 Janek S. Lobmaier
Janek S. Lobmaier Wilhelm K. Klatt
Wilhelm K. Klatt Stefan R. Schweinberger
Stefan R. Schweinberger- 1Department of Clinical Psychology and Psychotherapy, University of Zurich, Zurich, Switzerland
- 2Sigma-Zentrum für Akutmedizin, Fachkrankenhaus für Psychiatrie, Psychotherapie, Psychosomatische Medizin, Bad Säckingen, Germany
- 3Department for General Psychology and Cognitive Neuroscience, Institute of Psychology, Friedrich Schiller University, Jena, Germany
- 4Swiss Center for Affective Sciences, University of Geneva, Geneva, Switzerland
Introduction: Research has shown that women’s vocal characteristics change during the menstrual cycle. Further, evidence suggests that individuals alter their voices depending on the context, such as when speaking to a highly attractive person, or a person with a different social status. The present study aimed at investigating the degree to which women’s voices change depending on the vocal characteristics of the interaction partner, and how any such changes are modulated by the woman’s current menstrual cycle phase.
Methods: Forty-two naturally cycling women were recorded once during the late follicular phase (high fertility) and once during the luteal phase (low fertility) while reproducing utterances of men and women who were previously assessed to have either attractive or unattractive voices.
Results: Phonetic analyses revealed that women’s voices in response to speakers changed depending on their menstrual cycle phase (F0 variation, maximum F0, Centre of gravity) and depending on the stimulus speaker’s vocal attractiveness (HNR, Formants 1–3, Centre of gravity), and sex (Formant 2). Also, the vocal characteristics differed when reproducing spoken sentences of the stimulus speakers compared to when they read out written sentences (minimum F0, Formants 2–4).
Discussion: These results provide further evidence that women alter their voice depending on the vocal characteristics of the interaction partner and that these changes are modulated by the menstrual cycle phase. Specifically, the present findings suggest that cyclic shifts on women’s voices may occur only in social contexts (i.e., when a putative interaction partner is involved).
Introduction
Social interactions are an integral part of our daily lives. In the vast tapestry of human social interactions, the voice serves as a powerful medium to convey not only factual information, but also rich dynamic information about the speaker’s identity, emotions, and intentions (Schweinberger et al., 2014). From an evolutionary perspective, the voice may be understood as an “honest signal,” a concept rooted in the theory that certain traits and behaviors have evolved to convey truthful information to others about the individual’s fitness, health, or reproductive status. The human voice, particularly in women, may carry indicators of reproductive viability or general health. The pitch and tonal quality of a woman’s voice can signal her age and hormonal status, which are closely linked to fertility. In fact, research suggests that women’s voices sound most attractive during the high-fertility phase of the menstrual cycle (Pipitone and Gallup, 2008). Meanwhile, there is also evidence that people change their voices depending on the context, for example when speaking to a highly attractive person or a person with a different social status (e.g., Fraccaro et al., 2011; Hughes et al., 2010; Zraick et al., 2006). The aim of the present study was to investigate the extent to which women’s voices change depending on the vocal characteristics of the interaction partner, and whether such changes are modulated by the current phase of the woman’s menstrual cycle.
Hearing a person’s voice allows a listener to form impressions about the speaker’s personality. For example, men and women with a lower voice pitch are perceived as more competent and trustworthy than those with higher-pitched voices. Conversely, women with a higher voice pitch are judged as having a warmer personality than women with lower-pitched voices (Oleszkiewicz et al., 2017). In return, a speaker’s voice can be adapted, according to the circumstances in which a conversation takes place. For instance, women have been shown to speak with higher voice pitch, larger pitch range, expanded intonation contours, and slower speech rate when speaking to infants (i.e., “motherese”), compared to when speaking to adults (Fernald and Simon, 1984; Grieser and Kuhl, 1988), and this phenomenon has been shown to be universal in western and traditional cultures (Broesch and Bryant, 2015). Voice pitch is also affected by changes in tension (Titze, 1989), intonation, stress, and loudness of speech (Raphael et al., 2011), and women have been reported to speak in a lower or higher voice pitch when speaking to a superior or a subordinate, respectively (Zraick et al., 2006).
Voice pitch is typically measured by the mean fundamental frequency (mean F0), depicting the rate of vocal fold vibration. The standard deviation of the fundamental frequency (F0 SD) represents the variability in perceived voice pitch (i.e., intonation). Low values in F0 SD are perceived as a monotonous voice, higher values are found in melodious voices. Other measures often used to objectively measure voice characteristics include minimum fundamental frequency (F0min) and maximum fundamental frequency (F0max), Centre of gravity, Formants 1 to 4 (F1–F4), harmonics-to-noise ratio (HNR), Jitter, Shimmer, and variation in intensity (Intensity SD). F0min and F0max represent the upper and lower limits of the pitch range. Centre of gravity is the frequency which divides the voice spectrum into two halves, so a higher Centre of gravity means that a voice has more high-frequency energy in its spectrum. F1 to F4 are frequency ranges that are intensified within the spectrum. HNR is the ratio of harmonic to non-harmonic components within the voice spectrum and reflects breathiness of the voice. Jitter is a local variation in frequency, Shimmer is a local variation in amplitude; both Jitter and Shimmer are caused by irregular vocal fold vibration and are perceived as roughness in a speaker’s voice. Finally, Intensity SD indicates the variability in perceived loudness.
People seem to alter their voice when speaking to interaction partners they find attractive. Fraccaro et al. (2011) found that women speak at a higher pitch (higher mean F0) to men to whom they are attracted, whereas Hughes et al. (2010) reported that both women and men lower their voice pitch (mean F0) when speaking to an attractive opposite-sex target. When speaking to attractive women, both men and women appear to show a greater voice pitch variability (higher F0 SD; Leongómez et al., 2014). Farley et al. (2013) provided evidence suggesting that naïve listeners were able to identify whether a person was speaking to a romantic partner or a friend. Women used a deeper voice (lower mean F0) when talking to their romantic partners than to their friends. In contrast, men used a higher voice pitch when addressing their romantic partners. As a limitation, this study compared voice samples directed to opposite-sex partners and voice samples directed to same-sex friends, conflating sex of the interaction partner with intimacy. Nevertheless, these studies together suggest that women change their voices depending on the sex and attractiveness of the interaction partner. However, none of these studies controlled for a potential influence of the menstrual cycle.
Regarding attractiveness of voices, there is evidence that attractiveness increases with “averageness” of a voice – an effect that is potentially enhanced by larger harmonics-to-noise ratio in attractive voices (Bruckert et al., 2010; Zaske et al., 2020a). Several studies suggest that women’s voices, and voice attractiveness in particular, change during the menstrual cycle. Pipitone and Gallup (2008) found that the attractiveness of naturally cycling women’s voices increases with their conception probability. In a follow-up study, Shoup-Knox and Pipitone (2015) demonstrated that voices during high fertility period are not only rated as more attractive than low fertility voices but also lead to a higher galvanic skin response in the listeners, suggesting an increased arousal at a physiological level. Shoup-Knox et al. (2019) analysed Pipitone and Gallup’s (2008) recordings phonetically, finding a significantly lower Shimmer in high fertility compared to low fertility recordings of naturally cycling women. Bryant and Haselton (2009) found that women’s voice pitch (mean F0) was increased during high compared to low fertility when speaking the sentence “Hi, I’m a student at UCLA.” At first sight, these findings suggest that a higher pitch in women’s voices might convey a cue to fertility. Karthikeyan and Locke (2015) replicated the finding that highly fertile women’s voices are rated as more attractive, but they found that the women in their sample actually spoke in a lower voice pitch compared to when not fertile. A further study recorded women’s voices on a daily basis throughout their cycle (Fischer et al., 2011), finding that mean voice pitch and variation in voice pitch increase prior to ovulation and show a distinct drop on the day of ovulation.
Consistently, men rated the voices to be more attractive during the pre-ovulatory period than on the day of ovulation itself (Fischer et al., 2011). Banai (2017) compared the voices of naturally cycling women and women using hormonal contraceptives during menstruation, the late follicular and the luteal phase. She found naturally cycling women to have a higher minimum voice pitch (F0min) in the late follicular phase and a lower voice intensity in the luteal phase, each compared to the other phases. In hormonal contraceptive users, no voice changes across the cycle were detected. In contrast to Fischer et al. (2011), Banai (2017) did not find a significant effect in mean voice pitch (mean F0). This indicates that mean F0 alone does not seem to be a reliable cue to fertility. Similar to Banai (2017), La and Polo (2020) compared the voices of naturally cycling women with those taking hormonal contraceptives at three different times of the cycle, but in a double-blind design. In naturally cycling women, they found a significantly lower mean F0, F0 SD, and maximum F0 during menstruation, compared to the follicular and luteal phase. In women using hormonal contraceptives there was no cycle-dependent difference in these measures.
