




94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Psychol. , 17 May 2013
Sec. Psychology of Language
Volume 4 - 2013 | https://doi.org/10.3389/fpsyg.2013.00271
This article is part of the Research Topic Spatiotemporal Dynamics of Language Processing in the Brain: Challenges to Traditional Models. View all 16 articles
The core human capacity of syntactic analysis involves a left hemisphere network involving left inferior frontal gyrus (LIFG) and posterior middle temporal gyrus (LMTG) and the anatomical connections between them. Here we use magnetoencephalography (MEG) to determine the spatio-temporal properties of syntactic computations in this network. Listeners heard spoken sentences containing a local syntactic ambiguity (e.g., “… landing planes …”), at the offset of which they heard a disambiguating verb and decided whether it was an acceptable/unacceptable continuation of the sentence. We charted the time-course of processing and resolving syntactic ambiguity by measuring MEG responses from the onset of each word in the ambiguous phrase and the disambiguating word. We used representational similarity analysis (RSA) to characterize syntactic information represented in the LIFG and left posterior middle temporal gyrus (LpMTG) over time and to investigate their relationship to each other. Testing a variety of lexico-syntactic and ambiguity models against the MEG data, our results suggest early lexico-syntactic responses in the LpMTG and later effects of ambiguity in the LIFG, pointing to a clear differentiation in the functional roles of these two regions. Our results suggest the LpMTG represents and transmits lexical information to the LIFG, which responds to and resolves the ambiguity.
Over the last 150 years substantial efforts have been made to understand the brain bases of human language. What this research has shown is that language function is instantiated in a bilateral fronto-temporal-parietal system, with different regions and combinations of regions within this system involved in different aspects of language. However, there is little agreement on the details of how different aspects of language are represented and processed within this neural system (Grodzinsky, 2000; Friederici et al., 2003; Hagoort, 2005; Tyler et al., 2011). Recent attempts to integrate these disparate findings into a coherent framework have placed renewed emphasis on the bi-hemispheric foundations of human language, taking into account data on the neurobiology of auditory processing in non-human primates and human studies on brain and language (Rauschecker and Tian, 2000; Jung-Beeman, 2005; Tyler and Marslen-Wilson, 2008; Bozic et al., 2010).
This bi-hemispheric model claims that human language is subserved by two main processing networks: one involving a bilateral temporal-parietal system which supports the semantic/pragmatic aspects of language, and a second left hemisphere (LH) fronto-temporal system which supports syntactic computations (Tyler and Marslen-Wilson, 2008). Human neuropsychological and neuroimaging evidence for this dual processing model comes from a variety of sources. For example, a number of studies have revealed a marked hemispheric asymmetry in favor of the LH in both fronto-temporal regions and in the white matter connections between them (Parker et al., 2005), providing the basis for a more functionally specialized LH system. Fronto-temporal regions in the LH have been consistently associated with syntactic analysis, although the specific frontal and temporal regions vary across studies. Moreover, recent experiments have established that the integrity of the LH fronto-temporal system, and of the connecting white matter tracts, is essential for syntactic analysis while RH fronto-temporal homologs are unable to take over this key linguistic function (Tyler et al., 2010; Papoutsi et al., 2011; Griffiths et al., 2013). In addition, the arcuate fasciculus, one of the direct fronto-temporal connecting white matter tracts, is not well-established either in non-human primates (Rilling et al., 2008) or in young children (Brauer et al., 2011), neither of which have well-developed syntactic capacities.
In contrast, mapping spoken inputs onto semantic representations and constructing semantic/pragmatic interpretations involves bilateral superior/middle temporal regions (Binder et al., 1997; Crinion et al., 2003; Scott and Wise, 2004; Tyler et al., 2010). Brain-damaged patients with extensive LH perisylvian lesions can still understand the meaning and pragmatic implications of spoken language, suggesting that these aspects of language function are subserved by a bilateral temporal system, with the RH able to assume adequate functionality in the absence of contributions from the LH (Longworth et al., 2005; Wright et al., 2011).
Under certain processing conditions these two components of the bi-hemispheric language system may be complemented by the contribution of other systems that subserve general cognitive processing demands, such as processes of selection and competition involving bilateral inferior frontal cortices (Thompson-Schill et al., 1997; Badre and Wagner, 2004; Bilenko et al., 2008; Bozic et al., 2010; Zhuang et al., 2011). Not all linguistic computations involve these general purpose systems, only those in which non-linguistic processing demands of various sorts are high.
Within this general framework an important goal is to be able to characterize the properties of the networks involved in language function. Toward this end we focus here on the computational properties of the LH fronto-temporal system, exploring the types of syntactic computations that it supports during spoken language comprehension. Many studies investigating the brain bases of syntactic analyses have implicated regions of the L inferior frontal cortex, BA 44 and/or 45, and the temporal cortex, either superior temporal gyrus or middle temporal gyrus (MTG) (Friederici et al., 2003; Snijders et al., 2009). In our own research, we have consistently found that L BA 45 and left posterior middle temporal gyrus (LpMTG) are implicated in syntactic analysis, together with the white matter tracts that directly connect them – the arcuate fasciculus and the extreme capsule fiber bundles. Perhaps the strongest evidence for the essential contribution of L BA45 and LpMTG to syntactic processing comes from studies combining functional and structural neuroimaging data with measures of syntactic performance in chronic stroke patients with LH damage. These enable us to draw strong inferences about the brain regions that are essential for the performance of a given neurocognitive process (Chatterjee, 2005; Fellows et al., 2005; Price et al., 2006). In our studies with patients, we find that syntactic deficits result from damage to either the left inferior frontal gyrus (LIFG; primarily BA 45), LpMTG (Tyler et al., 2010, 2011) or to disrupted functional or anatomical connectivity between them (Papoutsi et al., 2011; Rolheiser et al., 2011; Griffiths et al., 2013), establishing the importance of interactivity between LIFG and LpMTG during syntactic analysis. However, little is known about the types of syntactic computations subserved by the LIFG and LpMTG, how they are distributed over time across these regions, the relationship between them, or to what extent LIFG and LMTG play different roles in the processing of syntax.
Our starting point for investigating the neural computations involved in syntactic analysis is the claim that the phonological properties of spoken words activate their semantic and syntactic properties, which are assessed and integrated into the existing contextual representation (Marslen-Wilson and Tyler, 1980). This claim is supported by behavioral studies showing the early activation of different lexical properties and their on-line integration into the developing sentential representation (Marslen-Wilson et al., 1988; Zwitserlood, 1989). Neural signatures of lexical activation were initially revealed in ERP studies that found different types of neural response elicited by a variety of syntactic manipulations. The most robust finding is the P600, a positive response to syntactic manipulations at approximately 600 ms triggered by ungrammatical or non-preferred continuations of sentence fragments (Hagoort et al., 1993; Osterhout and Holcomb, 1993), and by ambiguity resolution (Kaan and Swaab, 2003). Other effects include an early left-anterior negativity (ELAN) after 150–200 ms (Hahne and Friederici, 1999; Friederici and Alter, 2004) elicited by violations of word category (Lau et al., 2006), and a subsequent (300–500 ms) left-anterior negative effect in response to morphosyntactic violations (Neville et al., 1991). However, since EEG has limited spatial resolution, these effects have only been broadly differentiated across the scalp.
In the present study we use magnetoencephalography (MEG) to ask how the activation of syntactic information and its integration into the developing sentential representation is distributed over time across the left fronto-temporal language system. We use syntactic ambiguity, rather than anomalies or violations, because syntactic ambiguity is an aspect of language processing that occurs naturally and frequently and does not involve ungrammaticality, in case ungrammaticality and violations induce additional processes not typically observed in normal on-line comprehension. We present listeners with spoken phrases which can be locally syntactically ambiguous (referred to here as the central phrase; e.g., “juggling knives”), heard in a sentential context (“In the circus, juggling knives ….”). The phrases are syntactically ambiguous between different syntactic roles; they can either be interpreted as a noun-phrase which functions as the subject of the embedded clause, or as a verb phrase in which the verb “juggling” functions as a gerund and itself is the subject of the embedded sentence. This ambiguity can only be resolved when the listener hears the word that immediately follows the ambiguous phrase, which in this study is always a singular or plural form of the verb “to be,” and which is consistent with one interpretation or the other (e.g., “juggling knives is,” or “juggling knives are”). Listeners hear the sentence (spoken in a female voice) up to and including the central phrase, and after the offset of the phrase they hear a continuation word (“is”/“are”) spoken in a male voice and indicate whether the word forms a good or bad continuation of the sentence fragment. Note that both continuations are fully grammatical although one is always preferred over the other, as established in pre-tests (see below). Behavioral studies have shown that listeners’ sensitivity to the presence of this type of syntactic ambiguity is reflected in slower responses to the disambiguating word when it follows an ambiguous phrase compared with matched unambiguous phrases (Tyler and Marslen-Wilson, 1977; Tyler et al., 2011).
We chart the time-course of the activation and integration of syntactic information by measuring MEG responses at three time-points: from the onset of the central phrase (e.g., “juggling”), the onset of the second word in the phrase (“knives”) and the onset of the disambiguating word (Figure 1). Moreover, by focusing on the time-varying representations within the LH fronto-temporal language system, we can determine how neural computations in the frontal and temporal cortices change over time and investigate their relationship to each other as ambiguity is encountered and resolved.
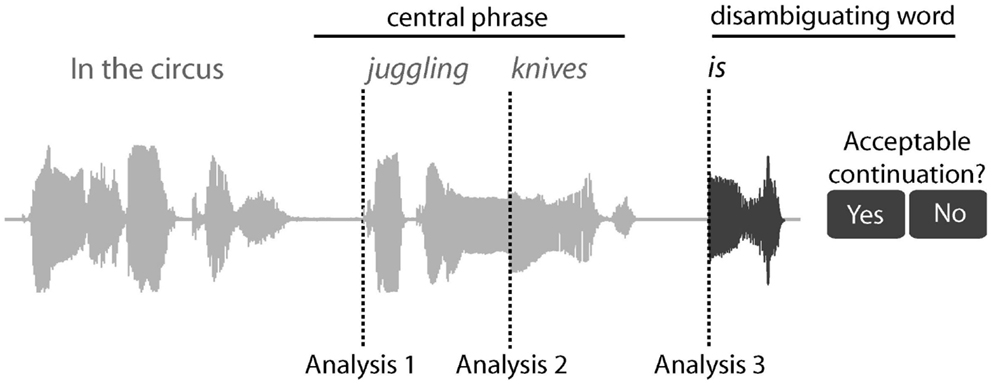
Figure 1. Sentence structure, task, and different analysis for the RSA analysis. An example sentence is shown, along with its sound wave, highlighting the central phrase and disambiguating word. After the disambiguating word, participants pressed one of two buttons to indicate whether the disambiguating word was an acceptable continuation for the sentence or not. The RSA analysis was conducted from three positions across the sentence; Analysis 1 from the onset of the central phrase, analysis 2 from the onset of the second word in the phrase, and analysis 3 from the onset of the disambiguating word.
