 Anuj Kumar Bharti
Anuj Kumar Bharti Sandeep Kumar Yadav
Sandeep Kumar Yadav Snehlata Jaswal
Snehlata Jaswal
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Psychol. , 05 February 2020
Sec. Cognition
Volume 11 - 2020 | https://doi.org/10.3389/fpsyg.2020.00033
This article is part of the Research Topic Understanding the Operation of Visual Working Memory in Rich Complex Visual Context View all 10 articles
Feature binding is a process that creates an integrated representation of an object. A change detection task with four stimuli is used to study color-shape binding of sequentially presented stimuli. Given the immense importance of locations in feature binding, and noting the confound of location information with simultaneous presentation, we compared simultaneous and sequential presentations when locations remained the same from study to test and when they changed randomly. In Experiment 1, sequential presentation implied showing the stimuli one by one to gradually build up the study display. There were no differences between the two modes of presentation in this experiment, although performance was better with unchanged locations than random locations. Experiment 2 used a sequential presentation when one stimulus vanished as the next was presented. An interaction effect showed that performance was much better with unchanged locations than random locations with simultaneous presentation, whereas locations had no effect in the sequential presentation condition. Three subsequent experiments, with drastically reduced presentation time for the display in the simultaneous presentation condition (Experiment 3), with blank intervals inserted after every stimulus in the sequential presentation condition (Experiment 4), and with a mask given immediately after the study-display presentation (Experiment 5), showed results similar to Experiment 2. Thus, we surmise that locations are a factor only in simultaneous presentation, and not in sequential presentation, and the differences between the two conditions can be attributed to post-perceptual factors within visual working memory.
Feature binding is the process by which different characteristics, such as, orientation, size, shape, color, and location, are integrated to create an object. Binding is a necessary process for accurate perception of the world. Not only does it allow the separation of figure and ground, but also the differentiation of one object from another. Objects in the real world differ in space as well as time. Presumably, feature binding helps us differentiate objects not only when they are present together at the same time in our experience, but also when they are experienced at different times, say in a sequence. Our aim in this research is to explore the factors – whether distinct or the same – which operate in the binding of simultaneously and sequentially presented stimuli.
For testing binding in laboratory environments, a change detection task is often used. A change detection task presents a study display and a test display. Participants need to detect whether the test display is the same or different as compared to the study display. The task can be used to test changes in uni-dimensional or multi-dimensional stimuli. When testing feature binding, all the features in the test display are the same as the study display, but their combination changes on some trials, thus the task essentially becomes “swap detection.”
Most studies of feature binding, using the swap detection task, simultaneously present the stimuli in the study display. Nevertheless, as mentioned earlier, the differentiation of objects can be over space or time. Differentiation over space (on diverse locations) is inevitable with simultaneous presentation, and separation over time yields sequential presentation. Accordingly, the array of objects in the swap detection task can be presented simultaneously or sequentially.
Simultaneous presentation of multiple objects utilizes the powerful cue of location and allows configural encoding as shown by many studies of uni-feature objects (Jiang et al., 2000; Blalock and Clegg, 2010). The importance of location in binding has been emphasized by feature integration theory (Treisman and Gelade, 1980; Treisman and Sato, 1990; Treisman, 2006; Huang et al., 2007) as well as guided search model (Wolfe, 1994). Feature integration theory (Treisman and Gelade, 1980) suggested that binding is mediated by the links of separate features to a common location. Treisman and Sato (1990) proposed that a “master map” of locations exists in our brain. Attention selects all the features associated with a particular location, and works as glue to bind those features. Neuroscientists have found the evidence for such a master map. O’ Keefe and Nadel (1978) found the existence of place cells in the hippocampus. Hartley et al. (2007) supported the role of the hippocampus in topographical processing in short-term memory. Jacobs et al. (2013) did single-cell recordings from patients of epilepsy, which indicated grid cells in the entorhinal cortex and place cells in the hippocampal region. Recently, Koen et al. (2017) showed that the hippocampus plays a critical role in forming and maintaining complex bindings. Several studies have also shown that activity in the retinotopically organized sub-regions of the visual and parietal cortex is critical for visual short-term memory storage (reviewed in Xu, 2017). Behavioral studies show that location is remembered better than colors (e.g., Wheeler and Treisman, 2002). Studies also show that bindings are more vulnerable to location change and suggest that location plays a central role not only in encoding but also in maintenance and retrieval of bound objects (Treisman and Zhang, 2006; Hollingworth, 2007; Richard et al., 2008; Logie et al., 2011). Although Udale et al. (2018) provide recent evidence for strategic retrieval and decision-making by participants when task demands discourage the use of location cues, “in place” matching appears to be the default strategy of most participants even in their work. Thus, simultaneous presentation of multiple objects is considered crucial for binding by many researchers.
Nevertheless, some researchers have contrasted simultaneous and sequential modes of presentation in binding tasks. Allen et al. (2006) used a shape-color binding task with both modes of presentation. Results showed that performance was less accurate with sequential mode of presentation. Brown and Brockmole (2010) tested binding deficits in older and younger people using simultaneous and sequential modes of presentation. Although the results did not show any effect of age on binding, performance was worse with sequential presentation for both groups.
Other research groups showed that sequential presentation is better than simultaneous presentation. Fougnie and Marois (2009) used a visual working memory task in which participants had to detect changes in color, shape, either color or shape, and binding. During the retention interval, they performed a multiple object-tracking task. Results suggested that impairment caused by the secondary task was significantly reduced when objects were shown sequentially at the center of the screen. A comparison of the results of their separate experiments with simultaneous and sequential presentations shows slightly better baseline performance by participants in the sequential condition. Yamamoto and Shelton (2009) used real-life scenarios and found that sequential presentation of objects makes it easy to memorize them. They used a room layout and six different objects. Participants were shown these objects either simultaneously for 30 s or sequentially for 2.5 s per object, with the whole array being shown twice. Results showed better performance with sequential presentation. Ihssen et al. (2010) have also shown the superiority of sequential presentation. Their experiment had three conditions. In simultaneous presentation, they showed eight objects at the same time for 700 ms. In the sequential mode, they showed two displays sequentially, containing four objects at a time for 350 ms. In the third condition, the eight objects were repeated (shown twice), with each display shown for 350 ms. Results showed better memory performance in the sequential and the repeated modes.
Thus, conflicting results for different modes of presentation are observed in research studies. Simultaneous presentation increases the competition among stimuli, and the errors from within the memory set are more common than when stimuli are presented sequentially. Emrich and Ferber (2012) used eight colored squares presented either simultaneously for 400 ms, or divided into two displays of four squares each, presented sequentially. Error in detection of a particular color was more with simultaneous presentation. Haskell and Anderson (2016) also found reduced error variance with sequential rather than simultaneous presentation of circular gratings requiring judgments of orientation. Reduced errors with sequential presentation could be associated with better or equivalent performance (to simultaneous presentation), obtained at times with sequential presentation, especially in real-life conditions, where experience or familiarity with stimuli might mitigate the effects of competition and increase the distinctiveness of stimuli.
However, in experimental tasks used in the laboratories, simultaneous presentation generally yields better performance. Perhaps, this is because it allows configural encoding of the rather simple stimuli used in laboratory experiments. Stimuli can be encoded and remembered in relation to each other and form a visual pattern more easily when presented simultaneously than when presented sequentially. The relative location of stimuli is a powerful cue in simultaneous presentations. If we really wish to compare simultaneous presentation with sequential presentation, confound of location with simultaneous presentation must be removed/controlled. This is particularly important in binding studies, given the immense importance of locations in binding.
Some researchers have used a single probe at test to negate the role of location. Other researchers have attempted to control the effect of location by presenting stimuli at unchanged locations. However, because other features may be addressed through a “location map,” presenting single probes or the test stimuli at unchanged locations is not an adequate control. The huge literature on classical conditioning shows that to really break a link, it is important to randomly associate the elements participating in the link (Rescorla, 1967). To make locations irrelevant, the best strategy is to randomize them from study to test.
Thus, to unravel the effects of mode of presentation and relative locations, it seems imperative to orthogonally manipulate these two variables. In the present experiments, simultaneous and sequential presentations are compared when stimuli are presented in unchanged locations and when they are presented in random locations.