However, overall, and despite considerable variability in study designs and findings reported above, a sizeable number of published findings indicate the existence of voice changes depending on the menstrual cycle.
A common explanation for cycle-dependent voice changes is based on the fact that levels of women’s reproductive hormones vary during the menstrual cycle, with a surge of estradiol in the late-follicular phase and high levels of progesterone in the luteal phase. Regarding the vocal apparatus, estradiol promotes cell differentiation and mucosa secretion, while progesterone enhances the acidity and viscosity of the mucus for water retention, resulting in increased mass of the vocal folds, which in turn promotes lower-frequency vibration (Abitbol et al., 1999; Karthikeyan and Locke, 2015). In addition, there is evidence for specific sex hormone receptors within the vocal fold mucosa (Schneider et al., 2007; but see Nacci et al., 2011). Together, these studies suggest that a woman’s vocal apparatus may change under the influence of cycle dependent hormone concentration, leading to perceivable changes in her voice.
It should be noted that not all studies found an effect of the menstrual cycle on women’s voices. For example, Barnes and Latman (2011) found no significant voice changes across the cycle and no differences between naturally cycling women and those taking hormonal contraceptives in mean F0, jitter, shimmer, relative average perturbation, peak-to-peak amplitude variation, HNR, degree of voice breaks, and number of voice breaks. Likewise, Meurer et al. (2009), Raj et al. (2010), Celik et al. (2013), and Plexico et al. (2020) found no evidence for cycle-dependent voice changes.
An alternative explanation for cycle effects on women’s voices – which might also explain conflicting results – refers to psychological changes which may lead to increased mating motivation when currently fertile (Haselton and Gildersleeve, 2016). Karthikeyan and Locke (2015) suggest that only when provided with a mating context, women may be motivated to speak and behave more attractively, showing subtle vocal behaviors that are phase-specific (see also Klatt et al., 2020). However, even within a mating context, Pavela Banai et al. (2022) did not detect cycle-related changes in mean F0 and F0 SD in naturally cycling women who were leaving voice messages directed to masculinized and feminized pictures of men and women. Given these inconsistent results, Pavela Banai et al. (2022) name several methodological issues in earlier studies on cycle-dependent voice changes. First, different cycle-tracking methods have been used (counting method, body temperature, assessment of hormone levels). Second, many studies focused on mean F0 only, disregarding other voice parameters. Third, a variety of vocal stimuli have been analysed (vowels, numbers, sentences, free speech) which differ in experimental control and ecological validity. For example, women’s mean F0 has been shown to differ significantly depending on whether they were counting, producing vowels, reading out, or speaking spontaneously (Zraick et al., 2000).
In addition to these issues, one could argue that when a mating context is created, it makes a difference whether or not you are leaving a voice message for a target with an attractive face (Hughes et al., 2010; Pavela Banai et al., 2022) or an attractive voice (e. g., Karthikeyan and Locke, 2015). Furthermore, we want to point out that for phonetic analyses, previous studies used different software applications and different frequency ranges when analysing voice recordings for mean F0, F0 SD, F0min, and F0max. It is reasonable that phonetic analyses will produce different results when the predefined search area for F0 parameters is different (see Table 1 for an overview of different studies and the respective F0 definitions). Also, despite the fact that mean F0 may be the easiest voice parameter to quantify, researchers interested in social mimicry of voices are well advised to also quantify other relevant vocal parameters.
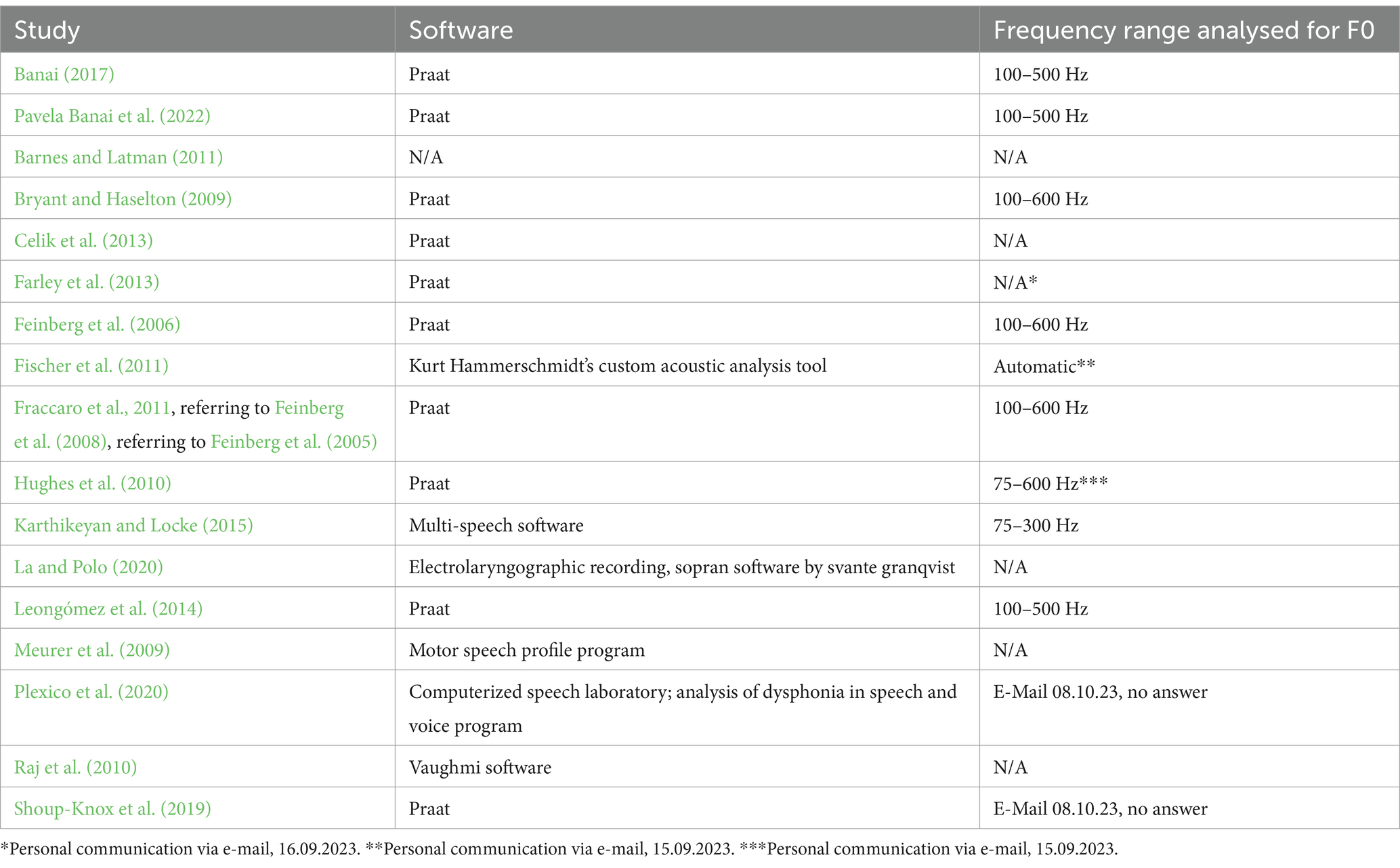
Table 1. Overview of frequency ranges used in phonetic analyses in previous studies.
Given that women’s voices can change depending on their current menstrual cycle phase, characteristics of the interaction partner and speech context, we aimed at further scrutinizing potential internal and external factors that may have an effect on women’s voices. Specifically, as an internal factor of the participants, we tested whether the menstrual cycle phase affects women’s voices. In addition, as an external factor, we manipulated the interaction partner of the women (operationalized here as the stimulus speaker). This interaction partner could either be a man or woman, with an attractive or unattractive voice. In contrast to studies in which conception probability was calculated using counting methods (Pipitone and Gallup, 2008; Puts et al., 2013), we verified the menstrual cycle phases by hormone tests based on urine (luteinising hormone LH) and saliva (estradiol, progesterone). We hypothesized that women alter their voices depending on sex and attractiveness of the stimulus speaker’s voice, and that these changes are modulated by the current menstrual cycle phase of the women. An effect of menstrual cycle was thought to occur more pronounced in response to men’s voices than to women’s voices, and more pronounced in response to attractive voices than to unattractive voices. Voice recordings were analysed phonetically for a large range of parameters that included mean F0, F0min, F0max, F0 SD, HNR, Jitter, Shimmer, Formants 1 to 4, Centre of gravity, and Intensity SD.
