
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
REVIEW article
Front. High Perform. Comput. , 19 February 2025
Sec. High Performance Big Data Systems
Volume 3 - 2025 | https://doi.org/10.3389/fhpcp.2025.1520207
This article is part of the Research Topic Recent Trends and Advances for Energy Efficient HPC Systems View all articles
 Estela Suarez1,2,3*
Estela Suarez1,2,3* Hendryk Bockelmann4
Hendryk Bockelmann4 Norbert Eicker1,5Jan Eitzinger6Salem El Sayed1Thomas Fieseler1
Norbert Eicker1,5Jan Eitzinger6Salem El Sayed1Thomas Fieseler1 Martin Frank7Peter Frech1Pay Giesselmann4Daniel Hackenberg8
Martin Frank7Peter Frech1Pay Giesselmann4Daniel Hackenberg8 Georg Hager6
Georg Hager6 Andreas Herten1Thomas Ilsche8
Andreas Herten1Thomas Ilsche8 Bastian Koller9Erwin Laure10
Bastian Koller9Erwin Laure10 Cristina Manzano1
Cristina Manzano1 Sebastian Oeste8Michael Ott11Klaus Reuter10Ralf Schneider9Kay Thust1Benedikt von St. Vieth1
Sebastian Oeste8Michael Ott11Klaus Reuter10Ralf Schneider9Kay Thust1Benedikt von St. Vieth1High Performance Computing (HPC) systems are among the most energy-intensive scientific facilities, with electric power consumption reaching and often exceeding 20 Megawatts per installation. Unlike other major scientific infrastructures such as particle accelerators or high-intensity light sources, which are few around the world, the number and size of supercomputers are continuously increasing. Even if every new system generation is more energy efficient than the previous one, the overall growth in size of the HPC infrastructure, driven by a rising demand for computational capacity across all scientific disciplines, and especially by Artificial Intelligence (AI) workloads, rapidly drives up the energy demand. This challenge is particularly significant for HPC centers in Germany, where high electricity costs, stringent national energy policies, and a strong commitment to environmental sustainability are key factors. This paper describes various state-of-the-art strategies and innovations employed to enhance the energy efficiency of HPC systems within the national context. Case studies from leading German HPC facilities illustrate the implementation of novel heterogeneous hardware architectures, advanced monitoring infrastructures, high-temperature cooling solutions, energy-aware scheduling, and dynamic power management, among other optimisations. By reviewing best practices and ongoing research, this paper aims to share valuable insight with the global HPC community, motivating the pursuit of more sustainable and energy-efficient HPC architectures and operations.
High Performance Computing (HPC) systems are indispensable instruments in scientific research, but at the same time energy-hungry infrastructures. Although the computational capacity per Watt of computers and processing units is improving over time (Strohmaier et al., 2024a; Koomey et al., 2011), the demand for more compute capacity—recently strongly driven by large-scale computations for Artificial Intelligence (AI)—is outpacing any emerging efficiencies, leading to the deployment of even more computing infrastructures and services (e.g., EuroHPC Joint Undertaking, 2024a). Existing and upcoming HPC facilities must provide significant computational power and, consequently, require large amounts of energy for Information Technology (IT) and cooling, making their sustainability a major concern.
The two most significant issues pertaining to these energy demands are the economic viability of maintaining the necessary infrastructure in the light of rising electricity prices and the considerable environmental impact of generating this electricity, which raise concerns in society. Germany is the second country worldwide in the amount of deployed data centers (Shankar, 2024), and at the same time is characterized by higher-than-average electricity costs in comparison to other countries, which is attributed in part to its particular energy mix and reliance on imported resources. To address societal concerns, policies have been implemented with the objective of addressing environmental impact. The German Energy Efficiency Act (German Federal Government, 2024a) mandates that businesses, in particular commercial data centers, and research institutions, including supercomputing centers, observe stricter energy consumption limits. Furthermore, the European Supply Chain Directive (European Parliament, 2024) has the objective of accounting for the energy consumed and CO2 generated during the entire life cycle of a given product, from the moment of fabrication until its end of life. For hosting sites to estimate the embedded carbon footprint in HPC systems, they must rely on manufacturers to explicitly state the embedded carbon in their products. From all the above it becomes imperative that energy efficiency measures have to be integrated into the design and operation of HPC sites in order to align with national and EU-wide sustainability goals and legislation. Numerous national and European R&D projects have developed specific components and strategies for energy efficiency, e.g., improved cooling and energy reuse, monitoring infrastructures, or hardware architectures. These new developments are first demonstrated on a small scale (e.g., on prototypes or test implementations) before being implemented in the production environment (Eicker, 2015; Kreuzer et al., 2021; The eeHPC Consortium, 2024).
This paper examines the latest developments and trends in energy efficiency at major German HPC centers, including Deutsches Klimarechenzentrum GmbH (DKRZ), Friedrich-Alexander-Universität Erlangen-Müurnberg (FAU), High-Performance Computing Center Stuttgart (HLRS), Jülich Supercomputing Center (JSC), Karlsruhe Institute of Technology (KIT), Leibniz Supercomputing Center (LRZ), Max Planck Computing and Data Facility (MPCDF) and Technische Universität Dresden (TUD). These institutions host and operate supercomputing facilities at European, German, and regional level. In November 2024 all together they host 20 machines ranging from ranking 18 (JETI at JSC) to 491 (HoreKa-Blue at KIT) in the Top 500 list, and 4 out of the 10 most energy-efficient systems in the Green 500 list (Strohmaier et al., 2024b). All these HPC centers balance the need for advanced computing infrastructure with sustainability efforts by exploring cutting-edge solutions such as energy-efficient hardware, advanced system monitoring and management, and optimized cooling systems. By presenting the experience applied by these institutions in production environments, we aim at inspiring others on applying similar techniques to reduce the energy footprint of HPC infrastructures.
The paper reports the experience from a representative set of German HPC sites, but our exchanges with international collaborators show that our observations are representative for the international landscape. The conclusions can therefore be generalized for other geographies. The contributions of this paper are:
• Report on the energy consumption and cost trends in the deployment and operation of HPC systems in Germany, the country with the second largest amount of data centers (Shankar, 2024).
• Describe energy efficiency trends at the infrastructure, system, monitoring, and software level.
• Give an overview of energy efficiency approaches at a number of major German HPC centers, covering European, national, and regional facilities. All participating hosting sites are publicly funded governmental institutions (research centers or universities) and provide compute time free of charge to academic users based on peer reviews. Systems are typically overbooked, not oversized, and the target in operations is to achieve maximum resource utilization at minimum energy consumption.
• Report on current techniques applied already in production, approaches explored in research activities, and observed trends.
Over the past decade, computing performance of HPC systems has continued to grow exponentially, driven by advances in microarchitecture and semiconductor technology (Strohmaier et al., 2024b). Manufacturing processes have been scaled down to single-digit nanometer units (Taiwan Semiconductor Manufacturing Company, 2024). Finer structures allow more transistors per chip, increasing computing power per physical area and per Watt, since signals have to travel shorter distances across the chip. However, with the breakdown of Dennard scaling and Moore's Law also coming to an end, the power draw of HPC systems is steadily increasing. While the power efficiency per Floating Point Operation (FLOP) has grown consistently, the demand for compute capacity has outpaced those improvements. For example, in the period from 2008 until 2024 the aggregate performance of all Top500 systems has increased 1,000-fold, while the energy efficiency has grown by only a factor 146 (see Figure 1) (Strohmaier et al., 2024b). Apparently, the HPC community is willing to keep up with the ensuing cost of energy and the challenges in terms of infrastructure, sustainability, economic viability, and technical feasibility.
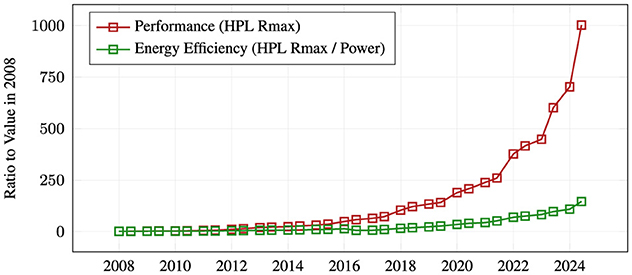
Figure 1. Supercomputer performance and energy efficiency over time: Performance (red, Rmax) measured with the HPL benchmark per Top500. Energy efficiency (green) calculated as the ratio of HPL performance and reported power consumption. Both are shown relative to the respective values in 2008. Data source (Strohmaier et al., 2024b). In 16 years, performance has grown by a factor of 1,000, while energy efficiency has grown by a factor of 146.
The increasing performance has led to an increase in power density, making traditional air cooling methods inadequate for heat dissipation. Direct liquid cooling, particularly with hot water, is advantageous in terms of energy reuse and infrastructure efficiency (see Section 3.3). However, as components such as Graphics Processing Units (GPUs) generate more and more heat, the demand for chilled water cooling systems has increased, creating a mismatch between cooling technology trends and energy efficiency goals.
Figure 2 shows the development of energy efficiency in terms of double precision (FP64) GFLOP/s/Watt over the last decade for Central Processing Units (CPUs) and GPUs. Intel was able to deliver a steady increase in energy efficiency up to the Skylake micro-architecture in 2017. Still this development stagnated in the last five years, because Intel struggled to further improve and shrink their in-house manufacturing process (Anton, 2018; Paul, 2018; Chaim, 2021). AMD on the other hand, due to technological limitations, was forced to go for a multi-die setup. This allowed them to employ more energy-efficient manufacturing processes more quickly, while at the same time delivering higher core counts, which Intel was not able to deliver with their monolithic chip designs. 2025 will show if multi-core chips can provide significant energy improvements again. While Intel is catching up with a smaller core, a multi-chip setup, and a competitive in-house manufacturing process, AMD for the first time employs full-width AVX512 execution units. It has to be seen if they can be implemented in an energy-efficient manner without sacrificing frequency. Taking into account the efficiency improvements that multi-core CPUs can deliver, Figure 2 also shows that they are not currently competitive with more specialized GPU accelerators in terms of the HPL energy efficiency, which is driven by peak floating-point throughput. Of course, this does not necessarily reflect energy efficiency for real-world application workloads. It is interesting that while GPUs deliver a superior energy efficiency compared to multi-core CPUs, the efficiency did not improve significantly over the last 10 years. Both GPU vendors provide even higher efficiencies when using the more specialized tensor core units. This leads to the conclusion that the largest increases in energy efficiency are enabled by specialization.
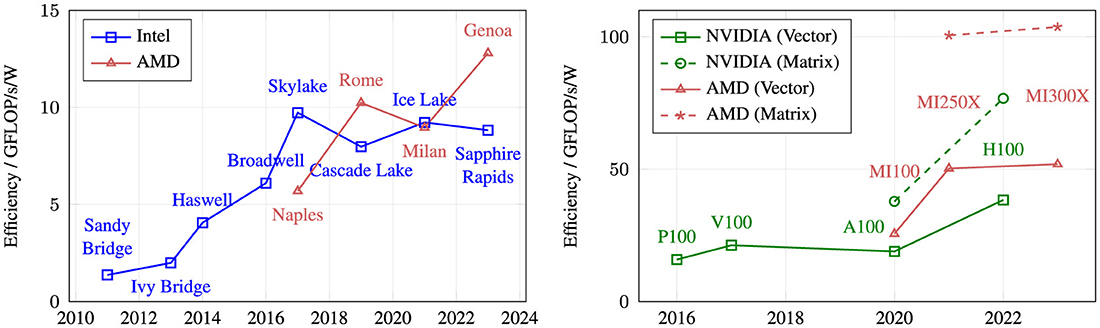
Figure 2. Energy efficiency for FP64 throughput of a selection of CPUs (left) and GPUs (right). Determined with theoretical peak performance and Thermal Design Power (TDP) of one socket/GPU using the “top-bin” Stock Keeping Unit (SKU) of each generation. For CPUs, the frequency used to determine peak performance is the lowest frequency measured with a very hot benchmark. For GPUs, the base frequency is taken, assuming continued computations. For GPUs, results with and without considering tensor cores for dedicated acceleration of matrix multiplication are shown, labeled as Matrix and Vector, respectively. The graphs compare similar, albeit not identical frequency types (measured vs. computed); cross-graph comparability is only limited.
The fact that increases in computational performance necessarily come with a higher power envelope has several implications. Although power capping or power limiting can be used successfully (cf. Section 4.3, and Zhao et al., 2023 and references therein), there is a delicate balance between power consumption and throughput. Electricity prices in Germany vary widely and are much higher for households (≈ €0.40 per kWh) than for industry (≈ €0.20 per kWh) (der Energie and Wasserwirtschafte, 2024). Given the large amount of electricity consumed by HPC infrastructures, the prices centers pay fall into the latter category. Figure 3 shows how electricity costs for industrial consumers have evolved over the last few years, based on statistics published by the German Association of Energy and Water Industries (der Energie and Wasserwirtschafte, 2024). The costs are broken down into the categories of procurement, network charges, operation (in blue), governmental levies to finance the development of the electricity network and new energy sources (in green)1 and the electricity tax (in orange). Until 2022, Germany's energy mix relied heavily on gas supplies from Russia, which stopped after the invasion of Ukraine and the subsequent international sanctions on Russian goods. This led to a sharp increase in electricity procurement costs in 2022, which the German government partially offset by reducing taxes and levies. Prices fell again in 2023, but even leaving aside the 2022 peak, the general trend shows an annual increase in electricity costs of ≈ 3%. These cost trends are based on averages, and it is important to note that the electricity prices paid by HPC sites vary considerably (from €0.15 kWh to €0.29 kWh for the sites in this study), as the institutions hosting the HPC centers have very different ways of purchasing electricity.
