 Yufei Guo
Yufei Guo Xuhui Huang
Xuhui Huang Zhe Ma1,2*
Zhe Ma1,2*- 1Intelligent Science & Technology Academy of CASIC, Beijing, China
- 2Scientific Research Laboratory of Aerospace Intelligent Systems and Technology, Beijing, China
The spiking neural network (SNN), as a promising brain-inspired computational model with binary spike information transmission mechanism, rich spatially-temporal dynamics, and event-driven characteristics, has received extensive attention. However, its intricately discontinuous spike mechanism brings difficulty to the optimization of the deep SNN. Since the surrogate gradient method can greatly mitigate the optimization difficulty and shows great potential in directly training deep SNNs, a variety of direct learning-based deep SNN works have been proposed and achieved satisfying progress in recent years. In this paper, we present a comprehensive survey of these direct learning-based deep SNN works, mainly categorized into accuracy improvement methods, efficiency improvement methods, and temporal dynamics utilization methods. In addition, we also divide these categorizations into finer granularities further to better organize and introduce them. Finally, the challenges and trends that may be faced in future research are prospected.
1. Introduction
The Spiking Neural Network (SNN) has been recognized as one of the brain-inspired neural networks due to its bio-mimicry of the brain neurons. It transmits information by firing binary spikes and can process the information in a spatial-temporal manner (Wu et al., 2019a; Wu Y. et al., 2019; Zhang et al., 2020a,b; Fang et al., 2021b). This event-driven and spatial-temporal manner makes the SNN very efficient and good at handling temporal signals, thus receiving a lot of research attention, especially recently.
Despite the energy efficiency and spatial-temporal processing advantages, it is a challenge to train deep SNNs due to the firing process of the SNN is undifferentiable, thus making it impossible to train SNNs via gradient-based optimization methods. At first, many works leverage the spike-timing-dependent plasticity (STDP) approach (Lobov et al., 2020), which is inspired by biology, to update the SNN weights. However, STDP cannot help train large-scale networks yet, thus limiting the practical applications of the SNN. There are two widely used effective pathways to obtain deep SNNs up to now. First, the ANN-SNN conversion approach (Han and Roy, 2020; Li et al., 2021a; Bu et al., 2022, 2023; Li and Zeng, 2022; Liu et al., 2022; Wang Y. et al., 2022) converts a well-trained ANN to an SNN by replacing the activation function from ReLU with spiking activation. It provides a fast way to obtain an SNN. However, it is limited in the rate-coding scheme and ignores the rich temporal dynamic behaviors of SNNs. Second, the surrogate gradient (SG)-based direct learning approach (Wu Y. et al., 2018; Fang et al., 2021a; Li et al., 2021b; Guo et al., 2022a) tries to find an alternative differentiable surrogate function to replace the undifferentiable firing activity when doing back-propagation of the spiking neurons. Since SG can handle temporal data and provide decent performance with few time-steps on the large-scale dataset, it has received more attention recently.
Considering the sufficient advantages and rapid development of the direct learning-based deep SNN, a comprehensive and systematic survey on this kind of work is essential. Previously related surveys (Ponulak and Kasinski, 2011; Roy et al., 2019; Tavanaei et al., 2019; Wang et al., 2020; Yamazaki et al., 2022; Zhang D. et al., 2022) have begun to classify existing works mainly based on the key components of SNNs: biological neurons, encoding methods, SNN structures, SNN learning mechanisms, software and hardware frameworks, datasets, and applications. Though such classification is intuitive to general readers, it is difficult for them to grasp the challenges and the landmark work involved. While in this survey, we provide a new perspective to summarize these related works, i.e., starting from analyzing the characteristics and difficulties of the SNN, and then classify them into (i) accuracy improvement methods, (ii) efficiency improvement methods, and (iii) temporal dynamics utilization methods, based on the solutions for corresponding problems or the utilization of SNNs' advantages.
Further, these categories are divided into finer granularities: (i) accuracy improvement methods are subdivided as improving representative capabilities and relieving training difficulties; (ii) efficiency improvement methods are subdivided as network compression techniques and sparse SNNs; (iii) temporal dynamics utilization methods are subdivided as sequential learning and cooperating with neuromorphic cameras. In addition to the classification by using strengths or overcoming weaknesses of SNNs, these recent methods can also be divided into the neuron level, network structure level, and training technique level, according to where these methods actually work. The classifications and main techniques of these methods are listed in Tables 1, 2. Finally, some promising future research directions are provided.
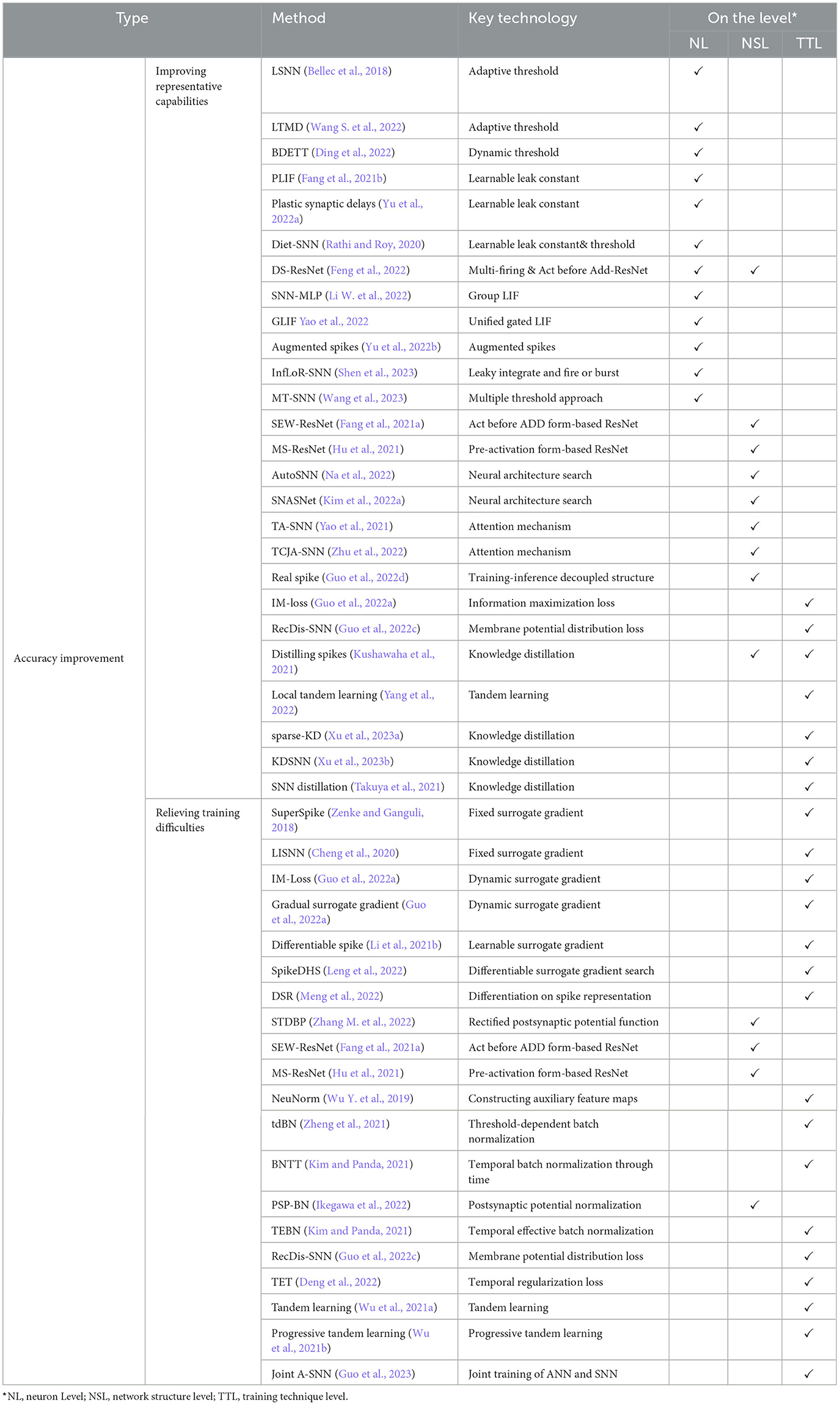
Table 1. Overview of direct learning-based deep spiking neural networks: part I.
