
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
MINI REVIEW article
Front. Physiol. , 07 January 2016
Sec. Systems Biology Archive
Volume 6 - 2015 | https://doi.org/10.3389/fphys.2015.00413
This article is part of the Research Topic The impact of systems medicine on human health and disease View all 11 articles
 Cheng Zhang1
Cheng Zhang1 Qiang Hua1,2*
Qiang Hua1,2*Genome-scale metabolic models (GEMs) have become a popular tool for systems biology, and they have been used in many fields such as industrial biotechnology and systems medicine. Since more and more studies are being conducted using GEMs, they have recently received considerable attention. In this review, we introduce the basic concept of GEMs and provide an overview of their applications in biotechnology, systems medicine, and some other fields. In addition, we describe the general principle of the applications and analyses built on GEMs. The purpose of this review is to introduce the application of GEMs in biological analysis and to promote its wider use by biologists.
Genome-scale metabolic models (GEMs) are reconstructions of the metabolic networks of many kinds of cells, including those of microorganisms, plants, and mammals. In some cases, GEMs could represent the whole tissue or body of a multicellular organism. In these metabolic networks, the gene-protein-reaction (GPR) relationships are annotated. In addition, all the reactions in GEMs are mass- and energy-balanced, ensuring stoichiometric balance. Thus, GEMs enable researchers to conduct system-level metabolic response analysis and flux simulation, which is not possible using general metabolic pathway databases such as KEGG. Furthermore, since GPR relationships are included in GEMs, other omics data such as transcriptomic and proteomic data could be systematically integrated into GEMs. Thus, GEM-based multi-omic analyses are more informative with stoichiometric balance and could possibly provide deeper biological insights.
In the past 15 years, GEMs have garnered considerable research attention. In 2000, the first GEM, a model of Escherichia coli MG1655, was reported (Edwards and Palsson, 2000). A few years later, a yeast GEM was published (Doerks et al., 2002), thus initiating a new era for systems biology. In the beginning, researchers tried to use GEM-based in silico simulations to guide the rational design of industrial microorganisms (hereafter referred to as in silico metabolic engineering). In 2003, a method called OptKnock (Burgard et al., 2003) was published and it employed a bi-level optimization program to search for reaction knockout targets that would yield overproduction of a desired biochemical while maintaining optimal growth. Following that, a series of in silico metabolic engineering methods were developed for various gene manipulations other than knock-out (Pharkya et al., 2004; Pharkya and Maranas, 2006; Choi et al., 2010; Ranganathan et al., 2010; Park et al., 2012; Chowdhury et al., 2014; Mahalik et al., 2014), leading to a marked expansion in the usage of GEMs. Furthermore, many of the in silico metabolic engineering methods were experimentally validated (Fong et al., 2005; Izallalen et al., 2008; Asadollahi et al., 2009; Brochado et al., 2010; Choi et al., 2010; Yim et al., 2011; Xu et al., 2011; Park et al., 2012; Ranganathan et al., 2012; Otero et al., 2013; Kim et al., 2014), which showed the power of GEM-based applications. With the development of systems biology, GEMs were also used as scaffolds for systematic integration of omics data because GEMs could be used to reconstruct the relationship among genes, enzymes, and metabolism. Numerous algorithms have been developed to integrate various types of omics data such as thermodynamics (Henry et al., 2007), transcriptomics/proteomics (Becker and Palsson, 2008; Colijn et al., 2009; Zur et al., 2010), fluxomics (Wiback et al., 2004), and metabolomics (Cakir et al., 2006). In return, the integration of omics data could improve the prediction of GEMs. More recently, GEM has been applied to systems medicine. Since the reconstruction of the first global GEM for humans, Recon 1, which was established in 2007 (Duarte et al., 2007), researchers have started to explore the possibility of clinical applications of GEMs and have reported several successful cases (Agren et al., 2014; Gatto et al., 2014; Jerby-Arnon et al., 2014). In fact, GEMs and their applications have received considerable attention recently.
Although GEMs are becoming increasingly popular, they are not easy to understand or use by non-experts. The complex code and script usually used for GEM-based computational applications and analyses are not readily available to the community of biologists, greatly hampering the wide usage of GEMs. In this review, we describe the key concepts and assumptions of GEMs. In addition, we describe the general principle of the applications and analyses built on GEMs. The information presented here is expected to promote the spread of GEM usage by biologists.
As mentioned above, GEMs are metabolic networks. Figure 1A shows a partly visualized glycolysis pathway in a GEM of E. coli, and within this part, we can see that metabolites are linked with each other by reactions, which are associated with enzymes, which are encoded by genes. It should be noted that the stoichiometric coefficient in metabolic reactions in Figure 1A (as shown in Figure 1B) could not be visualized in a graph. Therefore, GEMs employ a stoichiometric matrix (S matrix) to represent all the coefficients in metabolic reactions (Figure 1C). In the S matrix, the ijth element represents the stoichiometric coefficient of the ith metabolite in the jth reaction in the GEM. If the coefficient is positive, the metabolite is produced; otherwise, it's consumed. In addition, the GPR relationships in GEMs are simplified into a two-dimensional binary matrix showing the association between genes and reactions (Figure 1D), in which the ijth element is one if the ith reaction is associated with the jth gene, and it's zero if they aren't associated.