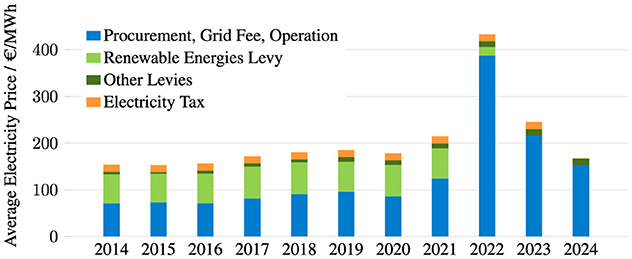
Figure 3. Average electricity price for new industrial consumers in Germany. Annual consumption 160,000 to 20 million kWh, medium-voltage supply. Data source (der Energie and Wasserwirtschafte, 2024).
The contribution of operational costs (including electricity and cooling costs) to the Total Cost of Ownership (TCO) of HPC systems hosted by our institutions ranges from 12% to 50%, where 50% means that running the system over 5 years costs the same amount of money as the initial purchase of the hardware (which typically includes a 5-year maintenance contract). Since the hosting site has little influence on the initial acquisition cost (only its negotiating skills), improving operational energy efficiency is the only strategy an HPC site can use to significantly reduce the TCO.
Legislation is a further driver enforcing energy efficiency measures in Germany. The Energy Efficiency Act (German Federal Government, 2024b), which has been derived from the European Energy Efficiency Directive (European Commission, 2024), mandates that: (i) data centers that are currently in operation must reach a Power Usage Efficiency (PUE) of less than or equal to 1.3 on a permanent basis by July 1st, 2030; and (ii) data centers that go into operation starting July 1, 2026 must be constructed and operated in such a way that at least 10% of the waste heat is reused (this share grows to 20% for data centers going into operation on July 1, 2028). The law also regulates air cooling temperatures, mandates the establishment of an energy management system, and contains further reporting duties.
The HPC centers involved in this study currently operate (as of September 2024) production supercomputers with an average power envelope per site ranging from ~1.1MW (KIT) to 4.7MW (MPCDF). However, all sites have plans to upgrade their infrastructures for their next generation systems, e.g., the JUPITER exascale system will raise the bar to 17MW when added to JSC's existing computing infrastructure. It is interesting to note that, despite the relatively wide range of system sizes, the breakdown of power consumption across the various components within the data center is quite homogeneous. We have collected in Table 1 average values, aggregating for each site the contributions of all systems it currently hosts. Most of the energy (78% to 86%) is consumed by the computer itself, where unfortunately it is not possible to separate the contribution from the processing units, memory and network in the measurements.2 The second consumer (7% to 15%) is the data center infrastructure, which needs electricity to run uninterruptible power supplies (UPS), pumps, climate machines (for air-cooled systems3), chillers (for cold-water cooled systems), dry coolers, etc. The remaining energy (3% to 8%) is consumed by storage systems. In the following, we look in detail at the approaches actively applied or planned to save energy at the data center level (Section 3) and the computer and storage systems (Section 4).
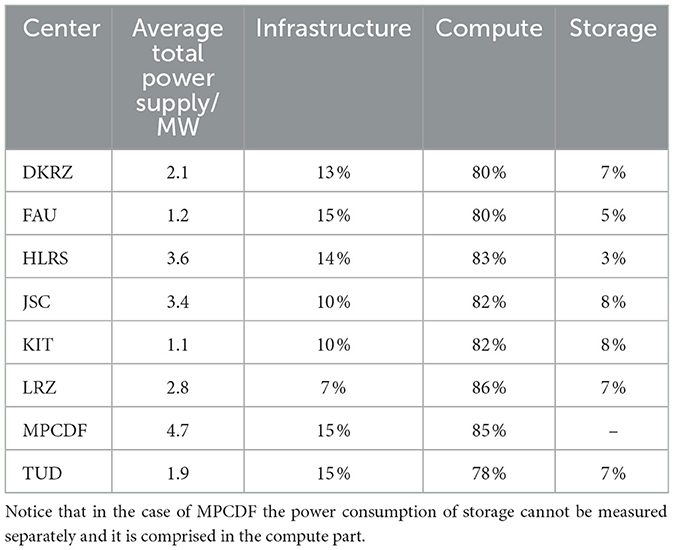
Table 1. Total power supply (in average) to each of the centers, broken then down on the relative consumption by three main components: infrastructure, compute, and storage.
Data centers, whether for HPC or cloud systems, consume resources in the form of electricity and water, with a significant fraction being used for their infrastructure. The growth in computing power comes with higher computing density and heavier equipment, which has consequences for the hosting data center. Cooling strategies are moving away from air-cooling to direct liquid cooling, utilizing higher operating temperatures to enable free cooling. Adiabatic cooling expands the range of free cooling but induces an increased demand for water. The following subsections describe these and further trends to reduce energy consumption at the data-center level.
To keep HPC operations sustainable, the growth in energy consumption needs to be compensated by increased usage of green energy so as to not increase the carbon footprint of HPC. Recent legislation in Germany requires data centers to continuously increase their energy efficiency and newly built data centers will have to source their energy completely from renewables by 2027, although several data centers have been doing this voluntarily for quite some time already.
The fraction of renewables in the German grid already exceeds 50% [Statistisches Bundesamt (Destatis), 2024] and with the ongoing expansion of wind and solar power generation, this fraction is only set to increase. While the intermittent generation of renewable electricity causes the grid stability to degrade [Federal Ministry for Economic Affairs and Climate Action (BMBK), 2025], HPC centers could act as dynamic loads that increase their power consumption at times of high availability of green energy and reduce it when wind and solar generation is low. This would not only stabilize the grid and help with the green transition, but also provide economic incentive for HPC operators as electricity prices can even turn negative when renewable production exceeds demand, meaning that consumers able and willing to absorb production peaks pay lower electricity costs or even get paid by the electricity company.
The technologies to implement such grid-demand-response schemes are available: power management capabilities as described in Section 4.3 can be used to modulate the power consumption of HPC systems dynamically and historical monitoring data of previous job executions could be leveraged to identify jobs with high power draw and schedule them at times of abundant energy (Section 6).
In past years, the state-of-the art HPC data center in Germany was usually planned, designed and built from scratch relying on highly customized buildings with energy and cooling infrastructure tailored to 2–3 generations of HPC systems. After about 10 years, infrastructure upgrades had to be put in place in order to keep up with the rise in energy consumption, cooling demands, and weight load of the HPC systems to be installed. After several decades and upgrades, delivering more energy and cooling into these customized buildings becomes more and more difficult as can currently be seen at the MPCDF, HLRS and JSC, where new data centers are now under construction or being planned for. While JSC has decided to set up a Modular Data Center (MDC), MPCDF, and HLRS are again setting up highly customized buildings. The MDC approach, or generally spoken container-based data centers as they are nowadays also used by commercial companies, allow for an exact match of the system requirements and data center provisioning without installation of over-capacities in infrastructure. In addition they significantly shorten planning and construction times, especially when it comes to standard IT. On the other hand, traditional building-based data centers, as planned at MPCDF and HLRS, provide a longer-term solution that can be tailored to wider campus infrastructure plans to maximize the waste heat utilization. In all cases a new data center construction does not imply the old facility will be dismantled, but rather its life will be extended as the older buildings will remain in operation hosting smaller scale HPC systems, cloud and storage systems, or regular IT services. In those cases infrastructure demands did not increase as significant as for large-scale GPU-accelerated HPC systems.
As of 2024, the trend to renew HPC data center infrastructure is not only forced due to system demands but also by the requirements of legislation (German Federal Government, 2024b). Legislative demands are fulfilled by both MDC and customized buildings, but they will become stricter in the future. After July 1st 2026, Data Centers (DCs) shall be constructed and operated in such a way that their proportion of reused energy reaches at least 10%, while those starting operation one or two years later must already reach 15% to 20% energy reuse, respectively. Taking these requirements into account, a foreseeable trend in Germany will probably be a change in data center operation away from a singular focus on the efficiency of the HPC system or the DC, toward integrated efficiency optimisation of the HPC system, DC and surrounding waste heat-absorbing district infrastructure.
Compared to traditional air cooling, the adoption of DLC adds cost and complexity at the interface between IT systems and data centers. However, due to the size and homogeneity of their compute clusters, HPC centers are ideally positioned to employ DLC. Operating DLC loops at higher temperatures (warm water, typically 30°C to 40°C inlet temperature) allows in Germany for year-round free cooling, eliminating the need for chillers and thereby reducing both capital and operating expenditure. In addition, the ever-growing Thermal Design Power (TDP) of today's CPUs and GPUs mandates DLC for HPC centers aiming for highest performance.
The experiences with operating DLC systems have been largely positive. In particular, fully integrated cooling solutions (w/o fans) have demonstrated excellent performance, achieving high delta T values (>10K) and transferring more than 95% of the heat generated by HPC systems into the water.
Some vendors upgrade air-cooled compute nodes with purpose-designed coldplates for liquid cooling. This approach greatly increases the range of configurations to choose from, but, depending on the temperature, typically only captures about 70% of the heat in water as some parts of the mainboards as well as power supply units and networking equipment remain air-cooled.
Table 2 summarizes information on water cooling adoption in German HPC centers, some of which have more than 10 years of experience operating DLC clusters. Some aspects are common for most centers: All large storage systems and special compute node configurations that require more flexibility (fat nodes, test systems, and similar) remain air-cooled but are supported, e.g., by using water-cooled doors. For air-cooling installations, there is little room for further innovation that could lead to improve, e.g., efficiency and operational aspects (Hackenberg and Patterson, 2016). Other thermal management technologies, such as immersion or two-phase cooling (Curtis et al., 2023), are currently not utilized in HPC operations at our German sites. For some centers the adaptation to warmer cooling temperatures has been delayed by site-specific infrastructure legacy constraints such as local cooling networks. However, all of those centers are in the process of transitioning to year-round (warm water DLC) free cooling without chillers for their compute clusters. Typical operating regimes comprise multiple DLC clusters at 2MW total power, or more.
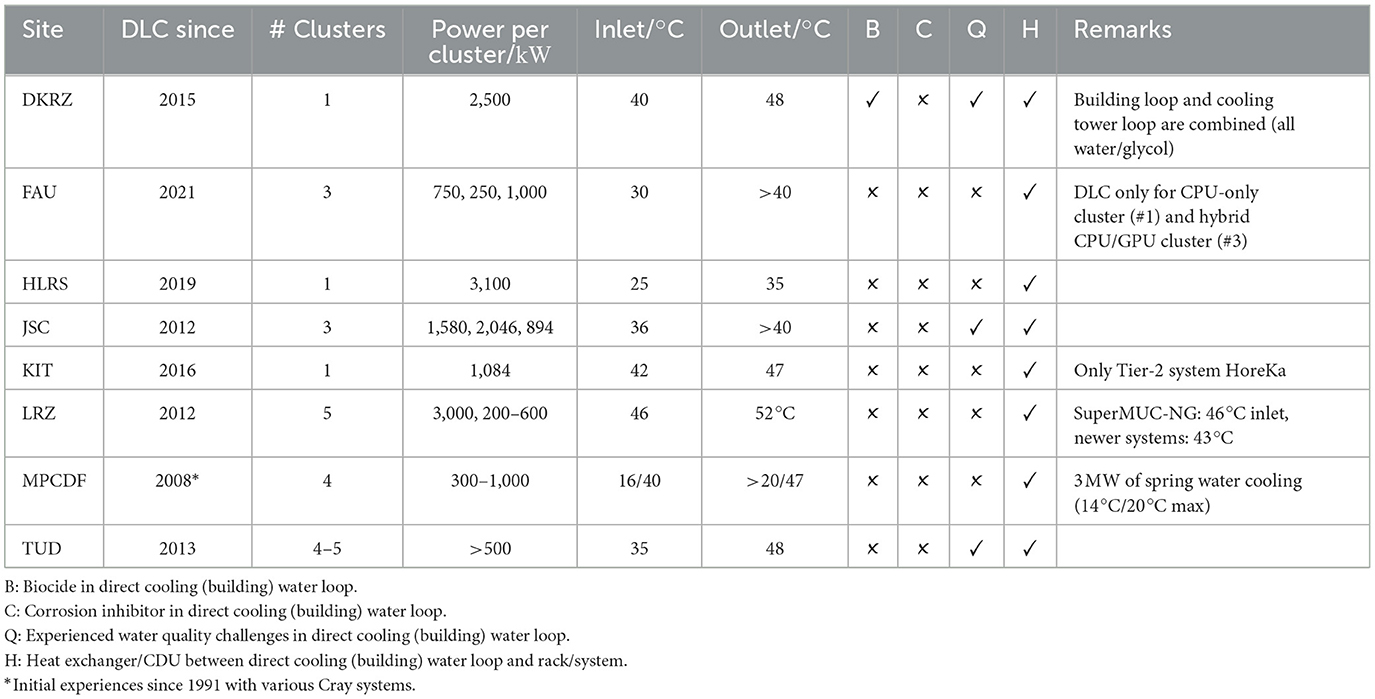
Table 2. Direct liquid cooling for various German HPC centers.
The design of the cooling loops needs to be carefully considered for DLC data centers, e.g., with respect to the number and placement of heat exchangers, while considering vendor interfaces. Most centers in this study operate three loops, separated by heat exchangers: water/glycol for the (closed loop) cooling towers, water for the main building loop, and typically some vendor-specific coolant for the rack-/system-level internal loop. Eliminating heat exchangers can improve efficiency. When building-loop water is circulated directly through compute nodes, maintaining high water quality (e.g., filtration and particle size) becomes critical, balancing efficiency with operational challenges (see below). Similarly, circulating building-loop water through cooling towers can improve efficiency, but preventing damage to the cooling loops is challenging when (unscheduled) system downtimes occur during freezing outside temperatures; alternatively, one large glycol loop can be operated at the expense of increased pump energy while saving heat exchanger installation and losses (cf. DKRZ). Alternative cooling strategies, such as using spring or lake water (cf. MPCDF), may offer highly efficient cooling, but only for certain locations.