Some recent experiments studying the effect of mode of presentation on bindings with locations controlled in different ways are relevant here. Gorgoraptis et al. (2011) found that sequential presentation leads to low memory precision and more misbindings. They tested the binding of color and orientation with both modes of presentation. In the study display, they presented a number of colored bars with different orientations. In response, participants needed to adjust the orientation of the probed colored bar. The test bar was always shown at fixation. Locations were randomized in the study display in each trial in sequential as well as simultaneous presentation modes. But, in the design of this study, location was only randomized as a controlled variable, it was not an independent variable to enable an assessment of its effect in the experimental results. In another study, Pertzov and Husain (2014) using sequential presentations only compared performance in same and different locations, showing the advantage of same locations. But, in this experiment also, mode of presentation and location were not completely crossed.
Jaswal and Logie (2011) studied simultaneous and sequential modes of presentation in separate experiments keeping locations constant in one condition and randomizing locations from study to test in the other condition. Performance was inferior with sequential presentation when the participants never saw all the stimuli together in the test display, even when locations of the stimuli remained unchanged. This suggests that simultaneous presentation is better, because it gains from the relative location information concomitant with simultaneous presentation. In fact, when location was randomized, and thus rendered irrelevant to the task, there was no significant difference in performance between the simultaneous and sequential presentation experiments. Nevertheless, simultaneous and sequential presentation modes were not directly compared in their experiments and the set size at six was well beyond visual working memory capacity. Our experiments remedy this shortcoming and compare simultaneous and sequential presentations in the same experiments with set size four.
In conclusion, behavioral studies have shown equivocal results regarding performance with simultaneous and sequential presentation. In most behavioral experiments, simultaneous presentation is confounded with location information that either encourages configural encoding (leading to better performance) or increases competition and misbinding (leading to decrement in performance). An important strategy for extricating the effects of mode of presentation and location is to manipulate both of them as separate independent variables. This is what we have done in our experiments. Five experiments are being reported here. In every experiment, simultaneous and sequential presentation modes are fully crossed with unchanged and randomized locations in a 2 × 2 design. The specific aims, design, and the results of each experiment are described in the next sections.
A random and independent sample of 18 participants was selected for each experiment. All experiments use a repeated measures design with both factors being within subjects. A priori analyses of such a design is not supported by programs such as G*Power which estimate sample sizes. Thus, the sample size was decided on the basis of similar experiments reported in Jaswal and Logie (2011), although these experiments never compared simultaneous and sequential presentations together. They used 12 participants, so we decided to use more participants than their experiments, and recruited 18 participants in each experiment. It is pertinent here to mention that repeated measures designs are more powerful than independent samples designs. Thus, there were 90 participants in all five experiments. All participants were male undergraduates in the age range 18–22 years, reported normal or corrected to normal visual accuracy, and were paid a nominal amount as honorarium. Informed consent was taken from all participants after explaining the task, but without revealing the hypotheses.
All experiments were designed in E Prime 2.0 (Psychology Software Tools, 2008) and were conducted on a Sony Vaio laptop with a 14 inch screen placed at a distance of about 70 cm from the participant. The screen had 100% brightness with a resolution of 1,366 × 768 pixels and an Intel HD Graphics card. The four stimuli in each display were random combinations of four shapes (diamond, ring, triangle, and plus) and four colors (red, green, yellow, and blue). All stimuli were made in a square frame (110 × 110 pixels) creating a visual angle of approximately 2.05° × 2.05° and were presented on a gray screen in a 3 × 4 invisible grid of 338 × 448 pixels such that they remained in foveal vision, subtending a visual angle of approximately 6.28° × 8.30°.
The experiment aimed to study the effect of mode of presentation and locations on feature binding, using a change detection paradigm. We compared simultaneous and sequential presentations as the two levels of mode of presentation, and unchanged and randomized locations as the two levels of locations. As we aimed to unravel the confound between simultaneous presentation and locations, keeping these two factors as the two independent variables seemed to be a good starting point.
In this experiment, the sequential condition involves presenting the stimuli one by one, to build up the study display, as shown in Figure 1. Thus, in the sequential condition, an additional (temporal) cue is present. This might enhance performance in the sequential presentation condition relative to the simultaneous presentation condition. On the other hand, performance might be reduced in the sequential presentation condition relative to simultaneous presentation, if presenting stimuli one by one hampers configural encoding.
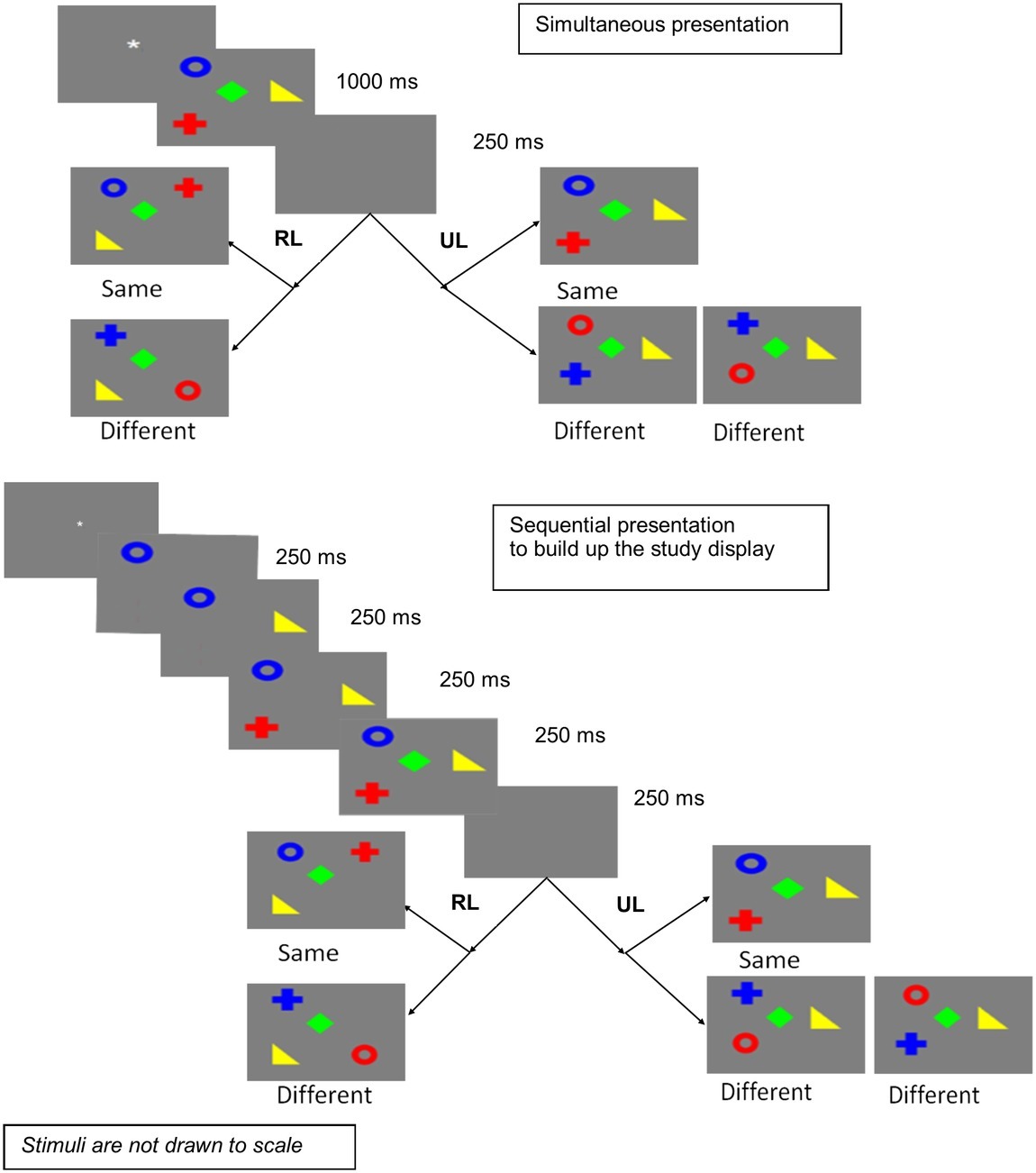
Figure 1. Simultaneous and sequential presentations in Experiment 1 (RL, random locations; UL, unchanged locations).
Further, unchanged locations from study to test are expected to yield better performance as compared to randomized locations, given the importance of locations as a cue in feature binding.
The experiment was designed as a 2 × 2 factorial experiment with repeated measures on both factors. The two independent variables were mode of presentation (simultaneous vs. sequential) and locations (unchanged vs. random). The trials for unchanged and random locations were mixed randomly within each block of simultaneous and sequential presentations, which were counterbalanced across participants. On half the trials comprising the unchanged locations condition, the stimuli appeared in the same locations as the study display. On the other half of the trials, comprising the random locations condition, the locations of stimuli in the test display were randomized from the study display to the test display. Figure 1 illustrates the design and procedure in each trial.
