 Glenn Byrenheid1
Glenn Byrenheid1 Serhii Stasyuk
Serhii Stasyuk- 1Institute of Mathematics, Friedrich-Schiller-University Jena, Jena, Germany
- 2Faculty of Mathematics, Chemnitz University of Technology, Chemnitz, Germany
- 3Department of Theory of Functions, Institute of Mathematics of NAS of Ukraine, Kyiv, Ukraine
In this article, we study the sampling recovery problem for certain relevant multivariate function classes on the cube [0, 1]d, which are not compactly embedded into . Recent tools relating the sampling widths to the Kolmogorov or best m-term trigonometric widths in the uniform norm are therefore not applicable. In a sense, we continue the research on the small smoothness problem by considering limiting smoothness in the context of Besov and Triebel-Lizorkin spaces with dominating mixed regularity such that the sampling recovery problem is still relevant. There is not much information available on the recovery of such functions except for a previous result by Oswald in the univariate case and Dinh Dũng in the multivariate case. As a first step, we prove the uniform boundedness of the ℓp-norm of the Faber coefficients at a fixed level by Fourier analytic means. Using this, we can control the error made by a (Smolyak) truncated Faber series in with q < ∞. It turns out that the main rate of convergence is sharp. Thus, we obtain results also for , a space “close” to , which is important in numerical analysis, especially numerical integration, but has rather poor Fourier analytical properties.
1. Introduction
In this article, we continue to study the approximation power of Smolyak sparse grid sampling recovery for multivariate function classes with small mixed smoothness and based on the multivariate Faber representation [1, 2] of f. The advantage of such a representation is the fact that the coefficient functionals only use discrete functional values of f, see (2.1) and (2.3) below, which allow for various applications. For instance, Kempka et al. [3] used the Faber system to analyze the path regularity of the Brownian motion, where a small smoothness setting is also required.
It provides a powerful tool for studying various situations of the sampling recovery problem where errors are measured in Lq. Surprisingly, the proposed method turned out to be sharp in several regimes. A systematic discretization of multivariate functions with mixed smoothness in terms of Faber coefficients is given [1, 2, 4, 5], see also [6] for further history. In this article, we study an endpoint situation for the sampling recovery problem on the cube [0, 1]d, where r = 1/p in the source space and the fine parameter θ ≤ 1 is sufficiently small. This still allows for an embedding into the continuous functions (therefore making function evaluations possible). However, the embedding into Lq is only compact if q < ∞.
Recent observations regarding the problem of optimal sampling recovery of function classes in L2 bring classes with mixed smoothness to the focus again since several newly developed techniques only work for Hilbert-Schmidt operators [7–9] or, more generally, in situations where certain asymptotic characteristics (approximation numbers) are square summable [10, 11]. We need new techniques for situations where this is not the case. In Temlyakov and Ullrich [12, 13], the authors consider the range of small smoothness where one is far away from square summability of the corresponding widths. However, we have the compact embedding into L∞ for those examples. This embedding seems to be of crucial importance when (non-linear) sampling widths (ϱm)m, defined by
with X = L2 are related to certain asymptotic characteristics such as Kolmogorov (dm)m or best m-term trigonometric widths (σm)m in L∞. It has been shown by Temlyakov [14], Bartel et al. [9] and Jahn et al. [15] that the following inequalities hold for relevant function classes F
Here, we have some constants C, D > 0 and oversampling parameter 1 < b ≤ 2 in the first relation. We speak about linear sampling widths denoted by if the reconstruction mapping R is linear. The second relation might not need a compact embedding into L∞ at first glance. However, the proof heavily relies on certain compactness properties of the embedding, see [15]. Clearly, a compact embedding into L∞ allows us to use the decaying Kolmogorov widths for controlling the linear sampling widths. As discussed by Temlyakov and Ullrich [12], sparse grid techniques [16] perform asymptotically worse by a log factor for classes with mixed smoothness compactly embedded into L∞.
In this article, we continue our research in this direction. Note that there are several relevant (multivariate) function classes F which are continuously but not compactly embedded into L∞. Thus, at least the first relation in (1.1) is useless. In fact, only few results have been published on reconstructing functions from samples, which only satisfy a Besov regularity with smoothness r = 1/p or Sobolev type regularity with r = 1 and p = 1. Our aim is to investigate this problem systematically in the Fourier analytic context. As a first step, we prove the following relation for the Faber coefficients of f, namely
in case 1/2 ≤ p ≤ ∞. Our contribution is a proof that works for Fourier analytic defined spaces and allows for incorporating also the extreme cases and [in contrast to Dũng [17], Theorem 3.2]. It represents an extreme case of the considered limit situation, in which the Faber approximation can benefit from the highest regularity of smoothness equals 2. The above relation directly implies that the truncated Faber representation still works well when we consider errors in Lq with q < ∞. We make progress toward the solution of an open problem mentioned [[18], Section 3.2]. The univariate class and its approximation by equidistant samples in [0, 1] have been considered by Oswald [19] in the beginning of the 80s. In 2011, Dũng [[17], Theorem 3.2] obtained results for the multivariate situation in the framework of Besov spaces with a bounded mixed difference. In contrast to the spaces considered by Dũng [17], we highlight that the Besov and Triebel-Lizorkin spaces considered here are defined using Fourier analytic building blocks. Note that in the considered limiting situation and p < 1, it is not yet known whether these spaces coincide with the ones considered by Dũng [see [20], Remark 2.3.4/2].
