 Lidan Liang
Lidan Liang Jing Lu
Jing Lu Jiwei Zhang
Jiwei Zhang Ningzhong Shi1
Ningzhong Shi1
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Psychol., 13 June 2022
Sec. Quantitative Psychology and Measurement
Volume 13 - 2022 | https://doi.org/10.3389/fpsyg.2022.889673
This article is part of the Research TopicTowards a Basic Standard Methodology for International Research in PsychologyView all 15 articles
In cognitive diagnostic assessments with time limits, not-reached items (i.e., continuous nonresponses at the end of tests) frequently occur because examinees drop out of the test due to insufficient time. Oftentimes, the not-reached items are related to examinees’ specific cognitive attributes or knowledge structures. Thus, the underlying missing data mechanism of not-reached items is non-ignorable. In this study, a missing data model for not-reached items in cognitive diagnosis assessments was proposed. A sequential model with linear restrictions on item parameters for missing indicators was adopted; meanwhile, the deterministic inputs, noisy “and” gate model was used to model the responses. The higher-order structure was used to capture the correlation between higher-order ability parameters and dropping-out propensity parameters. A Bayesian Markov chain Monte Carlo method was used to estimate the model parameters. The simulation results showed that the proposed model improved diagnostic feedback results and produced accurate item parameters when the missing data mechanism was non-ignorable. The applicability of our model was demonstrated using a dataset from the Program for International Student Assessment 2018 computer-based mathematics cognitive test.
In educational and psychological assessments, examinees often do not reach the end of the test which may be due to test fatigue or insufficient time. The percentage of not-reached items in large-scale cognitive testing varies across individuals, items, and countries. According to the 2006 Program for International Student Assessment (PISA) study, an average of 4% of items are not reached (OECD, 2009). In the PISA 2015 (OECD, 2018) computer-based mathematics cognitive dataset, the percentage of not-reached items in Chinese Taipei is approximately 3%, and the percentage of not-reached items for the science cluster in a Canadian sample is 2% (Pohl et al., 2019). According to the PISA 2018 (OECD, 2021) computer-based mathematics cognitive data, the proportion of nonresponses for each item ranges from 0 to 17.3% in some countries, and the maximum percentage of not-reached items is as high as 5%. Thus, the missing proportion at the item level is relatively high. In addition, the percentage of nonresponses per nation (OECD countries) ranges from 4% to15% according to the PISA 2006 study (OECD, 2009). Even though the overall proportion of item nonresponses is small, the rate of not-reached responses for a single item or specific examinee may be large.
Previous literature focused on missing data in the item response theory (IRT) framework, which has shown that simply ignoring nonresponses or treating them as incorrect leads to biased estimates of item and person parameters (Lord, 1974, 1983; Ludlow and O’Leary, 1999; Huisman, 2000). Often, Rubin (1976) missing data mechanisms are worth reviewing for statistical inference. The complete data include observed data and unobservable missing data, and there are three types of missing data mechanisms (Rubin, 1976; Little and Rubin, 2002): missing completely at random (MCAR), missing at random (MAR), and not missing at random (NMAR). MCAR refers to the probability of missing data as independent of both observed and missing data. MAR refers to the probability of missing data as only dependent on observed data. NMAR refers to the probability of missing data as dependent on the unobserved missing data itself, which is not ignorable. In general, MCAR and MAR mechanisms do not affect the parameter estimations of interest or the followed-up inference, thus missing data can be ignored in these two specific missing data mechanisms. However, Rose et al. (2010, 2017) showed that the proportion of examinees’ correct scores based on the observed item responses was negatively correlated with the item nonresponse rate, which suggests that simple questions are easy to answer, and numerous difficult items may be omitted. Item nonresponses may depend on the examinee’s ability and the difficulty of the items, and therefore the ignorable missing data mechanism assumption (MCAR or MAR) becomes highly questionable. This leads to the development of measurement models that consider the NMAR mechanism. Specifically, several scholars have proposed multidimensional IRT (MIRT) models to handle missing responses (e.g., Holman and Glas, 2005; Glas and Pimentel, 2008; Pohl et al., 2019; Lu and Wang, 2020). For example, Glas and Pimentel (2008) used a combination of two IRT models to model not-reached items for speeded tests according to the framework of the IRT. Subsequently, Rose et al. (2010) proposed latent regression models and multiple-group IRT models for non-ignorable missing data. Debeer et al. (2017) developed two item response tree models to handle not-reached items in various application scenarios.
Recently, cognitive diagnosis (von Davier, 2008, 2018, 2014; Xu and Zhang, 2016; Zhan et al., 2018; Zhang et al., 2020) has received considerable attention from researchers because cognitive diagnostic test enables the evaluation of the mastery of skills or attributes of respondents and allows diagnostic feedback for teachers or clinicians, which in turn aids in decision-making regarding remedial guidance or targeted interventions. In addition, the cognitive diagnostic test has improved on traditional tests. General educational examinations only provide test or ability scores in large-scale testing. However, we can neither conclude that examinees mastered the knowledge nor understand why examinees answered questions incorrectly from a single score. Moreover, it is impossible to infer differences in knowledge state and cognitive structures between individuals with the same score. Thus, the information provided by traditional IRT is not suitable for the needs of individual learning and development. To date, numerous cognitive diagnostic models (CDMs) have been developed, such as the deterministic inputs, noisy “and” gate (DINA) model (de la Torre and Douglas, 2004; de la Torre, 2009); the noisy inputs, deterministic, “and” gate model (NIDA; Maris, 1999); the deterministic inputs, noisy “or” gate (DINO) model (Templin and Henson, 2006); the log-linear CDM (Henson et al., 2009); and the generalized DINA model (de la Torre, 2011). Subsequently, a higher-order DINA (HO-DINA) model (de la Torre and Douglas, 2004) was proposed to link latent attributes via higher-order ability. Furthermore, Ma (2021) proposed a higher-order CDM with polytomous attributes for dichotomous response data.
Numerous studies have focused on item nonresponses in IRT models (Finch, 2008; Glas and Pimentel, 2008; Debeer et al., 2017). However, only a few studies have discussed missing data in cognitive assessments. Ömür Sünbül (2018) limited missing data mechanisms to MCAR and MAR in the DINA model and investigated different imputation approaches for dealing with item nonresponses, such as coding item responses as incorrect and using person mean imputation, two-way imputation, and expectation-maximization algorithm imputation. Heller et al. (2015) argued that CDMs may have underlying relationships with knowledge space theory (KST), which has been explored in several previous studies (e.g., Doignon and Falmagne, 1999; Falmagne and Doignon, 2011). Furthermore, de Chiusole et al. (2015) and Anselmi et al. (2016) have developed models for KST to consider different missing data mechanisms (i.e., MCAR, MAR, and NMAR). However, in their work, missing response data may not have been handled effectively, which may have biased results. Shan and Wang (2020) introduced latent missing propensities for examinees in the DINA model. They also included a potential category parameter, which affects the tendency to miss items. However, they did not provide a detailed explanation of the category parameters. Moreover, their model did not distinguish the type of item nonresponses.
The confound of different types of missing data produces inaccurate attribute profile estimations, which consequently results in incorrect diagnostic classifications. To the best of our knowledge, there has been no model developed to date that describes not-reached items in cognitive diagnosis. Thus, a missing model for not-reached items is proposed to fill this gap in cognitive diagnosis assessments. Specifically, a higher-order DINA model is used to model responses and an IRT model to describe missing indicators, which is a sequential model with linear restrictions on item parameters (Glas and Pimentel, 2008). The model is connected by bivariate normal distributions between examinees’ latent ability parameters and missing propensity parameters and between item intercept and interaction parameters.
The rest of this paper is organized as follows. First, an IRT model is introduced as a missing indicator model for not-reached items. Then, a higher-order DINA model is used for the observed responses and the correlation between person parameters. Second, the Markov chain Monte Carlo (MCMC) algorithm (Patz and Junker, 1999; Chen et al., 2000) is developed to estimate the model parameters of the proposed model. Simulation studies are conducted to assess the performance of the proposed model for different simulation conditions. Third, a real dataset from the PISA 2018 (OECD, 2021) computer-based mathematics data is analyzed. Concluding remarks and future perspectives are provided thereafter.
A two-dimensional data matrix with element Yij is considered, where examinees are indexed as i = 1,…,N and items are indexed as j = 1,…,J. If the ith examinee answers the jth item, the response is observed, and the Yij is equal to the observation yij, otherwise, it is missing data. For convenience, the sign “d” is used to mark the missing data and the relevant parameters.
Glas and Pimentel (2008) proposed a sequential model with a linear restriction on the item parameters to model the not-reached items. Specifically, the missing indicator matrix D with element dij is given by:
where dij = 1indicates that the ith examinee drops out the jth item. Because of the small overall proportion of not-reached responses, the appropriate model must have few parameters to be estimable (Lord, 1983). The one-parameter logistic model (1PLM; Rasch, 1960) is adopted to model the missing indicators, thus the dropping-out probability of examinee i on item j is:
and
where represents the so-called item difficulty parameter for item j, and denotes the ith examinee’s dropping-out propensity. Also, when j = J, where η0 is the difficulty threshold of the last item, and η1 models a uniform change in the probability as a function of the item position in the test. Usually, the parameter η1 is negative, and hence it is more likely to drop out the test at later position items of the test.
The DINA model describes the probability of the item response as a function of latent attributes, and the probability of the ith examinee responding to item j correctly is as follows:
where sj and gj are the slipping and guessing probabilities of the jth item, respectively, 1−sj−gj = IDIj is the jth item discrimination index (de la Torre, 2008), and αik is the kth attribute of the ith examinee, with αik = 1 if examinee i masters attribute k and αik = 0 if examinee does not master attribute k. The Q matrix (Tatsuoka, 1983) is an J×K matrix, with qjk, qjk = 1 denoting that the attribute k is required for answering the jth item correctly and qjk = 0 if the attribute k is not required for answering the jth item correctly.