Materials and methods
Participants
Eighty-three women were initially recruited for the present study. Participants were recruited from the subject pool of the university, via flyers and leaflets, the institutional website, free internet advertisements, and word-of-mouth recommendation. All of them provided written informed consent to participate and the study was approved by the local ethics committee (approval number: 2012-8-167070) and participants were treated in accordance with the Code of Ethics of the World Medical Association (Declaration of Helsinki). They were compensated either with course credits or 50 CHF (approximately 60 US$). The final sample consisted of 42 women (see below).
Stimuli
Recordings of stimulus speakers (spoken sentences) were taken from the Jena Speaker Set (JESS; Zaske et al., 2020b) which at the time consisted of 64 speakers (half of them women) who were recorded while speaking a series of neutral sentences. All sentences consisted of exactly five words and had the same syntactic structure (e.g., “Der Fahrer lenkt den Wagen”/“The driver steers the car,” see Supplementary Table S1 for the complete list of sentences used).
In order to identify the most attractive and most unattractive voices of the 64 stimulus speakers, an attractiveness rating was performed with an independent sample of participants using PsychoPy software (Peirce, 2007). Twenty-four listeners (half of them women, ranging in age between 20 and 39 years, M = 25.0, SD = 4.6) who were recruited via flyers and word-of-mouth recommendation were received individually in a quiet room. After giving informed consent, they were asked to take place in front of a laptop and to attach Sennheiser HD 439 headphones. Listeners were told that they would be hearing spoken sentences via headphones and that they were asked to respond to the question “How attractive do you find this voice?” on a 7-point likert scale that was showed on the screen (labelled “very attractive” and “very unattractive” at each end). Instructions were given verbally and onscreen. Listeners first completed three practice trials with sentences and stimulus speakers which were not used afterwards to get used to the task and to adjust the volume of the headphones. Voice recordings of the 64 stimulus speakers uttering the same two neutral sentences (“The train passes the town,” “The lemonade quenches the thirst”) were presented and rated for attractiveness separately in randomised order, resulting in 128 trials. The experiment took about 10 min to complete. Rank analyses identified the eight most attractive and eight most unattractive female and male speakers, respectively, resulting in 32 different stimulus speakers which were then used in the present study.
Procedure
Initially, all interested women were asked to complete an online survey with questions regarding age, smoking habits, mother tongue, reading disabilities, hearing problems, sexual orientation, relationship status, use of hormonal contraception, pregnancy, onset of last menstruation, regularity and length of menstrual cycle. To take part in this study, participants had to meet following inclusion criteria: No use of hormonal contraceptives (contraceptive pill, morning-after pill, hormonal contraceptive coil, contraceptive implants); no pregnancy, and no breastfeeding within the last three months; regular menstrual cycle (23–35 days in length); heterosexual orientation; German mother tongue; no dyslexia; no hearing problems; no chronic smoking (more than 20 cigarettes a week). All reported to be healthy (no mental and/or physical diseases) and not to have a hoarse voice, cough, or nasal congestion on the days of recording. Women who met the above-mentioned inclusion criteria were contacted by phone by a female research assistant who gave them detailed information about the procedure.
To determine time of highest fertility, participants completed a series of urine tests measuring a metabolite of luteinising hormone (LH) using one-step urine LH tests with a reported sensitivity of 10 mIU/ml (David One Step Ovulation Tests, Runbio Biotech, China, http://www.runbio-bio.com). Women were instructed to perform urine tests twice a day (morning and evening) starting three days before the date of predicted peak fertility (based on the average cycle length of each individual woman using forward and backward counting method). After a positive test result, participants continued performing LH tests until the results became negative for two consecutive days. Participants photographed each test using their smartphones and sent the picture to the research assistant, who verified whether the test was positive or not.
The women were either scheduled to be tested approximately two days before the calculated day of peak fertility and again seven days after a positive LH test result (late follicular–luteal menstrual cycle condition) or they were scheduled seven days after the LH surge (luteal–late follicular menstrual cycle condition). Participants of the luteal–late follicular menstrual cycle condition performed LH tests again in the following cycle and were scheduled to be tested two days before the calculated day of peak fertility. Thus, LH tests were used to determine peak fertility and to verify that the cycle was ovulatory. Late follicular recording sessions took place between 4 days before and 24 h after the LH surge, luteal phase recording sessions took place 6 to 13 days after the LH surge (see Table 2 for an overview of the time of recording relative to the LH surge). Order of recording sessions was counterbalanced across participants: half of the women completed the first session at high fertility and their second session in the luteal phase (late follicular–luteal menstrual cycle condition), and the other half were tested first during the luteal phase and then during high fertility (luteal–late follicular menstrual cycle condition).
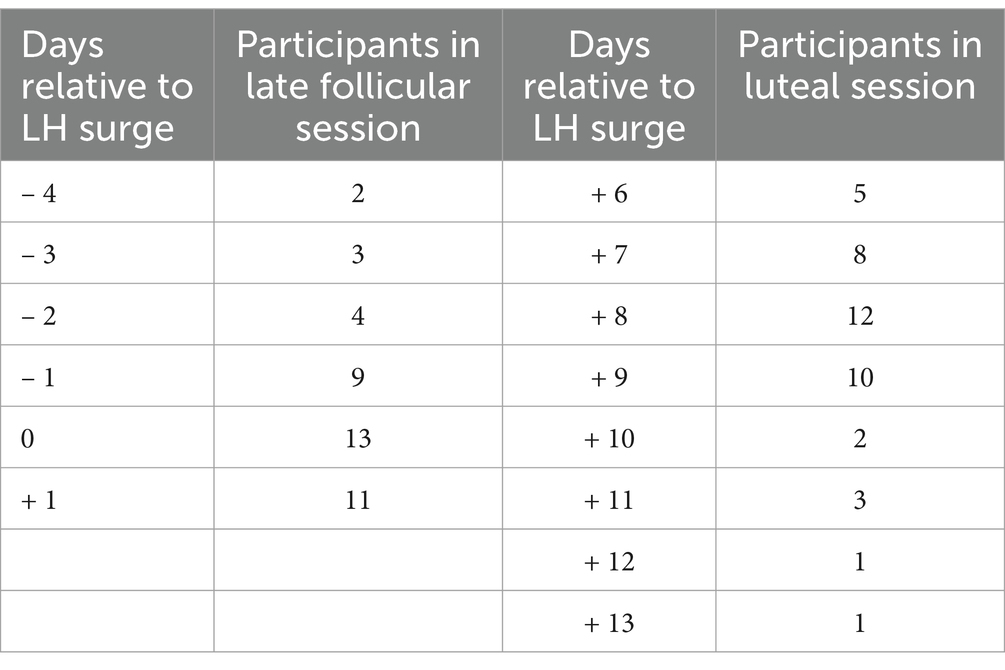
Table 2. Time of recording sessions relative to peak fertility as indicated by LH surge.
In order to assess phase-specific hormone levels, participants provided saliva samples from which estradiol, progesterone, testosterone, and cortisol levels were determined. Participants were instructed to refrain from eating and drinking anything but water for at least 30 min prior to saliva collection. Samples were collected by passive drool using a commercially available sampling device (SaliCaps, IBL International, Hamburg, Germany). The saliva samples were stored at −28°C and were later analysed by an independent laboratory (Dresden Lab Service GmbH, Dresden, Germany) using liquid chromatography with coupled tandem mass spectrometry (LC–MS/MS). LC–MS/MS has become the method of choice for steroid analysis because of its high sensitivity, better reproducibility, greater specificity, and ability to analyse multiple steroids simultaneously (see Gao et al., 2015 for methodological details on LC–MS/MS). Both recording sessions took place between 8 and 11 AM in order to control for circadian variability of hormone levels (Dabbs and Delarue, 1991; Wust et al., 2000).
