
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
METHODS article
Front. Psychol. , 30 November 2020
Sec. Quantitative Psychology and Measurement
Volume 11 - 2020 | https://doi.org/10.3389/fpsyg.2020.564707
This article is part of the Research Topic Cognitive Diagnostic Models: Methods for Practical Applications View all 21 articles
 Na Shan1,2*
Na Shan1,2* Xiaofei Wang2,3
Xiaofei Wang2,3The aim of cognitive diagnosis is to classify respondents' mastery status of latent attributes from their responses on multiple items. Since respondents may answer some but not all items, item-level missing data often occur. Even if the primary interest is to provide diagnostic classification of respondents, misspecification of missing data mechanism may lead to biased conclusions. This paper proposes a joint cognitive diagnosis modeling of item responses and item-level missing data mechanism. A Bayesian Markov chain Monte Carlo (MCMC) method is developed for model parameter estimation. Our simulation studies examine the parameter recovery under different missing data mechanisms. The parameters could be recovered well with correct use of missing data mechanism for model fit, and missing that is not at random is less sensitive to incorrect use. The Program for International Student Assessment (PISA) 2015 computer-based mathematics data are applied to demonstrate the practical value of the proposed method.
Cognitive diagnosis has recently received increasing concern in psychological and educational assessment, which can provide fine-grained classifications and diagnostic feedback for respondents from their performance on test items (Leighton and Gierl, 2007; Rupp et al., 2010). It is a useful tool to identify students' mastery status of different latent skills based on their responses to test items and to evaluate patients' presence of mental disorders based on their responses to diagnostic questions. More specifically, cognitive diagnosis has been used to study fraction subtraction (de la Torre and Douglas, 2004), language proficiency (von Davier, 2008; Chiu and Köhn, 2016), psychological disorders (Templin and Henson, 2006; Peng et al., 2019), and so forth.
Various cognitive diagnosis models (CDMs), also called diagnosis classification models, have been developed, such as the deterministic inputs, noisy “and” gate (DINA) model (Macready and Dayton, 1977; Junker and Sijtsma, 2001) and the deterministic inputs, noisy “or” gate (DINO) model (Templin and Henson, 2006). Most CDMs are parametric and model the probability of item response as a function of latent attributes. The simplicity and interpretability make the parametric CDMs popular in practice. More general CDMs, such as the log-linear cognitive diagnosis model (LCDM; Henson et al., 2009) and the generalized DINA model (de la Torre, 2011), assume a more flexible relationship between the item responses and latent attributes. Moreover, higher-order latent trait models for cognitive diagnosis (de la Torre and Douglas, 2004) have been introduced to link the correlated latent traits by a general high-order ability.
Multiple items are often used for cognitive diagnosis. When respondents choose to answer some but not all items, item-level missing data occur (Chen et al., 2020). Respondents may refuse to answer items that they deem too difficult, quit the test early because it is too long, or just skip items because of carelessness. Missing data lead to loss of information and may result in biased conclusions (Glas and Pimentel, 2008; Köhler et al., 2015; Kuha et al., 2018). Many studies have employed a complete case analysis that only use subjects without missing data (e.g., Xu and Zhang, 2016; Chen et al., 2017; Zhan et al., 2019a). In this case, the subjects with missing data cannot receive any diagnostic feedback and, more importantly, may produce biased results when subjects with complete data are systematically different from those with missing data (Pan and Zhan, 2020).
In the literature, three missing data mechanisms should be distinguished: missing completely at random (MCAR), missing at random (MAR), and missing not at random (MNAR) (Rubin, 1976; Little and Rubin, 2020). The MCAR holds if the probability of missingness is independent of both the observed and unobserved responses, whereas the MAR holds if the probability of missingness is independent of the unobserved responses given the observed responses. If either of these two conditions cannot be satisfied, i.e., the probability of missingness depends on the unobserved responses, the MNAR occurs. If the missing data mechanism is MCAR or MAR, unbiased estimation can be obtained from the observed data; if the missing data mechanism is MNAR, a model for the missing data mechanism should be included to obtain valid estimations of the primary parameters. Limited approaches have been proposed in CDMs incorporating missing data mechanisms. Ömür Sünbül (2018) considered MCAR and MAR in the DINA model. Recently, Ma et al. (2020) have used the sequential process model to accommodate omitted items due to MNAR, where the first internal task, i.e., making the decision to either skip the item or respond to it, is assumed to be affected by a latent categorical variable representing the response tendency. As stated by Heller et al. (2015), CDMs have connections to knowledge space theory (KST), which has been developed by Doignon and Falmagne (1985) (see also Doignon and Falmagne, 1999; Falmagne and Doignon, 2011). de Chiusole et al. (2015) and Anselmi et al. (2016) have developed models for the analysis of MCAR, MAR, and MNAR data in the framework of KST. In their work, the MCAR holds if the missing response pattern is independent of the individual's knowledge state (i.e., the collection of all items that an individual is capable of solving in a certain disciplinary domain) and of the observed responses; the MAR holds if the missing response pattern is conditionally independent of the knowledge state given the observed responses; and the MNAR holds if the missing response pattern depends on the knowledge state. In CDMs, the attribute profile (i.e., the collection of all attributes that an individual masters in a certain disciplinary domain) is similar to the knowledge state in KST. In our study, an additional latent categorical variable is introduced to indicate missingness propensity. This latent categorical variable affects the probability of missingness for each item and, in the meantime, may affect the latent attributes through the influence of the general high-order ability. The missing data mechanism can then be incorporated into cognitive diagnosis. Similar ideas can be seen in Holman and Glas (2005), Rose et al. (2015), and Kuha et al. (2018).
In this paper, we propose a joint cognitive diagnosis modeling including a higher-order latent trait model for item responses and a missingness propensity model for item-level missing data mechanism. We take the DINA model as an example for illustration because of its popular use, and the latent traits are linked by a general high-order ability. For a flexible specification of the missingness propensity model, the latent missingness propensity is represented by a categorical variable. The MNAR holds if the distribution of the general high-order ability depends on the latent classes, whereas the MCAR holds if the distribution of the general high-order ability is independent of the latent classes.