Concerning operational challenges for DLC installations, maintaining stable water quality is key. The warm water of DLC loops stimulates bacteria and/or micro-algae proliferation. Vendors address this issue with proprietary formula in the rack/system cooling loops. For the building water loop, it may be managed through chemical treatment (biocide), or through maintaining extremely clean (e.g., deionized) water, with most sites in this study choosing the latter. However, any water additive (glycol contamination, corrosion inhibitor, or even biocide) may eventually become food for some form of biology, creating an environment in which the additive balance must be continuously tuned. Therefore, regular (external) water quality analysis or continuous monitoring (pH, conductivity, total organic carbon) is required in any case.
The use of polyethylene/polypropylene piping can offer financial and flexibility advantages, but may also lead to uncontrollable oxygen diffusion into the water and hence increase the risk of corrosion. Particular care must be taken with metal mixes in the cooling loops and the associated chemical interactions that may strongly accelerate corrosion.
Another potential issue are water leaks, which do not happen frequently but have been seen in isolated cases, in particular located at the quick-connects inside the rack or at the connection between the water loops of rack and building. Leakage sensors with automatic monitoring and alarm systems can mitigate this risk.
Operational challenges for large centers may also include multi-MW load swings on timescales of seconds. However, this issue is much more prevalent on the electrical side (sub-second time scales) and can be managed particularly well for chiller-free (direct water) free cooling loops with a reasonably sized buffer tank (water storage), enabling simple control loops and very steady operation.
Looking ahead, cooling temperatures may decrease, as suggested by guidelines from the American Society of Heating, Refrigerating and Air-Conditioning Engineers (ASHRAE) (American Society of Heating Refrigerating and Air-Conditioning Engineers, 2021). This trend is understandable, because the density of compute power currently exceeding 150 kW per rack, and in the future 200 kW per rack and more, can no longer be sustained through improved processor manufacturing processes or higher acceptable device temperatures; lower cooling temperatures allow for higher heat dissipation. However, it may necessitate the reintroduction of chillers, which would be a significant setback in terms of both efficiency and environmental impact.
Waste heat reuse is among the most effective means to improve sustainability of data center operations. Due to their increased cooling temperatures, DLC installations are particularly well-suited for efficient heat reuse.
Any such project strongly depends on the local environment of the data center, because the waste heat needs to be consumed locally. Our survey in Table 3 shows energy reuse factors ranging from 0% to 20% for these DLC-enabled German HPC data centers. The current potential is not fully utilized, even though highly ambitious plans exist at several sites.
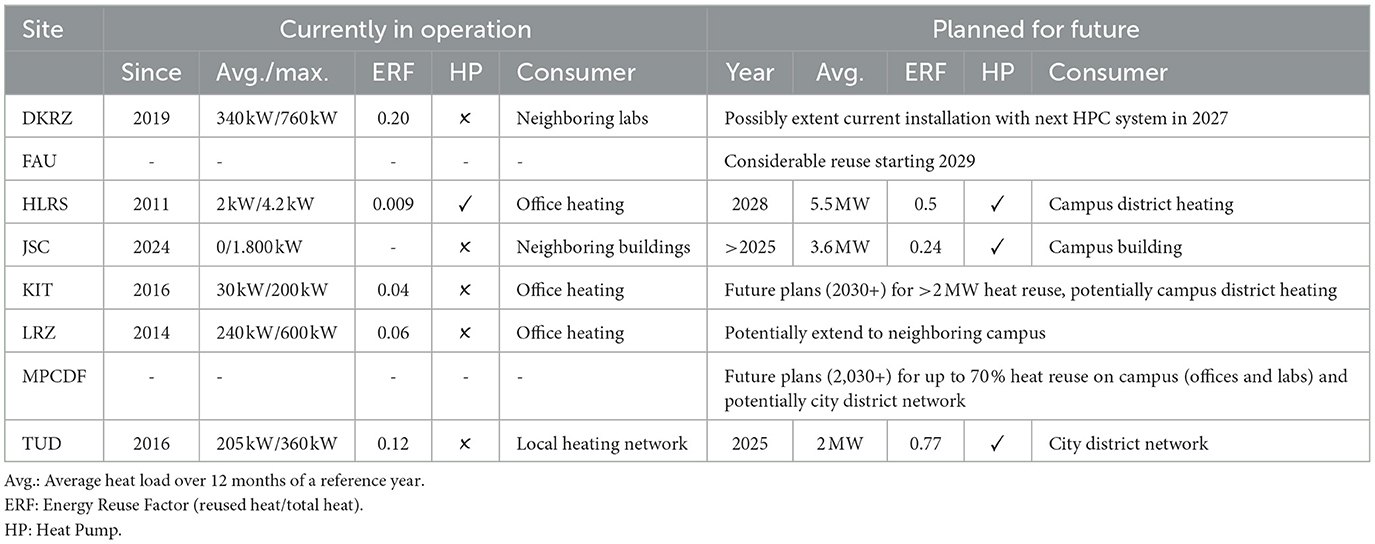
Table 3. Heat reuse for various German HPC centers.
In particular, year-round high levels of heat reuse are difficult to achieve, because heat generation of HPC centers often exceeds the heat demand of surrounding buildings even during winter. Usually, the most promising large scale heat sink are city-wide heat networks. In Germany, these usually operate at temperatures close to 100°C, requiring heat pumps to inject low-temperature data center waste heat. Operating heat networks at temperatures that would allow reusing HPC waste heat without heat pumps would be technically viable and overall more energy efficient. However, retrofitting all consumers (i.e., residential heating) is impractical within the typical life span of HPC data centers.
Political regulations have been put in place to mandate 20% heat reuse for data centers that go into operation in 2028 and later, but this would strongly influence the range of viable building sites and potentially harm data center business in Germany. The practical implications of this legislation are therefore still fiercely debated.
So far, no noteworthy projects that feed HPC data center heat into industry processes with year-round demand have emerged. Table 3 shows that, for now, the most promising approach is to use large heat pumps to increase the temperature to the levels required by district heating networks of cities or very large campuses (usually around 70°C to 90°C). At TUD, such a system will be fully operational in Q1 2025.
Ideally, heat reuse becomes the primary heat rejection mechanism, and cooling towers of the DLC loop will be relegated to a backup role. This may alter the cooling loop design in the future: the focus shifts from cooling-first to heat-reuse first, with a greater emphasis on strategically placing heat exchangers to optimize for efficient energy recovery, while the efficiency of the backup cooling becomes largely irrelevant.
Other ambitious projects exist, e.g., in the planning for the new HLRS data center, water-cooled CO2 compression chillers shall reuse waste heat from lower temperature cooling circuits, which are also necessary for air cooling and climate control. An innovative concept to use waste heat to drive adsorption chillers for cold water production has been evaluated by LRZ with convincing results (Wilde et al., 2017), but recent trends to lower water temperatures in DLC rendered this technology inefficient for data center use.
The physical limits to ever-shrinking structure sizes and the associated manufacturing challenges are slowing Moore's Law (Huang, 2015). The computing industry, and the HPC community in particular, are now trying to increase performance through diversification and specialization (Milojicic et al., 2021; Shalf, 2020).
Processing units are the most power-hungry part of an HPC system. Since the introduction of cluster computing, HPC systems have predominantly been built using high-speed networks to interconnect CPUs from the server market (Becker et al., 1995). Since around 2010, such clusters have started to integrate GPUs and other accelerators to increase performance per Watt (Carabaño et al., 2013; Enos et al., 2010; Betkaoui et al., 2010; Véstias and Neto, 2014). Compared to CPUs, accelerators pack a much larger number of simpler cores or execution units per area, sacrificing single-thread performance in favor of higher parallel computing throughput. They further increase energy efficiency by specializing their architecture to solve specific computations, relying on CPUs mainly for service tasks. The result are higher FLOP/Watt ratios for accelerated systems,4 at least when considering arithmetically intense applications such as the HPL benchmark (Strohmaier et al., 2024b).
The goal of heterogeneous HPC systems is to offer users different compute devices, allowing them to select those best suited for their applications. Depending on how tightly the CPU and accelerators are tied to each other, different heterogeneous system architectures are possible. The two extremes can be classified as monolithic and modular system architectures. A monolithic system packs many different kinds of processing units inside each node creating a system-wide homogeneous cluster (all nodes look the same) made of highly heterogeneous nodes (various compute devices inside the node). This approach minimizes the communication latency between host and accelerators (Schulz et al., 2021), but it can lead to low resource utilization and higher energy consumption. This can be mitigated by applying advanced scheduling techniques—to efficiently co-schedule complementary jobs and keep all accelerators busy—and dynamic power management—to switch off all unused devices (Suarez et al., 2021). Modular systems, on the other hand, are system-wide heterogeneous supercomputers made of a diversity of homogeneous clusters (modules) interconnected to each other via a high speed network (Suarez et al., 2019, 2021). Each module has a specific node architecture, with ideally only one kind of processing unit.5 This resource disaggregation makes it easier for the scheduler to reserve only the kind and amount of nodes needed by each job without blocking resources for others, but relies on a coarse-granular partition of the application codes to ensure that performance does not suffer from the larger inter-module communication latency (Kreuzer et al., 2021). It is worth noting that resource disaggregation can be beneficial for compute, but also for memory devices (Michelogiannakis et al., 2022; Aguilera et al., 2023). Interconnect technology is already supporting the creation of memory pools accessible via the network with network protocols such as Compute Express Link (CXL) (Gouk et al., 2023).
In the German landscape, all HPC centers included in this study host heterogeneous computers combining CPUs and GPUs. These are either operated as independent systems (e.g., FAU, LRZ) or partitions or modules in integrated machines (e.g., DKRZ, JSC, and MPCDF). The CPU systems/partitions consist of dual-socket nodes with x86 CPUs (Intel or AMD), sometimes organized in sub-partitions with different memory configurations (e.g., standard and large memory capacity). Only the planned JUPITER Booster at JSC will utilize non-x86 Arm CPUs in the NVIDIA Grace-Hopper configuration. The GPU systems currently all employ NVIDIA GPUs, mostly NVIDIA Ampere (A100) or NVIDIA Volta (V100), depending on the year of deployment, while a number of NVIDIA Ampere A40 are also installed, e.g., at FAU. Most recent and planned installations are foreseen with AMD MI300 GPUs (MPCDF and HLRS). All centers use Slurm as their batch scheduling system (SchedMD, 2024), supporting heterogeneous jobs and allowing applications to allocate resources across different compute partitions.
More hardware heterogeneity exists in small test platforms and also in cloud infrastructures operated by the German centers, e.g., MPCDF, TUD, KIT, and JSC all host a small number of different devices, e.g., AMD GPUs, Graphcore, Field Programmable Gate Arrays (FPGAs). In fact, with Moore's Law reaching its limits, a variety of accelerators addressing different use cases are emerging, many of which are targeting the vast AI market (Matsuoka, 2018). GPUs are still the most widely used accelerators in HPC, but new Application-Specific Integrated Circuit (ASIC) designs are attracting attention [e.g., Tensor Processing Units (TPUs) (Google, 2024), Graphcore (Graphcore, 2024), Cerebras (Cerebras, 2024), Groq (Graphcore, 2024), and SpiNNaker2 (SpiNNcloud Systems, 2024), etc.]. A common trend across all these accelerators is a strong focus on lower precision arithmetic. This shift is justified by the fact that the number of operations per second a processor can perform is inversely proportional to the number of bits required to encode its floating point numbers. The same applies to energy efficiency, which improves as arithmetic precision is decreased. However, lower precision arithmetic comes at the cost of higher uncertainty and less reproducible results. While this is acceptable for AI training applications, it remains to be seen how many traditional HPC codes can make the leap.
Hardware heterogeneity goes down from the node into the package level. Chiplet-based processor designs combine different kinds of technologies and manufacturing processes to achieve higher performance without continuously growing the die area. For example, AMD EPYC Rome mounts CPU and Input/Output (I/O) chiplets on top of an interposer to create an integrated processor with more than 100 cores (Suggs et al., 2020; AMD Corporation, 2024). Chiplet-based designs offer more flexibility and customization, as they allow to define for a processor generation a diversity of Stock Keeping Units (SKUs) with different numbers of CPU, accelerator, memory, and I/O components, keeping the rest of the architecture more or less untouched. Interesting trends also include the increasing number of companies developing CPUs for the server, HPC and AI markets using the Arm Instruction Set Architecture (ISA), [e.g., Fujitsu (Sato et al., 2020; Fujitsu, 2024), Ampere (Ampere Computing LLC, 2024), Apple (Apple, 2024), SiPEARL (SiPEARL, 2024), and NVIDIA (NVIDIA, 2023)], and the growing community around the open source RISC-V ISA (RISC-V Foundation, 2024). The European projects EPI (The EPI Consortium, 2024), EUPILOT (The EUPILOT Consortium, 2024), and EUPEX (The EUPEX Consortium, 2024), for example, work on Arm-based CPUs and a variety of RISC-V-based accelerators, targeting excellent energy-efficiency. These and upcoming R&D projects in Europe target future chiplet-based integration combining some of the developed processing technologies (EuroHPC Joint Undertaking, 2024b).
However, all the above discussed hardware heterogeneity comes at the cost of higher programming complexity, since most accelerators require specific programming models and force application codes to be ported and refactored (see Section 7).
Storage systems consume a smaller portion of total energy compared to the processing part. The German HPC centers reporting here offer 100s of Petabytes of storage space using a variety of file systems, in a mix of Non-Volatile Memory Express (NVMe), Hard Disk Drive (HDD), and Tape. Nonetheless, these HPC centers see no more than 8% of total power being consumed by storage, with some as low as 3% (see Table 1). On the other hand, storage systems tend to be unique, are tightly coupled with the HPC systems, have higher availability requirements, and represent higher risk on outages. Therefore, any power saving techniques need to be well tested and adhere to further stricter rules.
There are three aspects to consider when analyzing power consumption and evaluating energy-saving strategies for storage systems: (i) energy consumption for data at rest or idle, (ii) energy consumption for data access, and (iii) effect of storage components on energy consumption in other parts of the system.