Equation (4) can be reparameterized as the reparameterized DINA model (DeCarlo, 2011).
In addition, thus Equation (4) can be reformed as,
where βj and δj are the item intercept and interaction parameter, respectively, and they are assumed to follow a bivariate normal distribution as follows:
The higher-order structure is very flexible because it can reduce the number of model parameters and can provide higher-order abilities and more accurate attribute structures. Because the attributes in a test are often correlated, the higher-order structure (de la Torre and Douglas, 2004; Zhan et al., 2018) for the attributes is expressed as,
where P(αik = 1) is the probability that the ith examinee masters the kth attribute, is the higher-order ability of examinee i, and γk and λk are the slope and intercept parameters of attribute k, respectively. The slope parameter γk is positive because the knowledge attribute is mastered better with the increased ability .
If the observation probability p(yij|dij, βj, δj, αik) does not depend on θd, when θh and θd are independent, then the missing data are ignorable. In this situation, this model is treated as a MAR model. Let p(yij|dij, βj, δj, αik) be the measurement model for the observed data. In addition, let be the measurement model for the missing data indicators, and p(θh) and p(θd) are densities of θh and θd, respectively. To model non-ignorable missing data, it is assumed that and follow a bivariate normal distribution N(μP, ΣP); thus, the two models describe the two missing mechanisms (i.e., MAR and NMAR). Next, we introduce the two missing data models for the not-reached items.
The expression of the MAR model is as follows, and the likelihood function form of the MAR model can be written as,
where the MAR model is regarded as a model that ignores the missing data process. In fact, the latent variables and are independent in the MAR model. In other words, the model for the missing data process can be ignored in estimating the item response model.
The NMAR model is often called the non-ignorable model, and in this case, and are correlated. A covariance matrix is used to describe the relationship between the latent higher-order ability parameters and the missing propensity parameters in this model. Thus, the likelihood function of the NMAR model can be written as,
where the person parameters are assumed to follow a bivariate normal distribution, with mean vector and covariance matrix:
In Equations (2) and (9), the linear parts of 1PLM and the HO-DINA model can be written as follows:
To eliminate the trade-offs between ability and dropping-out threshold parameter and between the higher-order ability person parameter θh and the attribute intercept λk, the mean population level of person parameters is set to zero, that is, . 1 is fixed to eliminate the scale trade-off between and γk (Lord and Novick, 1968; Fox, 2010). In addition to the identifications, two local independence assumptions are made, that is, the αik values are conditionally independent given , and the Yij values are conditionally independent given αi.
In the Bayesian framework, two common Bayesian model evaluation criteria, the deviance information criteria (DIC; Spiegelhalter et al., 2002) and the logarithm of the pseudo-marginal likelihood (LPML, Geisser and Eddy, 1979; Ibrahim et al., 2001) are used to compare the differences in the missing mechanism models according to the results of MCMC sampling. Let,
The DIC is given by,
On the basis of the posterior distribution of Dev(Y,D,Ω), the DIC was defined as,
where , which is the posterior mean deviance and is a Bayesian measure of fit, r = 1,…,R denotes the rth iteration of the algorithm, and , which is the effective number of parameters, is a Bayesian measure of complexity, with . A smaller DIC indicates a better model fit.
The conditional predictive ordinate (CPO) index of the two models was computed. Let Qij,max = max1≤r≤R{−logf(Yij,Dij|Ωr)}. Thus,
The summary statistic for log is the sum of their logarithms, which is termed the LPML and is given by,
where the model with a larger LPML indicates a better fit to the data.
Three simulation studies were conducted to evaluate different aspects of the proposed model. Simulation study I was conducted to assess whether the MCMC algorithm could successfully recover parameters of the proposed model under different numbers of examinees and items. Simulation study II was conducted to investigate the parameter recovery of different numbers of attributes for the same examinees and items. Simulation study III intended to show the differences in model parameter estimates between the NMAR and MAR models for different dropping-out proportions and correlations among person parameters.
In the three simulation studies, the item parameters were sampled from the following distributions: (βjδj)∼MVN((μβμδ), ΣI), μβ = −2.197,μδ = 4.394, ΣI = (1−0.8−0.81). These values were used in Shan and Wang (2020) study. The dropping-out proportions across three levels (i.e., low, medium, and high) were varied by setting different combinations of η0 and η1. That is, the dropping-out proportion was 3.8 (low) when η0 = 1,η1 = −0.7; the dropping-out proportion was 12 (medium) when η0 = 1,η1 = −0.32; and the dropping-out proportion was 25% (high) when η0 = 1,η1 = −0.18.
The attribute intercept parameters were λ=(−1,−0.5, 0, 0.5, 1), and the attribute slope parameters wereγk = 1.5 for all attributes, which were consistent with those in the study by Shan and Wang (2020). Three Q matrices with different numbers of attributes (Figure 1) were considered, and the three Q matrices were taken from Xu and Shang (2018) study and Shan and Wang (2020) study.
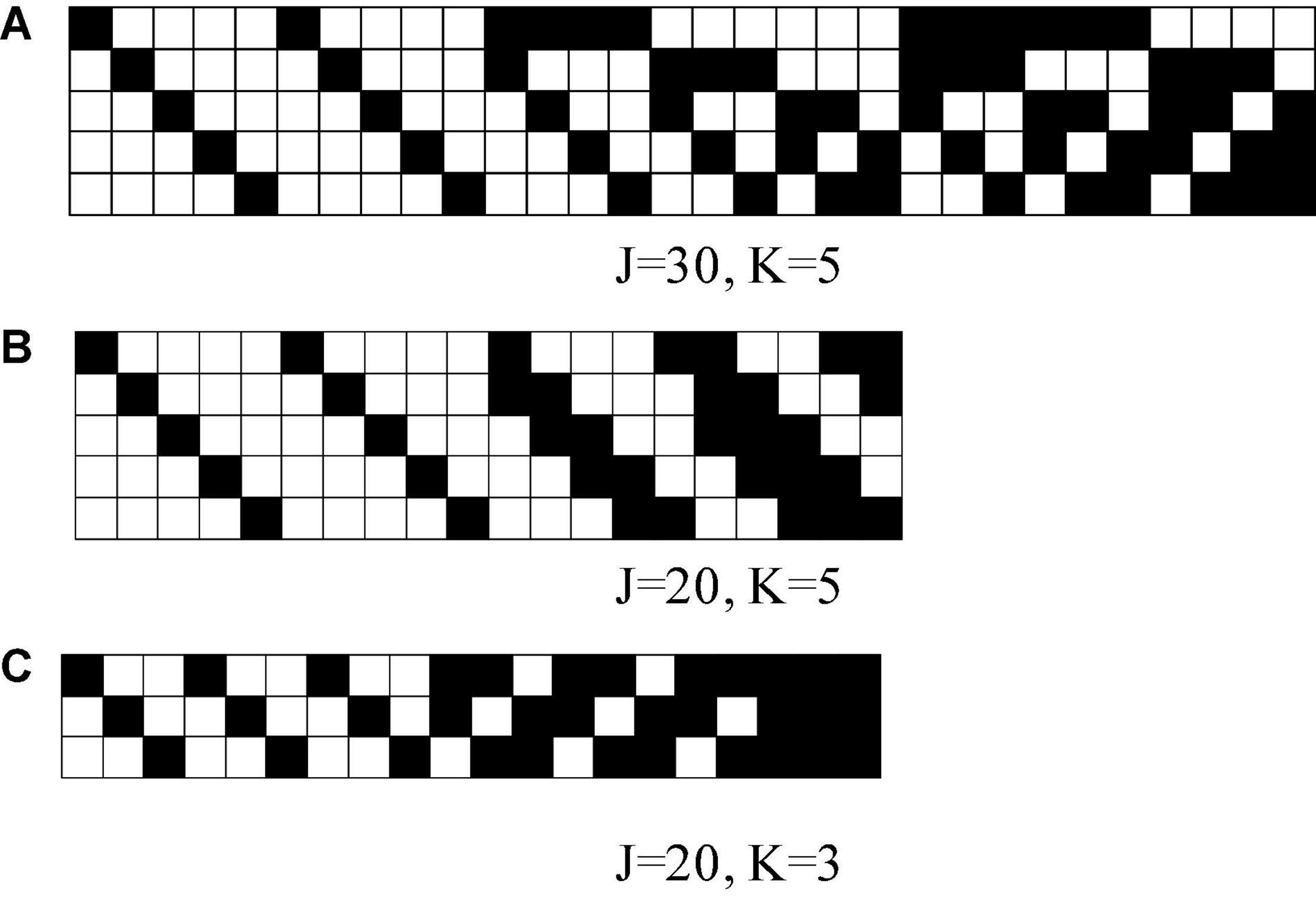
Figure 1. K-by-J Q matrices in simulation studies, where black means “1” and white means “0.” K is the number of attributes and J is the number of items.
The person parameters and were simulated from the bivariate normal distribution 0.25. Three levels of correlation between and were considered for 0 (uncorrelated), −0.5 (medium), and −0.8 (high). The missing data due to dropping-out items were simulated in the following manner. The three levels of dropping-out proportions were 3.8% (low), 12% (medium), and 25% (high).
