 Denise Reis Costa
Denise Reis Costa Maria Bolsinova
Maria Bolsinova Jesper Tijmstra
Jesper Tijmstra Björn Andersson
Björn Andersson
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Psychol. , 19 March 2021
Sec. Quantitative Psychology and Measurement
Volume 12 - 2021 | https://doi.org/10.3389/fpsyg.2021.579128
This article is part of the Research Topic Process Data in Educational and Psychological Measurement View all 29 articles
Log-file data from computer-based assessments can provide useful collateral information for estimating student abilities. In turn, this can improve traditional approaches that only consider response accuracy. Based on the amounts of time students spent on 10 mathematics items from the PISA 2012, this study evaluated the overall changes in and measurement precision of ability estimates and explored country-level heterogeneity when combining item responses and time-on-task measurements using a joint framework. Our findings suggest a notable increase in precision with the incorporation of response times and indicate differences between countries in how respondents approached items as well as in their response processes. Results also showed that additional information could be captured through differences in the modeling structure when response times were included. However, such information may not reflect the testing objective.
Computers have become increasingly common implements used in classroom activities over the past few decades. As a reflection of this trend, large-scale educational assessments have moved from paper and pencil based tests to administrated computer assessments. In addition to being more efficient and reducing human error, computer-based assessments allow for a greater variety of tasks. Further, interactive computer environments can be used to generate log files, which provide easy access to information concerning the examinee response process. These log files contain time-stamped data that provide a complete overview of all communication between the user-interface and server (OECD, 2019). As such, it is possible to trace how respondents interact with the testing platform while gathering information about the amount of time spent on each task.
The first computer-based administration of the Programme for International Student Assessment (PISA) dates back to 2006 (OECD, 2010). However, more extensive studies involving log files were enabled through the release of the PISA 2009 digital reading assessment (OECD, 2011). In this context, time-on-task and navigating behaviors can be extracted from these log files as relevant variables. The information derived from variables of this type can help teachers further understand the solution strategies used by students while also enabling a substantive interpretation of respondent-item interactions (Greiff et al., 2015; Goldhammer and Zehner, 2017). The variables taken from log files can also be included in sophisticated models designed to improve student proficiency estimations (van der Linden, 2007).
While log file data from computer-based assessments have been available for several years, few studies have investigated how they can be used to improve the measurement precision of resulting scores. Using released items from the 2012 PISA computer-based assessment of mathematics, this study thus explored the potential benefits of incorporating time-on-task variables when estimating student proficiency. We specifically compared three different models to advance the current understanding of what time-on-task adds to scores resulting from an international large-scale assessment program.
Several previous studies have investigated the relationship between time-on-task and item responses. For example, Goldhammer et al. (2015) studied the relationship between item responses and response times through a logical reasoning test, thus finding a non-linear relationship between reasoning skills and response times. Further, Goldhammer and Klein Entink (2011) investigated how time-on-task and item interactivity behaviors were related to item responses using complex problem-solving items. In addition, Naumann and Goldhammer (2017) found a non-linear relationship between time on task and performance on digital reading items from the PISA 2009 assessment. Finally, Goldhammer et al. (2014) studied the relationship between time-on-task, reading, and problem solving using PIAAC data. Results indicated that the association between time-on-task and performance varied from negative to positive depending on the subject matter and type of task.
In large-scale educational assessments, student proficiency is mainly estimated through the item response theory (IRT) framework (von Davier and Sinharay, 2013). Here, categorical item-response data are considered manifestations of an underlying latent variable that is interpreted as, for example, mathematics proficiency. While time-on-task can be incorporated in several different ways from an IRT perspective (van der Linden, 2007), the state-of-the-art view considers them as realizations of random variables, much like actual item responses (Kyllonen and Zu, 2016). A hierarchical model is most commonly used with time-on-task data. Specifically, a two-level structure is used to incorporate time-on-task, item responses, and latent variables into a single model (van der Linden, 2007). While the hierarchical modeling framework has the advantage of considering both response accuracy and response times as latent variables, it has practical limitations in that it requires specialized software for fitting the model. Molenaar et al. (2015) illustrated how the hierarchical model can be slightly simplified such that standard estimation techniques could be used. This type of formulation of the model allows the use of both generalized linear latent variable models (Skrondal and Rabe-Hesketh, 2004) and non-linear mixed models (Rijmen et al., 2003) with item-response and time-on-task data. Furthermore, the approach outlined by Molenaar et al. (2015) encompasses not only the standard hierarchical model (with the necessary simplification) but also its extensions which allow for more complex relationship between time-on-task and ability such as the model of Bolsinova and Tijmstra (2018). For these reasons, this study pursued the approach of Molenaar et al. (2015) for its analysis of PISA 2012 data.
This study investigated the utility of combining item responses with time-on-task data in the context of a large-scale computer-based assessment of mathematics. It also evaluated the properties of the employed model with respect to each participating country1. Specifically, the framework developed by Molenaar et al. (2015) was used to investigate how measurement precision was influenced by incorporating item responses and time-on-task data into a joint model. We also explored country-level heterogeneity in the time-on-task measurement model. As such, the model proposed for this analysis of computer-based large-scale educational assessments implied a different set of underlying assumptions than current procedures. Specifically, we viewed response-time data as comprising an extra information set that enabled us to gain additional insight regarding the latent construct of interest. This also implies that any inference regarding the underlying construct at the country level would potentially change through the proposed approach as opposed to current analysis methods, which this study also investigated. The three following research questions were thus proposed:
• RQ1: What changes occur in the overall ability estimates and their level of precision regarding PISA 2012 digital mathematics items when time-on-task data are included in the analysis?
• RQ2: How do time-on-task model parameters differ across items and countries?
• RQ3: What changes occur in country-level performance when time-on-task data are considered in the analysis?
Our findings should add to the current literature on the relationship between time-on-task and responses to performance items. Our results also have important implications for large-scale assessment programs in regard to evaluating the added measurement precision that is granted by incorporating additional data sources (e.g., time-on-task). Such investigations can inform large-scale assessment programs about whether and how time-on-task data should be included in models designed to generate operational results reports.
PISA administered its first computer-based mathematics literacy assessment as part of its fifth program edition. A total of 32 countries participated in this effort. In this context, 40 min were allocated for the computer-based portion of the test, with math items arranged in 20 min clusters that were assembled with digital reading or problem-solving prompts (OECD, 2014a). A total of 41 math items were selected for this assessment. These items varied from standard multiple-choice to constructed response formats.
Table 1 presents the characteristics of the PISA sample by country (sample size, Math performance, and variation) for the whole computer-based of mathematics clusters (41 items) as well as to the subsample with available and valid log-file data (10 items).
