 Xuemei Xue
Xuemei Xue Jing Lu
Jing Lu Jiwei Zhang
Jiwei Zhang- 1School of Mathematical Sciences, Xiamen University, Xiamen, China
- 2Key Laboratory of Applied Statistics of MOE, School of Mathematics and Statistics, Northeast Normal University, Changchun, China
- 3Key Lab of Statistical Modeling and Data Analysis of Yunnan Province, School of Mathematics and Statistics, Yunnan University, Kunming, China
In this paper, a new item-weighted scheme is proposed to assess examinees’ growth in longitudinal analysis. A multidimensional Rasch model for measuring learning and change (MRMLC) and its polytomous extension is used to fit the longitudinal item response data. In fact, the new item-weighted likelihood estimation method is not only suitable for complex longitudinal IRT models, but also it can be used to estimate the unidimensional IRT models. For example, the combination of the two-parameter logistic (2PL) model and the partial credit model (PCM, Masters, 1982) with a varying number of categories. Two simulation studies are carried out to further illustrate the advantages of the item-weighted likelihood estimation method compared to the traditional Maximum a Posteriori (MAP) estimation method, Maximum likelihood estimation method (MLE), Warm’s (1989) weighted likelihood estimation (WLE) method, and type-weighted maximum likelihood estimation (TWLE) method. Simulation results indicate that the improved item-weighted likelihood estimation method better recover examinees’ true ability level for both complex longitudinal IRT models and unidimensional IRT models compared to the existing likelihood estimation (MLE, WLE and TWLE) methods and MAP estimation method, with smaller bias, root-mean-square errors, and root-mean-square difference especially at the low-and high-ability levels.
Introduction
The measurement of change has been a topic to both practitioners and methodologists (e.g., Dearborne, 1921; Woodrow, 1938; Lord, 1963; Fischer, 1973, 1976, 1995; Rasch, 1980; Andersen, 1985; Wilson, 1989; Embretson, 1991, 1997; von Davier and Xu, 2011; Barrett et al., 2015). Item response theory (IRT), particularly, a family of Rasch models (RM), provides a new perspective to modeling change. Andersen (1985) proposed the multidimensional Rasch model for modeling growth in the repeated administration of the same items at different occasions. Embretson (1991) presented a special multidimensional Rasch model for measuring learning and change (MRMLC) based on IRT. Embretson’s model postulated the involvement of K abilities for K occasions. Specifically, the MRMLC assumes that on the first occasion (k = 1), performance depends on initial ability. The MRMLC further assumes that on later occasions (k > 1), performance also depends on k−1 additional abilities, termed “modifiabilities,” as well as initial ability. Thus, the number of abilities increases at each time point. The same items are repeated over occasions in Andersen’s model which may lead to practice effects or memory effects and result in local dependency among item responses (von Davier and Xu, 2011), whereas items in Embretson’s MRMLC are not necessarily repeated. Fischer (2001) extended the MRMLC to polytomous items by extending the partial credit model (PCM, Masters, 1982). This paper extends Embretson’s method to measure growth based on item responses from mixed-format tests composed of both dichotomous and polytomous items which are frequently used in large-scale educational assessments, such as the National Assessment of Educational Progress (NAEP) and the Program for International Student Assessment (PISA). For polytomous items, each response category provides information. If categories within an item are close together, the item information will be peaked near the center of the location parameter of category. However, if the categories are spread further apart, each can add information at a different location. Therefore, the item information for a polytomous item can have multiple peaks and can be spread over a broader extent of the ability range. Thus, polytomous items may contain more information than dichotomous items (e.g., Donoghue, 1994; Embretson and Reise, 2000, p. 95; Jodoin, 2003; Penfield and Bergeron, 2005; Yao, 2009; Christine, 2010; Tao et al., 2012). How to utilize the potential information difference hidden in different item types to improve estimates of the latent trait is the main concern in our study.
As mentioned above, it has been demonstrated that polytomous items can often provide more information than dichotomous items concerning the level of estimated latent trait (Tao et al., 2012). Meanwhile, different items of the same type may provide different amount of information about latent trait estimation. To improve the precision of ability estimation, the aim of this study is to develop an efficient item-weighting scheme by assigning different weights to different items in accordance with the amount of information for a certain latent trait level. As early as 40 years ago, Lord (1980) has considered to optimal item weights for dichotomously scored items. Tao et al. (2012) proposed a bias-reduced item-weighted likelihood estimation method, and Sun et al. (2012) proposed weighted maximum-a-posteriori estimation, which focused on differentiating the information gained from different item types. In their methods, the weights were pre-assigned and known or automatically selected such that the weights assigned to the polytomous items are larger than that assigned to the dichotomous items. They assign different weights to different item types, instead of assigning different weights to different items, and items of the same type all have the same weight. For convenience, we called these weighting methods type-weighted estimation. However, different items of the same type may have different information for a certain latent trait level; the same weights assigned to the same-type items may not be statistically optimal in terms of the precision and accuracy of ability estimation due to neglecting the difference in the individual item contribution. It is expected that assigning a weight for each item based on its own contribution may increase measurement precision.
The remainder of this paper is organized as follows. First, we present the MRMLC and its polytomous extension, and then the proposed item-weighted likelihood estimation (IWLE) method and the other two ability estimation methods: Warm’s (1989) weighted likelihood estimation (WLE) and type-weighted maximum likelihood estimation (TWLE). Second, we show that the IWLE is consistent and asymptotically normal with mean zero and a variance-covariance matrix, and the bias of IWLE is of order n−1. Third, a simulation study is conducted to compare the proposed IWLE method with MLE, MAP, WLE, and TWLE. Fourth, a simulation study is conducted to show IWLE can also be applied to general unidimensional item response models. Finally, we conclude this paper with discussion.
Materials and Methods
MRMLC and Its Polytomous Extension
The MRMLC assumes that the probability of a correct response by person l on item i at occasion k can be written as:
where Uilk is the response variable with values in {0,1}, θl1 is the initial ability of person l on the first occasion v = 1, θl2, …, θlk are modifiabilities that correspond to occasion k > 1, and bi is item difficulty Although the MRMLC may be applied to multiple occasions, for clarity, the model will be presented with only two occasions. To simplify the notation, the examinee subscript will not be shown in the following derivations. Using the abbreviated notations Pi1 and Pi2 for the probability of a correct item response for Occasions 1 and 2, respectively,
and
Regarding the polytomous items, we use the abbreviated notations Pij1 and Pij2 to denote the probability of selecting response category j (where j = 1, …, h) of polytomous item i for Occasions 1 and 2, respectively,
and
To develop a conditional maximum likelihood estimation method for item parameters in the learning process model, Embretson (1991) constructed a data design structure for item calibration in which item blocks are counterbalanced in several occasions over groups. This data design matrix is needed to determine the occasion on which an item appears for an individual. Every item must be observed on every occasion, but to preserve local independence, an item should be administered only once to an individual across the two occasions. To incorporate Embretson’s design structure, two groups of examinees are asked to respond to unique items on two occasions, kig is now defined as a binary variable to indicate the occasion on which item i is administered to group g(g = 1,2).
Specifically,
Thus, the probability of a response vector u = (u1, …, un) in group g, Pg for n items conditional on ability vector (θ1, θ2), item difficulty vector b and item occasion vector kg, for k1g, …, kng is given by:
where b = (b1, …, bn).
First, suppose that person l is assigned to a test condition group g that receives items I. For the following considerations, it is assumed that some of the items I = {I1, …, In} are presented at time point (Occasion) 1, called the “pretest,” denoted I1, and some items are presented at point time 2, called the “posttest,” denoted I2 according to Fischer (2001). The nonempty item subsets I1 and I2 may be completely different, may overlap, or may be identical. For convenience, however, a notation is adopted where I1 and I2 are considered disjoint subsets of I,I1 = {I1, …, In1} and I2 = {In1 + 1, …, In}. However, the cases in which I1 and I2 overlap are implicitly covered; it suffices to let some Ia ∈ I1 have the same parameters as some Ib ∈ I2. Let us consider mixed-format tests; specifically, k items I1, …, Ik are dichotomous and n1−k items Ik + 1, …, In1 are polytomous in the pretest; for the posttest, m−n1 items In1 + 1, …, Im are dichotomous and n−m items Im + 1, …, In are polytomous.
Maximum Likelihood Estimator
Now we consider the problem of likelihood estimation of ability θ = (θ1, θ2). The likelihood function of responses is the product of two types of likelihood functions given local independence:
where
and
are the likelihood functions of the dichotomous model and the polytomous model of a mixed-format longitudinal test, respectively, in which,
The response matrix U contains the responses to dichotomous items ui, vi and the responses to polytomous items uij, vij. The conventional maximum likelihood estimator (MLE) can be obtained by maximizing the log-likelihood function logL(θ|U).
Weighted Likelihood Estimator
Warm (1989) proposed a weighted likelihood estimation (WLE) method for dichotomous IRT model. Compared with the maximum likelihood estimation, Warm’s weighted likelihood estimation method can obtain less bias estimation. Penfield and Bergeron (2005) extended this method to the case of the generalized partial credit model (GPCM). The weighted likelihood function of a mixed-type model can be expressed as:
where w(θ) is the weighting function, in one or two parameter models of IRT. w(θ) is multiplied by the likelihood function L(θ|U), and the product is maximized. WLE was proved to yield asymptotically normally distributed estimates, with finite variance, and with bias of only o(n−1).
Item-Weighted Maximum Likelihood Estimator
In this section, we consider the following item-weighted likelihood function:
where
and
are the item-weighted likelihood functions of the dichotomous model and the polytomous model of a mixed-format longitudinal test, respectively. Here the weight vector:
(w1(θ), …, wn(θ)) satisfy wi(θ) > 0 for each i and .
Note that,
where Ii(θ) is the information function of item i given as:
Pi is the probability of a correct response to item i, Qi = 1−Pi, Pij is the probability of selecting response category j (where j = 1, …, h) of polytomous item i, and is the test information function consisting both dichotomous and polytomous items (Muraki, 1993). Using the information ratio of each item to the test at a certain ability level, the weights of items are determined.
