 Buwei Teng1
Buwei Teng1 Jun Ma
Jun Ma- 1Department of Hepatobiliary Surgery, The Affiliated Lianyungang Hospital of Xuzhou Medical University/The First People’s Hospital of Lianyungang, Lianyungang, China
- 2Department of Imaging, The Affiliated Huai’an Hospital of Xuzhou Medical University and the Second People’s Hospital of Huai’an, Huai’an, China
Purpose: The overall survival of patients with pancreatic cancer is extremely low. We aimed to establish machine learning (ML) based model to accurately predict three-year survival and prognosis of pancreatic cancer patients.
Methods: We analyzed pancreatic cancer patients from the Surveillance, Epidemiology, and End Results (SEER) database between 2000 and 2021. Univariate and multivariate logistic analysis were employed to select variables. Recursive Feature Elimination (RFE) method based on 6 ML algorithms was utilized in feature selection. To construct predictive model, 13 ML algorithms were evaluated by area under the curve (AUC), area under precision-recall curve (PRAUC), accuracy, sensitivity, specificity, precision, cross-entropy, Brier scores and Balanced Accuracy (bacc) and F Beta Score (fbeta). An optimal ML model was constructed to predict three-year survival, and the predictive results were explained by SHapley Additive exPlanations (SHAP) framework. Meanwhile, 101 ML algorithm combinations were developed to select the best model with highest C-index to predict prognosis of pancreatic cancer patients.
Results: A total of 20,064 pancreatic cancer patients from SEER database was consecutively enrolled. We utilized eight clinical variables to establish prediction model for three-year survival. CatBoost model was selected as the best prediction model, and AUC was 0.932 [0.924, 0.939], 0.899 [0.873, 0.934] and 0.826 [0.735, 0.919] in training, internal test and external test sets, with 0.839 [0.831, 0.847] accuracy, 0.872 [0.858, 0.887] sensitivity, 0.803 [0.784, 0.825] specificity and 0.832 [0.821, 0.853] precision. Surgery type had the greatest effects on three-year survival according to SHAP results. For prognosis prediction, “RSF+GBM” algorithm was the best prognostic model with C-index of 0.774, 0.722 and 0.674 in training, internal test and external test sets.
Conclusions: Our ML models demonstrate excellent accuracy and reliability, offering more precise personalized prognostic prediction to pancreatic cancer patients.
Introduction
Pancreatic cancer is a highly lethal disease with a dismal prognosis, and the 5-year survival rate is merely 9% (1). Only 1% of patients survive for 3 years or more after diagnosis of metastatic pancreatic cancer, while the incidence continues to climb steadily. Surgical resection is the only potential curative treatment, yet only a small proportion of pancreatic cancer patients are eligible for surgery at the time of initial diagnosis (2). This is largely because pancreatic cancer often lacks symptoms in its early stages, leading to most cases being diagnosed at an advanced stage (3). While some individuals may detect the disease through routine physical examinations and undergo early surgery, many patients still experience relapse and ultimately succumb to the disease (4). The treatment of pancreatic cancer mainly includes surgical resection, radiotherapy, chemotherapy and targeted therapy, but the overall efficacy is limited due to its high aggressiveness and the norm of late detection. Novel drugs targeting the KRAS gene, such as sotorasib and adagrasib, have demonstrated efficacy and tolerability in treating solid tumors, including pancreatic cancer, in clinical trials (5). Consequently, it is critical to promptly and early identify pancreatic cancer patients at high risk to optimize their treatment and improve prognosis. And exploring the prognostic risk factors for pancreatic cancer patients is crucial to assess their survival prospects.
Several biomarkers for prognosis prediction in pancreatic cancer have been identified in recent years, including CA19-9, circulating tumor DNA (ctDNA), microRNAs (miRNAs), and tumor mutational burden (TMB) (6). However, CA19-9 is not specific to pancreatic cancer and can be elevated in other conditions such as cholangitis, leading to false positives. Meanwhile, ctDNA analysis is limited by the low abundance of tumor DNA in the bloodstream, particularly in early-stage cancers, which may result in false negatives. And the clinical application of miRNAs is still in the early stages, and their stability in circulation poses challenges for reliable detection (7). Furthermore, TMB’s predictive value is still under investigation, and its utility may vary depending on the genetic landscape of the tumor and the therapeutic context (8). Recently, nomogram based on Cox model has been widely utilized in cancer prognosis prediction, but its sensitivity and specificity may be insufficient, calling an urgent need for predicting prognosis more accurately and specifically. Machine learning (ML) approach, a subset of artificial intelligence, has become increasingly popular due to its ability to handle complex, non-linear relationships, particularly effective with vast datasets and loosely structured information (9). With the advent of big data analytics and ML, new approaches for screening risk factors affecting prognosis have become feasible. Several predictive models leveraging these technologies have shown excellent performance and are increasingly being integrated into clinical settings (10, 11), while there is no ML-based sophisticated model to predict prognosis in pancreatic cancer so far, necessitating development and validation of a novel ML model.
The Surveillance, Epidemiology, and End Results (SEER) database (https://seer.cancer.gov/) is particularly valuable in this context, which encompasses a wide range of patient data, offering comprehensive clinicopathological statistics and follow-up information. This rich, real-world database is an ideal resource for developing and testing ML models in the medical field. However, it appears that there is still a gap in research specifically focused on developing models for three-year survival prediction and prognosis forecast of pancreatic cancer patients. Our study was committed to firstly developing and validating predictive and prognostic models utilizing multiple ML algorithms. This approach leverages extensive population data and the capabilities of ML, which is competent in providing personalized predictive tools that assist clinicians in effectively assessing the risk and prognosis of pancreatic cancer patients.
Materials and methods
Data source and characteristics
Clinicopathological data of patients with site recode ICD-O-3/WHO 2008 “pancreas” and AYA site recode 2020 Revision “9.3.9.2 Pancreas – adenocarcinoma” between 2000 and 2021 was retrieved from the SEER database. Additionally, clinicopathological information of pancreatic The First People’s Hospital of Lianyungang (2015–2024) was retrospectively collected through electronic medical record system. The study was conducted according to the guidelines of the Declaration of Helsinki and was approved by the Ethics Committee of The First People’s Hospital of Lianyungang (protocol code: KY-20210910004, approved on 2021-09-10). Informed consent was obtained from all subjects involved in this study. Inclusion criteria comprised individuals with ICD-O-3/WHO 2008 “pancreas” and AYA site recode 2020 Revision “9.3.9.2 Pancreas – adenocarcinoma” which are older than 18 years old. Exclusion criteria comprised patients lacking follow-up information of survival months and death cause, not diagnosed with positive histology, no surgery information, not first malignant tumor, without TNM stage or grade details. In SEER database, metastasis is characterized by spreading to distant organs during the initial cancer diagnosis. And we define the outcome of predictive model as three-year survival, indicating that patients are still alive at the timepoint of 36 months follow-up. The positive outcome was death of patient in three-year follow-up.
Extracted data were gathered on demographic data (age, gender, race, marital status household location and income), cancer characteristics (pathological grade, summary stage, TNM stage, tumor size, tumor primary location, pathology, metastasis information), therapeutic information (surgery, lymph node surgery, positive lymph node, radiotherapy, chemotherapy) and follow-up information (overall and cancer-specific survival status, survival months). Two continuous variables, age and tumor size, were divided into categorical variables. The age was split into five groups: “<50”, “50-59”, “60-69”, “70-79” and “>=80”. The tumor size was split into “<2cm”, “2-3.9cm”, “4-5.9cm”, “6-7.9cm”, “>8cm” and “Unknown”. “Metastasis” was defined as “yes” with metastasis either in brain, bone, liver, lung, and distant lymph nodes, as well as tumor categorized as M1 stage. The missing rate for each categorical variable is calculated and reported. For those classified data that is unknown, we classify its missing value into the “unknown” category. This processing ensures data integrity and avoids information loss due to missing data. We determined the minimum sample size needed for an external validation cohort by formula of Riley et al. (12).
Establishment and validation of predictive model for three-year survival
In the preliminary analysis, variables with P < 0.05 in the univariate and multivariate logistic analysis in the training set were included for the feature selection process. Subsequently, we employed Recursive Feature Elimination (RFE) method based on 6 ML algorithms, involving categorical boosting (CatBoost), random forest (RF), support vector machine (SVM), extreme gradient boosting (XGB), decision tree (DT) and gradient boosting machine (GBM), combined with 5-fold cross-validation, to sift through the clinical features. RFE works by building a model and identifying the most significant features in feature selection phase. This selection process is then iteratively repeated on the subset of remaining features until all features have been evaluated and ranked (13). Then Robust rank aggregation (RRA) algorithm was utilized to integrate the rank of variable importance from six ML algorithms utilized in RFE method to obtain a comprehensive ranking of all variables (14). We set random seed as “2024” in our analysis. In model development phase, we applied 13 ML algorithms, including CatBoost, RF, SVM, XGB, DT, GBM, k-nearest neighbor (KNN), logistic regression (LR), naive bayes classifier (NBC), linear discriminant analysis (LDA), quadratic discriminant analysis (QDA), neural network (NNET) and generalized linear model (GLM) to predict three-year survival via “mlr3” R package (15). This approach allows us to compare the performance of various models and select the best predictive model. To tackle the issue of class imbalance, which could significantly skew performance metrics, we implemented the Synthetic Minority Over-sampling Technique (SMOTE) for training our model (16). We further refined our approach by employing nested resampling, which involved a two-tiered k-fold cross-validation process: one for optimizing model hyperparameters and another nested within it for model selection. Meanwhile, we utilized a 1000-evaluation random search across a 5-fold cross-validation framework, repeated five times for each model. Subsequently, area under the curve (AUC), area under precision-recall curve (PRAUC), accuracy, sensitivity, specificity, precision, cross-entropy, Brier scores and Balanced Accuracy (bacc) and F Beta Score (fbeta) were calculated to select the best ML model. Internal validation was carried out through 5-fold cross-validation. Precision-recall curve (PRC) was employed to evaluate the performance of classification models in handling imbalanced datasets. Calibration curve was utilized to appraise model’s discriminative ability, and decision curve analysis (DCA) was applied to verify the clinic benefit of ML model via “runway” R package (https://github.com/ML4LHS/runway/). We set the selection criteria of our best model: highest AUC, highest PRAUC, and lowest Brier score, while also ensuring a good calibration curve, as well as outperforming balanced accuracy and F Beta Score. To quantify the impact of each variable, we calculated its mean contribution to the AUC as a percentage relative to the full model via “DALEX” R package (17). SHapley Additive exPlanations (SHAP) value were used to explain the best model predictions and to interpret the black-box ML model via “shapviz” R package (https://github.com/ModelOriented/shapviz) (18).