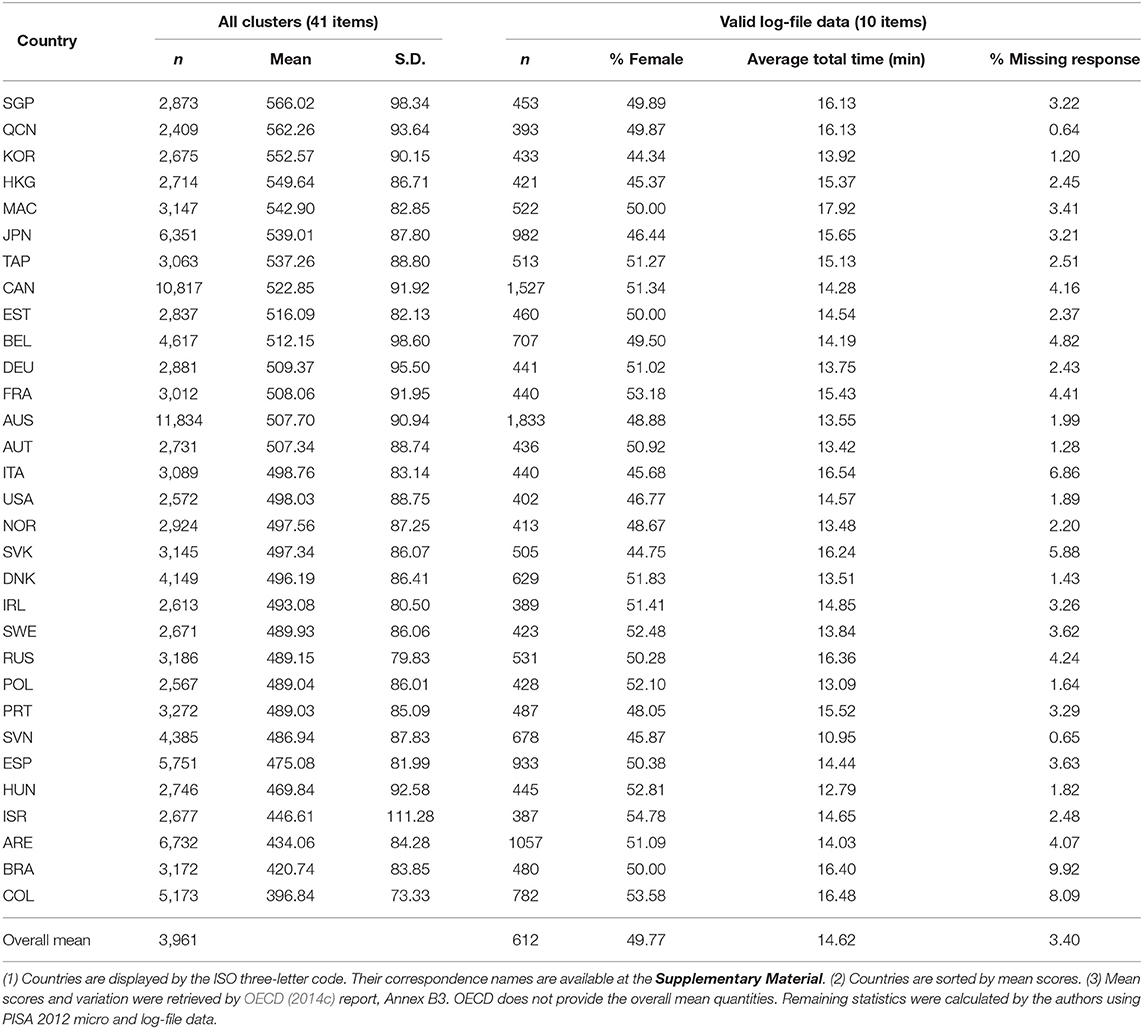
Table 1. Sample size, mean score, and variation in student performance on all clusters, as well as sample size, percentage of female, average total time, and percentage of missing responses for the 10 released and valid log-file data from the PISA 2012 computer-based mathematics by country.
We utilized data from a total of 18,970 students across 31 countries. We excluded data from Chile since log-file data for two of the analyzed items were unavailable (I20Q1 and I20Q3). Students with invalid information (e.g., those that did not receive final scores or had incomplete timing information) were also excluded from the analysis. On average, the sample size of each country is around 600 (S.D.= 333), the percentage of female is 50% across all the countries. The average total time on the 10 items varied from 10.95 to 17.92 min. Brazil was the country with the highest percentage of missing responses (9.92%) on the analyzed items.
The analyzed log-file data from 10 items were made publicly available on the OECD website. We thus extracted the time students spent on analyzed items and their final responses (i.e., response accuracy). All items were allocated in three units (CD production: items “I15Q1,” “I15Q2,” and “I15Q3”; Star points: items “I20Q1,” “I20Q2,” “I20Q3,” and “I20Q4”; Body Mass Index: items “I38Q3,” “I38Q5,” and “I38Q6”) and were administered in the same cluster.
Table 2 shows the reported item characteristics by OECD (international percent of correct responses, and thresholds used for scaling the items in PISA 2012) as well as the average response time and percentage of missing responses by item.
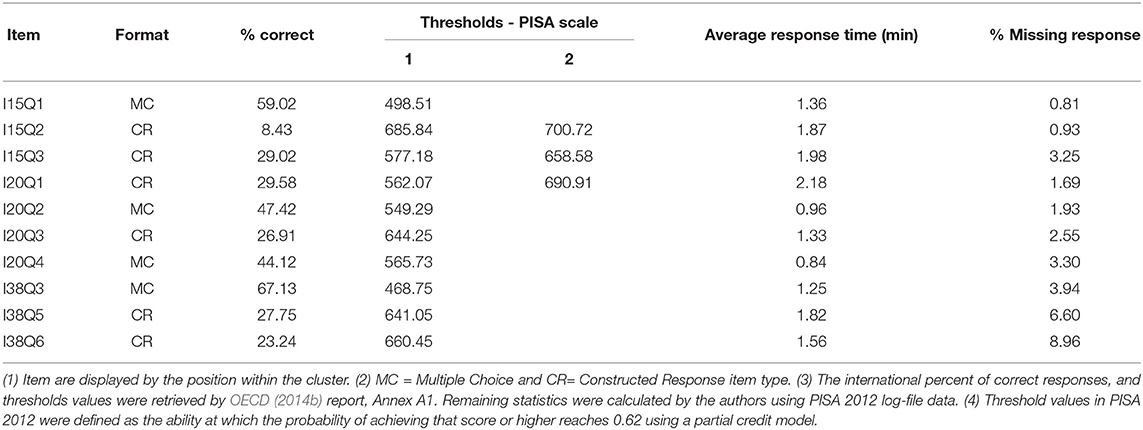
Table 2. Characteristics of the released PISA 2012 computer-based of mathematics items.
Although the effects of the item position were likely negligible due to the length of the computer-based assessment (OECD, 2014b), we were still able to determine that the percentages of missing data were larger for items located at the end of the cluster. We used the full information maximum likelihood approach (FIML) featured in Mplus version 7.3 (Muthén and Muthén, 2012) to incorporate all available data into our analyses. Doing this, the missing responses were treated as missing at random (MAR) and all the available data were incorporated in the modeling.