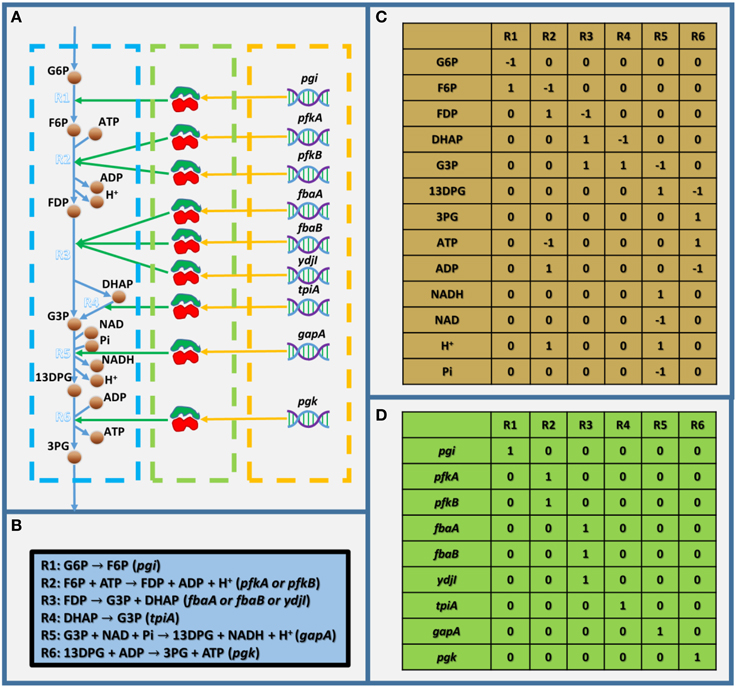
Figure 1. Toy model showing the basic structure of GEMs. (A) Visualized toy model,(B) biochemical equations within the toy model, (C) stoichiometric matrix of the toy model, and (D) gene-reaction association matrix. In (A), the dashed blue, green, and orange frames indicate the metabolic reactions, enzymes, and genes, respectively. G6P, D-glucose-6-phosphate; F6P, D-fructose-6-phosphate; FDP, D-fructose-1-6-bisphosphate; G3P, glyceraldehyde-3-phosphate; 13DPG, 3-phospho-D-glyceroyl-phosphate; 3PG, 3-phospho-D-glycerate; and Pi, phosphate.
GEMs have several notable features: (1) They are collections of existing knowledge of the metabolism of a specific organism, and in most GEM-based applications, it's assumed that the metabolic network is complete, with very few exceptions, such as for gap finding and gap filling (Latendresse, 2014). (2) They are stoichiometric-balanced networks, which means mass as well as energy balance, reduction, and proton balance are well considered. (3) GPR relationships are annotated in GEMs, but the interactions are not quantitatively described. (4) Even though GEMs describe the metabolism, concentrations of metabolites are not directly included and flux balance analysis (FBA; Orth et al., 2010) is employed for flux simulations, which assumes that there is no (unexpected) accumulation of metabolites within GEMs.
As mentioned above, since GEMs are complete metabolic networks, they can be used for gene/reaction essentiality analysis (EA; Edwards and Palsson, 2000). In general, EA identifies all essential genes or reactions whose knockout will disable a specific biological function through FBA. EA could be easily implemented in silico using GEMs by enumerating all single gene/reaction knockouts and testing whether their biological objectives are still functioning. In addition, synthetic lethality analysis (SLA), which scans for combinatory knockouts of multiple reactions/genes that lead to blocking of the target biological function, could also be implemented in a similar way. And recently, several methods have been developed to perform advanced SLA efficiently (Suthers et al., 2009; von Kamp and Klamt, 2014; Pratapa et al., 2015; Zhang et al., 2015).
It's generally believed that gene/reaction EA could be performed by topologic analysis of the metabolic network. However, since the stoichiometric coefficients are absent in topologic metabolic networks, they're less accurate. For example, Figure 2 shows the topologic network of the toy model from Figure 1. Based on its topologic properties, this metabolic work can use D-glucose-6-phosphate, NAD, and phosphate as substrates and produce 3-phospho-D-glycerate, NADH, and a proton. However, this pathway always consumes more ADP than it produces, and produces more ATP than it consumes. Therefore, this pathway will be blocked without ADP supplementation and this finding was not possible by topologic analysis.
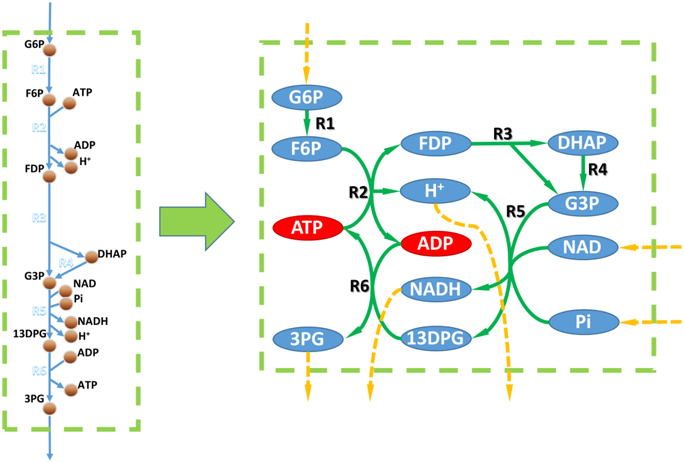
Figure 2. Metabolic networks vs. GEMs. Left, metabolic part of the toy model in Figure 1. Right, metabolic network based on the toy model. Circles linked to a dashed orange arrow are unbalanced metabolites within the metabolic network according to topological analysis. Red circles in the right part are metabolites that could not be balanced according to the flux balance analysis based on the toy model.