The priors of η0 and η1 were η0 ∼ N(0,2) and η1 ∼ N(0,2), respectively. The priors of the item parameters βj and δj were assumed to have a bivariate normal distribution: (βj δj)∼N((μβ μδ), ΣI). The priors of the person parameters were assumed to follow a bivariate normal distribution: (θh θd)∼N((00), ΣP). The priors of the higher-order structure parameters were expressed as λk∼N(0,4) and γk ∼ N(0,4)I(γk > 0), the priors of the covariance matrix of the person were expressed as σθhθd∼U(−1,1) and ∼Inv-(2,2), the priors of the covariance matrix of the item parameters were expressed as ΣI Inv-Wishart , and the hyperpriors were specified as ΣI0 = (1001), vI0 = 2,kI0 = 1,μβ∼N(−2.197,2), and μδ ∼ N(4.394,2)I(μδ > 0). The hyperpriors specified above were on a logit scale for β and δ and were consistent with those reported by Zhan et al. (2018). The mean guessing effect was set at 0.1, which was roughly equal to a logit value −2.197 for μβ. A standard deviation of on the logit scale for μβindicated that the simulated mean guessing effect changed from 0.026 to 0.314. In addition, the mean slipping effect was also set at 0.1, which indicated that μδ was approximately 4.394 on the logit scale. The simulated mean slipping effect changed from 0.007 to 0.653 under a standard deviation of on the logit scale for δ.
The initial values of the model parameters were as follows: βj = 0, δj = 0for j = 1,…,J,, for i = 1,…,N, σθhθd = 0, , η0 = 0,η1 = 0,μβ = 0,μδ = 0,ΣP = (1001), μP = (00), and . In addition, λk = 0,γk = 1for k = 1,,K, and α=(α11 ⋯ α1K ⋮ ⋱ ⋮ αN1 ⋯ αNK), where αik (i = 1,…,N,k = 1,…,K) were sampled from 0 to 1 randomly. The proposal variances were chosen to give Metropolis acceptance rates between 25% and 40%. The Markov chain length was set at 10,000 so that the potential scale reduction factor (PSRF; Brooks and Gelman, 1998) was less than 1.1 for all parameters, which implied proper chain convergence. Five thousand iterations were treated as burn-in. The final parameter estimates were obtained as the average of the post-burn-in iterations.
In terms of evaluation criteria, the bias and root mean squared error (RMSE) are used to assess the accuracy of the parameter estimates. In particular, the bias for parameter η was,
and the RMSE for parameter η is defined as,
where η is the true value of the parameter, and is the estimate for the rth replication. There were R = 30 replications for each simulation condition. The recoveries of attributes are evaluated using the attribute correct classification rate (ACCR) and the pattern correct classification rate (PCCR):
where is the indicator function that is, if , otherwise .
In simulation study I, the different numbers of examinees and items were considered to estimate the model parameters under a fixed number of five attributes. Three conditions were considered in this simulation: (a) 500 examinees and 30 items, (b) 1,000 examinees and 30 items, and (c) 500 examinees and 20 items. The correlation between and was −0.3, and the dropping-out proportion was medium.
Table 1 presents the bias and RMSE of the ability parameters and item parameters, as well as the attribute parameter estimates. For the 30 items and the 5 attributes (please see the first four columns of Table 1), the item parameter estimates improve when the number of examinees increases from 500 to 1,000, the bias and RMSE of δ and μβdecrease, and the RMSE of β,μδ, and item covariance matrix elements reduce. For the 500 examinees and the 5 attributes (please see the middle four columns of Table 1), the person parameter estimates improve when the number of items increases from 20 to 30, and θh and are more accurate. The ACCRs and PCCRs are presented in Table 2. The ACCRs and PCCRs could be recovered satisfactorily with a larger sample and longer test length. The ACCRs and PCCRs decrease when the number of examinees or test length decreases (please see the first three columns in Table 2), and the changes are particularly marked when the test length is reduced. Figure 2 shows the PSRF of several items and attribute parameters under 500 examinees and 30 items. It is observed that the item intercept parameter β, the interaction parameter δ, the attribute slope parameter γ, and the attribute intercept parameter λ converge at 5,000 iterations, and the convergence of β and δ are significantly faster than that of λ and γ.
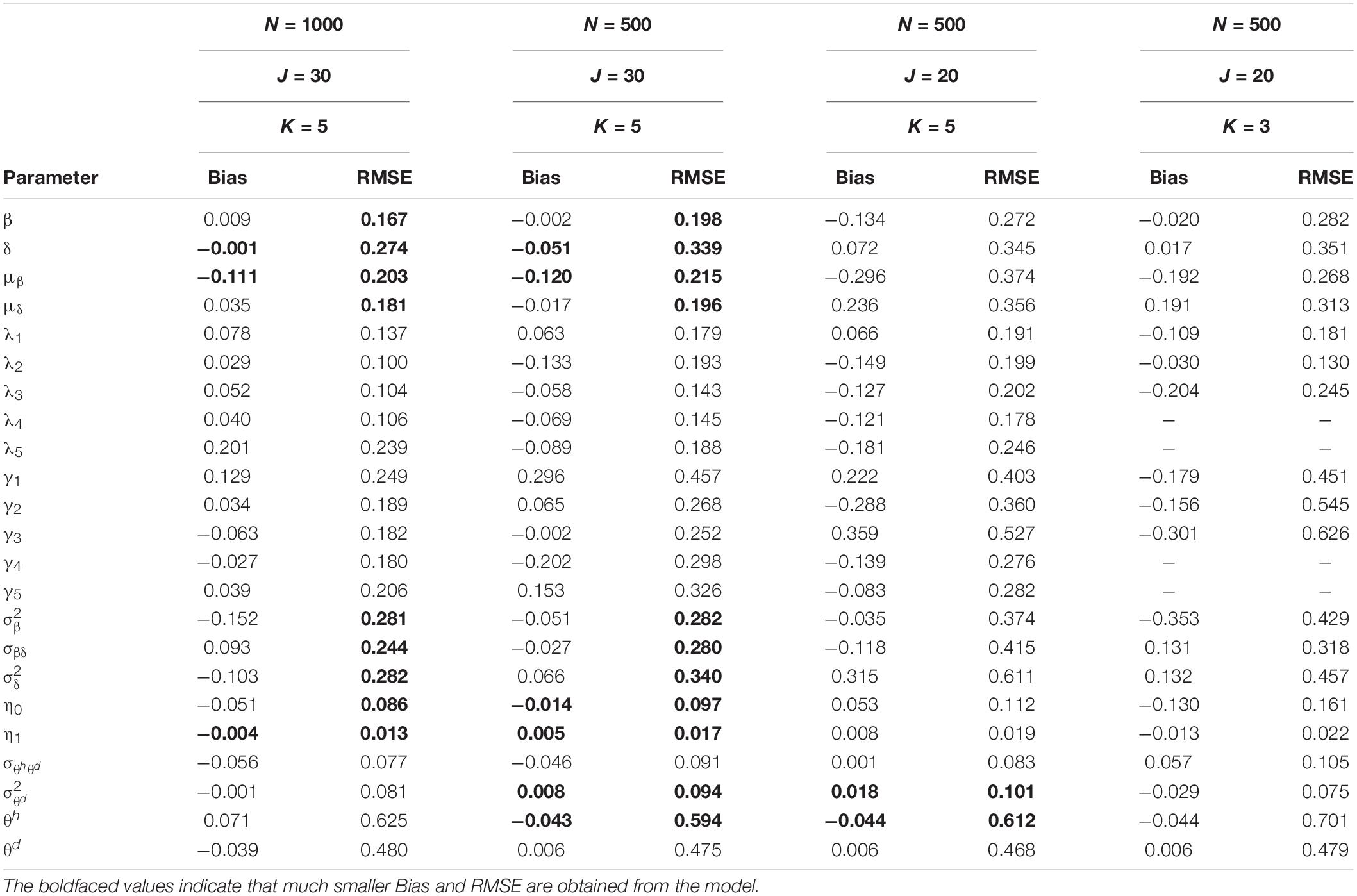
Table 1. Bias and RMSE of the parameter estimates in simulation studies I and II.
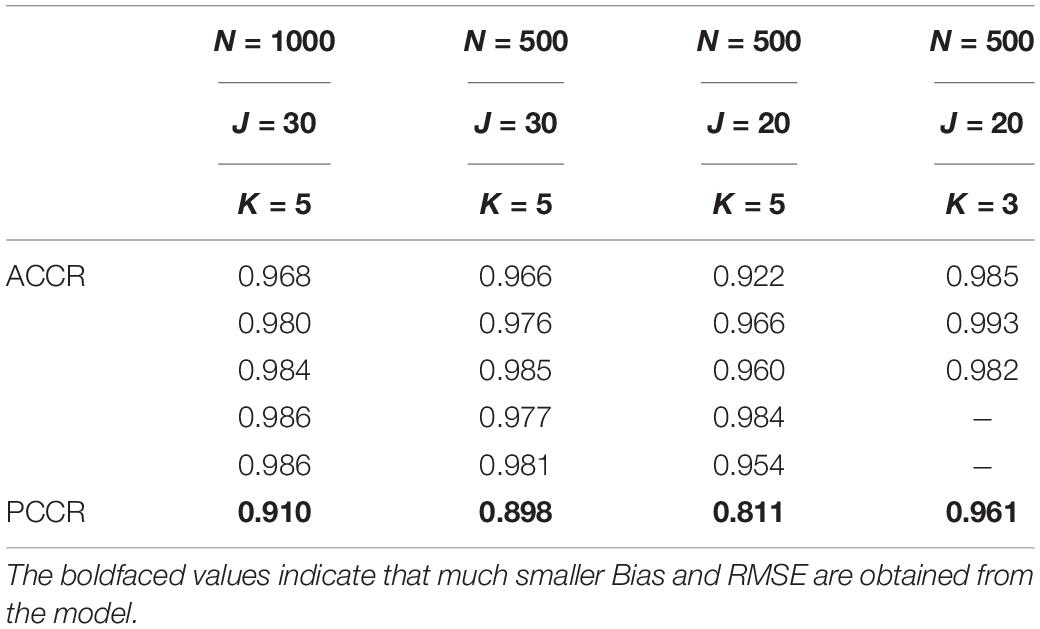
Table 2. ACCRs and PCCRs in simulation studies I and II.