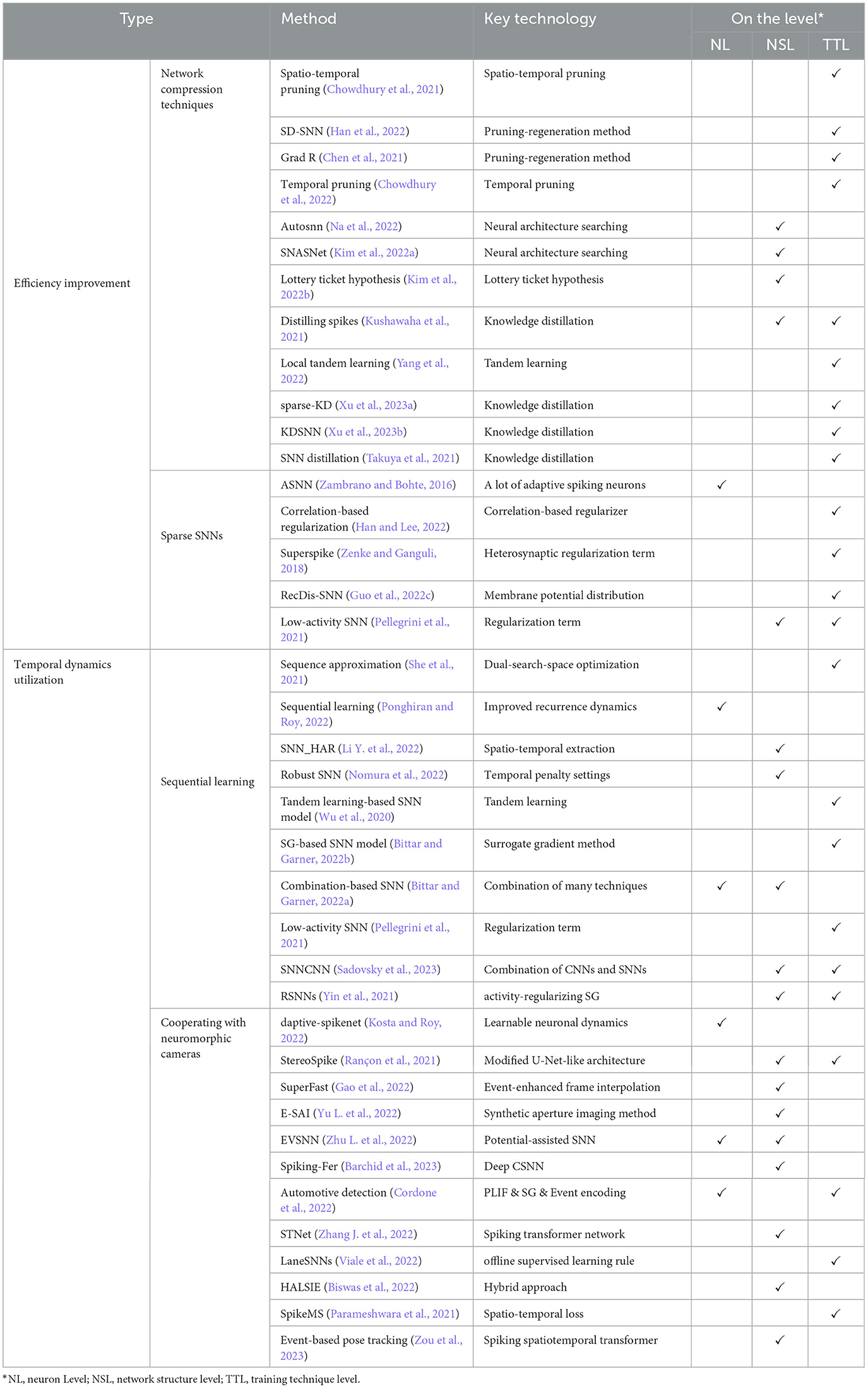
Table 2. Overview of direct learning-based deep spiking neural networks: part II.
The organization of the remaining part is given as follows, Section 2 introduces the preliminary for spiking neural networks. The characteristics and difficulties of the SNN are also analyzed in Section 2. Section 3 presents the recent advances falling into different categories. Section 4 points out future research trends and concludes the review.
2. Preliminary
Since the neuron models are not the focus of the paper, here, we briefly introduce the commonly used discretized Leaky Integrate-and-Fire (LIF) spiking neurons to show the basic characteristic and difficulties in SNNs, which can be formulated by
where is the membrane potential at t-th time-step for l-th layer, is the spike output from the previous layer, Wl is the weight matrix at l-th layer, Vth is the firing threshold, and τ is a time leak constant for the membrane potential, which is in (0, 1). When τ is 1, the above equation will degenerate to the Integrate-and-Fire (IF) spiking neuron.
Characteristic 1. Rich spatially-temporal dynamics. Seen from Equation (1), different from ANNs SNNs enjoy the unique spatial-temporal dynamic in the spiking neuron model.
Then, when the membrane potential exceeds the firing threshold, it will fire a spike and then fall to resting potential, given by
Characteristic 2. Efficiency. Since the output is a binary tensor, the multiplications of activations and weights can be replaced by additions, thus enjoying high energy efficiency. Furthermore, when there is no spike output generated, the neuron will keep silent. This event-driven mechanism can further save energy when implemented in neuromorphic hardware.
Characteristic 3. Limited representative ability. Obviously, transmitting information by quantizing the real-valued membrane potentials into binary output spikes will introduce the quantization error in SNNs, thus causing information loss (Guo et al., 2022b; Wang et al., 2023). Furthermore, the binary spike feature map from a timestep cannot carry enough information like the real-valued one in ANNs (Guo et al., 2022d). These two problems limit the representative ability of SNN to some extent.
Characteristic 4. Non-differentiability. Another thorny problem in SNNs is the non-differentiability of the firing function.
To demonstrate this problem, we formulate the gradient at the layer l by the chain rule, given by
where is the gradient of firing function at t-th time-step for l-th layer and is 0 almost everywhere, while infinity at Vth. As a consequence, the gradient descent either freezes or updates to infinity.
Most existing direct learning-based SNN works focus on solving difficulties or utilizing the advantages of SNNs. Boosting the representative ability and mitigating the non-differentiability can both improve SNN's accuracy. From this perspective, we organize the recent advances in the SNN field as accuracy improvement methods, efficiency improvement methods, and temporal dynamics utilization methods.
3. Recent advances
In recent years, a variety of direct learning-based deep spiking neural networks have been proposed. Most of these methods fall into solving or utilizing the intrinsic disadvantages or advantages of SNNs. Based on this, in the section, we classify these methods into accuracy improvement methods, efficiency improvement methods, and temporal dynamics utilization methods. In addition, these classifications are also organized in different aspects with a comprehensive analysis. Tables 1, 2 summarizes the surveyed SNN methods in different categories.
Note that the direct learning methods can be divided into time-based methods and activation-based methods based on whether the gradient represents spike timing (time-based) or spike scale (activation-based; Zhu Y. et al., 2022). In time-based methods, the gradients represent the direction where the timing of a spike should be moved, i.e., be moved leftward or rightward on the time axis. The SpikeProp (Bohte et al., 2002) and its variants (Booij and tat Nguyen, 2005; Xu et al., 2013; Hong et al., 2019) all belong to this kind of method and they adopt the negative inverse of the time derivative of membrane potential function to approximate the derivative of spike timing to membrane potential. Since most of the time-based methods would restrict each neuron to fire at most once, in Zhou et al. (2021), the spike time is directly taken as the state of a neuron. Thus the relation of neurons can be modeled by the spike time and the SNN can be trained similarly to an ANN. Though the time-based methods enjoy less computation cost than the activation-based methods and many works (Zhang and Li, 2020; Zhu Y. et al., 2022) have greatly improved the accuracy of the field, it is still difficult to train deep time-based SNN models and apply them to large-scale datasets, e.g., ImageNet. Considering the limits of the time-based methods and the topic of summarizing the recent deep SNNs here, we mainly focus on activation-based methods in the paper.
3.1. Accuracy improvement methods
As aforementioned, the limited information capacity and the non-differentiability of firing activity of the SNN cause its accuracy loss for wide tasks. Therefore, to mitigate the accuracy loss in the SNN, a great number of methods devoted to improving the representative capabilities and relief training difficulties of SNNs have been proposed and achieved successful improvements in the past few years.
3.1.1. Improving representative capabilities
Two problems result in the representative ability decreasing of the SNN, the process of firing activity will induce information loss, which has been proved in Guo et al. (2022b) and binary spike maps suffer the limited information capacity, which has been proved in Guo et al. (2022d). These problems can be mitigated on the neuron level, network structure level, and training technique level.
3.1.1.1. On the neuron level
A common way to boost the representative capability of the SNN is to make some hyper-parameters in the spiking neuron learnable. In LSNN (Bellec et al., 2018) and LTMD (Wang S. et al., 2022), the adaptive threshold spike neuron was proposed to enhance the computing and learning capabilities of SNNs. Further, a novel bio-inspired dynamic energy-temporal threshold, which can be adjusted dynamically according to input data for SNNs was introduced in the BDETT (Ding et al., 2022). Some works adopted the learnable membrane time constant in spiking neurons (Zimmer et al., 2019; Yin et al., 2020; Fang et al., 2021b; Luo et al., 2022; Yu et al., 2022a). Combining these two manners, Diet-SNN (Rathi and Roy, 2020) simultaneously adopted the learnable membrane leak and firing threshold.
There are also some works focusing on embedding more factors in the spiking neuron to improve its diversity. A multi-level firing (MLF) unit, which contains multiple LIF neurons with different level thresholds thus could generate more quantization spikes with different thresholds was proposed in DS-ResNet (Feng et al., 2022). A full-precision LIF to communicate between patches in Multi-Layer Perceptron (MLP), including horizontal LIF and vertical LIF in different directions was proposed in SNN-MLP (Li W. et al., 2022). SNN-MLP used group LIF to extract better local features. In GLIF (Yao et al., 2022), to enlarge the representation space of spiking neurons, a unified gated leaky integrate-and-fire Neuron was proposed to fuse different bio-features in different neuronal behaviors via embedding gating factors. In augmented spikes (Yu et al., 2022b), a special spiking neuron model was proposed to process augmented spikes, where additional information can be carried from spike strength and latency. This neuron model extends the computation with an additional dimension and thus could be of great significance for the representative ability of the SNN. In LIFB (Shen et al., 2023), a new spiking neuron model called the Leaky Integrate and Fire or Burst was proposed. The neuron model exhibits three modes including resting, regular spike, and burst spike, which significantly enriches the representative capability. Similar to LIFB, MT-SNN (Wang et al., 2023) proposed a multiple threshold approach to firing different spike modes to alleviate the quantization error, such that it could reach a high accuracy at fewer steps.
Different from these works, InfLoR-SNN (Guo et al., 2022b) proposed a membrane potential rectifier (MPR), which can adjust the membrane potential to a new value closer to quantization spikes than itself before firing activity. MPR directly handles the quantization error problem in SNNs, thus improving the representative ability.
