 Yabing Li1,2,3*
Yabing Li1,2,3* Xinglong Dong1
Xinglong Dong1- 1School of Computer Science and Technology, Xi'an University of Posts and Telecommunications, Xi'an, Shaanxi, China
- 2Shaanxi Key Laboratory of Network Data Analysis and Intelligent Processing, Xi'an University of Posts and Telecommunications, Xi'an, Shaanxi, China
- 3Xi'an Key Laboratory of Big Data and Intelligent Computing, Xi'an University of Posts and Telecommunications, Xi'an, Shaanxi, China
Background: K-complex detection traditionally relied on expert clinicians, which is time-consuming and onerous. Various automatic k-complex detection-based machine learning methods are presented. However, these methods always suffered from imbalanced datasets, which impede the subsequent processing steps.
New method: In this study, an efficient method for k-complex detection using electroencephalogram (EEG)-based multi-domain features extraction and selection method coupled with a RUSBoosted tree model is presented. EEG signals are first decomposed using a tunable Q-factor wavelet transform (TQWT). Then, multi-domain features based on TQWT are pulled out from TQWT sub-bands, and a self-adaptive feature set is obtained from a feature selection based on the consistency-based filter for the detection of k-complexes. Finally, the RUSBoosted tree model is used to perform k-complex detection.
Results: Experimental outcomes manifest the efficacy of our proposed scheme in terms of the average performance of recall measure, AUC, and F10-score. The proposed method yields 92.41 ± 7.47%, 95.4 ± 4.32%, and 83.13 ± 8.59% for k-complex detection in Scenario 1 and also achieves similar results in Scenario 2.
Comparison to state-of-the-art methods: The RUSBoosted tree model was compared with three other machine learning classifiers [i.e., linear discriminant analysis (LDA), logistic regression, and linear support vector machine (SVM)]. The performance based on the kappa coefficient, recall measure, and F10-score provided evidence that the proposed model surpassed other algorithms in the detection of the k-complexes, especially for the recall measure.
Conclusion: In summary, the RUSBoosted tree model presents a promising performance in dealing with highly imbalanced data. It can be an effective tool for doctors and neurologists to diagnose and treat sleep disorders.
1. Introduction
In addition to monitoring sleep disorder disease, sleep analysis hinged on an electroencephalogram (EEG) can also play a critical role in people's mental and physical health (Al-Salman et al., 2021, 2022b). K-complex, as one of the most prominent transient waveforms in sleep stage 2, is usually utilized for sleep research and clinical diagnosis (Al-Salman et al., 2019b; Latreille et al., 2020). Due to this significance, the determination of the k-complex in an epoch is extremely important for sleep experts. K-complex, which was first discovered in Loomis et al. (1938), is a transient waveform of more than ±75 mV for a first negative sharp wave immediately followed by a slower positive component, and it was also reported that the frequency scales focus on 12–14 Hz waves (Richard and Lengellé, 1998). The duration of k-complexes was between 1 and 2 s, and other studies reported that the maximum duration is between 1 and 3 s (Al-salman et al., 2018; Al-Salman et al., 2019b). In general, k-complex detection based on sleep specialist visually scored is regarded as the gold standard. However, it is time-consuming, subjective, and onerous (Lajnef et al., 2015). Thus, more and more researchers focus on developing an automatic k-complex detection method to speed up diagnosis and alleviate the burden of neurologists.
A large number of studies on the automated detection of the k-complexes have been developed, which focus on feature extraction, feature selection, and pattern recognition stages. Some studies presented the literature concerning feature extraction, such as temporal information (Hassan and Bhuiyan, 2016a, 2017a; Al-Salman et al., 2022a), spectral estimation (Herman et al., 2008; Hassan and Subasi, 2016), and chaotic information estimation (Peker, 2016; Al-salman et al., 2018; Al-Salman et al., 2019a; Nawaz et al., 2020). Aykut et al. employed features based on amplitude and duration properties of the k-complex waveform, and the results were evaluated with the ROC analysis which proved up to 91% success in detecting the k-complex (Erdamar et al., 2012). Hassan et al. presented a method of analyzing EEG waveforms based on the spectral features computed from tunable Q-factor wavelet transform (TQWT) sub-bands, and the reported results were significantly better than the existing results (Hassan and Bhuiyan, 2016b). The scheme based on TQWT and bootstrap aggregating for EEG signals was developed, and the results showed that the proposed method is superior in terms of sensitivity, specificity, and accuracy (Hassan et al., 2016). Tokhmpash et al. used the TQWT method to transform EEG signals, and then various features were extracted from the TQWT sub-bands. The empirical results showed the high efficiency of the proposed method in the analyzing of EEG signals (Tokhmpash et al., 2021). The TQWT is also applied to decompose an EEG signal into various sub-bands at different levels; the findings showed that the proposed scheme with estimating the Hjorth parameters preserves efficiency and is appropriate for the automated identification of EEG signals (Geetika et al., 2022). Some time and frequency analysis methods based on variational mode decomposition were utilized to determine the k-complex, and the highest average accuracy was obtained at 92.29% (Yücelbaş et al., 2017). Wessam proposed an efficient method based on fractal dimension to detect k-complexes from EEG signals, and the findings revealed that the proposed method yields better classification results than other existing methods (Al-Salman et al., 2019b).
However, to the best of our knowledge, one of the state-of-the-art linear or non-linear features in the detection of k-complex has not been undertaken yet. Hence, selecting optimal feature sets plays an essential role in the k-complex detection system. In recent years, various methods have been applied successfully in many fields to realize the optimal feature subset selection (Xu et al., 2020; Jainendra et al., 2021). Moreover, pattern recognition techniques also offer a great potential to analyze EEG signals more effectively, which is typically based on supervised or unsupervised approaches (Hassan and Bhuiyan, 2017b; Zhang et al., 2022). Rakesh et al. put forward a fuzzy neural network for k-complex and achieved better results with an accuracy of 87.65% and a sensitivity of 94.04% (Ranjan et al., 2018). Ankit et al. presented a sparse optimization method, and the authors concluded that the proposed method is promising for the practical detection of k-complex (Parekh et al., 2015). Huy et al. proposed a hybrid-synergic machine learning method to detect k-complex, and the results indicate that the performance of the proposed model was at least as good as a human expert (Vu et al., 2012). The ensemble model combining a least square support vector machine, k-means, and naive Bayes is used to identify the detection of the k-complex. The results demonstrate that the proposed approach is efficient in EEG signals (Al-Salman et al., 2019b).
To build a reliable detection model, adequate volumes of k-complexes and non-k-complex datasets are necessary. Unfortunately, the number of epochs obtained from EEG signals with non–k-complexes is greater to a larger degree than that of those with k-complexes. Considering that most classifiers have a strong ability to predict instances with majority volumes while having a weak ability to predict instances belonging to the minority volumes. Hence, the problem to classify imbalanced data effectively is becoming the biggest challenge in k-complex detection.
In this study, to develop and present a procedure of k-complex detection in an epoch, a robust method for the imbalance dataset was proposed based on TQWT coupled with the RUSBoosted tree classifier. The block diagram of the proposed methodology is depicted in Figure 1. Each EEG signal of 30 min was filtered with a fourth-order pass-band Butterworth filter at 0.5–30 Hz to smooth the EEG signal and remove the environment noise caused by muscle activity and eye movement. Then, the EEG signal was segmented into epochs of 0.5 s with an overlapping of 0.4 s, each epoch corresponding to a signal state for k-complex or non–k-complex. The multi-domain features (time, spectral, and chaotic theory) were extracted from each sub-bands of epoch based on TQWT decomposing. To minimize the complexity and reduce the dimensionality of features, the feature selection method based on search-based feature selection consistency (SFS consistency) is employed before classification. For further analysis, the RUSBoosted tree algorithm was implemented to improve the performance in recall for the imbalanced dataset.
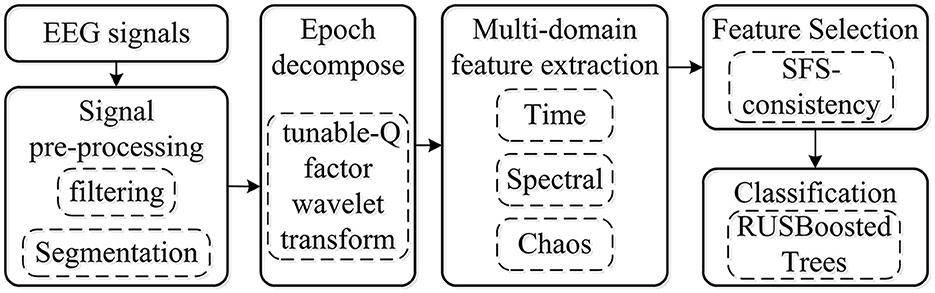
Figure 1. Schematic outline of the proposed computer-assisted k-complex detection scheme.
