 Chen Zhang1
Chen Zhang1 Stefan Sandfeld
Stefan Sandfeld Ruth Schwaiger
Ruth Schwaiger- 1Institute for Advanced Simulation – Materials Data Science and Informatics (IAS-9), Forschungszentrum Jülich GmbH, Jülich, Germany
- 2Institute for Applied Materials, Karlsruhe Institute of Technology (KIT), Karlsruhe, Germany
- 3Chair of Materials Data Science and Informatics, Faculty of Georesources and Materials Engineering, RWTH Aachen University, Aachen, Germany
- 4Institute of Energy and Climate Research – Structure and Function of Materials (IEK-2), Forschungszentrum Jülich GmbH, Jülich, Germany
- 5Chair of Energy Engineering Materials, Faculty of Georesources and Materials Engineering, RWTH Aachen University, Aachen, Germany
In this study, Cu-Cr composites were studied by nanoindentation. Arrays of indents were placed over large areas of the samples resulting in datasets consisting of several hundred measurements of Young’s modulus and hardness at varying indentation depths. The unsupervised learning technique, Gaussian mixture model, was employed to analyze the data, which helped to determine the number of “mechanical phases” and the respective mechanical properties. Additionally, a cross-validation approach was introduced to infer whether the data quantity was adequate and to suggest the amount of data required for reliable predictions–one of the often encountered but difficult to resolve issues in machine learning of materials science problems.
1 Introduction
Nanoindentation has emerged as a powerful technique for characterizing the mechanical properties of materials at small length scales (Shen, 2019; Golovin, 2021). By applying a force to a sharp indenter tip, while measuring the resulting displacement of the tip into the material, nanoindentation enables the characterization of the mechanical behavior, including hardness and elastic modulus (Oliver and Pharr, 1992), with high spatial resolution. In recent years, there has been growing interest in the application of statistical approaches to nanoindentation data analysis, offering new insights into material properties and behavior.
The traditional approach to nanoindentation testing involves conducting individual tests on small regions of a sample surface and averaging the resulting mechanical properties to obtain a representative value. While this method provides valuable information, it may overlook variations in mechanical properties within the material that may arise from statistical heterogeneity. Statistical nanoindentation techniques, on the other hand, seek to capture and analyze the full distribution of mechanical properties across a sample, allowing for a more comprehensive assessment of its mechanical behavior. Grid indentation (Constantinides et al., 2006; Nohava et al., 2012; Sanchez-Camargo et al., 2020), for example, is not only used for statistical analysis of the mechanical properties of multiphase materials (Ulm et al., 2007; Haušild et al., 2016; Hintsala et al., 2018), but also for mapping the mechanical properties (Tromas et al., 2012; Hintsala et al., 2018) to study the correlations between microstructural features and corresponding properties. Due to progress in equipment, it has become popular to study vast numbers of indents, which nowadays can be measured in remarkably little time. For example, around 500,000 indentations were reported in a study of an Al-Cu eutectic alloy and a duplex stainless steel (Besharatloo and Wheeler, 2021), 100,000 indentations were performed to analyze the properties of the Taza meteorite (Wheeler, 2021), and 212,500 indents were performed in a study of thermal-barrier coatings (Vignesh et al., 2019).
An important aspect of statistical nanoindentation is the application of advanced data analysis and machine learning techniques (Puchi-Cabrera et al., 2023) to extract meaningful information from indentation data. For example, data deconvolution can be performed by assuming multi-modal Gaussian distributions and fitting the probability distribution functions (Sorelli et al., 2008; Randall et al., 2009) or applying expectation maximization techniques (Veytskin et al., 2017). Recently, the effectiveness of different deconvolution methods was studied (Besharatloo and Wheeler, 2021). A convolutional neural network-based classifier (Kossman and Bigerelle, 2021) was developed to identify whether pop-in events were present in the load-displacement curves from nanoindentation tests to help understand the process that created pop-ins. Graph neural networks have been used for supervised learning of indentation data obtained from a polycrystalline steel in conjunction with electron back-scatter diffraction (EBSD) mappings (Karimi et al., 2023); they are able to also consider non-local information. In another study (Vignesh et al., 2019), the phase level features were extracted from spatial hardness and elastic modulus maps using a deconvolution method based on the KMeans clustering algorithm. The method was also employed for the examination of dual phase and high-strength low-alloy steels (Jentner et al., 2023). Similarly, Bayesian inference methods (Becker et al., 2022; Puchi-Cabrera et al., 2023) offer a probabilistic framework for estimating material properties and uncertainties, providing a more robust and comprehensive analysis of nanoindentation data.
In this study, we utilized Cu-Cr composites with controlled heterogeneity as a model material, characterized by varying fractions of the two material components. Our objective was to assess the effectiveness of the statistical nanoindentation technique in detecting variations in mechanical properties within a material. While the microstructures of the selected materials allow for precise positioning of indents and a conventional analysis, this controlled heterogeneity served as a basis for exploring fundamental methodological aspects, such as data processing, uncertainty quantification, and model selection. Unlike more complex materials with multiple, possibly unknown, phases and heterogeneous microstructures, the controlled heterogeneity in our composites simplifies the interpretation of the nanoindentation data by eliminating the complexities associated with unknown heterogeneity. Another key question that arises in the context of statistical nanoindentation is: How much data is necessary to obtain reliable and meaningful results? We address this question by systematically investigating the effects of data quantity on the statistical analysis of the nanoindentation data.
2 Materials and methodology
Cu-Cr composites as a two-phase model material with different compositions were evaluated. Four materials were studied with different fractions of Cr, i.e., 25 wt% Cr and 60 wt% Cr corresponding to 29.95 at% and 64.40 at% Cr, respectively, as well as Cu and Cr as reference samples. All materials were produced via field-assisted sintering technique (FAST) as described in detail in (von Klinski-Berger, 2015). Briefly, Cu powder with 99.9 at% purity and technically pure Cr powder (99.5 at%) were used and compacted at a temperature of 950°C and a pressure of 40 MPa, except for the Cr sample that was compacted at a temperature of 1,450°C. The composite samples (Figure 1) will be referred to as CuCr25 and CuCr60 according to their nominal compositions. For indentation testing, the sample surfaces were prepared applying standard grinding and polishing techniques using SiC paper and diamond suspensions with decreasing grain size down to 0.1 µm.

Figure 1. Optical micrographs of Cu-Cr composites produced by field-assisted sintering technique with (A) 25 wt% Cr, (referred to as CuCr25), and (B) 60 wt% Cr (referred to as CuCr60) were investigated by indentation.