The rest of this paper is organized as follows. Section 2 presents the proposed joint model for item responses and item-level missing data mechanism. The Bayesian approach is then developed for model parameter estimation using JAGS. In section 3, simulation studies are conducted to compare the performance of the parameter recovery under different missing data mechanisms. Real data analysis using the PISA 2015 computer-based mathematics data is given in section 4. Some concluding remarks are given in section 5.
We consider N subjects taking a test of I items, and there are K latent attributes to be evaluated. Let Yni be the response for subject n(n = 1, ⋯ , N) to item i(i = 1, ⋯ , I). Let Rni be a missingness indicator corresponding to Yni, where Rni = 1 if Yni is observed and Rni = 0 if Yni is missing.
Let ξn denote the latent missingness propensity for subject n. ξn is unobserved and has C categories, which we refer to as latent missingness classes. The missingess probability of (Rn1, ⋯ , RnI) is given by
where p(Rn1, ⋯ , RnI) is the joint probability of (Rn1, ⋯ , RnI), p(Rni | ξn = c) is the conditional probability of Rni given ξn = c and p(ξn = c) is the probability of ξn = c.
The latent missingness propensity ξn is specified as the categorical distribution
where π = (π1, ⋯ , πC) and . The conditional probability of Rni is specified as the logistic function
where τ0i and τci(c = 2, ⋯ , C) are the intercept and slope parameters, and ξ(c)(c = 2, ⋯ , C) are dummy variables for the missingness classes. A positive slope parameter τci is assumed, which means that the missingness probability reduces in the latter missingness class compared to the first class. Denote τ0 = (τ01, ⋯ , τ0I) and τc = (τc1, ⋯ , τcI) for c = 2, ⋯ , C. The idea of introducing latent variables to model the non-response mechanism have been proposed previously by, for example, Lin et al. (2004) and Hafez et al. (2015). The missingness propensity model is identifiable when C ≤ 2I/(1 + I).
The DINA model describes the probability of item response as a function of latent attributes as follows:
where p(Yni = 1) is the probability of a correct response for subject n to item i; si and gi are the slipping and guessing probability for item i respectively, and 1 − si − gi is the item discrimination index for item i (IDIi; de la Torre, 2008), αnk is the kth (k = 1, ⋯ , K) latent attribute for subject n, with αnk = 1 if subject n masters attribute k and αnk = 0 otherwise. The Q matrix is a I × K matrix with binary entries qik (Tatsuoka, 1983). For each i and k, qik = 1 indicates that attribute k is required to answer item i correctly and qik = 0 otherwise.
Equation (4) can be reparameterized, and it is called the reparameterized DINA model (DeCarlo, 2011) as
where βi = logit(gi) and δi = logit(1 − si) − logit(gi) are called item intercept and interaction parameter, respectively.
As stated in the literature (de la Torre and Douglas, 2004; Zhan et al., 2018a), attributes in a test are often correlated, and a higher-order structure for the attributes can be formulated by
where p(αnk = 1) is the probability of subject n's mastery of attribute k; θn is a general (higher-order) ability for subject n; and γk and λk are the slope and intercept parameter for attribute k. Denote γ = (γ1, ⋯ , γK) and λ = (λ1, ⋯ , λK). Following Zhan et al. (2018a), a positive slope parameter is assumed, which means the probability of mastery of attribute k increases as the general ability θn grows. Including a higher-order structure for cognitive diagnosis can not only reduce the number of model parameters for correlated latent attributes but also obtain an assessment for subjects' overall ability.
The distribution of the general ability θn may be affected by the latent missingness classes of ξn, and we suppose that
for n = 1, ⋯ , N and c = 1, ⋯ , C. If μc or (c = 1, ⋯ , C) may vary between different classes, the missing data mechanism is MNAR, and we set μ1 = 0 and for model identification. If μc and remain unchanged for different c, the probability of missingness does not depend on the responses and MCAR holds, and this is where we set θn ~ N(0, 1) for identification.
The parameters of the proposed model can be estimated using the Bayesian MCMC approach. JAGS (version 4.2.0; Plummer, 2015) and the R2jags package (Su and Yajima, 2020) in R (R Core Team, 2019) were used for estimation, and the JAGS code can be found in the Supplementary Material. The priors of the model parameters are given below. For the majority of the parameters, the conjugate priors are used. The priors and the hyper priors for the item parameters are assigned the same as those given in Zhan et al. (2018a), please find them for details. Moreover, the noninformative prior is used for Dirichlet distribution. The (truncated) normal distribution and the inverted gamma distribution priors are chosen to obtain dispersed values for each corresponding parameter.
The hyper priors are specified:
where I is a 2 × 2 identity matrix. In this case, the mean guessing and slipping probabilities are approximately equal to 0.1.
In this paper, the number of latent missingess classes C is taken as fixed. In fact, C can be selected by some information criterion, for example, deviance information criterion (DIC; Spiegelhalter et al., 2002), which can result in a statistically optimal number. In practice, it is efficient to determine C beforehand, using latent class analysis (Linzer and Lewis, 2011) just for the missingness indicators. In the following simulation studies, the number of latent missingess classes C is fixed to 2 for simplicity. For the values of C > 2, the results are similar and we report some results for C = 3 in the Supplementary Material.
Two simulation studies were conducted to evaluate the empirical performance of the proposed method. Simulation 1 aimed to examine the parameter recovery using the Bayesian MCMC algorithm when the simulated data were generated under MNAR. Under different conditions, models with MCAR and MNAR were fitted to the simulated data, respectively, where the distribution of the general higher-order ability was unrelated or related to the latent missingness classes in MCAR or MNAR. In Simulation 2, our purpose was to study the sensitivity of incorrect use of MNAR for model fit. Parameter recovery related to diagnostic classification are reported here. The other parameters about the missing data mechanisms can be recovered well but not reported here since they are not our primary interest.