2. Materials and methods
2.1. The EEG recordings
The EEG dataset analyzed in this study was acquired from 10 subjects (aged 28.1 ± 9.95 years, which consists of four men and six women). All were recorded at a sleep laboratory of a Belgium hospital (Brussels, Belgium) at a sampling frequency of 200 Hz, and can be found online at https://zenodo.org/record/2650142. The waveform of k-complex and non–k-complex is presented in Figure 2. The EEG recordings were visually scored by two experts with the specified recommendation (Devuyst et al., 2010). As the duration time of the k-complex is about 0.5–2 s, the EEG signals were divided into segments for k-complex detection using the sliding window technique (Siuly et al., 2011; Al-Salman et al., 2021). Based on previous empirically-based studies, the window size was selected as 0.5 s with an overlap of 0.4 s in this study (Al-Salman et al., 2019c). The multi-domain features based on the analysis of the EEG signals were employed to represent k-complex and non–k-complex from each 0.5 s EEG segment. All the analyses were carried out based on the Cz-A1 channel.
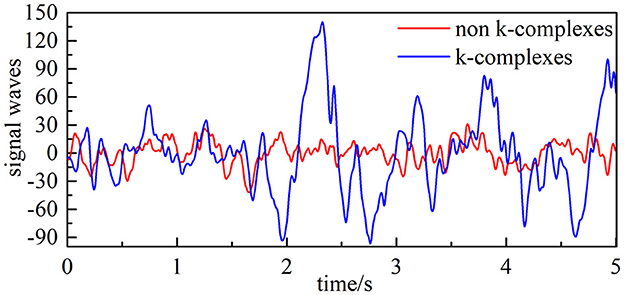
Figure 2. Filtered EEG signal (the blue line is EEG signals with k-complex, and the red line represents EEG signals with non–k-complex).
For the DREAMS database, only five of the 10 subjects are annotated by two experts, and the rest are annotated by expert 1. In this study, two different evaluation scenarios were used. The first scenario considers the annotations marked by expert 1 for all subjects, and the second scenario consists of the annotations marked by expert 2 for the five subjects. Table 1 presents the number of k-complex by the experts for Scenarios 1 and 2 in the DREAMS database. It is found that the number of k-complex by the first expert is dramatically greater than the number by the second expert. Therefore, the choice of different scenarios has a direct influence on the results and can be used to verify the performance of the proposed method.
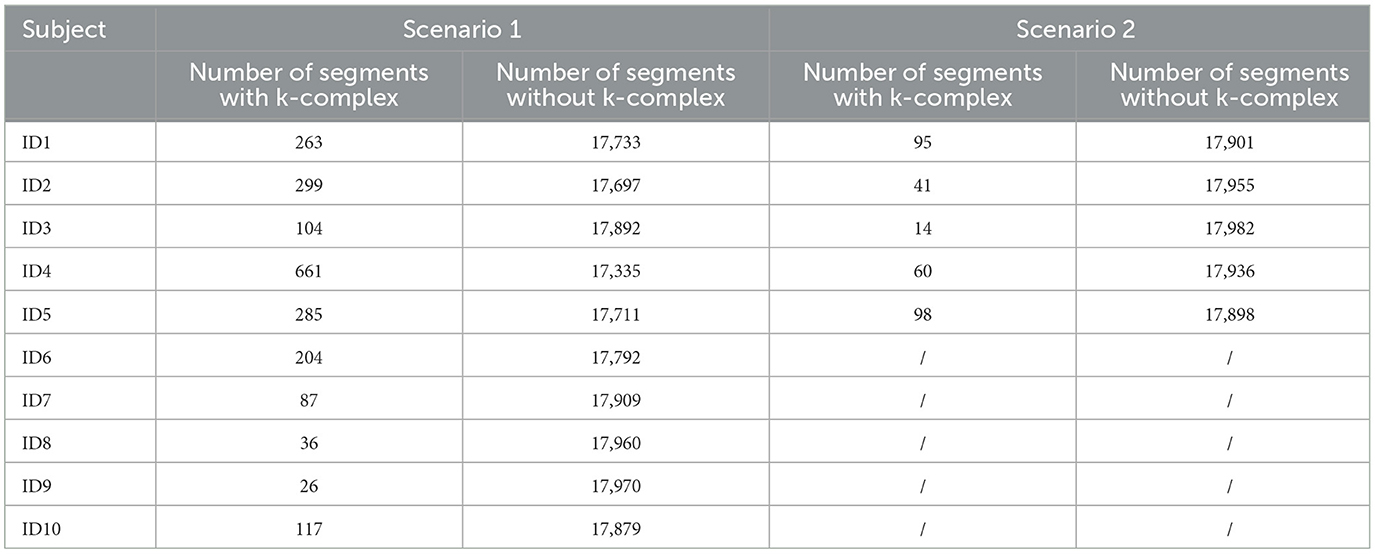
Table 1. Number of k-complex in each EEG recording.
2.2. Tunable Q-factor wavelet transform (TQWT)
The tunable Q-factor wavelet transform, which is proposed by Selesnick (2011), is a flexible discrete wavelet transform (DWT). Similar to the DWT, TQWT employs a two-channel filter bank, which consists of a low-pass filter with parameter α and a high-pass filter with parameter β, to decompose EEG signal into transient components and sustained components using adjustable Q-factors. It can be expressed mathematically as Equations 1, 2. For further analysis, the sustained component's output of the low-pass filter is regarded as the input signal for the next two-channel filter bank. The transient components' output of the high-pass filter for each layer is deemed as the output signal. One simple example of wavelet transform with J level is illustrated in Figure 3.
Here,
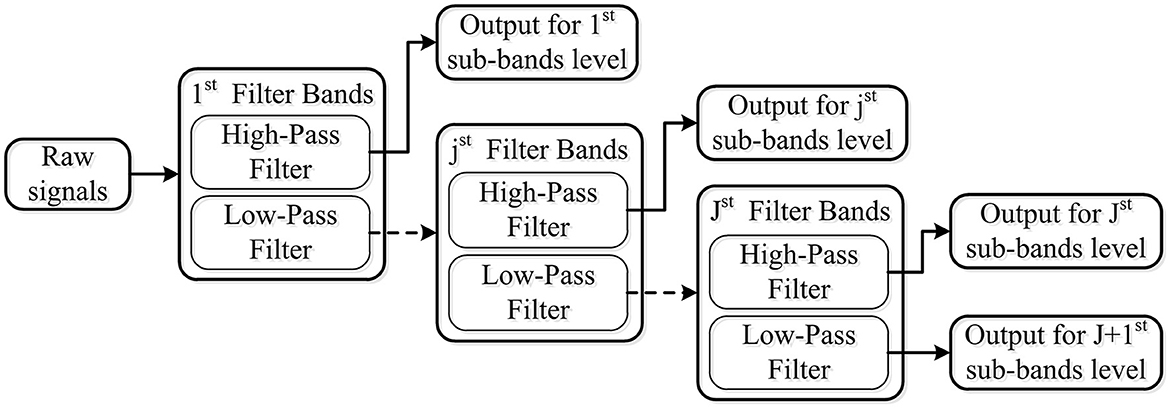
Figure 3. Wavelet transform with J level using a two-channel filter bank, which consists of the low-pass filter and high-pass filter.
Q-factor: This parameter determines the width of the band-pass filter. TQWT decomposition achieves flexibility by tuning and adapting this parameter of the wavelet transform. The higher the Q-factor is, the more effective the extraction of the sustained components. Meanwhile, the decomposing waveform based on a lower Q-factor is suitable for extracting the features of the transient component.
Number of decomposition levels (J): If the number of filter bands is denoted by J, an input signal will be decomposed into J+1 sub-bands. Among these bands, J sub-bands were obtained from the high-pass filter of each level filter band, and one came from the low-pass filter of the final level filter band. With the increase of the decomposition level, the time domain waveform becomes wider, and the features increase dramatically.
Taking into consideration various ranges of motivation, the TQWT is used in the proposed scheme (Hassan and Bhuiyan, 2016b). First of all, considering that k-complex waves are characterized by the appearance of multifarious rhythms, TQWT can improve localization in the frequency domain by varying the Q-factor. Hence, this decomposition method is suitable for spectral analysis. Second, the filters employed in TQWT are more computationally efficient in the frequency domain (Selesnick, 2011). Third, EEG is a non-stationary signal and its chaos properties alter between k-complex and non–k-complex. TQWT decomposition can also give the wave in the time domain; hence, it has emerged as a powerful technique in both time features and chaos features for EEG analysis (Fraiwan et al., 2010). These superiorities verified that the TQWT decomposition is an effective tool for the analysis of EEG and hence it is employed in the proposed scheme.
2.3. Multi-domain feature extraction from TQWT sub-bands
To derive salient features from the raw EEG data that can effectively reflect the epochs to the respective k-complex is the main objective of the feature extraction stage of the EEG-based k-complex detection system. Hence, a multi-domain method, based on time domain estimation, spectral estimation, and chaotic analysis, was employed to extract the representative features from each 5 s EEG epoch. A total of 25 hybrid features were extracted from each sub-band.