This study compared three measurement models to estimate student proficiency based on the abovementioned PISA dataset. All these models can be seen as special cases of the framework of Molenaar et al. (2015). They are:
• Model 1 (M1): It provided a baseline and thus only included response accuracy in a unidimensional IRT framework. The model can be seen as a special case of the framework of Molenaar et al. (2015) in which it is assumed that there is no relationship between latent proficiency and response time data.
• Model 2 (M2): A multidimensional latent variable model for the response accuracy and response times, where the response accuracy are related to a latent proficiency and the response times are related to a latent speed. The latent factors are assumed to be correlated. This is a variant of the model described in Molenaar et al. (2015): Here the relationship between the latent proficiency and response times is specified through the relationship between the latent proficiency and latent speed.
• Model 3 (M3): A multidimensional latent variable model for the response accuracy and response times, where response accuracy is related to a latent proficiency and the response times are related to a latent speed and proficiency. This is also a special case of the approach of Molenaar et al. (2015) in which the relationship between latent proficiency and response times goes not only through the relationship between latent proficiency and latent speed, but also through the direct relationship between the ability and individual response times. For this model we employed a particular rotation approach described in Bolsinova and Tijmstra (2018).
Figure 1 shows the graphical representation of the models across PISA countries. For comparability purposes, the items' parameters for response accuracy were fixed from model 1 into models 2 and 3. This approach assures that the models are on the same scale since the relationship between response accuracy and latent proficiency will be the same across models.
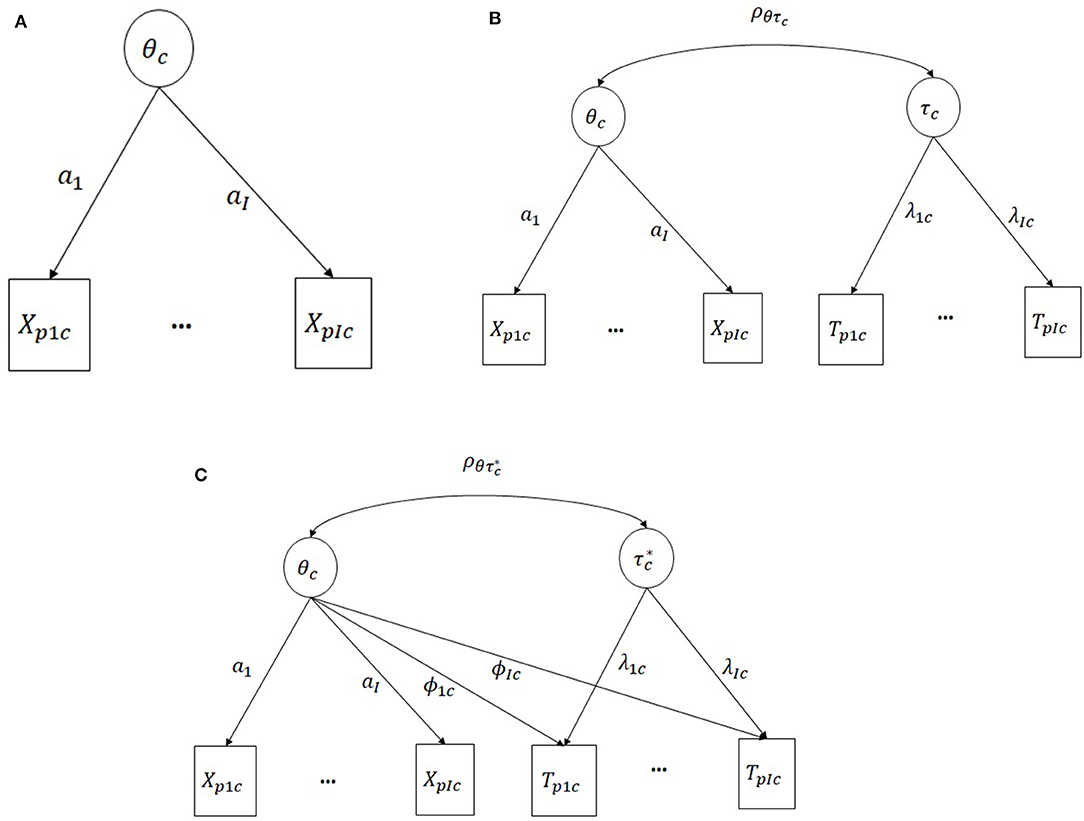
Figure 1. (A) M1: response accuracy only (B) M2: simple-structure hierarchical model (C) M3: Extended hierarchical model with cross-loadings. The parameter's sub-indices are: p, person; I, item; c, country.
This section discusses the mathematical formulations used in each model. The steps used to estimate model parameters for use with the PISA dataset and an analysis of measurement invariance across countries are discussed later.
Let X = (X1, …, XI) be a random vector of responses on the I items and T = (Tp1, …, TpI) be a random vector of response times on the same items with realizations xp· = (xp1, …, xpI) and tp· = (tp1, …, tpI), for each person p, respectively.
For response accuracy, we adopted the graded response model (GRM) used by Samejima (1969). This was done because some PISA items used a partial scoring method and, unlike other IRT models used for polytomous data (e.g., the partial credit model), the GRM is equivalent to simple factor analytic models in application to discrete data and can therefore be fitted using standard factor analysis software and structural equation models. The differences between the various IRT models used for polytomous data are usually very small; in our case, only three items out of 10 allowed partial scoring. The GRM specifies the conditional probability to obtain each category k ∈ [1:m], where m is the highest possible category for the item. The conditional probability of obtaining this score or higher, given the latent trait θ, is defined by
where ai is the item factor loading/discrimination parameter, and bik is the item category threshold parameter2. The probability of obtaining a particular response category k is then
where Pr(Xi ≥ 0) = 1 and Pr(Xi ≥ m + 1) = 0. When m = 2, the GRM reduces to the two-parameter logistic IRT model used by Birnbaum (1968), with only one difficulty parameter bi per item instead of multiple threshold parameters. M1 defined exclusively by Equation (2).
There are also cases in which both responses and response times are used to estimate respondent proficiency. Here, instead of simply specifying the model for response accuracy, we must specify the full model for the joint distribution of response accuracy and response times. For Model 2, we thus adopted the hierarchical modeling approach used by van der Linden (2007), which requires not only the specification of the measurement model for response accuracy (in our case, the GRM) but also the specification of the measurement model for the response times, and the models for the relationship of the latent variables in the two measurement models. The model used for the relationship between item parameters in the two measurement models is often specified, as well. However, as shown by Molenaar et al. (2015), excluding this relationship does not substantially change the parameter estimates, especially when large sample sizes are involved. Furthermore, the use of standard estimation techniques is prevented when including a model for the item parameters. Given the very large sample sizes available in this analysis, we thus specified a higher-order relationship on the person side (i.e., the model for latent variables), but did not do so on the item side.