In Simulation 1, three factors were manipulated, including (a) sample sizes (N) at two levels of 500 and 1,000; (b) test length (I) at two levels of 15 and 30; and (c) the probability of missingness for each item, high missingness (HM) and low missingness (LM). Five attributes (K = 5) were measured and the simulated Q matrices for two test length I = 15 and I = 30 were given in Figure 1, which were used in Zhan et al. (2018b). Most of the model parameters were assigned by referring to the real data analysis presented in Zhan et al. (2018a). Specifically, π = (0.3, 0.7), representing unequal probabilities for each latent class; τ2i = 1.2 for all items, τ0 = (0.0, 0.5, 0.0, 0.5, 0.0, 0.5, 0.0, 0.5, 0.0, 0.5, 0.0, 0.5, 0.0, 0.5, 0.0) for high missingness with I = 15, τ0 = (0.0, 0.5, 0.0, 0.5, 0.0, 0.5, 0.0, 0.5, 0.0, 0.5, 0.0, 0.5, 0.0, 0.5, 0.0, 0.5, 0.0, 0.5, 0.0, 0.5, 0.0, 0.5, 0.0, 0.5, 0.0, 0.5, 0.0, 0.5, 0.0, 0.5) for high missingness with I = 30, τ0 = (1.0, 1.5, 1.0, 1.5, 1.0, 1.5, 1.0, 1.5, 1.0, 1.5, 1.0, 1.5, 1.0, 1.5, 1.0) for low missingness with I = 15 and τ0 = (1.0, 1.5, 1.0, 1.5, 1.0, 1.5, 1.0, 1.5, 1.0, 1.5, 1.0, 1.5, 1.0, 1.5, 1.0, 1.5, 1.0, 1.5, 1.0, 1.5, 1.0, 1.5, 1.0, 1.5, 1.0, 1.5, 1.0, 1.5, 1.0, 1.5) for low miss -ingness with I = 30, corresponding to the missingness probability for each item between 0.22 and 0.31 in the case of high missingness and between 0.1 and 0.22 in the case of low missingness; μ2 = 1.0 and ; γk = 1.5 for all attributes and λ = (−1.0, −0.5, 0.0, 0.5, 1.0), indicating moderate correlations between attributes; μitem = (μβ, μδ) = (−2.197, 4.394) and
which was the mean vector and the covariance matrix for a bivariate normal distribution generating βi and δi. Other assignments for the model parameters, for example, equal probabilities for each latent class as those used in Ma et al. (2020), also make sense, and the results are similar to the above parameter settings.

Figure 1. K-by-I Q matrix for simulation study 1. Blank means “0,” gray means “1”; “*” denotes items used in I = 15 conditions; K = the number of attributes; I = test length.
In each of the eight conditions, models with MCAR and MNAR were fitted to the simulated data, respectively. Thirty replications were implemented for each fitted model. Pilot runs showed that the algorithm converged using 20, 000 iterations with a burn-in phase of 10, 000 iterations. The convergence of the chains was monitored by multivariate potential scale reduction factor, which were < 1.1 (Gelman and Rubin, 1992). The bias and the root mean square error (RMSE) of the Bayesian estimates were computed to assess the parameter recovery. For evaluating the classification of each attribute and attribute profiles, the attribute correct classification rate (ACCR) and the pattern correct classification rate (PCCR) were computed. More formally, if the kth (k = 1, ⋯ , K) latent attribute for subject n (n = 1, ⋯ , N), denoted as αk,n, is estimated by , ACCR for the kth latent attribute and PCCR can be expressed as and , respectively. Here is an indicator function such that if and zero otherwise.
Figure 2 presents the recovery of the item mean vector and the item covariance matrix for the models with MCAR and MNAR in all eight conditions. First, the patterns of the item parameter recovery were similar between MCAR and MNAR, especially the RMSEs of MCAR and MNAR were close in each condition. The item mean vector can be well recovered, as the bias were small and the RMSEs were relatively smaller than those of the item covariance matrix. The bias of the item mean vector under MNAR were smaller than those under MCAR at a higher sample size N = 1, 000. The RMSEs of the item mean vector decreased as test length increased. The bias and RMSEs of the item covariance matrix were relatively higher, and decreased as test length increased. The sample size had no consistent impact on the estimates of the item covariance matrix. Moreover, the missingness probabilities had little impact on the item parameter recovery.
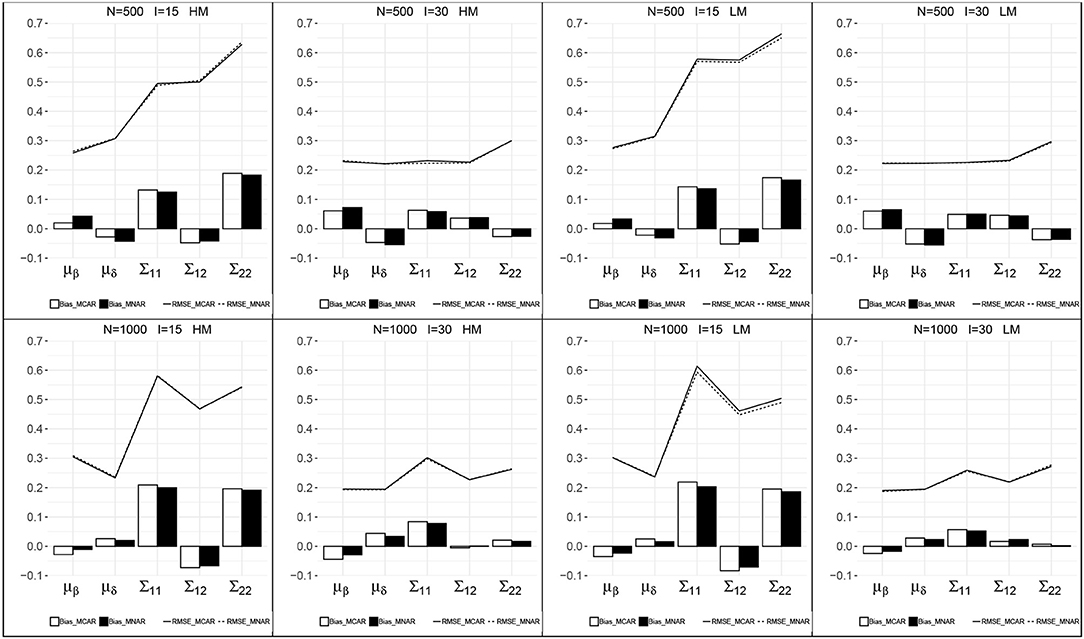
Figure 2. Recovery of the parameters in the item mean vector and the item covariance matrix. HM, high missingness; LM, low missingness.