The extraction feature methods based on the time domain have been proven to be an efficient method for analyzing the characteristics of EEG signals (Vidaurre et al., 2009). Though it is widely used in speech and audio signal classification (Chu et al., 2009), spectral features have been used for EEG signals (Hassan and Bhuiyan, 2016b). These features are typically calculated by applying a fast Fourier transform (FFT) to short-time window segments of EEG signals followed by further processing. Considering that the property of EEG signals is somewhat chaotic, in addition to the traditional features of the EEG signal, the chaotic features based on non-linear dynamical analysis are also highly recommended to investigate the dynamic characteristics of EEG (Li et al., 2017; Nawaz et al., 2020). In the current study, 12 time domain features, seven spectral features, and six chaotic features are extracted for further analysis, as shown in Figure 4.

Figure 4. Multi-domain features extraction framework.
We have computed the feature vector for each EEG sub-bands based on TQWT decomposition. As the decomposed EEG signals with J+1 sub-bands, the feature vector of J+1 sub-bands on each epoch is computed to construct a 25*(J+1)-dimensional feature vector.
2.4. Search-based feature selection using consistency measures
Considering that reducing the dimensionality of feature sets may be improving the performance in reducing costs and enhancing the ability of comprehensibility, another effective step in the detection system for k-complex is to find optimal feature subsets. Selection features based on search-based feature selection (SFS) analyses were used in this study to research and select the important features. The following context briefly illustrates the selection features (Dash and Liu, 2003; Hernández-Pereira et al., 2016).
The SFS method based on the consistency filter, as one of the most effective methods, traverses all the candidate subsets to find the best one using the evaluation measures based on the independence of an inductive algorithm (shown in Figure 5). The evaluation measure evaluates the attributes of selected features according to the inconsistency rate (IR). If the IR for current selection features is smaller than the pre-selection features, current selection features are deemed as the selected features. Although SFS has the disadvantage in time-consuming, it does not need the stopping criterion or a pre-specified threshold.
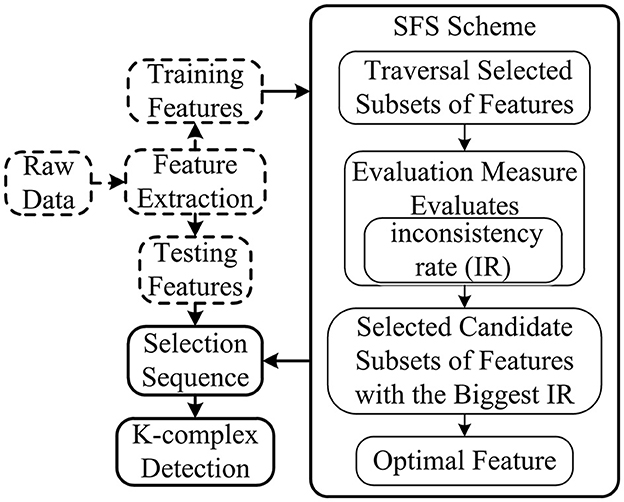
Figure 5. Scheme of SFS. The dimension of feature subsets is reduced based on features selected by SFS, and the selected features are used for further analysis.
2.5. RUSBoosted tree model for the k-complex detection
The distribution across k-complex or not is highly skewed: non–k-complexes have more epochs than those k-complexes. Therefore, the detection problem for the imbalanced dataset is a major challenge for k-complex detection. The RUSBoosted tree model, as an efficient way to overcome this problem, can improve the prediction performance by reducing bias between positive and negative samples at the expense of a slight decrease in the large group sets (Khoshnevis and Sankar, 2020; Jain and Ganesan, 2021; Noor et al., 2022).
The present research fused a random under-sampling (RUS) technique and adaptive boosting (AdaBoost) algorithm with a decision tree as the RUSBoosted tree model, as shown in Figure 6. First of all, to obtain the balanced distribution, the under-sampling method was implemented to deal with the minority and majority class size for the imbalanced training dataset. Second, considering the AdaBoost algorithm's ability to reduce bias and variance mistakes, it is employed to tackle problems involving imbalanced datasets. Hence, the RUS technique along with AdaBoost is utilized by combining an ensemble of decision trees as a classifier for further analysis.
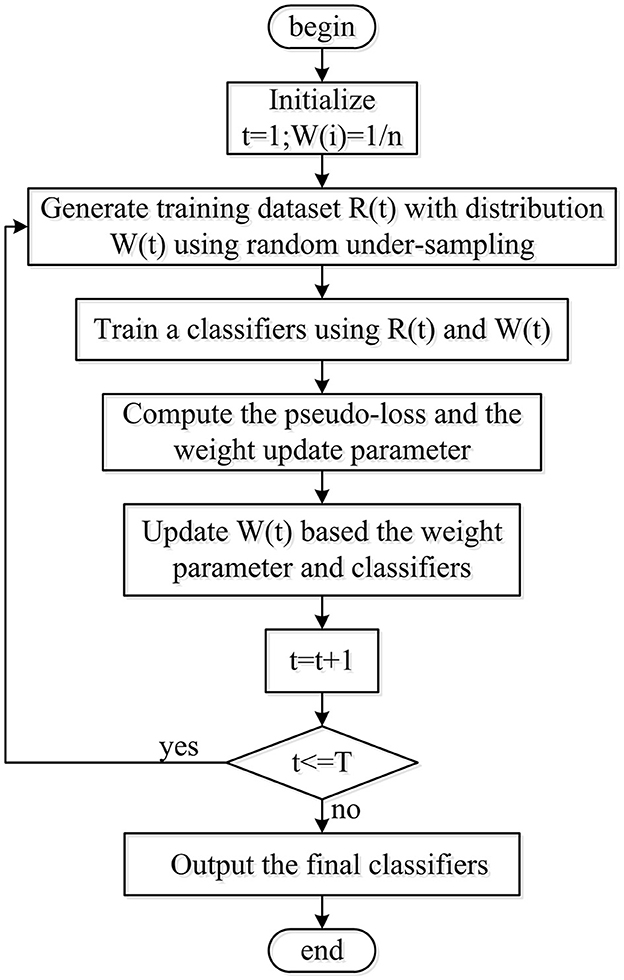
Figure 6. Flowchart for the RUSBoost implementation.
In this study, the parameters (i.e., the number of classifiers was selected as 30 for the model, with a maximum number of splits of 20 and a learning rate of 0.1) were melded into the RUSBoosted tree for the detection of k-complex.
2.6. Performance evaluation
First, statistical hypothesis testing is performed to validate the relevance and suitability of features according to discriminatory capability are statistically significant or not. If the features are not statistically significant, they have to be ignored for negative influence on performance. To estimate the significant level of k-complexes and non–k-complexes, we perform a one-way analysis of variance (ANOVA). The difference is considered to be statistically significant if the p-value is < 0.05 at a 95% confidence level.
Second, to evaluate the detection ability of the proposed method, some metrics based on the confusion matrix (shown in Table 2) were used. In Table 2, TP describes the situation that both the actual k-complexes and predicted states are yes. FN represent the situation that predicted k-complexes as no while actual k-complexes as yes. FP means the actual state is not k-complexes, which is adverse to the predicted label based on an algorithm. TN means the situation that both the actual k-complexes and predicted states are no.
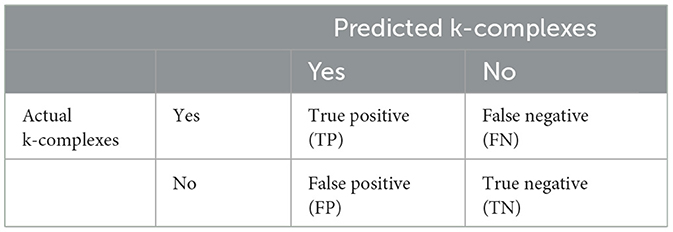
Table 2. Confusion matrix of the k-complex detection problem.
To evaluate the performance of the detection algorithm, Cohen's kappa coefficient, recall, and F-measure are computed. In addition to these metrics, the area under the ROC curve (AUC) was also used to estimate the performance of a classifier. Further details about the metrics are provided in the following paragraphs.
The kappa coefficient, calculated based confusion matrix, as a measurement for consistency tests, can also be used to measure classification accuracy. It is defined as Equation 4 as follows:
Here, Pe is obtained as follows:
Recall measure, which is also called sensitivity measurement, reflects the proportion of the actual positive prediction. It can be expressed mathematically from Equation 6 as follows:
F-measure is the top priority measurement in analyzing the overlapping between the two sets. It can be defined by weighted recall and precision, and β reflects the relative importance.
If the parameter of β > 1, it means that recall has more influence on F-measure. 0 < β < 1 reflects that precision has a broader effect on F-measure, compared with recall. β = 1 represents the measurement degenerates into standard F-measure. It is noted that β = 10 is selected.
To further illustrate the effectiveness of features selected using a feature selection-based consistency-based filter, the separability analysis using Fisher criteria was applied, which is obtained from Equation 9 as follows:
Here, Sw and Sm represent the within-class and between-class scatter matrix, respectively. tr(S) means the trace of square matrix S.
