 Huiqiang Hu1,2
Huiqiang Hu1,2 Tingting Wang1Yunpeng Wei1Zhenyu Xu1Shiyu Cao3
Tingting Wang1Yunpeng Wei1Zhenyu Xu1Shiyu Cao3 Ling Fu3Huaxing Xu1*Xiaobo Mao1,2*Luqi Huang1,2,4
Ling Fu3Huaxing Xu1*Xiaobo Mao1,2*Luqi Huang1,2,4- 1School of Electrical and Information Engineering, Zhengzhou University, Zhengzhou, China
- 2Research Center for Intelligent Science and Engineering Technology of Traditional Chinese Medicine, Zhengzhou University, Zhengzhou, Henan, China
- 3School of Pharmaceutical Sciences, Zhengzhou University, Zhengzhou, China
- 4State Key Laboratory for Quality Ensurance and Sustainable Use of Dao-di Herbs, National Resource Center for Chinese Materia Medica, China Academy of Chinese Medical Sciences, Beijing, China
Accurate assessment of isoflavone and starch content in Puerariae Thomsonii Radix (PTR) is crucial for ensuring its quality. However, conventional measurement methods often suffer from time-consuming and labor-intensive procedures. In this study, we propose an innovative and efficient approach that harnesses hyperspectral imaging (HSI) technology and deep learning (DL) to predict the content of isoflavones (puerarin, puerarin apioside, daidzin, daidzein) and starch in PTR. Specifically, we develop a one-dimensional convolutional neural network (1DCNN) model and compare its predictive performance with traditional methods, including partial least squares regression (PLSR), support vector regression (SVR), and CatBoost. To optimize the prediction process, we employ various spectral preprocessing techniques and wavelength selection algorithms. Experimental results unequivocally demonstrate the superior performance of the DL model, achieving exceptional performance with mean coefficient of determination (R2) values surpassing 0.9 for all components. This research underscores the potential of integrating HSI technology with DL methods, thereby establishing the feasibility of HSI as an efficient and non-destructive tool for predicting the content of isoflavones and starch in PTR. Moreover, this methodology holds great promise for enhancing efficiency in quality control within the food industry.
1 Introduction
Puerariae Thomsonii Radix (PTR), a perennial plant with a long history of use in Chinese medicine, has gained increasing popularity due to its well-documented therapeutic effects (Zhou et al., 2014). It is valued for its remarkable nutritional and bioactive profiles, offering a wide range of health benefits (Wagle et al., 2019; Lai et al., 2020). Rich in phytochemicals, PTR is particularly abundant in isoflavones, which serve as the primary bioactive compounds responsible for its diverse pharmacological activities (Xu et al., 2016). Notably, extensive research has focused on the presence of isoflavones in PTR, including puerarin, puerarin apioside, daidzin, and daidzein (Li et al., 2022a), highlighting their anti-inflammatory, antioxidant, and anti-cancer properties (Chen et al., 2017). Furthermore, these compounds have been associated with positive effects on cardiovascular health, reducing the risk of heart disease and stroke (Wang S. et al., 2023).
Alongside its medicinal value, PTR is extensively acknowledged as a nutritious food, providing essential nutrients such as starch, protein, and fiber that are integral to maintaining a balanced and healthy diet (Liang et al., 2017). Remarkably, PTR is particularly rich in starch, serving as an excellent source of energy and assisting in the regulation of healthy blood glucose levels (Liu et al., 2021). Furthermore, PTR boasts a significant dietary fiber content, which promotes digestive health, prevents constipation, and reduces the risk of colon cancer (Fu et al., 2023). Given its exceptional nutritional and therapeutic properties, PTR has garnered popularity as a sought-after ingredient in natural remedies and dietary supplements, offering a diverse array of health benefits (Zeng et al., 2019).
With the continuous improvement of living standards in the modern era, consumer concerns regarding food quality have gained significant prominence. Safeguarding the commercial value of PTR necessitates a focus on controlling the content of its bioactive compounds to ensure quality attributes (Li Q. et al., 2022; Zhang Y. et al., 2023). To facilitate quality control and assurance for commercial applications, it is essential to accurately predict the bioactive compound content of PTR. Traditional well-known chemical and physical strategies such as high-performance liquid chromatography (HPLC) (Niu et al., 2012), mass spectrometry (MS) (Liu et al., 2021; Shang et al., 2021), and spectrophotometry (Wong et al., 2015; Reddy et al., 2017), have been utilized for this purpose. However, these techniques come with inherent limitations, including time consumption, expensive equipment requirements, sample destruction, and the use of toxic reagents. Despite their high accuracy and sensitivity, these drawbacks have spurred the exploration of alternative methods that are faster, non-destructive, and cost-effective. Thus, there is a pressing need for a rapid, efficient, and non-destructive approach to ensure the quality of PTR.
Near-Infrared Spectroscopy (NIR) and Infrared Spectroscopy (IR) techniques offer notable advantages in substance analysis (Roggo et al., 2005; Tsuchikawa and Kobori, 2015), including non-destructive measurements and heightened sensitivity to trace components (Ozaki, 2012). However, their complexity requires specialized expertise for data interpretation, and their applicability is often limited to specific sample types (Ozaki, 2021). Additionally, these techniques may not fully capture the internal characteristics of the substances being examined. In certain situations, the acquired spectral information may be insufficient or inadequate to represent the entirety of the sample (Ozaki et al., 2021). Hyperspectral imaging (HSI) is an advanced analytical technique that combines spectroscopy and imaging to analyze the chemical and physical properties of a sample (Femenias et al., 2021). With its rapid analysis time, high spatial resolution, and the ability to simultaneously analyze multiple components, HSI has become an essential tool in the food industry for chemical property detection and quality control (He et al., 2023). By combining the rich spectral information with the capabilities of machine learning algorithms, we can effectively identify food adulteration, assess quality, and predict of component content (Kang et al., 2022; Teixido-Orries et al., 2023). However, the abundance of spectral bands in hyperspectral data poses challenges that require attention. Traditional machine learning models often rely on extensive feature engineering and selection to optimize their performance, which limits their practicality and effectiveness (Chen et al., 2014; Saha and Manickavasagan, 2021; Zhang et al., 2022a; Zhang L. et al., 2023).
Deep learning (DL) has gained tremendous popularity in recent years, driven by its remarkable ability to tackle complex problems (Mishra and Passos, 2021). aging, DL models can effectively exploit the extensive spectral information embedded within the data, leading to improved precision and resolution in regression and prediction tasks (Wang et al., 2021). For instance, Mansuri et al. (2022) employed Vis-NIR HSI to detect fungal contamination in maize kernels and developed partial least squares discriminant analysis (PLS-DA), artificial neural network (ANN), and 1DCNN models. Notably, the 1DCNN model outperformed the other methods, demonstrating superior detection accuracy (Mansuri et al., 2022). Similarly, Li et al. (2023) proposed a CNN model utilizing HSI to accurately identify adulteration in Atlantic salmon (Li et al., 2023). Cai et al. (2023) leveraged HSI and deep fusion learning approaches to determine the geographical origins of Radix Paeoniae Alba (Cai et al., 2023). Furthermore, Zhou et al. (2023) predicted lead content in oilseed rape leaves by combining fluorescence HSI with DL techniques (Zhou et al., 2023). In another study, Zeng et al. (2022) merged HSI and low-field nuclear magnetic resonance with DL to rapidly and non-destructively detect moisture content in salted sea cucumbers (Zeng et al., 2022). Additionally, Soni et al. (2021) quantified Clostridium sporogenes spores in food using HSI and compared the performance of 1DCNN and random forest models. The findings underscored the significant potential of DL, with the CNN exhibiting superior performance over the random forest model (Soni et al., 2021). These studies have substantiated the feasibility and superiority of employing DL models in conjunction with HSI for food analysis and safety inspection, surpassing traditional machine learning methods such as PLSR and RF.
As mentioned above, the combination of HSI and DL algorithms have shown significant potential for application in the field of food analysis in recent years. In this context, the main objectives of this study are as follows: (1) Explore the potential of HSI and data analysis methods to predict the levels of puerarin, puerarin apioside, daidzin, daidzein, and starch in PTR. (2) Following the conventional modeling process, compare the performance of typically used traditional machine learning prediction algorithms, with various spectral preprocessing techniques and wavelength selection methods. (3) Develop a 1DCNN model and establish its advantage by comparing its predictive performance with commonly used prediction algorithms. By addressing these objectives, this study aims to advance the accurate prediction of compounds in PTR using HSI technology and data analysis methods, providing valuable insights for quality evaluation and control in the food industry.
2 Materials and methods
2.1 Sample preparation
This study focused on kudzu (Pueraria thomsonii) sourced from Jiangxi Province, China. The kudzu plants were harvested during their second year of growth, and the root tuber epidermis was carefully removed using ultrasound-assisted washing. The PTR samples were then subjected to natural drying. A total of 1000 g of PTR was collected from the specified geographical origin, and 10 g of PTR were packed together to form one sample for hyperspectral image acquisition. In total, 100 samples were collected for analysis. During hyperspectral image acquisition, the PTR samples were individually placed on a black plate. Subsequently, the samples were freeze-dried and finely ground into powders to facilitate the analysis of puerarin, puerarin apioside, daidzin, daidzein, and starch.
2.2 Hyperspectral imaging system acquisition
The data collection process in this study involved the use of a hyperspectral imaging system equipped with two lenses: one for capturing visible light and the other for short-wave/long-wave near-infrared components (HySpex VNIR1800/HySpex SWIR 384, Norsk Elektro Optikk, Oslo, Norway). Specifically, our focus for the experiment was on the wavelength range of 948.72 − 2512.97 nm in the SWIR region, which comprised a total of 288 spectral bands. To ensure proper illumination of the samples, we employed two 150 W bromine-tungsten lamps (H-LAM, Norsk Elektro Optikk, Oslo, Norway) as the light source. The integration time for the SWIR lenses was set at 3500 µs. Throughout the data acquisition process, the samples were positioned on a conveyor belt moving at a constant speed of 2.0 mm/s, while maintaining a distance of 28 cm between the samples and the lenses, the dimensions of the black plate used to place the sample is 100 cm× 45 cm.
2.3 Data correcting
During the process of acquiring hyperspectral images, non-uniformity in the intensity of light and interference from dark currents can lead to uneven output images (Jia et al., 2020). This can be a negative impact on subsequent data analysis. To address this, it is critical to calculate the relative reflectance using both dark and white reference images. The corresponding correction method is calculated as the following equation.
