Abstract
Different patients have different rehabilitation requirements. It is essential to ensure the safety and comfort of patients at different recovery stages during rehabilitation training. This study proposes a multi-mode adaptive control method to achieve a safe and compliant rehabilitation training strategy. First, patients’ motion intention and motor ability are evaluated based on the average human–robot interaction force per task cycle. Second, three kinds of rehabilitation training modes—robot-dominant, patient-dominant, and safety-stop—are established, and the adaptive controller can dexterously switch between the three training modes. In the robot-dominant mode, based on the motion errors, the patient’s motor ability, and motion intention, the controller can adaptively adjust its assistance level and impedance parameters to help patients complete rehabilitation tasks and encourage them to actively participate. In the patient-dominant mode, the controller only adjusts the training speed. When the trajectory error is too large, the controller switches to the safety-stop mode to ensure patient safety. The stabilities of the adaptive controller under three training modes are then proven using Lyapunov theory. Finally, the effectiveness of the multi-mode adaptive controller is verified by simulation results.
1 Introduction
In recent years, the number of patients with movement disorders caused by stroke and spinal cord injury has increased rapidly, as has the corresponding rehabilitation demand. Traditional rehabilitation strategies rely on therapists to help patients participate in training, and there are some problems such as long rehabilitation cycle and low efficiency of rehabilitation which make it difficult to meet the growing recovery needs (Luo et al., 2019). As a new way of rehabilitation training, rehabilitation robots can effectively save medical resources and improve the efficiency of rehabilitation training. Therefore, this has received wide attention and recognition (Adhikari et al., 2023).
The control method plays a crucial role in the rehabilitation effect (Zhou et al., 2021) as the patient has been interacting with the robot during the training process. Traditional control methods may subject the patient to excessive torque, which increases the risk of secondary injury. In contrast, control methods based on human–robot interactive information can have good rehabilitation training effects (Guo et al., 2021). Such methods can not only effectively avoid potential injuries but also help improve recovery. Therefore, it is important to design a safe, natural, and compliant human–robot interaction control method for rehabilitation robot systems (Masengo et al., 2023; Bergmann et al., 2023; Li Z. et al., 2024; Lu et al., 2023).
For patients with weak motor ability, rehabilitation robots should provide enough assistive force to help complete training tasks. However, too much assistance may make patients slack off, and too little assistance will not help patients implement training tasks—both may reduce rehabilitation effects. In order to realize efficient rehabilitation training, human–robot interaction methods need to follow the assisted-as-need (AAN) principle (Li N. et al., 2024). At present, impedance control is usually used to implement the AAN strategy (Han et al., 2023). Mao et al. (2015) established a force field controller which constructs a virtual tunnel with impedance characteristics around the desired trajectory to assist the patient’s movement. Jamwal et al. (2016) built an impedance controller for an ankle robot to assist patient compliance. Due to individual differences, it is difficult to obtain optimal impedance parameters. In addition, the interaction force and motion speed change over time, and fixed impedance parameters usually cannot meet the practical needs. The dynamic relationship between motion and interaction force can be adjusted according to the actual task by using time-varying impedance control; thus, good dynamic interaction performance can be achieved (Liang et al., 2022). Asl et al. (2020) constructed an AAN impedance controller which utilizes velocity tracking errors to adjust impedance parameters online. However, only the damping parameter is adjusted in this study, and its adaptive adjustment ability is relatively limited. Han et al. (2023) proposed an AAN control strategy for rehabilitation robots based on patients’ motor intention and task performance. The learning efficiency of impedance parameters and the auxiliary level were adaptively adjusted according to the assessment results of interaction force and patient performance. The experimental results show that this method can motivate patients to increase their engagement.
For patients with a partial recovery of motor function or strong motor ability, interference with their movement should be reduced to provide sufficient freedom of movement (Han et al., 2023; Zhang and Cheah, 2015). Higher freedom of movement does not mean that patients can move without restriction. When the position and speed of robots reach a certain level, patients may be exposed to the potential risk of secondary injury (Gao et al., 2023). To ensure patient safety, control methods should have safety features such as emergency stops or motion position limitations.
To meet the needs of patients at different recovery stages and ensure their safety, multi-mode control strategies have been proposed (Zhang and Cheah, 2015; Li et al., 2021; Yang et al., 2023; Xu et al., 2019; Li et al., 2017a,b). Zhang and Cheah (2015) proposed a multi-mode control method for upper limb rehabilitation robots. The training mode is chosen based on the position error to realize safety assistance. Li et al. (2021) and Yang et al. (2023) also designed multi-mode control strategies and switched control modes according to the tracking error. These methods switch control modes according to the position errors, which will partly limit the movement freedom of patients with strong motor ability. To solve this problem, a patient’s bioelectrical or interactive force signals can be used as the basis for switching training modes. Xu et al. (2019) proposed a multi-mode adaptive control strategy for a sitting lower limb rehabilitation robot. The human–robot interaction torque is estimated by using an EMG-driven impedance model. Based on the estimated human–robot interaction torque, a smooth transition between the robot-dominant and human-dominant modes can be achieved. Compared with bioelectrical signals, interaction force signals are more reliable. Li et al. (2017a) proposed an adaptive control method to smoothly switch the training modes between robot- and human-dominant modes based on the human–robot interaction force to realize safe interaction between humans and robots. Since this method ignores trajectory errors, the trajectory errors in the human-dominant mode may be large, which will lead to a reduction in the training effect. In the multi-mode control strategy, relying on only a single signal cannot provide the most suitable rehabilitation training mode for patients. Li et al. (2017b) proposed a multi-mode control strategy in which the tracking error and human-robot interaction force are taken as the basis for mode switching. Based on the tracking error, the controller can switch flexibly between human- and robot-dominant modes. When the human–robot interaction force exceeds the safety threshold, the controller will switch to the safety-stop mode to ensure the patient’s safety. This method still uses the tracking error as the basis for switching between human- and robot-dominated modes, which will also limit the movement freedom of patients with strong motor ability. In addition, the interaction force signals cannot fully indicate the patients’ motor ability.
To solve such problems, a multi-mode adaptive control strategy for repetitive rehabilitation tasks is here proposed. The human–robot interaction force evaluation factor is introduced to assess a patient’s motor ability and motor intention online (Han et al., 2023). Based on the evaluation result of the patient’s motor ability and trajectory errors, the training mode can be freely switched between robot-dominant, patient-dominant, and safety-stop modes. In the robot-dominant mode, the robot’s assistance level and the learning efficiency of impedance parameters are periodically adjusted according to the trajectory error, speed error, the assessed motor ability, and the motion intention, so as to provide appropriate assistance for patients with different motor abilities. In the patient-dominant mode, the controller allows the patient to modify the reference speed so that patients with higher motor ability have enough freedom of movement. When the trajectory error exceeds the safe range, it switches to safety-stop mode to ensure patient safety. The proposed method is not only suitable for patients at different stages of recovery and with different motor abilities but can also stimulate their enthusiasm to participate in rehabilitation training, further enhancing the rehabilitation effect.
2 Dynamic model of the human–robot hybrid system
During the rehabilitation training, the lower limb rehabilitation robot is in close contact with the patients’ affected limb, forming a human–robot hybrid system. The hybrid system’s dynamic model is shown as Eq. 1.where represents the robot’s joint angle, and i denotes the number of the robot’s joints. and represent the angular speed and angular acceleration, respectively. , and denote the inertia matrix, the Coriolis and centrifugal matrix, and the gravity vector, respectively. τr and τh respectively represent the actuation torque and interaction torque exerted by patient. In this paper, the interaction force Fh is exerted on the robot end, give by Eq. 2.where J(q) represents the Jacobian matrix.
3 Multi-mode control method
The functions and designs of the three control modes are briefly introduced in this section. For repetitive tasks, when the patient does not have enough motor ability to independently complete the training task, the robot-dominant mode runs. Adaptive assistance is then provided according to the patient’s motor ability and motion intention. For patients with weak motor ability, the assistance level will be periodically increased. For patients with a certain motor ability but who cannot yet complete the task independently, the assistance intensity will reduce appropriately to encourage more active participation in the training task. When the patient has recovered part of the motor function and can complete the training task independently, the patient-dominant mode runs. In this case, only movement speed is adjusted to provide the patient with a high degree of freedom of movement. When the patient’s movement is abnormal or the task is too difficult, the robot’s trajectory may exceed the safe range. In this case, the safety-stop mode runs to ensure patient safety.