3.1.1.2. On the network structure level
To increase the SNN diversity, some works advocate for improving the SNN architecture. In SEW-ResNet (Fang et al., 2021a) and DS-ResNet (Feng et al., 2022), the widely used standard ResNet backbone is replaced by activation before addition form-based ResNet. In this way, the blocks in the network will fire positive integer spikes. Its representation capability will no doubt be increased, however, the advantages of event-driven and multiplication-addition transform in SNNs will be lost in the meantime. To solve the aforementioned problem, MS-ResNet (Hu et al., 2021) adopted the pre-activation form-based ResNet. In this way, the spike-based convolution can be retained. The difference between these methods is shown in Figure 1. However, these SNN architectures are all manually designed. For designing well-performed SNN models automatically, AutoSNN (Na et al., 2022) and SNASNet (Kim et al., 2022a) combined the Neural Architecture Search (NAS) approach to find better SNN architectures. And TA-SNN (Yao et al., 2021) and TCJA-SNN (Zhu et al., 2022) leveraged the learnable attention mechanism to improve the SNN performance.
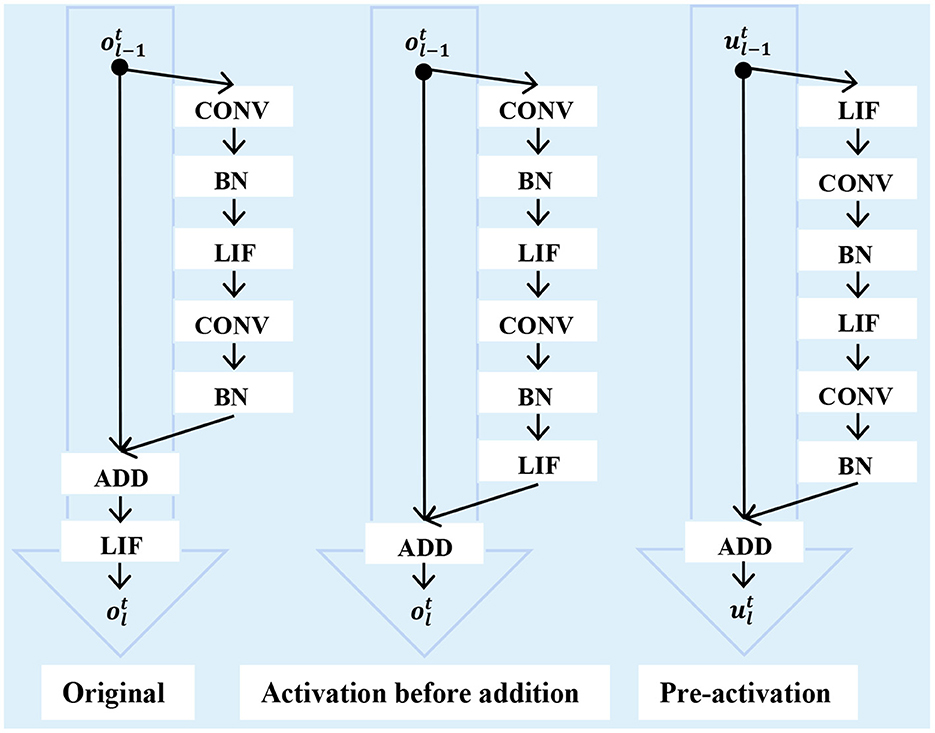
Figure 1. Different SNN ResNet architectures.
Different from changing the network topology, Real Spike (Guo et al., 2022d) provides a training-inference decoupled structure. This method enhances the representation capacity of the SNN by learning real-valued spikes during training. While in the inference phase, the rich representation capacity will be transferred from spike neurons to the convolutions by a re-parameterization technique, and meanwhile, the real-valued spikes will be transformed into binary spikes, thus maintaining the event-driven and multiplication-addition transform advantages of SNNs.
Besides, increasing the timestep of SNN will undoubtedly improve the SNN accuracy too, which has been proved in many works (Wu Y. et al., 2018, 2019; Fang et al., 2021a). To some extent, increasing the timestep is equivalent to increasing neuron output bits through the temporal dimension, which will increase the representation capability of feature map (Feng et al., 2022). However, using more timesteps achieves better performance at the cost of increasing inference time.
3.1.1.3. On the training technique level
Some works attempted to improve the representative capability of the SNN on the training technique level, which can be categorized as regularization and distillation. Regularization is a technique that introduces another loss term to explicitly regularize the membrane potential or spike distribution to retain more useful information in the network that could indirectly help train the network as follows,
where CE is the common cross-entropy loss, DL is the distribution loss for learning the proper membrane potential or spike, and λ is a coefficient to balance the effect of the two types of losses. IM-Loss (Guo et al., 2022a) argues that improving the activation information entropy can reduce the quantization error, and proposed an information maximization loss function that can maximize the activation information entropy. In RecDis-SNN (Guo et al., 2022c), a loss for membrane potential distribution to explicitly penalize three undesired shifts was proposed. Though the work is not designed for reducing quantization error specifically, it still results in a bimodal membrane potential distribution, which has been proven can mitigate the quantization error problem.
The distillation methodology aims to help train a small student model by transferring knowledge of a rather large trained teacher model based on the consensus that the representative ability of a teacher model is better than that of the student model. Recently, some interesting works that introduce the distillation method in the SNN domain were proposed. In Kushawaha et al. (2021), a big teacher SNN model is used to guide the small SNN counterpart learning. While in Yang et al. (2022), Takuya et al. (2021), and Xu et al. (2023a,b) an ANN-teacher is used to guide SNN-student learning. In specific, Local Tandem Learning (Yang et al., 2022) uses the intermediate feature representations of the ANN to supervise the learning of SNN. While in sparse-KD (Xu et al., 2023a), the logit output of the ANN was adopted to guide the learning of the SNN. Furthermore, KDSNN (Xu et al., 2023b) and SNN distillation (Takuya et al., 2021) used both feature-based and logit-based information to distill the SNN.
3.1.2. Relieving training difficulties
The non-differentiability of the firing function impedes the deep SNN direct training. To handle this problem, recently, using the surrogate gradient (SG) function for spiking neurons has received much attention. SG method utilizes a differentiable surrogate function to replace the non-differentiable firing activity to calculate the gradient in the back-propagation (Neftci et al., 2019; Wu Y. et al., 2019; Rathi and Roy, 2020; Fang et al., 2021a). Though the SG method can alleviate the non-differentiability problem, there exists an obvious gradient mismatch between the gradient of the firing function and the surrogate gradient. And the problem easily leads to under-optimized SNNs with severe performance degradation. Intuitively, an elaborately designed surrogate gradient can help to relieve the gradient mismatch in the backward propagation. As a consequence, some works are focusing on designing better surrogate gradients. In addition, the gradient explosion/vanishing problem in SNNs is severer over ANNs, due to the adoption of tanh-like function for most SG methods. There are also some works focusing on handling the gradient explosion/vanishing problem. Note that, these methods in this section can also be classified as the improvement on the neuron level, network structure level, and training technique level, which can be seen in the Table 1. Nevertheless, to better introduce these works, we still organize them as designing the better surrogate gradient and relieving the gradient explosion/vanishing problem.
3.1.2.1. Designing the better surrogate gradient
Most earlier works adopt fixed SG-based methods to handle the non-differentiability problem. For example, the derivative of a truncated quadratic function, the derivatives of a sigmoid, and a rectangular function were respectively adopted in Bohte (2011), Zenke and Ganguli (2018), and Cheng et al. (2020). However, such a strategy would limit the learning capacity of the network. To this end, a dynamic SG method was proposed in Guo et al. (2022a) and Chen et al. (2022), where the SG could change along with epochs as follows,
where φ(x) is the backward approximation function for the firing activity and K(i) is a dynamic coefficient that changes along with the training epoch as follows,
where Kmin and Kmax are the lower bound and the upper bound of K, and i is the index of epoch starting from 0 to N−1. The φ(x) and its gradient can be seen in Figure 2. Driven by K(i), it will gradually evolve to the firing function, thus ensuring sufficient weight updates at the beginning and accurate gradients at the end of the training. Nevertheless, the above SG methods are still designed manually. To find the optimal solution, in Li et al. (2021b), the Differentiable Spike method that can adaptively evolve during training to find the optimal shape and smoothness for gradient estimation based on the finite difference technique was proposed. Then, in Leng et al. (2022), combined with the NAS technique, a differentiable SG search (DGS) method to find the optimized SGs for SNN was proposed. Different from designing a better SG for firing function, DSR (Meng et al., 2022) derived that the spiking dynamics with spiking neural models can be represented as some sub-differentiable mapping and trained the SNNs by the gradients of the mapping, thus avoiding the non-differentiability problem in SNN training.
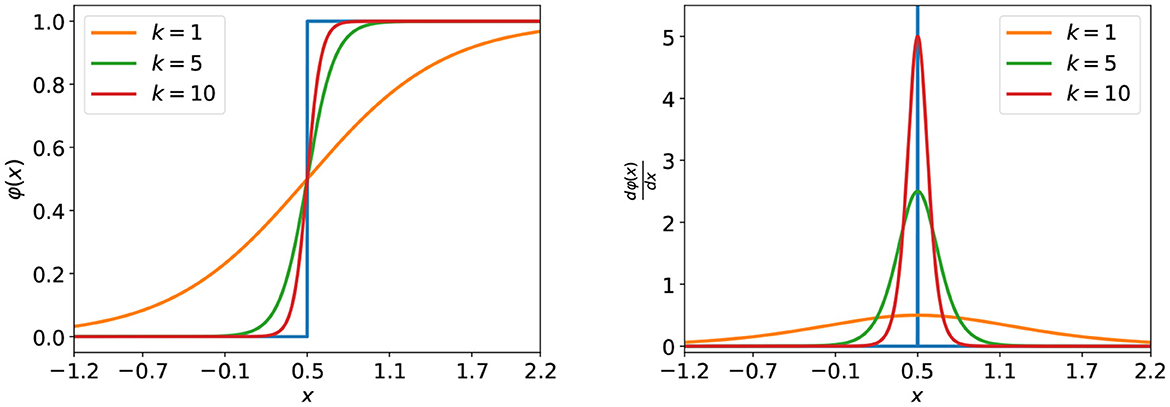
Figure 2. The approximation function (left) under different values of the coefficient, k and its corresponding gradient (right). The blue curves represent the firing function (left) and its true gradient (right).