The joint distribution of response accuracy and response times is conditional to both latent proficiency and speed (denoted by τ) in the hierarchical model. In this case, it is assumed to be a product of the marginal distribution of response accuracy, which only depends on latent proficiency, and the marginal distribution of response time, which only depends on latent speed. We refer to this as a simple-structure model because every observed variable therein is solely related to one latent variable. This differs from the extension of the hierarchical model used by Bolsinova and Tijmstra (2018), which includes direct relationships between response times and latent proficiency in addition to its relation to latent speed.
A lognormal model with item-specific loadings was used for the response times (Klein Entink et al., 2009). It is equivalent to the one-factor model used for log-transformed response times. The conditional distribution of response time on item i given the latent speed variable is defined by
which is the lognormal distribution in which the mean is dependent on the item time intensity ξi and the latent speed τ. The strength of the relationship between the response time and the latent speed depends on the factor loading λi. Meanwhile, denotes the item-specific residual variance.
The dependence between the latent proficiency and the latent speed variables is modeled using a bivariate normal distribution with correlation parameter ρ. This correlation between the latent variables specifies the indirect relationship between response times and latent proficiency. In turn, this allows us to strengthen the measurement of proficiency (i.e., increase measurement precision) by using the information contained in the response times. The magnitude of the improvement in measurement precision is solely determined by the size of the correlation between the latent speed and latent proficiency (Ranger, 2013).
M3 employed the same model for response accuracy as that used in M1 and M2. However, a different model was used for response times. That is, the mean of the lognormal distribution of response time was dependent on two latent variables, as follows:
where the cross-loading ϕi specifies the strength of the relationship between response time and proficiency. Here, an asterisk is used for the latent variable τ* because it should be interpreted differently from the simple-structure model (M2). Since the cross-loadings between latent proficiency and response time are freely estimated, the correlation between θ and τ* is not identified and is instead fixed to zero so that τ* can be interpreted as a latent variable, thus explaining the covariance of the response times that cannot be explained by latent proficiency. However, it is possible to rotate the latent variable τ* to match the latent speed variable of the simple-structure model. Following Bolsinova and Tijmstra (2018), we will apply a rotation of the factors such that τ* is the latent variable that explains most of the variance of response times. In that case, the correlation between latent proficiency and speed and the corresponding values for the transformed factor loading in the two dimensions can be calculated.
We used the LOGAN R package version 1.0 (Reis Costa and Leoncio, 2019) to extract student response times and accuracy from the PISA 2012 log file containing data for 10 digital math items. We then conducted analyses according to two steps.
First, we fitted all three models by combining the sample consisting of 31 countries to estimate model parameters at an international level. Then, we analyzed the models across PISA countries by fixing specific parameters from previous analyses to allow cross-model comparisons. We also evaluated parameter invariance in the response time model. All model parameters were estimated using the restricted maximum likelihood method in Mplus version 7.3 (Muthén and Muthén, 2012).
Table 3 summarizes the analytical framework used in the first step. Item discrimination (ais) and threshold parameters (bis) were freely estimated for Model 1, with the proficiency mean (μθ) and variance () fixed to 0 and 1, respectively. To enable model comparisons, the item discrimination and threshold parameters were not estimated for M2 and M3 but were rather fixed to the parameter estimates from M1. For these models, the response time parameters (ξis, λis, s, and ϕis) and the mean and variance of the proficiency were freely estimated.

Table 3. Framework for the estimation of international parameters for each analyzed model.
All analyses were conducted assuming the same graded response model for the item-response modeling. We evaluated the fit of the GRM model for M1 (in which the item discrimination and threshold parameters were freely estimated) by calculating two approximate fit statistics [i.e., the Root Mean Square Error of Approximation (RMSEA) and the Standardized Root Mean Square Residual (SRMR)] using the complete dataset in the mirt R package (Chalmers, 2012). As a guideline, cutoff value close to 0.08 for SRMR and a cutoff value close to 0.06 for RMSE indicated acceptable fit (Hu and Bentler, 1999).
We conducted country-level analyses in the second step. Table 4 shows the fixed and freely estimated parameters for each model. Here, models containing the suffix “_Full” indicate full measurement invariance. That is, we estimated each country's mean and variance for the latent variables (θc, τc, or ρθτc), fixing all item parameters (ais, bis, ξics, λics, s, or ϕics) with international estimates as derived in step one. Models containing the suffix “_Strong” indicate strong measurement invariance in which item-specific residual variances (s) are allowed to be estimated, instead. Weak measurement invariance models contain the suffix “_Weak.” Here, both the item-specific residual variance (s) and item-time intensity parameters (ξics) were freely estimated. In this case, however, the mean of the latent speed variable was fixed to 0 for model identification. Lastly, structural measurement invariance (suffix “_Struct”) indicates all time-related parameters are freely estimated (ξics, λics, s or ϕics). For model identification, we fixed the mean and the variance of the latent speed variable to 0 and 1, respectively. We also incorporated a new constraint in model “M3_Struct” to allow the free estimation of the cross-loading parameter (ϕics). In this case, we constrained the variance of the latent speed to be the same as the estimates from the M1_Full model to make sure that the correlations between Xis and θ will be the same as in model 1 and therefore θ will have similar interpretation as in M1.
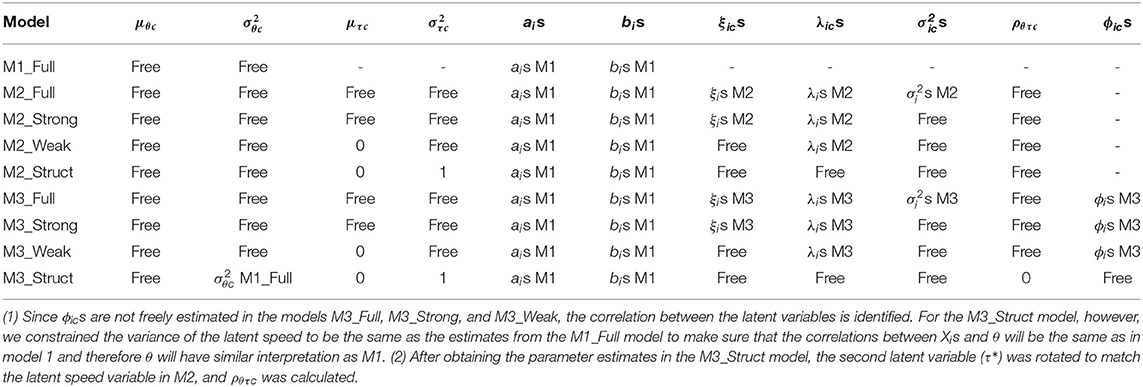
Table 4. Framework for the estimation of countries' parameters for each analyzed model.
We estimated student abilities using the Expected a Posteriori (EAP) approach (Bock and Mislevy, 1982) and evaluated measurement precision using the EAP-reliability method (Adams, 2005) and the average of the standard errors of the ability estimates. Finally, we computed the Bayesian Information Criterion (BIC) for model selection (Schwarz, 1978).