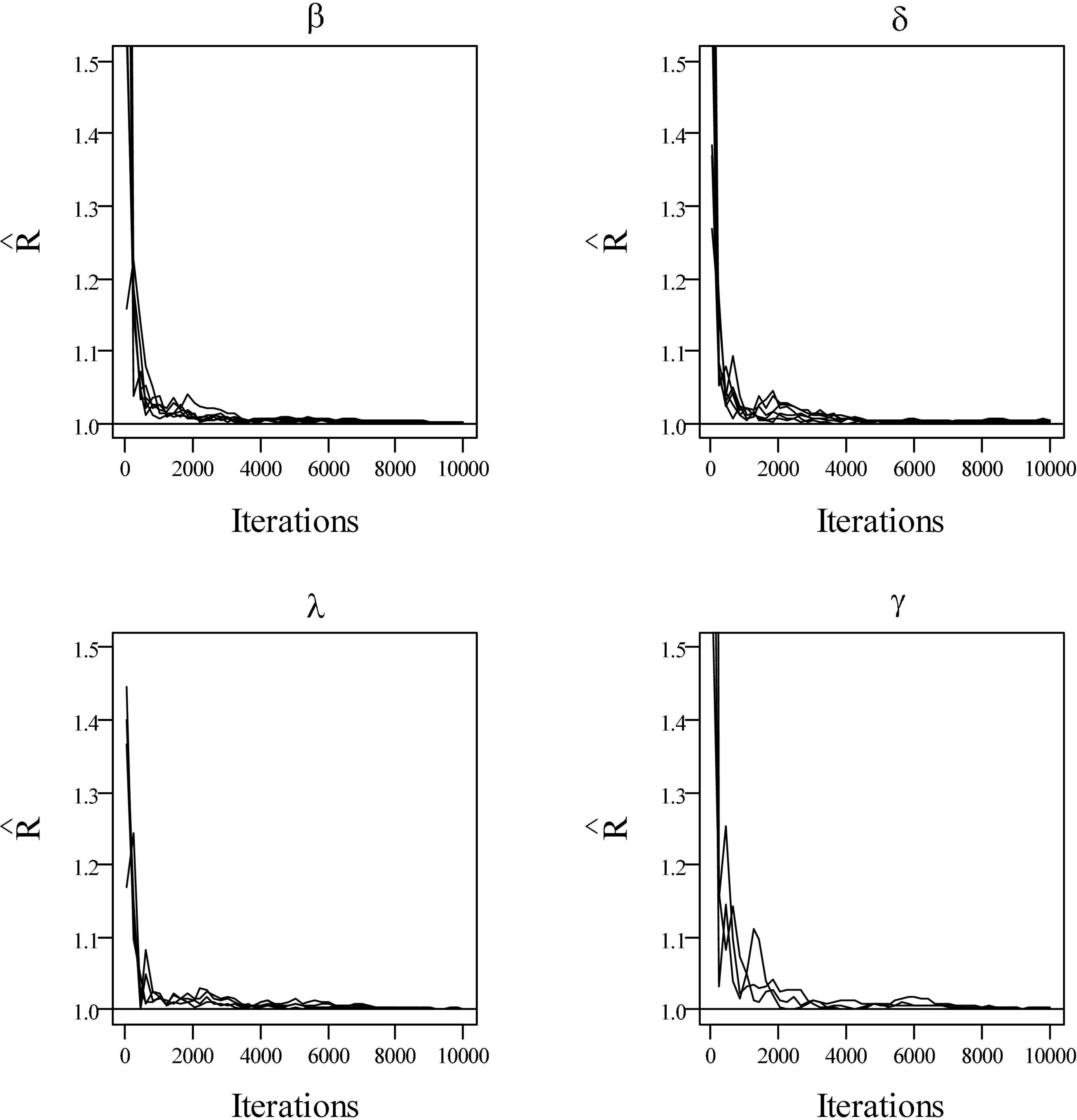
Figure 2. The trace plots of PSRF values for simulation study I.
This simulation study was conducted to investigate the parameter recovery of different numbers of attributes for fixed 500 examinees and 20 items. The correlation between and was set at −0.3, and the dropping-out proportion was medium.
The last four columns of Table 1 show the results of simulation study II. The RMSE of the estimates of item and person parameters with attribute K = 5 are smaller than those with attribute K = 3. The RMSE of the attribute slope parameters and intercept parameters recover more satisfactorily with attribute K = 3 than with attribute K = 5. The last two columns of Table 2 show the ACCRs and PCCRs for simulation study II. The ACCRs with attribute K = 3 are higher than those with attribute K = 5 and improve from 0.957 to 0.987 on average. Moreover, the PCCRs are significantly higher when the number of attributes decreases. That is, the PCCR with attribute K = 5 is 0.811, and the PCCR with attribute K = 3 is 0.961.
The purpose of this simulation study was to investigate the parameter recovery with the NMAR model, MAR model, and HO-DINA model that ignores the not-reached items under different simulation conditions. The data were generated using the proposed model with the NMAR mechanism. A total of 500 examinees answered 30 items, and each item had 5 attributes. Three dropping-out proportions (i.e., 3.8% [low], 12% [medium], and 25% [high]) and three correlations between and (i.e., 0 [uncorrelated], −0.5 [medium], and −0.8 [high]) were manipulated. Thus, there were 3 × 3 simulation conditions.
Table 3 shows the bias and RMSE of the parameters of three models with low dropping-out proportions under different correlations between and . Results show that the parameter estimates from the three models are similar when the correlation between and is 0. When the correlation between and increases, the bias and RMSE of η1, β, ΣI, and γ in the NMAR model are much smaller than those in the MAR and HO-DINA models. Moreover, for low dropping-out proportions, when the correlation between and increases, the bias of the person parameters of the three models changes very little, whereas the RMSE of the person parameters in the MAR and HO-DINA models increases significantly. As expected, the NMAR model has higher accuracy of parameters than that of the other two models. Furthermore, the parameter estimates of the MAR and HO-DINA models are similar for all simulation conditions because and are uncorrelated in both the MAR and HO-DINA models, which ignore the not-reached items. Table 4 shows the bias and RMSE of the parameters of the three models with medium dropping-out proportions under different correlations between and . Similar parameter estimates are obtained from the three models when the correlation between and is 0. When the correlation between and increases, not only the bias but also the RMSE of the person parameters are lower in the NMAR model than those in the MAR and HO-DINA models, and the other results are similar to those with low dropping-out proportions. Table 5 shows the bias and RMSE of the parameters of the three models with high dropping-out proportions under different correlations between and . We find that the parameter estimates improve significantly with high dropping-out proportions. Figure 3 shows the bias of the estimates of item mean vector and the item covariance matrix elements in the NMAR and MAR models under different dropping-out proportions and correlations between and . The results show that the estimates of the parameters are more accurate in the NMAR model than those in the MAR model when the correlation is increased. Moreover, it is observed that the bias of the parameters of the NMAR model is close to 0 as the correlation between and increases. In contrast, the bias of the parameters of the MAR model is significantly larger than that of the NMAR model. Figure 4 shows the RMSE of the estimates of the item mean vector and the item covariance matrix elements in the NMAR and MAR models under different dropping-out proportions and correlations between and . The results show that the RMSE of the item mean vector in the NMAR model improves slightly than that in the MAR model. Moreover, the RMSE of the item covariance matrix elements shows significant improvements, and the estimates of the item covariance matrix elements are precise when the correlation is high. Figure 5 shows the ACCRs and PCCRs under nine simulation conditions. Detailed results are provided in Supplementary Table 1. It is found that ACCRs and PCCRs in the NMAR model are improved significantly when the missing proportion or the correlation between and is high. This indicates that the MAR model could not recover the attribute pattern effectively when the missing data mechanism is indeed non-ignorable. Table 6 shows the model selection results. The differences in DIC and LPML are not obvious when the correlation between and is 0. The DICs of the NMAR model are smaller than those of the MAR model under nine simulation conditions. Moreover, the LPMLs of the NMAR model are higher than those of the MAR model. Thus, the DIC and LPML indices are able to select the true model accurately.