Notation. In general, ℕ denotes the natural numbers, ℕ0 = ℕ ∪ {0}, ℕ −1 = ℕ0 ∪ {−1}, ℤ denotes the integers, ℝ denotes the real numbers, and ℂ denotes the complex numbers. The letter d is always reserved for the underlying dimension in ℝd, ℤd, etc. For a ∈ ℝ, we denote a+: = max{a, 0}. For 0 < p ≤ ∞ and x ∈ ℝd, we denote with the usual modification in the case p = ∞. We further denote x+ : = ((x1)+, …, (xd)+) and |x|+ : = |x+|1. By (x1, …, xd) > 0, we mean that each coordinate is positive. If X and Y are two (quasi-)normed spaces, the (quasi-)norm of an element x in X will be denoted by ||x|X||. The symbol X↪Y indicates that the identity operator is continuous. For two sequences an and bn, we will write an ≲ bn if there exists a constant c > 0 such that an ≤ cbn for all n. We will write an ≍ bn if an ≲ bn and bn ≲ an.
2. The tensor Faber basis
As a main tool, we will use decompositions of functions in terms of a Faber series expansion.
2.1. The univariate Faber basis
Let us briefly recall the basic facts about the Faber basis taken from [[4], 3.2.1 and 3.2.2]. For j ∈ ℕ0 and , we denote the dyadic interval by Ij,k given by
Definition 2.1. [The univariate Faber system] Let
the Haar function and v(x) be the integrated Haar function, i.e.,
and for j ∈ ℕ0 and k ∈ 𝔻j, then
For notational reasons, we let v−1,0 = x and v−1,1 : = 1 − x for j = −1 and obtain the univariate Faber basis
where 𝔻−1: = 𝔻1 = {0, 1}.
Faber [21] observed that every continuous (non-periodic) function f on [0, 1] can be represented as
with uniform convergence [see e.g., [4], Theorem 2.1, Step 4]. The analysis of Besov and Triebel-Lizorkin spaces on ℝ as defined in Section 4 requires a version of the Faber representation acting on ℝ. For this purpose, we extend the number of translations to the whole integers and obtain
where v−1,k(·) := v0,0((· + 1 + k)/2).
2.2. The multivariate Faber basis
Let f(x1, …, xd) be a d-variate function, f ∈ C(ℝd). By fixing all variables except xi, we obtain by g(·) = f(x1, …, xi−1, ·, xi+1, …, xd), a univariate continuous function. By applying (2.2) in every such component, we obtain the representation
in C(K), K⊂ℝd compact, where
and |e(j)| denotes the cardinality of e(j). Here we put e(j) = {i : ji ≠ − 1} and .
In Section 6, we apply the Faber series expansion for functions on the d-variate unit cube [0, 1]d. For this purpose, we simply truncate the series expansion to all translations whose support has a non-empty intersection with [0, 1]d. That is
With similar arguments as above, we obtain for f ∈ C([0, 1]d) the representation
3. Faber coefficients and bandlimited functions
In the sequel we deal with two tensor domains. On the one hand the d-variate unit cube Id = [0, 1]d and on the other hand the d-variate Euclidean space ℝd. We use the notation
with the usual modification in case p = ∞. The space C(𝕀d) is often used as a replacement for . It denotes the collection of all continuous and bounded d-variate functions equipped with the uniform norm. The computation of the Fourier transform (and its inverse) of an L1-integrable d-variate function is performed by the integrals (ξ ∈ ℝd)
where ξ · x := ξ1x1 + ⋯ + ξdxd. To begin with, we recall the concept of a dyadic decomposition of the unity. The space consists of all infinitely many times differentiable compactly supported functions.
Definition 3.1. Let Φ(ℝ) be the collection of all systems satisfying
(i) supp φ0 ⊂ {x:|x| ≤ 2} ,
(ii) ,
(iii) for all ℓ ∈ ℕ0, it holds , and
(iv) for all x ∈ ℝ.
