 Shitao Zhang
Shitao Zhang- School of Network Communication, Zhejiang Yuexiu University, Shaoxing, China
Text sentiment classification is a fundamental sub-area in natural language processing. The sentiment classification algorithm is highly domain-dependent. For example, the phrase “traffic jam” expresses negative sentiment in the sentence “I was stuck in a traffic jam on the elevated for 2 h.” But in the domain of transportation, the phrase “traffic jam” in the sentence “Bread and water are essential terms in traffic jams” is without any sentiment. The most common method is to use the domain-specific data samples to classify the text in this domain. However, text sentiment analysis based on machine learning relies on sufficient labeled training data. Aiming at the problem of sentiment classification of news text data with insufficient label news data and the domain adaptation of text sentiment classifiers, an intelligent model, i.e., transfer learning discriminative dictionary learning algorithm (TLDDL) is proposed for cross-domain text sentiment classification. Based on the framework of dictionary learning, the samples from the different domains are projected into a subspace, and a domain-invariant dictionary is built to connect two different domains. To improve the discriminative performance of the proposed algorithm, the discrimination information preserved term and principal component analysis (PCA) term are combined into the objective function. The experiments are performed on three public text datasets. The experimental results show that the proposed algorithm improves the sentiment classification performance of texts in the target domain.
Introduction
News media platforms and various social media platforms produce a large amount of content every day, including a large number of comments generated by network users. These views and opinions often potentially express their feelings or sentiments. How to exploit users’ sentimental information and analyze their sentimental tendency from these massive comment data has potential application value in many aspects. For example, government departments analyze users’ attitudes toward specific events and topics, grasp public opinions, and keep abreast of public opinion to make appropriate decisions. Commercial enterprises can keep abreast of the market’s reputation by evaluating the relevant content of goods and services, to further improve the quality of their products and services.
Sentiment analysis, also known as sentiment classification, is the field of study that analyses the opinions, views, and sentimental attitudes that people display in texts (Wen et al., 2020; Birjali et al., 2021). Conventional sentiment classification methods are roughly grouped into sentiment dictionary methods and machine learning methods (Zhang et al., 2018; Ahuja et al., 2019). The classification method based on sentiment dictionary mainly uses a manually collated and constructed sentiment dictionary library. The sentiment score of the text is then calculated according to the predetermined rules. Finally, the results of sentiment classification can be obtained based on the obtained sentiment score. There are several obvious shortcomings in the classification method based on sentiment dictionaries. The accuracy of classification results depends on the size of the whole sentiment dictionary resources. When the number of dictionary resources is not large enough, the accuracy of classification results is often not high. In addition, such methods are also difficult to deal with the implied sentimental content. The core of the machine learning methods is the effective feature extraction and classifier. By constructing the feature set, the classifier is trained on the feature set of the training set, and the sentiment label is output for the unlabeled text. In recent years, the commonly used algorithms for text sentiment analysis and text classification include deep learning (Chen et al., 2020; Zhang et al., 2020), decision tree (Almunirawi and Maghari, 2016), support vector machine (Ahmad et al., 2017), sparse representation (Unnikrishnan et al., 2019; Gu et al., 2020), KNN classifier (Bozkurt et al., 2019), Naïve Bayes (Alshamsi et al., 2020), fuzzy logic (Chaturvedi et al., 2019), and extreme learning machine (Lauren et al., 2018; Waheeb et al., 2020).
However, machine learning methods depend on a large number of high-quality label texts, and the manually labeled samples obviously cannot fully meet the needs of sentiment analysis. The expression of sentiment in a text is closely related to the described semantic concept (domain), and the description of sentiment in different domains differs significantly. The distribution of data characteristics in different fields is also different. In this case, directly using the classifiers trained in other domains for text sentiment analysis will lead to the poor adaptability problem. For example, the word “unpredictable” expresses the positive sentiment in literary and artworks, such as “This movie is both exciting and unpredictable! The film is worth seeing!” but in the field of electronic, the word “unpredictable” expresses the negative sentiment, such as “Even if the power is maintained, it is unpredictable. It’s terrible!” As another example, the words “excellent” and “horrible” appear in both domains of electronic and literary works, but “high resolution” and “run fast” rarely appear in the field of literary works, and “printed well” rarely appears in the field of electronic products. Therefore, it is inappropriate to directly use the sentiment classifier trained in the electronic domain to predict the sentiment of comments in the literary works domain.
Recently, the research on cross-domain sentiment classifiers using transfer learning technology becomes a research hotspot (Meng et al., 2019). Transfer learning is a machine learning technology that extracts knowledge from the source domain (the similar but different domain) and applies it to the target domain (the current domain) (Jiang et al., 2020, 2021). The common transfer learning algorithms include sample-based algorithms and feature space-based algorithms (Fu and Liu, 2021; Zhao et al., 2021). The former includes feature selection and feature projection. The sample-based algorithm mainly selects the samples that are valuable for the classification of the target domain from the source domain. To reduce the impact of negative transfer, Gui et al. (2015) developed a negative transfer detection algorithm. This algorithm detected multiple quality levels and retained the high-quality samples. Chen et al. (2010) developed a combined feature level and instance level transfer learning algorithm. This algorithm combined the samples from different domains by evaluating the classification performance in the target domain. Tian et al. (2019) developed an instance-based algorithm for imbalanced cross-linguistic viewpoint analysis. This algorithm translated other relevant markup datasets into the target domain as the supplementary training data.
Feature space-based transfer learning methods include feature selection and feature projection (Xia et al., 2013). The purpose of feature selection is to find the shared features between different domains through some strategies; and then use these features for knowledge transfer. The feature projection strategy maps the features of each domain into a shared feature representation space and establishes the association between the features of each domain. The difference between feature projection and feature selection is that the projected features are not among the original features, but new features. Wu and Tan (2011) developed a two-stage transfer learning sentiment classification algorithm. In the “bridge-building” stage, a bridge between different domains was built to obtain some of the most reliable labeled texts in the target domain. In the “structure following” stage, the internal structure was adopted to label the texts by using the obtained reliable texts. Du et al. (2020) developed a Wasserstein-based transfer network. This algorithm also used a recurrent neural network to capture useful features. López et al. (2019) developed an evolutionary ensemble algorithm for text sentiment analysis. This algorithm was built on a set of evolutionary algorithms. The optimization of the model was achieved by optimizing each sub-algorithm. Wang et al. (2018) developed a measure index called sentiment-related index to measure associations between different domains, and then used this index as a bridge between different domains of features. Tang et al. (2021) developed a graph domain adversarial transfer network for text sentiment classification. This algorithm used a gradient reversal layer to obtain the domain-invariant text features and adopted a projection mechanism to obtain the domain-independent feature representations. Fei et al. (2020) developed a deep learning structure-based transfer learning algorithm, which combined the cross-entropy and weighted for word into the recurrent neural network framework.
Dictionary learning plays a key role in sparse representation and low-rank modeling. The basic operation in sparse representation is called “sparse coding,” which involves reconstructing the data representation using a sparse set of constructive blocks (called “atoms”), and the atoms are clustered in a structure called a “dictionary” (Gu et al., 2021; Ni et al., 2021). Therefore, the dictionary learning algorithm has data self-adaptability, which aims to learn a series of basic atoms from the dataset to linearly approximate the given data. Since dictionary learning learns a set of atoms to obtain discriminative feature representation, it performs well in classification tasks. In this study, I develop a transfer learning discriminative dictionary learning (TLDDL) algorithm for cross-domain text sentiment classification. Considering the distribution difference between different domains, I adopt the subspace technology to project all samples into a subspace. In the common subspace, a domain-invariant dictionary is built to connect different domains. Moreover, the discrimination information preserved term and PCA term are embedded into the objective function, so that the performance of TLDDL for classification tasks across domains is enhanced. TLDDL learns all parameters in an alternating iteration manner. By comparing several non-transfer learning and transfer learning algorithms on toutiao-text (Zhang et al., 2021), Chinese Weibo (Bai et al., 2020), and Amazon review (Pan et al., 2010) datasets, one can draw that the TLDDL algorithm is efficient.