Prognostic model based on integrative machine learning algorithms
Univariate and multivariate cox analysis were employed to define clinical variables with significant prognosis value in overall survival (OS). We integrated 10 ML algorithms involving random survival forest (RSF), elastic network (Enet), Lasso, Ridge, stepwise Cox, CoxBoost, partial least squares regression for Cox (plsRcox), supervised principal components (SuperPC), GBM and survival support vector machine (survival-SVM) to predict prognosis (in terms of OS) of pancreatic cancer patients. Altogether 101 prognostic ML algorithm combinations were trained in the training cohort, to develop the prognostic ML model according to the leave-one-out cross-validation (LOOCV) framework. Models with <3 clinical variable were removed. Subsequently, the concordance index (C-index) of every ML combination in training, testing and external validation cohorts was obtained (19). The top five ML combinations yielding the highest average C-index across three cohorts were selected for model evaluation via k-fold cross-validation, to mitigate overfitting and ensure the robustness and generalizability of model. Logarithmic loss, recall and decision calibration were utilized to select the best prognostic ML combination via “mlr3proba” R package (20). We incorporated variables from various feature selection patterns to compute risk scores using a linear combination function for each prognostic ML combination. The median risk score from the training cohort was chosen as the threshold to categorize patients in training, testing and external validation cohorts into high or low-risk groups. We utilized the Kaplan-Meier (KM) survival analysis and the log-rank test on these groups, using the “survival” and “survminer” R packages. AUC, time-dependent receiver operating characteristic (ROC) curves, calibration curves and DCA were employed to evaluate the precision, discrimination and clinical benefit of the model.
Results
Demographic composition and clinical baseline information
In the predictive model for three-year survival, a total of 20064 pancreatic cancer patients from SEER database and 103 patients from The First People’s Hospital of Lianyungang were included. We divided patients from SEER database randomly into training and internal validation sets in a 7:3 ratio, respectively. And pancreatic cancer patients from The First People’s Hospital of Lianyungang were assigned as the external validation set. In the trainset from SEER database, 2579 cases (18.3%) were alive at three-year follow-up, while 11548 cases (81.7%) did not. Detailed clinical information regarding the training and validation sets to predict three-year survival can be found in Table 1. For the outcomes (in terms of OS) of prognostic model, 13157 cases (93.1%) were dead at the time of follow-up, while 970 cases (6.87%) were alive (Table 1). In the training, internal validation and external validation sets, the median follow-up time was 12.0 [5.00;26.0], 12.0 [5.00;27.0] and 16.0 [6.00;30.5] (Table 1). The specific selection process of patients from SEER database is shown in Figure 1.
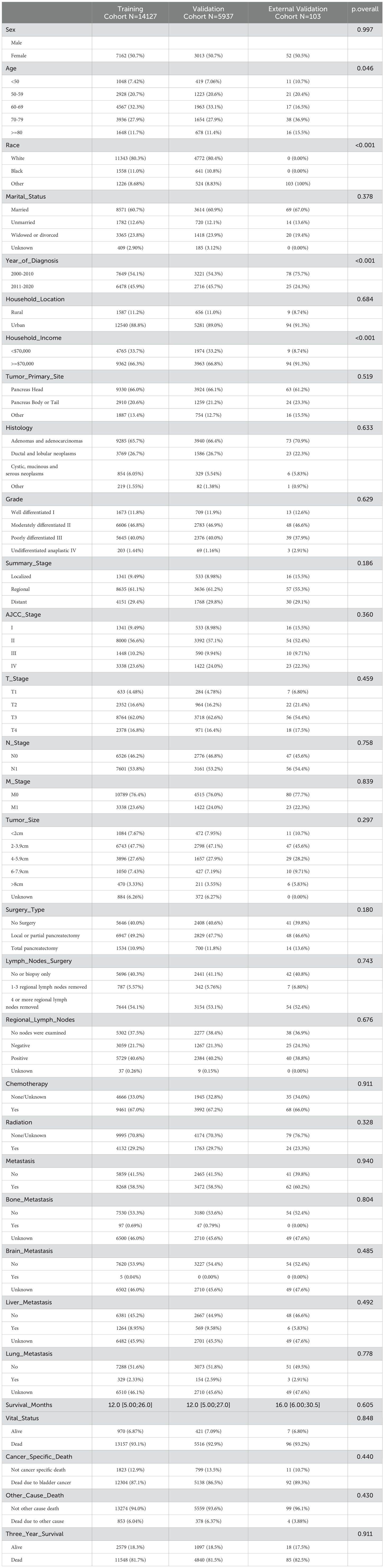
Table 1. Clinicopathological characteristics of patients with pancreatic cancer in the training, internal validation and external validation cohorts.
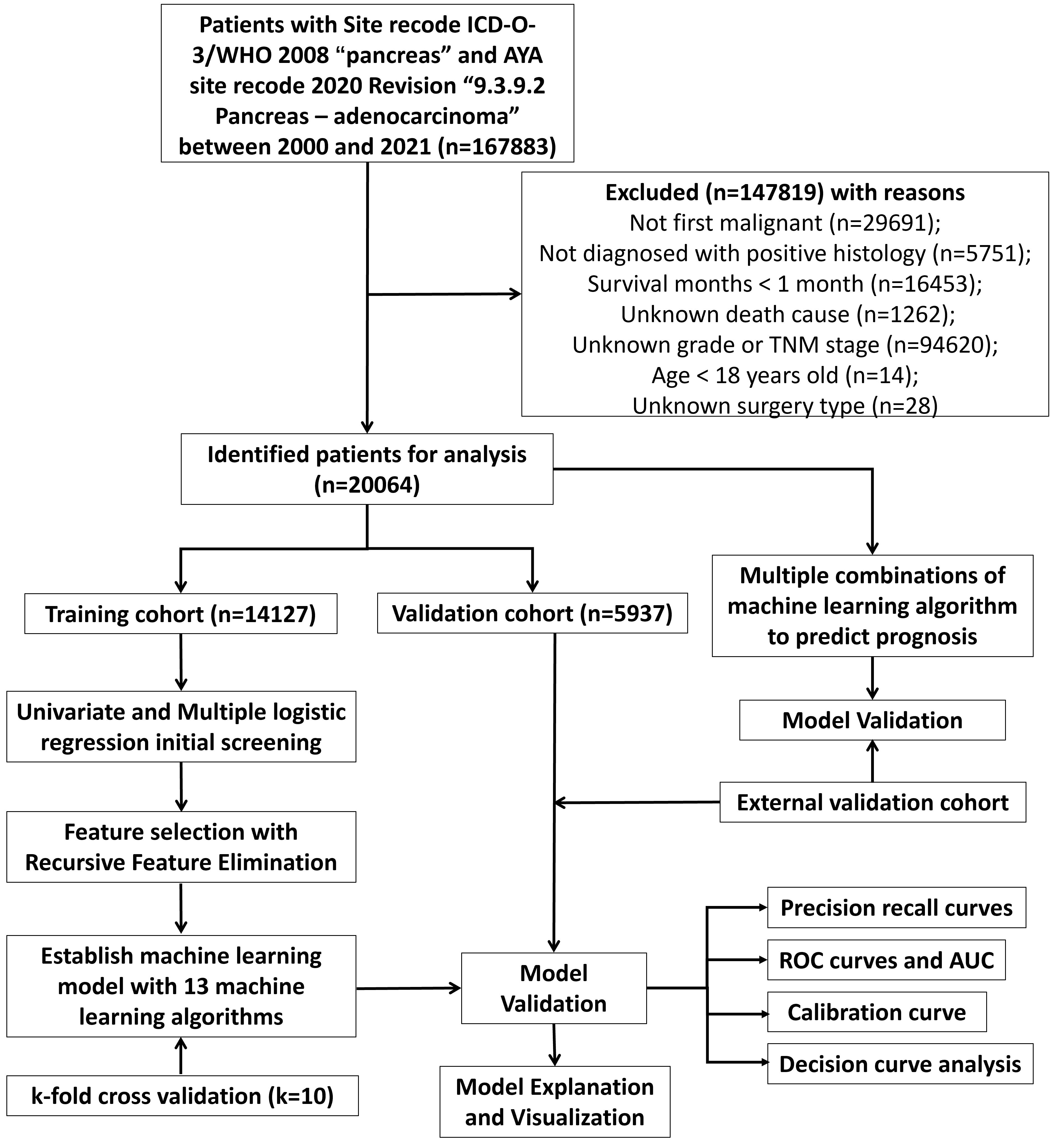
Figure 1. The workflow diagram for study design and patient screening.
Feature selection for the predictive model
We utilized “autoplot” function in “mlr3” R package to visualized the correlation coefficients of the baseline characteristics with three-year survival, which revealed that “AJCC stage” had the most significant correlation with three-year survival (Figure 2A). Based on our clinical experiences, we selected 24 variables for the logistic regression analysis (Table 2), while the variable with a correlation coefficient > 0.6 was removed. Subsequently, we performed univariate and multivariate logistic regression analysis in the training cohort to find the effective variables to predict three-year survival, which revealed that “Age” (OR 1.67(1.35-2.06)), “Marital_Status” (OR 1.27(1.14-1.42)), “Household_Income” (OR 0.75(0.68-0.83)), “Histology” (OR 0.5(0.43-0.59)), “Grade” (OR 2.4(1.59-3.72)), “Summary_Stage” (OR 3.12(2.27-4.31)), “Tumor_Size” (OR 2.63(2.08-3.34)), “AJCC_Stage” (OR 1.59(1.09-2.35)), “Surgery_Type” (OR 0.15(0.11-0.2)), “Radiotherapy” (OR 0.79(0.72-0.87)), “Chemotherapy” (OR 0.57(0.52-0.64)), “Lung_Metastasis” (OR 0.2(0.06-0.99)), “M_Stage” (OR 1.26(1.07-1.48)) were significantly powerful to predict three-year survival (P < 0.05, Table 2). The correlation analysis between the variables and three-year survival showed that “AJCC_stage” is the most influential factor (Figure 2B). Due to high correlation between “AJCC_stage” and “Summary_Stage”, we only choose “AJCC_stage” in the following analysis. Afterwards, we utilized Recursive Feature Elimination (RFE) method based on six ML algorithms (GBM, SVM, RF, DT, XGB and CatBoost), combined with 5-fold cross-validation, to sift through the clinic features (Figures 2C–H). Feature selection based on RFE found that the optimal selection was according to GBM algorithm, remaining 12 variables, with the highest AUC (0.819, Figure 2C). We utilized RRA algorithm to obtain the comprehensive ranking of the clinic variables in six ML algorithms, with the “AJCC_stage” considered most important (Supplementary Table 1). We finally select eight variables with frequencies more than 4, which indicates that these variables are important in most of the ML selection process, into the following procedures of model development (Supplementary Table 1).
