 Hongyue Zhu
Hongyue Zhu Wei Gao1
Wei Gao1 Xue Zhang
Xue Zhang- 1School of Mathematics and Statistics, Northeast Normal University, Changchun, China
- 2China Institute of Rural Education Development, Northeast Normal University, Changchun, China
Multilevel item response theory (MLIRT) models are used widely in educational and psychological research. This type of modeling has two or more levels, including an item response theory model as the measurement part and a linear-regression model as the structural part, the aim being to investigate the relation between explanatory variables and latent variables. However, the linear-regression structural model focuses on the relation between explanatory variables and latent variables, which is only from the perspective of the average tendency. When we need to explore the relationship between variables at various locations along the response distribution, quantile regression is more appropriate. To this end, a quantile-regression-type structural model named as the quantile MLIRT (Q-MLIRT) model is introduced under the MLIRT framework. The parameters of the proposed model are estimated using the Gibbs sampling algorithm, and comparison with the original (i.e., linear-regression-type) MLIRT model is conducted via a simulation study. The results show that the parameters of the Q-MLIRT model could be recovered well under different quantiles. Finally, a subset of data from PISA 2018 is analyzed to illustrate the application of the proposed model.
Introduction
Multilevel or hierarchical linear models are used widely in educational and psychological researches (e.g., Raudenbush, 1988; Goldstein, 1995; Snijders and Bosker, 1999). These models allow data to be collected at different levels; for example, test data are obtained from students, students are nested within schools, and so on. Item response theory (IRT) models can be plugged in multilevel models, known as multilevel IRT (MLIRT) models. In educational research and educational assessment, the MLIRT model is widely applied, where the main objective is to investigate the relationship between covariates (e.g., student’s social background, school financial resources) and outcome variables (e.g., student’s ability; Fox, 2010).
Adams et al. (1997) noted that a two-level IRT model could be seen as a multilevel perspective on item response modeling. In this formulation, we can divide the two-level IRT model in two components: the measurement part with the respective IRT measurement model and the structural part with the respective regression model. Furthermore, Kamata (2001) and Fox and Glas (2001) extended the two-level IRT model to three levels, with both studies proposing a two-level regression model (i.e., student-level and group-level covariates were analyzed in different levels) on the ability parameters as the structural model. Because the explanatory variables might not always be measured accurately, Fox and Glas (2003) showed how to model latent explanatory variables with measurement errors within the MLIRT model. Additionally, MLIRT models can also be applied to handle more-complicated factors such as longitudinal response data and response times. For example, Huang (2015); Schmidt et al. (2016) introduced MLIRT models for longitudinal data to assess the changes in students’ abilities over time. Also, when jointly modeling the responses and response times, the ability and speed parameters can be considered as outcome variables of a multivariate multilevel model for various analyses (e.g., Entink et al., 2009; Fox, 2010).
Regarding the estimation of MLIRT models, studies have shown that all the model parameters can be estimated simultaneously using a fully Bayesian method, regardless of whether the IRT model is a two-parameter model for dichotomous response data or a graded response model for polytomous response data (Fox, 2005; Natesan et al., 2010). Compared with the traditional two-stage estimation procedure, this estimation procedure in the MLIRT models leads to a proper treatment of the measurement error associated with the ability parameter (Adams et al., 1997; Fox and Glas, 2001, 2003; Fox, 2004, 2005, 2010). See Fox (2010) for more advantages of the MLIRT modeling framework.
One fact that needs to be noted is that the distribution of latent variables in the IRT model is often assumed to be normal (e.g., Bock and Lieberman, 1970; Bock and Aitkin, 1981; Wirth and Edwards, 2007). This assumption may be reasonably when students follow a normally distributed population, but in many cases, it is not satisfied (e.g., Woods, 2006, 2015; Woods and Thissen, 2006; Sass et al., 2008). It has been shown that when a non-normal latent distribution is assumed to be normal, estimates of IRT model parameters are biased (e.g., Stone, 1992; Sass et al., 2008; Woods, 2015). This issue has also been explored regarding multidimensional and graded response models (e.g., Finch, 2010, 2011; Svetina et al., 2017; Wang et al., 2018). However, there has been little attention to the non-normality of latent variables in the MLIRT framework.
On the other hand, the structural models in the MLIRT models are always linear regression (LR) approaches. Herein, LR generally assumes that the errors are normally distributed and should be homoscedastic, which are not often in accordance with practice, because of non-normality of latent variables or heterogeneity of errors (Harvey, 1976; Koenker and Bassett, 1978, 1982; Jarque and Bera, 1980; Tsionas, 2003). It is also well known that a LR model mainly focuses on the relation between explanatory variables and the conditional mean of latent variables, however, it is quite possible that the relationship between variables may vary at different points along the response distribution, researchers also might be interested in the relationships between variables on various locations of the distribution, such as on one or both of the tails of the distribution.
These problems can be addressed by the quantile regression (QR) (Koenker and Bassett, 1978), which is a valuable and robust tool for analyzing the conditional quantile functions of latent variables. When considering the relationship between explanatory variables and latent variables, QR allows to compute several different regression curves corresponding to the various percentage points of the distribution and thus obtain a more complete relationship between them. In addition, QR is regarded as a robust method in regression because the estimation results are insensitive to outliers or the non-normality of response distributions. Overview of QR methods, one can refer to Yu et al. (2003); Koenker and Ng (2005). As such, QR has been used by many researchers in the field of education (e.g., Wößmann, 2005; Haile and Nguyen, 2008; Chen and Chalhoub-Deville, 2014; Giambona and Porcu, 2015; Gürsakal et al., 2016; Costanzo and Desimoni, 2017). The aim of most studies has been to scrutinize inequality of opportunity in education through investigating the determinants of student achievement, or to analyze individual and/or family background determinants of student achievement with respect to test results.
In recent years, QR has also been applied successfully in latent variable models (e.g., Dunson et al., 2003; Allen and Powell, 2011; Burgette and Reiter, 2012; Wang et al., 2016; Feng et al., 2017; Belloni et al., 2019; Liu et al., 2020). Burgette and Reiter (2012) considered QR in a factor analysis model to analyze the effects of latent variables on the lower quantiles of the response distribution. Wang et al. (2016) introduced QR into a structural equation model (SEM) to assess the conditional quantile of the outcome latent variable given the explanatory latent variables and covariates. Liu et al. (2020) proposed a quantile hidden Markov model to examine the entire conditional distribution of the response given the hidden state and potential covariates. Factor analysis models can be converted to IRT models under possible parameterizations (Kamata and Bauer, 2008; Wang and Zhang, 2019). Therefore, it is reasonable and implementable to apply QR to MLIRT models.
This study is motivated by the MLIRT models focus largely on the relationship between variables at the mean level, which may result in neglecting potential differences across the response distribution. Herein, taking a two-level (i.e., item level and student level) IRT model as a demonstration, we embed the QR approach in a MLIRT model to obtain what we refer to as the quantile MLIRT (Q-MLIRT) model. This approach enables us to investigate the relationship between explanatory variables and latent variables at various locations of the response distribution, as well as having minimal assumptions on error terms, which is a flexible and applicable approach in general. Moreover, the Q-MLIRT model can be estimated in a Bayesian framework with a Markov chain Monte Carlo (MCMC) algorithm. It should be emphasized that the Q-MLIRT model is not a replacement but a supplement to the conventional MLIRT model. If the relationship between explanatory variables and latent variables on the entire distribution is of interest, Q-MLIRT is a good recommendation.
The rest of this paper is organized as follows. The proposed Q-MLIRT model is introduced in Section “Model Description,” the MCMC algorithm is presented in Section “Bayesian Estimation,” and a simulation study conducted to evaluate the empirical performance of the proposed method is reported in Section “Simulation Study.” A real data study to demonstrate the use of Q-MLIRT models is reported in Section “Empirical Example,” and finally a discussion and suggestions for further research are presented in Section “Discussion.”
Model Description
Before describing the Q-MLIRT model considered here, we revisit MLIRT models briefly. We consider only a two-level IRT model, namely an item level and a student level. As presented by Adams et al. (1997), the two-level IRT model consists of two components: the measurement part—an IRT measurement model—which describes the probability of observed responses conditional upon the latent variable, and the structural part—a LR model—which describes the between-student variation in the latent variable. The LR model is on ability parameters, where the ability parameter is dependent on the covariates:
where θi is the latent trait (i.e., ability) of student i (i = 1,…,n), Xi is a q × 1 vector of known covariates (e.g., gender, socioeconomic status, and major) for student i, and β is the corresponding q × 1 vector of regression coefficients. We assume that δi are independently and identically normally distributed with mean zero and variance α2. In this form, a student’s achievement or performance is represented as ability parameter θi, and the relationship between students’ abilities and the involved explanatory variables is reflected in the regression coefficients β. Note that the coefficients of all covariates are treated as fixed effects here.
LR analysis measures the relationship between explanatory variables and students’ abilities by modeling a conditional mean function of θi. Given explanatory variables Xi, then:
That is, the conditional distribution of θi is assumed to be a linear combination of covariates Xi with normally distributed errors. In usual LR approaches, the data are used to find out a single regression line that minimizes the sum of squared errors (least squared estimation) to estimate the relationship. Consequently, the focus is on average performance of response variables about covariates. However, as mentioned above, the errors may be non-normally distributed or even heteroscedastic in reality, and when a distribution is asymmetric (e.g., heavy-tailed or skewed), the mean is not the center of the distribution, while the median is likely to be a more appropriate measure of central tendency than the mean (Edgeworth, 1888; Fox, 1997; Koenker and Ng, 2005; Hao and Naiman, 2007; Trafimow et al., 2018). What is more, the relation between explanatory variables and latent variables may be different across the entire distribution. As a result, the conditional mean fails to meet the research needs in many cases. Therefore, we must provide an elaborate or specific description of the inter-relationship among latent variables and explanatory variables.