The corrected image is denoted by Inew, and it is obtained by applying a correction method to the original hyperspectral image Iraw, taking into account the dark reference image Idark and the white reference image Iwhite.
2.4 Measurement of total puerarin, puerarin apioside, daidzin, daidzein, and starch
2.4.1 Chemicals
Methanol (chromatography grade) and acetonitrile (chromatography grade) were obtained from Tianjin Siyou Fine Chemical Co., Ltd. Methanol (analytical grade) and formic acid (analytical grade) were obtained from Tianjin Zhiyuan Chemical Reagent Co., Ltd. Ultra-pure water was prepared in the laboratory using a Mili-Q Advantage A10 system from Merck KGaA (MA, USA). The standards used in this study included puerarin (lot number 110752-201816), daidzin (111738-201904), daidzein (111502-202003), which were purchased from the China Institute for Food and Drug Control. Furthermore, puerarin apioside (lot number 103654-50-8) was purchased from Chengdu Plantmark Pure Biotechnology Co., Ltd. All reagents were of analytical grade and were used without further purification.
2.4.2 Preparation of standard solution
Four distinct compounds, namely puerarin, puerarin apioside, daidzin, and daidzein, were each dissolved in methanol to prepare standard solutions with a 20 mg amount of each compound. The solutions were made up to a final volume of 10 mL in volumetric flasks to obtain the stock solutions for each compound. To prepare a mixed standard solution, suitable volumes of the stock solutions were combined and diluted with methanol to produce a concentration gradient. Standard curves were created for each compound using the appropriate volumes of the standard solutions. This rigorous method was employed to guarantee precise and dependable measurements of the compounds in subsequent experiments. The resulting mixed standard solution and individual standard curves will be used to determine the concentration of each compound in samples.
2.4.3 Isoflavones extraction in Puerariae Thomsonii Radix
Firstly, 1.0 g of the powder, which had passed through a sieve (50 mesh), was mixed with 50 mL of the 50% methanol solution. Ultrasonic extraction was then performed on the mixture at room temperature for 30 mins. The resulting mixture was cooled, and its weight was measured. Any weight loss was compensated for by adding more 50% methanol solution to the mixture. After shaking, the mixture was filtered, and the filtrate was collected for further analysis. To prepare the filtrate for injection, it was filtered through a 0.22 µm microfiltration membrane and then injected into a sample bottle using an automatic sampler.
2.4.4 HPLC system for isoflavones analysis
The HPLC K2025 liquid chromatography system was composed of a Binary pump, Autosampler, Column oven, and UV-VIS detector. For every analysis of the samples, a YMC-Pack Pro C18 reverse phase column was utilized with a mobile phase consisting of an aqueous solution containing 0.01% formic acid and acetonitrile. Detection was conducted at a wavelength of 250 nm, with the column temperature maintained at 30 °C, a flow rate of 1 mL/min, and an injection volume of 10L.
2.4.5 Quantification of starch
A sample of PTR weighing precisely 1.0 g, which had been passed through a sieve (50 mesh), was added to 10 mL of distilled water. The resulting mixture was homogenized in a blender, filtered, and the filtrate was subjected to centrifugation at 4500 rpm for 15 mins. The supernatant was then discarded, and the resulting precipitate was dried in a 70 °C oven until a constant weight was achieved. The mass of the precipitate was recorded for the calculation of starch content using the following formula.
Where, W is starch content, m1 is the mass of the dried precipitate, and m2 is sample mass.
2.5 Modeling
2.5.1 Spectral preprocessing
Preprocessing plays a crucial role in hyperspectral data analysis as it helps eliminate noise, correct instrument artifacts, and enhance the signal-to-noise ratio for further analysis. In this study, we evaluated several well-established preprocessing methods, including the standard normal variate (SNV), multiplicative scatter correction (MSC), Savitzky-Golay smoothing (SG), as well as the first derivative (FD) and second derivative (SD) methods. The goal was to identify the most effective preprocessing technique that would yield the most accurate predictive models.
2.5.2 Effective wavelength selection
In the analysis of hyperspectral data, the selection of appropriate spectral bands is of paramount importance for obtaining meaningful information and reducing data redundancy. Given the hundreds or thousands of spectral bands, noise and irrelevant spectral information are common, which can lead to inaccurate results or high computational costs in further data analysis. Effective band selection aims to improve the accuracy and efficiency of the analysis by reducing the dimensionality of the data while preserving the most informative spectral features. Furthermore, the selection of relevant bands can facilitate the interpretation of the data and provide insights into the underlying physical and chemical processes. Hence, it is a critical step in hyperspectral data analysis and has received significant attention in the literature.
Successive projections algorithm (SPA): The SPA operates by computing the coefficient of determination between each spectral band and the target variable, and subsequently selecting the feature with the highest absolute correlation in the initial iteration (Zhang et al., 2017). During each subsequent iteration, SPA eliminates the spectral band that has the least impact on the coefficient of determination of the remaining spectral bands until the desired number of features is achieved. In this manner, SPA effectively identifies a subset of the most relevant and informative spectral bands, while preserving the effective wavelengths that capture the most significant spectral features.
Competitive adaptive reweighted sampling (CARS): CARS is a potent algorithm that facilitates wavelength selection in HSI. Its underlying principle involves competitively sampling spectral bands iteratively. Every wavelength is assigned a weight that corresponds to its significance in the classification task (Li et al., 2009). CARS adaptively reweighs wavelengths during each iteration based on their discriminative power, and it ultimately selects the most informative subset of wavelengths.
Uninformative variable elimination (UVE): This algorithm achieved by measuring the relevance of each wavelength to the final task using statistical methods such as mutual information, coefficient of determination, or variance analysis. Wavelengths that exhibit low significance are subsequently removed, resulting in only informative wavelengths remaining for subsequent analysis (Cai et al., 2008).
2.5.3 Conventional data analysis approaches
Support vector regression (SVR): SVR is a powerful machine learning algorithm that is extensively used for regression tasks. The fundamental principle of SVR is to construct a hyperplane in a high-dimensional feature space that maximizes the margin between the training data points and the hyperplane, facilitating accurate regression (Dhiman et al., 2019).
To prevent overfitting and improve generalization, SVR incorporates a regularization parameter that balances the trade-off between maximizing the margin and minimizing the training error. By adjusting the regularization parameter, SVR can effectively handle overfitting and generalize well to new unseen data, providing robust and accurate regression results.
Partial least squares regression (PLSR): In the realm of HSI, PLSR is a frequently employed multivariate statistical technique for predicting the concentrations of chemical components in a sample. Its primary objective is to reveal the underlying relationship between the predictor variables (spectral features) and the response variable (chemical composition content).
PLSR achieves this by decomposing the predictor variable set into a reduced number of latent variables that capture the variance in the spectral data. It then performs regression analysis between these latent variables and the response variable. The latent variables are carefully selected to maximize the covariance between the predictor and response variables, thereby ensuring that they capture the critical information and relationships between the two sets (Li et al., 2022b).
CatBoost: Through the use of ordered boosting, random permutations, and gradient-based optimization, CatBoost is able to deliver cutting-edge performance across a range of domains. This versatile machine learning framework boasts a crucial advantage in its ability to effectively manage categorical variables with high cardinality and handle missing data, making it a valuable tool for real-world datasets (Dorogush et al., 2018). When combined with HSI, it offers an effective approach for accurately predicting the content of various sample components, particularly in the food industry, such as fat, protein, and moisture (Zou et al., 2023).
2.5.4 Deep learning approaches
One-dimensional convolutional neural networks (1DCNN) are becoming increasingly popular in HSI due to their remarkable ability to accurately predict the concentrations of chemical components in a sample (Mishra and Passos, 2021; Li et al., 2023). Essentially, 1DCNN is a type of neural network that utilizes convolutional layers to extract features from spectral data, which is treated as a one-dimensional sequence of data points, followed by fully connected layers to make precise predictions. By applying convolutional layers along the spectral axis, 1DCNN can capture spectral correlations and dependencies, thereby extracting relevant and discriminative features for predicting chemical composition content.
The 1DCNN architecture offers a notable advantage in handling large amounts of spectral data, making it well-suited for HSI applications with numerous spectral bands per pixel. This capability enables efficient processing of extensive datasets, resulting in highly accurate predictions. In this study, we employed a 1DCNN framework to predict the concentrations of puerarin, puerarin apioside, daidzin, daidzein, and starch in PTR, as shown in Figure 1. The designed CNN architecture comprises an input layer, three convolutional layers, two maxpooling layers, one fully connected layer, and an output layer. To be specific, the convolutional layers utilize a kernel size of 3×1, with 64, 32, and 32 kernels, respectively.

Figure 1 The CNN architecture utilized for predicting the levels of isoflavones and starch in PTR.
2.6 Performance evaluation metrics
This study employed several evaluation metrics to assess the accuracy and reliability of the models, including root mean squared error (RMSE), mean absolute error (MAE), coefficient of determination (R2) and residual predictive deviation (RPD).
Assuming that the predicted values and actual values are denoted by vectors and respectively, the formula for calculating the performance metric are as follows.
where n denotes the sample size, represents the predicted value of the ith element, yi represents the actual value of the ith element, and is the mean value.
When evaluating the performance of different models, the one that with the lowest RMSE is generally regarded as having better predictive accuracy. A lower MAE value suggests that the model has smaller prediction errors, while a higher RPD value indicates a better predictive accuracy compared to the reference data. Additionally, the model with the highest coefficient of determination indicates a stronger linear relationship between predicted and actual values, which is also an important factor to consider when comparing model performance.
2.7 Software tools and configurations
The correction and visualization of hyperspectral image data were carried out in the Environment for Visualizing Images (ENVI) 5.3 software from ITT Visual Information Solutions, Inc. in Boulder, CO, USA. The experiments for the proposed DL models were conducted on a server equipped with an Intel(R) Xeon(R) Platinum 8368 CPU @ 2.40GHz (251G RAM) and a GA100 graphics card (A100 PCIe 80GB GPU), running the Ubuntu Linux 21.04 operating system. The model’s compilation was created in the Python programming language (Python 3.7.10) and implemented using TensorFlow 2.2.0 and CUDA 11.7. During the network training, the cross-entropy loss function and the Adam optimization algorithm were utilized, while the learning rate, and batch size were set to 0.001 and 16, respectively. The dataset was randomly split into a training set (80% of the dataset) and a test set (20% of the dataset). To ensure the reliability of the results, all experiments were conducted and averaged over 10 independent runs.