3.1 Design of human–robot interaction force evaluation factor and mode shift factor
According to the functional requirements of the three control modes, a unified control law is established that includes the reference term, impedance learning term, sliding term, and compensation term, as shown below.where M, C, and G are abbreviations of , and , respectively. K(t) and D(t) denote variable stiffness and damping, respectively. L(t) denotes the sliding control gain, while e = qd − q represents the trajectory error between the desired qd and actual trajectory q. denotes the sliding vector. denotes the reference speed, where A is a symmetric positive definite matrix, is the modified speed determined by the interaction torque, α is the robot–patient mode shift factor determined by the patients’ motor ability, and β is the stop-mode shift factor, determined by the trajectory error. Before analyzing the change pattern of these two mode shift factors, the human–robot interaction force evaluation factors and are introduced to assess the patients’ motor ability and motion intention (Han et al., 2023) as shown in Eqs 4, 5.where represents the human–robot interaction force parallel to the desired trajectory. represents the human–robot interaction force perpendicular to the desired trajectory. represents the desired speed at the robot end. Fh can be obtained by the interaction force estimation methods (Lu et al., 2023; Liang et al., 2023). j denotes the jth training task, T denotes the task period. tj, and tj−1 represent the initial moments of the jth and (j − 1)th task, respectively.
When is positive, the patient’s movement speed is greater than the desired speed, and the robot is driven by the patient along the desired trajectory. On the other hand, when is negative, the patient is driven by the robot along the desired trajectory. means that the patient intends to deviate from the desired trajectory. The greater the , the stronger the patient’s motor ability. The larger is, the stronger the patient’s intention to move away from the desired trajectory.
The change pattern of α and β is designed as follows:where a and c are given values. denotes the Euclidean norm of e. If , then the task is too difficult or the patient’s movement is abnormal, which will lead to excessive trajectory errors or even secondary injury to the patient. The controller will then switch to safety-stop mode to ensure patient safety. If , then the patient is able to complete training task either with the robot’s assistance or independently. The controller will then switch to either robot-dominant or patient-dominant mode based on the value of α. If , then the patient can complete the task independently, and it will switch to patient-dominant mode. If , the patient’s motor ability is insufficient to complete the training task, and it will switch to the robot-dominant mode. In practice, c can be set to a constant close to 0. If the patient has good control over the affected limb, c can be slightly reduced, allowing the controller to easily enter and maintain the patient-dominant mode. If the patient has poor control over the affected limb, c can be slightly increased so that the controller is always in robot-dominant mode so that the robot can help the patient complete the training task and correct their wrong movements.
The control diagram is shown in Figure 1. To ensure patient safety, the safety-stop mode has the highest priority among the three modes, which is reasonable in practical applications. To ensure the smoothness of the mode switching process, transition intervals are added to Eqs 6, 7, and then the change pattern of α and β is modified as Eqs 8, 9.where b and d are given values. The modified α and β change smoothly as and e change. According to the patient’s motor ability and trajectory error, the controller switches freely between the three modes (Figure 2). However, is periodically adjusted, and it will cause α to be discontinuous in time. When α changes at t1, the changed α is expressed as α1 = α(t1), and we havewhere αs = α(t1 − ts), ts is the sampling time, and Tsmo is the smoothing time. Thus, α is smooth in time.
FIGURE 1

Multi-mode adaptive control block diagram.
FIGURE 2
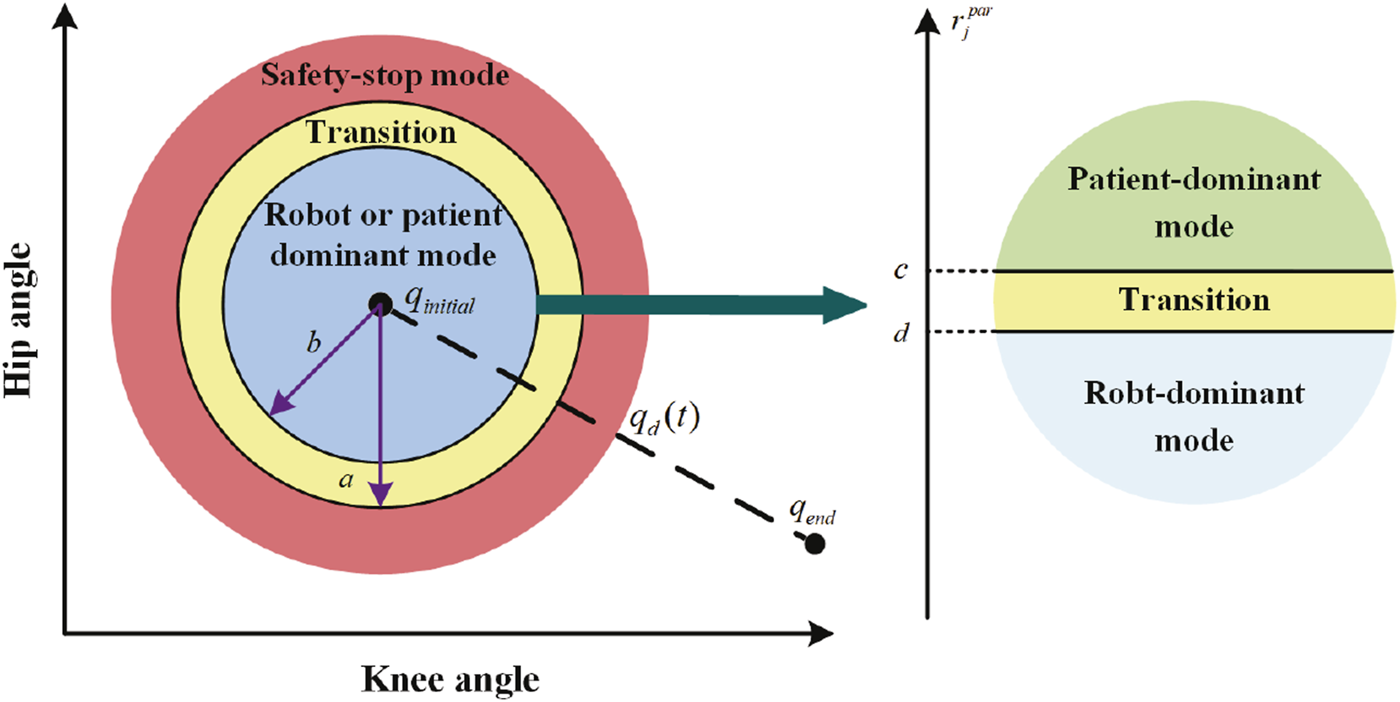
Training modes.
Although Eq. 10 can ensure the continuity of α, Tsmo may also cause a lag in mode switching. Therefore, the value of Tsmo should not be too large in practical applications.
3.2 The Robot-dominant mode
When α = 1, β = 0, the controller is in the robot-dominant mode. In this mode, the human–robot interaction torque is described as Eq. 11 (Han et al., 2023; Yang et al., 2011):where the stiffness parameters , damping parameters , and compensating torque are assumed to vary with time. The minimum quantities of stiffness, damping, and compensating torque are assumed to be Km(t), Dm(t), and , respectively, and
In this mode, Eq. 3 can be written as Eq. 13.where the update rules of K(t), D(t), L(t), and adhere to the following principles. 1) When is negative and its absolute value is large, the patient’s motor ability is insufficient to complete the desired training task. In this case, the robot should increase its assistance level to help the patient complete training task. When is negative and its absolute value is small, then, although the patient does not have the ability to complete the training task independently, the degree of active participation in the training is relatively high. In this case, the robot should reduce its assistance level to encourage the patient to further improve training enthusiasm. 2) The impedance parameters and torque compensation terms are adjusted adaptively by iterative learning. When the absolute value of is large, the learning speed increases to quickly correct the patient’s movement. When the absolute value of is small, the learning speed slows down.
The update law for L(t) is designed as follows:wherewhere η0 = 0. L0 is a positive definite matrix. In this mode, is periodically adjusted according to the value of as shown in Eqs 14, 15. and are given constants, and their values are smaller than c and d. In practice, these two parameters can be adjusted according to the patient’s motor ability. If their motor ability is weak, and can be set to smaller values so that the controller can more easily detect the patient’s effort and reduce the robot’s assistance level.
The update law for K(t), D(t), and are given as follows:where γj is updated as shown in Eq. 17.where denotes the iterative learning factor, and ζ denotes the update rate. γ0 = 0. QK, QD, and are symmetric positive definite matrices. During the first task cycle, K(t) = 0i×i, D(t) = 0i×i, and .
In this mode, based on the assessment of motor ability and motor intention, and γj are periodically adjusted to provide adaptive assistance for patients at different recovery stages.
3.3 The patient-dominant mode
When α = 0, β = 0, the controller is in the patient-dominant mode. In this mode, Eq. 3 can be written as Eq. 18.where is given in Eq. 19.where Llast denotes the last updated value of L(t) before entering this mode. denotes the smallest eigenvalue of Llast, and denotes the smallest eigenvalue of L0. From the definition of and s, we derive . In this mode, can be obtained by using the following impedance equation:where Mim and Bim denote the inertia and damping parameters, respectively.
