 Banghua Wu1†
Banghua Wu1†- 1School of Cyber Science and Engineering, Sichuan University, Chengdu, China
- 2School of Computer Science and Engineering, University of Electronic Science and Technology of China, Chengdu, China
Molecular generation is an important but challenging task in drug design, as it requires optimization of chemical compound structures as well as many complex properties. Most of the existing methods use deep learning models to generate molecular representations. However, these methods are faced with the problems of generation validity and semantic information of labels. Considering these challenges, we propose a cross-adversarial learning method for molecular generation, CRAG for short, which integrates both the facticity of VAE-based methods and the diversity of GAN-based methods to further exploit the complex properties of Molecules. To be specific, an adversarially regularized encoder-decoder is used to transform molecules from simplified molecular input linear entry specification (SMILES) into discrete variables. Then, the discrete variables are trained to predict property and generate adversarial samples through projected gradient descent with corresponding labels. Our CRAG is trained using an adversarial pattern. Extensive experiments on two widely used benchmarks have demonstrated the effectiveness of our proposed method on a wide spectrum of metrics. We also utilize a novel metric named Novel/Sample to measure the overall generation effectiveness of models. Therefore, CRAG is promising for AI-based molecular design in various chemical applications.
1 Introduction
The primary goal of the drug design process is to find new chemical compound structures that can adjust the given protein activities in a desired way. This process takes about 10 years and is accompanied by a huge expenditure of funds. Generally, a new drug needs to go through four stages before putting into the market: drug discovery, pre-clinical research, clinical research, and approval of listing (Khan et al., 2021). De novo drug design (Hartenfeller and Schneider, 2010) through existing computer technology can speed up drug development and save research costs. The tasks involved in de novo drug design include molecular generation (Gómez-Bombarelli et al., 2016; Cao and Kipf, 2018; Jin et al., 2018; You et al., 2018; Madhawa et al., 2019; Popova et al., 2019; Zhang et al., 2019; Hong et al., 2020; Zang and Wang, 2020; Bagal et al., 2021), drug and drug interactions (DDI) (Li et al., 2021; Lin et al., 2021; Lyu et al., 2021; Zhao et al., 2021), disease associations (Ding et al., 2020; Lei et al., 2020; Lei and Zhang, 2020; Mudiyanselage et al., 2020; Lei X.-J. et al., 2021; Lei X. et al., 2021; Wang Y. et al., 2021; Lei and Zhang, 2021; Yang and Lei, 2021; Zhang et al., 2021), and so on. Traditional molecular generation tasks follow a two-step strategy to design new molecules: synthesizing alternative compounds clinically and conducting experiments. However, these methods are faced with two huge challenges. One is that the chemical molecule space is discrete and vast, which has been estimated to be between 1023 and 1060 (Polishchuk et al., 2013). The other is that the relation between molecule structure and properties is quite sensitive, even small structural changes will lead to significant molecule property variations.
In the past few years, with the development of deep learning techniques, deep learning based methods have been proposed to overcome the problems in previous methods. Most of the existing methods learn to represent the molecular characteristics using deep networks and construct the relationship between atoms to express atomic information. Figure 1 illustrates the mainstream molecular generation methods, which can be summarized into two directions, i.e., bond-based methods and 3D structure-based methods. Among the bond-based methods, simplified molecular input linear entry specification (SMILES) (Merkwirth and Lengauer, 2005) and molecular graph (Simonovsky and Komodakis, 2018) are two widely used methods. The SMILES usually regards drug as a sequence with rich semantics. Most of the SMILES methods extract molecular information through recurrent neural networks (Segler et al., 2017), word2vec (Jaeger et al., 2018), seq2seq (Xu et al., 2017), or other language models. Besides, variational auto-encoders (VAEs) can achieve high reconstruction accuracy, which is of great significance for molecular generation tasks. Rafael et al. (Gómez-Bombarelli et al., 2016) propose to convert discrete representations of molecules into multi-dimensional continuous ones. Molecular graph based methods generally express atomic information through a node tensor, and the relation between atoms through an adjacency matrix to retain more molecular information. Researchers generally process molecular graphs according to four technical routes, based on the RNN model (Popova et al., 2019), based on the VAE model (Simonovsky and Komodakis, 2018), based on the GAN model (Cao and Kipf, 2018; Wang F. et al., 2021), and based on the flow model (Zang and Wang, 2020; Ma and Zhang, 2021). Among them, the methods based on the VAE model and the GAN model both show excellent effects. At present, researchers mainly advance in-depth research on bond-based generation models. In order to improve the effect of the generation models, researchers also mine the 3D structure information of molecules. The current methods are mainly based on spherical harmonic function (Tanaka et al., 1993) and based on coordinate feature (Guu et al., 2015).
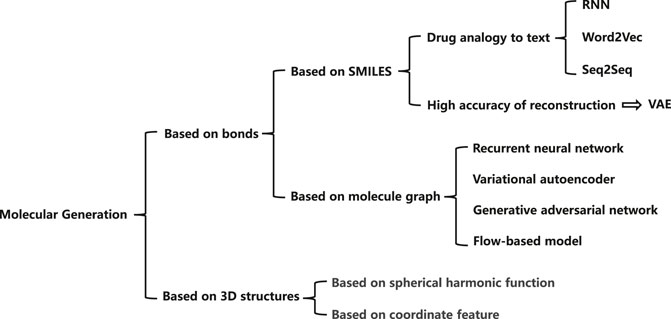
FIGURE 1. Current work on molecular generation for drug representation.
However, both the VAE-based and GAN-based methods mentioned above still remain some problems. Firstly, the majority of the VAE-based models utilize Kullback-Leibler divergence to approximately calculate the distribution of the source sampling space and the target space. This will cause the generation distribution of the final generative model can be greatly different from the actual distribution. Because the exact characteristics of the target distribution are unknown, VAE-based methods may result in unnatural molecules and reduce the validity of generated molecules. Secondly, the GAN-based model only trains a generator and a discriminator, which makes the representation of the latent vector unknown and the model difficult to be controlled. Thirdly, most GAN-based methods can not make good use of data labels and waste the properties information of the molecules.