The rest of this paper is organized as follows: the next section presents dictionary learning. The proposed TLDDL algorithm and its optimization are described in section “Transfer Learning Discriminative Dictionary Learning Algorithm”. Experimental results are given in section “Experiment.” Finally, section “Conclusion” concludes the paper.
Backgrounds
Given a data matrix Y, the dictionary learning algorithm attempts to learn the dictionary D so that the data Y can be approximately linearly expressed as Y≈DS. Dictionary learning can be represented as,
where Ti is the given threshold. S is the sparse coding matrix.
The constraints are used to constrain the complexity of the dictionary matrix. Dictionary learning can also be represented as the following optimization problem, where the constraints are replaced as well as the objective function,
Where ∥⋅∥0 represents the 0 norm of the vector. n and K are the number of training samples and atoms, respectively. It is difficult to optimize the 0 norm in Equations 1, 2, so the 1 norm is commonly used in dictionary learning. For the above optimization problem, after the transformation of the Lagrange equation, Equation 1 can be represented as follows,
It is easily can be seen that dictionary learning minimizes the reconstruction error , while the 1 norm of sparse coding si is as small as possible, that is, the sparsity of S is as strong as possible. λ is the trade-off parameter. The optimization process of dictionary learning generally includes two alternating iterative steps, one is to solve sparse coding S, and the other is to solve dictionary D. The optimization problem of sparse coding S is
And the optimization problem of dictionary D is
By alternately optimizing the above problems until convergence, the optimal D and S can be obtained. For the sample y on the test set, the corresponding sparse coding can be obtained by solving Equation 4, and then the classification is performed using the obtained sparse coding.
Transfer Learning Discriminative Dictionary Learning Algorithm
Objective Function
It is known that when there are few domain-invariant features between different domains, the cross-domain classification performance will decline. To extract as sufficient domain-invariant features as possible and reduce their differences between different domains, the TLDDL algorithm uses the dictionary learning model to learn a domain-invariant dictionary as a bridge to realize the association of the two domains. The source domain is Ys = {ys,1,ys,2,…,ys,ns}, and the target domain is Yt = {yt,1,yt,2,…,yt,nt}, where ns and nt are the number of the source domain and the target domain, respectively.
Firstly, I use the k-nearest neighbor knowledge to represent the local structure and label information of the original data. I think that if the sample yj is in the k-nearest neighbor of its same-class sample yi, then the corresponding sparse coding coefficients si and sj for yi and yj should also be closer to each other. On the other hand, it is necessary to minimize the within-class variance and maximize the between-class separability for the sparse coding coefficients.
Given the training samples yi and yj, the following within-class graph matrix Ewit and between-class graph matrix are defined as
where e(yi,yj) = exp(−∥yi−yj∥2/θ), θ is the tune parameter. Nwit(yi) is the k-nearest neighbors of yi belonging to the same class, and Nbet(yi) is the k-nearest neighbors of yi belonging to the different class.
Considering the within-class minimizing and between-class maximizing of sparse coding coefficients, I define the following discrimination information preserved term F1(St) in the source domain,
where , Tr(⋅) is the trace operator.
Similarly, I can obtain the discrimination information preserved term F1(St) in the target domain,
where .
When reconstructing the projection space, the proposed transfer learning algorithm not only needs to establish potential connections between multiple domains in the projection space, but also transfers the domain-invariant information from the source domain to the target domain. Meanwhile, TLDDL should also retain the identification information of label samples and maintain the discriminative information in the projection space. To achieve this goal, I establish the principal component analysis (PCA) term of the projection matrix. Based on the PCA criterion, the discrimination information in the original space will be retained in the projection space. The PCA terms of the projection matrix on the source and target domains are represented as
where Ps,Pt ∈ Rp×d, p and d are the dimensions of the projection subspace and original feature space, respectively.
Based on the traditional dictionary learning algorithm, TLDDL combined the discriminative information preserved terms and PCA terms of the projection matrix together, and builds a domain-invariant dictionary between different domains. The objective function of TLDDL is
where δ, γ and β are trade off parameters.
For Equation 12, the first and second terms inherit the dictionary learning algorithm and are used to reconstruct the data in the source and target domains. These two terms are also domain-invariant dictionary learning terms to realize the connection of knowledge between different domains. The third and fourth terms are discriminative information preserved terms. The fifth and sixth terms are PCA terms of the projection matrices. The last two terms are the regularization terms of the sparse coding matrices.
Optimization
Let Equation 12 can be simplified as,
The alternating iteration method is used to optimize variables {P,S,D}. In the optimization process, other variables are fixed and only one variable is optimized.
Fixed{S,D}, the optimization problem of parameter P can be written as,
Following the Proposition (2) in Shekhar et al. (2013), let
where W ∈ R(ns + nt)×p, C ∈ R(ns + nt)×K.
Equation 14 can be written as,
where M = YTY.
Then W has a closed-form solution as,
where M = ΘVΘT, and U can be obtained as,
where H = V1/2ΘT((I−−CS)(I−−CS)T−γI)ΘV1/2. Due to the orthonormality condition on U, Equation 19 has a closed-form solution. Therefore, P can then be updated by Equation 15.
Fixed{P,S}, the optimization problem of parameter D can be written as,
Using the Lagrange dual method, D can be obtained as,
where Δ is a diagonal matrix.
Fixed {P,D}, the optimization problem of parameter S can be written as,
By setting the derivative of S to zero, I get,
In this study, Equation 23 is solved by the Bartels-Stewart method (Kleinman and Rao, 2003).
The above optimization steps are summarized in Algorithm 1.

Algorithm 1. Algorithm 1 the TLDDL algorithm.
Test
For an unlabeled test text ytest, according to the obtained optimal projection matrix Pt and dictionary D, its sparse coding coefficient s* can be solved by the following problem,
I can obtain s* as follows,
Then, I compute the reconstruction error of ytest on the dictionary D = [D1,D2,…,DJ], where J is the number of sample classes. The reconstruction error of ytest on the jth sub dictionary Dj can be computed as follows,
where is the sparse coding coefficient of ytest on the Dj. Finally, the class label of ytest is the class with the smallest reconstruction error, i.e.,
Experiment
Datasets and Experiment Setup
The experiment adopts the Chinese corpus (including toutiao-text and Chinese Weibo datasets) to verify the proposed TLDDL algorithm. I select 13 categories in Chinese corpus includes: Story (Sto), Culture (Cul), Entertainment (Ent), Sports (Spo), Finance (Fin), House (Hou), Car, Education (Edu), Technology (Tec), Military (Mil), World (Wor), Agriculture (Agr), and Game (Gam). Each category represents a domain. In addition, the experiment adopts the English multi-domain dataset Amazon review dataset, which is often used in cross-domain sentiment classification. Amazon review dataset includes reviews of DVD, book (Boo), electronic (Ele), kitchen and household appliance (Kit). Each product also represents a domain. To facilitate comparison with existing methods, 2,000 comments are selected respectively, including 1,000 positive comments and 1,000 negative comments. I use 80% texts in the source domain and 10% texts in the target domain as the training dataset, and the rest of the texts in the target domain are used for testing.
