
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
BRIEF RESEARCH REPORT article
Front. Appl. Math. Stat., 28 October 2022
Sec. Dynamical Systems
Volume 8 - 2022 | https://doi.org/10.3389/fams.2022.1041588
This article is part of the Research TopicNew Trends in Control and Applications of Complex SystemView all 6 articles
 Fang Zhu1,2*
Fang Zhu1,2* Pengtong Li1
Pengtong Li1This paper presents a composite fuzzy learning finite-time prescribed performance control (PPC) approach for uncertain nonlinear systems with dead-zone inputs. First, a finite-time performance function is constructed by a quartic polynomial. Subsequently, with the help of an error transformation function, the restriction problem of the tracking error performance is transformed into a stability problem of an equivalent transformation system. In order to ensure that all signals of the closed-loop system are bounded, a finite-time PPC method combined with fuzzy logic systems (FLSs) is proposed. Although the tracking error can be guaranteed to be limited within a predefined range, the proposed finite-time PPC method only uses instantaneous data, which cannot guarantee the accurate estimation of unknown functions under the influence of dead-zone inputs. Therefore, based on the persistent excitation (PE) condition, a predictive error is defined by using online recorded data and instantaneous data, and a corresponding composite learning finite-time PPC method with parameter updating the law, which can not only achieve the control aim of the former method but also improve the control effect, is designed. The simulation results verified that the composite learning finite-time PPC method is more effective than the finite-time PPC method without learning.
The traditional control methods, such as adaptive control [1–3], feedback control [4–6], active control [7–9], impulsive control [10, 11], can ensure that the tracking error converges to a residual set whose size is usually unknown. Although these controllers can achieve satisfactory steady-state error performance, the transient error performance (including settling time and maximum overshoot) cannot be guaranteed. Thus, many researchers focused on the transient performance of control systems, and a lot of methods were proposed, for example, in Bechlioulis and Rovithakis [12], Niu and Zhao [13], Li and Tong [14], Yao and Tomizuka [15], and Zhi and Xu [16]. In order to ensure that the tracking error satisfies certain transient performance, a prescribed performance control (PPC) method was proposed by Bechlioulis and Rovithakis [12]. It is concluded that the characteristic of the PPC method is that the tracking error is limited within a small pre-defined range, and its convergence rate is not less than a predefined constant. Thus, the PPC method can ensure that the tracking error satisfies both steady-state performance and transient performance. Some recent research works on PPC can be referred to Kostarigka et al. [17], Zhang et al. [18], Zhang and Cheng [19], Bu et al. [20], Xiang and Liu [21], and Liu et al. [22]. Kostarigka et al. [17] designed a PPC method for the flexible joint robot with unknown or possibly variable elasticity in order to make the link position error meet the pre-set performance index. In Zhang et al. [18] proposed a PPC control strategy for a generic flexible air-breathing hypersonic vehicle, which ensures that the velocity and altitude tracking errors of the vehicle have ideal transient performance. For non-strict feedback systems with unmeasurable states, an observer-based neural adaptive prescribed performance control approach [19] was proposed to achieve expected output tracking performance. The PPC methods in Kostarigka et al. [17], Zhang et al. [18], Xiang et al. [23], and Zhang and Cheng [19] can not achieve the convergence of tracking error with sufficiently small overshoot. To solve this problem, an improved PPC control strategy combined with backstepping technology is proposed by Bu et al. [20] to guarantee the convergence of tracking error with small overshoot for uncertain nonlinear dynamic systems. Using a similar PPC strategy, the transient performance of tracking errors for uncertain systems with unknown control gain signs was discussed by Xiang and Liu [21]. In order to realize the finite-time control of tracking error, a finite-time performance function and a corresponding finite-time PPC method were proposed for strict-feedback nonlinear systems by Liu et al. [22]. However, it should be pointed out that the above PPC methods mainly focus on driving the tracking error to meet certain transient performances, in addition, although fuzzy logic systems (FLSs) or neural networks (NNs) are used to approximate the nonlinear functions of the controlled system, the approximation errors are not further discussed.
In practical control systems, using FLS or NN to deal with system uncertainty has brought us great help. However, if the parameter updating law of FLS or NN is designed based on instantaneous data, it may not guarantee the accurate estimation of the unknown function. To obtain an accurate estimation of system uncertainty, a valid strategy is to define a prediction error by using online recorded data together with instantaneous data, and then design a composite learning parameter updating law [24–32]. Based on a partial persistent excitation (PE) condition, an NN composite learning control scheme was proposed by Wang and Hill [24], which can accurately approximate the unknown function. In Pan and Yu [32], a composite learning robot control approach was developed to achieve accurate parameter estimation under an interval excitation (IE) condition. To the best of our knowledge, most of the composite learning control methods only consider linear input, and the existing results are not valid for nonlinear input, such as dead-zone and saturation. In addition, the composite learning control method can achieve the steady-state performance of the tracking error; however, whether it can be combined with PPC technology to achieve transient performance will become an interesting topic.