Implicit in most studies of syntactic ambiguity is the assumption that the activation of lexico-syntactic information, and its integration into the upcoming speech, is involved in processing syntactic ambiguity. Here we directly test these assumptions by using a specific form of multivariate pattern analysis (MVPA), representational similarity analysis (RSA, Kriegeskorte et al., 2008). RSA is founded on analyzing the similarity of brain activation patterns across different items, which serves to characterize the information represented in specific brain regions (Kriegeskorte et al., 2008), but can also uncover how this information changes over time (Su et al., 2012). We construct theoretically motivated models of similarity across the stimuli, based on lexico-semantic, ambiguity activation and ambiguity resolution differences between the stimuli, which we compare against the similarity of activation based on spatio-temporal patterns. This allows us to characterize the types of syntactic computations which occur within the fronto-temporal language network and how they change over time. We focus on two regions of interest (ROIs: LIFG (BA 45/47) and LpMTG) and their RH homologs, functionally defined from a previous fMRI study in which listeners heard a set of stimuli all of which were also included in the present MEG study (Tyler et al., 2011).
Thirteen healthy participants took part in the study, with an average age of 23 years (range 19–29 years). All were right-handed with normal hearing. All participants gave informed consent and the study was approved by the Cambridge Psychology Research Ethics Committee.
The stimuli were 175 spoken sentences, each containing a central phrase of the form “<verb> + ing <noun> + s” (e.g., “juggling knives”; see Table A1 in Appendix). One-third of the sentences contained central phrases that were syntactically unambiguous (e.g., “crying babies”) while the remaining two-thirds consisted of pairs of sentences featuring the two possible readings of syntactically ambiguous phrases (e.g., “In the circus, juggling knives is less dangerous than eating fire” and “In the circus, juggling knives are less sharp than people think”). In all cases, the central phrase was either followed by “is” or “are.” In addition 23 spoken sentences where the central phrase was followed by “was” or “were” were presented as filler items but are not included in the MEG analysis. The sentences were spoken by a female native speaker of British English and recorded in a soundproof booth in a random order, and were then truncated at the end of the central phrase. In a pretest, 23 participants (native British English speakers who did not take part in the main experiment) listened to the sentence fragments and wrote down plausible sentence completions. The proportion of completions consistent with “is” and “are” interpretations was calculated, giving a dominance score for each continuation. For the ambiguous item pairs, one continuation was dominant (i.e., had the higher dominance score) and the other was subordinate, giving 58 dominant and 60 subordinate items. The 57 unambiguous items always had a dominance score of 100% (i.e., the continuation responses were always consistent with the single possible interpretation). The mean [standard deviation (SD)] dominance score was 80% (13%) for the dominant items and 20% (13%) for the subordinate items. The three conditions (subordinate, dominant and unambiguous) were matched on lemma frequency of the two words in the central phrase and on the duration of the sentence fragment.
The participants were seated in a magnetically shielded room (IMEDCO GMBH, Switzerland) positioned under a MEG scanner and fitted with MEG-compatible earphones. Speech was delivered binaurally using ER3A insert earphones (Etymotic Research, Inc., IL, USA) through a pair of semi-flexible plastic tubes fitted with rubber ear inserts. Delays in sound delivery due to tube length and the computer’s sound card were 36 ± 1 ms jitter. This systematic delay was corrected for in the analysis. In the scanner, the sentences were presented in a pseudorandom order with the order of the dominant and subordinate versions of the ambiguous phrases counterbalanced across participants. Each trial consisted of the sentence fragment, followed by a 200 ms silent interval, and then the sentence’s disambiguating word (“is” or “are”) spoken by a male native speaker of British English. One “is” and “are” spoken token was used for all items. Participants were instructed to press a button labeled “yes” with the index finger of their right hand if the disambiguating word was an acceptable continuation of the sentence and a button labeled “no” with the middle finger of their right hand if the disambiguating word was unacceptable. The interval between stimuli was randomized between 1500 and 2500 ms.
Participants were instructed to refrain from blinking or moving their eyes during the presentation of the sentences. To facilitate this, the participants were asked to keep their eyes fixated on a small cross on a back-projected screen positioned 1 m in front of their visual field. The sentences were divided equally into six blocks of 2–3 min duration. Between each block was a short 10–20 s break to allow the participant to blink. The next block was presented when the participant indicated they were ready to continue.
Continuous MEG data were recorded using a whole-head 306 channel (102 magnetometers, 204 planar gradiometers). Vector-view system (Elekta Neuromag, Helsinki, Finland) located at the MRC Cognition and Brain Sciences Unit, Cambridge, UK. Eye movements and blinks were monitored with electro-oculogram (EOG) electrodes placed around the eyes, and five Head Position Indicator (HPI) coils were used to record the head position (every 200 ms) within the MEG helmet. Electro-cardiogram (ECG) electrodes were placed on the right shoulder blade and left torso to record cardiac muscular effects. The participants’ head shape was digitally recorded using a 3D digitizer (Fastrak Polhemus Inc., Colchester, VA, USA) using 70–100 points, along with the positions of the EOG electrodes, HPI coils, and fiducial points (nasion, left and right periauricular). MEG signals were recorded at a sampling rate of 2000 Hz and between 0.01 and 667 Hz. To facilitate source reconstruction, 1 mm × 1 mm × 1 mm T1-weighted MPRAGE scans were acquired during a separate session with a Siemens 3T Tim Trio scanner (Siemens Medical Solutions, Camberley, UK) located at the MRC Cognition and Brain Sciences Unit, Cambridge, UK.
Initial processing of the raw data used MaxFilter version 2.2 (Elektra-Neuromag) to detect static bad channels that were subsequently reconstructed along with any bad channels noted during acquisition or from visual inspection of the raw data afterward (between 4 and 15 bad channels). The temporal extension of the signal-space separation technique (SSS; Taulu et al., 2005) was applied to the data every 4 s in order to segregate the signals originating from within the participants’ head from those generated by external sources of noise. Head movement compensation (using data from the HPI coils) was performed, and the head position was transformed into a common head position to facilitate group sensor analyses.
The remaining processing used SPM8 (Wellcome Institute of Imaging Neuroscience, London, UK). The MEG data were down-sampled to 500 Hz and low pass filtered at 40 Hz using a bi-directional 5th order Butterworth digital filter. The continuous data were then divided into epochs at each of the three trigger points (Figure 1): first, from the onset of the central phrase (from −100 to 1000 ms as the mean length of the central phrase is 1070 ms); second, the onset of the second word in the central phrase (from −100 to 500 ms as the mean length of the second word is 566 ms); and third, the onset of the disambiguating word (from −100 to 800 ms, based on the latencies of behavioral responses). The baseline was defined as the average response between −100 and 0 ms relative to stimulus onset. The average response from the baseline period (−100 to 0 ms) was subtracted from all data points in the epoch. Using a baseline immediately prior to each epoch should help normalize effects accumulating before the onset of each word, so that each analysis is optimized to identify effects brought about by the epoch (or the offset of the previous word).
Automated artifact detection and visual inspection was used to exclude bad epochs. Epochs were excluded if the data were flat (zeroes) or if unusual steps were detected. With the remaining epochs, independent components analysis was used to remove artifactual signals generated by the eye movements or cardiac signals present in the MEG data by removing components that showed significant correlations with the vertical and horizontal EOG and ECG electrodes. A bootstrap permutation approach was used to determine the significance of the correlations.
The data were prepared for MEG ROI analysis (see ROI definitions) by constructing a source model over the cortical mesh surface for each participant. Structural MRI images were segmented and transformed to an MNI template brain using SPM8. Using the inverse transformation, individual scalp and cortical meshes were then constructed by warping canonical meshes of the MNI template to the participant’s MRI space. Co-registration between the MEG sensor coordinates and the participant’s MRI coordinates was achieved by aligning the digitized head and fiducial points to the outer scalp mesh. Source reconstruction used a cortically constrained minimum norm model in SPM8 with a single shell conductor model. The inversion was computed over the whole epoch and all models accounted for more than 95% of variance. From the resulting source models, the moment at any mesh point (vertex) may be extracted as a time-course over the epoch. We extracted the time-course of each vertex within each of our ROIs (see ROI definitions) that were then used for the RSA analysis.
Representational similarity analysis involves testing models of the information content of the stimuli by comparing the dissimilarity structure of the stimuli predicted by those models to the dissimilarity structure present in neural activation patterns. We constructed a number of representational dissimilarity matrices (RDMs), sensitive to the different kinds of information that we hypothesize is important at different points in the activation and resolution of syntactic ambiguity.
The first of these models (“disambiguating wordform”) is sensitive only to the identity of the disambiguating word; two stimuli are modeled as similar if and only if the same disambiguating wordform (“is” or “are”) was used with them. As disambiguating word identity was counterbalanced over the experimental conditions, this RDM is orthogonal to the three conditions of subordinate, dominant, and unambiguous (Figure 2A). This model distinguishes the acoustically different disambiguation words and was primarily included as a check on the sensitivity of the analysis method, since this RDM should correlate with similarity of activation patterns in auditory cortex. Such acoustic models were not generated for the two central phrase words, because each trial has unique acoustic information during these epochs.
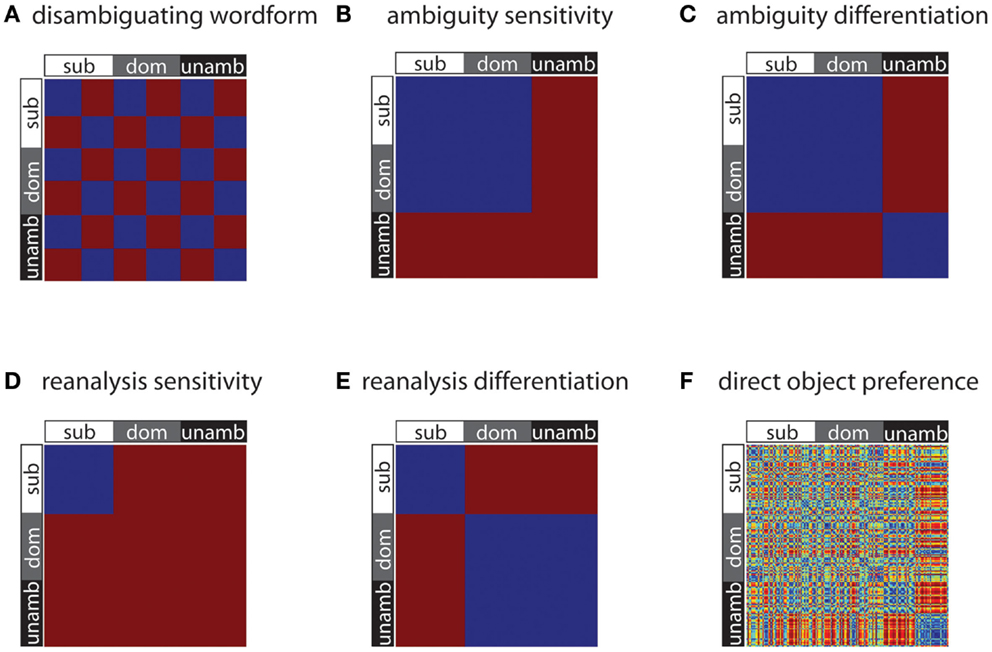
Figure 2. Model RDMs used in the analyses. Each RDM is a 198 × 198 matrix, with each entry being either a 0 (meaning no dissimilarity, depicted as blue) or 1 (meaning maximal dissimilarity, depicted as red). These RDMs test for differences in representational similarity across stimuli – for wordform (A), syntactic ambiguity (B, C), and syntactic reanalysis (D, E). Note that direct object preference (F) is a continuous-valued measure, and so dissimilarities based on object preference take on a range of values, from 0 to 1.