Table 1 summarizes the item parameter recovery for models with MCAR and MNAR in high missingness conditions. The results for low missingness are similar and presented in Supplementary Figure 1. The mean absolute value (MAV) of the bias and RMSE are reported. In each condition, the MAVs of the bias and RMSE under MCAR and MNAR were close. Detailed information about the recovery of each item parameter with MCAR and MNAR was similar and not reported here.
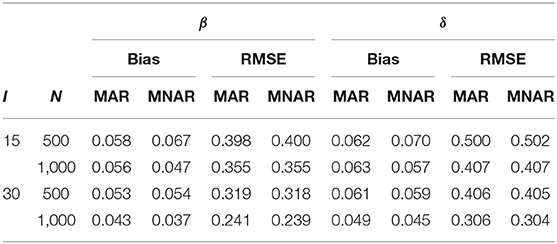
Table 1. Summary of the item parameters for high missingness conditions.
Table 2 summarizes the estimation of general ability parameter in high missingness conditions. The results for low missingness are similar and presented in Supplementary Figure 2. The MAV and Range of the bias and RMSE are reported. The correlation between the true and the estimated general abilities is also given. The MAVs of the bias under MCAR were much higher than those under MNAR, and the bias under MCAR were all negative, which can be seen from their Ranges. The MAVs of the RMSEs under MCAR were also higher than those under MNAR. The correlations under MNAR were higher than those under MAR. From the above results, we find that when data are generated with MNAR, incorrect use of missing data mechanism could lead to biased estimation of the general abilities.
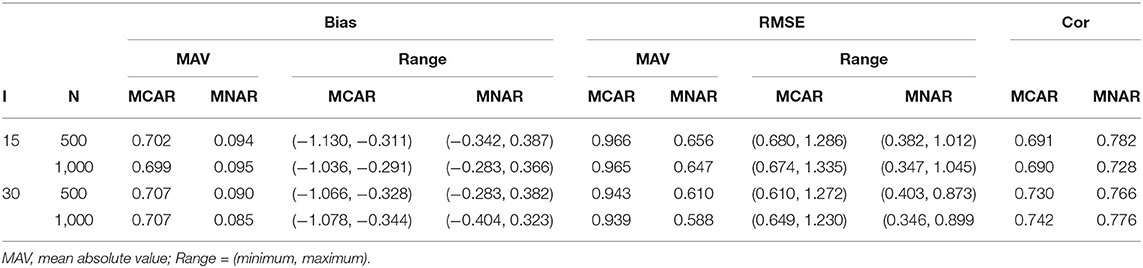
Table 2. Summary of the general ability for high missingness conditions.
Figures 3, 4 presents the recovery of higher-order parameters between the attributes and the general ability in each condition. For the attribute slope parameters, the bias was closer to zero and the RMSEs were relatively small. For the attribute intercept parameters, their recovery under MNAR were good with small bias and RMSEs. Under MCAR, the bias and RMSEs for attribute intercept parameters were large, with absolute values >1.0, and all the bias were negative.
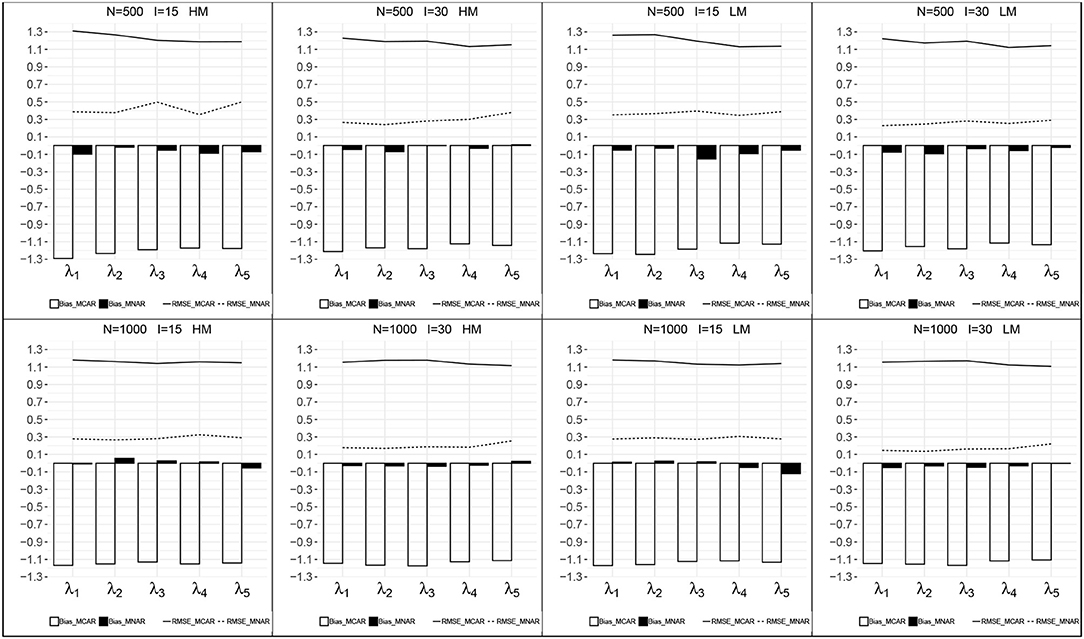
Figure 3. Recovery of the attribute intercept parameters. HM, high missingness; LM, low missingness.
