 Alberto Rodríguez-Lorenzana1
Alberto Rodríguez-Lorenzana1 Itziar Benito-Sánchez2,3
Itziar Benito-Sánchez2,3 Lila Adana-Díaz1
Lila Adana-Díaz1 Clara Patricia Paz1
Clara Patricia Paz1 Tarquino Yacelga Ponce1
Tarquino Yacelga Ponce1 Diego Rivera4
Diego Rivera4 Juan Carlos Arango-Lasprilla2,5,6*
Juan Carlos Arango-Lasprilla2,5,6*- 1Escuela de Psicología, Universidad de Las Américas, Quito, Ecuador
- 2Biocruces Bizkaia Health Research Institute, Barakaldo, Spain
- 3Biomedical Research Doctorate Program, University of the Basque Country (UPV/EHU), Leioa, Spain
- 4Departamento de Ciencias de la Salud, Universidad Pública de Navarra, Pamplona, Spain
- 5IKERBASQUE, Basque Foundation for Science, Bilbao, Spain
- 6Department of Cell Biology and Histology, University of the Basque Country (UPV/EHU), Leioa, Spain
Objective: To generate normative data for verbal fluency and naming test in an Ecuadorian adult population.
Methods: The sample consisted of 322 healthy adults (18–84 years old) recruited from Quito, Ecuador. The verbal fluency and Boston Naming Test (BNT) were administered as part of a larger comprehensive neuropsychological battery. Multiple linear regression analyses were used to generate the normative data taking into account age, education, and sex.
Results: For phonological verbal fluency, results indicated that only education was significantly related to the performance of the letters “A,” “S,” and “M.” However, the performance on the letter “F” was significantly associated with age and education. For semantic fluency, the performance on “animals” was significantly influenced by age, quadratic age, and education, whereas that for “fruits” was explained by quadratic age, education, and sex. The performance on the BNT was significantly influenced by age and education. A Microsoft Excel-based calculator was created to help clinicians to obtain the normative data on this test.
Conclusion: This normative data will help neuropsychologist in Ecuador to use these tests both in research and in their clinical practice to improve the diagnosis of cognitive deficits in the population.
Introduction
Language is involved in most complex activities undertaken by human beings (Roby-Brami et al., 2012). Through language, human beings have been able to preserve cultural meanings over time, thus differentiating human social communication from that of other species (Scott and Schoenberg, 2011; Jodar and Redolar, 2013).
Deficits in one or several of the components and/or functions of language are common in multiple neurological disorders and syndromes (Cuetos, 2012), such as Traumatic Brain Injury (Henry and Crawford, 2004a; Kavé et al., 2011), neurodegenerative diseases (e.g., Alzheimer disease, Parkinson disease, mild cognitive impairment, etc.; Clark et al., 2009; Gardini et al., 2013; Henry and Crawford, 2004b; McDowd et al., 2011), epilepsy (Gleissner and Elger, 2001; Thompson and Duncan, 2005), and stroke (Brady et al., 2001; Kim et al., 2011).
To evaluate language functioning in the presence of neurological alterations, several neuropsychological tests are typically used, for instance, the Boston Aphasia Diagnostic Test (BDAE; Goodglass and Kaplan, 1983), the Western Aphasia Battery (WAB; Kertesz, 1982), Token Test (De Renzi and Vignolo, 1962), the verbal fluency tests, and the Peabody Picture Vocabulary Test (Dunn, 1959). Of these tests, the verbal fluency and the Boston Naming Test (a subtest of the BDAE) are some of the most commonly used by neuropsychologists (Kaplan et al., 1983; Strauss et al., 2006; Lezak, 2012; Fonseca-Aguilar et al., 2015; Olabarrieta-Landa et al., 2016; Arango-Lasprilla et al., 2017).
Verbal fluency is the generation of words based on a specific criterion (letters, categories, actions, etc.). Within research and clinical practice, the most commonly used verbal fluency tests are phonological and semantic (Strauss et al., 2006; Marino and Alderete, 2010; Lezak, 2012). Phonological fluency requires executive functioning and the activation of areas within the frontal lobe, whereas semantic fluency taps into lexical access and vocabulary and requires participation of the temporal lobe (Olabarrieta-Landa et al., 2017). The assessment of this test must comply with certain rules including time limits for word generation, instructions about the types of words that must be evoked and/or omitted, and specific scoring guidelines (Olabarrieta-Landa et al., 2017).
In Spanish-speaking countries, numerous studies have been conducted to obtain normative data of verbal fluency tests, including Spain (Peña-Casanova et al., 2009b; Casals-Coll et al., 2013), Bolivia, Chile, Cuba, El Salvador, Guatemala, Honduras, México, Paraguay, Perú, Puerto (Olabarrieta-Landa et al., 2015a), Argentina (Marino and Alderete, 2010; Olabarrieta-Landa et al., 2015a), and Colombia (Olabarrieta-Landa et al., 2015c). The results of these studies with Spanish speakers indicate that performance on most verbal fluency tests is influenced by education, with higher schooling associated with better performance (Marino and Alderete, 2010; Casals-Coll et al., 2013; Olabarrieta-Landa et al., 2015a, b). Regarding gender, no significant differences were found in a study conducted in Spain (Casals-Coll et al., 2013) or in the study by Olabarrieta-Landa et al. (2015a) involving various Latin American (LA) countries. Gender differences were found only by Marino and Alderete (2010) in an Argentine population, with better performance by men on certain tests of semantic fluency (number of animals, number of tools) and phonological fluency (letter P, total score).
Research exploring age effects on verbal fluency in Spanish speakers has yielded mixed results. Regarding phonological fluency, in a study conducted by Olabarrieta-Landa et al. (2015a), performance worsened with increasing age in the majority of countries in Latin America; however, this effect was not evident in countries such as Argentina, Paraguay, and Guatemala for the letters “F,” “A,” and “S” and in Honduras only for the letter “F.” Regarding sematic fluency, Olabarrieta-Landa et al. (2015a) found that performance worsened with increasing age in all the LA countries studied. Nevertheless, Marino and Alderete (2010) found older age associated with better performance on the semantic fluency category tools in Argentina. These mixed results have been also found in two studies in Spain. For instance, Peña-Casanova et al. (2009a) in a sample of 346 healthy participants between 50 and 94 years old found a significant relationship between age and verbal fluency, but Casals-Coll et al. (2013) in a sample of 179 healthy participants 18 to 49 years old did not find this relationship.
The competence of naming linguistic concepts from visual stimuli involves the ability to integrate different cognitive components, such as perceptual recognition, semantic memory, and the lexical phonological output store (Fernández-Blázquez et al., 2012). The neuropsychological evaluation of naming is usually characterized by using tasks in which the evaluated person is asked to indicate the name of the object that is presented by means of a drawing (confrontation naming test; Harry and Crowe, 2014). The Boston Naming Test (BNT; Kaplan et al., 1983) is one of the most commonly utilized tests. There are different versions of this test, with an original version that consists of 60 items and reduced versions varying between 11 and 30 items. Normative studies in Spanish-speaking countries for the BNT show significant positive relationships between test performance and education (Aranciva et al., 2012; Fernández-Blázquez et al., 2012; Olabarrieta-Landa et al., 2015b). The association of test performance with age has been mixed. Olabarrieta-Landa et al. (2015b) found a negative correlation in certain Spanish-speaking countries, while Fernández-Blázquez et al. (2012) and Peña-Casanova et al. (2009a) found that this correlation exists only after 50 years of age. Regarding gender, Aranciva et al. (2012) found no significant differences, whereas Olabarrieta-Landa et al. (2015b) found better performance on the BNT by men in Mexico, Argentina, Chile, Cuba, Guatemala, and Bolivia.
In recent years, country-specific normative data have become available for neuropsychological tests commonly used in the majority of Spanish-speaking countries. However, country-specific data for Ecuador are lacking in the literature. The result is that professionals must interpret raw score or use norms from populations from other Spanish-speaking countries (Arango-Lasprilla and Rivera, 2015; Olabarrieta-Landa et al., 2015a, c). The aim of this study is to provide normative data for two of the most commonly used tests to measure verbal fluency and naming in the Ecuadorian adult population.
Materials and Methods
Participants
The sample consisted of 358 healthy individuals who were recruited from Quito, Ecuador. Participants’ ages ranged from 18 to 84 years (mean = 41.3, SD = 18.2). Education ranged from 2 to 25 years (mean = 13.2, SD = 4.6). The majority was women (54.04%), and the sample was primarily urban (82.8%). The sampling strategy was determined by taking into consideration factors such as literacy level; percentage of people with primary, secondary, and post–secondary education; and age distribution. It is important to note that generating normative data with a population sample from Quito could have some problems, such as overestimation/underestimation of normative data from other population areas of Ecuador. However, Quito is one of the most representative cities of Ecuador, with more than 2.8 million residents and included people from all the cities of the country. On the other hand, the sampling error in this study is ≈0.055 (accuracy level ≈94.5%), which allows us to make adequate inferences. The maximum error was established using classical estimation assuming infinite (very large) population sizes, where the case of maximum uncertainty was assumed (π = 1–π = 0.5) and a confidence interval of 95%. The demographic characteristics (age, education, and sex) can be found in Table 1.
