 Chunli Zhang
Chunli Zhang Lei Yan1,2†
Lei Yan1,2†- 1School of Automation and Information Engineering, Xi’an University of Technology, Xi’an, China
- 2Shaanxi Key Laboratory of Complex System Control and Intelligent Information Processing, Xi’an University of Technology, Xi’an, China
The paper proposes a low-pass filter adaptive iterative learning control (LPF-AILC) strategy for unmatched, uncertain, time-varying, non-parameterized nonlinear systems (NPNL systems). To address the difficulty of nonlinear parameterization terms in system models, a new function approximator (FSE-RBFNN), which combines the radial basis function neural network (RBFNN) and Fourier series expansion (FSE), is introduced to model each time-varying nonlinear parameterized function. The adaptive backstepping method is used to design control laws and parameter adaptive laws. In the process of controller design, we may encounter the problem of too many derivatives, which can cause parameter explosions after derivatives. Therefore, we introduce a first-order low-pass filter to solve this problem and simplify the structure of the controller. As the number of iterations increases, the maximum tracking error gradually decreases until it converges to the nearby region, approaching zero within the entire given interval
1 Introduction
Adaptive iterative learning control (AILC) is a useful control strategy for solving repetitive tracking control task problems for uncertain nonlinear systems. It continuously adjusts its control algorithm through iterative learning to gradually approach the ideal trajectory of the unknown system. AILC has extensive application value and promising development prospects for practical applications. Repeat systems include uncertain robotic manipulators and uncertain hard disk drivers. The task requirements specify that it can quickly achieve exact tracking as the number of iterations increases [1–4].
A non-parameterized nonlinear (NPNL) system refers to a dynamic characteristic that exhibits a complex nonlinear relationship and unknown parameters, making it difficult to design effective control strategies. It is particularly challenging to achieve high-precision tracking and control within a limited time frame. Traditional control methods often require the establishment of a mathematical model for the system, but for the NPNL system, this step is usually very difficult or even impossible to complete. AILC technology has become an important method for solving these problems [5, 6].
There are many challenging problems in the research of AILC. This paper considers three difficult problems of AILC. The first problem is the processing problem of uncertain nonlinear parameterization terms with time-varying parameters. In the field of control, the control problem of nonlinear systems with uncertain time-varying parameters is very challenging. Adaptive control and robust control are common methods to deal with uncertain problems [7, 8]. Through learning, adaptive control can mitigate the impact of uncertainties. In order to handle uncertain nonlinear terms, adaptive control is often combined with some approximation methods, such as neural networks (NNs) and Fuzzy Logic Systems (FLSs). However, these adaptive controls only solve the uncertain linearly parameterized disturbances and ensure the stability of the system [7–20]. For the uncertain system, a fuzzy AILC was presented [21]. The composite energy function–adaptive iterative learning control (CEF–AILC) is an effective scheme for systems with time-varying disturbances [21–23]. Few AILC research results focus on uncertain, non-parameterized nonlinear systems [24–26]. Specifically, for systems with non-separable time-varying parameters, the tracking control problem on finite time intervals is still an open problem.
The second problem of AILC is ensuring complete tracking over a finite time interval when the initial state has errors. In these studies [27–31], the stability analysis section requires that initial state errors be strictly zero. Although the research on this problem is well done in traditional D-type or P-type ILC [32–41], it has not been well solved based on Lyapunov analysis for AILC. Specifically, in the presence of an initial state error, ensuring the system’s completion of accurate tracking tasks within a specified time frame presents a complex challenge. [39] solved the tracking control problem of the unmatched uncertain NPNL systems. [41] solved the tracking problem of a class of high-order nonlinear systems with random initial state shifts, which relaxes the requirement of initial positioning in ILC. So far, no relevant research results have been found for AILC applied to NPNL systems with uncertain time-varying parameters and initial state errors.
The last problem is parameter explosions after the derivative of the virtual controller. When designing a controller, we may encounter the problem of too many derivatives, which can cause parameter explosions after derivatives. Addressing this issue and streamlining the controller’s structure to ensure the effective tracking of the non-parametric, nonlinear, time-varying system is a challenging and crucial problem. [42–44] employed a first-order low-pass filter to address the challenge of parameter explosions and achieve satisfactory performance. Therefore, we introduce a first-order low-pass filter to solve this problem and simplify the structure of the controller.
Motivated by the above discussion, we will use a low-pass filter AILC (LPF-AILC) method for uncertain time-varying NPNL systems. The AILC is given by the adaptive backstepping technique and Lyapunov-like theorem. In response to the difficult issues discussed above, the main contributions of this article are as follows:
1) An LPF-AILC strategy is proposed for a class of strongly time-varying, non-parameterized, nonlinear systems combined with a new approximation method.