Now we fix a system φ = {φn}n ∈ ℕ0 ∈ Φ(ℝ). for , let the building blocks fℓ be given by
Because of the Paley-Wiener theorem, the functions fℓ are entire analytic functions and therefore continuous. The goal of this section is to derive bounds for fixed “levels” j of the Faber expansion (2.3) of such a bandlimited function fℓ. To be more precise, we aim at bounds for Clearly, due to the compact support of vj,k, we may replace vj,k by the characteristic function χj,k of the parallelepiped . Note that for any continuous function f ∈ C(ℝd)
where 0 < p ≤ ∞. To perform this, we need some tools from harmonic analysis. We state a mixed version of the Peetre maximal inequality, proved in [[20], 1.6.4].
Lemma 3.2. [Peetre maximal inequality] Let 0 < p ≤ ∞ and a > 1/p (a > 0 in case p = ∞). Furthermore, let such that , where . Then there is a constant c > 0, only depending on a and p but not on f and b, such that
The following univariate pointwise estimate connecting differences between bandlimited functions and Peetre maximal operator is taken from [[22], Lemma 3.3.1].
Lemma 3.3. Let a, b > 0 and f ∈ L1(ℝ) with . Then there exists a constant C > 0 such that
The bound may be slightly improved when replacing pointwise estimates with estimates involving Lp norms. We have the following.
Lemma 3.4. Let j, ℓ ∈ ℕ0, a > 0, 0 < p ≤ ∞, and f ∈ C(ℝ). Then we have
independent of x ∈ ℝ, j, ℓ, and f.
Proof. We start with a pointwise estimate
Taking Lp-norms on both sides gives
Finally, we trivially observe
In the next lemma, we combine both univariate bounds and derive a multivariate estimate via iteration with respect to coordinate directions. Let f ∈ L1(ℝd) and fj+ℓ denotes the bandlimited function from (3.1).
Lemma 3.5. Let 0 < p ≤ ∞, , and ℓ ∈ ℤd. Then we have
Proof. Step 1. To provide a technically transparent proof of this lemma, we start with the univariate case (d = 1). In the second part of this proof, we deal with the multivariate case, which requires more involved notation. For x ∈ ℝ, we define
Let x ∈ [2−jk, 2−j(k + 1)]. For this x, we have
Since χj,k(x) do not overlap, we receive
By Lemma 3.4, we find
for some a > 0, which is at our disposal.
In case ℓ ≤ 0, we may continue arguing pointwise. First of all, we have
Using Lemma 3.3 and the fact that ℓ ≤ 0, we obtain
Combining (3.3) and (3.4) gives
Choosing a > 1/p and applying the Peetre maximal inequality in Lemma 3.2 gives the result for d = 1.
Step 2. We deal with the multivariate case and start with a pointwise estimate of
where we apply the above procedure in every direction. In order not to drown in notation, we introduce the following direction-wise maximal operator
where . Clearly, for x ∈ ℝd, we have
Here we use the fact that we have in every direction
including the case j = −1, where the difference is replaced by the function value at the respective point. This case is included in () since for ℓi < 0 there is nothing to prove in this case. We use the triangle inequality in order to estimate the difference by point evaluations. Taking sup over the step length of this absolutely valued point evaluations leads to the direction-wise maximal operator. In case ℓi ≤ 0, we keep the direction-wise difference. Nevertheless, in order to get rid of the characteristic function, we have to additionally apply a direction-wise sup also in this case. Since it holds that
with |f| ≤ |g|, we first estimate
pointwise from above using Lemma 3.3 iteratively. This gives
for any a > 0. The maximal operators go on the same coordinates. Since ℓi ≤ 0 we clearly also have
It remains to apply and take the Lp-norm, p < ∞. Here we use Lemma 3.4 iteratively:
Finally, we use the trivial estimate [already known from (3.2)] to replace the operators by the Peetre maximal function. This gives
if we choose a > 1/p. For the sake of completeness, let us additionally consider the case p = ∞. We have
if we choose a > 0.
4. Besov and Triebel-Lizorkin spaces with mixed smoothness
For the definition of the corresponding function spaces on ℝd, we refer to [1, 20, 23]. The corresponding function spaces on [0, 1]d are defined via restrictions of functions on ℝd [see [1], Section 3.4]. In this section, we mainly focus on the definition of Besov and Triebel-Lizorkin spaces with dominating mixed (in the sequel only called mixed) smoothness on ℝd since they are crucial for our subsequent analysis. We closely follow [[20], Chapter 2] and use the building blocks fj(·) defined in (3.1).
Definition 4.1. [Mixed Besov and Triebel-Lizorkin spaces] (i) Let 0 < p, θ ≤ ∞, and r > (1/p − 1)+. If θ ≤ min{p, 1}, we admit r = (1/p − 1)+. Then is defined as the collection of all f ∈ Lmax{p, 1}(ℝd) such that
is finite (with the usual modification if θ = ∞).