A more appropriate analysis can be achieved from conditional quantiles of θi. QR provides a suitable method for modeling conditional quantile functions (Koenker and Hallock, 2001). Under a number of different quantiles τ ∈ (0,1), we say the τth quantile of δi is the value qτ, for which p(δi < qτ) = τ, that is Qτ(δi) = qτ. The τth conditional quantile of θi can be then expressed as:
where βτ is a q × 1 vector of QR coefficients depend on τ, and it reflects the relationship between Xi and the τth conditional quantile of θi, which means the marginal effects of the explanatory variables may differ over quantiles of the distribution of θi. Since numerous quantiles (e.g., 25%, 50%, 75%) are modeled in QR, it is possible to understand the relationship between variables at various locations of the response distribution. For example, when τ = 0.5, is the conditional median of θi, and βτ reflects the relationship between explanatory variables and the conditional median of θi. In QR approaches, the classical inference of βτ is through a minimization of the weighted sum of absolute residuals for all the observations.
Therefore, θi can be assessed in the following QR-type structural model, by the τth conditional quantile of θi plus an error term:
Unlike in the LR model [i.e., Eq. (1)], here the distribution of δi is not specified. The only assumption is that the τth quantile of δi is zero, that is qτ = 0, so that we have Eq. (3). In other words, the QR structural model does not rely on any parametric specification of the conditional distribution of θi. Note that when the error term δi in Eq. (4) is normally or symmetrically distributed, results of LR and QR at the median (τ = 0.5) are consistent, in other words, the MLIRT model of Eq. (1) is a special version of the Q-MLIRT model with normality of δi and τ = 0.5.
Therefore, the two-level Q-MLIRT model can be defined by combining Eq. (4) with an IRT model, namely:
where we adopt a two-parameter normal ogive (2PNO) model in the first level. In this article, only dichotomously scored items are considered. Here, Φ denotes the cumulative standard normal distribution function, Yik = 1 means a correct response of student i on item k(k = 1,…K), and ak and bk are the discrimination and difficulty parameters, respectively, of item k. The second level is QR on the ability parameters with an arbitrary quantile τ ∈ (0,1), and the parameters have the same meanings as those in Eq. (4).
Herein, we fix the item parameters of one item as known (i.e., a_1=1 and b_1=0) to identify the Q-MLIRT model as did Fox and Glas (2001). In the subsequent analysis, we show that the proposed model offers a more complete view of the relationship among explanatory variables and latent variables at various locations of the response distribution, including the central tendency, upper tail, and lower tail. In many cases, the error terms are non-normally distributed or heterogeneous, which fails to meet the assumption of LR, but nevertheless QR is also suitable for such cases.
Bayesian Estimation
We adopt the Bayesian estimation approach in the QR structural model (e.g., Yu and Moyeed, 2001; Lee and Neocleous, 2010; Reich et al., 2011; Wang et al., 2016). Combined with the Gibbs sampling method for 2PNO models (Albert, 1992), a fully Bayesian approach is presented to estimate the parameters of the Q-MLIRT model. Similar to Wang et al. (2016), we adopt the asymmetric Laplace distribution1 (ALD1; Yu and Moyeed, 2001) to approximate the distribution of error terms in the QR structural model. More details about the ALD and the Bayesian QR method are presented in Appendix. Specifically, we assume δi∼ALD(0,ω,τ), then θi follows . As shown by Reed and Yu (2009); Kozumi and Kobayashi (2011), if a random variable follows ALD (μ,ω,τ) then it can be represented as a normal distribution, so we obtain:
where , , and e = {e1,e2,⋯,en} follows an exponential distribution with scale parameter ω. That is to say, the parameter space is augmented by a latent variable e. This mixed representation of enables Bayesian inference based on the Gibbs sampling algorithm to estimate the parameters of the QR structural model.
Gibbs Sampling
From Eq. (5), the observations consist of the item responses Y in the first level and the explanatory variables X in the second level. As a result, the full posterior distribution of the parameters given the observed data is:
where the augmented data zik follow:
where φ is the normal probability density function (PDF) and I(⋅) is an indicator function.
The following conjugate prior distributions of the model parameters are used:
where μa, σa, μb, σb, Λ0β, H0β, α0ω, and β0ω are hyperparameters. The detailed procedure of the Gibbs sampling algorithm is summarized below.
Step 1: Sampling zik. Let ξ be the vector of all item parameters, given the parameters θ and ξ, the variables zik are independent. For i = 1,…,n and k = 1,…,K, the fully conditional posterior distribution of zik can be written as:
Step 2: Sampling ak. According to the principle of conjugate distribution and combined with the prior of a, the fully conditional posterior density of a_k follows:
Step 3: Sampling b_k. The fully conditional posterior density of bk is:
Step 4: Sampling θi. The ability parameters are independent given other parameters. Using Eqs. (6) and (8), it follows that:
Eq. (11) is a normal model, where θi has a normal prior parameterized by βτ,ei, and ω. So the fully conditional posterior density of θi is given by:
where , .
Step 5: Sampling ω. Letting v = ω−1 and using the gamma conjugate prior density for v and the PDF of , the fully conditional posterior distribution of v is given by:
from which we have:
Step 6: Sampling ei. From Eq. (6) together with an exponential distribution of e_i with scale parameter ω, the fully conditional posterior distribution of follows an inverse Gaussian distribution.
Step 7: Sampling βτ . Because Eq. (6) is a normal distribution conditionally on e_i, it is straightforward to derive the fully conditional posterior distribution of βτ, which is given by:
where and .
Simulation Study
In this section, a simulation study is carried out to evaluate the performance of the Q-MLIRT model. We evaluate the parameter recovery with the Gibbs sampler. The Gibbs sampling algorithm is implemented in MATLAB (MathWorks, 2016), and the source code is available to readers upon request.
Simulation Design
Two covariates X1 and X2 are considered, which are independent standard normal variables. The latent variable θi(i = 1,…,n) is generated from three different models:
Case 1: θi = β1Xi1 + β2Xi2 + δi, δi∼N(0, 0.5)
Case 2: θi = β1Xi1 + β2Xi2−ρτ|β1Xi1 + β2Xi2| + |β1Xi1 + β2Xi2|δi, δi∼N(0, 1)
Case 3:θi = β1Xi1 + β2Xi2 + δi. δi∼Gamma(0.5, 1)−0.5
Parameters β1 and β2 are set to 0.5. Case 1 represents a normal and homoscedastic error model, the assumption of which conforms to that of LR models, case 2 represents a heteroscedastic error model, and case 3 represents a skewed error model. Of these, cases 2 and 3 evaluate the Q-MLIRT model with heavy-tailed and non-normal latent variables, respectively. For cases 1 and 3, the conditional τth quantile of θ takes the form Qτ(θ|X1,X2) = β0τ + β1τX1 + β2τX2, where β0τ = ρτ, β1τ = 0.5, β2τ = 0.5 for τ ∈ (0,1), and ρτ is the τth quantile of δi. For case 2, the conditional quantile function is Qτ(θ|X1,X2) = β1X1 + β2X2−ρτ|β1X1 + β2X2| + ρτ|β1X1 + βX2| = β1τX1 + β2τX2, where β1τ = 0.5 and β2τ = 0.5 for τ ∈ (0,1).
In order to estimate the QR coefficients β1τ and β2τ under different quantiles, and compare with their theoretical values 0.5, three quantile levels (i.e., τ = 0.25, 0.5, and 0.75) are chosen, which represent the lower, central, and upper tail of the response distribution, respectively. We consider three sample sizes (i.e., n = 500, 1000, 2000) and two test lengths (i.e., K = 20, 40). Overall, there are 54 conditions (3 structural models × 3 quantiles × 3 sample sizes × 2 test lengths). Response patterns are generated by the 2PNO model, with the discrimination parameters generated from U(0.5, 1.5) and the difficulty parameters generated from N(0,0.5).
For the conjugate normal prior of βτ, we set the prior mean Λ0β = (0, 0, 0) and the covariance matrix H0β is 100 times an identity matrix; which is a type of weakly informative prior. For the conjugate inverse gamma prior of ω, we set α0ω = 28 and β0ω = 4. For the prior of item parameters a and b, we set μa = 0, σa = 200 and μb = 0, σb = 100, respectively.
The Gibbs sampling estimation procedure of the Q-MLIRT model was iterated 10,000 times. A burn-in period of 5,000 iterations was used, and the parameter estimate was the mean of the posterior distribution of the parameter. The convergence of the Gibbs sampler was checked by the Gelman–Rubin method (Gelman and Rubin, 1992), and the values of the potential scale reduction factor (PSRF) in the burn-in period were less than 1.10 for all parameters. Overall, 100 replications were conducted across all simulation conditions.
A related issue must be considered in the application of Q-MLIRT, namely that the estimates of item parameters differ for different quantiles because of the fact that the fully conditional posterior distribution of item parameters depends on τ. As can be seen from Eq. (6), the location and scale of θi are changed in the estimation process of item parameters under different quantiles. In this case, bias may not make sense, a large bias does not mean poor estimates, and the results of different quantiles are also not comparable. We expect the estimates of item parameters under different quantiles are close to each other after some transformation. To this end, we introduce a new measurement that is actually suitable for situations in which item parameters are estimated on different IRT scales, to further illustrate the similarity and comparability between them.