Essentially, if a GEM is well established, its EA and SLA results could be very accurate. For example, in the most used E. coli and S. cerevisiae GEMs, around 90% of the predicted essential genes have been validated in vivo (true-negative; Feist et al., 2007; Heavner et al., 2013). This is within expectation, because if a function is blocked in silico, it's very unlikely that there could be a complimentary solution in vivo to recover it. The explanation for the very few false-negative predictions (negative growth in silico and positive growth in vivo) is that there's a knowledge gap, such as unknown enzyme or unknown function of an existing enzyme, which leads to the underestimation of the capability of the GEM. On the other hand, even if the GEMs are 100% complete, there may still be false-positive predictions since the missing information of regulation and protein (enzyme) efficiency could lead to extra constraints to GEMs, thereby rendering a nonessential reaction/gene in silico essential in vivo. It's worth mentioning that, after a certain period of adaptive evolution, a false-positive knockout could become nonessential in vivo again (Patil et al., 2005). EA and SLA have mainly been used to validate newly constructed GEMs and in recent years, EA and SLA were applied to study of systems medicine (see Section Using GEMs in Studies of Systems Medicine).
Recently, increasing volumes of transcriptomic, proteomic, and metabolomics data are becoming publically available, and it's believed that GEMs are good scaffolds to make use of these multi omics data. In GEMs, omics data could be quantitatively integrated as constraints for metabolic fluxes, thereby allowing systematic and quantitative evaluation of these data, which was not possible using traditional metabolic networks. This is the most significant advantage of using GEMs as scaffolds.
Although, GEMs are metabolic networks, the most used omic data for GEMs are transcriptomic and proteomic. This is because the technic is really advancing in the field and makes large number of high quality transcriptomic and proteomic data available. However, since the GPR relationships are qualitative in GEMs (Figure 1C), one needs to make assumptions to define the quantitative relationship between gene/protein expression and metabolic fluxes when integrating transcriptomic or proteomic data into GEMs. This is problematic because the complicated relation between fluxes and expression level of genes and enzymes in vivo are unlikely to be captured by a general assumption (MacHado and Herrgård, 2014). On the other hand, there're many well-defined approaches to integrate fluxomics and metabolomics, data (Khodayari et al., 2014; Martín et al., 2015; Miskovic et al., 2015). However, it's very difficult (if not impossible) to get genome scale data of them. Hence, we suggest that even though omics data are integrated, one should be skeptical about the quantitative results of simulations or predictions from GEMs.
Nonetheless, we believe that it is better to qualitatively interpret the omics data using GEMs. For instance, it would be much more reliable to use omics data to determine the presence or absence of reactions and to construct high-quality and specific GEMs (Zur et al., 2010; Agren et al., 2012, 2014; Mardinoglu et al., 2013; Yizhak et al., 2014). In addition, many researchers started to integrate significance of differential expression of genes with GEMs rather than their quantitative expression to interpret the biological information behind omic data (Patil and Nielsen, 2005; Cakir et al., 2006; Jensen and Papin, 2011; Fang et al., 2012; Navid and Almaas, 2012). Moreover, qualitative interpretation of omics data with GEMs have recently been applied to systems medicine (see Section Using GEMs in Studies of Systems Medicine). These studies demonstrated the usefulness of GEMs as scaffolds. In short, we suggest that GEMs are powerful platforms for integration of omics data for gaining biological insights rather than quantitative results.
Using GEMs for in silico metabolic engineering has been a widely discussed topic for years. It's generally believed that GEM-based methods could predict gene modification strategies for overproduction of desired biochemicals and thus, accelerate the overall metabolic engineering process. In the last decade, various kinds of in silico metabolic engineering methods had been developed and many of them were applied experimentally (Kim et al., 2015; Long et al., 2015; MacHado and Herrgård, 2015).
Although in silico metabolic engineering methods seemed quite different from each other, they follow a similar procedure: (1) they define what a desired strain is and (2) identify approaches that push the wild-type strain to become the desired one. So far, a variety of approaches were used in in silico metabolic engineering, such as reaction/gene knock-out (Burgard et al., 2003; Patil et al., 2005; Kim et al., 2012; Ren et al., 2013; Ruckerbauer et al., 2014; Zhang et al., 2015), overexpression/suppression (Pharkya and Maranas, 2006; Choi et al., 2010; Ranganathan et al., 2010; Park et al., 2012; Chowdhury et al., 2014), foreign pathway knock-in (Pharkya et al., 2004), and swapping the co-factor for a target enzyme (NADH to NADPH or vice versa; King and Feist, 2013). However, the methods for knock-out identification are the majority since a knockout is much easier to define in silico than up-/down-regulation of genes as mentioned before. On the other hand, different methods could have independent definition of desired strains. For instance, some of the methods define the desired strain by simply setting thresholds for growth and production, respectively, and others could define the desired strain following some biological assumptions (Edwards et al., 2001; Segrè et al., 2002).
Interestingly, methods pursuing different type of desired strains could all lead to experimentally valid strategies for metabolic engineering (Fong et al., 2005; Trinh et al., 2008; Fowler et al., 2009; Choi et al., 2010; Yim et al., 2011; Ng et al., 2012; Nocon et al., 2014), but the production of target products predicted in silico seldom achieved in vivo. The explanation to this is complicated, and could come from both the computational and experimental side. However, one of the key reasons should be that GEM with only metabolic network is not enough to quantitatively predict the behavior of strains in vivo. In conclusion, we suggested that all kinds of in silico metabolic engineering methods are instructive, but it's better to use them for gaining information rather than to develop exact strategies.