To address the above issues, in this paper, we propose a cross-adversarial learning method for molecular generation taking the advantages of both VAE-based and GAN-based methods, namely CRAG. On one hand, an adversarially regularized autoencoder (Zhao et al., 2018) is combined with a discrete autoencoder to generate the GAN-regularized latent representation, which utilizes a more flexible prior distribution to provide a smoother discrete coding space. On the other hand, we utilize an adversarial method of projected gradient descent (Madry et al., 2018) to generate adversarial samples, which achieves data augmentation without changing the real molecular distribution and solves the problem of estimating the representation distribution. The method of training CRAG based on GAN-like structure through adversarial samples is called cross-adversarial learning. Therefore, our model can achieve high validity and uniqueness in molecular generation.
In general, the contributions of this paper can be summarized as follows:
• We propose an adversarially regularized encoder-decoder based on projected gradient descent to generate discrete variables, namely CRAG. CRAG combines the advantages of both the VAE-based and GAN-based methods, which can provide a smoother discrete coding space.
• We utilize an adversarial method of projected gradient descent to generate adversarial samples with property information, which augmented data without changing the real molecular distribution and solves the problem of estimating the representation distribution. This generation process through adversarial training achieves cross-adversarial training of the CRAG.
• The effectiveness of the proposed approach is analyzed and confirmed through extensive experiments on two public datasets. The results show that CRAG outperforms state-of-the-art models in terms of the validity, uniqueness, and novelty of each generated molecule.
2 Related Work
2.1 Molecular Generation
Molecular generation is a part of de novo drug design. The generative model can capture potential rules for data distribution, so that the model can infer the molecules through the reverse mapping between the structure and the properties under the constraints of the given property conditions. The generative model needs to have high reconstruction accuracy, and the model should make the generated new molecules have high validity, high uniqueness, and high novelty.
We can classify the widely used molecular generation models based on the methods of learning data distribution and the way of generating molecules. According to the idea of “drug analogy to text”, DeepGMG (Li et al.,2018) and MolecularRNN (Popova et al.,2019) can analyze molecular information by constructing recurrent neural networks, which is in a step-by-step fashion by adding nodes and edges one by one. But the reconstruction accuracy of these models is very low. Therefore, researchers utilize the high reconstruction accuracy of VAE-based models, which assume a simple variational distribution of the latent vectors. Such as GraphVAE (Simonovsky and Komodakis, 2018), which generates a molecular in a one-shot fashion by a single step. JT-VAE (Jin et al., 2018) also presents good performance on molecular generation by using junction trees. In order to solve the problem that it is difficult for VAE-based models to estimate the distribution, GAN-based models such as MolGAN (Cao and Kipf, 2018) and GCPN (You et al., 2018) have appeared. Of course, for the purpose of taking advantages of both VAEs and GANs, the ARAE (Hong et al., 2020) method is a wise choice. Flow-based model is another major type of generative model method besides the above methods. For example, the more well-known are GraphNVP (Madhawa et al., 2019) and MoFlow (Zang and Wang, 2020). Details are shown in Table 1.
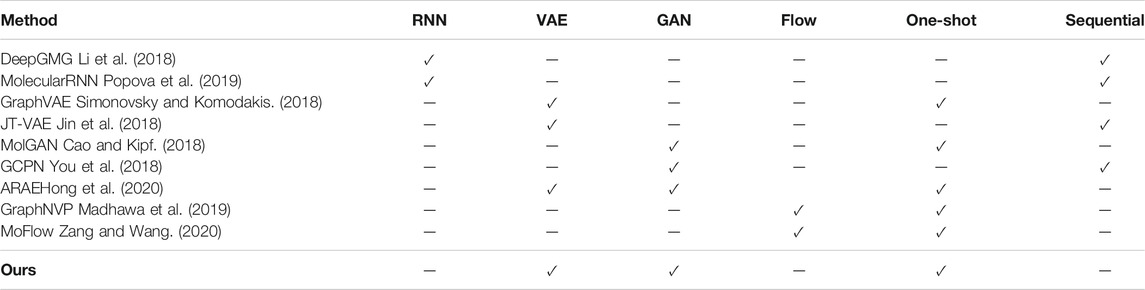
TABLE 1. Mainstream methods of molecular generation.
2.2 Adversarially Regularized Autoencoder
Adversarially Regularized Autoencoder (ARAE) (Zhao et al., 2018) was proposed to address the aforementioned problem of VAE-based and GAN-based methods. It combines a discrete autoencoder with a GAN-regularized latent representation, which utilizes a more flexible prior distribution to provide a smoother discrete coding space (Kong and Kim, 2019). The encoder network parameterized by θ outputs the true latent vector z from the given input x. The decoder network parameterized by ϕ reconstructs the inputs from the latent vector. According to the idea of GANs, the generator parameterized by ψ outputs the distribution of generated random vector
where the reconstruction loss caused by encoder and decoder can be written as:
and W is the Wasserstein distance (Arjovsky et al., 2017) between pθ, the distribution from a discrete encoder model, and pψ, a prior distribution. The W function which is adversarially optimized for the generator and encoder, can be written as:
with the 1-Lipschtiz continuity
2.3 Projected Gradient Descent
Projected gradient descent is a first-order attack method (Madry et al., 2018), which demonstrates excellent adversarial robustness. Adversarial training through the projected gradient descent can effectively improve the robustness of the model. The model is divided into two parts, which are the maximization of the internal loss function and the minimization of external experience risk. For each data point x, we introduce a set of perturbations
Equation 4 shows the implementation details of the projected gradient descent for our CRAG. The goal of inner maximization is to find the corresponding adversarial samples in the original data, so that it can achieve high loss. The goal of outer minimization is to find suitable network parameters to train a more robust neural network to defend against attacks samples.