3.1.2.2. Relieving the gradient explosion/vanishing problem
The gradient explosion or vanishing problem is still severe in SG-only methods. There are three kinds of methods to solve this problem: using improved neurons or architectures, improved batch normalizations, and regularization. In Zhang M. et al. (2022), a simple yet efficient rectified linear postsynaptic potential function (ReL-PSP) for spiking neurons, which benefits for handling the gradient explosion problem, was proposed. On the network architecture level, SEW-ResNet (Fang et al., 2021a) showed that standard spiking ResNet is inapplicable to overcome identity mapping and vanishing/explosion gradient problems and advised using ResNet with activation before addition form. Recently, the pre-activation form-based ResNet was explored in MS-ResNet (Hu et al., 2021). This network topology can simultaneously handle the gradient explosion/vanishing problem and retain the advantages of the SNN.
The normalization approaches are widely used in ANNs to train well-performed models, and these approaches are also introduced in the SNN field to handle the vanishing/explosion gradient problems. For example, NeuNorm (Wu Y. et al., 2019) normalized the data along the channel dimension like BN in ANNs through constructing auxiliary feature maps. Threshold-dependent batch normalization (tdBN; Zheng et al., 2021) considers the SNN normalization from a temporal perspective and extends the scope of BN to the additional temporal dimension. Furthermore, some works (Kim and Panda, 2021; Duan et al., 2022; Ikegawa et al., 2022) argued that the distributions of different timesteps vary wildly, thus bringing a negative impact when using shared parameters. Subsequently, the temporal Batch Normalization Through Time (BNTT), postsynaptic potential normalization (PSP-BN), and temporal effective batch normalization (TEBN) that can regulate the spike flows by utilizing separate sets of BN parameters on different timesteps were proposed. Though adopting temporal BN parameters on different timesteps can obtain more well-performed SNN models, this kind of BN technique can not fold the BN parameters into the weights and will increase the computations and running time in the inference stage, which should also be noticed.
Using the regularization loss can also mitigate the gradient explosion/vanishing problem. In RecDis-SNN (Guo et al., 2022c), a new perspective to further classify the gradient explosion/vanishing difficulty of SNNs into three undesired shifts of the membrane potential distribution was presented. To avoid these undesired shifts, a membrane potential regularization loss was proposed in RecDis-SNN, this loss introduces no additional operations in the SNN inference phase. In TET (Deng et al., 2022), an extra temporal regularization loss to compensate for the loss of momentum in the gradient descent with SG methods was proposed. With this loss, TET can converge into flatter minima with better generalizability.
Since ANNs are fully differentiable to be trained with gradient descent, there is also some work utilizing ANN to guide the SNN's optimization (Wu et al., 2021a,b; Guo et al., 2023). In Wu et al. (2021a) a tandem learning framework was proposed, that consists of an SNN and an ANN that share the same weight. In this framework, the spike count as the discrete neural representation in the SNN would be presented to the coupled ANN activation function in the forward phase. And in the backward phase, the error back-propagation is performed on the ANN to update the shared weight for both the SNN and the ANN. Furthermore, in Wu et al. (2021b), a progressive tandem learning framework was proposed, that introduces a layer-wise learning method to fine-tune the shared network weights. Considering the difference between the ANN and SNN, Joint A-SNN (Guo et al., 2023) developed a partial weight-sharing regime for the joint training of weight-shared ANN and SNN, that applies the Singular Value Decomposition (SVD) to the weights parameters and keep the same eigenvectors while the separated eigenvalues for the ANN and SNN.
3.2. Efficiency improvement methods
An important reason why have SNNs received extensive attention recently is that they are seen as more energy efficient than ANNs due to their event-driven computation mechanism and the replacement of energy-consuming weight multiplication with addition. To further explore the efficiency advantages of SNNs so that they can be applied to energy-constrained devices is also a hot topic in the SNN field. This kind of method can be mainly categorized into network compression techniques and sparse SNNs.
3.2.1. Network compression techniques
Network compression techniques have been widely used in ANNs. There are also some works applying these techniques in SNNs. In the literature, approaches for compressing deep SNNs can be classified into three categories: parameter pruning, NAS, and knowledge distillation.
3.2.1.1. Parameter pruning
Parameter pruning mainly focuses on eliminating the redundant parameters in the model by removing the uncritical ones. SNNs, unlike their non-spiking counterparts, consist of a temporal dimension. Along with considering temporal information, a spatial and temporal pruning of SNNs is proposed in Chowdhury et al. (2021). Generally speaking, pruning will cause accuracy degradation to some extent. To avoid this, SD-SNN (Han et al., 2022) and Grad R (Chen et al., 2021) proposed the pruning-regeneration method for removing the redundancy in SNNs from the brain development plasticity mechanism. With synaptic regeneration, these works can effectively prevent and repair over-pruning. Recently, an interesting temporal pruning, which is specific for SNNs, was proposed in Chowdhury et al. (2022). This method starts with an SNN of T timesteps and reduces T every iteration of training, which results in a continuum of accurate and efficient SNNs from T timesteps, down to 1 timestep.
3.2.1.2. Neural architecture searching
Obviously, a compact network carefully designed can reduce the storage and computation complexity of SNNs. However, due to the limitations of humans' inherent knowledge, it is difficult for people to jump out of their original thinking paradigm and design an optimal compact model. Therefore, there are some works using NAS techniques to let the algorithm automatically design the compact neural architecture (Kim et al., 2022a; Na et al., 2022). Furthermore, in Kim et al. (2022b), the lottery ticket hypothesis was investigated which shows that dense SNN networks contain smaller SNN subnetworks, i.e., winning tickets, which can achieve comparable performance to the dense ones, and the smaller compact one is picked as to be used network.
3.2.1.3. Knowledge distillation
The knowledge distillation methods aim at obtaining a compact model from a large model. In Kushawaha et al. (2021), a larger teacher SNN model is used to distill a smaller SNN model. And in Yang et al. (2022), Takuya et al. (2021), and Xu et al. (2023a,b), the same architecture ANN-teacher is used to distill SNN-student.
3.2.2. Sparse SNNs
Different from ANNs, SNNs transmit information by spike events, and the computation occurs only when the neuron receives spike events. Benefitting from this event-driven computation mechanism, SNNs can greatly save energy and run efficiently when implemented on neuromorphic hardware. Hence, limiting the firing rate of spiking neurons to achieve a sparse SNN is also a widely used way to improve the efficiency of the SNN. These kinds of methods can limit the firing rate of the SNN on both the neuron level and training technique level.
3.2.2.1. On the neuron level
In ASNN (Zambrano and Bohte, 2016), an adaptive SNN based on a group of adaptive spiking neurons was proposed. These adaptive spiking neurons can optimize their firing rate using asynchronous pulsed Sigma-Delta coding efficiently.
3.2.2.2. On the training technique level
In Han and Lee (2022), a correlation-based regularizer, which is incorporated into a loss function, was proposed to minimize the redundancies between the features at each layer for structural sparsity. Obviously, this method is beneficial for energy-efficient. Superspike (Zenke and Ganguli, 2018) added a heterosynaptic regularization term to the learning rule of the hidden layer weights to avoid pathologically high firing rates. RecDis-SNN (Guo et al., 2022c) incorporated a membrane potential loss into the SNN to regulate the membrane potential distribution to an appropriate range to avoid high firing rates. In Pellegrini et al. (2021), to enforce sparse spiking activity, a l1 or l2 regularization on the total number of spikes emitted by each layer was applied.
3.3. Temporal dynamics utilization methods
Different from ANNs, SNNs enjoy rich temporal dynamics characteristics, which makes them more suitable for some particular temporal tasks and some vision sensors with high resolution in time, e.g., neuromorphic cameras, which can capture temporally rich information asynchronously inspired by the information process form of eyes. Given such characteristics, a great number of methods falling in sequential learning and cooperating with neuromorphic cameras have been proposed for SNNs.
3.3.1. Sequential learning
As aforementioned in Section 2, SNNs maintain a dynamic state in the neuron memory. In Ponghiran and Roy (2022), the usefulness of the inherent recurrence dynamics of the SNN for sequential learning was demonstrated, that it can retain important information. Thus, SNNs show better performance on sequential learning compared to ANNs with similar scales in many works. In She et al. (2021), a function approximation theoretical basis was developed that any spike-sequence-to-spike-sequence mapping functions can be approximated by an SNN with one neuron per layer using skip-layer connections. And then, based on the basis, a suitable SNN model for the classification of spatio-temporal data was designed. In Li Y. et al. (2022), SNNs were leveraged to study the Human Activity Recognition (HAR) task. Since SNNs allow spatio-temporal extraction of features and enjoy low-power computation with binary spikes, they can reduce up to 94% energy consumption while achieving better accuracy compared with homogeneous ANN counterparts. In Nomura et al. (2022), an interesting phenomenon was found that SNNs trained with the appropriate temporal penalty settings are more robust against adversarial images than ANNs.
As the common sequential signal, many preliminary works on speech recognition systems based on spiking neural networks have been explored (Tavanaei and Maida, 2017a,b; Wu et al., 2018a,b, 2019b, 2020; Zhang et al., 2019; Hao et al., 2020). In Wu et al. (2020), a deep spiking neural network was trained by the tandem learning method to handle the large vocabulary automatic speech recognition task. The experimental results demonstrated that the deep SNN trained could compete with its ANN counterpart while requiring as low as 0.68 times total synaptic operations to their ANN counterparts. There are also some works training deep SNN directly with SG methods for the speech task. In Ponghiran and Roy (2022), inspired by the LSTM, a custom version of SNNs was defined that combines a forget gate with multi-bit outputs instead of binary spikes, yielding better accuracy than that of LSTMs, but with 2 × fewer parameters. In Bittar and Garner (2022b), the spiking neural networks trained like recurrent neural networks only using the standard surrogate gradient method can achieve promising results on speech recognition tasks, which shows the advantage of SNNs to handle this kind of task. In Bittar and Garner (2022a), a combination of adaptation, recurrence, and surrogate gradient techniques for spiking neural networks was proposed. And with these improvements, light spiking architectures that are not only able to compete with ANN solutions but also retain a high degree of compatibility with them were yielded. In Pellegrini et al. (2021), the dilated convolution spiking layers and a new regularization term to penalize the averaged number of spikes were used to train low-activity supervised convolutional spiking neural networks. The results showed that the SNN models can reach an error rate very close to standard DNNs while very energy efficient for speech tasks. In Sadovsky et al. (2023), a new technique for speech recognition that combines convolutional neural networks with spiking neural networks was presented to create an SNNCNN model. The results showed that the combination of CNNs and SNNs outperforms both MLPs and ANNs, providing a new route to further improvements in the field. In Yin et al. (2021), an activity-regularizing surrogate gradient method combined with recurrent networks of tunable and adaptive spiking neurons for SNNs was proposed, and the method performed well on the speech recognition task.
