 Veronika Lerche
Veronika Lerche Andreas Voss
Andreas Voss- Quantitative Research Methods, Institute of Psychology, Ruprecht-Karls-Universität Heidelberg, Heidelberg, Germany
The diffusion model (Ratcliff, 1978) takes into account the reaction time distributions of both correct and erroneous responses from binary decision tasks. This high degree of information usage allows the estimation of different parameters mapping cognitive components such as speed of information accumulation or decision bias. For three of the four main parameters (drift rate, starting point, and non-decision time) trial-to-trial variability is allowed. We investigated the influence of these variability parameters both drawing on simulation studies and on data from an empirical test-retest study using different optimization criteria and different trial numbers. Our results suggest that less complex models (fixing intertrial variabilities of the drift rate and the starting point at zero) can improve the estimation of the psychologically most interesting parameters (drift rate, threshold separation, starting point, and non-decision time).
The diffusion model (Ratcliff, 1978) is a popular mathematical model that recently attracted the attention of researchers of diverse fields of psychology (see Voss et al., 2013, for a recent review; see for example Brown and Heathcote, 2008, for another popular sequential sampling model). The model provides information about the cognitive processes underlying binary decision tasks. This becomes possible because the diffusion model parameters validly map specific latent cognitive processes (e.g., speed of information accumulation, decision bias). Despite the increased popularity of the diffusion model, there is a lack of research investigating how different model specifications influence the quality of the parameter estimation (see Lerche et al., 2016, for an exception). In particular, little to no information is available on the costs and benefits of model complexity. While the basic diffusion model (Ratcliff, 1978) comprises only four parameters, Ratcliff and Rouder (1998) and Ratcliff and Tuerlinckx (2002) suggested that it may be necessary to allow for intertrial variability of parameter values, because psychological processes (such as expectations or attention) will shift from trial to trial. This led to the inclusion of three so-called intertrial variability parameters.
Since then, these additional parameters have been estimated in almost all published diffusion model studies (e.g., Ratcliff et al., 2004b; Spaniol et al., 2008; Yap et al., 2012; Allen et al., 2014; van Ravenzwaaij et al., 2014), even if trial numbers were small to moderate (e.g., Metin et al., 2013). This might be problematic, because in this case the parameter estimation might become unstable.
The aim of the present article is to compare the performance of more parsimonious with more complex models. In doing so, we do not question the theoretic rationale of the intertrial variabilities. We are aware that in all applications there will be fluctuations in psychological processes. Nonetheless, we argue that sometimes the available data might not suffice to get reliable estimates for the full diffusion model. Thus, neglecting these fluctuations might lead to more accurate and stable results.
In the following sections, we first give a short introduction to the diffusion model. Then, we elaborate on necessary choices regarding estimation procedures and model specifications. Finally, we present data from a simulation study (Study 1) and from a test-retest study (Study 2).
Parameters of the Diffusion Model
The diffusion model can be applied to binary decision tasks (e.g., lexical decision tasks [LDTs], or perceptual tasks such as color discrimination). One central supposition is that information is accumulated continuously and that this accumulation process ends as soon as one of two thresholds is reached. Each threshold is associated with one of the two responses of the binary task (or, alternatively, with correct vs. erroneous responses). Figure 1 shows an example of such a decision process.
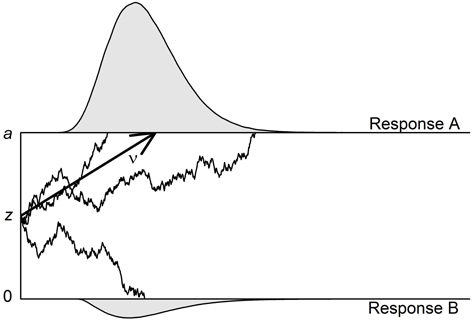
Figure 1. Illustration of the diffusion model with three of its four main parameters. The two thresholds that are associated with Response A (upper threshold; correct response in this illustration) and Response B (lower threshold; erroneous response) are separated by the distance a. The accumulation of information starts at starting point z, which is here centered between the thresholds. The mean drift rate (ν) is positive so that the upper threshold is reached more often than the lower threshold. In two of the three exemplary trials, the processes reach the upper threshold—resulting in one fast and one very slow correct response—and in one trial, the process reaches the lower threshold. The non-decisional component (t0) as well as the intertrial variabilities (St0, Sν, and SZr) are not depicted.
The four parameters of the basic diffusion model are the (1) drift rate (ν), (2) threshold separation (a), (3) starting point (z), and (4) non-decision time (t0). The drift rate ν informs about the speed and direction of information accumulation. Positive (negative) drift rates indicate an average slope of information accumulation toward the upper (lower) threshold. The absolute value of the drift rate is a measure of the speed of information uptake with higher values indicating faster accumulation. The drift rate can be interpreted as a measure of subjective task difficulty: (absolute) drift rates will be higher for easier tasks. The diffusion model assumes that information uptake is a stochastic (i.e., noisy) process. Thus, the process does not necessarily end at the same time or at the same threshold, even if the same information is available.
The threshold separation (a) represents the chosen response criterion. Higher distances go along with longer information uptake and fewer erroneous responses. While in Figure 1 the process is assumed to start in the center between the two thresholds, it might also start at a position closer to the upper or lower threshold. If the starting point z (or, zr = z/a) is located closer to one of two thresholds, less evidence needs to be accumulated before the participant decides for this option.
Finally, to the time taken by the decision process (illustrated in Figure 1) adds the non-decision time t0. It includes the duration of all processes that take place before (e.g., encoding of information) and after (e.g., motoric response execution) the decisional process. In most diffusion model studies one or more of these four parameters are in the focus of the research questions. Importantly, in several validation studies it was demonstrated that these parameters are sensitive to specific experimental manipulations, which supports the parameters' validity (e.g., Voss et al., 2004; Wagenmakers et al., 2008a; Arnold et al., 2015).
Ratcliff and Rouder (1998) suggest the inclusion of intertrial variabilities for two parameters, namely for the drift rate (sν) and the starting point (szr) (see also Laming, 1968, for an earlier account on intertrial variability). An important advantage of including these intertrial variability parameters in the model is that they provide an explanation for differences in speed of correct responses and errors. Specifically, if the drift rate varies from trial to trial, the model predicts slower errors than correct responses. Imagine trials with a drift rate that is higher than the average drift rate. In this case, all responses (including errors) are fast while the error rate is low. A drift rate that is lower than the average, on the other hand, results in a higher percentage of errors which are slow. Thus, the intertrial variability of the drift causes the majority of errors to be slow. A pattern of faster errors than correct responses can be explained by intertrial variability of the starting point. A starting point that is close to the lower (error) threshold increases the number of errors and decreases the decision time for those. If, on the other hand, the starting point is closer to the upper threshold (associated with correct responses), errors are slow but rare.
Later, a third variability parameter was included into the model: the intertrial variability of the non-decision time (st0; Ratcliff and Tuerlinckx, 2002). A high intertrial variability of non-decision time accounts for a higher number of fast responses (i.e., the skew of the predicted RT distribution is reduced). Thereby, the model might also become less susceptible to the impact of fast contaminants. With the three intertrial variabilities, the diffusion model includes seven parameters (for a model with one further parameter, see Voss et al., 2010).
In most diffusion model studies intertrial variabilities are included not because they are important to answer a psychological research question, but rather to improve model fit and, possibly, to avoid a bias in the other parameters. In the present article, we test whether excluding the intertrial parameters derogates the estimation of the four main diffusion model parameters.
Necessary Choices in Estimation Procedures and Model Specifications
In the first decades after the introduction of the diffusion model in 1978, the parameter estimation was restricted to researchers with sound mathematical and programming skills. Now, several user-friendly software solutions exist that enable any researcher to apply a diffusion model to their data. Amongst these programs are EZ (Wagenmakers et al., 2007, 2008b; Grasman et al., 2009), DMAT (Vandekerckhove and Tuerlinckx, 2007, 2008), fast-dm (Voss and Voss, 2007, 2008; Voss et al., 2015), and HDDM (Wiecki et al., 2013). Even if these programs are easy to use, they require the users to make several choices in terms of the parameter estimation procedure (with the exception of EZ that works with closed-form equations and offers fewer degrees of freedom in model definition). One such choice regards the optimization criterion, another the complexity of the model (i.e., the number of estimated parameters).