Women’s voices were recorded in a soundproof recording booth under standardised conditions. A Beyerdynamic MC 930 condenser microphone with a popkiller and 48 V phantom power was placed about 20 centimetres away from the participant’s mouth and connected to a Zoom H4n digital audio recorder (uncompressed WAV, 48 kHz, 16-bit sampling rate). Before starting the experiment proper, participants were asked to read out a short newspaper article about voice research presented on a computer screen to warm up their voices and to adjust the recording level to −12 to −6 dB. Each woman absolved two recording sessions (one in the late follicular and one in the luteal phase), and each recording session consisted of two blocks. In the first block the woman read aloud presented written sentences; in the second block, the task was to reproduce spoken sentences verbally which were presented via headphones. Written and spoken sentences were identical in content. At the beginning of the first block, the instruction to read out presented written sentences in a natural manner was given verbally and onscreen. Twenty-four sentences of affectively neutral content (see Supplementary Table S1) were presented. Sentences were displayed on a laptop screen in 25 pt. Arial using PsychoPy software (Peirce, 2007). The screen was placed in front of the participant at a distance of approximately 50 centimetres. Sentences were presented consecutively in randomised order for five seconds each. After three practice trials with sentences which were not used subsequently, the experimenter left the booth and the participant started the first block of the recording session (written sentences). The participant indicated by knocking on the booth’s door when the block was finished. The experimenter returned, asked the participant to attach Sennheiser HD 439 headphones and prepared the second block of the recording session (spoken sentences). Participants were told that they would be hearing spoken sentences via headphones and that they were to reproduce these sentences in a natural manner. Instructions were given verbally and onscreen. Sentences were presented separately in randomised order. Participants first completed three practice trials with sentences and stimulus speakers which were not used in the experiment proper. Subsequently, they were given the opportunity to adjust the volume of the headphones. After that, the experimenter left the booth and the participant started the second block (spoken sentences). Again, the participant indicated by knocking on the booth’s door when the block was finished. Both recording sessions (late follicular and luteal phase) consisted of these two blocks, following the same procedure except that participants were fully debriefed after the second recording session. Each recording session took about 45 min to complete.
Of the 83 women who initially entered the study, some had to be excluded because their recordings were unusable due to misspeaking (N = 12), because they had anovulatory cycles during the recording period (i.e., no LH surge, N = 8), did not conduct the required LH tests during the peri-ovulatory period (N = 3), were tested in the wrong cycle phase (too early/too late as revealed by LH tests, N = 8), or dropped out due to personal reasons (N = 10). Thus, the final sample consisted of 42 women between 19 and 35 years of age (M = 22.6, SD = 3.4). From these, a total of 2,016 uncompressed WAV voice samples (42 participants × 2 menstrual cycle phases × 24 sentences) were cut from raw recordings using Audacity® software (Audacity Team, 2023).
Variables and statistical analyses
Praat software version 6.3.16 (Boersma and Weenink, 2023) was used to analyse the voice samples for the following phonetic parameters: Mean F0, F0 SD, F0min, F0max, Centre of gravity, Formants 1 to 4, HNR, Jitter, Shimmer, and Intensity SD. For analyses of mean F0, F0 SD, F0min, and F0max, the frequency range was set to 100–500 Hz and for formant analyses, the maximum frequency was set to 5,500 Hz, as suggested by Boersma and Weenink (2023) for female voices. Apart from that, default settings were used.
Control condition: reading written sentences aloud
In the control condition (where participants read the sentences out loud from the computer screen), for each woman, values of individual vocal parameters were averaged over the 24 sentences, separately for both menstrual cycle phases for further analyses. We then calculated one-factor (participant’s menstrual cycle phase: Late follicular vs. luteal phase) repeated measures ANOVA’s, separately for each of the vocal parameters using Bonferroni correction.
We also ran Pearson correlations between the hormone levels and the vocal parameters, separately for the late follicular and luteal phase. We present these correlations in the Supplementary material.
Experimental condition: reproduction of spoken sentences
In the Experimental condition (where participants reproduced the sentences after hearing them being spoken), for each woman, values of individual vocal parameters were averaged over the individual sentences, separately for menstrual cycle phase of the woman, stimulus speaker’s vocal attractiveness, and stimulus speaker’s sex, for further analyses. We then calculated 2 (participant’s menstrual cycle phase: Late follicular vs. luteal phase) × 2 (stimulus speaker’s vocal attractiveness: Attractive vs. unattractive) × 2 (stimulus speaker’s sex: Female vs. male) repeated measures ANOVA separately for each of the vocal parameters. The Huynh-Feldt epsilon correction for heterogeneity of covariances (Huynh and Feldt, 1976) was used when sphericity could not be assumed. For post-hoc pairwise comparisons we used the Bonferroni correction. To correct for multiple testing, we used the Holm-Bonferroni method. We report the corrected alongside the uncorrected p-values.
We also ran Pearson correlations between the hormone levels and the vocal parameters, separately for the late follicular and luteal phase. We present these correlations in the Supplementary material.
Phonetic analysis of the stimulus speakers’ voices
To examine whether the effects in women’s voices in reaction to the stimulus speakers’ voice characteristics may be driven by social mimicry or accommodation, also the stimulus speakers’ voices were analysed phonetically for the same parameters as the participants using Praat software version 6.3.16 (Boersma and Weenink, 2023). Female and male stimulus speakers’ voices were analysed separately because of sex-specific pre-adjustments in the phonetic software (Leongómez et al., 2014). For analyses of mean F0, F0 SD, F0min, and F0max of the female stimulus speakers, frequency range was set to 100–500 Hz; for formant analyses, the maximum frequency was set to 5,500 Hz (same as for analyses performed with the participants’ voices). For analyses of mean F0, F0 SD, F0min, and F0max of the male stimulus speakers, frequency range was set to 75–300 Hz;for formant analyses, the maximum frequency was set to 5,000 Hz, as suggested by Boersma and Weenink (2023). Apart from that, default settings were used.
Results
Control condition: reading written sentences aloud
The one-factor (participant’s menstrual cycle phase: Late follicular vs. luteal phase) repeated measures ANOVAs indicated no effect of menstrual cycle phase on any of the phonetic measures (all ps > 0.30). ANOVA results and descriptive statistics are provided in Table 3.
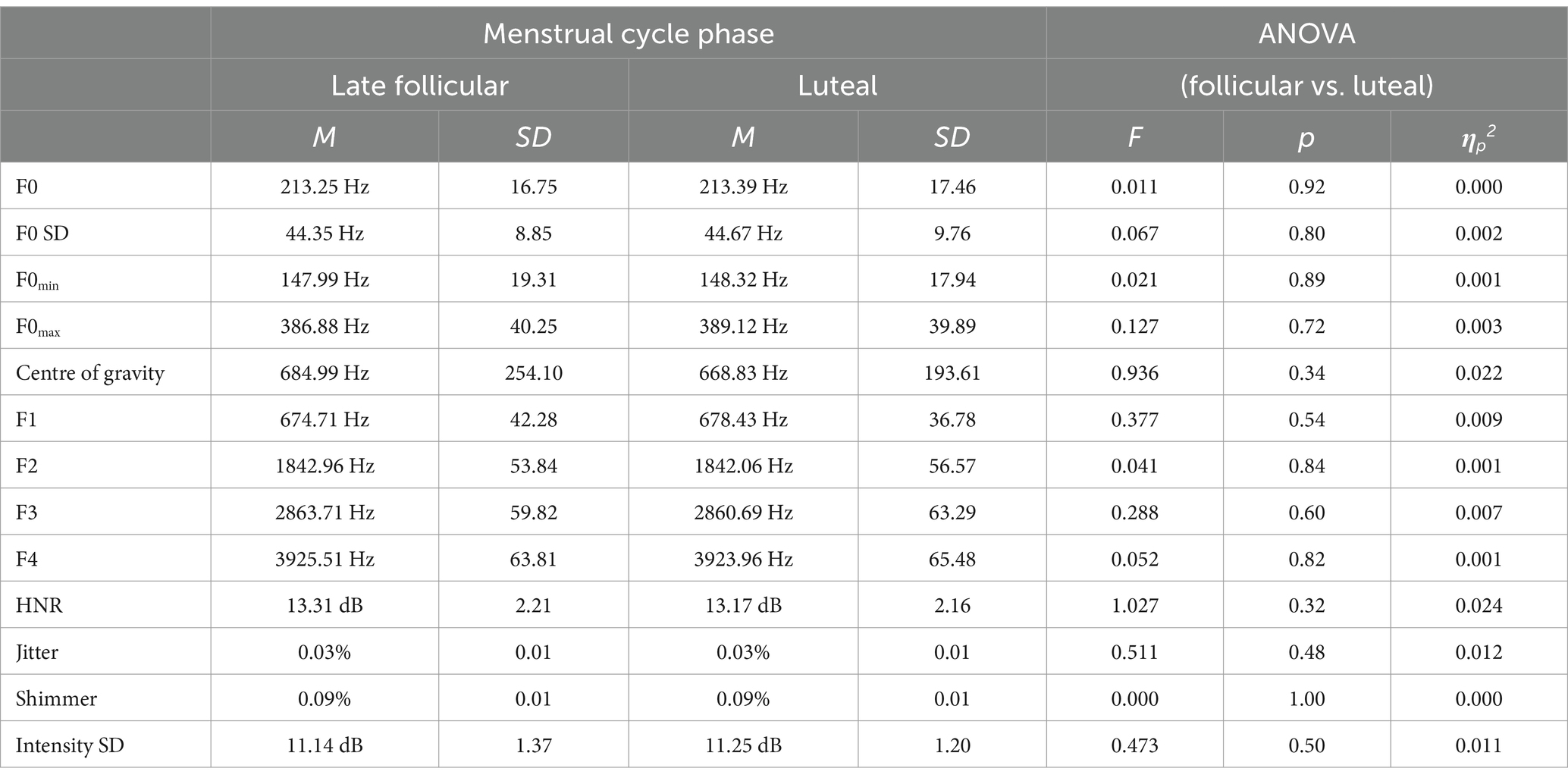
Table 3. Control condition (reading aloud written sentences): phonetic parameters depending on participants’ menstrual cycle phase.