I investigate the performance of TLDDL compared with several algorithms on two text corpora. For comparison, the K-SVD algorithm (Aharon et al., 2006) is used as the baseline of the proposed algorithm. The size of dictionary in K-SVD is set to 300. In addition, six transfer learning algorithms are used, including: ARTL (Long et al., 2014), DMTTL (Zheng et al., 2019), SMITL (Liu et al., 2018), WAAR (Jia et al., 2018), and SFA (Pan et al., 2010). In ARTL, the parameter λ is set in the grid {10−2,10−1,…,102}, the parameter γ is set in the grid {0.01,0.05,0.1,0.5,1.5,10}, and the parameter σ is set in the grid {0.01, 0.02, 0.1, 0.5, 1, 2, 5}. In DMTTL, the parameters λ,λs,λt are set in the grid {10−4,10−3,…,103}, γ is set in the grid {102,5×102,…,2×104}. In SMITL, the Gaussian kernel is used, and the kernel and penalty parameters are set in the grid {10−4,10−3,…,103}. In WAAR, the parameter l is set to 600, min-support = 0.014, min-confidence = 0.08, and ε = 0.005. In SFA, the parameters l, k and γ are set to 500, 100 and 0.6, respectively. In the proposed TLDDL, the subspace dimension and the size of dictionary are set to 500 and 300, respectively. The parameters δs, δt, γs, γt, βs and βtare set in the grid {0.01, 0.05,…, 2}. In the experiments, the dimension of the text word vectors is set to 300. I take the first 100 text units in each text. Following (Meng et al., 2019), a convolutional neural network composed of five layers is used to extract the text features. The mini-batch size is set to 16, and the number of convolution kernels is set to 256. Finally, these vectors are set to 768 dimensions when I treat them into the training model. All the experiments are executed in Matlab 2018a environment. I repeat the experiments five times. The performances of experimental results are generally evaluated based on accuracy, precision, recall, and F1-score.
Experiments on Chinese Corpus
Tables 1–4 show the classification results on Chinese corpus based on accuracy, precision, recall, and F1-score, respectively. For example, task “Stor→Cul” indicates that the source domain is “Story” and the target domain is “Culture.” In the respect of classification accuracy, the best average accuracy obtained by TLDDL is 81.23%, followed by SFA, and its average accuracy is 79.24%. The non-transfer learning algorithm K-SVD is the lowest. In the respect of precision, recall, and F1-score, all transfer learning algorithms are always better than the non-transfer learning algorithm K-SVD in each classification task. The proposed TLDDL algorithm also obtains the best performance. Compared with the second-best algorithm, the average precision, recall, and F1 score exceed 1.99, 1.97, and 1.96%, respectively. Therefore, the generalization ability of the proposed TLDDL algorithm is higher. The experimental results indicate that under the framework of the dictionary learning algorithm, TLDDL uses the projection technology to reduce the differences between different domains, and builds a domain-invariant dictionary to establish a bridge between the related domains. The transferring discriminative information of the source domain to the target domain can improve the cross-domain classification performance.
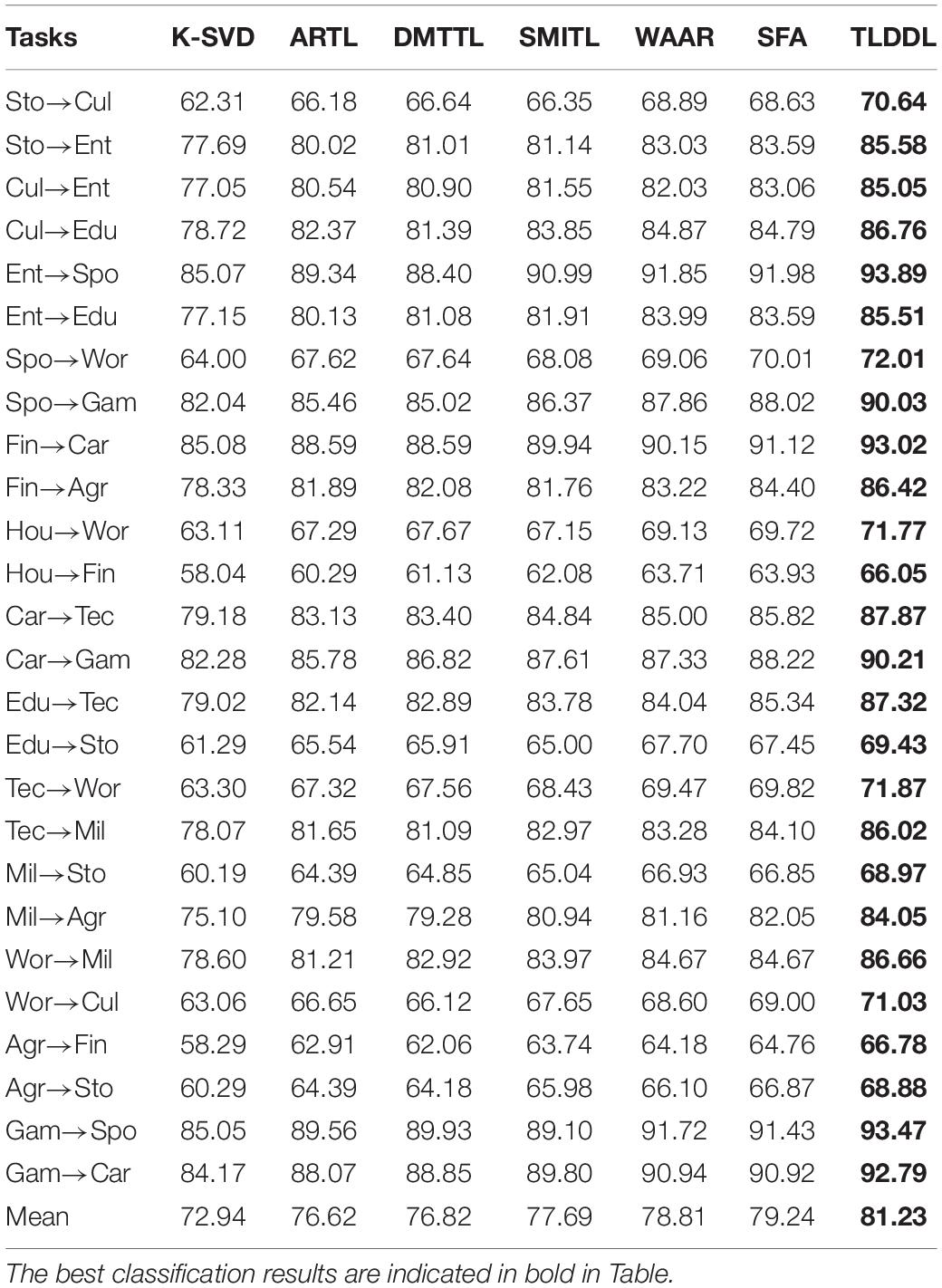
Table 1. Accuracy results for each cross-domain task on Chinese corpus.
