T. K., and Onghena, P. (2019). A randomization test wrapper for synthesizing single-case experiments using multilevel models: a Monte Carlo simulation study. Behav. Res. Methods 52, 654–666. doi: 10.3758/s13428-019-01266-6
Morris, T. P., White, I. R., and Crowther, M. J. (2019). Using simulation studies to evaluate statistical methods. Stat. Med. 38, 2074–2102. doi: 10.1002/sim.8086
Nießl, C., Herrmann, M., Wiedemann, C., Casalicchio, G., and Boulesteix, A. (2021). Over-optimism in benchmark studies and the multiplicity of design and analysis options when interpreting their results. WIREs Data Mining Knowl. Discovery 12:1441. doi: 10.1002/widm.1441
Nkechi, E. M., Chekwube, B. D., Paul, O. C., and Chizoba, K. L. (2022). A Monte Carlo simulation comparison of methods of detecting outliers in time series data. J. Stat. Appl. Probabil. 11, 819–834. doi: 10.18576/jsap/110306
Ospina, R., and Marmolejo-Ramos, F. (2019). Performance of some estimators of relative variability. Front. Appl. Math. Stat. 5:43. doi: 10.3389/fams.2019.00043
Pawel, S., Kook, L., and Reeve, K. (2023). Pitfalls and potentials in simulation studies: questionable research practices in comparative simulation studies allow for spurious claims of superiority of any method. Biom. J. 66:e2200091. doi: 10.1002/bimj.202200091
Paxton, P., Curran, P. J., Bollen, K. A., Kirby, J., and Chen, F. (2001). Monte Carlo experiments: design and implementation. Struct. Equ. Model. Multidiscip. J. 8, 287–312. doi: 10.1207/s15328007sem0802_7
Reed, G. F., Lynn, F., and Meade, B. D. (2002). Use of coefficient of variation in assessing variability of quantitative assays. Clin. Vaccine Immunol. 9, 1235–1239. doi: 10.1128/cdli.9.6.1235-1239.2002
Rücker, G., and Schwarzer, G. (2014). Presenting simulation results in a nested loop plot. BMC Med. Res. Methodol. 14:129. doi: 10.1186/1471-2288-14-129
Seibold, H., Charlton, A., Boulesteix, A. L., and Hoffmann, S. (2021). Statisticians, roll up your sleeves! There’s a crisis to be solved. Significance 18, 42–44. doi: 10.1111/1740-9713.01554
Siepe, B. S., Bartoš, F., Morris, T., Boulesteix, A.-L., Heck, D. W., and Pawel, S. (2024). Simulation studies for methodological research in psychology: a standardized template for planning, preregistration, and reporting. Psychol. Methods. doi: 10.1037/met0000695
Svetina, D., Feng, Y., Paulsen, J., Valdivia, M., Valdivia, A., and Dai, S. (2018). Examining DIF in the context of CDMs when the Q-matrix is Misspecified. Front. Psychol. 9:696. doi: 10.3389/fpsyg.2018.00696
Tibbe, T. D., and Montoya, A. K. (2022). Correcting the Bias correction for the bootstrap confidence interval in mediation analysis. Front. Psychol. 13:810258. doi: 10.3389/fpsyg.2022.810258
Tofighi, D. (2020). Bootstrap model-based constrained optimization tests of indirect effects. Front. Psychol. 10:2989. doi: 10.3389/fpsyg.2019.02989
Vallejo, G., Arnau, J., Bono, R., Fernández, P., and Tuero-Herrero, E. (2010). Nested model selection for longitudinal data using information criteria and the conditional adjustment strategy. Psicothema 22, 323–333.
Vallejo, G., Fernández, M. P., Livacic-Rojas, P. E., and Tuero-Herrero, E. (2011). Selecting the best unbalanced repeated measures model. Behav. Res. Methods 43, 18–36. doi: 10.3758/s13428-010-0040-1
Wei, D., and Zhan, P. (2023). Bayesian estimation for the random moderation model: effect size, coverage, power of test, and type І error. Front. Psychol. 14:1048842. doi: 10.3389/fpsyg.2023.1048842
White, I. R., Pham, T. M., Quartagno, M., and Morris, T. P. (2024). How to check a simulation study. Int. J. Epidemiol. 53:134. doi: 10.1093/ije/dyad134
Zivich, P. N., Edwards, J. K., Lofgren, E. T., Cole, S. R., Shook-S, B. E., and Lessler, J. (2023). Transportability without positivity: a synthesis of statistical and simulation modeling. Epidemiology 35, 23–31. doi: 10.1097/ede.0000000000001677
Zumbo, B. D., and Harwell, M. R. (1999). The methodology of methodological research: Analyzing the results of simulation experiments. Informe nº ESQBS992. Prince George, B.C.: Edgeworth Laboratory for Quantitative Behavioral Science, University of Northern British Columbia.
Zumbo, B. D., and Jennings, M. J. (2002). The robustness of validity and efficiency of the related samples t-test in the presence of outliers. Psicológica 23, 415–450.
LMM - Linear mixed model
DGP - Data generating process
IC - Information criteria
AIC - Akaike IC
AICC - AIC corrected
HQIC - Hannan-Quinn IC
BIC - Bayesian IC
CAIC - Consistent AIC
S1, S2 y S3 - Scenario 1, Scenario 2 and Scenario 3, respectively
CM - Covariance matrix
CS - Compound symmetry
RCL - Linear random coefficients
ARH (1) - Heterogeneous first-order autoregressive
TOEPH - Heterogeneous Toeplitz
UN - Unstructured
N - Sample size
MMs - Missingness mechanism
MCAR - Completely randomized
MAR - Randomized
MNAR - Non-randomized
CD - Complete data
CV - Coefficient of variation
Keywords: Monte Carlo simulation studies, Analysis Plan, results tables vs. Traceability Tables, Variability Set, demo example, repeated measures design results, linear mixed model, information criteria
Citation: Fernández-García MP, Vallejo-Seco G, Livácic-Rojas P and Herrero-Díez FJ (2025) Proposal of an alternative way of reporting the results of comparative simulation studies. Front. Psychol. 16:1549767. doi: 10.3389/fpsyg.2025.1549767
Edited by:
Fernando Marmolejo-Ramos, Flinders University, AustraliaReviewed by:
Alejandro Marín-Gutiérrez, Universidad de Oviedo, SpainCopyright © 2025 Fernández-García, Vallejo-Seco, Livácic-Rojas and Herrero-Díez. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: María Paula Fernández-García, cGF1bGFAdW5pb3ZpLmVz
†These authors have contributed equally to this work and share first authorship
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.