Optimization Criterion
The diffusion model programs allow the choice between different optimization criteria. Fast-dm-30 (Voss et al., 2015), for example, allows the choice between Kolmogorov-Smirnov (KS), a chi-square (CS) and a maximum likelihood (ML) based criterion. These criteria differ in the degree of usage of information with CS taking account of the least amount of information (RTs are grouped into bins) and ML using data from each single trial. On a continuum of information usage, with CS at the one end and ML at the other, KS can be positioned somewhere in between (see Voss et al., 2015, for a more detailed comparison of these three criteria). Related to information usage is the performance in parameter recovery. As a row of simulation studies by Lerche et al. (2016) shows, ML performs best, followed by KS and CS. The high efficiency of ML, however, comes with a cost: in the presence of fast contaminants (i.e., data not resulting from a diffusion process with the RTs situated at the lower tail of the distribution), the estimates obtained with ML are often severely biased. KS, on the other hand, turned out to be the least influenced by these contaminants.
Model Complexity
Most diffusion model programs allow an estimation of all seven parameters of the diffusion model. Furthermore, they also offer the possibility of fixing one or more of the parameters to a constant value, thereby specifying less complex models. As already mentioned, the intertrial variabilities are usually estimated not due to the theoretical interest in these parameters (see Ratcliff, 2008; Starns and Ratcliff, 2012, for an exception), but to avoid a biased estimation of the basic diffusion model parameters.
However, several simulation studies show that these parameters (especially, the variability of drift rate and starting point) are estimated less accurately than the other parameters (e.g., Vandekerckhove and Tuerlinckx, 2007; van Ravenzwaaij and Oberauer, 2009; Lerche et al., 2016). This raises the question of whether the inclusion of intertrial variability parameters really improves the estimation of the other parameters. Based on such findings, in some recent studies the intertrial variabilities have been deliberately fixed. For example, Germar et al. (2014) fixed all three intertrial variabilities at zero (see also Ratcliff and Childers, 2015). Note that also in earlier work the intertrial variabilities have sometimes been fixed at zero, because the application of the EZ method does not allow to include these parameters (e.g., Schmiedek et al., 2007; Wagenmakers et al., 2007, 2008b; Grasman et al., 2009; van Ravenzwaaij et al., 2012; Dutilh et al., 2013).
Whereas Ratcliff and Rouder (1998) and Ratcliff and Tuerlinckx (2002), who argued for the inclusion of intertrial variabilities, typically used very high trial numbers (at least 1000 trials per participant), more recently the model has also been applied to data sets with significantly smaller trial numbers (e.g., with only 100, see Metin et al., 2013). This raises the question of whether small data sets provide enough information to estimate the full (seven-parameter) model. Lerche et al. (2016) systematically investigated the number of trials that allow for a precise estimation of the diffusion model parameters. They simulated data sets both on the basis of a seven-parameter model (i.e., with the assumption of intertrial variabilities) and on the basis of more restricted models. For example, in a four-parameter model the three intertrial variabilities were fixed at zero both for the generation of data and for the reestimation of parameters. The comparison of these models revealed that—as expected—for more complex models higher trial numbers are required. Besides, as Lerche et al. (2016) show, the required number of trials also depends on the used optimization criterion. The authors found that the three optimization criteria KS, ML, and CS perform equally well for very high trial numbers. However, for small and moderate trial numbers, accuracy of estimates from CS based parameter search was inacceptable.
The findings by Lerche et al. (2016) raise the issue of whether less complex models (i.e., models with fixations) also perform better when the true (data generating) model is more complex (i.e., includes variabilities). A study by van Ravenzwaaij et al. (2016) speaks in favor of this hypothesis. The authors compared the performance of EZ (Wagenmakers et al., 2007) with the performance of a diffusion model estimation including all three intertrial variability parameters (using Quantile Maximum Proportion Estimation, see Heathcote et al., 2002). Interestingly, the power of between-group difference detection for both drift rate and threshold separation was higher for EZ than for the more complex model even if there were substantial intertrial variabilities in the data generating models. Thus, it seems that simpler models can outperform more complex models.
We further tackled this question in two studies, a simulation study (Study 1) and a test-retest study (Study 2). In Study 1, the performance of the estimation procedure is measured by deviations and correlations between the true and the recovered parameter values. In Study 2, the estimation performance is assessed by means of the correlations between the parameters of two different sessions.
Study 1: Simulation Study
Study 1 is a simulation study in which we reanalyzed data sets of the seven-parameter model from Lerche et al. (2016).
Method
Lerche et al. (2016) simulated data sets with different numbers of trials and reestimated parameters in order to deduce guidelines on requisite trial numbers. In Study 1, we reanalyzed a part of their data sets, namely the data sets that were created on the basis of the seven-parameter model (i.e., the model that includes intertrial variabilities and a bias in the starting point; see also Table 1). Here, we only briefly present their study design with a focus on the differences between the two studies. Please refer to Lerche et al. (2016) for more details on their simulation procedure.
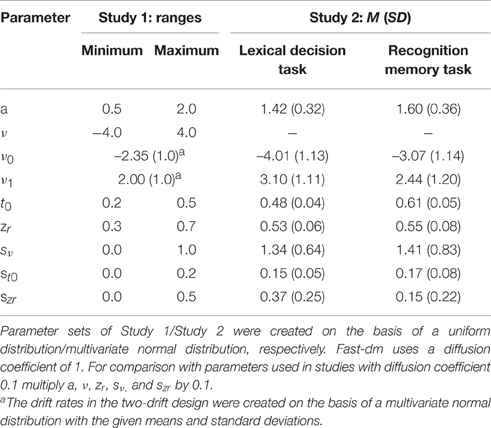
Table 1. Parameter ranges (Study 1) and means and standard deviations (Study 2) used for generation of parameter sets.
The authors constructed data sets for two different experimental designs: a one-drift design and a two-drift design. Whereas the one-drift design simulates choices between two stimuli with the same absolute drift rate value, in the two-drift design the drift rate for one stimulus is larger than for the other stimulus (dz = 0.35). Accordingly, in the one-drift design, only one drift rate was estimated. In the two-drift design, two drift rates (with opposite signs) were estimated simultaneously. One-thousand different parameter sets with random parameter values were used for each experimental design. For each parameter set seven data sets were created, using construct-samples1, with different trial numbers (24—48—100—200—500—1000—5000). Then, 4% of the simulated trials were randomly selected and substituted for by either fast or slow contaminants, resulting in three contamination conditions (no contaminants—fast contaminants—slow contaminants). More specifically, in the condition with fast contaminants, the responses of the contaminant trials were set by chance to 0 or 1 (simulating guesses) and the simulated RTs from these trials were substituted for by RTs situated at the lower edge of the original distribution (range: tmin − 100 ms to tmin + 100 ms, with tmin = t0 − st0/2). In the condition with slow contaminants, only the response times were replaced, using values lying 1.5–5 interquartile ranges above the third quartile of the original RT distribution.
For each condition (stimulus design × trial number × contamination condition), Lerche et al. (2016) reestimated all seven parameters and compared them with their true values (in the remainder of this article termed “seven-parameter model”). In the present study, we additionally use more parsimonious models for parameter estimation. In particular, in the “five-parameter model”, two of the intertrial variabilities (sν and szr) were fixed at zero (i.e., we assumed that these two parameters do not vary from trial to trial). We fixed these two intertrial variabilities, because several studies have shown that they are recovered poorly (e.g., van Ravenzwaaij and Oberauer, 2009). The intertrial variability of the non-decision time, on the other hand, is estimated better and could counteract the negative influence of fast contaminants. Thus, this parameter was kept in the model even if it is psychologically less interesting than the main diffusion model parameters (a, ν, t0, zr). Furthermore, we used a “four-parameter model” (i.e., the “basic” model) with additional fixation of the intertrial variability of the non-decision time (i.e., st0 = 0). Note that these fixations are always false assumptions (“false fixations”), since the data generating model included all three intertrial variabilities. Finally, we estimated a “three-parameter model” in which we additionally fixed the starting point to the center between the two thresholds (i.e., zr = 0.5). For the parameter estimation, we used fast-dm-30 (Voss et al., 2015) and estimated the parameters with each of the three implemented optimization criteria (i.e., KS, ML, and CS).