It is known that if θi have a transformation relationship on two scales, namely:
where p and t are constants, then the relationships between the item parameters can be formulated as:
In this case, we can use similarity functions, such as the cosine function, to measure the similarity of item parameters at different scales. Two vectors are defined to be similar if the distance between them is small, which is measured by the cosine of the angle between them. Let a = (a1,…,ak) and be the discrimination parameter vectors on two different scales, then the cosine similarity between the two vectors is defined as:
If , then cos(a,a*) = 1. Similarly, the cosine similarity between two difficulty parameter vectors b = (b1,…,bk) and can be defined as:
where Eb and Eb* are the means of the elements in vectors b and b∗, respectively. If , then cos(b,b*) = 1.
In this sense, if the cosine of the angle between the true-parameter vector and the estimated-parameter vector is close to 1, it can be concluded that these two vectors are very similar and close, and the estimates can also be called “good estimates;” conversely, if the cosine is away from 1, it indicates that these two vectors are very different, and the estimates can also be called “bad estimates.” The higher the cosine similarity, the closer they are. Note that the “good” and “bad” estimates are just defined in the context of the transformation relationship that we considered as above, and accuracy of all the item parameters’ estimations is measured by the cosine similarity. The upshot is, when the estimated results of item parameters under each quantile are close to each other and are both good (i.e., the calculated cosine similarity of item parameters under each quantile is close to 1), we say that the item parameters are well recovered and that any group of estimates can be selected. Otherwise, the recovery of item parameters is poor and the results of different quantiles are not comparable to one another to some extent.
Given that there is no existing work on Q-MLIRT in the literature, we compare the estimated results with the two-level structural IRT model denoted in Eq. (1), where the structural model is a LR on θi. Hereafter, we refer to it as the mean regression multilevel IRT (M-MLIRT) model. We estimate it through a fully Bayesian estimation procedure that is easily extracted from the estimation procedure in Fox and Glas (2001). We use the average root-mean-square error (RMSE), the average bias, and the average cosine similarity to evaluate parameter recovery.
Simulation Results
Tables 1, 2 summarize the parameter recovery of the item parameters for the Q-MLIRT model in comparison to the M-MLIRT model for small and large test lengths respectively. In general, the item parameters are estimated accurately in all the cases (i.e., cases 1, 2, and 3). For each sample size, estimates of the item parameters of the Q-MLIRT model under different quantiles are close to the true parameter values, reflected mainly in the facts that (i) the cosine similarities between the true-parameter vector and the estimated-parameter vectors under different quantiles are all very close to 1 and (ii) the RMSEs are all small. In addition, when the sample size increases from 500 to 2,000, the cosine similarities increase, the RMSE and the bias in almost cases decrease for the estimates of item parameters. Results show that with increasing test length, the accuracy of almost all item parameters’ estimations also has some improvement, this could because we can get more accurate information from students as they answer more items.
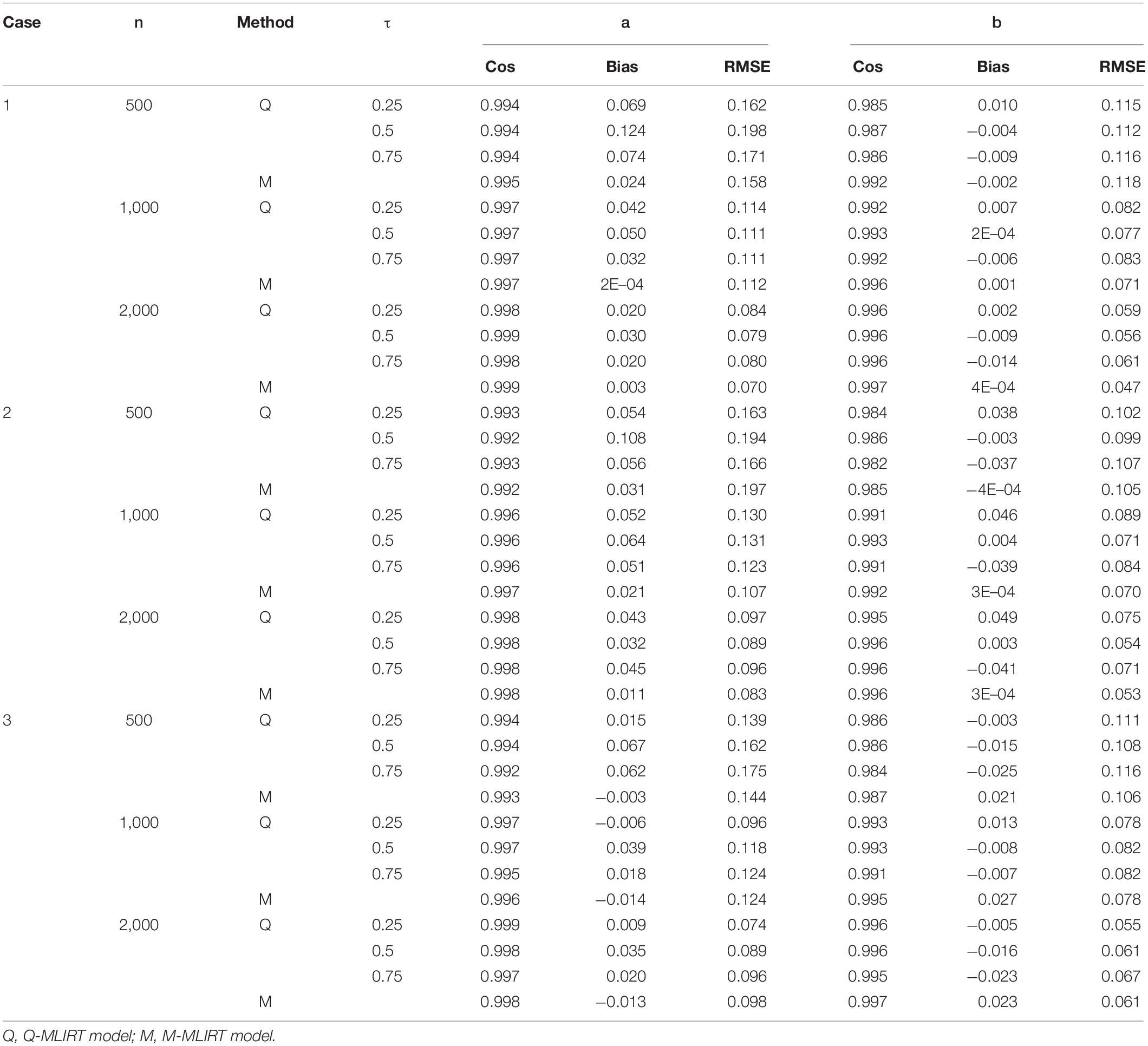
Table 1. Summary of parameter recovery of item parameters when K = 20.
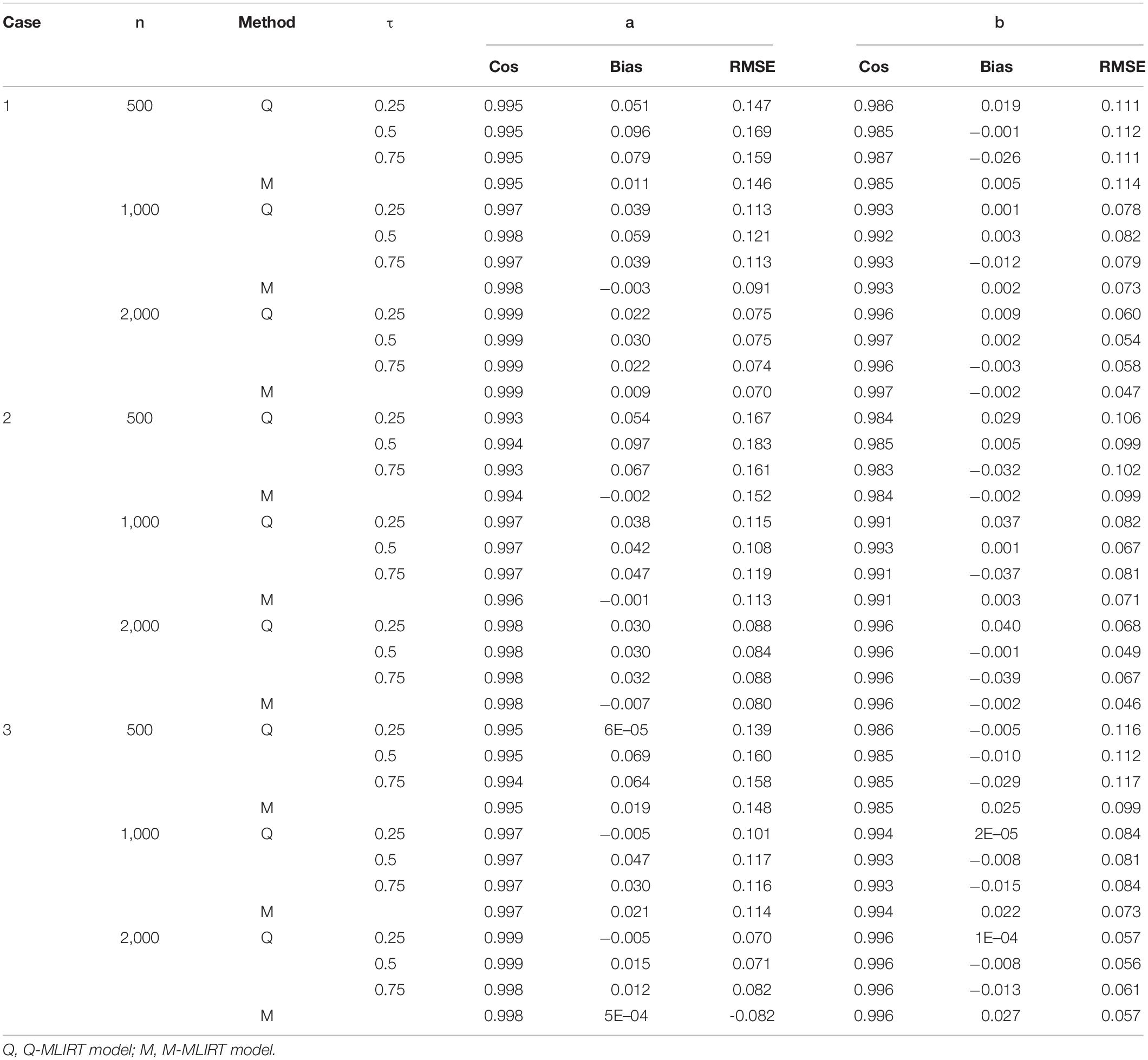
Table 2. Summary of parameter recovery of item parameters when K = 40.