We addressed our research questions by assessing the results according to the following three steps: (1) we estimated the overall ability estimates and their level of precision regarding PISA 2012 digital math items by the three measurement models, (2) presented our findings about the invariance of response-time model parameters across items and countries, and (3) showed changes in country-level performance when time-on-task was considered.
We first investigated the model fit for the graded response model. This model was assessed as having a good fit based on its SRMSR (0.036). It also exhibited acceptable fit according to its RMSEA (0.050). We thus concluded that our baseline model had sufficiently good overall fit for continued analyses, including those related to time-on-task variables.
Table 5 shows the overall estimates for student abilities and the measurement precision of these estimates in relation to the PISA 2012 digital math items across the different models. Although there was no substantial difference, M2 and M3 (i.e., the simple-structure hierarchical model and the cross-loadings model, respectively) exhibited increased measurement precision (as captured by larger EAP reliability estimates and smaller average standard errors) when response times were included in the modeling framework.
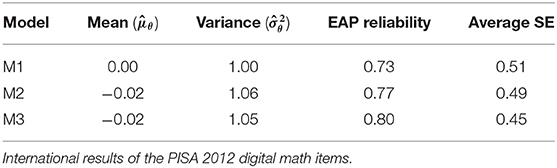
Table 5. Estimated means and variances of students' abilities, EAP reliability and average of the standard errors for the three measurement models.
We investigated measurement invariance of the time-on-task parameters for each country with both M2 and M3. We also calculated the BIC for each individual model and summarized these statistics to identify the level of invariance that best represented the data overall (Table 6). As such, the assumption of invariance of the model's parameters does not hold for most countries and models. Weak measurement invariance were preferred in most of the cases (i.e., there was country-specific heterogeneity in the time intensity (ξi) and residual variance () parameters for the time-on-task measurement models).
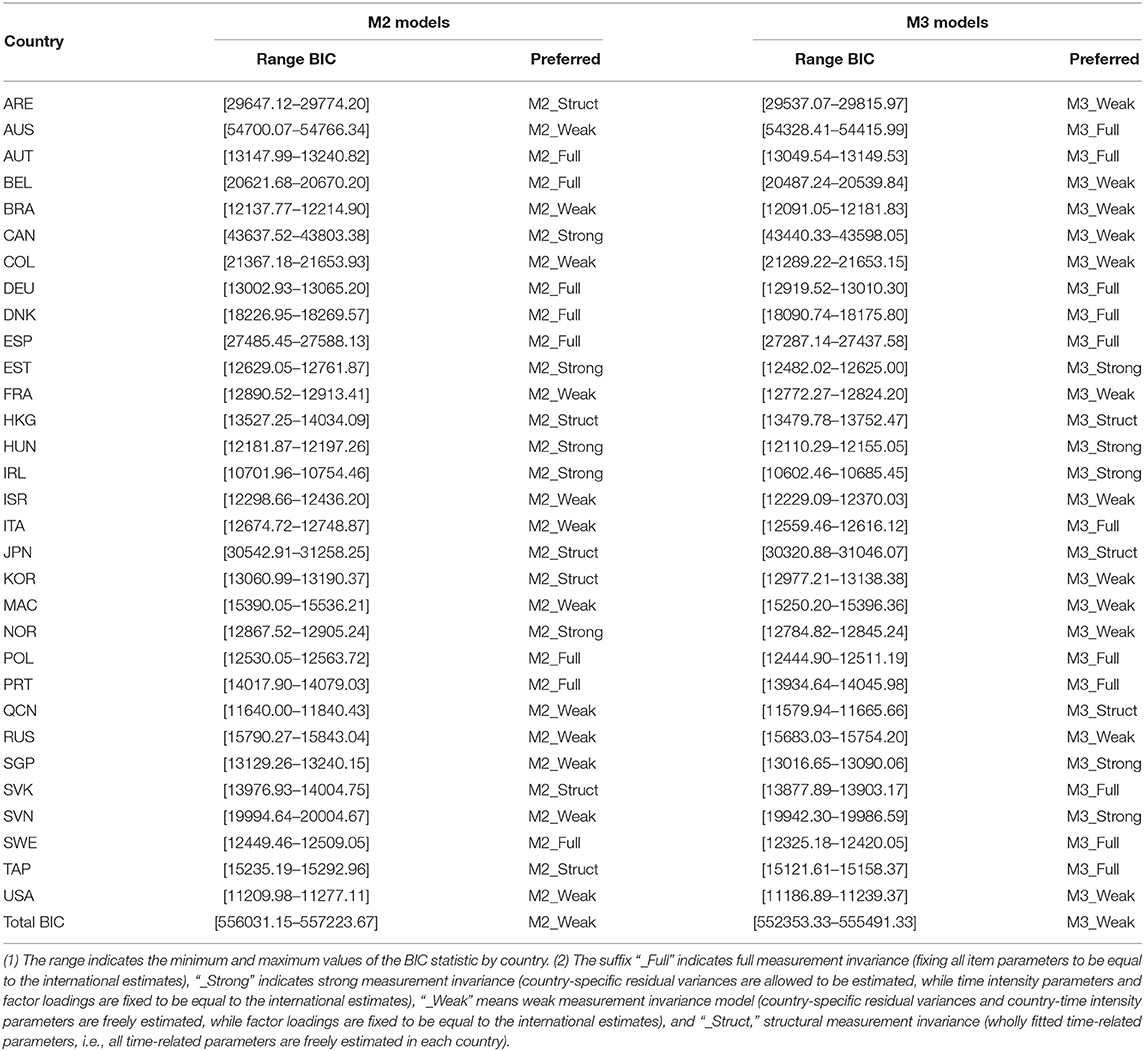
Table 6. Model fit statistics (BIC) by model and country.
To illustrate the differences in the time-on-task measurement model parameters, Figure 2 presents the estimated time-intensity parameters for each item in each country as applied to the preferred model in the simple-structure framework (M2). The graph indicates that students in all analyzed countries placed the most effort into answering the first item, I20Q1, from Unit 20 (Star Point unit). However, the pattern of estimated time-intensity between different items varied according to country. For example, the estimated time intensity of item I38Q06 was larger than that of item I15Q01 for several countries, but the opposite was found for about just as many countries.