(ii) Let 0 < p < ∞, 0 < θ ≤ ∞, and r > (1/p − 1)+. Then is defined as the collection of all f ∈ Lmax{p, 1}(ℝd) such that
is finite (with the usual modification if θ = ∞).
It is noted that this definition is independent of the chosen system φ in the context of equivalent (quasi-)norms. Moreover, in the case min{p, θ} ≥ 1, the defined spaces are Banach spaces, whereas they are quasi-Banach spaces in the case min{p, θ} < 1. For details, we refer to [[20], Section 2.2.4]. In the next lemma, there appears the condition r > (1/p − 1)+, which is caused by the parameter range in our Definition 4.1. All the subsequent embeddings, of course, also hold true for the general situation, where r ∈ ℝ. We have the following elementary embeddings [see [20], Section 2.2.3].
Lemma 4.2. Let 0 < p < ∞ (including p = ∞ in the B-case), 0 < θ ≤ ∞, and r > (1/p − 1)+. If θ ≤ min{p, 1}, we admit r = (1/p − 1)+ in the B-case. Furthermore, let A ∈ {B, F}.
(i) If ε > 0 and 0 < v ≤ ∞, then
(iia) If p < u < ∞, 0 < θ, θ1, θ2 ≤ ∞, and r−1/p = t−1/u then
(iib) (Jawerth-Franke embedding I) If 0 < p < u < ∞, 0 < w ≤ ∞, and r − 1/p = t − 1/u then
(iic) (Jawerth-Franke embedding II) If 0 < p < u ≤ ∞, 0 < θ ≤ ∞, and r − 1/p = t − 1/u then
(iiia) If r > 1/p (including p = ∞, r > 0), then
(iiib) If r = 1/p and θ ≤ 1, then we still have
and especially the limiting case
(iiic) It holds
(iv) If 1 < p < ∞ and r > 0, then
Proof. The embeddings (i), (iia), (iiia), (iiib), and (iv) are standard and can be found in [[20], Chapter 2] especially we refer to [[20], Remark 2, p. 132], which includes the limiting case p = ∞ in (iiib). As for the Jawerth-Franke type embeddings, we refer to [[24], Theorem 1.2 and 1.4] and the summary [[6], Lemma 3.4.2 and 3.4.3]. See also [[6], Rem. 3.4.4] for further references, especially for the mixed smoothness case. Finally, the embedding in (iiic) is a consequence of (iic) and (iiib).
4.1. Spaces on domains
We aim for approximating functions defined on the unit cube [0, 1]d with the above regularity assumptions. This requires the definition of function spaces on domains. The domain Ω⊂ℝd represents an open connected set. Later, when dealing with continuous bounded functions, we may use as well compact sets like [0, 1]d.
Definition 4.3. Let Ω be a domain in ℝd.
1. Furthermore, let 0 < p, θ ≤ ∞, and r > (1/p − 1)+. If in case θ ≤ min{p, 1}, we admit r = (1/p − 1)+. Then we define
where
2. In case 0 < p < ∞, 0 < θ ≤ ∞, and r > (1/p − 1)+, we define
where
On bounded domains Ω, all the embeddings in Lemma 4.2 keep valid. In addition, we have the following embeddings. If 0 < p2 < p1 ≤ ∞ (F-case: pi < ∞), 0 < θ ≤ ∞, and |Ω| < ∞, then
and
Clearly, this is a trivial consequence of the embedding
It is well-known that spaces with sufficiently large smoothness, namely r > 1/p, are compactly embedded into . This is a direct consequence of results on entropy numbers of the classes in [see [25], Cor. 23, (iii) or [12], Theorem 6.2], and the embeddings stated in Lemma 4.2 above.
However, in case r = 1/p, we do not have a compact embedding. For the convenience of the reader, we give a direct proof.
Lemma 4.4. [Non-compactness of limiting embeddings] (i) Let 0 < p ≤ ∞ and θ ≤ min{p, 1}. Then the embedding
is not compact.
(ii) If p ≤ 1 and 0 < θ ≤ ∞, then the embedding
is not compact.