Our evaluation criteria are similar to those by Lerche et al. (2016): We analyzed (1) correlations between the true and the reestimated parameter values, (2) biases (i.e., deviations between the true and the reestimated parameter values), and (3) estimation precision (i.e., squared deviations between the true and the reestimated parameter values). For criterion 1 and criterion 3 we additionally computed an average measure across parameters. Specifically, for criterion 1, we calculated the mean correlation over the four main diffusion model parameters using Fisher's Z-transformation2. The mean estimation precision was calculated on the basis of the formula stated below. Most importantly, differences between the estimated and the true parameter values were computed and weighted against the best possible accuracy that can be reached by each parameter. In contrast to Lerche et al. (2016), we computed the mean based on only the four basic diffusion model parameters (i.e., a, ν, t0, and zr)2,3.
If the interest of the researcher lies in relationships between the diffusion model parameters and external criteria, the correlation criterion is of most relevance. A disadvantage of correlation coefficients is that they can mask possible biases in parameter estimation (e.g., if a parameter is systematically over- or underestimated, still high correlation coefficients result). The bias criterion tackles such systematical deviations in parameter estimation. Finally, the estimation precision criterion is the strictest criterion, since it takes into account any inaccuracy in parameter estimation. This criterion is of relevance if the diffusion model parameters are to be used as diagnostic measures. Such a potential future use of diffusion model parameters requires very accurate parameter estimates.
Results
In Figure 2, results are presented for the one-drift design for uncontaminated data. Figures 3, 4 show results for the conditions of slow and fast contaminants, respectively. In the left column, the 95% quantiles of the mean estimation precision (criterion 3) are shown (thus, for most data sets, the mean estimation precision is smaller than the values from the figure). In the right column, mean correlation coefficients (criterion 1) are depicted. Results are presented as a function of number of trials, optimization criterion and model complexity4. Additionally, Table 2 (for the one-drift design) and Table 3 (for the two-drift design) sum up which model (model with 3, 4, 5, or 7 parameters) shows the best performance in terms of the correlations (first value), the mean bias across data sets (second value) and the 95% quantiles of estimation precision (third value) depending on the optimization criterion (KS/ML/CS), type of contamination (none/fast/slow) and number of trials. Note that in some conditions, several models manifest almost identical performance and that in these tables no information on the size of the differences between the models is given.
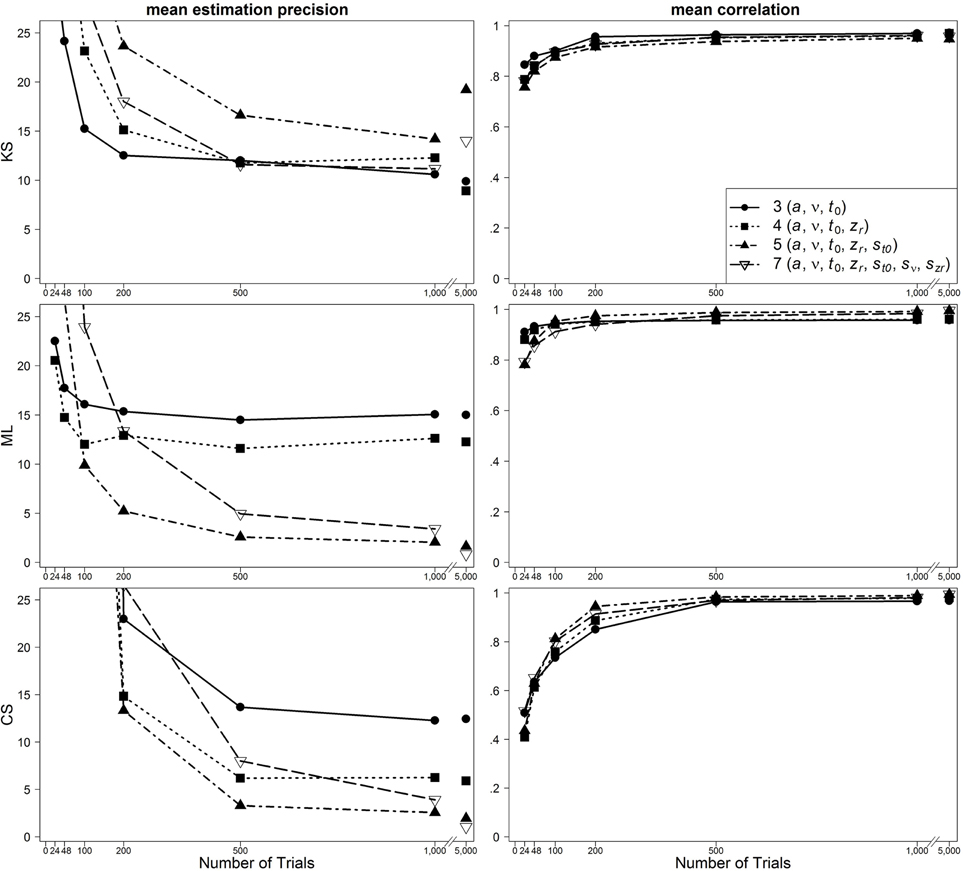
Figure 2. Scatter plot of 95% quantiles of mean estimation precision (left column) and mean correlation between true and reestimated parameters (right column) for uncontaminated data sets in the one-drift design. On the basis of data sets with at least 4% of trials at each threshold. Quantiles exceeding the mean estimation precision of 25 are not depicted.
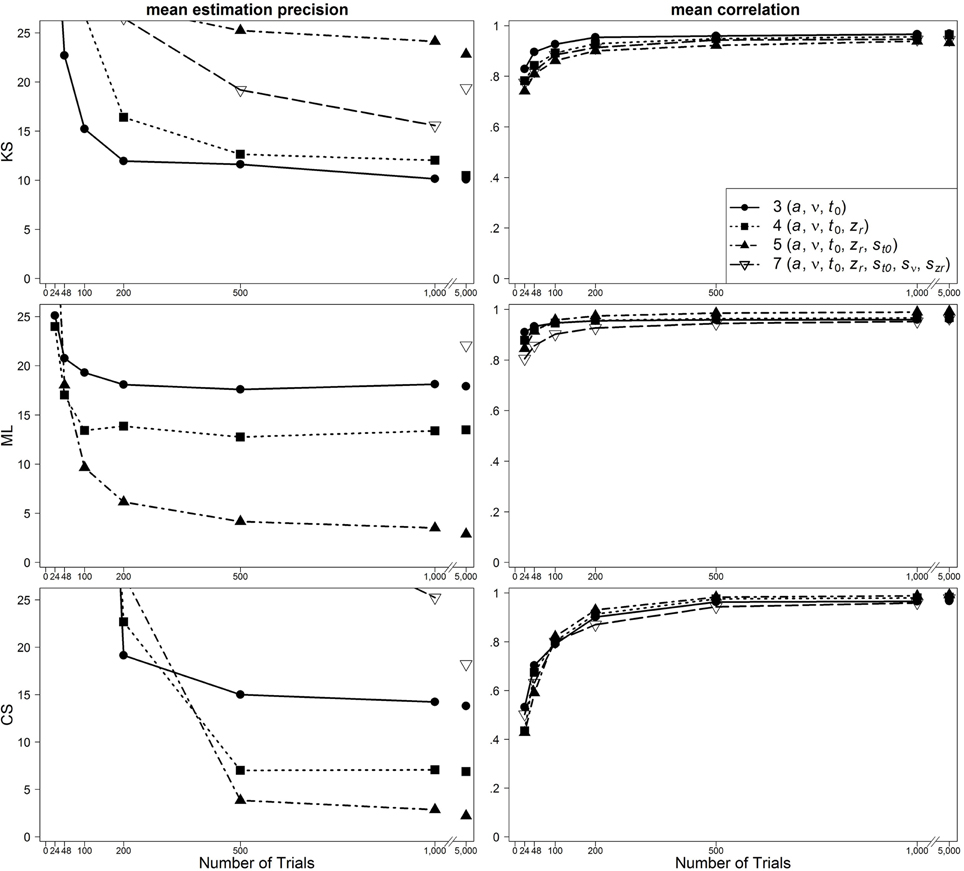
Figure 3. Scatter plot of 95% quantiles of mean estimation precision (left column) and mean correlation between true and reestimated parameters (right column) for data sets with slow contaminants in the one-drift design. On the basis of data sets with at least 4% of trials at each threshold. Quantiles exceeding the mean estimation precision of 25 are not depicted.