Inspired by the above discussion, a composite learning finite-time PPC was proposed for an uncertain multi-input multi-output (MIMO) nonlinear second-order system. Compared with Xiang et al. [23], the highlights of this paper are presented as follows: 1) The proposed method in this paper ensures that the tracking error is limited within the predefined region at the settling time. 2) By using online recorded data and instantaneous data, composite learning parameter updating laws are designed. 3) The proposed control method overcomes the influence of dead-zone inputs and realizes accurate estimation of unknown functions.
The paper is arranged as follows. The control problem and some preliminaries are presented in Section 2. The composite learning finite-time PPC method is designed in Section 3. Some simulation results are shown in Section 4. The conclusion is provided in Section 5.
Consider a MIMO nonlinear second-order system whose dynamics can be described as
where is a state vector, and are the first derivative and the second derivative of ξ, respectively. is the nonlinear function vector; is the control input vector and is the output of dead-zone function vector in the actuator, which is described as
where mi1 and mi2 represent the right and the left slopes of the dead-zone and are assumed to satisfy that mi1 = mi2 = mi. and bi stand for the breakpoints of the dead-zone.
From Equation (2), the equivalent form of Γ(u(t)) can be expressed as
where M = diag(m1, m2, ⋯ , mn), and △ui(t) is described as
where is defined as . Substituting (Equations 3–1), the system (Equation 1) can be rewritten as
where .
The following assumptions and lemmas are provided to facilitate control analysis.
Assumption 1. State vectors ξ and are measurable.
Assumption 2. is an unknown continuous function.
Remark 1. Assumptions 1 and 2 are common assumptions for the second-order nonlinear system [8, 23].
Lemma 1. Assume that f(x) is a continuous function, which is defined on a compact set Ωx, then there exists an optimal FLS φT(x)θ* satisfies
where is the ideal weight vector, m ∈ ℕ is the number of the fuzzy rules, is the desired level, and φ(x) is a basis function vector, which can be expressed as
where is a Gaussion function, , and are the center vector and the width of φj(x), respectively.
According to Lemma 1, the unknown function can be written as
where is the basis function vector and is the estimation error satisfying , is a positive constant. can be defined as
where is an adjustable parameter vector. In this paper, is applied to approximate .
Let , , , and is the estimated parameter error, where and . Thus, the system (Equation 5) can be modified as
The tracking error e is defined as and is a reference signal vector, where ξdi, , and are continuous, recurrent, and available.
Definition 1. Pan and Yu [27] proposed that if the inequality holds for a bounded signal ϕ(t), then it is said that ϕ(t) satisfies the PE condition, where μ, τd are positive constants and I is an identity matrix.
Lemma 2. Pan and Yu [27] proposed that if x is recurrent, then there exists a regression vector φ(x) in Equation (7) such that the PE condition is satisfied.
Remark 2. In Pan et al. [26, 31], Liu et al. [29], and Pan and Yu [32], a PE condition criterion for in Equation (8) is given, that is, by calculating the minimum singular value of . If the minimum singular value of is greater than zero, can be regarded as satisfying the PE condition, i.e., there exists a positive constant μi such that , and μi is only used for the theoretical proof of the proposed control method in this paper.
Remark 3. In Wang and Yang [33], a recurrent trajectory is described as periodic or period-like trajectory, that is, given a ø-neighborhood and a constant time T(ø), the return time of the recurrent trajectory to any point in the ø-neighborhood will not exceed T(ø). If a recurrent trajectory ξ is given in advance and |ζ − ξ| < ø holds after a certain time, ζ can also be regarded as a recurrent trajectory.
Lemma 3. (Boundedness of basis function). There exists a positive constant ψ, which is independent of x, such that φ(x) in Equation (7) satisfies .
First, a finite-time performance function p(t, α0, α∞, Te) is introduced as
where α0 and α∞ are the initial value and boundary value of the performance function p(t, α0, α∞, Te), respectively. Te is the predefined experienced time of p(t, α0, α∞, Te) than that from α0 to α∞. To guarantee that p(t, α0, α∞, Te), ṗ(t, α0, α∞, Te), and are continuous at t = Te, parameters α1, α2, α3, and α4 are designed as
For the tracking error , assume that each ei satisfies the following prescribed performance boundary (PPB):
where pi(t, αi0, αi∞, Te) and are the lower boundary and the upper boundary of ei, respectively. The designed parameters satisfy and .
In this paper, a transformation variable zi is defined as
where .
Obviously, the following result holds:
Lemma 4. The boundedness of zi can guarantee that ei satisfies the PPB (13).