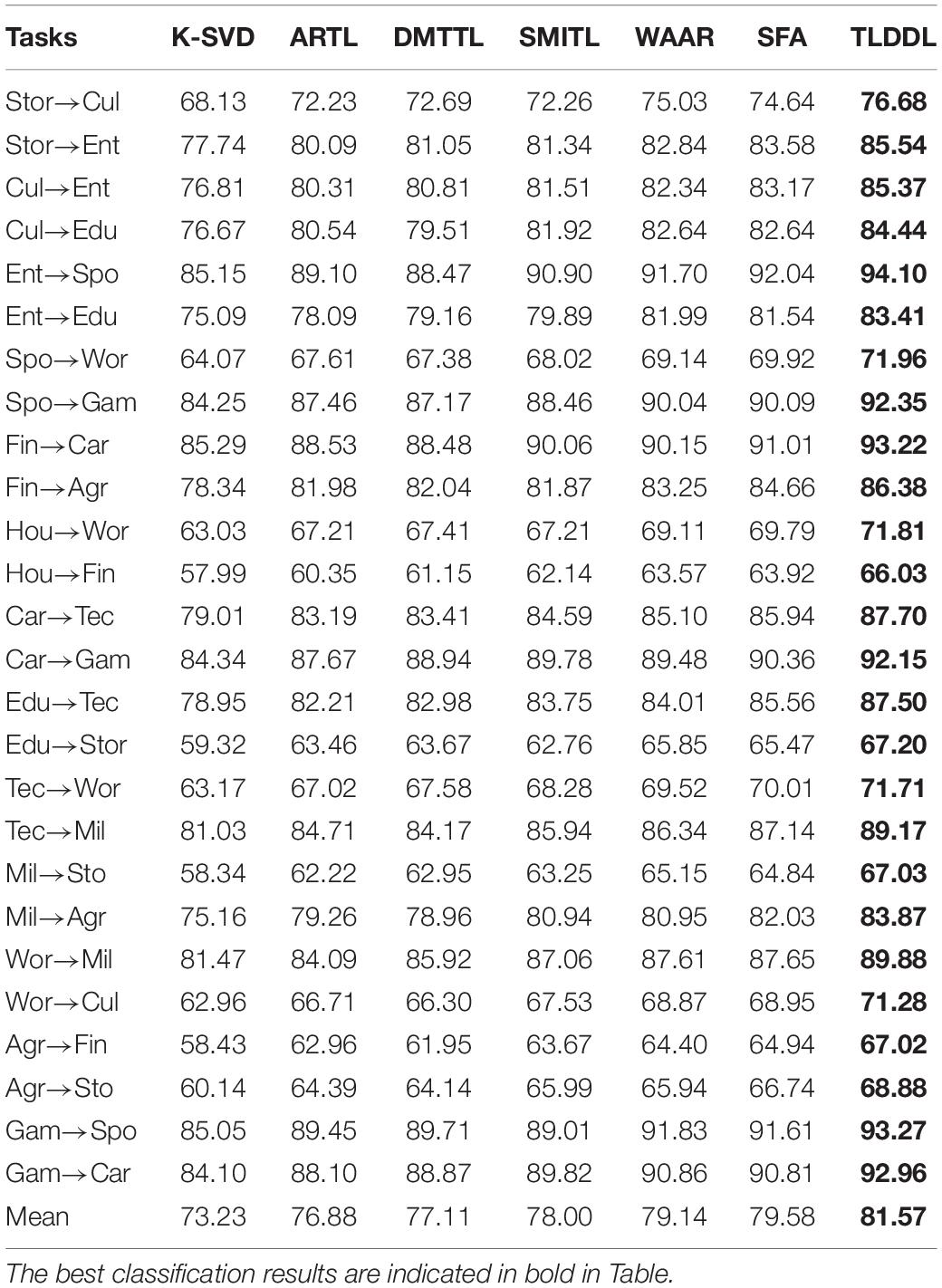
Table 2. Precision results for each cross-domain task on Chinese corpus.
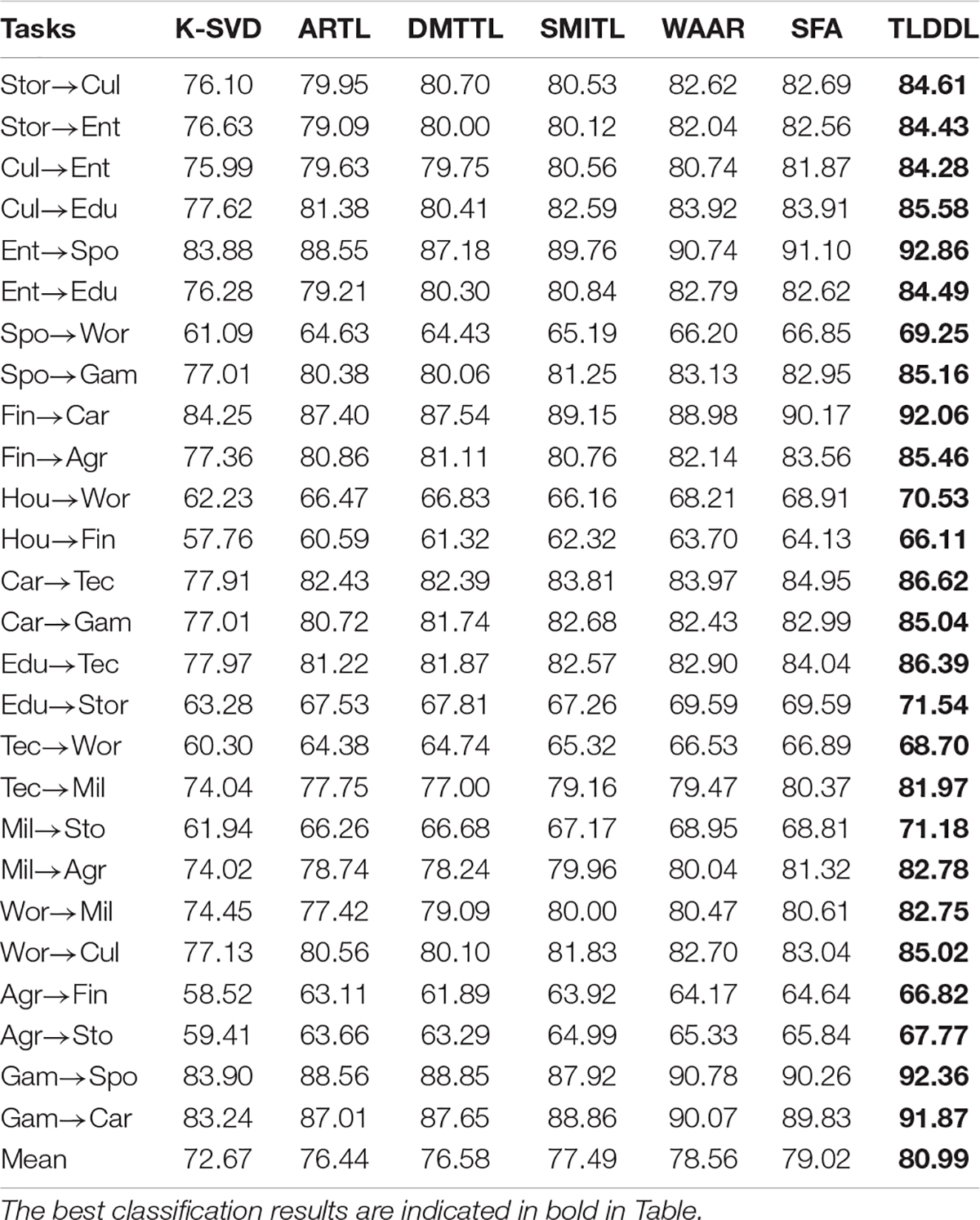
Table 3. Recall results for each cross-domain task on Chinese corpus.