Experimental condition: reproduction of spoken sentences
The 2 (participant’s menstrual cycle phase: Late follicular vs. luteal phase) × 2 (stimulus speaker’s vocal attractiveness: Attractive vs. unattractive) × 2 (stimulus speaker’s sex: Female vs. male) repeated measures ANOVA was calculated on each of the vocal parameters. The results of the 2 (late follicular vs. luteal phase) × 2 (attractive vs. unattractive) × 2 (stimulus speaker’s sex) repeated measures ANOVAs are shown in Table 4, descriptive statistics are given in Table 5. Menstrual cycle phase of the participants had a significant main effect on F0 SD, F0max, and Centre of gravity. When recorded in the late follicular phase, women spoke with lower F0 SD, lower F0max, and higher Centre of gravity compared to the luteal phase. When correcting for multiple testing, menstrual cycle phase had an effect only on F0max. Stimulus speaker’s voice attractiveness showed a significant effect on five phonetic measures. HNR was lower in response to stimulus speakers with attractive voices than in response to speakers with less attractive voices, implying that participants used a breathier and hoarser voice when reacting to attractive voices than when reacting to unattractive voices. Formants 1 to 3, reflecting frequencies that are intensified relative to the rest of the vocal spectrum, were significantly higher in frequency when responding to attractive stimulus speakers compared to unattractive stimulus speakers. Additionally, women showed a higher frequency in Centre of gravity in response to attractive stimulus speakers compared to unattractive stimulus speakers. When correcting for multiple testing, the effect remained significant only for Center of Gravity and F1. The sex of the stimulus speaker had a significant effect only on Formant 2, which was higher in frequency when women responded to a female stimulus speaker, compared to when responding to a male stimulus speaker. This effect was also significant after correcting for multiple testing. No significant main effects were observed in mean F0, F0min, Jitter, Shimmer, Formant 4 and Intensity SD. No interaction reached statistical significance (all ps ≥ 0.05; see Supplementary Table S2).

Table 4. Experimental condition (reproduction of spoken sentences), inferential statistics: phonetic parameters depending on menstrual cycle phase of the participants, voice attractiveness of the stimulus speaker, and sex of the stimulus speaker.
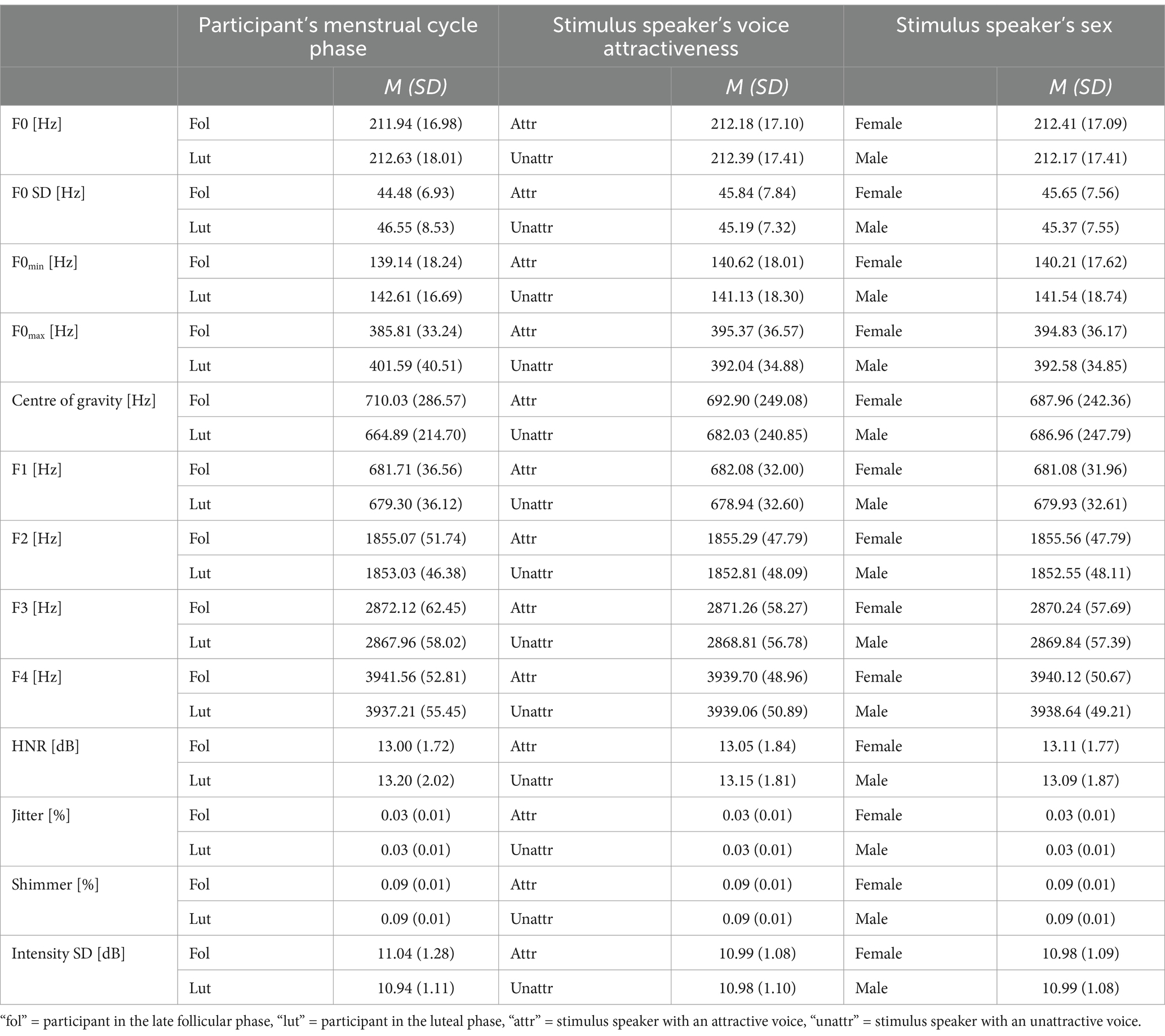
Table 5. Experimental condition (reproduction of spoken sentences), descriptive statistics: phonetic parameters depending on menstrual cycle phase of the participants, attractiveness of the stimulus speaker, and sex of the stimulus speaker.
Phonetic analysis of the stimulus speakers’ voices
Phonetic analyses of the stimulus speakers revealed that stimulus speakers with attractive voices of both sexes had higher formants and a higher Centre of gravity than stimulus speakers with less attractive voices (for more detailed results, see Supplementary Tables S3, S4). The differences in these parameters were reflected in women’s voices when responding to attractive versus unattractive stimulus speakers (Formants 1–3, centre of gravity).