3.3.2. Cooperating with neuromorphic cameras
Neuromorphic camera, which is also called event-based cameras, have recently shown great potential for high-speed motion estimation owing to their ability to capture temporally rich information asynchronously. SNNs, with their spatio-temporal and event-driven processing mechanisms, are very suitable for handling such asynchronous data. Many excellent works combine SNNs and neuromorphic cameras to solve real-world large-scale problems. In Hagenaars et al. (2021) and Kosta and Roy (2022), an event-based optical flow estimation method was presented. In StereoSpike (Rançon et al., 2021) a depth estimation method was provided. SuperFast (Gao et al., 2022) leveraged an SNN and an event camera to present an event-enhanced high-speed video frame interpolation method. SuperFast can generate a very high frame rate (up to 5,000 FPS) video from the input low frame rate (25 FPS) video. Furthermore, Based on a hybrid network composed of SNNs and ANNs, E-SAI (Yu L. et al., 2022) provided a novel synthetic aperture imaging method, which can see through dense occlusions and extreme lighting conditions from event data. And in EVSNN (Zhu L. et al., 2022) a novel Event-based Video reconstruction framework was proposed. To fully use the information from different modalities, HALSIE (Biswas et al., 2022) proposed a hybrid approach for semantic segmentation comprised of dual encoders with an SNN branch to provide rich temporal cues from asynchronous events, and an ANN branch for extracting spatial information from regular frame data by simultaneously leveraging image and event modalities.
There are also some works that apply this technique in autonomous driving. In Cordone et al. (2022), fast and efficient automotive object detection with spiking neural networks on automotive event data was proposed. In Zhang J. et al. (2022), a spiking transformer network, STNet, which can dynamically extract and fuse information from both temporal and spatial domains was proposed for single object tracking using event data. Besides, since event cameras enjoy extremely low latency and high dynamic range, they can also be used to handle the harsh environment, i.e., extreme lighting conditions or dense occlusions. LaneSNNs (Viale et al., 2022) presented an SNN-based approach for detecting the lanes marked on the streets using the event-based camera input. The experimental results show a very low power consumption of about 1 W, which can significantly increase the lifetime and autonomy of battery-driven systems.
Based on the event-based cameras and SNNs, some works attempted to assist the behavioral recognition research. For examples, Spiking-Fer (Barchid et al., 2023) proposed a new end-to-end deep convolutional SNN method to predict facial expression. SpikeMS (Parameshwara et al., 2021) proposed a deep encoder-decoder SNN architecture and a novel spatio-temporal loss for motion segmentation using the event-based DVS camera as input. In Zou et al. (2023), a dedicated end-to-end sparse deep SNN consisting of the Spike-Element-Wise (SEW) ResNet and a novel Spiking Spatiotemporal Transformer was proposed for event-based pose tracking. This method achieves a significant computation reduction of 80% in FLOPS, demonstrating the superior advantage of SNN in this kind of task.
4. Future trends and conclusions
The spiking neural networks, born in mimicking the information process of brain neurons, enjoy many specific characteristics and show great potential in many tasks, but meanwhile suffer from many weaknesses. As a consequence, a number of direct learning-based deep SNN solutions for handling these disadvantages or utilizing the advantages of SNNs have been proposed recently. As we summarized in this survey, these methods can be roughly categorized into (i) accuracy improvement methods, (ii) efficiency improvement methods, and (iii) temporal dynamics utilization methods. Though successful milestones and progress have been achieved through these works, there are still many challenges in the field.
On the accuracy improvement aspect, the SNN still faces serious performance loss, especially for the large network and datasets. The main reasons might include:
• Lack of measurement of information capacity: it is still unclear how to precisely calculate the information capacity of the spike maps and what kind of neuron types or network topology is suitable for preserving information while the information passing through the network, even after firing function. We believe SNN neurons and architectures should not be referenced from brains or ANNs completely. Specific designs in regard to the characteristic of SNNs for preserving information should be explored. For instance, to increase the spiking neuron representative ability, the binary spike {0, 1}, which is used to mimic the activation or silence in the brain, can be replaced by ternary spike {-1, 0, 1}, thus the information capacity of the spiking neuron will be boosted, but the event-driven and multiplication-free operation advantages of the binary spike can be preserved still. And as aforementioned, the widely used standard ResNet backbone in ANNs is not suitable for SNNs. And the PreAct ResNet backbone performs better since the membrane potential in neurons before the firing function will be added to the next block, thus the complete information will be transmitted simultaneously. While for the standard ResNet backbone, only quantized information is transmitted. To further preserve the information, adding the shortcut layer by layer in the PreAct ResNet backbone is better in our experiment, which is much different from the architectures in ANNs and is a promising exploration direction.
• Inherent optimization difficulties: It is still a difficult problem to optimize the SNN in a discrete space, even though many novel gradient estimators or approximate functions have been proposed, there are still some huge obstacles in the field. Such as the gradient explosion/vanishing problem, with the increasing timestep, the problem along with the gradient errors will become severer and make the network hard to converge. Thus, how to completely eliminate the impact of this problem to directly train an SNN with large timesteps is still under exploration. We believe more theoretical studies and practical tricks will emerge to answer this question in the future.
It is also worth noting that accuracy is not the only criterion of SNNs, the versatility is another key criterion, that measures whether a method can be used in practice. Some methods proposed in prior works are very versatile, such as learnable spike factors proposed in Real Spike (Guo et al., 2022d), membrane potential rectifier proposed in InfLoR-SNN (Guo et al., 2022b), temporal regularization loss proposed in TET (Deng et al., 2022), etc. These methods enjoy simple implementation and low coupling, thus having become common widely used practices to improve the accuracy of SNNs. Some methods improve the accuracy of SNNs by designing complex spiking neurons or specific architectures. Such improvements usually show a stronger ability to increase performance. However, as we have pointed out before, some of them suffer complicated computation and even lose the energy-efficiency advantage, which violates the original intention of SNNs. Therefore, purely pursuing high accuracy without considering versatility has limited significance in practice. The balance between accuracy and versatility is also an essential criterion for SNN research that should be considered in the following works.
On the efficiency improvement aspect, some prior works ignore the important fact, that the event-driven paradigm and friendly to the neuromorphic hardware make SNNs much different from ANNs. When implemented on the neuromorphic hardware, the computation in the SNN occurs only if the spiking neuron receives spike events. Hence, the direct reason for improving the efficiency of the SNN is reducing the the number of the firing spikes, not reducing network size. Some methods intending to improve the efficiency of SNNs by pruning inactive neurons as doing in ANNs can not make sense. We even think that under the condition the SNN network size does not exceed the capacity of the neuromorphic hardware, enlarging the network size but limiting the number of the firing spikes at the same time may be a potential route to improve the accuracy and efficiency simultaneously. In this way, different weights of the SNN may respond to different data, thus being equivalent to improving the representative capabilities of the SNN. However, a more systematic study needs to be done in the future.
On the temporal dynamics utilization aspect, a great number of interesting methods have been proposed and shown wide success. We think it is a very potential direction in the SNN field. Some explainable machine learning-related study indicates that different network types follow different patterns and enjoy different advantages. In this sense, it might be more meaningful to dive into the temporal dynamics of the SNN deeply, but not to pursue higher accuracy as ANNs. Meanwhile, considering the respective advantages, to use ANNs and SNNs together needs to be studied further.
Last but not least, more special applications for SNNs also should be explored still. Though SNNs have been used widely in many fields, including the neuromorphic camera, HAR task, speech recognition, autonomous driving, etc., as aforementioned and the object detection (Kim et al., 2020; Zhou et al., 2020), object tracking (Luo et al., 2020), image segmentation (Patel et al., 2021), robotic (Stagsted et al., 2020; Dupeyroux et al., 2021), etc., where some remarkable studies have applied SNNs on recently, compared to ANNs, their real-world applications are still very limited. Considering the unique advantage, efficiency of SNNs, we think there is a great opportunity for applying SNNs in the Green Artificial Intelligence (GAI), which has become an important subfield of Artificial Intelligence and has notable practical value. We believe many studies focusing on using SNNs for GAI will emerge soon.
Author contributions
YG and XH wrote the paper with ZM being active contributors toward editing and revising the paper as well as supervising the project. All authors contributed to the article and approved the submitted version.
Funding
This work was supported by grants from the National Natural Science Foundation of China under contract Nos. 12202412 and 12202413.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Barchid, S., Allaert, B., Aissaoui, A., Mennesson, J., and Djéraba, C. (2023). Spiking-FER: spiking neural network for facial expression recognition with event cameras. arXiv preprint arXiv:2304.10211.
Bellec, G., Salaj, D., Subramoney, A., Legenstein, R., and Maass, W. (2018). “Long short-term memory and learning-to-learn in networks of spiking neurons,” in Advances in Neural Information Processing Systems, Vol. 31. (Montréal, QC: Palais des Congrés de Montréal).
Biswas, S. D., Kosta, A., Liyanagedera, C., Apolinario, M., and Roy, K. (2022). Halsie-hybrid approach to learning segmentation by simultaneously exploiting image and event modalities. arXiv preprint arXiv:2211.10754.