2) The processing problem of uncertain time-varying nonlinear parameterization terms was solved. This is a very important and difficult problem. Specifically, in the field of AILC, no relevant research results have been found.
3) The difficulty problem of AILC is ensuring complete tracking on a given interval when the initial state has errors.
4) The problem of parameter explosions was solved by applying a derivative to the virtual controller and simplifying its structure.
In this paper, a combination of Fourier series expansion and radial basis function neural network (RBFNN) (FSE-RBFNNs) is used to model the uncertain, time-varying nonlinear dynamics by using their uniform approximation [24, 38]. An updating time-varying boundary layer is used to design the error function to deal with the initial state error. A common convergence series sequence is employed to mitigate the impact of approximation errors on the control performance of the system. A low-pass filter was introduced to solve the problem of parameter explosions resulting from the derivative of the virtual controller and simplify the structure of the controller. Theoretical analysis can demonstrate the bounded nature of all signals within the closed-loop system. The maximum value of errors will gradually converge to a narrow range close to zero as the boundary layer width satisfies the convergence condition with the number of iterations. Finally, two simulation examples are given to prove the effectiveness and correctness of the control method.
2 Problem description and mathematical foundations
2.1 Problem description
Uncertain time-varying NPNL systems are considered:
where
The design objective of this article is to find
2.2 Mathematical foundations
The mathematical knowledge used in this article is provided with relevant references, and the specific definitions and principles will not be elaborated. Here, we only provide the conclusions that need to be used in this article.
In system (1), the processing of unknown time-varying, nonlinear, parameterized function terms
A new FSE-RBFNN approximator is built:
representing
where
Lemma 1[38]: For
where
Because
Lemma 2[38]: In the surrogate model (4), the following conclusion holds:
where
For the processing of the supremum of each error term, this article introduces the following typical series sequence:
Lemma 2[39] For a sequence
Assumption 2: The initial error value at the beginning of each iteration should meet
Considering the initial errors, a new function
where
with
In order to prevent the problem of gradient explosion, we introduce the first-order low-pass filter
where
3 AILC design
Based on the above mathematical foundations, we present the specific controller design process.
3.1 Designing the AILC controller
Step 1: Denote
We recall that
Given the derivative of
Therefore, the derivative of
The error compensation mechanism is considered as follows:
Using Equation 18, we can find the time derivative of the error function as follows:
The unknown time-varying, nonlinear functions
where
Consider
By substituting Equations 20, 21 into Equation 19, we obtain
where
Using Equations 7, 23, Equation 22 can be rewritten as
Let
Remark 1: This assumption is easily satisfied because 1)
The Lyapunov-like function is chosen as follows:
where
where for any
We choose
so Equation 27 becomes
Step 2: Denote
The derivative of
Let the error compensation mechanism be defined as follows:
Using Equation 32, we can find the time derivative of error function as
The uncertain time-varying, nonlinear functions
where
Let the virtual control be defined as follows:
Substituting Equations 34, 35 into Equation 33, we obtain
where
Using Equations 7, 37, Equation 36 can be written as
Let
The Lyapunov-like function was chosen as follows:
where
We choose
Then, Equation 41 can be changed as
Step i:
Therefore,
Let the error compensation mechanism be defined as
Using Equation 47, we can find the time derivative of the error function as
The uncertain time-varying, nonlinear functions
where
Define
By substituting Equations 49, 50 into Equation 48, we obtain
where
Using Equations 7, 52, Equation 51 can be reformulated as
Let
Consider the following nonnegative function:
where
We choose
Then, Equation 56 can be written as
Step n: Denote
The derivative of
Let the error compensation mechanism be defined as
Using Equation 61, we can obtain the time derivative of the error function as
The overall approximation capability of the RBFNN asserts that the unknown nonlinear functions
where
Define
By substituting Equations 63, 64 into Equation 62, we can conclude that
where
Using Equations 7, 66, Equation 65 can be reformulated as
Let
Assumption 4: The remainder
Remark 2: This assumption is reasonable because 1)
Let the following non-negative function be defined as
where
We choose
Then, Equation 70 can be written as
For the initial state, we rely on the following set of assumed conditions:
Assumption 2: When
3.2 Stability and convergence analysis
Theorem 1: For nonlinear system (1) with assumptions 2, 3, and 4, if we design virtual controllers (21), (35), (50), controller (64), and parameter updating laws (28), (42), (57), (71),then all signals in the closed-loop system are bounded within the interval [0, T]. We obtain
In other words,
Proof: In accordance with Assumption 2, we find that
Let
Using Equation 9, we obtain
Based on Equation 69, for any given value of
Based on Equation 76,
Then, we need to prove that
With specified initial conditions,
As shown in Equation 79, choosing an appropriate value for
The derivative of
where
4 Illustrative examples
4.1 Number simulation
This section includes an example illustrating the effectiveness of the proposed adaptive iterative learning controller.