Proof. We show the non-compactness of the embedding (4.1) first in the case d = 1. Clearly, by standard (tensorization) arguments, this would also imply the non-compactness in higher dimensions. Note further that the non-compactness of (4.2) is implied by the Jawerth-Franke embedding [see Lemma 4.2, (iib)]
together with the non-compactness of (4.1). So, it remains to be proved the non-compactness of for any θ ≤ min{p, 1} and 0 < p ≤ ∞. This fact is certainly known and can be found in the literature. However, we would like to present a direct argument here since it fits the scope of the article. The idea is to find a sequence (gj)j of functions with for all j, which is not convergent in L∞([0, 1]). A straightforward choice for the gj is the Faber basis functions (L∞-normalized hat functions) for different levels j. To be more precise, we let j = 0, 1, 2, ... and consider the sequence (gj)j: = (vj,0)j ∈ ℕ0. Clearly, we always have
In case k > j, we even obtain (due to cancellation)
see, for instance [[2], (3.19) and (3.20)]. According to [[26], p. 110] we can equivalently describe the norm of in terms of differences. Note that here we have to use differences of sufficiently high order m > s since 1/p may get large. The estimate from above implies
in case s ≤ 1/p. Hence, the elements vj,0 have uniformly (in j) bounded quasi-norm in . However, it holds
if j ≠ ℓ, see, for instance, Figure 1. This directly disproves the compactness of the unit ball of in L∞([0, 1]).
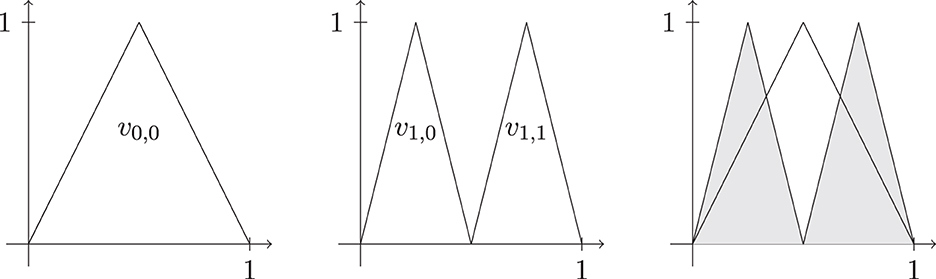
Figure 1. Univariate hierarchical Faber basis on [0, 1] for levels j ∈ {0, 1} and their union.
Remark 4.5. We need to formulate the definition of the Kolmogorov widths to demonstrate some relations with approximative characteristics considered here. For a compact set F↪X of a Banach space X, we define the Kolmogorov widths as follows:
and
Clearly, considering F as the unit ball in with θ ≤ min{p, 1} and then
by Lemma 4.4.
5. The decay of the Faber coefficients
Now we are ready for proving our main tool: an assertion about the decay of the Faber coefficients of functions from . In order to do so we need to define the following space of doubly indexed sequences.
Definition 5.1. Let 0 < p, θ ≤ ∞ and r ≥ 1/p.
(i) The sequence space is the collection of all doubly indexed sequences such that
is finite (with the usual modification if max{p, θ} = ∞).
(ii) Let Ω ⊂ ℝd be a compact domain. We define the index set 𝔻j(Ω) to be the set of all k ∈ ℤd such that xj,k ∈ Ω. The space is defined as the space of all doubly indexed sequences such that
is finite (with the usual modification if max{p, θ} = ∞).
Remark 5.2. (i) In case Ω = [0, 1]d we have 𝔻j(Ω) = 𝔻j, which was defined right before (2.4). In a certain sense the elements of are restrictions of elements in to indices related to Ω. (ii) These sequence spaces already appeared in [[23], Def. 2.1, 3.2]. Let 0 < p, θ ≤ ∞ and r ∈ ℝ. The spaces and are Banach spaces if min{p, θ}≥1. In case min{p, θ} < 1 the space is a quasi-Banach space. Moreover, if u: = min{p, θ, 1} it is a u-Banach space, i.e.,
Here is the first main result.
Proposition 5.3. Let 1/2 ≤ p ≤ ∞. Then there exists a constant c > 0 (independent of f) such that
for all .
Proof. Let us put u = min{p, 1}. We make use of the decomposition (2.3) in a slightly modified way. For fixed we write . Putting this into (5.1) and using the u-triangle inequality yields
Applying Lemma 3.5 we obtain
since the sup stays finite since 1/2 ≤ p ≤ ∞.
As a direct consequence we have the following restricted version.
Corollary 5.4. Let 1/2 ≤ p ≤ ∞. Then there exists a constant c > 0 such that
for all .
Proof. Assume . Then, by Definition 4.3 there is a with g|Ω = f. By Proposition 5.3 we obtain
Since for and k ∈ 𝔻j(Ω) we have
we obtain
The last inequality holds for every extension g of f. Taking the infimum yields the result.
The last corollary can be interpreted as a generalization of [[2], Proposition 3.4] to the limiting smoothness case r = 1/p. Related results concerning non-limiting smoothness were obtained in [1, 5, 27].
