 Mingqing Jiao1,2*
Mingqing Jiao1,2*- 1School of Management and Economics, Jingdezhen Ceramic University, Jingdezhen, China
- 2School of Management and Economics, Beijing Institute of Technology, Beijing, China
This work aims to solve the complex problems of non-linearity, instability, and multiple economic factors in the tax forecast of the ceramic industry to ensure the sustainable development of the ceramic industry. The key influential indicators of the tax forecast are obtained by analyzing the principal components affecting the tax index. In addition, a human-computer interaction (HCI) system is established based on cognitive psychology theory to improve the user-friendliness of tax analysis. At the same time, the tax data of the ceramic industry in Jingdezhen City, Jiangxi Province in different years are used for the empirical analysis of the tax prediction of different prediction models, including particle swarm optimization (PSO) algorithm, and fusion algorithm (FA), and support vector machine (SVM). This work comprehensively analyzes the influence of the optimized tax supervision mode on the economic development of the ceramic industry and provides ideas for the development of the ceramic industry in Jingdezhen. The research results demonstrate that the main indicator affecting tax revenue is the added value of the primary and secondary industries. The optimized SVM based on grid search method can provide a comprehensive data base for tax forecasting. The optimization of the computer system based on cognitive psychology improves the model prediction accuracy by 10%, and the absolute error decreases from 6.9 to 1.8%. The tax forecast results indicate that the tax imbalance in Jingdezhen is increasing. Therefore, the government needs to attach great importance to the development of the ceramic industry and strictly implement the tax policy. The tax supervision model can alleviate the problems of low fiscal contribution rate, tax evasion, and management loopholes. In addition, the SVM tax prediction model optimized by grid search method will lay a theoretical foundation for the research and application of taxation in the ceramic industry.
Introduction
The rapid progress of China’s economy, the deepening of domestic reform, and the accelerated pace of opening up have sped up China’s economic development (Wang et al., 2016; Zheng and Walsh, 2019; Bruton et al., 2021). Taxation is the main source of China’s fiscal revenue and affects the per capita disposable income and residents’ quality of life. It is also closely related to enterprises’ financial burden and development (Li et al., 2019; Xiao, 2020). Taxation helps the government reallocate resources, adjust economic structure, promote employment, and stabilize people’s life. It provides a basic guarantee for the rapid and stable development of the national economy (Gilley, 2017; Fan and Liu, 2020). Tax forecast considers the changes of factors affecting tax revenue and historical tax data and implements scientific judgment on the prospect of tax revenue through specific models and analysis methods (Graham et al., 2017). On the one hand, it is necessary to predict and analyze the tax revenue before the change of national tax policy. The prediction results can help the tax personnel arrange the tax plan and tax situation effectively, providing a theoretical basis for the decision-making of relevant departments (Bratten et al., 2017). On the other hand, a proper tax platform can adjust resource allocation, expand the scale of related enterprises, and achieve sustainable development, taking into account some industry development and income imbalances.
Human-computer interaction (HCI) is a discipline for designing and evaluate computer systems for human use. Specifically, HCI improves the efficiency of people using computers by improving the input and output of computers. Computer science has had a profound influence on the development of cognitive psychology, studying the use of new computer interface methods to optimize the design of desired attributes (learning ability, probing ability, and use efficiency). From the perspective of cognitive psychology (Choi and Luo, 2019), HCI combines computer interfaces with psychological patterns of human activity and computer interfaces with existing social practices or existing sociocultural values. It can provide a practical communication point for analyzing socio-economic and cultural development and establish a circulating information exchange network between people, computers, and society.
Jingdezhen city in Jiangxi Province is famous for its ceramics. In Jingdezhen, there are about 3,000 ceramic enterprises, 96% of which are private enterprises. A series of problems, such as the management system of small workshops and the large tax burden of large and medium-sized ceramic enterprises, have hindered the development of the ceramic industry (Mirfakhradini et al., 2018; Atilgan Türkmen et al., 2021). In recent years, due to the high attention of the Jiangxi provincial Party committee and government, the tax department has continuously strengthened its tax work. However, the current ceramic tax collection and management situation is not optimistic because of the complexity of the industry. The main problems are that the industrial development is relatively backward, the protection of technology inheritance is not high, and the lack of cooperation opportunities with ceramic research institutions. Therefore, using new techniques and methods to achieve accurate tax forecasting is of great significance for solving problems in the ceramic industry.
Research on the precise tax forecast mainly focuses on applying new algorithms to build diverse forecast models. Höglund (2017) used a genetic algorithm (GA) combined with a linear discriminant analysis model. The analysis results of the tax data of many enterprises proved that the model can effectively judge whether the inspected enterprises pay taxes normally. Mabe-Madisa (2018) used practical learning classification intelligent algorithms to classify compliant and non-compliant taxpayers. Rahimikia et al. (2017) utilized a hybrid intelligent system consisting of the multi-layered perceptron neural network, the support vector machine (SVM), logistic regression classification model, and harmonious search optimization algorithm to detect tax evasion by Iranian enterprises. The authors verified the model’s effectiveness in taxation. Namazi and Sadeghzadeh Maharluie (2018) applied the decision tree algorithm to forecast the tax evasion of listed companies in the Tehran Stock Exchange (TSE). They found that the algorithm could effectively supervise the tax evasion of TSE listed companies. Andini et al. (2018) effectively supervised taxation and provided information for tax policy decisions by using machine learning algorithms. Lee (2021) researched the accuracy of economic tax expense forecasts and examined whether the strength of investor protection affects analysts’ tax expense forecast accuracy. The findings suggested that firms with high accuracy in analysts’ tax forecasts have low tax avoidance levels. Dobroviè et al. (2021) established an analysis and prediction model of tax evasion in European Union (EU) countries. Through the econometric prediction model, EU countries were divided into five reference groups according to the value of value-added tax (VAT) difference according to the results of cluster analysis. The results showed that taking appropriate measures can improve the accuracy of forecasts in the economic field. The above studies show that the use of new algorithms and models for tax forecasting has become one of the research hotspots in this field.
In the research results of the above-mentioned stages, the data of tax indicators are mainly carried out through principal component analysis (PCA) to eliminate redundant variables between tax indicators. In addition, SVM, particle swarm optimization (PSO) algorithm, and fusion algorithm (FA) are used to conduct in-depth training on the tax data of different years of the ceramic industry in Jingdezhen City, Jiangxi Province. A HCI system is established based on cognitive psychology to improve the analysis efficiency. Finally, the different models are compared and analyzed to determine the effectiveness of the appropriate model. In addition, a reasonable solution to the tax problem in Jingdezhen City is proposed based on the influence of the tax supervision mode on the economic development of the ceramic industry. The innovation of the research lies in the comparison of different algorithms, providing a creative study for tax administration. This work offers a theoretical basis for the sustainable development of the ceramic industry in Jingdezhen City, Jiangxi Province.
Materials and methods
Current status of tax collection and management of the ceramic industry
The current status of ceramic industry development in Jingdezhen is understood by reviewing the literature. The current problems in taxation are as follows. First, the macroscopic tax burden of the ceramic industry is low, and the tax share of the ceramic industry is far lower than the total output value. In recent years, the tax burden of the ceramic industry in Jingdezhen only accounts for 1.3% of the macroscopic industry tax burden. 2013 witnessed the highest proportion, which was 1.4%. In 2015, the proportion was only 0.74%. The data show that the ceramic industry, as the primary source of income in Jingdezhen, has not been reflected in taxation. Second, the types of enterprises are diversified, but there are few large and medium-sized enterprises. There were 6,525 ceramic enterprises and 4,261 individual enterprises from 2014 to 2018. In 2016, only 10 enterprises had a tax payment of more than 10 million Chinese Yuan (CNY), and only three enterprises had a tax payment of 500,000 to 1 million CNY. Therefore, most of the enterprises in Jingdezhen are small enterprises, which severely restricts the expansion of the national tax revenue. Third, tax payment is principally based on value-added tax, corporate income tax, and personal income tax. There are a few types of taxes, and the output value of each tax is low.
The main problems in the development of Jingdezhen ceramic industry are as follows. First of all, the ceramic industry chain is long, and there are drawbacks in the management of the tax management department. Due to the wide range of material sources in the ceramic industry, the chains between various industries are fragmented, and there is no suitable sharing platform. As a result, it is challenging for tax officials to grasp key tax indicators such as the utilization rate of raw materials and electricity consumption. Second, tax evasion prevails. The proportion of ceramic tax continues to decline with the continuous development of the ceramic industry. For example, the tax administration did not report ceramic artists truthfully; nonetheless, most studios and small businesses did not enforce tax policies, which contributed to a climate of tax evasion. Third, the tax collection and management of ceramics is weak. While the number of tax bureaus continues to increase every year, most are senior executives, and the number of ceramic tax collectors has not increased, making tax collection incredibly difficult. Fourth, the sharing of information on tax collection and management of ceramics is low. The ceramic industry takes its information protection very seriously. Therefore, it is difficult for the tax management department to obtain relevant information of taxpayers and to ensure the authenticity of the obtained information, resulting in the problem of information asymmetry.