Proof. From Equation (14), one obtains that . Since zi is bounded, which means . Obviously, . The proof is completed.
z is defined as , the derivative of z becomes
where r = diag(r1, r2, ···, rn), , and
Remark 4. If ei is limited within PPB (Equation 13), then 0 < ϱi(t) < 1 and 0 < 1 − ϱi(t) < 1, which implies that ri is negative and bounded. For t ≥ Te, one has pi(t, αi0, αi∞, Te) = αi∞, ṗi(t, αi0, αi∞, Te) = 0, , and , then and Πi = 0. Obviously, there exists a minimum value such that during t ∈ [Te, ∞).
z1 and z2 are defined as z1 = z, , the transformation system is given as follows:
where , , and .
First, introduce a variable as
where c = diag(c1, c2, ⋯ , cn), ci is designed as positive constant. From Equations (15) and (18), the time derivative of σ becomes
In order to make variable σ and the estimated error bounded, the following theorem shows the first main result of this paper.
Theorem 1. For the MIMO nonlinear second-order system (Equation 1) with Assumptions 1 and 2, if the controller u is designed as
where K = diag(k1, k2, ⋯ , kn), ki is the positive parameter. And the updating law is chosen as
where and are designed positive constants. All signals in Equation (22) are bounded, and then ei satisfies PPB (Equation 13). Meanwhile, ξ1 and ξ2 are recurrent after Te.
Proof. Consider the following Lyapunov function
Substituting Equations (19)–(21) into , one gets
By using Young's inequality, one obtains
Because r and are bounded, there exists an unknown upper bound such that . Therefore,
where , . The following compact sets are defined as follows:
Obviously, if σ ∉ Ωσ or , one has . Thus, σ and are semiglobally uniformly bounded. Notice that , selecting Lyapunov function. Let , one has
where , . The compact set is defined as , if z1 ∉ Ωz1, . So, z1 is bounded, and then
where . According to Lemma 4, the boundedness of z1 ensures that all tracking errors ei meet PPB (Equation 13), which means that after Te. Because ξdi is recurrent, according to the description of recurrent trajectory in Remark 3, we know that ξi is also recurrent.
Form Equation (15), one gets , and according to Remark 4, one has , Πi = 0 after Te. Thus
It can be found that is limited within the - neighborhood of after Te. Since is recurrent, therefore, is also recurrent. Therefore, we can conclude that ξ1 and ξ2 are recurrent vector after time Te. □
Remark 5. Notice that the parameter updating law (Equation 21) in Theorem 1 only uses instantaneous data, which may not estimate the unknown function accurately. Therefore, we need to use online recorded data and instantaneous data to design composite learning parameter updating law.
Define , t ≥ τd + Te. Notice that is recurrent vector after Te, according to Lemma 2 and Remark 2, if the selected fuzzy basis function in Equation (8) satisfies that the minimum singular value of Gi(t) is greater than zero, it means that Gi(t) satisfies the PE condition, i.e. there exists a positive constant μi such that Gi(t) ≥ μiI.
From Equation (5), one gets
Multiplying to both sides of Equation (30) and integrating over [t − τd, t], one has
Therefore, one obtains
Because is not measurable, a second-order filter is used to estimate :
with and ωi2(0) = 0, where α denotes the natural frequency and β stands for the damping factor. According to Lemma 2 in Hu and Zhang [34], and can be estimated by ωi1 and ωi2, respectively. Moreover, for any given positive constant πi, there exist corresponding α and β so that holds.
Define a prediction error ϵi(t) as
where εei(t) is a lumped approximation error given by
From Equations (32) and (35), ϵi(t) can be computed by
Obviously, by using Lemma 3 and Lemma 2 in Hu and Zhang [34]. Therefore, we modify the updating law (Equation 21) as follows
where is a designed positive constant.
The following theorem shows the second main result of this paper.
Theorem 2. For the MIMO nonlinear second-order system (Equation 1) with assumptions 1 and 2, if the selected based function in Equation (8) satisfies Gi(t) ≥ μiI after Te + τd, then, the controller (Equation 20) and the composite learning law (Equation 37) guarantee that each tacking error ei satisfies PPB (Equation 13) at t ∈ [0, ∞) and converges to a small neighborhood of zero during t ∈ [Te + τd, ∞).
Proof. Theorem 1 has proved that ei satisfies PPB (Equation 13) at t ∈ [0, Te + τd] and is recurrent after Te. If the selected based function in Equation (8) satisfies Gi(t) ≥ μiI after Te + τd, then we just need to prove the stability of σ and at t ∈ [Te + τd, ∞).