Each trial started with a fixation display. When the participants were ready, they pressed any key to move to the study display. The study display comprised four stimuli, which were random combinations of four colors and four shapes in each trial. The participant was to remember the bindings between colors and shapes. Simultaneous presentation implied all four stimuli presented at the same time in a single display. For sequential presentation, stimuli were presented one by one such that the display was gradually built up. Previous stimuli remained on screen as the next appeared. The study display remained on the screen for 1,000 ms for simultaneous presentation. In the sequential presentation condition, starting from the first stimulus, each next stimulus appeared after 250 ms, with all four on screen only for the last 250 ms out of a total of 1,000 ms. Thus, the total exposure duration for both presentation modes was the same. Thereafter, a blank interval was introduced for 250 ms and then a test display appeared with four stimuli. The task of the participant was to detect if any of the four stimuli changed in the binding of color and shape from the study display to the test display in each trial. The binding change happened only on 50% trials in each condition. When the change occurred, it was actually a swap between any two stimuli. Note that the participants cannot do the swap detection task if they remembered the colors alone or shapes alone, as all the colors, and all the shapes, were repeated in the test display. Whenever a swap occurred, half the time colors changed locations, and half the time, shapes changed locations. This is experienced as different only when locations are unchanged. In the randomized locations condition, the experience of the participants does not differ for color swaps or shape swaps. The participants pressed equally separated keys for “different” and “same” to record whether they were able to detect a change in binding in each trial.
The participant had to complete the experiment in a single session. Before commencing the experiment, each participant completed 24 practice trials for each block, i.e., 48 trials in all. The experiment was completed in two blocks of 192 trials each, 384 trials in all. There was an equal number of each trial type in each block for practice as well as experimental trials. Articulatory suppression was used in each trial. The participant had to say the word “the” repeatedly from the fixation screen until after the response was given.
Mean change detection performance calculated from d primes is shown in Figure 2 for all experiments.
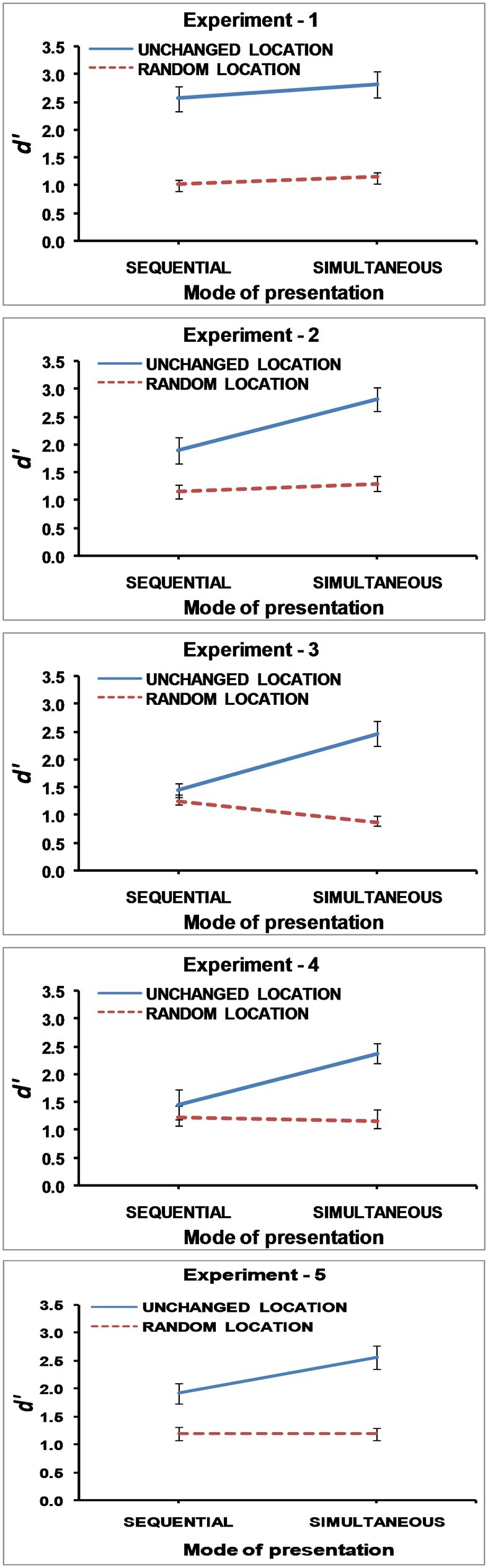
Figure 2. Mean d prime scores in Experiment 1, 2, 3, 4, and 5. The error bars represent ±1 Standard Error.
A repeated measures ANOVA revealed a significant main effect of unchanged and random locations, F(1,17) = 82.592, MSE = 0.559, p < 0.001, partial η2 = 0.829, BF10 = 2.549 × 1011 such that overall performance was reduced when locations were randomly changed from study to test display than when locations were unchanged. Neither the main effect of mode of presentation, F(1,17) = 1.089, MSE = 0.609, p = 0.311, partial η2 = 0.060, BF01 = 3.44, nor the interaction effect, was significant, F(1,17) = 0.140, MSE = 0.394, p = 0.713, partial η2 = 0.008, BF01 = 3.230. The model comprising both the main effects and the interaction effect (BF10 = 3.464 × 1010) was compared with a model comprising only the main effects (BF10 = 1.119 × 1011). The model comprising only the main effects better fit the data by a factor of 3.23:1.
Table 1 shows the means of d prime scores in all experimental conditions in this and all other experiments. Table 2 shows the hits and Table 3 shows the false alarms in all experiments.
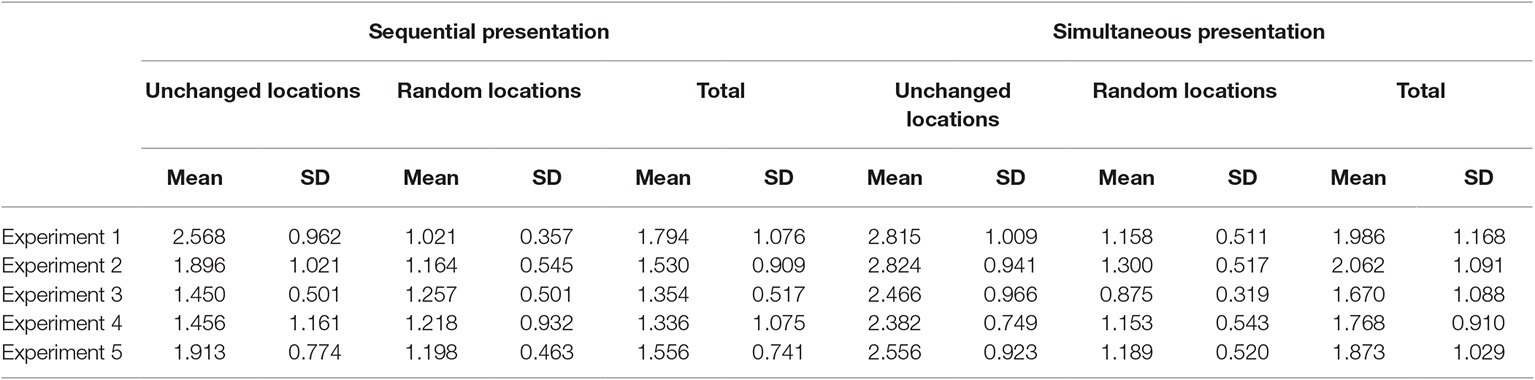
Table 1. Mean d prime scores in all experimental conditions in the five experiments.