Human-computer interaction model of support vector regression combined with cognitive psychology
Cognitive psychology refers to a process of thinking and reasoning based on mental processing (Biggs et al., 2018). The changing process of cognitive psychology is a complex psychological mechanism, primarily including feeling, perception, memory, thinking, and language. When the human brain receives external information, it needs to process the input information and convert it into internal psychological activities to control human behavior. From the perspective of cognitive psychology, the HCI process is a person’s cognitive process. The improvement of humanistic characteristics in human-computer interface is to improve the efficiency and availability of information interaction in human-computer interface, prevent cognitive errors, and improve the cognitive efficiency of human beings. Based on the analysis of the user’s thinking and behavior model, a comprehensive cognitive model is established through the analysis of the human thinking process to find out the main factors affecting the efficiency of HCI. It is necessary to encode the external stimulus information in a certain way under HCI so that the brain can use the information. The encoded information becomes a mental representation, representing the process by which the computer or human brain processes the model data. It eventually stays in the human consciousness and is long-term stored in the working memory for future use in human life and work.
The human-machine interface becomes the communication point between the human user and the computer. In addition, the HCI subjects include computers and computer users. Information processing models are used to process received stimulus information and take corresponding actions through perception, cognition, and response systems (Renoult and Mendelson, 2019). HCI is the intersection of computer science technology and cognitive psychology. In other words, HCI uses knowledge from cognitive psychology to help humans process relevant external information. The HCI system is designed based on cognitive psychology theory. Figure 1 shows the information processing process of the HCI system.
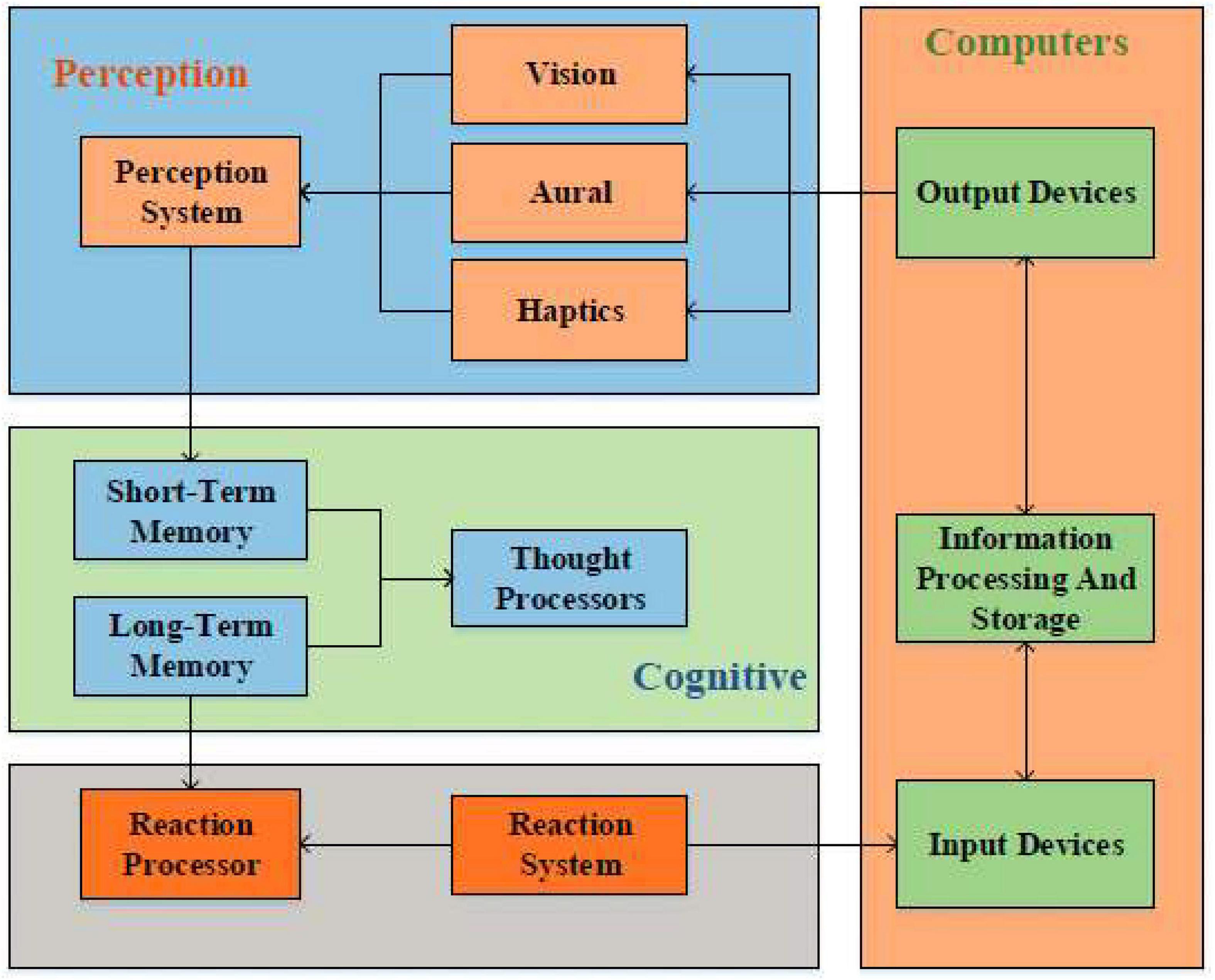
Figure 1. Information processing process of the human-computer interaction (HCI) system.
Support vector regression is a binary classification model and a general term for the supervised learning model and its related learning algorithms. It is used for classification analysis and regression analysis of data. Its basic model is a linear classifier with intervals defined in the feature space. The x input space is mapped to a high-level feature space through nonlinear transformation, and the linear function of this feature space is used to fit the sample data. Figure 2 is its schematic diagram. In the feature space, the linear function is defined as Eq. (1).
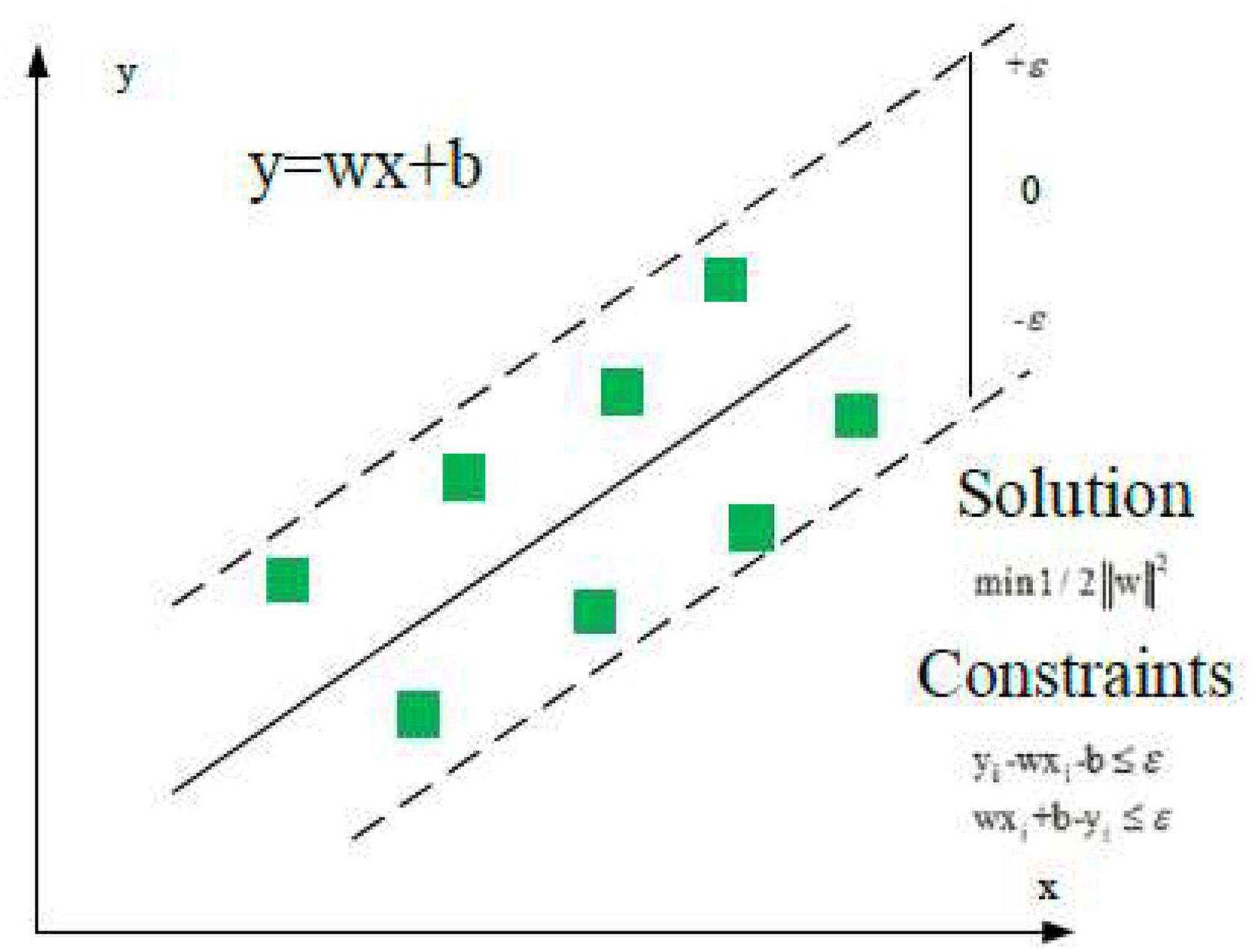
Figure 2. Schematic diagram of support vector regression (SVR) model.