In IRT, the item and test information functions relate to how well an examinee’s ability is being estimated over the whole ability scale; they are usually used to calculate the standard error of measurement and the reliability. Since the test information is a function of proficiency (or whatever trait or skill is measured) and the items on the test, the expression of the proposed weights involves the ability level θ and item characteristic parameters. The weights may be “adaptive” in the sense that they are allowed to be estimated based on the ability level and individual test items. By using the information ratio of each item to the test to determine the weights, so the more information an item has at a certain ability level, the larger weight could be assigned to it. According to the proposed weighting method, the weight for the polytomous item is then larger than that for the dichotomous item and the weights for the same type item are different due to the difference between the amounts of item information. The weight assigned to each item just indicates its contribution to the precision for ability parameter estimation. This item weighting scheme maximizes the information obtained from both different types of items and different items of the same type and may lead to more accurate estimates of the latent trait than equally weighting all items. If each item with same scoring procedure has same item information at a certain latent trait level, the weights are equal between them. Hence, the proposed item-weighted likelihood method may be an extension of the method proposed by Tao et al. (2012). The item-weighted likelihood estimator (IWLE) can be obtained by maximizing the item-weighted log-likelihood function logIWL(θ|U) (for derivation details, see Supplementary Appendix A). Maximum likelihood estimator (Lord, 1983) was shown to have bias of O(n−1). When the weights are determined at a certain ability level, with some assumptions made by Lord (1983), the bias of the item-weighted maximum likelihood estimation also has bias of O(n−1). The approach and techniques of this derivation were taken from, and parallel closely, the derivations in Lord (1983). The asymptotic properties of IWLM can be obtained by generalizing those of Bradley and Gart (1962) (for more details, see Supplementary Appendix B).
Type-Weighted Maximum Likelihood Estimator
In contrast to the MLE, the type-weighted maximum likelihood estimator (TWLE) yields usable ability estimator for mixed-type tests composed of both dichotomous and polytomous items (Sun et al., 2012). The type-weighted likelihood function of a mixed-type model can be expressed as:
where
, and , are test information of the dichotomous and polytomous model based on the longitudinal model, respectively. According to the weighting scheme proposed by Sun et al. (2012), the ratio parameters α, β determined to make sure that the weight assigned to the polytomously scored item is larger than that assigned to the dichotomously scored item. Three steps are needed to determine the ratio parameters α, β and the two weights. First, we obtain the ML estimator and take it as the initial estimator. Second, if , the two ratio parameters are all equal to 1. Otherwise, we may set α and β to be a small value ε (such as ε < 0.4) to make sure . Then, no change is needed for either α or β if . Otherwise, we may increase α in increments of 0.05 or less, or decrease β in increments of 0.05 or less. We adjust α and β to ensure . Third, we maximize the type-weighted log-likelihood function logTWL(θ|U) to obtain with the obtained α and β values from the above. If , the is the TWLE. Otherwise, the ratio parameters should be adjusted continually basing on the above process until .
The above three-weighted estimations TWLE, WLE, and IWLE have different weighting schemes. For TWLE, the larger weights are assigned to the polytomous items and the smaller weights are assigned to the dichotomous items. This method only assigns different weights to different item types, instead of assigning different weights to different items, thus items of the same type all have the same weight. However, different items of the same type may have different information about a certain latent trait level; the same weights assigned to the same-type items may not be statistically optimal in terms of the precision and accuracy of ability estimation due to neglecting the difference in the individual item contribution. The proposed IWLE assigns different weights to different items in accordance with the amount of the information an item provides at a certain latent trait level. Using the information ratio of each item to the test, the weights of items are determined. This improved IWLE procedure that incorporates item weights in likelihood functions for the ability parameter estimation may increase measurement precision. The WLE provides a bias correction to the maximum likelihood method. The weight function is multiplied by the likelihood function L(θ|U) in the WLE method, which provides a correction to the maximum likelihood estimation method by solving an weighted, log-likelihood equation. The WLE and IWLE are both consistent and asymptotically normal with mean zero and a variance-covariance matrix, and the bias of the estimators is of order n−1.
Simulation Study 1
Simulation Design
In this section, the performance of the three weighting methods, the WLE, the type-weighted likelihood estimation (TWLE), and IWLE are compared. To investigate the effects of the test-length and the proportion of dichotomous and polytomous items in a mixed-format test on the properties of the θ estimators, nine artificial tests were constructed at each time point, three of them short (10 items with 7, 5, and 3 dichotomous items), three medium (30 items with 20, 15, and 10 dichotomous items), and three long (60 items with 40, 30, and 20 dichotomous items). In the simulation, the 3 levels of test length were representative of those encountered in measuring settings using fixed-length tests. The 3 levels of proportion of dichotomous and polytomous items (λ = 2,1,0.5) were selected, so that we may have a thorough investigation into the property of different weighting methods.
The item parameters and ability parameters are set as follows. The difficulty parameters of the dichotomous items were randomly generated from the standard normal distribution N(0,1). The polytomously scored items with four-category were constructed. The step parameters of each polytomous item were randomly generated from four normal distributions:
bi1 ∼ N(−1.5, 0.2), bi2 ∼ N(−0.5, 0.2), bi3 ∼ N(0.5, 0.2), and bi4 ∼ N(1.5, 0.2).
This pattern of location parameters centers items on zero and thus centers the test on zero. In the simulation, 17 equally spaced θ1 values were considered, ranging from –4.0 to 4.0 in increments of 0.5. We set 3 values of θ2(0.6,0.8, and 1.0) for 3 different initial ability levels: high (value of θ1 larger than 2), medium (value of θ1 between –2 and 2), and low (value of θ1 smaller than –2), respectively. Thus, a high initial ability will have low gain, a medium initial ability will have moderate gain, and a low initial ability will have high gain. At each level of (θ1, θ2), N(N = 1000) replications were administered for all 9 tests. In each replication, the dichotomous item responses were simulated according to the MRMLC model as presented in Equations 2 and 3, and the polytomous item responses were simulated according to the PCM as presented in Equations 4 and 5. For the tests containing response patterns consisting of all correct responses for dichotomous items and all 4s for polytomous items or all incorrect responses for dichotomous items and all 4s, the Newton-Raphson algorithm cannot converge, and thus the likelihood estimators could not be obtained. These response patterns were removed from the analysis, and the same item responses were scored using the WLE, TWLE, and IWLE procedures. In the simulation, the θ in the weight for each item is taken as , the MLE of θ. All levels of the number of items, the proportion of dichotomous and polytomous items, and the number of examinee were crossed, resulting in 27 conditions of test properties at each time point. For each of the 27 conditions of test properties, the WLE, TWLE, and IWLE were obtained for each of the response patterns.
Evaluation Criteria
The bias, absolute bias, root mean squared error (RMSE) and root mean squared difference (RMSD) of the ability estimates were used as evaluation criteria to examine all estimation methods. The absolute bias is calculated using Equation 13. In Equation 13,θ denotes the true ability value and the corresponding ability estimate for the l th replication.
RMSE and RMSD are calculated using Equation 14 and 15, respectively:
N is the number of replications. In simulation studies, we fix the number of replications at 1000, that is, N = 1000.
Results of Simulation
The weights of IWLE for 6 dichotomous and 3 polytomous items are shown in Figures 1, 2 The purpose of these figures is to give more intuition in terms of our item weighting scheme. The weights are based on the individual test items and the ability level, with θ1 ranging from –4.0 to 4.0 and 3 values of θ2(0.6,0.8, and 1.0). We can find that the different items are designed with different weights. In addition, the weights assigned to polytomous items are larger than that of dichotomous items.
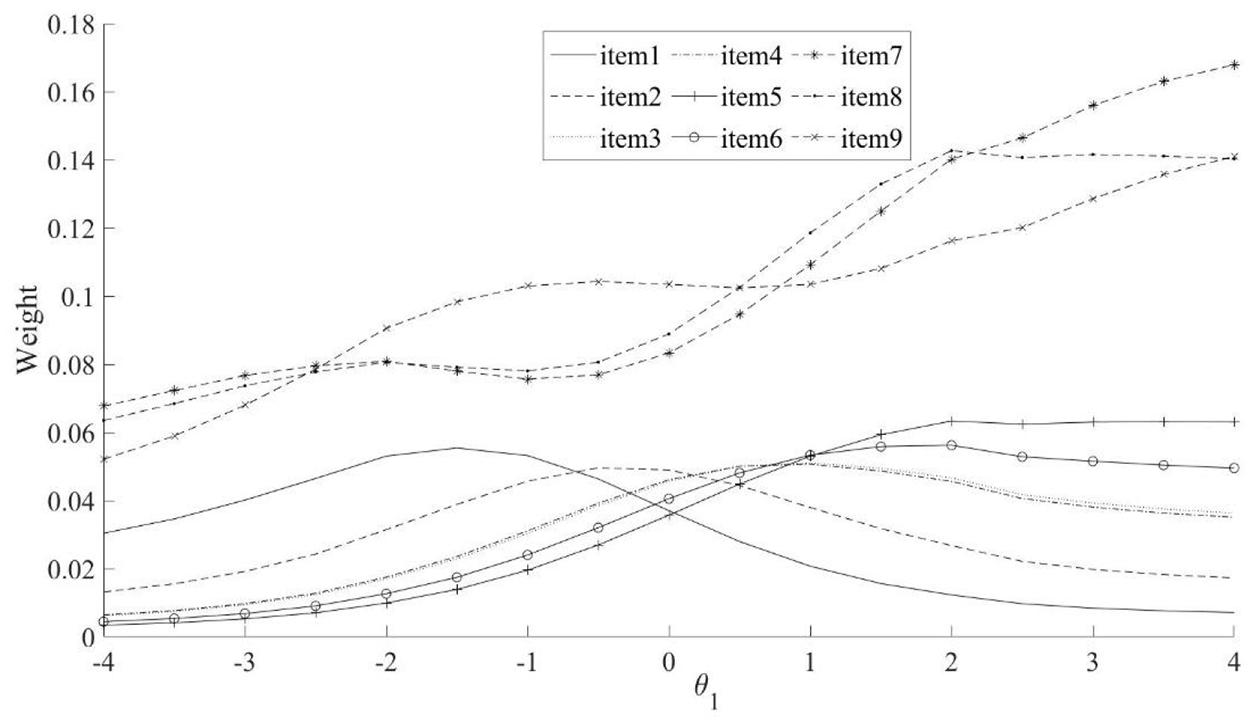
Figure 1. The weights of IWLE based on θ1 for dichotomous items (item 1 to 6) and polytomous items (items 7 to 9) in test 1.