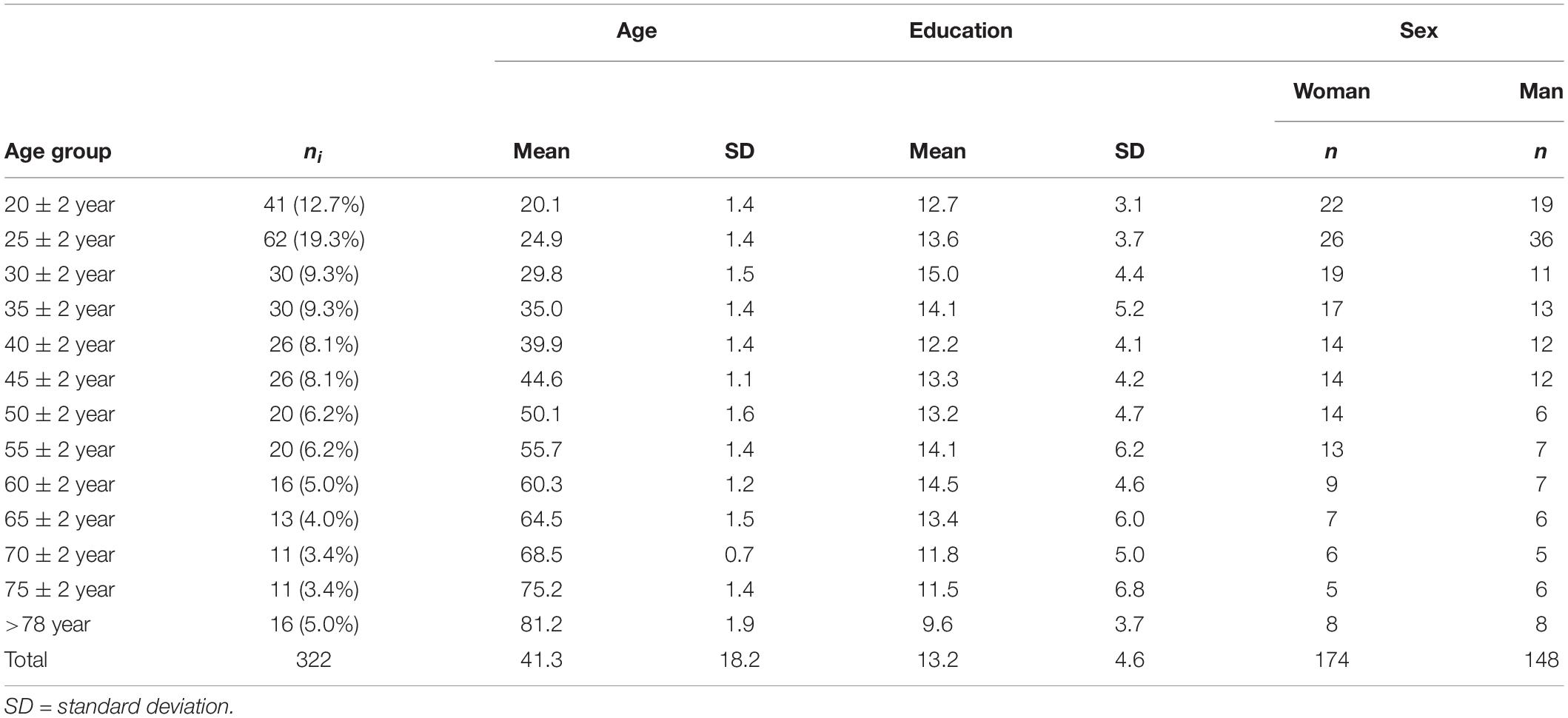
Table 1. Demographic characteristics of the sample.
To be eligible to participate, individuals had to meet the following inclusion criteria: (a) were between 18 and 84 years of age, (b) were born and currently live in Ecuador, (c) spoke Spanish as their native language, (d) had completed at least 1 year of formal education, (e) were able to read and write at the time of evaluation, (f) scored ≥23 on the Mini-Mental State Examination (MMSE; Villaseñor-Cabrera et al., 2010), (g) scored ≤4 on the Patient Health Questionnaire 9 (PHQ-9, Kroenke et al., 2001), (h) scored ≥90 on the Barthel Index (Mahoney and Barthel, 1965), (i) have no history of diagnosed neurological or psychiatric conditions, (j) have no history of alcohol abuse or other psychotropic substances, (k) no history of systemic diseases that affect cognition (e.g., diabetes mellitus), (l) not regularly using pain medications or others that may affect cognitive functioning, (m) not having severe vision and/or hearing deficits, and (n) not having a history of learning or neurodevelopmental problems. All test participants were volunteers who did not receive financial compensation for participation.
The final sample was 322 because 36 participants were excluded (18 score < 23 in MMSE; 9 score > 4 in the PHQ-9; and 9 score < 90 in the Barthel Index). Participants’ mean MMSE score was 28.65 (range = 23–30; SD = 1.457). For the PHQ-9, the mean was 1.74 (range = 0–4; SD = 1.215). Finally, for the Barthel Index, the mean was 100, because all participants score the highest.
Procedure
The present study was conducted as part of a larger study to generate normative data for a series of neuropsychological measures in Spanish-speaking populations (Guàrdia-Olmo et al., 2015; Rivera and Arango-Lasprilla, 2017). The ethics committee of the Universidad San Francisco de Quito approved the study.
Participants were volunteers from the community recruited through announcements distributed in local business, community centers, and the university. All the persons who showed interest in participating were contacted by one member of the research team, who explained the characteristics of the study and answered any questions that the person might have. People who agreed to participate signed the informed consent, and then their sociodemographic data were collected; it was followed by the application of the PHQ-9, the Barthel Index, and the MMSE to verify inclusion and exclusion criteria. A comprehensive battery of neuropsychological tests including those who measured verbal fluency and naming was administered to those participants who met the inclusion criteria. The administration of the tests was carried out by undergraduate psychology students under the supervision of a neuropsychologist in the facilities of the Universidad Las Américas. The assessment lasted between 80 and 120 min. Data collection started in May 2017 and ended in March 2019.
Measures
Patient Health Questionnaire 9 (PHQ-9)
It is a nine-item scale that assesses the presence of depressive symptoms based on the criteria of the Diagnostic and Statistical Manual of Mental Disorders (Baader et al., 2012).
Mini-Mental State Examination (MMSE)
It is a screening test that assesses cognitive function and is sensitive to its deterioration. The test examines five major areas of mental functioning: orientation, retention, attention and calculation, memory, and language. A score of 23 or less indicates cognitive decline (Tombaugh et al., 1996).
Barthel Index for Activities of Daily Living
It provides measures of the individual’s performance, on 10 activities of daily life (feeding, bathing, grooming, dressing, bowels, bladder, toilet use, transfers, mobility, and stairs; Shah et al., 1989). A total score between 0 and 20 suggests total dependence; 21–60, severe dependence; 61–90, moderate dependence; 91–99, mild dependence; and 100, independence.
Verbal Fluency Tests (VFT)
The aim of the phonological VFT (P-VFT) is to produce as many words as possible that begin with a specified letter within 60 s. For this study, the following letters were selected: F, A, S, and M. The letters F, A, and S correspond to the original stimuli of the test and are the most frequently used letters in the literature (Olabarrieta-Landa et al., 2017). The letter M was included because it is one of the letters with higher frequency in Spanish language (Artiola et al., 1999; Peña-Casanova et al., 2009b). In Semantic Verbal Fluency Test (S-VFT), the participant is required to produce as many words as possible belonging to a certain category in 60 s (in this study, animals and fruits). The total score consisted of the total correct answers for each letter or category. Proper names, intrusions, and perseverations were not allowed. In case of supracategory, both supracategory (e.g., bird) and examples of it (e.g., crow, sparrow) were allowed. For the exact instructions and scoring rules, refer to Strauss et al., 2006 (p. 499).
Boston Naming Test (BNT)
The BNT present 60 pictures (Standard version) or 15 pictures (Short version) in order of increasing difficulty. The aim of the task is to denominate each picture. If the correct answer is not given spontaneously, the examiner provides a semantic clue (in case of misrecognition error) or phonological clue (when the semantic clue is still not enough, or during the spontaneous response there has been an error that is not a misrecognition error). For this study, the Spanish Standard and Short versions of the BNT (Kaplan et al., 2005) were used, and the total score was considered as the sum of correct spontaneous answers plus correct answers followed by a semantic clue.
Statistical Analyses
Exploratory Data Analysis
Pearson correlations between the VFT scores (including letters F, A, S, M; categories animals, fruits), BNT scores (Standard and Short), and the sociodemographic (age, education and sex) variables were computed. Mean total P-VFT score was calculated summing up F, A, S, and M total scores and dividing it by 4: [(F + A + S + M)/4]. Mean total S-VFT score was calculated summing up animals and fruits total scores and dividing it by 2: [(animals + fruits)/2].
