 Mariagrazia Benassi1
Mariagrazia Benassi1 Sara Garofalo1*
Sara Garofalo1* Federica Ambrosini1
Federica Ambrosini1 Rosa Patrizia Sant’Angelo2Roberta Raggini2Giovanni De Paoli2Claudio Ravani2
Rosa Patrizia Sant’Angelo2Roberta Raggini2Giovanni De Paoli2Claudio Ravani2 Sara Giovagnoli1Matteo Orsoni1Giovanni Piraccini2
Sara Giovagnoli1Matteo Orsoni1Giovanni Piraccini2- 1Department of Psychology, University of Bologna, Bologna, Italy
- 2AUSL della Romagna, SPDC Psychiatric Emergency Unit, Cesena, Italy
The heterogeneity of cognitive profiles among psychiatric patients has been reported to carry significant clinical information. However, how to best characterize such cognitive heterogeneity is still a matter of debate. Despite being well suited for clinical data, cluster analysis techniques, like the Two-Step and the Latent Class, received little to no attention in the literature. The present study aimed to test the validity of the cluster solutions obtained with Two-Step and Latent Class cluster analysis on the cognitive profile of a cross-diagnostic sample of 387 psychiatric inpatients. Two-Step and Latent Class cluster analysis produced similar and reliable solutions. The overall results reported that it is possible to group all psychiatric inpatients into Low and High Cognitive Profiles, with a higher degree of cognitive heterogeneity in schizophrenia and bipolar disorder patients than in depressive disorders and personality disorder patients.
Introduction
The traditional categorical nosology which mostly characterizes both research and clinical activity in psychology and psychiatry has been largely criticized in favor of a dimensional approach, which may better reflect the overlapping features of different disorders (Ivleva et al., 2012; Owoeye et al., 2013; van Os and Reininghaus, 2016). Cognitive impairment reflects one of the aspects shared by many psychiatric disorders, and it presents important overlaps with epidemiological, symptomatologic, and biological measures, as well as other risk factors (Smith and Weissman, 1992; Berrettini, 2000; Cosgrove and Suppes, 2013; Cross-Disorder Group of the Psychiatric Genomics Consortium, 2013; Owoeye et al., 2013; Tamminga et al., 2014; Pearlson, 2015). The heterogeneity of cognitive profiles found among psychiatric patients has been reported to carry significant information about biomarkers, etiologies, and clinical factors (Mesholam-Gately et al., 2009; Bora, 2016), and about prognosis and treatment planning (Burdick et al., 2014; Lewandowski et al., 2014), which might have important implications for their treatment and prognosis (Cochrane et al., 2012). Interestingly, these findings are in line with the so-called genetic overlap among schizophrenia, bipolar disorder, depression, and personality disorder diagnosis that has been documented so far in different studies (Witt et al., 2017; Gandal et al., 2019). However, how to best characterize such cognitive heterogeneity across or within specific diagnostic categories in an informative way is still a matter of debate, and the use of well-suited statistical techniques to achieve stable and robust conclusions on this issue appears critical.
Clustering techniques can serve this purpose by identifying homogeneous subgroups presenting similar characteristics within a large cross-diagnostic sample (Allen and Goldstein, 2013). Amongst the several approaches available, the Two-Step cluster analysis (Chiu et al., 2001; Bacher et al., 2004) and the Latent Class cluster analysis appear to be well suited for clinical data, as they can handle ordinal as well as nominal variables, which can be more informative for clinical practice (Kent et al., 2014). Indeed, data obtained from classical neuropsychological tests are not purely quantitative and are better represented as nominal measures, i.e., classifying subjective performance according to normative values that specify whether the score is “above,” “within,” or “below” the normative range. Nevertheless, the most commonly used clustering methods adopted by previous studies investigating cognitive profiles of psychiatric inpatients are either hierarchical (Goldstein and Shelly, 1987; Hermens et al., 2011; Cotrena et al., 2017; Van Rheenen et al., 2017; Crouse et al., 2018; Lewandowski et al., 2018) or k-means (Lee et al., 2017). However, such methods present several limitations, like applicability to continuous variables only, assumption of normality of distribution, and an arbitrary choice of the number of clusters (Bacher et al., 2004; Matthiesen, 2010; Everitt, 2011; Mooi and Sarstedt, 2011).