From Tables 1, 2, it is also indicated that, as for the estimation of item parameters, the item parameters’ estimations of the M-MLIRT model and the Q-MLIRT model are close in each case, mainly from the reflect of the cosine similarities and RMSEs. It should be noted that although for case 2 and case 3, the distribution of ability is non-normal, it seems not to have effects on the estimation of item parameters for the MLIRT model. Specifically, for case 3, the bias of the difficulty parameters for the M-MLIRT model are always larger than the Q-MLIRT model, but from the cosine similarity and RMSE points of view, the estimates of the difficulty parameters for the M-MLIRT model and Q-MLIRT model are close. The relationship between the cosine similarity and the bias, and how they behave in more different situations, are worthy of further study and discussion.
Tables 3, 4 give the estimated results of the structural regression coefficients for the Q-MLIRT model in comparison with those of the M-MLIRT model. First, it can be concluded that the regression coefficients are estimated accurately in all the cases (cases 1, 2, and 3) for the Q-MLIRT model. When the sample size increases from 500 to 2,000, the RMSEs decrease with increasing sample size, which means that the estimates are increasingly stable. The bias of regression coefficients also decreases obviously with increasing sample size, especially when τ = 0.5. The trends are less obvious for quantiles 0.25 and 0.75, mainly because there are few samples at the upper and lower tails (τ = 0.75 and 0.25, respectively) of the conditional distribution of θi. Nevertheless, the directions of the bias are increasingly consistent with increasing sample size, especially when n = 2,000, which means that the estimates tend to true and stable values. From Table 4, the results show that as larger test length leads to more accurate estimations of the structural regression coefficients, mainly reflecting in the decreased biases and RMSEs in almost all conditions. Together with the estimation of item parameters, it can be concluded that the increase of test length will improve the accuracy of parameter estimation of the Q-MLIRT model, especially for the structural regression coefficients.
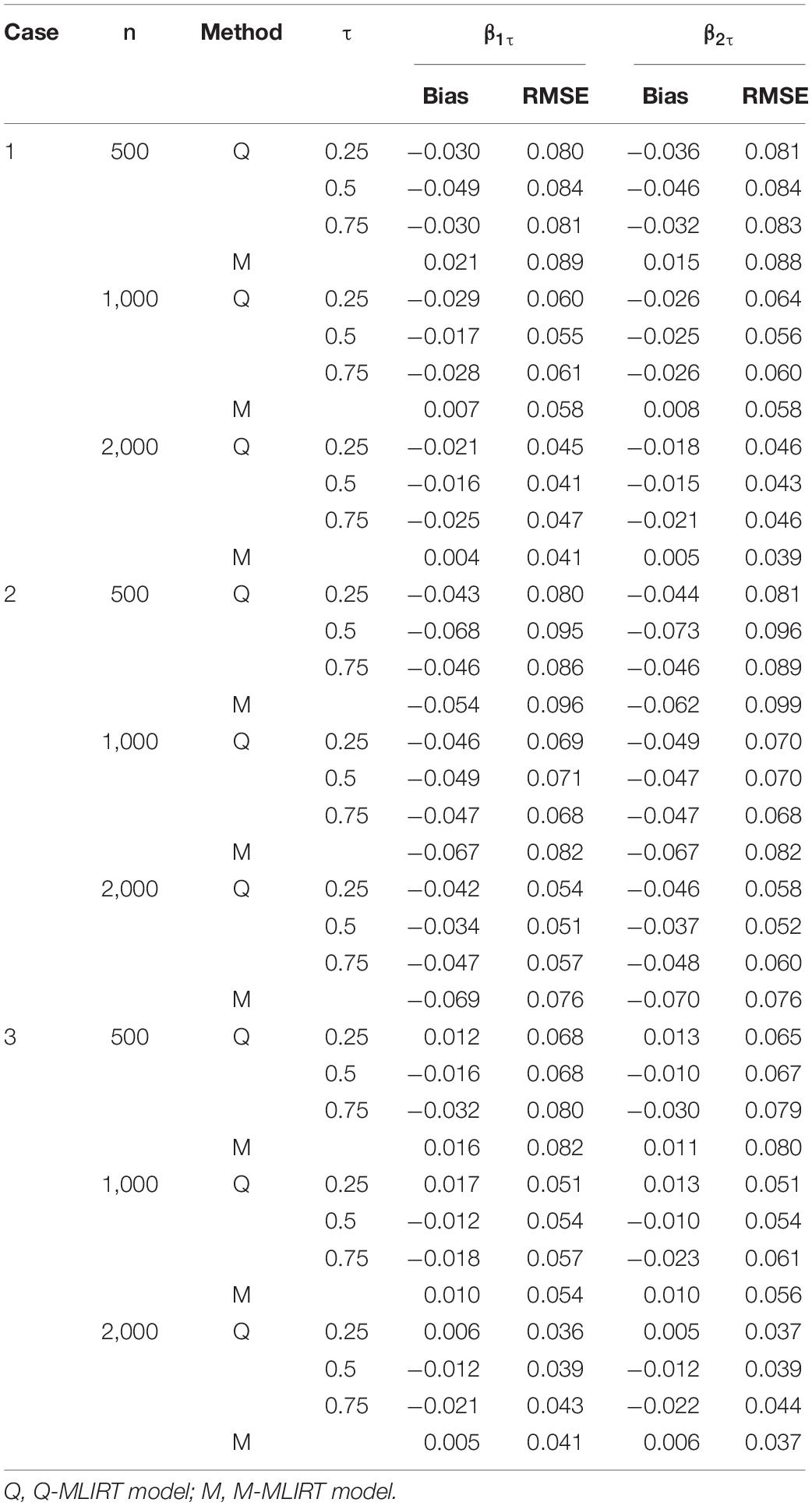
Table 3. Bayesian estimates of regression coefficients when K = 20.
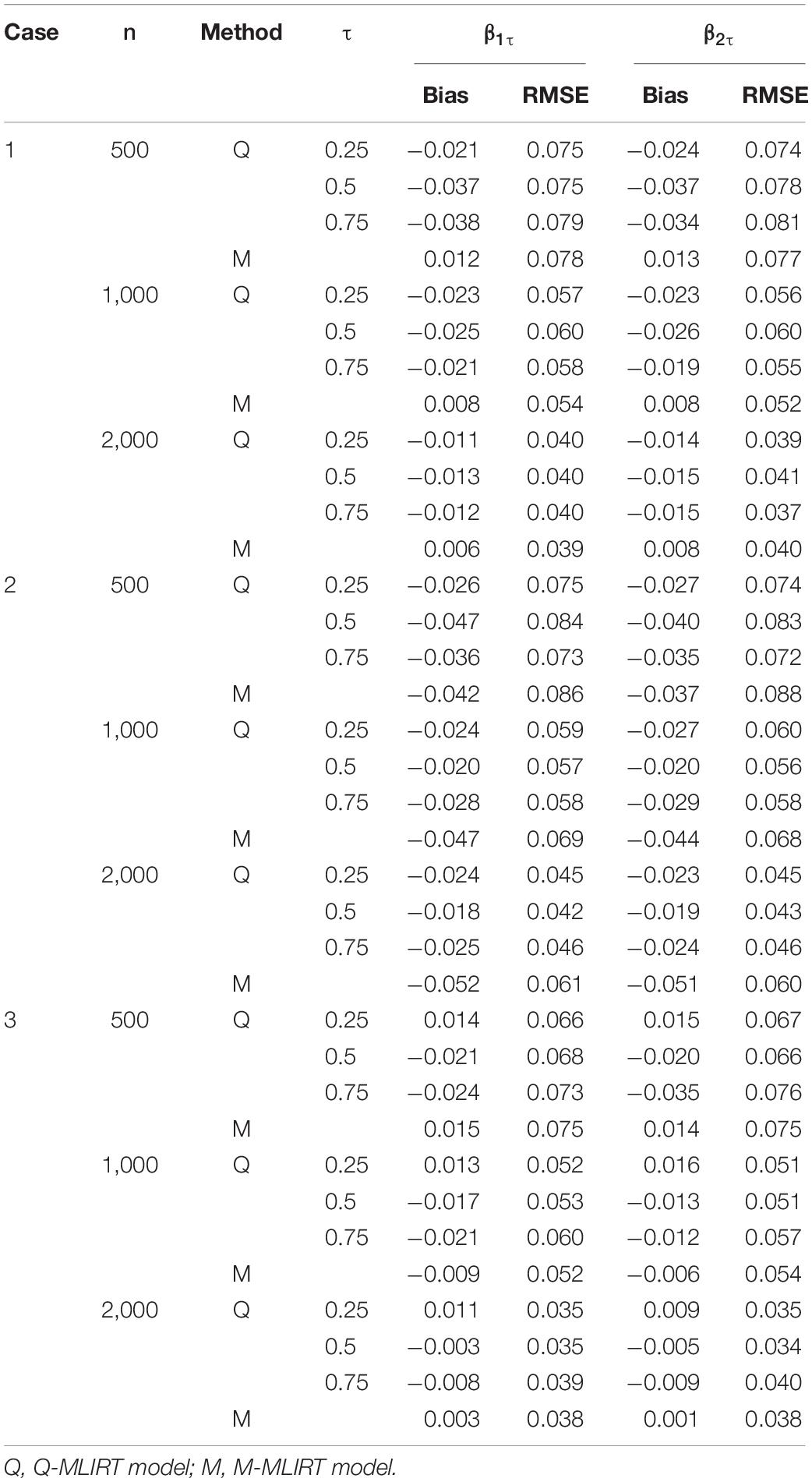
Table 4. Bayesian estimates of regression coefficients when K = 40.