The Effects of Demographic Variables and the Derivation of Normative Data
Verbal fluency (F, A, S, M, and mean P-VFT scores), semantic fluency (animals, fruits, and mean S-VFT scores), and BNT (Standard and Short scores) scores were computed separately evaluating the effects of demographic variables on each score by means of multiple linear regression analyses. The full regression models included as predictors the following: age, age2, education, education2, sex, and all two-way interactions between these variables. Age and education were centered (= calendar age in years – mean age in the sample; education in years – mean education in the sample) before computing the quadratic age and education to avoid multicollinearity (Kutner et al., 2005). Quadratic age and years of education were added into the full model to allow for quadratic effects between these independent variables and the scores of each test. Sex was dummy coded as man = 1 and woman = 0. The full regression model can be formally described as follows:
with the term Interactionsi referring to all two-way interactions between the fixed effects. The predictors that were not statistically significant in the multiple regression model were removed, and the reduced model was readjusted. A Bonferroni-corrected α level of 0.005 (= 0.05/10) was used. No predictor was removed if it was also included in a higher-order term in the model (Aiken et al., 1991). For all multiple linear regression models, the following assumptions were evaluated: multicollinearity (variance inflation factor [VIF] ≤ 10), homoscedasticity (participants were grouped into quartiles of the predicted scores, and the Levene test was applied on the residuals), normality of the standardized residuals (Kolmogorov–Smirnov test), and the existence of influential values assess (calculation of the maximum Cook’s distance, and subsequently related to an F(p,n−p) distribution; Kutner et al., 2005). An α level of 0.005 was used in all analyses.
The normative data that fit for the demographic variables were established through a four-step procedure, using the final regression model obtained at the end of the procedure (Rivera et al., 2019, 2020): (a) The expected test score (Ŷi) is computed based on the fixed effect parameter estimates of the established final regression model: Ŷi = B0 + B1X1i + B2X2i + … +BkXki. (b) To obtain the residual value (ei), a subtraction between the raw score of the neuropsychological test (Yi) and the predicted value previously calculated was performed (Ŷi), as shown in the following formula: ei = Yi – Ŷi. (c) Using the residual standard deviation (SDe) value provided by the regression model (Table 2), residuals were standardized: zi = ei/SDe. (d) Finally, using the standard normal cumulative distribution function, the exact percentile corresponding to the z score previously calculated was obtained (if the model assumption of normality of the residuals was met in the normative sample), or via the empirical cumulative distribution function of the standardized residuals (if the standardized residuals were not normally distributed in the normative sample; for further information about BNT Standard score, see Supplementary Appendix 1). This four-step process was applied to the VFT (F, A, S, M, and mean P-VFT, animals, fruits, and mean S-VFT) scores and BNT (Standard and Short total score) scores separately.
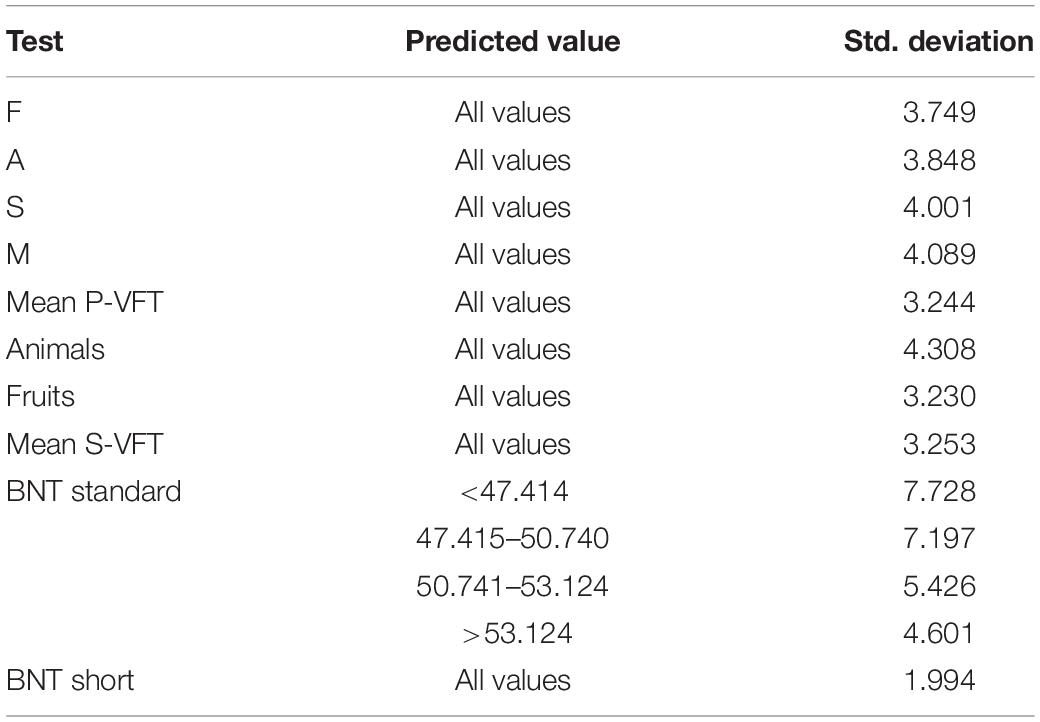
Table 2. Standard deviation (residual) for final multiple linear regression models.
Adjusted R2 values are provided for all final models. All analyses were performed using SPSS version 23 (IBM Corp., 2015).
Results
Exploratory Data Analysis
Table 3 shows the intercorrelation between all the scores (letters F, A, S, M, animals and fruits categories, Standard and Short BNT) and the sociodemographic variables (age, education and sex).
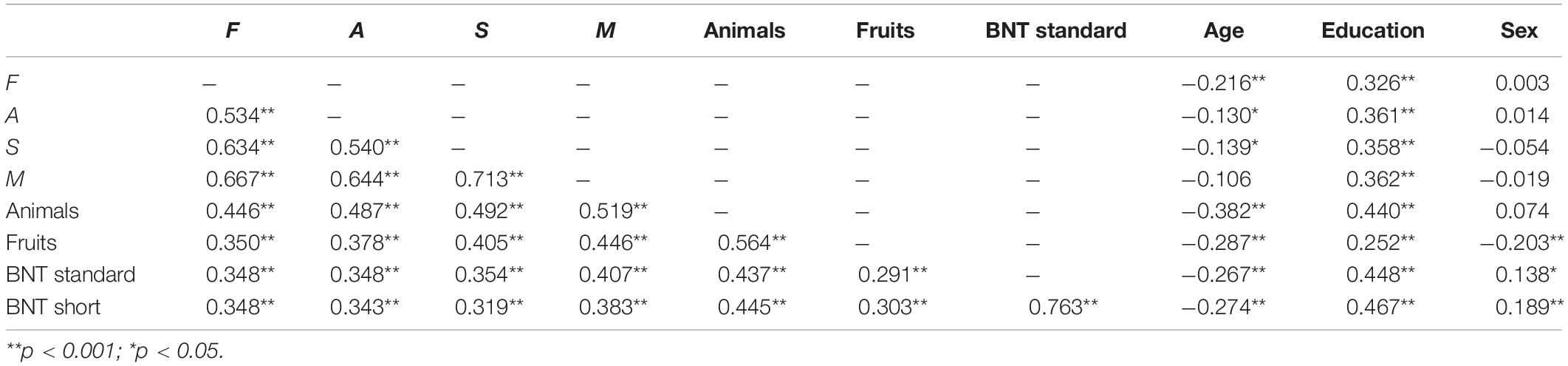
Table 3. Correlations between all VFT scores and demographic variables.
The intercorrelation between letters F, A, S, and M scores can be seen with age (all r ≥ —0.130—; p < 0.001) and education (all r ≥ 0.326; p < 0.001). Sex was no significant with any score. In view of the high correlations between all phonological VFT scores (r ≥ 0.534; p < 0.001), a mean P-VFT total score [(F + A + S + M)/4] was calculated, and normative data were provided for this overall test score summary metric.
For animals and fruits categories, the intercorrelation was with age (r ≥ —0.287—; p < 0.001), education (r ≥ 0.252; p < 0.001), and sex (r = −0.203; p < 0.001; in fruits). In view of the high correlations between all semantic VFT scores (r ≥ 0.564; p < 0.001), a mean S-VFT total score [(animals + fruits)/2] was calculated, and normative data were provided for this overall test score summary metric.
Finally, the intercorrelation between BNT Standard and Short scores was with age (all r ≥ —0.267—; p < 0.001), education (all r ≥ 0.448; p < 0.001), and sex (all r ≥ 0.138; p < 0.05).
Model Assumptions
The assumptions of multiple linear regression analysis were fulfilled for all final models. There was no multicollinearity (VIF values in all models were at most 1.997, and therefore well below the threshold value = 10; collinearity tolerance values did not exceed the value of 1) or influencing cases (the maximum distance Cook’s value was 0.182; relating this value to an F(3,319) distribution produces the 9th percentile value, which is well below the threshold percentile value = 50). Levene test suggested that there was homoscedasticity in all models except for the standard BNT score. The standardized residuals of all models were normally distributed (as evaluated with the Kolmogorov–Smirnov test).