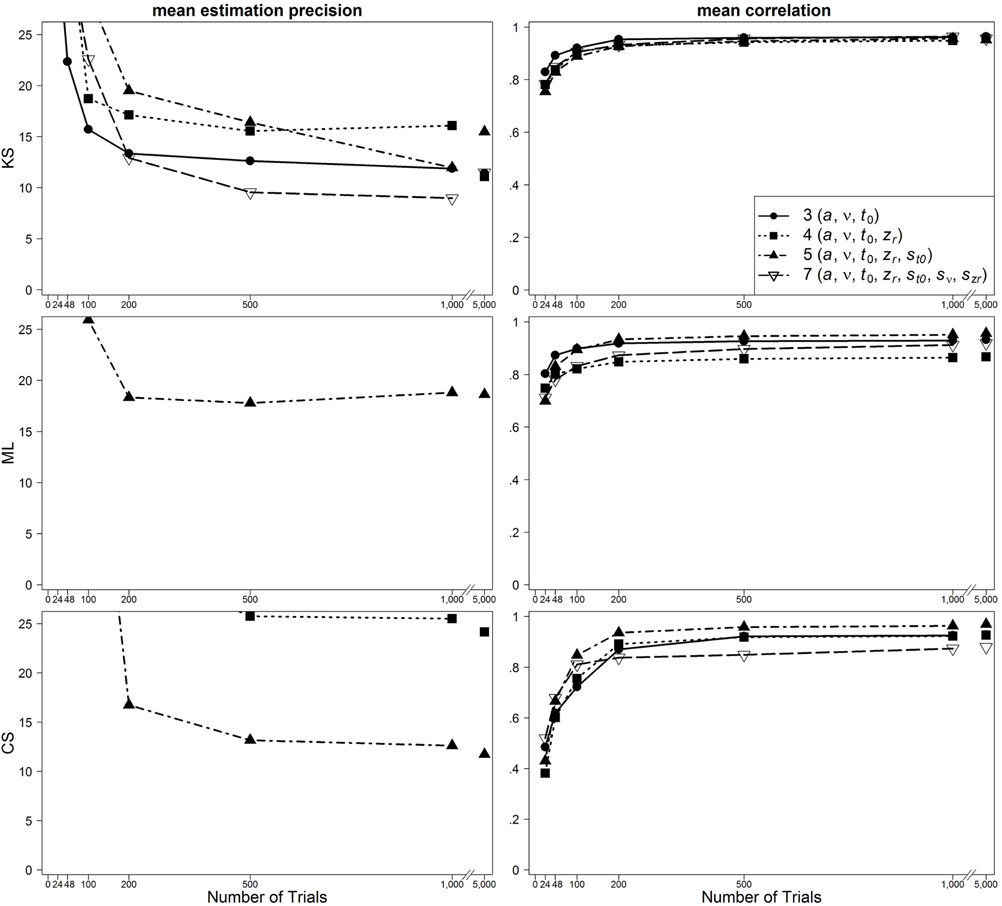
Figure 4. Scatter plot of 95% quantiles of mean estimation precision (left column) and mean correlation between true and reestimated parameters (right column) for data sets with fast contaminants in the one-drift design. On the basis of data sets with at least 4% of trials at each threshold. Quantiles exceeding the mean estimation precision of 25 are not depicted.
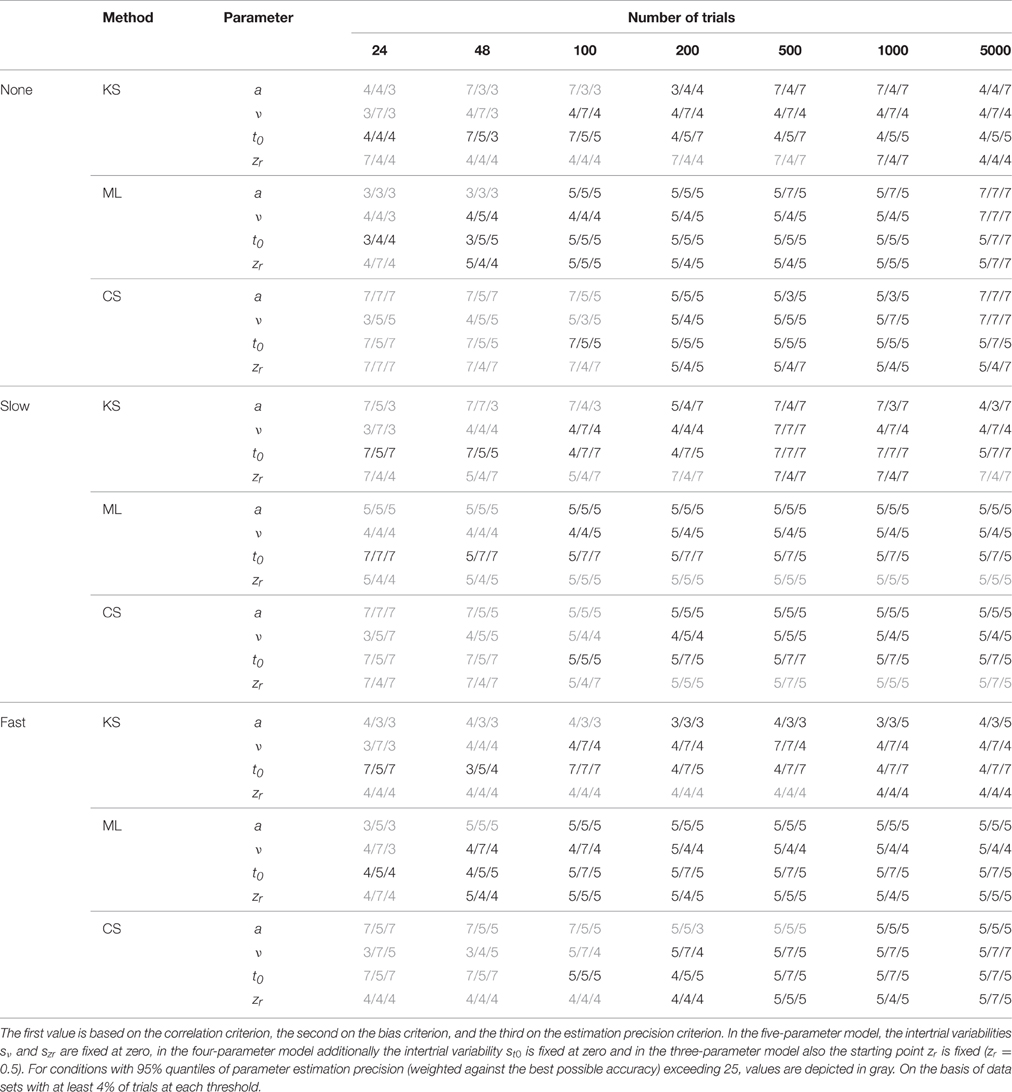
Table 2. Model superiority for the one-drift design, depending on the type of contamination, the method, the parameter, and the number of trials.