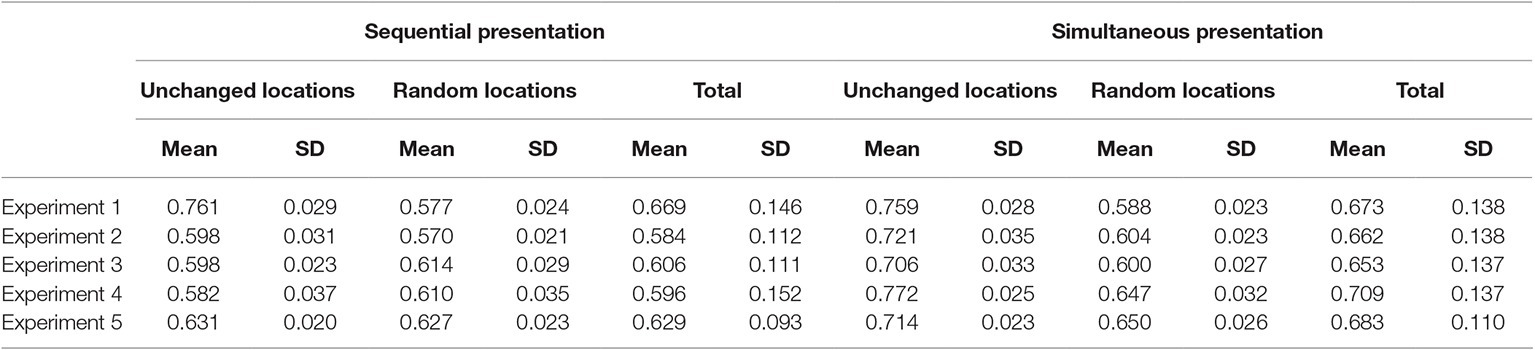
Table 2. Hits in all experimental conditions in the five experiments.
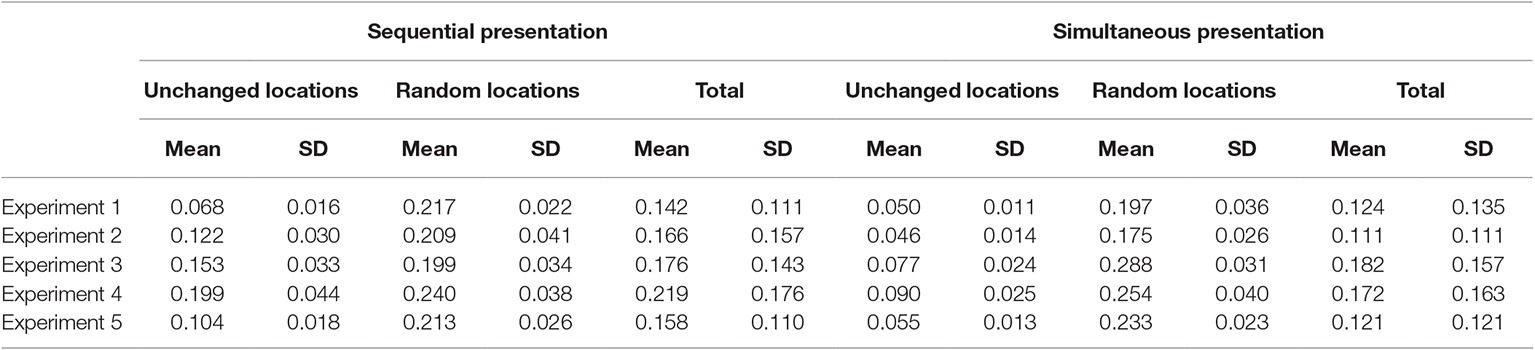
Table 3. False alarms in all experimental conditions in the five experiments.
In accordance with earlier studies, (Jaswal and Logie, 2011; Logie et al., 2011), Figure 2 clearly shows that performance is better with unchanged locations than random locations. However, there is no significant difference between simultaneous and sequential presentation. Building up the study display by presenting stimuli one by one, and thus providing an additional temporal code, does not lead to any better performance than simultaneous presentation. This suggests that the difference between the two modes of presentation is not contingent on a temporal code alone. Perhaps other factors are more important in making simultaneous presentation better than sequential presentation. Alternatively, similar performance in the two modes of presentation may result because simultaneous presentation is also like sequential presentation as participants most likely encode even simultaneously presented stimuli one by one as suggested by eye-tracking studies (e.g., Becker and Rasmussen, 2008).
For sequential presentation in this experiment, stimuli were presented one by one such that the previous stimulus vanished as the next was presented. In such a sequential presentation, retention of the earlier stimuli becomes difficult because any given stimulus may overwrite the representation of the earlier stimuli. In the absence of previous stimuli, relational or configural encoding is much more difficult. Thus, this kind of presentation utilizes only a temporal cue in the absence of configural encoding. The performance of the participants is expected to be lesser with sequential presentation as compared to simultaneous presentation.
Further, because the representation of stimuli includes location as a feature and is thus a spatiotopic representation, feature swaps in the unchanged locations condition will be easier to detect than in the random locations condition. Also, since this spatiotopic representation is expected to exist more clearly with simultaneous presentation, therefore, the difference in performance between the unchanged and randomized locations conditions is likely to be more with simultaneous presentation rather than sequential presentation.
The design and procedure were the same as Experiment 1, except that sequential presentation involved presenting the stimuli one by one such that the previous stimulus vanished as the next stimulus was presented. Figure 3 depicts the procedure.
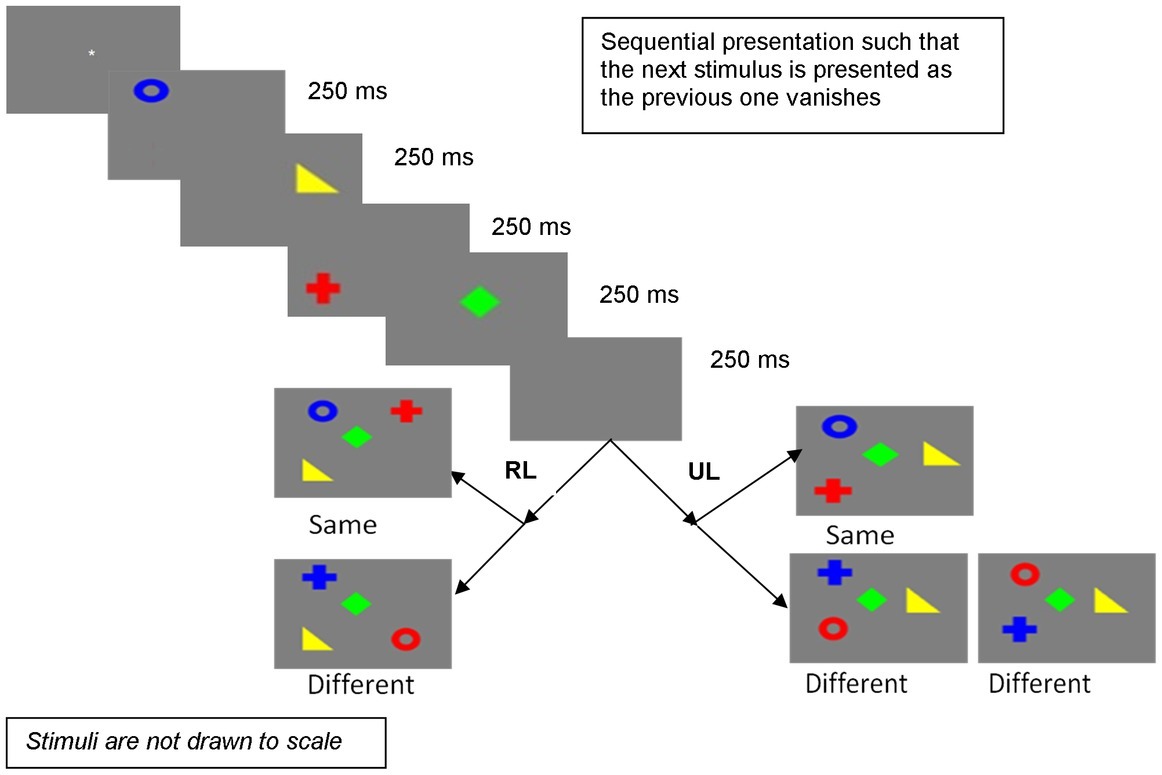
Figure 3. Sequential presentation in Experiment 2 (RL, random locations; UL, unchanged locations).
A repeated measures ANOVA revealed a significant main effect comparing unchanged and randomized locations, F(1,17) = 34.587, MSE = 0.662, p < 0.001, partial η2 = 0.670, BF10 = 6.939 × 105. Overall performance was reduced when locations were randomly changed from study to test display than when locations were unchanged. The main effect comparing simultaneous and sequential presentations was also significant, F(1,17) = 15.609, MSE = 0.327, p < 0.001, partial η2 = 0.479, BF10 = 3.245, with performance being better with simultaneous presentation than sequential presentation of stimuli. The interaction between mode of presentation and locations, F(1,17) = 10.370, MSE = 0.272, p < 0.005, partial η2 = 0.379, BF10 = 4.378, was also significant. Figure 2, which shows the mean change detection performance calculated from d primes, substantiates that the difference in performance between unchanged locations and randomized locations is much greater with simultaneous presentation, t(17) = 6.608, p < 0.001, d = 1.577, BF10 = 4.607 × 103, than with sequential presentation, t(17) = 3.254, p < 0.005, d = 0.767 BF10 = 9.994.