Bittar, A., and Garner, P. (2022a). A surrogate gradient spiking baseline for speech command recognition. Front. Neurosci. 16:865897. doi: 10.3389/fnins.2022.865897
Bittar, A., and Garner, P. N. (2022b). Surrogate gradient spiking neural networks as encoders for large vocabulary continuous speech recognition. arXiv preprint arXiv:2212.01187.
Bohte, S. M. (2011). “Error-backpropagation in networks of fractionally predictive spiking neurons,” in International Conference on Artificial Neural Networks (Espoo: Springer), 60–68. doi: 10.1007/978-3-642-21735-7_8
Bohte, S. M., Kok, J. N., and La Poutre, H. (2002). Error-backpropagation in temporally encoded networks of spiking neurons. Neurocomputing 48, 17–37. doi: 10.1016/S0925-2312(01)00658-0
Booij, O., and tat Nguyen, H. (2005). A gradient descent rule for spiking neurons emitting multiple spikes. Inform. Process. Lett. 95, 552–558. doi: 10.1016/j.ipl.2005.05.023
Bu, T., Ding, J., Yu, Z., and Huang, T. (2022). “Optimized potential initialization for low-latency spiking neural networks,” in Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 36 (Columbia), 11–20. doi: 10.1609/aaai.v36i1.19874
Bu, T., Fang, W., Ding, J., Dai, P., Yu, Z., and Huang, T. (2023). Optimal ann-snn conversion for high-accuracy and ultra-low-latency spiking neural networks. arXiv preprint arXiv:2303.04347.
Chen, Y., Yu, Z., Fang, W., Huang, T., and Tian, Y. (2021). Pruning of deep spiking neural networks through gradient rewiring. arXiv preprint arXiv:2105.04916. doi: 10.24963/ijcai.2021/236
Chen, Y., Zhang, S., Ren, S., and Qu, H. (2022). “Gradual surrogate gradient learning in deep spiking neural networks,” in ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 8927–8931. doi: 10.1109/ICASSP43922.2022.9746774
Cheng, X., Hao, Y., Xu, J., and Xu, B. (2020). “LISNN: improving spiking neural networks with lateral interactions for robust object recognition,” in IJCAI, 1519–1525. doi: 10.24963/ijcai.2020/211
Chowdhury, S. S., Garg, I., and Roy, K. (2021). “Spatio-temporal pruning and quantization for low-latency spiking neural networks,” in 2021 International Joint Conference on Neural Networks (IJCNN), 1–9. doi: 10.1109/IJCNN52387.2021.9534111
Chowdhury, S. S., Rathi, N., and Roy, K. (2022). “Towards ultra low latency spiking neural networks for vision and sequential tasks using temporal pruning,” in Computer Vision-ECCV 2022, eds S. Avidan, G. Brostow, M. Cissé, G. M. Farinella, and T. Hassner (Cham: Springer Nature Switzerland), 709–726. doi: 10.1007/978-3-031-20083-0_42
Cordone, L., Miramond, B., and Thierion, P. (2022). Object detection with spiking neural networks on automotive event data. arXiv preprint arXiv:2205.04339. doi: 10.1109/IJCNN55064.2022.9892618
Deng, S., Li, Y., Zhang, S., and Gu, S. (2022). Temporal efficient training of spiking neural network via gradient re-weighting. arXiv preprint arXiv:2202.11946.
Ding, J., Dong, B., Heide, F., Ding, Y., Zhou, Y., Yin, B., et al. (2022). “Biologically inspired dynamic thresholds for spiking neural networks,” in Advances in Neural Information Processing Systems, eds A. H. Oh, A. Agarwal, D. Belgrave, and K. Cho (New Orleans, LA).
Duan, C., Ding, J., Chen, S., Yu, Z., and Huang, T. (2022). “Temporal effective batch normalization in spiking neural networks,” in Advances in Neural Information Processing Systems, eds A. H. Oh, A. Agarwal, D. Belgrave, and K. Cho.
Dupeyroux, J., Hagenaars, J. J., Paredes-Vallés, F., and de Croon, G. C. (2021). “Neuromorphic control for optic-flow-based landing of MAVs using the loihi processor,” in 2021 IEEE International Conference on Robotics and Automation (ICRA), 96–102. doi: 10.1109/ICRA48506.2021.9560937
Fang, W., Yu, Z., Chen, Y., Huang, T., Masquelier, T., and Tian, Y. (2021a). Deep residual learning in spiking neural networks. Adv. Neural Inform. Process. Syst. 34, 21056–21069. doi: 10.48550/arXiv.2102.04159
Fang, W., Yu, Z., Chen, Y., Masquelier, T., Huang, T., and Tian, Y. (2021b). “Incorporating learnable membrane time constant to enhance learning of spiking neural networks,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2661–2671. doi: 10.1109/ICCV48922.2021.00266
Feng, L., Liu, Q., Tang, H., Ma, D., and Pan, G. (2022). “Multi-level firing with spiking DS-ResNet: enabling better and deeper directly-trained spiking neural networks,” in Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, IJCAI 2022, ed L. D. Raedt (Vienna), 2471–2477. ijcai.org. doi: 10.24963/ijcai.2022/343
Gao, Y., Li, S., Li, Y., Guo, Y., and Dai, Q. (2022). Superfast: 200x video frame interpolation via event camera. IEEE Trans. Pattern Anal. Mach. Intell. 45, 7764–7780. doi: 10.1109/TPAMI.2022.3224051
Guo, Y., Chen, Y., Zhang, L., Liu, X., Wang, Y., Huang, X., et al. (2022a). “IM-loss: information maximization loss for spiking neural networks,” in Advances in Neural Information Processing Systems, eds A. H. Oh, A. Agarwal, D. Belgrave, and K. Cho (New Orleans, LA).
Guo, Y., Chen, Y., Zhang, L., Wang, Y., Liu, X., Tong, X., et al. (2022b). “Reducing information loss for spiking neural networks,” in Computer Vision-ECCV 2022, eds S. Avidan, G. Brostow, M. Cissé, G. M. Farinella, and T. Hassner (Cham: Springer Nature Switzerland), 36–52. doi: 10.1007/978-3-031-20083-0_3
Guo, Y., Peng, W., Chen, Y., Zhang, L., Liu, X., Huang, X., et al. (2023). Joint a-SNN: joint training of artificial and spiking neural networks via self-distillation and weight factorization. Pattern Recogn. 2023:109639. doi: 10.1016/j.patcog.2023.109639
Guo, Y., Tong, X., Chen, Y., Zhang, L., Liu, X., Ma, Z., et al. (2022c). “RECDIS-SNN: rectifying membrane potential distribution for directly training spiking neural networks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 326–335. doi: 10.1109/CVPR52688.2022.00042
Guo, Y., Zhang, L., Chen, Y., Tong, X., Liu, X., Wang, Y., et al. (2022d). “Real spike: learning real-valued spikes for spiking neural networks,” in Computer Vision-ECCV 2022: 17th European Conference (Tel Aviv: Springer), 52–68. doi: 10.1007/978-3-031-19775-8_4
Hagenaars, J., Paredes-Vallés, F., and De Croon, G. (2021). Self-supervised learning of event-based optical flow with spiking neural networks. Adv. Neural Inform. Process. Syst. 34, 7167–7179. doi: 10.48550/arXiv.2106.01862
Han, B., and Roy, K. (2020). “Deep spiking neural network: energy efficiency through time based coding,” in European Conference on Computer Vision (Glasgow: Springer), 388–404. doi: 10.1007/978-3-030-58607-2_23
Han, B., Zhao, F., Zeng, Y., and Pan, W. (2022). Adaptive sparse structure development with pruning and regeneration for spiking neural networks. arXiv preprint arXiv:2211.12219. doi: 10.48550/arXiv.2211.12219
Han, C. S., and Lee, K. M. (2022). “Correlation-based regularization for fast and energy-efficient spiking neural networks,” in Proceedings of the 37th ACM/SIGAPP Symposium on Applied Computing, SAC '22 (New York, NY: Association for Computing Machinery), 1048–1055. doi: 10.1145/3477314.3507085
Hao, Y., Huang, X., Dong, M., and Xu, B. (2020). A biologically plausible supervised learning method for spiking neural networks using the symmetric STDP rule. Neural Netw. 121, 387–395. doi: 10.1016/j.neunet.2019.09.007
Hong, C., Wei, X., Wang, J., Deng, B., Yu, H., and Che, Y. (2019). Training spiking neural networks for cognitive tasks: a versatile framework compatible with various temporal codes. IEEE Trans. Neural Netw. Learn. Syst. 31, 1285–1296. doi: 10.1109/TNNLS.2019.2919662
Hu, Y., Wu, Y., Deng, L., and Li, G. (2021). Advancing residual learning towards powerful deep spiking neural networks. arXiv preprint arXiv:2112.08954.