The second-order pure-feedback nonlinear system described is considered as follows:
where
where
In accordance with Theorem 1, the adaptive iterative learning controller is chosen as
The error compensation mechanism is
where
The parameter adaptive iterative learning laws are provided by (57):
where
Figures 1–3 show the tracking performance of the system output and expected output without iteration and at 50th and 100th iterations, respectively. Figures 4, 5 show that as the number of iterations increases, the system error may converge to a small region near the zero point. Furthermore, observations shown in Figures 6–10 confirm that both control signals
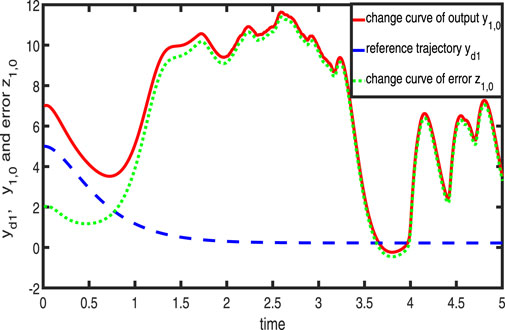
Figure 1. Variation in
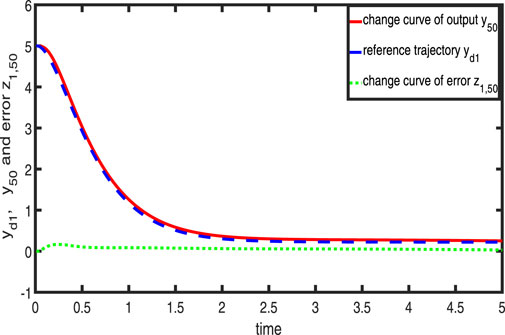
Figure 2. Variation in
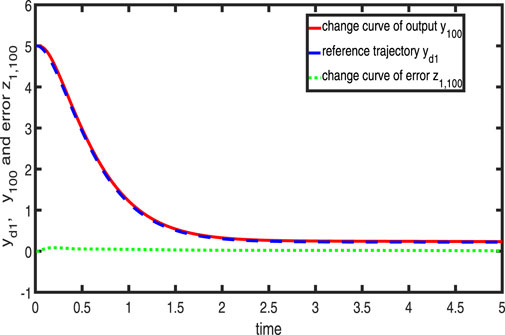