In Eq. (2), w denotes the weight; b is the offset top; φ(x1) represents the nonlinear mapping function; s. t. y1 means making y1 satisfy a certain equation; α denotes the Lagrange multiplier vector. Then, the function can be written as:
This work introduces the Lagrangian multiplier, forming the Lagrangian function:
There are Eq. (5) ∼ Eq. (8) according to the Karush–Kuhn–Tucker condition.
In the feature spaces φ(xi) and φ(xj), the product of φ(xi)T and φ(xj) needs to satisfy the Mercer condition that can be used as the kernel function. k(xi,xj) = φ(xi)Tφ(xj), where k(xi,xj)is the kernel function. Here, a Gaussian radial basis kernel function with good generalization ability is utilized, which can be expressed as Eq. (9).
Eq. (10) describes the SVR matrix.
In Eq. (10), A = K + V,K = (kij)N×N, V = diag(1/C,1/C1/C); E stands for an Nx1 matrix with all elements being 1. Therefore, the regression model of SVR can be written as Eq. (11).
Forecast algorithms of taxation data
(1) The gale-shapley (GS) algorithm is a new algorithm based on cross-validation (CV). Figure 3 presents the K-CV method used here. First, the original data are averagely divided into K combinations. Data corresponding to each set is a test unit, and the remaining K-1 sets are training sets. Then, K models are obtained after training, and the accuracy of each model after all classifications is averaged and utilized as the performance evaluation indicator of each model. The parameters are optimized by selecting a gridded component in a certain area, and the combination with the highest accuracy among all the combinations is searched and regarded as the optimal parameter combination of parameters.
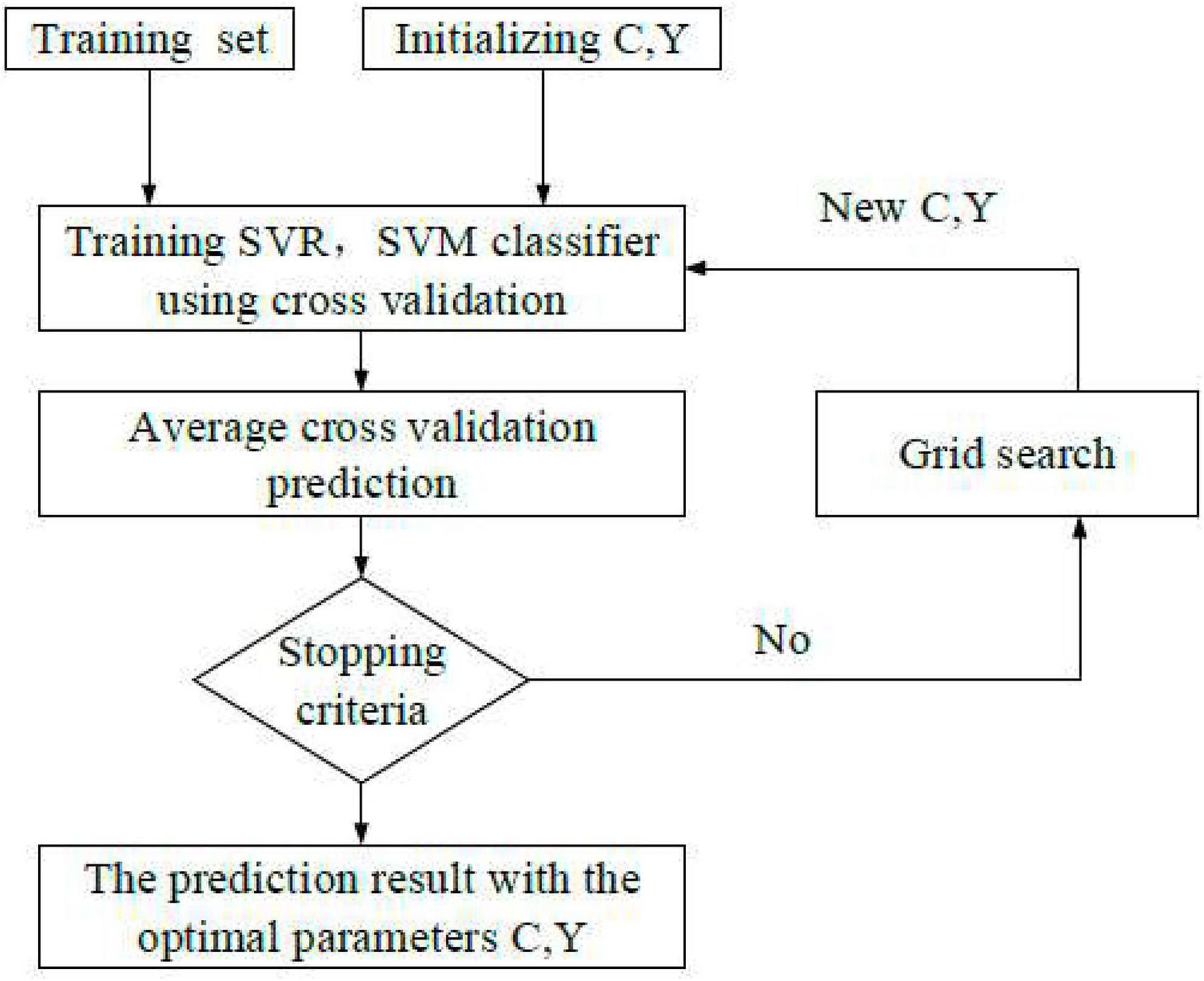
Figure 3. Algorithm flow of GS.
(2) Grey models (GM) (1,1) generates a set of new data series with apparent trends for some data series accumulatively. Besides, a model to make forecasts is built according to the growth trend of the new data series. Then, the reverse calculation is performed by the subtraction method to restore the original data sequence, thereby obtaining the prediction results, as shown in Figure 4 (Han and Hong, 2018).