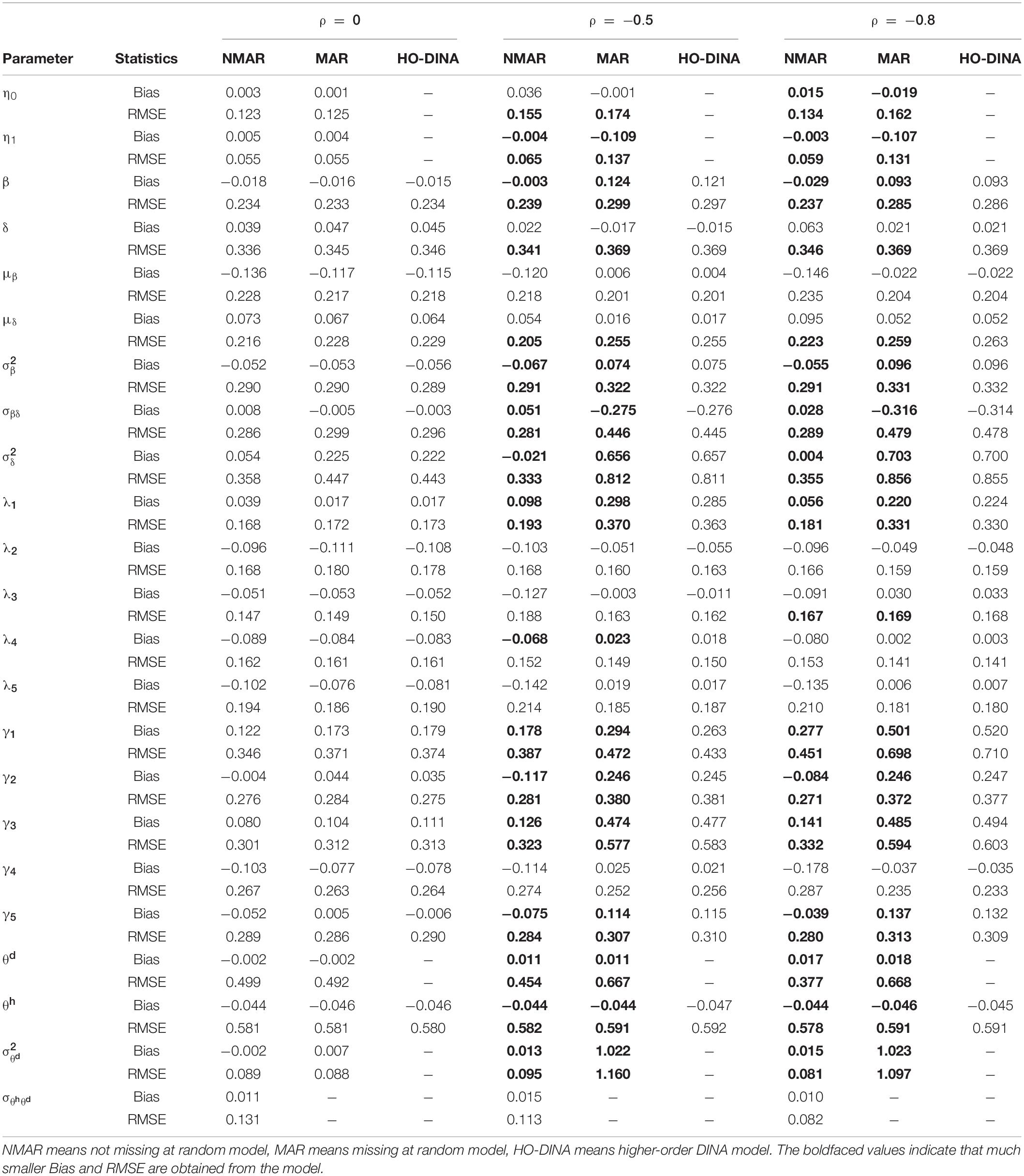
Table 3. Bias and RMSE of parameter estimates of three models with low dropping-out proportion under different correlations between and in simulation study III.
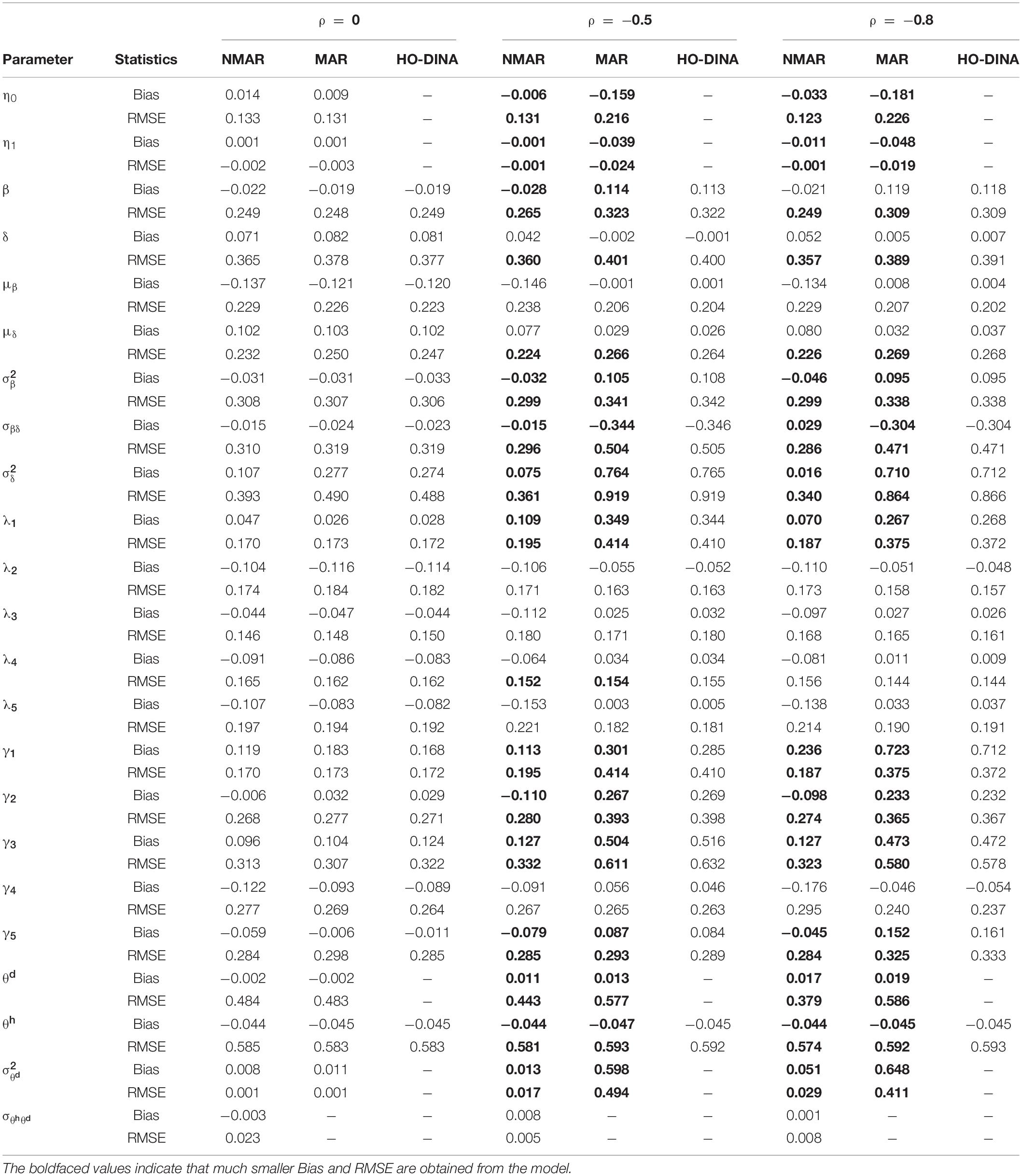
Table 4. Bias and RMSE of parameter estimates of three models with medium dropping-out proportion under different correlations between and in simulation study III.
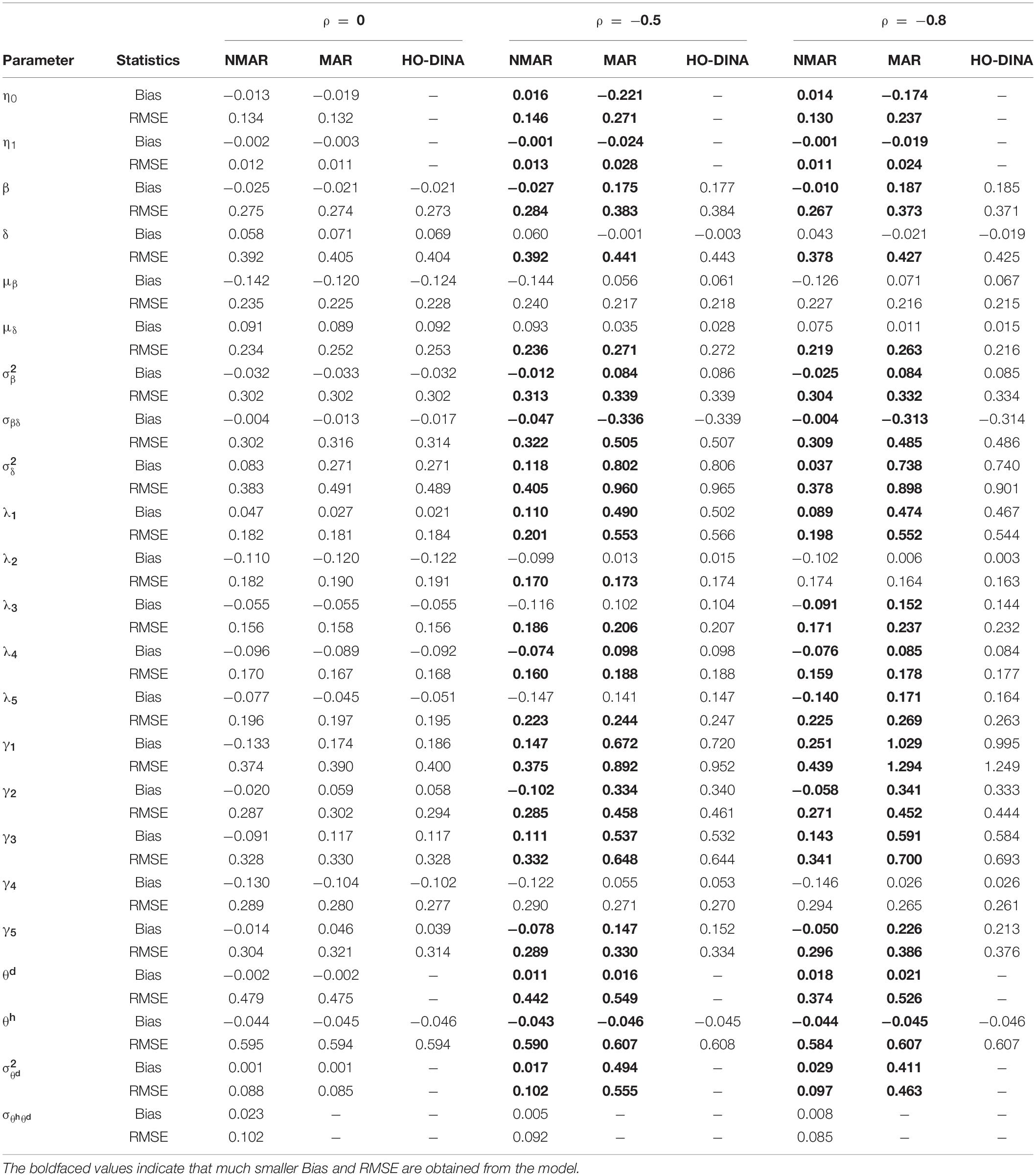
Table 5. Bias and RMSE of parameter estimates of three models with high dropping-out proportion under different correlations between and in simulation study III.