Storage systems are sized for both capacity and performance, and this in turn determines a baseline power consumption. This baseline, or energy consumed while the data is at rest, represents the largest share of a storage system's overall power usage, and it is hardly possible to reduce it. For example, the strategy of switching off idle components used in computing clusters is not feasible for a storage system without large data migrations or risking data loss. Over time, storage systems have benefited from the advances in semiconductor technologies, leading to drives with larger capacity and a smaller set of servers required for the same number of drives. This has led to newer, bigger, faster storage systems consuming less energy. For example, the JSC's storage cluster JUST5 (Jülich Supercomputing Centre, 2024b) consumed an average of 157kW power offering 70PB storage capacity and ~400GB/s bandwidth, while the newly installed JUST6 consumes about 108kW (0.7×) offering 150PB (2.1×) and ~600GB/s (1.5×). Future cheaper high capacity Solid-State Drives (SSDs) replacing HDDs shall reduce power consumption per storage unit (Tomes and Altiparmak, 2017) but require a larger number of servers to leverage.
Regarding the second aspect (energy consumption for data accesses), storage systems under load consume only slightly more energy than at idle. For example, observations on JSC's, HLRS's as well as LRZ's storage clusters show that power consumption during operation does not vary by more than 12% from the highest peak.6 This observation is supported by the fact that storage appliances typically run their corresponding processors in performance mode and disks are not turned off, whereas idling HPC compute nodes could be turned off or at least put into powersaving modes. At the same time, vendors only commit to a certain performance when the appliances power settings are not touched.
The third aspect is the effect of the storage system on the energy consumption of other components, for example, idling compute nodes due to slow I/O. There are strategies that could help mitigate this effect: accurately sizing the storage system, adding local storage, improving caching, asynchronous I/O, etc. However current observations show that the peak performance of storage systems is rarely reached during production (Maloney et al., 2024), suggesting that optimizing applications' I/O behavior would be a better approach. Alternatively, deploying NVMe based storage systems, which are less sensitive to I/O patterns, could automatically reduce idle times on I/O.
As HPC systems are growing ever larger and becoming increasingly power hungry, managing their power consumption is important for their (energy-efficient) operation. All modern CPUs and GPUs provide software interfaces to either limit their power consumption directly or by controlling the operating frequency and voltage (Dynamic Voltage and Frequency Scaling (DVFS)) and hence the power consumption indirectly.
While higher clock frequencies in general translate into higher performance of these devices, they are usually detrimental to their energy efficiency: depending on the characteristics of a particular workload, the highest frequency may not always yield the shortest runtimes, e.g., because CPU cores are waiting for slow memory transfers. In particular, memory-bound workloads typically do not benefit from higher frequencies and can be executed at lower frequencies with negligible impact on performance and runtime (Bhalachandra et al., 2017). Indeed, as the energy consumption of an application run is the product of its runtime and average power consumption, a reduced frequency can yield energy savings for such workloads. In contrast, the energy efficiency of a compute-bound workload may benefit from higher frequencies as a potential increase in average power consumption may be compensated by shorter runtimes (Auweter et al., 2014).
Multiple approaches exist to leverage such energy saving schemes in production HPC environments: the simplest approach is to let the user select a frequency as they should know the characteristics of their applications best.7 Batch schedulers such as Slurm provide control parameters for job scripts that allow users to set the frequency for their jobs. However, a single frequency may only be optimal for some phases of an application run, but inadequate for others (Corbalan et al., 2020). To deal with such situations, more sophisticated runtime systems such as EAR (Corbalan et al., 2020) (deployed at LRZ), GEOPM (Eastep et al., 2017) or HPE PowerSched (Simmendinger et al., 2024) (deployed at HLRS) are required. They dynamically set optimal frequencies at runtime and use online monitoring to assess the current characteristics of the workload and hence can accommodate different execution phases.
Another important field for power control are over-provisioned systems, i.e., systems that have a peak power consumption above the limits of their supporting electrical or cooling infrastructure. In day-to-day operations, HPC systems typically draw around 65% of their peak power consumption. So, it can be cost-effective to design the supporting infrastructure for this lower power limit. However, this requires the system to stay below this limit at all times. The simplest approach here would be to enforce the same static power cap on each individual compute node to ensure that the total power limit is not exceeded. However, this may leave compute capacity stranded as the power characteristics of the various workloads running on the system could be very different. Here, again, a dynamic approach as implemented by HPE PowerSched and deployed at HLRS can assign dynamic power limits to individual jobs to best utilize the supporting infrastructure and maximize system throughput.
Even though HPC systems strive for a high utilization, idle power consumption is also of concern as certain situations (backfilling, maintenance) can lead to entire compute nodes being fully idle for longer periods of time. Recent CPU-based systems exhibit a wide range of power consumption in idle (Tröpgen et al., 2024), which puts a new emphasis on considering idle power consumption for procurement and its optimisation during operation (Ilsche et al., 2024).
The energy efficiency of a system as complex as an HPC infrastructure can only be optimized if it is first properly quantified, which requires careful monitoring of all the components that contribute to energy consumption. The size and complexity of HPC center environments place high demands on the collection and storage of metrics. Table 4 showcases the range of requirements of the represented German HPC monitoring systems with up to 8 million total metrics and up to 10 updates per second for each time series. At the same time, agents collecting data on the compute nodes should not interfere with regular production codes. Batch jobs with complex sets of used resources are typically not directly supported in generic monitoring stacks. Because performance is a key focus of HPC systems, continuous cluster-wide measurement of hardware performance counters provides critical data to judge the efficiency of batch jobs. In addition, HPC is a multi-user environment with different levels of trust, therefore strict security and access control are required, especially if unprivileged HPC users have access to the monitoring system.
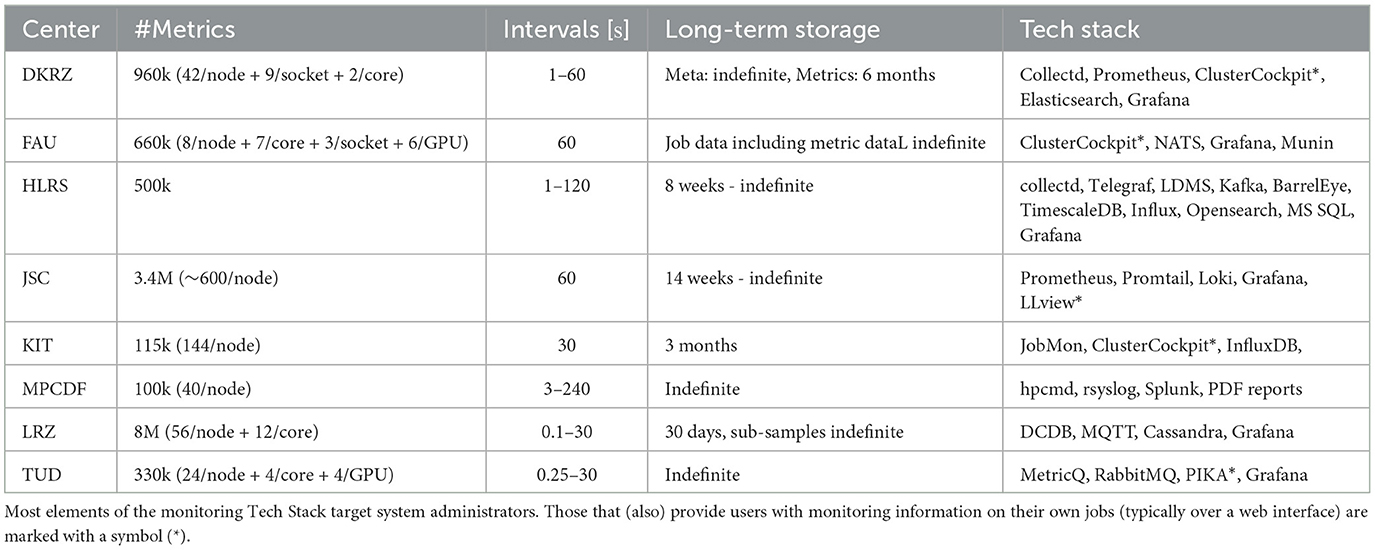
Table 4. Characteristics of monitoring installations on German HPC data centers.
Figure 4 shows typical components of a monitoring stack in HPC environments. For data collection, a node collector running on all compute nodes retrieves metrics from various interfaces. These values are then either sent to or fetched by a communication component, typically a message broker, for processing, storage, and visualization. Metrics from infrastructure components such as power distribution, cooling infrastructure, file systems, and network are retrieved out-of-band using different communication protocols. Because the central notion of work on HPC systems is a batch job, the monitoring system must integrate with the batch job scheduler (e.g., PBS, LSF, Slurm, etc.). Typically, a web interface provides access to the monitoring data. Different user groups (HPC users, project managers, support staff, and administrators) may have different data access restrictions and require specific views. Automatic analysis of jobs and general system attributes can be used to focus attention on where immediate action is required, including automatic alerting (e.g., via e-mail).
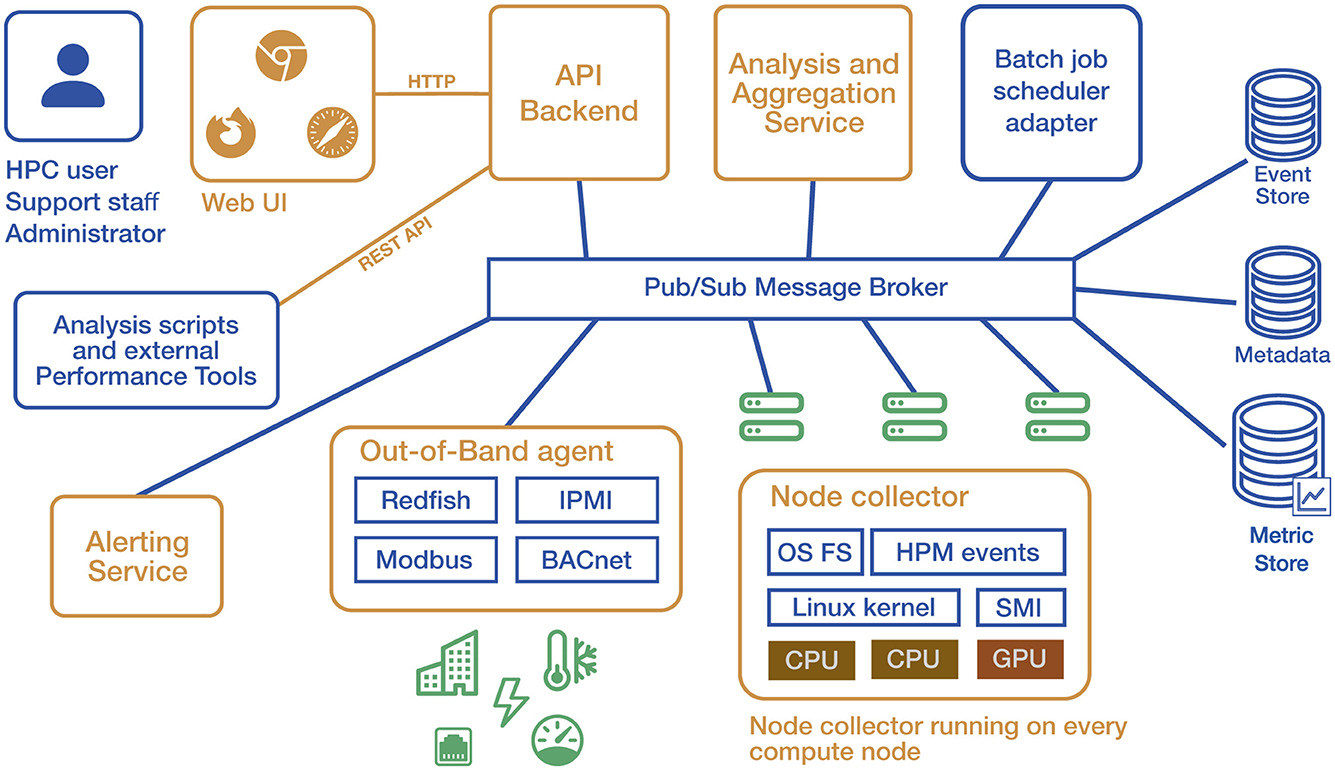
Figure 4. Typical components of a monitoring setup in HPC-Cluster environments.
Monitoring of HPC systems and their supporting infrastructure require the collection of relevant metrics from a wide variety of different sources: the compute nodes, the network infrastructure, the storage system, and ideally also the building infrastructure. There is no common Application Programming Interface (API) to collect such data and multiple different interfaces need to be queried for different sub-components. For example, within a compute node, there are many sub-components such as CPUs, GPUs, and network interfaces, each of which has their own and often vendor-specific interfaces. Some sub-components even have multiple interfaces, depending on the type of metric to be collected.
Most metrics for compute nodes need to be collected in-band, i.e., by a daemon running on the compute node itself (the node collector). This daemon will perturb other processes and great care must be taken to keep the overhead minimal in order to not interfere with the user applications running on the node. In particular the measurement of Hardware Performance Monitoring (HPM) metrics involves a significant overhead (Röhl et al., 2014). A common practice is to benchmark a very demanding application, as e.g., the HPL benchmark, with and without monitoring, to proof that there is no measurable influence. Even if there was a small overhead, the benefit of a monitoring system that allows to detect pathological jobs and gives support personnel and users critical insight into job runs, usually overcompensates any potential cost. Also, for some metrics, such as HPM, exclusive access is required, which may conflict with other tools, e.g., for performance profiling. There exist multiple generic node collectors that already implement the data collection, namely collectd (The collectd Project, 2024), cc-metric-collector (part of ClusterCockpit) (Eitzinger et al., 2019), and Telegraf (InfluxData, 2024c). The access to HPM metrics can be provided via the PAPI (Browne et al., 2000) and LIKWID (Hager et al., 2010) libraries, or using the Linux perf_event interface.