To compare the results of Experiment 1 and 2, three-way analysis of variance was carried out, taking experiments as a between-subjects factor, and mode of presentation and locations as the two repeated measures factors. The main effect of experiments was not significant. However, the interaction of experiments with location, F(1,34) = 3.311, MSE = 0.611, p < 0.078, partial η2 = 0.089, BF10 = 1.404, and the three-way interaction, F(1,34) = 3.136, MSE = 0.333, p < 0.086, partial η2 = 0.084, BF01 = 1.127, trend toward significance. The three-way interaction was assessed by comparing the model comprising the three-way interaction and all possible main and two-way interaction effects (BF10 = 1.062 × 1018) with a model comprising all three main effects and the three possible two-way interaction effects (BF10 = 1.197 × 1018). The data fit better with a model without the three-way interaction only by a factor of 1.127:1. This ratio being quite low, and the p < 0.084 of the three-way interaction trending toward significance, we infer that the performance of participants is different in the two experiments.
The sequential presentation in this experiment presents a stimulus as the previous one vanishes. This provides a temporal cue, but does not allow configural encoding. Thus, we find that performance is not only better with simultaneous presentation, but also that within this condition, performance is better with unchanged locations, because it is in this condition that maximum advantage can be derived from configural encoding aided by the feature of locations.
Mode of presentation has a significant effect only in Experiment 2, not in Experiment 1. This implies that location is a more advantageous cue than temporal presentation for feature binding. The experiment clearly revealed the advantage of configural encoding with the aid of location information for simultaneous presentation of stimuli. The temporal cue alone is not sufficient for feature binding in the visual domain.
Since it is only in Experiment 2 that mode of presentation showed a significant difference, the further reported experiments also used sequential presentation with the previous stimulus vanishing as the next one is presented.
One of the reasons for simultaneous presentation yielding better performance than sequential presentation in Experiment 2 could be its presentation time, i.e., 1,000 ms. This presentation time was kept at 1000 ms in Experiment 2 to equate it with the total presentation time of the sequential presentation, where each of the four stimuli was presented for 250 ms. In Experiment 3, we reduced the presentation time of the study display in the simultaneous presentation condition to 250 ms to make it equal to one stimulus of sequential display. Thus, one can say that participants were tested at the other logical extreme, as far as presentation time was concerned. Longer presentation time generally leads to better performance, although there are thresholds for liftoff of performance as well as when it reaches an asymptote (Busey and Loftus, 1994; Loftus and McLean, 1999). The time-based resource-sharing model of working memory (Barrouillet et al., 2004; Barrouillet and Camos, 2007) suggests that increasing the study display duration should improve performance for it allows more time for encoding and processing of stimuli. Pashler (1988) reported a significant but small increase in memory for 10 consonants presented simultaneously for 100, 300, and 500 ms. Liu and Jiang (2005) asked participants to remember objects in scene images to find that 250 ms allowed only about one object to be retained in memory. If the superior performance in simultaneous condition is indeed due to the long presentation time, reducing the presentation time of the study display in this way should drastically reduce performance in the simultaneous presentation condition, rendering it lesser than or no different from performance under the sequential presentation condition.
The design and procedure were the same as Experiment 2 except that the study display in the simultaneous presentation condition was shown only for 250 ms.
Mean change detection scores calculated from d primes are shown in Figure 2. A repeated measures ANOVA revealed the main effect of unchanged and randomized locations, F(1,17) = 60.598, MSE = 0.237, p < 0.001, partial η2 = 0.781, BF10 = 3.984 × 104, in that overall performance was reduced when locations were randomly changed from study to test display than when locations were unchanged. The main effect comparing simultaneous and sequential presentations was also significant, F(1,17) = 7.459, MSE = 0.242, p < 0.014, partial η2 = 0.305, BF01 = 1.226, with performance being better with simultaneous than sequential presentation. The interaction effect was also significant, F(1,17) = 23.061, MSE = 0.381, p < 0.001, partial η2 = 0.576, BF10 = 1.760 × 104. As depicted in Figure 2, there is a significant difference between unchanged and randomized locations with simultaneous presentation, t(17) = 7.137 p < 0.001, d = 1.682, BF10 = 1.121 × 104, but the difference is not significant for sequential presentation, t(17) = 1.406, p = 0.178, d = 0.331, BF01 = 1.773.
A comparison of Experiment 2 and 3 by using a three-way ANOVA showed that neither the main effect of experiments nor any of its interactions were significant. Bayes factors were computed for each combination of main and interaction effects. A model comprising the three-way interaction with all the three main and interaction effects (BF10 = 5.608 × 1016) was compared with a model of three possible main and interaction effects without the three-way interaction effect (BF10 = 7.173 × 1016). The model with a three-way interaction was a slightly better fit for the data by a factor of 1.27:1.
The pattern of results obtained in this experiment is the same as that obtained in Experiment 2. Reducing the presentation time of the simultaneous display to a quarter of what it was in Experiment 2 had no effect on the performance of participants. Shorter exposure to the stimuli does not decrease (or increase) the performance of the participants, there being simply no significant difference between Experiment 2 and 3. These results indicate that the presentation time of the study display is not an important factor in the performance of the participants. Nevertheless, note that this experiment made changes only to the simultaneous presentation condition.
Although it seems that better performance under simultaneous presentation condition is obtained regardless of presentation time, one may argue that it is the time given for encoding the stimulus in the sequential condition, which is not enough. Ricker and Cowan (2014) tested forgetting in working memory as a function of time. They formulated the experiment comparing simultaneous and sequential conditions such that a blank interval is introduced between the stimuli in the sequential mode. Presumably, this helped in proper encoding of a stimulus, and it made performance in the sequential condition better than the performance in the simultaneous condition. Although they had tested memory for single features, analogously, we inserted blank intervals after each stimulus in the sequential presentation condition in Experiment 4, with a view to improving performance in this condition. We reasoned that blank intervals would aid consolidation or at least protect each stimulus from being overwritten by subsequent stimuli, and hence improve performance in the sequential condition.
The design and procedure are the same as in Experiment 2 (depicted in Figure 3), except two related changes. In this experiment, a blank interval of 250 ms was introduced after each stimulus in the sequential presentation condition. Thus, the total time for sequential presentation becomes 1,750 ms, with four stimuli presented for 250 ms each and three blank intervals of 250 ms between the stimuli. The second change was an increase in display time for simultaneous presentation to 1,750 ms, to equalize it with the presentation time for sequential presentation. Experiment 3 (and its comparison with Experiment 2) had already shown that increasing the exposure duration has little effect on performance in the simultaneous condition. Also, a close study of Rhodes et al. (2016) showed that increasing presentation time from 900 to 2,500 ms yielded no significant difference in the retention of their participants for simultaneously presented stimuli.
Mean change detection performance calculated from d primes is shown in the Figure 2. A repeated measures ANOVA revealed the main effect of unchanged and randomized locations, F(1,17) = 31.006, MSE = 0.313 p < 0.001, partial η2 = 0.646, BF10 = 72.278, in that overall performance was reduced when locations were randomly changed from study to test display than when locations were unchanged. The main effect of simultaneous and sequential presentations is not significant, F(1,17) = 3.096, MSE = 1.085, p = 0.096, partial η2 = 0.154, BF10 = 1.47. Nevertheless, the interaction effect was significant, F(1,17) = 11.826, MSE = 0.372, p < 0.003, partial η2 = 0.410, BF10 = 6.027. Figure 2 clearly depicts that the differential effect of unchanged and randomized locations is significant in the simultaneous presentation condition, t(17) = 8.438, p < 0.001, d = 1.989, BF10 = 8.765 × 104, but not in the sequential presentation condition, t(17) = 1.026, p = 0.319, d = 0.242, BF01 = 2.617.
A comparison of Experiment 2 and 4 through a three-way ANOVA showed that neither the main effect of experiments nor any of its interactions were significant. Bayes factors were computed for all the combinations of main and interaction effects. To observe the three-way interaction effect, a model comprising the three-way interaction effect along with all the main and two-way interaction effects (BF10 = 2.587 × 1010) was compared with a model of all main and two-way interaction effects only (BF10 = 7.445 × 1010). The data fit better with the model without the three-way interaction effect by a factor of 2.87:1.