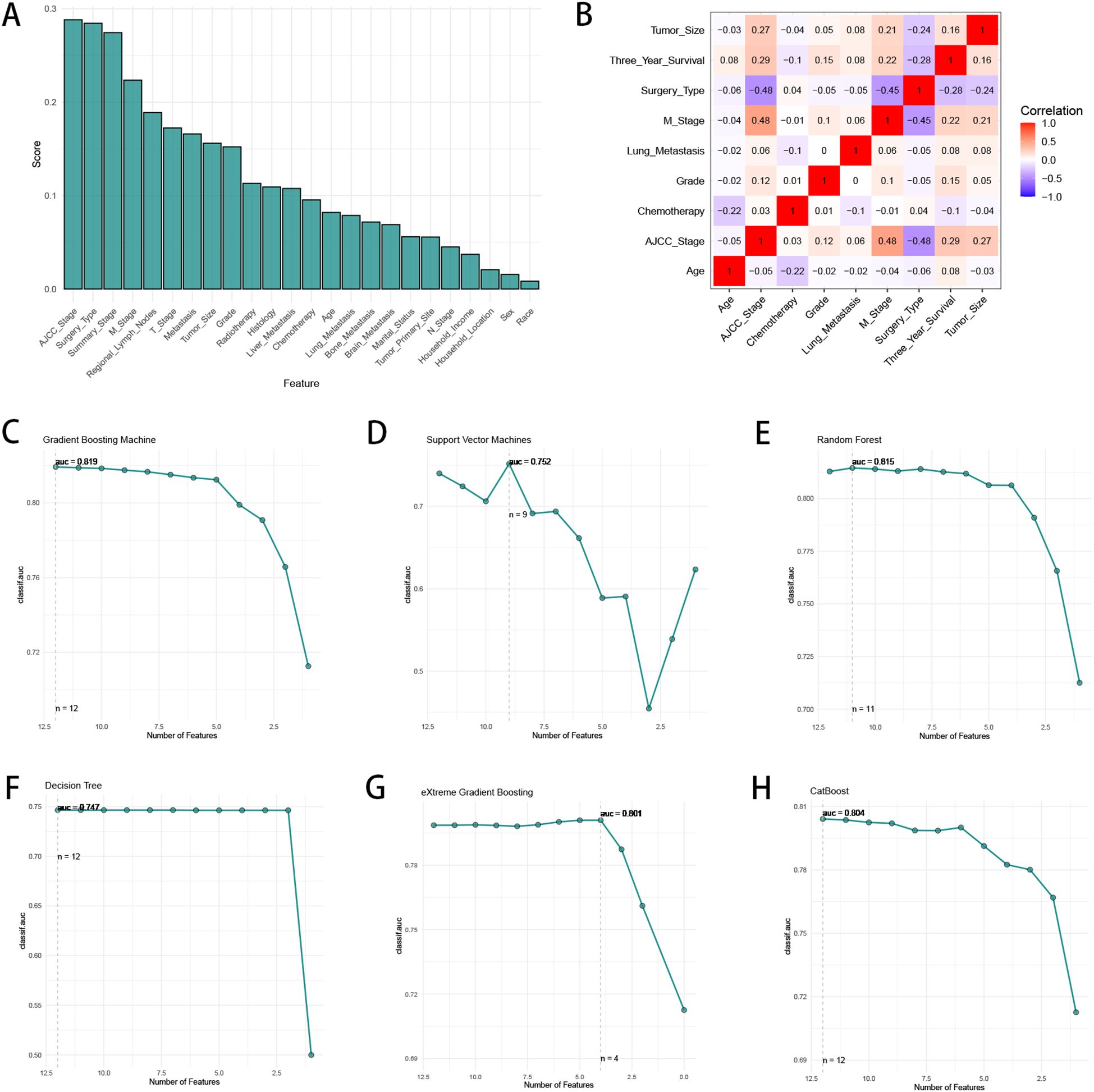
Figure 2. The process of feature selection. (A) The correlation coefficients of the baseline characteristics with three-year survival. (B) The heatmap of Spearman’s correlation analysis of the clinic variables with three-year survival. The correlation index ranges from -1.0 to 1.0, with a brighter color indicating a stronger correlation. (C–H) Feature selection process with Recursive Feature Elimination (RFE) method based on six ML algorithms (GBM, SVM, RF, DT, XGB and CatBoost).
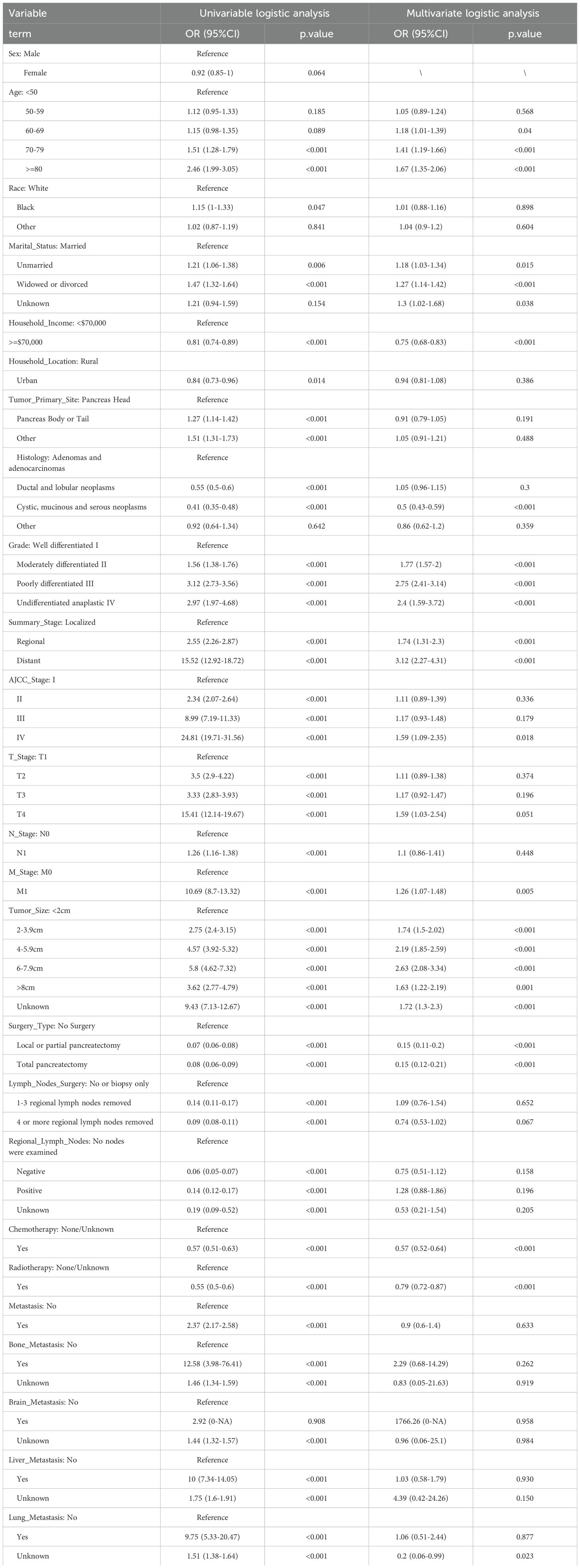
Table 2. Univariate and multivariate logistics analysis of pancreatic cancer patients for 3-year survival in the training cohort.
Development and validation of predictive model for three-year survival
To establish a precise model to predict three-year survival, we utilized the eight variables (“AJCC_Stage”, “Chemotherapy”, “Age”, “Grade”, “Lung_Metastasis”, “M_Stage”, “Surgery_Type”, “Tumor_Size”) selected by RFE and RRA. A total of 13 ML models, comprising CatBoost, RF, SVM, XGB, DT, GBM, KNN, LR, NBC, LDA, QDA, NNET and GLM algorithms, were developed by incorporating the above selection of eight variables in the training set. Hyperparameters were fine-tuned by performing 5-cross validation and random searches. Then we evaluated the 13 ML models in the internal validation and external validation cohorts, respectively. Finally, ROC curves analysis found that CatBoost model had the highest AUC in the training (0.932 [0.924, 0.939]), internal validation (0.899 [0.873, 0.934]) and external validation (0.826 [0.735, 0.919]) cohorts (Figures 3A, 4A, 5A). CatBoost model has the accuracy of 0.839 [0.831, 0.847], sensitivity of 0.872 [0.858, 0.887], specificity of 0.803 [0.784, 0.825] and precision of 0.832 [0.821, 0.853]. After grid search in hyperparameter tuning, the best hyperparameter metric of CatBoost was depth, 5; learning_rate, 0.01678325; iterations, 548; 12_leaf_reg, 7.409126. The precision-recall curves (PRC) revealed that CatBoost model was powerful in handling imbalanced datasets (Figures 3B, 4B, 5B). Calibration plots showed that CatBoost algorithm had the best fitting ability and could accurately predict three-year survival (Figures 3C, 4C, 5C). This indicates that the model’s probability estimates are reliable and well-calibrated, as it ensures that the risk estimates provided by the model can be trusted to reflect the true likelihood of patient outcomes. DCA curves suggested that CatBoost algorithm had the best clinical application value and could effectively help predict three-year survival (Figures 3D, 4D, 5D). This implies that using the CatBoost model to guide clinical decision-making would result in more effective identification of patients who are likely to benefit from certain interventions, such as more aggressive treatment or intensive monitoring. The accuracy, sensitivity, specificity, precision, cross-entropy, Brier scores, Balanced Accuracy (bacc) and F Beta Score (fbeta) of the 13 ML models were calculated to comprehensively evaluate the model performance, which revealed that CatBoost model was robust in predicting three-year survival (Figures 3E, 4E, 5E). The results of tenfold cross-validation indicated that CatBoost exhibited the best performance (Figure 3F). Confusion matrix displayed the outstanding predictive ability of CatBoost in the internal validation and external validation cohorts (Figures 4F, 5F). Therefore, CatBoost was chosen as the best model for the next step.