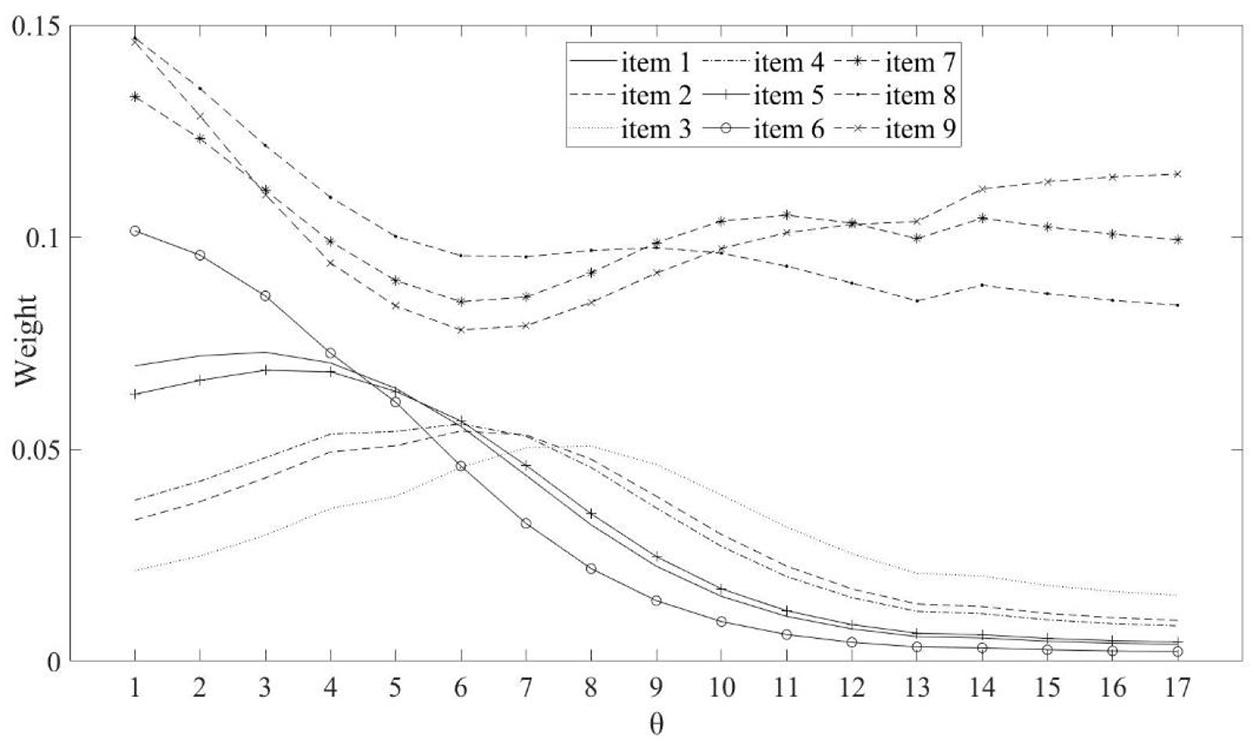
Figure 2. Weights based on θ(θ = (θ1, θ2)) at 17 ability levels for dichotomous items (item 1 to 6) and polytomous items (items 7 to 9) in test 2.
Table 1 shows the correlation between the estimated abilities and the true abilities for all three weighting estimation methods under nine conditions. The higher degree of correlation obtained by the IWLE ability estimates indicates that the IWLE produces better quality ability estimates. The results in Table 1 indicate that the longer tests provide higher correlation between the estimated abilities and the true abilities. In the tests with the same length, higher proportion of polytomous and dichotomous items also provide higher correlation between the estimated abilities and the true abilities.

Table 1. Correlation between the estimated abilities and the true abilities for all three weighting estimation methods under nine conditions.
The simulation results of 3 test lengths show similar trends for the three weighting estimators: WLE, TWLE, and IWLE. Due to page limitation, only those for the 30-item test are presented. The complete results can be obtained from the author. Tables 2–7 displays the obtained values of absolute bias, and RMSD for WLE, TWLE, and IWLE at 17 different levels of initial ability θ1(−4,−3.5,,3.5,4) and 3 different levels of growth θ2(0.6,0.8,1) in the simulation scenarios.
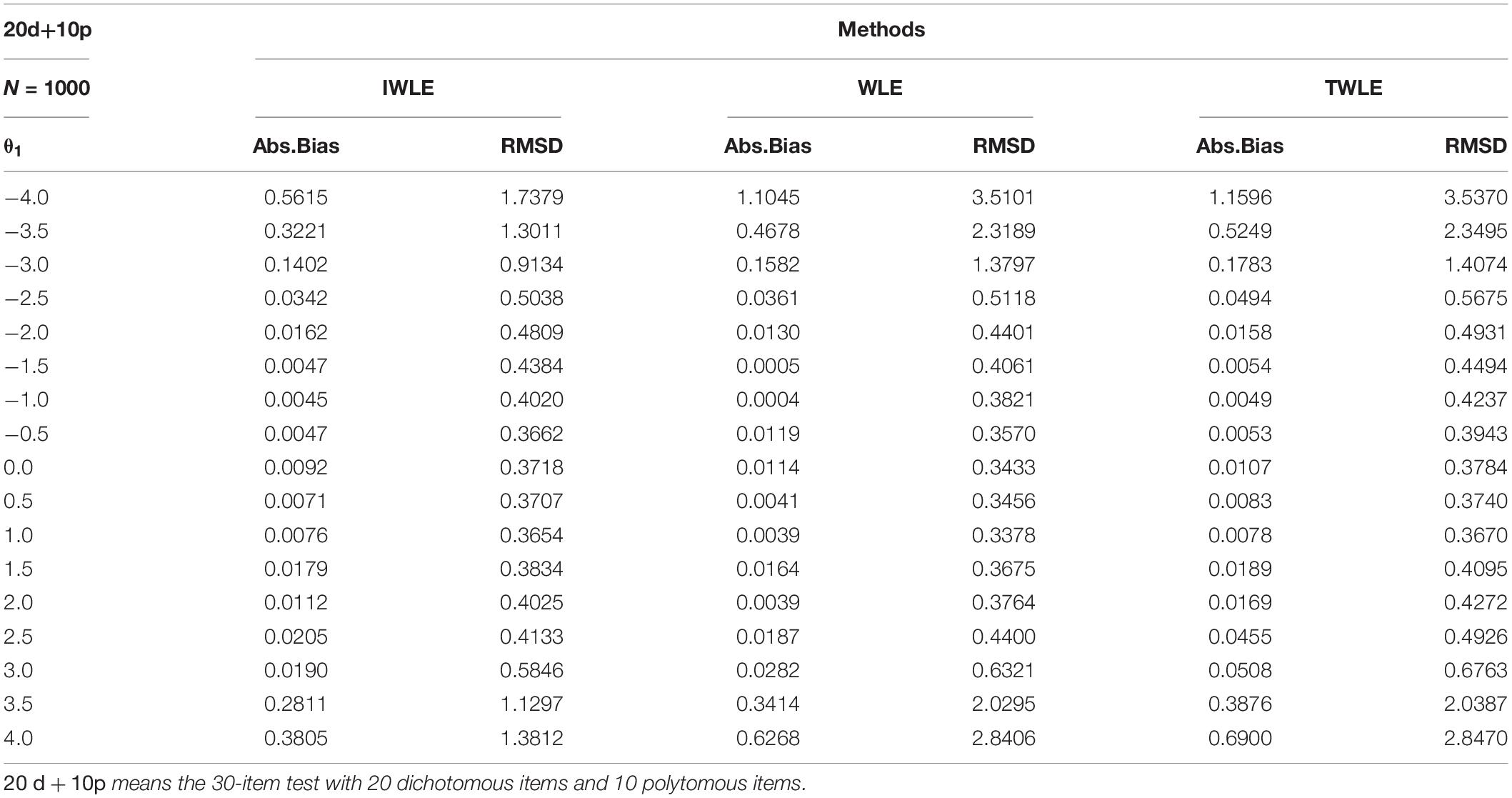
Table 2. Absolute bias and root mean squared difference for WLE, TWLE, and IWLE at 17 different levels of initial ability on 20d+10p.
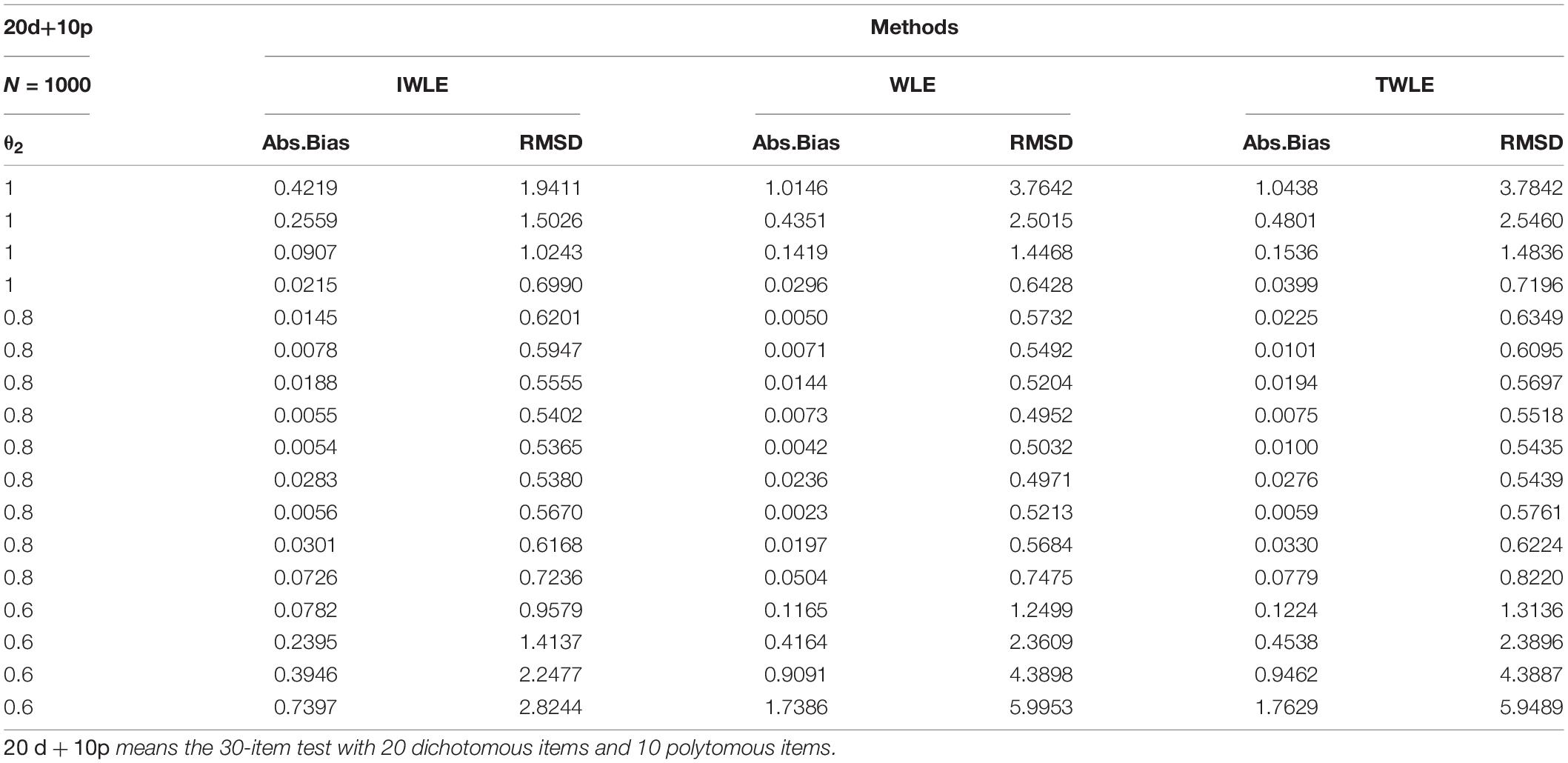
Table 3. Absolute bias and root mean squared difference for WLE, TWLE, and IWLE at 3 different levels of growth on 20d+10p.