The other RDMs presented in Figure 2 test for differences due to syntactic processing, such as effects due to competition between parse possibilities and effects due to syntactic reanalysis when the disambiguating verb is inconsistent with the preferred interpretation of the central phrase. The ambiguity sensitivity RDM (Figure 2B) tests whether ambiguous items, irrespective of the dominance of the subsequent disambiguating word, give rise to similar activation patterns. Common to the ambiguous items is that they are associated with multiple possible syntactic analyses and the potential competition between them, and this model assumes that this processing results in a specific pattern of neural activity for the ambiguous items. Since the unambiguous items are not associated with multiple meanings, the neural patterns for these items are hypothesized to be uncorrelated, and so are modeled as dissimilar in this RDM.
The ambiguity differentiation RDM is the same as the ambiguity sensitivity RDM, except that pairs of unambiguous items are also modeled as similar to each other (Figure 2C). Note that the ambiguity differentiation RDM tests for differences between the activation patterns for ambiguous and unambiguous items, whereas the ambiguity sensitivity RDM test for specific patterns of activation associated with the processing of ambiguity (Figure 3). Furthermore, presence or absence of ambiguity is a property of the central phrase itself, independent of the identity of the subsequent disambiguating word, and for this reason subordinate and dominant items are modeled in the same way for this pair of RDMs.
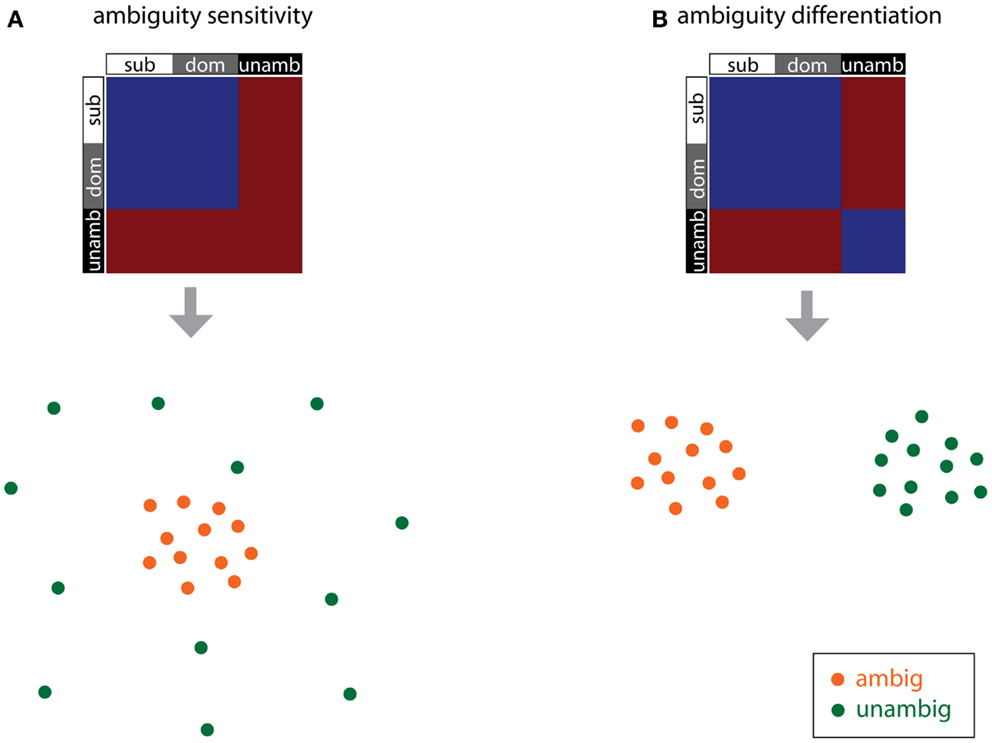
Figure 3. RDMs and corresponding cartoon multidimensional scaling plots for the ambiguity sensitivity and ambiguity differentiation models. (A) The ambiguity sensitivity RDM tests the hypothesis that a distinct pattern of neural activity, associated with the processing of multiple syntactic parses, arises for the ambiguous items (i.e., the subordinate and dominant conditions). This pattern of neural activity does not arise for unambiguous items and so unambiguous items have uncorrelated activation patterns (dissimilar to each other and also dissimilar to the ambiguous items). (B) The ambiguity differentiation RDM tests the hypothesis that ambiguous items and unambiguous items give rise to different distinct patterns of activation: ambiguous items are similar to each other, unambiguous items are similar to each other, and ambiguous and unambiguous items differ.
The next pair of models test for differences due to syntactic reanalysis. The reanalysis sensitivity RDM tests whether the subordinate items (for which the central phrase is followed by a disambiguating verb consistent with the less dominant interpretation), give rise to similar patterns of activation (Figure 2D). For the subordinate items, the competition between multiple possible syntactic readings is resolved in favor of the less preferred reading, and so these items require a process of revision or reanalysis in order to correctly integrate the disambiguating wordform with the preceding sentence fragment. This model assumes that this process of reanalysis and integration gives rise to a specific pattern of neural activation for these items. The reanalysis differentiation RDM is the same as the reanalysis sensitivity RDM, except that items which do not require reanalysis (i.e., dominant and unambiguous) are modeled as being similar to each other; this model thus differentiates items requiring reanalysis from those which do not (Figure 2E).
According to lexicalist accounts of sentence processing, lexico-syntactic knowledge associated with each word guides activation of candidate parses and should therefore be influential in both the creation of local ambiguities and in the ambiguity resolution process (Tyler and Marslen-Wilson, 1977; Marslen-Wilson et al., 1988; MacDonald et al., 1994). For example, verb subcategorization frame (SCF) preferences may affect sentence processing by placing constraints on how potential arguments are incorporated into the emerging representation. Furthermore, it has often been hypothesized that such knowledge reflects statistical data on words’ usage in language (Merlo, 1994; Garnsey et al., 1997; Lapata et al., 2001). The final RDM we included in our analyses was designed to be sensitive to lexico-syntactic properties of the verb used in the first word of the central phrase (e.g., “juggle” in “juggling knives”) because we hypothesized that verbs with different lexico-syntactic properties would give rise to different patterns of activation. In particular, we hypothesized that verb subcategorization behavior would be one factor influencing processing as the central phrase is being heard. For verbs with a high probability of occurrence with noun-phrase direct object complements (e.g., “mark”) we predicted a preference to interpret the first word of the central phrase as a gerund, because in such cases the following noun is likely to function as the verb’s theme (e.g., “marking essays”), whereas for verbs with a low probability of occurrence with direct object complements there would be a stronger preference for adjectival readings (e.g., “yawning audiences”). Given these considerations, we predicted that verbs with different likelihoods of taking direct object complements should show different patterns of activation.
To obtain SCF frequency distributions for each verb we used VALEX, an automatically acquired subcategorization lexicon for 6,397 English verbs that is derived from large, cross domain corpora (Korhonen et al., 2006). Earlier studies have typically estimated lexico-syntactic information using behavioral pre-tests; however, the extent to which such approaches truly reflect statistical information in the language is unclear. VALEX includes statistical information about the relative frequency of occurrence of each of 163 possible SCF types with each verb (Figure 4). For each verb and SCF pair, the lexicon also gives the syntax of the arguments (for example, subject or complement), as well as the part-of-speech tags and lexical tokens found for those arguments for all instances of the verb in the corpus.
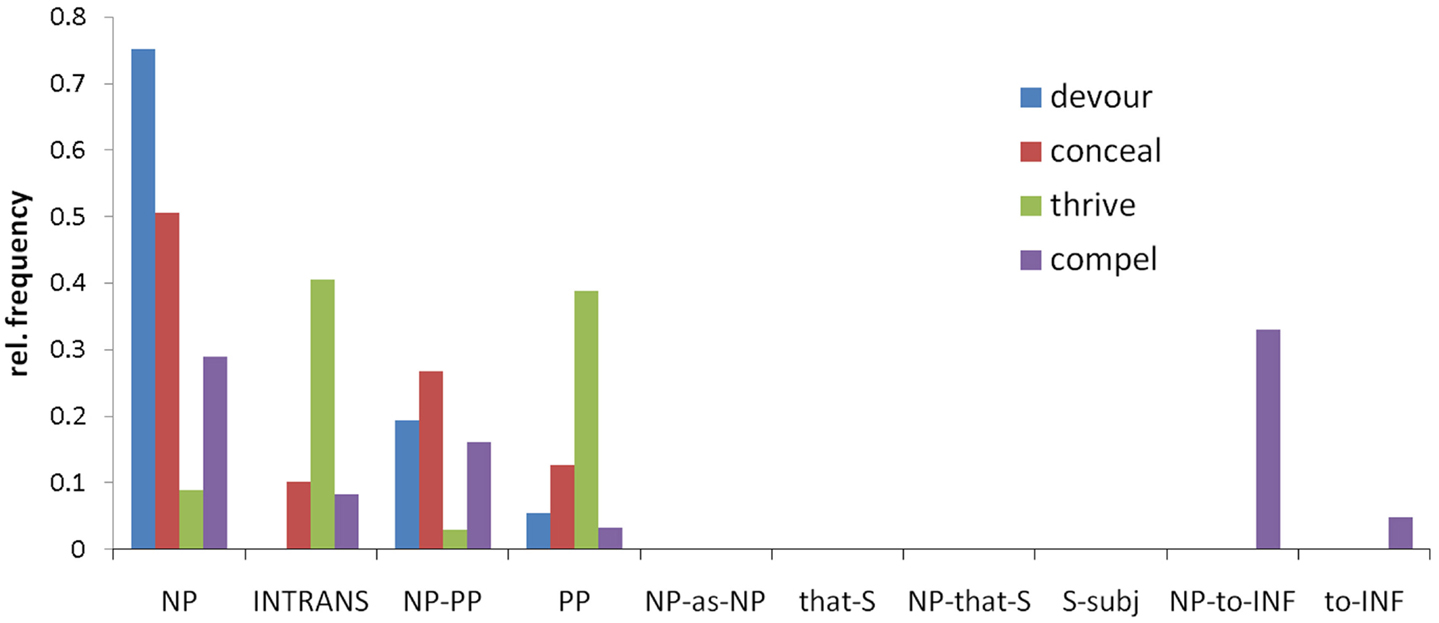
Figure 4. The relative frequency distributions for four example verbs over the 10 most common subcategorization frames, which are labeled by a description of their argument structure. Different verbs have different distributions, illustrating the differences in their subcategorization frame behavior. NP, noun-phrase complement (e.g., “he devoured the meal”); INTRANS, intransitive (e.g., “he thrived”); PP, prepositional phrase complement (e.g., “he thrived in school”); S, sentential complement; INF, verb infinitive.