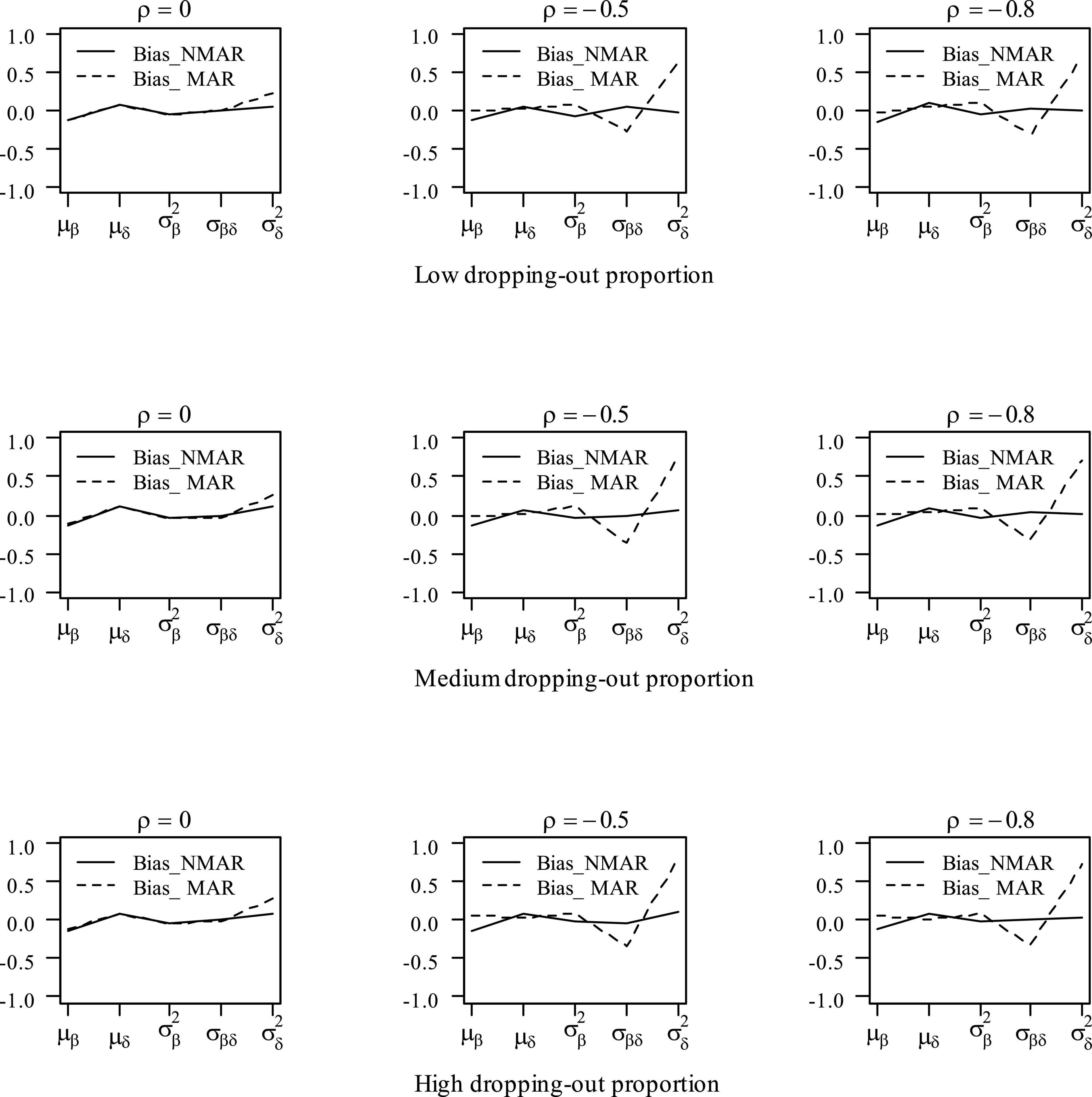
Figure 3. Bias of parameter estimates in the mean item vector and the item covariance matrix elements under different dropping-out proportions and correlations between and in simulation study III. Note that the Bias_NMAR is the bias of parameter estimates in NMAR model, and Bias_MAR is the bias of parameter estimates in the MAR model.
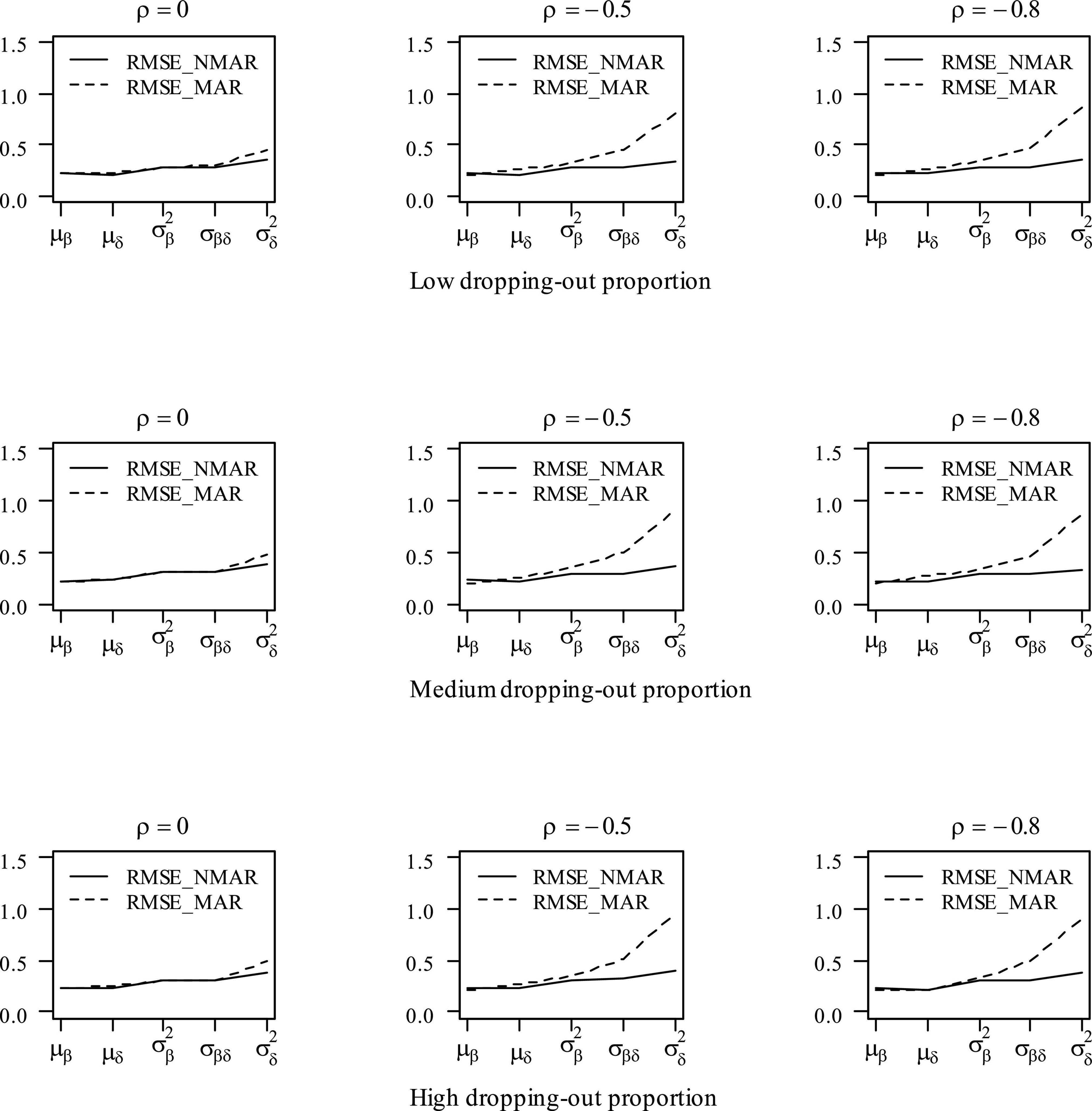
Figure 4. RMSE of parameter estimates in the mean item vector and the item covariance matrix elements under different dropping-out proportions and correlations between and in simulation study III. Note that the Bias_NMAR is the bias of parameter estimates in the NMAR model, and Bias_MAR is the bias of parameter estimates in the MAR model.