The Effects of Demographic Variables
Phonological Verbal Fluency
The final multiple linear regression models for letters F, A, S, M, and mean P-VFT scores were significant (Table 4). Letters F, A, S, M, and the mean P-VFT total score were positively influenced by education, so those with higher education generated more words in each letter. Letter F score was also negatively influenced by age, showing that young people have better performance. The amount of variance (adjusted for the number of predictors in the final model; adjusted R2) explained by these predictors was 13% for letters F, A, and M; 12% for letter S; and 17% for the mean P-VFT total score. A, S, M, and P-VFT scores were not affected by sex and all two-level interactions.
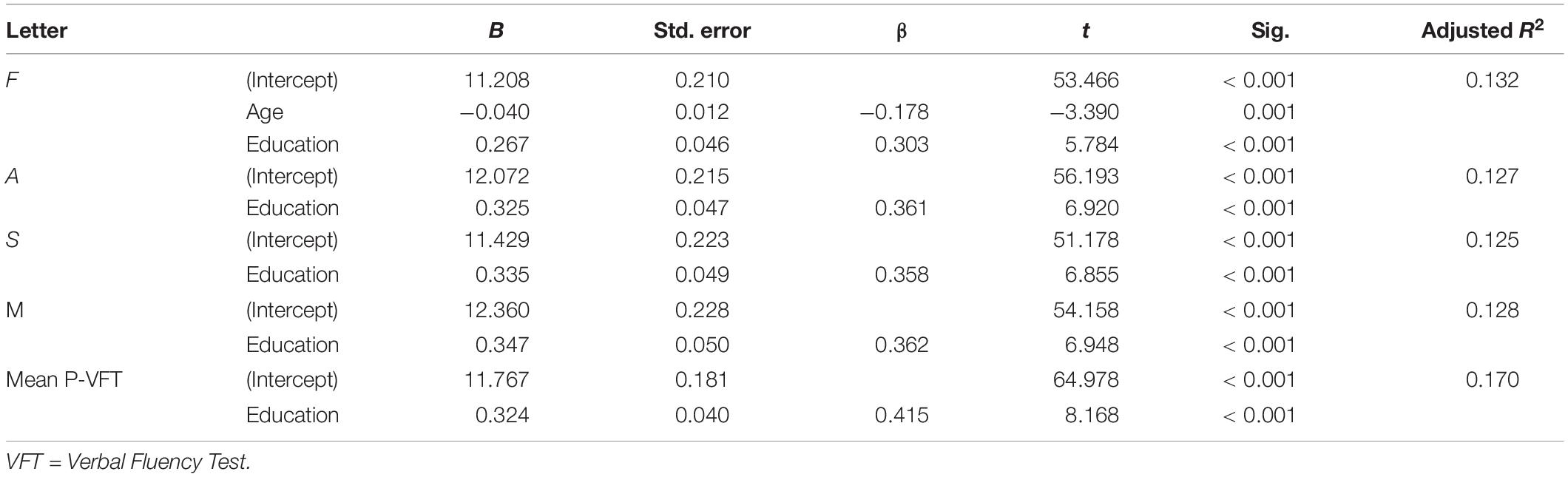
Table 4. Final multiple linear regression models for Phonological VFT.
Semantic Verbal Fluency
The amount of variance explained after adjusted for the number of predictors in animals final model was 32%; for fruits model, 25%; and for mean S-VFT total scores model, 33% (Table 5). The animals and fruits categories and the mean S-VFT total scores were negatively affected by quadratic age effect, showing a curvilinear pattern of the scores according to age, with a fall after the age of 40 years (Figures 1, 2). All scores were affected by education, so that those with higher education generated more words in each category. Fruits score was also negatively affected by sex, with women obtaining better scores than men.
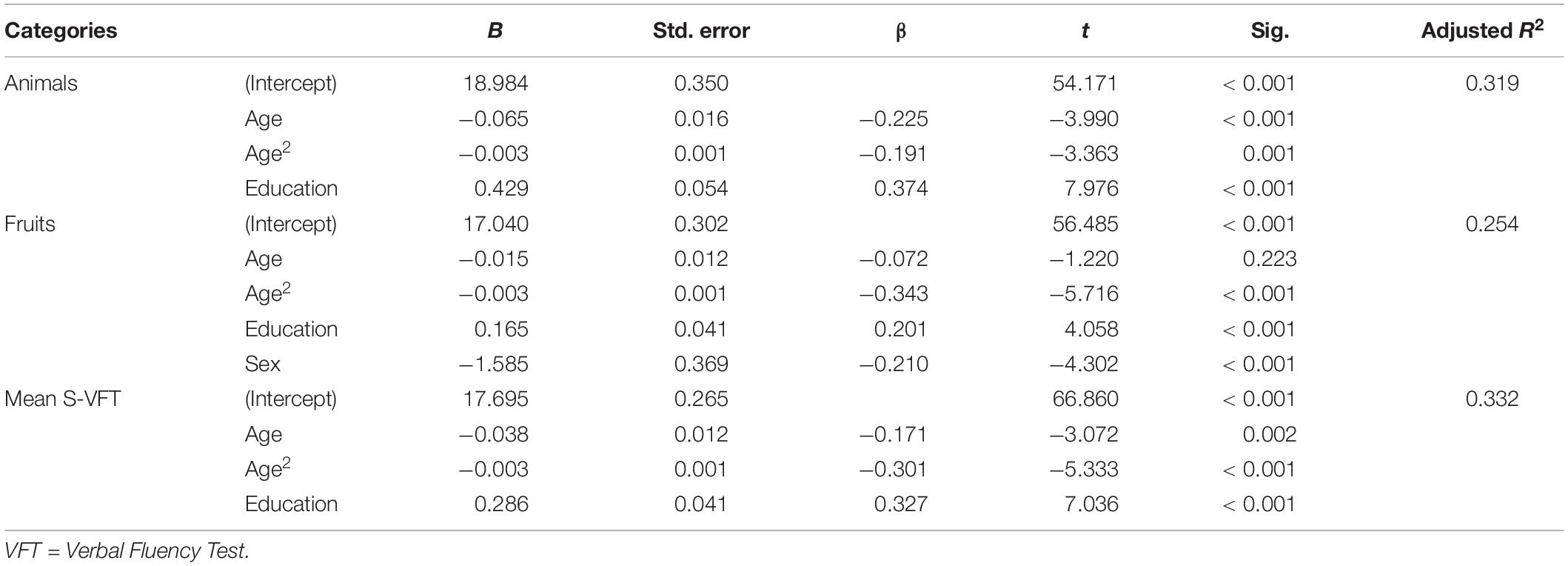
Table 5. Final multiple linear regression models for Semantic VFT.
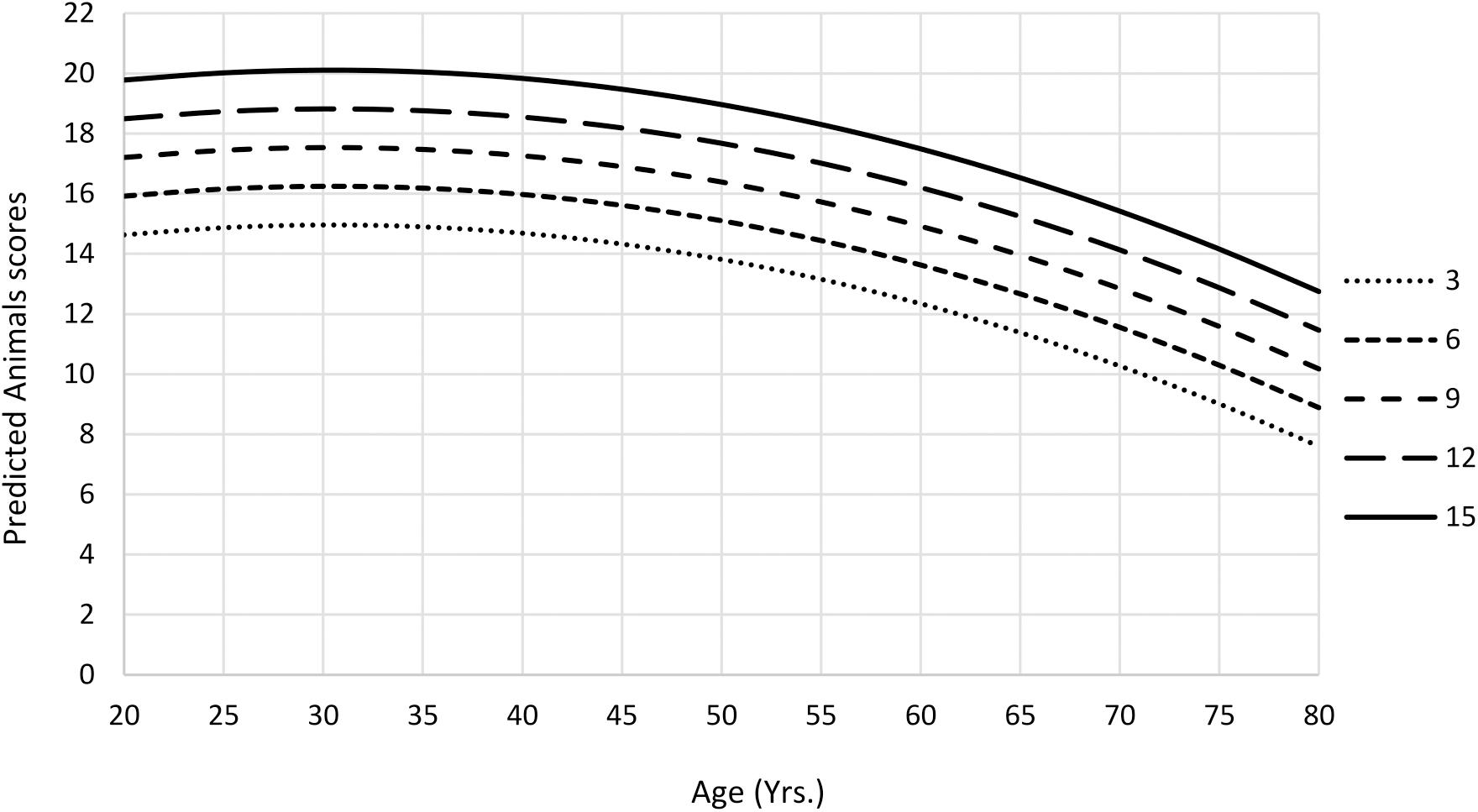
Figure 1. Predicted mean Animals scores as a function of age and education from Ecuadorean sample.