When comparing the estimation of regression coefficients of the M-MLIRT model and the Q-MLIRT model, we find that: first, M-MLIRT slightly outperforms Q-MLIRT in case 1. This is because that the error distribution in case 1 is normal, which meets the assumption of the LR model, so we expect the M-MLIRT model to outperform in that case; second, for case 2, the regression coefficients estimated by the M-MLIRT model are worse than those by the Q-MLIRT model to some extent. Specifically, the results are similar at τ = 0.5 when the sample size is small, but with increasing sample size, there are larger bias and RMSE for the estimates of the M-MLIRT model than those of the Q-MLIRT model. This is mainly because the error is heteroscedastic and the distribution of θi is heavy-tailed, and LR models are sensitive to heavy-tailed distributions and extreme outliers. For case 3, the results are close to each other, although the error term has a skewed distribution. It is perhaps that the degree of skewness of the distribution in case 3 is insufficient to influence the estimation of the regression coefficients in MLIRT.
Empirical Example
The main research question in this section is how the explanatory variables of interest regarding individual characteristics and family background are related to students’ achievement in mathematics. It is quite possible that the relation between explanatory variables and students’ achievement may differ across different levels of students’ achievement, while LR only provides us the information about the conditional mean of students’ achievement and ignores the characteristics of the entire distribution of students’ achievement. Thus, the proposed Q-MLIRT model is expected to achieve a more appropriate analysis.
Data Source
In this section, a subset of the PISA 2018 mathematics data was analyzed. There were 24 test forms/booklets that contained clusters of items from the mathematics domain. Each test form included four clusters, two clusters of items from the reading domain and one or two clusters of items from the mathematics domain. We chose a group of students from the United States who were administered test forms 1 to 6 for analysis. Each of these forms contained two mathematics clusters. Therefore, there were six clusters (i.e., M01-M06) in which contained 64 mathematical items. Because each student received one of the forms from his or her assigned group, and each form contained different items, so each student answered about 20 items and each item was answered about by 375 students. The sample size was n = 840 after eliminating students with missing data, and there were K = 64 dichotomous items. More information on the PISA 2018 data can be found at www.oecd.org/pisa/data/2018database/.
Three individual and family background variables, that have been used in most studies (e.g., Adams et al., 1997; Fox and Glas, 2001; Fox, 2005; Lu et al., 2018), were chosen as explanatory variables of interest. The student-grade variable (X1) equaled −1, 0, and 1, which represented grade 9, grade 10, grade 11, respectively. The corresponding number of students in each grade was 59, 630, and 150. Since only one student was in grade 12, so her was removed, hence the final sample size was n = 839. The student-gender variable (X2) equaled 0 (female) or 1 (male), the corresponding number of students was 421 and 418. The ESCS (economic, social, and cultural status of parents) variable (X3) was normally standardized. Information of these explanatory variables are summarized in Table 5.

Table 5. Summary of explanatory variables.
Method
The PISA 2018 technical report stated that the item parameters were calibrated by the two-parameter logistic model (2PLM) or the generalized partial credit model (GPCM). As only dichotomously scored items are considered, we use the 2PNO model here, and we fix the first discrimination parameter to one and the first difficulty parameter to zero to identify the model. To assess the effects of the explanatory variables above on students with different ability levels, the QR model is given by:
where i = 1,…,839, βτ = (β0τ,β1τ,β2τ,β3τ)T is a 4 × 1 vector of unknown QR coefficients under the τth quantile of the ability distribution, Xi = (1,X1i,X2i,X3i)T is a 4 × 1 vector that represents the explanatory variables of student i, the distribution of the error term is assumed as AL(0,ω,τ). The estimation was conducted for the quantiles of τ = 5%, 10%, 25%, 50%, 75%, 90%, and 95% to obtain a more thorough overview of the relationship between these explanatory variables and students’ mathematical achievement.
In the Bayesian analysis, the hyperparameters of the prior distributions were given as assigned in the simulation study. In the implementation of the Gibbs sampling algorithm, 10,000 iterations were done to estimate the parameters with an initial burn-in of 5,000 iterations. Convergence of the chains was checked by PSRF, and the PSRF values were less than 1.10 in the burn-in phase for all parameters under each quantile.
The M-MLIRT model was also used to fit the data, and compared with the Q-MLIRT model using deviance information criterion (DIC, Spiegelhalter et al., 2002). The model with smaller DIC was recommended as a better-fitting one. The DIC calculated using the joint likelihood conditioned on parameters at all levels. For the Q-MLIRT model, the joint likelihood is:
and the joint DIC for the τth quantile of the Q-MLIRT model is defined as:
For the M-MLIRT model, the joint likelihood is:
and the joint DIC is defined as:
Interested readers can refer to Celeux et al. (2006); Wang et al. (2013), Zhang et al. (2019) for more information of the joint DIC.
Results
The parameter estimates of the Q-MLIRT model under various quantiles and the M-MLIRT model (reported in column “M”) are presented in Tables 6, 7. For the limited space, we only present the results of the item parameters of cluster 1 from form 1, there are 9 items. From Table 6, it is showed that the estimates of item parameters obtained based on the M-MLIRT model are close to the results obtained from the Q-MLIRT model, especially at 50% quantile. We calculated the cosine similarity between each two discrimination-parameter vectors and each two difficulty-parameter vectors estimated under different quantiles, and these values were all very close to 1, that means they are very similar to each other, and we can choose any group of them as the estimations. Figure 1 shows item parameter estimates of the M-MLIRT model and three selected groups of item parameters estimated under τ = 25%, 50%, and 75% of the Q-MLIRT model, which represent the corresponding results of the lower, middle, and higher quantiles, respectively. As can be seen, all the estimates of item parameters under different quantiles are close and of the same size order.
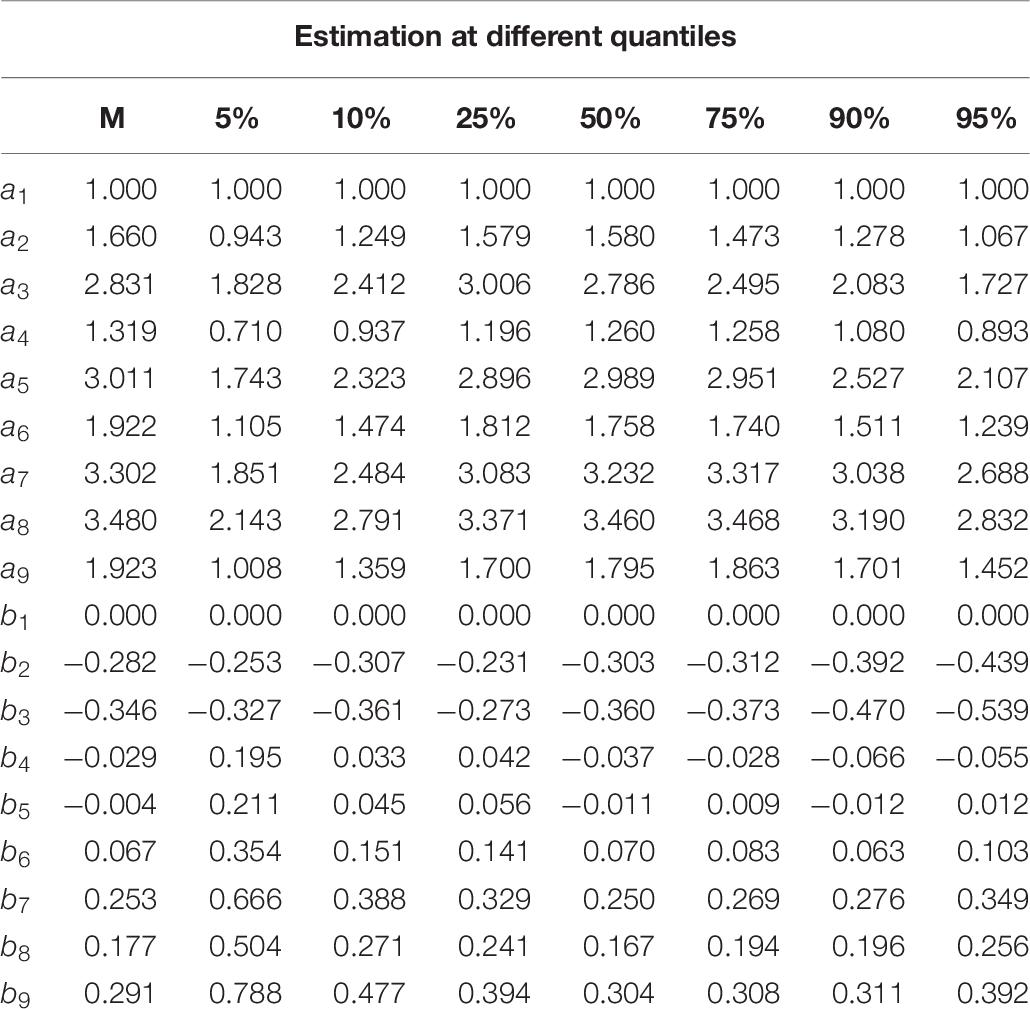
Table 6. Item parameter estimates of PISA data.