6. Application for sampling recovery in Lq with q < ∞
In this section, we would like to apply the Faber embedding in Corollary 5.4 for sampling recovery on the unit cube Ω = [0, 1]d. As we have shown in Lemma 4.4, we cannot expect an error decay of a sampling recovery operator in the worst case when we measure the error in . Hence, we focus on the recovery in with q < ∞. Based on the Faber representation, we will use a sparse grid truncation in order to obtain a recovery operator. Let
with the notation from Section 2.
Lemma 6.1. The following estimates hold true for α > 0
(i)
(ii)
Proof. We refer to [[28], p. 10, Lemma D].
We first consider the case where p = q.
Theorem 6.1. Let 1/2 ≤ p < ∞. Then there is a constant C > 0 (independent of n and f) such that
holds for all n ∈ ℕ.
Proof. The representation in (2.4) allows us to express and estimate the error by u = min{p, 1}
Finally applying Proposition 5.3 or Corollary 5.4 yields
where the sum is estimated by Lemma 6.1.
Remark 1. A one-dimensional version of the above result has been proven by Oswald [19] about four decades ago. Dũng proved in [[17], Theorem 3.2] that a related result for slightly different Besov-type function spaces, especially not including the case p = 1/2.
In the situation p < q, we loose in the main rate. This phenomenon has been observed earlier in the literature [see [6]]. We will use Jawerth-Franke type embeddings to improve the order of the logarithmic term.
Theorem 6.2. Let 1/2 ≤ p < q < ∞. Then
Proof. Using Jawerth-Franke I (see Lemma 4.2), we obtain
where we used the inverse Faber characterization for spaces with positive smoothness [cf. [1], Theorem 4.18]. This reference deals with the ℝd case but can be easily extended by standard arguments as shown, for instance, in the proof of Corollary 5.4 or following the arguments in [[1], Theorem 4.25] to the unit cube setting. Finally applying Proposition 5.3 yields
Let us now deal with the space , which is embedded into C([0, 1]d), as shown in Lemma 4.2, (iiic). By Jawerth-Franke embedding II [(Lemma 4.2, (iic)], we even know that for every 1 < p < ∞, we have . As a direct corollary of Theorems 6.1 and 6.2, we make the new observations.
Theorem 6.3. (i) It holds for any small ε > 0
(ii) For any 1 < q < ∞ we have
Proof. By the embedding for p > 1, we may apply Theorem 6.2 to obtain the result. For (i), we simply choose small q > 1 and use the fact that the Lq-norm dominates the L1-norm. Clearly, the logterm can be dropped in this regime.
6.1. Sampling widths
Let us focus our considerations toward the problem of optimal sampling recovery. We compare the number m of samples to the resulting error in an algorithm and call the quantity
the m-th sampling width. If, in addition, the mapping is linear, then we obtain the linear sampling widths
where A ∈ {B, F}. Therefore, according to the definitions mentioned above, we have
In the next theorems, we apply the linear algorithm Inf [cf. (6.1)] to obtain upper bounds for and ϱm.
Theorem 6.4. Let 1/2 ≤ p < ∞. Then
for all m ∈ ℕ.
Proof. The upper bound is due to Theorem 6.1 recognizing that the algorithm In in (6.1) samples f in m ≍ 2nnd−1 nodes. This can be trivially checked by applying Lemma 6.1, (ii). For the sake of completeness, we refer to [[1], Section 5.1] where further properties of this operator were studied.
Theorem 6.5. Let 1/2 ≤ p < q < ∞. Then
(i)
and
(ii)
for all m ∈ ℕ.
Proof. The upper bound in (i) is due to Theorem 6.2 taking the number of sampling nodes into account, see Theorem 6.4. The upper bound in (ii) is due to Theorem 6.3.
6.2. Lower bounds
The linear width of class F in a normed space X has been introduced by Tikhomirov [29] more than 60 years ago. It is defined by
Romanyuk [30, 31] proved for F, the unit ball in , that in case 1 ≤ p ≤ q ≤ 2 and q > 1
We obtain the following lower bounds for the (linear) sampling widths.
Theorem 6.6. (i) Let 1 ≤ p ≤ q < ∞. Then we have
(ii) If, additionally, 1 ≤ p ≤ q ≤ 2 and q > 1, then
Proof. The result in (ii) follows immediately from (6.2). For the lower bound in (i), we use a fooling function that is constructed as the simple tensor function, containing the univariate fooling function obtained from [32] in the first direction smooth compactly supported (bump) functions in all remaining directions. We obtain our result by considering that all corresponding norms have product properties related to simple tensor functions.
7. Outlook and discussion
In this article, we have shown that for the sampling recovery problem the compact embedding into is not necessary. There are several relevant multivariate function classes that fall under this scope, such as limiting mixed Besov and Triebel-Lizorkin spaces with smoothness r = 1/p and further parameter conditions to ensure the embedding into the class of continuous functions. We were able to give upper bounds for the sampling widths in with q < ∞, which are sharp in the polynomial main rate. As for the right order of the logarithm, the situation is completely open.