The 163 SCFs were partitioned into those that specify NP direct object complements and those which do not, and the total relative frequency of frames specifying NP direct object complements for each verb was calculated (Table 1). Given our prediction that verbs with a high probability of occurrence with direct object complements would show different patterns to those with low probability of occurrence with direct object complements, we calculated dissimilarity between pairs of stimuli as the absolute difference in their direct object probability scores (Figure 2F). Note that this RDM only incorporates information about the verb’s lexico-syntactic behavior; in particular it does not contain information about the noun that follows it, nor does it contain information about the subsequent disambiguating word.
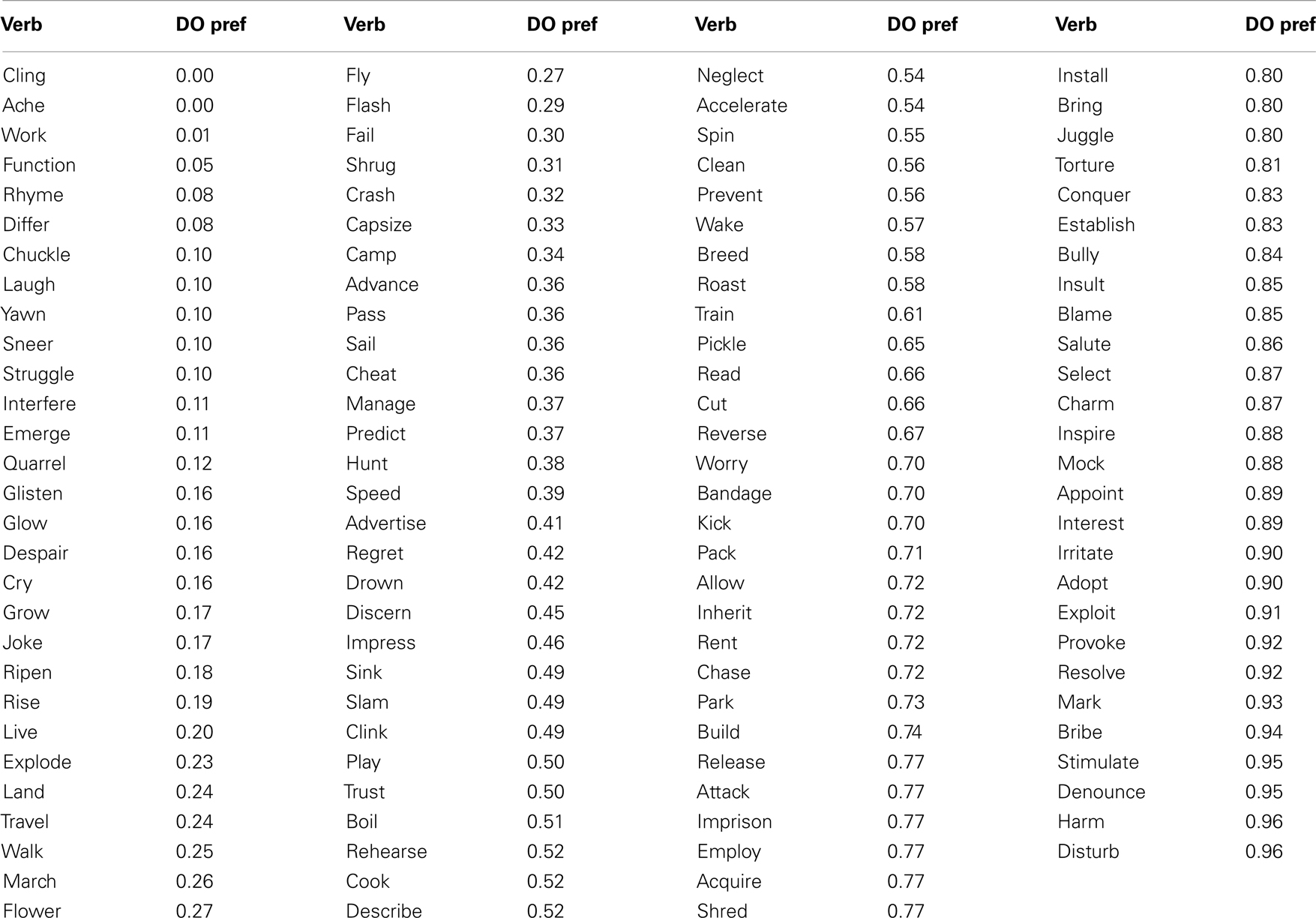
Table 1. Direct object preference scores (“DO pref”), calculated from VALEX, for each of the verbs used in the study.
Our ROIs for the MEG analysis were functionally defined from a previous fMRI study in which 15 independent participants (aged 19–24 years) heard the stimuli included in the MEG study. Unlike in the present study, the participants in the fMRI study merely attentively listened to the sentences instead of performing a task, and they heard the entire sentence without disruption (see Tyler et al., 2011 for scanning details). Consistent with previous research, fMRI analysis showed increased activity in left BA45/47 and left posterior MTG during subordinate compared to dominant sentences (voxelwise p < 0.01, cluster p < 0.05; Figure 5A), In order to test for potential bilateral contributions to syntactic analysis we also created right hemisphere homologs of these LH ROIs Figure 5B. To provide a baseline for testing the efficacy of the ROI RDM approach, we also included anatomically defined ROIs of bilateral Heschl’s gyrus (HG) which we predicted would show sensitivity effects for the disambiguating wordform RDM.
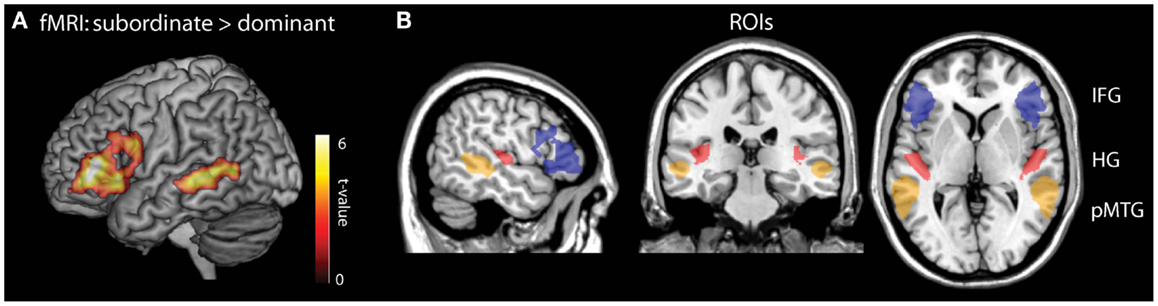
Figure 5. Regions of interest (ROIs) used in the MEG RSA analysis. (A) Functional ROIs were obtained from an fMRI contrast of subordinate > dominant sentences. (B) The entire complement of ROIs used included the fMRI defined LIFG (blue) and LpMTG (orange) with the anatomically defined Heschl’s gyrus (red). Each region also has a right hemisphere homolog.
In the RSA, the goal is to chart the time-course of the different kinds of processing involved in local ambiguity resolution by testing for effects of these RDMs during the three different epochs. The onsets of these three epochs are defined with respect to three key trigger points within the stimuli where different kinds of linguistic information are available. For the earliest epoch (the first word in the central phrase), we predict effects associated with the activation of verb lexico-syntactic knowledge, but only after the lexical identity of the word has been established (e.g., after the word’s recognition point; Marslen-Wilson, 1987) or during the processing of the second word in the central phrase. Given the lexical nature of the direct object preference measure, and on the assumption that posterior middle temporal regions represent lexical-level information relevant to processing verbs in context (Hickok and Poeppel, 2007; Tyler et al., 2008; Rodd et al., 2010), these direct object preference effects are most likely to be seen in LpMTG.
In contrast, the ambiguity RDMs should not show effects during processing of the first word in the central phrase, because the ambiguity RDMs are sensitive to the ambiguity of the phrase, not the ambiguity of the first word. In fact, during the first epoch, both adjectival and gerundive usages are still possible for all stimuli, including those in the unambiguous condition. For example, “crying babies” is one of our unambiguous phrases, requiring an adjectival reading, but, at the point “crying” is heard, both adjectival and gerundive continuations are still possible (for example, the sentence may continue “crying loudly is …”). The distinctions captured by the ambiguity differentiation and ambiguity sensitivity RDMs do not exist during the first epoch. This is not to say that there are no differences between items at this point that may affect processing, but such differences must necessarily be properties of the first word alone. The direct object preference measure is one example of such a property.
During the second epoch, information about the second word in the central phrase becomes available. Once the second word has been recognized, the stimuli are distinguished by whether or not the central phrase is ambiguous, and so the detection of an ambiguity, or the concurrent access of multiple representations associated with the ambiguity, should disassociate neural activation patterns for the ambiguous items (subordinate and dominant conditions) from the activation patterns for the unambiguous items. We therefore predict effects of the two ambiguity RDMs during the second epoch. As mentioned above, we also predict continued lexical effects associated with the direct object preference RDM, as the preceding verb’s probability of taking a direct object influences the likelihood of incorporating the noun as the verb’s theme or agent. Furthermore, as the activation of different possibilities for the verbs SCF behavior are a key factor causing local ambiguity, we hypothesize that effects for the direct object preference RDM should precede effects associated with the ambiguity models.
The first two epochs were designed so that they did not overlap with the onset of the disambiguating word, and so for these epochs there is no information about how the ambiguity is ultimately resolved. We therefore do not test RDMs that are sensitive to the identity of the disambiguating wordform in the analyses for the first two epochs (i.e., we excluded the disambiguating wordform RDM and the two reanalysis RDMs).
The third epoch begins at the onset of the disambiguating word, and is designed to include the resolution of the local ambiguity. As the disambiguating words were either “is” or “are,” the disambiguating wordform RDM represents whether these words are acoustically the same or different, and we thus predict that this RDM will correlate most strongly with activation patterns in auditory cortex at early time-points in the third epoch. We also predict early effects of ambiguity during this epoch, as competition between the multiple candidate representations that arise from ambiguous central phrases is processed in inferior frontal cortex. We anticipate that later processes of reanalysis and integration will depend on LIFG (Hagoort, 2005). Whether the LpMTG is also involved in ambiguity resolution and reanalysis remains to be determined. Although the LpMTG co-activates with the LIFG in fMRI studies of syntactic ambiguity, fMRI does not enable the various processes involved in activation, selection, and reanalysis to be separated out and therefore there are no clear predictions from previous studies concerning the role of the LpMTG in ambiguity resolution.
These six theoretically motivated RDMs were statistically compared to RDMs derived from the source localized ROI data. For each ROI we extracted the time-course of each vertex for each trial that was used to construct the MEG-based RDMs.