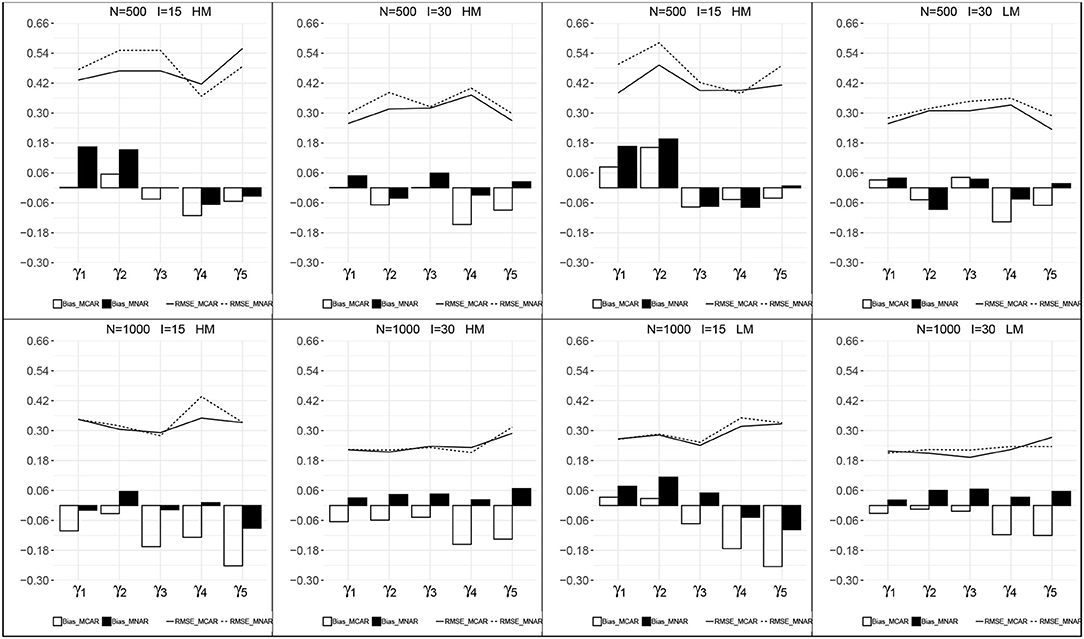
Figure 4. Recovery of the attribute slope parameters. HM, high missingness; LM, low missingness.
Figure 5 shows the correct classification rates for each attribute and attribute profiles in all conditions. All ACCRs were > 0.90 and all PCCRs were > 0.70, which indicated a good recovery of the mastery status of attributes. ACCRs and PCCRs raised as test length increased and changed little as sample size increased. The correct classification rates of MCAR and MNAR were very close in each condition. These results may be caused by the fact that the impact of the missing data mechanism on the latent attributes is indirect through the general high-order ability, and we assume the same model for item response under both missing data mechanisms.
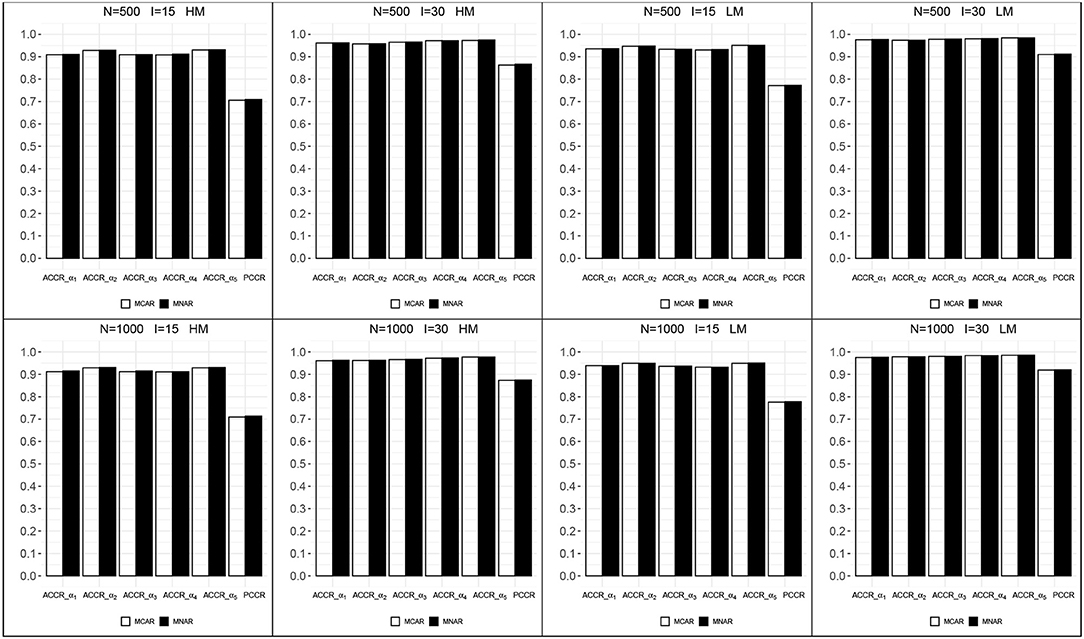
Figure 5. The correct classification rates for each attribute and attribute profiles. HM, high missingness; LM, low missingness.
The aim of Simulation 2 was to empirically examine the sensitivity of incorrect use of MNAR for model fit. In this study, the simulated data were generated with MCAR, i.e., the distribution of the general higher-order ability is independent of the latent missingness classes, and we set θn ~ N(0, 1) for identification. The other settings were the same as those used for N = 500, J = 15 and low missingness in Simulation 1, which is a weak condition studied in Simulation Study 1.
Table 3 presents the bias and RMSE for the item mean vector, the item covariance matrix and the higher-order structure parameters. The recovery of the item parameter mean vector and covariance matrix were similar under MCAR and MNAR. For the higher-order structure parameters, unlike the results in Simulation Study 1, the recovery of the parameters under MNAR were as good as those under MCAR.

Table 3. Recovery of the item mean vector, the item covariance matrix, the attribute slope, and intercept.