From a detailed examination of the cluster solutions proposed from previous literature (Supplementary Table S1) on major psychiatric diagnoses, most studies reported either three (Hermens et al., 2011; Lee et al., 2015; Cotrena et al., 2017; Van Rheenen et al., 2017; Crouse et al., 2018) or four clusters (Goldstein and Shelly, 1987; Lewandowski et al., 2014, 2018; Reser et al., 2015), while only a few found two clusters (Lee et al., 2017). In all these studies, executive functions seemed to be the most important measures to explain the heterogeneity of psychiatric patients’ cognitive profiles. Most studies focused on only one or two diagnostic categories, like schizophrenia and bipolar disorder (Goldstein and Shelly, 1987; Heinrichs and Zakzanis, 1998; Dawes et al., 2011; Hermens et al., 2011; Allen and Goldstein, 2013; Burdick et al., 2014; Cotrena et al., 2017; Lee et al., 2017; Roux et al., 2017; Van Rheenen et al., 2017; Crouse et al., 2018; Kollmann et al., 2019), with a few exceptions (Hermens et al., 2011; Lewandowski et al., 2014, 2018; Lee et al., 2015; Reser et al., 2015), thus limiting potential information about the differences and similarities between different diagnoses. Indeed, despite personality disorder being characterized by cognitive impairments similar to those presented by other psychiatric dysfunctions, like memory, attention, language, and executive functions (Dinn and Harris, 2000; Morgan and Lilienfeld, 2000; Dell’Osso et al., 2010; Cochrane et al., 2012; Rosell et al., 2014; Fineberg et al., 2015; Koch and Exner, 2015; McClure et al., 2016), these patients have been inexplicably neglected in this line of research.
Based on these considerations, the general goal of the present study was to identify subgroups of psychiatric inpatients based on cognitive nominal measures assessed in a large cross-diagnostic cohort (N = 387) including Schizophrenia Spectrum and Other Psychotic Disorders (SZ), personality disorders (PD), bipolar and related disorders (BD), and depressive disorders (DD). More specifically, we aimed to verify the best solution among those previously reported in the literature (ranging from two to four clusters; see Supplementary Table S1). The presence of a single cluster for all the diagnoses would suggest that all patients share a unique cognitive profile. The presence of two or more clusters would suggest the presence of different cognitive endophenotypes (e.g., preserved/impaired performances in specific cognitive domains or within specific diagnoses). To achieve a stable and robust solution, we provided several methodological and statistical improvements that allowed overcoming the limitations of previous similar studies (Hermens et al., 2011; Reser et al., 2015; Van Rheenen et al., 2017; Crouse et al., 2018). In particular: the stability of the clustering solution (Kraus et al., 2011) was checked by directly comparing two different techniques—Two-step and Latent Class cluster analysis—on several indexes of fit [Akaike information criterion (AIC), Bayes information criterion (BIC), and entropy]; the external validity of the solution was tested by comparing the obtained clustering solution on a different set of cognitive tests; the internal validity of the clustering solution was evaluated by running the same cluster analysis within each diagnostic subsample.
Materials and Methods
Participants
Three hundred and eighty-seven participants were recruited from the Psychiatric Emergency Unit of the Health Clinical Service Azienda USL della Romagna (Cesena, Italy). Following the DSM-5 and ICD-10 criteria, patients with SZ, PD, BD, and DD were included in the study. The Mini-International Neuropsychiatric Interview (Sheehan et al., 1998) and the Structured Clinical Interview (First Michael et al., 1996) were used to confirm the psychiatric diagnosis. Exclusion criteria were insufficient Italian language skills, presence of neurological disorders, and severe visual or verbal impairments.
The participants were 189 males and 198 females with a mean age of 45.7 years. All the four diagnoses included were sufficiently represented numerically: 28% (n = 110) of the subjects had a diagnosis of SZ, 35% (n = 134) had a diagnosis of BD, 24% (n = 93) had a diagnosis of DD, and 13% (n = 50) had a diagnosis of PD. The demographic and clinical characteristics of the whole sample are reported in Table 1. Differences in cognitive performance among diagnoses are reported in the Supplementary Information and Supplementary Figure S1.