To evaluate the performance of the proposed method, the 5-fold cross-validation method is utilized. The k-complex segments and non–k-complex segments are divided into five groups, respectively. For each time, the training dataset consists of four k-complex groups and four non–k-complex, while the resting groups are deemed as testing groups. All groups are tested in turn. In this study, the overall performance is computed over the five iterations.
3. Results and discussion
3.1. Parameter selection for TQWT
The selected optimal parameters to decompose the EEG epoch are J and Q. The detection performance (kappa measures and recall value) based on the aforementioned procedure of feature extraction and selection has been analyzed sequentially for incremental values of Q range from 1 to 10 with an increment of one. Figures 7, 8 depict the influence of parameters on detection performance for the k-complex. It is observed from Figure 7 that the optimal parameter of J is 3, in which the best kappa measures and recall value are achieved. The optimal value for J is determined in the same way. From our experimental analyses, as shown in Figure 8, it has been observed that the best matrices are achieved for Q = 4.
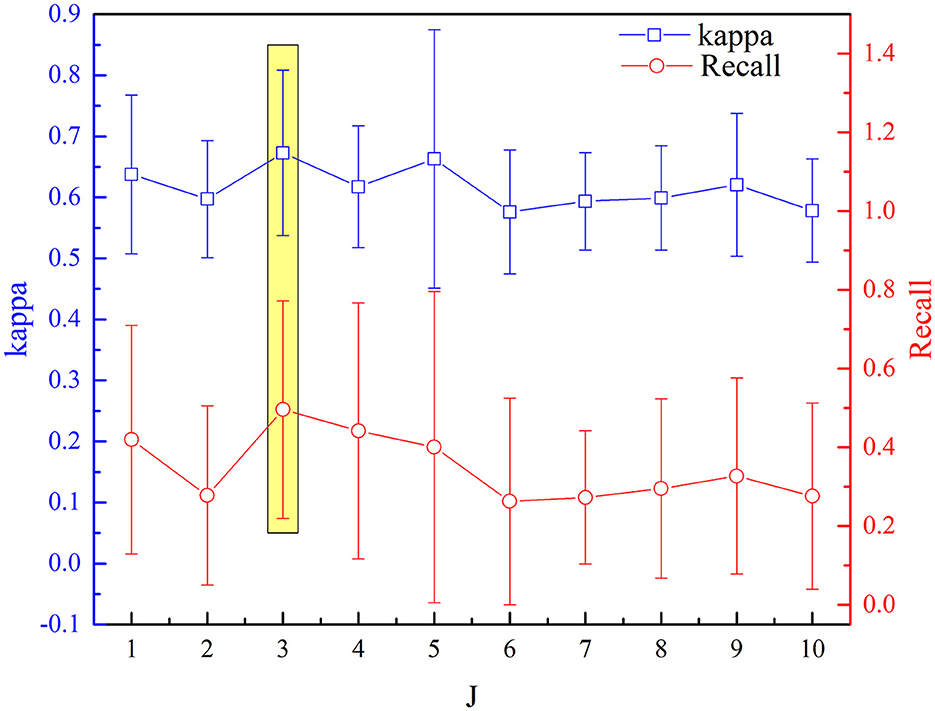
Figure 7. Variation of kappa and recall value with J for the detection of k-complexes.
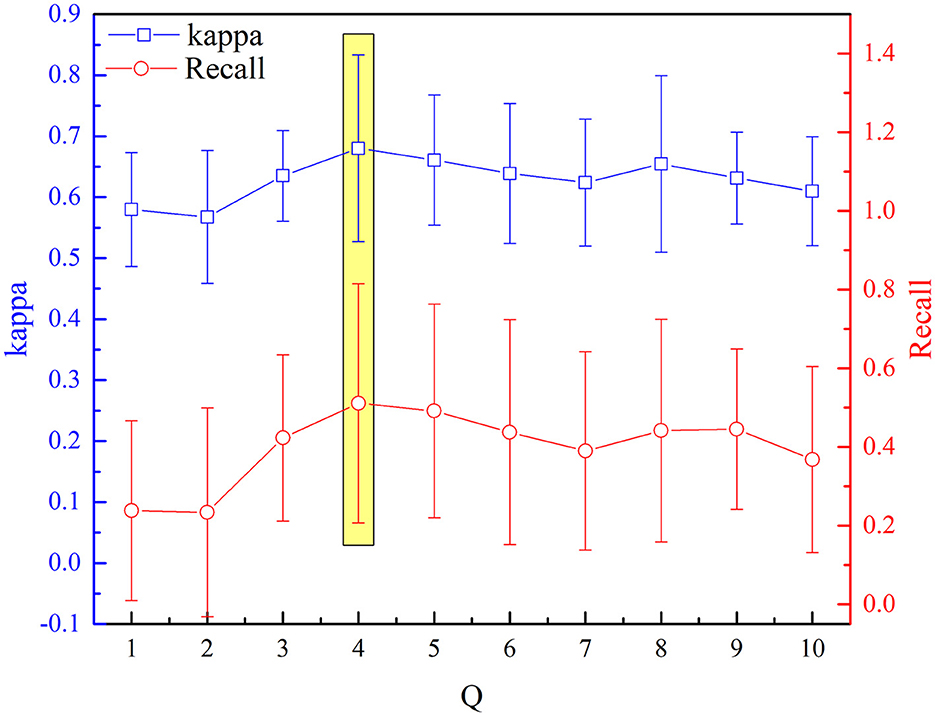
Figure 8. Variation of kappa and recall value with Q for the detection of k-complexes.
3.2. Quality evaluation for feature extraction and selection
In this section, the results of all the features computed from various TQWT sub-bands were present in terms of significance, as shown in Table 3. The test is performed at a 95% confidence level. It can be observed from Table 3 that the features highlighted in bold are not significant (p > 0.05), and a difference is statistically significant if p ≤ 0.05. The results show that the performance of time domain features to classify k-complex was significantly better than other features for sub-bands 1 and 2. In sub-band 3, spectral features significantly outperformed time and chaotic features. However, the statistical performance of time features in sub-band 4 was the worst in all three kinds of features. Based on these results, we can conclude that not all of the sub-bands features achieved good discriminatory capability for k-complex detection. Hence, it is necessary to select some of these features to improve the k-complex detection performance and decrease time consumption.
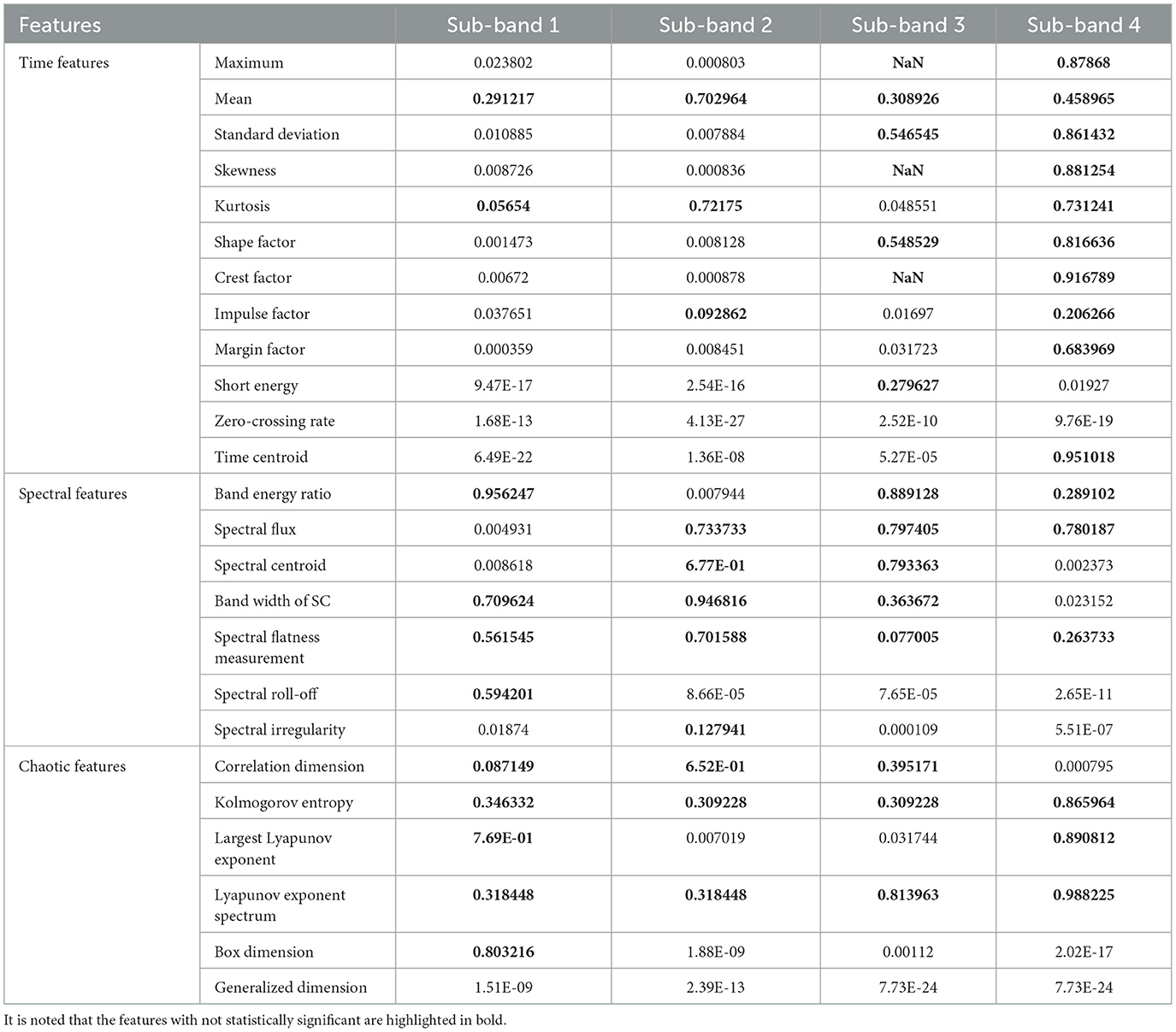
Table 3. The P-value of the proposed features computed from various TQWT sub-bands indicates the difference in features between k-complex and non–k-complex.