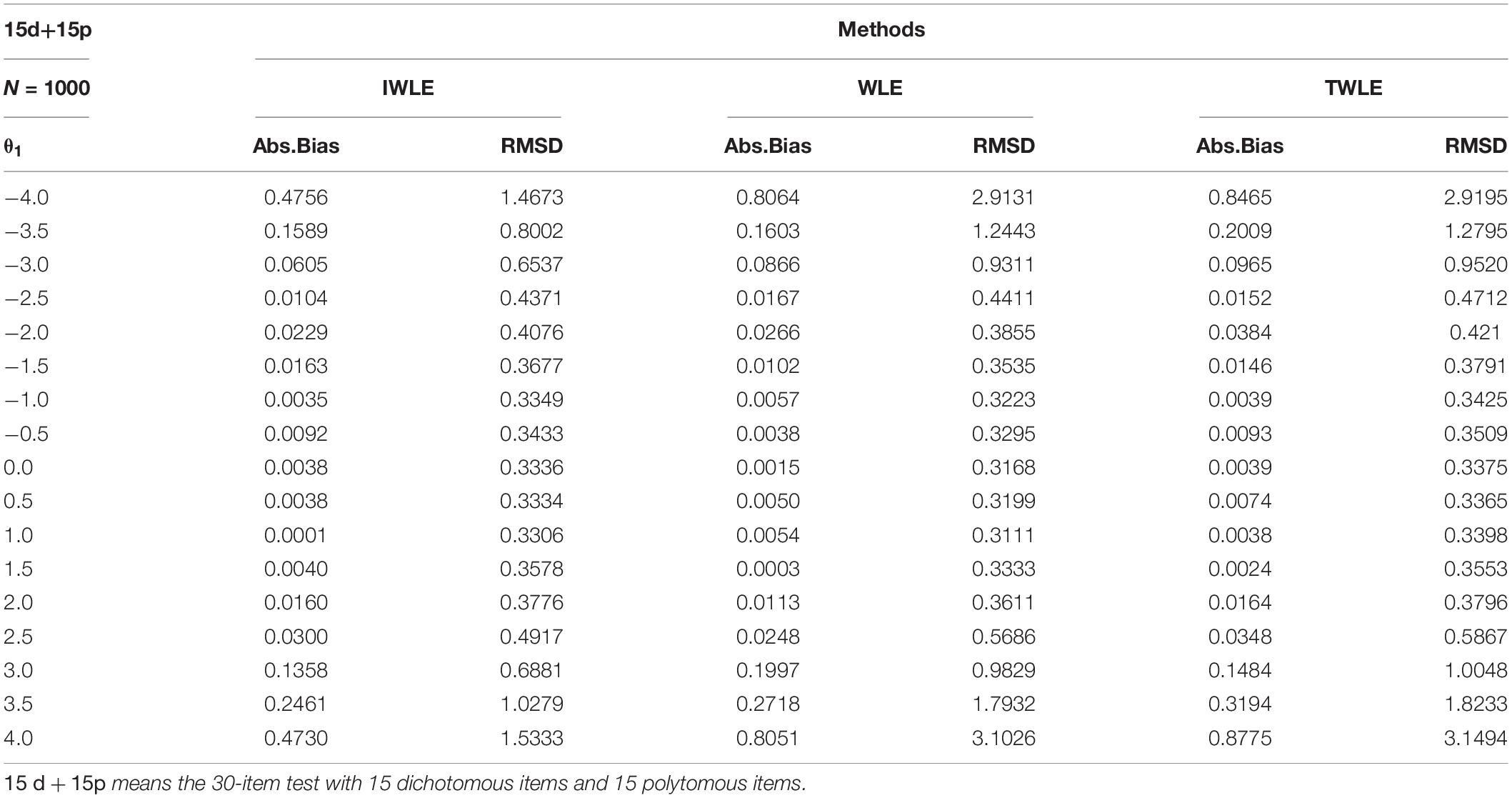
Table 4. Absolute bias and root mean squared difference for WLE, TWLE, and IWLE at 17 different levels of initial ability on 15d+15p.
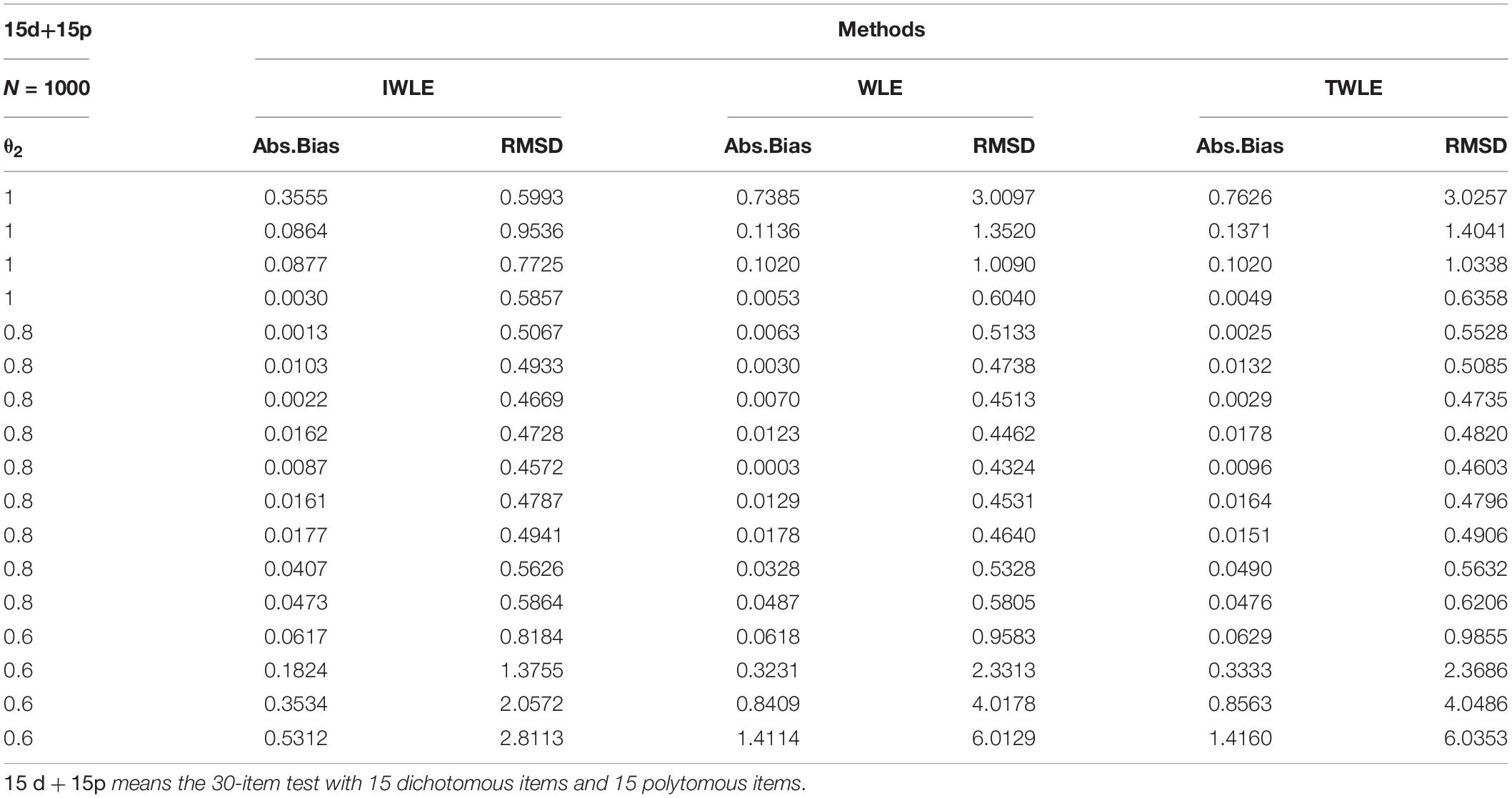
Table 5. Absolute bias and root mean squared difference for WLE, TWLE, and IWLE at 3 different levels of growth on 15d+15p.