3 Results and discussion
3.1 Content of isoflavones and starch in PTR
The contents of isoflavones and starch in PTR samples were determined and presented in Table 1. Among the total samples, starch had the highest mean concentration of 506.71 mg/g with a standard deviation of 29.08 mg/g, while daidzein had the lowest mean concentration of 0.2901 mg/g with a standard deviation of 0.07 mg/kg. In general, the trends in the concentrations of isoflavones and starch were similar across most samples. Nonetheless, the results indicate that the starch content in PTR samples remains relatively constant.

Table 1 Content of isoflavones and starch in PTR.
3.2 Spectral characteristics of PTR
The spectral reflectance of PTR samples was analyzed over the range of 948.72−2512.97 nm, and the mean, minimum, maximum, and standard deviation values are depicted in Figure 2. The observed spectral reflectance exhibited a decrease with increasing wavelength, which is consistent with the typical optical properties of PTR. The spectral profile displayed multiple peaks and valleys corresponding to absorptions, where the primary absorption bands were appeared at 990 nm, 1200 nm, 1450 nm, 1550 nm, 1765 nm, 1942 nm, 2112 nm, and 2278 nm. Specifically, the absorption peaks around 990 nm and 1450 nm can be attributed to the third overtone of O-H stretching in alcohol or phenol-OH and the first overtone stretching of O-H in water (Barbin et al., 2013; Zhang et al., 2019). Similarly, the absorption peak around 1200 nm primarily arises from the second overtone of C-H stretching in starch (He et al., 2013). Moreover, the absorption peaks at 1550 nm and around 1765 nm correspond to the first overtone stretching and the third overtone stretching of N-H (Lü et al., 2017), respectively. Additionally, the absorption peak around 2278 nm mainly results from the first overtone stretching of C-H in aliphatic compounds such as fatty acids (He et al., 2017). Furthermore, the absorption peaks around 1942 nm and 2112 nm mainly attributed to the characteristic absorption of N-H and -NH2 groups, which are associated with the presence of proteins and amino acids in PTR (Wang et al., 2013; Qiu et al., 2021). Therefore, the obtained spectral profile provides a solid foundation for qualitative analysis of various PTR attributes using chemometrics and hyperspectral techniques.
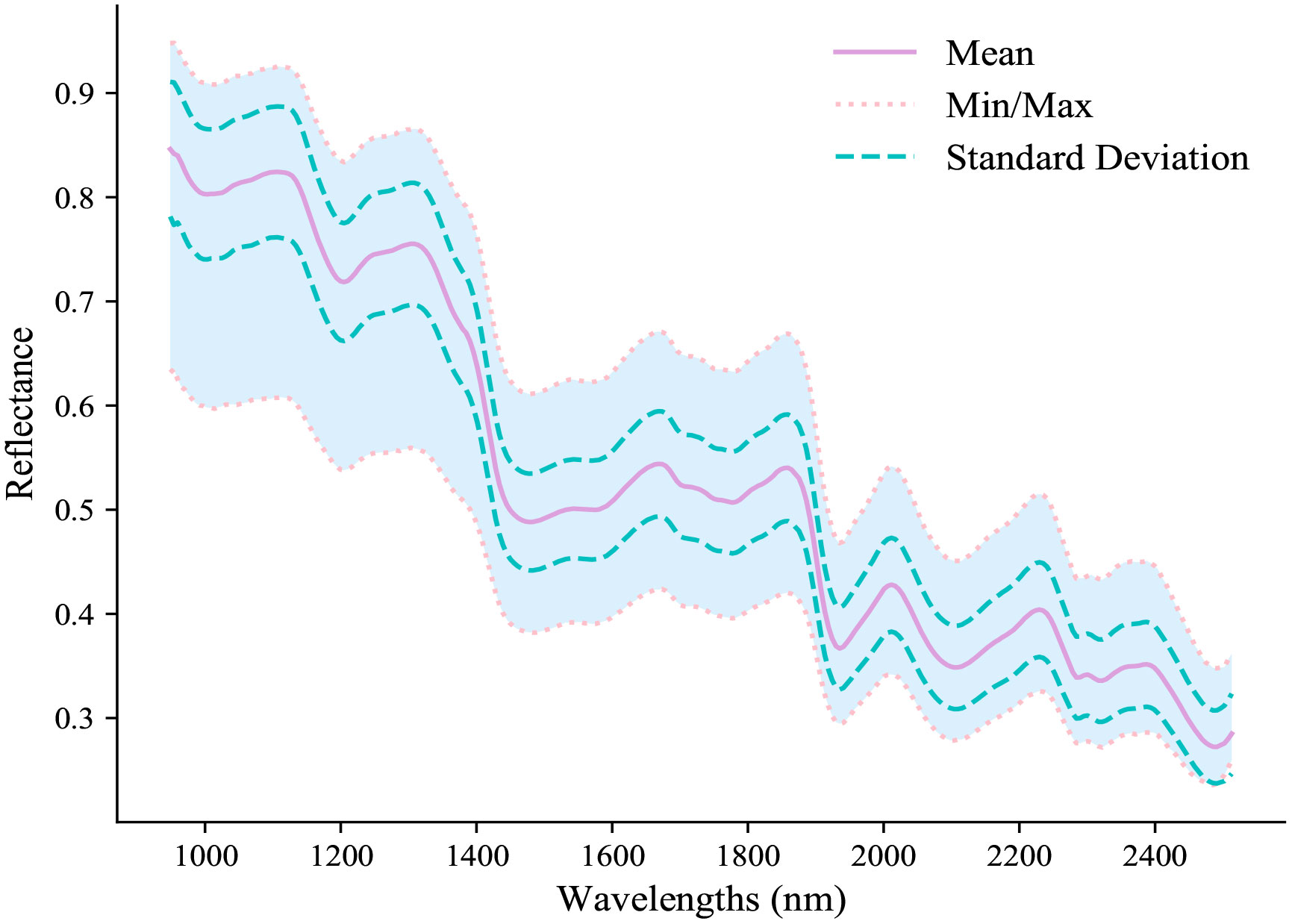
Figure 2 The mean, minimum, maximum and standard deviation spectral reflectance for PTR.
However, the intricate composition of PTR samples presents a challenge for the direct quantification of isoflavones and starch levels using wavelengths from the spectral curve. Thus, further research is crucial to validate these observations and construct accurate and reliable models that can predict the concentrations of isoflavones and starch based on spectral data. In this regard, chemometric approaches were employed to explore the correlation between spectral reflectance and the levels of isoflavone and starch in the samples. This will help overcome the limitations of conventional analytical techniques and enhance the efficiency and accuracy of quality control in the food industry.
3.3 Prediction model’s performance when considering full wavelengths
3.3.1 Conventional prediction models
Firstly, we conducted a comparison of three models: SVR, PLSR, and CatBoost. In order to enhance the prediction performance, various preprocessing methods were evaluated, including SNV, MSC, SG, FD, and SD, as discussed in section 2.5.1. The prediction results of the model combinations are summarized in Supplementary Table 1 (see Supplementary materials). When comparing the results with the original spectral data, it was observed that the preprocessing methods led to varying degrees of improvement in predictive performance. Among these preprocessing methods, SG exhibited superior performance in predicting the contents of isoflavones and starch.
Regarding the prediction of isoflavone and starch contents, all three models demonstrated good performance, with most of the R2 exceeding 0.8 and the RPD values greater than 2.5. These results indicate that the combination of HSI technology and data analysis methods is feasible for determining the levels of puerarin, puerarin apioside, daidzin, daidzein, and starch in PTR. It is worth noting that the prediction performance of the three models, combined with all the preprocessing methods, was highest for the starch content compared to other components. The average values of R2, RPD, RMSE, and MAE for starch were found to be 0.8527, 2.6258, 11.7018, and 8.3385, respectively.
Furthermore, Figure 3 illustrates the regression results for the reference and predicted values of the four isoflavones and starch contents obtained by applying the traditional model using full wavelengths. It showcases the best performance achieved by this model. The PLSR yielded better predictions for the content of daidzein and starch, resulting in the lowest values of RMSE (0.01645, 10.3977) and MAE (0.01366, 7.5668), as well as the highest RPD (2.4413, 2.9242) and R2 (0.8322, 0.8781). On the other hand, CatBoost exhibited the best prediction accuracy for puerarin, puerarin apioside, and daidzin contents, with the lowest values of RMSE (0.2315, 0.036, 0.0372) and MAE (0.1783, 0.0287, 0.0284), as well as the highest RPD (2.7749, 2.5964, 2.6968) and R2 (0.8681, 0.8417, 0.8575).