We investigate the AUC and time performance for two different feature sets, namely all features and selected features. The comparisons of the performance are shown in Figure 9. It is evident that the AUC based on selection features is slightly incremented than all feature sets. Compared with the performance of all feature sets, there is a dramatic decrement in time comparison for selected feature sets.
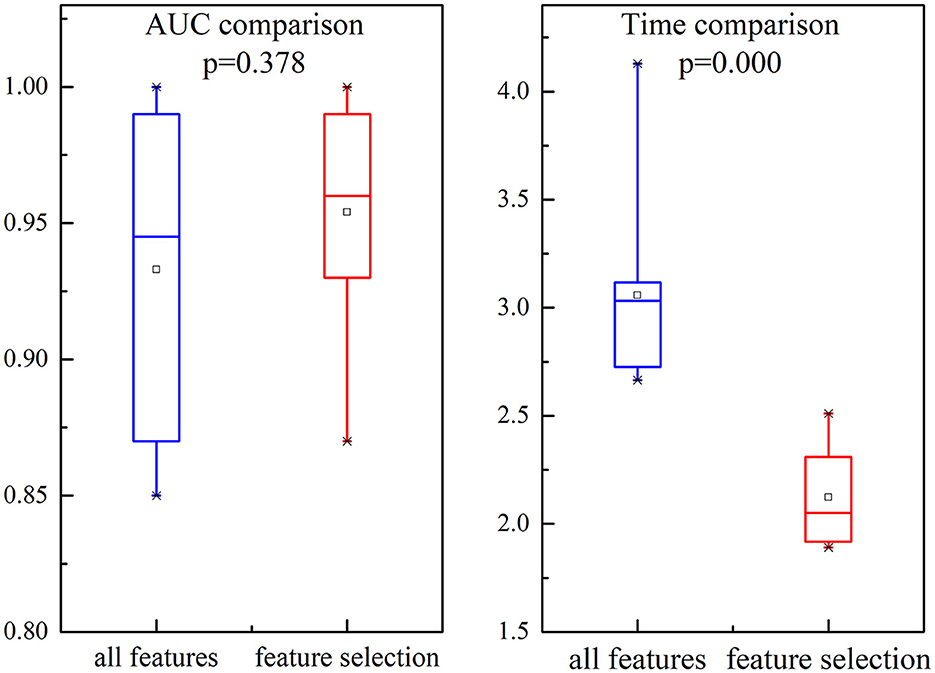
Figure 9. Illustration of the comparison for AUC and time in all features and selected features. Each box represents the 25–75th percentiles, the central line is the median value, and the tiny vertical lines extend to the most extreme data not considered outliers, which are plotted individually.
In this study, we also investigate the separability of the two different feature sets using JF. The larger the value of JF is, the more separable the features are. Figure 10 presents the value of JF and compares different feature sets (all features or selected features are used). It is evident that the JF based on selected features is higher, which confirmed that the selected features can characterize the k-complex effectively. It can be confirmed by the inferences drawn from Figure 9. According to these results, the feature selection method was more effective, particularly in AUC, time comparison, and separability estimation. Furthermore, the experimental outcomes presented in Figures 9, 10 confirm that the feature selection method is more effective.
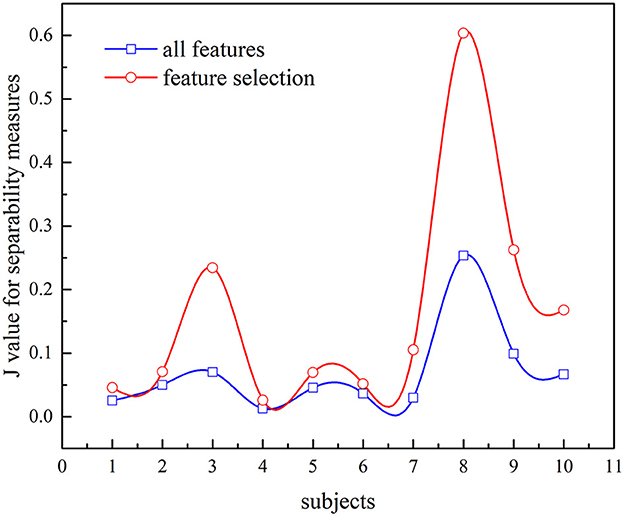
Figure 10. Comparison of JF values between all features and feature selection for k-complex detection.
3.3. Performance for various classification models
For this research, we have verified several classification methods such as linear discriminant analysis (LDA), logistic regression, linear support vector machine (linear SVM), and RUSBoosted tree. Figure 11A indicates the receiver operating characteristic (ROC) curve for different classification methods. According to the results, the line in the upper left represents better performance in the detection of k-complexes. The area under the curve (AUC) of 1 indicates a perfect classification performance. Although this comparison is for the data set of subject 1, it has to be noticed that the k-complex classification can be improved using RUSBoosted tree methods. Figure 11B demonstrates a box plot of the area under the curve (AUC) for different pattern recognition methods. The AUC was obtained as 0.931 ± 0.085, 0.814 ± 0.166, 0.925 ± 0.127, and 0.954 ± 0.043 for LDA, logistic regression, linear SVM, and RUSBoosted tree, respectively. According to these results, we conclude that the AUC of the RUSBoosted tree is significantly better than others.
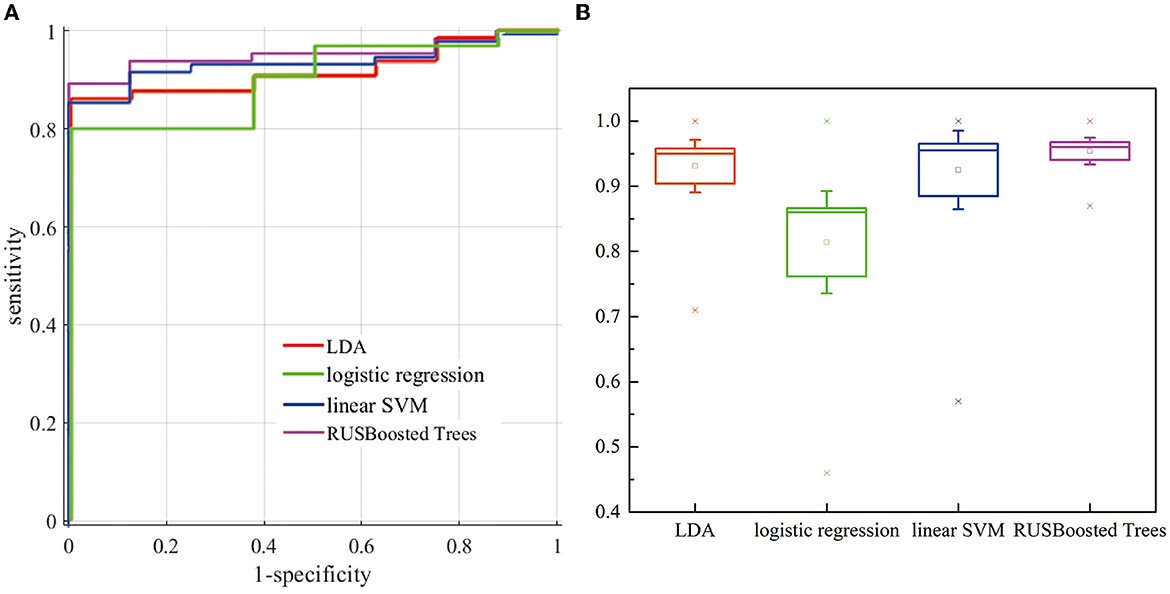
Figure 11. (A) Evaluation of the ROC curves (the plot of sensitivity vs. (1-specificity) for distinguishing k-complexes) for subjects 1. (B) Comparison of AUC for different methods.