Figure 3. Variation in
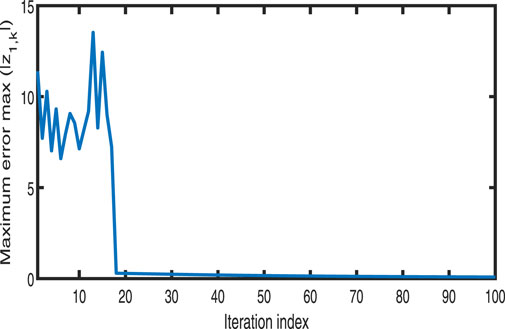
Figure 4. Variation in
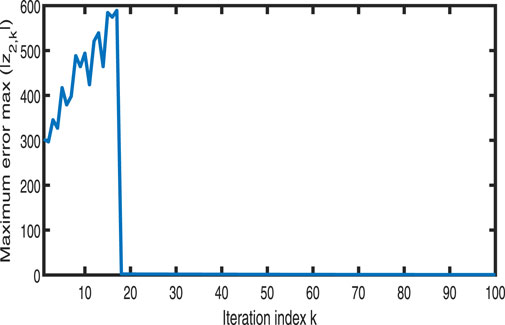
Figure 5. Variation in
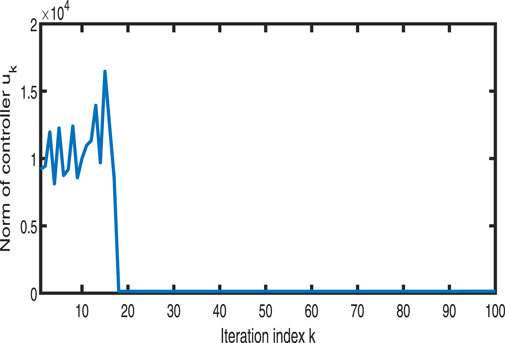
Figure 6. Variation in
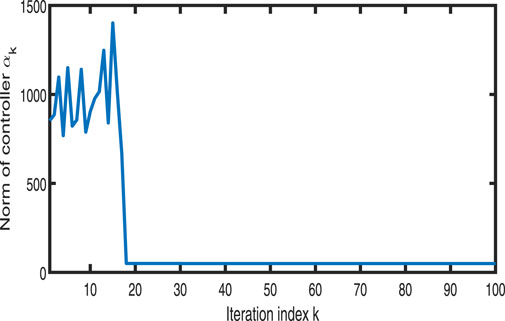
Figure 7. Variation in
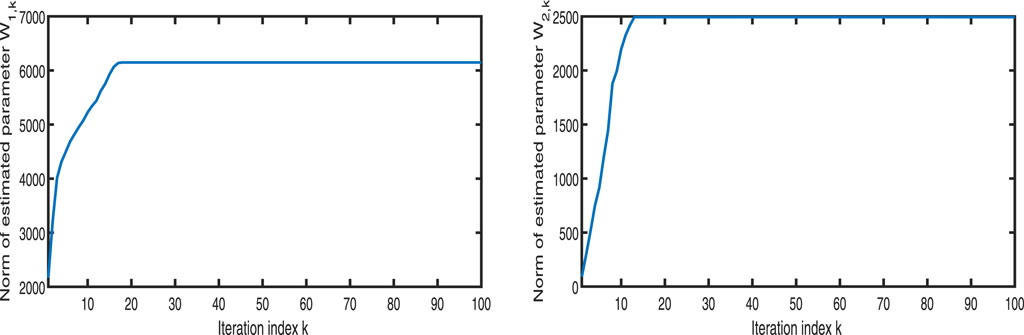
Figure 8. Variation in
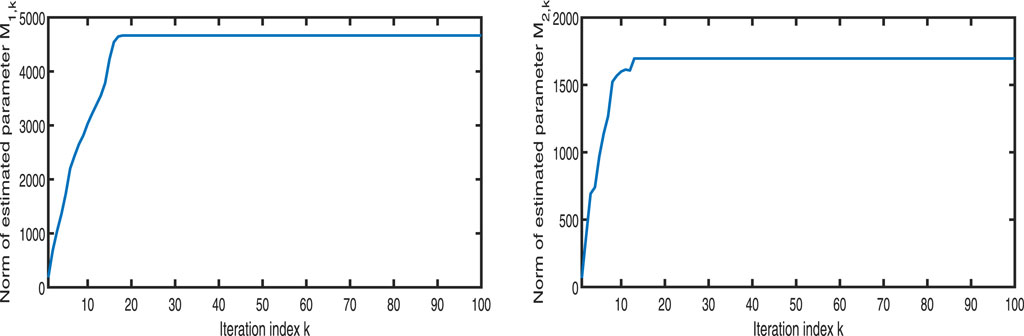
Figure 9. Variation in
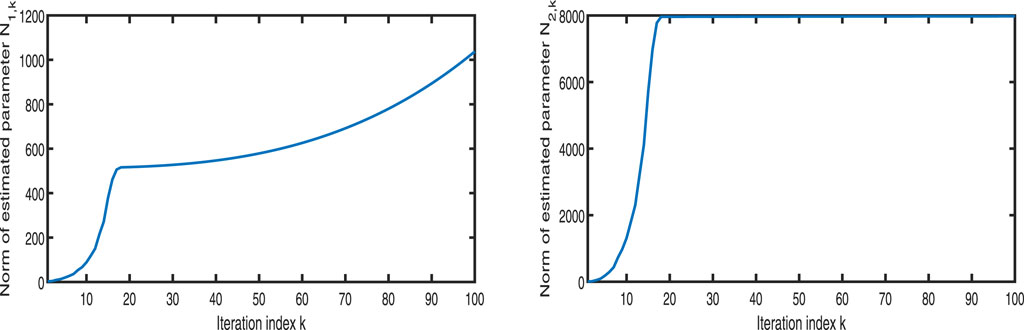
Figure 10. Variation in
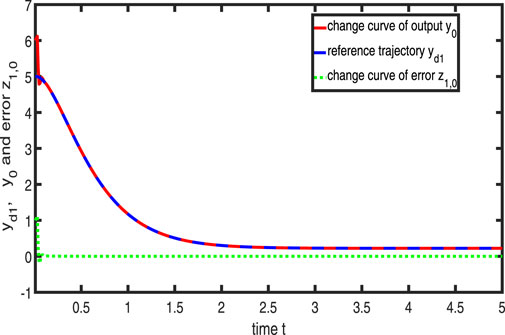
Figure 11. Variation in
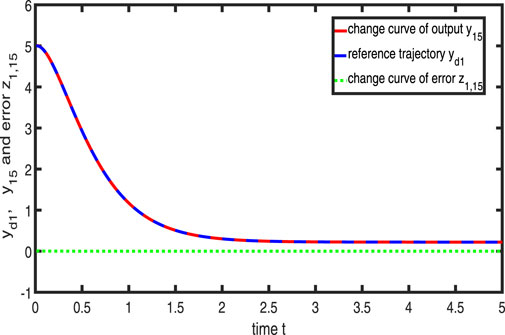
Figure 12. Variation in
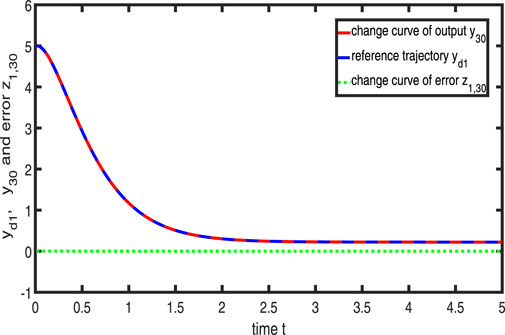
Figure 13. Variation in
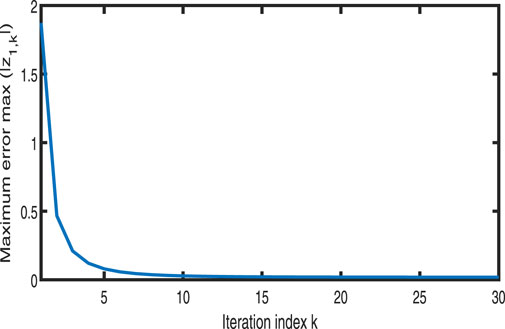
Figure 14. Variation in
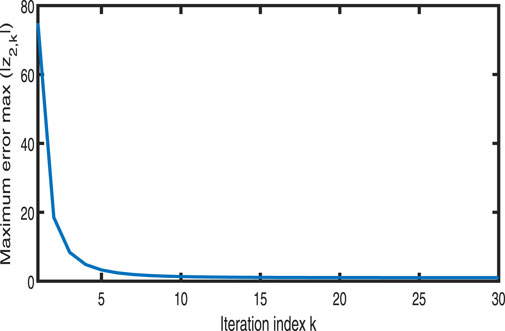
Figure 15. Variation in