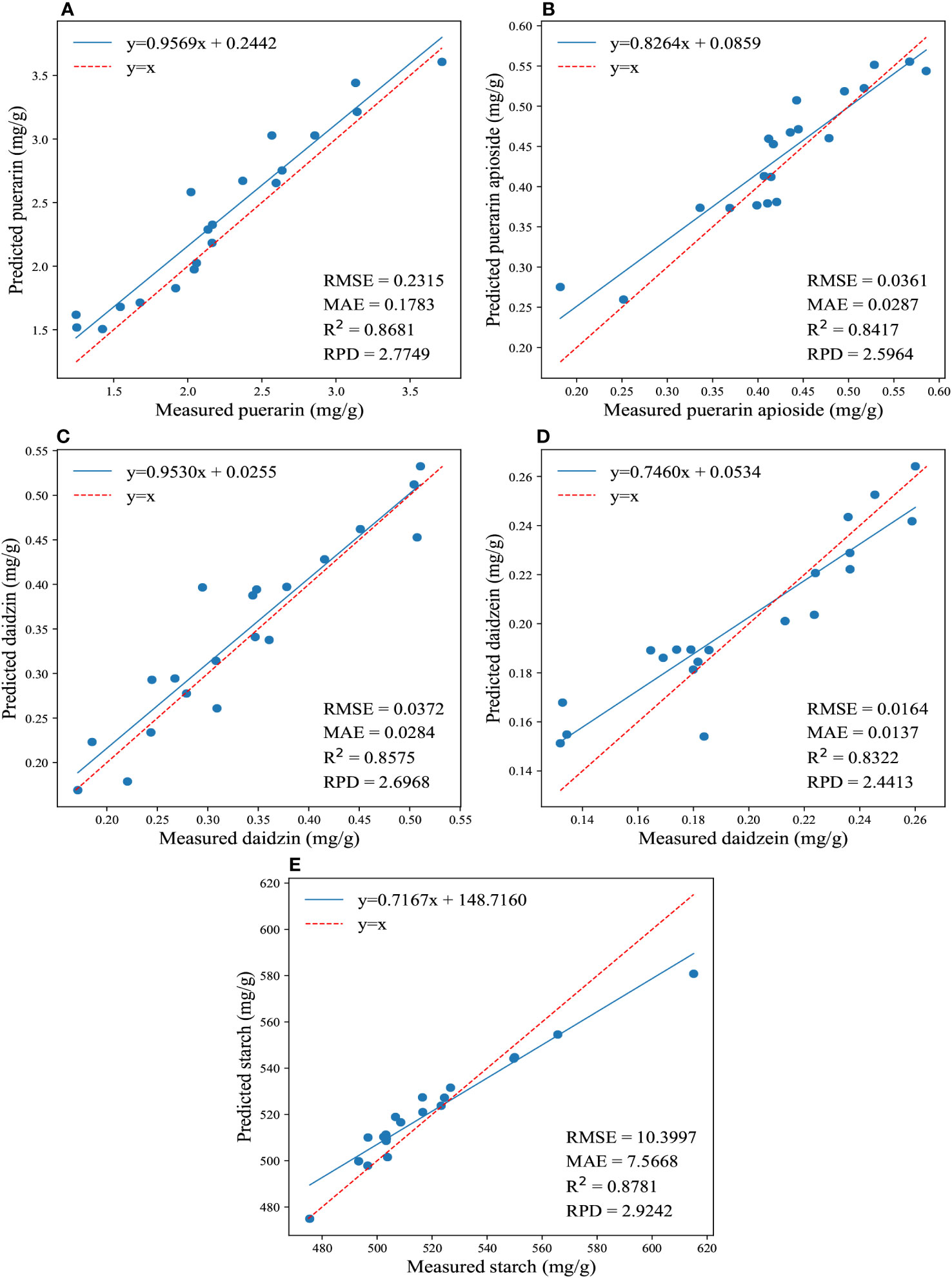
Figure 3 The regression results for the reference and predicted values of the four isoflavones and starch contents are depicted in (A-E), which illustrate the predictions of puerarin, puerarin apioside, daidzin, daidzein, and starch contents using the full wavelengths and conventional models.
Overall, the combination of HSI and traditional machine learning techniques has proven to be a valuable approach for predicting the levels of isoflavones and starch in PTR. Among the findings of the experiment, CatBoost demonstrated superior performance compared to the other investigated models. Nevertheless, there is still room for further improvement in the predictive accuracy of these models. One promising direction for enhancement is the incorporation of advanced wavelength selection methods.
3.3.2 Deep learning prediction model
In subsection 3.3.1, it has been demonstrated that the SG yields the best preprocessing results. Therefore, in following experiment, only the SG method was employed as the preprocessing technique. The outcomes of predicting the isoflavones and starch contents based on full wavelengths using the 1DCNN model are presented in Table 2. The results clearly indicate that the 1DCNN model outperformed the previously compared traditional models. The preprocessed data were directly fed into the 1DCNN, resulting in average R2 values above 0.90 and RPD values exceeding 3.20 for the five different components analyzed in PTR.
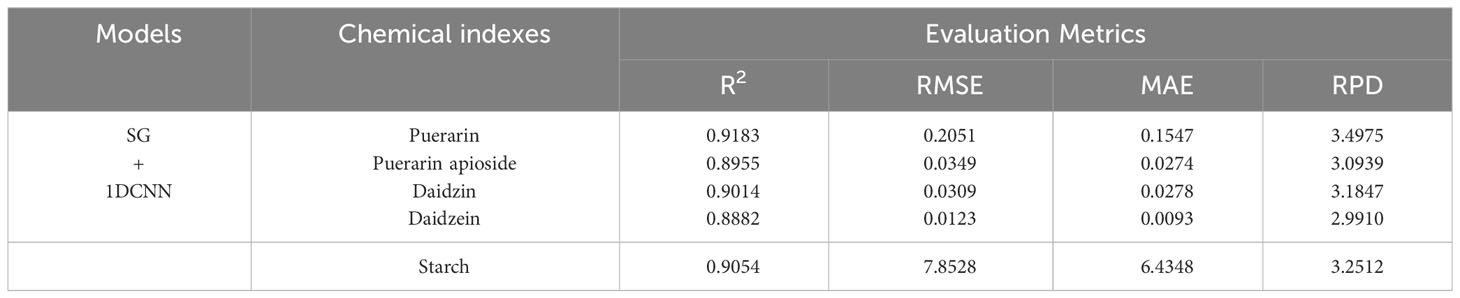
Table 2 The prediction results of the content of puerarin, puerarin apioside, daidzin, daidzein, and starch in PTR using 1DCNN with full wavelengths.
In terms of predicting puerarin, the 1DCNN model demonstrated improved performance compared to the traditional models, with an average increase of 0.0546 and 0.7804 in R2 and RPD, respectively. Similarly, for puerarin apioside, the 1DCNN model surpassed the other models, yielding an average increase of 0.0696 and 0.6653 in R2 and RPD, respectively. Furthermore, the 1DCNN model exhibited enhanced prediction results for daidzin and daidzein, resulting in average increases of 0.0566, 0.0673 and 0.6226, 0.6252 in R2 and RPD, respectively. Likewise, the 1DCNN model showcased superior performance in predicting starch, with average increases of 0.0359 and 0.4598 in R2 and RPD, respectively.
The regression results for the reference and predicted values of the four isoflavones and starch contents are shown in Figure 4. Overall, the 1DCNN model displayed superior and consistent performance in predicting the contents of puerarin and starch in PTR. Remarkably, notwithstanding without very complex design, the 1DCNN model outperformed traditional algorithms, highlighting the superiority of DL algorithms. Moreover, it should be emphasized that prediction results can be influenced by different parameter settings. In our study, we set the epoch to 200 for predicting the concentrations of the four isoflavones, and 1000 for determining the starch content. These findings suggest that utilizing a CNN model with spectral data is a feasible and effective approach for predicting the isoflavones and starch contents in PTR root.
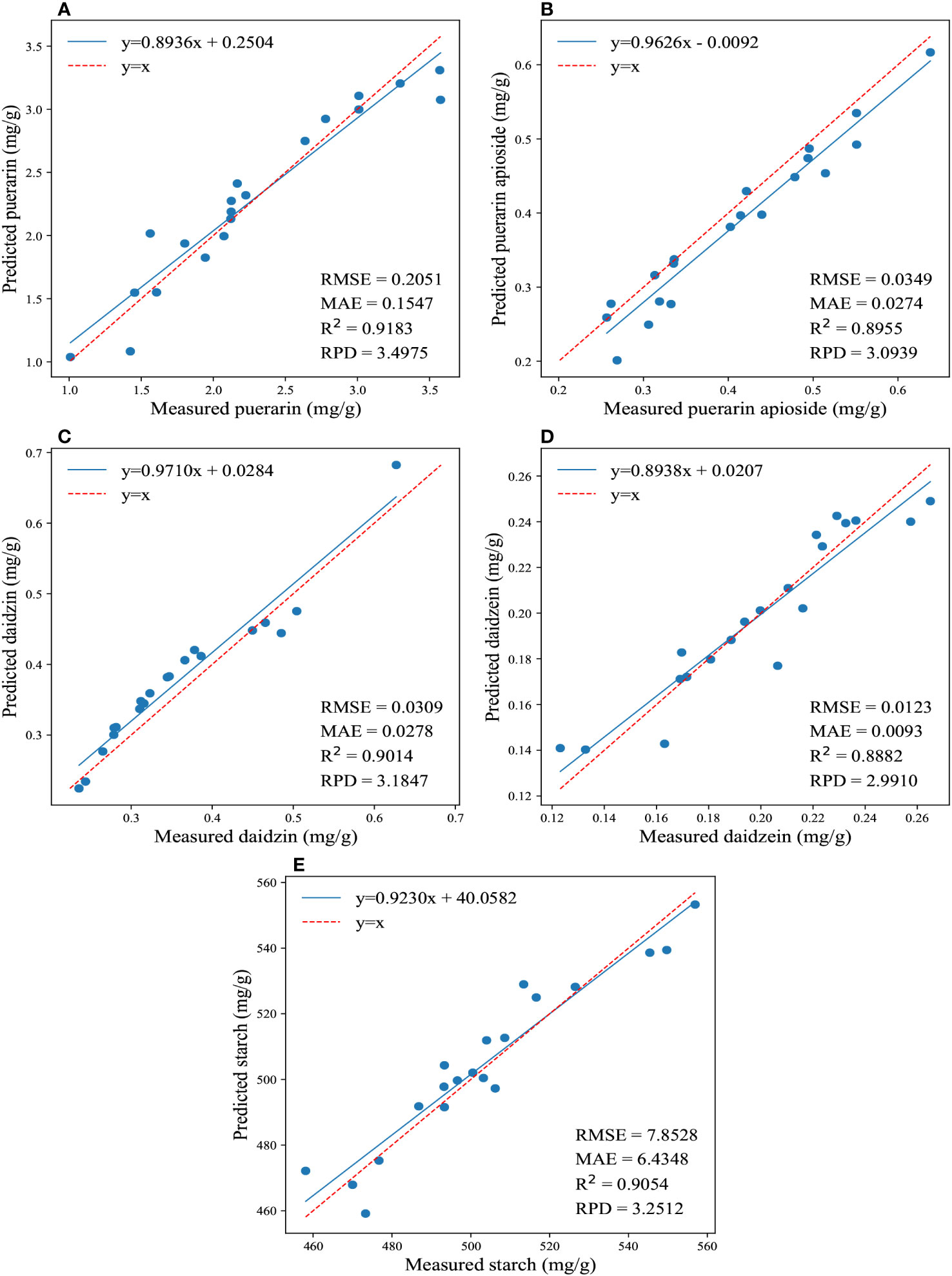
Figure 4 The regression results for the reference and predicted values of the four isoflavones and starch contents are depicted in (A-E), which illustrate the predictions of puerarin, puerarin apioside, daidzin, daidzein, and starch contents using the full wavelengths and 1DCNN.