Table 4 summarizes the recovery of the item and the general ability parameter, where the mean, standard deviation, minimum, and maximum of the bias and RMSE are reported. It also shows the correct classification rates for each attribute and attribute profiles. The results under MCAR and MNAR were similar, with mean bias close to zero and approximately equal correct classification rates for the recovery of each attribute and attribute profile. From Tables 3, 4, we found that when the data were generated under MCAR, the missing data mechanism used in the model fit had little impact on the results for diagnostic classification in our framework.
Table 4. Summary of the item parameter, general ability, and attributes.
To illustrate the application of the proposed method, the PISA 2015 computer-based mathematics data were used. The data include item scores and response times for each item, and we only select dichotomous item scores for illustration. Four attributes belonging to the mathematical content knowledge were evaluated, i.e., change and relationship (α1), quantity (α2), space and shape (α3) and uncertainty and data (α4). I = 9 items with dichotomous responses were selected, with items IDs CM033Q01, CM474Q01, CM155Q01, CM155Q04, CM411Q01, CM411Q02, CM803Q01, CM442Q02, and CM034Q01. The Q matrix was shown in Table 5. Item responses with code 0 (no credit), code 1 (full credit), and code 9 (noresponse) were considered here. The responses “nonresponse” (code 9) were treated as missing data and might be due to a MNAR mechanism. N = 758 test-takers from Albania with responses 0, 1, and 9 to each of the nine items were used for analysis. The missing rate (i.e., the proportion of “nonresponse”) for each item ranged from 0 to 14.78%. The models with missing data mechanisms MCAR and MNAR were both fitted to the data. The number of latent missingess classes C = 2 was determined by latent class analysis. Then, the analysis was specified in the same way as the simulation study. The DIC was applied to compare model fit for models under different missing data mechanisms.

Table 5. The Q matrix in the real data.
The DIC values under MCAR and MNAR were 11454.2 and 10406.3, respectively, which indicated that MNAR was preferred with a lower DIC value. We were only interested in the results concerning diagnostic classification. Table 6 reports the estimated parameters and its corresponding standard deviations for the item mean vector, the item covariance matrix, and the attribute intercept and slope parameters. The results for the item mean vector and covariance matrix were similar under different missing data mechanisms, and the estimated Σ12 was −1.069, which indicated that items with a higher intercept corresponded to a lower interaction. μβ was estimated to be −2.033, which means that the mean guessing probability was approximate 0.12. All estimated attribute intercept and slope parameters were positive. The estimations for the item covariance matrix and the attribute intercept and slope parameters were poor, which were consistent with previous studies (de la Torre and Douglas, 2004; Zhan et al., 2018a). Table 7 reports the estimated item parameters. All δi were positive, which means that all items satisfy gi < 1 − si. Only βi for CM033Q01 was positive, which means that the guessing probability of this item is higher than 0.5.

Table 6. Estimates and standard errors of the parameters for the real data.
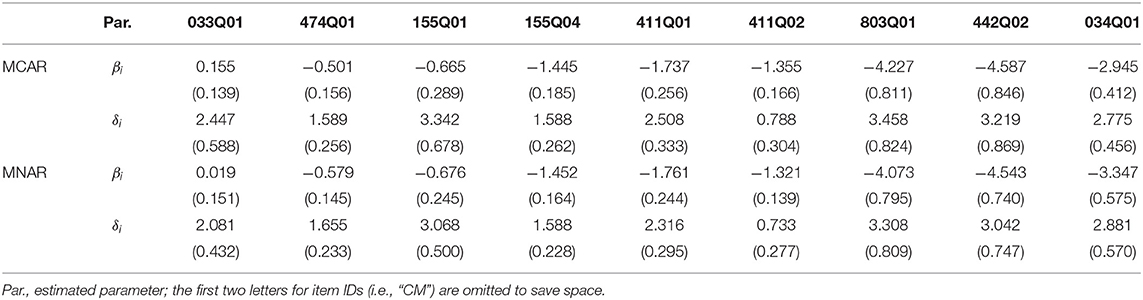
Table 7. Estimates and standard errors of the parameters for the real data.
Though there were 16 possible attribute patterns for four attributes, 15 attribute patterns except (0101) were found in the estimated attributes under both MCAR and MNAR. Figure 6 presents the top five most frequent attribute patterns in the real data under MCAR and MNAR. The most prevalent attribute pattern was (0000) and the second most prevalent pattern was (1111) under both MCAR and MNAR, where the corresponding proportions were slightly different. The third and the fourth most prevalent patterns under MCAR and MNAR were reverse. The above results indicate that the missing data mechanisms have some influences on the estimated attribute patterns.
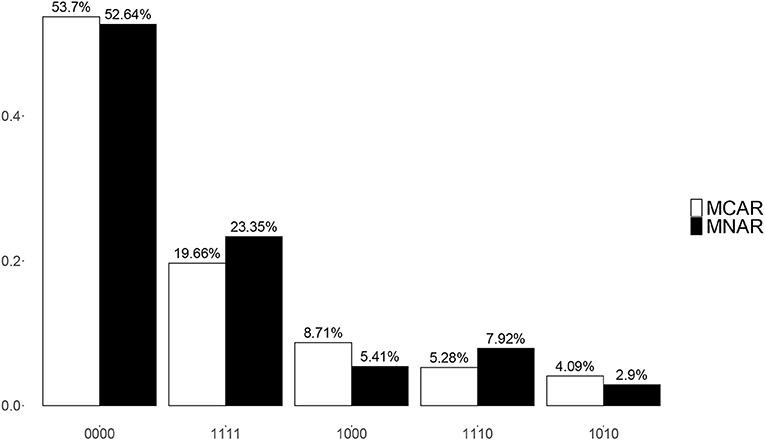
Figure 6. Posterior mixing proportions for top 5 most frequent attribute patterns under MCAR and MNAR in the real data.