Consider the following Lyapuonv function
Substituting Equations (19), (20), and (37) into , one gets
Substituting Gi(t) ≥ μiI, t ∈ [Te + τd, ∞) to , one has
where . Applying Young's inequality, one gets
Substituting the first inequality of Equations (24) and (41) into Equation (40) shows that
where , . Let . From Equation (42), it yields
Solving the inequality (Equation 43) leads to
which means σ and tend to neighborhood of zero that can be arbitrarily diminished by properly designed parameters ki, , and are chosen. Since σ is bounded, similar to the derivation of Theorem 1, we can conclude that ei is limited within .
Remark 6. Theorem 1 shows a finite-time PPC method without learning. The parameter adaptive law uses instantaneous data, which does not guarantee the accurate estimation of the unknown function (see Figures 2A–D in Section 4). Theorem 2 improves the parameter adaptive law by using online recorded data and instantaneous data after the preset time Te. Figures 4A–C in Section 4 show the control effect. Obviously, the unknown functions are not affected by the dead-zone inputs and are accurately estimated.
In this section, an inverted double pendulum system [35] (shown in Figure 1) was studied to illustrate the different control effectiveness of the proposed two methods. The dynamic model of the inverted double pendulum system (IBPS) was expressed as
where θi and were the angles and angular velocities of the inverted double pendulum. , , , , , , and were external disturbances for the IBPS (Equation 45), and control coefficient . The parameter values of the IBPS were selected as ma = mb = 50, L = 2gr = 2k = 2l = 2, δ1 = sin(2t), δ2 = sin(3t) + L. Let , the reference signal , . The initial angles and angular velocities were set as and . The control parameters were chosen as , k1 = k2 = 10, and c1 = c2 = 5. Let and and . The fuzzy membership functions were defined as
where , and 3. The initial values of and were designed as zero, parameters , , and in Equations (21) and (37) were set as , , and . The parameters α and β in Equation (33) were designed as α = 100 and β = 0.7. The tracking errors were defined as e1 = θ1 − ξd1 and e2 = θ2 − ξd2, and the following prescribed performance boundary conditions were chosen:
where Te = 5. The method in Theorem 1 was denoted as the TPPC method (Equation 20) without learning. Based on the above designed parameters and initial values, the simulation results of the IBPS by using the TPPC method (Equation 20) without learning are shown in Figures 2A–D.