Ikegawa, S.-I., Saiin, R., Sawada, Y., and Natori, N. (2022). Rethinking the role of normalization and residual blocks for spiking neural networks. Sensors 22:2876. doi: 10.3390/s22082876
Kim, S., Park, S., Na, B., and Yoon, S. (2020). “Spiking-yolo: spiking neural network for energy-efficient object detection,” in Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 34, 11270–11277. doi: 10.1609/aaai.v34i07.6787
Kim, Y., Li, Y., Park, H., Venkatesha, Y., and Panda, P. (2022a). “Neural architecture search for spiking neural networks,” in Computer Vision-ECCV 2022: 17th European Conference (Tel Aviv: Springer), 36–56. doi: 10.1007/978-3-031-20053-3_3
Kim, Y., Li, Y., Park, H., Venkatesha, Y., Yin, R., and Panda, P. (2022b). “Exploring lottery ticket hypothesis in spiking neural networks,” in European Conference on Computer Vision (Springer), 102–120. doi: 10.1007/978-3-031-19775-8_7
Kim, Y., and Panda, P. (2021). Revisiting batch normalization for training low-latency deep spiking neural networks from scratch. Front. Neurosci. 2021:1638. doi: 10.3389/fnins.2021.773954
Kosta, A. K., and Roy, K. (2022). Adaptive-spikeNet: event-based optical flow estimation using spiking neural networks with learnable neuronal dynamics. arXiv preprint arXiv:2209.11741. doi: 10.48550/arXiv.2209.11741
Kushawaha, R. K., Kumar, S., Banerjee, B., and Velmurugan, R. (2021). “Distilling spikes: Knowledge distillation in spiking neural networks,” in 2020 25th International Conference on Pattern Recognition (ICPR), 4536–4543. doi: 10.1109/ICPR48806.2021.9412147
Leng, L., Che, K., Zhang, K., Zhang, J., Meng, Q., Cheng, J., et al. (2022). “Differentiable hierarchical and surrogate gradient search for spiking neural networks,” in Advances in Neural Information Processing Systems, eds A. H. Oh, A. Agarwal, D. Belgrave, and K. Cho (New Orleans, LA).
Li, W., Chen, H., Guo, J., Zhang, Z., and Wang, Y. (2022). “Brain-inspired multilayer perceptron with spiking neurons,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 783–793. doi: 10.1109/CVPR52688.2022.00086
Li, Y., Deng, S., Dong, X., Gong, R., and Gu, S. (2021a). “A free lunch from ANN: towards efficient, accurate spiking neural networks calibration,” in International Conference on Machine Learning, 6316–6325.
Li, Y., Guo, Y., Zhang, S., Deng, S., Hai, Y., and Gu, S. (2021b). Differentiable spike: Rethinking gradient-descent for training spiking neural networks. Adv. Neural Inform. Process. Syst. 34, 23426–23439.
Li, Y., Yin, R., Park, H., Kim, Y., and Panda, P. (2022). Wearable-based human activity recognition with spatio-temporal spiking neural networks. arXiv preprint arXiv:2212.02233. doi: 10.48550/arXiv.2212.02233
Li, Y., and Zeng, Y. (2022). Efficient and accurate conversion of spiking neural network with burst spikes. arXiv preprint arXiv:2204.13271. doi: 10.24963/ijcai.2022/345
Liu, F., Zhao, W., Chen, Y., Wang, Z., and Jiang, L. (2022). “Spikeconverter: an efficient conversion framework zipping the gap between artificial neural networks and spiking neural networks,” in Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 36 (Columbia), 1692–1701. doi: 10.1609/aaai.v36i2.20061
Lobov, S. A., Mikhaylov, A. N., Shamshin, M., Makarov, V. A., and Kazantsev, V. B. (2020). Spatial properties of STDP in a self-learning spiking neural network enable controlling a mobile robot. Front. Neurosci. 14:88. doi: 10.3389/fnins.2020.00088
Luo, X., Qu, H., Wang, Y., Yi, Z., Zhang, J., and Zhang, M. (2022). Supervised learning in multilayer spiking neural networks with spike temporal error backpropagation. IEEE Trans. Neural Netw. Learn. Syst. 1–13. doi: 10.1109/TNNLS.2022.3164930
Luo, Y., Xu, M., Yuan, C., Cao, X., Xu, Y., Wang, T., et al. (2020). SiamSNN: spike-based siamese network for energy-efficient and real-time object tracking. arXiv preprint arXiv:2003.07584. doi: 10.1007/978-3-030-86383-8_15
Meng, Q., Xiao, M., Yan, S., Wang, Y., Lin, Z., and Luo, Z.-Q. (2022). “Training high-performance low-latency spiking neural networks by differentiation on spike representation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 12444–12453. doi: 10.1109/CVPR52688.2022.01212
Na, B., Mok, J., Park, S., Lee, D., Choe, H., and Yoon, S. (2022). AutoSNN: towards energy-efficient spiking neural networks. arXiv preprint arXiv:2201.12738. doi: 10.48550/arXiv.2201.12738
Neftci, E. O., Mostafa, H., and Zenke, F. (2019). Surrogate gradient learning in spiking neural networks: bringing the power of gradient-based optimization to spiking neural networks. IEEE Signal Process. Mag. 36, 51–63. doi: 10.1109/MSP.2019.2931595
Nomura, O., Sakemi, Y., Hosomi, T., and Morie, T. (2022). Robustness of spiking neural networks based on time-to-first-spike encoding against adversarial attacks. IEEE Trans. Circuits Syst. II 69, 3640–3644. doi: 10.1109/TCSII.2022.3184313
Parameshwara, C. M., Li, S., Fermüller, C., Sanket, N. J., Evanusa, M. S., and Aloimonos, Y. (2021). “Spikems: deep spiking neural network for motion segmentation,” in 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 3414–3420. doi: 10.1109/IROS51168.2021.9636506
Patel, K., Hunsberger, E., Batir, S., and Eliasmith, C. (2021). A spiking neural network for image segmentation. arXiv preprint arXiv:2106.08921. doi: 10.48550/arXiv.2106.08921
Pellegrini, T., Zimmer, R., and Masquelier, T. (2021). “Low-activity supervised convolutional spiking neural networks applied to speech commands recognition,” in 2021 IEEE Spoken Language Technology Workshop (SLT), 97–103. doi: 10.1109/SLT48900.2021.9383587
Ponghiran, W., and Roy, K. (2022). “Spiking neural networks with improved inherent recurrence dynamics for sequential learning,” in Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 36 (Columbia), 8001–8008. doi: 10.1609/aaai.v36i7.20771
Ponulak, F., and Kasinski, A. (2011). Introduction to spiking neural networks: Information processing, learning and applications. Acta Neurobiol. Exp. 71, 409–433.
Rançon, U., Cuadrado-Anibarro, J., Cottereau, B. R., and Masquelier, T. (2021). Stereospike: depth learning with a spiking neural network. arXiv preprint arXiv:2109.13751.
Rathi, N., and Roy, K. (2020). Diet-SNN: direct input encoding with leakage and threshold optimization in deep spiking neural networks. arXiv preprint arXiv:2008.03658.
Roy, K., Jaiswal, A., and Panda, P. (2019). Towards spike-based machine intelligence with neuromorphic computing. Nature 575, 607–617. doi: 10.1038/s41586-019-1677-2
Sadovsky, E., Jakubec, M., and Jarina, R. (2023). “Speech command recognition based on convolutional spiking neural networks,” in 2023 33rd International Conference Radioelektronika (RADIOELEKTRONIKA) (Pardubice), 1–5. doi: 10.1109/RADIOELEKTRONIKA57919.2023.10109082
She, X., Dash, S., and Mukhopadhyay, S. (2021). “Sequence approximation using feedforward spiking neural network for spatiotemporal learning: theory and optimization methods,” in International Conference on Learning Representations.
Shen, G., Zhao, D., and Zeng, Y. (2023). Exploiting high performance spiking neural networks with efficient spiking patterns. arXiv preprint arXiv:2301.12356. doi: 10.48550/arXiv.2301.12356
Stagsted, R., Vitale, A., Binz, J., Renner, A., and Sandamirskaya, Y. (2020). “Towards neuromorphic control: a spiking neural network based PID controller for UAV,” in Robotics: Science and Systems 2020 (Corvallis, OR: Oregon State University). doi: 10.15607/RSS.2020.XVI.074
Takuya, S., Zhang, R., and Nakashima, Y. (2021). “Training low-latency spiking neural network through knowledge distillation,” in 2021 IEEE Symposium in Low-Power and High-Speed Chips (COOL CHIPS), 1–3. doi: 10.1109/COOLCHIPS52128.2021.9410323
Tavanaei, A., Ghodrati, M., Kheradpisheh, S. R., Masquelier, T., and Maida, A. (2019). Deep learning in spiking neural networks. Neural Netw. 111, 47–63. doi: 10.1016/j.neunet.2018.12.002
Tavanaei, A., and Maida, A. (2017a). “Bio-inspired multi-layer spiking neural network extracts discriminative features from speech signals,” in Neural Information Processing, eds D. Liu, S. Xie, Y. Li, D. Zhao, and E. S. M. El-Alfy (Cham: Springer International Publishing), 899–908. doi: 10.1007/978-3-319-70136-3_95
Tavanaei, A., and Maida, A. S. (2017b). A spiking network that learns to extract spike signatures from speech signals. Neurocomputing 240, 191–199. doi: 10.1016/j.neucom.2017.01.088
Viale, A., Marchisio, A., Martina, M., Masera, G., and Shafique, M. (2022). “LaneSNNs: spiking neural networks for lane detection on the loihi neuromorphic processor,” in 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 79–86. doi: 10.1109/IROS47612.2022.9981034
Wang, S., Cheng, T. H., and Lim, M.-H. (2022). “LTMD: learning improvement of spiking neural networks with learnable thresholding neurons and moderate dropout,” in Advances in Neural Information Processing Systems, eds A. H. Oh, A. Agarwal, D. Belgrave, and K. Cho (New Orleans, LA).
Wang, X., Lin, X., and Dang, X. (2020). Supervised learning in spiking neural networks: a review of algorithms and evaluations. Neural Netw. 125, 258–280. doi: 10.1016/j.neunet.2020.02.011
Wang, X., Zhang, Y., and Zhang, Y. (2023). MT-SNN: enhance spiking neural network with multiple thresholds. arXiv preprint arXiv:2303.11127.