A nanoindenter G200 XP (Agilent/Keysight Technologies, Inc., CA, United States) equipped with a diamond Berkovich tip was used to investigate the mechanical properties of the composite samples. The samples were indented to different depths using the so-called Express Test option. Arrays of indents covering areas up to 500 μm × 500 µm were made in different locations on the sample surface. The indentation depths ranged from 200 to 2,000 nm and the distance between individual indents was maintained approximately constant between 20 and 23 µm for all depths. Hardness
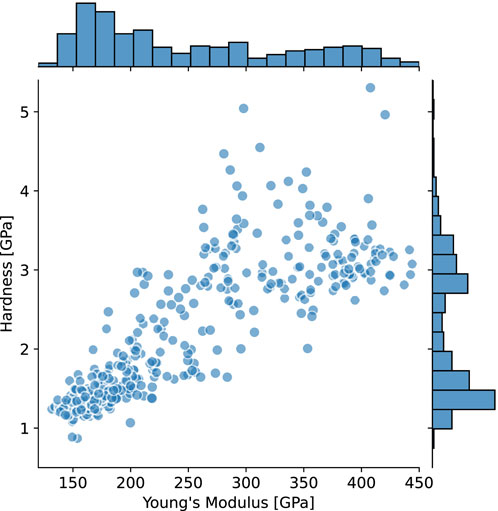
Figure 2. Scatter plot with marginal histograms of all obtained values for Young’s modulus and hardness measured for CuCr60 at an average indentation depth of 1 µm.
The Cu-Cr composites consisted of two distinct phases with average Cr particle diameters of approximately 30 µm on the indented surface; thus, upon indenting the surface we assume that either one or the other element dominates or the properties of a mixture of both phases is measured. However, the “mixture of elements” might as well be more than “just the sum of its parts” since additional effects, e.g., related to the presence of interfaces, might occur during indentation. Furthermore, we assume that similar local microstructural or chemical properties lead to similar measurement data and that the mechanical properties exhibit gradual changes over the surface.
Thus, the data-science task is to analyze a number of data records consisting of the given feature variables
The goal of this work is to perform a clustering analysis, during which data points with similar elastic properties are grouped together, i.e., for each pair
For the clustering, we use the Gaussian mixture model (GMM), which is a robust and well-established probabilistic clustering model in the statistics literature [see, e.g. (Bishop and Nasrabadi, 2006; Reynolds, 2009; Reynolds and Rose, 1995)]. The GMM technique has been used successfully in a wide range of materials science applications. It has, for example, been applied to the automated analysis and visualization of continuum fields in atomistic simulations to extract distributions of total strain, elastic strain, and rotation for individual grains (Prakash and Sandfeld, 2022), or to determine the so-called grain orientation spread based on electron back-scatter diffraction (Yeo et al., 2023). In the analysis of high resolution high-angle annular dark-field scanning transmission electron microscopy data, the GMM was used to estimate the number of atoms of crystalline nanostructures assuming that the total scattered intensity is proportional to the number of atoms per atom column (De Backer et al., 2013). Furthermore, X-ray diffraction investigations using GMM allowed the automatic extraction of charge density wave order parameters and the detection of intraunit cell ordering and its fluctuations from a series of high-volume X-ray diffraction measurements (Venderley et al., 2022).
Using nanoindentation data to investigate the distribution of heterogeneous materials has great potential, provided the GMM technique is applied properly and a sufficient amount of data is available. Here, each “phase” is assumed to correspond to an individual Gaussian distribution of Young’s modulus and hardness. These materials “phases” are commonly referred to as components in the context of machine learning. We assume that the distribution of experimental data was generated by a combination of Gaussian processes, which are represented by the probability density functions (PDFs)
where
The Bayesian Information Criterion
where
3 Results and discussion
In the following, we will start with the description of the data cleaning process and the analysis of the one-component metallic composites using a 1D Gaussian mixture model. Then, the CuCr25 and CuCr60 composites are investigated using both 1D and 2D GMM for an average indentation depth of 1 µm. Finally, a comprehensive analysis is conducted to examine the influence of sample size on the robustness of the model as well as the influence of indentation depth.
3.1 Preparation of the datasets
Figure 3A illustrates the original datasets comprising the measured
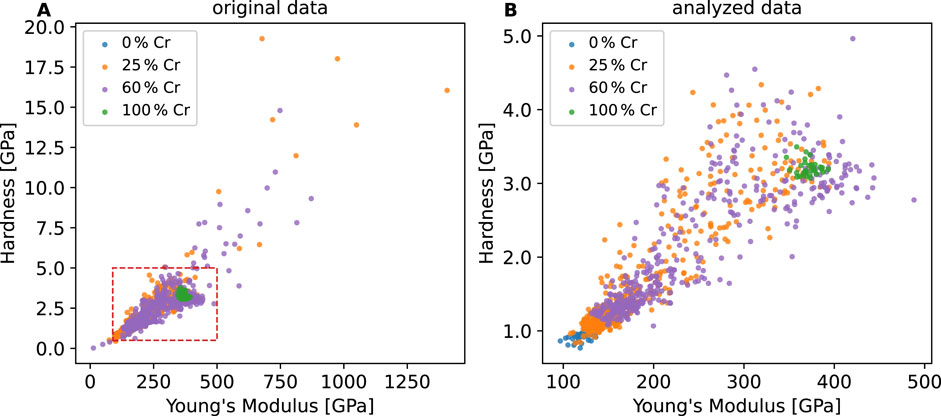
Figure 3. The experimentally obtained distributions of Young’s modulus and hardness for 0 wt%, 25 wt%, 60 wt% and 100 wt% Cr content. (A) The experimental data in its original form, (B) The cleaned and preprocessed data set used in our analysis. The rectangle in (A) indicates the region illustrated in (B).