Using GEMs for systems medicine studies have recently been highlighted (Mardinoglu and Nielsen, 2015; Yizhak et al., 2015). GEMs simulate the human metabolism in a holistic way, and this greatly advances systems medicine studies by enabling systematic evaluation of metabolic feature of human disease. Great efforts had been made in reconstructing GEMs of human, and there're now several publically available generic human metabolic networks such as Recon 1, Recon 2, EHMN, and HMR (Duarte et al., 2007; Ma et al., 2007; Agren et al., 2012; Thiele et al., 2013). In addition, since the technology is advancing, tissue specific or cell specific genomic, proteomic and transcriptomic data are becoming available (Cancer Genome Atlas Research Network, 2008; Uhlén et al., 2015). These led to rapid development in reconstruction of high quality tissue or cancer specific GEMs (Zur et al., 2010; Agren et al., 2012, 2014; Mardinoglu et al., 2013) and, therefore, enabled more confident interpretation of metabolism of diseases.
For instance, cancer specific GEMs together with EA and SLA analysis were recently used for identification of oncogenes/metabolites and biomarkers for diagnosing specific cancer (Agren et al., 2014; Jerby-Arnon et al., 2014; Gatto et al., 2015; Gatto and Nielsen, 2015). Since this procedure mainly uses the true-negative part of EA and SLA, the analysis could be highly reliable. For example, (Agren et al., 2014) identified 101 drug targets for liver cancer treatment; and 83 of them are currently in use or have shown strong correlation with cancer progression. In addition, together with multi-omic data, GEMs were used to find the mechanistic explanation of various diseases. By interpreting clinical omic data with GEMs, the mechanistic understanding of non-alcoholic fat liver disease and type two diabetes were reported (Mardinoglu et al., 2014; Väremo et al., 2015). Moreover, GEMs were also used to explore the effect of microbiota (Ji and Nielsen, 2015). By simulate and predict the interaction of gut microbiota and their effect on hosts, several recent studies revealed that microbiota modulate the amino acid and glutathione metabolism of their host (Shoaie et al., 2013, 2015; Mardinoglu et al., 2015). These exciting studies exhibited the great potential of GEMs in the field of systems medicine, and hopefully there would be much more excellent works coming out.
GEMs are very useful platforms and tools for systems biology, but they're still very young compared to traditional ones. Fluxes of reactions could be quantitatively simulated using GEMs, although caution should be exercised before drawing conclusions based on simulated fluxes owing to the huge solution space of GEMs (Reed, 2012). Although solution space could be reduced by adding constraints through integration of omics data, it would be better to gain biological insights by qualitative interpretation of omics data rather than quantitative fluxes.
In order to achieve accurate quantitative prediction, the scope of GEMs should be expanded. The establishment of ME-models set a good example for this (Thiele et al., 2009, 2012). In ME-models, the interaction of genes (mRNA), enzymes, and metabolic fluxes are quantitatively expressed, enabling proper integration of transcriptomic and proteomic data. However, it is still difficult to integrate metabolomics data into ME-models. A potential option to integrate metabolite concentration into GEMs is cybernetic modeling. However, to date, there has been no study on genome-scale cybernetic modeling because there are too many parameters to simulate, making it computationally infeasible.
In general, no model is perfect. Genome-scale modeling methods are still under development and have several drawbacks. In addition, it has been recently reported that many published GEMs are of low qualities (Chindelevitch et al., 2014; Ravikrishnan and Raman, 2015). Therefore, they should be used with caution. As concluded in this review, GEMs are more suitable for qualitative applications at this stage, such as EA and SLA analysis. When using GEMs for quantitative applications such as in silico metabolic engineering, one should be aware of the key assumption behind the method and take the results as instructions. However, it should also be noted that, GEMs are open platforms and have great potential in a wide array of applications. Currently, GEMs are used for simulating the interactions between multiple organisms, multiple tissues (Bordbar et al., 2011), and even between microbiota and human tissues. On the other hand, EA and SLA were developed years ago, but they were not used in the discovery of anti-cancer drugs until recent years. These are good examples of how to explore novel applications based on classical methods. Thus, in future, GEMs can be expected to be more widely used in biotechnology, bioengineering, and many other fields.
CZ conducted the writing of this paper, and QH modified and edited it.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
This work was funded by National Basic Research Program of China (973 Program) (2012CB721101), and China Scholarship Council.