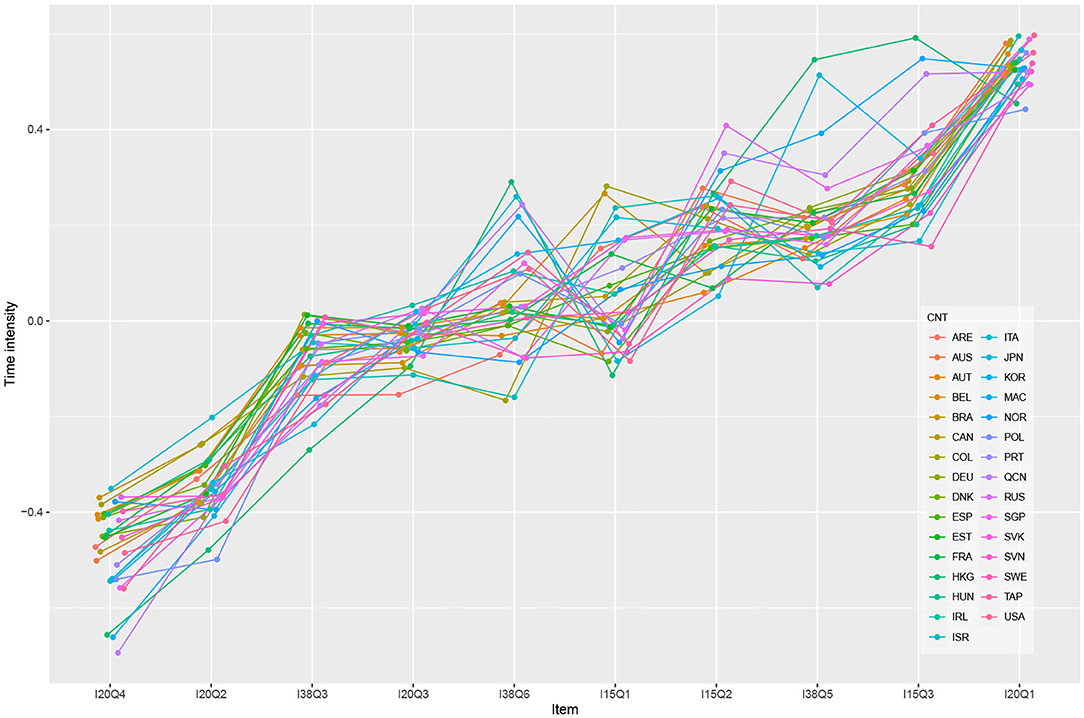
Figure 2. Estimates of the countries' time intensity for model 2—Weak measurement invariance.
Figure 3 shows the estimated country means in computer-based mathematical literacy and the associated confidence intervals for the three measurement models. The estimated means did not show substantial discrepancies for the analyzed countries between the different models.
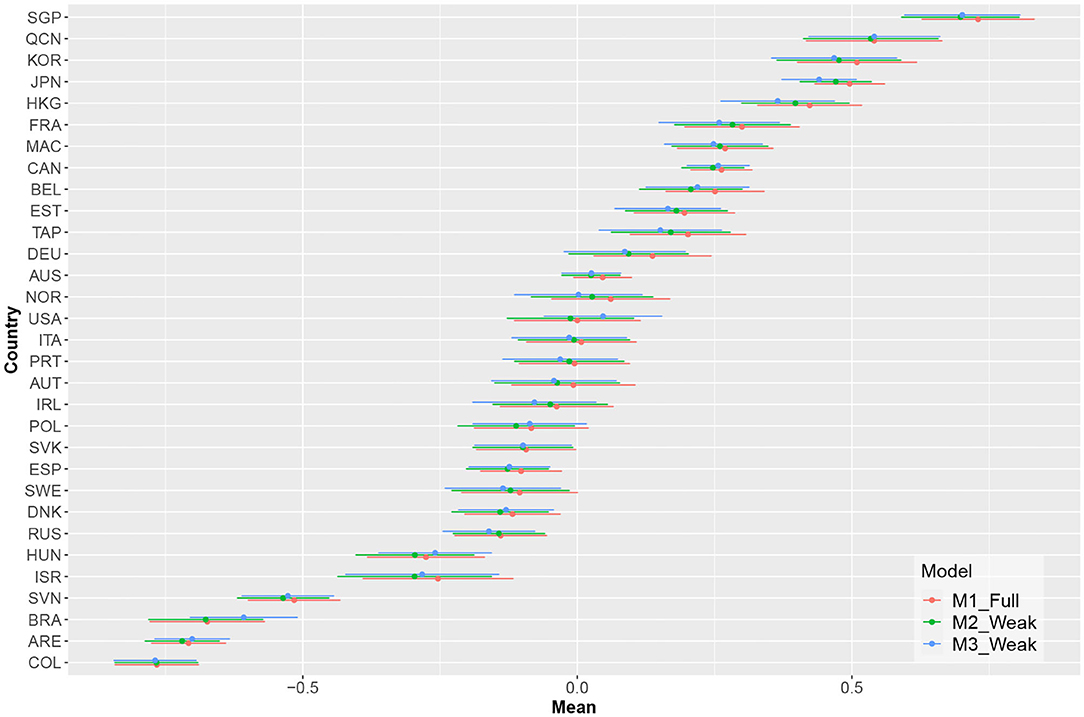
Figure 3. Estimates of the countries' means and their respective confidence intervals for the different models.
Figure 4 shows the estimated reliability of the EAP ability estimates for each country. Measurement precision increased for all countries when time-on-task variables were included; here, the model containing cross-loadings had the highest estimated EAP reliability. As illustrated in Figure 5, there was a decrease in average standard errors for ability estimates when time-on-task variables were included.
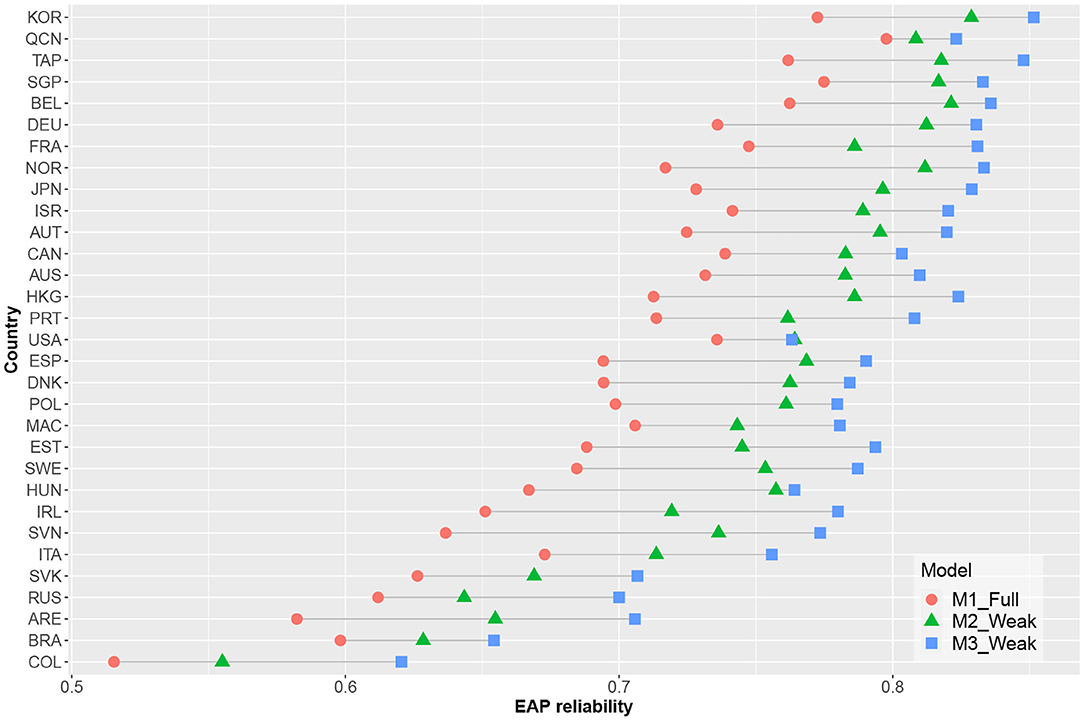
Figure 4. EAP reliabilities estimates per country and model.