3.2 Mechanical properties of the pure Cu and pure Cr specimens
The mechanical properties of pure Cu and pure Cr were analyzed for the indentation depth of 800–1,200 nm. The probability density function (PDF) plots of
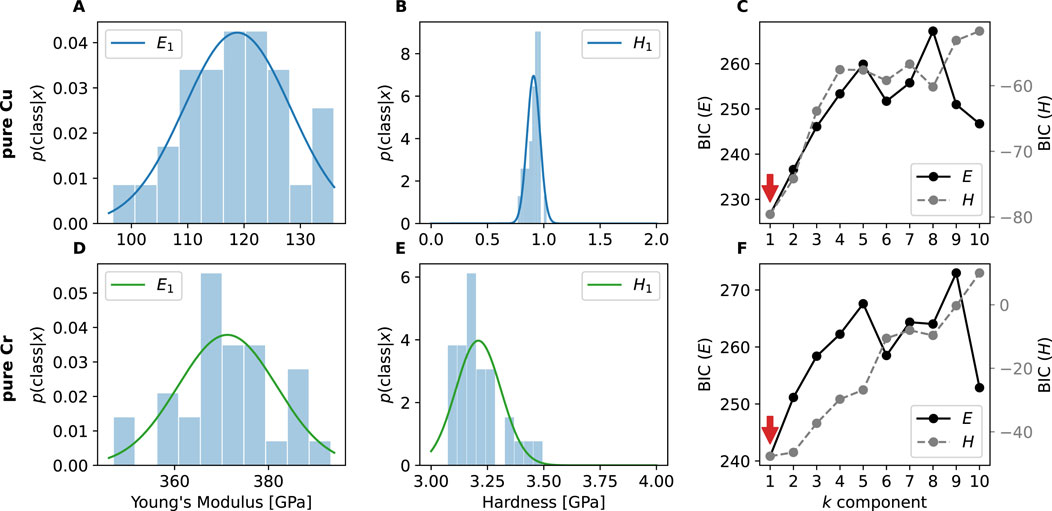
Figure 4. Probability density functions (left and middle column) and plot of BIC (right column) of pure Cu and Cr. The BIC values are shown for both, Young’s modulus (left “
3.3 Mechanical properties of the CuCr25 and CuCr60 specimens
The histograms of
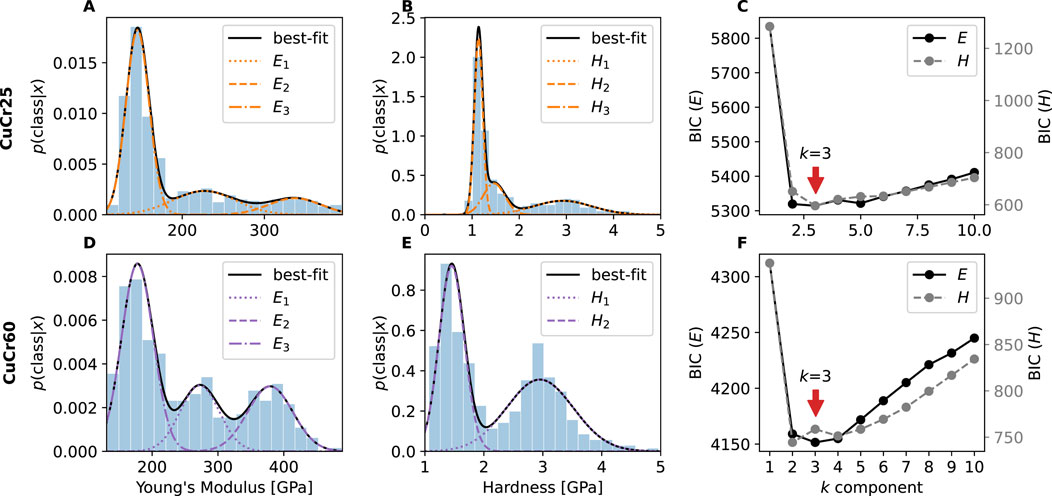
Figure 5. 1D GMM results of CuCr25 and CuCr60 at 800–1,200 nm indentation depth. CuCr25: (A) Histogram of
The BIC values for both the modulus and the hardness cover a range of around 500 and
How many free parameter need to be determined by how many data points? Taking CuCr60, for example, there are
Are the differences of the BIC values as a function of
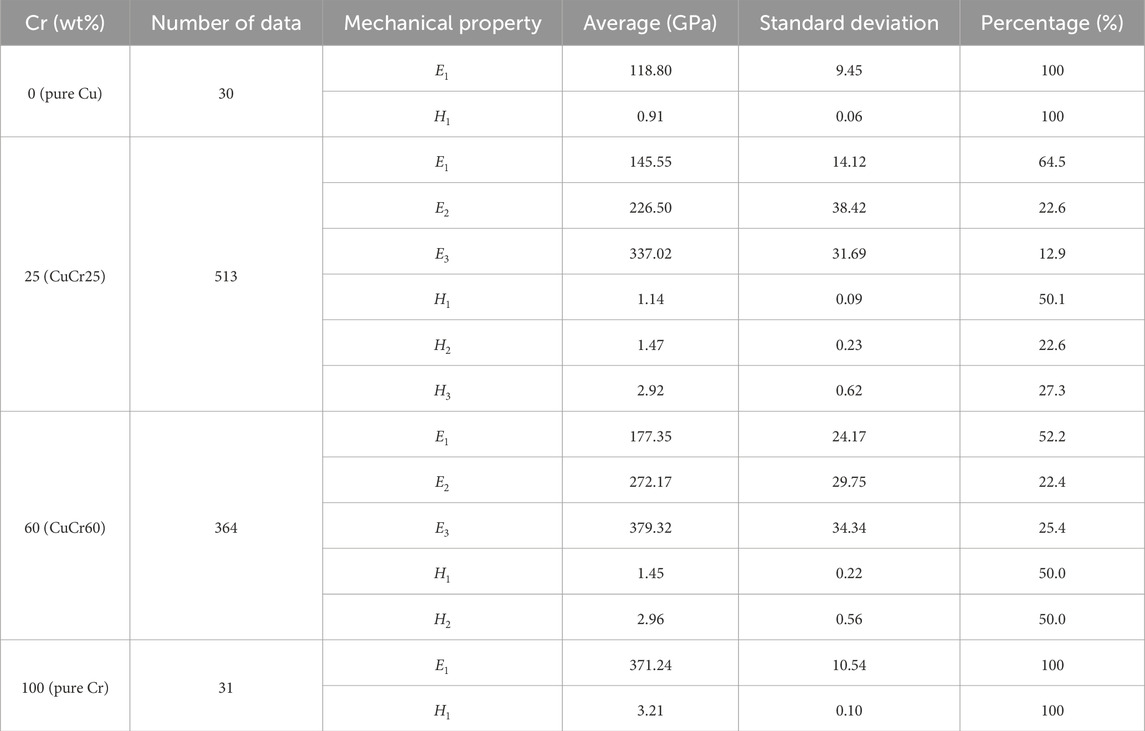
Table 1. 1D mechanical property fitting based on the optimal BIC results at 800–1,200 nm depth.
As stated above, our GMM analysis of CuCr25 shows the presence of three mechanical phases as well as differences in the properties of nominally identical phases. In CuCr25, for example, the Cu-rich phase accounts for 64.5 vol% (defined by
These differences in the mechanical properties fitted by GMM are likely related to the diffusion of one phase into the other, the presence of foreign particles or pores, or the influence of the surrounding material. Assuming that a small amount of Cr, i.e., 0.4 at% - 3 at%, can be dissolved in the Cu matrix (Jacob et al., 2000; Chakrabarti and Laughlin, 1984), the Cr solid solution likely contributes to the difference of the modulus of the Cu phase in the composite samples. In addition, the presence of Cr nanoparticles of 100–200 nm in size was reported (von Klinski-Berger, 2015), which as well results in a higher Young’s modulus value of the Cu phase in CuCr25 and CuCr60. Finally, considering the relative densities of 99.4% and 98.3% for CuCr25 and CuCr60, respectively, compared to 97.7% for the pure Cu sample, a Young’s modulus value with an estimated reduction up to 9% (Lebedev et al., 1995) can be expected. The reduction of the modulus of the Cr phase in CuCr25 (i.e.,
We now take a look at the outcomes of the 2D GMM with independent feature variables
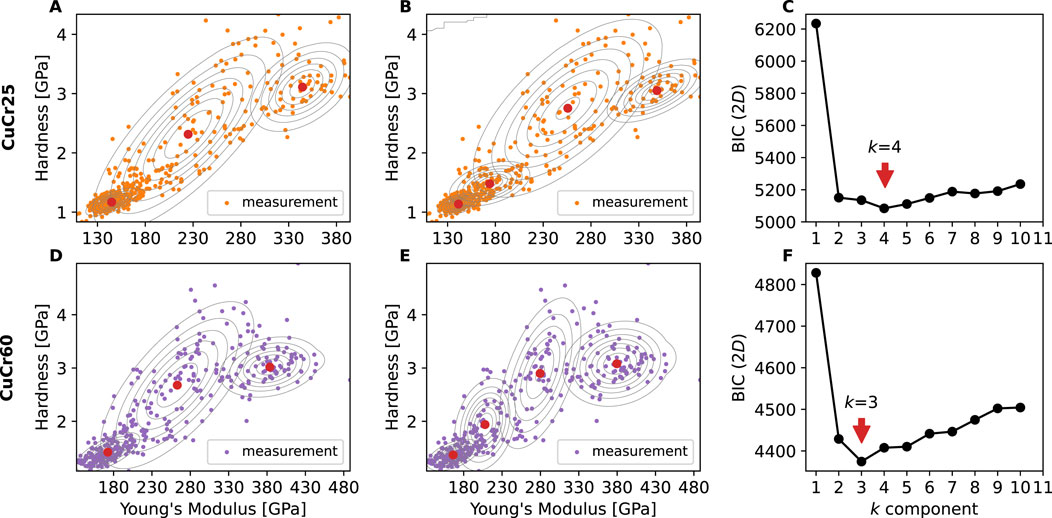
Figure 6. 2D Gaussian mixture model clustering of CuCr25 and CuCr60. CuCr25: (A) Three components. (B) Four components and (C) 2D BIC; CuCr60: (D) Three components (E) Four components and (F) 2D BIC. The ellipses in A, B, D, and E are isolines of the Gaussian distributions and the red points represent the average values of the different components.