Other components such as network switches, power distribution units, or the data center building infrastructure can be queried out-of-band from a management node via the network without involving the compute nodes. Rather than minimal perturbation, such software is optimized for covering a large number of devices and high message throughput. While there is a trend, at least for IT components, toward the RedFish standard to make monitoring data available via a well-defined and well-documented API out-of-band, other decades-old protocols and interfaces such as Simple Network Management Protocol (SNMP) and Intelligent Platform Management Interface (IPMI) or Modbus and BACnet are still widespread. Many of these out-of-band interfaces have high latency and are hence not suitable for high frequency telemetry. Additionally, the timestamp associated with the measured event may be inaccurate if it is not provided by the device itself but by the querying daemon. Some of the existing node collectors also support accessing external components via out-of-band plugins.
Collection of monitoring data needs careful planning. The number of metrics available, particularly on compute nodes, can be overwhelming (Netti et al., 2019). For some metrics it may not always be clear what exactly is being measured and where. The collection interval needs to be carefully chosen, based on the update frequency of underlying sensors, frequency of change, and expected data volume. Most importantly, a versatile naming scheme for metrics needs to be chosen that works for all metrics regardless of their domain. For example, HPC systems are typically hierarchically organized (e.g., partitions, racks, nodes, sockets, CPUs, and cores), while their supporting infrastructure may not be. Once the naming scheme has been settled and the metrics to be collected chosen, it is also important to record meta information for all metrics: what exactly are they measuring, unit of measurement, update frequency, etc. The ClusterCockpit project proposes a generic data structure specification as JavaScript Object Notation (JSON) schema, that also includes metric lists (The ClusterCockpit Project, 2024).
Processing the collected data can be challenging due to the number of metrics, varying update rates, the number of monitored nodes, and the overall event/data rate. Generic solutions for time series data that cover ingestion, processing, storage, retrieval, and often specific data collection agents can be used in the HPC data center monitoring context. InfluxData (2024a), for example, ingests data from clients via a simple line protocol, particularly in conjunction with Telegraf. A pull-based mechanism enables centralized control of update rates and simplifies client configuration. In contrast, the push method offers easier network access configuration, particularly for clients in restricted networks, and incurs lower latency between data collection and processing.
Additionally, there are several solutions focusing on HPC data center monitoring, namely ClusterCockpit (Eitzinger et al., 2019) (FAU), DCDB (Netti et al., 2019) (LRZ), HPCMD (Stanisic and Reuter, 2020) (MPCDF), and MetricQ (Ilsche et al., 2019) (TUD). In these systems, the data collecting agents publish data to messaging systems (NATS, MQTT, rsyslog, RabbitMQ respectively), which enables flexible consumption for storage, transformation/aggregation or live analysis. NATS and MQTT are more lightweight whereas RabbitMQ allows metric-identifier-based routing of messages, enabling full decoupling of clients from consumers.
Given the high cardinality and in some cases high individual data rate, scalable time series storage is particularly challenging. The specific solutions differ in their implementation8: DCDB uses Apache Cassandra, a scalable, open-source NoSQL database. ClusterCockpit implements a custom in-memory database using fixed-duration ring-buffers for fixed-rate time-series data. Long-term data in ClusterCockpit is aggregated by job and stored in a job archive. MetricQ leverages the Hierarchical Timeline Aggregation (HTA) concept, which aggregates data in different levels on ingestion. This scheme allows efficient and complete aggregate queries over large amounts of data points.
Efficient system operation relies on data—including energy monitoring data—to provide actionable insights. For day-to-day operations, the data is often presented in dashboards (Bates et al., 2016), but the information is also used in form of reports for strategic decisions, e.g., capacity planning.
A widely-used (for example at DKRZ, JSC, and LRZ) web-interface for visual data presentation is Grafana (Grafana Labs, 2024), which supports many built-in data sources (e.g., InfluxDB and Prometheus) but also custom data sources. It is highly customisable, offering a “bird's-eye” view of a full system down to single rack or even node analysis, where multiple data sources allow the integration of e.g., additional infrastructure information. TUD uses the MetricQ WebView interface for explorative interactive monitoring data visualization. This custom implementation supports low-latency zooming and displays time-series statistics using a min/max/average band for each metric. ClusterCockpit and PIKA (Dietrich et al., 2020) provide their own custom web-interfaces, including user interface elements and authentication mechanisms that might be difficult to implement in generic solutions. In ClusterCockpit a special emphasis is put on a flexible search, filter and sorting user interface with high plot render speed.
Monitoring data is also used for alerting, i.e., directly notifying operators about anomalies, e.g., power consumption that is outside of the expected range. For example, the TICK-stack around InfluxDB, includes Kapacitor (InfluxData, 2024b), which pushes alerts to handlers, including email or instant messengers. Prometheus provides a dedicated Alertmanager service, which queries Prometheus for metrics and can render different alerts across multiple different channels. As another example, TUD uses a custom agent subscribed to the stream of metric monitoring data that checks if values exceed thresholds or are not updated in expected intervals. This agent then pushes alerts via the NSCA protocol to a Centreon installation that covers the general IT-Infrastructure of the university and handles notification via E-Mail.
Job-specific analysis refers to the detection of job features or the classification of jobs, which allows for more meaningful cluster-usage statistics and detecting faulty jobs or jobs with high optimisation potential. One use case is to detect the actual application or software stack used in a job. This enables HPC center administrators to gain insights about how a system is used by a specific application and in turn for a better tailoring of the system hardware to the application mix.
For classifying job performance or energy behavior often simple job statistics (called job footprint in the following) are used, e.g., average or maximum for a set of metrics. This job footprint is often based on metrics that describe the resource utilization of a job, e.g., flop rates, memory bandwidth, load, memory capacity used, and file and network I/O utilization. There are attempts to formulate simple rules based on this job footprint and use threshold-based binning of jobs to classify them. Due to the varying length and number of resources used, Machine Learning (ML) on the time series data is feasible but challenging. There are ongoing investigations how ML can be used to provide additional insights, but none of the German sites in this study are using this in production at present. A use-case for classification is automatically notifying support personnel or users from a job or user requiring attention. Some centers already use script based notification of users for faulty jobs, but detection of such jobs or users is still performed by manual monitoring of the job data at many of the centers participating in this paper.
For administrators and support personnel, overview of and insight into the data after the classification can be obtained by routinely inspecting graphical dashboards that list recent problematic jobs. JSC uses LLview to monitor the overall system utilization and provide detailed insights into specific jobs via detailed job reports available to end-users (Jülich Supercomputing Centre, 2024a). It significantly simplifies spotting under-utilized resources without the need for additional instrumentation of the used codes. LLview is designed to re-use the data provided by Slurm and by the above mentioned system monitoring Prometheus, where the latter is continuously extended to support additional metrics of particular interest, e.g., GPU utilization. MPCDF uses Splunk dashboards that identify jobs with harmful behavior (e.g., issuing file open and close operations at high frequency on the shared file system) or wrong resource requests (e.g., not using GPUs on GPU nodes). Based on similar logic, HPC users get notified for individual jobs via the stdout stream at the end of a job about obvious inefficiencies.
Another use-case of job footprints and classifications is cross-job analysis to investigate similarities or differences across user groups, application classes, and applications (Maloney et al., 2024). Statistics about the resource utilization of jobs are very important for preparing cluster procurements, decide on what systems are suited for a user or application class, and to optimize scheduling and resource management policies.
Energy efficiency is as much about keeping the power consumption of the system and its infrastructure as low as possible, as it is about ensuring that hardware resources are optimally utilized to deliver the maximum overall throughput of application results. Resources are shared between many users simultaneously executing their codes on HPC systems. Jobs are submitted via a batch system, which establishes a schedule to decide which jobs enter the system at which time to utilize certain resources. Scheduling and resource management systems are responsible for fairly allocating those resources according to the users' requests, the system capabilities, and a number of constraints and scheduling policies decided by the system owner. In contrast to commercial data centers, in the public funding and academic context of the HPC sites in this study maximum system occupancy (90% or even above) is targeted, so that typically oversubscription of user requests is the norm, and hardware overprovisioning the exception.
While in the past a number of scheduling software solutions were used (e.g., Torque/Maui, PBS, LSF, etc.), today basically all German (and European) HPC centers employ Slurm (SchedMD, 2024). This product has become the de-facto scheduling solution in HPC. This has some advantages for the users, who can use almost the same job scripts to launch their jobs on different systems, but constrains all HPC sites to the limitations of this particular scheduling software, e.g., the limited capabilities of Slurm on dynamic scheduling or support of heterogeneous jobs. Furthermore, this bares the danger of a monoculture, since there is only one private company controlling the development of the code and offering commercial support for this solution. A promising alternative is the Flux scheduler (LLNL, 2024), which has been first used at large scale with the El Capitan system (LLNL, 2025) at Lawrence Livermore National Laboratory (LLNL).
The scheduling policies used today at German sites statically allocate a number of full nodes for a given time window, according to the user's request. But users tend to be conservative in their estimations, asking for longer time-windows than their jobs actually need. Therefore, when a job's execution finishes, most probably the scheduler has to drop the current schedule and create a new one. Furthermore, since free nodes were filled with smaller jobs by the backfiller, the next large job will not be swiftly started but has to wait according to the original schedule. Overall, this will result in a disadvantage of large jobs and creates fragmentation of resources, that might require queue cleaning actions to get an appropriate combination of nodes to allocate new large jobs, at the cost of idle resources.
Several studies have shown that a significant amount of user jobs do not fully utilize the node resources (Peng et al., 2020; Michelogiannakis et al., 2022; Li et al., 2023; Maloney et al., 2024). Even worse, recent systems come with very fat nodes hosting dozens of CPU cores, multiple GPUs, and other accelerators, making it more challenging for an individual user to fully employ all available devices. Node-sharing and co-scheduling of jobs with complementary profiles (e.g., compute bound with memory bound jobs, and CPU-only with GPU-centric jobs) could allow HPC centers to increase the amount of jobs simultaneously running on the system, with the potential to increase system utilization and throughput. However, it also bears the risk of disturbing interference between those jobs to appear.
Energy-aware scheduling policies are applied in production already at several German sites. At JSC, idle nodes are powered down by Slurm, which can reduce the power draw of systems with idle times significantly. To give an example, the power consumption of the JUSUF system at JSC was reduced by 25% from roughly 660 MWh in 2022 to 495 MWh in 2023 by putting a rather large implementation effort for the power down feature, with the benefit that this now can be transferred to all given and future systems. In addition to the feature mentioned above, users are allowed to set the power per node depending on their needs, by reducing the operational frequency to the minimum possible without impacting application performance. Furthermore, topology-aware scheduling is currently employed at HLRS to allocate neighboring nodes to minimize network congestion. Note that HLRS uses a hypercube network topology, much more sensitive to increased latency across network hops than the tree-like interconnect topologies (e.g., dragonfly+) used by the other German HPC sites. LRZ has employed policies to encourage users to improve the energy efficiency of their codes, gathering mixed experiences.
In the German and European context the strong motivation to establish GreenHPC has led to funding a number of R&D projects targeting at improving scheduling mechanisms, to allow for more efficient resource sharing, dynamic allocation, job malleability, and enhanced energy-efficiency. The general trend in these projects goes toward developing a fully integrated system operations software stack, in which the scheduler is coupled to the monitoring system and a data analytics infrastructure, bringing together and establishing correlations between job profiles, hardware capabilities, and energy use. The goal is to increase the scheduler's intelligence, by feeding it continuously with system and data center monitoring information. Analyzing extensive monitoring data will help to understand the actual resource utilization per job to adapt/optimize scheduling decisions on the fly and provides the potential to even predict the behavior of future jobs for a more energy and resource-efficient scheduling. The German Federal Ministry of Education and Research (BMBF) EE-HPC project (The eeHPC Consortium, 2024) develops a production-grade framework for energy-efficient HPC operation by continuously adopting job-specific power-cap settings through direct optimisation using hardware performance counter metrics. This framework allows one to set optimal power-cap settings for every job with regard to energy-delay product, but also can be used to enforce a global system power-cap limit.
Due to the strong motivation to establish GreenHPC, methodologies developed in research projects are gradually being transitioned into production. For example, the PowerSched Framework (Simmendinger et al., 2024) has been applied in production at HLRS since February 2024. However, it is evident that very advanced and dynamic methodologies, such as those leveraging node-local DVFS at high frequency, are not yet applied in production as they are known to impact highly synchronized applications. Instead, more conservative approaches like the one implemented in PowerSched, which sets power limits per job (i.e., for all nodes of the job in lockstep), are adopted first. This allows for an evaluation of the system-wide performance impact of the application job mix executed on the HPC system and facilitates a smoother transition to more complex methodologies without significantly disturbing users.
Very large HPC infrastructures, which are themselves a major power consumer, are considering using such intelligent integrated solutions to react to the demands in the national electricity network, in a similar manner as large industrial infrastructures do. Increasing operations during phases with electricity overproduction (e.g., sunny/windy days with high electricity producing via renewable energies), would allow optimal HPC operations not only from the pure energy consumption perspective, but also reducing CO2 emissions and minimizing costs (Wassermann et al., 2024). Furthermore, HPC centers are used to managing preempt-able jobs, and could hold a queue of useful computational workloads that can be run to help stabilize power grid systems with significant fractions of Distributed Energy Resource (DER) generation. However, such advanced approaches pose difficult challenges to HPC scheduling systems and their capability to predict future system behavior, adding another layer of complexity well beyond what HPC operation tools are currently able to cope with.
With continuous improvements in HPC hardware and infrastructure, another important contributor to efficiency gains is related to the scientific workloads. By leveraging the hardware improvements effectively for better performance, shorter runtimes and thus, in most cases, more energy efficiency can be achieved. There are various approaches to achieving better hardware utilization through means of software, a fundamental component of HPC.