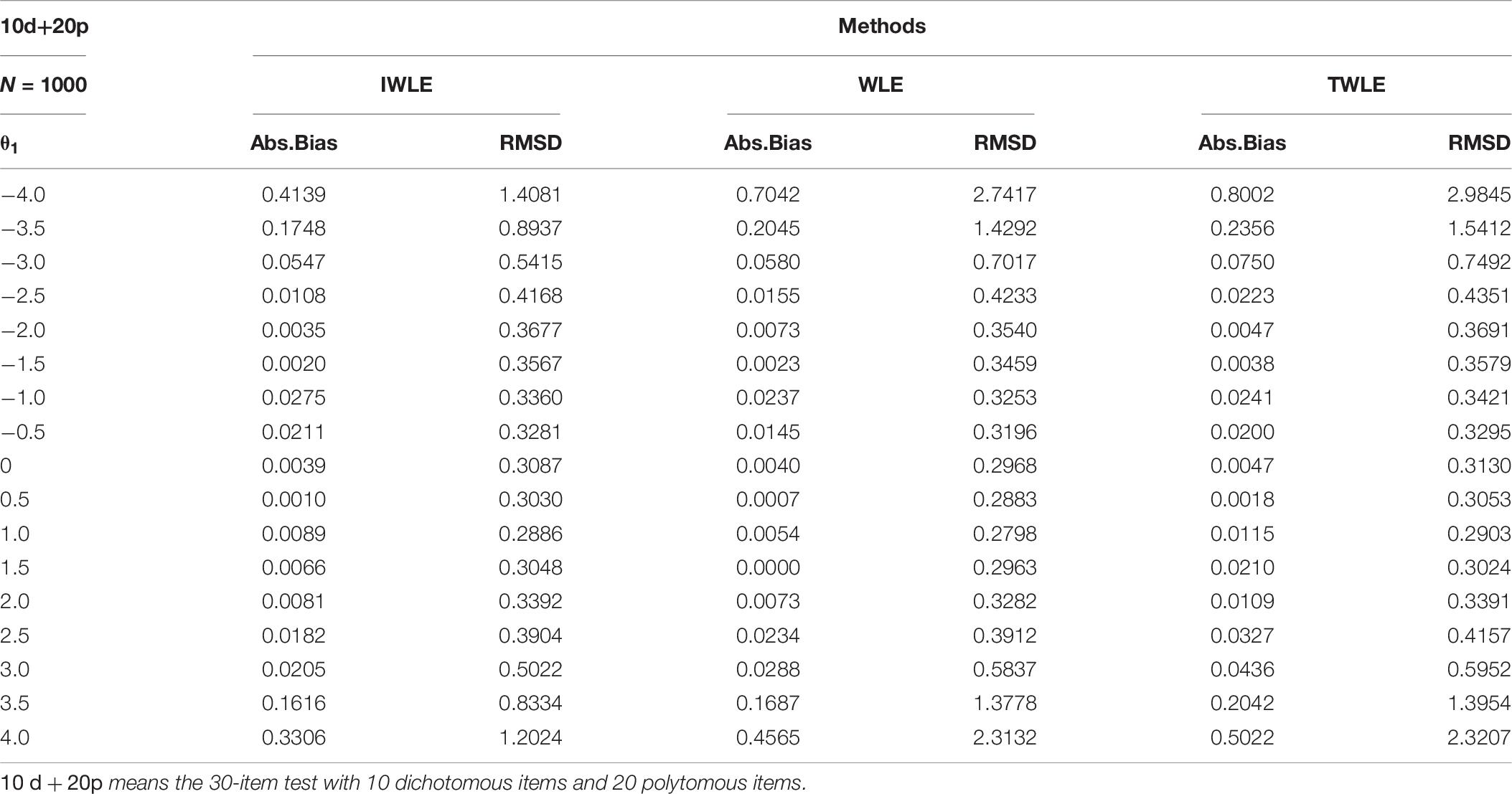
Table 6. Absolute bias and root mean squared difference for WLE, TWLE, and IWLE at 17 different levels of initial ability for 10d + 20p.
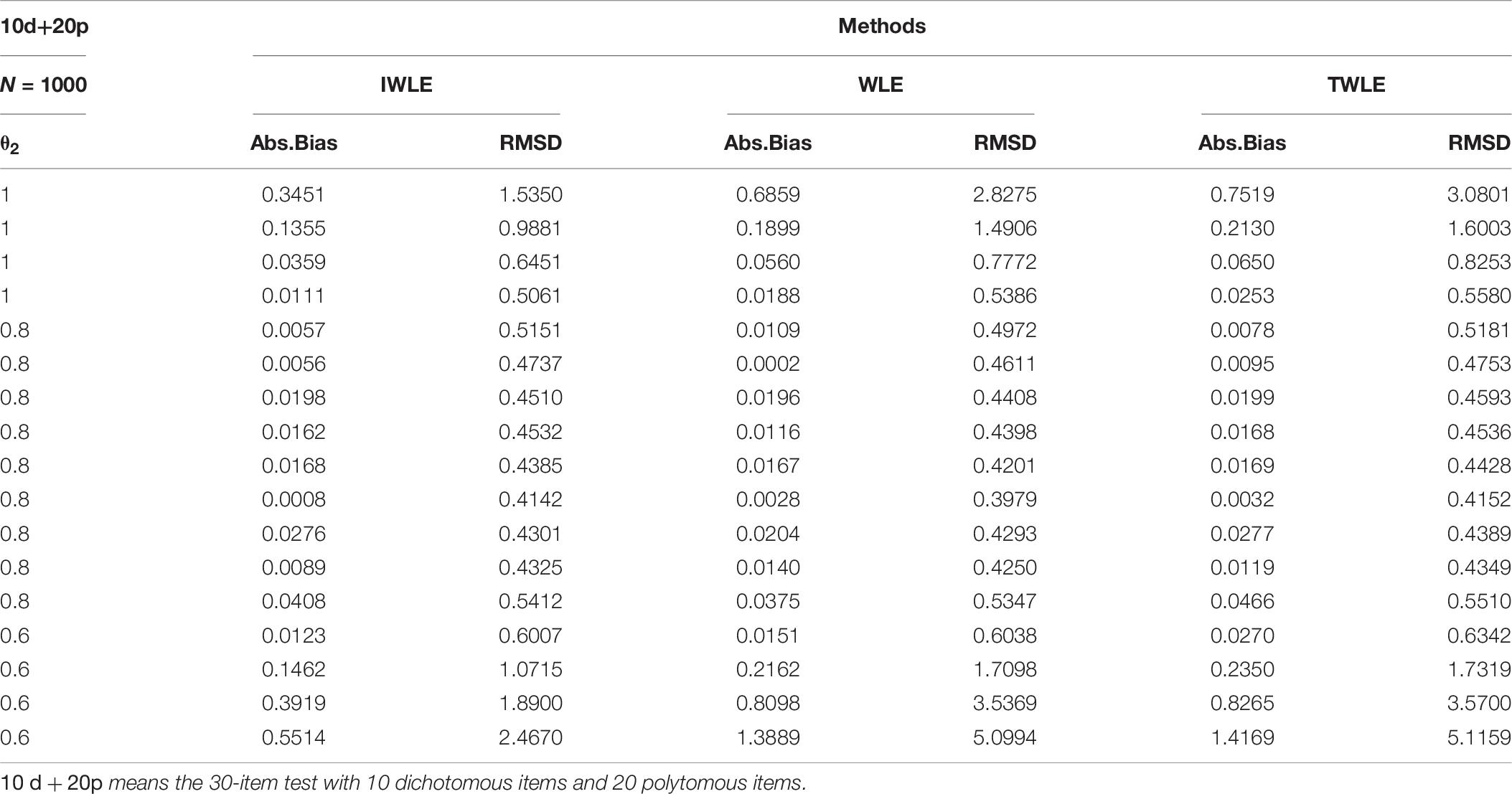
Table 7. Absolute bias and root mean squared difference for WLE, TWLE, and IWLE at 3 different levels of growth for 10d + 20p.
Examining these results, the following general trends are observed. The absolute bias are all nearly to zero for three estimators when |θ1| < 2, or θ2 = 0.8, but IWLE has a considerably less absolute bias than the other two estimators when |θ1| > 2 or θ2 = 0.6 and 1. We note that in the 3 simulation scenarios the absolute bias of IWLE is slightly larger than that of WLE at some level of θ1 when |θ1| < 2, but is considerably smaller than that of WLE at the low and the high levels of ability. IWLE consistently displays the level of absolute bias that is smaller than that of TWLE, especially substantially smaller than that of TWLE at the low and the high levels of ability. In addition, the absolute bias of WLE is less than that of TWLE at the extremes of ability level. However, the changes are observed when the proportion of the dichotomous and polytomous items in mixed-type test is changed. With the number of polytomous items increased, the absolute bias produced by TWLE and WLE are more similar, even TWLE produces a little larger absolute bias than WLE at the extremes of ability level. The similar change patterns are also observed for RMSD produced by three estimators. The RMSD of IWLE is slightly larger than that of WLE at some level of θ1 when |θ1| < 2, but is considerably smaller than that of WLE and TWLE at the low and the high levels of ability.
To investigate the performance of the proposed IWLE method, an simulation study was conducted for the comparison of the five estimators: MLE, MAP [with a non-informative prior distribution U(4,4)] WLE, TWLE, and IWLE under the above simulation condition. Figures 3–8 show the results of RMSE calculated from 30-item test in the following simulation scenarios:
(1). 30-item test includes 20 dichotomous items and 10 polytomous items (20d + 10p).
(2). 30-item test includes 15 dichotomous items and 15 polytomous items (15d + 15p).
(3). 30-item test includes 10 dichotomous items and 20 polytomous items (10d + 20p).
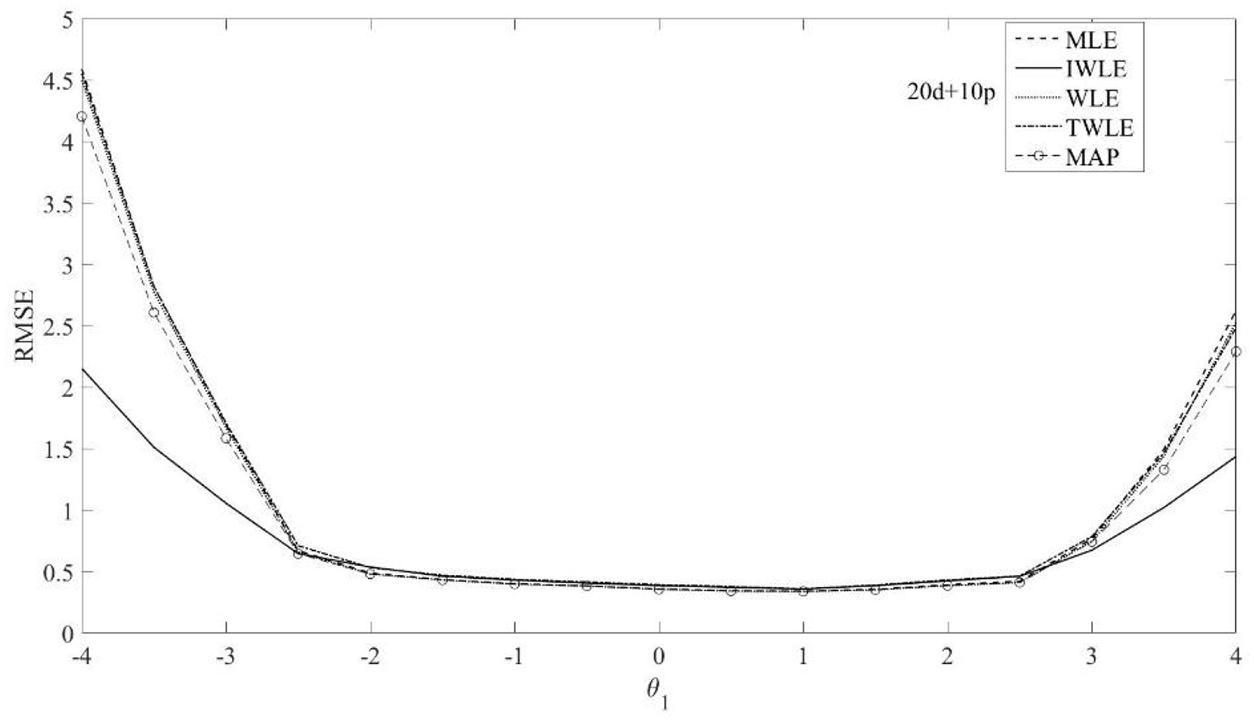
Figure 3. RMSE of the five θ1 estimation methods MLE, MAP, IWLE, WLE, and TWLE for 20d+10p.