Based on Figure 6C, one could say that four mechanical phases are the ideal match for the CuCr25 composite. Given the anomaly in the upper left corner of Figure 6B, though, the best assumption remains at three, which will be further discussed in Section 3.4. As shown in Table 2, in the 2D GMM, which combines both
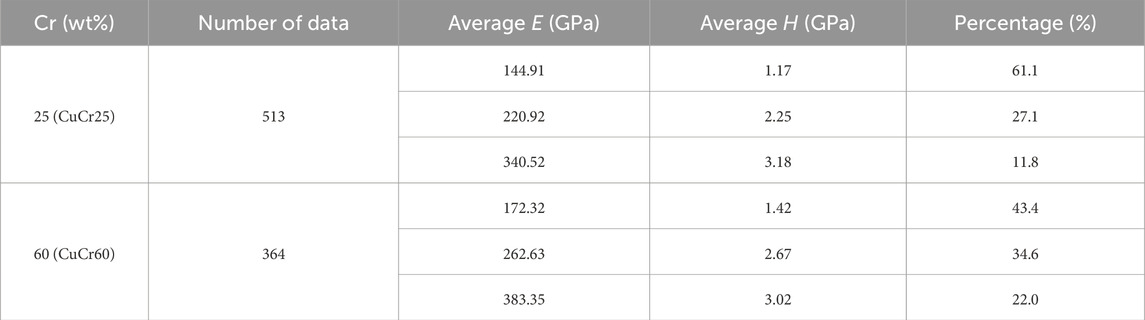
Table 2. 2D mechanical property fitting based on the optimal BIC results at 800–1,200 nm depth.
The 2D GMM analysis (in Figure 5F) also reveals that CuCr60 contains three mechanical phases in the depth range of 800–1,200 nm. The fitted result for the volume of Cr in 1D is 47.8 vol% based on the modulus values, which is less than the nominal value (i.e., 65 vol% Cr). By contrast, the 2D GMM result indicates a Cr volume fraction of 56.6 vol% (Table 2). The difference between the 1D GMM
In the above analysis of CuCr60, the size of the dataset was 364, collected over an area of 500 × 500 μm2. To increase the size of the dataset, we merged it with two more nanoindentation areas (100 × 100 μm2 and 300 × 300 μm2) and analyzed the data using the procedures described above. The results are summarized in Tables 3, 4. Merging the three datasets now includes indentation depths ranging from 500 nm to almost 2,000 nm with 97.8% of the data lying between 800–1,200 nm indentation depth. As shown in Figure 7A, the distribution ranges of the data are congruent indicating that the microstructure of the material was comparable over the different areas indented.
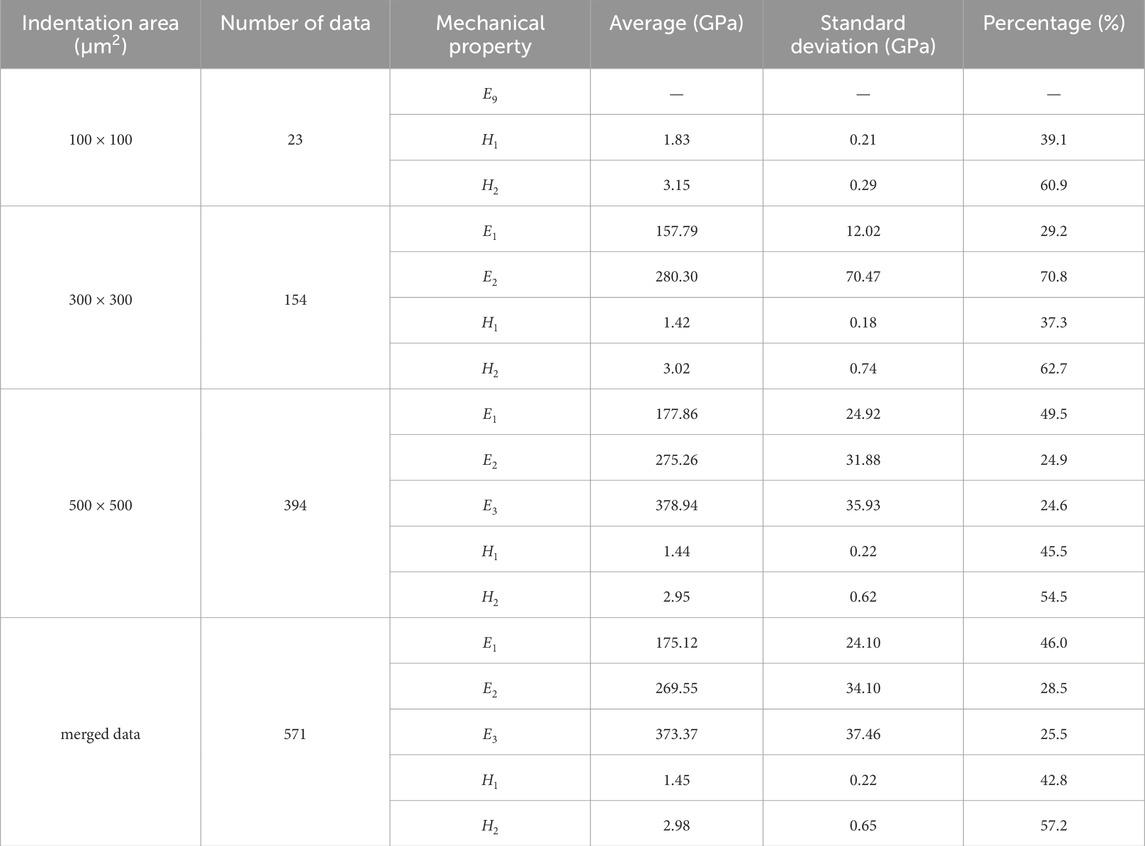
Table 3. 1D mechanical property fitting of CuCr60 based on the optimal BIC results at 500 nm–2000 nm depth encompassing data of three different arrays.