3 Methods
In this section, we will elaborate on the details of the proposed cross-adversarial learning method. As shown in Figure 2, CRAG mainly consists of the following components: an encoder and a decoder are used to learn latent representation, a property predictor that is used to predict molecular properties, a projected gradient descent block for generating adversarial samples, and a discriminator that is used to judge whether the input molecule is a true or adversarial sample.
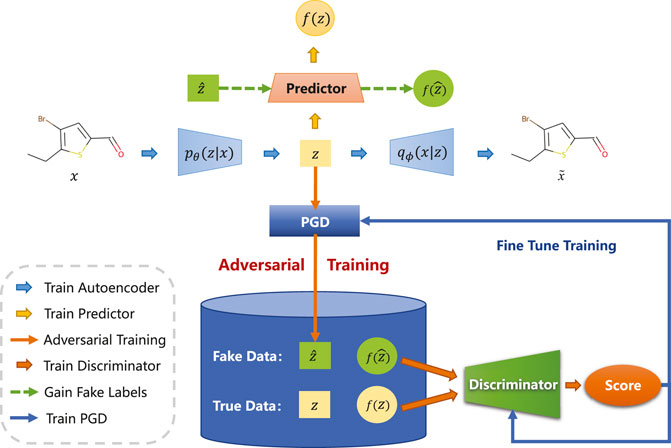
FIGURE 2. Illustration of the overall architecture. CRAG consists of an adversarially regularized encoder-decoder block, a property predictor block, and a projected gradient descent block. In particular, pθ(z|x) and qϕ(x|z) denote the probabilistic encoder and the probabilistic decoder. The property prediction network fω is used to predict the property of molecules. Projected gradient descent block generates adversarial samples
3.1 Adversarially Regularized Encoder-Decoder Block
Adversarially regularized encoder-decoder block combines a discrete autoencoder with a GAN-regularized latent representation (Zhao et al., 2018). It is trained to optimize three parts of the model (Kong and Kim, 2019). The first part of the adversarially regularized encoder-decoder is a variational autoencoder, which minimizes the reconstruction loss to obtain a continuous latent representation of a molecule. The second part is a discriminator, which maximizes the distance between real data distribution and fake data distribution to achieve an adversarial attack. The third part is the encoder and generator, which minimizes the distance between real data distribution and fake data distribution to generate adversarial samples.
3.1.1 Autoencoder
Define
The parameters are trained based on the cross-entropy reconstruction loss:
Our goal is to minimize the reconstruction loss of the autoencoder. Thus, we can not only find a suitable drug molecule representation but also help to find the specific structure of the molecule in the de novo drug design.
3.1.2 Generative Adversarial Networks
GANs are a class of parameterized implicit generative models (Goodfellow et al., 2014). GAN-based methods mainly focus on two optimization goals: one is the problem of maximizing the distribution distance of the discriminator, and the other is the problem of minimizing the distribution distance between encoder and generator. This optimization process can be regarded as a dynamic game between the discriminator and the generator.
For the first optimization, the goal of the discriminator is to distinguish the generated samples from the real data as much as possible, which can be written as:
where fω is the property prediction network parameterized by ω. During the training process, the generating samples
For the second optimization, The goal of the generator gψ is to generate real samples to deceive the discriminator as much as possible. We introduce a property predictor block to replace the traditional generator. In the traditional adversarially regularized autoencoder structure, a generator takes latent vector
In this paper, we utilize a projected gradient descent block to generate adversarial samples with property information and achieve cross-adversarial of our CRAG. The projected gradient descent block will be presented in the next section.
3.1.3 Property Predictor Block
In order to improve efficiency, the property predictor fω is implemented as a two-layer perceptron, which can effectively mine the real data distribution information. After the training of the predictor, the generated adversarial samples can be labeled to the corresponding adversarial labels by the predictor.
3.2 Projected Gradient Descent Block
Based on the adversarially regularized autoencoder, we use projected gradient descent to add property information for adversarial samples and achieve cross-adversarial learning for CRAG. Projected gradient descent is a gradient-based adversarial attack model (Madry et al., 2018). Through the previous introduction, the property predictor is parameterized by ω. For each latent vector z, we introduce a set of allowed perturbations
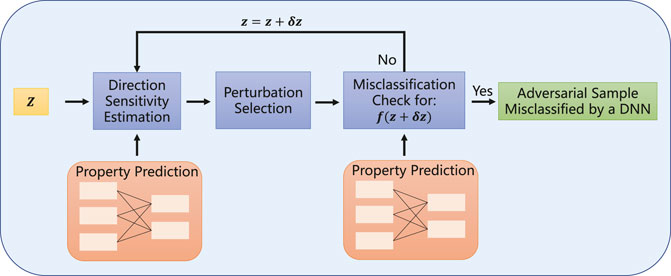
FIGURE 3. Details of the projected gradient descent block. Projected gradient descent continues to add small perturbations δ to the real sample z until it successfully interferes with their label categories, thereby generating adversarial sample
As a result, the adversarial sample
where
3.3 Overall Model and Training
After introducing all the building blocks of our work, we give the final training objective and explain the optimization process, as shown in Algorithm 1. First, we trained an autoencoder to convert discrete data forms into continuous latent vectors. Then we put the obtained latent vector z into the PGD module to generate adversarial samples
Algorithm 1. CRAG training.

The training process of CRAG involves the optimization process of three objectives, as shown in Eq. 10. The first is to minimize the reconstruction loss of the variational autoencoder, the second is to maximize the distribution distance of the discriminator, and the third is to minimize the distribution distance between the encoder and the generator.