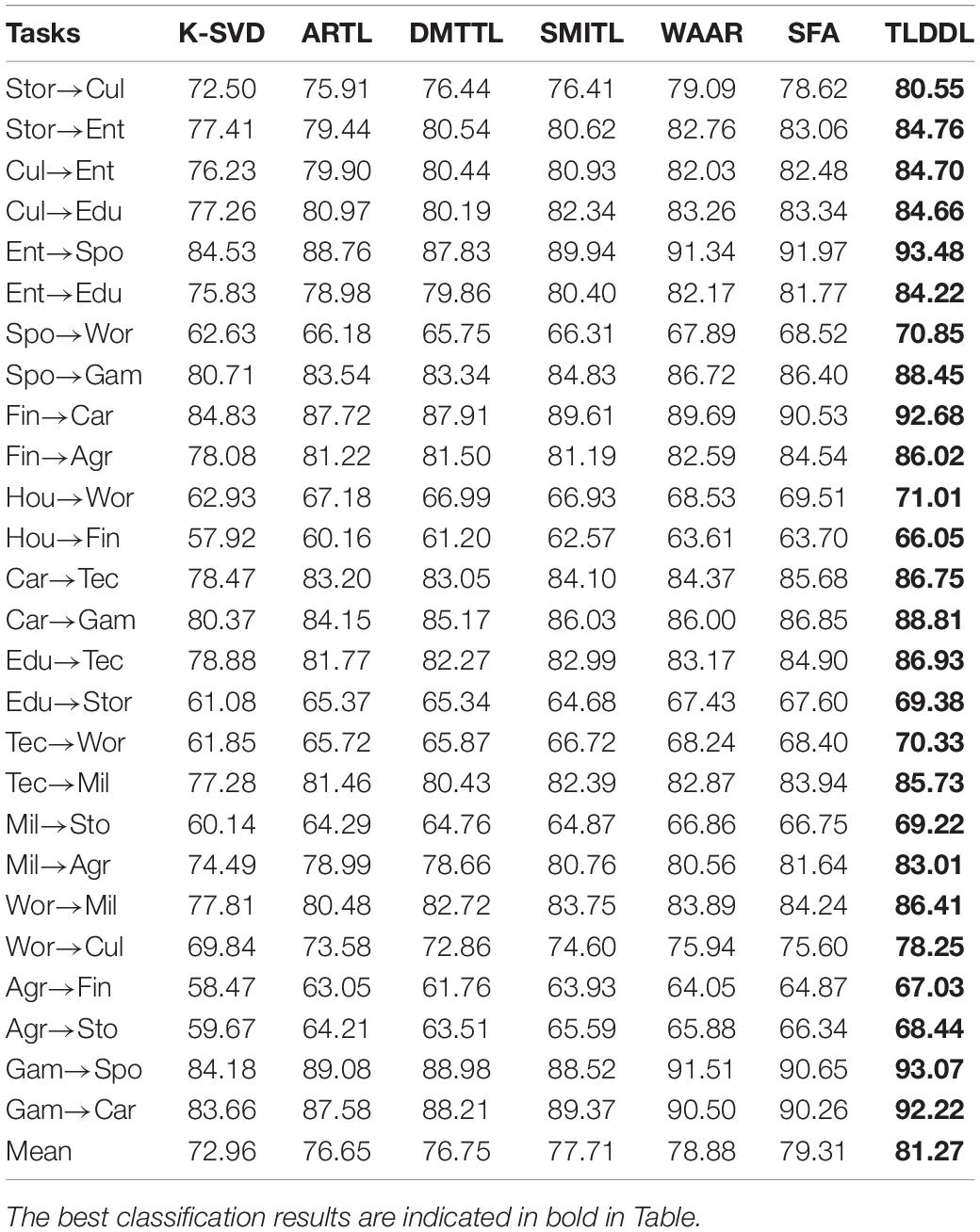
Table 4. F1-score results for each cross-domain task on Chinese corpus.
Experiments on English Corpus
Tables 5–8 show the classification results on the English corpus based on accuracy, precision, recall, and F1-score, respectively. I can see that all transfer learning algorithms outperform the baseline algorithm K-SVD. Some tasks have high classification performance, such as DVD→Boo and Boo→DVD. The reason for the high classification performance is that the differences between the source domain and the target domain are similar. Some tasks have low classification performance, such as DVD→Ele and DVD→Kit. The reason is that the domain-invariant information transferring from the source domain to the target domain is insufficient due to the great differences between domains. The results in Tables 5–8 show that the TLDDL algorithm obtains the best performance. TLDDL obtains the classification performance 81.26, 81.67, 80.87, and 81.25% in the respect of accuracy, precision, recall and F1-score, respectively. TLDDL is 1.02, 0.94, 0.98, and 1.00% higher than the second-best algorithm in four evaluation indexes. The results indicate that joint learning of projection technology and dictionary learning is an efficient strategy in cross-domain text classification tasks. In addition, the discrimination information preserved and PCA terms are helping to improve the generalization of the classifier.
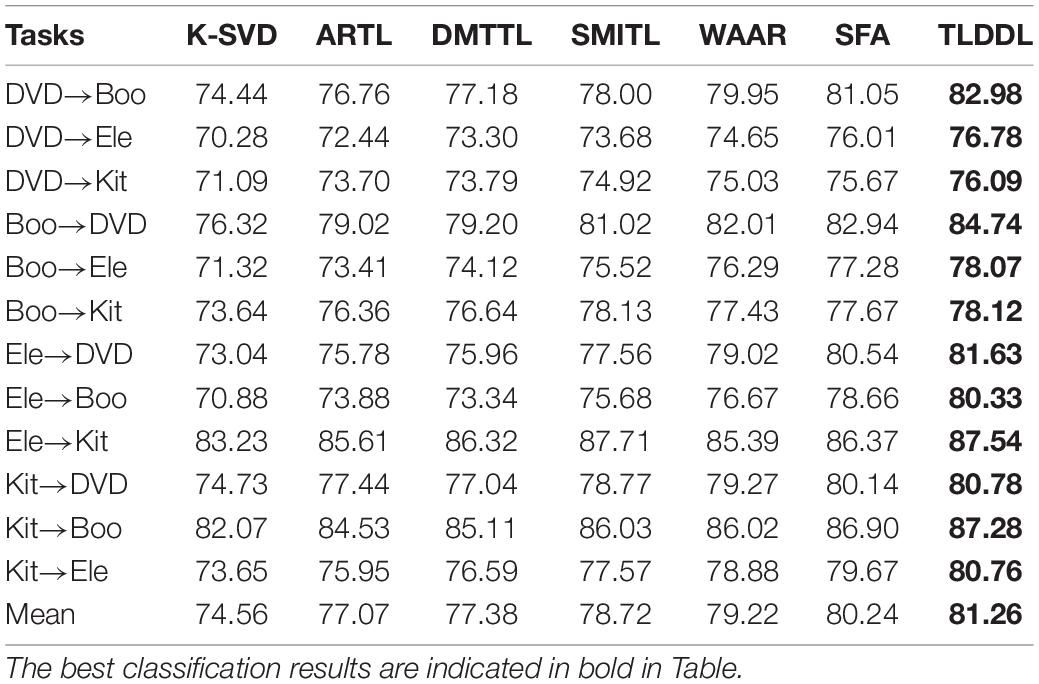
Table 5. Accuracy results for each cross-domain task on English corpus.