3.4 Prediction model’s performance when considering effective wavelengths
In this section, three methods, namely SPA, CARS, and UVE, were employed to select effective wavelengths, aiming to improve the prediction performance of the models. For the prediction of puerarin, the three methods selected 14, 19, and 25 important variables from the full range of wavelengths. Similarly, for the prediction of puerarin apioside, 10, 17, and 22 significant wavelengths were chosen. For daidzin and daidzein, SPA, CARS, and UVE selected 16, 31, and 33, as well as 12, 23, and 28 important variables, respectively, from a pool of 288 variables. Lastly, 13, 28, and 30 significant wavelengths were chosen for starch content prediction.
The specific distribution of the selected feature wavelengths for each component prediction is shown in Figure 5. It is evident that despite the distinct principles guiding the three wavelength selection methods, they consistently converge on similar significant wavelength ranges. These selected wavelengths are primarily concentrated within regions that exhibit prominent and representative features, aligning with the absorption bands illustrated in Figure 2. As depicted in Figure 2, which are known to be highly correlated with the respective chemical constituents. This consistency in wavelength selection reinforces the notion that these specific regions of the spectrum contain valuable information that is closely linked to the chemical composition being analyzed.
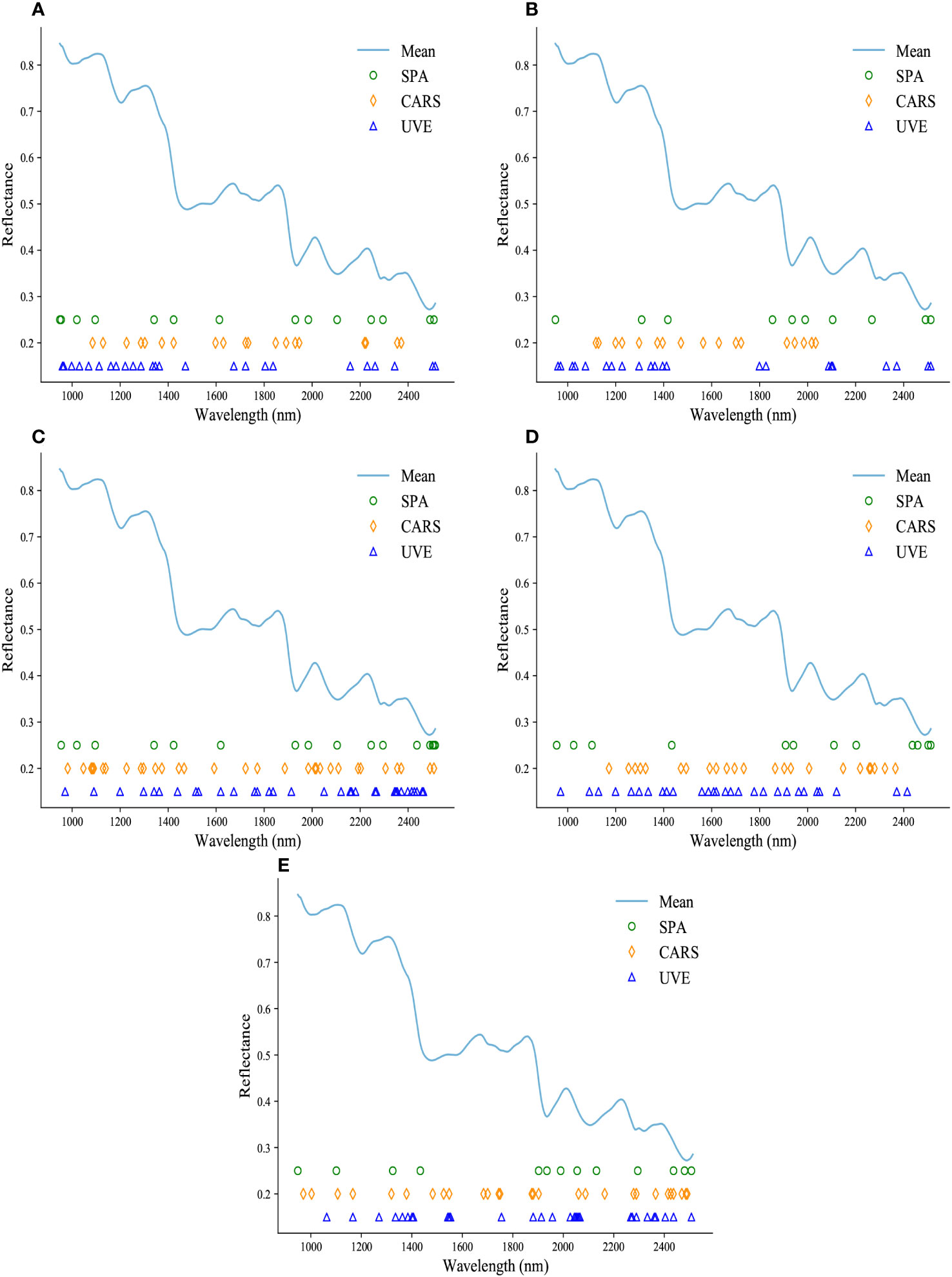
Figure 5 The specific locations of important wavelengths extracted by SPA, CARS, and UVE are presented in (A-E), showcasing the prediction of puerarin, puerarin apioside, daidzin, daidzein, and starch contents.
Supplementary Table 2 (see Supplementary materials) presents the prediction results of these algorithms for the three traditional models. From the results in Supplementary Table 2, it is evident that all three band selection methods improved the prediction ability of the traditional models. Notably, SPA exhibited the most substantial improvement, surpassing CARS and UVE.
In addition, Figure 6 illustrates the regression results for the reference and predicted values of the four isoflavones and starch contents by applying the aforementioned three traditional model, showcasing the best performance achieved. For the prediction of puerarin, puerarin apioside, daidzin, and daidzein, the SG-SPA-CatBoost combination demonstrated the best performance among the conventional algorithms. The average values of the R2, RPD, RMSE, and MAE were determined to be 0.8703, 2.783, 0.0775, and 0.0640, respectively. Conversely, for starch prediction, SG-SPA-PLSR exhibited the highest prediction accuracy, with the lowest RMSE (10.667) and MAE (7.533), as well as the highest RPD (2.9692) and R2 (0.8876).
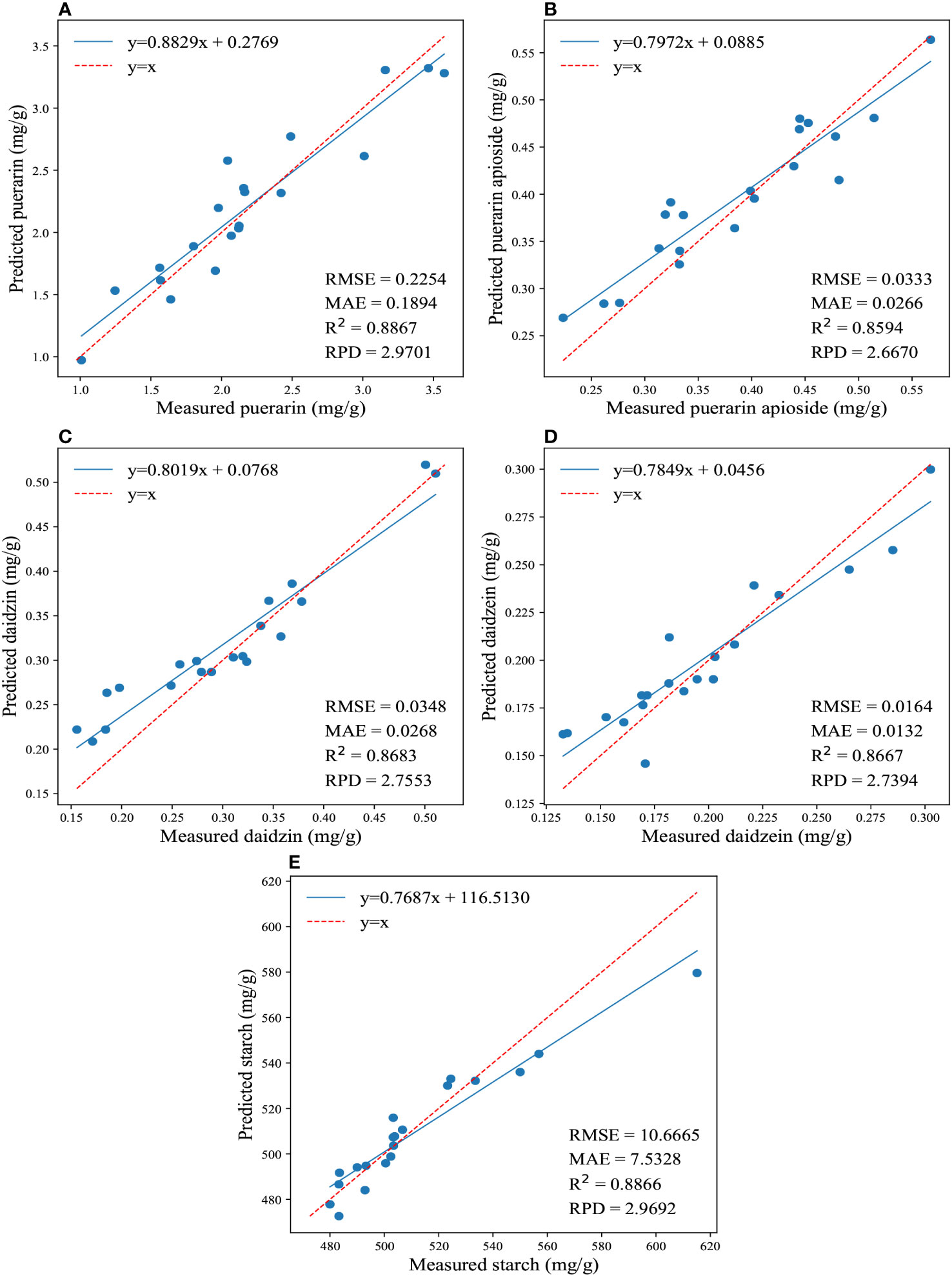
Figure 6 The regression results for the reference and predicted values of the four isoflavones and starch contents are depicted in (A-E), which illustrate the predictions of puerarin, puerarin apioside, daidzin, daidzein, and starch contents using the effective wavelengths and conventional models.