4 Results
In this section, to verify the effectiveness of our method CRAG, we perform the experiences on two publicly available datasets (Polykovskiy et al., 2018) which are widely used for molecular generation.
4.1 Experimental Setup
4.1.1 Evaluation Metrics
In the molecular generation task, three metrics of validity, uniqueness, and novelty are commonly used to evaluate the effect of the generative model. These three metrics are usually checked by using RDKit (Bento et al., 2020). In order to evaluate the comprehensive performance of the CRAG on these three metrics, we have introduced a new metric called Novel/Sample (Hong et al., 2020), which refers to the multiplication of the three metrics. Specifically, we utilize the following four metrics to evaluate the performance of our method.
• Validity refers to the ratio of the number of valid molecules to the number of generated samples.
• Novelty refers to the ratio of the number of molecules not included in the training set to the number of unique molecules.
• Uniqueness refers to the ratio of the number of unrepeated molecules to the number of valid molecules.
• Novel/Sample (Hong et al., 2020) refers to the ratio of the number of valid, unique, and novel molecules to the total number of generated samples.
4.1.2 Evaluation Baselines
To demonstrate the effectiveness of CRAG, we compare CRAG with state-of-the-art molecular generation methods as follows.
• ChemicalVAE (Gómez-Bombarelli et al., 2016) converts the SMILES representation of molecules to form a multidimensional continuous representation based on variational autoencoder, which is jointly trained on properties.
• GrammarVAE (Kusner et al., 2017) encodes and decodes directly to parse trees, which are represented as context-free grammar. GrammarVAE can effectively guarantee the validity of the generated outputs.
• GraphVAE (Simonovsky and Komodakis, 2018) is formulated in the framework of variational autoencoder, sidestep hurdles associated with linearization of discrete structures by having a decoder output a probabilistic fully connected graph of a predefined maximum size directly at once.
• GraphVAE/imp (Simonovsky and Komodakis, 2018) is implicit node probability based on the GraphVAE model, which assumes the independence of node and edge probabilities, and allows for isolated nodes or edges. Taking further advantage of the fact that the molecule is a connected graph, studied the effect of making node probabilities a function of edge probabilities.
• GraphVAE NoGM (Simonovsky and Komodakis, 2018) learns to reproduce particular node permutations in the training set based on the GraphVAE model. It investigates the importance of graph matching by using identity assignment instead, which corresponds to the canonical ordering of SMILES strings from RDKit.
• MolGAN (Cao and Kipf, 2018) uses Generative Adversarial Networks (GANs) to directly manipulate graph structure data and is combined with reinforcement learning objectives to encourage the generation of molecules with specific desired chemical properties.
• ARAE (Hong et al., 2020) basically uses latent variables like VAEs, but the distribution of the latent variables is obtained by adversarial training like GANs.
4.1.3 Datasets
In order to train and test CRAG, we used QM9 and ZINC datasets, which are widely used in experiments and comparisons of various data-driven molecular property prediction methods (Irwin et al., 2012). The QM9 dataset (Ruddigkeit et al., 2012) contains about 133, 885 molecules of up to 9 heavy atoms: carbon (C), oxygen (O), nitrogen (N), fluorine (F), and so on. (Ramakrishnan et al., 2014). Among them, 10,000 molecules are selected as the test set. The ZINC dataset used in our experiments contains about 249, 455 molecules, which were randomly selected from the drug-like subset of the ZINC database. Data is split in the same way as the QM9 data set, and 10,000 molecules are also selected as the test set. The processing details of the ZINC database are consistent with ChemicalVAE (Gómez-Bombarelli et al., 2016).
4.1.4 Implementation Details
Our whole architecture is optimized with Adam (Kingma and Ba, 2015) optimizer. Specifically, the initial learning rates of the autoencoder, generator, and discriminator are set as 10–3, 10–5, and 2 × 10–6, respectively. Each of the encoder and the decoder are composed of a single LSTM layer, and the dimension of outputs is 300. The LSTM layer of the encoder reads sequential SMILES strings and transforms them into latent vectors. For adversarial training, we use two fully-connected layers with a hidden dimension of 200 for the generator and the discriminator. The predictor network is also composed of two fully-connected layers with a hidden dimension of 200. Our model is implemented with PyTorch.
4.2 Experimental Results
4.2.1 Smoother Discrete Coding Space
It is well known that the training of generative adversarial networks (GANs) is relatively unstable. Here, we show the convergence of the four evaluation metrics for the first 80 epochs with the ZINC dataset in Figure 4.
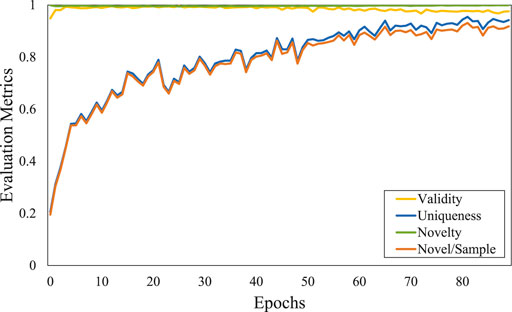
FIGURE 4. Convergence of the four evaluation metrics with the ZINC dataset.
In each epoch, 10, 000 molecules were generated and the four metrics were calculated. In the process of generating molecules, the PGD module is used to gradually increase the tiny noise to generate molecules with tiny changes. The research of the variation process of the generated molecules in the latent space is of great significance to the application of molecule generation. Figure 5 shows the visualization of the latent space for molecular generation by a given molecule.