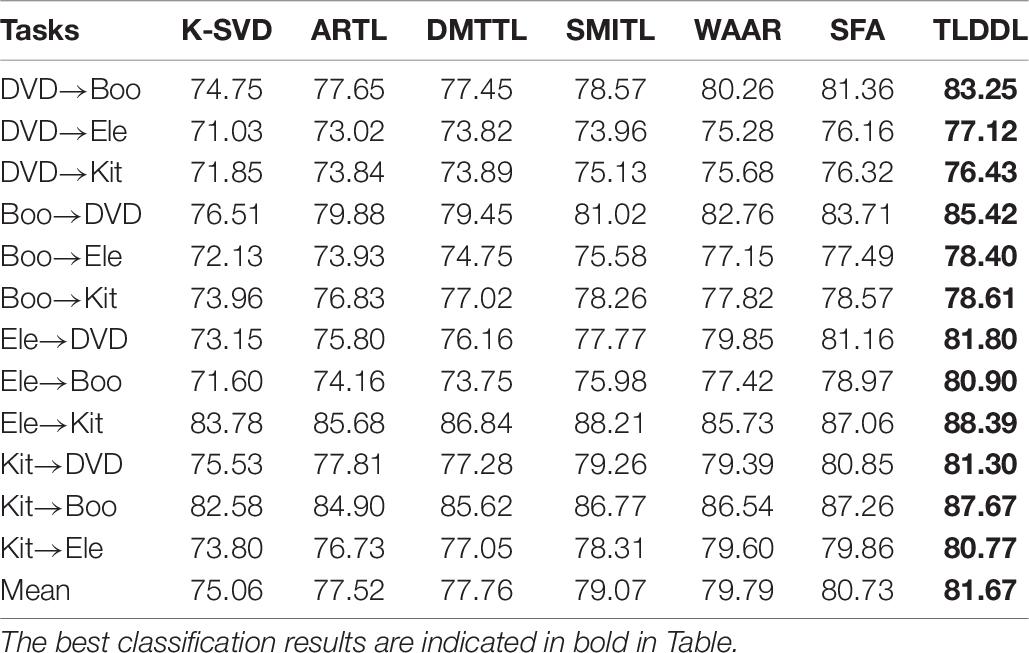
Table 6. Precision results for each cross-domain task on English corpus.
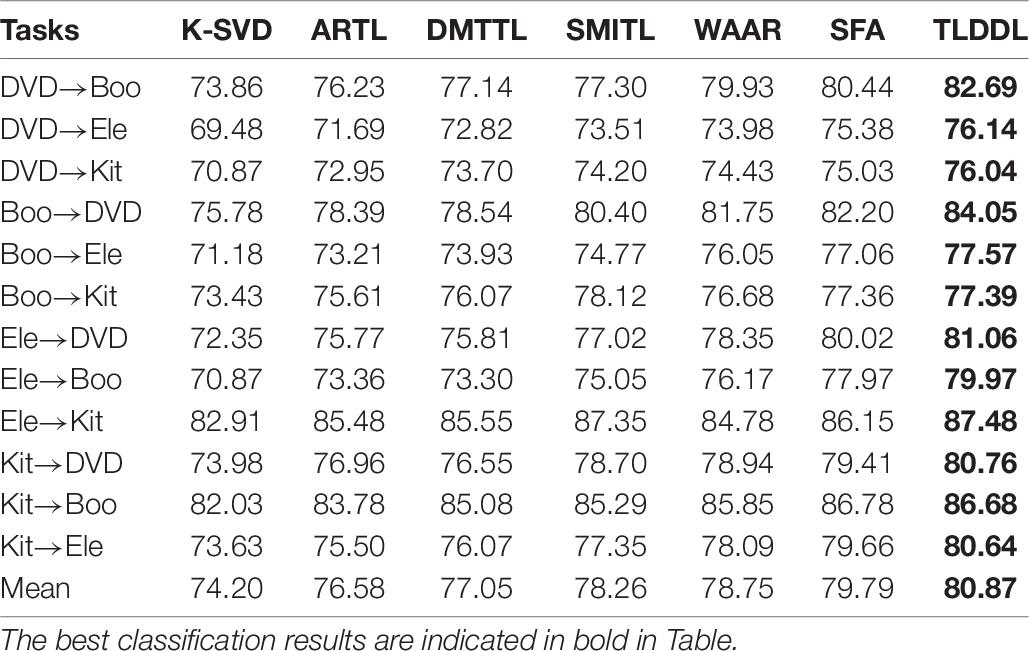
Table 7. Recall results for each cross-domain task on English corpus.
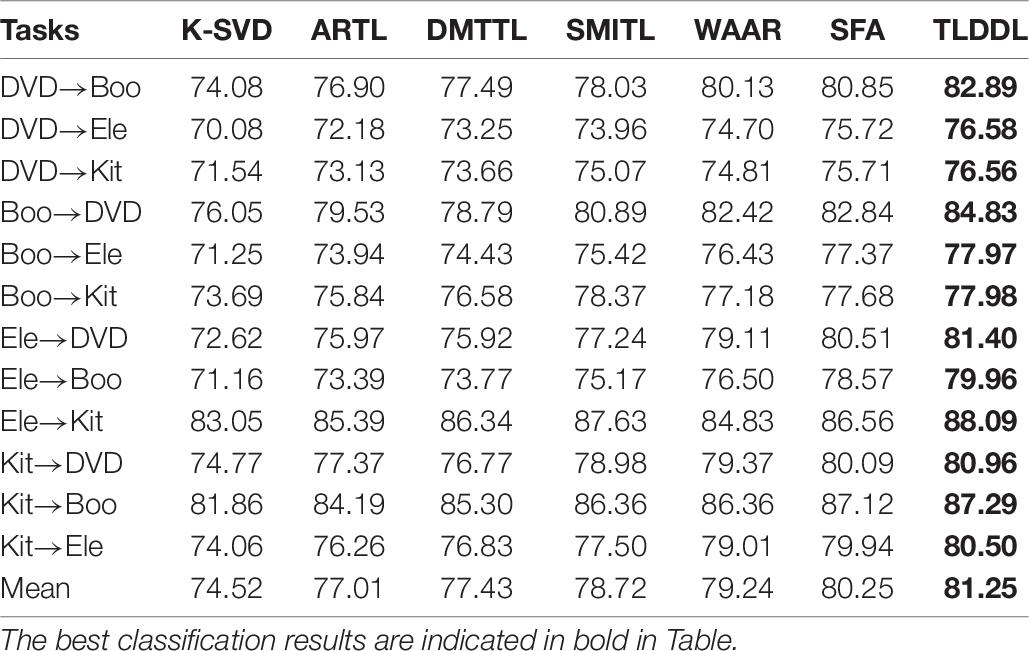
Table 8. F1-score results for each cross-domain task on English corpus.
Experiments With Different Training Samples in the Target Domain
To show the influence of the number of training samples in the target domain on the proposed TLDDL algorithm, I compare its classification accuracy on the Chinese and English corpora in Figure 1. The size of nt is set to be 0, 50, 100, 200, 400, and 500, respectively. Since the size of nt should be less than that of ns, the maximum size of nt is set to 500. The results of Sto→Cul and Fin→Agr on the Chinese corpus are shown in Figure 1A. When the size of nt is 0, the classification accuracy of the two tasks is the lowest. With the increase of the size of nt, the classification accuracy is gradually improved. When the size of nt exceeds 200, the classification accuracy reaches a relatively stable state. The results of Boo→Ele and Kit→Boo on the English corpus are shown in Figure 1B. I can see that the classification accuracy of TLDDL increases rapidly after adding the training samples in nt. When nt reaches 200, the classification accuracy is stable and the growth rate of accuracy is small. Considering the practical application scenarios of transfer learning, 200 texts selected in the target domain for training are reasonable.