Agren, R., Bordel, S., Mardinoglu, A., Pornputtapong, N., Nookaew, N., and Nielsen, J. (2012). Reconstruction of genome-scale active metabolic networks for 69 human cell types and 16 cancer types using INIT. PLoS Comput. Biol. 8:e1002518. doi: 10.1371/journal.pcbi.1002518
Agren, R., Mardinoglu, A., Asplund, A., Kampf, C., Uhlen, M., and Nielsen, J. (2014). Identification of anticancer drugs for hepatocellular carcinoma through personalized genome-scale metabolic modeling. Mol. Syst. Biol. 10, 721. doi: 10.1002/msb.145122
Asadollahi, M. A., Maury, J., Patil, K. R., Schalk, M., Clark, A., and Nielsen, J. (2009). Enhancing sesquiterpene production in Saccharomyces cerevisiae through in silico driven metabolic engineering. Metab. Eng. 11, 328–334. doi: 10.1016/j.ymben.2009.07.001
Becker, S. A., and Palsson, B. O. (2008). Context-specific metabolic networks are consistent with experiments. PLoS Comput. Biol. 4:e1000082. doi: 10.1371/journal.pcbi.1000082
Bordbar, A., Feist, A., Usaite-Black, R., Woodcock, J., Palsson, B., and Famili, I. (2011). A multi-tissue type genome-scale metabolic network for analysis of whole-body systems physiology. BMC Syst. Biol. 5:180. doi: 10.1186/1752-0509-5-180
Brochado, A., Matos, C., Møller, B., Hansen, J., Mortensen, U., and Patil, K. (2010). Improved vanillin production in baker's yeast through in silico design. Microb. Cell Factories 9:84. doi: 10.1186/1475-2859-9-84
Burgard, A. P., Pharkya, P., and Maranas, C. D. (2003). Optknock: a bilevel programming framework for identifying gene knockout strategies for microbial strain optimization. Biotechnol. Bioeng. 84, 647–657. doi: 10.1002/bit.10803
Cakir, T., Patil, K. R., Onsan, Z. I., Ulgen, K. O., Kirdar, B., and Nielsen, J. (2006). Integration of metabolome data with metabolic networks reveals reporter reactions. Mol. Syst. Biol. 2:50. doi: 10.1038/msb4100085
Cancer Genome Atlas Research Network, (2008). Comprehensive genomic characterization defines human glioblastoma genes and core pathways. Nature 455, 1061–1068. doi: 10.1038/nature07385
Chindelevitch, L., Trigg, J., Regev, A., and Berger, B. (2014). An exact arithmetic toolbox for a consistent and reproducible structural analysis of metabolic network models. Nat. Commun. 5:4893. doi: 10.1038/ncomms5893
Choi, H. S., Lee, S. Y., Kim, T. Y., and Woo, H. M. (2010). In silico identification of gene amplification targets for improvement of lycopene production. Appl. Environ. Microbiol. 76, 3097–3105. doi: 10.1128/AEM.00115-10
Chowdhury, A., Zomorrodi, A. R., and Maranas, C. D. (2014). k-OptForce: integrating kinetics with flux balance analysis for strain design. PLoS Comput. Biol. 10:e1003487. doi: 10.1371/journal.pcbi.1003487
Colijn, C., Brandes, A., Zucker, J., Lun, D. S., Weiner, B., Farhat, M. R., et al. (2009). Interpreting expression data with metabolic flux models: predicting mycobacterium tuberculosis mycolic acid production. PLoS Comput. Biol. 5:e1000489. doi: 10.1371/journal.pcbi.1000489
Doerks, T., Copley, R. R., Schultz, J., Ponting, C. P., and Bork, P. (2002). Systematic identification of novel protein domain families associated with nuclear functions. Genome Res. 12, 47–56. doi: 10.1101/gr.203201
Duarte, N. C., Becker, S. A., Jamshidi, N., Thiele, I., Mo, M. L., Vo, T. D., et al. (2007). Global reconstruction of the human metabolic network based on genomic and bibliomic data. Proc. Natl. Acad. Sci. U.S.A. 104, 1777–1782. doi: 10.1073/pnas.0610772104
Edwards, J. S., Ibarra, R. U., and Palsson, B. O. (2001). In silico predictions of Escherichia coli metabolic capabilities are consistent with experimental data. Nat. Biotech. 19, 125–130. doi: 10.1038/84379
Edwards, J. S., and Palsson, B. O. (2000). The Escherichia coli MG1655 in silico metabolic genotype: its definition, characteristics, and capabilities. Proc.Natl Acad. Sci. U.S.A. 97, 5528–5533. doi: 10.1073/pnas.97.10.5528
Fong, S. S., Burgard, A. P., Herring, C. D., Knight, E. M., Blattner, F. R., Maranas, C. D., et al. (2005). In silico design and adaptive evolution of Escherichia coli for production of lactic acid. Biotechnol. Bioeng. 91, 643–648. doi: 10.1002/bit.20542
Fang, X., Wallqvist, A., and Reifman, J. (2012). Modeling phenotypic metabolic adaptations of Mycobacterium tuberculosis H37Rv under Hypoxia. PLoS Comput. Biol. 8:e1002688. doi: 10.1371/journal.pcbi.1002688
Feist, A. M., Henry, C. S., Reed, J. L., Krummenacker, M., Joyce, A. R., Karp, P. D., et al. (2007). A genome-scale metabolic reconstruction for Escherichia coli K-12 MG1655 that accounts for 1260 ORFs and thermodynamic information. Mol. Syst. Biol. 3, 121. doi: 10.1038/msb4100155
Fowler, Z. L., Gikandi, W. W., and Koffas, M. A. (2009). Increased malonyl coenzyme a biosynthesis by tuning the Escherichia coli metabolic network and its application to flavanone production. Appl. Environ. Microbiol. 75, 5831–5839. doi: 10.1128/AEM.00270-09
Gatto, F., Miess, H., Schulze, A., and Nielsen, J. (2015). Flux balance analysis predicts essential genes in clear cell renal cell carcinoma metabolism. Sci. Rep. 5:10738. doi: 10.1038/srep10738
Gatto, F., and Nielsen, J. (2015). In search for symmetries in the metabolism of cancer. Wiley Interdiscip. Rev. Syst. Biol. Med. doi: 10.1002/wsbm.1321. [Epub ahead of print].