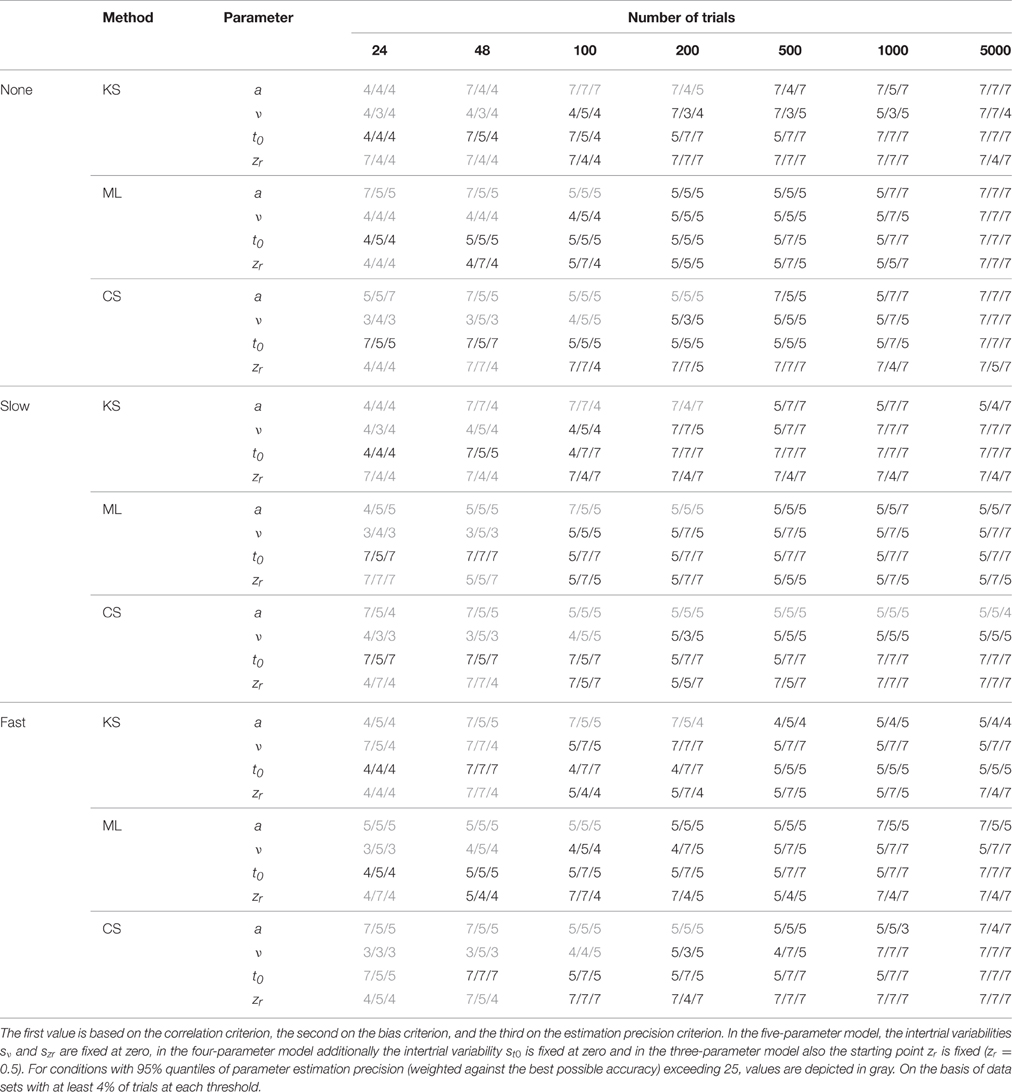
Table 3. Model Superiority for the two-drift design, depending on the type of contamination, the method, the parameter, and the number of trials.
One main finding is that in most conditions the seven-parameter model does not provide the most accurate or unbiased estimates, although this is the true model. For ML, the pattern is quite consistent: in most cases, the five-parameter model reveals the best results. For CS, the findings are similar: The five-parameter model shows the best performance. In contrast to the results from ML, the CS procedure more often gets best results from the full seven-parameter model, even for smaller trial numbers. Note, however, that for small trial numbers the performance of CS is generally so poor for all models that results cannot be reasonably interpreted. Therefore, we generally do not recommend using CS for small trial numbers (see also Lerche et al., 2016). For KS more often than for ML and CS, models less complex than the five-parameter model (i.e., the three- or four-parameter models) bring forth the best results. Furthermore, here, more often than for ML and CS, the seven-parameter model performs best. A comparison of the different parameters reveals that for a and t0 the five-parameter model and for v and zr the four-parameter model result in the best recovery.
Discussion
Study 1 demonstrates that even if the three parameters a, v, and t0 vary from trial to trial (and the starting point is not situated centrally), the seven-parameter model does not always provide the most accurate results.
For data sets with fast contaminants, Lerche et al. (2016) (focusing on the mean precision criterion) showed that a KS based parameter search generally recovers parameters better than ML and CS. Interestingly, in the present analyses, ML and CS show a good performance for data contaminated by fast contaminants, if the five-parameter model is used (see Figure 4). Thus, the inclusion of the intertrial variability of t0 seems to help to counteract the negative influence of fast contaminants. For KS, on the other hand, a similarly good performance is found for all applied models.
To test the stability of our results, we conducted additional analyses in which the parameter search started with other initial values for the intertrial variabilities. The default initial values of the intertrial variabilities incorporated in fast-dm are the following: sν = 0.5; szr = 0.3; st0 = 0.2. In one of the additional estimation series, we set all three intertrial variabilities to zero. In another, we set them to the maximum values used for simulation of data sets (see Table 1). Finally, in a third series of parameter estimation, we set them to half of the maximum values. The main results are very similar for all series of analyses in that the seven-parameter model is mostly outperformed by less complex models.
A caveat of our simulation study is that we made assumptions about the proportion and type of contamination that might not accurately reflect the contamination of real data. We are also not sure about the true range of intertrial variabilities in empirical studies. Another way to analyze the performance of different estimation procedures is provided by a test-retest study.
Study 2: Test-Retest Study
The main aim of Study 2 was to test whether the conclusions from Study 1 also hold for empirical data. For this purpose, we reanalyzed data from a test-retest study by Lerche and Voss (2016).
Method
In Study 1 of Lerche and Voss (2016), 105 participants worked at two sessions—separated by 1 week—on an LDT and a Recognition Memory Task (with pictures as stimuli; RMT). As in Study 1 we used fast-dm-30 and fitted the model using KS, ML, and CS procedures. We also compared the four models differing in complexity as introduced in Study 1. One response (“words” in the LDT and “old pictures” in the RMT) was assigned to the upper threshold, the other response (“non-words” and “new pictures”) to the lower threshold. In each model, we estimated two drift rates (for the different stimulus types). Both drift rates were then combined to an overall measure of speed of information accumulation, termed νtotal by computing the difference between the drift for words (old pictures) and for non-words (new pictures).
For each of the basic diffusion model parameters (a, νtotal, t0, and zr) the Pearson correlation between the two sessions was calculated5. To make results more accessible, as in Study 1, the mean over these four coefficients (without zr in the three-parameter model) was computed using Fisher's Z-transformation (in the remainder of this article termed “mean retest reliability”). Retest correlation coefficients were computed not only for parameters estimated from the actual data (i.e., 200 trials from the RMT, and 400 trials from the LDT), but also for parameters estimated from subsets of data with smaller trial numbers (specifically, for the first 32, 48, 100, and 200 trials of each participant).
Additionally, we wanted to test whether our main findings from Study 1 hold for a different strategy of data simulation. The parameter sets by Lerche et al. (2016) were created using uniform distributions across value ranges typically observed in previous diffusion model studies (only for the drift rates in the two-drift design a multivariate normal distribution was used). Lerche and Voss (2016), on the other hand, based their random parameter sets on multivariate normal distributions defined by the means, standard deviations and correlations of parameter estimates from the data of the LDT and RMT (Table 1). Importantly, as in the simulation study by Lerche et al. (2016), there were substantial intertrial variabilities. Data sets were created using different trial numbers (32—48—100—200—400—1000—5000) and assuming equal parameter sets for both sessions (i.e., no state influences). This allows an estimation of the maximum retest reliability coefficients. Again, in contrast to Lerche and Voss (2016), we estimated parameters using models with different complexity.