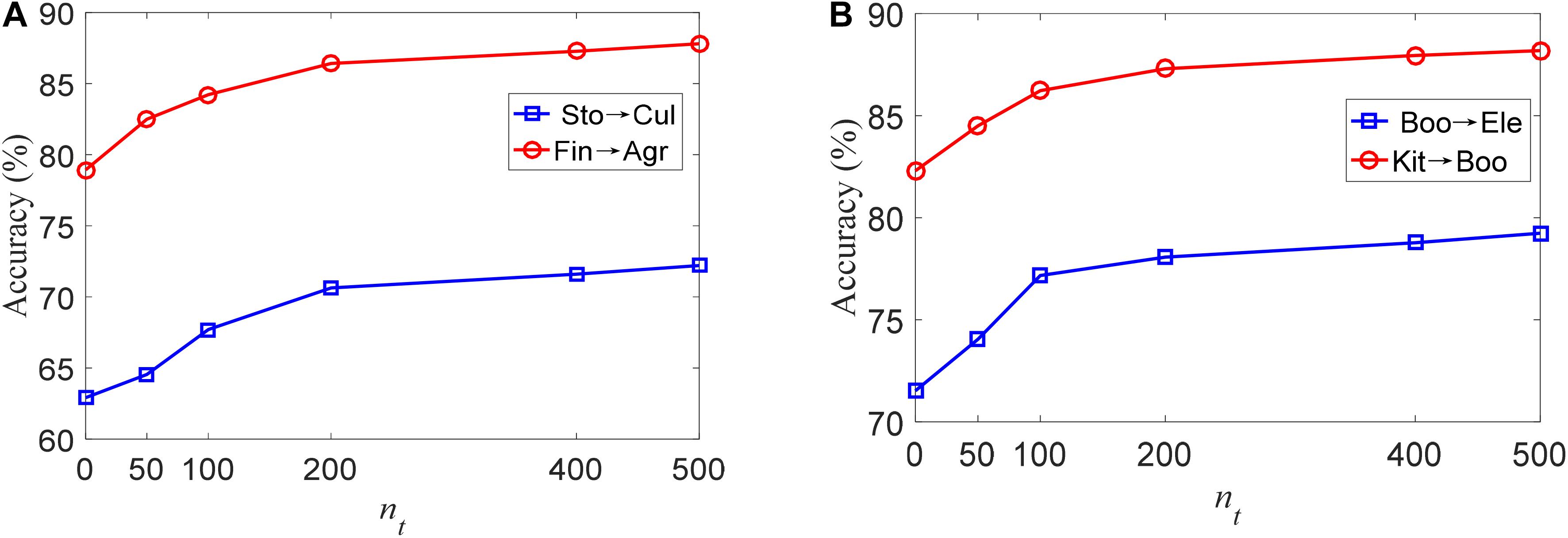
Figure 1. The accuracy of TLDDL with different size of nt, (A) Chinese corpus; (B) English corpus.
Conclusion
In this study, I have developed a transfer learning classification algorithm for cross-domain text sentiment classification. Inspired by the advantage of dictionary learning in knowledge reconstruction and sparse representation, I proposed to employ subspace projection and transfer learning into the framework of dictionary learning. Considering the within-class minimizing and between-class maximizing of sparse coding coefficients, I define the following discrimination information preserved term in the objective function; meanwhile, I adopt the PCA term in the objective function to retain the discrimination knowledge. In such an algorithm, a domain-invariant dictionary is built to establish a connection between different domains. Experimental results indicate that the TLDDL algorithm achieves good classification performance. In the future, from the perspective of multiple learning strategies on dictionary learning, I will consider how to realize transfer learning of multi-source and heterogeneous data in the proposed algorithm. In addition, from the perspective of extracting features, I will investigate how to automatically implement feature selection and building a classifier in a model framework.
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found here: The toutiao-text dataset is addressed as: https://github.com/aceimnorstuvwxz/toutiao-multilevel-text-classfication-dataset. The Chinese Weibo dataset is addressed as: http://tcci.ccf.org.cn/conference/2014/pages/page04_sam.html. The Amazon review dataset is addressed as: http://jmcauley.ucsd.edu/data/amazon/.
Author Contributions
SZ conceived and developed the theoretical framework of the manuscript, carried out experiment and data process, and drafted the manuscript.
Conflict of Interest
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Aharon, M., Elad, M., and Bruckstein, A. (2006). K-SVD: an algorithm for designing overcomplete dictionaries for sparse representation. IEEE Trans. Signal Process. 54, 4311–4322. doi: 10.1109/TSP.2006.881199
Ahmad, M., Aftab, S., and Ali, I. (2017). Sentiment analysis of tweets using SVM. Int. J. Comput. Appl. 177, 975–8887. doi: 10.5120/ijca2017915758
Ahuja, R., Chug, A., Kohli, S., Gupta, S., and Ahuja, P. (2019). The impact of features extraction on the sentiment analysis. Procedia Comput. Sci. 152, 341–348. doi: 10.1016/j.procs.2019.05.008
Almunirawi, K. M., and Maghari, A. (2016). A comparative study on serial decision tree classification algorithms in text mining. Int. J. Intell. Comput. Res. 7, 754–760. doi: 10.20533/ijicr.2042.4655.2016.0093
Alshamsi, A., Bayari, R., and Salloum, S. (2020). Sentiment analysis in English texts. Adv. Sci. Technol. Eng. Syst. J. 5, 1683–1689. doi: 10.25046/aj0506200
Bai, H., Yu, H., Yu, G., and Huang, X. (2020). A novel emergency situation awareness machine learning approach to assess flood disaster risk based on Chinese Weibo. Neural Comput. Appl. doi: 10.1007/s00521-020-05487-1 [Epub ahead of print].
Birjali, M., Kasri, M., and Beni-Hssane, A. (2021). A comprehensive survey on sentiment analysis: approaches, challenges and trends. Knowl. Based Syst. 226:107134. doi: 10.1016/j.knosys.2021.107134
Bozkurt, F., Çoban, O., Gunay, F., and Yucel Altay, S. (2019). High performance twitter sentiment analysis using CUDA based distance kernel on GPUs. Tehnicki Vjesnik-Technical Gazette 26, 1218–1227.
Chaturvedi, I., Satapathy, R., Cavallari, S., and Cambria, E. (2019). Fuzzy commonsense reasoning for multimodal sentiment analysis. Pattern Recognit. Lett. 125, 264–270. doi: 10.1016/j.patrec.2019.04.024
Chen, D., Xiong, Y., Yan, J., Xue, G. R., Wang, G., and Zheng, C. (2010). Knowledge transfer for cross domain learning to rank. Inf. Retrieval 13, 236–253.
Chen, L. C., Lee, C. M., and Chen, M. Y. (2020). Exploration of social media for sentiment analysis using deep learning. Soft Comput. 24, 8187–8197. doi: 10.1007/s00500-019-04402-8
Du, Y., He, M., Wang, L., and Zhang, H. (2020). Wasserstein based transfer network for cross-domain sentiment classification. Knowl. Based Syst. 204:106162. doi: 10.1016/j.knosys.2020.106162
Fei, R., Yao, Q., Zhu, Y., Xu, Q., and Hu, B. (2020). Deep learning structure for cross-domain sentiment classification based on improved cross entropy and weight. Sci. Program. 2020:3810261. doi: 10.1155/2020/3810261
Fu, Y., and Liu, Y. (2021). Cross-domain sentiment classification based on key pivot and non-pivot extraction. Knowl. Based Syst. 228:107280.