Regarding stimulus speaker’s sex, not surprisingly, analyses showed that female stimulus speakers had higher frequencies in mean F0, F0 SD, F0min, F0max, and Formants 2–4 than male stimulus speakers, as well as higher voice quality according to higher HNR, lower Jitter, and lower Shimmer (see Supplementary Table S5). The difference in Formant 2 was reflected in women’s voices when responding to male versus female stimulus speakers.
Taken together, phonetic analyses of the stimulus speakers’ voices suggest that the shifts observed in women’s voices – depending on stimulus speaker attractiveness and sex – are at least in part explainable by social mimicry or accommodation (Chartrand and Lakin, 2013; Gregory and Webster, 1996).
General effect of the predefined frequency range in phonetic analysis
Previous studies (e.g., Hughes et al., 2010; Karthikeyan and Locke, 2015) used different frequency ranges in phonetic analysis of their voice recordings compared to other studies (e.g., Leongómez et al., 2014). To test whether phonetic analyses produce different results depending on the search area in frequency range, we repeated the phonetic analysis with Praat software’s default frequency range (75–600 Hz instead of 100–500 Hz as suggested for female voices by Boersma and Weenink, 2023). As expected, the results of mean F0, F0 SD, F0min, and F0max differed significantly between predefined frequency range of 75–600 Hz and 100–500 Hz. Also, HNR and Shimmer were significantly different when Praat’s default frequency range was used (see Supplementary Table S6, S7).
Hormone assays
Hormone levels of the participants during the late follicular and luteal phase are shown in Table 6. A Kolmogorov–Smirnov test indicated that hormonal data were not normally distributed. Hence, nonparametric Wilcoxon signed-rank tests were used to compare the hormone levels between both cycle phases. These analyses revealed that, as expected, progesterone levels were significantly higher in the luteal phase than in the late follicular phase (Z = −3.748, p < 0.001). Levels of estradiol (Z = −1.389, p = 0.17), testosterone (Z = −0.312, p = 0.76), and cortisol (Z = −0.772, p = 0.44), however, did not differ between the two phases.

Table 6. Hormone levels in the two cycle phases of the participants.
We found no significant correlation between hormones and vocal parameters during the late follicular phase, neither in the baseline condition (reading sentences out loud) nor in the treatment condition (repeating spoken sentences). During the luteal phase, however, estradiol levels were negatively correlated with mean F0 values and HNR, and positively correlated with jitter and shimmer. In the treatment condition, testosterone levels were negatively correlated with F1, F2, F3 and F4. Cortisol levels were negatively correlated with F0min and F1. Estradiol levels were positively correlated with jitter (see correlation matrices in the Supplementary material).
Discussion
The aim of the present study was to investigate whether and how women’s voices change during the menstrual cycle when responding to female or male speakers with attractive or unattractive voices. For this purpose, the voice of naturally cycling women was recorded during the late follicular phase and during the luteal phase while speaking sentences in response to a stimulus speaker (experimental condition) and when reading aloud the sentences from the computer screen (control condition). Based on earlier studies, we expected that the menstrual cycle of the participants would have an influence on women’s voices. We also hypothesized that women would alter their voices depending on whether they were responding to male (vs. female) stimulus speakers with attractive (vs. unattractive) voices. Phonetic analyses confirmed these predictions in part. In the experimental condition, some vocal parameters of women’s voices were indeed affected by their current menstrual cycle phase (but only F0max when correcting for multiple testing), and by the vocal attractiveness (only Center of Gravity and F1 when correcting for multiple testing) and sex of the stimulus speaker (only F2, when correcting for multiple testing). We observed no interaction between cycle phase and stimulus attractiveness, suggesting that women in the fertile phase did not react specifically to attractive voices. By contrast, in the control condition, in which women merely read out sentences off a computer screen, we observed no effects of menstrual cycle on women’s voices.
In the experimental condition, where women “responded” to recordings of other speakers by repeating spoken sentences, we found some evidence for an effect of the current menstrual cycle phase on women’s vocal characteristics. In the control condition however, where the sentences had to be read aloud without any external vocal input, phonetic analyses showed no effect of participants’ current menstrual cycle phase. While this is inconsistent with some studies which found a cycle effect on women’s voices (Banai, 2017; Bryant and Haselton, 2009; Fischer et al., 2011; Tatar et al., 2015), it is in line with other studies that failed to find a menstrual cycle effect (Barnes and Latman, 2011; Celik et al., 2013; Meurer et al., 2009; Raj et al., 2010). The fact that we only found menstrual cycle effects when women responded to stimulus speakers but not when reading sentences out loud could contribute in part to understanding such inconsistencies across previous published studies and supports the notion that cycle-dependent voice changes need a social trigger to unfold.
When responding to stimulus speakers with attractive voices, women spoke with a breathier and hoarser voice, characterized by lower HNR (note that this effect just failed to reach statistical significance when correcting for multiple testing). Breathiness has been argued to be a feminine trait and is related to desirability in women (Henton and Bladon, 1985). We also observed heightened formant frequencies (in Formants 1–3, only in Formant 1 when correcting for multiple testing), and a higher Centre of gravity when the women responded to more attractive stimulus speakers compared to relatively unattractive stimulus speakers. Centre of gravity is the frequency which divides the voice spectrum into two halves, so a higher Centre of gravity when responding to attractive stimulus speakers means that women’s voices had more high-frequency energy compared to when responding to unattractive stimulus speakers. Of relevance, higher-frequency female voices have been reported to be more attractive than female voices with lower frequencies (Collins and Missing, 2003; Jones et al., 2010). Taken together, these findings suggest that women tried to make their voices sound more desirable and more attractive when speaking to stimulus speakers with attractive voices. In case of male targets, this could be a sign of increased mating motivation, whereas in case of female targets it could serve competitive needs in order to sound more attractive than a rival.
Notably, we did not observe a systematic variation in mean F0, suggesting that women did not generally speak in a higher (Fraccaro et al., 2011) or lower voice pitch (Hughes et al., 2010) when speaking to stimulus speakers with attractive voices. In contrast to Fraccaro et al. (2011) and Hughes et al. (2010), who presented the speakers with photographs of people they were allegedly speaking to, we asked our participants to respond to more or less attractive male and female voice recordings. Our finding might either relate to the inconsistency of the published findings discussed above, or alternatively suggests that the vocal channel alone may not be sufficient to evoke an effect.
With regard to sex of the stimulus speakers, women responded with a higher-frequency Formant 2 to female speakers than to male speakers. Phonetic analysis revealed that this effect might be the result of social mimicry or accommodation, as the speakers were mirroring characteristics of the stimulus speakers (Chartrand and Lakin, 2013; Gregory and Webster, 1996).
The observation that a cycle effect occurred in the experimental condition (responding to stimulus speakers, social context) but not in the control condition (reading sentences aloud, no social context) does not support the assumption that hormone-driven changes in laryngeal mucus and vocal folds are responsible for cycle dependent vocal changes (Abitbol et al., 1999). Furthermore, according to Abitbol et al. (1999), we would expect higher vocal frequencies during the follicular phase. Instead, we observed a higher F0max in the luteal phase than in the follicular phase. Overall, our findings suggest that an effect of the menstrual cycle on a woman’s voice does not occur by default and as a result of hormone-driven biological inevitabilities, but instead needs a social trigger to unfold. This interpretation corresponds to the findings of Bryant and Haselton (2009) who found an effect of menstrual cycle only when women spoke a social sentence, not vowels, further suggesting that cycle-dependent voice changes may occur during social communication only. Likewise, Karthikeyan and Locke (2015) supposed that only when women are motivated to speak and behave attractively, subtle cycle-dependent voice changes may occur. Accordingly, Klatt et al. (2020) found an effect of menstrual cycle phase only if the women uttered sentences with a social content, but not when they spoke neutral sentences.
In previous studies, different software applications and different predefined frequency ranges have been used in phonetic analyses of human voices, which is problematic in terms of comparability of the results (see Table 1). By using different presettings in frequency range, we demonstrate that the chosen frequency range has an effect on phonetic raw data. We repeated phonetic analyses with the default presettings of Praat software (75–600 Hz instead of 100–500 Hz), as did for example Hughes et al. (2010). The Praat output was significantly different in mean F0, F0 SD, F0min, F0max, HNR, and Shimmer, depending on recording condition. Given these results, it is possible that the inconsistent results of previous studies on female voices partially trace back to the variety of phonetic analysis software and different frequency ranges which have been used. Voice changes during the menstrual cycle are subtle and therefore difficult to detect. In order to increase the comparability of future studies, we recommend that researchers develop unified standards for phonetic analysis. Specifically, we recommend using Praat software with the respective settings for male and female voices suggested by the Praat developers.