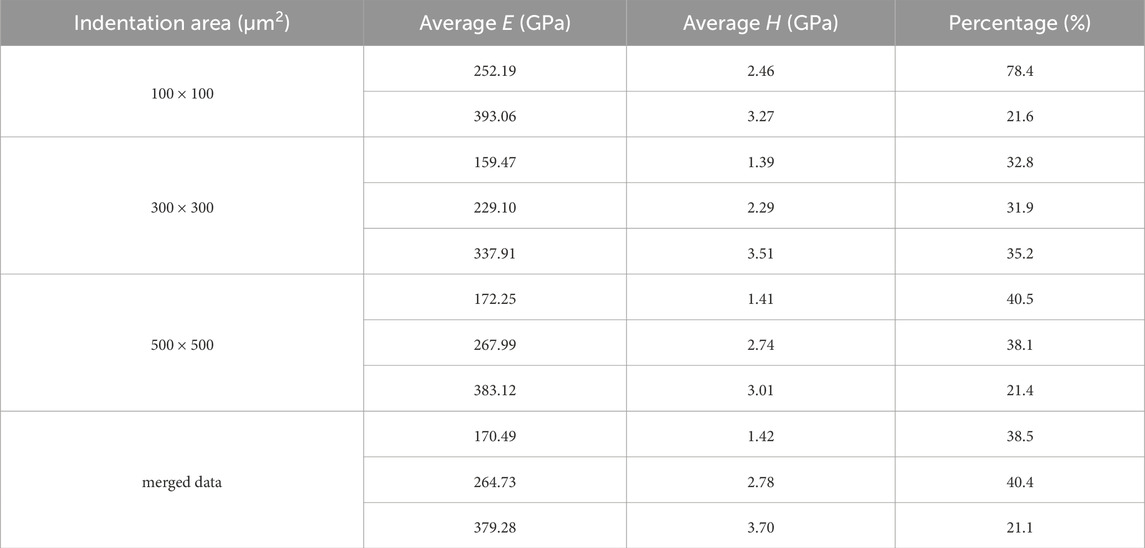
Table 4. 2D mechanical property fitting of CuCr60 based on the optimal BIC results at 500 nm–2000 nm depth encompassing data of three different arrays.
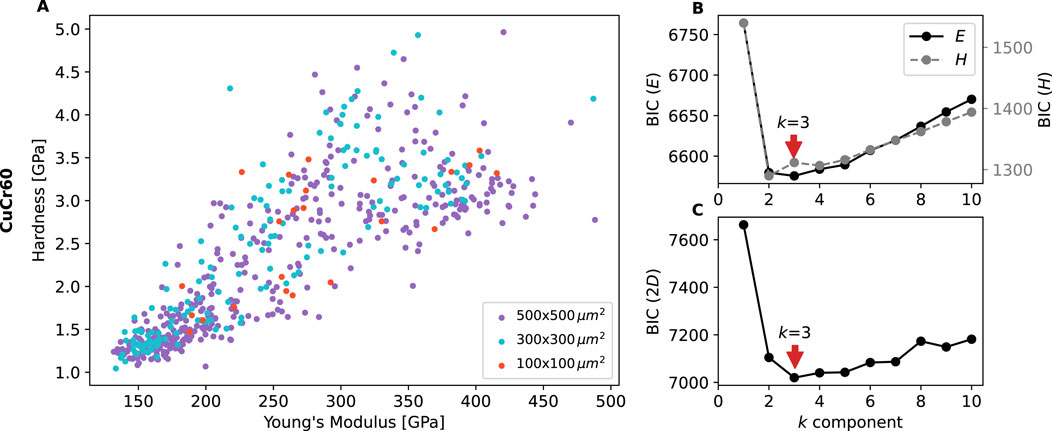
Figure 7. (A) Distribution of the CuCr60 data over the depth range of 500–2,000 nm (combined datasets for indentation arrays of 100 × 100 μm2, 300 × 300 μm2, and 500 × 500 μm2) (B) 1D BIC for
As shown in Figure 7B, the most likely number of phases determined by analyzing Young’s Modulus is three, while two phases are most probable when analyzing the hardness. The 2D fit, though, also indicates
3.4 Cross-validation of GMM
The amount of required training data has been an often encountered concern in clustering algorithms for machine learning. In contrast to the model selection criteria used in the GMM with BIC, we will now focus on the robustness and validity of the clustering results as a function of the size of the dataset. Clustering together with cross validation is used to evaluate the effect of data size on the results and to identify the amount of experimental data required to achieve the same level of performance. We applied the following procedure:
1. Given the whole dataset
2.
3. The adjusted Rand index (ARI) is used to represent the performance level of the clustering algorithms. In general, the ARI approaches 0.0 for random clustering, reaches 1.0 for identical clusterings, but can go as low as −0.5 for highly discordant clusterings (Chacón and Rastrojo, 2023).
Figure 8A illustrates the outcomes of
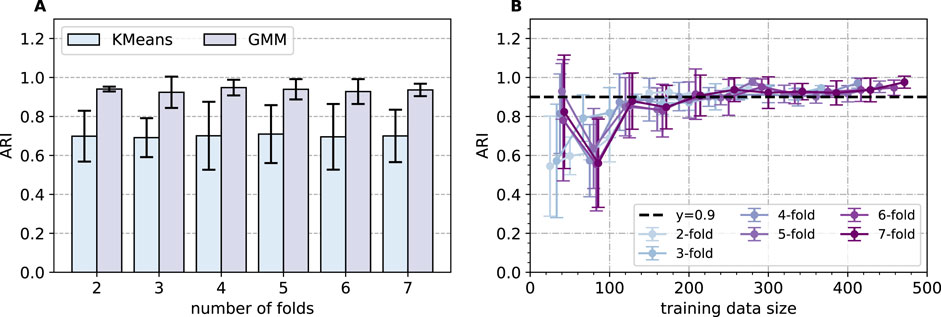
Figure 8.
For the CuCr60 composite, a total of 571 datapoints were collected by merging data from three different indentation areas. We developed an approach to assess varying sizes of datasets, starting with taking 50 data records as the dataset of interest, and increasing by increments of 50 until reaching a dataset containing 550 data points. During the process of training a model, a fraction of
Overall, our analysis indicates that the GMM algorithm exhibits superior accuracy when the average model performance approaches 0.9. Nevertheless, in the pursuit of enhanced generalizability, we aim to minimize errors further, ideally pushing the lower boundary of performance beyond 0.9. To achieve this, it is recommended to initiate the training process using a dataset comprising more than 400 datapoints as a starting point, as it appears to yield more reliable results.