To ensure the stability of human–robot interactions and encourage active patient participation, τc was utilized to appropriately compensate τh (Zhang and Cheah, 2015). When the absolute value of the angle θh,s between τh and s is smaller than θς and , then the patient exerts an interactive force to drive the robot close to the reference speed—that is, the patient’s motion intention can be seen as correct. In this case, τh is retained. When , then the patient’s motion intention cannot be seen as quite correct. In this case, τh is compensated to its nearest unit vector sς1 or sς2 to ensure that the angle between the compensated torque and s is equal to θς. When , the patient’s motion intention cannot be seen as correct. In this case, τc is utilized to neutralize τh—that is, τc + τh = 0. The schematic diagram of the compensation principle is shown in Figure 3. In this mode, τc + τh can be expressed as Eqs 21−23whereandwhere smin is a small positive number. ensures the smoothness of τc + τh at s = 0. sς equals sς1 or sς2.
FIGURE 3
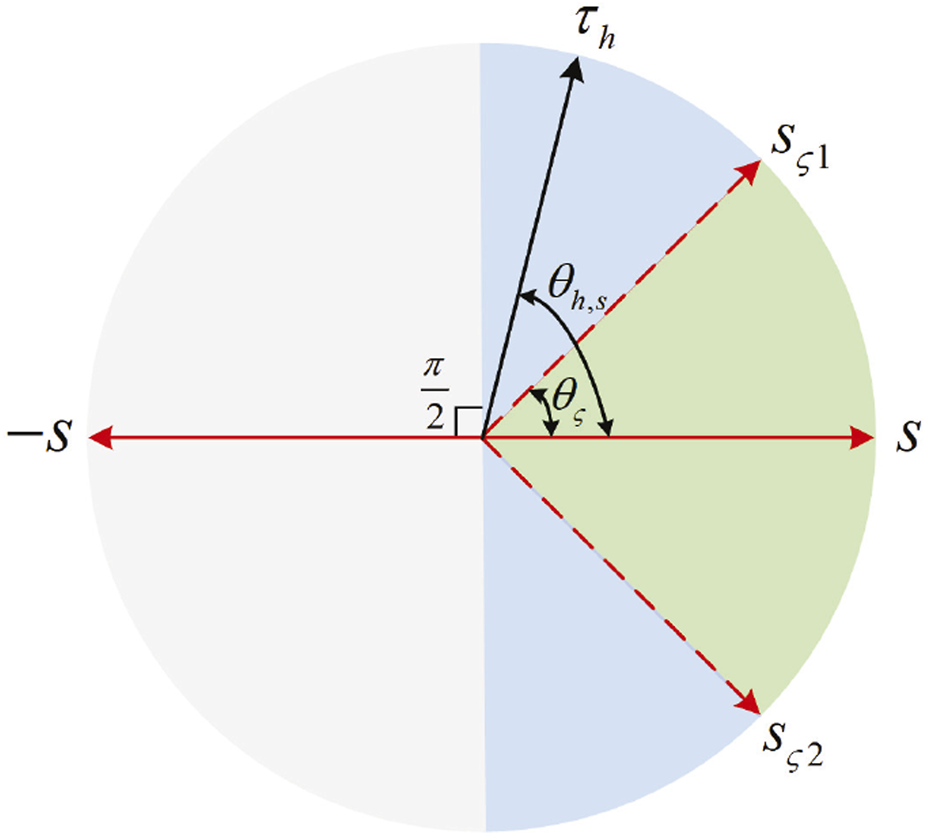
Schematic diagram of the compensation principle. When , τh is retained. When , τh is compensated to sς1 or sς2. When , τc is utilized to neutralize τh.
In this mode, the impedance learning term is removed, and the sliding mode control term is converted to a speed control term. In addition, the patient can modify the reference speed, improving compliance with and the flexibility of rehabilitation training. τc is used to compensate τh appropriately. Compared with the robot-dominant mode, the patient-dominant mode further improves the patient’s freedom of movement.
3.4 The safety-stop mode
When α = 0, β = 1, the controller is in the safety-stop mode. In this mode, Eq. 3 can be written as Eq. 24.where is given as Eq. 25.τc is utilized to neutralize τh—that is, τc + τh = 0. From the definition of and s, we derive .
In this mode, the impedance learning term is removed, and the sliding mode control term is converted to a damping control term. The robot stops moving to ensure the patient’s safety.
4 Stability analysis
In this section, the Lyapunov stability theorem is used to establish the stability of the human–robot interaction process. Specifically, in the robot-dominant mode, s is limited to a certain bound. Under the assumption of Eq. (12), the learning errors of impedance parameters and torque compensation terms are bounded (Han et al., 2023). In the patient-dominant mode, the robot’s speed converges to . When it switches to the safety-stop mode, the robot’s speed decreases to zero.
The Lyapunov candidate function is chosen as Eq. 26.wherewhere represents the column vectorization operator. ⊗ represents the Kronecker product.
4.1 Stability analysis in the robot-dominant mode
In this mode, the system is stable if is non-growing in each task cycle (Han et al., 2023).
Taking the derivative of , we derive
Since is an antisymmetric matrix, we can obtain Eq. 32.
Combining Eq. 31 and the definition of s, we then have
Since α = 1, β = 0, Eq. 33 can be expressed as Eq. 34.Then, we can get Eq. 35
Since L(t) is periodically adjusted, the following inequality can be obtained:where λL is the smallest eigenvalue of L(σ).
According to Eqs 12, 28, 36, we thus obtain Eq. 37that is,
According to Eqs 27–29, we obtain
Since , , and are periodic, Eq. 16 can be written as Eq. 40.
Since is symmetric, Item a in Eq. 39 can be expressed thus:
Similarly, Item b and Item c in Eq. 39 can be expressed as follows:and
By bringing Eqs 41–43 into Eq. 39, we obtain
By bringing Eqs 38, 44 into Eq. 30, we obtain Eq. 45.
Since , we can obtain Eq. 46
A sufficient condition for ΔV to be non-positive definite is
When Item d in Eq. 47 is equal to zero, we obtain
According to LaSalle’s theorem, and will converge on the invariant set Ωi of ΔV = 0. Based on Eq. 48, a boundary set Ω can be designed as Eq. 49:
Since , , and are non-negative and 1 + γj and λL are positive numbers, the boundary set Ω is in the first quadrant, as shown in Figure 4.
FIGURE 4
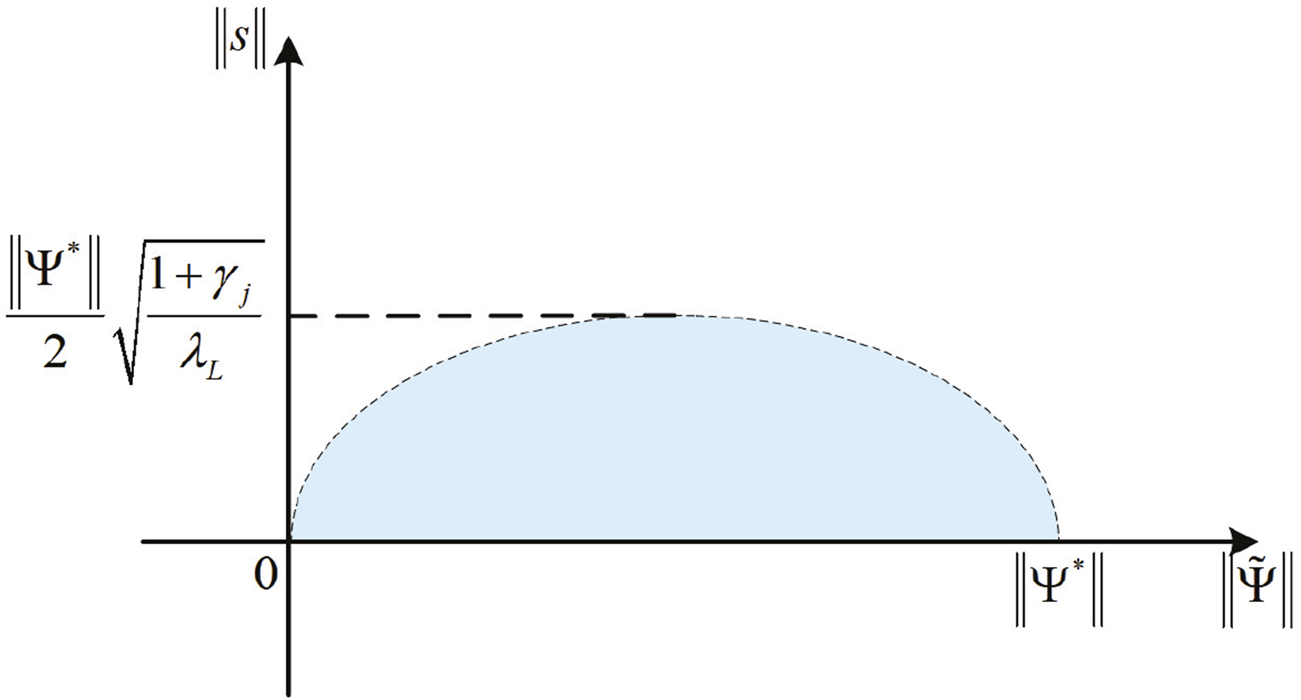
Schematic diagram of the boundary set Ω.