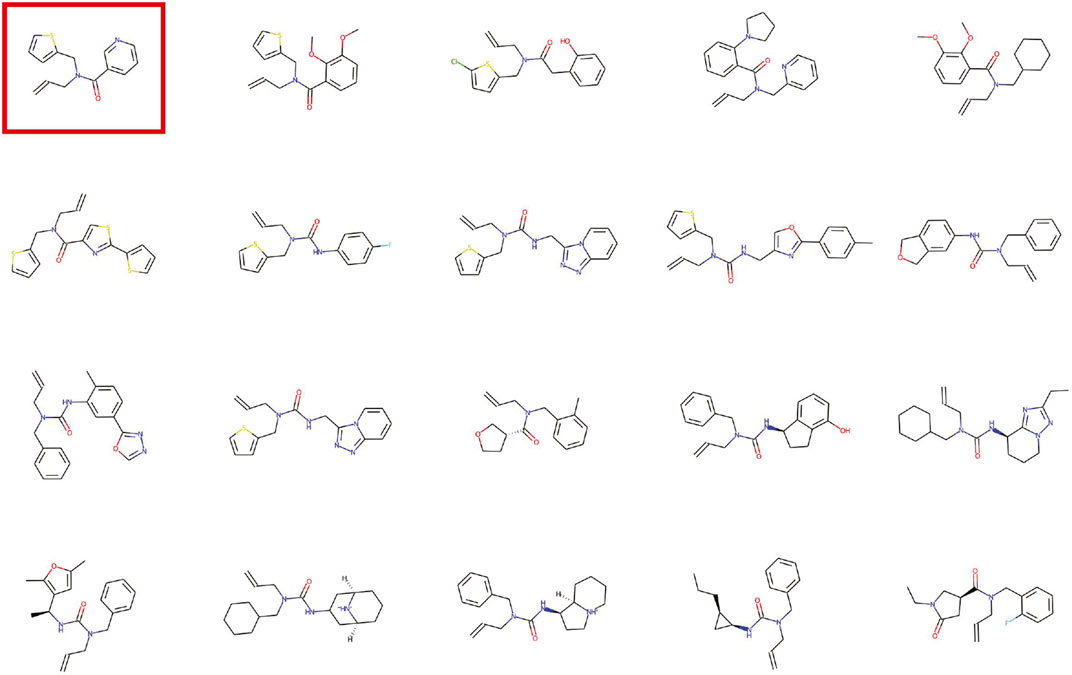
FIGURE 5. Visualization of the latent space for molecular generation by a given molecule. The red circled molecule is the given molecule.
4.2.2 Performance of CRAG on Molecular Generation
We compare the performance of CRAG to those of ChemicalVAE, GrammarVAE, GraphVAE, MolGAN, and ARAE. All of these models are trained based on VAEs or GANs. We summarize the metrics of validity, uniqueness, and novelty, as shown in Table 2.
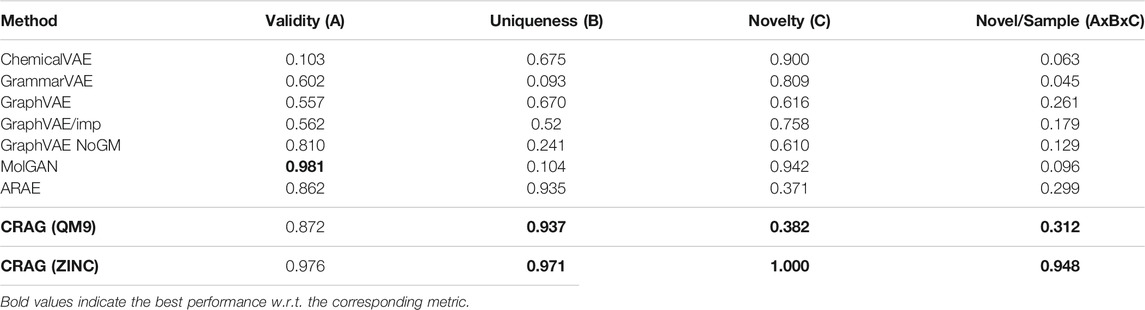
TABLE 2. Performance of benchmark models and our CRAG model on the QM9 and the ZINC datasets. Baseline results are taken from (Cao and Kipf, 2018), and Baseline results are based on the QM9 dataset.
As expected, CRAG combines the advantages of the VAE-based methods and the GAN-based methods and improves the uniqueness and novelty of these models, but our model does not perform well in terms of validity. This is caused by the huge chemical space of the ZINC dataset, limiting the chances of producing new molecules. MolGAN, similar to our model, is trained based on the idea of adversarial attack. From Table 2, we can find that MolGAN shows high validity. This is because it sacrifices uniqueness, which means that a high value of a metric can be achieved by sacrificing other metrics. It is not advisable in the real task of de novo drug design. Therefore, we propose to use another metric: Novel/Sample (A×B×C), which is combined with validity (A), uniqueness (B), and novelty (C). This metric can be more suitable to evaluate the practicability of the generative model in real tasks. On the other hand, CRAG combines projected gradient descent to generate adversarial samples, which provides property information for adversarial samples and achieves cross-adversarial learning for CRAG. The model performance of CRAG is better than the ARAE-only (Hong et al., 2020) model.
In general, CRAG outperforms other models. The average effect of CRAG on the three metrics is expressed by Novel/Sample, which also shows that CRAG can be well applied on actual tasks.
4.2.3 Performance of CRAG on Conditional Molecular Generation
In the field of de novo drug design, generation models are often required to generate related molecules based on specified molecular properties. In this section, we perform conditional molecular generation tasks based on the CRAG model, namely CCRAG (Conditional CRAG). In order to quantitatively compare the effectiveness of the generated molecules, we use the following three auxiliary indicators: logP, SAS, and TPSA. The water-octanol partition coefficient (logP) is defined as the ratio of a chemical’s concentration in the octanol phase to its concentration in the aqueous phase of a two-phase octanol/water system. Synthetics Accessibility Score (SAS) reflects the difficulty of synthesizing drug molecules. The score of SAS is between 1 (easy to make) and 10 (very difficult to make). Topological polar surface area (TPSA) estimates the polar surface area (PSA) of a compound from the bonding mode (topology) of the atoms in the molecule without considering the three-dimensional structure of the molecule. We simultaneously controlled the three properties of the molecule (logP, SAS, and TPSA), resulting in 10,000 molecules with given target properties. logP, SAS, and TPSA can be calculated by RDkit (Bento et al., 2020).