The purpose of this investigation is to establish the suitability of the RUSBoosted tree algorithm for imbalanced dataset problems. The performance of the RUSBoosted tree algorithm is investigated for several traditionally state-of-the-art classifiers including LDA, logistic regression, and linear SVM. For further evaluation, Figure 12 reports the performance of some of these classifiers for the proposed scheme. The kappa coefficient, recall measure, AUC, and F10-score were used to evaluate the effectiveness of the proposed scheme. The proposed method achieved an average performance of recall measure, AUC, and F10-score of 92.34 ± 7.06%, 95.4 ± 4.32%, and 83.59 ± 8.23%, respectively. Depending on the results, the performance based on the kappa coefficient, recall measure, and F10-score provided evidence that the RUSBoosted tree surpassed other algorithms in the detection of the k-complexes. However, the performances based on the kappa coefficient using the RUSBoosted tree (54.22 ± 4.04%) are slightly worse than linear discriminant analysis (59.26 ± 14.67%). In summary, the prediction results confirmed a superiority value for different metrics and a balanced classification performance. It also indicated that the prediction algorithm based on the RUSBoosted tree model was tending to outperform than the traditional classifiers, especially for the minority classes.

Figure 12. Performance comparison of the proposed method with different machine learning algorithms for the detection of k-complexes [LDA (red diamond), logistic regression (green circle), linear SVM (blue diamond), and RUSBoosted tree (pink star)]. Error bars correspond to the standard error of the mean.
3.4. Performance comparison of the proposed method based on the ratio of segment number
To verify the performance of the proposed methods, the execution time, recall, and F10 scores are used. Figure 13 presents the execution time of the RUSBoosted tree model and the others classifiers. For further analysis, we assume that the number of the segments of the k-complex is fixed at 263, and the number of the segments of the non–k-complex is outnumbering k-complex (the number of segments of the non–k-complex increased from 1 to 10 times compared to the number of the segments of k-complex, and the number of segments was selected randomly from the database). The time to train the classification model was deemed as execution time. According to Figure 13, the slowest execution time was recorded with the RUSBoosted tree model compared with other classifiers. Along with the increasing number of segments, the execution time is also increased dramatically. In addition, the performance was also compared with the other three classifiers based on recall and F10 scores. Figure 14 achieves the results that the proposed method is slightly increased along with the increase in the ratio of the number of the segments between non–k-complex and k-complex. While the other classifiers' performance significantly decreased. High F10 values mean that the proposed method is inclined to small samples. From these results, we can get the conclusion that the proposed method was suitable to deal with the imbalanced dataset.
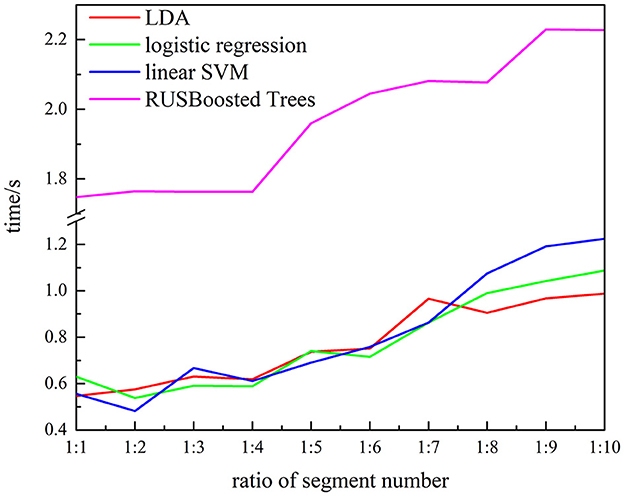
Figure 13. Relationship between the execution time and ratio of segment numbers for subject 1 (the number of k-complex is fixed as 263, and the segment number of non–k-complex is multiple of the number of k-complex from 1 to 10).
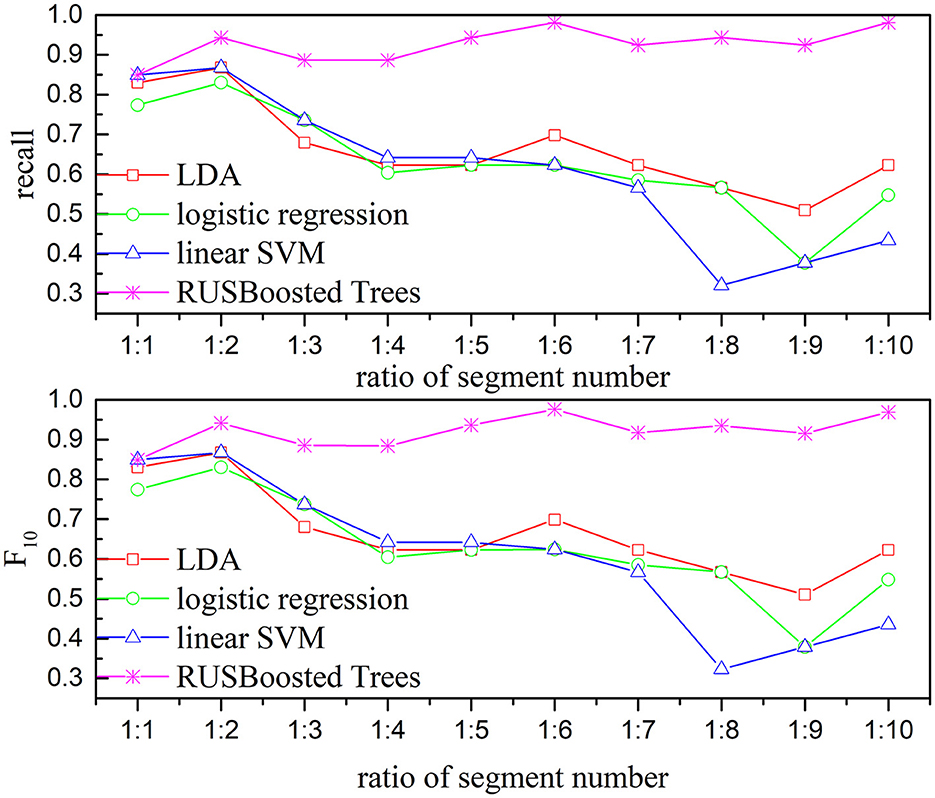
Figure 14. Relationship between the performance-based kappa and F10 and the ratio of segments number for subject 1 (the number of k-complex is fixed as 263, and the segment number of non–k-complex is multiple of the number of k-complex from 1 to 10).
3.5. Comparison with existing methods based on Scenario 1
According to previously reported methods, some of the automatic k-complex detection methods have been estimated using the same database as discussed in Section 2.1. In Table 4, the proposed method is compared with existing methods. Krohne et al. (2014) detected k-complexes using wavelet transformation combined with feature thresholds with the same database. In this study, pseudo-k-complexes were identified from each EEG segment and then the feature threshold method was used to reject false positives. A mean recall of 74% was achieved. Parekh et al. (2015) reported their results of the k-complex detection using a fast non-linear optimization algorithm, an average recall and kappa of 61% and 0.54 were achieved, respectively. Another study was made by Ranjan et al. (2018), in which a fuzzy algorithm combined with an artificial neural network was used to detect k-complex, they reported an average accuracy and specificity of 87.65 and 76.2%, respectively. A fractal dimension coupled with an undirected graph features technique was utilized by Al-Salman et al. (2019b) to detect k-complexes. The accuracy and specificity of 97 and 94.7% were reported, and the performance was highest than others. Oliveira et al. (2020) focused on designing a multitaper-based k-complex detection method in EEG signals and achieved a recall of 85.1%. The proposed method outperforms the other methods in almost all performance metrics (accuracy and specificity), except the method of fractal dimension coupled with undirected graph features (Al-Salman et al., 2019b). In terms of recall and kappa, the proposed method achieves the highest performance. These results demonstrated that the proposed method achieved a better performance in terms of detection performance.
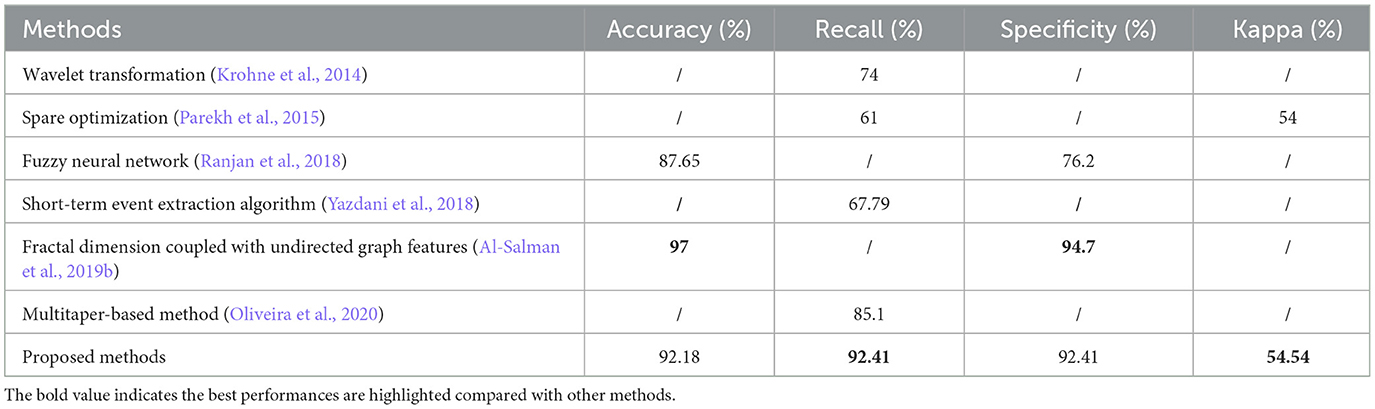
Table 4. Performance comparisons between the proposed method and other different detection methods with the same datasets based on Scenario 1.