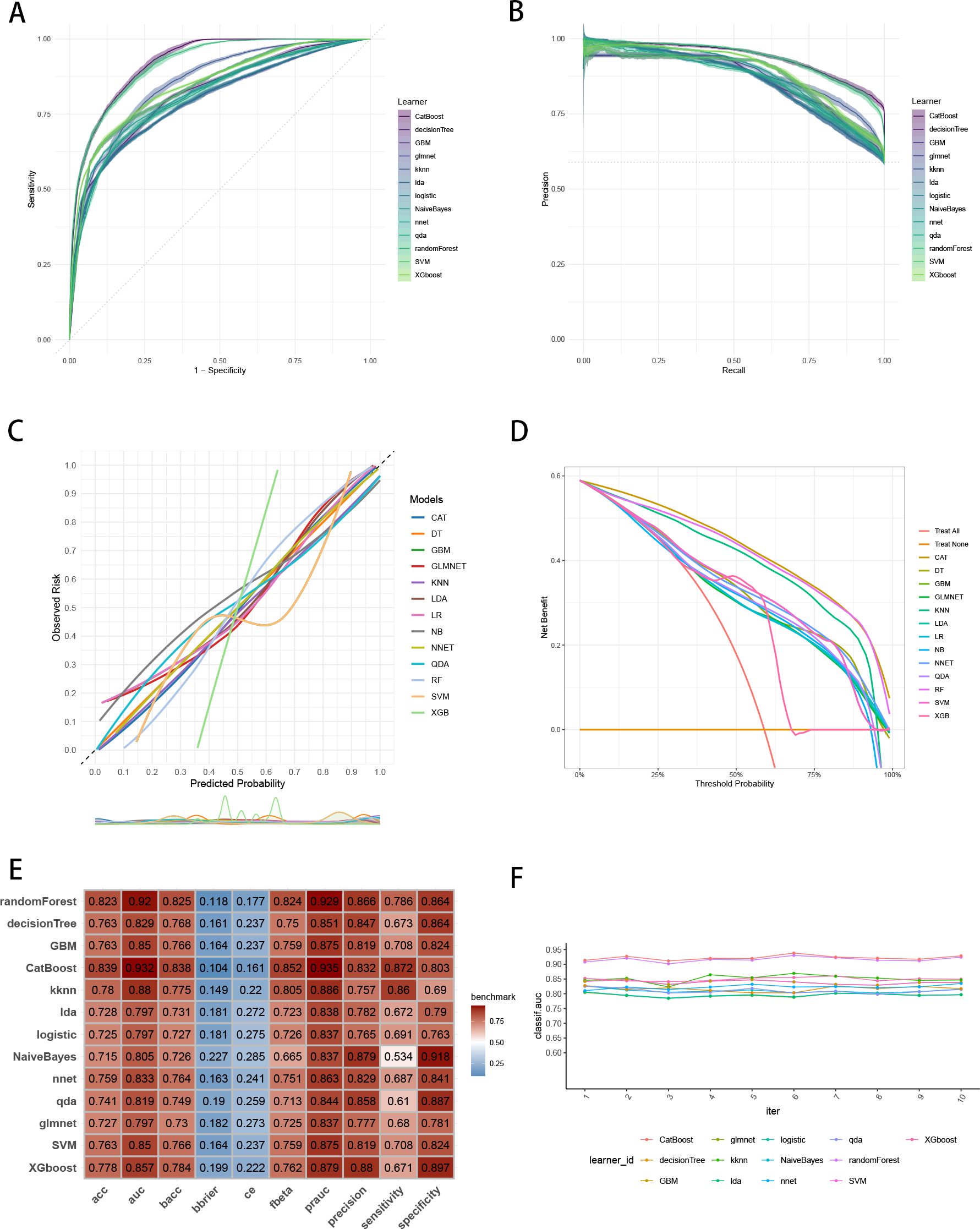
Figure 3. Establishment and evaluation of the ML models in the training set. (A) ROC curves of different ML models in the training set. (B) PR curves of different ML models in the training set. (C) Calibration curves of different ML models in the training set. (D) DCA curves of different ML models in the training set. (E) The performance of 13 ML models in terms of AUC, PRAUC, accuracy, sensitivity, specificity, precision, cross-entropy, Brier scores and Balanced Accuracy (bacc) and F Beta Score (fbeta) in the training set. (F) Ten-fold cross-validation results of different ML models in the training set. ML, machine learning; CAT, categorical boosting; LR, logistic regression; DT, decision tree; RF, random forest; XGB, extreme gradient boosting; GBM, gradient boosting machine; NB, Naive Bayes; LDA, linear discriminant analysis; QDA, quadratic discriminant analysis; NNET, neural network; GLMNET, generalized linear models with elastic net regularization; SVM, support vector machine; KNN, k-nearest neighbor.
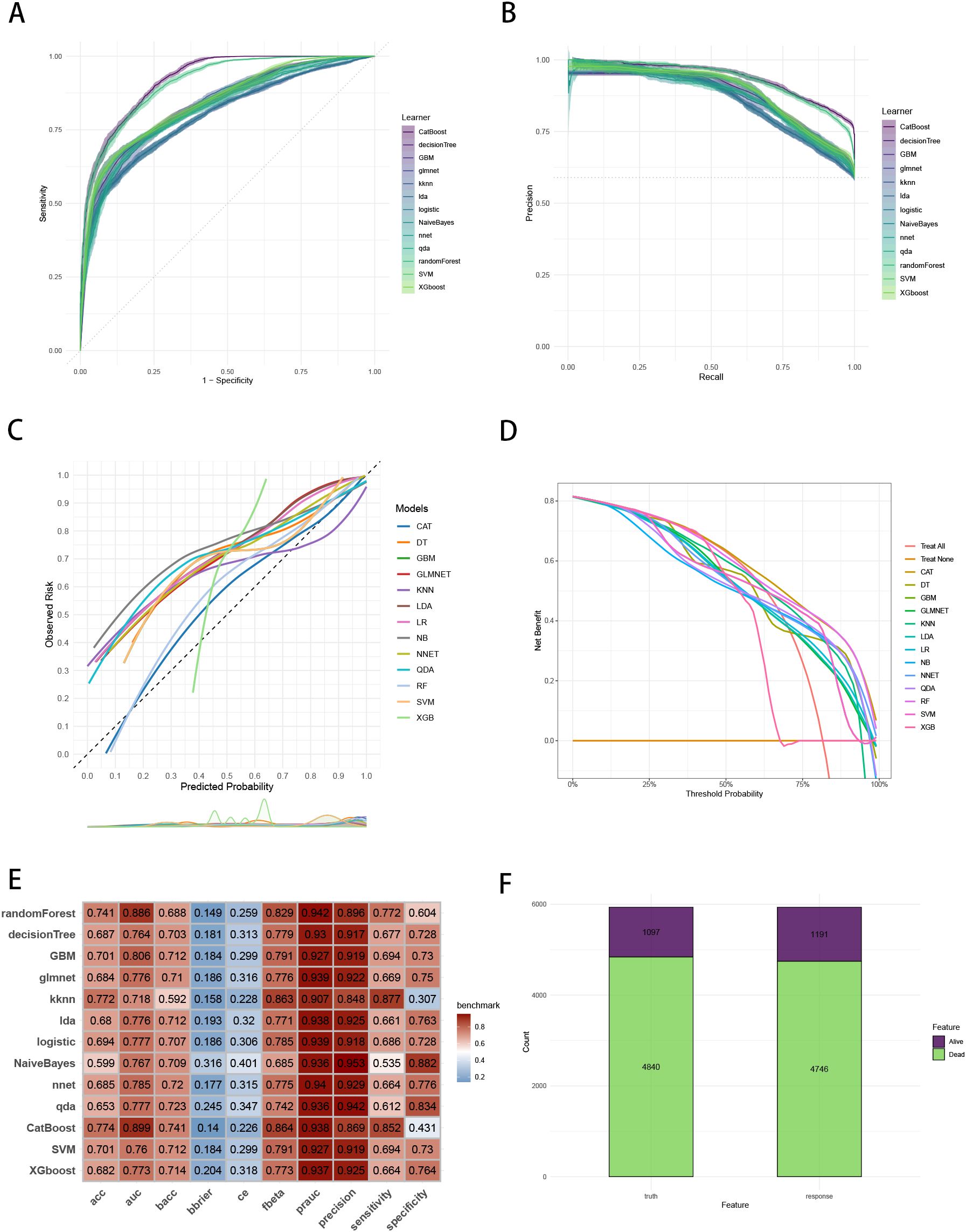
Figure 4. Evaluation of the ML models in the internal validation set. (A) ROC curves of different ML models in the internal validation set. (B) PR curves of different ML models in the internal validation set. (C) Calibration curves of different ML models in the internal validation set. (D) DCA curves of different ML models in the internal validation set. (E) The performance of 13 ML models in terms of AUC, PRAUC, accuracy, sensitivity, specificity, precision, cross-entropy, Brier scores and Balanced Accuracy (bacc) and F Beta Score (fbeta) in the internal validation set. (F) Confusion matrix of the best ML model in the internal validation set. ML, machine learning; CAT, categorical boosting; LR, logistic regression; DT, decision tree; RF, random forest; XGB, extreme gradient boosting; GBM, gradient boosting machine; NB, Naive Bayes; LDA, linear discriminant analysis; QDA, quadratic discriminant analysis; NNET, neural network; GLMNET, generalized linear models with elastic net regularization; SVM, support vector machine; KNN, k-nearest neighbor.