This study has some limitations. First, mostly Swiss-German speaking individuals with different regional dialects were asked to speak standard German during recording. Potentially this may have resulted in moderately elevated stress for the speakers, making them feeling slightly uncomfortable, and this could have affected their voices over and above any effect of their current menstrual cycle phase or the stimulus speakers’ voices. Second, reproducing the same sentences multiple times may lead to spontaneously occurring variation during speech since a speaker does not pronounce a sentence in exactly the same way every time (Fitch, 1990). This spontaneous variation might have interfered with voice changes evoked by the stimulus speaker. Thirdly, and most obviously, the participants were asked to repeat sentences spoken by stimulus speakers without any real interaction taking place. Although we opted for the present experimental design because allowing natural oral interaction between participants would have significantly confined experimental control, it is plausible that stronger social mimicry effects can be observed in a real social interaction situation. Finally, this was a complex study that demanded enormous commitment from the study participants. It is therefore understandable that some women did not take part until the end. Unfortunately, we no longer have access to the full set of data from the excluded participants, as in some cases, the ethical protocol demanded us to delete them. However, as the women left the study at different stages and for different reasons, we assume that there is no systematic reason for their quitting the study.
In the present study, we took great care in scheduling the cycle-dependent recording sessions and in standardisation of the recording procedure which has sometimes been neglected in previous studies. In the present study, the fertile window of the speakers was determined using LH tests and confirmed with hormone assays of saliva. We minimized potential confounding variables such as irregularity of menstrual cycle, mother tongue, smoking, respiratory diseases, time of the day, and background noise.
Taken together, the present study offers additional evidence that women’s voices subtly change depending on their current menstrual cycle phase and depending on the attractiveness and sex of the stimulus speaker. Importantly, an effect of menstrual cycle was only found when responding to stimulus speakers and not when reading the sentences aloud, suggesting that cycle-dependent voice changes need a social trigger to unfold.
Data availability statement
The original contributions presented in the study are included in the article/Supplementary material, further inquiries can be directed to the corresponding author.
Ethics statement
The studies involving humans were approved by Ethics commission of the Faculty of Human Sciences, University of Bern. The studies were conducted in accordance with the local legislation and institutional requirements. The participants provided their written informed consent to participate in this study.
Author contributions
JL: Data curation, Writing – review & editing, Writing – original draft, Supervision, Project administration, Methodology, Funding acquisition, Conceptualization. WK: Writing – review & editing, Writing – original draft, Software, Methodology, Investigation, Formal analysis, Data curation, Conceptualization. SS: Writing – review & editing, Writing – original draft, Resources, Methodology, Conceptualization.
Funding
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This research was funded by SNF Project no. PP00P1_139072.
Acknowledgments
The authors wish to thank Sabrina Beeler, Vera Bergamaschi, Gina Camenzind, Emilia da Costa, Fion Emmenegger, Rahel Gfeller, Nik Hunziker, Claudia Ramseier, and Arjeta Velii for their assistance at various stages of this project. We also thank Pavel Šebesta for his help with the phonetic analysis.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpsyg.2024.1401158/full#supplementary-material
References
Abitbol, J., Abitbol, P., and Abitbol, B. (1999). Sex hormones and the female voice. J. Voice 13, 424–446. doi: 10.1016/s0892-1997(99)80048-4
Audacity Team. (2023). Audacity (R): Free audio editor and recorder [Computer program]. Version 3.3. Available at: https://www.audacityteam.org/ (Accessed May 06, 2023).
Banai, I. P. (2017). Voice in different phases of menstrual cycle among naturally cycling women and users of hormonal contraceptives. PLoS One 12:e0183462. doi: 10.1371/journal.pone.0183462
Barnes, L., and Latman, N. (2011). Acoustic measure of hormone affect on female voice during menstruation. Int. J. Humanit. Soc. Sci. 1, 5–10.
Boersma, P., and Weenink, D. (2023). Available at: https://www.fon.hum.uva.nl/praat/ (last accessed on 03.09.2023).
Broesch, T. L., and Bryant, G. A. (2015). Prosody in infant-directed speech is similar across western and traditional cultures. J. Cogn. Dev. 16, 31–43. doi: 10.1080/15248372.2013.833923
Bruckert, L., Bestelmeyer, P., Latinus, M., Rouger, J., Charest, I., Rousselet, G. A., et al. (2010). Vocal attractiveness increases by averaging. Curr. Biol. 20, 116–120. doi: 10.1016/j.cub.2009.11.034
Bryant, G. A., and Haselton, M. G. (2009). Vocal cues of ovulation in human females. Biol. Lett. 5, 12–15. doi: 10.1098/rsbl.2008.0507
Celik, Ö., Celik, A., Atespare, A., Boyaci, Z., Celebi, S., Gündüz, T., et al. (2013). Voice and speech changes in various phases of menstrual cycle. J. Voice 27, 622–626. doi: 10.1016/j.jvoice.2013.02.006
Chartrand, T. L., and Lakin, J. L. (2013). The antecedents and consequences of human behavioral mimicry. Annu. Rev. Psychol. 64, 285–308. doi: 10.1146/annurev-psych-113011-143754
Collins, S. A., and Missing, C. (2003). Vocal and visual attractiveness are related in women. Anim. Behav. 65, 997–1004. doi: 10.1006/anbe.2003.2123
Dabbs, J. M., and Delarue, D. (1991). Salivary testosterone measurements among women—relative magnitude of circadian and menstrual cycles. Horm. Res. 35, 182–184. doi: 10.1159/000181899
Farley, S. D., Hughes, S. M., and LaFayette, J. N. (2013). People will know we are in love: evidence of differences between vocal samples directed toward lovers and friends. J. Nonverbal Behav. 37, 123–138. doi: 10.1007/s10919-013-0151-3
Feinberg, D. R., DeBruine, L. M., Jones, B. C., and Perrett, D. I. (2008). The role of femininity and averageness of voice pitch in aesthetic judgments of women’s voices. Percept. 37, 615–623. doi: 10.1068/p5514
Feinberg, D. R., Jones, B. C., DeBruine, L. M., Moore, F. R., Smith, M. J. L., Cornwell, R. E., et al. (2005). The voice and face of woman: One ornament that signals quality?. Evol. Hum. Behav. 26, 398–408. doi: 10.1016/j.evolhumbehav.2005.04.001
Feinberg, D. R., Jones, B. C., Smith, M. L., Moore, F. R., DeBruine, L. M., Cornwell, R. E., et al. (2006). Menstrual cycle, trait estrogen level, and masculinity preferences in the human voice. Horm Behav. 49, 215–222. doi: 10.1016/j.yhbeh.2005.07.004
Fernald, A., and Simon, T. (1984). Expanded intonation contours in mothers' speech to newborns. Dev. Psychol. 20, 104–113. doi: 10.1037/0012-1649.20.1.104
Fischer, J., Semple, S., Fickenscher, G., Juergens, R., Kruse, E., Heistermann, M., et al. (2011). Do women's voices provide cues of the likelihood of ovulation? The importance of sampling regime. PLoS One 6:e24490. doi: 10.1371/journal.pone.0024490
Fitch, J. L. (1990). Consistency of fundamental frequency and perturbation in repeated phonations of sustained vowels, reading, and connected speech. J. Speech Hear. Disord. 55, 360–363. doi: 10.1044/jshd.5502.360