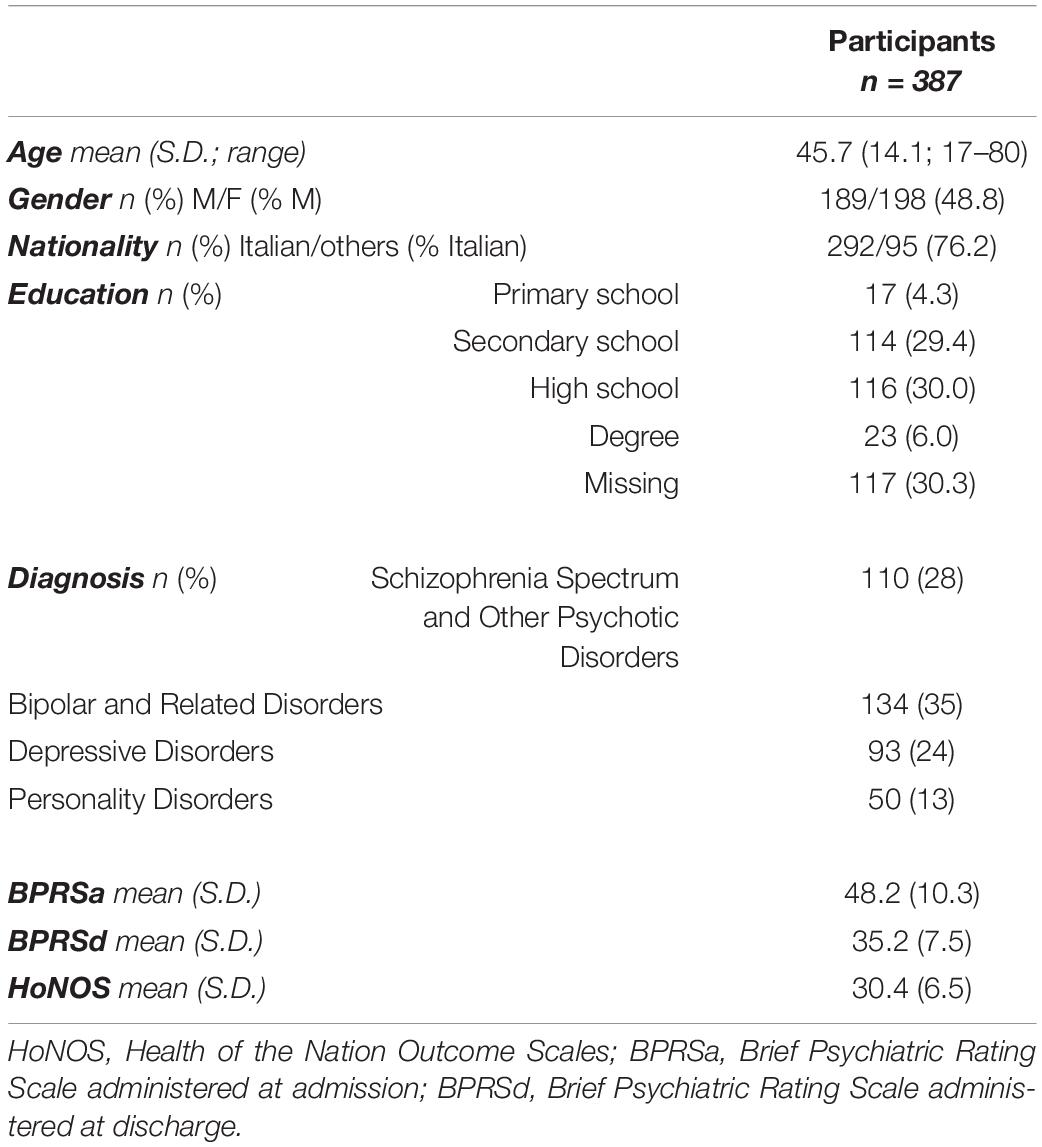
Table 1. Demographic and clinical characteristics of the whole sample.
All procedures complied with the ethical standards of the relevant national and institutional committees on human experimentation and with the Helsinki Declaration of 1975, as revised in 2008. The study was approved by the Research Ethical Committee of the AUSL Romagna (Regional Health Clinical Service). Written informed consent was acquired from each participant or, whenever necessary, from a parent or legal guardian.
Information about medication at the time of assessment was obtained from the medication list. All the patients were taking various combinations of mood stabilizers, antipsychotics, and antidepressants.
Cognitive and Clinical Assessment
The inpatients, admitted during the acute phase of illness, were recruited during the hospitalization. A team of psychologists and psychiatrists performed cognitive and clinical assessments. The complete assessment lasted approximately 3 h (see Supplementary Information for a comprehensive description of the tests used in the study).
The severity of symptomatology was measured at admission and at discharge with the Brief Psychiatric Rating Scale Expanded Version 4.0 (BPRS) (Ventura et al., 1993), while health and social functioning were measured with the Health of the Nation Outcome Scales—Roma (HoNOS) (Morosini et al., 2003).