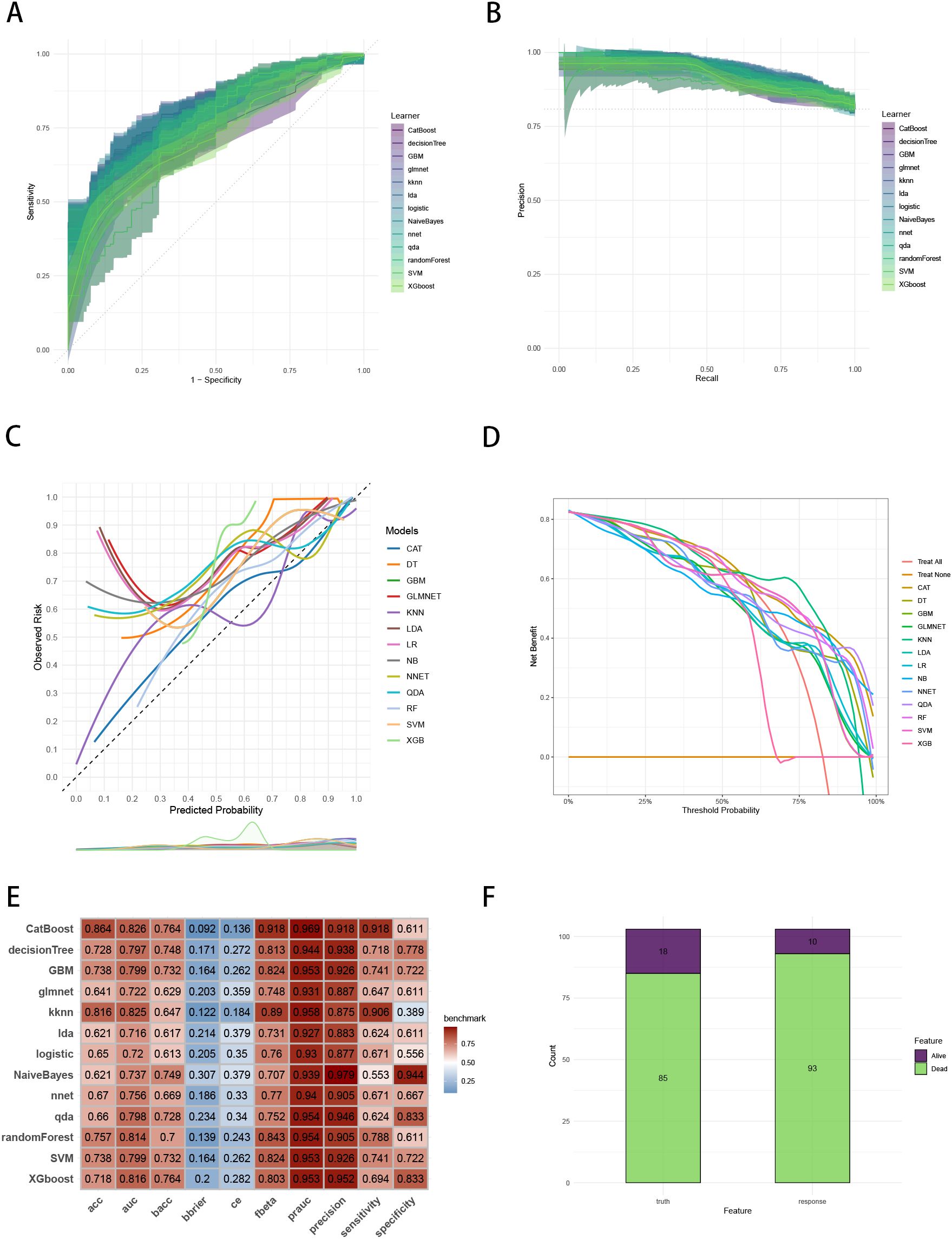
Figure 5. Evaluation of the ML models in the external validation set. (A) ROC curves of different ML models in the external validation set. (B) PR curves of different ML models in the external validation set. (C) Calibration curves of different ML models in the external validation set. (D) DCA curves of different ML models in the external validation set. (E) The performance of 13 ML models in terms of AUC, PRAUC, accuracy, sensitivity, specificity, precision, cross-entropy, Brier scores and Balanced Accuracy (bacc) and F Beta Score (fbeta) in the external validation set. (F) Confusion matrix of the best ML model in the external validation set. ML, machine learning; CAT, categorical boosting; LR, logistic regression; DT, decision tree; RF, random forest; XGB, extreme gradient boosting; GBM, gradient boosting machine; NB, Naive Bayes; LDA, linear discriminant analysis; QDA, quadratic discriminant analysis; NNET, neural network; GLMNET, generalized linear models with elastic net regularization; SVM, support vector machine; KNN, k-nearest neighbor.
Model interpretation
We calculated the feature importance rankings of each ML models and illustrated eight of them, including CatBoost, GBM, GLM, NB, KNN, RF, NNET and SVM (Figure 6A). The importance scores were determined by leveraging the inherent attributes of various ML algorithms, which revealed that the risk factors most associated with three-year survival were “Surgery Type”, “AJCC Stage” and “M Stage”. Subsequently, we utilized SHAP framework to interpret CatBoost model. We illustrated all of the risk factors evaluated by the mean absolute SHAP value, which revealed that “Surgery Type” was the most impactful variable (Figure 6B). Besides, beeswarm plot elucidated the influence of various risk factors on three-year survival (Figure 6C). The y-axis denotes the magnitude of the risk factors, while the x-axis represents their impact on the model’s output, specifically three-year survival, as measured by the SHAP value. It was observed that no surgery, higher grade, older age, have lung metastasis, no chemotherapy, higher AJCC stage and M1 stage are associated with an increased likelihood of death in three-year follow-up. To illustrate the model’s interpretability, we highlighted two representative cases. SHAP values were used to understand the impact of each feature on the model’s prediction. In our study, lower SHAP values indicate a higher likelihood of three-year survival, while higher SHAP values suggest a higher probability of death within the three-year follow-up. We chose median value (0.0962) as the cut-off point for predicting the low or high probability of three-year survival. For instance, the first patient with three-year survival had a lower SHAP value and a prediction score of 0.0276, indicating a higher likelihood of three-year survival (Figure 6D). In contrast, the second patient without three-year survival showed a higher SHAP value and a prediction score of 0.187, suggesting a higher probability of death in three-year follow-up (Figure 6E).
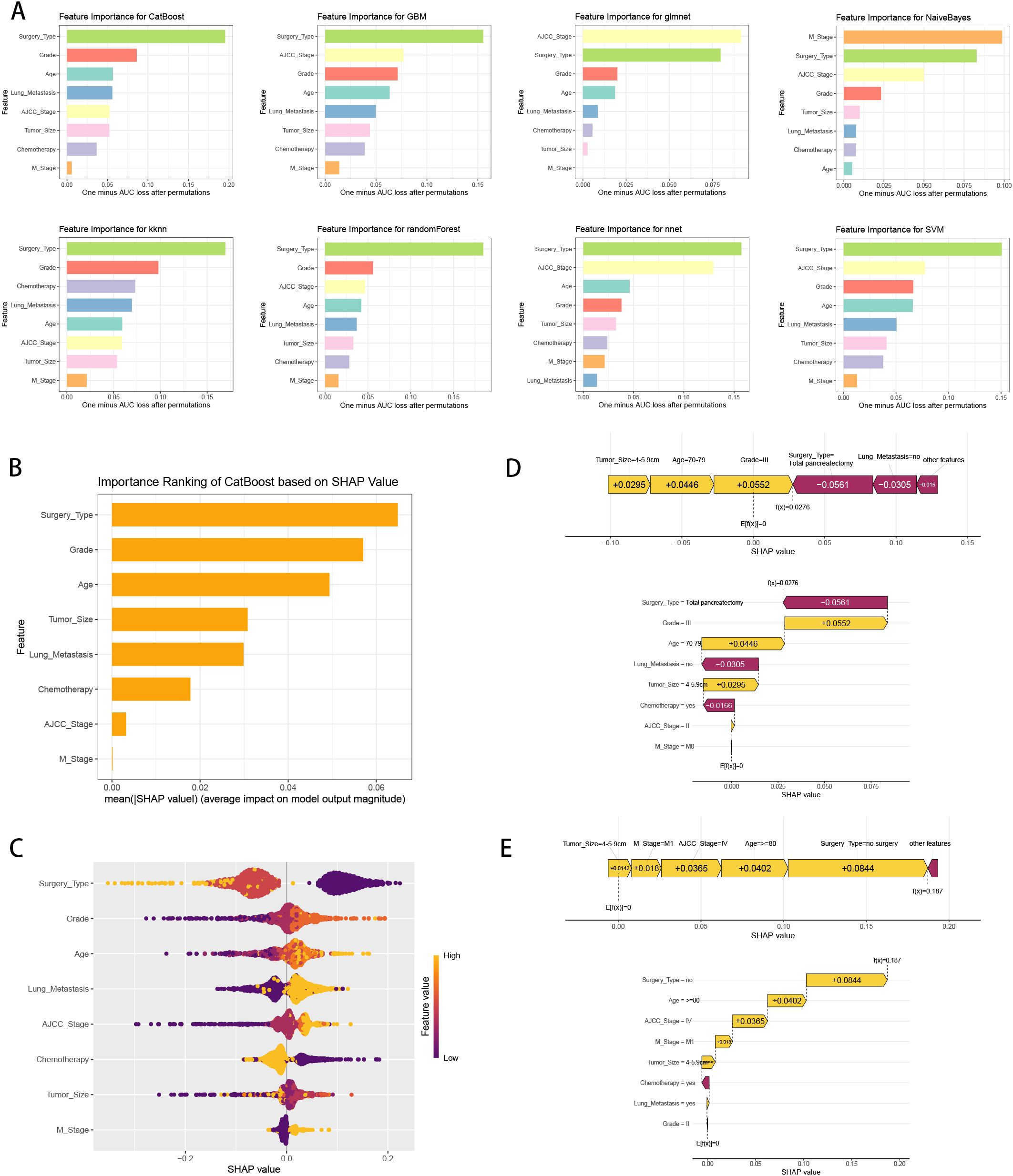
Figure 6. ML model interpretation. (A) Importance ranking of features in eight ML prediction algorithms (CatBoost, GBM, GLM, NB, KNN, RF, NNET and SVM). (B) The importance ranking of different variables according to the mean (|SHAP value|) using the optimal CatBoost model. (C) The importance ranking of different risk factors with stability and interpretation using the optimal CatBoost model. The higher SHAP value of a feature is given, the higher risk of distant metastasis the patient would have. The yellow part in feature value represents higher value. (D) SHAP value explanation in a classical sample with three-year survival. (E) SHAP value explanation in a classical sample without three-year survival.