Modern processors with many concurrent execution threads, like many-core CPUs or massively-parallel GPUs, are enabled through effective programming models, making the distinct features of the devices abstractly available to programmers. The models are plentiful (Herten, 2023) and include, for example, CUDA (NVIDIA, 2024b) and HIP (AMD, 2024a), used for NVIDIA and AMD GPUs, respectively, which promote the Single Instruction, Multiple Threads (SIMT) programming model to drive the many threads of the GPUs individually; or SYCL (Khronos, 2024), which is more general and provides building blocks for execution of parallel algorithms with implicit parallelisation on many different hardware platforms. Through these models, programmers can effectively utilize the underlying hardware resources and gain both performance and energy efficiency improvements. While lower-level approaches like CUDA can serve one specific hardware design, the higher-level approaches of SYCL, Kokkos (Trott et al., 2022), or ALPAKA (Zenker et al., 2016) allow for more portability between hardware designs. The convergence toward higher-level, abstract programming models eases the burden of individual programmers by relying on pre-developed primitives with excellent performance, prepared by a community of hardware-conscious engineers. In some cases, the development of implementations of these programming models are conducted in the open as open source software, levering the benefits of open discussions and support by the large community (Trott et al., 2022; Alpay et al., 2022). Another prominent high-level programming model is OpenMP (OpenMP Architecture Review Board, 2024), which is arguably the easiest entry-point for parallel programming and enables generation of parallel code identified by the compiler. These high-level abstractions lower the barriers to entry for new HPC users and offer productive ways for performance-conscious programming. Interoperability with low-level/native programming models can be exploited by advanced performance engineers to further optimize performance and energy efficiency.
Further abstraction with potential for even more efficiency gains can be achieved by relying on libraries. These packages, sometimes only available in binary form from hardware vendors, offer implementations of algorithms and patterns, usually with high grade of sophistication and deep hardware focus. A famous example are the Basic Linear Algebra Subprograms (BLAS) APIs, which are implemented for nearly all hardware devices by their vendors [e.g., oneMKL (Intel) (Intel, 2024) and cuBLAS (NVIDIA) (NVIDIA, 2024a)]. Of course, also here, community-driven libraries in the open-source realm exist, like BLIS (Van Zee and van de Geijn, 2015), an extensible library with many hardware-specific micro-kernels (Nassyr et al., 2023; Nassyr and Pleiter, 2024). Libraries exist beyond computational algorithms. NCCL (NVIDIA, 2024c), for example, can improve GPU-centric communication significantly over the HPC-default Message Passing Interface (MPI), in AI applications and beyond (Wu and Di Napoli, 2023).
Separation of performance-critical code and user-facing interfaces offers a productive way to gain performance, ideally relying on well-defined APIs implemented by advanced libraries. The approach allows moving away from strict, compiled languages like C++, toward more agile languages with shorter turn-around times, like Python. The same approach essentially enables the ongoing AI revolution, in which frameworks such as PyTorch implement the user-facing API, using hardware-specific libraries [like MlOpen (AMD, 2024b) and oneDNN (UXL Foundation, 2024)] in the back-end, augmented with Just-in-Time (JIT) compilation facilities for customization. Julia is another high-level programming language which is JIT-compiled, offering a productive alternative to the classical low-level languages (Hunold and Steiner, 2020; Teichgräber, 2022).
Many of the hardware-centric advancements are in code generation. Some domain-specific frameworks exist to generate low-level, hardware-optimized code through higher level definitions. Examples are gt4py (Paredes et al., 2023) for the climate domain or pystencils (Bauer et al., 2019) for, among others, numerical Computational Fluid Dynamics (CFD) simulations; both optimize operations on a grid. Even generic domain-specific languages exist, like AnyDSL (Leißa et al., 2018), which utilizes partial evaluation to generate hardware-specific code. All frameworks, runtimes, and (JIT) compiled programs benefit from continuously maturing compiler infrastructures, especially open source software. Of distinct importance is LLVM (LLVM Foundation, 2024), which has emerged as the key enabler of modern compilation workflows, covering language-specific frontends (e.g., C++, Fortran), advanced optimisations in the intermediate languages (e.g., MLIR), versatile back-ends for many hardware architectures (e.g., x86, RISC-V, PTX), linking (e.g., LTO), and runtimes (like OpenMP). The open-source-nature of the compiler infrastructure allows contributions from research institutions, industrial corporations, and hardware vendors.
In the heterogeneous, quickly evolving hardware landscape, co-design is essential to align application requirements and hardware opportunities. Close collaboration between hardware consumers and producers allows informing hardware-fitting algorithms, enablement through effective compiler and framework/library support, and design decisions for the hardware. An example of a hardware-conscious implementation is temporal blocking of sparse matrix power kernels, which enables cache reuse and corresponding performance gains for traditionally memory-bound algorithms (Alappat et al., 2023, 2024).
A possible path to understanding application performance on specific hardware is thorough analytic, white-box performance models. Such models abstract the intricacies of the hardware, the software, and their interactions. A prominent example is the Roofline Model, which only assumes two hardware bottlenecks (computational peak performance and memory data transfer) and reduces the software to a single number (operational intensity) (Williams et al., 2009). Many extensions of the Roofline Model exist and can be coupled with energy models (Hager et al., 2013; Hofmann et al., 2018). Although such white-box models lack accuracy due to their inherent simplifications, they are indispensable for guiding design decisions for applications without time-consuming and complex in-depth research. A key component of this process is bottleneck awareness, which not only allows to select the most appropriate hardware, but also the energy-relevant execution modalities such as clock frequency (DVFS) and number of cores per chip (concurrency throttling) (Hager et al., 2013; Wittmann et al., 2016).
Selecting hardware components and a system design appropriate for the site's user portfolio is also crucial to maximize energy efficiency in real-world operations. Therefore, in addition to synthetic benchmarks (e.g., HPL or High Performance Conjugate Gradients (HPCG)), application-based benchmarks are typically included in the procurement and acceptance of HPC systems (Herten et al., 2024) as well. The selection of use cases in the procurement benchmark suite represents the current major consumers of computing time, but also the expected evolution of the user portfolio, e.g., a larger set of deep learning training applications. Different components or phases of a single application may have unique hardware requirements. For example, the ICON climate and weather model offers opportunities for substantial energy efficiency gains when running on heterogeneous hardware. This is because the model's coarse-grained task parallelism, comprising different components such as atmosphere, ocean, radiation, and biogeochemical modules, allows for tailored deployment on the most suitable hardware, reducing overall energy consumption. However, a major challenge is to support the various programming models that are required for this optimisation (Adamidis et al., 2024). This task is being tackled as part of the GreenHPC project EECliPs (DKRZ, 2025), for example.
The techniques for increasing performance and energy efficiency on modern hardware devices are quite involved and complex. It requires a well-educated workforce. Starting at university, where HPC-related courses are offered, but continuing during the professional career, where HPC basics and advanced topics are covered in courses. The German HPC community, especially the Gauss Center for Supercomputing (GCS) and the German National High Performance Computing Alliance (NHR) of Tier-2 centers, but also the local HPC networks of the federal states, offer a plethora of courses for HPC users and developers on various skill levels. The centers work with the HPC Certification Forum to map these courses to a tree of well-defined skills, enabling the attendees to compile the course program that fits their needs best.
The number and size of HPC infrastructures are growing, driven by the demand for compute time in the HPC and AI communities. This trend, together with increasing environmental concerns, electricity prices, and regulatory policies, is driving HPC hosting sites to develop and implement strategies to maximize the energy efficiency of their operations. The experience of German centers hosting jointly ≈300PFLOP/s compute performance (status 2024) shows that no single measure alone can achieve the efficiency targets set. A holistic approach to energy efficiency is required, including green power supply, power capping, optimized cooling systems, heat recovery, careful selection and combination of processing and storage technologies, comprehensive monitoring software, advanced scheduling and resource management techniques, and application optimisation measures.
The German sites reporting here are already implementing solutions in all these areas and have concrete plans for future extension. Direct liquid cooling strategies are already in place and waste heat is reused at many sites. Hardware heterogeneity, especially in terms of processing units, is increasing as the end of Moore's Law makes higher efficiency per component possible only through specialization. Heterogeneous system architectures are widely used, where processing heterogeneity is organized in partitions or compute modules. Maximizing resource utilization in such systems requires advanced scheduling and resource management techniques, with increasing interest on node sharing and dynamic scheduling mechanisms. Comprehensive monitoring solutions for data center, system components and user jobs are utilized; however, homogenisation and closer cooperation in this area could be beneficial. Last but not least, the HPC sites are investing significant efforts in user support to optimize application codes for highest performance, and are also developing optimized libraries, programming models and tools to improve energy efficiency from the user perspective.
Looking into the future, the German HPC sites are involved in a number of research projects and initiatives to further improve energy efficiency in HPC. Data center upgrades include medium- and long-term plans to increase the rate of waste heat reuse, but these plans could be jeopardized by the increasing power density of newer processors (especially GPUs) and their need for lower cooling temperatures. The choice of processing technologies for future system upgrades will largely be based on the highest achievable performance per Watt. As a result, future systems are likely to be more heterogeneous in terms of hardware, and there will be a need for more dynamic resource allocation, possibly taking into account variations in the power grid. Such load management and advanced scheduling software does not yet exist, or at least not in production quality. Therefore, a number of research and development projects are underway in Germany and Europe-wide to develop integrated system monitoring and management solutions to address this need. Other projects are devoted to programming models, algorithms and tools for improved application efficiency, since these require ongoing efforts to adapt to new hardware features. The use of arithmetic with reduced precision has attracted particular interest, which is supported by the growing trend toward ML applications and specialized hardware.
Energy efficiency will remain a key issue in the design, deployment, operation and use of future HPC systems, requiring the attention of all stakeholders: component suppliers, system integrators, hosting site operators, system software designers, programming model engineers, application developers, and users.
ES: Writing – original draft, Writing – review & editing. HB: Writing – original draft, Writing – review & editing. NE: Writing – review & editing. JE: Writing – original draft, Writing – review & editing. SE: Writing – original draft. TF: Writing – original draft. MF: Writing – original draft. PF: Writing – original draft. PG: Writing – original draft. DH: Writing – original draft, Writing – review & editing. GH: Writing – review & editing. AH: Writing – original draft, Writing – review & editing. TI: Writing – original draft, Writing – review & editing. BK: Writing – review & editing. EL: Writing – review & editing. CM: Writing – original draft, Writing – review & editing. SO: Writing – review & editing. MO: Writing – original draft, Writing – review & editing. KR: Writing – review & editing. RS: Writing – original draft, Writing – review & editing. KT: Writing – review & editing. BS: Writing – review & editing.
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. The results of the DKRZ are part of the work from the GreenHPC projects EE-HPC (grant number 16ME0586) and EECliPs (grant number 16ME0599K), funded by the BMBF. ClusterCockpit development was funded as part of the GreenHPC project EE-HPC (grant number 16ME0586).
ES was employed by SiPEARL.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The author(s) declare that Gen AI was used in the creation of this manuscript. The tool “deepl write” was used in selected paragraphs purely for language refinement purposes, without changing the meaning or adding anything to the text originally formulated by the author(s). No content was generated with generative AI.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
1. ^We show separately (in light green) the highest levy, the levy for renewable energies, which was in force until 2021.
2. ^Some research projects provide these details, but reliable statistics for the large production systems are not yet available.
3. ^A clear trend over the last 10 years shows that all sites are moving away from pure air-cooled systems toward direct liquid cooling (see Section 3.3 for details), but some specialized systems still require air cooling.
4. ^Abundant literature exists studying the performance and energy efficiency of different kernels and applications on CPUs, GPUs, or other acceleration devices (e.g., McIntosh-Smith et al., 2012; Qasaimeh et al., 2019; Cebrian et al., 2012; Samsi et al., 2023; Hu et al., 2022; Afzal et al., 2023); hence we decided not to show additional benchmarking results here.
5. ^Many-core accelerators (e.g., Intel Xeon Phi) could be used to build an accelerator-only cluster. For modules based on GPUs, which require a host CPU, the latter is chosen with few cores and lowest possible power consumption, purely to steer the GPU, not for application computation.
6. ^For JSC's storage cluster (IBM Storage Scale) the variation observed is 12%, for HLRS's (Luster) 9.4%, and for LRZ's (IBM Storage Scale) 8.8%.
7. ^Unfortunately, experience shows that users are not well informed about the performance and energy properties of their applications, not even about simple things like memory boundedness. This might change if centers started to account energy (kWh) instead of CPU or GPU hours, giving users a stronger incentive to care about resource efficiency.
8. ^All solutions provide interchangeable storage back-ends, listed are the defaults.
Adamidis, P., Pfister, E., Bockelmann, H., Zobel, D., Beismann, J.-O., and Jacob, M. (2024). The real challenges for climate and weather modelling on its way to sustained exascale performance: a case study using ICON (v2.6.6). Geosci. Model Dev. Discuss. (in press). doi: 10.5194/gmd-2024-54
Afzal, A., Hager, G., and Wellein, G. (2023). “SPEChpc 2021 benchmarks on Ice Lake and Sapphire Rapids Infiniband clusters: a performance and energy case study,” in Proceedings of the SC '23 Workshops of The International Conference on High Performance Computing, Network, Storage, and Analysis, SC-W '23 (New York, NY, USA: Association for Computing Machinery), 1245–1254. doi: 10.1145/3624062.3624197
Aguilera, M. K., Amaro, E., Amit, N., Hunhoff, E., Yelam, A., and Zellweger, G. (2023). Memory disaggregation: why now and what are the challenges. SIGOPS Oper. Syst. Rev. 57, 38–46. doi: 10.1145/3606557.3606563
Alappat, C., Hager, G., Schenk, O., and Wellein, G. (2023). Level-based blocking for sparse matrices: sparse matrix-power-vector multiplication. IEEE Trans. Paral. Distr. Syst. 57, 581–597. doi: 10.1109/TPDS.2022.3223512
Alappat, C., Thies, J., Hager, G., Fehske, H., and Wellein, G. (2024). “Algebraic temporal blocking for sparse iterative solvers on multi-core CPUs,” in The International Journal of High Performance Computing Applications. doi: 10.1177/10943420241283828
Alpay, A., Soproni, B., Wünsche, H., and Heuveline, V. (2022). “Exploring the possibility of a hipSYCL-based implementation of oneAPI,” in Proceedings of the 10th International Workshop on OpenCL. doi: 10.1145/3529538.3530005
AMD (2024a). HIP. Available at: https://github.com/ROCm/HIP (accessed October 12, 2024).