Results
In Figure 5, the retest reliabilities are presented for the four main diffusion model parameters for both LDT and RMT as a function of model complexity (estimations are based on the complete data, i.e., 400 and 200 trials for LDT and RMT, respectively). Again, applying the full seven-parameter model does not result in the highest correlations; retest-reliability is higher for less complex models. Whereas, for non-decision time and starting point retest reliabilities for all models are similar, there are larger differences for drift rate and threshold separation. Notable is the poor estimation of drift rates from the seven-parameter model for estimations based on ML or CS. For ML and CS, the five-parameter shows the best performance, whereas for KS, the even more restricted four-parameter model mostly outperforms the other models. Figure 6 shows the influence of the number of trials on retest reliability. Mean reliability coefficients are shown both for the empirical data sets (depicted in black) and the data sets that were simulated on the basis of the parameter ranges observed in the empirical data (depicted in gray). Most importantly, for neither the empirical nor the simulated data does the seven-parameter model show the highest retest correlations. It is noteworthy that for CS and ML, even in the condition with 1000 trials, the seven-parameter model be still worse than the other models6.
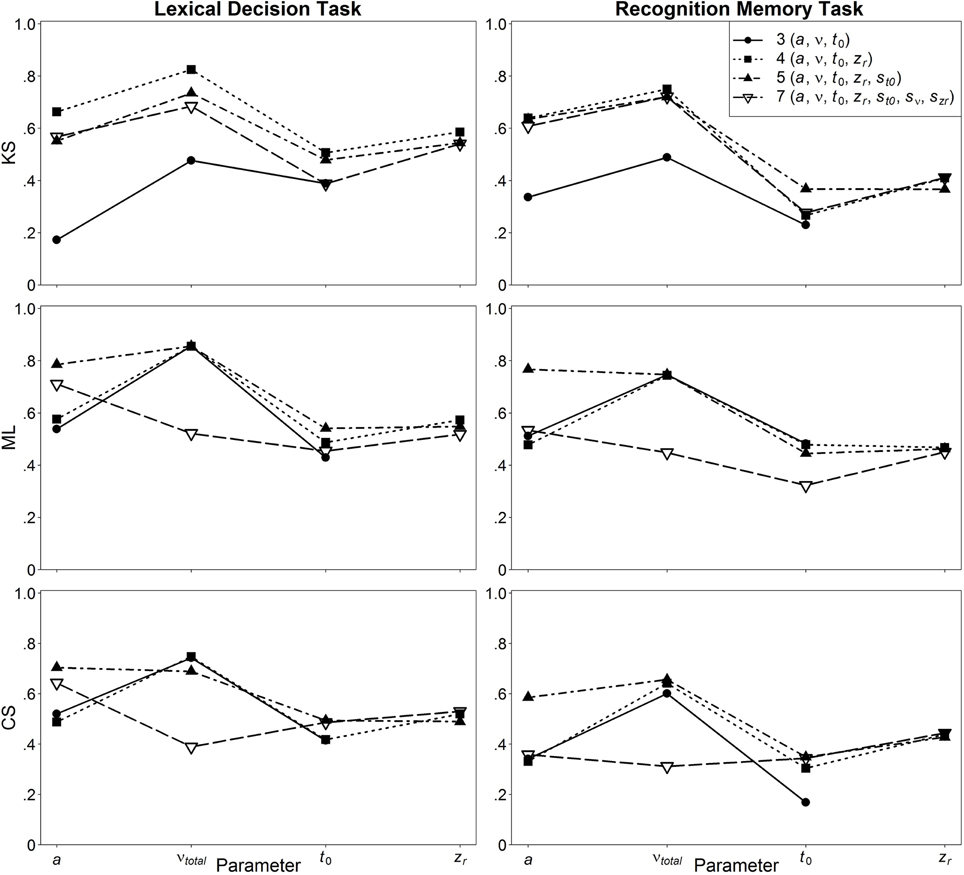
Figure 5. Retest reliability depending on model complexity and method.
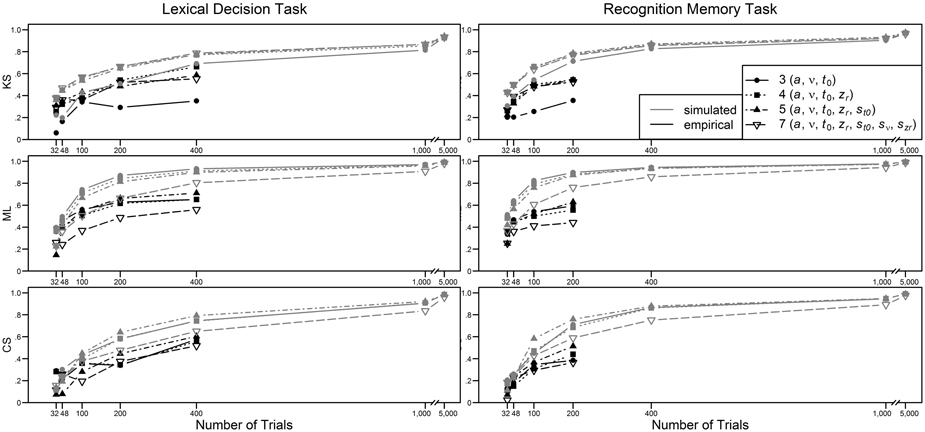
Figure 6. Mean retest reliability depending on model complexity, method, type of data (empirical vs. simulated), and number of trials.
Discussion
The main findings from Study 2 are in line with those from Study 1 in that the seven-parameter model does not always show the best performance (here, in terms of the test-retest correlation coefficients). In fact, it is mostly outperformed by less complex models such as the five-parameter model. In the simulation study—which was based on the multivariate distributions of estimated parameters—a similar pattern emerged. This suggests that the main findings do not depend on the particular simulation strategy of Study 1.
Interestingly, using the CS or ML criterion, only at 5000 trials does the seven-parameter model catch up with the more restricted models. Note that sometimes CS has been used for data sets with such high trial numbers. In these studies, the use of a seven-parameter model is justified. Our results, however, suggest that it would be equally effective to use a more restricted model. In addition, it would be more efficient, since the time needed for parameter estimation is prolonged when models with intertrial variabilities are estimated. For smaller trial numbers, on the other hand, the use of the seven-parameter model can lead to worse parameter estimates than the use of more restricted models.
General Discussion
In recent years, an increase in the number of researchers interested in the diffusion model and a higher variability regarding the addressed research topics and experimental designs is evident. For example, while in the past the diffusion model has almost exclusively been used for data sets with very large trial numbers (even >1000; e.g., Ratcliff et al., 2004a; Wagenmakers et al., 2008a; Leite and Ratcliff, 2011), more recently, it has also often been employed for studies with small to moderate trial numbers (e.g., Klauer et al., 2007; Boywitt and Rummel, 2012; Karalunas et al., 2012; Karalunas and Huang-Pollock, 2013; Metin et al., 2013; Pe et al., 2013; Arnold et al., 2015).
Usually, complex models (i.e., with all seven distinct diffusion model parameters and, additionally, parameters varying between several conditions) are used. This has been done even if the number of trials is essentially smaller (e.g., 100 trials, see Metin et al., 2013) than in the studies that originally argued for the inclusion of intertrial variabilities (Ratcliff and Rouder, 1998; Ratcliff and Tuerlinckx, 2002). Especially for small to moderate trial numbers, the choices of model complexity and of optimization criteria for parameter estimation are crucial. Therefore, a systematic comparison of different estimation procedures and a spreading of this knowledge is important in order to support a reasonable use of the diffusion model. With the studies reported here we make a step in this direction.