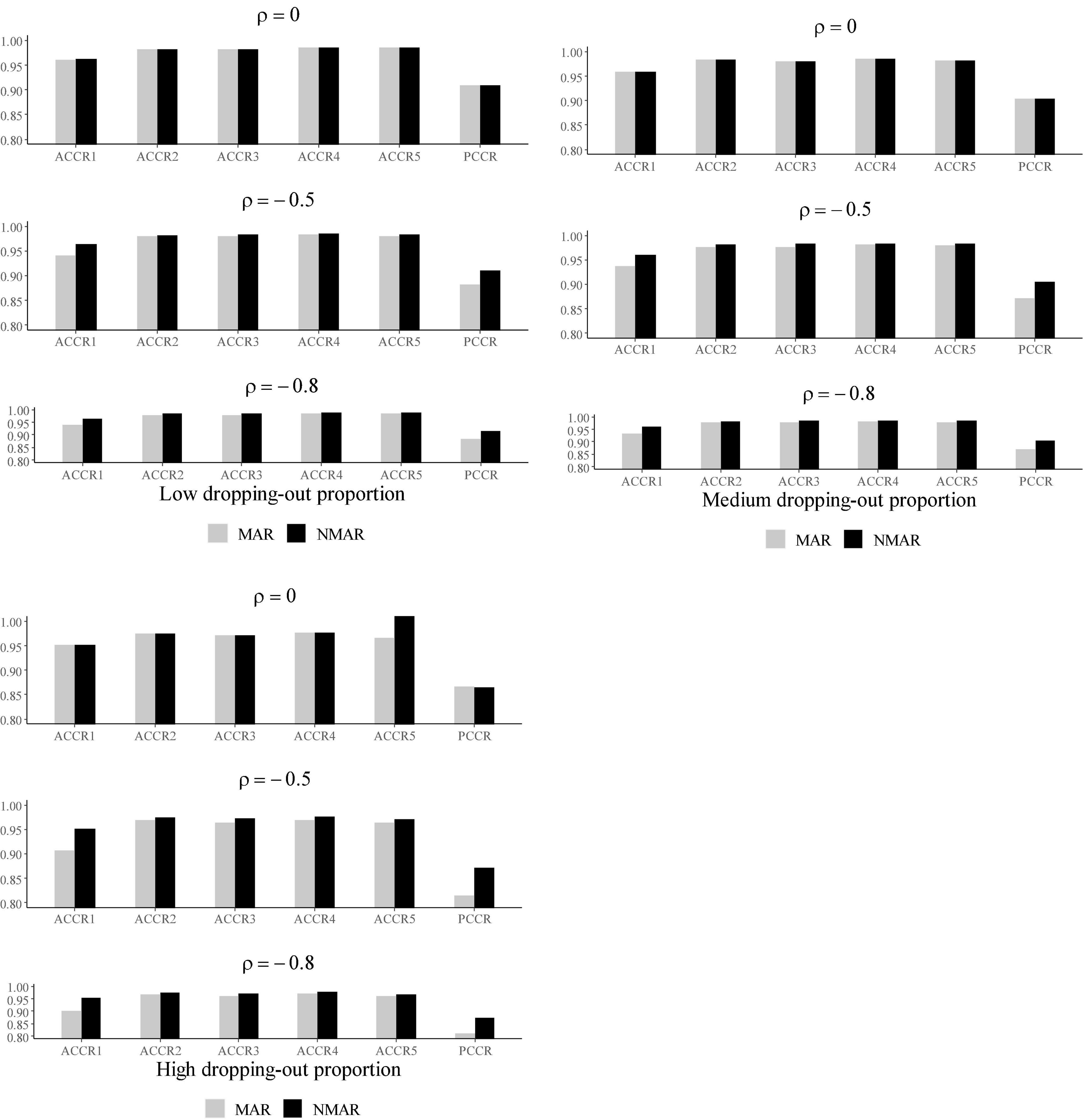
Figure 5. The ACCRs and PCCRs of NMAR and MAR models under different correlations between and and different dropping-out proportions in simulation study III.
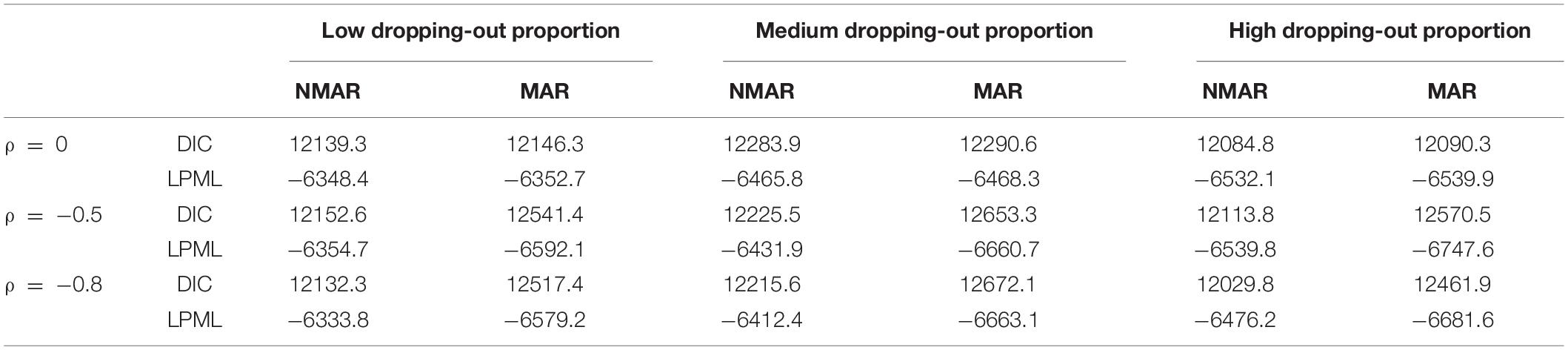
Table 6. DICs and LPMLs of NMAR and MAR models under different correlations between and and different dropping-out proportions in simulation study III.
This study analyzed one dataset from the computer-based PISA 2018 (OECD, 2021) mathematics cognitive test with nine items in Albania, which was also used in the study by Shan and Wang (2020). According to the PISA 2018 (OECD, 2021) mathematics assessment framework, four attributes belonging to the mathematical content knowledge were assessed: change and relationship (α1), quantity (α2), space and shape (α3), and uncertainty and data (α4). Item responses were coded 0 (no credit), 1 (full credit), 6 (not reached), 7 (not applicable), 8 (invalid), and 9 (nonresponse). There were 798 examinees after removing examinees with codes 7 (not applicable) and 8 (invalid). In addition, 224 examinees with code 9 were also removed from this study because this study mainly focused on dropping-out missingness. Thus, the final sample was 574. The overall not-reached proportion was about 2%, and the not-reached proportions at the item level were from 0.7% to 3.3%. The item IDs and Q matrices are presented in Table 7.

Table 7. The Q matrix in the real data.
The DIC and LPML of the NMAR model in the real data were 5,760.28 and −3,040.03, respectively, and the DIC and LPML of the MAR model were 6,521.21 and −3,213.94, respectively. These two model fit indices indicated that the NMAR model fits the real data better than the MAR model. Thus, the NMAR model was adopted to fit this real dataset.
Tables 8, 9 show the estimated values and standard deviations of the item, person, and attribute parameters. Results show that the correlation coefficient of the person parameters is negative (i.e., −0.516), which indicates that the examinees with the higher abilities are less likely to drop out of the test. The estimated attribute slope parameters are positive, which implies that the knowledge attribute is better mastered with the increased ability . The item mean parameter μβ is estimated to be −1.749, which shows that the mean guessing probability is approximately 0.15. In addition, for the estimation of item parameters, only βj for CM033Q01 is positive, while the βj values for other items are negative, which implies that the guessing probability of item CM033Q01 is higher than 0.5 and the guessing probability of all other items is lower than 0.5. All δj are positive, which satisfiesgj < 1−sj, as expected. Supplementary Figure 1 shows the proportions of attribute patterns for examinees with not-reached items, which illustrate that the most prevalent attribute pattern for examinees with not-reached items is (0000), which is unsurprising.

Table 8. Estimates and standard errors of the parameters for the real data.

Table 9. Estimates and standard errors of the item parameters for the real data.
Not-reached items occurred frequently in cognitive diagnosis assessments. Missing data could help researchers understand examinees’ attributes, skills, or knowledge structures. Studies dealing with item nonresponses have used imputation approaches in cognitive diagnosis models, which may lead to biased parameter estimations. Shan and Wang (2020) introduced latent missing propensities of examinees for a cognitive diagnosis model that was governed by the potential category variables. However, their model did not distinguish the type of item nonresponses, which could result in inaccurate inferences regarding cognitive attributes and patterns.
In this study, a missing data model for not-reached items in cognitive diagnosis assessments was proposed. A DINA model was used as the response model, and a 1PLM was used as the missing indicator model. The two models were connected by two bivariate normal distributions for person parameters and item parameters. This new model was able to obtain more fine-grained attributes or knowledge structure as diagnostic feedback for examinees.
Simulation studies were conducted to evaluate the performance of the MCMC algorithm using the proposed model. The results showed that not-reached items provide useful information for further understanding the knowledge structure of examinees. Additionally, the HO-DINA model for the cognitive diagnosis assessments explained examinees’ cognitive processes, thus precise estimations of parameters were obtained from the proposed NMAR model. We compared the recovery of parameters under the two missing mechanisms, which revealed that the bias and RMSE of person parameters decreased significantly when using the proposed NMAR model when the missing proportion and the correlation of ability parameters were high. Moreover, considerable differences in the ACCRs and PCCRs between the NMAR and MAR models were found. With regard to model selection, the proposed NMAR model fitted the data better than the MAR model when the missing data mechanism was non-ignorable. The proposed NMAR model was successfully applied to the 2018 computer-based PISA mathematics data.
Several limitations of the study warrant mentioning, alongside future research avenues. First, this study only modeled not-reached items; however, examinees may skip the items in a cognitive test, which is another type of missing data that needs to be explored further. Second, missing data mechanisms in cognitive assessments may depend on individual factors, such as sex, culture, and race. In addition, different training and problem-solving strategies of examinees, and different school locations may also affect the pattern of nonresponses. Future studies can extend our model to account for the above-mentioned factors. Third, future studies could also incorporate the additional sources of process data, such as the response times, to explore the missing data mechanisms.
Publicly available datasets were analyzed in this study. This data can be found here: https://www.oecd.org/PISA/.
LL completed the writing of the article. JL provided the original thoughts. LL and JL provided key technical support. JZ, JL, and NS completed the article revisions. All authors contributed to the article and approved the submitted version.