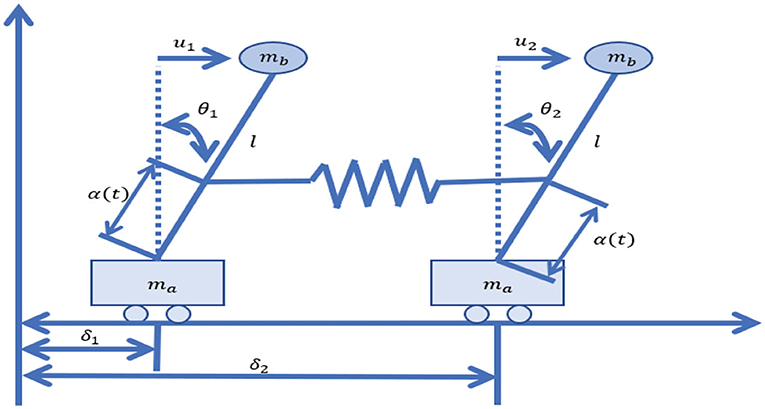
Figure 1. The inverted double pendulum system.
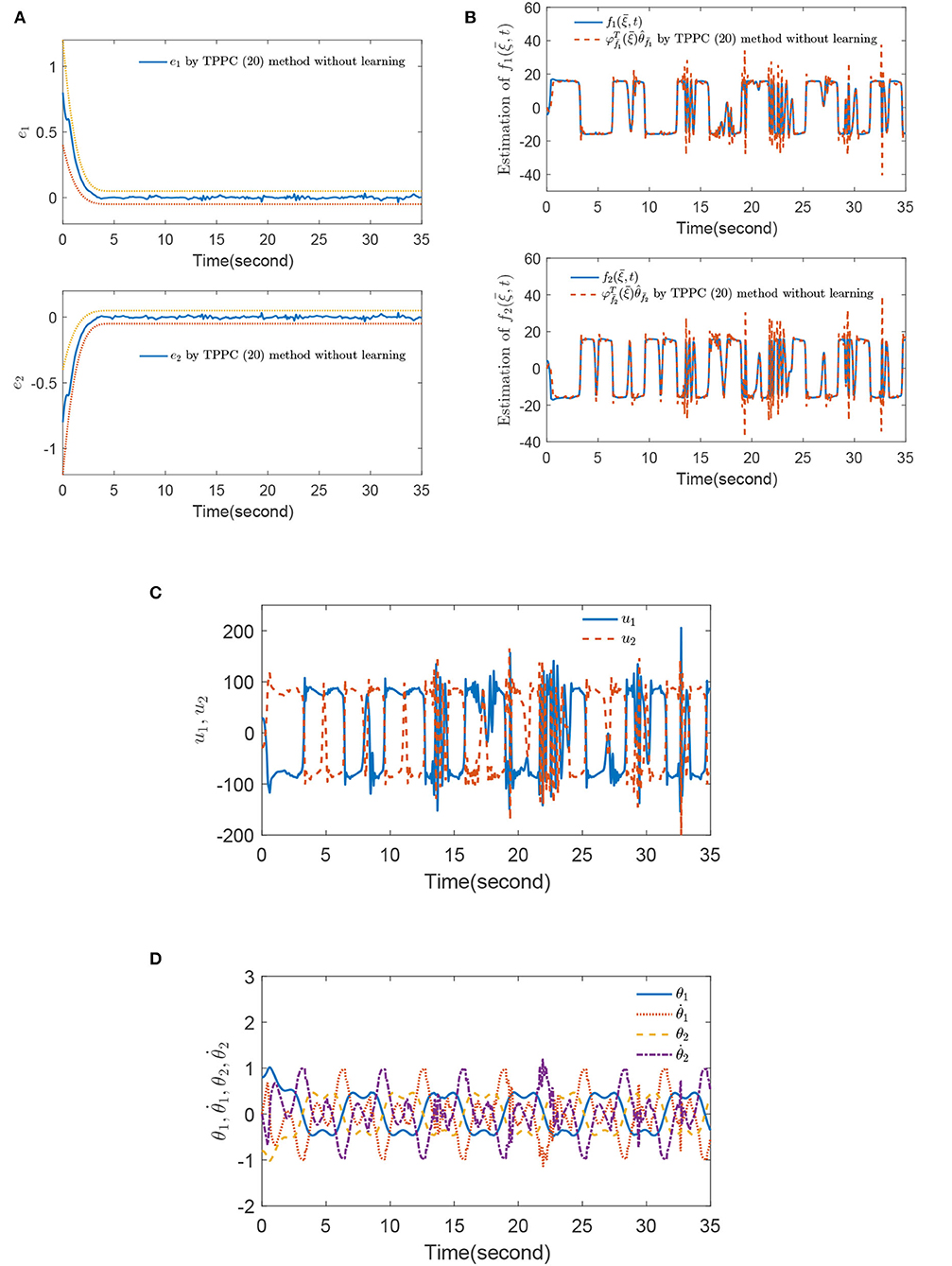
Figure 2. (A) Tracking errors e1 and e2, (B) estimation of and , (C) control inputs u1 and u2, and (D) states , and by using the time prescribed performance control (TPPC) method (Equation 20) without learning.
Figure 2A shows that tracking errors e1 and e2 are limited within PPBs (Equation 47). However, it was found that and appeared as some large jumps after 10 s in Figure 2B, indicating that the parameter updating law (Equation 21) cannot ensure that the unknown functions and are accurately estimated. From Figure 2C, one finds that each jump of controllers u1 and u2 is consistent with each fluctuation of and , which indicates that the TPPC method (Equation 20) without learning cannot overcome the influence of dead-zone inputs Γ1(ςu1) and Γ2(ςu2). Meanwhile, Figure 2D shows that states , and are recurrent, which also confirms the conclusion of Theorem 1.
Before using the method in Theorem 2, we need to verify whether is always true after time Te + τd. According to Remark 2, we only need to verify that the minimum singular value of G(t) is greater than zero. The method in Theorem 2 was denoted as the TPPC (Equation 20) method with learning and let τd = 3 and
Figure 3 shows that the selected fuzzy basic vector satisfies λmin{G(t)} > 0 for t ≥ Td + τd, which means that there is a constant μ such that G(t) ≥ μI holds. The simulation results of the IBPS by using the TPPC method (Equation 20) with learning are displayed in Figures 4A–C. By comparing Figure 2A with Figure 4A, the tracking error control effect of the TPPC method (Equation 20) with learning is obviously better than that of the TPPC method (Equation 20) without learning after Te + τd. By comparing the estimation effect of unknown functions in Figures 2B, 4B, and do not show big fluctuation in Figure 4 by using the TPPC method (Equation 20) with learning and unknown functions and are estimated accurately. Figure 4C shows that controllers u1 and u2 were stable without large fluctuation by the TPPC method (Equation 20) with learning. Through the comparison of simulation results, the control effect of the TPPC method (Equation 20) with learning was obviously better than that of the TPPC method (Equation 20) without learning, which also confirmed the theoretical analysis of this paper.