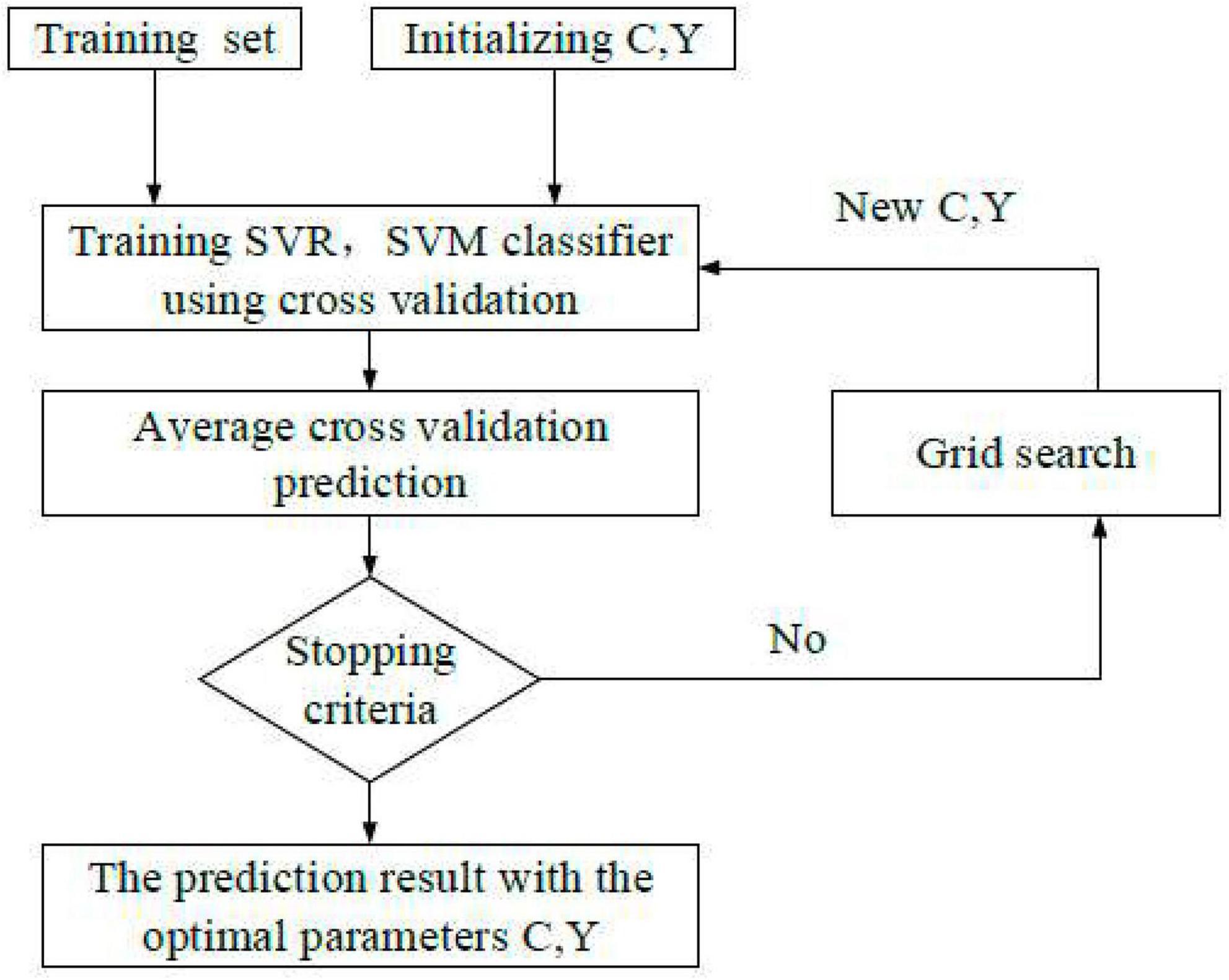
Figure 4. Algorithm flow of GM (1,1).
(3) Genetic algorithm shows the process of natural selection based on the theory of biological genetics. In this process, the most suitable individuals are selected for reproduction. The population evolved through replication, crossover, mutation, and other operations, according to the theories about the survival of the fittest and information exchange (Metawa et al., 2017). The optimization process of GA is as follows. First, the genetic population is decoded into the SVM model, and the fitness is calculated after substituting the individuals into the model. If the conditions are not met, the individuals will return to the genetic population for selection. The individuals can pass the optimized SVM model if the conditions are met.
(4) The PSO algorithm is inspired by bird swarms searching for something, which arranges complex events systematically and logically. It can provide candidate solutions (Wang et al., 2018). The essence of the fundamental particle swarm algorithm’s continuous optimization algorithm is iterative update optimization, which can randomly assign and select multiple particles. Each substance’s gradual adaptation value can be calculated according to the adaptation function’s definition. In the update of the intermediate position velocity, the optimal position can be changed according to the above equations, and the gradual adaptation value can be repeatedly calculated. When the search for the global optimal combined solution ends, the particles in the algorithm update the original position and velocity according to the velocity position. The particle velocity update equation in dimensional space can be written as:
where C1 stands for the historical optimal weight coefficient when the particle itself searches; C2 represents the global optimal weight coefficient when the particle itself searches; rand1 () and rand2 () refer to random numbers between 0–1; Vmax denotes the maximum velocity limit; Viq signifies the velocity of some spatial dimension. Eq. (14) indicates the particle position update in q-dimensional space.
In Eq. (14), r refers to the elastic coefficient of the velocity variable in the update equation. The original historical position and velocity of the particle and the state and position of the historical movement of the population affect the velocity and position of the particle in the population. The goal is to find the optimal combination through complex cooperation.
Principal component analysis
Principal component analysis is a linear statistical method in feature extraction to reduce the dimension of input features from the original data (Aït-Sahalia and Xiu, 2019). Orthogonal transformation is utilized to convert the set of n samples of P possible related features into n sample sets of m (m < 1) unrelated features of the principal component. First, the random variables are collected; the n samples form a sample array, and the following transformation is made to the sample array:
Eq. (15) is standardized to obtain the coefficient matrix associated with the standardized matrix Z.
The characteristic equation of the matrix related to the sample is substituted to find the characteristic root of p and determine the m value according to the cumulative rate of the eigenvalues. Finally, the orthogonalized variables are converted into principal components to comprehensively evaluate the m principal components. In addition, the final evaluation value is solved through weighted summation. The weight is the variance contribution rate of each principal component.
Normalization processing
Many scholars have verified that experimental data of different dimensions will affect the forecast results and model accuracy of the forecast model (Tian et al., 2017). The measurement units of the included taxation data are different, and the difference in the data value of related indicators is also large. It is necessary to standardize the taxation data before model training, i.e., to normalize all data to the [0, 1] interval. This operation can eliminate the impacts of the difference between forecast indicator data on the performance of the taxation forecast model. The specific processing is shown in Eq. (17).
In Eq. (17), represents the normalized taxation value, xi represents the index column data, andxmax,xmin represents the maximum and minimum values of the data in the index column, respectively.
Model evaluation indicators
Three evaluation indicators are designed as follows. (1) Mean absolute error (MAE) is the average of the absolute values of the deviations of all individual observations from the arithmetic mean. MAE can avoid the problem that the errors cancel each other out. Therefore, it can accurately show the actual forecast error. (2) Mean square error (MSE) is a measure that indicates the degree of difference between the quantity to be estimated and the estimating quantity. (3) Root mean square error (RMSE) is the square root of the ratio of the square of the deviation of the forecast value and the true value to the number of observations n. In the actual measurement, the number of observations n is always limited, and the true value can only be indicated by a reliable (optimal) value instead. In Eq. (18) ∼ Eq. (20), represents the actual value, and vi represents the forecast value.
Sample data collection and analysis
The total tax revenue data (Y, ten thousand CNY) of Jingdezhen City from 2009 to 2019 are chosen. The following ten major impact indicators are through literature review, according to the size of the influencing factors. The added value of the primary, secondary, and tertiary industries is X1, X2, and X3, respectively; the total industrial output value is X4; the fixed asset investment is X5; the total retail sales of social consumer goods is X6; the commodity sales is X7; the total value of foreign trade import and export is X8; the deposit balance of urban and rural residents is X9. The measuring unit of all indicators is 10,000 CNY. The experimental data come from China Statistical Yearbook and China Tax Yearbook. The data from 2000 to 2010 are selected as the training data, and the data from 2015 to 2019 are selected as the test data. Table 1 summarizes the detailed data.