Prognostic model establishment and performance
To explore the prognostic values of multiple variables, we performed univariate and multivariate Cox analysis to found that “Sex” (HR 0.934(0.907-0.963)), “Race” (HR 1.071(1.022-1.123)), “Age” (HR 1.19(1.119-1.264)), “Marital_Status” (HR 1.137(1.086-1.191)), “Household_Income” (HR 0.866(0.837-0.896)), “Household_Location” (HR 0.945(0.899-0.993)), “Tumor_Primary_Site” (HR 0.946(0.91-0.983)), “Histology” (HR 0.706(0.66-0.755)), “Grade” (HR 1.334(1.271-1.401)), “Tumor_Size” (HR 1.325(1.238-1.417)), “AJCC_Stage” (HR 0.712(0.643-0.789)), “T_Stage” (HR 1.127(1.024-1.242)), “Surgery_Type” (HR 0.491(0.45-0.535)), “Lymph_Nodes_Surgery” (HR 0.846(0.761-0.94)), “Regional_Lymph_Nodes” (HR 0.709(0.65-0.774)), “Radiotherapy” (HR 0.905(0.873-0.938)), “Chemotherapy” (HR 0.582(0.562-0.602)), “Bone_Metastasis” (HR 1.196(1.006-1.422)), “Liver_Metastasis” (HR 1.338(1.224-1.463)), “Lung_Metastasis” (HR 1.338(1.224-1.463)) and “Metastasis” (HR 0.781(0.709-0.861)) were independent prognosis variables for predicting OS in pancreatic cancer patients (P < 0.05, Table 3). Incorporating these clinical variables, 101 prognostic ML algorithm combinations were constructed via LOOCV framework. The C-index of each ML combination was calculated in training, internal validation and external validation datasets (Figure 7A). Among top five ML combinations with highest C-index across three cohorts, logarithmic loss, recall and decision calibration were calculated to assess the model performances, discovering the well calibration and precision of “RSF+GBM” model (Supplementary Figure 1). The best ML model combination was “RSF+GBM”, which was established based on RSF algorithm in feature selection (Figure 7B), and GBM algorithm in model construction (Figure 7C), with the highest average C-index (0.723) across three datasets (Figure 7A). Finally, a 20-variable “RSF+GBM” prognostic ML model was accordingly established to predict OS of pancreatic patients, with “Surgery Type” being the most significant variable both in the feature importance visualization of RSF and GBM model (Figures 7B, C). ROC curves of 1-, 3- and 5-year OS showed well specificity of “RSF+GBM” model (Figure 7D). Time dependent ROC curves indicated that the curve of “RSF+GBM” model was upper than other curves at most of the time points, indicating that “RSF+GBM” model remarkably outperformed conventional clinical variables in capability of discrimination and prediction (Figure 7E). Calibration curves (Figure 7F) and DCA curves (Figure 7G) showed that “RSF+GBM” model is well-behaved in accuracy and clinical benefit. Based on risk scores calculated by GBM algorithm, we utilized the median risk score to divide patients in the training, internal validation and external validation cohorts into low-risk and high-risk groups, respectively. Obliviously, the low-risk group owned a relatively longer OS than the high-risk group in the training, internal validation and external validation cohorts, respectively (Figure 7H). The K-M curves validated the capability of risk stratification of “RSF+GBM” model. All these metrics collectively indicated that “RSF+GBM” model demonstrated stability and robustness in model performances. In conclusion, we have successfully developed a “RSF+GBM” model to predict OS in pancreatic cancer patients, which outperforming other models and was well behaved in model performances.
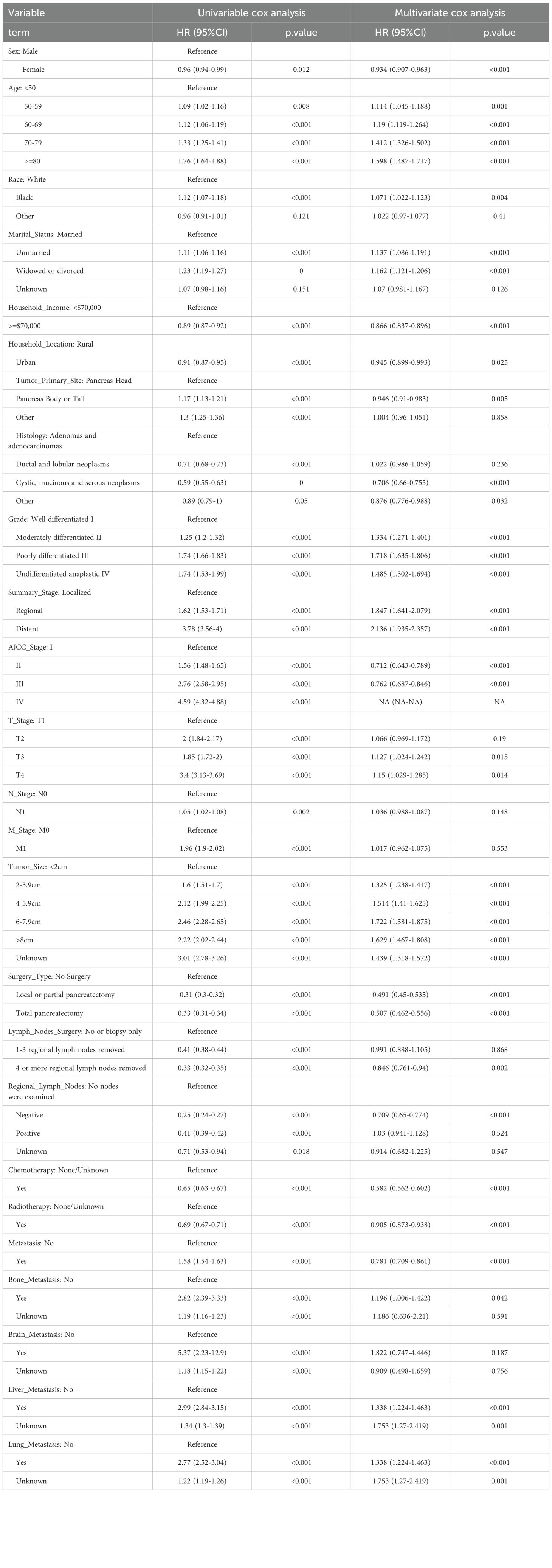
Table 3. Univariate and multivariate cox regression analysis of pancreatic cancer patients for overall survival in the training cohort.
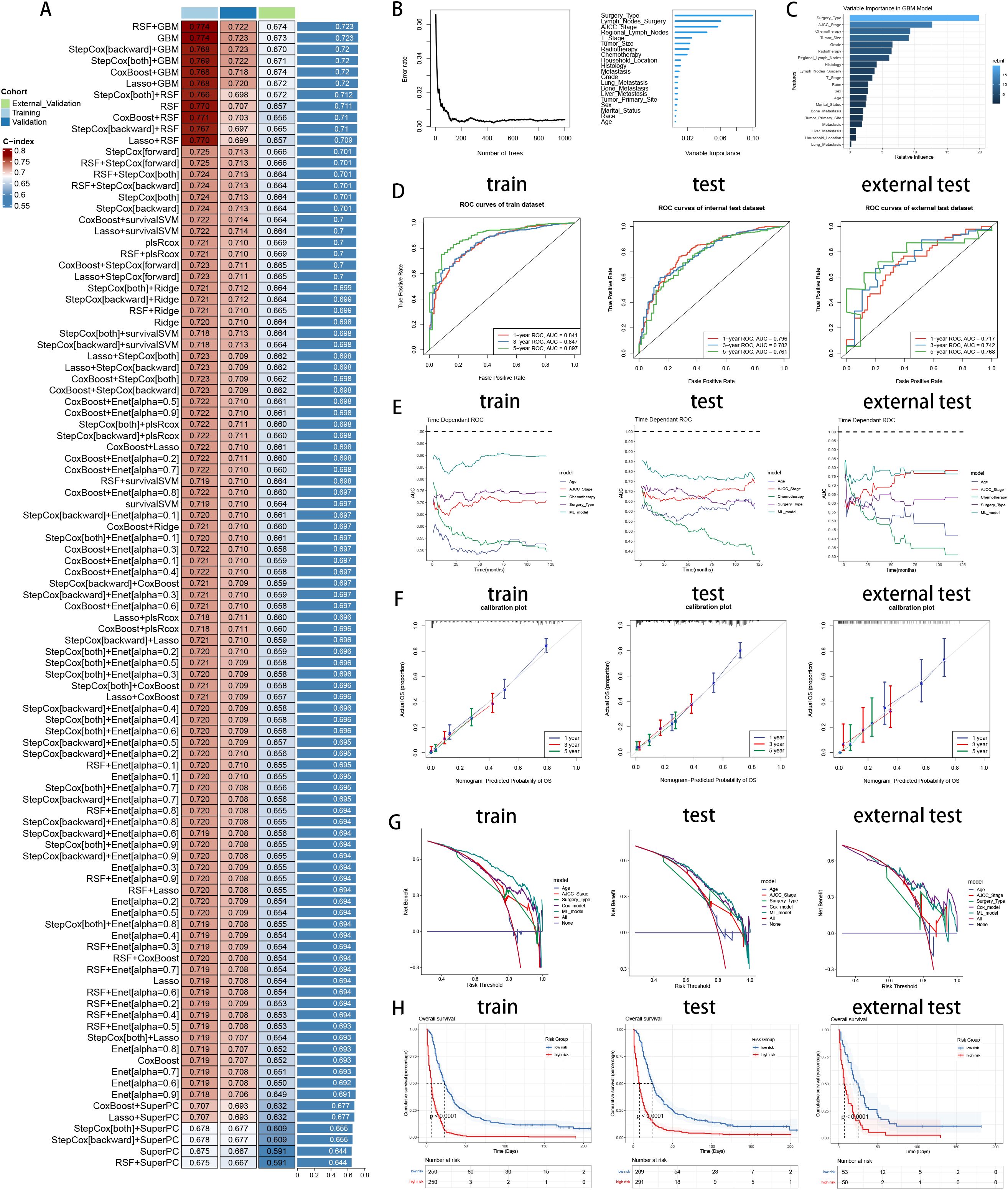
Figure 7. Establishment and validation of prognostic model for pancreatic cancer patients. (A) A total of 101 kinds of prognostic models via a leave-one-out cross-validation framework and further calculated the C-index of each model. (B) Feature selection process by RSF algorithm. (C) Model construction by GBM algorithm and visualization of feature importance. (D) ROC curves of ML model in training, internal validation and external validation cohorts. (E) Time dependent AUC values of ML model in training, internal validation and external validation cohorts. (F) Calibration curves of ML model in training, internal validation and external validation cohorts. (G) DCA curves of ML model in training, internal validation and external validation cohorts. (H) K-M curves of low-risk and high-risk groups divided by ML model in training, internal validation and external validation cohorts. Left: training cohort, Middle: internal validation cohort, Right: external validation cohort.