Wang, Y., Zhang, M., Chen, Y., and Qu, H. (2022). “Signed neuron with memory: towards simple, accurate and high-efficient ANN-SNN conversion,” in International Joint Conference on Artificial Intelligence. doi: 10.24963/ijcai.2022/347
Wu, J., Chua, Y., and Li, H. (2018a). “A biologically plausible speech recognition framework based on spiking neural networks,” in 2018 International Joint Conference on Neural Networks (IJCNN). doi: 10.1109/IJCNN.2018.8489535
Wu, J., Chua, Y., Zhang, M., Li, G., Li, H., and Tan, K. C. (2021a). A tandem learning rule for effective training and rapid inference of deep spiking neural networks. IEEE Trans. Neural Netw. Learn. Syst. 34, 446–460. doi: 10.1109/TNNLS.2021.3095724
Wu, J., Chua, Y., Zhang, M., Li, H., and Tan, K. C. (2018b). A spiking neural network framework for robust sound classification. Front. Neurosci. 12:836. doi: 10.3389/fnins.2018.00836
Wu, J., Chua, Y., Zhang, M., Yang, Q., Li, G., and Li, H. (2019a). “Deep spiking neural network with spike count based learning rule,” in 2019 International Joint Conference on Neural Networks (IJCNN), 1–6. doi: 10.1109/IJCNN.2019.8852380
Wu, J., Pan, Z., Zhang, M., Das, R. K., Chua, Y., and Li, H. (2019b). “Robust sound recognition: a neuromorphic approach,” in Interspeech, 3667–3668.
Wu, J., Xu, C., Han, X., Zhou, D., Zhang, M., Li, H., et al. (2021b). Progressive tandem learning for pattern recognition with deep spiking neural networks. IEEE Trans. Pattern Anal. Mach. Intell. 44, 7824–7840. doi: 10.1109/TPAMI.2021.3114196
Wu, J., Yılmaz, E., Zhang, M., Li, H., and Tan, K. (2020). Deep spiking neural networks for large vocabulary automatic speech recognition. Front. Neurosci. 14:199. doi: 10.3389/fnins.2020.00199
Wu, Y., Deng, L., Li, G., Zhu, J., and Shi, L. (2018). Spatio-temporal backpropagation for training high-performance spiking neural networks. Front. Neurosci. 12:331. doi: 10.3389/fnins.2018.00331
Wu, Y., Deng, L., Li, G., Zhu, J., Xie, Y., and Shi, L. (2019). “Direct training for spiking neural networks: faster, larger, better,” in Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 33, 1311–1318. doi: 10.1609/aaai.v33i01.33011311
Xu, Q., Li, Y., Fang, X., Shen, J., Liu, J. K., Tang, H., et al. (2023a). Biologically inspired structure learning with reverse knowledge distillation for spiking neural networks. arXiv preprint arXiv:2304.09500. doi: 10.48550/arXiv.2304.09500
Xu, Q., Li, Y., Shen, J., Liu, J. K., Tang, H., and Pan, G. (2023b). Constructing deep spiking neural networks from artificial neural networks with knowledge distillation. arXiv preprint arXiv:2304.05627. doi: 10.48550/arXiv.2304.05627
Xu, Y., Zeng, X., Han, L., and Yang, J. (2013). A supervised multi-spike learning algorithm based on gradient descent for spiking neural networks. Neural Netw. 43, 99–113. doi: 10.1016/j.neunet.2013.02.003
Yamazaki, K., Vo-Ho, V.-K., Bulsara, D., and Le, N. (2022). Spiking neural networks and their applications: a review. Brain Sci. 12:863. doi: 10.3390/brainsci12070863
Yang, Q., Wu, J., Zhang, M., Chua, Y., Wang, X., and Li, H. (2022). Training spiking neural networks with local tandem learning. arXiv preprint arXiv:2210.04532. doi: 10.48550/arXiv.2210.04532
Yao, M., Gao, H., Zhao, G., Wang, D., Lin, Y., Yang, Z., et al. (2021). “Temporal-wise attention spiking neural networks for event streams classification,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 10221–10230. doi: 10.1109/ICCV48922.2021.01006
Yao, X., Li, F., Mo, Z., and Cheng, J. (2022). GLIF: a unified gated leaky integrate-and-fire neuron for spiking neural networks. in 36th Conference on Neural Information Processing Systems (NeurIPS 2022). (New Orleans, LA).
Yin, B., Corradi, F., and Boht, S. (2021). Accurate and efficient time-domain classification with adaptive spiking recurrent neural networks. Nat. Mach. Intell. 3, 905–913. doi: 10.1038/s42256-021-00397-w
Yin, B., Corradi, F., and Bohté, S. M. (2020). “Effective and efficient computation with multiple-timescale spiking recurrent neural networks,” in International Conference on Neuromorphic Systems 2020, 1–8. doi: 10.1145/3407197.3407225
Yu, L., Zhang, X., Liao, W., Yang, W., and Xia, G.-S. (2022). Learning to see through with events. IEEE Trans. Pattern Anal. Mach. Intell. 1–18. doi: 10.1109/TPAMI.2022.3227448
Yu, Q., Gao, J., Wei, J., Li, J., Tan, K. C., and Huang, T. (2022a). Improving multispike learning with plastic synaptic delays. IEEE Trans. Neural Netw. Learn. Syst. 1–12. doi: 10.1109/TNNLS.2022.3165527
Yu, Q., Song, S., Ma, C., Pan, L., and Tan, K. C. (2022b). Synaptic learning with augmented spikes. IEEE Trans. Neural Netw. Learn. Syst. 33, 1134–1146. doi: 10.1109/TNNLS.2020.3040969
Zambrano, D., and Bohte, S. M. (2016). Fast and efficient asynchronous neural computation with adapting spiking neural networks. arXiv preprint arXiv:1609.02053. doi: 10.48550/arXiv.1609.02053
Zenke, F., and Ganguli, S. (2018). Superspike: supervised learning in multilayer spiking neural networks. Neural Comput. 30, 1514–1541. doi: 10.1162/neco_a_01086
Zhang, D., Zhang, T., Jia, S., Wang, Q., and Xu, B. (2022). Recent advances and new frontiers in spiking neural networks. arXiv preprint arXiv:2204.07050. doi: 10.24963/ijcai.2022/790
Zhang, J., Dong, B., Zhang, H., Ding, J., Heide, F., Yin, B., et al. (2022). “Spiking transformers for event-based single object tracking,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 8801–8810. doi: 10.1109/CVPR52688.2022.00860
Zhang, M., Luo, X., Chen, Y., Wu, J., Belatreche, A., Pan, Z., et al. (2020a). An efficient threshold-driven aggregate-label learning algorithm for multimodal information processing. IEEE J. Select. Top. Signal Process. 14, 592–602. doi: 10.1109/JSTSP.2020.2983547
Zhang, M., Wang, J., Wu, J., Belatreche, A., Amornpaisannon, B., Zhang, Z., et al. (2022). Rectified linear postsynaptic potential function for backpropagation in deep spiking neural networks. IEEE Trans. Neural Netw. Learn. Syst. 33, 1947–1958. doi: 10.1109/TNNLS.2021.3110991
Zhang, M., Wu, J., Belatreche, A., Pan, Z., Xie, X., Chua, Y., et al. (2020b). Supervised learning in spiking neural networks with synaptic delay-weight plasticity. Neurocomputing 409, 103–118. doi: 10.1016/j.neucom.2020.03.079
Zhang, M., Wu, J., Chua, Y., Luo, X., Pan, Z., Liu, D., et al. (2019). MPD-Al: an efficient membrane potential driven aggregate-label learning algorithm for spiking neurons. Proc. AAAI Conf. Artif. Intell. 33, 1327–1334. doi: 10.1609/aaai.v33i01.33011327
Zhang, W., and Li, P. (2020). Temporal spike sequence learning via backpropagation for deep spiking neural networks. Adv. Neural Inform. Process. Syst. 33, 12022–12033.
Zheng, H., Wu, Y., Deng, L., Hu, Y., and Li, G. (2021). “Going deeper with directly-trained larger spiking neural networks,” in Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 35, 11062–11070. doi: 10.1609/aaai.v35i12.17320
Zhou, S., Chen, Y., Li, X., and Sanyal, A. (2020). Deep SCNN-based real-time object detection for self-driving vehicles using lidar temporal data. IEEE Access 8, 76903–76912. doi: 10.1109/ACCESS.2020.2990416
Zhou, S., Li, X., Chen, Y., Chandrasekaran, S. T., and Sanyal, A. (2021). “Temporal-coded deep spiking neural network with easy training and robust performance,” in Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 35, 11143–11151. doi: 10.1609/aaai.v35i12.17329
Zhu, L., Wang, X., Chang, Y., Li, J., Huang, T., and Tian, Y. (2022). “Event-based video reconstruction via potential-assisted spiking neural network,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 3594–3604. doi: 10.1109/CVPR52688.2022.00358
Zhu, R. -J., Zhao, Q., Zhang, T., Deng, H., Duan, Y., Zhang, M., et al. (2022). TCJA-SNN: Temporal-channel joint attention for spiking neural networks. arXiv [Preprint]. arXiv: 2206.10177. Available online at: https://arxiv.org/pdf/2206.10177.pdf
Zhu, Y., Yu, Z., Fang, W., Xie, X., Huang, T., and Masquelier, T. (2022). “Training spiking neural networks with event-driven backpropagation,” in 36th Conference on Neural Information Processing Systems (NeurIPS 2022) (New Orleans, LA).
Zimmer, R., Pellegrini, T., Singh, S. F., and Masquelier, T. (2019). Technical report: supervised training of convolutional spiking neural networks with pytorch. arXiv preprint arXiv:1911.10124.
Keywords: spiking neural network, brain-inspired computation, direct learning, deep neural network, energy efficiency, spatial-temporal processing
Citation: Guo Y, Huang X and Ma Z (2023) Direct learning-based deep spiking neural networks: a review. Front. Neurosci. 17:1209795. doi: 10.3389/fnins.2023.1209795
Received: 21 April 2023; Accepted: 01 June 2023;
Published: 16 June 2023.
Edited by:
Lei Deng, Tsinghua University, ChinaReviewed by:
Jibin Wu, Hong Kong Polytechnic University, Hong Kong SAR, ChinaZhaofei Yu, Peking University, China
Copyright © 2023 Guo, Huang and Ma. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Zhe Ma, bWF6aGVfdGh1QDE2My5jb20=