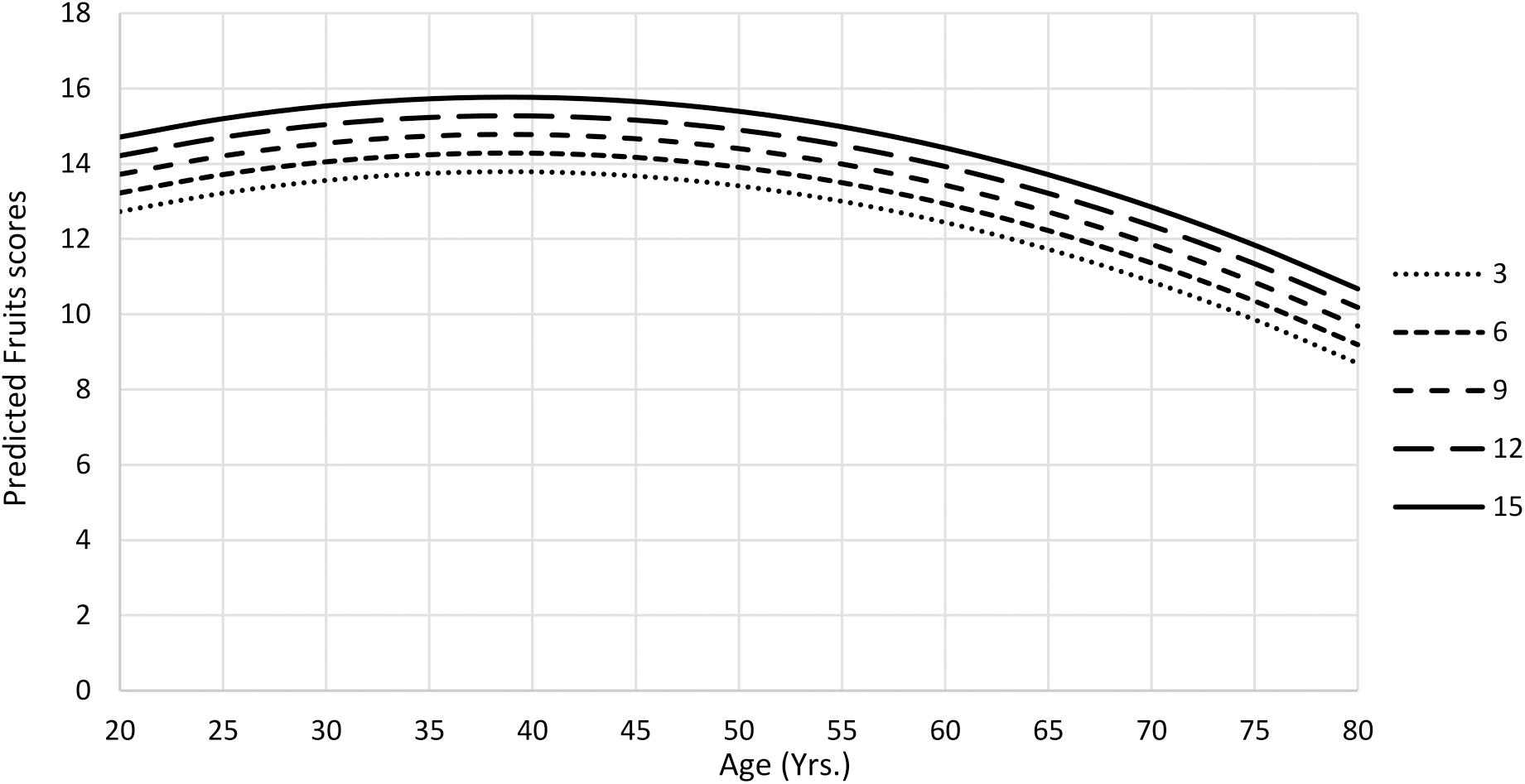
Figure 2. Predicted mean Fruits scores as a function of age and education from Ecuadorean sample.
Boston Naming Test
The final multiple linear regression models for BNT Standard and BNT Short scores were significant (Table 6). The amount of variance explained after adjusting for the number of predictors in BNT Short final model was 24%, and for BNT Standard, final model was 26%. Both BNT Short and Standard total scores were negatively influenced by age and increased linearly as a function of education, showing young and more educated people have better performance (Figure 3).
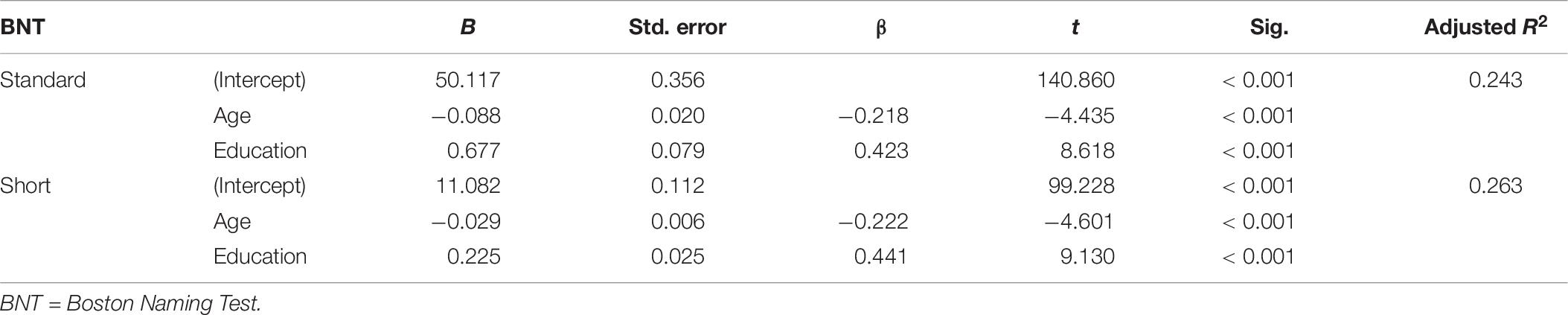
Table 6. Final multiple linear regression models for BNT.