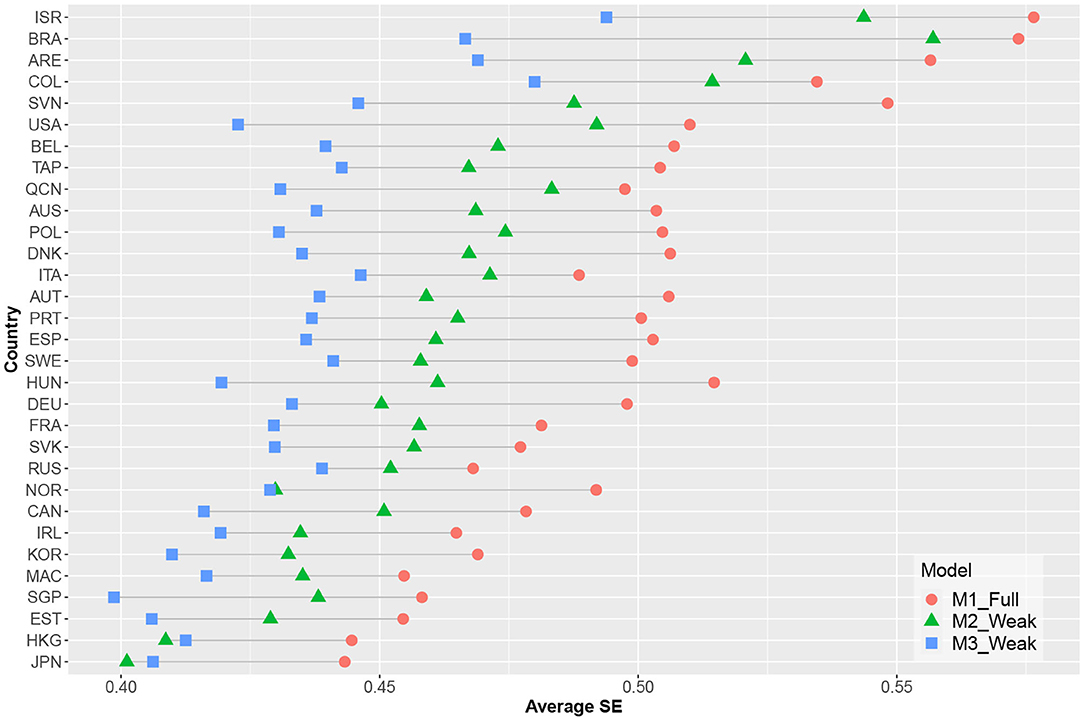
Figure 5. Average standard errors of abilities' estimates per country and model.
Figure 6 shows the correlations between EAP ability estimates from the baseline model and from those including time-on-task variables. Ability estimates from models that included cross-loadings generally had lower correlations with the baseline model-based ability estimates as compared to models that did not include cross-loadings. This indicates that the ability estimates from model 3 captured an additional source of information. However, this may not have reflected the test objective (i.e., estimating student computer-based mathematical literacy).

Figure 6. Correlations between EAP estimates.
This study examined the extent to which inferences about ability in large-scale educational assessments were affected by and improved by including time-on-task information in the statistical analyses. This issue was specifically explored using data from the PISA 2012 Computed-Based Assessment of Mathematics. In line with statistical theory, model-based measurement precision (as captured by the EAP reliability estimates) improved when using the standard hierarchical model as opposed to the response accuracy only model for each of the 31 considered countries that participated in the PISA program. This increase was notable for most countries, with many showing increases in estimated EAP reliability at or above 0.05. If such a version of the hierarchical model can adequately capture the data structure, then this suggests it can also provide a notable increase in precision over the default response-accuracy only models.
For practically all countries, model-based measurement precision was further increased when using the extended version of the hierarchical model, which allowed a direct link between response times and ability by including cross-loadings (i.e., rather than using the standard hierarchical model). This model successfully extended the hierarchical model by considering overall response speed as relevant to the estimated ability while also allowing individual item-response times to be linked to said ability if such patterns were present in the data. Thus, the model allowed time-on-task to provide more collateral information when estimating ability than was possible when using the standard hierarchical model. This increased precision was also notable for most countries (generally between 0.02 and 0.03). However, the increase was generally less sizable than those obtained by using the hierarchical model instead of a response-accuracy only model. Thus, the biggest gain in precision was already obtained by using a simple-structure hierarchical model; extending the model by incorporating cross-loadings generally only resulted in modest additional gains.
We investigated the extent to which time-on-task parameters could be considered invariant across countries for both the simple-structure hierarchical model and the extension that included cross-loadings. The results suggested that only weak measurement invariance existed. As such, full or strong measurement invariance did not hold. That is, our findings suggest that countries may differ both in item time-intensity (capturing how much time respondents generally spent on items) and the item-specific variability of the response times (i.e., the degree to which respondents differed in the amounts of time they spent on particular items). This suggests relevant differences between countries in regard to how respondents approached items as well as in their response processes.
Measurement precision improved for all countries when using the selected versions of M2 and M3 (i.e., over the precision levels obtained using M1). Since changing the model used to analyse the data may also affect model-based inferences, we also analyzed the extent to which such inferences would be affected by these changes. Here, no country showed a substantial change in estimated mean, thus suggesting that the overall assessment of proficiency levels for different countries was not heavily affected by a model change. However, the estimated correlations between the individual ability estimates obtained using M1, M2, and M3 showed small deviations from 1 for many countries, suggesting that the ability being estimated does not overlap perfectly across the three models. The differences between M1 and M3 were most notable in this regard. That is, they generally resulted in the lowest correlations between ability estimates. It is thus not surprising that these two models had the lowest correlation; they also had the largest differences in modeling structure. However, one should carefully consider which of the models best operationalizes the specific ability that will be estimated. Additional validation research is thus needed to determine whether the inclusion of time-on-task information results in overall improved measurement quality.
Publicly available datasets were analyzed in this study. This data can be found here: https://www.oecd.org/pisa/pisaproducts/database-cbapisa2012.htm.
DRC: conceptualization. DRC, MB, JT, and BA: methodology and paper writing. DRC: data analysis. All authors contributed to the article and approved the submitted version.
The authors received financial support from the research group Frontier Research in Educational Measurement at University of Oslo (FREMO) for the publication of this article. JT was supported by the Gustafsson & Skrondal Visiting Scholarship at the Centre for Educational Measurement, University of Oslo.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpsyg.2021.579128/full#supplementary-material
TABLE S1. List of country codes.