Gu, X., Fan, Y., Zhou, J., and Zhu, J. (2021). Optimized projection and fisher discriminative dictionary learning for EEG emotion recognition. Front. Psychol. 12:705528. doi: 10.3389/fpsyg.2021.705528
Gu, X., Lu, L., Qiu, S., Zou, Q., and Yang, Z. (2020). Sentiment key frame extraction in user-generated micro-videos via low-rank and sparse representation. Neurocomputing 410, 441–453. doi: 10.1016/j.neucom.2020.05.026
Gui, L., Lu, Q., Xu, R., Wei, Q., and Cao, Y. (2015). “Improving transfer learning in cross lingual opinion analysis through negative transfer detection,” in International Conference on Knowledge Science, Engineering and Management, (China: Springer). doi: 10.1007/978-3-319-25159-2_36
Jia, X., Jin, Y., Li, N., and Su, X. (2018). Words alignment based on association rules for cross-domain sentiment classification. Front. Inf. Technol. Electronic.Eng. 19:260–272. doi: 10.1631/FITEE.1601679
Jiang, Y., Gu, X., Ji, D., and Jian, P. (2020). Smart diagnosis: a multiple-source transfer TSK fuzzy system for EEG seizure identification. ACM Trans. Multimed. Comput. Commun. Appl. 59, 1–21. doi: 10.1145/3340240
Jiang, Y., Gu, X., Wu, D., Hang, W., Xue, J., Qiu, S., et al. (2021). A novel negative-transfer-resistant fuzzy clustering model with a shared cross-domain transfer latent space and its application to brain CT image segmentation. IEEE/ACM Trans. Comput. Biol. Bioinform. 18, 40–52. doi: 10.1109/TCBB.2019.2963873
Kleinman, D. L., and Rao, P. K. (2003). Extensions to the Bartels-Stewart algorithm for linear matrix equations. IEEE Trans. Autom. Control 23, 85–87. doi: 10.1109/TAC.1978.1101681
Lauren, P., Qu, G., Yang, J., Watta, P., Huang, G. B., and Lendasse, A. (2018). Generating word embeddings from an extreme learning machine for sentiment analysis and sequence labeling tasks. Cognit. Comput. 10, 625–638. doi: 10.1007/s12559-018-9548-y
Liu, B., Xiao, Y., and Hao, Z. (2018). A selective multiple instance transfer learning method for text categorization problems. Knowl. Based Syst. 141, 178–187. doi: 10.1016/j.knosys.2017.11.019
Long, M., Wang, J., Ding, G., Pan, S. J., and Yu, P. S. (2014). Adaptation regularization: a general framework for transfer learning. IEEE Trans. Knowl. Data Eng. 26, 1076–1089. doi: 10.1109/TKDE.2013.111
López, M., Valdivia, A., Martínez-Cámara, E., Luzón, M. V., and Herrera, F. (2019). E2sam: evolutionary ensemble of sentiment analysis methods for domain adaptation. Inf. Sci. 480, 273–286. doi: 10.1016/j.ins.2018.12.038
Meng, J., Long, Y., Yu, Y., Zhao, D., and Liu, S. (2019). Cross-domain text sentiment analysis based on CNN_FT method. Information 10:162.
Ni, T., Ni, Y., Xue, J., and Wang, S. (2021). A domain adaptation sparse representation classifier for cross-domain electroencephalogram-based emotion classification. Front. Psychol. 12:721266. doi: 10.3389/fpsyg.2021.721266
Pan, S. J., Ni, X., Sun, J. T., Yang, Q., and Chen, Z. (2010). “Cross-domain sentiment classification via spectral feature alignment,” in Proceedings of the 19th International Conference on World Wide Web, (Carolina: ACM Digital Library), 26–30. doi: 10.1145/1772690.1772767
Shekhar, S., Patel, V. M., Nguyen, H. V., and Chellappa, R. (2013). “Generalized domain-adaptive dictionaries,” in IEEE Conference on Computer Vision and Pattern Recognition, (Portland: IEEE), 361–368. doi: 10.1109/CVPR.2013.53
Tang, H., Mi, Y., Xue, F., and Cao, Y. (2021). Graph Domain Adversarial Transfer Network for Cross-Domain Sentiment Classification. IEEE Access 9, 33051–33060. doi: 10.1109/ACCESS.2021.3061139
Tian, F., Wu, F., Fei, X., Shah, N., and Wang, Y. (2019). Improving generalization ability of instance transfer-based imbalanced sentiment classification of turn-level interactive Chinese texts. Serv. Oriented Comput. Appl. 13, 155–167. doi: 10.1007/s11761-019-00264-y
Unnikrishnan, P., Govindan, V. K., and Madhu Kumar, S. (2019). Enhanced sparse representation classifier for text classification. Expert Syst. Appl. 129, 260–272. doi: 10.1016/j.eswa.2019.04.003
Waheeb, S. A., Ahmed Khan, N., Chen, B., and Shang, X. (2020). Machine Learning Based Sentiment Text Classification for Evaluating Treatment Quality of Discharge Summary. Information 11:281. doi: 10.3390/info11050281
Wang, L., Niu, J., Song, H., and Atiquzzaman, M. (2018). SentiRelated: a cross-domain sentiment classification algorithm for short texts through sentiment related index. J. Netw. Comput. Appl. 101, 111–119. doi: 10.1016/j.jnca.2017.11.001
Wen, J., Zhang, G., Zhang, H., Yin, W., and Ma, J. (2020). Speculative text mining for document-level sentiment classification. Neurocomputing 412, 52–62. doi: 10.1016/j.neucom.2020.06.024
Wu, Q., and Tan, S. (2011). A two-stage framework for cross-domain sentiment classification. Expert Syst. Appl. 38, 14269–14275. doi: 10.1016/j.eswa.2011.04.240
Xia, R., Zong, C., Hu, X., and Cambria, E. (2013). Feature ensemble plus sample selection: domain adaptation for sentiment classification. IEEE Intell. Syst. 28, 10–18. doi: 10.1109/MIS.2013.27
Zhang, H., Sun, S., Hu, Y., Liu, J., and Guo, Y. (2020). Sentiment classification for Chinese text based on interactive multitask learning. IEEE Access 8, 129626–129635. doi: 10.1109/ACCESS.2020.3007889
Zhang, K., Hei, X., Fei, R., Guo, Y., and Jiao, R. (2021). “Cross-domain text classification based on BERT model,” in International Conference on Database Systems for Advanced Applications, (Taipei: Springer), doi: 10.1007/978-3-030-73216-5_14
Zhang, S., Wei, Z., Yin, W., and Tao, L. (2018). Sentiment analysis of Chinese micro-blog text based on extended sentiment dictionary. Future Gener. Comput. Syst. 81, 395–403. doi: 10.1016/j.future.2017.09.048
Zhao, C., Wang, S., Li, D., Liu, X., Yang, X., and Liu, J. (2021). Cross-domain sentiment classification via parameter transferring and attention sharing mechanism. Inf. Sci. 578, 281–296. doi: 10.1016/j.ins.2021.07.001
Keywords: transfer learning, text sentiment, cross-domain, intelligent model, sentiment classification
Citation: Zhang S (2021) Sentiment Classification of News Text Data Using Intelligent Model. Front. Psychol. 12:758967. doi: 10.3389/fpsyg.2021.758967
Received: 15 August 2021; Accepted: 08 September 2021;
Published: 28 September 2021.
Edited by:
Yizhang Jiang, Jiangnan University, ChinaReviewed by:
Jing Xue, Wuxi People’s Hospital Affiliated to Nanjing Medical University, ChinaTongguang Ni, Changzhou University, China
Copyright © 2021 Zhang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Shitao Zhang, d2lzZXBybzE5ODJAMTYzLmNvbQ==