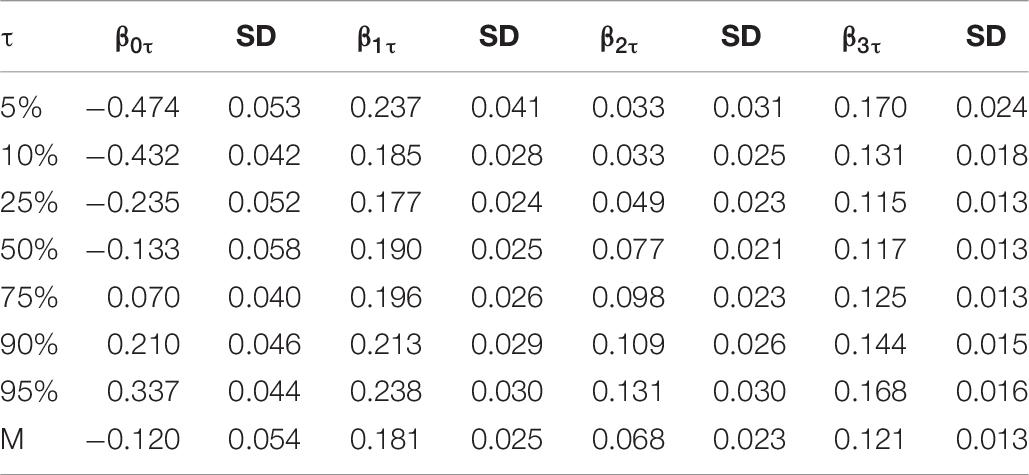
Table 7. Structural regression coefficient estimates of PISA data.
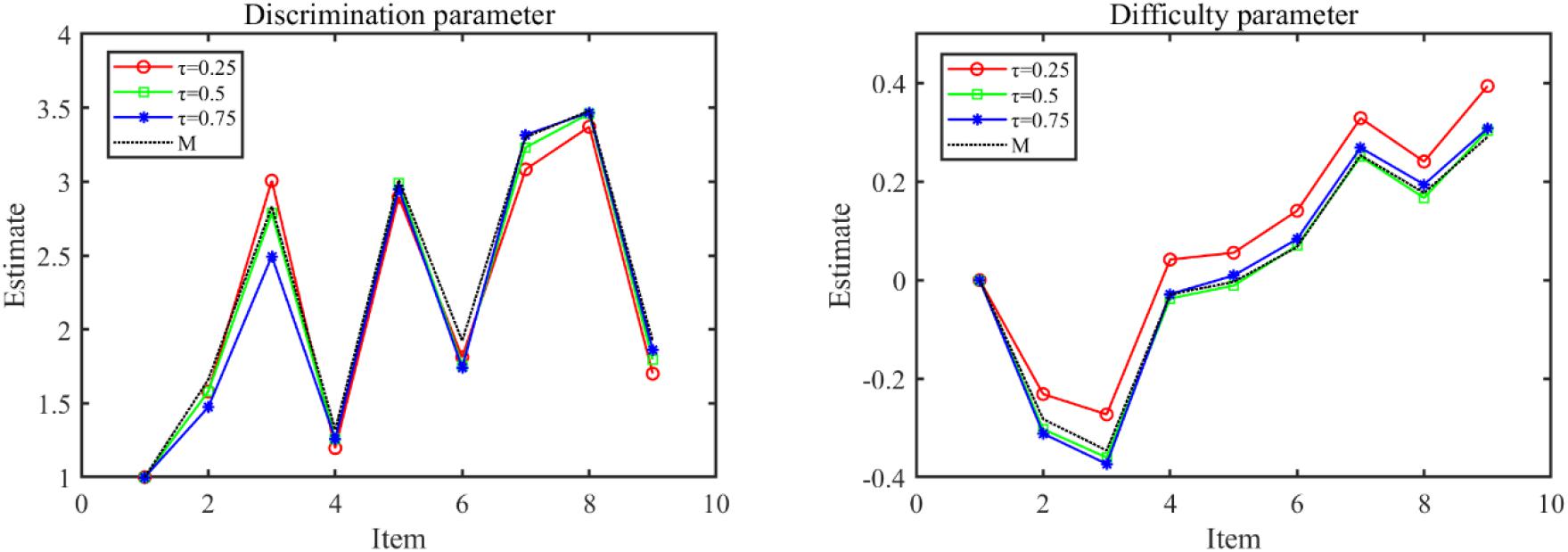
Figure 1. Item parameter estimates of the M-MLIRT(M) model and the Q-MLIRT model under different quantiles (τ = 25, 50, and 75%).
The relationship between students’ mathematical achievement and the predictors can be deduced from the structural regression coefficients, the estimates of the QR and LR coefficients associate with the posterior standard deviations (SD) are showed in Table 7. The results of the M-MLIRT model show that, on average, the student grade and family background (i.e., ESCS) variables have significantly positive correlations with students’ mathematical achievement. Specifically, students in higher grades perform better, and students whose parents have higher economic, social, and cultural status have better mathematical achievement. But for gender, results of M-MLIRT show that there is a weakly positive correlation between gender and mathematical achievement, the performance of male students is slightly better than female students.
When the results of M-MLIRT and Q-MLIRT are compared, it is argued that there are several differences between these two models. The results of the Q-MLIRT model show that relationships between these explanatory variables and students’ mathematical achievement are different across the achievement distribution. First, we find positive correlations between those explanatory variables and mathematical achievement at various locations along the distribution, and the results of Q-MLIRT at 50% quantile are as close as the M-MLIRT. For student grade and family background variables, it is found that the positive correlations between them and mathematical achievement are more significant at lower and higher quantiles of the distribution, that is the relationships between them and mathematical achievement are stronger in students with high-ability and low-ability. Regarding gender, we find that the QR structural coefficient of gender increases from 5% quantile towards the 95% quantile of the achievement distribution, which means that male students perform better than female students in mathematics, and the difference is exacerbated among high-ability students. This finding is consistent with González de San Román and De La Rica (2012). They analyzed gender gaps in PISA test scores in their study, and showed that in most PISA participating countries, male students outperformed than female students in mathematical achievement, moreover, gender gap in test scores differed significantly in different parts of the test score distribution, where the gap increased from the lower tail to the upper tail. The structural regression coefficients across the various quantiles are illustrated further in Figure 2.
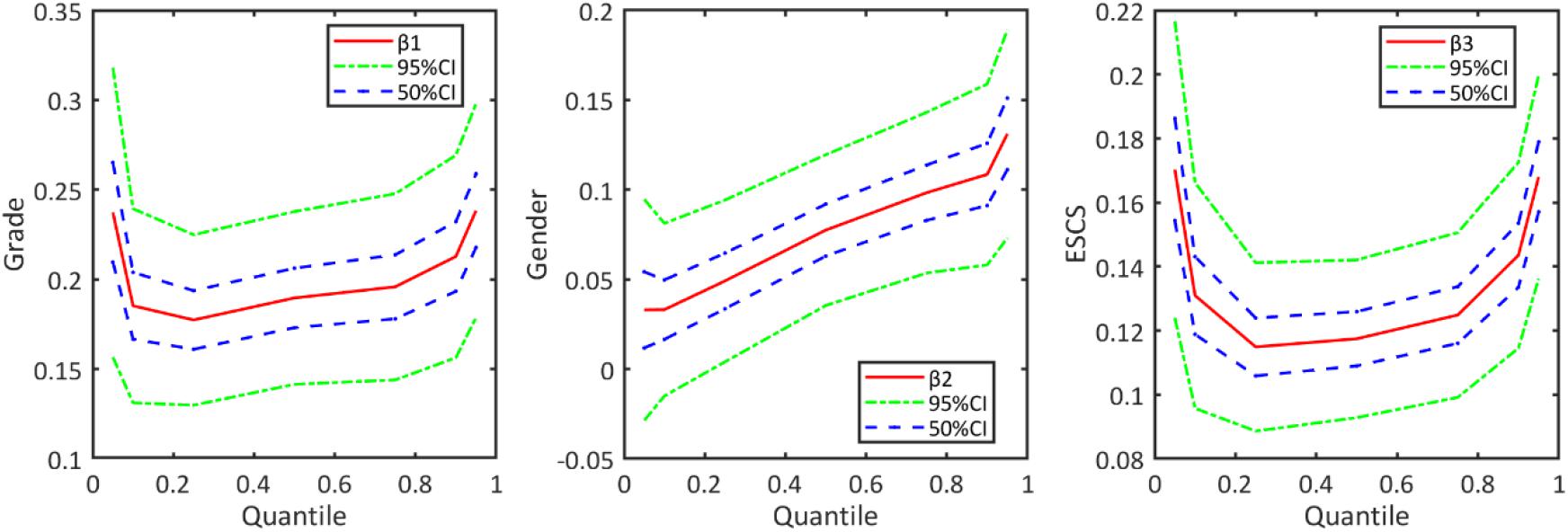
Figure 2. Regression coefficients of Q-MLIRT model across different quantiles in the analysis of PISA data, along with the corresponding 50 and 95% credible intervals.
In addition, Table 8 shows a comparison of the Q-MLIRT model and the M-MLIRT model based on the joint DIC. Results indicate that for the Q-MLIRT model, 25% quantile is the best-fitting, followed by quantiles at 75%, 50%, 10%, 5%, 90% and 95% ones. And the fitting situation of M-MLIRT is nearly equally to the Q-MLIRT model when the quantile is 50% or 75%, this is consistent with what is found in the estimation of parameters, that the parameter estimation results of M-MLIRT is mostly close to the results of Q-MLIRT at 50% and 75% quantiles.

Table 8. Comparing the Q-MLIRT and M-MLIRT using joint DIC for PISA data.