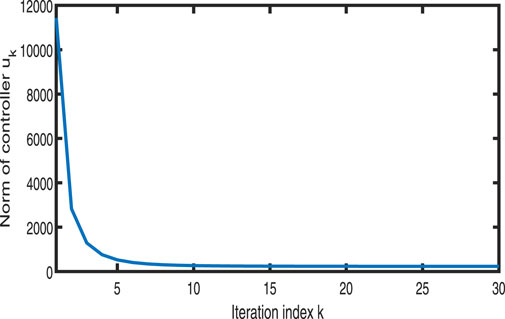
Figure 16. Variation in
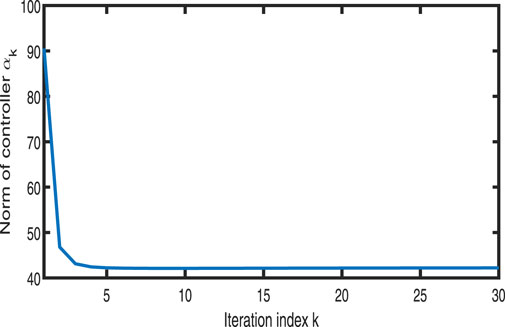
Figure 17. Variation in

Figure 18. Variation of
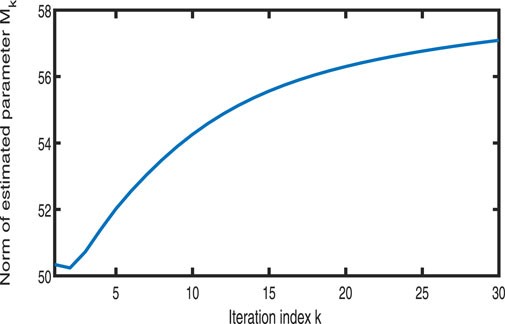
Figure 19. Variation in
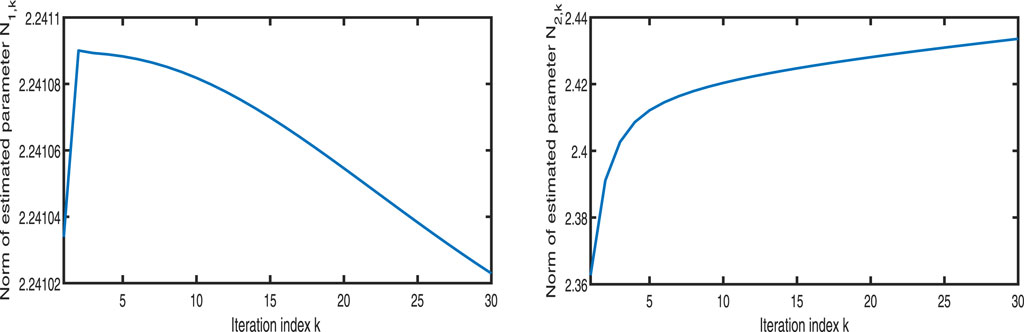
Figure 20. Variation in
4.2 Simulation of a single-joint robotic arm
In this section, we conducted simulation verification on a single degree-of-freedom robotic arm system to assess the performance of the proposed control method. The dynamic equation of a single degree-of-freedom robotic arm is
where
where
and its reference model is derived as
where
In accordance with Theorem 1, the adaptive iterative learning controller is chosen as
The error compensation mechanism is
where
The parameter adaptive iterative learning laws are provided by (57).