Table 3 displays the prediction results of the effective wavelengths and CNN model, while Figure 7 illustrates the regression results for the reference and predicted values of the four isoflavones and starch contents by utilizing the effective wavelengths and 1DCNN. However, it is important to highlight that in the case of the CNN model, the inclusion of effective wavelength selection did not result in a significant improvement in performance, and in some cases, even led to a slight decrease compared to the model using full wavelengths. Nevertheless, it remains evident that DL models are less susceptible to the impact of different wavelength selection methods, and the CNN model utilizing full wavelengths consistently demonstrated superior performance. This underscores the inherent strength of DL in effectively handling intricate and highly complex data. By virtue of the end-to-end training process, DL models autonomously extract non-linear hidden features from samples in a globally optimized manner. It is this interconnected process that explains the underlying reason for the observed decrease in performance of the CNN model when wavelength selection is employed.

Table 3 The prediction results of the content of puerarin, puerarin apioside, daidzin, daidzein, and starch in PTR using 1DCNN with effective wavelengths.
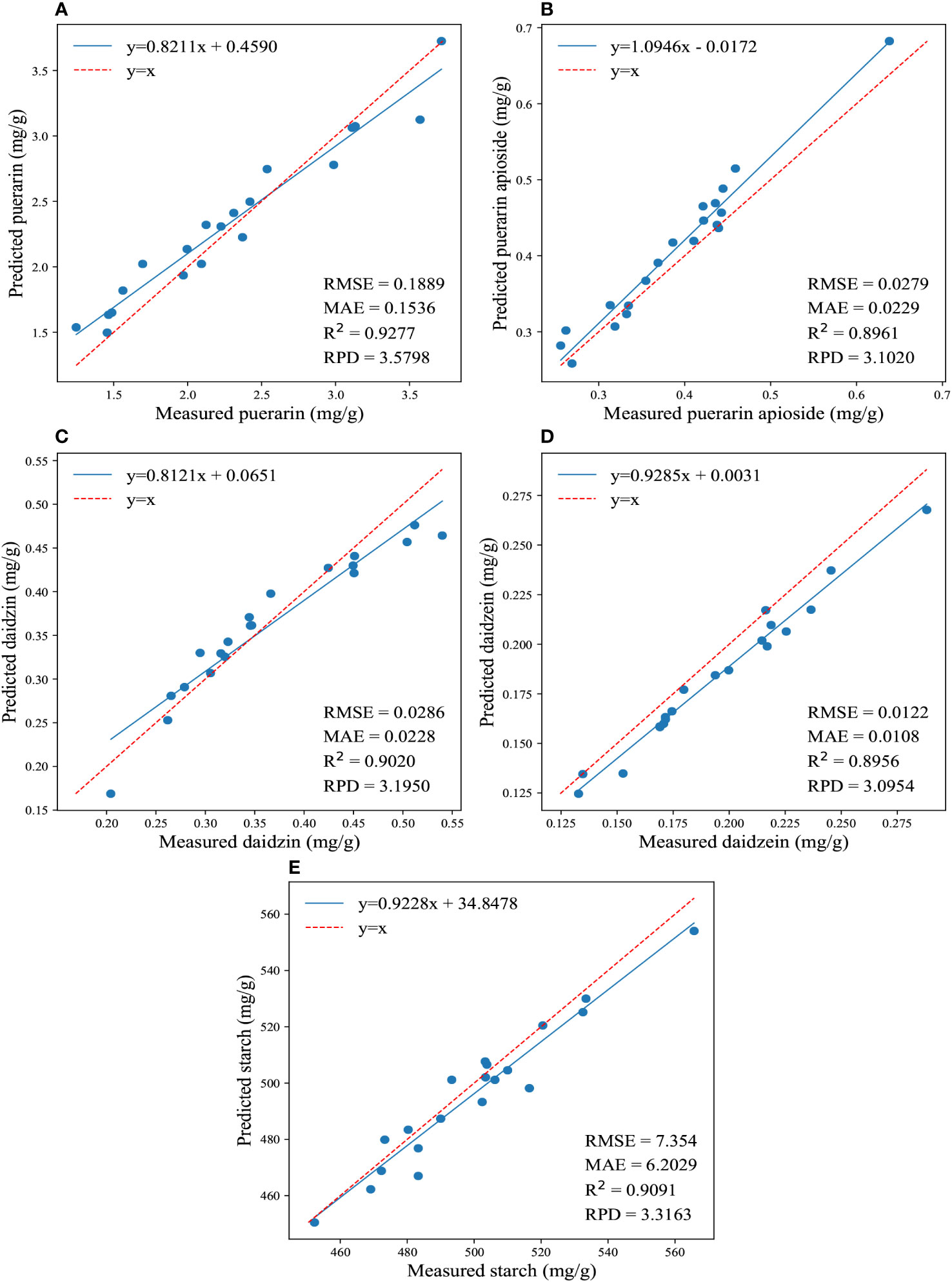
Figure 7 The regression results for the reference and predicted values of the four isoflavones and starch contents are displayed in (A-E), illustrating the prediction of puerarin, puerarin apioside, daidzin, daidzein, and starch contents using the effective wavelengths and 1DCNN.
3.5 Discussion
The constituents and their corresponding concentrations are quintessential to determine the intrinsic quality and commercial value of a material. In this study, we employed a combination of HSI and data analysis techniques to accurately predict the content of key compounds in PTR. Through a comprehensive analysis of the results, it was evident that the integration of HSI with a deep learning model achieved satisfactory predictive performance. Given its convenience, non-destructiveness, and high-efficiency, this approach could serve as a viable and beneficial alternative to complicated physical and chemical procedures. It could be implemented in off‐line rapid analysis or on‐line quality control for quality evaluation of PTR.
First, among the traditional algorithms compared in this study, the performance of PLSR algorithm was found to be relatively stable and moderate overall, which is consistent with its frequent utilization in similar studies involving hyperspectral prediction (Aredo et al., 2017; Hu et al., 2021). However, Catboost algorithm, despite being less commonly used in hyperspectral analysis, emerged as a robust competitor in our study. It outperformed PLSR and SVR in predicting certain components and exhibited slightly superior overall performance compared to PLSR and SVR. This can be attributed to CatBoost’s unique characteristics, including the utilization of ensemble models, embedded regularization, and automatic handling of categorical features. These features contribute to enhanced learning capability, improved generalization, and increased robustness of the model (Hancock and Khoshgoftaar, 2020). Consequently, CatBoost exhibits better performance in predicting hyperspectral data compared to PLSR and SVR, particularly in scenarios with limited sample sizes. Unsurprisingly, the presence of redundant spectral bands significantly impacts the performance of the algorithms, presenting a notable challenge for traditional methods. In the comparison of various band selection algorithms (SPA, CARS, VUE), it was determined that SPA yielded the best results. Introducing the SPA significantly improved the algorithm’s performance, as observed in numerous similar studies (Zhang et al., 2017; Zhu et al., 2017).
In contrast, our study demonstrates that deep learning methods exhibit superior and robust predictive performance. The average R2 for component prediction reaches 0.9, even without the need for wavelength selection. This remarkable performance can be attributed to the autonomous learning capability of deep learning models, which effectively capture intricate mapping relationships between spectra and components, unaffected by spectral redundancy and noise. These findings are consistent with previous research studies (Dargan et al., 2020; Zhang C. et al., 2020; Wang et al., 2021). Interestingly, our investigation reveals that the introduction of wavelength selection does not significantly enhance the performance. This observation may be attributed to the distinct approach of CNN as end-to-end learning models, which differ in learning feature representations compared to traditional methods. Consequently, the feature subset selected for traditional models may have limited impact on CNNs, leading to negligible performance improvements. Moreover, it is worth mentioning that the 1DCNN used in our study was relatively simple, incorporating commonly used convolution and pooling modules. Recent advancements in deep learning have introduced innovative techniques, particularly attention mechanisms, which enable models to differentially process various features (Sun et al., 2019). By assigning greater weights to key features, attention mechanisms enhance the influence of crucial features, thereby facilitating more accurate judgments and predictions in spectral classification and prediction tasks (Zhang et al., 2022a; Wang Y. et al., 2023). Therefore, the utilization of more complex deep networks and mechanisms, such as attention, holds potential for further improving prediction performance.
Furthermore, although CNN have shown remarkable success in various component prediction tasks (Dargan et al., 2020; Zhang C. et al., 2020; Wang et al., 2021; Zhang et al., 2022a), including the findings of this study, they are not without limitations. One such limitation is the challenge in interpreting the learning process of CNNs. The interpretability of deep learning can be crucial in understanding and explaining the importance of specific spectral bands (Zhang L. et al., 2020). Furthermore, to fully harness the power of deep learning models, a larger quantity of collected sample data is expected. Currently, some studies have started exploring the utilization of generative adversarial networks (GANs) for generating reliable synthetic spectral data as a form of data augmentation (Wang et al., 2019; Zhang et al., 2022b). This technique has demonstrated the potential to further enhance the performance of CNNs in spectral prediction tasks.
Finally, with the deepening comprehension of the intrinsic mechanisms of CNNs, research combining CNNs and spectroscopy for food quality evaluation has been gaining momentum. These studies indicate that CNNs still hold strong potential even in small sample scenarios and, in many cases, outperform traditional modeling methods (Zhang C. et al., 2020; Zhang et al., 2021; Li et al., 2023), consistent with the findings of this study. Therefore, further development of the combination of CNNs and spectroscopy, leveraging the strengths of CNNs in processing images and high-dimensional data, is expected to bring new advances in fields such as food analysis and quality assessment. However, it is important to address and mitigate the drawbacks and limitations of CNNs, employing targeted strategies in their application.
4 Conclusions
The accurate detection of isoflavones and starch content in PTR is of paramount importance in ensuring its quality and safety. In this study, we pioneered a noninvasive, efficient detection method using HSI and machine learning algorithms to predict puerarin, puerarin apioside, daidzin, daidzein, and starch content in PTR. By employing various spectral preprocessing techniques and wavelength selection methods, we compared several traditional machine learning algorithms (PLS, SVM, CatBoost) with a 1DCNN model. Our results unequivocally demonstrated that the combination of HSI and 1DCNN yielded superior predictive performance, with an average R2 exceeding 0.9 for all components. Importantly, unlike traditional methods, the performance of the 1DCNN model was not significantly dependent on feature wavelength selection.