Another three-way ANOVA comparing Experiment 3 and 4 also did not show any differences between these experiments. Bayes factors were computed for all the possible combinations of main and interaction effects. The model comprising the three-way interaction and all the main and two-way interaction effects (BF10 = 2.897 × 1010) was compared with a model comprising only the main and two-way interaction effects (BF10 = 5.256 × 1010). The data fit better with the model without the three-way interaction by a factor of 1.818:1.
The main effect of locations and the interaction of locations and mode of presentation, both, are significant, as might be expected on the basis of the previous experiments. There is nothing new here. What is relatively more informative is that in this experiment, there is no significant difference between the two presentation modes. This might be because the overall performance in the simultaneous presentation condition decreased as compared with Experiment 2 (although the decrease does not lead to a significant main effect of experiments in the three-way ANOVA). The decrease in the performance of the participants in the simultaneous presentation condition with unchanged locations could be because the participants lost the iconic memory for the study display over the blank period. Alternatively, if the stimuli were already in the visual working memory, the participants could not sustain the relational encoding of the multiple stimuli in visual working memory. The next experiment will address whether and how far performance in this condition gains from iconic memory.
The performance of the participants in the sequential presentation condition remains the same as earlier experiments. Thus, it seems that the blank intervals, which yielded better performance with sequential presentation of uni-feature stimuli in the experiment by Ricker and Cowan (2014), conferred no advantage in our experiment to the multi-feature sequentially presented stimuli for feature binding. Blank intervals may protect uni-feature objects from decay and interference, but have no effect on bindings.
Better performance with simultaneous presentation of stimuli may also result due to iconic memory of the visual display for simultaneous presentation, affording the correct response more easily, especially in the unchanged location condition. Iconic memory preserves the stimulus pattern for some time after it has been presented, and then visual information is transferred to visual short-term memory. Masks of different kinds have often been used to wipe out iconic memory (e.g., Sperling, 1960; Neisser, 1967; Turvey, 1973; Becker et al., 2000). Studies by Phillips (1974); Loftus et al. (1985); Loftus et al. (1992) suggest that the icon does not persist beyond the initial 100–300 ms, and in fact, longer the stimulus presentation, shorter the duration for which the icon lasts (Coltheart, 1980).
Thus, to obliterate the effects of iconic memory from performance, we decided to use a visual noise mask for 250 ms immediately after the study display in all experimental conditions, and explore whether any changes would result in the pattern of performance. Particularly, we expected that if iconic memory is the reason why simultaneously presented stimuli are better retained with unchanged locations, performance in this condition would reduce as compared to Experiment 2. However, if the stimulus representations are already in visual working memory, then they would be immune to the mask and there will be no changes in the performance of the participants, as suggested by Phillips (1974) who distinguished between sensory storage and visual short-term memory, showing that the former could be masked by noise masks, but the latter was impervious to masking. Smithson and Mollon (2006) also concluded from their study that a mask cannot penetrate higher levels of visual analysis and leaves intact the conceptual, abstract representations of stimuli.
The design and procedure remained the same as Experiment 2. The only change was a noise mask introduced immediately after the stimulus display for 250 ms (the same duration as the study display). Thereafter, the test display was immediately presented.
Repeated measures ANOVA showed the significant main effect of the mode of presentation, F(1,17) = 6.949, MSE = 0.260, p = 0.017, partial η2 = 0.290, BF01 = 1.29, with simultaneous presentation being better than sequential presentation. The main effect of locations was also significant, F(1,17) = 43.690, MSE = 0.446, p < 0.001, partial η2 = 0.720, BF10 = 4.25 × 106, with performance being better with unchanged locations than random locations. The interaction effect was also significant, F(1, 17) = 5.468, MSE = 0.351, p = 0.032, partial η2 = 0.243, BF10 = 2.80. The difference of unchanged and randomized location was higher in simultaneous [t(17) = 5.761, p = 0.001] than sequential [t(17) = 3.981, p = 0.001] presentation. Figure 2 shows the results. The similar pattern of results for Experiment 2 and 5 is clearly visible. The three-way ANOVA carried out to compare Experiment 2 and 5 showed that neither the main effect of experiments nor any of the interactions involving experiments were significant.
Visual noise masks were used in this experiment to eradicate the effect of iconic memory in the performance of the participants. It was of particular interest whether performance in the unchanged locations condition for simultaneously presented stimuli would reduce as compared to Experiment 2. However, there was simply no effect of the mask on the general performance level of the participants or particularly with simultaneous presentation and unchanged locations.
A three-way ANOVA was performed with Experiment 2, 3, 4, and 5 as the between-subjects factor and mode of presentation and locations as repeated measures. Neither the main effect of experiments nor any interaction of experiments with other factors was significant. Bayes factors were computed for every combination of main and interaction effects. A model comprising the three-way interaction and all the main and two-way interaction effects (BF10 = 2.026 × 1027) was compared with the model with only the main and two-way interaction effects (BF10 = 7.388 × 1027). The data fit better with the model without the three-way interaction by a factor of 3.64:1.
This research aimed to compare sequentially presented feature bindings with simultaneously presented bindings, hoping to reveal the factors, which lead to differential performance with these two modes of presentation. Previous studies, which compare simultaneous and sequential presentations, have shown mixed results, although in most studies the performance of participants is better with simultaneous presentation. We particularly designed experiments to disentangle the confound of locations with simultaneous presentation as many theories and studies have stressed the importance of locations in the process of binding (e.g., Wolfe, 1994; Treisman and Zhang, 2006; Logie et al., 2011).
The results of Experiment 1 show that merely adding a temporal cue, i.e., presenting stimuli one by one to build up the study display has no differential effect on the performance of the participants as compared to when the stimuli are simultaneously presented. Nevertheless, locations had a significant effect, with performance being significantly better when locations remained the same, than when they were randomized from study to test. This was true regardless of whether the stimuli were presented simultaneously or sequentially.
However, Experiment 2 showed a significant difference between the two modes of presentation as well as a significant interaction. In this experiment, stimuli were presented in the sequential mode of presentation such that as one stimulus was presented, the previous one vanished. Performance was worse with sequential presentation as compared to simultaneous presentation perhaps because the participants were never able to “see” the stimuli in relation to each other in the sequential presentation condition. Presumably, they were building up a mental representation of the stimuli presented in sequence, as they knew they would be tested with a whole display, having understood the experimental task, and having done many practice trials. However, in building this mental pattern/representation, it was harder for them to take advantage of the spatial relationship among the stimuli with sequential presentation such that one stimulus vanished as the next was presented. In Experiment 1, where the study display was gradually built up, they could take advantage of unchanged locations and hence the performance is not any different in the sequential presentation condition as compared with the simultaneous presentation condition.
Coming back to Experiment 2, encoding the stimuli in a configuration or pattern led to enhanced performance in the simultaneous presentation condition with unchanged locations. However, unchanged locations from study to test did not confer any advantage if the stimuli were sequentially presented. Indeed, for sequentially presented stimuli, performance was statistically not different for unchanged and random locations, indicating that location was simply not a factor in the performance of the participants with sequentially presented stimuli.
These results are in contrast to that of Pertzov and Husain (2014) who used sequential presentations of four stimuli testing the binding between color and orientation, and compared performance in same and different locations. They showed that there were less errors in the “different locations” condition. However, the differences in their experimental task as compared to ours must be noted. In their experiment, same location condition meant presenting the stimuli in exactly the same location one after the other, which does not make location unnecessary to the task, rather it makes it relevant, and thus, a factor creating confusion. In contrast, in our experiments, the stimuli are presented in different locations, which remain unchanged from study to test. Thus, in our task, locations aid in differentiating the stimuli. In their “different” locations condition, the stimuli are presented in different locations in the sequence, and tested by a probe in the center of the screen. In this case too, locations are not irrelevant to the task and the binding of other features (color and orientation in this case) may be addressed through locations, as suggested by feature integration theory (Treisman and Sato, 1990) and related studies (e.g., Treisman and Zhang, 2006; Logie et al., 2011).