From the inequality (Eq. 47), and will converge on the invariant set Ωi of ΔV = 0, and Ωi ⊆Ω. γj and L(t) can be used to regulate the boundary set Ω. If λL increases, then a smaller is allowed, which means an increase in motion accuracy. If λL decreases, the system will allow for larger motion errors.
4.2 Stability analysis in the patient-dominant mode
In this mode, α = 0, β = 0. and its derivative are expressed as follows.and
By the definition of , it is positive definite. From the definition of τc + τh, the angle between τc + τh and s is less than or equal to —that is . Hence, we can get , and . Since is bounded, s is bounded.
To determine the consistent continuity of , Eq. 51 is derived as Eq. 52:where . Due to the human motion ability limitation, τh and can be assumed to be bounded. The boundedness of and ensures that τc + τh is bounded. can be expressed as Eq. 53The boundedness of s suggests the boundedness of and . Since is bounded, is too. According to Eq. 20, the boundedness of τh ensures that is bounded, so that is also bounded. The is bounded due to the boundedness of , , , , , and . Therefore, is bounded. According to Barbalat’s lemma, , which means that if t → ∞, s → 0. From the definition of s, the robot’s speed converges to —that is, .
4.3 Stability analysis in the safety-stop mode
When the trajectory error is too large, it will switch to the patient-dominant mode—α = 0, β = 1. and its derivative are the same as Eqs 50, 51. In this mode, is positive definite and τc + τh = 0; thus, we obtain , and . Since is bounded, s is bounded. The derivation of is given as Eq. 54where . The boundedness of τr + τh ensures the boundedness of and . Therefore, is bounded. According to Barbalat’s lemma, , so that if t → ∞, s → 0. From the definition of s, the robot will stop moving.
5 Simulations
A two-degree-of-freedom lower limb rehabilitation robot is used to verify the effectiveness of the proposed method. As shown in Figure 5, m1 and m2 represent the mass of the thigh and calf, respectively. l1 and l2 represent the length of the thigh and calf, respectively. lc1 denotes the distance from the hip joint to the center of mass of the thigh. lc2 denotes the distance from knee joint to the center of mass of the calf. The dynamic model of this hybrid system is described as Eq. 55where . and represent the inertia of the thigh and calf, respectively. , M21 = M12, M22 = I2, , , , C22 = 0, and . G1 = (m1lc1 + m2l1)gcos(q1) + m2lc2gcos(q1 + q2). G2 = m2lc2gcos(q1 + q2). g is the acceleration of gravity. The desired trajectory is designed as Eq. 56.The initial angle of the robot is set to . The initial parameters of the proposed method and lower limb rehabilitation robot are listed in Table 1. The values of η and ζ are given as Eqs 57, 58
FIGURE 5
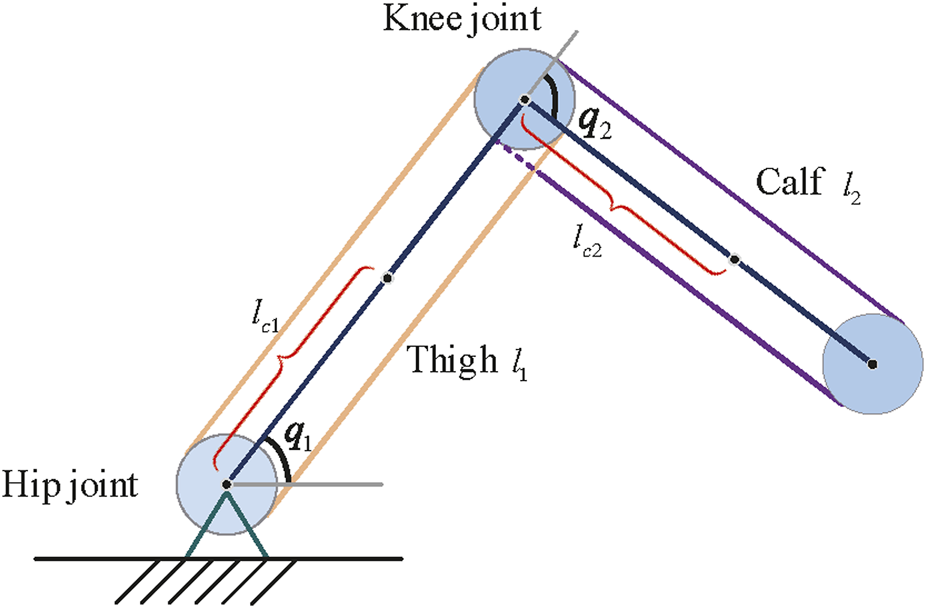
Simplified structure of a lower limb rehabilitation robot.
TABLE 1
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| a | π/12 | ||
| b | π/18 | smin | 0.008 |
| c | −0.1 | θς | 4π/9 |
| d | −0.4 | −1 | |
| L0 | 0 | ||
| −2 | A | ||
| −1 | m1 | 8 | |
| 0.1 | m2 | 8 | |
| 0.5 | l1 | 0.5 | |
| QK | l2 | 0.6 | |
| QD | lc1 | 0.3 | |
| T | 10 | lc2 | 0.4 |
| Mim | Tsmo | 1.7 | |
| Bim |
Initialization parameters in simulation.
The simulation process consists of 28 task cycles, each lasting 10 s. The results of the human–robot interaction force evaluation for each task cycle are given in Figure 6, which shows the patients’ motor ability and motion intention under different task cycles. The simulation results are shown in Figure 7.
FIGURE 6
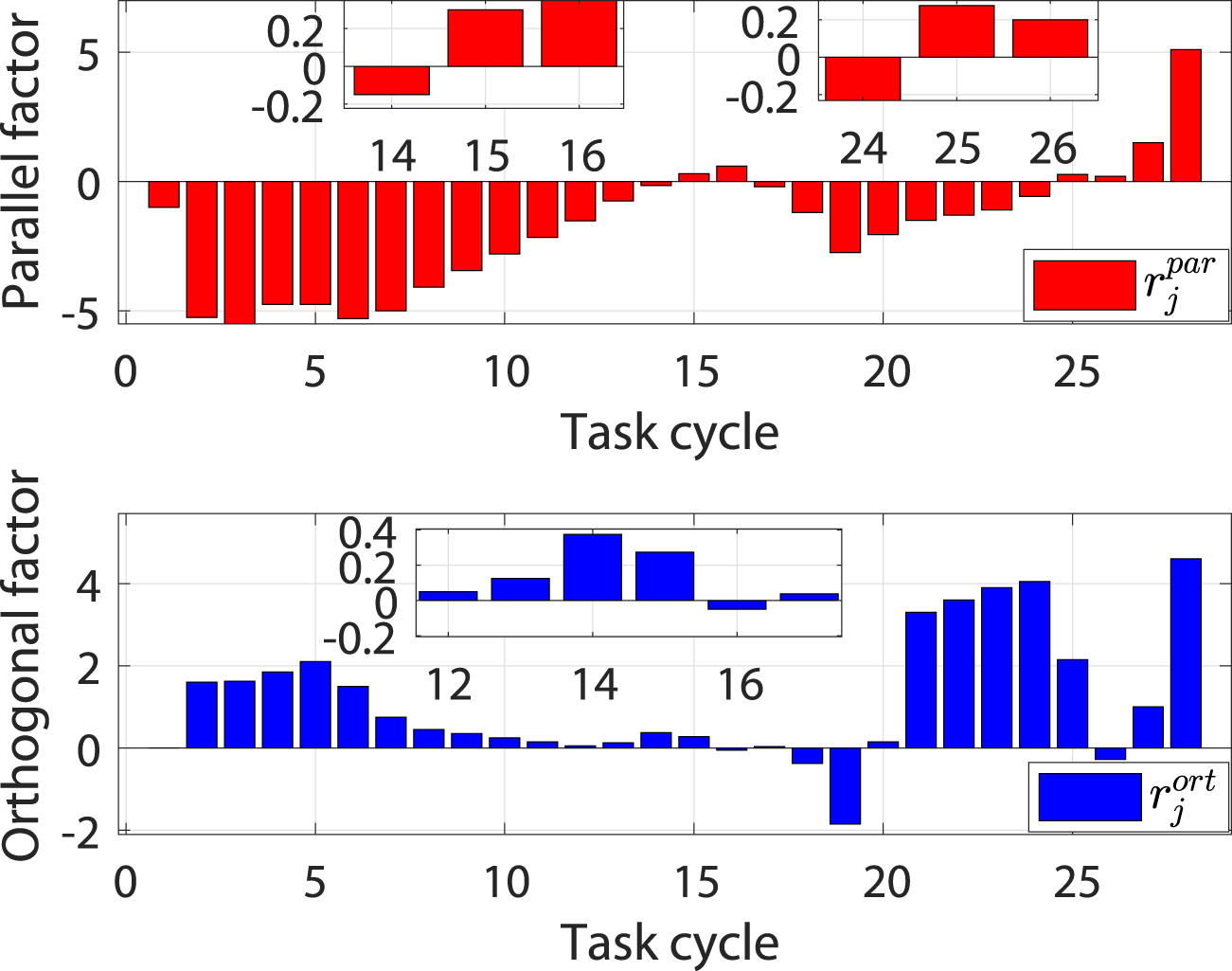
Evaluation results of the human–robot interaction force under different task cycles.