Overall, our findings highlight the tremendous potential of HSI coupled with a deep learning model in simultaneously determining multiple key components in PTR. Considering the advantages of spectral detection, this approach offers a viable and efficient solution for non-destructive quality control assessment of PTR, which can be applicable to both off-line and on-line settings. Furthermore, future research can delve into advanced deep learning techniques like attention mechanisms to boost predictive capabilities and broaden HSI applications in quality assessment.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Author contributions
HH: Data curation, Writing – original draft. TW: Investigation, Writing – review & editing. YW: Data curation, Writing – review & editing. ZX: Methodology, Writing – review & editing. SC: Data curation, Writing – review & editing. LF: Data curation, Formal Analysis, Writing – review & editing. HX: Writing – review & editing. XM: Writing – review & editing. LH: Funding acquisition, Investigation, Writing – review & editing.
Funding
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This work was supported by the Key Project at Central Government Level (grant numbers 2060302-2101-26) and the Innovation Team and Talents Cultivation Program of National Administration of Traditional Chinese Medicine (grant numbers ZYYCXTD-D-202205).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpls.2023.1271320/full#supplementary-material
Supplementary Table 1 | Prediction results of the content of puerarin, puerarin apioside, daidzin, daidzein, and starch in PTR by traditional models using full wavelengths.
Supplementary Table 2 | Prediction results of the content of puerarin, puerarin apioside, daidzin, daidzein, and starch in PTR by using effective wavelengths and traditional algorithms.
References
Aredo, V., Velásquez, L., Siche, R. (2017). Prediction of beef marbling using hyperspectral imaging (hsi) and partial least squares regression (plsr). Sci. Agropecuaria 8 (2), 169–174. doi: 10.17268/sci.agropecu.2017.02.09
Barbin, D. F., ElMasry, G., Sun, D.-W., Allen, P. (2013). Non-destructive determination of chemical composition in intact and minced pork using near-infrared hyperspectral imaging. Food Chem. 138 (2-3), 1162–1171. doi: 10.1016/j.foodchem.2012.11.120
Cai, Z., Huang, Z., He, M., Li, C., Qi, H., Peng, J., et al. (2023). Identification of geographical origins of radix paeoniae alba using hyperspectral imaging with deep learning-based fusion approaches. Food Chem. 422, 136169. doi: 10.1016/j.foodchem.2023.136169
Cai, W., Li, Y., Shao, X. (2008). A variable selection method based on uninformative variable elimination for multivariate calibration of near-infrared spectra. Chemometrics Intelligent Lab. Syst. 90 (2), 188–194. doi: 10.1016/j.chemolab.2007.10.001
Chen, Y., Cai, W., Xu, B. (2017). Phytochemical profiles of edible kudzu (pueraria thomsonii benth) grown in China as affected by thermal processing. J. Food Process. Preservation 41 (1), e12754.
Chen, Y. G., Song, Y. L., Wang, Y., Yuan, Y. F., Huang, X. J., Ye, W. C., et al. (2014). Metabolic differentiations of pueraria lobata and pueraria thomsonii using 1h nmr spectroscopy and multivariate statistical analysis. J. Pharm. Biomed. Anal. 93, 51–58. doi: 10.1016/j.jpba.2013.05.017
Dargan, S., Kumar, M., Ayyagari, M. R., Kumar, G. (2020). A survey of deep learning and its applications: a new paradigm to machine learning. Arch. Comput. Methods Eng. 27, 1071–1092. doi: 10.1007/s11831-019-09344-w
Dhiman, H. S., Deb, D., Guerrero, J. M. (2019). Hybrid machine intelligent svr variants for wind forecasting and ramp events. Renewable Sustain. Energy Rev. 108, 369–379. doi: 10.1016/j.rser.2019.04.002
Dorogush, A. V., Ershov, V., Gulin, A. (2018). Catboost: gradient boosting with categorical features support. arXiv preprint arXiv 1810.11363, 2018
Femenias, A., Bainotti, M. B., Gatius, F., Ramos, A. J., Marín, S. (2021). Standardization of near infrared hyperspectral imaging for wheat single kernel sorting according to deoxynivalenol level. Food Res. Int. 139, 109925. doi: 10.1016/j.foodres.2020.109925
Fu, M., Jahan, M. S., Tang, K., Jiang, S., Guo, J., Luo, S., et al. (2023). Comparative analysis of the medicinal and nutritional components of different varieties of pueraria thomsonii and pueraria lobata. Front. Plant Sci. 14, 1028. doi: 10.3389/fpls.2023.1115782
Hancock, J. T., Khoshgoftaar, T. M. (2020). Catboost for big data: an interdisciplinary review. J. Big Data 7 (1), 1–45. doi: 10.1186/s40537-020-00369-8
He, H.-J., Chen, Y., Li, G., Wang, Y., Ou, X., Guo, J. (2023). Hyperspectral imaging combined with chemometrics for rapid detection of talcum powder adulterated in wheat flour. Food Control 144, 109378. doi: 10.1016/j.foodcont.2022.109378
He, X., Liu, X., Nie, B., Song, D. (2017). Ftir and raman spectroscopy characterization of functional groups in various rank coals. Fuel 206, 555–563. doi: 10.1016/j.fuel.2017.05.101
He, H.-J., Wu, D., Sun, D.-W. (2013). Non-destructive and rapid analysis of moisture distribution in farmed atlantic salmon (salmo salar) fillets using visible and near-infrared hyperspectral imaging. Innovative Food Sci. Emerg. Technol. 18, 237–245. doi: 10.1016/j.ifset.2013.02.009
Hu, N., Li, W., Du, C., Zhang, Z., Gao, Y., Sun, Z., et al. (2021). Predicting micronutrients of wheat using hyperspectral imaging. Food Chem. 343, 128473. doi: 10.1016/j.foodchem.2020.128473
Jia, B., Wang, W., Ni, X., Lawrence, K. C., Zhuang, H., Yoon, S. C., et al. (2020). Essential processing methods of hyperspectral images of agricultural and food products. Chemometrics Intelligent Lab. Syst. 198, 103936. doi: 10.1016/j.chemolab.2020.103936
Kang, Z., Zhao, Y., Chen, L., Guo, Y., Mu, Q., Wang, S. (2022). Advances in machine learning and hyperspectral imaging in the food supply chain. Food Eng. Rev. 14 (4), 596–616. doi: 10.1007/s12393-022-09322-2
Lai, Y., Quan, H., Shao, F., Meng, X., Zhu, W., Zhang, P., et al. (2020). Three new isoflavones from pueraria thomsonii benth and their protective effects on h2o2-induced oxidative injury in h9c2 cardiomyocytes. Phytochem. Lett. 39, 90–93. doi: 10.1016/j.phytol.2020.07.013
Li, Y., Kumar, P. S., Ran, Y., Tan, X., Zhao, R., Ai, L., et al. (2022a). Production of bioactive compounds from callus of pueraria thomsonii benth with promising cytotoxic and antibacterial activities. Arabian J. Chem. 15 (6), 103854. doi: 10.1016/j.arabjc.2022.103854
Li, H., Liang, Y., Xu, Q., Cao, D. (2009). Key wavelengths screening using competitive adaptive reweighted sampling method for multivariate calibration. Analytica Chim. Acta 648 (1), 77–84. doi: 10.1016/j.aca.2009.06.046
Li, Q., Liu, W., Feng, Y., Hou, H., Zhang, Z., Yu, Q., et al. (2022). Radix puerariae thomsonii polysaccharide (rpp) improves inflammation and lipid peroxidation in alcohol and high-fat diet mice by regulating gut microbiota. Int. J. Biol. Macromol. 209, 858–870. doi: 10.1016/j.ijbiomac.2022.04.067
Li, Y., Ma, B., Li, C., Yu, G. (2022b). Accurate prediction of soluble solid content in dried hami jujube using swir hyperspectral imaging with comparative analysis of models. Comput. Electron. Agric. 193, 106655. doi: 10.1016/j.compag.2021.106655
Li, P., Tang, S., Chen, S., Tian, X., Zhong, N. (2023). Hyperspectral imaging combined with convolutional neural network for accurately detecting adulteration in atlantic salmon. Food Control 147, 109573. doi: 10.1016/j.foodcont.2022.109573
Liang, J., Maeda, T., Tao, X. L., Wu, Y. H., Tang, H. J. (2017). Physicochemical properties of pueraria root starches and their effect on the improvement of buckwheat noodle quality. Cereal Chem. 94 (3), 554–559. doi: 10.1094/CCHEM-08-16-0219-R
Liu, D., Ma, L., Zhou, Z., Liang, Q., Xie, Q., Ou, K., et al. (2021). Starch and mineral element accumulation during root tuber expansion period of pueraria thomsonii benth. Food Chem. 343, 128445. doi: 10.1016/j.foodchem.2020.128445
Lü, C, Jiang, X, Zhou, X, Zhang, Y, Zhang, N, Wei, C, et al. (2017) Variable selection based near infrared spectroscopy quantitative and qualitative analysis on wheat wet gluten. AOPC 2017: Optical Spectroscopy and Imaging. SPIE. 10461, 20–27.
Mansuri, S. M., Chakraborty, S. K., Mahanti, N. K., Pandiselvam, R. (2022). Effect of germ orientation during vis-nir hyperspectral imaging for the detection of fungal contamination in maize kernel using pls-da. Ann. 1d-cnn Modelling Food Control 139, 109077. doi: 10.1016/j.foodcont.2022.109077
Mishra, P., Passos, D. (2021). Deep multiblock predictive modelling using parallel input convolutional neural networks. Analytica Chim. Acta 1163, 338520.