The identical approach for sampling was employed in the examination of CuCr25. Figure 9 shows the outcomes of
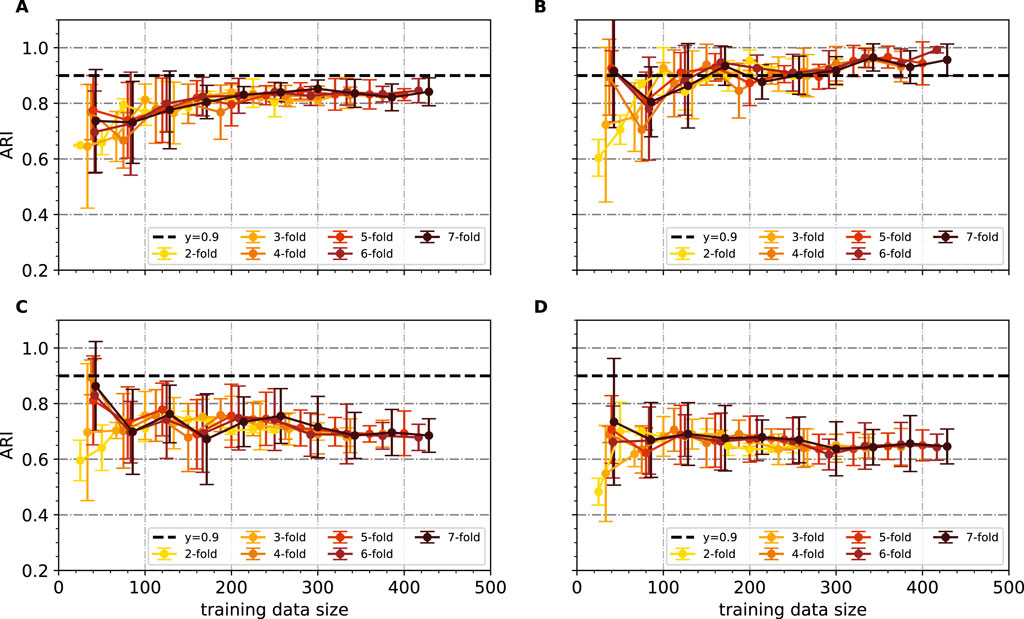
Figure 9.
3.5 Effect of indentation depth
Figure 10A shows the 2D mapping of
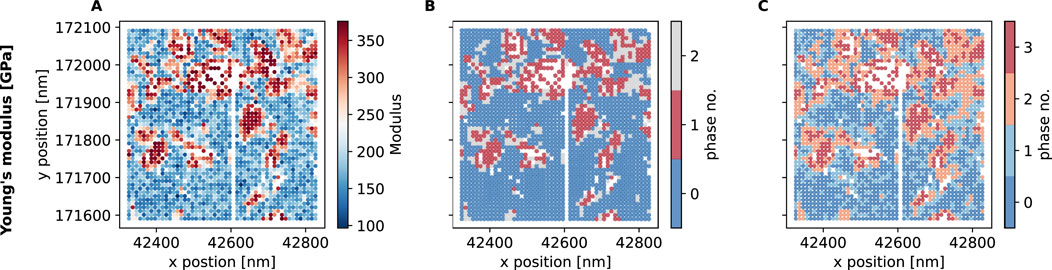
Figure 10. Elastic modulus of CuCr25 based on idents in the depth range of 200–600 nm. (A) Young’s modulus distribution over the testing area. (B) Young’s modulus distribution of 1D GMM clustering. (C) 2D GMM clustering results
The clustering results assign fractions of the Cu-phase at different depths to the fourth mechanical phase. Therefore, datasets containing data at different depths, need to be evaluated in subsets when determining the number of mechanical phases. Accordingly, we further examined the phase composition using a 1D Gaussian mixing model for different depth ranges covering 100 nm each. The results are shown in Table 5. Based on this analysis, the occurrence of additional phases can be observed at higher depths, i.e., in the 400 nm and 500 nm regimes, along with a significant reduction in Cu content.
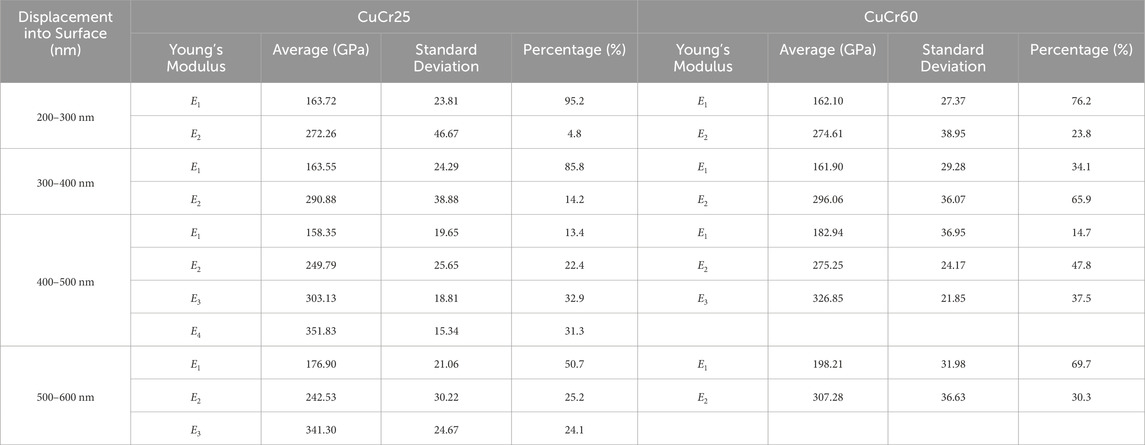
Table 5. Indentation results of CuCr25 and CuCr60 composites in the depth range 200 nm–600 nm determined by 2D GMM.
The hardness distribution for the CuCr25 and CuCr60 composites at depths ranging from 200 nm to 1200 nm is shown in Figure 11. The data was grouped in 50 bins of equal size with the shaded area indicating the standard deviation. For metals typically an indentation size effect is observed, i.e., the hardness increases with decreasing indentation depth (Wang et al., 2021; Ma et al., 2021; Pharr et al., 2010). This indentation size effect is observed here for indentation depths between 450 and 600 nm, while for lower depths it is obscured by the combined effects of microstructural changes over the depth as well as the presence of at least two phases. This apparent nanoscale softening may also be influenced by the distance between indents relative to the size of the different phases possibly favoring a particular property value.
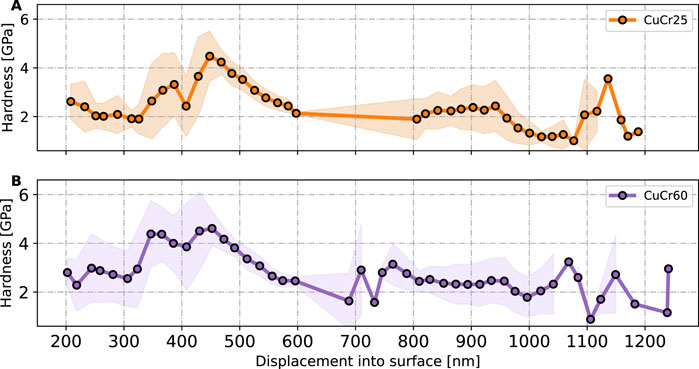
Figure 11. Hardness of CuCr25 and CuCr60 composites at different indentation depths. (A) CuCr25, with 3,812 data points in the range 200–600 nm, and (B) CuCr60, with 3,254 data points in the range 200–600 nm depth. The mean of the hardness with the respective standard deviation as shaded area is shown. The mean hardness assumes an approximately constant value for depths greater than 600 nm.