FIGURE 7
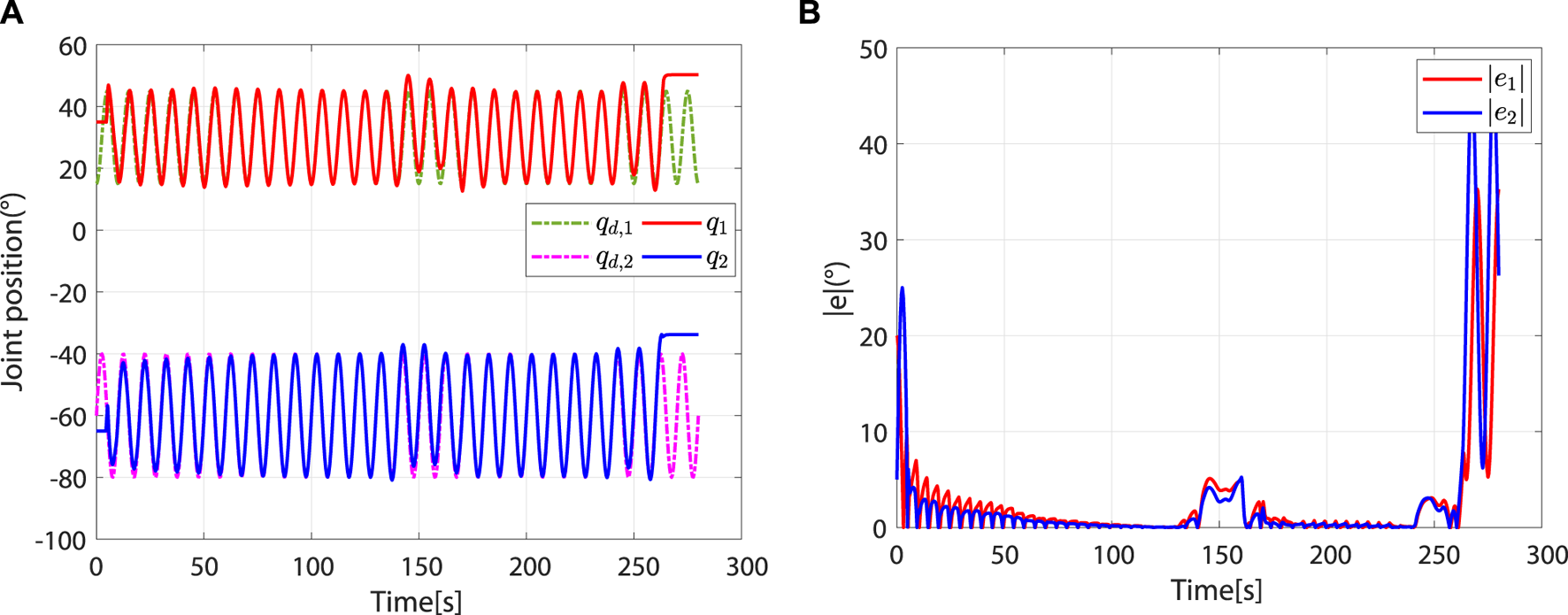
Entire simulation results of hip and knee joints. (A) Desired and actual trajectories. (B) Absolute values of trajectory errors.
At the beginning, the controller is in safety-stop mode due to . In this mode, τh is neutralized by τc. At approximately 4.44 s, . Meanwhile, due to , the controller leaves the safety-stop mode and gradually transitions to the robot-dominant mode (Figure 8).
FIGURE 8
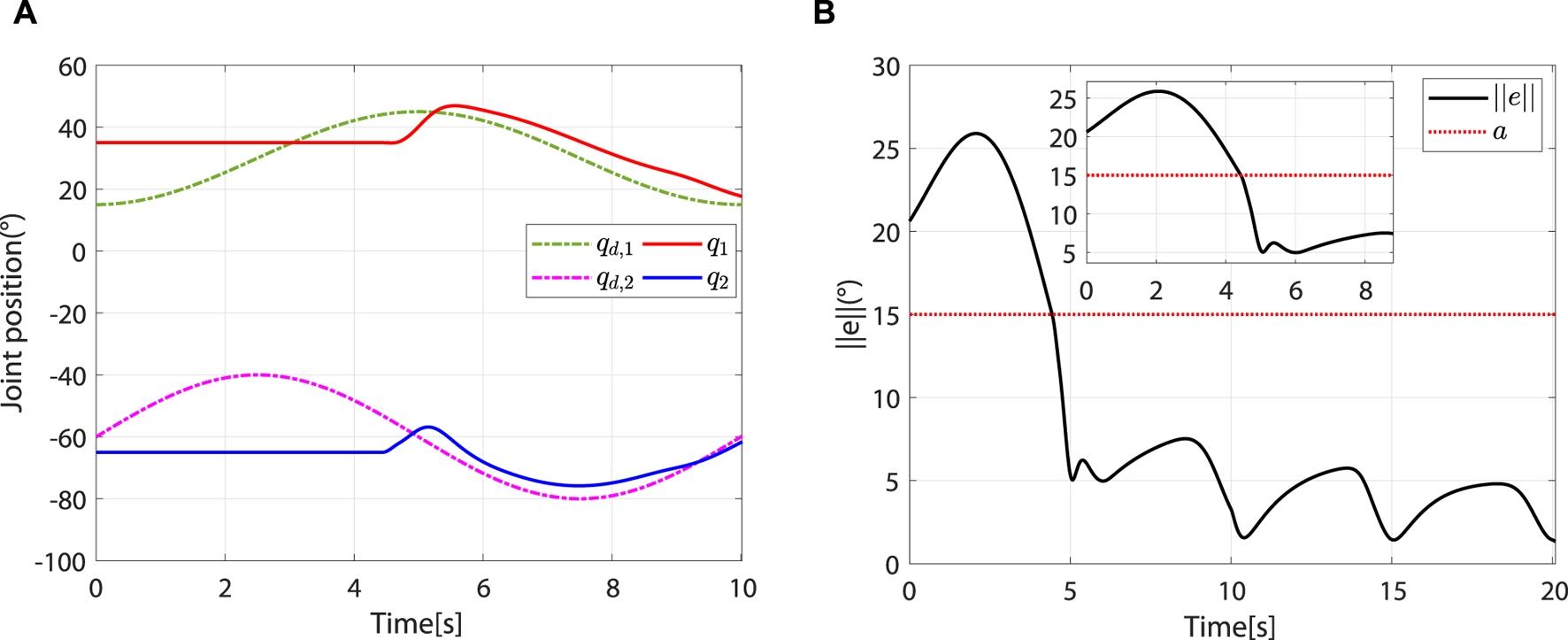
The controller leaves the safety-stop mode at approximately 4.44 s. (A) Desired and actual trajectories. (B) At approximately 4.44 s, .
In the robot-dominant mode, according to and , the robot’s assistance level is adaptively adjusted to help the patient complete the desired task. The change trends of ηj and γj are shown in Figure 9A. When , L(t) increases periodically with ηj. Although there are fluctuations in the changes of and , the trajectory error decreases periodically (Figure 9B). The increase of the eigenvalue of L(t) improves motion accuracy. When , ηj remains unchanged. When , L(t) decreases periodically with ηj. It can be observed that is greater than in the second to seventh task cycle, which means that the patient intends to move away from the desired trajectory. γj will then reduce to a lower value to increase the learning rate of the impedance parameters, thus correcting the patient’s motion trajectory (Figure 9A). However, with the gradual reduction of γj, the impedance parameters present a tendency to decrease periodically (Figures 9C, D). According to Eq. 16, this phenomenon is attributed to the improvement of motion accuracy.