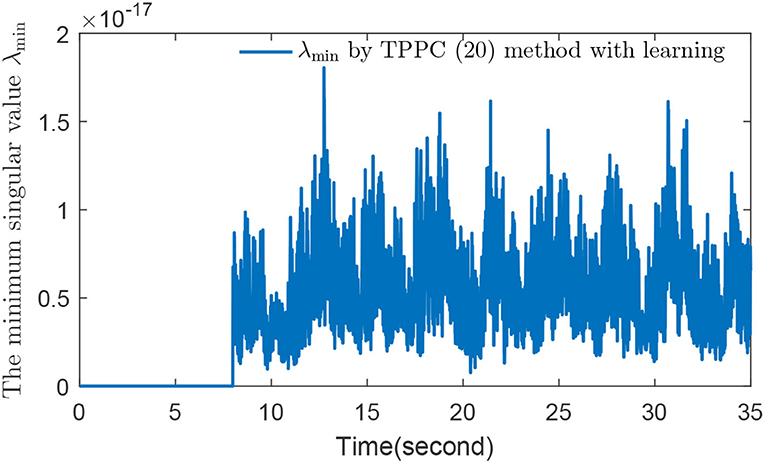
Figure 3. The minimum singular value λmin of G(t).
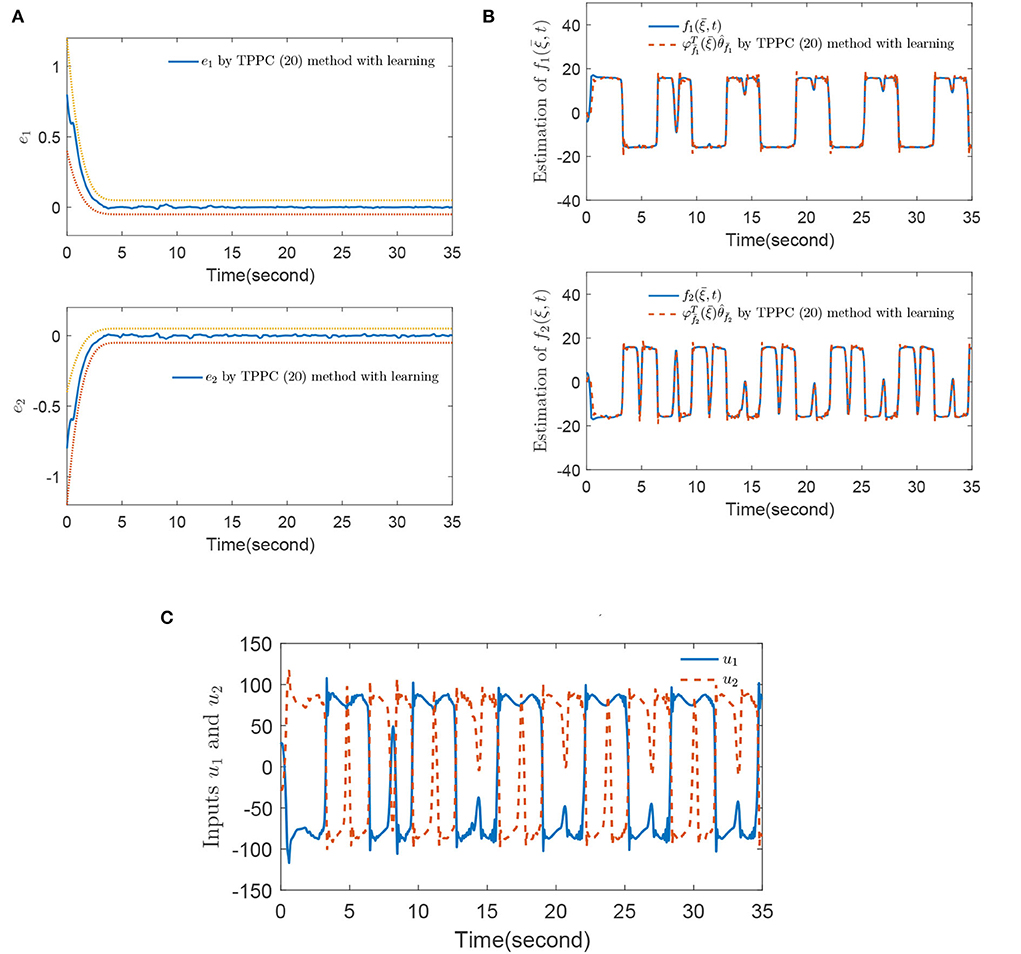
Figure 4. (A) Tracking errors e1 and e2, (B) estimation of and , and (C) control inputs u1 and u2 by using the TPPC method (Equation 20) with learning.
In this paper, a composite learning finite-time PPC method was proposed for uncertain nonlinear systems with dead-zone inputs. A finite-time performance function and a transformation function were introduced, which can ensure that the racking error can be limited within a predefined region at a settling time. Then, in order to improve the accurate estimation effect of the unknown function, a prediction error was defined and a corresponding composite learning parameter law was designed. The simulation comparison of IBPS showed the superiority of the control effect of the proposed composite learning finite-time PPC method. Meanwhile, one can notice the limitation of the proposed method in this paper is that all states must be measurable. If some states are unmeasurable, the results of this paper cannot be obtained. Therefore, it is necessary to further study the problem of effective estimation of uncertainties based on partially measurable states.