Figure 12 depicts the distribution of Young’s modulus in CuCr25 in the range between 250–600 nm, whose 2D top view is depicted in Figure 10A). The distribution of Young’s modulus exhibits a certain degree of continuity, and the majority of the changes are gradual. The green hue represents the Cu-phase, while the orange color represents the Cr-phase. Observation reveals that the yellow and light-green portions (the third mechanical phase) can be considered the Cu and Cr intersection region. Figure 12 depicts the marker size adjusted according to the indent size on the surface, which increases as the indentation depth increases. Based on this observation and also on the analysis results listed in Table 5, we observe an increase of the Cr-phase in both the CuCr25 and the CuCr60 composites in the range of 200–500 nm, which can explain the increase in hardness in the low-depth regimes (cf. Figure 11). Thus, it is critical to identify the characteristic microstructures not only on the surface tested but also in the sub-surface region of the material.
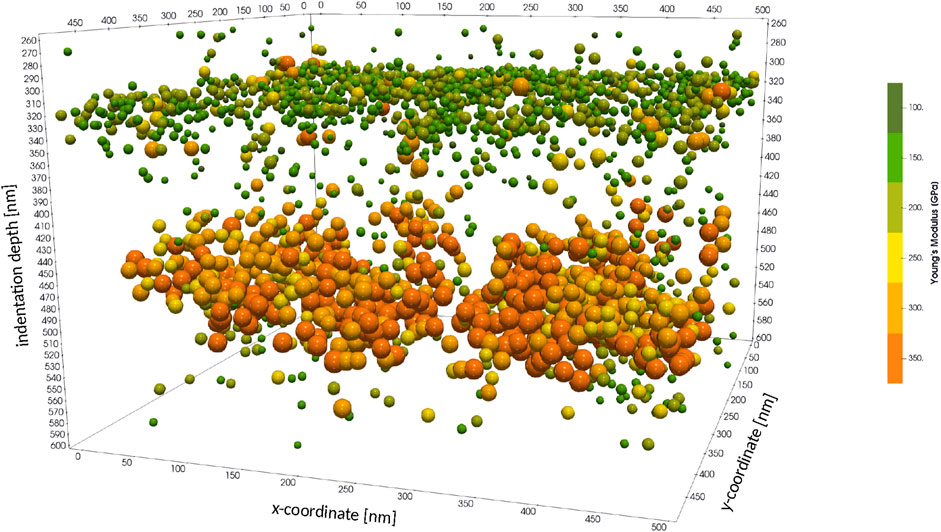
Figure 12. Young’s modulus at different locations
4 Conclusion
Cu-Cr composites were studied by indentation as a model material to evaluate the ability to determine the properties of individual phases as well as the number of phases present. 1D and 2D Gaussian mixture models were trained and the most likely number of components identified based on the BIC. Using cross-validation we showed that the GMM gave more accurate results than KMeans clustering. Investigating the dependence of the cross-validation results on the size of the datasets helped to understand what a reasonable amount of data for the training of such models might be. Our analysis revealed that 450 data-pairs were sufficient for accurate phase volume prediction.
Clearly, the presented GMM-based method has limitations, e.g., it implicitly assumes that indents into different phases also result in different properties. As a consequence, it must be expected that the predictions are getting worse the more similar two (or more) phases become. GMM is a simple yet robust method, which is not able to utilize all available microstructural information. For example, locality effects due to the fact that nearby indents may be correlated cannot be captured. Extending GMM, e.g., in terms of engineered features, could be a possible solution.
While large datasets produced in a very short time are quite impressive, also conventional nanoindentation approaches with typically fewer data can be used. Variations of the phase composition over the depth as well as the distance between indents relative to the size of the microstructural features may favor a particular phase. To avoid such bias indentation depth and characteristic microstructures need to be critically evaluated.
Data availability statement
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found below: https://zenodo.org/doi/10.5281/zenodo.8336071
Author contributions
CZ: Formal Analysis, Investigation, Software, Visualization, Writing–original draft, Data curation, Methodology. CB: Data curation, Investigation, Writing–review and editing. SS: Conceptualization, Supervision, Validation, Writing–original draft, Writing–review and editing, Formal Analysis, Resources. RS: Conceptualization, Supervision, Validation, Writing–original draft, Formal Analysis, Resources, Writing–review and editing.
Funding
The author(s) declare that financial support was received for the research, authorship, and/or publication of this article. StS gratefully acknowledges funding through the Helmholtz Foundation Model Initiative of the project “SOL-AI”.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fmats.2024.1440608/full#supplementary-material
References
Becker, B. R., Hintsala, E. D., Stadnick, B., Hangen, U. D., and Stauffer, D. D. (2022). Automated analysis method for high throughput nanoindentation data with quantitative uncertainty. J. Appl. Phys. 132, 185101. doi:10.1063/5.0098493
Besharatloo, H., and Wheeler, J. M. (2021). Influence of indentation size and spacing on statistical phase analysis via high-speed nanoindentation mapping of metal alloys. J. Mater. Res. 36, 2198–2212. doi:10.1557/s43578-021-00214-5
Bos, C. (2019). Micromechanical characterization of heterogeneous materials, statistical analysis of nanoindentation data. Karlsruhe: Karlsruhe Institute of Technology (KIT). doi:10.5445/IR/1000098226
Chacón, J. E., and Rastrojo, A. I. (2023). Minimum adjusted rand index for two clusterings of a given size. Adv. Data Analysis Classif. 17, 125–133. doi:10.1007/s11634-022-00491-w
Chakrabarti, D. J., and Laughlin, D. E. (1984). The cr-cu (chromium-copper) system. Bull. Alloy Phase Diagrams 5, 245–268. doi:10.1007/bf02868543
Constantinides, G., Chandran, K. R., Ulm, F.-J., and Van Vliet, K. (2006). Grid indentation analysis of composite microstructure and mechanics: principles and validation. Mater. Sci. Eng. A 430, 189–202. doi:10.1016/j.msea.2006.05.125
De Backer, A., Martinez, G. T., Rosenauer, A., and Van Aert, S. (2013). Atom counting in haadf stem using a statistical model-based approach: methodology, possibilities, and inherent limitations. Ultramicroscopy 134, 23–33. doi:10.1016/j.ultramic.2013.05.003
Gideon, S. (1978). Estimating the dimension of a model. Ann. Statistics 6, 461. doi:10.1214/aos/1176344136
Golovin, Y. (2021). Nanoindentation and mechanical properties of materials at submicro- and nanoscale levels: recent results and achievements. Phys. Solid State 63, 1–41. doi:10.1134/s1063783421010108
Haušild, P., Materna, A., Kocmanová, L., and Matějíček, J. (2016). Determination of the individual phase properties from the measured grid indentation data. J. Mater. Res. 31, 3538–3548. doi:10.1557/jmr.2016.375
Hintsala, E., Hangen, U., and Stauffer, D. (2018). High-throughput nanoindentation for statistical and spatial property determination. JOM 70, 494–503. doi:10.1007/s11837-018-2752-0
Jacob, K., Priya, S., and Waseda, Y. (2000). A thermodynamic study of liquid Cu-Cr alloys and metastable liquid immiscibility. Zeitschrift für Metallkunde/Materials Res. Adv. Tech. 91, 594–600. doi:10.1515/ijmr-2000-910710
Jentner, R. M., Srivastava, K., Scholl, S., Gallardo-Basile, F.-J., Best, J. P., Kirchlechner, C., et al. (2023). Unsupervised clustering of nanoindentation data for microstructural reconstruction: challenges in phase discrimination. Materialia 28, 101750. doi:10.1016/j.mtla.2023.101750
Karimi, K., Salmenjoki, H., Mulewska, K., Kurpaska, L., Kosińska, A., Alava, M. J., et al. (2023). Prediction of steel nanohardness by using graph neural networks on surface polycrystallinity maps. Scr. Mater. 234, 115559. doi:10.1016/j.scriptamat.2023.115559
Kossman, S., and Bigerelle, M. (2021). Pop-in identification in nanoindentation curves with deep learning algorithms. Materials 14, 7027. doi:10.3390/ma14227027
Lebedev, A., Berunkov, Y., Romanov, A., Kopylov, V., Filonenko, V., and Gryaznov, V. (1995). Softening of the elastic modulus in submicrocrystalline copper. Mater. Sci. Eng. A 203, 165–170. doi:10.1016/0921-5093(95)09868-2
Ma, X., Higgins, W., Liang, Z., Zhao, D., Pharr, G. M., and Xie, K. Y. (2021). Exploring the origins of the indentation size effect at submicron scales. Proc. Natl. Acad. Sci. 118, e2025657118. doi:10.1073/pnas.2025657118
Nohava, J., Hausild, P., Houdková, S., and Enzl, R. (2012). Comparison of isolated indentation and grid indentation methods for hvof sprayed cermets. J. Therm. Spray. Tech. 21, 651–658. doi:10.1007/s11666-012-9733-6
Oliver, W. C., and Pharr, G. M. (1992). An improved technique for determining hardness and elastic modulus using load and displacement sensing indentation experiments. J. Mater. Res. 7, 1564–1583. doi:10.1557/jmr.1992.1564
Öztuna, D., Elhan, A. H., and Tüccar, E. (2006). Investigation of four different normality tests in terms of type 1 error rate and power under different distributions. Turkish J. Med. Sci. 36, 171–176.