FIGURE 9
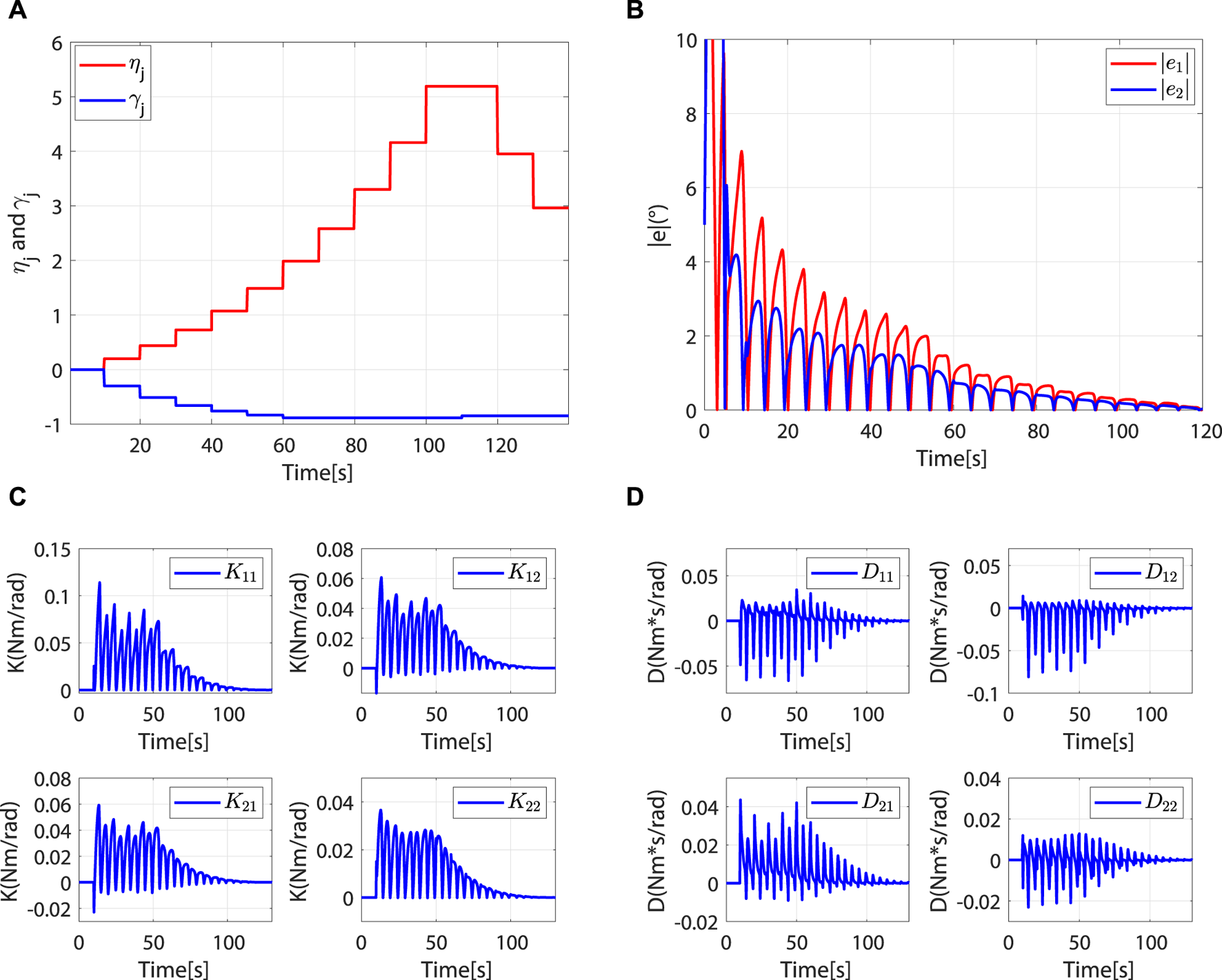
The controller is in the robot-dominant mode, and the robot assisted the patient to complete the rehabilitation task. (A)ηj and γj. (B) Absolute values of trajectory errors. (C)K(t). (D)D(t).
When , the controller breaks away from the robot-dominant mode and transitions to the patient-dominant mode. When , the controller is in patient-dominant mode. As the controller switches from robot-dominant to patient-dominant mode, greater trajectory errors are allowed, which provides greater freedom of movement (Figures 10A, B). In addition, the robot’s speed gradually converges to (Figure 10C). This phenomenon is consistent with theory.
FIGURE 10
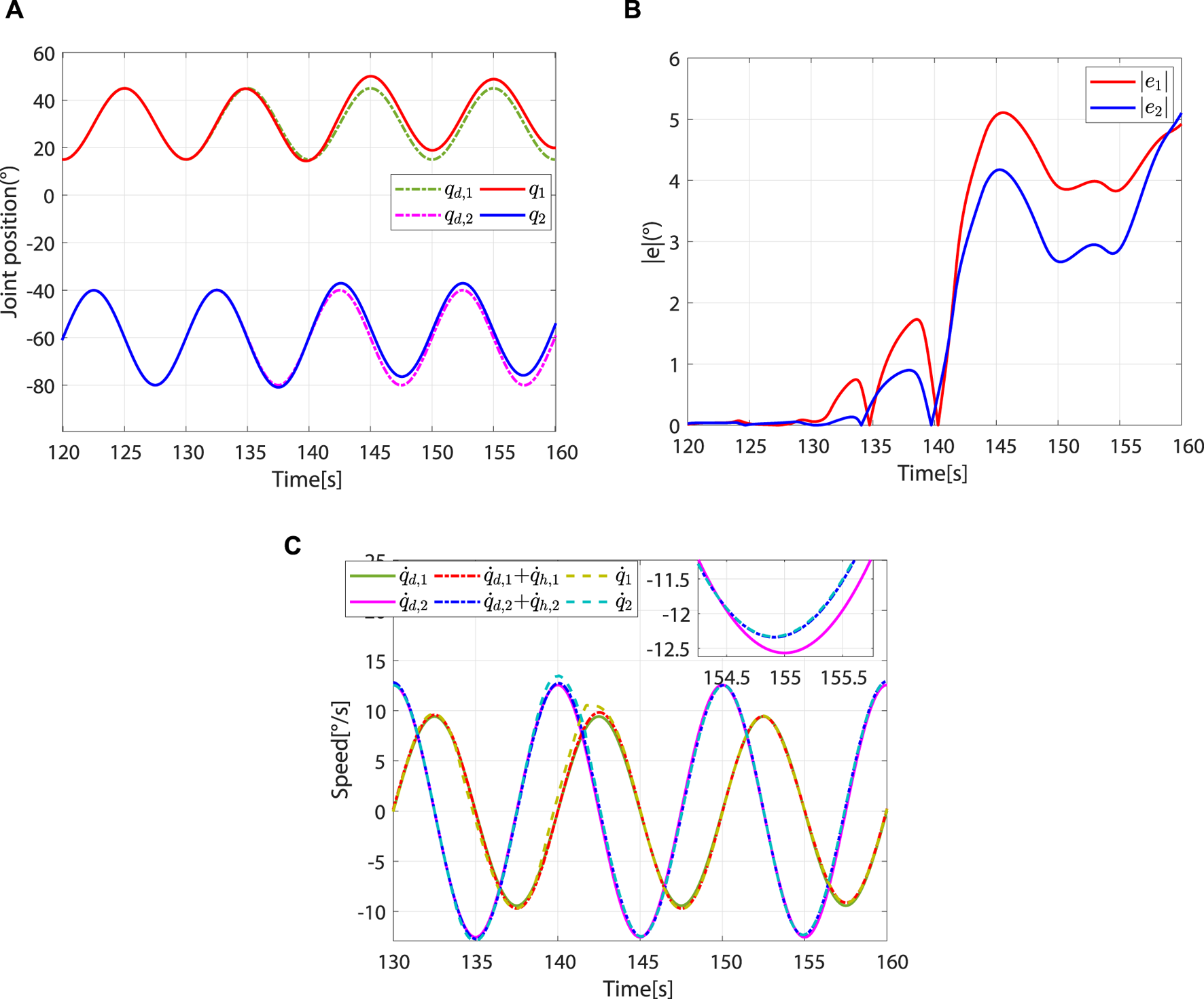
Controller switches from robot-dominant to patient-dominant mode and remains in the patient-dominant mode. (A) Desired and actual trajectories. (B) Absolute values of the trajectory errors. (C) Desired angular speed, reference angular speed, and actual angular speed.
As decreases, the controller switches again to the robot-dominant mode. Compared to the patient-dominant mode, the trajectory error is significantly reduced at this point (Figure 11A). From 190 to 230 s, ηj does not change. Affected by the vertical interaction force, γj decreases periodically (Figure 11B). From Figures 11C–E, the impedance parameter and torque compensation term increase periodically to correct patient motion, and the trajectory error is gradually reduced (Figure 11A).