where
Figures 11–13 show the tracking performance of the system output and expected output without iteration and at 15th and 30th iterations, respectively. Figures 14, 15 show that as the number of iterations increases, the system error may converge to a small region near the zero point. Furthermore, observations from Figures 16–20 confirm that both control signals
5 Conclusion
This article presents a solution to the complete trajectory, following challenges within a finite time frame for a category of nonlinearly parameterized systems characterized by time-varying disturbed functions and initial state errors. A new FSE neural network is used to learn the time-varying, nonlinearly parameterized term. Based on this and Lyapunov theory, we proposed the new LPF-AILC method. A low-pass filter is used to solve the problem of parameter explosion after obtaining the derivative of the virtual controller. The unmatched uncertainties, nonlinear parameterization, and initial state errors are well considered. Two simulation examples have proven the feasibility of the control approach. This article does not mention time-delay issues, but they often exist in practical systems. Our future work should consider solving the complete tracking problem on a finite time interval for these complex systems with time delays. This is a more interesting issue. In addition, there are two deficiencies in the controller design process: the assumption of time-varying parameters being periodic and the jitter issues caused by the low-pass filter. These challenges will be carefully considered and addressed in our future work.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Author contributions
CZ: conceptualization, funding acquisition, investigation, methodology, and writing–review and editing. LY: formal analysis, software, writing–original draft, and writing–review and editing. YG: investigation, validation, and writing–original draft. JY: funding acquisition, supervision, and writing–review and editing. FQ: funding acquisition, supervision, and writing–review and editing.
Funding
The authors declare that financial support was received for the research, authorship, and/or publication of this article. This work is supported by the National Natural Science Foundation (NNSF) of China (grants 62073259 and 61973094), the Natural Science Basis Research Plan in Shaanxi Province of China (2023-JC-QN-0752), the Science and Technology Plan Project of Xi’an City (No. 23GXFW0062), and the Shaanxi Provincial Key R& D Program General Project (No. 2024GX-YBXM-106).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Arimoto S, Kawamura S, Miyazaki F. Bettering operation of robots by learning. J Robot Syst (1984) 1(2):123–40. doi:10.1002/rob.4620010203
3. Ahn HS, Chen YQ, Moore KL. Iterative learning control: brief survey and categorization. IEEE Trans Syst Man Cybernetics-C, Appl Rev (2007) 37(6):1099–121. doi:10.1109/tsmcc.2007.905759
4. Xu J-X, Yan R, Chen Y-Q. “On initial conditions in iterative learning control,” in 2006 American Control Conference, Minneapolis, MN, United States (2006). doi:10.1109/ACC.2006.1655358
5. Chen Y, Huang D, Xu C, Dong H. Iterative learning tracking control of high-speed trains with nonlinearly parameterized uncertainties and multiple time-varying delays. IEEE Trans Intell Transportation Syst (2022) 23(11):20476–88. doi:10.1109/tits.2022.3183608
6. Zhang C, Yan L, Gao Y, Wang W, Li K, Wang D, et al. A new adaptive iterative learning control of finite-time hybrid function projective synchronization for unknown time-varying chaotic systems. Front Phys (2023) 11:1127884. doi:10.3389/fphy.2023.1127884
7. Lu Y. Adaptive-Fuzzy control compensation design for direct adaptive fuzzy control. IEEE Trans Fuzzy Syst (2018) 26(6):3222–31. doi:10.1109/tfuzz.2018.2815552
8. Yang Z, Wang S. Adaptive prescribed performance control for nonlinear robotic systems. J Franklin Inst (2023) 360(2):1378–94. doi:10.1016/j.jfranklin.2022.10.044