Fraccaro, P. J., Jones, B. C., Vukovic, J., Smith, F. G., Watkins, C. D., Feinberg, D. R., et al. (2011). Experimental evidence that women speak in a higher voice pitch to men they find attractive. J. Evol. Psychol. 9, 57–67. doi: 10.1556/JEP.9.2011.33.1
Gao, W., Stalder, T., and Kirschbaum, C. (2015). Quantitative analysis of estradiol and six other steroid hormones in human saliva using a high throughput liquid chromatography-tandem mass spectrometry assay. Talanta 143, 353–358. doi: 10.1016/j.talanta.2015.05.004
Gregory, S. W., and Webster, S. (1996). A nonverbal signal in voices of interview partners effectively predicts communication accommodation and social status perceptions. J. Pers. Soc. Psychol. 70, 1231–1240. doi: 10.1037/0022-3514.70.6.1231
Grieser, D. L., and Kuhl, P. K. (1988). Maternal speech to infants in a tonal language: support for universal prosodic features in motherese. Dev. Psychol. 24, 14–20. doi: 10.1037/0012-1649.24.1.14
Haselton, M. G., and Gildersleeve, K. (2016). Human ovulation cues. Curr. Opin. Psychol. 7, 120–125. doi: 10.1016/j.copsyc.2015.08.020
Henton, C. G., and Bladon, R. A. W. (1985). Breathiness in Normal female speech—inefficiency versus desirability. Lang. Commun. 5, 221–227. doi: 10.1016/0271-5309(85)90012-6
Hughes, S. M., Farley, S. D., and Rhodes, B. C. (2010). Vocal and physiological changes in response to the physical attractiveness of conversational partners. J. Nonverbal Behav. 38, 107–127. doi: 10.1007/s10919-013-0163-z
Huynh, H., and Feldt, L. S. (1976). Estimation of the box correction for degrees of freedom from sample data in randomized block and split-plot designs. J. Educ. Behav. Stat. 1, 69–82. doi: 10.3102/10769986001001069
Jones, B. C., Feinberg, D. R., DeBruine, L. M., Little, A. C., and Vukovic, J. (2010). A domain-specific opposite-sex biasin human preferences for manipulated voice pitch. Anim. Behav. 79, 57–62. doi: 10.1016/j.anbehav.2009.10.003
Karthikeyan, S., and Locke, J. L. (2015). Men’s evaluation of women’s speech in a simulated dating context: effects of female fertility on vocal pitch and attractiveness. Evol. Behav. Sci. 9, 55–67. doi: 10.1037/ebs0000014
Klatt, W. K., Mayer, B., and Lobmaier, J. S. (2020). Content matters: cyclic effects on women's voices depend on social context. Horm. Behav. 122:104762. doi: 10.1016/j.yhbeh.2020.104762
La, F. M. B., and Polo, N. (2020). Fundamental frequency variations across the menstrual cycle and the use of an Oral contraceptive pill. J. Speech Lang. Hear. Res. 63, 1033–1043. doi: 10.1044/2020_JSLHR-19-00277
Leongómez, J. D., Binter, J., Kubicová, L., Stolarová, P., Klapilová, K., Havlicek, J., et al. (2014). Vocal modulation during courtship increases proceptivity even in naive listeners. Evol. Hum. Behav. 35, 489–496. doi: 10.1016/j.evolhumbehav.2014.06.008
Meurer, E. M., Garcez, V., von Eye Corleta, H., and Capp, E. (2009). Menstrual cycle influences on voice and speech in adolescent females. J. Voice 23, 109–113. doi: 10.1016/j.jvoice.2007.03.001
Nacci, A., Fattori, B., Basolo, F., Filice, M. E., De Jeso, K., Giovanni, L., et al. (2011). Sex hormone receptors in vocal fold tissue: a theory about the influence of sex hormones in the larynx. Folia Phoniatr. Logop. 63, 77–82. doi: 10.1159/000316136
Oleszkiewicz, A., Pisanski, K., Lachowicz-Tabaczek, K., and Sorokowska, A. (2017). Voice-based assessments of trustworthiness, competence, and warmth in blind and sighted adults. Psychon. Bull. Rev. 24, 856–862. doi: 10.3758/s13423-016-1146-y
Pavela Banai, I., Burriss, R. P., and Šimić, N. (2022). Voice changes across the menstrual cycle in response to masculinized and feminized man and woman. Adapt. Hum. Behav. Physiol. 8, 238–262. doi: 10.1007/s40750-022-00190-y
Peirce, J. W. (2007). PsychoPy - psychophysics software in python. J. Neurosci. Methods. 162, 8–13. doi: 10.1016/j.jneumeth.2006.11.017
Pipitone, R. N., and Gallup, G. G. Jr. (2008). Women's voice attractiveness varies across the menstrual cycle. Evol. Hum. Behav. 29, 268–274. doi: 10.1016/j.evolhumbehav.2008.02.001
Plexico, L. W., Sandage, M. J., Kluess, H. A., Franco-Watkins, A. M., and Neidert, L. E. (2020). Blood plasma hormone-level influence on vocal function. J. Speech Lang. Hear. Res. 63, 1376–1386. doi: 10.1044/2020_JSLHR-19-00224
Puts, D. A., Bailey, D. H., Cardenas, R. A., Burriss, R. P., Welling, L. L. M., Wheatley, J. R., et al. (2013). Women's attractiveness changes with estradiol and progesterone across the ovulatory cycle. Horm. Behav. 63, 13–19. doi: 10.1016/j.yhbeh.2012.11.007
Raj, A., Gupta, B., Chowdhury, A., and Chadha, S. (2010). A study of voice changes in various phases of menstrual cycle and in postmenopausal women. J. Voice 24, 363–368. doi: 10.1016/j.jvoice.2008.10.005
Raphael, L. J., Borden, G. J., and Harris, K. S. (2011). Speech science primer. Philadelphia, PA: Lippincott Williams and Wilkins.
Schneider, B., Cohen, E., Stani, J., Kolbus, A., and Rudas, M. (2007). Towards the expression of sex hormone receptors in the human vocal fold. J. Voice 21, 502–507. doi: 10.1016/j.jvoice.2006.01.002
Schweinberger, S. R., Kawahara, H., Simpson, A. P., Skuk, V. G., and Zäske, R. (2014). Speaker perception. WIREs Cogn. Sci. 5, 15–25. doi: 10.1002/wcs.1261
Shoup-Knox, M. L., Ostrander, G. M., Reimann, G. E., and Pipitone, R. N. (2019). Fertility-dependent acoustic variation in Women's voices previously shown to affect listener physiology and perception. Evol. Psychol. 17:1474704919843103. doi: 10.1177/1474704919843103
Shoup-Knox, M. L., and Pipitone, R. N. (2015). Physiological changes in response to hearing female voices recorded at high fertility. Physiol. Behav. 139, 386–392. doi: 10.1016/j.physbeh.2014.11.028
Tatar, E. C., Sahin, M., Demiral, D., Bayir, O., Saylam, G., Ozdek, A., et al. (2015). Normative values of voice analysis parameters with respect to menstrual cycle in healthy adult Turkish women. J. Voice 30, 322–328. doi: 10.1016/j.jvoice.2015.04.014
Titze, I. R. (1989). On the relation between subglottal pressure and fundamental frequency in phonation. J. Acoust. Soc. Am. 85, 901–906. doi: 10.1121/1.397562
Wust, S., Wolf, J., Hellhammer, D. H., Federenko, I., Schommer, N., and Kirschbaum, C. (2000). The cortisol awakening response—normal values and confounds. Noise Health 2, 79–88.
Zaske, R., Skuk, V. G., Golle, J., and Schweinberger, S. R. (2020a). The Jena speaker set (JESS)-a database of voice stimuli from unfamiliar young and old adult speakers. Behav. Res. Methods 52, 990–1007. doi: 10.3758/s13428-019-01296-0
Zaske, R., Skuk, V. G., and Schweinberger, S. R. (2020b). Attractiveness and distinctiveness between speakers' voices in naturalistic speech and their faces are uncorrelated. R. Soc. Open Sci. 7:201244. doi: 10.1098/rsos.201244
Zraick, R. I., Gentry, M. A., Smith-Olinde, L., and Gregg, B. A. (2006). The effect of speaking context on elicitation of habitual pitch. J. Voice 20, 545–554. doi: 10.1016/j.jvoice.2005.08.008
Keywords: menstrual cycle, social mimicry, accommodation, attractiveness, phonetics
Citation: Lobmaier JS, Klatt WK and Schweinberger SR (2024) Voice of a woman: influence of interaction partner characteristics on cycle dependent vocal changes in women. Front. Psychol. 15:1401158. doi: 10.3389/fpsyg.2024.1401158
Edited by:
Lisa L. M. Welling, Oakland University, United StatesReviewed by:
Geoff Kushnick, Australian National University, AustraliaJan Havlicek, Charles University, Czechia
Copyright © 2024 Lobmaier, Klatt and Schweinberger. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Janek S. Lobmaier, ai5sb2JtYWllckBwc3ljaG9sb2dpZS51emguY2g=