AMD (2024b). MlOpen. Available at: https://rocm.docs.amd.com/projects/MIOpen/en/latest/index.html (accessed October 10, 2024).
AMD Corporation (2024). AMD EPYC Rome architecture. Available at: https://www.amd.com/system/files/documents/4th-gen-epyc-processor-architecture-white-paper.pdf (accessed September 12, 2024).
American Society of Heating Refrigerating and Air-Conditioning Engineers (2021). Emergence and Expansion of Liquid Cooling in Mainstream Data Centers. Technical report, FixMe.
Ampere Computing LLC (2024). Ampere Computing processors. Available at: https://amperecomputing.com/products/processors (accessed October 15, 2024).
Anton, S. (2018). Intel delays mass production of 10 nm cpus to 2019. Available at: https://www.anandtech.com/show/12693/intel-delays-mass-production-of-10-nm-cpus-to-2019 (accessed January 10, 2025).
Apple (2024). Apple M4 chip. Available at: https://www.apple.com/newsroom/2024/05/apple-introduces-m4-chip (accessed October 15, 2024).
Auweter, A., Bode, A., Brehm, M., Brochard, L., Hammer, N., Huber, H., et al. (2014). “A case study of energy aware scheduling on supermuc,” in Proceedings of the 29th International Conference on Supercomputing (ISC 2014) (Springer-Verlag). doi: 10.1007/978-3-319-07518-1_25
Bates, N., Hsu, C.-H., Imam, N., Wilde, T., and Sartor, D. (2016). “Re-examining HPC energy efficiency dashboard elements,” in IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW). doi: 10.1109/IPDPSW.2016.184
Bauer, M., Hötzer, J., Ernst, D., Hammer, J., Seiz, M., Hierl, H., et al. (2019). “Code generation for massively parallel phase-field simulations,” in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC'19) (Association for Computing Machinery). doi: 10.1145/3295500.3356186
Becker, D. J., Sterling, T., Savarese, D., Dorband, J. E., Ranawak, U. A., and Packer, C. V. (1995). “BEOWULF: a parallel workstation for scientific computation,” in International Conference on Parallel Processing.
Betkaoui, B., Thomas, D. B., and Luk, W. (2010). “Comparing performance and energy efficiency of FPGAS and GPUS for high productivity computing,” in 2010 International Conference on Field-Programmable Technology, 94–101. doi: 10.1109/FPT.2010.5681761
Bhalachandra, S., Porterfield, A., Olivier, S. L., Prins, J. F., and Fowler, R. J. (2017). “Improving energy efficiency in memory-constrained applications using core-specific power control,” in Proceedings of the 5th International Workshop on Energy Efficient Supercomputing, E2SC'17 (Association for Computing Machinery). doi: 10.1145/3149412.3149418
Browne, S., Dongarra, J., Garner, N., Ho, G., and Mucci, P. (2000). A portable programming interface for performance evaluation on modern processors. Int. J. High Perform. Comput. Applic. 14, 189–204. doi: 10.1177/109434200001400303
Carabaño, J., Dios, F., Daneshtalab, M., and Ebrahimi, M. (2013). “An exploration of heterogeneous systems,” in 8th International Workshop on Reconfigurable and Communication-Centric Systems-on-Chip (ReCoSoC). doi: 10.1109/ReCoSoC.2013.6581542
Cebrian, J. M., Guerrero, G. D., and García, J. M. (2012). “Energy efficiency analysis of gpus,” in 2012 IEEE 26th International Parallel and Distributed Processing Symposium Workshops and PhD Forum, 1014–1022. doi: 10.1109/IPDPSW.2012.124
Cerebras (2024). Cerebras. Available at: https://cerebras.ai/ (accessed October 15, 2024).
Chaim, G. (2021). The summer Intel fell behind. Available at: https://www.theverge.com/22597713/intel-7nm-delay-summer-2020-apple-arm-switch-roadmap-gelsinger-ceo (accessed January 10, 2025).
Corbalan, J., Alonso, L., Aneas, J., and Brochard, L. (2020). “Energy optimization and analysis with EAR,” in IEEE International Conference on Cluster Computing (CLUSTER). doi: 10.1109/CLUSTER49012.2020.00067
Curtis, R., Shedd, T., and Clark, E. B. (2023). “Performance comparison of five data center server thermal management technologies,” in 2023 39th Semiconductor Thermal Measurement, Modeling and Management Symposium (SEMI-THERM). doi: 10.23919/SEMI-THERM59981.2023.10267908
der Energie, B., and Wasserwirtschafte, V. (2024). Bdew-strompreisanalyse juli 2024 - analysis of electricity prices 2024.
Dietrich, R., Winkler, F., Knüpfer, A., and Nagel, W. (2020). “Pika: Center-wide and job-aware cluster monitoring,” in 2020 IEEE International Conference on Cluster Computing (CLUSTER). doi: 10.1109/CLUSTER49012.2020.00061
DKRZ (2025). EECliPs. Available at: https://www.dkrz.de/en/projects-and-partners/projects-1/eeclips (accessed January 13, 2025).
Eastep, J., Sylvester, S., Cantalupo, C., Geltz, B., Ardanaz, F., Al-Rawi, A., et al. (2017). “Global extensible open power manager: a vehicle for HPC community collaboration on co-designed energy management solutions,” in High Performance Computing, 394–412. doi: 10.1007/978-3-319-58667-0_21
Eicker, N. (2015). “Taming heterogeneity by segregation-the DEEP and DEEP-ER take on heterogeneous cluster architectures,” in International Workshop on Language, Network and System Software, Akihabara (Japan), 29 Oct 2015–30 Oct 2015.
Eitzinger, J., Gruber, T., Afzal, A., Zeiser, T., and Wellein, G. (2019). “Clustercockpit – a web application for job-specific performance monitoring,” in HPCMASPA 2019, the Workshop for Monitoring and Analysis for High Performance Computing Systems and Applications. doi: 10.1109/CLUSTER.2019.8891017
Enos, J., Steffen, C., Fullop, J., Showerman, M., Shi, G., Esler, K., et al. (2010). “Quantifying the impact of gpus on performance and energy efficiency in hpc clusters,” in International Conference on Green Computing, 317–324. doi: 10.1109/GREENCOMP.2010.5598297
EuroHPC Joint Undertaking (2024a). AI-factories initiative from EuroHPC. Available at: https://eurohpc-ju.europa.eu/eurohpc-joint-undertaking-launches-ai-factories-calls-boost-european-leadership-trustworthy-ai-2024-09-10_en (accessed September 11, 2024).
EuroHPC Joint Undertaking (2024b). EuroHPC JU decission to fund RISC-V chiplet development. Available at: https://eurohpc-ju.europa.eu/document/download/38934e8b-30c9-4af6-b948-d73ab9107ce5_en?filename=Decision%2041.2022%20on%20EuroHPC%20Work%20Plan%20and%20Budget%202022%20%20VF.pdf (accessed October 15, 2024).
European Commission (2024). EU Energy Efficiency Directive. Available at: https://energy.ec.europa.eu/topics/energy-efficiency/energy-efficiency-targets-directive-and-rules/energy-efficiency-directive_en (accessed October 14, 2024).
European Parliament (2024). EU supply chain directive: corporate sustainability due diligence and amending Directive. Available at: https://eur-lex.europa.eu/eli/dir/2024/1760/oj (accessed October 9, 2024).
Federal Ministry for Economic Affairs and Climate Action (BMBK) (2025). System Stability Roadmap. Available at: https://www.bmwk.de/Redaktion/EN/Dossier/system-stability-roadmap.html (accessed January 13, 2025).
Fujitsu (2024). Fujitsu A64Fx. Available at: https://www.fujitsu.com/global/products/computing/servers/supercomputer/a64fx/ (accessed October 15, 2024).
German Federal Government (2024a). Energy Efficiency Act in Germany. Available at: https://www.bundesregierung.de/breg-en/federal-government/the-energy-efficiency-act-2184958 (accessed 2024-09-12.
German Federal Government (2024b). Gesetz zur Steigerung der Energieeffizienz in Deutschland (Energieeffizienzgesetz - EnEfG) §4. Available at: https://www.gesetze-im-internet.de/enefg/BJNR1350B0023.html#BJNR1350B0023BJNG000400000 (accessed 2024-09-30.
Google (2024). TPU (Cloud). Available at: https://cloud.google.com/tpu/docs (accessed October 15, 2024).
Gouk, D., Kwon, M., Bae, H., Lee, S., and Jung, M. (2023). Memory Pooling with CXL. IEEE Micro. 41, 48–57. doi: 10.1109/MM.2023.3237491
Grafana Labs (2024). Grafana. Available at: https://grafana.com (accessed October 25, 2024).
Graphcore (2024). Graphcore. Available at: https://www.graphcore.ai/ (accessed October 15, 2024).
Hackenberg, D., and Patterson, M. K. (2016). “Evaluation of a new data center air-cooling architecture: the down-flow plenum,” in 2016 15th IEEE Intersociety Conference on Thermal and Thermomechanical Phenomena in Electronic Systems (ITherm). doi: 10.1109/ITHERM.2016.7517576
Hager, G., Treibig, J., Habich, J., and Wellein, G. (2013). Exploring performance and power properties of modern multicore chips via simple machine models. Concurrency Computat.: Pract. Exper. 28, 189-210. doi: 10.1002/cpe.3180
Hager, G., Wellein, G., and Treibig, J. (2010). “LIKWID: a lightweight performance-oriented tool suite for x86 multicore environments,” in 2012 41st International Conference on Parallel Processing Workshops (IEEE Computer Society).
Herten, A. (2023). “Many cores, many models: GPU programming model vs. vendor compatibility overview,” in Proceedings of the SC '23 Workshops of The International Conference on High Performance Computing, Network, Storage, and Analysis. doi: 10.1145/3624062.3624178
Herten, A., Achilles, S., Alvarez, D., Badwaik, J., Behle, E., Bode, M., et al. (2024). Application-driven exascale: the JUPITER benchmark suite. arXiv:2408.17211. doi: 10.1109/SC41406.2024.00038
Hofmann, J., Hager, G., and Fey, D. (2018). “On the accuracy and usefulness of analytic energy models for contemporary multicore processors,” in 33rd International Conference on High Performance Computing (ISC). doi: 10.1007/978-3-319-92040-5_2
Hu, Y., Liu, Y., and Liu, Z. (2022). “A survey on convolutional neural network accelerators: GPU, FPGA and ASIC,” in 2022 14th International Conference on Computer Research and Development (ICCRD), 100–107. doi: 10.1109/ICCRD54409.2022.9730377
Huang, A. (2015). Moore's law is dying (and that could be good). IEEE Spectrum. 52, 43–47. doi: 10.1109/MSPEC.2015.7065418
Hunold, S., and Steiner, S. (2020). “Benchmarking Julia's communication performance: is julia hpc ready or full HPC?” in IEEE/ACM Performance Modeling, Benchmarking and Simulation of High Performance Computer Systems (PMBS). doi: 10.1109/PMBS51919.2020.00008
Ilsche, T., Hackenberg, D., Schöne, R., Bielert, M., and Höpfner, F. E.. (2019). “Metricq: a scalable infrastructure for processing high-resolution time series data,” in IEEE/ACM Industry/University Joint International Workshop on Data-center Automation, Analytics, and Control (DAAC). doi: 10.1109/DAAC49578.2019.00007
Ilsche, T., Schrader, S., and Schöne, R. (2024). “Optimizing idle power of HPC systems:practical insights and methods,” in IEEE International Conference on Cluster Computing (CLUSTER). doi: 10.1109/CLUSTERWorkshops61563.2024.00014
InfluxData (2024a). InfluxDB. Available at: https://www.influxdata.com (accessed October 25, 2024).
InfluxData (2024b). Kapacitor. Available at: https://www.influxdata.com/time-series-platform/kapacitor (accessed October 25, 2024).
InfluxData (2024c). Telegraf . Available at: https://www.influxdata.com/time-series-platform/telegraf (accessed October 25, 2024).
Intel (2024). OneMKL. Available at: https://www.intel.com/content/www/us/en/developer/tools/oneapi/onemkl.html (accessed October 10, 2024).
Jülich Supercomputing Centre (2024a). LLview job monitoring. Available at: https://www.fz-juelich.de/en/ias/jsc/services/user-support/software-tools/llview (accessed October 20, 2024).
Jülich Supercomputing Centre (2024b). JUelich STorage cluster JUST. Available at: https://www.fz-juelich.de/en/ias/jsc/systems/storage-systems/just (accessed October 11, 2024).
Khronos (2024). SYCL. Available at: https://www.khronos.org/sycl/ (accessed October 10, 2024).
Koomey, J., Berard, S., Sanchez, M., and Wong, H. (2011). Implications of historical trends in the electrical efficiency of computing. IEEE Annals of the History of Computing. 33, 46–54. doi: 10.1109/MAHC.2010.28
Kreuzer, A., Suarez, E., Eicker, N., and Lippert, T. (2021). Porting applications to a Modular Supercomputer - Experiences from the DEEP-EST project. Schriften des Forschungszentrums Jülich IAS Series.
Leißa, R., Boesche, K., Hack, S., Pérard-Gayot, A., Membarth, R., Slusallek, P., et al. (2018). Anydsl: a partial evaluation framework for programming high-performance libraries. Proc. ACM Program. Lang. 2, 1–30. doi: 10.1145/3276489
Li, J., Michelogiannakis, G., Cook, B., Cooray, D., and Chen, Y. (2023). “Analyzing resource utilization in an HPC system: a case study of NERSC's perlmutter,” in International Conference on High Performance Computing (ISC). doi: 10.1007/978-3-031-32041-5_16
LLNL (2024). Flux scheduler. Available at: https://github.com/flux-framework (accessed October 20, 2024).