Gatto, F., Nookaew, I., and Nielsen, J. (2014). Chromosome 3p loss of heterozygosity is associated with a unique metabolic network in clear cell renal carcinoma. Proc. Natl. Acad. Sci. U.S.A. 111, E866–E875. doi: 10.1073/pnas.1319196111
Heavner, B. D., Smallbone, K., Price, N. D., and Walker, L. P. (2013). Version 6 of the consensus yeast metabolic network refines biochemical coverage and improves model performance. Database (Oxford) 2013:bat059. doi: 10.1093/database/bat059
Henry, C. S., Broadbelt, L. J., and Hatzimanikatis, V. (2007). Thermodynamics-based metabolic flux analysis. Biophys. J. 92, 1792–1805. doi: 10.1529/biophysj.106.093138
Izallalen, M., Mahadevan, R., Burgard, A., Postier, B., Didonato, R. Jr., Sun, J., et al. (2008). Geobacter sulfurreducens strain engineered for increased rates of respiration. Metab. Eng. 10, 267–275. doi: 10.1016/j.ymben.2008.06.005
Jensen, P. A., and Papin, J. A. (2011). Functional integration of a metabolic network model and expression data without arbitrary thresholding. Bioinformatics 27, 541–547. doi: 10.1093/bioinformatics/btq702
Jerby-Arnon, L., Pfetzer, N., Waldman, Y. Y., McGarry, L., James, D., Shanks, E., et al. (2014). Predicting cancer-specific vulnerability via data-driven detection of synthetic lethality. Cell 158, 1199–1209. doi: 10.1016/j.cell.2014.07.027
Ji, B., and Nielsen, J. (2015). From next-generation sequencing to systematic modeling of the gut microbiome. Front. Genet. 6:219. doi: 10.3389/fgene.2015.00219
Khodayari, A., Zomorrodi, A. R., Liao, J. C., and Maranas, C. D. (2014). A kinetic model of Escherichia coli core metabolism satisfying multiple sets of mutant flux data. Metab. Eng. 25, 50–62. doi: 10.1016/j.ymben.2014.05.014
Kim, B., Kim, W. J., Kim, D. I., and Lee, S. Y. (2015). Applications of genome-scale metabolie network model in metabolic engineering. J. Ind. Microbiol. Biotechnol. 42, 339–348. doi: 10.1007/s10295-014-1554-9
Kim, J., Reed, J. L., and Maravelias, C. T. (2012). Large-scale bi-level strain design approaches and mixed-integer programming solution techniques. PLoS ONE 6:e24162. doi: 10.1371/journal.pone.0024162
Kim, M., Sang Yi, J., Kim, J., Kim, J. N., Kim, M. W., and Kim, B. G. (2014). Reconstruction of a high-quality metabolic model enables the identification of gene overexpression targets for enhanced antibiotic production in Streptomyces coelicolor A3(2). Biotechnol. J. 9, 1185–1194. doi: 10.1002/biot.201300539
King, Z. A., and Feist, A. M. (2013). Optimizing cofactor specificity of oxidoreductase enzymes for the generation of microbial production strains—OptSwap. Ind. Biotechnol. 9, 236–246. doi: 10.1089/ind.2013.0005
Latendresse, M. (2014). Efficiently gap-filling reaction networks. BMC Bioinformatics 15:225. doi: 10.1186/1471-2105-15-225
Long, M. R., Ong, W. K., and Reed, J. L. (2015). Computational methods in metabolic engineering for strain design. Curr. Opin. Biotech. 34, 135–141. doi: 10.1016/j.copbio.2014.12.019
Ma, H., Sorokin, A., Mazein, A., Selkov, A., Selkov, E., Demin, O., et al. (2007). The Edinburgh human metabolic network reconstruction and its functional analysis. Mol. Syst. Biol. 3:135. doi: 10.1038/msb4100177
MacHado, D., and Herrgård, M. (2014). Systematic evaluation of methods for integration of transcriptomic data into constraint-based models of metabolism. PLoS Comput. Biol. 10:e1003580. doi: 10.1371/journal.pcbi.1003580
MacHado, D., and Herrgård, M. (2015). Co-evolution of strain design methods based on flux balance and elementary mode analysis. Metab. Eng. Commun. 2, 85–92. doi: 10.1016/j.meteno.2015.04.001
Mahalik, S., Sharma, A. K., and Mukherjee, K. J. (2014). Genome engineering for improved recombinant protein expression in Escherichia coli. Microb. Cell Factories 13, 177. doi: 10.1186/s12934-014-0177-1
Mardinoglu, A., Agren, R., Kampf, C., Asplund, A., Nookaew, I., Jacobson, P., et al. (2013). Integration of clinical data with a genome-scale metabolic model of the human adipocyte. Mol. Syst. Biol. 9. doi: 10.1038/msb.2013.5
Mardinoglu, A., Agren, R., Kampf, C., Asplund, A., Uhlen, M., and Nielsen, J. (2014). Genome-scale metabolic modelling of hepatocytes reveals serine deficiency in patients with non-alcoholic fatty liver disease. Nat. Commun. 5. doi: 10.1038/ncomms4083
Mardinoglu, A., and Nielsen, J. (2015). New paradigms for metabolic modeling of human cells. Curr. Opin. Biotechnol. 34, 91–97. doi: 10.1016/j.copbio.2014.12.013