3.6. Comparison based on different scenarios
As already mentioned, some of the automatic k-complex detection methods have been proposed and compared with the proposed method with the regard to the scenarios previously discussed, as shown in Table 5. In Scenario 1, the proposed methods achieved a mean accuracy of 92.19 ± 3.9% and a mean recall of 92.41 ± 7.47%. The proposed method achieved a dramatically better recall than others (Devuyst et al., 2010; Yazdani et al., 2018; Oliveira et al., 2020), but slightly worse accuracy. A higher recall value indicates that the proposed method is able to detect the most of small samples (true k-complex marked by an expert).
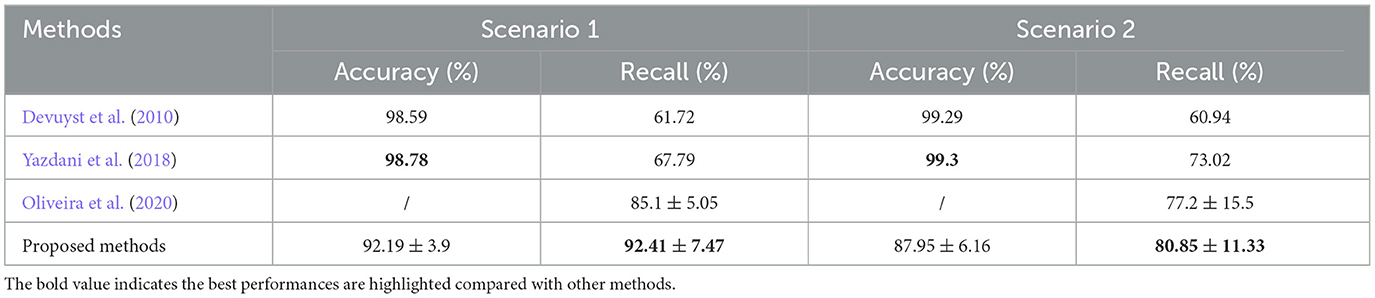
Table 5. Performance comparisons between the proposed method and other existing methods for Scenarios 1 and 2.
In Scenario 2, compared to previous studies, the trade-off accuracy and recall obtained from the proposed method are similar to those obtained in Scenario 1. Compared to Scenario 1, the mean accuracy and recall are smaller, i.e., 87.95 ± 6.16% and 80.85 ± 11.33%, respectively. The reason why the recall and accuracy decrease for the scenario may be that the second expert marked few labels as k-complex compared to expert 1. It is consistent with Table 1. It is denoted that the proposed method was effective to detect the k-complex.
4. Conclusion
This study developed a k-complex detection scheme, consisting of TQWT, multi-domain features, feature selection, and RUSBoosted tree algorithm to overcome the shortages of the existing classification–misclassification of classifier training from the imbalanced data. According to the results, the highest recall value was achieved for the proposed scheme. The results denoted that the methods could be worth utilizing in the automatic identify the k-complex for sleep specialists. It has been evidenced that the proposed scheme is comparable to or better than the state-of-the-art classifiers. The results also show that the ability of the RUSBoosted tree model to deal with the imbalanced classification problems compared with the state-of-art methods is quite well. In general, according to the experimental outcomes, we can conclude that the proposed scheme can relieve physicians of the burden of visually inspecting a large volume of EEG data.
However, the study suffers from several drawbacks. First, it is necessary for researchers to locate the locations of the k-complex in the related epochs. Second, the proposed scheme relied on a single channel to detect k-complex. While as one of the important features of brain activity, the interaction between brain regions is not fully utilized.
Data availability statement
Publicly available datasets were analyzed in this study. This data can be found at: https://zenodo.org/record/2650142.
Ethics statement
Ethical review and approval was not required for the study on human participants in accordance with the local legislation and institutional requirements. Written informed consent for participation was not required for this study in accordance with the national legislation and the institutional requirements. Written informed consent was not obtained from the individual(s) for the publication of any potentially identifiable images or data included in this article.
Author contributions
YL contributed to the conception and design of the study. YL and XD performed the statistical analysis and wrote the first draft of the manuscript. Both authors contributed to the manuscript revision and read and approved the submitted version.
Funding
Funding was provided by the Natural Science Basic Research Program of Shaanxi Program (2022JQ-598), the Scientific Research Plan Projects of Shaanxi Education Department (20JK0917), and the Doctoral Scientific Research Starting Foundation of Xi'an University of Posts and Telecommunications (315020018). This study also obtained support from Shaanxi's Key Disciplines of Special Funds to Finance Projects.
Acknowledgments
The authors would like to express our gratitude to the reviewers and the editor for their valuable and insightful suggestions.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Al-Salman, W., Li, Y., Oudah, A. Y., and Almaged, S. (2022a). Sleep stage classification in EEG signals using the clustering approach based probability distribution features coupled with classification algorithms. Neurosci. Res. 2022, S0168–0102. doi: 10.1016/j.neures.2022.09.009
Al-Salman, W., Li, Y., and Wen, P. (2019a). Detecting sleep spindles in EEGs using wavelet fourier analysis and statistical features. Biomed. Sign. Process. Contr. 48, 80–92. doi: 10.1016/j.bspc.2018.10.004
Al-Salman, W., Li, Y., and Wen, P. (2019b). Detection of EEG K-complexes using fractal dimension of time frequency images technique coupled with undirected graph features. Front. Neuroinformat. 13, 1–19. doi: 10.3389/fninf.2019.00045
Al-Salman, W., Li, Y., and Wen, P. (2019c). K-complexes detection in EEG signals using fractal and frequency features coupled with an ensemble classification model. Neuroscience 422, 119–133. doi: 10.1016/j.neuroscience.2019.10.034
Al-Salman, W., Li, Y., and Wen, P. (2021). Detection of k-complexes in EEG signals using a multi-domain feature extraction coupled with a least square support vector machine classifier. Neurosci. Res. 172, 26–40. doi: 10.1016/j.neures.2021.03.012
Al-salman, W., Li, Y., Wen, P., and Diykh, M. (2018). An efficient approach for EEG sleep spindles detection based on fractal dimension coupled with time frequency image. Biomed. Sign. Process. Contr. 41, 210–221. doi: 10.1016/j.bspc.2017.11.019
Al-Salman, W., Li, Y., Wen, P., Miften, F. S., Oudah, A. Y., and AlGhayab, H. R. (2022b). Extracting epileptic features in EEGs using a dual-tree complex wavelet transform coupled with a classification algorithm. Brain Res. 1779, 147777. doi: 10.1016/j.brainres.2022.147777
Chu, S., Narayanan, S., and Kuo, C.-C. J. (2009). Environmental sound recognition with time–frequency audio features. IEEE Trans. Audio Speech Lang. Process. 17, 1142–1158. doi: 10.1109/TASL.2009.2017438
Dash, M., and Liu, H. (2003). Consistency-based search in feature selection. Artif. Intell. 151, 155–176. doi: 10.1016/S0004-3702(03)00079-1
Devuyst, S., Dutoit, T., Stenuit, P., and Kerkhofs, M. (2010). “Automatic K-complexes detection in sleep EEG recordings using likelihood thresholds,” in Annual International Conference of the IEEE Engineering in Medicine and Biology (Buenos Aires: IEEE), 2626447.