9. Kong X, Yu F, Yao W, Cai S, Zhang J, Lin H. Memristor-induced hyperchaos, multiscroll and extreme multistability in fractional-order HNN: image encryption and FPGA implementation. Neural Networks (2024) 171:85–103. doi:10.1016/j.neunet.2023.12.008
10. Yu F, Kong X, Yao W, Zhang J, Cai S, Lin H, et al. Dynamics analysis, synchronization and FPGA implementation of multiscroll Hopfield neural networks with non-polynomial memristor. Chaos, Solitons & Fractals (2024) 179:114440. Article ID 114440. doi:10.1016/j.chaos.2023.114440
11. Hu X, Xu B, Hu C. Robust adaptive fuzzy control for HFV with parameter uncertainty and unmodeled dynamics. IEEE Trans Ind Electronics (2018) 65(11):8851–60. doi:10.1109/tie.2018.2815951
12. Liu Z, Shi J, Zhao X, Zhao Z, Li H -X. Adaptive fuzzy event-triggered control of aerial refueling hose system with actuator failures. IEEE Trans Fuzzy Syst (2022) 30(8):2981–92. doi:10.1109/tfuzz.2021.3098733
13. Hu X, Li Y -X, Tong S, Hou Z. Event-triggered adaptive fuzzy asymptotic tracking control of nonlinear pure-feedback systems with prescribed performance. IEEE Trans Cybernetics (2023) 53(4):2380–90. doi:10.1109/tcyb.2021.3118835
14. Zhang C, Tian X, Yan L. Adaptive iterative learning control method for finite-time tracking of an aircraft track angle system based on a neural network. Front Phys (2022) 10:1048942. doi:10.3389/fphy.2022.1048942
15. Pang N, Wang X, Wang Z. Event-triggered adaptive control of nonlinear systems with dynamic uncertainties: the switching threshold case. IEEE Trans Circuits Syst Express Briefs (2022) 69(8):3540–4. doi:10.1109/tcsii.2022.3164572
16. Liu X, Xu B, Cheng Y, Wang H, Chen W. Adaptive control of uncertain nonlinear systems via event-triggered communication and NN learning. IEEE Trans Cybernetics (2023) 53(4):2391–401. doi:10.1109/tcyb.2021.3119780
17. Yang X, Zheng X. Gradient descent algorithm-based adaptive NN control design for an induction motor. IEEE Trans Syst Man, Cybernetics: Syst (2021) 51(2):1027–34. doi:10.1109/tsmc.2019.2894661
18. Li K, Li Y. Adaptive neural network finite-time dynamic surface control for nonlinear systems. IEEE Trans Neural Networks Learn Syst (2021) 32(12):5688–97. doi:10.1109/tnnls.2020.3027335
19. Lin H, Deng X, Yu F, Sun Y. Grid multi-butterfly memristive neural network with three memristive systems: modeling, dynamic analysis, and application in police IoT. IEEE Internet Things J (2024) 1. doi:10.1109/jiot.2024.3409373
20. Li J, Wang C, Deng Q. Symmetric multi-double-scroll attractors in Hopfield neural network under pulse controlled memristor. Nonlinear Dyn (2024) 112:14463–77. doi:10.1007/s11071-024-09791-6
21. Chien CJ. A combined adaptive law for fuzzy iterative learning control of nonlinear systems with varying control tasks. IEEE Trans Fuzzy Syst (2008) 16(1):40–51. doi:10.1109/tfuzz.2007.902021
22. Xu JX, Yan R. Adaptive learning control for finite interval tracking based on constructive function approximation and wavelet. IEEE Trans Neural Networks (2011) 22(6):893–905. doi:10.1109/tnn.2011.2132143
23. Taybi A, Chien CJ. A unified adaptive iterative learning control framework for uncertain nonlinear systems. IEEE Trans Automatic Control (2007) 52(10):1907–13. doi:10.1109/TAC.2007.906215
24. Ji H, Hou Z, Zhang R. Adaptive iterative learning control for high-speed trains with unknown speed delays and input saturations. IEEE Trans Automation Sci Eng (2016) 13(1):260–73. doi:10.1109/tase.2014.2371816
25. Li JM, Wang YL, Li XM. Adaptive iterative learning control for nonlinear parameterized-systems with unknown time-varying delays. Control Theor Appl (2011) 28(6):861–8. doi:10.7641/j.issn.1000-8152.2011.6.ccta091224
26. Zhang C-L, Li J-M. Adaptive iterative learning control for nonlinear time-delay systems with periodic disturbances using FSE-neural network. Int J Automation Comput (2011) 8(4):403–10. doi:10.1007/s11633-011-0597-x
27. Park BH, Kuc TY, Lee JS. Adaptive learning of uncertain robotic systems. Int J Control (1996) 65(5):725–744. doi:10.1080/00207179608921719
28. Choi JY, Lee JS. Adaptive iterative learning control of uncertain robotic systems. Proc Inst Elect Eng D (2000) 147(2):217–23. doi:10.1049/ip-cta:20000138