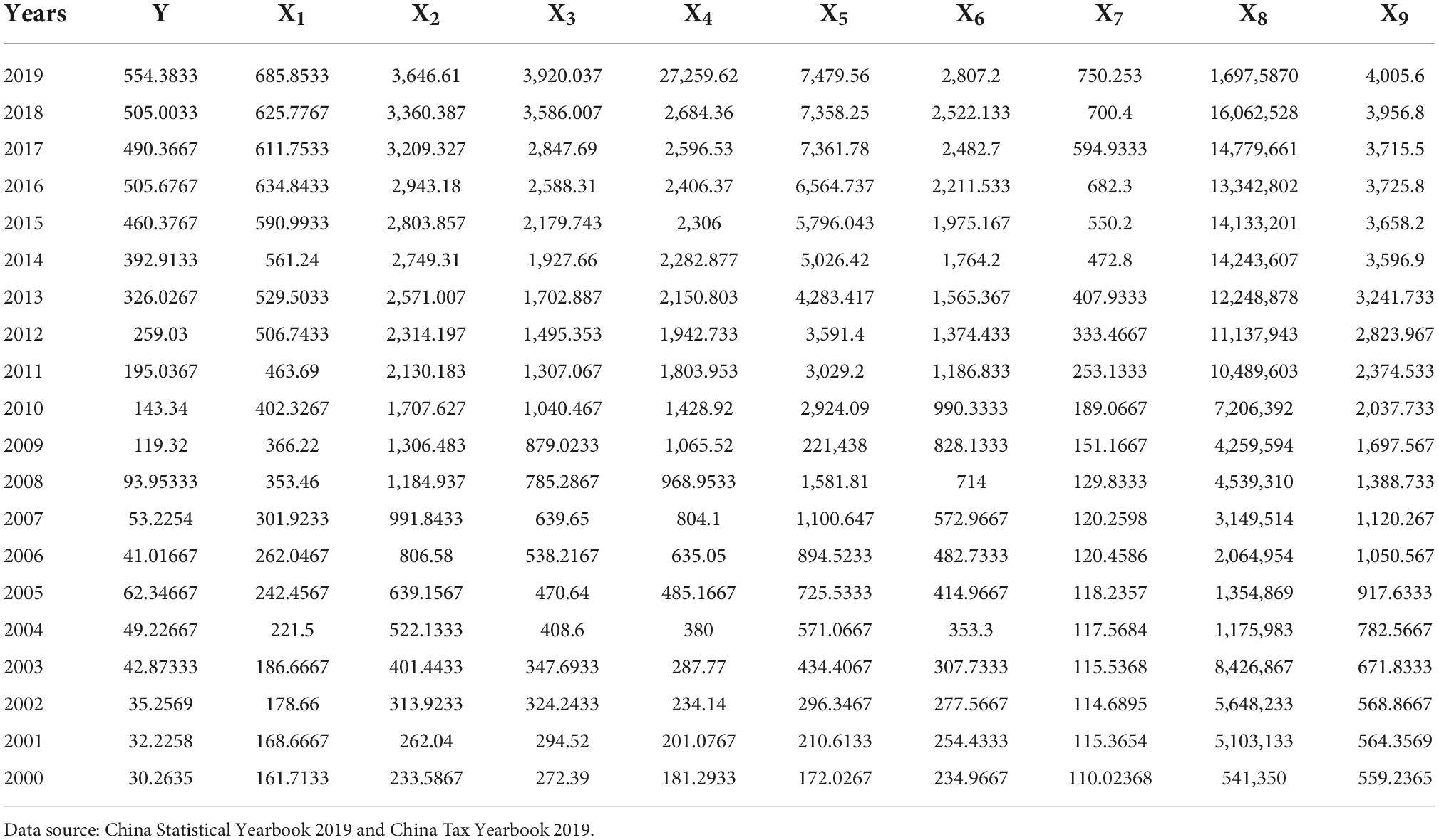
Table 1. Tax revenue model data.
Construction of Jingdezhen ceramic industry taxation fusion model based on support vector machine
The problems in the tax management of Jingdezhen are analyzed accurately based on the review and research on literature, models, and data. To this end, a sustainable ceramic tax service platform is built, as shown in Figure 5. The specific process is as follows. (1) The major factors affecting tax revenue are determined based on literature and PCA; the tax-related data published by the National Bureau of Statistics are collected according to the indicators. (2) The taxation data are standardized to eliminate the impacts of the dimensional differences between the various indicator factors on the taxation forecast results. (3) The GM (1,1) algorithm is utilized for taxation indicators so that the models are established to solve the forecast values of data in different years. (4) A forecast model is built based on SVM, the model parameters are initialized, and the forecast value of taxation is calculated based on the default value. (5) The training set is learned, the test set is utilized for tests, the taxation forecast results are output, and the errors and effects of the forecast model are analyzed.
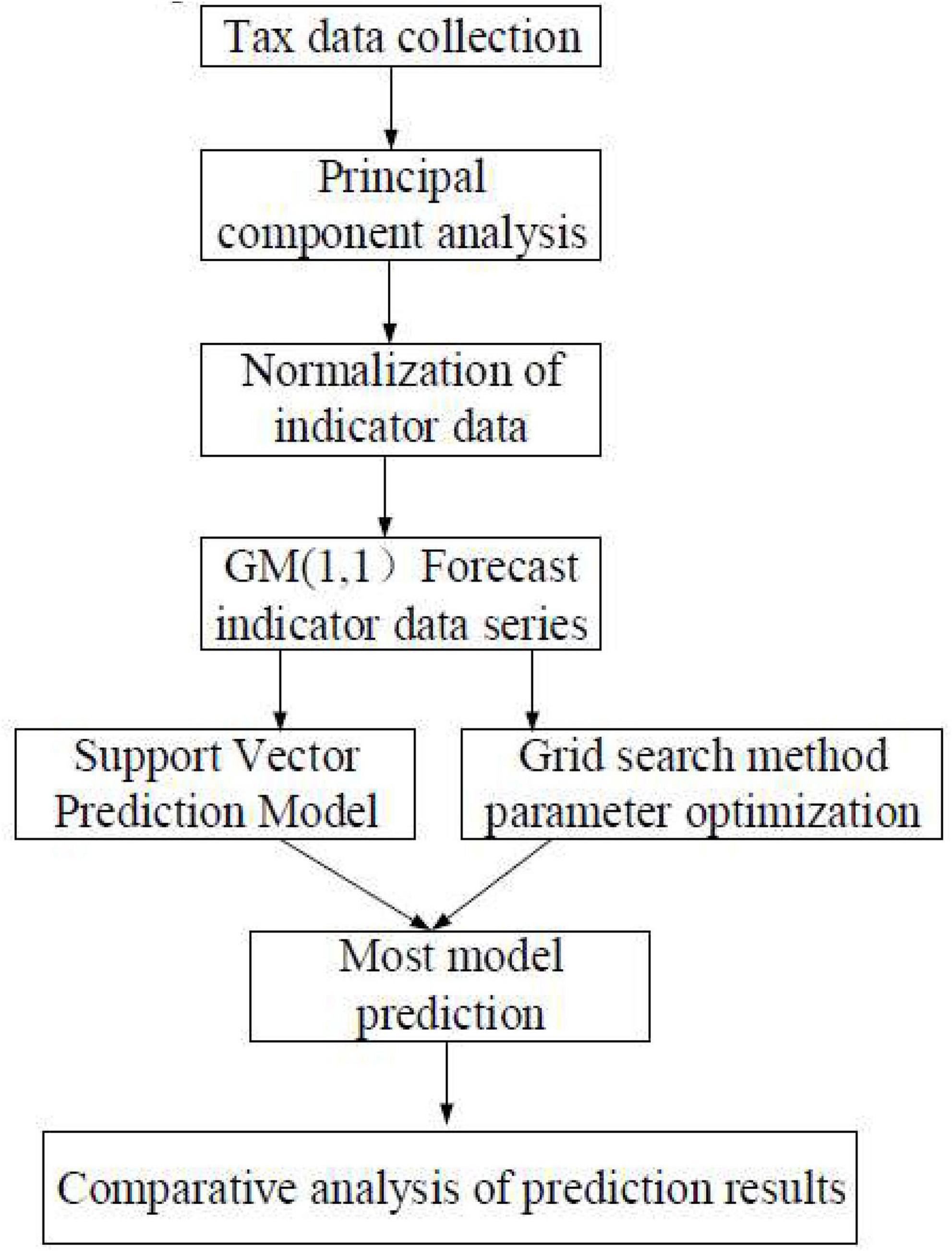
Figure 5. Construction of the taxation fusion model based on support vector machine (SVM) for the ceramic industry in Jingdezhen.
Results
Principal component analysis of factors affecting the taxation of the ceramic industry
Principal component analysis is carried out on the influential factors of the taxation of the ceramic industry by using mathematical statistical calculation tools. The results in Table 2 indicate that the variance contribution rate of the added value of the primary industry is 0.952; the variance contribution rate of the added value of the secondary industry is 0.0386; the variance contribution rate of the added value of the tertiary industry is 0.0065; the variance contribution rate of the industrial output value is 0.002; the variance contribution rate of fixed asset investment is 0.0004, of which the contribution rate of the first five components reaches 99.95%, and the remaining components only account for 0.05%. Among them, the primary industry refers to the sector that produces products that can be consumed without further processing, such as the agricultural sector. The secondary industry refers to the sector that reprocesses primary products. The tertiary industry refers to the sector that provides various services for production and consumption in the process of reproduction. The most significant tax impact on the ceramic industry is the total output value of the primary industry, followed by the secondary industry. Therefore, the first five metrics are used as principal components and input to the SVM for training and learning.