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
All authors listed have made a substantial, direct, and intellectual contribution to the work and approved it for publication.
This work was supported by the Natural Science Foundation for the Higher Education Institutions of Anhui Province of China (KJ2021A0965).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
1. Lymperopoulos G, Ioannou P. Building temperature regulation in a multi-zone HVAC system using distributed adaptive control. Energy Build. (2020) 215:109825. doi: 10.1016/j.enbuild.2020.109825
2. Wang P, Wen G, Huang T, Yu W, Lv Y. Asymptotical neuro-adaptive consensus of multi-agent systems with a high dimensional leader and directed switching topology. IEEE Trans Neural Netw Learn Syst. (2022) doi: 10.1109/TNNLS.2022.3156279 [Epub ahead of print].
3. El Hamidi K, Mjahed M, El Kari A, Ayad H. Adaptive control using neural networks and approximate models for nonlinear dynamic systems. Model Simul Eng. (2020) 2020:8642915. doi: 10.1155/2020/8642915
4. Gammons MV, Renko M, Flack JE, Mieszczanek J, Bienz M. Feedback control of Wnt signaling based on ultrastable histidine cluster co-aggregation between Naked/NKD and Axin. Elife. (2020) 9:e59879. doi: 10.7554/eLife.59879
5. Nguyen AT, Coutinho P, Guerra TM, Palhares R, Pan J. Constrained output-feedback control for discrete-time fuzzy systems with local nonlinear models subject to state and input constraints. IEEE Trans Cybern. (2020) 51:4673–84. doi: 10.1109/TCYB.2020.3009128
6. Wang P, Yu W, Wen G, Yu X, Huang T. A chattering free consensus controller for multiple Lur systems with a non-autonomous leader and directed switching topology. Sci China Technol Sci. (2022). doi: 10.1007/s11431-022-2175-5
7. Wang P, Wen G, Huang T, Yu W, Ren Y. Observer-based consensus protocol for directed switching networks with a leader of nonzero inputs. IEEE Trans Cybern. (2020) 52: 630–40. doi: 10.1109/TCYB.2020.2981518
8. Wang S, Bekiros S, Yousefpour A, He S, Castillo O, Jahanshahi H. Synchronization of fractional time-delayed financial system using a novel type-2 fuzzy active control method. Chaos Solitons Fractals. (2020) 136:109768. doi: 10.1016/j.chaos.2020.109768
9. Singh J, Jafari S, Khalaf A, Pham V, Roy B. A modified chaotic oscillator with megastability and variable boosting and its synchronisation using contraction theory-based control which is better than backstepping and nonlinear active control. Pramana. (2020) 94:1–14. doi: 10.1007/s12043-020-01993-y
10. Li X, Peng D, Cao J. Lyapunov stability for impulsive systems via event-triggered impulsive control. IEEE Trans Automat Contr. (2020) 65:4908–3. doi: 10.1109/TAC.2020.2964558
11. Stamov T, Stamova I. Design of impulsive controllers and impulsive control strategy for the Mittag-Leffler stability behavior of fractional gene regulatory networks. Neurocomputing. (2021) 424:54–62. doi: 10.1016/j.neucom.2020.10.112
12. Bechlioulis CP, Rovithakis GA. Robust adaptive control of feedback linearizable MIMO nonlinear systems with prescribed performance. IEEE Trans Automat Contr. (2008) 53:2090–9. doi: 10.1109/TAC.2008.929402
13. Niu B, Zhao J. Barrier Lyapunov functions for the output tracking control of constrained nonlinear switched systems. Syst Control Lett. (2013) 62:963–71. doi: 10.1016/j.sysconle.2013.07.003
14. Li Y, Tong S. Prescribed performance adaptive fuzzy output-feedback dynamic surface control for nonlinear large-scale systems with time delays. Inf Sci. (2015) 292:125–42. doi: 10.1016/j.ins.2014.08.060
15. Yao B, Tomizuka M. Smooth robust adaptive sliding mode control of manipulators with guaranteed transient performance. In: Proceedings of 1994 American Control Conference-ACC '94. Baltimore, MD: IEEE (1996).