Let us comment on the particular case of L1-smoothness spaces. Smoothness spaces built upon with smoothness r = 1 play an important role in numerical integration. This includes, for instance, the space defined using weak derivatives. This space cannot be described using Fourier analytical means and is therefore difficult to handle. However, these spaces are considered in the scope of this article since we also have r = 1/p and a non-compact embedding into . A Faber characterization is shown, similar to above, including
In particular, this would imply the following so-called sampling inequality
This extends the result in [[33], Prop. 2] in several directions. On the one hand, we consider the multivariate case, and on the other hand, the space is larger than .
Having (7.1) at hand, the following slightly sharper version of Theorem 6.3 is immediate.
Theorem 7.1. For any 1 ≤ q < ∞, we have
A proper Fourier analytical replacement of the spaces are the spaces . However, these spaces are not really comparable, especially when q = ∞. Using the methods in [[34], Theorem 1.9], there is strong evidence for proving a version of (7.1) also for the spaces . This would imply a version of Theorem 7.1. By well-known arguments, a cubature formula with performance
can be constructed by integrating the approximand. Note that there were efforts made in the literature to treat such limiting cases, see, for instance [[35], Cor. 6.5]. Suboptimal bounds were proven there. Note that results for such limiting cases are related to the Kokhsma-Hlawka inequality, showing that QMC-cubature in is related to the star discrepancy of the cubature nodes.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author contributions
All authors listed have made a substantial, direct, and intellectual contribution to the work and approved it for publication.
Funding
SS was supported by the German Academic Exchange Service (DAAD, Grant 57588362) and by the Philipp Schwartz Initiative of the Alexander von Humboldt Foundation.
Acknowledgments
The authors would like to thank the referees for their useful remarks for improving the quality of this manuscript. Additionally, the authors thank Winfried Sickel and Dinh Dũng for discussion and their comments on earlier versions of this manuscript.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Byrenheid G. Sparse representation of multivariate functions based on discrete point evaluations [Dissertation]. Institut für Numerische Simulation; Universität Bonn, Bonn, Germany (2018).
2. Hinrichs A, Markhasin L, Oettershagen J, Ullrich T. Optimal quasi-Monte Carlo rules on order 2 digital nets for the numerical integration of multivariate periodic functions. Numer Math. (2016) 134:163–96. doi: 10.1007/s00211-015-0765-y
3. Kempka H, Schneider C, Vybiral J. Path regularity of Brownian motion and Brownian sheet. Constr Approx. (2022). doi: 10.1007/s00365-023-09647-z
4. Triebel H. Bases in Function Spaces, Sampling, Discrepancy, Numerical Integration. Vol. 11 of EMS Tracts in Mathematics. Zürich: European Mathematical Society (EMS) (2010). doi: 10.4171/085
5. Triebel H. Faber Systems and Their Use in Sampling, Discrepancy, Numerical Integration. EMS Series of Lectures in Mathematics. Zürich: European Mathematical Society (EMS) (2012). doi: 10.4171/107
6. Dũng D, Temlyakov VN, Ullrich T. Hyperbolic Cross Approximation. In: Tikhonov S, , editor. Advanced Courses in Mathematics. CRM Barcelona. Cham: Birkhäuser; Springer (2018). doi: 10.1007/978-3-319-92240-9
7. Krieg D, Ullrich M. Function values are enough for L2-approximation. Found Comp Math. (2021) 21:1141–51. doi: 10.1007/s10208-020-09481-w
8. Nagel N, Schäfer M, Ullrich T. A new upper bound for sampling numbers. Found Comp Math. (2022) 22:445–68. doi: 10.1007/s10208-021-09504-0
9. Bartel F, Schäfer M, Ullrich T. Constructive subsampling of finite frames with applications in optimal function recovery. Appl Comput Harmon Anal. (2023) 65:209–248. doi: 10.1016/j.acha.2023.02.004
10. Krieg D, Ullrich M. Function values are enough for L2-approximation. II. J Complex. (2021) 66:14. doi: 10.1016/j.jco.2021.101569
11. Dolbeault M, Krieg D, Ullrich M. A sharp upper bound for sampling numbers in L2. Appl Comput Harmon Anal. (2023) 63:113–34. doi: 10.1016/j.acha.2022.12.001
12. Temlyakov VN, Ullrich T. Approximation of functions with small mixed smoothness in the uniform norm. J Approx Theory. (2022) 277:105718. doi: 10.1016/j.jat.2022.105718
13. Temlyakov V, Ullrich T. Bounds on Kolmogorov widths and sampling recovery for classes with small mixed smoothness. J Complex. (2021) 67:101575. doi: 10.1016/j.jco.2021.101575
14. Temlyakov V. On optimal recovery in L2. J Complex. (2021) 65:101545. doi: 10.1016/j.jco.2020.101545
15. Jahn T, Ullrich T, Voigtlaender F. Sampling numbers of smoothness classes via ℓ1-minimization. J Complex. (2022). doi: 10.48550/arXiv.2212.00445
16. Bungartz HJ, Griebel M. Sparse grids. Acta Numer. (2004) 13:147–269. doi: 10.1017/S0962492904000182
17. Dũng D. B-spline quasi-interpolant representations and sampling recovery of functions with mixed smoothness. J Complex. (2011) 27:541–67. doi: 10.1016/j.jco.2011.02.004
18. Ullrich T. Smolyak's algorithm, sparse grid approximation and periodic function spaces with dominating mixed smoothness (PhD thesis). Friedrich-Schiller-Universität Jena, Jena, Germany (2007).