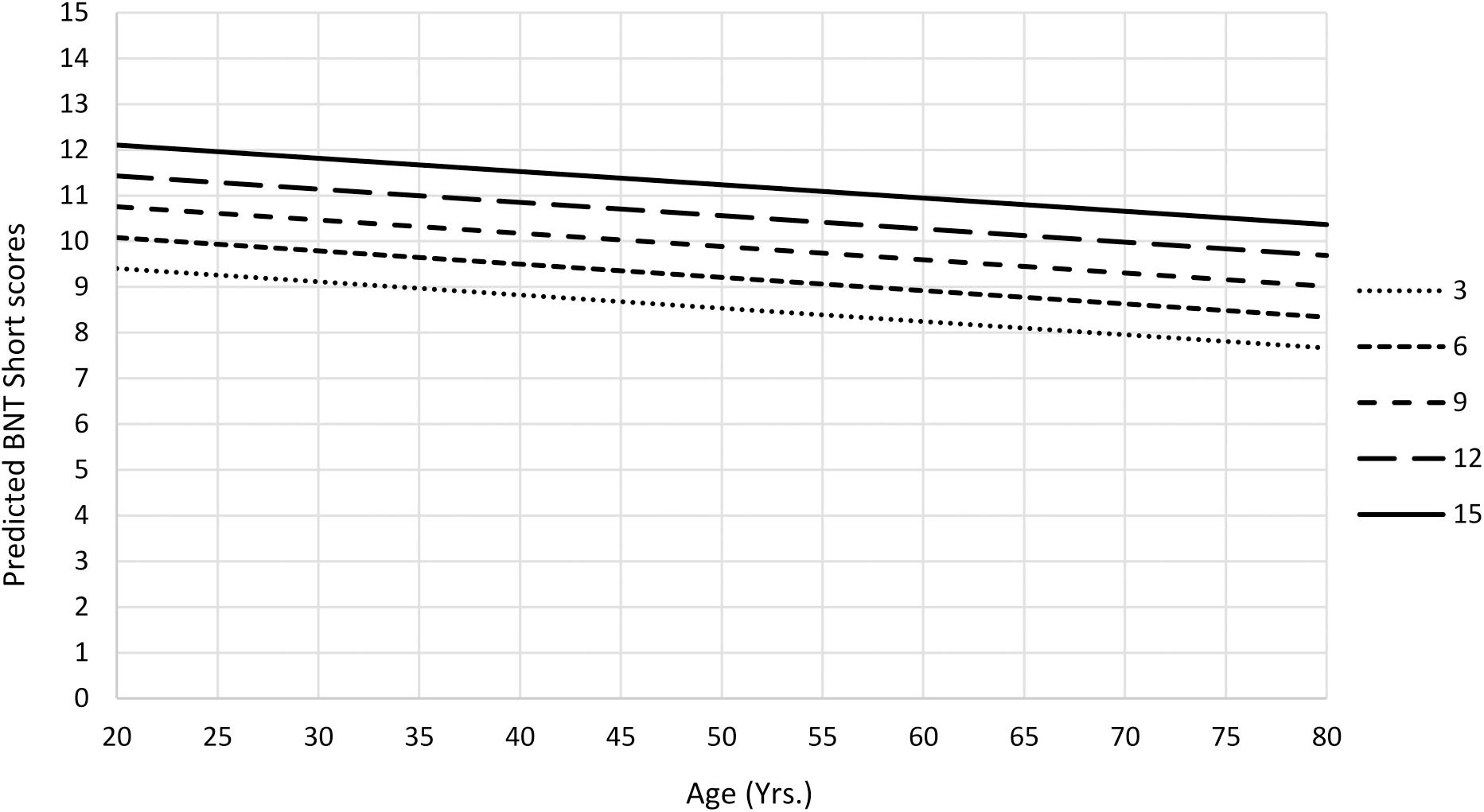
Figure 3. Predicted mean BNT Short scores as a function of age and education from Ecuadorean sample.
Normative Data Calculator
The four-step normative procedure explained above allows determining an exact percentile value for VFT and BNT test scores. However, this method can be prone to human error due to the number of required computations by hand. To enhance user-friendliness, the authors created a calculator in Microsoft Excel that conducts all required computations. The clinician simply fills in raw VFT and BNT scores and demographic characteristics (i.e., age, education, and sex), and the software automatically computes the standardized residuals and their corresponding exact percentile values. This tool is freely available for all users and may be downloaded at https://neuropsychologylearning.com/datos-normativos-archivos-descargables/.
Discussion
The aim of the current study was to generate normative data for the Verbal Fluency Test and for the Boston Naming Test for an Ecuadorian adult population, while controlling the effect of sociodemographic variables, such as age, sex, and level of education, on performance. In addition, this study presents a calculator of normative data, which simplifies the procedure to obtain the norms. This calculator allows reducing time and possible human errors when data are visualized in tables (Ramírez et al., 2012).
Linear regression models for phonological fluency explained approximately 13% of the variance for all letters considered. For letters “A,” “S,” and “M,” the results were similar to those found by Casals-Coll et al. (2013) in Spain with young adults (18–49 years old) and Olabarrieta-Landa et al. (2015a) in Argentina, Guatemala, and Paraguay with adults in a wider age range from 18 to 95 years, in which performance was only associated with education; scores improved as level of education increased. Age was not a significant predictor of performance. However, it differs from the study by Peña-Casanova et al. (2009a) carried out in Spain with older adults (50–94 years) and from the study by Olabarrieta-Landa et al. (2015a) in other LA countries such as Puerto Rico, Peru, Mexico, Honduras, El Salvador, Cuba, Chile, and Bolivia. The differences with Peña-Casanova et al. (2009a) study may be explained because of the different letters used in the study. While Peña-Casanova and colleagues used the letters “M,” “P,” and “R,” the most appropriate for Spanish vocabulary, in the present study the letters “F,” “A,” “S,” and “M” (the most frequently used letters in the literature) were used. Furthermore, the α level to avoid type I error differs among studies. In this study, the threshold was adjusted to 0.005 (Van Der Elst et al., 2006; Rivera et al., 2019), whereas in Peña-Casanova et al. (2009a), it was at 0.05.
Finally, for letter “F,” the results are consistent with those found by Olabarrieta-Landa et al. (2015a) in Bolivia, Chile, Cuba, El Salvador, Mexico, Peru, and Puerto Rico, and by Peña-Casanova et al. (2009a) in which both age and education were positively related to performance on this letter. Nevertheless, in other LA countries such as Argentina, Guatemala, Honduras, and Paraguay, the effect was only explained by education but not by age. No gender effect was noted in the models, which was generally consistent with prior research with the exception of Marino and Alderete (2010) conducted in Argentina, in which sex and education significantly affected performance.
Models for semantic fluency explained 25% to 32% of the variance. For “animals,” the variables age, quadratic age, and education significantly explained the performance (32% of the variance). The results are consistent with the study of Olabarrieta-Landa et al. (2015a), for several LA countries, Argentina, Bolivia, Chile, Cuba, El Salvador, Guatemala, Honduras, Mexico, Paraguay, Peru, and Puerto Rico, in which scores worsen with increasing age, whereas scores improved when the number of years of education increased; in that study, quadratic age was not included in the model. Gender did not significantly explain performance; however, Marino and Alderete (2010) found that in Argentina this variable jointly with education was associated with performance; men with more years of education had better performance scores than women. Scores for “fruits” were significantly associated by quadratic age, education, and sex. People with greater levels of education and younger named a greater number of fruits. However, after age 40 years, the number of named fruits decreased, which is explained by the quadratic distribution of the scores. Women presented better performance in this category than did men. The influence of education is consistent with previous studies (Marino and Alderete, 2010; Casals-Coll et al., 2013; Olabarrieta-Landa et al., 2015a). However, the present study is one of the first studies in Spanish-speaking countries that included in the model the quadratic age, which enhanced the interpretability of the results.
The BNT was used for the assessment of naming. The results obtained in the present study were similar to those found in a previous study conducted in Latin America in which BNT scores decreased linearly as a function of age and improved as number of years of education increased in several countries, such as Chile, Cuba, El Salvador, Guatemala, Mexico, and Puerto Rico (Olabarrieta-Landa et al., 2015b). These results are also consistent with those of the study conducted by Fernández-Blázquez et al. (2012), although with older adults in Spain. Only the study of Aranciva et al. (2012) found no significant relationship between age and performance in this test; nevertheless, it can be an effect of the limited range of age (18–49 years) of the population in that study. In the present study, gender was not a significant predictor of the performance on BNT scores, similarly to previous studies (Aranciva et al., 2012; Fernández-Blázquez et al., 2012).
The results of the present study have important implications. To our knowledge, this is the first study in Ecuador that presents normative data for two of the most common neuropsychological tests that are used to assess verbal fluency and naming functions. This referential data will allow clinicians to have more precise interpretation of scores and the variables to consider when these tests are used in this population. In the past, the interpretation of scores for these tests in this country was done using raw data or normative data from other countries such as United States, United Kingdom, Canada, and Spain, which possibly resulted in biases and identification of false-positive cases. Suppose we need to find the percentile score for an Ecuadorian man, who is 60 years old, has 5 years of education, and scored 12 on animals. Based on the normative data done by Tombaugh et al. (1999) for Canada, this person would have obtained an adjusted z score of −0.705 (percentile 24). With the normative data obtained by Peña-Casanova et al. (2009a) for Spain, the Neuronorma Scaled Score would have been of 7 (percentile 11–18). If we compared with other LA Spanish-speaking countries, such as Mexico or Paraguay (Olabarrieta-Landa et al., 2015a), the adjusted z scores would have been of −0.927 (percentile 18) for Mexico. With the norms generated in this study, this person would have obtained an adjusted z score of −0.279 (percentile 39). The previous norms from other countries placed the individual in percentiles much lower than the one obtain using the country-specific norms presented here. This is only one example to illustrate the potential biases of using other norms to interpret raw scores.
Moreover, compared with other studies that have been done in Lain America, this study presents a novel methodology for the calculation of the normative data, which lead to more accurate data than in previous studies. First, to avoid multicollinearity within the multiple regression model, age and education were centered. Second, quadratic age and education were included in the model, which allowed to test whether there is an age or education range in which the performance starts to decrease. Third, all the possible interactions between the variables were tested to determine which variables significantly explain the performance in each test.