16. Zhi D, Xu L. Direct power control of DFIG with constant switching frequency and improved transient performance. IEEE Trans Energy Convers. (2007) 22:110–8. doi: 10.1109/TEC.2006.889549
17. Kostarigka AK, Doulgeri Z, Rovithakis GA. Prescribed performance tracking for flexible joint robots with unknown dynamics and variable elasticity. Automatica. (2013) 49:1137–47. doi: 10.1016/j.automatica.2013.01.042
18. Zhang L, Tong S, Li Y. Prescribed performance adaptive fuzzy output-feedback control of uncertain nonlinear systems with unmodeled dynamics. Nonlinear Dyn. (2014) 77:1653–65. doi: 10.1007/s11071-014-1407-0
19. Zhang G, Cheng D. Observer-based neuro-adaptive prescribed performance control of nonstrict feedback systems and its application. Optik. (2019) 181:264–77. doi: 10.1016/j.ijleo.2018.12.018
20. Bu X, Wu X, Huang J, Wei D. A guaranteed transient performance-based adaptive neural control scheme with low-complexity computation for flexible air-breathing hypersonic vehicles. Nonlinear Dyn. (2016) 84:2175–94. doi: 10.1007/s11071-016-2637-0
21. Xiang W, Liu H. Fuzzy adaptive prescribed performance tracking control for uncertain nonlinear systems with unknown control gain signs. IEEE Access. (2019) 7:149867–77. doi: 10.1109/ACCESS.2019.2946601
22. Liu Y, Liu X, Jing Y. Adaptive fuzzy finite-time stability of uncertain nonlinear systems based on prescribed performance. Fuzzy Sets Syst. (2019) 374:23–39. doi: 10.1016/j.fss.2018.12.015
23. Xiang W, Sun Y, Li N, Yang C. Uncertain chaotic gyros synchronization using adaptive fuzzy prescribed performance control with unknown dead-zone input. Int J Innovat Comput Inf Control. (2017) 13:429–440. doi: 10.1155/2017/4386515
24. Wang C, Hill DJ. Learning from neural control. IEEE Trans Neural Netw. (2006) 17:130–46. doi: 10.1109/TNN.2005.860843
25. Jamil ARM, Ganguly KK, Nower N. Adaptive traffic signal control system using composite reward architecture based deep reinforcement learning. IET Intell Transport Syst. (2021) 14:2030–41. doi: 10.1049/iet-its.2020.0443
26. Pan Y, Zhou Y, Sun T, Er MJ. Composite adaptive fuzzy H∞ tracking control of uncertain nonlinear systems. Neurocomputing. (2013) 99:15–24. doi: 10.1016/j.neucom.2012.05.011
27. Pan Y, Yu H. Composite learning from adaptive dynamic surface control. IEEE Trans Automat Contr. (2015) 61:2603–9. doi: 10.1109/TAC.2015.2495232
28. Soukkou Y, Labiod S, Tadjine M. Composite adaptive dynamic surface control of nonlinear systems in parametric strict-feedback form. Trans Inst Meas Control. (2018) 40:1127–35. doi: 10.1177/0142331216675672
29. Liu H, Pan Y, Cao J. Composite learning adaptive dynamic surface control of fractional-order nonlinear systems. IEEE Trans Cybern. (2019) 50:2557–67. doi: 10.1109/TCYB.2019.2938754
30. Liu H, Pan Y, Li S, Chen Y. Adaptive fuzzy backstepping control of fractional-order nonlinear systems. IEEE Trans Syst Man Cybern Syst. (2017) 47:2209–17. doi: 10.1109/TSMC.2016.2640950
31. Pan Y, Sun T, Yu H. Composite adaptive dynamic surface control using online recorded data. Int J Robust Nonlinear Control. (2016) 26:3921–36. doi: 10.1002/rnc.3541
32. Pan Y, Yu H. Composite learning robot control with guaranteed parameter convergence. Automatica. (2018) 89:398–406. doi: 10.1016/j.automatica.2017.11.032
33. Wang M, Yang A. Dynamic learning from adaptive neural control of robot manipulators with prescribed performance. IEEE Trans Syst Man Cybern Syst. (2017) 47:2244–55. doi: 10.1109/TSMC.2016.2645942
34. Hu J, Zhang H. Immersion and invariance based command-filtered adaptive backstepping control of VTOL vehicles. Automatica. (2013) 49:2160–7. doi: 10.1016/j.automatica.2013.03.019
Keywords: nonlinear system, performance function, partial persistent excitation, dead-zone input, finite-time
Citation: Zhu F and Li P (2022) Composite fuzzy learning finite-time prescribed performance control of uncertain nonlinear systems with dead-zone inputs. Front. Appl. Math. Stat. 8:1041588. doi: 10.3389/fams.2022.1041588
Received: 11 September 2022; Accepted: 04 October 2022;
Published: 28 October 2022.
Edited by:
Peijun Wang, Anhui Normal University, ChinaReviewed by:
Yude Ji, Hebei University of Science and Technology, ChinaCopyright © 2022 Zhu and Li. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Fang Zhu, emh1ZmFuZzE5ODMwNUAxMjYuY29t
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.