Could the relatively long presentation time of 1,000 ms for all four stimuli cause better performance because in sequential presentation only 250 ms was given for each stimulus? If this was so, then giving less time to perceive stimuli in the simultaneous condition should decrease performance. However, the results of Experiment 3 showed that this was not the case. Even reducing the presentation time of the simultaneously presented stimuli to 250 ms and thus making it equal to the presentation time of a single stimulus in the sequential condition did not affect the performance of the participants. Probably this is because all stimuli in the simultaneous presentation condition have already been encoded even at 250 ms and performance has therefore reached an asymptote. Vogel et al. (2006) have suggested that about 60 ms are required to encode the first stimulus, followed by 50 ms per stimuli for the rest of them. Although this study was with colored squares (uni-feature objects), in an earlier study, Luck and Vogel (1997) reported that the capacity of visual short-term memory is about the same for uni-feature and multi-feature objects, which is four objects. Despite suggestions that visual working memory capacity is also affected by complexity and resource demand of stimuli (Alvarez and Cavanagh, 2004; Ma et al., 2014), we believe that our four objects, which are rather simple conjunctions of color and shapes, are well within visual working memory capacity, and so presumably all stimuli in the display could be encoded within 250 ms.
Some researchers have argued that what happens in the maintenance period is as important as initial encoding; and performance is worse with sequential presentation because each stimulus gets overwritten by subsequent stimuli (Ricker and Cowan, 2014). The fourth experiment was designed to test whether introducing blank intervals after every stimulus would allow the participant to consolidate its memory and/or protect it from being overwritten by the next stimulus and hence increase the performance of the participants in the sequential presentation condition. The results did show no significant difference between sequential and simultaneous presentation conditions. However, a comparison of Experiment 2 and 4 revealed that performance did not increase in sequential presentation condition. Rather, it decreased in the simultaneous presentation condition with unchanged locations, probably because of the very long presentation time in this condition leading to forgetting. Thus, the blank intervals, which yielded better performance with sequential presentation in the experiment by Ricker and Cowan (2014) conferred no advantage in the sequential presentation condition in our experiment. This might be because the experiments by Ricker and Cowan were testing memory for unfamiliar shapes, whereas we were testing feature bindings. Presumably, feature bindings are already represented in the visual short-term memory beyond iconic memory, and hence do not benefit by the opportunity of consolidation (or protection) given by blank intervals to rather fragile representations of features in the initial stage of processing.
The idea that feature bindings are represented in visual short-term memory beyond iconic storage is also substantiated by Experiment 5, where we attempted to use pattern masks comprising visual noise to disrupt iconic memory representations. However, there were no significant differences in the performance of the participants as compared to Experiment 2, substantiating that feature bindings are held in the visual working memory and are thus only affected by factors, which organize information after basic perceptual processing. Supportive evidence that VSTM representations are immune to masking is offered by several studies (e.g., Phillips, 1974; Smithson and Mollon, 2006; Sligte et al., 2008).
Consequently, we conclude that the differences between simultaneous and sequential presentations are not due to ostensible perceptual differences, but due to factors and processes that affect the organization of material/stimuli in the visual working memory. All manipulations, which could have affected perceptual processing of stimuli, viz., altering the presentation time, and inserting blank intervals after each stimulus presented in a sequence, or presenting a noise mask after the stimulus presentation, had no effect on the levels of performance of the participants. So the differential performance between simultaneous and sequential modes of presentation cannot be attributed to factors in perceptual processing. The significant interaction effect obtained in all experiments where stimuli were presented in the sequential condition such that one stimulus vanished as the next appeared substantiates that location as a feature contributes to making performance better with simultaneous presentation. The significant advantage of unchanged locations as compared to randomized locations is clear in the simultaneous presentation condition in all experiments. It is clear that this advantage accrues only when stimuli can be encoded in relation to each other, being presented together in multiple locations.
However, in the case of stimuli presented sequentially, location is simply not relevant to performance as keeping it the same or randomizing it has no effect on the performance of the participants. Perhaps this is because these stimuli are already represented in visual working memory. This idea is further substantiated by the last three experiments, which show that the performance in the sequential presentation condition is immune to manipulations designed to alter the encoding of stimuli such as changes to presentation time, or inserting blank intervals, or using a noise mask immediately after stimulus presentation. Also, as suggested by one of the reviewers, performance in the sequential presentation condition could have been worse because participants were required to maintain items for a longer duration in this condition, particularly in the experiment where blank intervals were inserted. Clearly, this difficulty in “maintenance” would occur only if the stimuli were already present in visual working memory. In sum, we speculate that sequences are encoded or consolidated into visual working memory relatively automatically and perhaps sooner as compared to simultaneously presented stimuli. Analogous to the advantage that sentences have over lists in verbal working memory due to long-term knowledge (Allen et al., 2018), perhaps sequences of visual stimuli too benefit from temporal cues which are simply absent in simultaneously presented stimuli. Alternatively, competition among simultaneously presented stimuli may act as a bottleneck and retard the progress of these early visual representations into working memory. This idea is supported by the experimental finding that differences between simultaneous and sequential presentations are evident only at larger set sizes and are not shown with set sizes within working memory capacity (Igel and Harvey, 1991; Dent and Smyth, 2006). Another explanation could be that participants are using different strategies to process simultaneously and sequentially presented stimuli. Udale et al. (2018) have argued that participants can use different strategies to encode and process stimuli when required by task demands in the absence of locations being relevant. In fact, they also suggest individual differences among participants in the use of these strategies. Much further research is required to explore exactly which factors and processes in visual working memory are relevant for binding sequentially presented stimuli.
On the basis of current studies, it may be concluded that while performance with simultaneous presentation relies on location information, performance with sequential presentation is relatively immune to presence/absence of location information. It is also clear that post-perceptual processes within visual working memory are presumably responsible for the differences in performance due to simultaneous and sequential presentation.
The datasets generated for this study are available on request to the corresponding author.
The studies involving human participants were reviewed and approved by Research Ethics Committee, Department of Psychology, Chaudhary Charan Singh University, Meerut. The participants provided their written informed consent to participate in this study.
AB carried out this research as part of PhD. He was supported for PhD by a fellowship from the Ministry of Human Resource Development, India.
AB, SY, and SJ together conceptualized the study and wrote the paper.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Allen, R. J., Baddeley, A., and Hitch, G. J. (2006). Is the binding of visual features in working memory resource demanding? J. Exp. Psychol. Gen. 135, 298–313. doi: 10.1037/0096-3445.135.2.298
Allen, R. J., Hitch, G. J., and Baddeley, A. D. (2018). Exploring the sentence advantage in working memory: insights from serial recall and recognition. Q. J. Exp. Psychol. 71, 2571–2585. doi: 10.1177/1747021817746929
Alvarez, G. A., and Cavanagh, P. (2004). The capacity of visual short-term memory is set both by visual information load and by number of objects. Psychol. Sci. 15, 106–111. doi: 10.1111/j.0963-7214.2004.01502006.x
Barrouillet, P., Bernardin, S., and Camos, V. (2004). Time constraints and resource sharing in adults’ working memory spans. J. Exp. Psychol. Gen. 133, 83–100. doi: 10.1037/0096-3445.133.1.83
Barrouillet, P., and Camos, V. (2007). “The time-based resource-sharing model of working memory” in The cognitive neuroscience of working memory. eds. N. Osaka, R. H. Logie, and M. D’Esposito (New York: Oxford University Press), 59–80.
Becker, M. W., Pashler, H., and Anstis, S. M. (2000). The role of iconic memory in change-detection tasks. Perception 29, 273–286. doi: 10.1068/p3035
Becker, M. W., and Rasmussen, I. P. (2008). Guidance of attention to objects and location by long term memory of natural scenes. J. Exp. Psychol. Learn. Mem. Cogn. 34, 1325–1338. doi: 10.1037/a0013650
Blalock, L. D., and Clegg, B. A. (2010). Encoding and representation of simultaneous and sequential arrays in visuospatial working memory. Q. J. Exp. Psychol. 63, 856–862. doi: 10.1080/17470211003690680
Brown, L., and Brockmole, J. (2010). The role of attention in binding visual features in working memory: evidence from cognitive ageing. Q. J. Exp. Psychol. 63, 2067–2079. doi: 10.1080/17470211003721675
Busey, T. A., and Loftus, G. R. (1994). Sensory and cognitive components of visual information acquisition. Psychol. Rev. 101, 446–469. doi: 10.1037/0033-295X.101.3.446
Coltheart, M. (1980). Thepersistencies of vision. Philos. Trans. R. Soc. London, Ser. B: Biol. Sci. 290, 57–69. doi: 10.1098/rstb.1980.0082
Dent, K., and Smyth, M. M. (2006). Capacity limitations and representational shifts in spatial short term memory. Vis. Cogn. 13, 529–572. doi: 10.1080/13506280444000760
Emrich, S., and Ferber, S. (2012). Competition increase binding errors in visual working memory. J. Vis. 12, 1–16. doi: 10.1167/12.4.12
Fougnie, D., and Marois, R. (2009). Attentive tracking disrupts feature binding in visual working memory. Vis. Cogn. 17, 48–66. doi: 10.1080/13506280802281337
Gorgoraptis, N., Catalao, R., Bays, P., and Husain, M. (2011). Dynamic updating of working memory resources for visual objects. J. Neurosci. 31, 8502–8511. doi: 10.1523/JNEUROSCI.0208-11.2011
Hartley, T., Bird, C. M., Chan, D., Cipolotti, L., Husain, M., Vargha-Khadem, F., et al. (2007). The hippocampus is required for short-term topographical memory in humans. Hippocampus 17, 34–48. doi: 10.1002/hipo.20240
Haskell, C., and Anderson, B. (2016). Attentional effects on orientation judgements are dependent on memory consolidation processes. Q. J. Exp. Psychol. 69, 2147–2165. doi: 10.1080/17470218.2015.1105830
Hollingworth, A. (2007). Object-position binding in visual memory for natural scenes and object arrays. J. Exp. Psychol. Hum. Percept. Perform. 33, 31–47. doi: 10.1037/0096-1523.33.1.31
Huang, L., Treisman, A., and Pashler, H. (2007). Characterizing the limits of human visual awareness. Science 317, 823–825. doi: 10.1126/science.1143515
Igel, A., and Harvey, L. O. (1991). Spatial distortions in visual perception. Gestalt Theory 13, 210–231.