FIGURE 11

Controller switches from patient-dominant to robot-dominant mode and remains in the robot-dominant mode. (A) Absolute values of trajectory errors. (B)ηj and γj. (C)K(t). (D)D(t). (E)τc(t).
When , the controller switches to the patient-dominant mode again, where the patient’s freedom of movement increases and the robot’s speed converges to (Figure 12). To test the safety stop function of the controller during rehabilitation training, the excessive and are applied, which will cause to increase sharply and (Figure 13A). In this case, the controller switches to the safety-stop mode to ensure patient safety (Figure 13B), and the actual speed of the robot decreases rapidly to zero (Figure 13C).
FIGURE 12
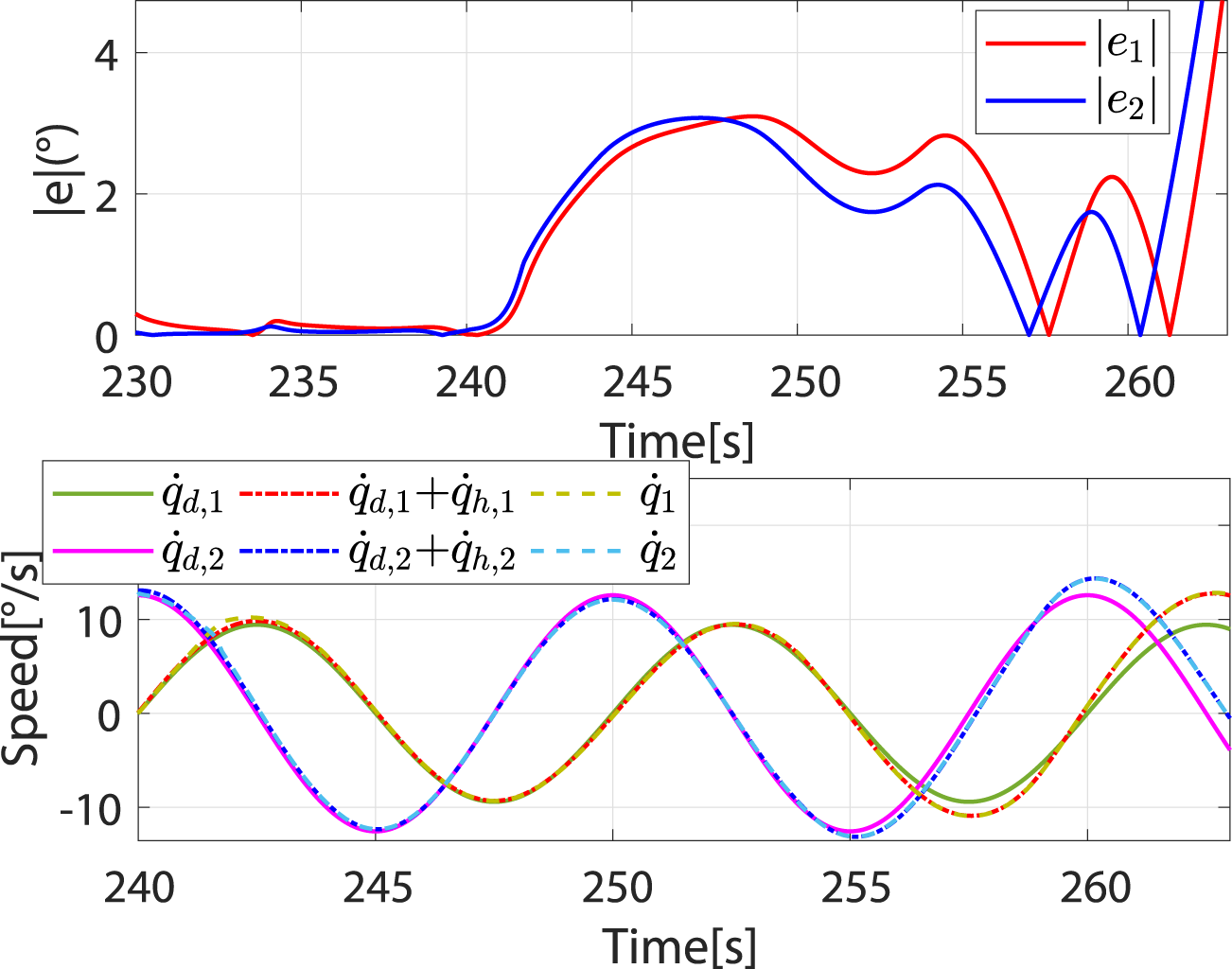
Speed and absolute values of trajectory errors when controller switches again from robot-dominant to patient-dominant mode.
FIGURE 13
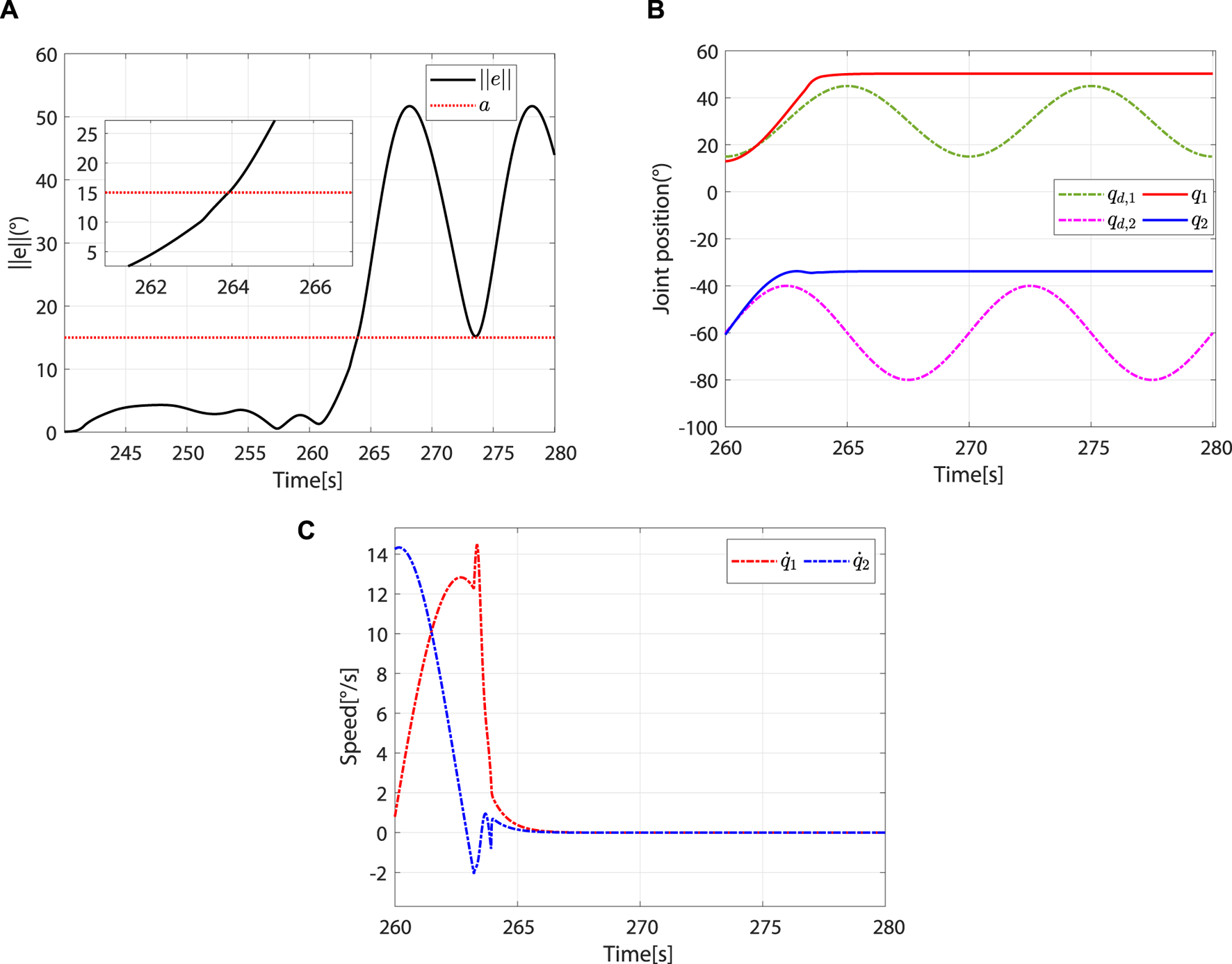
The controller switches to the safety-stop mode. (A) At approximately 263.92 s, . (B) Desired and actual trajectories. (C) Actual angular speed.
The effectiveness of the proposed method is demonstrated by the trajectory errors, adaptive change of controller parameters, and joint angular speed during human–robot interaction in three modes. In addition, the simulation includes the transition process between each mode, and the system can still run stably during this transition process.