Table 3 summarizes the performance of CCRAG on the four indicators of validity, uniqueness, and novelty. CCRAG has a high success rate in conditional generation tasks, so CCRAG can easily control the generation of multi-property molecules under given fixed conditions.
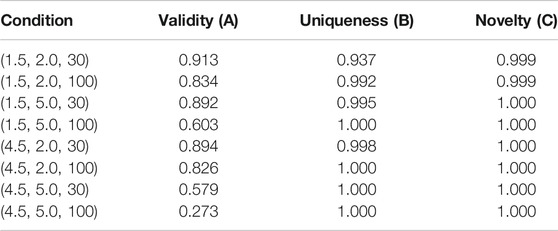
TABLE 3. Performance of CRAG on Conditional Molecular Generation on the ZINC dataset, where the three conditions of logP, SAS, and TPSA are simultaneously controlled.
4.2.4 Property-Targeted Molecule Optimization
Optimizing a given molecule according to specific molecular properties is also one of the common tasks in de novo drug design. Here, we performed the quantification of drug-like properties (QED) (Bickerton et al., 2012) to the greatest extent given a single molecule. QED reflects the underlying distribution of molecular properties, which is intuitive, transparent, and straightforward to be implemented in many practical settings, and allows compounds to be ranked by their relative merit.
Figure 6 demonstrates a simple linear regression yields successful molecular optimization. We trained a linear regression model for molecular optimization with QED values. We selected a molecule with a low QED score and visualize the optimization process. The molecule can be optimized according to its gradient direction, so the molecule can obtain a greater increase in QED value with smaller possible changes.

FIGURE 6. Chemical property optimization. Given the left-most molecule, we optimize the molecule in the direction of maximizing its QED property.
5 Conclusion
In this paper, we propose a cross-adversarial learning method, named CRAG, for molecular generation using adversarial examples. Our model combines both the facticity of VAE-based methods and the diversity of GAN-based methods to further exploit the complex properties of Molecules. CRAG is based on a latent variable model to obtain the latent variables directly in GANs through adversarial training, rather than approximated by a predefined function. In adversarial training, CRAG uses continuous latent vectors instead of discrete molecular structures to avoid the difficulty of dealing with discrete variables. In addition, we also generate adversarial molecules through projected gradient descent to provide more property information and achieve cross-adversarial learning of CRAG. Extensively conducted on two benchmark datasets, which show the high uniqueness and high novelty of CRAG for molecular generation. Through the Novel/Sample metric, CRAG is validated to have a better overall effect, which indicates a promising sign that CRAG could become a new platform for AI-based molecular design in various chemical applications in the future.
Data Availability Statement
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author.
Author Contributions
BW and LL designed the study. LL performed computations and data analyses. KZ and YC supervised the study. All authors contributed to writing the manuscript. All authors read and approved the final manuscript.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Arjovsky, M., Chintala, S., and Bottou, L. (2017). Wasserstein GAN. arXiv preprint arXiv:1701.07875.
Bagal, V., Aggarwal, R., Vinod, P. K., and Priyakumar, U. D. (2021). Molgpt: Molecular Generation Using a Transformer-Decoder Model. J. Chem. Inf. Model. doi:10.1021/acs.jcim.1c00600
Bento, A. P., Hersey, A., Félix, E., Landrum, G., Gaulton, A., Atkinson, F., et al. (2020). An Open Source Chemical Structure Curation Pipeline Using Rdkit. J. Cheminform 12, 51. doi:10.1186/s13321-020-00456-1
Bickerton, G. R., Paolini, G. V., Besnard, J., Muresan, S., and Hopkins, A. L. (2012). Quantifying the Chemical beauty of Drugs. Nat. Chem. 4, 90–98. doi:10.1038/nchem.1243
Cao, N. D., and Kipf, T. (2018). Molgan: An Implicit Generative Model for Small Molecular Graphs. arXiv preprint arXiv:1805.11973.
Ding, Y., Chen, B., Lei, X., Liao, B., and Wu, F. X. (2020). Predicting Novel Circrna-Disease Associations Based on Random Walk and Logistic Regression Model. Comput. Biol. Chem. 87, 107287. doi:10.1016/j.compbiolchem.2020.107287
Gómez-Bombarelli, R., Duvenaud, D., Hernández-Lobato, J. M., Aguilera-Iparraguirre, J., Hirzel, T. D., Adams, R. P., et al. (2016). Automatic Chemical Design Using a Data-Driven Continuous Representation of Molecules. arXiv preprint arXiv:1610.02415.
Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., et al. (2014). Generative Adversarial Networks. arXiv preprint arXiv:1406.2661.
Guu, K., Miller, J., and Liang, P. (2015). “Traversing Knowledge Graphs in Vector Space,” in Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, September 17-21, 2015 (EMNLP 2015), 318–327. doi:10.18653/v1/d15-1038
Hartenfeller, M., and Schneider, G. (2010). De Novo drug Design. Methods Mol. Biol. 672, 299–323. doi:10.1007/978-1-60761-839-3_12
Hong, S. H., Ryu, S., Lim, J., and Kim, W. Y. (2020). Molecular Generative Model Based on an Adversarially Regularized Autoencoder. J. Chem. Inf. Model. 60, 29–36. doi:10.1021/acs.jcim.9b00694
Irwin, J. J., Sterling, T., Mysinger, M. M., Bolstad, E. S., and Coleman, R. G. (2012). ZINC: A Free Tool to Discover Chemistry for Biology. J. Chem. Inf. Model. 52, 1757–1768. doi:10.1021/ci3001277
Jaeger, S., Fulle, S., and Turk, S. (2018). Mol2vec: Unsupervised Machine Learning Approach with Chemical Intuition. J. Chem. Inf. Model. 58, 27–35. doi:10.1021/acs.jcim.7b00616
Jin, W., Barzilay, R., and Jaakkola, T. S. (2018). “Junction Tree Variational Autoencoder for Molecular Graph Generation,” in Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, July 10-15, 2018 (PMLR), 80, 2328–2337. of Proceedings of Machine Learning Research.