When multiple items are used to classify subjects' mastery status of latent attributes, it is almost inevitable that item-level missing data will occur. It is possible that the missing data mechanism is related to the item responses, and without very strong assumptions, item-level non-response can be thought to depend on some latent variables. Motivated by this idea, we have proposed a joint modeling method incorporating item responses and missing data mechanism for cognitive diagnosis. A latent categorical variable is employed to describe the latent missingness propensity, which can avoid distributional assumptions and result in a more flexible model. Then, the latent missingness classes are linked to each item missingness indicator by the logistic function. Applying the hierarchical modeling framework, the general higher-order ability's distribution is affected by the latent missingness class in the case of MNAR and is independent of the latent missingness class in the case of MCAR.
A Bayesian MCMC method is used to estimate the model parameters under the missing data mechanisms MCAR and MNAR. The simulation study demonstrates that when the data are generated under MNAR, the estimated general ability and the attribute intercept parameters have higher bias if an incorrect missing data mechanism is used for model fit; when the data are generated under MCAR, the results between different missing data mechanisms do not have much difference. Similar results about the impact of the missing data mechanisms have been found by de Chiusole et al. (2015) in the framework of KST. The PISA 2015 computer-based mathematics data are used to explore the magnitude and direction of item and person parameters, and the results support the MNAR in the real data analysis.
Our proposed method can be further investigated in several aspects. First, the proposed model has good performance with DINA model used for illustration, and the joint modeling method can be extended to other types of CDMs for further studies. Second, this study assumes that each latent attribute is a binary variable. When polytomous attributes are involved in CDMs (Zhan et al., 2019b), modified higher-order CDMs could be utilized in the framework of our model. Third, multiple sources of data about a subject behavior, for example, response time and other process data, can be combined to build up a more general model, which could provide a more comprehensive reflection of individual behavior. Finally, the number of latent missingness classes can be varied. For selecting it, Akaike information criterion (AIC), Bayesian information criterion (BIC) or DIC, can be utilized to compare different models under various choices.
Publicly available datasets were analyzed in this study. This data can be found at: http://www.oecd.org/pisa.
NS provided original idea of the paper. XW provided the technical support. Both authors contributed to the article and approved the submitted version.
The research of NS was supported in part by the National Natural Science Foundation of China (grant number 11871013) and the Project of the Educational Department of Jilin Province of China (grant number 2016315). The research of XW was supported in part by the Fundamental Research Funds for the Central Universities (grant number 2412019FZ030) and Jilin Provincial Science and Technology Development Plan funded Project (grant number 20180520026JH).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpsyg.2020.564707/full#supplementary-material
Anselmi, P., Robusto, E., Stefanutti, L., and de Chiusole, D. (2016). An upgrading procedure for adaptive assessment of knowledge. Psychometrika 81, 461–482. doi: 10.1007/s11336-016-9498-9
Chen, L., Savalei, V., and Rhemtulla, M. (in press). Two-stage maximum likelihood approach for item-level missing data in regression. Behav. Res. Methods. doi: 10.3758/s13428-020-01355-x
Chen, Y., Li, X., Liu, J., and Ying, Z. (2017). Regularized latent class analysis with application in cognitive diagnosis. Psychometrika 82, 660–692. doi: 10.1007/s11336-016-9545-6
Chiu, C. Y., and Köhn, H. F. (2016). The reduced RUM as a logit model: parameterization and constraints. Psychometrika 81, 350–370. doi: 10.1007/s11336-015-9460-2
de Chiusole, D., Stefanutti, L., Anselmi, P., and Robusto, E. (2015). Modeling missing data in knowledge space theory. Psychol. Methods 20, 506–522. doi: 10.1037/met0000050
de la Torre, J. (2008). An empirically based method of Q-matrix validation for the DINA model: development and applications. J. Educ. Meas. 45, 343–362. doi: 10.1111/j.1745-3984.2008.00069.x
de la Torre, J. (2011). The generalized DINA model framework. Psychometrika 76, 179–199. doi: 10.1007/s11336-011-9207-7
de la Torre, J., and Douglas, J. A. (2004). Higher-order latent trait models for cognitive diagnosis. Psychometrika 69, 333–353. doi: 10.1007/BF02295640
DeCarlo, L. T. (2011). On the analysis of fraction subtraction data: the DINA model, classification, latent class sizes, and the q-matrix. Appl. Psych. Meas. 35, 8–26. doi: 10.1177/0146621610377081
Doignon, J. P., and Falmagne, J. C. (1985). Spaces for the assessment of knowledge. Int. J. Man Mach. Stud., 23, 175–196. doi: 10.1016/S0020-7373(85)80031-6
Doignon, J. P., and Falmagne, J. C. (1999). Knowledge Spaces. Berlin; Heidelberg; New York, NY: Springer-Verlag.
Falmagne, J. C., and Doignon, J. P. (2011). Learning Spaces: Interdisciplinary Applied Mathematics. Berlin; Heidelberg: Springer.
Gelman, A., and Rubin, D. B. (1992). Inference from iterative simulation using multiple sequences. Stat. Sci. 7, 457–472. doi: 10.1214/ss/1177011136
Glas, C. A. W., and Pimentel, J. L. (2008). Modeling nonignorable missing data in speeded tests. Educ. Psychol. Meas. 68, 907–922. doi: 10.1177/0013164408315262
Hafez, M. S., Moustaki, I., and Kuha, J. (2015) Analysis of multivariate longitudinal data subject to nonrandom dropout. Struct. Equat. Model. 22, 193–201. doi: 10.1080/10705511.2014.936086
Heller, J., Stefanutti, L., Anselmi, P., and Robusto, E. (2015). On the link between cgnitive diagnostic models and knowledge space theory. Psychometrika 80, 995–1019. doi: 10.1007/s11336-015-9457-x
Henson, R. A., Templin, J. L., and Willse, J. T. (2009). Defining a family of cognitive diagnosis models using log-linear models with latent variables. Psychometrika 74, 191–210. doi: 10.1007/s11336-008-9089-5
Holman, R., and Glas, C. A. W. (2005). Modelling non-ignorable missing-data mechanisms with item response theory models. Br. J. Math. Stat. Psychol. 58, 1–17. doi: 10.1348/000711005X47168
Junker, B. W., and Sijtsma, K. (2001). Cognitive assessment models with few assumptions, and connections with nonparametric item response theory. Appl. Psychol. Meas. 25, 258–272. doi: 10.1177/01466210122032064
Köhler, C., Pohl, S., and Carstensen, C. H. (2015). Taking the missing propensity into account when estimating competence scores: evaluation of item response theory models for nonignorable omissions. Educ. Psychol. Meas. 75, 850–874. doi: 10.1177/0013164414561785
Kuha, J., Katsikatsou, M., and Moustaki, I. (2018). Latent variable modelling with non-ignorable item non-response: multigroup response propensity models for cross-national analysis. J. R. Stat. Soc. A 181, 1169–1192. doi: 10.1111/rssa.12350
Leighton, J, and Gierl, M. (2007). Cognitive Diagnostic Assessment for Education: Theory and Applications. Cambridge, UK: Cambridge University Press.