19. Oswald P. Lp-Approximation durch Reihen nach dem Haar-Orthogonalsystem und dem Faber-Schauder-System. J Approx Theory. (1981) 33:1–27. doi: 10.1016/0021-9045(81)90086-1
20. Schmeisser HJ, Triebel H. Topics in Fourier Analysis and Function Spaces. A Wiley-Interscience Publication. Chichester: John Wiley & Sons, Ltd. (1987).
22. Ullrich T. Function spaces with dominating mixed smoothness, characterization by differences. Tech Rep Jenaer Schriften zur Math Inform. (2006).
23. Vybiral J. Function spaces with dominating mixed smoothness. Dissert Math. (2006) 436:73. doi: 10.4064/dm436-0-1
24. Hansen M, Vybíral J. The Jawerth–Franke embedding of spaces with dominating mixed smoothness. Georg Math J. (2009) 16:667–82. doi: 10.1515/GMJ.2009.667
25. Mayer S, Ullrich T. Entropy numbers of finite dimensional mixed-norm balls and function space embeddings with small mixed smoothness. Constr Approx. (2021) 53:249–79. doi: 10.1007/s00365-020-09510-5
26. Triebel H. Theory of Function Spaces. Modern Birkhäuser Classics. Basel: Birkhäuser/Springer Basel AG (2010).
27. Ullrich T. Optimal cubature in Besov spaces with dominating mixed smoothness on the unit square. J Complex. (2014) 30:72–94. doi: 10.1016/j.jco.2013.09.001
28. Temlyakov V. Approximation of functions with bounded mixed derivative. Proc Steklov Inst Math. (1986) 20:173
29. Tikhomirov VM. Diameters of sets in functional spaces and the theory of best approximations. Russ Math Surv. (1960) 15:75–111. doi: 10.1070/RM1960v015n03ABEH004093
30. Romanyuk AS. Approximation of the Besov classes of periodic functions of several variables in the space Lq. Ukr Math J. (1991) 43:1297–306. doi: 10.1007/BF01061817
31. Romanyuk AS. Kolmogorov and trigonometric widths of the Besov classes of multivariate periodic functions. Sb Math. (2006) 197:69–93. doi: 10.1070/SM2006v197n01ABEH003747
32. Novak E, Triebel H. Function spaces in Lipschitz domains and optimal rates of convergence for sampling. Constr Approx. (2006) 23:325–50. doi: 10.1007/s00365-005-0612-y
33. Schmeisser HJ, Sickel W. Sampling theory and function spaces. In: Applied Mathematics Reviews. Vol. 1. River Edge, NJ: World Science Publication (2000). p. 205–84. doi: 10.1142/9789812792686_0008
34. Garrigós G, Seeger A, Ullrich T. Haar frame characterizations of Besov-Sobolev spaces and optimal embeddings into their dyadic counterparts. J Fourier Anal Appl. (2023) 29:39. doi: 10.1007/s00041-023-10013-7
Keywords: sampling recovery, limiting smoothness, non-compact embedding, Faber basis, mixed smoothness
Citation: Byrenheid G, Stasyuk S and Ullrich T (2023) Lp-Sampling recovery for non-compact subclasses of L∞. Front. Appl. Math. Stat. 9:1216331. doi: 10.3389/fams.2023.1216331
Received: 03 May 2023; Accepted: 08 June 2023;
Published: 24 August 2023.
Edited by:
Frank Filbir, Helmholtz Association of German Research Centres (HZ), GermanyReviewed by:
Feng Dai, University of Alberta, CanadaJan Vybiral, Czech Technical University in Prague, Czechia
Copyright © 2023 Byrenheid, Stasyuk and Ullrich. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Serhii Stasyuk, c3Rhc3l1a0BpbWF0aC5raWV2LnVh