Mardinoglu, A., Shoaie, S., Bergentall, M., Ghaffari, P., Zhang, C., Larsson, E., et al. (2015). The gut microbiota modulates host amino acid and glutathione metabolism in mice. Mol. Syst. Biol. 11, 834. doi: 10.15252/msb.20156487
Martín, H. G., Kumar, V. S., Weaver, D., Ghosh, A., Chubukov, V., Mukhopadhyay, A., et al. (2015). A method to constrain genome-scale models with 13C labeling data. PLoS Comput. Biol. 11:e1004363. doi: 10.1371/journal.pcbi.1004363
Miskovic, L., Tokic, M., Fengos, G., and Hatzimanikatis, V. (2015). Rites of passage: requirements and standards for building kinetic models of metabolic phenotypes. Curr. Opin. Biotech. 36, 146–153. doi: 10.1016/j.copbio.2015.08.019
Navid, A., and Almaas, E. (2012). Genomic-level transcription data of Yersinia pestis analyzed with a new metabolic constraint-based approarch. BMC Syst. Biol. 6:150. doi: 10.1186/1752-0509-6-150
Ng, C. Y., Jung, M., Lee, J., and Oh, M. K. (2012). Production of 2, 3-butanediol in Saccharomyces cerevisiae by in silico aided metabolic engineering. Microb. Cell Factories 11:68. doi: 10.1186/1475-2859-11-68
Nocon, J., Steiger, M. G., Pfeffer, M., Sohn, S. B., Kim, T. Y., Maurer, M., et al. (2014). Model based engineering of Pichia pastoris central metabolism enhances recombinant protein production. Metab. Eng. 24, 129–138. doi: 10.1016/j.ymben.2014.05.011
Orth, J. D., Thiele, I., and Palsson, B. O. (2010). What is flux balance analysis? Nat. Biotechnol. 28, 245–248. doi: 10.1038/nbt.1614
Otero, J. M., Cimini, D., Patil, K. R., Poulsen, S. G., Olsson, L., and Nielsen, J. (2013). Industrial systems biology of Saccharomyces cerevisiae enables novel succinic acid cell factory. PLoS ONE 8:e54144. doi: 10.1371/journal.pone.0054144
Park, J. M., Park, H. M., Kim, W. J., Kim, H. U., Kim, T. Y., and Lee, S. Y. (2012). Flux variability scanning based on enforced objective flux for identifying gene amplification targets. BMC Syst. Biol. 6, 106–106. doi: 10.1186/1752-0509-6-106
Patil, K. R., and Nielsen, J. (2005). Uncovering transcriptional regulation of metabolism by using metabolic network topology. Proc. Natl. Acad. Sci. U.S.A. 102, 2685–2689. doi: 10.1073/pnas.0406811102
Patil, K. R., Rocha, I., Förster, J., and Nielsen, J. (2005). Evolutionary programming as a platform for in silico metabolic engineering. BMC Bioinformatics 6:308. doi: 10.1186/1471-2105-6-308
Pharkya, P., Burgard, A. P., and Maranas, C. D. (2004). OptStrain: a computational framework for redesign of microbial production systems. Genome Res. 14, 2367–2376. doi: 10.1101/gr.2872004
Pharkya, P., and Maranas, C. D. (2006). An optimization framework for identifying reaction activation/inhibition or elimination candidates for overproduction in microbial systems. Metab. Eng. 8, 1–13. doi: 10.1016/j.ymben.2005.08.003
Pratapa, A., Balachandran, S., and Raman, K. (2015). Fast-SL: an efficient algorithm to identify synthetic lethal sets in metabolic networks. Bioinformatics 31, 3299–3305. doi: 10.1093/bioinformatics/btv352
Ranganathan, S., Suthers, P. F., and Maranas, C. D. (2010). OptForce: an optimization procedure for identifying all genetic manipulations leading to targeted overproductions. PLoS Comput. Biol. 6:e1000744. doi: 10.1371/journal.pcbi.1000744
Ranganathan, S., Tee, T. W., Chowdhury, A., Zomorrodi, A. R., Yoon, J. M., Fu, Y., et al. (2012). An integrated computational and experimental study for overproducing fatty acids in Escherichia coli. Metab. Eng. 14, 687–704. doi: 10.1016/j.ymben.2012.08.008
Ravikrishnan, A., and Raman, K. (2015). Critical assessment of genome-scale metabolic networks: the need for a unified standard. Brief. Bioinform. 16, 1057–1068. doi: 10.1093/bib/bbv003
Reed, J. L. (2012). Shrinking the metabolic solution space using experimental datasets. PLoS Comput. Biol. 8:e1002662. doi: 10.1371/journal.pcbi.1002662
Ren, S., Zeng, B., and Qian, X. (2013). Adaptive bi-level programming for optimal gene knockouts for targeted overproduction under phenotypic constraints. BMC Bioinformatics 14(Suppl. 2):S17. doi: 10.1186/1471-2105-14-s2-s17
Ruckerbauer, D. E., Jungreuthmayer, C., and Zanghellini, J. (2014). Design of optimally constructed metabolic networks of minimal functionality. PLoS ONE 9:e92583. doi: 10.1371/journal.pone.0092583
Segrè, D., Vitkup, D., and Church, G. M. (2002). Analysis of optimality in natural and perturbed metabolic networks. Proc. Natl. Acad. Sci. U.S.A. 99, 15112–15117. doi: 10.1073/pnas.232349399