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., et al. (2011). Scikit-learn: machine learning in python. J. Mach. Learn. Res. 12, 2825–2830.
Pharr, G. M., Herbert, E. G., and Gao, Y. (2010). The indentation size effect: a critical examination of experimental observations and mechanistic interpretations. Annu. Rev. Mater. Res. 40, 271–292. doi:10.1146/annurev-matsci-070909-104456
Prakash, A., and Sandfeld, S. (2022). Automated analysis of continuum fields from atomistic simulations using statistical machine learning. Adv. Eng. Mater. 24, 2200574. doi:10.1002/adem.202200574
Puchi-Cabrera, E. S., Rossi, E., Sansonetti, G., Sebastiani, M., and Bemporad, E. (2023). Machine learning aided nanoindentation: a review of the current state and future perspectives. Curr. Opin. Solid State Mater. Sci. 27, 101091. doi:10.1016/j.cossms.2023.101091
Randall, N. X., Vandamme, M., and Ulm, F.-J. (2009). Nanoindentation analysis as a two-dimensional tool for mapping the mechanical properties of complex surfaces. J. Mater. Res. 24, 679–690. doi:10.1557/jmr.2009.0149
Reynolds, D. (2009). “Gaussian mixture models,” in Encyclopedia of Biometrics. Editors S. Z. Li, and A. Jain(Boston, MA: Springer). doi:10.1007/978-0-387-73003-5_196
Reynolds, D. A., and Rose, R. C. (1995). Robust text-independent speaker identification using Gaussian mixture speaker models. IEEE Trans. Speech Audio Process. 3, 72–83. doi:10.1109/89.365379
Sanchez-Camargo, C.-M., Hor, A., Salem, M., and Mabru, C. (2020). A robust method for mechanical characterization of heterogeneous materials by nanoindentation grid analysis. Mater. and Des. 194, 108908. doi:10.1016/j.matdes.2020.108908
Shen, Y. (2019). “Nanoindentation for testing material properties,” in Handbook of mechanics of materials. Editors S. Schmauder, C. Chen, K. Chawla, N. Chawla, W. Chen, and Y. Kagawa (Singapore: Springer), 1981–2012.
Sorelli, L., Constantinides, G., Ulm, F.-J., and Toutlemonde, F. (2008). The nano-mechanical signature of ultra high performance concrete by statistical nanoindentation techniques. Cem. Concr. Res. 38, 1447–1456. doi:10.1016/j.cemconres.2008.09.002
Tromas, C., Arnoux, M., and Milhet, X. (2012). Hardness cartography to increase the nanoindentation resolution in heterogeneous materials: application to a ni-based single-crystal superalloy. Scr. Mater. 66, 77–80. doi:10.1016/j.scriptamat.2011.09.042
Ulm, F.-J., Vandamme, M., Bobko, C., Alberto Ortega, J., Tai, K., and Ortiz, C. (2007). Statistical indentation techniques for hydrated nanocomposites: concrete, bone, and shale. J. Am. Ceram. Soc. 90, 2677–2692. doi:10.1111/j.1551-2916.2007.02012.x
Venderley, J., Mallayya, K., Matty, M., Krogstad, M., Ruff, J., Pleiss, G., et al. (2022). Harnessing interpretable and unsupervised machine learning to address big data from modern x-ray diffraction. Proc. Natl. Acad. Sci. 119, e2109665119. doi:10.1073/pnas.2109665119
Veytskin, Y., Tammina, V., Bobko, C., Hartley, P., Clennell, M., Dewhurst, D., et al. (2017). Micromechanical characterization of shales through nanoindentation and energy dispersive x-ray spectrometry. Geomech. Energy Environ. 9, 21–35. doi:10.1016/j.gete.2016.10.004
Vignesh, B., Oliver, W., Siva Kumar, G., and Sudharshan Phani, P. (2019). Critical assessment of high speed nanoindentation mapping technique and data deconvolution on thermal barrier coatings. Mater. Des. 181, 108084. doi:10.1016/j.matdes.2019.108084
von Klinski-Berger, K. (2015). Charakterisierung von Kupfer-Chrom-Verbundwerkstoffen für die Schalttechnik. Technische Universität Darmstadt.
Wang, J., Volz, T., Weygand, S., and Schwaiger, R. (2021). The indentation size effect of single-crystalline tungsten revisited. J. Mater. Res. 36, 2166–2175. doi:10.1557/s43578-021-00221-6
Wheeler, J. (2021). Mechanical phase mapping of the taza meteorite using correlated high-speed nanoindentation and edx. J. Mater. Res. 36, 94–104. doi:10.1557/s43578-020-00056-7
Keywords: unsupervised learning, cross-validation, Gaussian mixture model, Cu-Cr composite, mechanical properties, nanoindentation
Citation: Zhang C, Bos C, Sandfeld S and Schwaiger R (2024) Unsupervised learning of nanoindentation data to infer microstructural details of complex materials. Front. Mater. 11:1440608. doi: 10.3389/fmats.2024.1440608
Received: 29 May 2024; Accepted: 30 October 2024;
Published: 04 December 2024.
Edited by:
John L. Provis, Paul Scherrer Institut (PSI), SwitzerlandReviewed by:
Kelvin Xie, Texas A and M University, United StatesStefanos Papanikolaou, National Centre for Nuclear Research, Poland
Copyright © 2024 Zhang, Bos, Sandfeld and Schwaiger. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Stefan Sandfeld, cy5zYW5kZmVsZEBmei1qdWVsaWNoLmRl