With two diverse approaches, we analyzed the influence of the model complexity on the accuracy of parameter estimation. We were particularly interested in the influence of the intertrial variabilities (Ratcliff and Rouder, 1998; Ratcliff and Tuerlinckx, 2002) that have proven to be more difficult to estimate than the other diffusion model parameters (e.g., van Ravenzwaaij and Oberauer, 2009). In Study 1, we reanalyzed data sets from a simulation study by Lerche et al. (2016). The data sets were created assuming the presence of intertrial variabilities and a starting point of the diffusion process that was allowed to differ from the center between the thresholds. In Study 2, data from a test-retest study and a further simulation study by Lerche and Voss (2016) were analyzed. While in Study 1 deviations and correlations between the true and the recovered parameter values served as the performance measures, in Study 2 we examined the retest reliability coefficients. In both studies, the parameters were estimated using differently complex models.
Our results for both the simulated and the empirical data sets indicate that the most complex model (the “full” model comprising all seven parameters) is often not the best choice. A five-parameter model (with fixation of sν and szr to zero) generally provides accurate estimates, especially when the maximum likelihood (ML) or the chi-square (CS) criterion is applied. For ML and CS, an additional fixation of st0 is not advisable, since these two criteria are sensitive to the presence of fast contaminants (see also Lerche et al., 2016) and st0 helps to counteract the negative influence of this type of contamination. Thus, keeping st0 in the model can help to reach better estimation of the psychologically most interesting parameters (a, ν, t0, and zr). For Kolmogorov-Smirnov (KS)—a criterion that is generally less sensitive to fast contaminants—the even less complex four-parameter model (i.e., the basic diffusion model with all intertrial variabilities fixed at zero) often provides the most accurate results.
Note that our results are in line with recent findings by van Ravenzwaaij et al. (2016). In their study, a model with fixed intertrial variabilities had a higher power to detect differences between conditions than a model including intertrial variabilities. Specifically, results from the EZ approach (Wagenmakers et al., 2007)—which fixes the starting point at the center between the two thresholds and the intertrial variabilities at zero—were compared to the application of a full diffusion model analysis. Even if the data were generated based on a full diffusion model, EZ outperformed the full diffusion model both for detection of drift rate and threshold separation differences. For non-decision time, the efficiency of both procedures was similar.
For future research, it would be interesting to analyze further experimental paradigms using test-retest studies. Besides, one could use different fixation strategies (e.g., instead of fixation at zero, the intertrial variabilities could be fixed at values typically observed in previous studies). To sum up, our results generally speak in favor of the use of less complex models. Thus, if the diffusion model is applied to get accurate estimates of cognitive processes (mapped by a, ν, t0, or zr), a less complex model will often supply more reliable estimates. In particular, it is helpful to fix the intertrial variabilities of starting point and drift rate (szr and sν) at zero.
Author Contributions
Both VL and AV contributed equally to the conception and interpretation of this work. Data were analyzed by VL and the manuscript was drafted by VL and revised by AV. Both authors approve of the final version and agree on being accountable for this work.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The reviewer VN and the handling Editor declared their shared affiliation, and the handling Editor states that the process nevertheless met the standards of a fair and objective review.
Acknowledgments
This research was supported by a grant from the Deutsche Forschungsgemeinschaft to AV (Grant No. VO1288/2-2). We acknowledge financial support by Deutsche Forschungsgemeinschaft and Ruprecht-Karls-Universität Heidelberg within the funding programme Open Access Publishing.
Footnotes
1. ^Construct-samples is part of fast-dm and offers the possibility of constructing data sets based on a diffusion process.
2. ^In the three-parameter model, the mean was based on a, ν, and t0. In the two-drift design, first the mean for the criterion performance of the two drift rates was calculated.
3. ^“Best possible accuracies” of the main diffusion model parameters: a − 0.054; ν − 0.270; t0 − 0.032; zr − 0.035. These values are based on an optimal condition of parameter estimation (5000 trials, no contaminants, ML estimation; for more details, please refer to Lerche et al., 2016).
4. ^Surprisingly, in some conditions, the estimation precision of KS decreased from 1000 to 5000 trials. This effect is based on a few models with very bad fit that strongly influence the reported 95% quantiles. If medians are examined instead of the 95% quantiles, the estimation precision—as expected—augments from 1000 to 5000 trials, or decreases only marginally. The KS-based search is more prone to get stuck in local minima for larger data sets. Artificial local minima can arise when calculation precision is too low. Exemplarily, we selected the ten data sets that showed the worst performance in the condition with 5000 trials in the one-drift model with no contaminants. We then reestimated parameters for these data sets with the seven-parameter model with increased precision of calculation (the fast-dm precision criterion was increased from 3 to 4). This improved parameter estimation notably for the condition with 5000 trials. More specifically, the mean across these ten data sets dropped to less than half, whereas there was less improvement for the condition with 1000 trials. Accordingly, for higher trial numbers, we recommend using higher precision settings in fast-dm.
5. ^Prior to the correlational analyses, we identified bivariate outliers with the Mahalanobis distance (D2) and excluded participants with extremely high values (p < 0.001) from the respective analysis (resulting in at most four excluded participants).
6. ^Note that we also analyzed the Associative Priming Task presented in Lerche and Voss (2016; Study 2) using models with different complexity. We found very similar results in that the seven-parameter model did not show the highest retest reliabilities.
References
Allen, P. A., Lien, M.-C., Ruthruff, E., and Voss, A. (2014). Multitasking and aging: do older adults benefit from performing a highly practiced task? Exp. Aging Res. 40, 280–307. doi: 10.1007/s00426-014-0608-y
Arnold, N. R., Bröder, A., and Bayen, U. J. (2015). Empirical validation of the diffusion model for recognition memory and a comparison of parameter-estimation methods. Psychol. Res. 79, 882–898. doi: 10.1007/s00426-014-0608-y
Boywitt, C. D., and Rummel, J. (2012). A diffusion model analysis of task interference effects in prospective memory. Mem. Cogn. 40, 70–82. doi: 10.3758/s13421-011-0128-6
Brown, S. D., and Heathcote, A. (2008). The simplest complete model of choice response time: linear ballistic accumulation. Cogn. Psychol. 57, 153–178. doi: 10.1016/j.cogpsych.2007.12.002
Dutilh, G., Forstmann, B. U., Vandekerckhove, J., and Wagenmakers, E.-J. (2013). A diffusion model account of age differences in posterror slowing. Psychol. Aging 28, 64. doi: 10.1037/a0029875
Germar, M., Schlemmer, A., Krug, K., Voss, A., and Mojzisch, A. (2014). Social influence and perceptual decision making: a diffusion model analysis. Pers. Soc. Psychol. Bull. 40, 217–231. doi: 10.1177/0146167213508985
Grasman, R. P. P. P., Wagenmakers, E.-J., and van der Maas, H. L. J. (2009). On the mean and variance of response times under the diffusion model with an application to parameter estimation. J. Math. Psychol. 53, 55–68. doi: 10.1016/j.jmp.2009.01.006
Heathcote, A., Brown, S., and Mewhort, D. J. K. (2002). Quantile maximum likelihood estimation of response time distributions. Psychon. Bull. Rev. 9, 394–401. doi: 10.3758/BF03196299
Karalunas, S. L., and Huang-Pollock, C. L. (2013). Integrating impairments in reaction time and executive function using a diffusion model framework. J. Abnorm. Child Psychol. 41, 837–850. doi: 10.1007/s10802-013-9715-2
Karalunas, S. L., Huang-Pollock, C. L., and Nigg, J. T. (2012). Decomposing attention-deficit/hyperactivity disorder (ADHD)-related effects in response speed and variability. Neuropsychology 26, 684–694. doi: 10.1037/a0029936
Klauer, K. C., Voss, A., Schmitz, F., and Teige-Mocigemba, S. (2007). Process components of the implicit association test: a diffusion-model analysis. J. Pers. Soc. Psychol. 93, 353–368. doi: 10.1037/0022-3514.93.3.353
Leite, F. P., and Ratcliff, R. (2011). What cognitive processes drive response biases? A diffusion model analysis. Judgm. Decis. Mak. 6, 651–687.