This work was supported by the National Natural Science Foundation of China (Grant No. 12001091), China Postdoctoral Science Foundations (Grant Nos. 2021M690587 and 2021T140108), and the Fundamental Research Funds for the Central Universities of China (Grant No. 2412020QD025).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpsyg.2022.889673/full#supplementary-material
Anselmi, P., Robusto, E., Stefanutti, L., and de Chiusole, D. (2016). An upgrading procedure for adaptive assessment of knowledge. Psychometrika 81, 461–482. doi: 10.1007/s11336-016-9498-9
Brooks, S. P., and Gelman, A. (1998). General methods for monitoring convergence of iterative simulations. J. Comput. Graph. Stat. 7, 434–455. doi: 10.1080/10618600.1998.10474787
Chen, M. H., Shao, Q. M., and Ibrahim, J. G. (2000). Monte Carlo Methods in Bayesian Computation. New York, NY: Springer. doi: 10.1007/978-1-4612-1276-8
de Chiusole, D., Stefanutti, L., Anselmi, P., and Robusto, E. (2015). Modeling missing data in knowledge space theory. Psychol. Methods 20, 506–522. doi: 10.1037/met0000050
de la Torre, J. (2008). An empirically based method of Q-matrix validation for the DINA model: Development and applications. J. Educ. Meas. 45, 343–362. doi: 10.1111/j.1745-3984.2008.00069.x
de la Torre, J. (2009). DINA model and parameter estimation: a didactic. J. Educ. Behav. Stat. 34, 115–130. doi: 10.3102/1076998607309474
de la Torre, J. (2011). The generalized DINA model frame work. Psychometrika 76, 179–199. doi: 10.1007/s11336-011-9207-7
de la Torre, J., and Douglas, J. A. (2004). Higher-order latent trait models for cognitive diagnosis. Psychometrika 69, 333–353. doi: 10.1007/BF02295640
Debeer, D., Janssen, R., and De Boeck, P. (2017). Modeling skipped and not-reached items using irtrees. J. Educ. Meas. 54, 333–363. doi: 10.1111/jedm.12147
DeCarlo, L. T. (2011). On the analysis of fraction subtraction data: the DINA model, classification, latent class sizes, and the Q-matrix. Appl. Psychol. Meas. 35, 8–26. doi: 10.1177/0146621610377081
Doignon, J. P., and Falmagne, J. C. (1999). Knowledge Spaces. New York:NY: Springer. doi: 10.1007/978-3-642-58625-5
Falmagne, J. C., and Doignon, J. P. (2011). Learning Spaces: Interdisciplinary Applied Mathematics. New York:NY: Springer. doi: 10.1007/978-3-642-01039-2
Finch, H. (2008). Estimation of item response theory parameters in the presence of missing data. J. Educ. Meas. 45, 225–245. doi: 10.1111/j.1745-3984.2008.00062.x
Fox, J. P. (2010). Bayesian Item Response Modeling: Theory and Applications. New York:NY: Springer. doi: 10.1007/978-1-4419-0742-4
Geisser, S., and Eddy, W. F. (1979). A predictive approach to model selection. J. Am. Stat. Assoc. 74, 153–160. doi: 10.1080/01621459.1979.10481632
Glas, C. A. W., and Pimentel, J. L. (2008). Modeling nonignorable missing data in speeded tests. Educ. Psychol. Meas. 68, 907–922. doi: 10.1177/0013164408315262
Heller, J., Stefanutti, L., Anselmi, P., and Robusto, E. (2015). On the link between cognitive diagnostic models and knowledge space theory. Psychometrika 80, 995–1019. doi: 10.1007/s11336-015-9457-x
Henson, R. A., Templin, J. L., and Willse, J. T. (2009). Defining a family of cognitive diagnosis models using log-linear models with latent variables. Psychometrika 74, 191–210. doi: 10.1007/s11336-008-9089-5
Holman, R., and Glas, C. A. W. (2005). Modelling non-ignorable missing-data mechanisms with item response theory models. Br. J. Math. Stat. Psychol. 58, 1–17. doi: 10.1111/j.2044-8317.2005.tb00312.x
Huisman, M. (2000). Imputation of missing item responses: Some simple techniques. Q. Q. 34, 331–351. doi: 10.1023/A:1004782230065
Ibrahim, J. G., Chen, M. H., and Sinha, D. (2001). Bayesian Survival Analysis. New York:NY: Springer. doi: 10.1007/978-1-4757-3447-8
Little, R. J. A., and Rubin, D. B. (2002). Statistical Analysis With Missing Data, 2nd Edn. New York:NY: Springer. doi: 10.1002/9781119013563
Lord, F. M. (1974). Estimation of latent ability and item parameters when there are omitted responses. Psychometrika 39, 247–264. doi: 10.1007/BF02291471
Lord, F. M. (1983). Maximum likelihood estimation of item response parameters when some responses are omitted. Psychometrika 48, 477–482. doi: 10.1007/BF02293689
Lord, F. M., and Novick, M. R. (1968). Statistical Theories Of Mental Test Scores. Berlin: Addison-Wesley.
Lu, J., and Wang, C. (2020). A response time process model for not-reached and omitted items. J. Educ. Meas. 57, 584–620. doi: 10.1111/jedm.12270
Ludlow, L. H., and O’Leary, M. (1999). Scoring omitted and not-reached items: practical data analysis implications. Educ. Psychol. Meas. 59, 615–630. doi: 10.1177/0013164499594004
Ma, W. (2021). A Higher-Order Cognitive Diagnosis Model With Ordinal Attributes For Dichotomous Response Data. Multivariate Behavioral Research. Milton Park: Taylor & Francis. doi: 10.1080/00273171.2020.1860731
Maris, E. (1999). Estimating multiple classification latent class models. Psychometrika 64, 187–212. doi: 10.1007/BF02294535
Ömür Sünbül, S. (2018). The impact of different missing data handling methods on DINA model. Int. J. Eval. Res. Educ. 7, 77–86. doi: 10.11591/ijere.v1i1.11682
Patz, R. J., and Junker, B. W. (1999). A straightforward approach to Markov chain Monte Carlo methods for item response models. Journal of Educational and Behavioral Statistics 24, 146–178. doi: 10.3102/10769986024002146
Pohl, S., Ulitzsch, E., and von Davier, M. (2019). Using response times to model not-reached items due to time limits. Psychometrika 84, 892–920. doi: 10.1007/s11336-019-09669-2
Rasch, G. (1960). Probabilistic Models For Some Intelligence And Attainment Tests. Copenhagen Denmark: Danish Institute for Educational Research.
Rose, N., von Davier, M., and Nagengast, B. (2017). Modeling omitted and not-reached items in IRT models. Psychometrika 82, 795–819. doi: 10.1007/s11336-016-9544-7
Rose, N., von Davier, M., and Xu, X. (2010). Modeling nonignorable missing data with IRT. Research Report No. RR-10-11. Princeton, NJ: Educational Testing Service. doi: 10.1002/j.2333-8504.2010.tb02218.x
Rubin, D. B. (1976). Inference and missing data. Biometrika 63, 581–592. doi: 10.1093/biomet/63.3.581
Shan, N., and Wang, X. (2020). Cognitive diagnosis modeling incorporating item-level missing data mechanism. Front. Psychol. 11:564707. doi: 10.3389/fpsyg.2020.564707
Spiegelhalter, D. J., Best, N. G., Carlin, B. P., and van der Linde, A. (2002). Bayesian measures of model complexity and fit. J. Royal Stat. Soci. Series B 64, 583–639. doi: 10.1111/1467-9868.00353
Tatsuoka, K. K. (1983). Rule space: An approach for dealing with misconceptions based on item response theory. J. Educ. Meas. 20, 345–354. doi: 10.1111/j.1745-3984.1983.tb00212.x
Templin, J. L., and Henson, R. A. (2006). Measurement of psychological disorders using cognitive diagnosis models. Psychol. Methods 11, 287–305. doi: 10.1037/1082-989X.11.3.287
von Davier, M. (2008). A general diagnostic model applied to language testing data. Br. J. Math. Stat. Psychol. 61, 287–307. doi: 10.1348/000711007X193957
von Davier, M. (2014). The Log-Linear Cognitive Diagnostic Model As A Special Case Of The General Diagnostic Model. Research Report No. RR-14-40. Princeton, NJ: Educational Testing Service. doi: 10.1002/ets2.12043
von Davier, M. (2018). Diagnosing diagnostic models: FromVon Neumann’s elephant to model equivalencies and network psychometrics. Meas. Int. Res. Pers. 16, 59–70. doi: 10.1080/15366367.2018.1436827
Xu, G., and Shang, Z. (2018). Identifying latent structures in restricted latent class models. J. Am. Stat. Assoc. 113, 1284–1295. doi: 10.1080/01621459.2017.1340889
Xu, G., and Zhang, S. (2016). Identifiability of diagnostic classification models. Psychometrika 81, 625–649. doi: 10.1007/s11336-015-9471-z
Zhan, P., Jiao, H., and Liao, D. (2018). Cognitive diagnosis modelling incorporating item response times. Br. J. Math. Stat. Psychol. 71, 262–286. doi: 10.1111/bmsp.12114
Keywords: cognitive diagnosis assessments, missing data mechanism, not-reached items, Bayesian analysis, sequential model
Citation: Liang L, Lu J, Zhang J and Shi N (2022) Modeling Not-Reached Items in Cognitive Diagnostic Assessments. Front. Psychol. 13:889673. doi: 10.3389/fpsyg.2022.889673
Received: 04 March 2022; Accepted: 03 May 2022;
Published: 13 June 2022.
Edited by:
Fco. Pablo Holgado-Tello, National University of Distance Education (UNED), SpainCopyright © 2022 Liang, Lu, Zhang and Shi. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jing Lu, bHVqMjgyQG5lbnUuZWR1LmNu; Jiwei Zhang, emhhbmdqdzcxM0BuZW51LmVkdS5jbg==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.