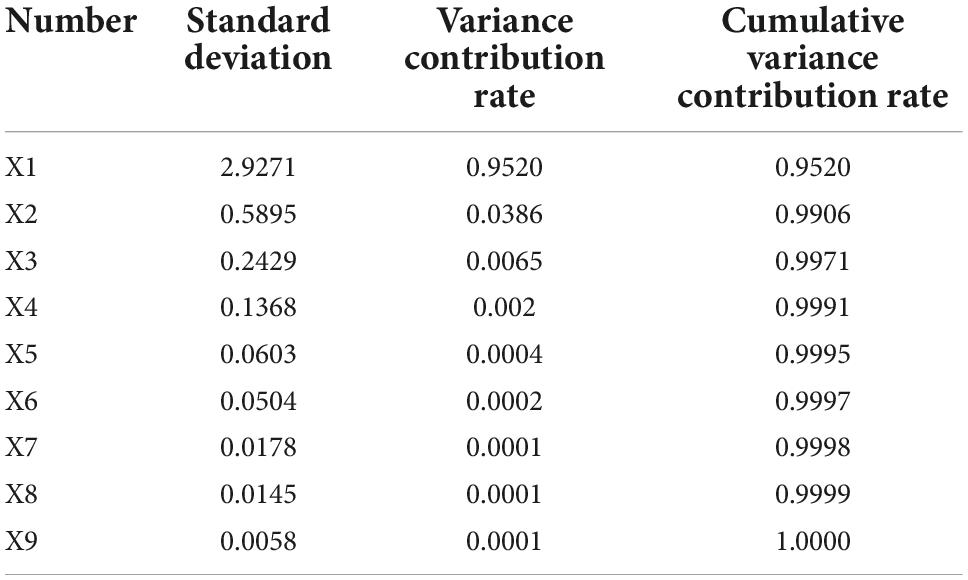
Table 2. Principal component analysis (PCA) results of factors affecting the taxation of ceramic industry.
Parameter optimization of ceramic industry taxation forecast model
Figure 6 presents the parameter optimization experimental results of the six algorithms. Figure 6 suggests that the overall fluctuation of the PSO algorithm is significant, but it can be kept stable in general. The average fitness function of GA decreases as the number of iterations increases. The fitness of the GS algorithm is the best; the optimal fitness and the average fitness appear earlier. For the GM algorithm, the optimal fitness value does not intersect with the average fitness value. In terms of the SVM algorithm, there are many intersections. For the FA, there is no intersection in the early stage; however, a small amount of intersection occurs later. According to the above results, the forecast curve of the six parameter optimization methods has a high degree of fitness with the actual value, and a good forecast effect is achieved. Among them, FA has the best optimization effect, followed by the GS algorithm and the support vector algorithm.
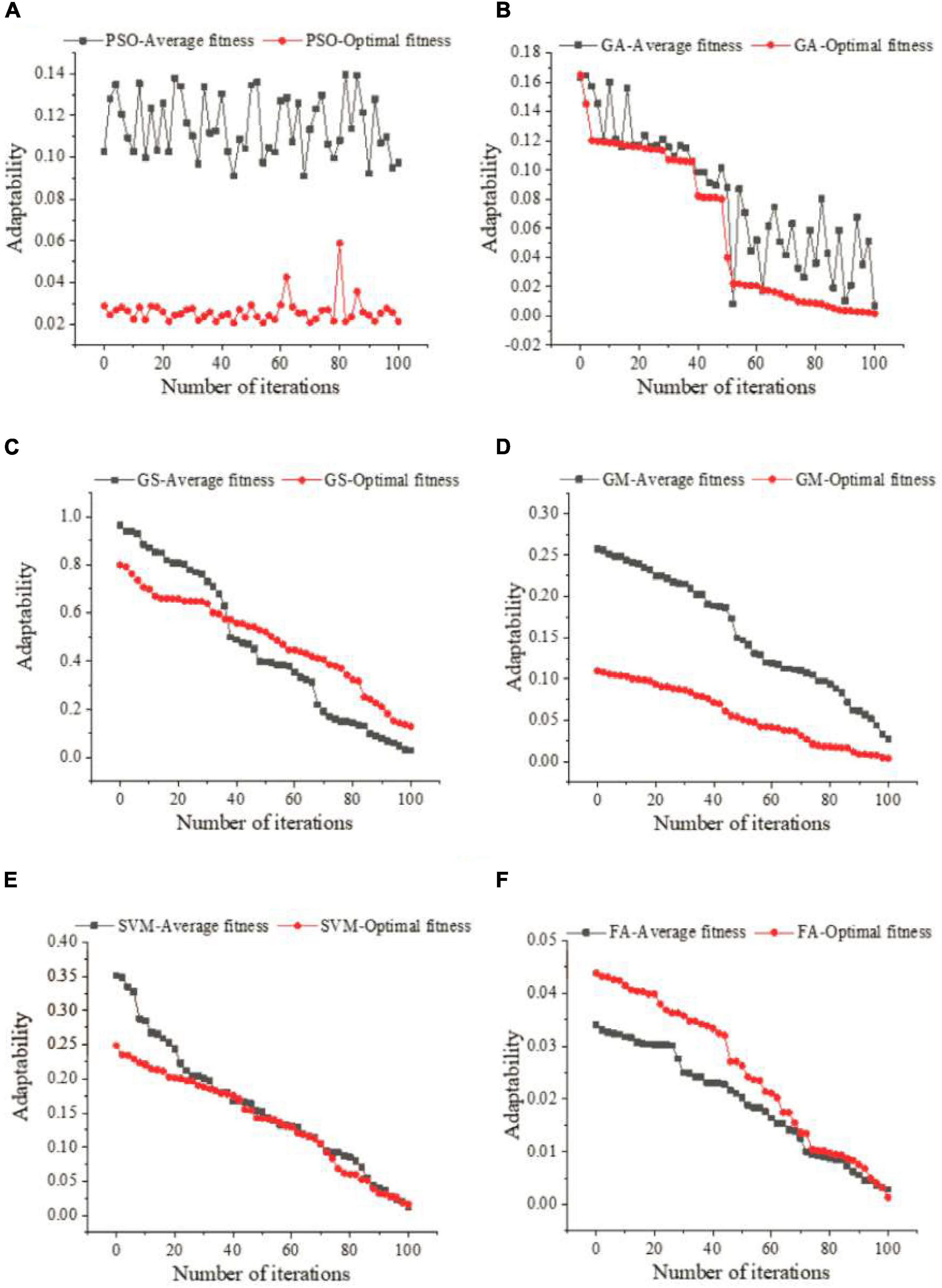
Figure 6. (A) Parameter optimization curve of PSO algorithm. (B) Parameter optimization curve of GA algorithm. (C) Parameter optimization curve of GS algorithm. (D) Parameter optimization curve of GM algorithm. (E) Parameter optimization curve of SVM algorithm. (F) Parameter optimization curve of FA algorithm.
Performance analysis of the ceramic industry taxation forecast model
The two major indicators that affect the principal components of the taxation of the ceramic industry are chosen. The first industry added value and the second industry added value are utilized to evaluate the performance of the model. The results are shown in Figure 7, where actual vector (AV) is the actual value of ceramic tax revenue. According to Figure 7, the FA is superior to other algorithms in terms of the forecast value of the added value of the first industry and the added value of the second industry. In combination with Table 3, it is found that the forecast value of the GM algorithm is less stable, while the results of FA are stable. In addition, the forecast accuracy of FA is also higher than other algorithms. Specifically, the forecast accuracy of FA is improved by 10%, and the absolute error is reduced from 6.9 to 1.8%. Forecasting related industries in Jingdezhen by using the fusion model has found that the primary industry will increase rapidly from 2020 to 2025, while the added value of the secondary industry will increase more slowly; in addition, the tertiary industry will continue to increase, but its added value will increase slowly.