29. Liu G, Hou Z. Adaptive iterative learning control for subway trains using multiple-point-mass dynamic model under speed constraint. IEEE Trans Intell Transportation Syst (2021) 22(3):1388–400. doi:10.1109/tits.2020.2970000
30. Ji H, Hou Z, Zhang R. Adaptive iterative learning control for high-speed trains with unknown speed delays and input saturations. IEEE Trans Automation Sci Eng (2016) 13(1):260–73. doi:10.1109/tase.2014.2371816
31. Geng Y, Ruan X, Xu J. Adaptive iterative learning control of switched nonlinear discrete-time systems with unmodeled dynamics. IEEE Access (2019) 7:118370–80. doi:10.1109/access.2019.2936763
32. Heinzinger G, Fenwick D, Paden B, Miyazaki F. Stability of learning control with disturbances and uncertain initial conditions. IEEE Trans Automat Contr (1992) 37:110–4. doi:10.1109/9.109644
33. Chien CJ, Liu JS. AP-type iterative learning controller for robust output tracking of nonlinear time-varying systems. Int J Control (1996) 64(2):319–34. doi:10.1080/00207179608921630
34. Park KH, Bien Z, Hwang DH. A study on the robustness of a PID-type iterative learning controller against initial state error. Int J Syst Sci (1999) 30(1):49–59. doi:10.1080/002077299292669
35. Sun M, Wang D. Iterative learning control with initial rectifying action. Automatica (2002) 38:1177–82. doi:10.1016/s0005-1098(02)00003-1
36. Chien CJ, Hsu CT, Yao CY. Fuzzy system based adaptive iterative learning control for nonlinear plants with initial state errors. IEEE Trans Fuzzy Syst (2004) 12(5):724–32. doi:10.1109/tfuzz.2004.834806
37. Wu XJ, Wu XL, Ran Zhen XY, Luo XJ, Zhu QM. Adaptive control for time-delay non-linear systems with non-symmetric input non-linearity. Int J Model Identification Control (2011) 13(3):152–60. doi:10.1504/ijmic.2011.041302
38. Luo XY, Wu XJ, Guan XP. Adaptive backstepping fault-tolerant controlfor unmatched non-linear systems against actuator dead-zone. IET Control Theor Appl. (2010) 4(5):879–88. doi:10.1049/iet-cta.2009.0086
39. Wu X, Wu X, Luo X, Zhu Q, Guan X. Neural network-based adaptive tracking control for nonlinearly parameterized systems with unknown input nonlinearities. Neurocomputing (2012) 82:127–42. doi:10.1016/j.neucom.2011.10.019
40. Chen WS. Adaptive backstepping dynamic surface control for systems with periodic disturbances using neural networks. IET Control Theor Appl (2009) 3(10):1383–94. doi:10.1049/iet-cta.2008.0322
41. Zhu S, Ming-Xuan SUN, Xiong-Xiong HE. Iterative learning control of strict-feedback nonlinear time-varying systems. ACTA AUTOMATICA SINICA (2010) 36(3):454–8. doi:10.3724/SP.J.1004.2010.00454
42. Yu H, Li Y. Adaptive obstacle avoidance control based on first-order low-pass filter for cleaning robots. Marseille, France: OCEANS 2019 - Marseille (2019). p. 1–6.
43. Zhang C, Tian X, Gao Y, Qian F. Command filter AILC for finite time accurate tracking of aircraft track angle system based on fuzzy logic. Adv Math Phys (2023) 2023:11. Article ID 4744873. doi:10.1155/2023/4744873
Keywords: adaptive iterative learning control, time-varying non-parameterized nonlinear systems, backstepping method, Fourier series expansion-radial basis function neural network, initial state errors, low-pass filter
Citation: Zhang C, Yan L, Gao Y, Yao J and Qian F (2024) FSE-RBFNN-based LPF-AILC of finite time complete tracking for a class of time-varying NPNL systems with initial state errors. Front. Phys. 12:1442486. doi: 10.3389/fphy.2024.1442486
Received: 02 June 2024; Accepted: 02 August 2024;
Published: 21 August 2024.
Edited by:
Fei Yu, Changsha University of Science and Technology, ChinaReviewed by:
Jinping Jia, Tianshui Normal University, ChinaYichao Yan, University of Electronic Science and Technology of China, China
Njitacke Tabekoueng Zeric, University of Buea, Cameroon
Copyright © 2024 Zhang, Yan, Gao, Yao and Qian. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Junliang Yao, eWFvanVubGlhbmdAeGF1dC5lZHUuY24=
†ORCID: Lei Yan, orcid.org/0000-0001-5894-7588; Yangjie Gao, orcid.org/0009-0009-9651-5757; Junliang Yao, orcid.org/0000-0001-6041-9813; Fucai Qian, orcid.org/0000-0001-8461-1420