LLNL (2025). El Capitan, NNSA's first exascale machine. Available at: https://asc.llnl.gov/exascale/el-capitan (accessed January 25, 2025).
LLVM Foundation (2024). LLVM. Available at: https://llvm.org/ (accessed October 15, 2024).
Maloney, S., Suarez, E., Eicker, N., Guimarães, F., and Frings, W. (2024). “Analyzing HPC monitoring data with a view towards efficient resource utilization,” in 2024 IEEE 36th International Symposium on Computer Architecture and High Performance Computing (SBAC-PAD) (IEEE). doi: 10.1109/SBAC-PAD63648.2024.00023
Matsuoka, S. (2018). “Cambrian explosion of computing and big data in the post-moore era,” in Proceedings of the 27th International Symposium on High-Performance Parallel and Distributed Computing. doi: 10.1145/3208040.3225055
McIntosh-Smith, S., Wilson, T., Ibarra, A. I., Crisp, J., and Sessions, R. B. (2012). Benchmarking energy efficiency, power costs and carbon emissions on heterogeneous systems. Comput. J. 55, 192–205. doi: 10.1093/comjnl/bxr091
Michelogiannakis, G., Klenk, B., Cook, B., Teh, M. Y., Glick, M., Dennison, L., et al. (2022). A case for intra-rack resource disaggregation in HPC. ACM Trans. Archit. Code Optim. 19, 1–26. doi: 10.1145/3514245
Milojicic, D., Faraboschi, P., Dube, N., and Roweth, D. (2021). “Future of HPC: diversifying heterogeneity,” in Design, Automation and Test in Europe Conference and Exhibition (DATE). doi: 10.23919/DATE51398.2021.9474063
Nassyr, S., Mood, K. H., and Herten, A. (2023). Programmatically reaching the roof: automated blis kernel generator for SVE and RVV. Technical report.
Nassyr, S., and Pleiter, D. (2024). “Exploring processor micro-architectures optimised for BLAS3 micro-kernels,” in Euro-Par: Parallel Processing. doi: 10.1007/978-3-031-69766-1_4
Netti, A., Müller, M., Auweter, A., Guillen, C., Ott, M., Tafani, D., et al. (2019). “From facility to application sensor data: modular, continuous and holistic monitoring with dcdb,” in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC '19, New York, NY, USA (Association for Computing Machinery). doi: 10.1145/3295500.3356191
NVIDIA (2023). NVIDIA Grace CPU Superchip Whitepaper. Available at: https://resources.nvidia.com/en-us-grace-cpu/nvidia-grace-cpu-superchip (accessed February 3, 2025).
NVIDIA (2024a). cuBLAS. Available at: https://developer.nvidia.com/cublas (accessed October 10, 2024).
NVIDIA (2024b). CUDA Toolkit. Available at: https://developer.nvidia.com/cuda-toolkit (accessed October 10, 2024).
NVIDIA (2024c). NCCL. Available at: https://developer.nvidia.com/nccl (accessed October 10, 2024).
OpenMP Architecture Review Board (2024). OpenMP. Available at: https://www.openmp.org/ (accessed October 15, 2024).
Paredes, E. G., Groner, L., Ubbiali, S., Vogt, H., Madonna, A., Mariotti, K., et al. (2023). Gt4py: High performance stencils for weather and climate applications using python. arXiv preprint arXiv:2311.08322.
Paul, A. (2018). Intel's 10nm Is Broken, Delayed Until 2019. Available at: https://www.tomshardware.com/news/intel-cpu-10nm-earnings-amd,36967.html (accessed January 10, 2025).
Peng, I., Pearce, R., and Gokhale, M. (2020). “On the memory underutilization: Exploring disaggregated memory on HPC systems,” in 32nd IEEE International Symposium on Computer Architecture and High Performance Computing (SBAC-PAD). doi: 10.1109/SBAC-PAD49847.2020.00034
Qasaimeh, M., Denolf, K., Lo, J., Vissers, K., Zambreno, J., and Jones, P. H. (2019). “Comparing energy efficiency of cpu, gpu and fpga implementations for vision kernels,” in 2019 IEEE International Conference on Embedded Software and Systems (ICESS), 1–8. doi: 10.1109/ICESS.2019.8782524
RISC-V Foundation (2024). RISC-V Instruction Set Architecture specifications. Available at: https://riscv.org/technical/specifications/ (accessed October 15, 2024).
Röhl, T., Treibig, J., Hager, G., and Wellein, G. (2014). “Overhead analysis of performance counter measurements,” in PSTI 2014, the Fifth International Workshop on Parallel Software Tools and Tool Infrastructures. doi: 10.1109/ICPPW.2014.34
Samsi, S., Zhao, D., McDonald, J., Li, B., Michaleas, A., Jones, M., et al. (2023). “From words to watts: benchmarking the energy costs of large language model inference,” in 2023 IEEE High Performance Extreme Computing Conference (HPEC), 1–9. doi: 10.1109/HPEC58863.2023.10363447
Sato, M., Ishikawa, Y., Tomita, H., Kodama, Y., Odajima, T., Tsuji, M., et al. (2020). “Co-design for a64fx manycore processor and fugaku,” in SC20: International Conference for High Performance Computing, Networking, Storage and Analysis. doi: 10.1109/SC41405.2020.00051
SchedMD (2024). Slurm scheduler. Available at: https://slurm.schedmd.com/ (accessed September 12, 2024).
Schulz, M., Kranzlmüller, D., Schulz, L. B., Trinitis, C., and Weidendorfer, J. (2021). “On the inevitability of integrated HPC systems and how they will change HPC system operations,” in Proceedings of the 11th International Symposium on Highly Efficient Accelerators and Reconfigurable Technologies. doi: 10.1145/3468044.3468046
Shalf, J. (2020). The future of computing beyond Moore's law. Phil. Trans. R. Soc. A. 378:61. doi: 10.1098/rsta.2019.0061
Shankar, S. (2024). Challenging trends in energy of computing for data centers. Computer 57, 134–142. doi: 10.1109/MC.2024.3468568
Simmendinger, C., Marquardt, M., Mäder, J., and Schneider, R. (2024). “Powersched - managing power consumption in overprovisioned systems,” in IEEE International Conference on Cluster Computing Workshops (CLUSTER Workshops). doi: 10.1109/CLUSTERWorkshops61563.2024.00012
SiPEARL (2024). Rhea chip. Available at: https://sipearl.com/wp-content/uploads/2024/05/PR_SiPearl_Rhea1_EN.pdf (accessed October 15, 2024).
SpiNNcloud Systems (2024). SpiNNaker2. Available at: https://spinncloud.com/portfolio/spinnaker2/ (accessed October 15, 2024).
Stanisic, L., and Reuter, K. (2020). MPCDF HPC Performance Monitoring System: Enabling Insight via Job-Specific Analysis. Cham: Springer International Publishing. doi: 10.1007/978-3-030-48340-1_47
Statistisches Bundesamt (Destatis) (2024). Bruttostromerzeugung in Deutschland: energy mix in Germany. Available at: https://www.destatis.de/DE/Themen/Branchen-Unternehmen/Energie/Erzeugung/Tabellen/bruttostromerzeugung.html (accessed October 15, 2024).
Strohmaier, E., Dongarra, J., Simon, H., and Meuer, M. (2024a). Green500. Available at: https://top500.org/lists/green500/ (accessed September 11, 2024).
Strohmaier, E., Dongarra, J., Simon, H., and Meuer, M. (2024b). Top500. Available at: https://top500.org (accessed September 12, 2024).
Suarez, E., Eicker, N., and Lippert, T. (2019). “Modular supercomputing architecture: from idea to production,” in Contemporary High Performance Computing: From Petascale toward Exascale (CRC press). doi: 10.1201/9781351036863-9
Suarez, E., Eicker, N., Moschny, T., and Lippert, T. (2021). Critical Analysis of the Modular Supercomputing Architecture, volume 48 of Schriften des Forschungszentrums Jülich IAS Series. Forschungszentrum Jülich GmbH Zentralbibliothek, Verlag Jülich.
Suggs, D., Subramony, M., and Bouvier, D. (2020). The AMD “Zen 2” processor. IEEE Micro. 40, 45–52. doi: 10.1109/MM.2020.2974217
Taiwan Semiconductor Manufacturing Company (2024). TSMP manufacturing trends. Available at: https://www.tsmc.com/english/dedicatedFoundry/technology/logic (accessed september 11, 2024).
Teichgräber, J. M. R. (2022). “Julia: A competitive high-level choice for performance portability in HPC?” in MPCDF Seminar (Performance) Portable Programming of HPC Applications.
The ClusterCockpit Project (2024). ClusterCockpit Generic Datastructure Specification. Available at: https://github.com/ClusterCockpit/cc-specifications/tree/master/datastructures (accessed October 25, 2024).
The collectd Project (2024). Collectd - The system statistics collection daemon. Available at: https://www.collectd.org (accessed October 25, 2024).
The eeHPC Consortium (2024). eeHPC project. Available at: https://eehpc.clustercockpit.org/ (accessed October 25, 2024).
The EPI Consortium (2024). European Processor Inititative (EPI). Available at: https://www.european-processor-initiative.eu/ (accessed October 15, 2024).
The EUPEX Consortium (2024). EUPEX project. Available at: https://eupex.eu/ (accessed October 15, 2024).
The EUPILOT Consortium (2024). EUPILOT project. Available at: https://eupilot.eu/ (accessed October 15, 2024).
The Prometheus Project (2024). Prometheus. Available at: https://prometheus.io (accessed October 25, 2024).
Tomes, E., and Altiparmak, N. (2017). “A comparative study of HDD and SSD RAIDs' impact on server energy consumption,” in IEEE International Conference on Cluster Computing (CLUSTER). doi: 10.1109/CLUSTER.2017.103
Tröpgen, H., Schöne, R., Ilsche, T., and Hackenberg, D. (2024). “16 years of SPEC power: an analysis of x86 energy efficiency trends,” in IEEE International Conference on Cluster Computing, (CLUSTER). doi: 10.1109/CLUSTERWorkshops61563.2024.00020
Trott, C. R., Lebrun-Grandié, D., Arndt, D., Ciesko, J., Dang, V., Ellingwood, N., et al. (2022). Kokkos 3: programming model extensions for the exascale era. IEEE Trans. Paral. Distr. Syst. 33, 805–817. doi: 10.1109/TPDS.2021.3097283
UXL Foundation (2024). oneDNN. Available at: https://github.com/oneapi-src/oneDNN (accessed October 10, 2024).
Van Zee, F. G., and van de Geijn, R. A. (2015). BLIS: a framework for rapidly instantiating BLAS functionality. ACM Trans. Mathem. Softw. 41, 1–33. doi: 10.1145/2764454
Véstias, M., and Neto, H. (2014). “Trends of CPU, GPU and FPGA for high-performance computing,” in 2014 24th International Conference on Field Programmable Logic and Applications (FPL), 1–6. doi: 10.1109/FPL.2014.6927483
Wassermann, C., Bielert, M., Vanberg, G., Hackenberg, D., Terboven, C., and Muller, M. S. (2024). “Calculating user-centric carbon footprints for HPC,” in 2024 IEEE International Conference on Cluster Computing Workshops (CLUSTER Workshops) (IEEE Computer Society), 26–35. doi: 10.1109/CLUSTERWorkshops61563.2024.00015
Wilde, T., Ott, M., Auweter, A., Meijer, I., Ruch, P., Hilger, M., et al. (2017). “Coolmuc-2: a supercomputing cluster with heat recovery for adsorption cooling,” in 2017 33rd Thermal Measurement, Modeling and Management Symposium (SEMI-THERM). doi: 10.1109/SEMI-THERM.2017.7896917
Williams, S., Waterman, A., and Patterson, D. (2009). Roofline: an insightful visual performance model for multicore architectures. Commun. ACM 52, 65–76. doi: 10.1145/1498765.1498785
Wittmann, M., Hager, G., Zeiser, T., Treibig, J., and Wellein, G. (2016). Chip-level and multi-node analysis of energy-optimized lattice Boltzmann CFD simulations. Concurr. Comput. 65, 2295-2315. doi: 10.1002/cpe.3489
Wu, X., and Di Napoli, E. (2023). “Advancing the distributed multi-GPU ChASE library through algorithm optimization and NCCL library,” in Proceedings of the SC '23 Workshops of The International Conference on High Performance Computing, Network, Storage, and Analysis.
Zenker, E., Worpitz, B., Widera, R., Huebl, A., Juckeland, G., Knüpfer, A., et al. (2016). “Alpaka-an abstraction library for parallel kernel acceleration,” in IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW). doi: 10.1109/IPDPSW.2016.50
Keywords: high-performance computing (HPC), energy efficiency, data center, cooling, monitoring, hardware, heterogeneous compute architectures
Citation: Suarez E, Bockelmann H, Eicker N, Eitzinger J, El Sayed S, Fieseler T, Frank M, Frech P, Giesselmann P, Hackenberg D, Hager G, Herten A, Ilsche T, Koller B, Laure E, Manzano C, Oeste S, Ott M, Reuter K, Schneider R, Thust K and von St. Vieth B (2025) Energy-aware operation of HPC systems in Germany. Front. High Perform. Comput. 3:1520207. doi: 10.3389/fhpcp.2025.1520207
Received: 30 October 2024; Accepted: 24 January 2025;
Published: 19 February 2025.
Edited by:
James A. Ang, Pacific Northwest National Laboratory (DOE), United StatesReviewed by:
Terry Jones, Oak Ridge National Laboratory (DOE), United StatesCopyright © 2025 Suarez, Bockelmann, Eicker, Eitzinger, El Sayed, Fieseler, Frank, Frech, Giesselmann, Hackenberg, Hager, Herten, Ilsche, Koller, Laure, Manzano, Oeste, Ott, Reuter, Schneider, Thust and von St. Vieth. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Estela Suarez, ZS5zdWFyZXpAZnotanVlbGljaC5kZQ==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.