Here we used a sliding time-window approach, where for one time-point, the MEG data for all vertices and all time-points ±50 ms are concatenated into a single vector (length = vertices × time-points). We then calculated the dissimilarity between all item pairs using 1 – Pearson’s correlation as a distance measure. Therefore, each MEG-based RDM incorporates data from all vertices without averaging across them and reflects dissimilarity based on spatio-temporal patterns. This process was then repeated for all time-points resulting in one RDM per time-point for each ROI. The MEG-based RDMs were then correlated with the relevant theoretical model RDMs using Spearman’s rank correlation to obtain a similarity time-course reflecting the relatedness of the two dissimilarity matrices. A single time-course was obtained per model RDM per participant, at each of the three trigger points. To evaluate whether each model RDM was significantly reflected in the MEG data across the group, a one-sample t-test was conducted at each point in time (alpha = 0.05), and corrected for multiple comparisons using cluster-based permutation testing (Maris and Oostenveld, 2007). We only report effects which are cluster-level significant at 0.05 unless noted.
We analyzed participants’ rejection rates – i.e., the frequency with which they rejected the disambiguating word as an acceptable continuation of the sentence fragment. The rejection rates were analyzed using a repeated measures ANOVA with three conditions (subordinate, dominant, and unambiguous). There was a main effect of condition [F(2, 24) = 24.17; p < 0.001], with the largest proportion of unacceptable decisions for the subordinate (34%), fewer for dominant (13%), and the least for the unambiguous condition (6%). The RTs showed a similar pattern, with a main effect of condition [F(2, 24) = 8.72; p = 001] and judgment latencies to the subordinate continuations (863 ms) being longer than for the dominant continuations (820 ms) which in turn were longer than the unambiguous sentences (769 ms). These results suggest that participants initially base their analysis on the preferred interpretation of the ambiguous phrase (the dominant reading) which then has to be revised when they encounter a disambiguating word which is inconsistent with that interpretation. This requirement to reinterpret leads to many items being judged as unacceptable and slower decision latencies. Performance in this task provides a measure of participants’ sensitivity to syntactic information during the processing of a spoken sentence (Tyler et al., 2011).
In order to test the time-course of activation and integration of syntactic information in the frontal-temporal language network, we performed an RSA analysis on the MEG data at three positions within the spoken sentence (Figure 1). By comparing the similarity of MEG activity patterns to those predicted by different properties of the sentence, we can uncover the kinds of processes different regions are engaged in and how they evolve over time.
Our initial RSA analyses aimed to determine the kinds of information processed within the fronto-temporal language network while participants listened to the central phrase section of the sentence. Our first analysis tested for effects of the activation of lexico-syntactic knowledge linked to the first verb in the central phrase, and for ambiguity effects that may arise during the central phrase, however our RSA analysis failed to find significant effects for any of these model RDMs. This may be because the ambiguity in the phrase is more closely linked to the second word of the phrase, at which point the central phrase becomes ambiguous (e.g., when planes is heard in the phrase landing planes) or unambiguous (e.g., when babies is heard in the phrase crying babies). Effects relating to the activation of lexico-syntactic knowledge cannot be activated immediately upon the onset of the first word, but become available gradually over time as sufficient acoustic information accrues and the word can be recognized (Marslen-Wilson, 1987). Therefore, they may not be detectable until later in the word.
From the onset of the second word in the central phrase, our RSA analysis revealed two marginally significant effects in the LpMTG (Table 2; Figure 6). We found a similarity effect in the LpMTG that matched the direct object preference RDM from the onset of the second word to 118 ms post-onset. The rapid nature of this effect means it is likely to be a reflection of similarity patterns representing the activation of the first word’s lexico-syntactic properties. Although these effects are only marginally significant we report them here and include them in our on interpretation of the results because we believe them to be reliable and interpretable in relation to current models of language processing.
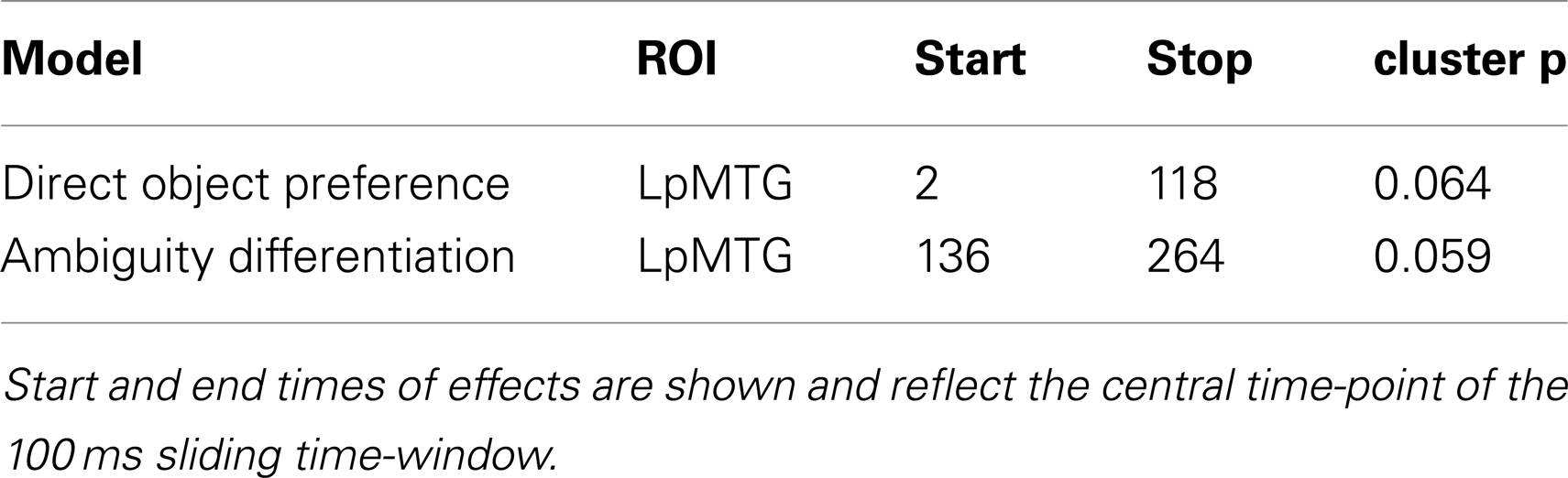
Table 2. RSA results from the onset of the second word in the central phrase.
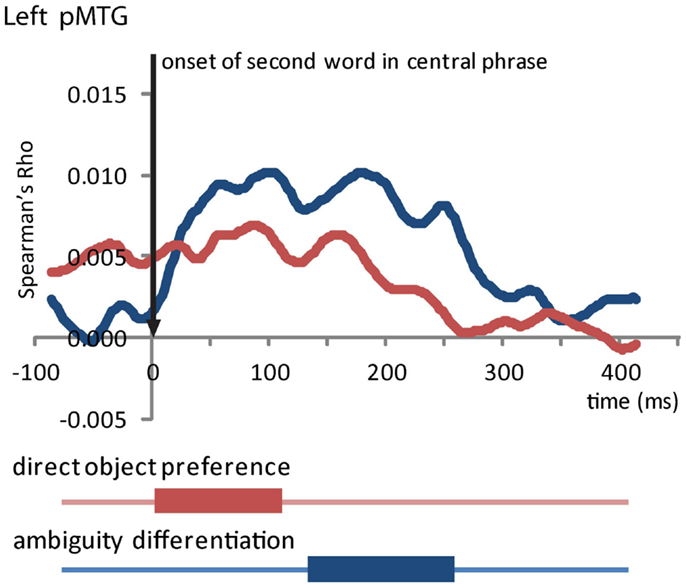
Figure 6. Effects in the LpMTG from the onset of the second word in the central phrase. Plot shows the time-course of similarity between the model RDM and the LpMTG RDMs. Time periods of significant similarity are shown below plot by solid bars.
In addition, we also found an effect in the LpMTG of the ambiguity differentiation RDM from 136 to 264 ms after the onset of the second word. There were no effects in the LIFG (no clusters identified) or the RH (RIFG p’s > 0.15, RpMTG no clusters identified, RHG p’s > 0.14) and no further effects in LpMTG (all p’s > 0.2). This analysis shows that during the central phrase, the LpMTG activation patterns shift from representing the lexico-syntactic information about the first word in the central phrase to reflecting the degree of ambiguity in the central phrase as more of the phrase is heard. The accumulated ambiguity contained in the central phrase can only be resolved once the subsequent disambiguating word form is heard.
In order to determine the kinds of information processed when participants hear the disambiguating word which initiates the resolution of the preceding ambiguity, we performed RSA time-course analysis from the onset of the disambiguating word by testing model RDMs capturing ambiguity and reanalysis (Table 3).
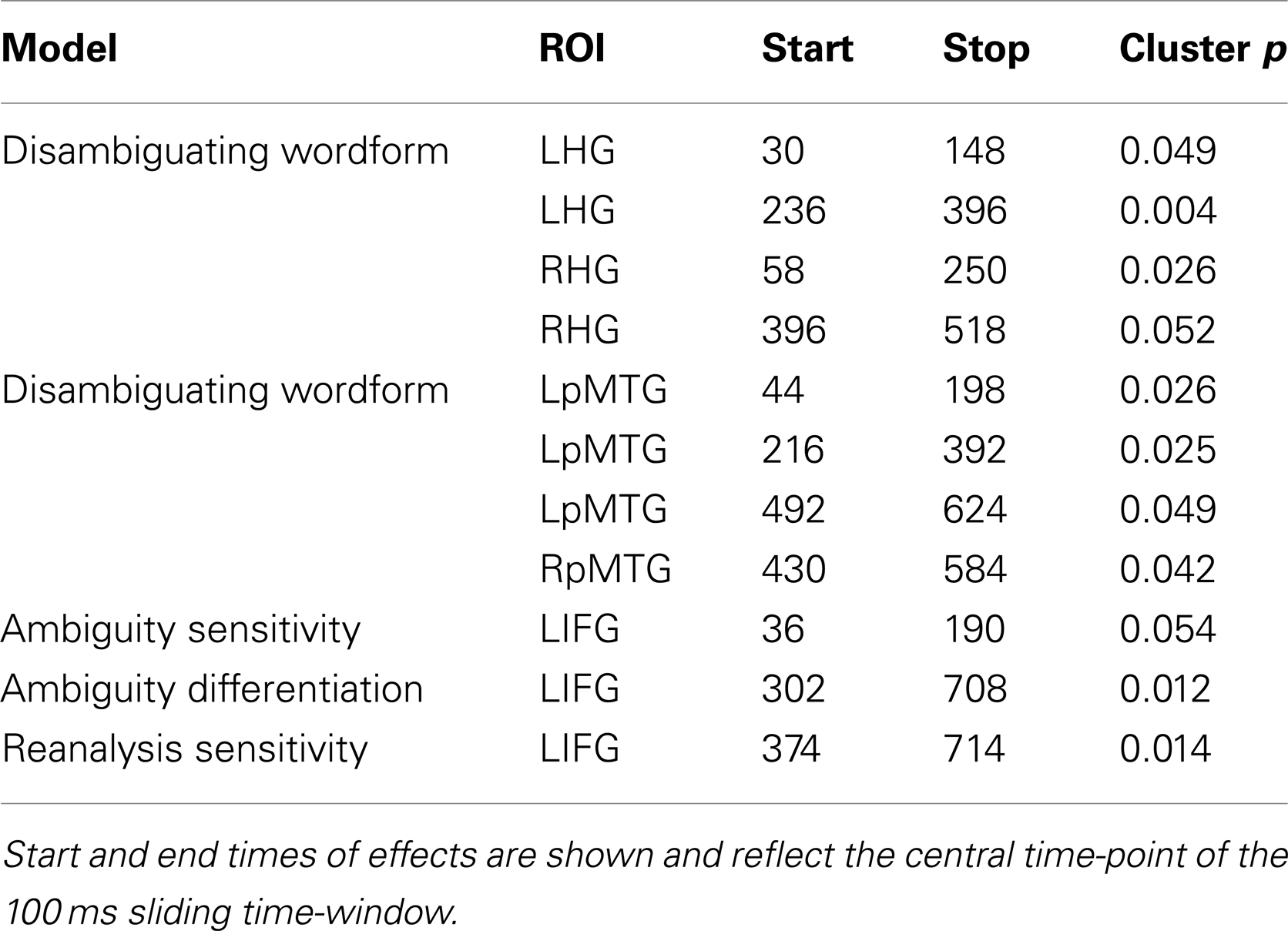
Table 3. RSA results from the onset of the disambiguating word.