Discussion
Pancreatic cancer is among the most invasive and deadly malignancies, with projections suggesting it could become the second leading cause of cancer-related deaths by 2030 (21). Although radical surgery offers a chance for a cure, high rates of postoperative recurrence and mortality remain a significant concern (22). Given these challenges, accurately predicting survival rates and identifying prognostic risk factors is of critical importance for pancreatic cancer patients. In this study, we focused on developing novel predictive and prognostic ML models to early predict three-year survival, and to forecast the prognosis of pancreatic cancer patients. By gathering clinical data on several key variables and establishing ML models via benchmark framework, we were able to calculate risk scores related to prediction and prognosis, enabling us to precisely predict the probability of three-year survival and the prognosis of patients. The model analyzes various clinical and demographic features to provide a risk score for three-year survival and prognosis, which helps clinicians determine the intensity and type of treatment required for each patient, outperforming the existing models without ML algorithms (23, 24).
The clinical importance of this work lies in its potential to enhance patient management and treatment planning for those diagnosed with pancreatic cancer. By providing an accurate risk stratification tool, our model can significantly aid clinicians in making more informed, personalized treatment decisions. For instance, patients identified as high-risk for three-year mortality could be prioritized for aggressive surgical interventions, adjuvant therapies, and closer post-operative monitoring, which may improve their chances of survival. Conversely, patients deemed low-risk could benefit from less intensive treatments, thereby avoiding the potential side effects and complications associated with overtreatment. Additionally, the model’s predictions can help the selection of adjuvant therapies, the frequency of follow-up visits, and the need for additional laboratory tests. By integrating the prediction model into clinical workflows, we enable data-driven decision-making that optimizes patient outcomes and resource allocation. As a result, it helps in standardizing care across different healthcare providers and institutions, potentially reducing variability in treatment approaches and outcomes for pancreatic cancer patients.
Moreover, the highlight of our study lies in showcasing how interpretable ML algorithms, particularly through the use of SHAP values, can effectively decipher key factors contributing to predict three-year survival. CatBoost algorithm is a gradient boosting framework based on the symmetric decision tree (oblivious trees) algorithm, which boasts high accuracy and requires fewer parameters, making it efficient and effective in handling categorical features (25). CatBoost’s performance rivals that of other advanced machine learning algorithms, demonstrating its superiority in many applications. But the black-box feature of CatBoost model necessitated its interpretation and explanation with vivid figures. CatBoost’s SHAP summary plots and force maps serve as valuable tools, offering clinicians a visual and intuitive means to understand and identify the critical features influencing three-year survival, which not only elucidates the pivotal risk factors but also improves the interpretability of ML models in clinical settings. Meanwhile, several advanced ML techniques, including feature selection through RFECV, hyperparameter optimization with GridSearchCV, and addressing sample imbalance using SMOTE oversampling, had significantly enhanced the prediction accuracy for the probability of three-year survival. Overall, our precise ML prediction model allowed clinicians to schedule personalized treatment plans, helping them tailor therapy methods in time and enhance prognosis of pancreatic cancer patients.
Researchers have previously shown that old age, high histological grade, large tumor size, AJCC stage, surgery type and metastasis are associated with poorer long-term survival outcomes for pancreatic cancer patients (26, 27). In clinical practice, serum CA199 and CEA levels are commonly used biomarkers in pancreatic cancer, and high levels of CA199 are generally associated with a worse prognosis. Meanwhile, the methylation status of NPTX2, BMP3 and SPARC genes plays an important role in the prognosis of pancreatic cancer. Researchers suggest that methylation of these genes could be used as non-invasive biomarkers to assess prognosis and monitor disease progression in patients with pancreatic cancer (28). In our analysis, we performed univariate and multivariate logistic and cox regression analyses to discover important predictive factors for three-year survival, as well as independent risk factors for prognosis. Based on clinical variables which can be easily obtained during clinical practices, we succeeded in constructing a powerful CatBoost model to early predict three-year survival.
In our research, we observed that patients with pancreatic cancer who undergo surgical resection demonstrated significantly improved survival rates, as supported by Hester et al.’s analysis of the National Cancer Database (29). However, surgery alone is often insufficient for achieving long-term survival, with median survival times typically ranging between 8 to 10 months, frequently accompanied by tumor recurrence (30). Chemotherapy, both as a neoadjuvant (preoperative) and adjuvant (postoperative) treatment, has been identified through logistic and cox regression analyses as a key independent factor in enhancing patient survival. Specifically, adjuvant chemotherapy has been shown to double median survival rates compared to patients who do not receive it, while neoadjuvant chemotherapy improves overall survival and increases the likelihood of R0 resection, making it a valuable treatment option (31). Additionally, age is an independent risk factor, with older patients exhibiting lower survival rates, likely due to diminished immunity and physical decline, which is also common in other types of cancer. Moreover, we found that race does play a role in pancreatic cancer prognosis. African Americans have a higher rate of pancreatic cancer than other racial groups, and their overall survival rate is lower. This difference may be related to a variety of factors, including socioeconomic status, access to and quality of health care, and genetic and environmental factors (32).
Gender can influence the prognosis of pancreatic cancer, though the impact is complex and varies depending on several factors (33). Our analysis results show that women generally have a slightly better overall survival (OS) compared to men. This improved survival in women has also been observed in studies analyzing the outcomes of both standard treatments and more aggressive chemotherapy regimens like FOLFIRINOX (34). Moreover, our analysis displayed that metastasis in pancreatic cancer significantly affected prognosis, with different metastatic sites influencing survival outcomes differently (35). Common sites of distant metastasis in pancreatic cancer include the peritoneum and liver, followed by the lungs, bones, and other organs (36). Liver metastasis is the most common and is associated with the poorest prognosis, often due to the liver’s role in filtering blood and its involvement in the metabolism of cancer drugs. Lung metastasis, while also serious and crucial, generally presents a slightly better prognosis compared to liver involvement. Peritoneal metastasis reflects a more extensive spread of the disease within the abdominal cavity. This type of metastasis is particularly challenging because it often leads to complications such as ascites (the accumulation of fluid in the abdomen), which can be difficult to manage and severely impacts the patient’s quality of life. Overall, the presence of metastasis generally indicates an advanced disease and a poor prognosis, due to the difficulty of achieving complete surgical resection and the challenges in effectively targeting metastatic sites with systemic therapies.
While this study boasts certain strengths, it also faces multiple limitations. Firstly, we calculated the needed sample size for our external validation set, but we were unable to gather a large enough external validation set due to the limited number of patients with complete follow-up information. Although we recognize that large sample sizes improve the reliability of model evaluations, we have tried to collect the largest sample size available in the current research environment. Despite the small set of external validations, we maximize the reliability of validation by using a 10-fold cross-validation approach to assess the model’s ability to generalize. In future studies, we plan to increase the sample size of the external validation set, thereby further verifying the universality and reliability of the model. Secondly, our study relies on retrospective datasets sourced from the SEER database, causing possibility of selection bias. Meanwhile, the inconsistent data collection across multiple hospitals, as well as the retrospective study design, led to some missing clinical feature data. Thirdly, the absence of some key clinicopathological parameters is noted, due to the unavailability of image data and laboratory test indicators from the SEER database. The study predominantly utilizes baseline characteristics and routine clinical data as variables, without some important indicators such as CA199, CEA and KRAS gene mutation. To enhance the model’s predictive accuracy and identify risk factors, a broad range of features was included, which somewhat complicates its practical application in a clinical setting. Finally, the model has yet to be implemented in clinical practice, thus necessitating prospective, multicenter, and large-scale validations to fully ascertain its generalizability in the future.
Conclusions
In this study, we developed a CatBoost predictive model based on ML benchmark framework, to more accurately predict three-year survival for pancreatic cancer patients, surpassing traditional models in effectiveness and performances. We successfully identified significant predictive factors for three-year survival of pancreatic cancer. Meanwhile, we establish a GBM prognostic model to predict prognosis of pancreatic cancer patients for achieving personalized medicine. This research laid a foundation for future efforts aimed at enhancing three-year survival prediction and prognosis forecasting, which could help clinicians in decision making and therapy plan tailoring.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Ethics statement
The studies involving humans were approved by Ethics Committee of The First People’s Hospital of Lianyungang. The studies were conducted in accordance with the local legislation and institutional requirements. Written informed consent for participation was not required from the participants or the participants’ legal guardians/next of kin in accordance with the national legislation and institutional requirements. Written informed consent was obtained from the individual(s) for the publication of any potentially identifiable images or data included in this article.
Author contributions
BT: Data curation, Formal analysis, Investigation, Methodology, Validation, Visualization, Writing – original draft. XZ: Data curation, Formal analysis, Investigation, Methodology, Validation, Visualization, Writing – original draft. MG: Data curation, Formal analysis, Writing – original draft. MM: Data curation, Formal analysis, Writing – original draft. WL: Conceptualization, Investigation, Supervision, Writing – review & editing. JM: Conceptualization, Investigation, Supervision, Writing – review & editing.
Funding
The author(s) declare that no financial support was received for the research, authorship, and/or publication of this article.