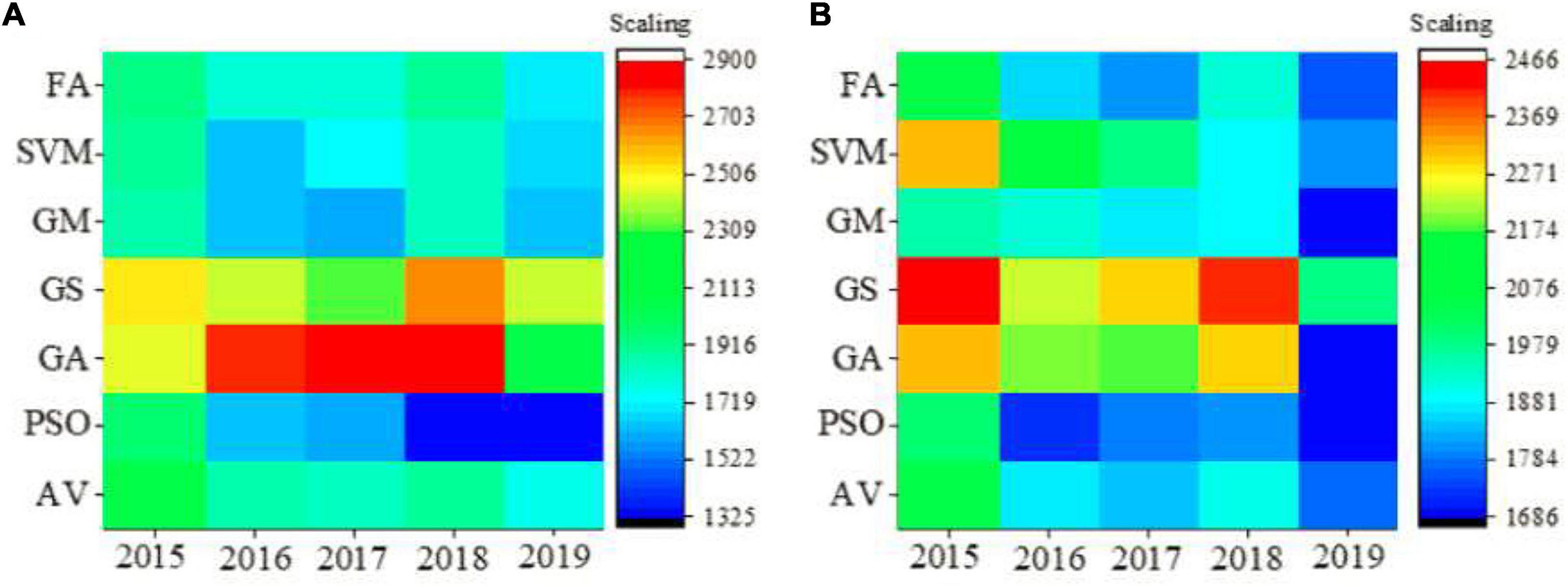
Figure 7. (A) Prediction result of tax model of the first industry in ceramic industry. (B) Prediction result of tax model of the second industry in ceramic industry.
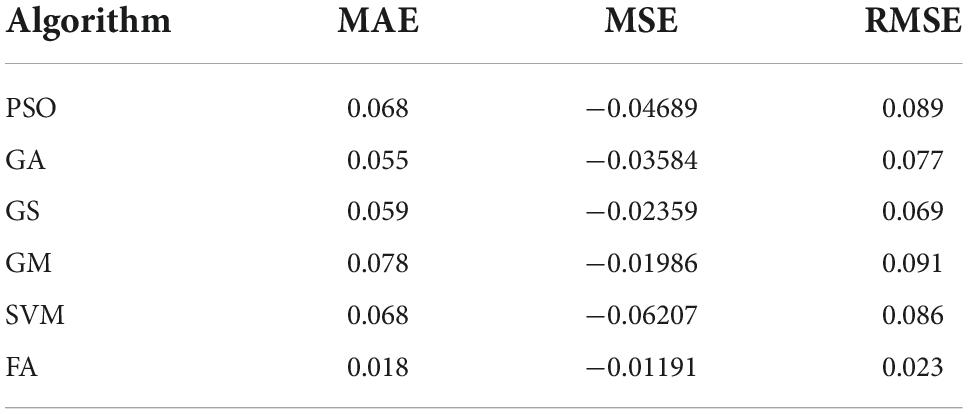
Table 3. Taxation forecast error results.
Research on user experience based on human-computer interaction
Five users are invited to evaluate the designed cognitive psychology-based HCI system’s user satisfaction and data analysis accuracy. Table 4 shows the results.
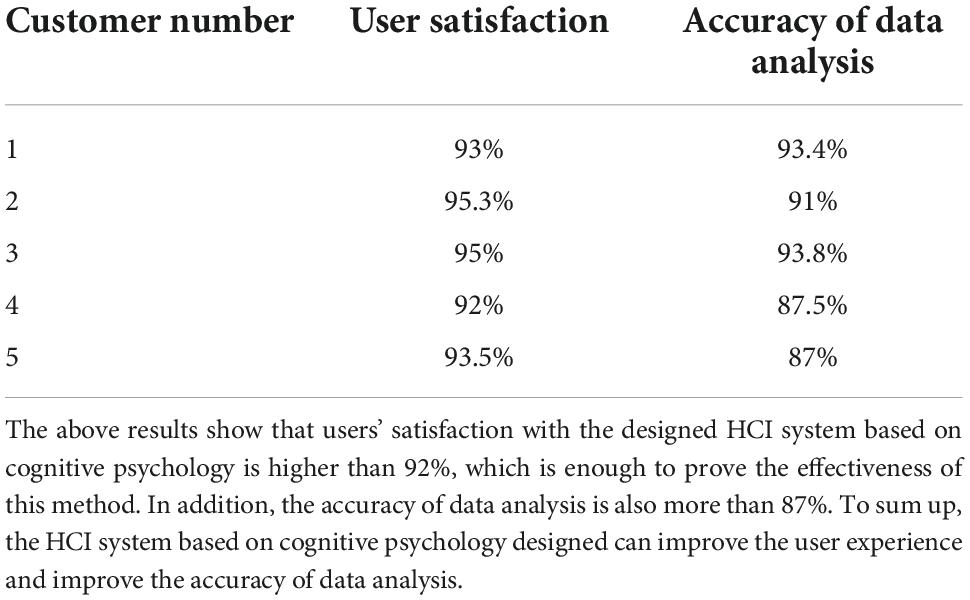
Table 4. Analysis of product satisfaction based on human-computer interaction (HCI).
Discussion
The material basis of economic development is the primary industry, which has been confirmed again by the above experiments. The added value of the primary industry has the greatest impact on taxation. Jingdezhen is the capital of ceramics, and the ceramics manufacturing industry belongs to the secondary industry. However, as the results above show, Jingdezhen’s secondary industry clearly owes taxes. The model prediction results also suggest that the primary industry in Jingdezhen will continue to grow between 2020 and 2025. On the contrary, the growth of the secondary industry will slow down, resulting in tax imbalances and problems with the industrial structure. The above exploration found that Jingdezhen has a series of small workshop-like management systems, with a large number of ceramic employees, but a small proportion of tax revenue. At the same time, large and medium-sized ceramic enterprises have a high tax burden (Li, 2020). These problems hinder the development of the ceramic industry, which has been reported in many literatures. For example, Wu et al. (2020) studied the early development of Jingdezhen ceramic glaze, chemically revealed how the glaze evolved in different periods in Jingdezhen through the chemical analysis of glaze, and proposed a possible early glaze formula. The research revealed the progress and development of Jingdezhen ceramic technology. Nie (2020) studied the economic function data of machine learning and computer interaction platforms. The parameters were selected through the support vector algorithm, and the problem of fast data flow was effectively solved. Kuo et al. (2019) conducted research on HCI system design and college students’ learning motivation. HCI projects all applied interdisciplinary knowledge and skills in the field of Science, Technology, Engineering, and Mathematics. Research showed that computer systems based on HCI technology can help improve the accuracy of economic forecasts. Similarly, the above results also show that the results fluctuate greatly in different algorithms. Therefore, the proposed tax model can provide good ideas for the development of the ceramic industry in Jingdezhen. According to the experimental results, the following countermeasures are proposed. (1) It is recommended that the Municipal Party Committee and the Municipal Government of Jingdezhen City attach great importance to the current taxation status, set up a leading group, integrate the current resources, and enhance the integrating strength of the enterprises. (2) By strictly implementing the taxation system and adding law enforcement personnel, the unqualified enterprises are cleaned up comprehensively to ensure the market order. (3) A ceramic marketing platform is built to manage the production, sales, promotion, and tax collection of the ceramic industry in a way that allows the participants to share information.
Conclusion
It is the mainstream of modern cognitive psychology to study the process of psychological cognition with the method of information processing. Therefore, the computer management system based on HCI begins to play a vital role in the field of economic and tax forecasting. This work conducts PCA on the factors affecting the taxation of Jingdezhen City and uses different algorithm models to train the taxation data of the ceramic industry in different years in Jingdezhen City. A suitable prediction model is determined through comparison and parameter optimization. In addition, a HCI system is designed based on the cognitive psychology theory, and the impact of Jingdezhen’s tax management on the economic development of the ceramic industry is analyzed. Finally, a reasonable solution is put forward for the taxation problem in Jingdezhen City. The most significant tax impact on the ceramic industry is the total output value of the primary industry, followed by the secondary industry. The tax collection and management fusion model based on SVM has high stability and accuracy. Tax forecasts suggest that Jingdezhen’s tax imbalance has increased. Therefore, the government needs to attach great importance to the development of the ceramic industry, strictly implement tax policies, and implement intensive management. The future tax is predicted and judged based on historical tax data through the SVM tax collection and management fusion model.