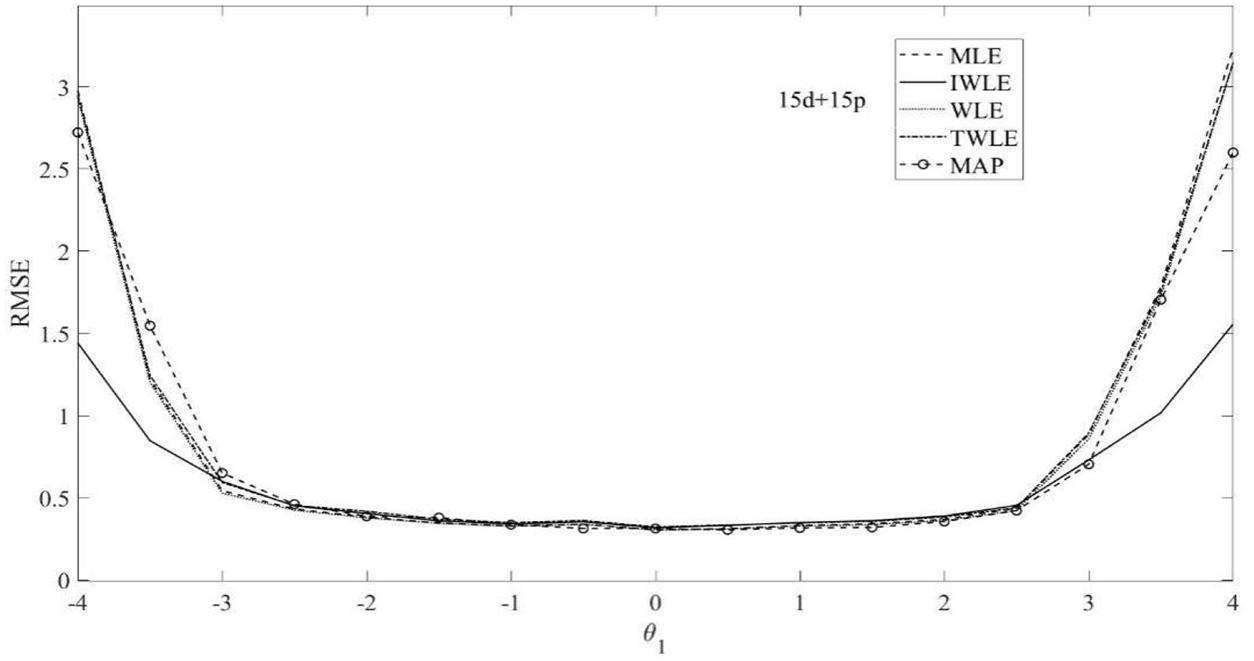
Figure 4. RMSE of the five θ1 estimation methods MLE, MAP, IWLE, WLE, and TWLE for 15d+15p.

Figure 5. RMSE of the five θ1 estimation methods MLE, MAP, IWLE, WLE, and TWLE for 10d+20p.
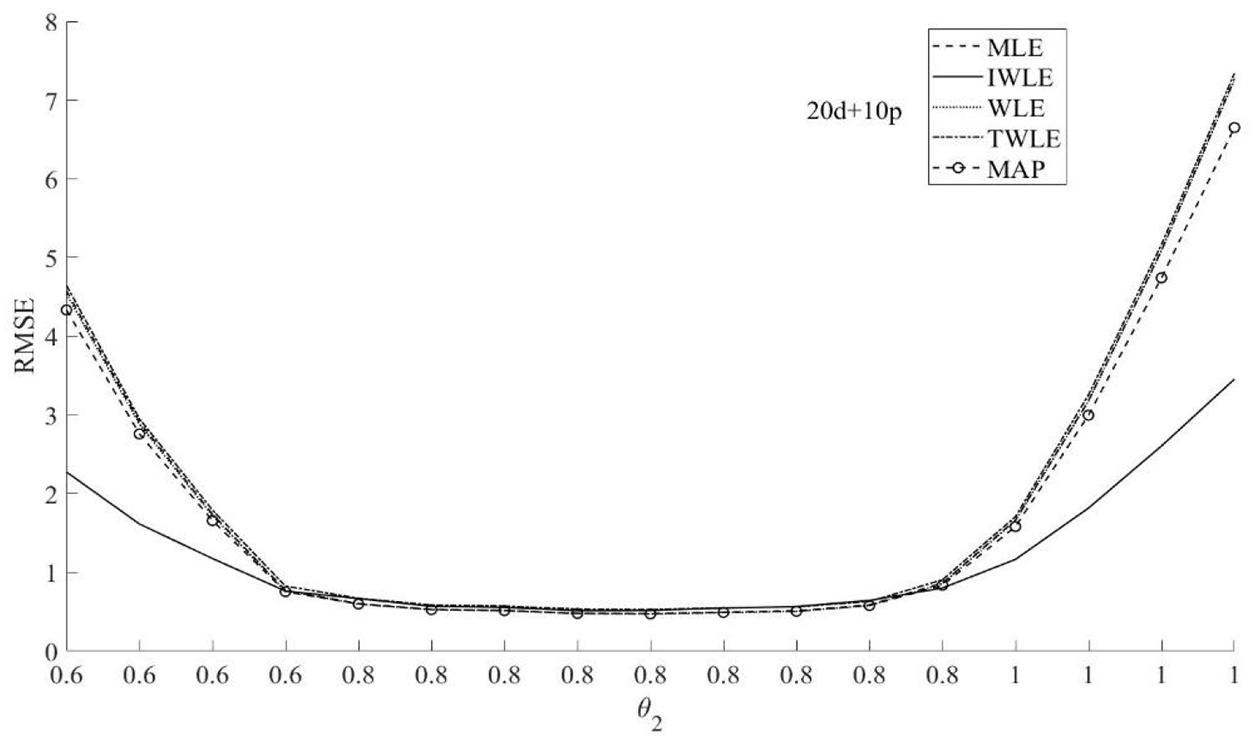
Figure 6. RMSE of the five θ2 estimation methods MLE, MAP, IWLE, WLE, and TWLE for 20d+10p.
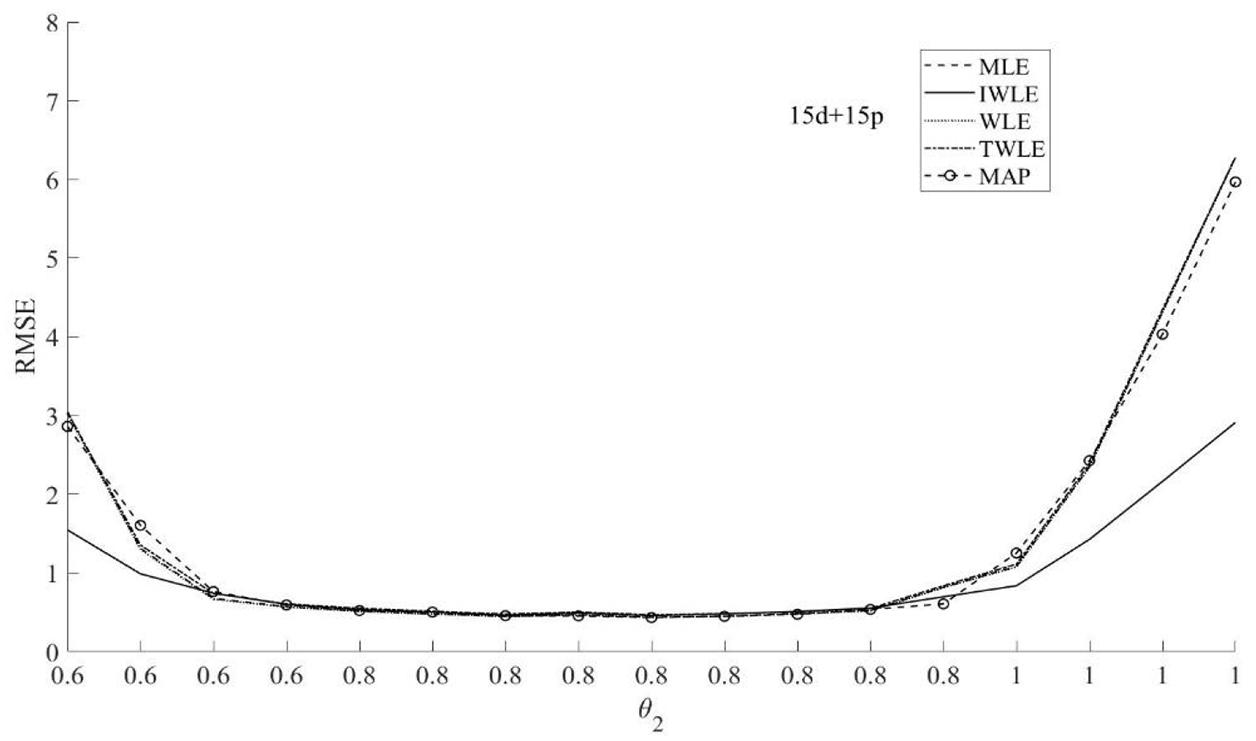
Figure 7. RMSE of the five θ2 estimation methods MLE, MAP, IWLE, WLE, and TWLE for 15d+15p.