We first tested whether activity patterns in primary auditory cortex follow the similarity structure defined by the acoustic input (i.e., the disambiguating wordform). We found early similarity effects in bilateral HG that reflected the similarity structure predicted by the disambiguating wordform (i.e., “is” or “are”; Figure 7A, left), showing that responses in primary auditory regions reflect the auditory input, peaking around 94 ms, and showing a recurring pattern over time. A similar early effect was seen in LpMTG peaking at 106 ms. Subsequent peaks in the RH occurred approximately 200 ms later than those in the LH (Figure 7A, right). There were no further effects in either HG or pMTG and no further effects for the disambiguating wordform model [LHG p’s > 0.26, RHG p’s > 0.33, LpMTG p’s > 0.45, RpMTG p’s > 0.19, wordform model p’s > 0.13 (LIFG)].
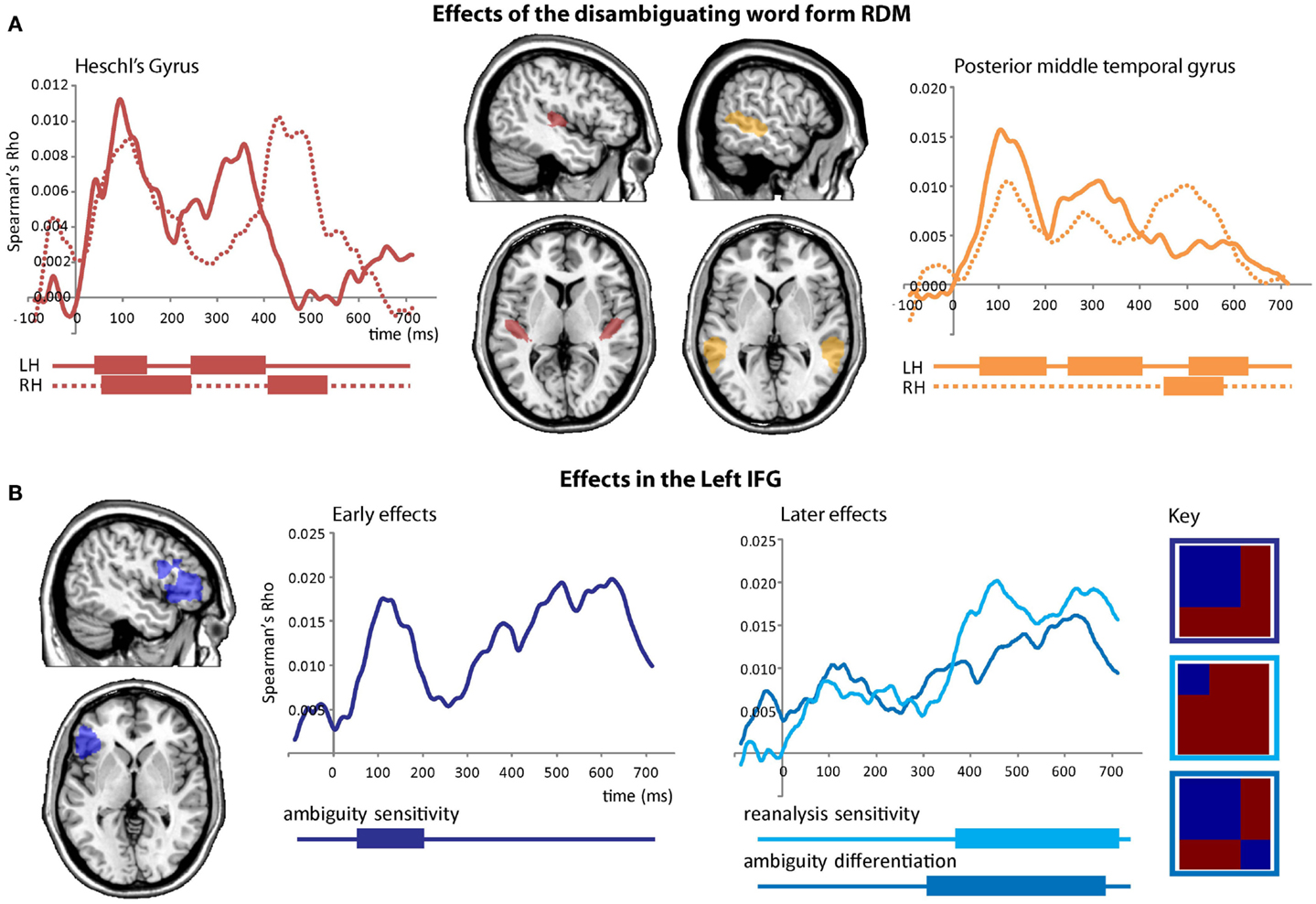
Figure 7. Effects from the onset of the disambiguating word. (A) Effects of the disambiguating word form RDM captures similarity according to the acoustic input which is found in bilateral HG and pMTG. Plots show time-course of similarity between the disambiguating word form RDM and HG RDMs (red), and pMTG RDMs (orange). Significant effects are shown below plots by solid bars. (B) Early and later effects in the left IFG for ambiguity RDMS and the syntactic reanalysis RDM.
Three RSA effects were found in the LIFG, each relating to various aspects of syntactic ambiguity. There was an early significant effect, peaking around 120 ms, for the ambiguity sensitivity RDM (Figure 7B, left). This finding was confirmed by visualizing the LIFG similarity patterns at 120 ms which showed that all ambiguous items were more similar to other ambiguous items than to unambiguous items, with no differentiation between subordinate and dominant continuations (Figure 8B). This was also evident by tracking the within-condition similarity over time, where early time periods showed subordinate and dominant items have a similar degree of within-condition similarity that was greater than the within-condition similarity for the unambiguous items (Figure 8A). These results show the early activation in the LIFG represents the processing of ambiguity associated with both the subordinate and dominant sentence continuations.
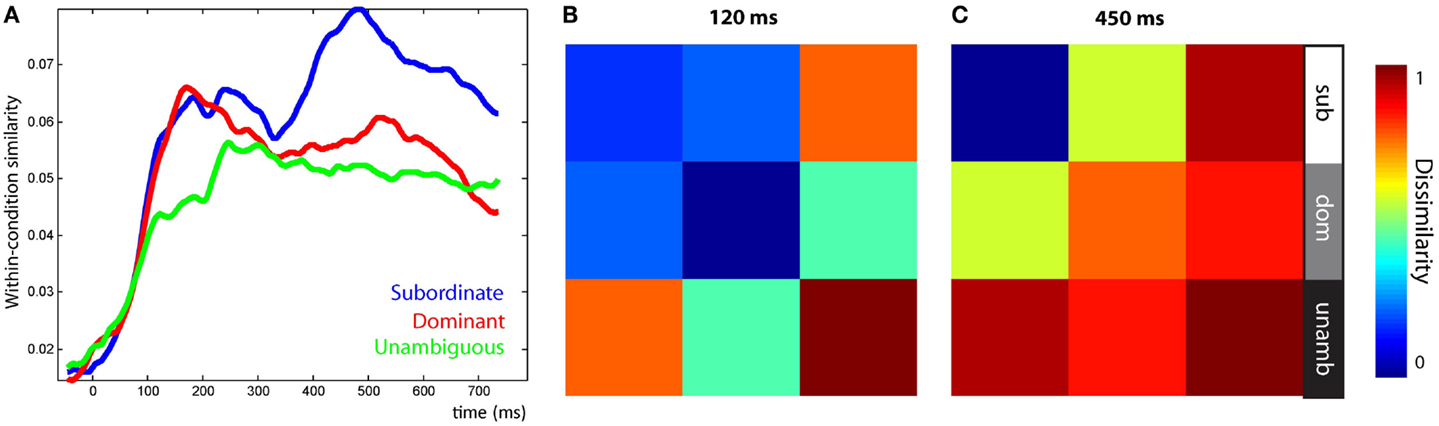
Figure 8. Visualization of similarity patterns in the LIFG from the onset of the disambiguating word. (A) Within-condition similarity time-courses show the group average similarity between items from the same conditions, plotted over time. (B) RDM of the LIFG after 120 ms shows ambiguous items are self-similar before, (C) subordinate items become self-similar, shown at 450 ms. RDMs show the average similarity within each of the nine conditional combinations.
There were two significant late effects in the LIFG occurring between 300 and 700 ms associated with the ambiguity differentiation and reanalysis sensitivity RDMs (Figure 7B, right). Ranking the two models by their fit to the MEG data showed the top model was the reanalysis sensitivity RDM that captures high similarity within the subordinate items and low similarity within both the dominant and unambiguous items. This sensitivity to subordinate items is confirmed by visualizing the data RDM after 450 ms that shows a subordinate sensitive pattern (Figure 8C). Further, the within-condition similarity time-course shows the subordinate items are more similar to each other than either the dominant or unambiguous items, a pattern that emerges after 300 ms (Figure 8A). These results suggest that as listeners integrate the sentence fragment with the disambiguating word, the LIFG is initially sensitive to the presence of multiple representations carried by the phrase that were previously represented in the LpMTG. The activation of multiple representations when the disambiguating word is heard may trigger competitive activation in the LIFG. Only later, as the ambiguity begins to be resolved, is the LIFG sensitive to the difference between subordinate and dominant readings, reflecting their different integration demands.
In summary, the RSA analysis from the onset of the disambiguating verb shows information relating to the verb-form in HG and pMTG within 100 ms. Subsequently, peaking at 120 ms the LIFG represents the ambiguous items (both subordinate and dominant items) in a similar fashion, and differentiates them from the unambiguous items. The posterior MTG and HG then show evidence for the reactivation of representations of the disambiguating word, before finally the LIFG shows sensitivity to representing information about subordinate items that require additional reanalysis.