Erdamar, A., Duman, F., and Yetkin, S. (2012). A wavelet and teager energy operator based method for automatic detection of K-complex in sleep EEG. Expert Syst. Appl. 39, 1284–1290. doi: 10.1016/j.eswa.2011.07.138
Fraiwan, L., Lweesy, K., Khasawneh, N., Fraiwan, M., Wenz, H., and Dickhaus, H. (2010). Classification of sleep stages using multi-wavelet time frequency entropy and LDA. Methods Inform. Med. 49, 230–237. doi: 10.3414/ME09-01-0054
Geetika, K., Pramod, G., Raj, S. R., and Bilas, P. R. (2022). EEG signal based seizure detection focused on Hjorth parameters from tunable-Q wavelet sub-bands. Biomed. Sign. Process. Contr. 76, 103645. doi: 10.1016/j.bspc.2022.103645
Hassan, A. R., and Bhuiyan, M. I. H. (2016a). Automatic sleep scoring using statistical features in the EMD domain and ensemble methods. Biocybernet. Biomed. Eng. 36, 248–255. doi: 10.1016/j.bbe.2015.11.001
Hassan, A. R., and Bhuiyan, M. I. H. (2016b). A decision support system for automatic sleep staging from EEG signals using tunable Q-factor wavelet transform and spectral features. J. Neurosci. Methods 271, 107–118. doi: 10.1016/j.jneumeth.2016.07.012
Hassan, A. R., and Bhuiyan, M. I. H. (2017a). Automated identification of sleep states from EEG signals by means of ensemble empirical mode decomposition and random under sampling boosting. Comput. Methods Progr. Biomed. 140, 201–210. doi: 10.1016/j.cmpb.2016.12.015
Hassan, A. R., and Bhuiyan, M. I. H. (2017b). An automated method for sleep staging from EEG signals using normal inverse gaussian parameters and adaptive boosting. Neurocomputing 219, 76–87. doi: 10.1016/j.neucom.2016.09.011
Hassan, A. R., Siuly, S., and Zhang, Y. (2016). Epileptic seizure detection in EEG signals using tunable-Q factor wavelet transform and bootstrap aggregating. Comput. Methods Progr. Biomed. 137, 247–259. doi: 10.1016/j.cmpb.2016.09.008
Hassan, A. R., and Subasi, A. (2016). Automatic identification of epileptic seizures from EEG signals using linear programming boosting. Comput. Methods Progr. Biomed. 136, 65–77. doi: 10.1016/j.cmpb.2016.08.013
Herman, P., Prasad, G., McGinnity, T. M., and Coyle, D. (2008). Comparative analysis of spectral approaches to feature extraction for EEG-based motor imagery classification. IEEE Trans. Neural Syst. Rehabil. Eng. 16, 317–326. doi: 10.1109/TNSRE.2008.926694
Hernández-Pereira, E., Bolón-Canedo, V., Sánchez-Maroño, N., Álvarez-Estévez, D., Moret-Bonillo, V., and Alonso-Betanzos, A. (2016). A comparison of performance of K-complex classification methods using feature selection. Informat. Sci. 328, 1–14. doi: 10.1016/j.ins.2015.08.022
Jain, R., and Ganesan, R. A. (2021). Reliable sleep staging of unseen subjects with fusion of multiple EEG features and RUSBoost. Biomed. Sign. Process. Contr. 70, 103061. doi: 10.1016/j.bspc.2021.103061
Jainendra, S., Miguel, B.-A., Joan, O., Nandi, G. C., and Domenec, P. (2021). Feature extraction and selection for emotion recognition from electrodermal activity. IEEE Trans. Affect. Comput. 12, 1949–3045. doi: 10.1109/TAFFC.2019.2901673
Khoshnevis, S. A., and Sankar, R. (2020). Classification of the stages of Parkinson's disease using novel higherorder statistical features of EEG signals. Neural Comput. Appl. 33, 7615–7627. doi: 10.1007/s00521-020-05505-2
Krohne, L. K., Hansen, R. B., Christensen, J. A. E., Sorensen, H. B. D., and Jennum, P. (2014). “Detection of K-complexes based on the Wavelet Transform,” in 2014 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (Chicago, IL: IEEE), 6944859.
Lajnef, T., Chaibi, S., Eichenlaub, J.-B., Ruby, P. M., Aguera, P.-E., Samet, M., et al. (2015). Sleep spindle and K-complex detection using tunable Q-factor wavelet transform and morphological component analysis. Front. Hum. Neurosci. 9, 414. doi: 10.3389/fnhum.2015.00414
Latreille, V., Ellenrieder, N., Peter-Derex, L., François Dubeau Gotman, J., and Frauscher, B. (2020). The human K-complex: Insights from combined scalp-intracranial EEG recordings. NeuroImage 213, 116748. doi: 10.1016/j.neuroimage.2020.116748
Li, Y., Xie, S., Zhao, J., Liu, C., and Xie, X. (2017). Improved GP algorithm for the analysis of sleep stages based on grey model. ScienceAsia 43, 312–318. doi: 10.2306/scienceasia1513-1874.2017.43.312
Loomis, A. L., Harvey, E. N., and Hobart, G. A. (1938). Distribution of disturbance patterns in the human electroencephalogram, with special reference to sleep. J. Neurophysiol. 1, 413–430. doi: 10.1152/jn.1938.1.5.413
Nawaz, R., Cheah, K. H., Nisar, H., and Yap, V. V. (2020). Comparison of different feature extraction methods for EEG-based emotion recognition. Biocybernet. Biomed. Eng. 40, 910–926. doi: 10.1016/j.bbe.2020.04.005
Noor, N. S. E. M., Ibrahim, H., Lah, M. H. C., and Abdullah, J. M. (2022). Prediction of recovery from traumatic brain injury with EEG power spectrum in combination of independent component analysis and RUSBoost model. BioMedInformatics 2, 10007. doi: 10.3390/biomedinformatics2010007
Oliveira, G. H. B. S., Coutinho, L. R., Silva, J. C. d., Pinto, I. J. P., Ferreira, J. M. S., Silva, F. J. S., et al. (2020). Multitaper-based method for automatic k-complex detection in human sleep EEG. Expert Syst. Appl. 151, 1–16. doi: 10.1016/j.eswa.2020.113331
Parekh, A., Selesnick, I. W., Rapoport, D. M., and Ayappa, I. (2015). Detection of K-complexes and sleep spindles (DETOKS) using sparse optimization. J. Neurosci. Methods 251, 37–46. doi: 10.1016/j.jneumeth.2015.04.006
Peker, M. (2016). An efficient sleep scoring system based on EEG signal using complex-valued machine learning algorithms. Neurocomputing 207, 165–177. doi: 10.1016/j.neucom.2016.04.049
Ranjan, R., Arya, R., Fernandes, S. L., Sravya, E., and Jain, V. (2018). A fuzzy neural network approach for automatic K-complex detection in sleep EEG signal. Patt. Recogn. Lett. 115, 74–83. doi: 10.1016/j.patrec.2018.01.001
Richard, C., and Lengellé, R. (1998). Joint time and time-frequency optimal detection of K-complexes in sleep EEG. Comput. Biomed. Res. 31, 209–229. doi: 10.1006/cbmr.1998.1476
Selesnick, I. W. (2011). Wavelet transform with tunable Q-factor. IEEE Trans. Sign. Process. 59, 3560–3575. doi: 10.1109/TSP.2011.2143711
Siuly, A., Li, Y., and Wen, P. (2011). Clustering technique-based least square support vector machine for EEG signal classification. Comput. Methods Progr. Biomed. 104, 358–372. doi: 10.1016/j.cmpb.2010.11.014
Tokhmpash, A., Hadipour, S., and Shafai, B. (2021). Epileptic seizure detection using tunable Q-factor wavelet transform and machine learning. Adv. Neuroergon. Cogn. Eng. 259, 78–85. doi: 10.1007/978-3-030-80285-1_10
Vidaurre, C., Krämer, N., Blankertz, B., and Schlögl, A. (2009). Time domain parameters as a feature for EEG-based brain-computer interfaces. Neural Netw. 22, 1313–1319. doi: 10.1016/j.neunet.2009.07.020
Vu, H. Q., Li, G., Sukhorukova, N. S., Beliakov, G., Shaowu, L., Philippe, C., et al. (2012). K-complex detection using a hybrid-synergic machine learning method. IEEE Trans. Syst. Man Cybernet. 42, 1478–1490. doi: 10.1109/TSMCC.2012.2191775
Xu, X., Wei, F., Zhu, Z., Liu, J., and Wu, X. (2020). “EEG feature selection using orthogonal regression: Application to emotion recognition,” in IEEE International Conference on Acoustics, Speech and Signal Processing (Barcelona: IEEE), 9054457.
Yazdani, S., Fallet, S., and Vesin, J.-M. (2018). A novel short-term event extraction algorithm for biomedical signals. IEEE Trans. Biomed. Eng. 65, 754–762. doi: 10.1109/TBME.2017.2718179
Yücelbaş, C., Yücelbaş, S., Özşen, S., Tezel, G., Küççüktürk, S., and Yosunkaya, S. (2017). A novel system for automatic detection of K-complexes in sleep EEG. Neural Comput. Appl. 29, 137–157. doi: 10.1007/s00521-017-2865-3
Keywords: k-complexes detection, electroencephalogram (EEG), multi-domain features extraction, tunable-Q factor wavelet transform, RUSBoosted tree model
Citation: Li Y and Dong X (2023) A RUSBoosted tree method for k-complex detection using tunable Q-factor wavelet transform and multi-domain feature extraction. Front. Neurosci. 17:1108059. doi: 10.3389/fnins.2023.1108059
Received: 25 November 2022; Accepted: 10 February 2023;
Published: 14 March 2023.
Edited by:
Rong Wang, Xi'an University of Science and Technology, ChinaReviewed by:
Yanbing Jia, Henan University of Science and Technology, ChinaBinqiang Chen, Xiamen University, China
Wessam Al-Salman, University of Southern Queensland, Australia
Copyright © 2023 Li and Dong. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yabing Li, bGl5YWJpbmdAeHVwdC5lZHUuY24=