Limitations
The results of this study should be interpreted in light of the following limitations. First, the data were collected in the Metropolitan District of Quito, which is one of the most representative cities of Ecuador, which have residents from all the cities of the country. Generating normative data with a population sample from Quito can overestimate/underestimate the normative data in other population areas of Ecuador. Future studies might include participants from rural areas and other different regions of the country in order to have a more representative sample of the Ecuadorian population. Second, another variable that was not considered in the study was bilingualism, which previous studies have shown to influence cognitive performance. Although in Ecuador, Spanish is the official language, approximately 34% of the population is indigenous, and there are 18 indigenous native languages (Haboud et al., 2016). Then, it is relevant for future studies to assess the level of bilingualism on these populations and to determine its influence on the results. Third, in this study, the number of years of education was considered, and other variables related to the quality of education were not included on the data collection variables. Future studies might include this variable and to determine its influence on the test performance. Finally, this study only presented normative data in healthy Ecuadorian individuals. Future studies should be done with clinical populations (e.g., Alzheimer, traumatic brain injury, stroke, etc.) in order to determine the specific cutoff scores on these tests by group.
Conclusion
The purpose of this study was to develop normative data for two of the most common neuropsychological tests used by neuropsychologist in Ecuador to measure verbal fluency and naming in adult population. Results show that education had a significant positive effect on the performance of letters “A,” “S,” and “M”; the performance improved when the number of years of education increased. For letter “F,” in addition to education, the age was also significantly associated with the performance, such as the older that person is, the worse the performance. For semantic fluency, the performance on “animals” improved when the person has a greater number of years of education and when the person is younger. However, when including age2, it is evident that the number of fruits named increased until the age 40 years, and then it starts to decrease. Education and age had similar association in regard to the performance on “fruits”; however, women named more fruits than did men. The BNT scores were significantly explained by age and education.
Verbal fluency and naming problems are very common symptoms reported in a variety of patients with neurological disorders. Therefore, it is expected that this normative data will be widely used and contributed to improve the clinical practice of neuropsychologists in Ecuador, helping clinicians to avoid the malpractice of using raw scores or normative data from other countries when conducting neuropsychological evaluations.
Data Availability Statement
Research data are not shared publicly due to stipulations made by the research ethics committee at the time of approval regarding the storage and confidentiality of patient data. For requests please contact the corresponding author.
Ethics Statement
The studies involving human participants were reviewed and approved by the Ethics Committee of the Universidad San Francisco de Quito. The patients/participants provided their written informed consent to participate in this study.
Author Contributions
AR-L: conceptualization, investigation, resources, writing – original draft, project administration, and funding acquisition. IB-S: formal analysis, writing – review and editing. LA-D: conceptualization, investigation, resources, writing – original draft, and funding acquisition. CP: conceptualization, investigation, resources, writing – original draft, and funding acquisition. TY: conceptualization, investigation, resources, writing – original draft, project administration, and funding acquisition. DR: methodology, formal analysis, writing – review and editing. JA-L: conceptualization, methodology, writing – review and editing, and supervision.
Funding
The study was funded by Universidad de Las Américas, through the university’s General Research Directorate.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpsyg.2020.00830/full#supplementary-material
References
Aiken, L. S., West, S. G., and Reno, R. R. (1991). Multiple Regression: Testing and Interpreting Interactions. New York, NY: Sage Publications.
Aranciva, F., Casals-Coll, M., Sánchez-Benavides, G., Quintana, M., Manero, R. M., Rognoni, T., et al. (2012). Estudios normativos españoles en población adulta joven (Proyecto NEURONORMA jóvenes): normas para el Boston Naming Test y el Token Test. Neurologia 27, 394–399. doi: 10.1016/j.nrl.2011.12.016
Arango-Lasprilla, J. C., and Rivera, D. (eds) (2015). Neuropsicología en Colombia: Datos Normativos, Estado Actual y Retos A Futuro. Caldas: Universidad Autónoma de Manizales.
Arango-Lasprilla, J. C., Stevens, L., Morlett Paredes, A., Ardila, A., and Rivera, D. (2017). Profession of neuropsychology in Latin America. Appl. Neuropsychol. 24, 318–330. doi: 10.1080/23279095.2016.1185423
Artiola, L., Hermosillo, D., Heaton, R., and Pardee, R. E. (1999). Manual de Normas y Procedimientos Para la bater’ıa Neuropsicolíogica En Español. Tucson: AZ.
Baader, T., Molina, J. L., Venezian, S., Rojas, C., Farías, R., Fierro-Freixenet, C., et al. (2012). Validación y utilidad de la encuesta PHQ-9 (Patient Health Questionnaire) en el diagnóstico de depresión en pacientes usuarios de atención primaria en Chile. Rev. Chilena Neuro Psiquiatr. 50, 10–22.
Brady, C. B., Spiro, A. III, McGlinchey-Berroth, R., Milberg, W., and Gaziano, J. M. (2001). Stroke risk predicts verbal fluency decline in healthy older men: evidence from the normative aging study. J. Gerontol. Ser. B 56, 340–346. doi: 10.1093/geronb/56.6.P340
Casals-Coll, M., Sánchez-Benavides, G., Quintana, M., Manero, R. M., Rognoni, T., Calvo, L., et al. (2013). Estudios normativos españoles en población adulta joven (proyecto NEURONORMA jóvenes): normas para los test de fluencia verbal. Neurologia 28, 33–40. doi: 10.1016/j.nrl.2012.02.010
Clark, L. J., Gatz, M., Zheng, L., Chen, Y. L., McCleary, C., and Mack, W. J. (2009). Longitudinal verbal fluency in normal aging, preclinical, and prevalent Alzheimer’s disease. Am. J. Alzheimer’s Dis. Other Dement. 24, 461–468. doi: 10.1177/1533317509345154
Cuetos, F. (2012). Neurociencia Del Lenguaje: Bases Neurológicas e Implicaciones Clínicas. Madrid: Editorial Médica Panamericana.
De Renzi, E., and Vignolo, L. (1962). The Token Test: a sensitive test to detect receptive disturbances in aphasics. Brain 85, 665–678. doi: 10.1093/brain/85.4.665
Dunn, L. M. (1959). Peabody Picture Vocabulary Test—Revised. Circle Pines, MN: American Guidance Service.
Fernández-Blázquez, M. A., Ruiz-Sánchez de León, J. M., López-Pina, J. A., Llanero-Luque, M., Montenegro-Peña, M., and Montejo-Carrasco, P. (2012). Nueva versión reducida del test de denominación de Boston para mayores de 65 años: aproximación desde la teoría de respuesta al ítem. Rev. Neurol. 55, 399–407.
Fonseca-Aguilar, P., Olabarrieta-Landa, L., Rivera, D., Aguayo Arelis, A., Ortiz Jiménez, X. A., Rabago Barajas, B. V., et al. (2015). Current state of professional Neuropsychological practice in Mexico. Psicol. Desde Caribe 32, 344–364.
Gardini, S., Cuetos, F., Fasano, F., Pellegrini, F. F., Marchi, M., Venneri, A., et al. (2013). Brain structural substrates of semantic memory decline in mild cognitive impairment. Curr. Alzheimer Res. 10, 373–389. doi: 10.2174/1567205011310040004
Gleissner, U., and Elger, C. E. (2001). The hippocampal contribution to verbal fluency in patients with temporal lobe epilepsy. Cortex 37, 55–63. doi: 10.1016/S0010-9452(08)70557-4
Goodglass, H., and Kaplan, E. (1983). Boston Diagnostic Aphasia Examination (BDAE). Philadelphia: Lea & Febiger.
Guàrdia-Olmo, G., Pero-Cebollero, M., Rivera, D., and Arango-Lasprilla, J. C. (2015). Methodology for the development of normative data for ten Spanish-language neuropsychological tests in eleven Latin American countries. Neuro Rehabil. 37, 493–499. doi: 10.3233/NRE-151277
Haboud, M., Howard, R., Cru, J., and Freeland, J. (2016). “Linguistic human rights and language revitalization in latin america and the caribbean,” in Indigenous Language Revitalization in the Americas, eds S. Coronel-Molina and T. McCarty (New York, NY: Routledge), 201–224.
Harry, A., and Crowe, S. F. (2014). Is the boston naming test still fit for purpose? Clin. Neuropsychol. 28, 486–504. doi: 10.1080/13854046.2014.892155
Henry, J. D., and Crawford, J. R. (2004a). A meta-analytic review of verbal fluency performance following focal cortical lesions. Neuropsychology 18, 284–295. doi: 10.1037/0894-4105.18.2.284
Henry, J. D., and Crawford, J. R. (2004b). Verbal fluency deficits in Parkinson’s disease: a meta-analysis. J. Int. Neuropsychol. Soc. 10, 608–622. doi: 10.1017/S1355617704104141
Jodar, M., and Redolar, D. (2013). “Neuropsicología del lenguaje,” in Neuropsicología, ed. M. Jodar (Barcelona: Editorial UOC), 111–169.