To sum up, the analysis results make it clear that the Q-MLIRT model offers a more comprehensive picture of the relationship between students’ mathematical achievement and the student-background variables. The results suggest that the relationships between students’ mathematical achievement and its predictors differ across different levels of student ability, which can’t be achieved with MLIRT. We find that for students with lower and higher mathematical performances in PISA, their achievements are related more closely to grade, and the socioeconomic status of their family, and the gender difference is more pronounced among high-level students. In this respect, Q-MLIRT is a useful research tool to better understand the relationship between students’ individual characteristics or family background factors and educational achievement. Note that the results, together with some educational knowledge, would provide a deeper insight for related educators on mathematical learning, and these findings will also help them to develop more-targeted policies for students of different ability levels.
Discussion
In this article, a quantile-regression-type structural model was introduced to MLIRT models. The main advantage of this form is that it offers a richer analysis of the relationship between covariates and latent variables. Meanwhile, Q-MLIRT is more robust and is applicable to various distribution of latent variables. In other words, it is more flexible and applicable in general. We also proposed a fully Bayesian estimation algorithm for the Q-MLIRT model so that the parameters in the model could be estimated simultaneously. In addition, we proposed a new evaluation index based on the cosine similarity function to evaluate further the accuracy of the item parameter estimates under different quantiles.
In the simulation study, we used Gibbs sampling to estimate the Q-MLIRT model. The results showed that the parameters could be recovered well in almost all conditions. The Q-MLIRT model was applied to analyze a PISA data set, and the results provided more specific and in-depth insights into the relationship between the explanatory variables of interest and students’ achievement. Also, note that the item parameter estimates differ for different quantiles, although we know they are very close to each other according to the cosine similarity evaluation. An alternative and easy way of applying the Q-MLIRT model in practical problems is to obtain the item parameters at a certain quantile first, such as τ = 0.5 of the model, and then, for analysis with a different value of τ, the item parameters are pre-fixed (Wang et al., 2016).
This study was the first attempt at combining the QR approach with the IRT model in a multilevel modeling framework. However, this study focused only on item response data nested within students. We intend to extend the model to a higher level (school level) and estimate how the school level affects students’ abilities. Moreover, we considered herein only dichotomous response data and one-dimensional ability parameters, whereas Q-MLIRT could be applied to multidimensional and/or polytomous data. In addition, the explanatory variables that we have considered are known covariates, whereas it would make sense to consider latent explanatory variables measured by observations with measurement errors. Finally, variable selection would be of interest applied in Q-MLIRT, especially when some explanatory variables are either insignificant or significant only under some quantiles but not others.
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found here: https://www.oecd.org/pisa/data/2018database.
Author Contributions
HZ did the simulation study and analysis on real data, and completed the writing of the article. WG provided key theoretical and technical support. XZ provided original thoughts and article revisions. All authors contributed to the article and approved the submitted version.
Funding
This research was partly supported by the National Natural Science Foundation of China (Grant 12001092) and the Key Laboratory of Applied Statistics of MOE.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
Adams, R. J., Wilson, M., and Wu, M. (1997). Multilevel item response models: an approach to errors in variable regression. J. Educ. Behav. Stat. 22, 47–76. doi: 10.2307/1165238
Albert, J. H. (1992). Bayesian estimation of normal ogive item response curves using Gibbs sampling. J. Educ. Stat. 17, 251–269. doi: 10.3102/10769986017003251
Allen, D. E., and Powell, S. R. (2011). “Asset pricing, the fama–french factor model and the implications of quantile-regression analysis,” in Financial Econometrics Modeling: Market Microstructure, Factor Models and Financial Risk Measures, eds G. N. Gregoriou and R. Pascalau (London: Palgrave Macmillan), 176–193. doi: 10.1057/9780230298101_7
Belloni, A., Chen, M., and Padilla, O. H. M. (2019). High dimensional latent panel quantile regression with an application to asset pricing. arXiv [Preprint]. arXiv:1912.02151.
Bock, R. D., and Aitkin, M. (1981). Marginal maximum likelihood estimation of item parameters: application of an EM algorithm. Psychometrika 46, 443–459. doi: 10.1007/bf02293801
Bock, R. D., and Lieberman, M. (1970). Fitting a response model for dichotomously scored items. Psychometrika 35, 179–197. doi: 10.1007/bf02291262
Burgette, L. F., and Reiter, J. P. (2012). Modeling adverse birth outcomes via con?rmatory factor quantile regression. Biometrics 68, 92–100. doi: 10.1111/j.1541-0420.2011.01639.x
Celeux, G., Forbes, F., Robert, C. P., and Titterington, D. M. (2006). Deviance information criteria for missing data models. Bayesian Anal. 1, 651–673. doi: 10.1214/06-ba122
Chen, F., and Chalhoub-Deville, M. (2014). Principles of quantile regression and an application. Lang. Test. 31, 63–87. doi: 10.1177/0265532213493623
Costanzo, A., and Desimoni, M. (2017). Beyond the mean estimate: a quantile regression analysis of inequalities in educational outcomes using INVALSI survey data. Large Scale Assess. Educ. 5:14. doi: 10.1186/s40536-017-0048-4
Dunson, D. B., Watson, M., and Taylor, J. A. (2003). Bayesian latent variable models for median regression on multiple outcomes. Biometrics 59, 296–304. doi: 10.1111/1541-0420.00036
Entink, R. K., Fox, J.-P., and van Der Linden, W. J. (2009). A multivariate multilevel approach to the modeling of accuracy and speed of test takers. Psychometrika 74, 21–48. doi: 10.1007/s11336-008-9075-y
Feng, X.-N., Wang, Y., Lu, B., and Song, X.-Y. (2017). Bayesian regularized quantile structural equation models. J. Multivariate Anal. 154, 234–248. doi: 10.1016/j.jmva.2016.11.002
Finch, H. (2010). Item parameter estimation for the MIRT model: bias and precision of confirmatory factor analysis—based models. Appl. Psychol. Meas. 34, 10–26. doi: 10.1177/0146621609336112
Finch, H. (2011). Multidimensional item response theory parameter estimation with nonsimple structure items. Appl. Psychol. Meas. 35, 67–82. doi: 10.1177/0146621610367787
Fox, J. (1997). Applied Regression Analysis, Linear Models, and Related Methods. Thousand Oaks, CA: Sage Publications, Inc.
Fox, J.-P. (2004). Applications of multilevel IRT modeling. Sch. Eff. Sch. Improv. 15, 261–280. doi: 10.1080/09243450512331383212
Fox, J.-P. (2005). Multilevel IRT using dichotomous and polytomous response data. Br. J. Math. Stat. Psychol. 58, 145–172. doi: 10.1348/000711005x38951
Fox, J.-P. (2010). Bayesian Item Response Modeling: Theory and Applications. New York, NY: Springer. doi: 10.1007/978-1-4419-0742-4
Fox, J.-P., and Glas, C. A. W. (2001). Bayesian estimation of a multilevel IRT model using Gibbs sampling. Psychometrika 66, 271–288. doi: 10.1007/bf02294839
Fox, J.-P., and Glas, C. A. W. (2003). Bayesian modeling of measurement error in predictor variables using item response theory. Psychometrika 68, 169–191. doi: 10.1007/bf02294796
Gelman, A., and Rubin, D. B. (1992). Inference from iterative simulation using multiple sequences. Statist. Sci. 7, 457–472. doi: 10.1214/ss/1177011136
Giambona, F., and Porcu, M. (2015). Student background determinants of reading achievement in Italy. A quantile regression analysis. Int. J. Educ. Dev. 44, 95–107. doi: 10.1016/j.ijedudev.2015.07.005
González de San Román, A., and De La Rica, S. (2012). Gender Gaps in PISA Test Scores: The Impact of Social Norms and the Mother’s Transmission of Role Attitudes. IZA Discussion Paper No. 6338. Bonn: Institute of Labor Economics (IZA).
Gürsakal, S., Murat, D., and Gürsakal, N. (2016). Assessment of PISA 2012 results with quantile regression analysis within the context of inequality in educational opportunity. Alphanumeric J. 4, 41–54. doi: 10.17093/aj.2016.4.2.5000186603
Haile, G. A., and Nguyen, A. N. (2008). Determinants of academic attainment in the United States: a quantile regression analysis of test scores. Educ. Econ. 16, 29–57. doi: 10.1080/09645290701523218
Harvey, A. C. (1976). Estimating regression models with multiplicative heteroscedasticity. Econometrica 44, 461–465. doi: 10.2307/1913974
Huang, H. Y. (2015). A multilevel higher order item response theory model for measuring latent growth in longitudinal data. Appl. Psychol. Meas. 39, 362–372. doi: 10.1177/0146621614568112
Jarque, C. M., and Bera, A. K. (1980). Efficient tests for normality, homoscedasticity and serial independence of regression residuals. Econ. Lett. 6, 255–259. doi: 10.1016/0165-1765(80)90024-5
Kamata, A. (2001). Item analysis by the hierarchical generalized linear model. J. Educ. Meas. 38, 79–93. doi: 10.1111/j.1745-3984.2001.tb01117.x
Kamata, A., and Bauer, D. J. (2008). A note on the relation between factor analytic and item response theory models. Struct. Equ. Model. 15, 136–153. doi: 10.1080/10705510701758406
Koenker, R., and Bassett, G. Jr. (1978). Regression quantiles. Econometrica 46, 33–50. doi: 10.2307/1913643
Koenker, R., and Bassett, G. Jr. (1982). Robust tests for heteroscedasticity based on regression quantiles. Econometrica 50, 43–61. doi: 10.2307/1912528
Koenker, R., and Hallock, K. (2001). Quantile regression. J. Econ. Perspect. 15, 143–156. doi: 10.1257/jep.15.4.143
Koenker, R., and Ng, P. (2005). Inequality constrained quantile regression. Sankhya 67, 418–440. doi: 10.1017/CBO9780511754098
Kozumi, H., and Kobayashi, G. (2011). Gibbs sampling methods for Bayesian quantile regression. J. Stat. Comput. Simul. 81, 1565–1578. doi: 10.1080/00949655.2010.496117
Lee, D., and Neocleous, T. (2010). Bayesian quantile regression for count data with application to environmental epidemiology. J. R. Stat. Soc. Ser. C Appl. Stat. 59, 905–920. doi: 10.1111/j.1467-9876.2010.00725.x
Liu, H., Song, X., Tang, Y., and Zhang, B. (2020). Bayesian quantile nonhomogeneous hidden markov models. Statist. Methods Med. Res. doi: 10.1177/0962280220942802
Lu, J., Zhang, J., and Tao, J. (2018). Slice–gibbs sampling algorithm for estimating the parameters of a multilevel item response model. J. Math. Psychol. 82, 12–25. doi: 10.1016/j.jmp.2017.10.005
Natesan, P., Limbers, C., and Varni, J. W. (2010). Bayesian estimation of graded response multilevel models using Gibbs sampling: formulation and illustration. Educ. Psychol. Meas. 70, 420–439. doi: 10.1177/0013164409355696
Raudenbush, S. W. (1988). Educational applications of hierarchical linear models: a review. J. Educ. Stat. 13, 85–116. doi: 10.3102/10769986013002085
Reed, C., and Yu, K. (2009). A Partially Collapsed Gibbs Sampler for Bayesian Quantile Regression. Technical Report. London: Brunel University.