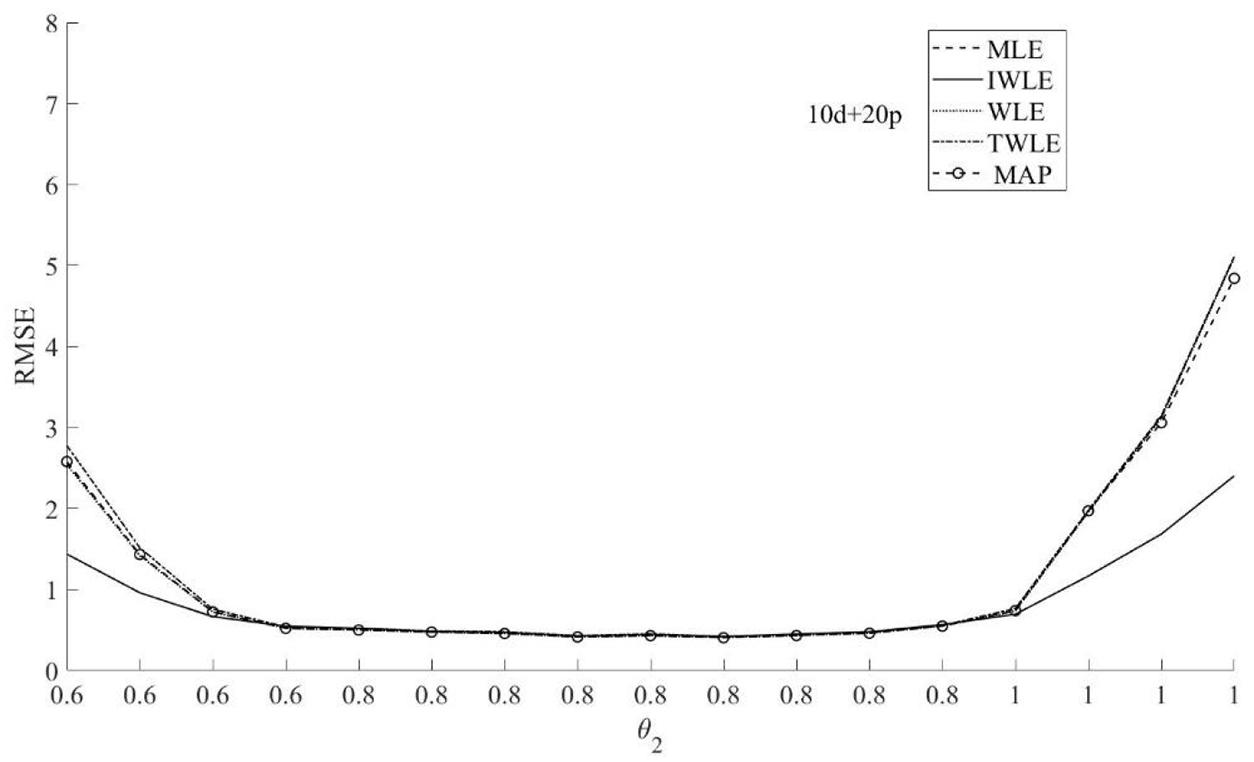
Figure 8. RMSE of the five θ2 estimation methods MLE, MAP, IWLE, WLE, and TWLE for 10d+20p.
The RMSE presented in Figures 3–5 show that among the five θ1 estimation methods, IWLE has a slight large RMSE when |θ1| < 2, but is considerably smaller than that of MLE, MAP, WLE and TWLE at extreme levels of the latent trait. The RMSE of WLE is very similar to that of MLE and TWLE. EAP has lower RMSE than MLE, WLE, TWLE, and IWLE in the middle of the ability range because of the shrinkage. The RMSE plotted in Figures 6–8 shows the similar change patterns for θ2.
The proposed IWLE method outperforms the MLE, MAP, WLE and TWLE in terms of controlling the absolute bias, RMSE, and RMSD at the low and the high levels of ability, but has a slight large RMSE and RMSD in the middle range of the ability scale.
In general, test length had a dramatic impact on the relative performance of the five estimators. We can observe the strongest differences between the five estimators are obtained when the test length is short. The absolute bias, RMSE, and RMSD of five estimation methods have a slightly decrease with the length of test increased. The proportion of dichotomous and polytomous items in a mixed-format test appears to affect the absolute bias, RMSE, and RMSD of five estimation methods.
Simulation Study 2
When we only care about the ability of the examinee without considering the ability growth at multiple time points, the unidimensional IRT models are the focus of many educational psychometrists. In fact, our IWLE method can’t only be used to analyze multidimensional IRT models, but also can be implemented for unidimensional IRT models. In this simulation study, we evaluate the accuracy of the IWLE method in the unidimensional models.
The proposed IWLE method is applied to the unidimensional IRT models for mixed-format test that is the combination of the two-parameter logistic model and the partial-credit model. We consider the following item-weighted likelihood function:
where
and
Pi(θ) is determined by dichotomously scored items; Pik(θ) is determined by polytomously scored items. Here the weight wi(θ) assigned to item i is defined as equation 4, and The 3 levels of test length (10 items, 30 items and 60 items) and the 3 levels of proportion of dichotomous and polytomous items (λ = 2,1,0.5) were selected. The item parameters were generated similar to simulation 1, and 17 equally spaced θ1 values were considered, ranging from –4.0 to 4.0 in increments of 0.5.
The simulation results of three test lengths show similar trends. The proposed IWLE method outperforms the MLE in terms of the absolute bias, RMSE and RMSD at the low and high levels of ability. However, the IWLE has a slight large absolute bias, RMSE and RMSD in the middle range of the ability scale compared with the MLE. Figures 9–11 show the results of RMSE calculated from 30-item test. According to the simulation results, we find that the IWLE can also be applied to the general unidimensional IRT models for tests composed of both dichotomous and polytomous items.
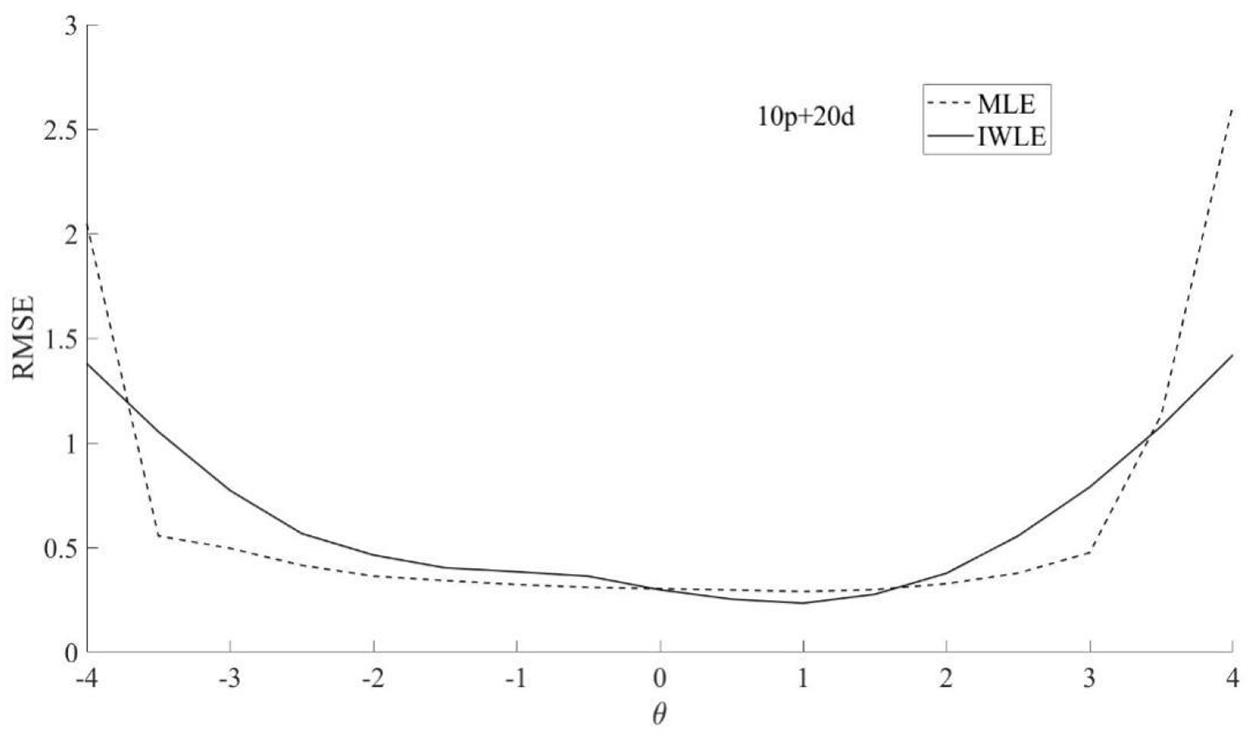
Figure 9. RMSE of the two θ estimation methods MLE and IWLE for 10p+20d.

Figure 10. RMSE of the two θ estimation methods MLE and IWLE for 15p+15d.
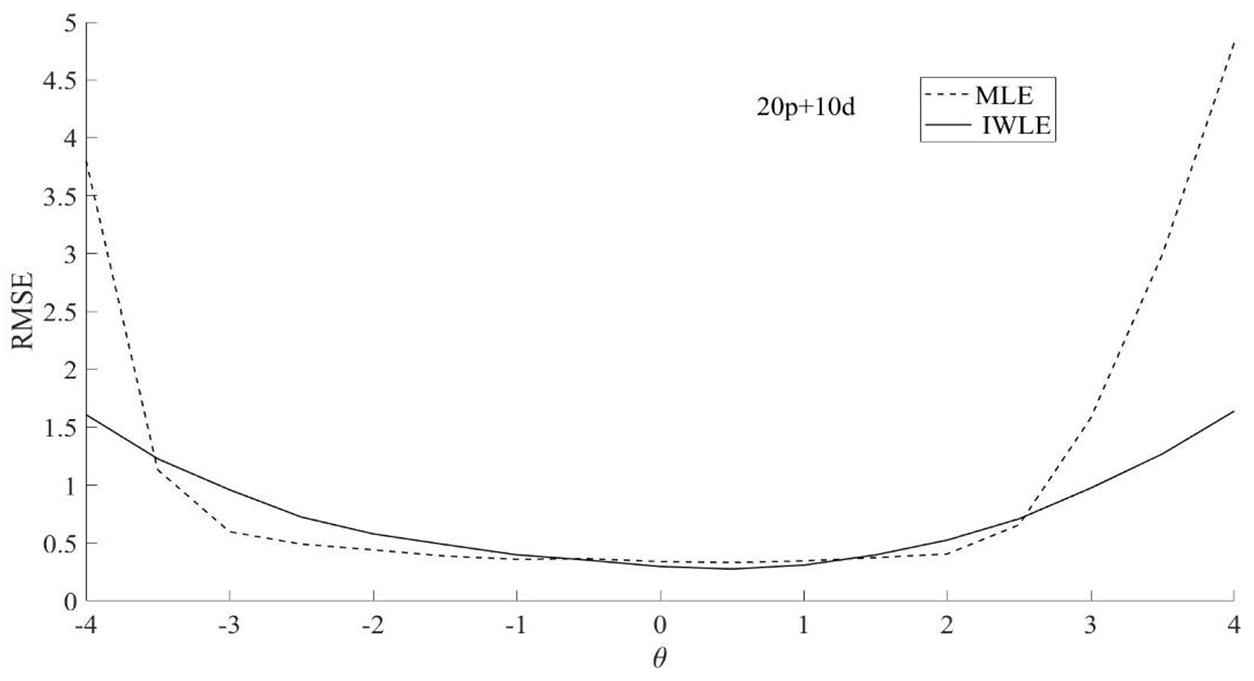
Figure 11. RMSE of the two θ estimation methods MLE and IWLE for 20p+10d.