Khan, S. R., Al Rijjal, D., Piro, A., and Wheeler, M. B. (2021). Integration of Ai and Traditional Medicine in Drug Discovery. Drug Discov. Today 26, 982–992. doi:10.1016/j.drudis.2021.01.008
Kingma, D. P., and Ba, J. (2015). “Adam: A Method for Stochastic Optimization,” in 3rd International Conference on Learning Representations, San Diego, CA, USA, May 7-9, 2015 (ICLR 2015). Conference Track Proceedings.
Kong, H., and Kim, W. (2019). Generating Summary Sentences Using Adversarially Regularized Autoencoders with Conditional Context. Expert Syst. Appl. 130, 1–11. doi:10.1016/j.eswa.2019.04.014
Kusner, M. J., Paige, B., and Hernández-Lobato, J. M. (2017). “Grammar Variational Autoencoder,” in Proceedings of the 34th International Conference on Machine Learning, Sydney, NSW, Australia, August 2017 (ICML 2017), 70, 61945–111954. of Proceedings of Machine Learning Research.
Lei, X.-J., Bian, C., and Pan, Y. (2021a). Predicting Circrna-Disease Associations Based on Improved Weighted Biased Meta-Structure. J. Comput. Sci. Technol. 36, 288–298. doi:10.1007/s11390-021-0798-x
Lei, X., Mudiyanselage, T. B., Zhang, Y., Bian, C., Lan, W., Yu, N., et al. (2021b). A Comprehensive Survey on Computational Methods of Non-coding RNA and Disease Association Prediction. Brief. Bioinform 22, bbaa350. doi:10.1093/bib/bbaa350
Lei, X., Tie, J., and Fujita, H. (2020). Relational Completion Based Non-negative Matrix Factorization for Predicting Metabolite-Disease Associations. Knowledge-Based Syst. 204, 106238. doi:10.1016/j.knosys.2020.106238
Lei, X., and Zhang, C. (2020). Predicting Metabolite-Disease Associations Based on Linear Neighborhood Similarity with Improved Bipartite Network Projection Algorithm. Complex, 1–11. doi:10.1155/2020/9342640
Lei, X., and Zhang, W. (2021). Logistic Regression Algorithm to Identify Candidate Disease Genes Based on Reliable Protein-Protein Interaction Network. Sci. China Inf. Sci. 64. doi:10.1007/s11432-018-1512-0
Li, P., Wang, J., Qiao, Y., Chen, H., Yu, Y., Yao, X., et al. (2021). An Effective Self-Supervised Framework for Learning Expressive Molecular Global Representations to Drug Discovery. Brief. Bioinform 22, bbab109. doi:10.1093/bib/bbab109
Li, Y., Vinyals, O., Dyer, C., Pascanu, R., and Battaglia, P. W. (2018). Learning Deep Generative Models of Graphs. arXiv preprint arXiv:1803.03324.
Lin, S., Wang, Y., Zhang, L., Chu, Y., Liu, Y., Fang, Y., et al. (2021). Mdf-sa-ddi: Predicting Drug–Drug Interaction Events Based on Multi-Source Drug Fusion, Multi-Source Feature Fusion and Transformer Self-Attention Mechanism. Brief. Bioinform. 20, bbab421. doi:10.1093/bib/bbab421
Lyu, T., Gao, J., Tian, L., Li, Z., Zhang, P., and Zhang, J. (2021). “MDNN: A Multimodal Deep Neural Network for Predicting Drug-Drug Interaction Events,” in Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI 2021, Virtual Event/Montreal, Canada, 19-27 August 2021 (ijcai.org), 3536–3542. doi:10.24963/ijcai.2021/487
Ma, C., and Zhang, X. (2021). “GF-VAE: A Flow-Based Variational Autoencoder for Molecule Generation,” in CIKM ’21: The 30th ACM International Conference on Information and Knowledge Management, Virtual Event, Queensland, Australia, November 1 - 5, 2021 (ACM), 1181–1190.
Madhawa, K., Ishiguro, K., Nakago, K., and Abe, M. (2019). Graphnvp: An Invertible Flow Model for Generating Molecular Graphs. arXiv preprint arXiv:1905.11600.
Madry, A., Makelov, A., Schmidt, L., Tsipras, D., and Vladu, A. (2018). “Towards Deep Learning Models Resistant to Adversarial Attacks,” in 6th International Conference on Learning Representations, Vancouver, BC, Canada, April 30 - May 3, 2018 (ICLR 2018). Conference Track Proceedings (OpenReview.net).
Merkwirth, C., and Lengauer, T. (2005). Automatic Generation of Complementary Descriptors with Molecular Graph Networks. J. Chem. Inf. Model. 45, 1159–1168. doi:10.1021/ci049613b
Mudiyanselage, T. B., Lei, X., Senanayake, N., Zhang, Y., and Pan, Y. (2020). “Graph Convolution Networks Using Message Passing and Multi-Source Similarity Features for Predicting Circrna-Disease Association,” in IEEE International Conference on Bioinformatics and Biomedicine, BIBM 2020, Virtual Event. South Korea. December 16-19, 2020. IEEE, 343–348. doi:10.1109/bibm49941.2020.9313455
Polishchuk, P. G., Madzhidov, T. I., and Varnek, A. (2013). Estimation of the Size of Drug-like Chemical Space Based on GDB-17 Data. J. Comput. Aided Mol. Des. 27, 675–679. doi:10.1007/s10822-013-9672-4
Polykovskiy, D., Zhebrak, A., Sanchez-Lengeling, B., Golovanov, S., Tatanov, O., Belyaev, S., et al. (2018). Molecular Sets (MOSES): A Benchmarking Platform for Molecular Generation Models. arXiv preprint arXiv:1811.12823.