Niu, Y., Li, H., Dong, J., Wang, H., Hashi, Y., Chen, S. (2012). Identification of isoflavonoids in radix puerariae for quality control using on-line high performance liquid chromatography-diode array detector-electrospray ionizationmass spectrometry coupled with post-column derivatization. Food Res. Int. 48 (2), 528–537. doi: 10.1016/j.foodres.2012.05.021
Ozaki, Y. (2012). Near-infrared spectroscopy—its versatility in analytical chemistry. Analytical Sci. 28 (6), 545–563. doi: 10.2116/analsci.28.545
Ozaki, Y. (2021). Infrared spectroscopy—mid-infrared, near-infrared, and farinfrared/terahertz spectroscopy. Analytical Sci. 37 (9), 1193–1212. doi: 10.2116/analsci.20R008
Ozaki, Y., Huck, C., Tsuchikawa, S., Engelsen, S. B. (2021). Near-infrared spectroscopy: theory, spectral analysis, instrumentation, and applications. Singapore: Springer. doi: 10.1007/978-981-15-8648-4
Qiu, T., Yang, Y., Sun, H., Hu, T., Wang, X., Wang, Y., et al. (2021). Rapid discrimination and quantification of kudzu root with its adulterant part using ft-nir and a machine learning algorithm. Vibrational Spectrosc. 116, 103289. doi: 10.1016/j.vibspec.2021.103289
Reddy, C. K., Luan, F., Xu, B. (2017). Morphology, crystallinity, pasting, thermal and quality characteristics of starches from adzuki bean (vigna angularis l.) and edible kudzu (pueraria thomsonii benth). Int. J. Biol. Macromol. 105, 354–362. doi: 10.1016/j.ijbiomac.2017.07.052
Roggo, Y., Jent, N., Edmond, A., Chalus, P., Ulmschneider, M. (2005). Characterizing process effects on pharmaceutical solid forms using near-infrared spectroscopy and infrared imaging. Eur. J. Pharmaceut. Biopharmaceut. 61 (1-2), 100–110. doi: 10.1016/j.ejpb.2005.04.005
Saha, D., Manickavasagan, A. (2021). Machine learning techniques for analysis of hyperspectral images to determine quality of food products: A review. Curr. Res. Food Sci. 4, 28–44. doi: 10.1016/j.crfs.2021.01.002
Shang, X., Huang, D., Wang, Y., Xiao, L., Ming, R., Zeng, W., et al. (2021). Identification of nutritional ingredients and medicinal components of pueraria lobata and its varieties using uplc-ms/ms-based metabolomics. Molecules 26 (21), 6587. doi: 10.3390/molecules26216587
Soni, A., Al-Sarayreh, M., Reis, M. M., Brightwell, G. (2021). Hyperspectral imaging and deep learning for quantification of clostridium sporogenes spores in food products using 1d-convolutional neural networks and random forest model. Food Res. Int. 147, 110577. doi: 10.1016/j.foodres.2021.110577
Sun, H., Zheng, X., Lu, X., Wu, S. (2019). Spectral–patial attention network for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 58 (5), 3232–3245.
Teixido-Orries, I., Molino, F., Femenias, A., Ramos, A. J., Marín, S. (2023). Quantification and classification of deoxynivalenol-contaminated oat samples by near-infrared hyperspectral imaging. Food Chem. 417, 135924. doi: 10.1016/j.foodchem.2023.135924
Tsuchikawa, S., Kobori, H. (2015). A review of recent application of near infrared spectroscopy to wood science and technology. J. Wood Sci. 61 (3), 213–220. doi: 10.1007/s10086-015-1467-x
Wagle, A., Seong, S. H., Jung, H. A., Choi, J. S. (2019). Identifying an isoflavone from the root of pueraria lobata as a potent tyrosinase inhibitor. Food Chem. 276, 383–389. doi: 10.1016/j.foodchem.2018.10.008
Wang, C., Liu, B., Liu, L., Zhu, Y., Hou, J., Liu, P., et al. (2021). A review of deep learning used in the hyperspectral image analysis for agriculture. Artif. Intell. Rev. 54 (7), 5205–5253. doi: 10.1007/s10462-021-10018-y
Wang, D., Vinson, R., Holmes, M., Seibel, G., Bechar, A., Nof, S., et al. (2019). Early detection of tomato spotted wilt virus by hyperspectral imaging and outlier removal auxiliary classifier generative adversarial nets (or-ac-gan). Sci. Rep. 9 (1), 1–14. doi: 10.1038/s41598-019-40066-y
Wang, L., Wang, Q., Liu, H., Liu, L., Du, Y. (2013). Determining the contents of protein and amino acids in peanuts using near-infrared reflectance spectroscopy. J. Sci. Food Agric. 93 (1), 118–124. doi: 10.1002/jsfa.5738
Wang, Y., Xiong, F., Zhang, Y., Wang, S., Yuan, Y., Lu, C., et al. (2023). Application of hyperspectral imaging assisted with integrated deep learning approaches in identifying geographical origins and predicting nutrient contents of coix seeds. Food Chem. 404, 134503. doi: 10.1016/j.foodchem.2022.134503
Wang, S., Yao, W., Zhu, X., Wang, J., Lu, L., Zhu, N., et al. (2023). Exploring the mechanism of the antithrombotic effects of pueraria lobata and pueraria lobata var. thomsonii based on network pharmacology. J. Ethnopharmacol. 300, 115701. doi: 10.1016/j.jep.2022.115701
Wong, K. H., Razmovski Naumovski, V., Li, K. M., Li, G. Q., Chan, K. (2015). The quality control of two pueraria species using raman spectroscopy coupled with partial least squares analysis. J. Raman Spectrosc. 46 (4), 361–368. doi: 10.1002/jrs.4652
Xu, X., Zheng, N., Chen, Z., Huang, W., Liang, T., Kuang, H. (2016). Puerarin, isolated from pueraria lobata (willd.), protects against diabetic nephropathy by attenuating oxidative stress. Gene 591 (2), 411–416.
Zeng, F., Li, T., Zhao, H., Chen, H., Yu, X., Liu, B. (2019). Effect of debranching and temperature-cycled crystallization on the physicochemical properties of kudzu (pueraria lobata) resistant starch. Int. J. Biol. Macromol. 129, 1148–1154. doi: 10.1016/j.ijbiomac.2019.01.028
Zeng, F., Shao, W., Kang, J., Yang, J., Zhang, X., Liu, Y., et al. (2022). Detection of moisture content in salted sea cucumbers by hyperspectral and low field nuclear magnetic resonance based on deep learning network framework. Food Res. Int. 156, 111174. doi: 10.1016/j.foodres.2022.111174
Zhang, L., An, D., Wei, Y., Liu, J., Wu, J. (2022a). Prediction of oil content in single maize kernel based on hyperspectral imaging and attention convolution neural network. Food Chem. 395, 133563. doi: 10.1016/j.foodchem.2022.133563
Zhang, L., Guan, Y., Wang, N., Ge, F., Zhang, Y., Zhao, Y. (2023). Identification of growth years for puerariae thomsonii radix based on hyperspectral imaging technology and deep learning algorithm. Sci. Rep. 13 (1), 14286.
Zhang, C., Jiang, H., Liu, F., He, Y. (2017). Application of near-infrared hyperspectral imaging with variable selection methods to determine and visualize caffeine content of coffee beans. Food Bioprocess Technol. 10, 213–221. doi: 10.1007/s11947-016-1809-8
Zhang, Y., Jiang, H., Wang, W. (2019). Feasibility of the detection of carrageenan adulteration in chicken meat using visible/near-infrared (vis/nir) hyperspectral imaging. Appl. Sci. 9 (18), 3926. doi: 10.3390/app9183926
Zhang, L., Sun, H., Rao, Z., Ji, H. (2020). Non-destructive identification of slightly sprouted wheat kernels using hyperspectral data on both sides of wheat kernels. Biosyst. Eng. 200, 188–199. doi: 10.1016/j.biosystemseng.2020.10.004
Zhang, L., Wang, Y., Wei, Y., An, D. (2022b). Near-infrared hyperspectral imaging technology combined with deep convolutional generative adversarial network to predict oil content of single maize kernel. Food Chem. 370, 131047. doi: 10.1016/j.foodchem.2021.131047
Zhang, C., Wu, W., Zhou, L., Cheng, H., Ye, X., He, Y. (2020). Developing deep learning based regression approaches for determination of chemical compositions in dry black goji berries (Lycium ruthenicum Murr.) using near-infrared hyperspectral imaging. Food Chem. 319, 126536.
Zhang, Y., Xu, D., Xing, X., Yang, H., Gao, W., Project, P. L. (2023). The chemistry and activity-oriented characterization of isoflavones difference between roots of pueraria lobata and p. thomsonii guided by feature-based molecular networking. Food Chem. 422, 136198.
Zhang, X., Yang, J., Lin, T., Ying, Y. (2021). Food and agro-product quality evaluation based on spectroscopy and deep learning: A review. Trends Food Sci. Technol. 112, 431–441. doi: 10.1016/j.tifs.2021.04.008
Zhou, Y. X., Zhang, H., Peng, C. (2014). Puerarin: a review of pharmacological effects. Phytother. Res. 28 (7), 961–975. doi: 10.1002/ptr.5083
Zhou, X., Zhao, C., Sun, J., Cao, Y., Yao, K., Xu, M. (2023). A deep learning method for predicting lead content in oilseed rape leaves using fluorescence hyperspectral imaging. Food Chem. 409, 135251. doi: 10.1016/j.foodchem.2022.135251
Zhu, H., Chu, B., Zhang, C., Liu, F., Jiang, L., He, Y. (2017). Hyperspectral imaging for presymptomatic detection of tobacco disease with successive projections algorithm and machine-learning classifiers. Sci. Rep. 7 (1), 4125.
Keywords: Puerariae Thomsonii Radix, isoflavones and starch content, hyperspectral imaging, deep learning, one-dimensional convolutional neural network
Citation: Hu H, Wang T, Wei Y, Xu Z, Cao S, Fu L, Xu H, Mao X and Huang L (2023) Non-destructive prediction of isoflavone and starch by hyperspectral imaging and deep learning in Puerariae Thomsonii Radix. Front. Plant Sci. 14:1271320. doi: 10.3389/fpls.2023.1271320
Received: 02 August 2023; Accepted: 03 October 2023;
Published: 25 October 2023.
Edited by:
Muhammad Fazal Ijaz, Melbourne Institute of Technology, AustraliaReviewed by:
Rudiati Evi Masithoh, Gadjah Mada University, IndonesiaAbid Hussain, Karakoram International University, Pakistan
Copyright © 2023 Hu, Wang, Wei, Xu, Cao, Fu, Xu, Mao and Huang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Huaxing Xu, eHVodWF4aW5nQHp6dS5lZHUuY24=; Xiaobo Mao, bWFpbC1teGJAenp1LmVkdS5jbg==