Kaplan, E., Goodglass, H., and Weintraub, S. (1983). The Boston Naming Test: Experimental edition (1978), 2nd Edn. Philadelphia: Lea & Febiger.
Kaplan, E., Goodglass, H., and Weintraub, S. (2005). Test de Vocabulario de Boston, 2 Edición Edn. Madrid: Editorial Médica Paramericana, S.A.
Kavé, G., Heled, E., Vakil, E., and Agranov, E. (2011). Which verbal fluency measure is most useful in demonstrating executive deficits after traumatic brain injury? J. Clin. Exp. Neuropsychol. 33, 358–365. doi: 10.1080/13803395.2010.518703
Kim, H., Kim, J., Kim, D. Y., and Heo, J. (2011). Differentiating between aphasic and nonaphasic stroke patients using semantic verbal fluency measures with administration time of 30 seconds. Eur. Neurol. 65, 113–117. doi: 10.1159/000324036
Kroenke, K., Spitzer, R. L., and Williams, J. B. (2001). The PHQ-9. J. Gen. Intern. Med. 16, 606–613.
Kutner, M. H., Nachtsheim, C. J., Neter, J., and Li, W. (2005). Applied Linear Statistical Models, 5th Edn. New York, NY: McGraw Hill.
Mahoney, F. I., and Barthel, D. (1965). Functional evaluation: the Barthel Index. Maryland State Med. J. 14, 56–61.
Marino, D. J. C., and Alderete, A. M. (2010). Valores normativos de pruebas de fluidez verbal categoriales, fonológicas, gramaticales y combinadas y análisis comparativo de la capacidad de iniciación. Rev. Neuropsicol. Neuropsiquiatr. Neuroci. 10, 79–93. doi: 10.1017/CBO9781107415324.004
McDowd, J., Hoffman, L., Rozek, E., Lyons, K. E., Pahwa, R., Burns, J., et al. (2011). Understanding verbal fluency in healthy aging, Alzheimer’s disease, and Parkinson’s disease. Neuropsychology 25, 210–225. doi: 10.1037/a0021531
Olabarrieta-Landa, L., Caracuel, A., Pérez-García, M., Panyavin, I., Morlett-Paredes, A., and Arango-Lasprilla, J. C. (2016). The profession of neuropsychology in Spain: results of a national survey. Clin. Neuropsychol. 30, 1335–1355. doi: 10.1080/13854046.2016.1183049
Olabarrieta-Landa, L., Rivera, D., Galarza-Del-Angel, J., Garza, M. T., Saracho, C. P., Rodríguez, W., et al. (2015a). Verbal fluency tests: normative data for the Latin American Spanish speaking adult population. Neuro Rehabil. 37, 515–561. doi: 10.3233/NRE-151279
Olabarrieta-Landa, L., Rivera, D., Morlett-Paredes, A., Jaimes-Bautista, A., Garza, M. T., Galarza-Del-Angel, J., et al. (2015b). Standard form of the Boston Naming Test: normative data for the Latin American Spanish speaking adult population. NeuroRehabilitation 37, 501–513. doi: 10.3233/NRE-151278
Olabarrieta-Landa, L., Rivera, D., Vergara Torres, G. P., Lozano Plaza, J. E., Quijano, M. C., De los Reyes Aragón, C. J., et al. (2015c). “Datos normativos del test de fluidez verbal semántica y fonológica para población Colombiana,” in Neuropsicología en Colombia: Datos normativos, Estado Actual y Retos a Futuro, eds J. I. C. I. Arango-Lasprilla and D. Rivera (Manizales: Universidad Autónoma de Manizales), 178–207.
Olabarrieta-Landa, L., Torre, E. L., López-Mugartza, J. C., Bialystok, E., and Arango-Lasprilla, J. C. (2017). Verbal fluency tests: developing a new model of administration and scoring for Spanish language. NeuroRehabilitation 41, 539–565. doi: 10.3233/NRE-162102
Peña-Casanova, J., Quiñones-Úbeda, S., Gramunt-Fombuena, N., Aguilar, M., Casas, L., Molinuevo, J. L., et al. (2009a). Spanish Multicenter Normative Studies (NEURONORMA Project): norms for Boston naming test and token test. Arch. Clin. Neuropsychol. 24, 343–354. doi: 10.1093/arclin/acp039
Peña-Casanova, J., Quinones-Ubeda, S., Gramunt-Fombuena, N., Quintana-Aparicio, M., Aguilar, M., Badenes, D., et al. (2009b). Spanish Multicenter Normative Studies (NEURONORMA Project): norms for verbal fluency tests. Arch. Clin. Neuropsychol. 24, 395–411. doi: 10.1093/arclin/acp042
Ramírez, A. M., Consuelo, M., Ponce, E., García, R. Z., Solís, J. E. M., and Cortés, C. H. (2012). Sistema para la aplicación de pruebas psicológicas vía web. Control 22, 5–13.
Rivera, D., and Arango-Lasprilla, J. C. (2017). Methodology for the development of normative data for Spanish-speaking pediatric populations. NeuroRehabilitation 41, 581–592. doi: 10.3233/NRE-172275
Rivera, D., Olabarrieta-Landa, L., Van der Elst, W., Gonzalez, I., Ferrer-Cascales, R., Peñalver Guia, A. I., et al. (2020). Regression-based normative data for children from latin america: phonological verbal fluency letters M, R, and P. Assessment 6:1073191119897122. doi: 10.1177/1073191119897122
Rivera, D., Olabarrieta-Landa, L., Van der Elst, W., Gonzalez, I., Rodríguez-Agudelo, Y., Aguayo Arelis, A., et al. (2019). Normative data for verbal fluency in healthy Latin American adults: Letter M, and fruits and occupations categories. Neuropsychology 33:287. doi: 10.1037/neu0000518
Roby-Brami, A., Hermsdörfer, J., Roy, A. C., and Jacobs, S. (2012). A neuropsychological perspective on the link between language and praxis in modern humans. Philos. Trans. R. Soc. B 367, 144–160. doi: 10.1098/rstb.2011.0122
Scott, J. G., and Schoenberg, M. R. (2011). “Language problems and assessment: the aphasic patient,” in The Little Black Book of Neuropsychology, eds M. R. Schoenberg and J. G. Scott (Berlin: Springer Science & Business Media), 159–178. doi: 10.1007/978-0-387-76978-3
Shah, S., Vanclay, F., and Cooper, B. (1989). Improving the sensitivity of the Barthel Index for stroke rehabilitation. J. Clin. Epidemiol. 42, 703–709. doi: 10.1016/0895-4356(89)90065-6
Strauss, E., Sherman, E. M. S., and Spreen, O. (2006). A Compendium of Neuropsychological Tests: Administration, Norms, And Commentary, 3rd Editio Edn. New York, NY: Oxford University Press.
Thompson, P. J., and Duncan, J. S. (2005). Cognitive decline in severe intractable epilepsy. Epilepsia 46, 1780–1787. doi: 10.1111/j.1528-1167.2005.00279.x
Tombaugh, T. N., Kozak, J., and Rees, L. (1999). Normative data stratified by age and education for two measures of verbal fluency: FAS and animal naming. Arch. Clin. Neuropsychol. 14, 167–177.
Tombaugh, T. N., McDowell, I., Kristjansson, B., and Hubley, A. M. (1996). Mini-Mental State Examination (MMSE) and the Modified MMSE (3MS): a psychometric comparison and normative data. Psychol. Assess. 8:48. doi: 10.1016/j.archger.2010.02.005
Van Der Elst, W., Van Boxtel, M. P., Van Breukelen, G. J., and Jolles, J. (2006). Normative data for the Animal, Profession and Letter M Naming verbal fluency tests for Dutch speaking participants and the effects of age, education, and sex. J. Int. Neuropsychol. Soc. 12, 80–89. doi: 10.1017/S1355617706060115
Keywords: language, neuropsychological tests, standardization, Ecuador, normative data, verbal fluency, naming
Citation: Rodríguez-Lorenzana A, Benito-Sánchez I, Adana-Díaz L, Paz CP, Yacelga Ponce T, Rivera D and Arango-Lasprilla JC (2020) Normative Data for Test of Verbal Fluency and Naming on Ecuadorian Adult Population. Front. Psychol. 11:830. doi: 10.3389/fpsyg.2020.00830
Received: 08 February 2020; Accepted: 03 April 2020;
Published: 27 May 2020.
Edited by:
Micaela Mitolo, IRCCS Institute of Neurological Sciences of Bologna (ISNB), ItalyReviewed by:
Marco Pitteri, University of Verona, ItalyGonzalo Sánchez-Benavides, BarcelonaBeta Brain Research Center, Spain
Copyright © 2020 Rodríguez-Lorenzana, Benito-Sánchez, Adana-Díaz, Paz, Yacelga Ponce, Rivera and Arango-Lasprilla. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Juan Carlos Arango-Lasprilla, jcalasprilla@gmail.com