Although previous studies have established the importance of functional connectivity between LIFG and LpMTG in syntactic processing, the differential roles that these two regions play, the types of computations they subserve and the functional relationship between them remain unclear. To address these issues, in the present study, we constructed sentences containing syntactically ambiguous and unambiguous phrases and tested a variety of RDMs reflecting lexico-syntactic information, ambiguity sensitivity and ambiguity resolution against the similarity of neural spatio-temporal activation patterns using MEG. The results show that the LpMTG is sensitive to both the form of a word and its lexical properties. The LIFG, in contrast, appears blind to these features of the speech input and instead responds to the competitive consequences of multiple syntactic representations and determines their resolution. These processes appear to be largely sequential with information flowing from LpMTG to the LIFG.
This pattern of results is revealed in the multivariate similarity structure at each epoch (see Figure 9 for summary). We found no effects of any of the model RDMs at the first word in the central phrase, but marginal effects of both lexico-syntactic properties and ambiguity were seen during the second word, suggesting that the ambiguity status of the central phrase is only determined when both words in the phrase have become available. Although these effects were only marginal, we believe them to be relevant and interpretable in the context of current models of on-line language processing. One factor that may contribute to the weakness of some effects is in the inherent difficulty of obtaining accurate word-onsets from the continuous speech signals. Given the sensitivity of MEG to variations in the acoustic signal, even small discrepancies can influence the results. As a result, the majority of studies employing sentence paradigms use written text presented one word at a time, however this processes is undeniably very different to naturalistic language comprehension. Here we analyze points within continuous speech to alleviate this problem though other issues such as reduced signal-to-noise and word onset variability may count against us.
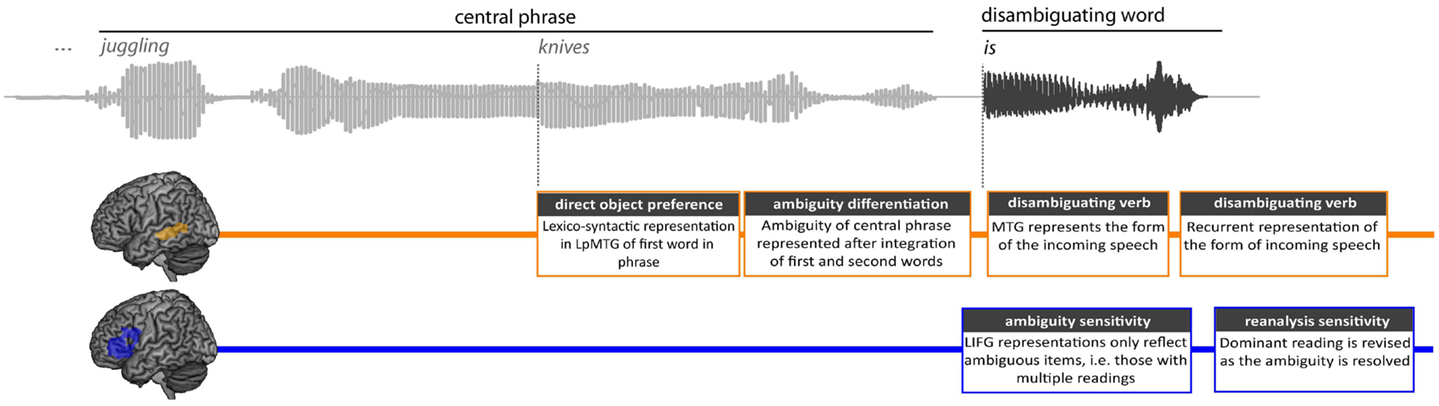
Figure 9. Summary of results in the left fronto-temporal language network showing RSA effects in the LpMTG and LIFG during the central phrase and the subsequent disambiguation.
The effect of the lexico-syntactic RDM, located in the LpMTG and first seen toward the onset of the second word, reflects the lexico-syntactic properties of the preceding word which are captured in the VALEX-derived estimates of the frequency with which a verb takes a direct object (the direct object preference RDM). The earliness of these lexico-syntactic effects suggest that the LpMTG may be sensitive to the integration of the properties of the two words in the phrase, with the first word’s lexically based syntactic constraints being reflected in the early processing of the following noun. These results are consistent with lexically driven models of sentence processing which claim that as each word is heard the properties associated with that word start to be activated and integrated into the upcoming sentence (Marslen-Wilson, 1973; Marslen-Wilson and Tyler, 1980; MacDonald et al., 1994). At this point in time, no such effects were seen in the LIFG. Only the LpMTG appeared to be sensitive to lexically driven information, a finding consistent with claims that lexical representations are associated with the LpMTG (Indefrey and Cutler, 2004; Hagoort, 2005; Thompson et al., 2007; Tyler et al., 2008; Snijders et al., 2010).
It is only after the lexical properties of the first and second words have been integrated that the phrases are distinguished by whether or not they are ambiguous. Consistent with this, slightly later in the processing of the second word of the phrase, around 136 ms, we start to see the patterns of activation in the LpMTG shift from reflecting the lexico-syntactic properties of the first word to the properties of the ambiguity differentiation RDM. At this point in time, the phrase’s ambiguity becomes established. The ambiguity differentiation RDM discriminates between the ambiguous and unambiguous items, while treating the subordinate and dominant items the same, suggesting that the LpMTG is responsive to the commonality between the two sets of ambiguous items – namely, that they are both associated with multiple syntactic interpretations. One possibility suggested by this pattern of results is that effects in the LpMTG may not require the involvement of the LIFG. Changing sensitivity to different aspects of the input over time may not be under the dynamic control of the LIFG, and sustained activation of the LpMTG may not always be modulated by the involvement of the LIFG during integration (see also Snijders et al., 2010).
The LIFG only showed sensitivity to RDMs when the disambiguating wordform was heard. This is the earliest point at which the ambiguity can be resolved and it is here that the LIFG seems to play a major role. Early in the processing of the disambiguating word, there are recurrent effects of the phonological form of the verb in bilateral HG between 30 and 400 ms with slightly later effects in the LpMTG. Although the verb effects in LpMTG peaked slightly later than HG, suggesting a flow of information, it could also be that both ROI effects originate from the same the underlying source. To fully address this issue would require evidence from a more spatially accurate approach (e.g., fMRI). Although the LIFG is not sensitive to these form-based processes, it does show early effects of the ambiguity sensitivity RDM followed by the ambiguity differentiation RDM, perhaps in response to earlier ambiguity effects in the LpMTG during the second word in the phrase. The LIFG’s sensitivity to the ambiguity is soon followed by its resolution, where the LIFG is critically involved in the reanalysis required when the disambiguating verb is consistent with the less dominant interpretation.
We found no evidence that the LIFG showed any interest in the activation and integration of lexico-syntactic information within the central phrase, or in the effects of ambiguity which became available once the words in the central phrase were integrated, during the processing of the second word in the central phrase. The LIFG only became involved in the processing of ambiguity resolution when triggered by the presence of the disambiguating word. Moreover, the role of the LIFG seems to be quite specific; it only became involved in the integration of upcoming words when the disambiguating word occurred, requiring the current (dominant) interpretation of the sentence to be revised. This suggests in turn that the LIFG is involved in detecting the presence of a structural ambiguity that requires resolution and/or selection between the syntactic possibilities in the context of the disambiguating word. One interpretation of these results is that they argue against those models which assume that the LIFG inevitably operates in a top-down fashion to guide interpretation (Federmeier, 2007), or to maintain or update representations in the LpMTG. It looks from these results as though the LIFG is primarily responsive to processes involving competition and re-evaluation, and that it might not always be involved in processes of integration, when lexical representations need to be combined to form a structured sequence. The present results give no evidence for the LIFG supporting the integration between the words in the central phase, as the LIFG showed no sensitivity to the ambiguity or to lexical integration processes during the processing of the second word in the phrase. Further studies are required to fully establish the role of the LIFG in on-line language processing.
The results of this study go some way to addressing an important issue left unanswered by previous fMRI studies of fronto-temporal connectivity during syntactic processing (Snijders et al., 2010; Papoutsi et al., 2011), concerning the dynamic interplay between LpMTG and LIFG. While the analyses reported here suggest that information flows one way from LpMTG to LIFG, they are not unequivocal. However, further support for this claim comes from an independent set of analyses on the MEG data in which we carried out time-frequency analysis and phase locking analyses and then computed Granger causality measures to determine the directionality of the effects between LpMTG and LIFG (Cheung et al., in preparation). This analysis showed that the LpMTG drives activity in the LIFG within the 1–20 Hz frequency bands. However, since recurrent activity between regions is an ubiquitous part of network function (Friston, 2003), we anticipate that the normal functioning of the fronto-temporal network includes repeated, recurrent activity between LIFG and LMTG. This may function as background activity as speech is heard and processed, and what we see here is the modulation of this system in cases of sentential ambiguity that must be resolved in order that the listener can compute a coherent representation of an utterance. In future studies we hope to investigate these and related issues in greater detail.
In summary, this study aimed to characterize the syntactic computations that occur within the LIFG and LpMTG core language network as spoken sentences are heard and processed, and the relationship between them. We focused on syntactic ambiguity since it is a normal and frequent aspect of English and, we would argue, invokes the kinds of processes that are routinely used as we seamlessly construct representations of spoken language. However, further studies will need to determine whether the effects we have observed here do indeed generalize to other kinds of syntactic analysis.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The research leading to these results has received funding from the European Research Council under the European Community’s Seventh Framework Program (FP7/2007-2013)/ERC Grant agreement no. 249640 to Lorraine K. Tyler; a Medical Research Council (UK) program grant to Lorraine K. Tyler (grant number G0500842); and a University of Cambridge Isaac Newton Trust award to Lorraine K. Tyler.
Badre, D., and Wagner, A. D. (2004). Selection, integration, and conflict monitoring: assessing the nature and generality of prefrontal cognitive control mechanisms. Neuron 41, 473–487.
Bilenko, N. Y., Grindrod, C. M., Myers, E. B., and Blumstein, S. E. (2008). Neural correlates of semantic competition during processing of ambiguous words. J. Cogn. Neurosci. 21, 960–975.
Binder, J. R., Frost, J. A., Hammeke, T. A., Cox, R. W., Rao, S. M., and Prieto, T. (1997). Human brain language areas identified by functional magnetic resonance imaging. J. Neurosci. 17, 353–362.
Bozic, M., Tyler, L. K., Ives, D. T., Randall, B., and Marslen-Wilson, W. D. (2010). Bihemispheric foundations for human speech comprehension. Proc. Natl. Acad. Sci. U.S.A. 107, 17439–17444.
Brauer, J., Anwander, A., and Friederici, A. D. (2011). Neuroanatomical prerequisites for language functions in the maturing brain. Cereb. Cortex 21, 459–466.
Chatterjee, A. (2005). A madness to the methods in cognitive neuroscience? J. Cogn. Neurosci. 17, 847–849.
Crinion, J. T., Lambon-Ralph, M. A., Warburton, E. A., Howard, D., and Wise, R. J. S. (2003). Temporal lobe regions engaged during normal speech comprehension. Brain 126, 1193–1201.
Federmeier, K. D. (2007). Thinking ahead: the role and roots of prediction in language comprehension. Psychophysiology 44, 491–505.