1. ^We use “country” as a generic term referring to all countries and economies participating in the PISA study. A list of the countries codes is displayed in the Supplementary Material.
2. ^The logistic function was used here because it is more common than the cumulative normal function used in IRT applications, including for large-scale international assessments such as PISA.
Adams, R. J. (2005). Reliability as a measurement design effect. Stud. Educ. Eval. 31, 162–172. doi: 10.1016/j.stueduc.2005.05.008
Birnbaum, A. L. (1968). “Some latent trait models and their use in inferring an examinee's ability,” in Statistical Theories of Mental Test Scores, eds F. M. Lord and M. R. Novick (Reading: Addison-Wesley), 397–479.
Bock, R. D., and Mislevy, R. J. (1982). Adaptive EAP estimation of ability in a microcomputer environment. Appl. Psychol. Meas. 6, 431–444. doi: 10.1177/014662168200600405
Bolsinova, M., and Tijmstra, J. (2018). Improving precision of ability estimation: getting more from response times. Brit. J. Math. Stat. Psychol. 71, 13–38. doi: 10.1111/bmsp.12104
Chalmers, R. P. (2012). mirt: a multidimensional item response theory package for the R environment. J. Stat. Softw. 48, 1–29. doi: 10.18637/jss.v048.i06
Goldhammer, F., and Klein Entink, R. H. (2011). Speed of reasoning and its relation to reasoning ability. Intelligence 39, 108–119. doi: 10.1016/j.intell.2011.02.001
Goldhammer, F., Naumann, J., and Greiff, S. (2015). More is not always better: the relation between item response and item response time in Raven's matrices. J. Intell. 3, 21–40. doi: 10.3390/jintelligence3010021
Goldhammer, F., Naumann, J., Stelter, A., Tóth, K., Rölke, H., and Klieme, E. (2014). The time on task effect in reading and problem solving is moderated by task difficulty and skill: insights from a computer-based large-scale assessment. J. Educ. Psychol. 106, 608–626. doi: 10.1037/a0034716
Goldhammer, F., and Zehner, F. (2017). What to make of and how to interpret process data. Measurement 15, 128–132. doi: 10.1080/15366367.2017.1411651
Greiff, S., Wüstenberg, S., and Avvisati, F. (2015). Computer-generated log-file analyses as a window into students' minds? A showcase study based on the PISA 2012 assessment of problem solving. Comput. Educ. 91, 92–105. doi: 10.1016/j.compedu.2015.10.018
Hu, L. T., and Bentler, P. M. (1999). Cutoff criteria for fit indexes in covariance structure analysis: Conventional criteria versus new alternatives. Struct. Equat. Model. 6, 1–55. doi: 10.1080/10705519909540118
Klein Entink, R. H., Fox, J.-P., and van der Linden, W. J. (2009). A multivariate multilevel approach to the modeling of accuracy and speed of test takers. Psychometrika 74:21. doi: 10.1007/s11336-008-9075-y
Kyllonen, P., and Zu, J. (2016). Use of response time for measuring cognitive ability. J. Intell. 4:14. doi: 10.3390/jintelligence4040014
Molenaar, D., Tuerlinckx, F., and van der Maas, H. L. (2015). A generalized linear factor model approach to the hierarchical framework for responses and response times. Brit. J. Math. Stat. Psychol. 68, 197–219. doi: 10.1111/bmsp.12042
Naumann, J., and Goldhammer, F. (2017). Time-on-task effects in digital reading are non-linear and moderated by persons' skills and tasks' demands. Learn. Individ. Diff. 53, 1–16. doi: 10.1016/j.lindif.2016.10.002
OECD (2010). PISA Computer-Based Assessment of Student Skills in Science. Technical report, Paris. doi: 10.1787/9789264082038-en
OECD (2011). PISA 2009 Results: Students On Line: Digital Technologies and Performance. OECD Publishing, Paris. doi: 10.1787/9789264112995-en
OECD (2014a). Pisa 2012 Results: Creative Problem Solving: Students' Skills in Tackling Real-Life Problems. Vol. 5. Technical report, Paris.
OECD (2014c). Results: What Students Know and Can Do Student Performance in Mathematics, Reading and Science. OECD Publishing, Paris.
OECD (2019). Beyond Proficiency: Using Lof Files to Understand Respondent Behaviour in the Survey of Adult Skills. OECD Publishing, Paris. doi: 10.1787/0b1414ed-en
Ranger, J. (2013). A note on the hierarchical model for responses and response times in tests of van der linden (2007). Psychometrika 78, 538–544. doi: 10.1007/s11336-013-9324-6
Reis Costa, D., and Leoncio, W. (2019). LOGAN: Log File Analysis in International Large-Scale Assessments. (R package version 1.0.0). Available online at: https://cran.r-project.org/web/packages/LOGAN/index.html
Rijmen, F., Tuerlinckx, F., De Boeck, P., and Kuppens, P. (2003). A nonlinear mixed model framework for item response theory. Psychol. Methods 8, 185–205. doi: 10.1037/1082-989X.8.2.185
Samejima, F. (1969). Estimation of latent ability using a response pattern of graded scores. Psychometrika. 34, 1–97. doi: 10.1007/BF03372160
Schwarz, G. (1978). Estimating the dimension of a model. Ann. Stat. 6, 461–464. doi: 10.1214/aos/1176344136
Skrondal, A., and Rabe-Hesketh, S. (2004). Generalized Latent Variable Modeling:Multilevel, Longitudinal and Structural Equation Models. Boca Raton, FL: Chapman & Hall/CRC.
van der Linden, W. J. (2007). A hierarchical framework for modeling speed and accuracy on test items. Psychometrika 72:287. doi: 10.1007/s11336-006-1478-z
von Davier, M., and Sinharay, S. (2013). “Analytics in international large-scale assessments: item response theory and population models,” in Handbook of International Large-Scale Assessment: Background, Technical Issues, and Methods of Data Analysis, eds L. Rutkowski, M. von Davier, and D. Rutkowski (Boca Raton, FL: CRC Press), 155–174.
Keywords: log files, computer-based assessment, time on task, measurement precision, measurement invariance, PISA
Citation: Reis Costa D, Bolsinova M, Tijmstra J and Andersson B (2021) Improving the Precision of Ability Estimates Using Time-On-Task Variables: Insights From the PISA 2012 Computer-Based Assessment of Mathematics. Front. Psychol. 12:579128. doi: 10.3389/fpsyg.2021.579128
Received: 01 July 2020; Accepted: 22 February 2021;
Published: 19 March 2021.
Edited by:
Ian van der Linde, Anglia Ruskin University, United KingdomReviewed by:
Qiwei He, Educational Testing Service, United StatesCopyright © 2021 Reis Costa, Bolsinova, Tijmstra and Andersson. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Denise Reis Costa, ZC5yLmNvc3RhQGNlbW8udWlvLm5v
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.