Shoaie, S., Ghaffari, P., Kovatcheva-Datchary, P., Mardinoglu, A., Sen, P., Pujos-Guillot, E., et al. (2015). Quantifying diet-induced metabolic changes of the human gut microbiome. Cell Metab. 22, 320–331. doi: 10.1016/j.cmet.2015.07.001
Shoaie, S., Karlsson, F., Mardinoglu, A., Nookaew, I., Bordel, S., and Nielsen, J. (2013). Understanding the interactions between bacteria in the human gut through metabolic modeling. Sci. Rep. 3, 2532. doi: 10.1038/srep02532
Suthers, P. F., Zomorrodi, A., and Maranas, C. D. (2009). Genome-scale gene/reaction essentiality and synthetic lethality analysis. Mol. Syst. Biol. 5, 301. doi: 10.1038/msb.2009.56
Thiele, I., Fleming, R. M. T., Que, R., Bordbar, A., Diep, D., and Palsson, B. O. (2012). Multiscale modeling of metabolism and macromolecular synthesis in E. coli and its application to the evolution of codon usage. PLoS ONE 7:e45635. doi: 10.1371/journal.pone.0045635
Thiele, I., Jamshidi, N., Fleming, R. M., and Palsson, B. O. (2009). Genome-scale reconstruction of Escherichia coli's transcriptional and translational machinery: a knowledge base, its mathematical formulation, and its functional characterization. PLoS Comput. Biol. 5:e1000312. doi: 10.1371/journal.pcbi.1000312
Thiele, I., Swainston, N., Fleming, R. M., Hoppe, A., Sahoo, S., Aurich, M. K., et al. (2013). A community-driven global reconstruction of human metabolism. Nat. Biotech. 31, 419–425. doi: 10.1038/nbt.2488
Trinh, C. T., Unrean, P., and Srienc, F. (2008). Minimal Escherichia coli cell for the most efficient production of ethanol from hexoses and pentoses. Appl. Environ. Microbiol. 74, 3634–3643. doi: 10.1128/AEM.02708-07
Uhlén, M., Fagerberg, L., Hallström, B. M., Lindskog, C., Oksvold, P., Mardinoglu, A., et al. (2015). Tissue-based map of the human proteome. Science 347:1260419. doi: 10.1126/science.1260419
Väremo, L., Scheele, C., Broholm, C., Mardinoglu, A., Kampf, C., Asplund, A., et al. (2015). Proteome- and transcriptome-driven reconstruction of the human myocyte metabolic network and its use for identification of markers for diabetes. Cell Rep. 11, 921–933. doi: 10.1016/j.celrep.2015.04.010
von Kamp, A., and Klamt, S. (2014). Enumeration of smallest intervention strategies in genome-scale metabolic networks. PLoS Comput. Biol. 10:e1003378. doi: 10.1371/journal.pcbi.1003378
Wiback, S. J., Mahadevan, R., and Palsson, B. O. (2004). Using metabolic flux data to further constrain the metabolic solution space and predict internal flux patterns: the Escherichia coli spectrum. Biotechnol. Bioeng. 86, 317–331. doi: 10.1002/bit.20011
Xu, P., Ranganathan, S., Fowler, Z. L., Maranas, C. D., and Koffas, M. A. G. (2011). Genome-scale metabolic network modeling results in minimal interventions that cooperatively force carbon flux towards malonyl-CoA. Metab. Eng. 13, 578–587. doi: 10.1016/j.ymben.2011.06.008
Yim, H., Haselbeck, R., Niu, W., Pujol-Baxley C, C., Burgard, A., Boldt, J., et al. (2011). Metabolic engineering of Escherichia coli for direct production of 1, 4-butanediol. Nat. Chem. Biol. 7, 445–452. doi: 10.1038/nchembio.580
Yizhak, K., Chaneton, B., Gottlieb, E., and Ruppin, E. (2015). Modeling cancer metabolism on a genome-scale. Mol. Syst. Biol. 11:817. doi: 10.15252/msb.20145307
Yizhak, K., Dévédec, S. E. L., Rogkoti, V. M., Baenke, F., de Boer, V. C., Frezza, C., et al. (2014). A computational study of the Warburg effect identifies metabolic targets inhibiting cancer migration. Mol. Syst. Biol. 10:744. doi: 10.15252/msb.20145746
Zhang, C., Ji, B., Mardinoglu, A., Nielsen, J., and Hua, Q. (2015). Logical transformation of genome-scale metabolic models for gene level applications and analysis. Bioinformatics 31, 2324–2331. doi: 10.1093/bioinformatics/btv134
Keywords: genome-scale metabolic models, systems biology, metabolic capability analysis, in silico metabolic engineering, systems medicine
Citation: Zhang C and Hua Q (2016) Applications of Genome-Scale Metabolic Models in Biotechnology and Systems Medicine. Front. Physiol. 6:413. doi: 10.3389/fphys.2015.00413
Received: 29 October 2015; Accepted: 15 December 2015;
Published: 07 January 2016.
Edited by:
Xiaogang Wu, Institute for Systems Biology, USAReviewed by:
Stephen Fong, Virginia Commonwealth University, USACopyright © 2016 Zhang and Hua. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Qiang Hua, cWh1YUBlY3VzdC5lZHUuY24=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.