Ihssen, N., Linden, D. E. J., and Shapiro, K. (2010). Improving visual short-term memory by sequencing the stimulus array. Psychon. Bull. Rev. 17, 680–686. doi: 10.3758/PBR.17.5.680
Jacobs, J., Weidemann, C. T., Miller, J. F., Solway, A., Burke, J. F., Wei, X. X., et al. (2013). Direct recordings of grid-like neuronal activity in human spatial navigation. Nat. Neurosci. 16, 1188–1190. doi: 10.1038/nn.3466
Jaswal, S., and Logie, R. H. (2011). Configural coding in visual feature binding. J. Cogn. Psychol. 23, 586–603. doi: 10.1080/20445911.2011.570256
Jiang, Y., Olson, I. R., and Chun, M. M. (2000). Organization of visual short-term memory. J Exp Psychol Learn Mem Cogn. 26, 683–702. doi: 10.1037/0278-7393.26.3.683
Koen, J. D., Borders, A. A., Petzold, M. T., and Yonelinas, A. P. (2017). Visual short-term memory for high resolution associations is impaired in patients with medial temporal lobe damage. Hippocampus 27, 184–193. doi: 10.1002/hipo.22682
Liu, K., and Jiang, Y. (2005). Visual working memory for briefly presented scenes. J. Vis. 5, 650–658. doi: 10.1167/5.7.5
Loftus, G. R., Duncan, J., and Gehrig, P. (1992). On the time course of perceptual information that results from a brief visual presentation. J. Exp. Psychol. Hum. Percept. Perform. 18, 530–549.
Loftus, G. R., Johnson, C. A., and Shimamura, A. P. (1985). How much is an icon worth? J. Exp. Psychol. Hum. Percept. Perform. 11, 1–13. doi: 10.1037//0096-1523.11.1.1
Loftus, G. R., and McLean, J. E. (1999). A front end to a theory of picture recognition. Psychon. Bull. Rev. 6, 394–411. doi: 10.3758/BF03210828
Logie, R. H., Brockmole, J. R., and Jaswal, S. (2011). Feature binding in visual short term memory is unaffected by task irrelevent changes of location, shape, and colour. Mem. Cogn. 39, 29–36. doi: 10.3758/s13421-010-0001-z
Luck, S. J., and Vogel, E. K. (1997). The capacity of visual working memory for features and conjunctions. Nature 390, 279–281. doi: 10.1038/36846
Ma, W. J., Husain, M., and Bays, P. M. (2014). Changing concepts of working memory. Nat. Neurosci. 17, 347–356. doi: 10.1038/nn.3655
Pashler, H. (1988). Familiarity and visual change detection. Percept. Psychophys. 44, 369–378. doi: 10.3758/BF03210419
Pertzov, Y., and Husain, M. (2014). The privileged role of location in visual working memory. Atten. Percept. Psychophys. 76, 1914–1924. doi: 10.3758/s13414-013-0541-y
Phillips, W. A. (1974). On the distinction between sensory storage and short-term visualmemory. Atten. Percept. Psychophys. 16, 283–290. doi: 10.3758/BF03203943
Psychology Software Tools (2008). E-prime 2.0 [computer software]. Pittsburgh, PA: Psychological Software Tools.
Rescorla, R. A. (1967). Pavlovian conditioning and its proper control procedures. Psychol. Rev. 74, 71–80. doi: 10.1037/h0024109
Rhodes, S., Parra, M. A., and Logie, R. H. (2016). Ageing and feature binding in visual working memory: the role of presentation time. Q. J. Exp. Psychol. 69, 654–668. doi: 10.1080/17470218.2015.1038571
Richard, A. M., Luck, S. J., and Hollingworth, A. (2008). Establishing object correspondence across eye movements: flexible use of spatiotemporal and surface feature information. Cognition 109, 66–88. doi: 10.1016/j.cognition.2008.07.004
Ricker, T. J., and Cowan, N. (2014). Differences between presentation methods in working memory procedures: a matter of working memory consolidation. J. Exp. Psychol. Learn. Mem. Cogn. 40, 417–428. doi: 10.1037/a0034301
Sligte, I. G., Scholte, H. S., and Lamme, V. A. (2008). Are there multiple visual short-term memory stores? PLoS One 3:e1699. doi: 10.1371/journal.pone.0001699
Smithson, H., and Mollon, J. (2006). Do masks terminate the icon? Q. J. Exp. Psychol. 59, 150–160. doi: 10.1080/17470210500269345
Sperling, G. (1960). The information available in brief visual presentations. Psychol. Monogr. Gen. Appl. 74, 1–29. doi: 10.1037/h0093759
Treisman, A. (2006). How the deployment of attention determines what we see. Vis. Cogn. 14, 411–443. doi: 10.1080/13506280500195250
Treisman, A. M., and Gelade, G. (1980). A feature-integration theory of attention. Cogn. Psychol. 12, 97–136. doi: 10.1016/0010-0285(80)90005-5
Treisman, A., and Sato, S. (1990). Conjunction search revisited. J. Exp. Psychol. Hum. Percept. Perform. 16, 459–478. doi: 10.1037//0096-1523.16.3.459
Treisman, A., and Zhang, W. (2006). Location and binding in visual working memory. Mem. Cogn. 34, 1704–1719. doi: 10.3758/BF03195932
Turvey, M. T. (1973). On peripheral and central processes in vision: inferences from an information-processing analysis of masking with patterned stimuli. Psychol. Rev. 80, 1–52. doi: 10.1037/h0033872
Udale, R., Farrell, S., and Kent, C. (2018). Task demands determine comparison strategy in whole probe change detection. J. Exp. Psychol. Hum. Percept. Perform. 44, 778–796. doi: 10.1037/xhp0000490
Vogel, E. K., Woodman, G. F., and Luck, S. J. (2006). The time course of consolidation in visual working memory. J. Exp. Psychol. Hum. Percept. Perform. 32, 1436–1451. doi: 10.1037/0096-1523.32.6.1436
Wheeler, M. E., and Treisman, A. M. (2002). Binding in short-term visual memory. J. Exp. Psychol. Gen. 131, 48–69. doi: 10.1037/0096-3445.131.1.48
Wolfe, J. M. (1994). Guided search 2.0- a revised model of visual search. Psychon. Bull. Rev. 1, 202–238. doi: 10.3758/BF03200774
Xu, Y. (2017). Reevaluating the sensory account of visual working memory storage. Trends Cogn. Sci. 21, 794–815. doi: 10.1016/j.tics.2017.06.013
Keywords: feature binding, simultaneous presentation, sequential presentation, locations, visual working memory
Citation: Bharti AK, Yadav SK and Jaswal S (2020) Feature Binding of Sequentially Presented Stimuli in Visual Working Memory. Front. Psychol. 11:33. doi: 10.3389/fpsyg.2020.00033
Edited by:
Zaifeng Gao, Zhejiang University, ChinaReviewed by:
Shouxin Li, Shandong Normal University, ChinaCopyright © 2020 Bharti, Yadav and Jaswal. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Snehlata Jaswal, c25laC5qYXN3YWxAZ21haWwuY29t
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.