Discussion and Conclusion
In this study, an improved IWLE procedure that incorporates item weights in likelihood functions for the ability parameter estimation is proposed. The weights may be “adaptive” in the sense that they are allowed to be estimated with the ability level and individual test items. We assign different weights to different items in accordance with the amount of the information an item provides at a certain latent trait level. Using the information ratio of each item to the test, the weights of items are determined. We also give the rigorous derivations for asymptotic properties and the bias of IWL estimators. The results from the simulation study clearly demonstrate that the proposed IWLE method outperforms the usual, MLE, MAP, WLE and TWLE in terms of controlling absolute bias, RMSE, and RMSD especially at low and high ability levels. Latent trait estimation is one of the most important components in IRT, but when an examinee scores high (or low) in a test, we known that the examinee is high (or low) on the trait but we do not have a very precise estimate of how high (or low). It could be considerably higher (or lower) than the test instrument’ scale reaches. In the case, improving latent trait estimation especially at extreme levels of ability scale is worthy of attention.
Improving latent trait estimation is always important in longitudinal survey assessments, such as the Early Childhood Longitudinal Study (ECLS) and the PISA (von Davier and Xu, 2011), which aims at tracking growth of a representative sample of the target population over time. The proposed weighting scheme also can be applied in the general unidimensional item response models. Other issues should be further explored. First, the proposed weighting scheme could be generalized to other application settings where latent ability needs to be estimated for each person such as computerized adaptive testing (CAT). Second, although the Rasch model and the PCM are commonly used in practical tests, there are other more general item response models, for instance the three-parameter logistic (3PL) model and the generalized partial credit model. Therefore, it is worth studying the extension of the IWLE to these more complex models, with different test lengths and sample sizes. Third, more than two occasions can be considered in longitudinal study, so the proposed weighting method can be generalized to deal with more general situations. Finally, the proposed IWLE method can be extended to multidimensional longitudinal IRT model.
From a practical point of view, we would not use a test that is way too difficult or way too easy items. This is because each item should have a certain discrimination to distinguish the examinees with different ability levels. In fact, the reliability and validity of the test items are pre-calibrated before the actual assessment. When the examinees answer the pre-calibrated test, some examinees answer all items correctly while others do not answer all items correctly. In this case, the extreme ability estimator will occur. Thus, the extreme ability occur because there are large differences between examinees’ abilities rather than items being too difficult or too easy (the test items are pre-calibrated, reliable and valid). In addition, the examinees were obtained through a multistage stratified sample in the actual assessment. In the first stage, the sampling population is classified according to district, and schools are selected at random. In the second stage, students are selected at random from each school. Therefore, in this case, there are some extreme cases of the examinees’ ability. For example, some examinees with high abilities answer all the items correctly, or some examinees with low abilities answered all the items incorrectly. Traditional methods (WLE and TWLE) fail to estimate these extreme abilities. However, our IWLE method is more accurate in estimating these extreme abilities. This is the main advantage of our item-weighted scheme.
Data Availability Statement
The raw data supporting the conclusion of this article will be made available by the authors, without undue reservation.
Author Contributions
XX completed the writing of the article. XX and JL provided key technical support. JZ provided original thoughts and article revisions. All authors contributed to the article and approved the submitted version.
Funding
This work was supported by the National Natural Science Foundation of China (Grant No. 12001091), China Postdoctoral Science Foundations (Grant Nos. 2021M690587 and 2021T140108). In addition, this work was also supported by the Fundamental Research Funds for the Central Universities of China (Grant No. 2412020QD025).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpsyg.2021.580015/full#supplementary-material
References
Andersen, E. B. (1985). Estimating latent correlations between repeated testings. Psychometrika 50, 3–16. doi: 10.1007/bf02294143
Barrett, J., Diggle, P., Henderson, R., and Taylor-Robinson, D. (2015). Joint modelling of repeated measurements and time-to-event outcomes: flexible model specification and exact likelihood inference. J. R. Stat. Soc. Ser. B 77, 131–148. doi: 10.1111/rssb.12060
Bradley, R. A., and Gart, J. J. (1962). The asymptotic properties of ML estimators when sampling from associated populations. Biometrika 49, 205–214. doi: 10.2307/2333482
Chanda, K. C. (1954). A note on the consistency and maxima of the roots of likelihood equations. Biometrika 41, 56–61. doi: 10.2307/2333005
Chiang, C. L. (1956). On best regular asymptotically normal estimates. Ann. Math. Statist. 27, 336–351. doi: 10.1214/aoms/1177728262
Cramér, H. (1962). Random Variables and Probability Distributions. Cambridge, MA: Cambridge University Press.
Dearborne, D. F. (1921). Intelligence and its measurement: a symposium. J. Educ. Psychol. 12, 271–275.
Donoghue, J. R. (1994). An empirical examination of the IRT information of polytomously scored reading items under the generalized partial credit model. J. Educ. Meas. 41, 295–311. doi: 10.1111/j.1745-3984.1994.tb00448.x
Embretson, S. E. (1991). A multidimensional latent trait model for measuring learning and change. Psychometrika 56, 495–515. doi: 10.1007/bf02294487
Embretson, S. E. (1997). “Multicomponent response models,” in Handbook of Modern Item Response Theory, eds W. van der Linden and R. Hambleton (New York, NY: Springer-Verlag), 305–321. doi: 10.1007/978-1-4757-2691-6_18
Embretson, S. E., and Reise, S. P. (2000). Item Response Theory for Psychologists. Mahwah, NJ: Erlbaum.
Firth, D. (1993). Bias reduction of maximum likelihood estimates. Biometrika 80, 27–38. doi: 10.1093/biomet/80.1.27
Fischer, G. H. (1973). The linear logistic test model as an instrument in educational research. Acta Psychol. 37, 359–374. doi: 10.1016/0001-6918(73)90003-6
Fischer, G. H. (1976). “Some probabilistic models for measuring change,” in Advances in Psychological and Educational Measurement, eds D. N. M. de Gruijter and L. J. T. van der Kamp (New York, NY: Wiley), 97–110.
Fischer, G. H. (1995). Some neglected problems in IRT. Psychometrika 60, 459–487. doi: 10.1007/bf02294324
Fischer, G. H. (2001). “Gain scores revisited under an IRT perspective,” in Essays on Item Response Theory, eds A. Boomsma, M. A. J. Van Duijn, and T. A. B. Snijders (New York, NY: Springer), 43–68. doi: 10.1007/978-1-4613-0169-1_3
Jodoin, M. G. (2003). Measurement efficiency of innovative item formats in computer-based testing. J. Educ. Meas. 40, 1–15. doi: 10.1111/j.1745-3984.2003.tb01093.x
Lord, F. M. (1963). “Elementary models for measuring change,” in Problems in Measuring Change, ed. C. W. Harris (Madison: University of Wisconsin press), 21–38.
Lord, F. M. (1980). Applications of Item Response Theory to Practical Testing Problems. Hillsdale, NJ: Erlbaum.
Lord, F. M. (1983). Unbiased estimators of ability parameters of their variance, and of their parallel-forms reliability. Psychometrika 48, 233–245. doi: 10.1007/bf02294018
Masters, G. N. (1982). A rasch model for partial credit scoring. Psychometrika 47, 149–174. doi: 10.1007/bf02296272
Muraki, E. (1993). Information functions of the generalized partial credit model. Appl. Psychol. Meas. 17, 351–363. doi: 10.1177/014662169301700403
Penfield, R. D., and Bergeron, J. M. (2005). Applying a weighted maximum likelihood latent trait estimator to the generalized partial credit model. Appl. Psychol. Meas. 29, 218–233. doi: 10.1177/0146621604270412
Rasch, G. (1980). Probabilistic Model for Some Intelligence and Achievement Tests, Expanded Edition. Chicago, IL: University of Chicago Press.
Sun, S.-S., Tao, J., Chang, H.-H., and Shi, N.-Z. (2012). Weighted maximum-a-posteriori estimation in tests composed of dichotomous and polytomous items. Appl. Psychol. Meas. 36, 271–290. doi: 10.1177/0146621612446937
Tao, J., Shi, N.-Z., and Chang, H.-H. (2012). Item-weighted likelihood method for ability estimation in tests composed of both dichotomous and polytomous items. J. Educ. Behav. Stat. 37, 298–315. doi: 10.3102/1076998610393969
von Davier, M., and Xu, X. (2011). Measuring growth in a longitudinal large-scale assessment with a general latent variable model. Psychometrika 76, 318–336. doi: 10.1007/s11336-011-9202-z
Wang, S., and Wang, T. (2001). Precision of Warm’s weighted likelihood estimates for a polytomous model in computerized adaptive testing. Appl. Psychol. Meas. 25, 317–331. doi: 10.1177/01466210122032163
Wang, T., Hanson, B. A., and Lau, C. A. (1999). Reducing bias in CAT ability estimation: a comparison of approaches. Appl. Psychol. Meas. 23, 263–278. doi: 10.1177/01466219922031383
Warm, T. A. (1989). Weighted likelihood estimation of ability in item response theory. Psychometrika 54, 427–450. doi: 10.1007/bf02294627
Wilson, M. (1989). Saltus: a psychometric model for discontinuity in cognitive development. Psychol. Bull. 105, 276–289. doi: 10.1037/0033-2909.105.2.276
Woodrow, H. (1938). The relationship between abilities and improvement with practice. J. Psychol. 29, 215–230. doi: 10.1037/h0058249
Keywords: longitudinal model, item-weighted likelihood, mixed-format test, dichotomous item response, polytomous item response
Citation: Xue X, Lu J and Zhang J (2021) Item-Weighted Likelihood Method for Measuring Growth in Longitudinal Study With Tests Composed of Both Dichotomous and Polytomous Items. Front. Psychol. 12:580015. doi: 10.3389/fpsyg.2021.580015
Received: 04 July 2020; Accepted: 21 June 2021;
Published: 27 July 2021.
Edited by:
Salvador Cruz Rambaud, University of Almería, SpainReviewed by:
Chester Chun Seng Kam, University of Macau, ChinaPhilipp Doebler, Technical University Dortmund, Germany
Copyright © 2021 Xue, Lu and Zhang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jing Lu, bHVqMjgyQG5lbnUuZWR1LmNu; Jiwei Zhang, emhhbmdqdzcxM0BuZW51LmVkdS5jbg==