6 Conclusion
This study proposes a multi-mode adaptive control method, including robot-dominant, patient-dominant, and safety-stop modes. The patient’s motor ability and the system’s trajectory error are taken as the basis for mode switching. Based on the patients’ motor ability, the controller can switch between robot-dominant and patient-dominant modes. Trajectory errors are used to determine whether to switch to the safety-stop mode. The proposed control strategy is not only suitable for patients with different motor abilities and rehabilitation stages but also guarantees safety during rehabilitation training. Since the transition between robot-dominant and patient-dominant modes does not depend on the trajectory errors, the patient-dominant mode allows for greater trajectory errors than the robot-dominated mode, and the reference speed can be modified by the patient, improving their freedom of movement. The stability of the proposed method under three control modes is analyzed using Lyapunov theory. Numerical simulations are carried out on a two-degree-of-freedom lower limb rehabilitation robot to verify the effectiveness of the proposed method. Our future work will focus on clinical applications.
Statements
Data availability statement
The original contributions presented in the study are included in the article/supplementary material; further inquiries can be directed to the corresponding author.
Author contributions
XL: conceptualization, formal analysis, and writing–original draft. YY: methodology, software, and writing–original draft. SD: data curation, formal analysis, and writing–review and editing. ZG: conceptualization, validation, and writing–review and editing. ZL: investigation and writing–review and editing. SL: investigation, validation, and writing–review and editing. TS: formal analysis, project administration, software, and writing–original draft.
Funding
The authors declare that financial support was received for the research, authorship, and/or publication of this article. This work was supported by the National Key R&D Program of China under Grant 2023YFE0202100; the Natural Science Foundation of China under grants 62373013, 62103007, 62203442, and 62003005; the R&D Program of Beijing Municipal Education Commission under grants KM202110009009 and KM202210009010; the Natural Science Foundation of Beijing under grants L202020 and 4204097; and the Talent Fund of Beijing Jiaotong University under grant KAIXKRC24003532.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1
AdhikariB.BharadwajV. R.MillerB. A.NovakV. D.JiangC. (2023). Learning skill training schedules from domain experts for a multi-patient multi-robot rehabilitation gym. IEEE Trans. Neural Syst. Rehabil. Eng.31, 4256–4265. 10.1109/TNSRE.2023.3326777
2
AslH. J.YamashitaM.NarikiyoT.KawanishiM. (2020). Field-based assist-as-needed control schemes for rehabilitation robots. IEEE ASME Trans. Mechatron.25, 2100–2111. 10.1109/TMECH.2020.2992090
3
BergmannL.VossD.LeonhardtS.NgoC. (2023). Lower-limb exoskeleton with compliant actuators: human cooperative control. IEEE Trans. Med. Robot.5, 717–729. 10.1109/TMRB.2023.3290982
4
GaoM.ChenJ.LiM.DaiJ. S. (2023). “Design and evaluation of a novel self-adaptive ankle rehabilitation exoskeleton with elastic modules,” in 2023 international conference on advanced robotics and mechatronics (ICARM), 900–905. 10.1109/ICARM58088.2023.10218858
5
GuoL.LuZ.YaoL. (2021). Human-machine interaction sensing technology based on hand gesture recognition: a review. IEEE Trans. Hum. Mach. Syst.51, 300–309. 10.1109/THMS.2021.3086003
6
HanS.WangH.YuH. (2023). Human-robot interaction evaluation-based AAN control for upper limb rehabilitation robots driven by series elastic actuators. IEEE Trans. Robot.39, 3437–3451. 10.1109/TRO.2023.3286073
7
JamwalP. K.HussainS.GhayeshM. H.RogozinaS. V. (2016). Impedance control of an intrinsically compliant parallel ankle rehabilitation robot. IEEE Trans. Ind. Electron.63, 3638–3647. 10.1109/TIE.2016.2521600
8
LiN.YangY.LiG.YangT.WangY.ChenW.et al (2024a). Multi-sensor fusion-based mirror adaptive assist-as-needed control strategy of a soft exoskeleton for upper limb rehabilitation. IEEE Trans. Autom.21, 475–487. 10.1109/TASE.2022.3225727
9
LiX.PanY.ChenG.YuH. (2017a). Adaptive human-robot interaction control for robots driven by series elastic actuators. IEEE Trans. Robot.33, 169–182. 10.1109/TRO.2016.2626479
10
LiX.PanY.ChenG.YuH. (2017b). Multi-modal control scheme for rehabilitation robotic exoskeletons. Int. J. Robot. Res.36, 759–777. 10.1177/0278364917691111
11
LiX.YangQ.SongR. (2021). Performance-based hybrid control of a cable-driven upper-limb rehabilitation robot. IEEE Trans. Biomed. Eng.68, 1351–1359. 10.1109/TBME.2020.3027823
12
LiZ.ZhangT.HuangP.LiG. (2024b). Human-in-the-loop cooperative control of a walking exoskeleton for following time-variable human intention. IEEE Trans. Cybern.54, 2142–2154. 10.1109/TCYB.2022.3211925
13
LiangX.SuT.ZhangZ.ZhangJ.LiuS.ZhaoQ.et al (2022). An adaptive time-varying impedance controller for manipulators. Front. Neurorobot.16, 789842. 10.3389/fnbot.2022.789842
14
LiangX.YanY.SuT.GuoZ.LiuS.ZhangH.et al (2023). “Kalman filter and moving average method based human-robot interaction torque estimation for a lower limb rehabilitation robot,” in 2023 international conference on advanced robotics and mechatronics (ICARM), 1083–1088. 10.1109/ICARM58088.2023.10218932
15
LuZ.HeB.CaiY.ChenB.YaoL.HuangH.et al (2023). Human-machine interaction technology for simultaneous gesture recognition and force assessment: a review. IEEE Sens. J.23, 26981–26996. 10.1109/JSEN.2023.3314104
16
LuoL.PengL.WangC.HouZ.-G. (2019). A greedy assist-as-needed controller for upper limb rehabilitation. IEEE Trans. Neural Netw. Learn. Syst.30, 3433–3443. 10.1109/TNNLS.2019.2892157
17
MaoY.JinX.Gera DuttaG.ScholzJ. P.AgrawalS. K. (2015). Human movement training with a cable driven arm exoskeleton (CAREX). IEEE Trans. Neural Syst. Rehabil. Eng.23, 84–92. 10.1109/TNSRE.2014.2329018
18
MasengoG.ZhangX.DongR.AlhassanA. B.HamzaK.MudaheranwaE. (2023). Lower limb exoskeleton robot and its cooperative control: a review, trends, and challenges for future research. Front. Neurorobot.16, 913748. 10.3389/fnbot.2022.913748
19
XuJ.LiY.XuL.PengC.ChenS.LiuJ.et al (2019). A multi-mode rehabilitation robot with magnetorheological actuators based on human motion intention estimation. IEEE Trans. Neural Syst. Rehabil. Eng.27, 2216–2228. 10.1109/TNSRE.2019.2937000
20
YangC.GaneshG.HaddadinS.ParuselS.Albu-SchaefferA.BurdetE. (2011). Human-like adaptation of force and impedance in stable and unstable interactions. IEEE Trans. Robot.27, 918–930. 10.1109/TRO.2011.2158251
21
YangR.ShenZ.LyuY.ZhuangY.LiL.SongR. (2023). Voluntary assist-as-needed controller for an ankle power-assist rehabilitation robot. IEEE Trans. Biomed. Eng.70, 1795–1803. 10.1109/TBME.2022.3228070
22
ZhangJ.CheahC. C. (2015). Passivity and stability of human-robot interaction control for upper-limb rehabilitation robots. IEEE Trans. Robot.31, 233–245. 10.1109/TRO.2015.2392451
23
ZhouJ.LiZ.LiX.WangX.SongR. (2021). Human-robot cooperation control based on trajectory deformation algorithm for a lower limb rehabilitation robot. IEEE ASME Trans. Mechatron.26, 3128–3138. 10.1109/TMECH.2021.3053562
Summary
Keywords
impedance control, rehabilitation robot, multi-mode adaptive control, human–robot interaction, rehabilitation training strategy
Citation
Liang X, Yan Y, Dai S, Guo Z, Li Z, Liu S and Su T (2024) Multi-mode adaptive control strategy for a lower limb rehabilitation robot. Front. Bioeng. Biotechnol. 12:1392599. doi: 10.3389/fbioe.2024.1392599
Received
27 February 2024
Accepted
10 April 2024
Published
16 May 2024
Volume
12 - 2024
Edited by
Wujing Cao, Chinese Academy of Sciences (CAS), China
Reviewed by
Chong Li, Tsinghua University, China
Jianlong Hao, Shanxi University of Finance and Economics, China
Bingshan Hu, University of Shanghai for Science and Technology, China
Updates
Copyright
© 2024 Liang, Yan, Dai, Guo, Li, Liu and Su.
This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Tingting Su, sutingting@bjut.edu.cn
Disclaimer
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.