Acknowledgments
We are grateful to the Surveillance, Epidemiology, and End Results (SEER) database for providing data.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fonc.2024.1488118/full#supplementary-material
References
1. Siegel RL, Miller KD, Wagle NS, Jemal A. Cancer statistics, 2023. CA Cancer J Clin. (2023) 73:17–48. doi: 10.3322/caac.21763
2. Vincent A, Herman J, Schulick R, Hruban RH, Goggins M. Pancreatic cancer. Lancet. (2011) 378:607–20. doi: 10.1016/S0140-6736(10)62307-0
3. Gillen S, Schuster T, Meyer Zum Büschenfelde C, Friess and J. Kleeff H. Preoperative/neoadjuvant therapy in pancreatic cancer: a systematic review and meta-analysis of response and resection percentages. PLoS Med. (2010) 7:e1000267. doi: 10.1371/journal.pmed.1000267
4. Zhao Z, Liu W. Pancreatic cancer: A review of risk factors, diagnosis, and treatment. Technol Cancer Res Treat. (2020) 19:1533033820962117. doi: 10.1177/1533033820962117
5. He Q, Liu Z, Wang J. Targeting KRAS in PDAC: A new way to cure it? Cancers (Basel). (2022) 14(20):4982. doi: 10.3390/cancers14204982
6. Tempero MA, Malafa MP, Chiorean EG, Czito B, Scaife C, Narang AK, et al. Pancreatic adenocarcinoma, version 1.2019. J Natl Compr Canc Netw. (2019) 17:202–10. doi: 10.6004/jnccn.2019.0014
7. Mitchell PS, Parkin RK, Kroh EM, Fritz BR, Wyman SK, Pogosova-Agadjanyan EL, et al. Circulating microRNAs as stable blood-based markers for cancer detection. Proc Natl Acad Sci U S A. (2008) 105:10513–8. doi: 10.1073/pnas.0804549105
8. Chalmers ZR, Connelly CF, Fabrizio D, Gay L, Ali SM, Ennis R, et al. Analysis of 100,000 human cancer genomes reveals the landscape of tumor mutational burden. Genome Med. (2017) 9:34. doi: 10.1186/s13073-017-0424-2
9. Collins GS, Dhiman P, Andaur Navarro CL, Ma J, Hooft L, Reitsma JB, et al. Protocol for development of a reporting guideline (TRIPOD-AI) and risk of bias tool (PROBAST-AI) for diagnostic and prognostic prediction model studies based on artificial intelligence. BMJ Open. (2021) 11:e048008. doi: 10.1136/bmjopen-2020-048008
10. Pera M, Gibert J, Gimeno M, Garsot E, Eizaguirre E, Miró M, et al. Machine learning risk prediction model of 90-day mortality after gastrectomy for cancer. Ann Surg. (2022) 276:776–83. doi: 10.1097/SLA.0000000000005616
11. Zhuang D, Li T, Xie H, Sheng J, Chen X, Li X, et al. A dynamic nomogram for predicting intraoperative brain bulge during decompressive craniectomy in patients with traumatic brain injury: a retrospective study. Int J Surg. (2023) 110(2):909–20. doi: 10.1097/JS9.0000000000001348
12. Riley RD, Debray TPA, Collins GS, Archer L, Ensor J, van Smeden M, et al. Minimum sample size for external validation of a clinical prediction model with a binary outcome. Stat Med. (2021) 40:4230–51. doi: 10.1002/sim.v40.19
13. Wang K, Tian J, Zheng C, Yang H, Ren J, Liu Y, et al. Interpretable prediction of 3-year all-cause mortality in patients with heart failure caused by coronary heart disease based on machine learning and SHAP. Comput Biol Med. (2021) 137:104813. doi: 10.1016/j.compbiomed.2021.104813
14. Kolde R, Laur S, Adler P, Vilo J. Robust rank aggregation for gene list integration and meta-analysis. Bioinformatics. (2012) 28:573–80. doi: 10.1093/bioinformatics/btr709
15. Lang M, Binder M, Richter J, Schratz P, Pfisterer F, Coors S, et al. mlr3: A modern object-oriented machine learning framework in R. J Open Source Software. (2019) 4:1903. doi: 10.21105/joss.01903
16. Wang K, Tian J, Zheng C, Yang H, Ren J, Li C, et al. Improving risk identification of adverse outcomes in chronic heart failure using SMOTE+ENN and machine learning. Risk Manag Healthc Policy. (2021) 14:2453–63. doi: 10.2147/RMHP.S310295
17. Biecek P. Dalex: Explainers for complex predictive models in R. J Mach Learn Res. (2018) 19:1–5. doi: 10.5555/3291125.3309646
18. Lo YT, Liao JC, Chen MH, Chang CM, Li CT. Predictive modeling for 14-day unplanned hospital readmission risk by using machine learning algorithms. BMC Med Inform Decis Mak. (2021) 21:288. doi: 10.1186/s12911-021-01639-y
19. Liu Z, Liu L, Weng S, Guo C, Dang Q, Xu H, et al. Machine learning-based integration develops an immune-derived lncRNA signature for improving outcomes in colorectal cancer. Nat Commun. (2022) 13:816. doi: 10.1038/s41467-022-28421-6
20. Sonabend R, Király FJ, Bender A, Bischl B, Lang M. mlr3proba: an R package for machine learning in survival analysis. Bioinformatics. (2021) 37:2789–91. doi: 10.1093/bioinformatics/btab039
21. Rahib L, Smith BD, Aizenberg R, Rosenzweig AB, Fleshman JM, Matrisian LM. Projecting cancer incidence and deaths to 2030: the unexpected burden of thyroid, liver, and pancreas cancers in the United States. Cancer Res. (2014) 74:2913–21. doi: 10.1158/0008-5472.CAN-14-0155
22. Fatima J, Schnelldorfer T, Barton J, Wood CM, Wiste HJ, Smyrk TC, et al. Pancreatoduodenectomy for ductal adenocarcinoma: implications of positive margin on survival. Arch Surg. (2010) 145:167–72. doi: 10.1001/archsurg.2009.282
23. You K, Lei K, Wang X, Hu R, Zhang H, Xu J, et al. A novel nomogram based on the number of positive lymph nodes can predict the overall survival of patients with pancreatic head cancer after radical surgery. World J Surg Oncol. (2024) 22:241. doi: 10.1186/s12957-024-03519-x
24. Peng W, Yu X, Yang R, Nie S, Jian X, Zeng P. Construction and validation of a nomogram for cancer specific survival of postoperative pancreatic cancer based on the SEER and China database. BMC Gastroenterol. (2024) 24:104. doi: 10.1186/s12876-024-03180-4
25. Zhang C, Chen X, Wang S, Hu J, Wang C, Liu X. Using CatBoost algorithm to identify middle-aged and elderly depression, national health and nutrition examination survey 2011-2018. Psychiatry Res. (2021) 306:114261. doi: 10.1016/j.psychres.2021.114261
26. Zhang W, Ji L, Wang X, Zhu S, Luo J, Zhang Y, et al. Nomogram predicts risk and prognostic factors for bone metastasis of pancreatic cancer: A population-based analysis. Front Endocrinol (Lausanne). (2021) 12:752176. doi: 10.3389/fendo.2021.752176
27. Li Q, Feng Z, Miao R, Liu X, Liu C, Liu Z. Prognosis and survival analysis of patients with pancreatic cancer: retrospective experience of a single institution. World J Surg Oncol. (2022) 20:11. doi: 10.1186/s12957-021-02478-x
28. García-Ortiz MV, Cano-Ramírez P, Toledano-Fonseca M, Cano MT, Inga-Saavedra E, Rodríguez-Alonso RM, et al. Circulating NPTX2 methylation as a non-invasive biomarker for prognosis and monitoring of metastatic pancreatic cancer. Clin Epigenet. (2023) 15:118. doi: 10.1186/s13148-023-01535-4
29. Hester CA, Augustine MM, Choti MA, Mansour JC, Minter RM, Polanco PM, et al. Comparative outcomes of adenosquamous carcinoma of the pancreas: An analysis of the National Cancer Database. J Surg Oncol. (2018) 118:21–30. doi: 10.1002/jso.v118.1
30. Groot VP, Rezaee N, Wu W, Cameron JL, Fishman EK, Hruban RH, et al. Patterns, timing, and predictors of recurrence following pancreatectomy for pancreatic ductal adenocarcinoma. Ann Surg. (2018) 267:936–45. doi: 10.1097/SLA.0000000000002234
31. Luo G, Fan Z, Gong Y, Jin K, Yang C, Cheng H, et al. Characteristics and outcomes of pancreatic cancer by histological subtypes. Pancreas. (2019) 48:817–22. doi: 10.1097/MPA.0000000000001338
32. Jiang Z, Zheng X, Li M, Liu M. Improving the prognosis of pancreatic cancer: insights from epidemiology, genomic alterations, and therapeutic challenges. Front Med. (2023) 17:1135–69. doi: 10.1007/s11684-023-1050-6
33. Pijnappel EN, Schuurman M, Wagner AD, de Vos-Geelen J, van der Geest LGM, de Groot JB, et al. Sex, gender and age differences in treatment allocation and survival of patients with metastatic pancreatic cancer: A nationwide study. Front Oncol. (2022) 12:839779. doi: 10.3389/fonc.2022.839779
34. Kim J, Ji E, Jung K, Jung IH, Park J, Lee JC, et al. Gender differences in patients with metastatic pancreatic cancer who received FOLFIRINOX. J Pers Med. (2021) 11(2):83. doi: 10.3390/jpm11020083
35. Usón PLSJ, Tolentino FDS, Santos VM, Rother ET, Maluf FC. The impact of metastatic sites in advanced pancreatic adenocarcinoma, systematic review and meta-analysis of prospective randomized studies. PLoS One. (2020) 15:e0230060. doi: 10.1371/journal.pone.0230060
Keywords: machine learning, pancreatic cancer, three-year survival, prognosis prediction, SEER
Citation: Teng B, Zhang X, Ge M, Miao M, Li W and Ma J (2024) Personalized three-year survival prediction and prognosis forecast by interpretable machine learning for pancreatic cancer patients: a population-based study and an external validation. Front. Oncol. 14:1488118. doi: 10.3389/fonc.2024.1488118
Received: 29 August 2024; Accepted: 19 September 2024;
Published: 21 October 2024.
Edited by:
Pengpeng Zhang, Nanjing Medical University, ChinaReviewed by:
Luo Qiang, Children’s Hospital of Chongqing Medical University, ChinaZhaokai Zhou, First Affiliated Hospital of Zhengzhou University, China
Copyright © 2024 Teng, Zhang, Ge, Miao, Li and Ma. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jun Ma, ZHJtYWp1bjIzNEAxNjMuY29t; Wei Li, cG93ZXI4NDQ2QDE2My5jb20=