Reich, B. J., Fuentes, M., and Dunson, D. B. (2011). Bayesian spatial quantile regression. J. Am. Stat. Assoc. 106, 6–20. doi: 10.1198/jasa.2010.ap09237
Sass, D. A., Schmitt, T. A., and Walker, C. M. (2008). Estimating non-normal latent trait distributions within item response theory using true and estimated item parameters. Appl. Meas. Educ. 21, 65–88. doi: 10.1080/08957340701796415
Schmidt, S., Zlatkin-Troitschanskaia, O., and Fox, J.-P. (2016). Pretest-posttest-posttest multilevel IRT modeling of competence growth of students in higher education in Germany. J. Educ. Meas. 53, 332–351. doi: 10.1111/jedm.12115
Snijders, T. A. B., and Bosker, R. J. (1999). Multilevel Analysis: An introduction to Basic and Advanced Multilevel Modeling. London: Sage.
Spiegelhalter, D. J., Best, N. G., Carlin, B. P., and Van Der Linde, A. (2002). Bayesian measures of model complexity and fit. J. R. Statist. Soc. Ser. B (Statist. Methodol.) 64, 583–639. doi: 10.1111/1467-9868.00353
Stone, C. A. (1992). Recovery of marginal maximum likelihood estimates in the two-parameter logistic response model: an evaluation of MULTILOG. Appl. Psychol. Meas. 16, 1–16. doi: 10.1177/014662169201600101
Svetina, D., Valdivia, A., Underhill, S., Dai, S., and Wang, X. (2017). Parameter recovery in multidimensional item response theory models under complexity and nonnormality. Appl. Psychol. Meas. 41, 530–544. doi: 10.1177/0146621617707507
Trafimow, D., Wang, T., and Wang, C. (2018). Means and standard deviations, or locations and scales? That is the question! New Ideas Psychol. 50, 34–37. doi: 10.1016/j.newideapsych.2018.03.001
Tsionas, E. G. (2003). Bayesian quantile inference. J. Stat. Comput. Simul. 73, 659–674. doi: 10.1080/0094965031000064463
Wang, C., Chang, H. H., and Douglas, J. A. (2013). The linear transformation model with frailties for the analysis of item response times. Br. J. Math. Statist. Psychol. 66, 144–168. doi: 10.1111/j.2044-8317.2012.02045.x
Wang, C., Su, S., and Weiss, D. J. (2018). Robustness of parameter estimation to assumptions of normality in the multidimensional graded response model. Multivariate Behav. Res. 53, 403–418. doi: 10.1080/00273171.2018.1455572
Wang, C., and Zhang, X. (2019). A note on the conversion of item parameters standard errors. Multivariate Behav. Res. 54, 307–321. doi: 10.1080/00273171.2018.1513829
Wang, Y., Feng, X. N., and Song, X. Y. (2016). Bayesian quantile structural equation models. Struct. Equ. Model. 23, 246–258. doi: 10.1080/10705511.2015.1033057
Wirth, R. J., and Edwards, M. C. (2007). Item factor analysis: current approaches and future directions. Psychol. Methods 12:58. doi: 10.1037/1082-989x.12.1.58
Woods, C. M. (2006). Ramsay-curve item response theory (RC-IRT) to detect and correct for nonnormal latent variables. Psychol. Methods 11, 253–270. doi: 10.1037/1082-989x.11.3.253
Woods, C. M. (2015). “Estimating the latent density in unidimensional IRT to permit non-normality,” in Handbook of Item Response Theory Modeling: Applications to Typical Performance Assessment, eds S. P. Reise and D. A. Revicki (Abingdon: Routledge), 60–84.
Woods, C. M., and Thissen, D. (2006). Item response theory with estimation of the latent population distribution using spline-based densities. Psychometrika 71:281. doi: 10.1007/s11336-004-1175-8
Wößmann, L. (2005). The effect heterogeneity of central examinations: evidence from TIMSS, TIMSS-Repeat and PISA. Educ. Econ. 13, 143–169. doi: 10.1080/09645290500031165
Yu, K., Lu, Z., and Stander, J. (2003). Quantile regression: applications and current research areas. J. R. Stat. Soc. 52, 331–350. doi: 10.1111/1467-9884.00363
Yu, K., and Moyeed, R. A. (2001). Bayesian quantile regression. Stat. Probabil. Lett. 54, 437–447. doi: 10.1016/S0167-7152(01)00124-9
Yu, K., and Zhang, J. (2005). A three-parameter asymmetric Laplace distribution and its extension. Commun. Stat. Theory Methods 34, 1867–1879. doi: 10.1080/03610920500199018
Zhang, X., Tao, J., Wang, C., and Shi, N. Z. (2019). Bayesian model selection methods for multilevel IRT models: a comparison of five DIC-Based indices. J. Educ. Meas. 56, 3–27.
Appendix
Here we give more details about the ALD and the Bayesian QR method. We consider a general QR model given by:
where y_i and di denote response variable and a 4 × 1 vector of covariates for the ith observation, rτ is a 4 × 1 vector of QR coefficients under the τth quantile of y_i, and the τth quantile of εi is assumed to be zero. The QR model does not have a specific likelihood function because the distribution of the error term εi is not specified. Yu and Moyeed (2001) first proposed Bayesian QR methods, they assigned each error term an asymmetric Laplace distribution (ALD), and considered MCMC methods for posterior inference.
About the main properties of the ALD(μ,ω,τ), parameters μ and τ in ALD satisfy: μ is the τth quantile of the distribution, and if X∼ALD(0,1,τ), then G = μ + ωX∼ALD(μ,ω,τ). In particular, the mean and variance of g are given by and respectively. These important features of ALD have been generally adopted for the quantile inference (Yu et al., 2003). Further details about ALD can be found in Yu and Zhang (2005).
By assuming the error terms in Eq. (A1) distributed as ALD(0,ω,τ), then y_i follows , in this case the likelihood function for the model (i.e., Eq. A1) is:
Yu and Moyeed (2001) noted that the maximum likelihood estimation of rτ is equivalent to the solution of the frequentist approach to the estimation of coefficients, which is to solve the following optimization problem as pointed out by Koenker and Bassett (1978):
As discussed in Yu and Moyeed (2001), the use of ALD for the error terms provides a natural way to deal with the Bayesian QR problem.
Since ALD is not a standard distribution so that it lacks a conjugate prior, direct use of the likelihood above is rather inconvenient for Bayesian inference. In this case, Reed and Yu (2009); Kozumi and Kobayashi (2011) used a mixture representation of ALD to develop the Gibbs sampling algorithm to estimate the parameters in QR. Specifically, if a random variable y follows ALD(μ,ω,τ), then it can be represented as the following form:
where , , e follows exponential distribution with scale parameter ω, and σ is a standard normal distribution. That is to say, y is augmented by a latent variable e, thus the conditional distribution of y is normal with mean μ + k1e and variance k2ωe. It has been shown that the mixture representation provided fully conditional posterior densities and simplified the existing estimation procedures for QR models.
1A random variable g is said to follow ALD(μ,ω,τ) if it has density , where μ is the location parameter, ω is the scale parameter, τ is the skewness parameter, and ρτ(x) = x(τ−I(x < 0)) is called the check function.
Keywords: multilevel item response theory, quantile regression, Bayesian analysis, Gibbs sampling, non-normality of latent variable
Citation: Zhu H, Gao W and Zhang X (2021) Bayesian Analysis of a Quantile Multilevel Item Response Theory Model. Front. Psychol. 11:607731. doi: 10.3389/fpsyg.2020.607731
Received: 18 September 2020; Accepted: 07 December 2020;
Published: 08 January 2021.
Edited by:
Alexander Robitzsch, IPN - Leibniz Institute for Science and Mathematics Education, GermanyReviewed by:
Matthias Trendtel, Technical University of Dortmund, GermanyPeida Zhan, Zhejiang Normal University, China
Xiangnan Feng, Fudan University, China
Copyright © 2021 Zhu, Gao and Zhang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Xue Zhang, emhhbmd4ODE1QG5lbnUuZWR1LmNu