Popova, M., Shvets, M., Oliva, J., and Isayev, O. (2019). Molecularrnn: Generating Realistic Molecular Graphs with Optimized Properties. arXiv preprint arXiv:1905.13372.
Ramakrishnan, R., Dral, P. O., Rupp, M., and von Lilienfeld, O. A. (2014). Quantum Chemistry Structures and Properties of 134 Kilo Molecules. Sci. Data 1, 140022. doi:10.1038/sdata.2014.22
Ruddigkeit, L., van Deursen, R., Blum, L. C., and Reymond, J. L. (2012). Enumeration of 166 Billion Organic Small Molecules in the Chemical Universe Database GDB-17. J. Chem. Inf. Model. 52, 2864–2875. doi:10.1021/ci300415d
Segler, M. H. S., Kogej, T., Tyrchan, C., and Waller, M. P. (2017). Generating Focussed Molecule Libraries for Drug Discovery with Recurrent Neural Networks. arXiv preprint arXiv:1701.01329.
Simonovsky, M., and Komodakis, N. (2018). “Graphvae: Towards Generation of Small Graphs Using Variational Autoencoders,” in Artificial Neural Networks and Machine Learning - ICANN 2018 - 27th International Conference on Artificial Neural Networks, Rhodes, Greece, October 4-7, 2018 (Springer), 11139, 412–422. Proceedings, Part Iof Lecture Notes in Computer Science. doi:10.1007/978-3-030-01418-6_41
Tanaka, K., Sano, M., Mukawa, N., and Kaneko, H. (1993). “3d Object Representation Using Spherical Harmonic Functions,” in Proceedings of 1993 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, July 26 - 30, 1993 (IROS 1993IEEE), 1873–1880.
Wang, F., Feng, X., Guo, X., Xu, L., Xie, L., and Chang, S. (2021a). Improving De Novo Molecule Generation by Embedding Lstm and Attention Mechanism in Cyclegan. Front. Genet. 12, 709500. doi:10.3389/fgene.2021.709500
Wang, Y., Lei, X., and Pan, Y. (2021b). “Predicting Microbe-Disease Association via Tripartite Network and Relation Graph Convolutional Network,” in Bioinformatics Research and Applications - 17th International Symposium, Shenzhen, China, November 26-28, 2021 (ISBRA 2021Springer), 13064, 92–104. Proceedingsof Lecture Notes in Computer Science. doi:10.1007/978-3-030-91415-8_9
Xu, Z., Wang, S., Zhu, F., and Huang, J. (2017). “Seq2seq Fingerprint: An Unsupervised Deep Molecular Embedding for Drug Discovery,” in Proceedings of the 8th ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics, BCB 2017, Boston, MA, USA, August 20-23, 2017 (ACM), 285–294.
Yang, J., and Lei, X. (2021). Predicting Circrna-Disease Associations Based on Autoencoder and Graph Embedding. Inf. Sci. 571, 323–336. doi:10.1016/j.ins.2021.04.073
You, J., Liu, B., Ying, R., Pande, V. S., and Leskovec, J. (2018). Graph Convolutional Policy Network for Goal-Directed Molecular Graph Generation. arXiv preprint arXiv:1806.02473.
Zang, C., and Wang, F. (2020). “Moflow: An Invertible Flow Model for Generating Molecular Graphs,” in KDD ’20: The 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual Event, CA, USA, August 23-27, 2020 (ACM), 617–626. doi:10.1145/3394486.3403104
Zhang, C., Lyu, X., Huang, Y., Tang, Z., and Liu, Z. (2019). “Molecular Graph Generation with Deep Reinforced Multitask Network and Adversarial Imitation Learning,” in 2019 IEEE International Conference on Bioinformatics and Biomedicine, BIBM 2019, San Diego, CA, USA, November 18-21, 2019 (IEEE), 326–329. doi:10.1109/bibm47256.2019.8983277
Zhang, Y., Lei, X., Pan, Y., and Pedrycz, W. (2021). Prediction of Disease-Associated Circrnas via Circrna-Disease Pair Graph and Weighted Nuclear Norm Minimization. Knowledge-Based Syst. 214, 106694. doi:10.1016/j.knosys.2020.106694
Zhao, C., Liu, S., Huang, F., Liu, S., and Zhang, W. (2021). “CSGNN: Contrastive Self-Supervised Graph Neural Network for Molecular Interaction Prediction,” in Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI 2021, Virtual Event/Montreal, Canada, August 2021 (ijcai.org), 193756–273763. doi:10.24963/ijcai.2021/517
Zhao, J. J., Kim, Y., Zhang, K., Rush, A. M., and LeCun, Y. (2018). “Adversarially Regularized Autoencoders,” in Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, July 10-15, 2018 (PMLR), 80, 5897–5906. of Proceedings of Machine Learning Research.
Keywords: molecular generation, adversarial learning, projected gradient descent, adversarially regularized autoencoder, generative adversarial network
Citation: Wu B, Li L, Cui Y and Zheng K (2022) Cross-Adversarial Learning for Molecular Generation in Drug Design. Front. Pharmacol. 12:827606. doi: 10.3389/fphar.2021.827606
Received: 02 December 2021; Accepted: 30 December 2021;
Published: 21 January 2022.
Edited by:
Xiujuan Lei, Shaanxi Normal University, ChinaCopyright © 2022 Wu, Li, Cui and Zheng. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Kai Zheng, zhengkai@uestc.edu.cn
†These authors have contributed equally to this work and share first authorship