Lin, H., McCulloch, C. E., and Rosenheck, R. A. (2004). Latent pattern mixture models for informative intermittent missing data in longitudinal studies. Biometrics 60, 295–305. doi: 10.1111/j.0006-341X.2004.00173.x
Linzer, D. A., and Lewis, J. B. (2011). poLCA: an R package for polytomous variable latent class analysis. J. Stat. Softw. 42, 1–29. doi: 10.18637/jss.v042.i10
Little, R. J., and Rubin, D. B. (2020). Statistical Analysis With Missing Data, 3rd Edn. New York, NY: John Wiley and Sons, Inc.
Ma, W., Jiang, Z., and Schumacker, R. E. (2020). “Modeling omitted items in cognitive diagnosis models [Roundtable Session],” in AERA Annual Meeting (San Francisco, CA).
Macready, G. B., and Dayton, C. M. (1977). The use of probabilistic models in the assessment of mastery. J. Educ. Behav. Stat. 2, 99–120. doi: 10.3102/10769986002002099
Ömür Sünbül, S. (2018). The impact of different missing data handling methods on DINA model. Int. J. Eval. Res. Educ. 7, 77–86. doi: 10.11591/ijere.v1i1.11682
Pan, Y., and Zhan, P. (2020). The impact of sample attrition on longitudinal learning diagnosis: a prologue. Front. Psychol. 11:1051. doi: 10.3389/fpsyg.2020.01051
Peng, S., Wang, D., Gao, X., Cai, Y., and Tu, D. (2019). The CDA-BPD: retrofitting a traditional borderline personality questionnaire under the cognitive diagnosis model framework. J. Pac. Rim. Psychol. 13:e22. doi: 10.1017/prp.2019.14
Plummer, M. (2015). JAGS Version 4.0.0 User Manual. Lyon. Retrieved from: https://sourceforge.net/projects/mcmc-jags/files/Manuals/4.x/.
R Core Team (2019). R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing.
Rose, N., von Davier, M., and Nagengast, B. (2015). Commonalities and differences in IRT-based methods for nonignorable item nonresponses. Psychol. Test Assess. Model. 57, 472–498.
Rubin, D. B. (1976). Inference and missing data (with discussion). Biometrika 63, 581–592. doi: 10.1093/biomet/63.3.581
Rupp, A., Templin, J., and Henson, R. (2010) Diagnostic Measurement: Theory, Methods, Applications. New York, NY: Guilford Press.
Spiegelhalter, D. J., Best, N. G., Carlin, B. P., and van der Linde, A. (2002). Bayesian measures of model complexity and fit. J. R. Stat. Soc. B 64, 583–639. doi: 10.1111/1467-9868.00353
Su, Y. S., and Yajima, M. (2020). R2jags: Using R to Run ‘JAGS'. R package version 0.6-1. Retrieved from: https://CRAN.R-project.org/package=R2jags.
Tatsuoka, K. K. (1983). Rule space: an approach for dealing with misconceptions based on item response theory. J. Educ. Meas. 20, 345–354. doi: 10.1111/j.1745-3984.1983.tb00212.x
Templin, J. L., and Henson, R. A. (2006). Measurement of psychological disorders using cognitive diagnosis models. Psychol. Methods 11, 287–305. doi: 10.1037/1082-989X.11.3.287
von Davier, M. (2008). A general diagnostic model applied to language testing data. Br. J. Math. Stat. Psychol. 61, 287–301. doi: 10.1348/000711007X193957
Xu, G., and Zhang, S. (2016). Identifiability of diagnostic classification models. Psychometrika 81, 625–649. doi: 10.1007/s11336-015-9471-z
Zhan, P., Jiao, H., and Liao, D. (2018a). Cognitive diagnosis modelling incorporating item response times. Br. J. Math. Stat. Psychol. 71, 262–286. doi: 10.1111/bmsp.12114
Zhan, P., Jiao, H., Liao, D., and Li, F. (2019a). A longitudinal higher-order diagnostic classification model. J. Educ. Behav. Stat. 44, 251–281. doi: 10.3102/1076998619827593
Zhan, P., Jiao, H., Liao, M., and Bian, Y. (2018b). Bayesian DINA modeling incorporating within-item characteristic dependency. Appl. Psych. Meas. 43, 143–158. doi: 10.1177/0146621618781594
Keywords: cognitive diagnosis, item-level, missing data, missing data mechanism, cognitive diagnosis model
Citation: Shan N and Wang X (2020) Cognitive Diagnosis Modeling Incorporating Item-Level Missing Data Mechanism. Front. Psychol. 11:564707. doi: 10.3389/fpsyg.2020.564707
Received: 22 May 2020; Accepted: 28 October 2020;
Published: 30 November 2020.
Edited by:
Tao Xin, Beijing Normal University, ChinaReviewed by:
Pasquale Anselmi, University of Padua, ItalyCopyright © 2020 Shan and Wang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Na Shan, ZGFubjI4NUBuZW51LmVkdS5jbg==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.