Defects still exist due to limited time. Future research should focus on the following aspects. (1) Data should be more diverse. The data structure is relatively simple. For the subsequent prediction results, only the primary and secondary industries are analyzed, and the impact of other indicators is not deeply analyzed. (2) There is no in-depth analysis of the prediction function of the model. Different algorithms are compared and analyzed only through simple prediction analysis. These are worth noting by the future work.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the author, without undue reservation.
Ethics statement
The studies involving human participants were reviewed and approved by Jingdezhen Ceramic University Ethics Committee. The patients/participants provided their written informed consent to participate in this study. Written informed consent was obtained from the individual(s) for the publication of any potentially identifiable images or data included in this article.
Author contributions
The author confirms being the sole contributor of this work and has approved it for publication.
Conflict of interest
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Aït-Sahalia, Y., and Xiu, D. (2019). Principal component analysis of high-frequency data. J. Am. Stat. Assoc. 114, 287–303. doi: 10.1080/01621459.2017.1401542
Andini, M., Ciani, E., de Blasio, G., D’Ignazio, A., and Salvestrini, V. (2018). Targeting with machine learning: An application to a tax rebate program in Italy. J. Econ. Behav. Organ. 156, 86–102. doi: 10.1016/j.jebo.2018.09.010
Atilgan Türkmen, B., Budak Duhbaci, T., and Karahan Özbilen, S. (2021). Environmental impact assessment of ceramic tile manufacturing: A case study in Turkey. Clean Technol. Environ. Policy 23, 1295–1310. doi: 10.1007/s10098-021-02035-w
Biggs, A. T., Kramer, M. R., and Mitroff, S. R. (2018). Using cognitive psychology research to inform professional visual search operations. J. Appl. Res. Mem. Cogn. 7, 189–198. doi: 10.1016/j.jarmac.2018.04.001
Bratten, B., Gleason, C. A., Larocque, S. A., and Mills, L. F. (2017). Forecasting taxes: New evidence from analysts. Account. Rev. 92, 1–29. doi: 10.2308/accr-51557
Bruton, G. D., Ahlstrom, D., and Chen, J. (2021). China has emerged as an aspirant economy. Asia Pac. J. Manag. 38, 1–15. doi: 10.1007/s10490-018-9638-0
Choi, T. M., and Luo, S. (2019). Data quality challenges for sustainable fashion supply chain operations in emerging markets: Roles of blockchain, government sponsors and environment taxes. Transp. Res. Part E Logist. Transp. Rev. 131, 139–152. doi: 10.1016/j.tre.2019.09.019
Dobroviè, J., Rajnoha, R., and Šuleø, P. (2021). Tax evasion in the EU countries following a predictive analysis and a forecast model for Slovakia. Oecon. Copernicana 12, 701–728. doi: 10.24136/oc.2021.023
Fan, Z., and Liu, Y. (2020). Tax compliance and investment incentives: Firm responses to accelerated depreciation in China. J. Econ. Behav. Organ. 176, 1–17. doi: 10.1016/j.jebo.2020.04.024
Gilley, B. (2017). Taxation and authoritarian resilience. J. Contemp. China 26, 452–464. doi: 10.1080/10670564.2016.1245891
Graham, J. R., Hanlon, M., Shevlin, T., and Shroff, N. (2017). Tax rates and corporate decision-making. Rev. Financ. Stud. 30, 3128–3175. doi: 10.1093/rfs/hhx037
Han, J. Y., and Hong, S. Y. (2018). Precipitation forecast experiments using the Weather Research and Forecasting (WRF) Model at gray-zone resolutions. Weather Forecast. 33, 1605–1616. doi: 10.1175/WAF-D-18-0026.1
Höglund, H. (2017). Tax payment default prediction using genetic algorithm-based variable selection. Expert Syst. Appl. 88, 368–375. doi: 10.1016/j.eswa.2017.07.027
Kuo, H. C., Tseng, Y. C., and Yang, Y. T. C. (2019). Promoting college student’s learning motivation and creativity through a STEM interdisciplinary PBL human-computer interaction system design and development course. Think. Skills Creat. 31, 1–10. doi: 10.1016/j.tsc.2018.09.001
Lee, Y. J. (2021). The effects of analysts’ tax expense forecast accuracy on corporate tax avoidance: An international analysis. J. Contemp. Account. Econ. 17:100243. doi: 10.1016/j.jcae.2021.100243
Li, W., Pittman, J. A., and Wang, Z. T. (2019). The determinants and consequences of tax audits: Some evidence from China. J. Am. Taxation Assoc. 41, 91–122. doi: 10.2308/atax-52136
Li, Y. C. (2020). Research on the protection and inheritance strategies of jingdezhen ceramic intangible cultural heritage from the perspective of cultural and creative industry. Stud. Lit. Lang. 21, 34–37. doi: 10.3968/11800
Mabe-Madisa, G. V. (2018). A decision tree and Naïve Bayes algorithm for income tax prediction. Afr. J. Sci. Technol. Innov. Dev. 10, 401–409. doi: 10.1080/20421338.2018.1466440
Metawa, N., Hassan, M. K., and Elhoseny, M. (2017). Genetic algorithm based model for optimizing bank lending decisions. Expert Syst. Appl. 80, 75–82. doi: 10.1016/j.eswa.2017.03.021
Mirfakhradini, S. H., Safari, K., Shaabani, A., Valaei, N., and Mohammadi, K. (2018). Customer involvement in new product development of tile and ceramic industry. Int. J. Product. Qual. Manag. 25, 108–138. doi: 10.1504/IJPQM.2018.094295
Namazi, M., and Sadeghzadeh Maharluie, M. (2018). Predicting tax evasion by decision tree algorithms. Q. Financ. Account. 9, 76–101.
Nie, X. (2020). Research on economic function data and entrepreneurship analysis based on machine learning and computer interaction platform. J. Intell. Fuzzy Syst. 39, 5635–5647. doi: 10.3233/JIFS-189043
Rahimikia, E., Mohammadi, S., Rahmani, T., and Ghazanfari, M. (2017). Detecting corporate tax evasion using a hybrid intelligent system: A case study of Iran. Int. J. Account. Inf. Syst. 25, 1–17. doi: 10.1016/j.accinf.2016.12.002
Renoult, J. P., and Mendelson, T. C. (2019). Processing bias: Extending sensory drive to include efficacy and efficiency in information processing. Proc. R. Soc. B 286:20190165. doi: 10.1098/rspb.2019.0165
Tian, L., Goldstein, A., Wang, H., Ching Lo, H., Sun Kim, I. K., Welte, T., et al. (2017). Mutual regulation of tumour vessel normalization and immunostimulatory reprogramming. Nature 544, 250–254. doi: 10.1038/nature21724
Wang, D., Tan, D., and Liu, L. (2018). Particle swarm optimization algorithm: An overview. Soft Comput. 22, 387–408. doi: 10.1007/s00500-016-2474-6
Wang, S., Li, Q., Fang, C., and Zhou, C. (2016). The relationship between economic growth, energy consumption, and CO2 emissions: Empirical evidence from China. Sci. Total Environ. 542, 360–371. doi: 10.1016/j.scitotenv.2015.10.027
Wu, J., Ma, H., Wood, N., Zhang, M., Qian, W., Wu, J., et al. (2020). Early development of Jingdezhen ceramic glazes. Archaeometry 62, 550–562. doi: 10.1111/arcm.12539
Xiao, C. (2020). Intergovernmental revenue relations, tax enforcement and tax shifting: Evidence from China. Int. Tax Public Finance 27, 128–152. doi: 10.1007/s10797-019-09546-9
Keywords: HCI, cognitive psychology, ceramic industry, tax collection and management, industrial economic development, Jingdezhen
Citation: Jiao M (2022) The use of cognitive psychology-based human-computer interaction tax system in ceramic industry tax collection and management and economic development of Jingdezhen city. Front. Psychol. 13:944924. doi: 10.3389/fpsyg.2022.944924
Received: 16 May 2022; Accepted: 16 September 2022;
Published: 20 October 2022.
Edited by:
Yu-Sheng Su, National Taiwan Ocean University, TaiwanReviewed by:
Chia-Chen Chen, National Chung Hsing University, TaiwanLiubov Skavronskaya, University of the Sunshine Coast, Australia
Copyright © 2022 Jiao. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Mingqing Jiao, MDI1NTE1QGpjaS5lZHUuY24=