Lerche, V., and Voss, A. (2016). Retest reliability of the parameters of the Ratcliff diffusion model. Psychol. Res. doi: 10.1007/s00426-016-0770-5. [Epub ahead of print].
Lerche, V., Voss, A., and Nagler, M. (2016). How many trials are required for parameter estimation in diffusion modeling? A comparison of different optimization criteria. Behav. Res. Methods. doi: 10.3758/s13428-016-0740-2. [Epub ahead of print].
Metin, B., Roeyers, H., Wiersema, J. R., van der Meere, J. J., Thompson, M., and Sonuga-Barke, E. (2013). ADHD performance reflects inefficient but not impulsive information processing: a diffusion model analysis. Neuropsychology 27, 193–200. doi: 10.1037/a0031533
Pe, M. L., Vandekerckhove, J., and Kuppens, P. (2013). A diffusion model account of the relationship between the emotional flanker task and rumination and depression. Emotion 13, 739–747. doi: 10.1037/a0031628
Ratcliff, R. (1978). A theory of memory retrieval. Psychol. Rev. 85, 59–108. doi: 10.1037/0033-295X.85.2.59
Ratcliff, R. (2008). Modeling aging effects on two-choice tasks: response signal and response time data. Psychol. Aging 23, 900–916. doi: 10.1037/a0013930
Ratcliff, R., and Childers, R. (2015). Individual differences and fitting methods for the two-choice diffusion model of decision making. Decision 2, 237–279. doi: 10.1037/dec0000030
Ratcliff, R., and Rouder, J. N. (1998). Modeling response times for two-choice decisions. Psychol. Sci. 9, 347–356. doi: 10.1111/1467-9280.00067
Ratcliff, R., Thapar, A., Gomez, P., and McKoon, G. (2004a). A diffusion model analysis of the effects of aging in the lexical-decision task. Psychol. Aging 19:278. doi: 10.1037/0882-7974.19.2.278
Ratcliff, R., Thapar, A., and McKoon, G. (2004b). A diffusion model analysis of the effects of aging on recognition memory. J. Mem. Lang. 50, 408–424. doi: 10.1016/j.jml.2003.11.002
Ratcliff, R., and Tuerlinckx, F. (2002). Estimating parameters of the diffusion model: approaches to dealing with contaminant reaction times and parameter variability. Psychon. Bull. Rev. 9, 438–481. doi: 10.3758/BF03196302
Schmiedek, F., Oberauer, K., Wilhelm, O., Süß, H.-M., and Wittmann, W. W. (2007). Individual differences in components of reaction time distributions and their relations to working memory and intelligence. J. Exp. Psychol. Gen. 136, 414–429. doi: 10.1037/0096-3445.136.3.414
Spaniol, J., Voss, A., and Grady, C. L. (2008). Aging and emotional memory: cognitive mechanisms underlying the positivity effect. Psychol. Aging 23, 859–872. doi: 10.1037/a0014218
Starns, J. J., and Ratcliff, R. (2012). Age-related differences in diffusion model boundary optimality with both trial-limited and time-limited tasks. Psychon. Bull. Rev. 19, 139–145. doi: 10.3758/s13423-011-0189-3
Vandekerckhove, J., and Tuerlinckx, F. (2007). Fitting the Ratcliff diffusion model to experimental data. Psychon. Bull. Rev. 14, 1011–1026. doi: 10.3758/BF03193087
Vandekerckhove, J., and Tuerlinckx, F. (2008). Diffusion model analysis with MATLAB: a DMAT primer. Behav. Res. Methods 40, 61–72. doi: 10.3758/BRM.40.1.61
van Ravenzwaaij, D., Boekel, W., Forstmann, B. U., Ratcliff, R., and Wagenmakers, E.-J. (2014). Action video games do not improve the speed of information processing in simple perceptual tasks. J. Exp. Psychol. Gen. 143, 1794–1805. doi: 10.1037/a0036923
van Ravenzwaaij, D., Donkin, C., and Vandekerckhove, J. (2016). The EZ diffusion model provides a powerful test of simple empirical effects. Psychon. Bull. Rev. doi: 10.3758/s13423-016-1081-y. [Epub ahead of print].
van Ravenzwaaij, D., Dutilh, G., and Wagenmakers, E.-J. (2012). A diffusion model decomposition of the effects of alcohol on perceptual decision making. Psychopharmacology 219, 1017–1025. doi: 10.1007/s00213-011-2435-9
van Ravenzwaaij, D., and Oberauer, K. (2009). How to use the diffusion model: parameter recovery of three methods: Ez, fast-dm, and DMAT. J. Math. Psychol. 53, 463–473. doi: 10.1016/j.jmp.2009.09.004
Voss, A., Nagler, M., and Lerche, V. (2013). Diffusion models in experimental psychology. A practical introduction. Exp. Psychol. 60, 385–402. doi: 10.1027/1618-3169/a000218
Voss, A., Rothermund, K., and Voss, J. (2004). Interpreting the parameters of the diffusion model: an empirical validation. Mem. Cogn. 32, 1206–1220. doi: 10.3758/BF03196893
Voss, A., and Voss, J. (2007). Fast-dm: a free program for efficient diffusion model analysis. Behav. Res. Methods 39, 767–775. doi: 10.3758/BF03192967
Voss, A., and Voss, J. (2008). A fast numerical algorithm for the estimation of diffusion model parameters. J. Math. Psychol. 52, 1–9. doi: 10.1016/j.jmp.2007. 09.005
Voss, A., Voss, J., and Klauer, K. C. (2010). Separating response-execution bias from decision bias: arguments for an additional parameter in Ratcliff's diffusion model. Br. J. Math. Stat. Psychol. 63, 539–555. doi: 10.1348/000711009X477581
Voss, A., Voss, J., and Lerche, V. (2015). Assessing cognitive processes with diffusion model analyses: a tutorial based on fast-dm-30. Front. Psychol. 6:336. doi: 10.3389/fpsyg.2015.00336
Wagenmakers, E.-J., Ratcliff, R., Gomez, P., and McKoon, G. (2008a). A diffusion model account of criterion shifts in the lexical decision task. J. Mem. Lang. 58, 140–159. doi: 10.1016/j.jml.2007.04.006
Wagenmakers, E.-J., van der Maas, H. L. J., Dolan, C. V., and Grasman, R. P. P. P. (2008b). EZ does it! Extensions of the EZ-diffusion model. Psychon. Bull. Rev. 15, 1229–1235. doi: 10.3758/PBR.15.6.1229
Wagenmakers, E.-J., van der Maas, H. L. J., and Grasman, R. P. P. P. (2007). An EZ-diffusion model for response time and accuracy. Psychon. Bull. Rev. 14, 3–22. doi: 10.3758/BF03194023
Wiecki, T. V., Sofer, I., and Frank, M. J. (2013). HDDM: hierarchical bayesian estimation of the drift-diffusion model in python. Front. Neuroinform. 7:14. doi: 10.3389/fninf.2013.00014
Keywords: diffusion model, fast-dm, parameter estimation, mathematical models, reaction time methods
Citation: Lerche V and Voss A (2016) Model Complexity in Diffusion Modeling: Benefits of Making the Model More Parsimonious. Front. Psychol. 7:1324. doi: 10.3389/fpsyg.2016.01324
Received: 21 January 2016; Accepted: 18 August 2016;
Published: 13 September 2016.
Edited by:
Dietmar Heinke, University of Birmingham, UKReviewed by:
KongFatt Wong-Lin, Ulster University, UKDon Van Ravenzwaaij, University of Groningen, Netherlands
Vilius Narbutas, University of Birmingham, UK
Copyright © 2016 Lerche and Voss. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Veronika Lerche, dmVyb25pa2EubGVyY2hlQHBzeWNob2xvZ2llLnVuaS1oZWlkZWxiZXJnLmRl