Fellows, L. K., Heberlein, A. S., Morales, D. A., Shivde, G., Waller, S., and Wu, D. H. (2005). Method matters: an empirical study of impact in cognitive neuroscience. J. Cogn. Neurosci. 17, 850–858.
Friederici, A. D., and Alter, K. (2004). Lateralization of auditory language functions: a dynamic dual pathway model. Brain Lang. 89, 267–276.
Friederici, A. D., Ruschemeyer, S.-A., Hahne, A., and Fiebach, C. J. (2003). The role of left inferior frontal and superior temporal cortex in sentence comprehension: localizing syntactic and semantic processes. Cereb. Cortex 13, 170–177.
Garnsey, S. M., Pearlmutter, N. J., Myers, E., and Lotocky, M. A. (1997). The contributions of verb bias and plausibility to the comprehension of temporarily ambiguous sentences. J. Mem. Lang. 37, 58–93.
Griffiths, J. D., Marslen-Wilson, W. D., Stamatakis, E. A., and Tyler, L. K. (2013). Functional organization of the neural language system: dorsal and ventral pathways are critical for syntax. Cereb. Cortex 23, 139–147.
Grodzinsky, Y. (2000). The neurology of syntax: language use without Broca’s area. Behav. Brain Sci. 23, 1–21.
Hagoort, P. (2005). On Broca, brain, and binding: a new framework. Trends Cogn. Sci. (Regul. Ed.) 9, 416–423.
Hagoort, P., Brown, C., and Groothusen, J. (1993). The syntactic positive shift (sps) as an erp measure of syntactic processing. Lang. Cogn. Process. 8, 439–483.
Hahne, A., and Friederici, A. D. (1999). Electrophysiological evidence for two steps in syntactic analysis. Early automatic and late controlled processes. J. Cogn. Neurosci. 11, 194–205.
Hickok, G., and Poeppel, D. (2007). The cortical organization of speech processing. Nat. Rev. Neurosci. 8, 393–402.
Indefrey, P., and Cutler, A. (2004). “Pre-lexical and lexical processing in listening,” in The Cognitive Neurosciences, 3rd Edn, ed. M. S. Gazzaniga (Cambridge, MA: MIT Press), 759–774.
Jung-Beeman, M. (2005). Bilateral brain processes for comprehending natural language. Trends Cogn. Sci. (Regul. Ed.) 9, 512–518.
Kaan, E., and Swaab, T. Y. (2003). Repair, revision and complexity in syntactic analysis: an electrophysiological differentiation. J. Cogn. Neurosci. 15, 98–110.
Korhonen, A., Krymolowski, Y., and Briscoe, T. (2006). “A large subcategorization lexicon for natural language processing applications,” in 5th International Conference on Language Resources and Evaluation (LREC), Genoa.
Kriegeskorte, N., Mur, M., Ruff, D. A., Kiani, R., Bodurka, J., Esteky, H., et al. (2008). Matching categorical object representations in inferior temporal cortex of man and monkey. Neuron 60, 1126–1141.
Lapata, M., Keller, F., and Walde, S. S. (2001). Verb frame frequency as a predictor of verb bias. J. Psycholinguist. Res. 30, 419–435.
Lau, E., Stroud, C., Plesch, S., and Phillips, C. (2006). The role of structural prediction in rapid syntactic analysis. Brain Lang. 98, 74–88.
Longworth, C., Marslen-Wilson, W. D., Randall, B., and Tyler, L. K. (2005). Getting to the meaning of the regular past tense: evidence from neuropsychology. J. Cogn. Neurosci. 17, 1087–1097.
MacDonald, M., Perlmutter, N., and Seidenberg, M. (1994). The lexical nature of syntactic ambiguity resolution. Psychol. Rev. 101, 676–703.
Maris, E., and Oostenveld, R. (2007). Nonparametric statistical testing of EEG- and MEG-data. J. Neurosci. Methods 164, 177–190.
Marslen-Wilson, W. D. (1973). Linguistic structure and speech shadowing at very short latencies. Nature 244, 522–523.
Marslen-Wilson, W. D. (1987). Functional parallelism in spoken word-recognition. Cognition 25, 71–102.
Marslen-Wilson, W. D., Brown, C. M., and Tyler, L. K. (1988). Lexical representations in spoken language comprehension. Lang. Cogn. Process. 3, 1–16.
Marslen-Wilson, W. D., and Tyler, L. K. (1980). The temporal structure of spoken language understanding. Cognition 8, 1–71.
Merlo, P. (1994). A corpus-based analysis of verb continuation frequencies for syntactic processing. J. Psycholinguist. Res. 23, 435–457.
Neville, H., Nicol, J. L., Barss, A., Forster, K. I., and Garrett, M. F. (1991). Syntactically based sentence processing classes: evidence from event-related brain potentials. J. Cogn. Neurosci. 3, 151–165.
Osterhout, L., and Holcomb, P. J. (1993). Event-related potentials and syntactic anomaly: evidence of anomaly detection during the perception of continuous speech. Lang. Cogn. Process. 8, 413–437.
Papoutsi, M., Stamatakis, E. A., Griffiths, J. D., Marslen-Wilson, W. D., and Tyler, L. K. (2011). Is left fronto-temporal connectivity essential for syntax? Effective connectivity, tractography and performance in left-hemisphere damaged patients. Neuroimage 58, 656–664.
Parker, G. J. M., Luzzi, S., Alexander, D. C., Wheeler-Kingshott, C. A. M., Ciccarelli, O., and Lambon Ralph, M. A. (2005). Lateralization of ventral and dorsal auditory-language pathways in the human brain. Neuroimage 24, 656–666.
Price, C. J., Crinion, J., and Friston, K. J. (2006). Design and analysis of fMRI studies with neurologically impaired patients. J. Magn. Reson. Imaging 23, 816–826.
Rauschecker, J. P., and Tian, B. (2000). Mechanisms and streams for processing of ‘what’ and ‘where’ in auditory cortex. Proc. Natl. Acad. Sci. U.S.A. 97, 11800–11806.
Rilling, J. K., Glasser, M. F., Preuss, T. M., Ma, X., Zhao, T., Hu, X., et al. (2008). The evolution of the arcuate fasciculus revealed with comparative DTI. Nat. Neurosci. 11, 426–428.
Rodd, J. M., Longe, O. A., Randall, B., and Tyler, L. K. (2010). The functional organisation of the fronto-temporal language system: evidence from syntactic and semantic ambiguity. Neuropsychologia 48, 1324–1335.
Rolheiser, T., Stamatakis, E. A., and Tyler, L. K. (2011). Dynamic processing in the human language system: synergy between the arcuate fascicle and extreme capsule. J. Neurosci. 31, 16949–16957.
Scott, S. K., and Wise, R. J. S. (2004). The functional neuroanatomy of prelexical processing in speech perception. Cognition 92, 13–45.
Snijders, T. M., Petersson, K. M., and Hagoort, P. (2010). Effective connectivity of cortical and subcortical regions during unification of sentence structure. Neuroimage 52, 1633–1644.
Snijders, T. M., Vosse, T., Kempen, G., Van Berkum, J. J. A., Petersson, K. M., and Hagoort, P. (2009). Retrieval and unification of syntactic structure in sentence comprehension: an fMRI study using word-category ambiguity. Cereb. Cortex 19, 1493–1503.
Su, L., Fonteneau, E., Marslen-Wilson, W., and Kriegeskorte, N. (2012). “Spatiotemporal searchlight representational similarity analysis in EMEG source space,” in 2nd International Workshop on Pattern Recognition in NeuroImaging, London, 97–100.
Taulu, S., Simola, J., and Kojola, M. (2005). Applications of the signal space separation method. IEEE Trans. Signal Process. 53, 3359–3372.
Thompson, C. K., Bonakdarpour, B., Fix, S. C., Blumenfeld, H. K., Parrish, T. B., Gitelman, D. R., et al. (2007). Neural correlates of verb argument structure processing. J. Cogn. Neurosci. 19, 1753–1767.
Thompson-Schill, S. L., D’Esposito, M., Aguirre, G. K., and Farah, M. J. (1997). Role of left inferior prefrontal cortex in retrieval of semantic knowledge: a reevaluation. Proc. Natl. Acad. Sci. U.S.A. 94, 14792–14797.
Tyler, L. K., and Marslen-Wilson, W. D. (1977). The on-line effects of semantic context on syntactic processing. J. Verbal Learning Verbal Behav. 16, 683–692.
Tyler, L. K., and Marslen-Wilson, W. D. (2008). Fronto-temporal brain systems supporting spoken language comprehension. Philos. Trans. R. Soc. Lond. B Biol. Sci. 363, 1037–1054.
Tyler, L. K., Marslen-Wilson, W. D., Randall, B., Wright, P., Devereux, B. J., Zhuang, J., et al. (2011). Left inferior frontal cortex and syntax: function, structure and behaviour in patients with left hemisphere damage. Brain 134, 415–431.
Tyler, L. K., Randall, B., and Stamatakis, E. A. (2008). Cortical differentiation for nouns and verbs depends on grammatical markers. J. Cogn. Neurosci. 20, 1381–1389.
Tyler, L. K., Shafto, M. A., Randall, B., Wright, P., Marslen-Wilson, W. D., and Stamatakis, E. A. (2010). Preserving syntactic processing across the adult life span: the modulation of the frontotemporal language system in the context of age-related atrophy. Cereb. Cortex 20, 352–364.
Wright, P., Randall, B., Marslen-Wilson, W. D., and Tyler, L. K. (2011). Dissociating linguistic and task-related activity in LIFG. J. Cogn. Neurosci. 23, 404–413.
Zhuang, J., Randall, B., Stamatakis, E. A., Marslen-Wilson, W., and Tyler, L. K. (2011). The interaction of lexical semantics and cohort competition in spoken word recognition: an fMRI study. J. Cogn. Neurosci. 23, 3778–3790.
Zwitserlood, P. (1989). The locus of the effects of sentential-semantic context in spoken word processing. Cognition 32, 25–64.

Table A1. The 175 sentences.
Keywords: syntax, sentence processing, syntactic ambiguity, language networks, magnetoencephalography, representational similarity analysis
Citation: Tyler LK, Cheung TPL, Devereux BJ and Clarke A (2013) Syntactic computations in the language network: characterizing dynamic network properties using representational similarity analysis. Front. Psychol. 4:271. doi: 10.3389/fpsyg.2013.00271
Received: 16 January 2013; Accepted: 26 April 2013;
Published online: 17 May 2013.
Edited by:
Tamara Swaab, University of California, Davis, USAReviewed by:
Tineke Snijders, Radboud University Nijmegen, NetherlandsCopyright: © 2013 Tyler, Cheung, Devereux and Clarke. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits use, distribution and reproduction in other forums, provided the original authors and source are credited and subject to any copyright notices concerning any third-party graphics etc.
*Correspondence: Lorraine K. Tyler, Department of Psychology, Centre for Speech, Language and the Brain, University of Cambridge, Downing Street, Cambridge CB3 2EB, UK. e-mail:bGt0eWxlckBjc2wucHN5Y2hvbC5jYW0uYWMudWs=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.