Each patient completed two self-report questionnaires concerning the quality of life and the level of disability experienced during their daily life, respectively, the World Health Organization Quality of Life—BREF (WhoQoL) (Skevington et al., 2004) and the World Health Organization Disability Assessment Schedule 2.0—36 items (WhoDAS) (Üstün, 2010). The UKU Side Effect rating scale (Lingjaerde et al., 1987) was administered to evaluate the severity of pharmacological treatment side effects.
The Tower of London—Drexel University (ToL) (Culbertson and Zillmer, 2001) was used to assess planning abilities and problem-solving. The Modified Wisconsin Card Sorting Test (MCST) (Caffarra et al., 2004) was used to analyze the tendency toward perseveration and shifting. The Attentional Matrices (AM) (Spinnler and Tognoni, 1987) test was applied to evaluate selective visual attention. The Stroop Word Interference Test (STROOP) (Caffarra et al., 2002) was used as an index of selective attention, inhibitory control, and processing speed. The Italian standardized version of Raven’s Colored Progressive Matrices (CPM-47) (Pruneti et al., 1996) was used to evaluate fluid intelligence.
A set of other cognitive measures was collected to explore the external validity of the clusters. Global cognitive functioning was assessed using the Mini Mental State Examination (MMSE) (Folstein et al., 1975) and the Clock Drawing Test (CDT) (Watson et al., 1993). Mental flexibility and verbal intelligence were assessed using Test dei Giudizi verbali e dei Compiti Astratti (Verbal abilities and abstract thinking test, GCA) (Spinnler and Tognoni, 1987). The Digit Span (Orsini et al., 1987) was used to assess short-term memory (SPAN Forward) and working memory (SPAN Backward).
For each test included in the cognitive assessment, detailed information about the purpose of the instrument, number of items and subscales, response recording method, administration time, scores, and psychometric properties is reported in the Supplementary Information.
Statistical Analysis
The variables used in the present study were standardized according to the normative scores available for each test (see Supplementary Information) by applying the following formula: z = (x - μ)/σ, where x is the subject’s raw score, μ represents the average obtained in the normative population, and σ is the normative population standard deviation. Then, following the indication of common clinical practice and the general guidelines for neuropsychological assessment (Mitrushina et al., 2005), the standardized scores were transformed into three categories: scores below the 10th percentile (corresponding to z score < -1.3) indicated cognitive deficit; scores equal or above the 10th and below the 90th percentile (corresponding to z score > = -1.3 and < 1.3) indicated normal cognitive functioning; and scores equal to or above the 90th percentile (corresponding to z score > = 1.3) indicated superior cognitive ability.
The variables included in both cluster analyses were: ToL (Total Number of Moves, Number of Correct Moves, Rule Violations, and Time Violations subscales), MCST (number of categories and Perseverative Errors subscales), CPM-47 total score, AM total score, and STROOP (Time and Errors subscales). The Two-Step cluster analysis is a hybrid approach which first uses a distance measure to separate groups and then a probabilistic approach (similar to latent class analysis) to choose the optimal subgroup model (Gelbard et al., 2007; Kent et al., 2014). Such a technique presents several advantages compared to more traditional techniques, like determining the number of clusters based on a statistical measure of fit (AIC or BIC) rather than on an arbitrary choice, using categorical and continuous variables simultaneously, analyzing atypical values (i.e., outliers), and being able to handle large datasets (Chiu et al., 2001; Bacher et al., 2004; Gelbard et al., 2007; Mooi and Sarstedt, 2011; Kent et al., 2014). Comparative studies regarded Two-Step cluster analysis as one of the most reliable in terms of the number of subgroups detected, classification probability of individuals to subgroups, and reproducibility of findings on clinical and other types of data (Bacher et al., 2004; Gelbard et al., 2007; Kent et al., 2014). The Two-Step cluster analysis was implemented in IBM SPSS Statistics (version 23.0) (Chiu et al., 2001; Bacher et al., 2004). In the first step (pre-clustering), a sequential approach is used to pre-cluster the cases based on the definition of dense regions in the analyzed attribute-space. In the second step (clustering), the pre-clusters are statistically merged in a stepwise way until all clusters are in one cluster.
The Latent Class cluster analysis consists of finding latent factors or class referred to a specific model that, from manifest variables, determines the differences among groups of subjects (Vermunt and Magidson, 2002, 2009; Allen and Goldstein, 2013; Kent et al., 2014). This approach is a model-based clustering technique in which, starting from the distribution of the data, each case or observation is probabilistically clustered into a latent class (McLachlan and Peel, 2000; Vermunt and Magidson, 2009). The model parameters are estimated as the proportion of observations in each latent class, and they are determined by the conditional probability of observing each response for each manifest variable in a given class. The cases presenting similar responses to the manifest variables are more likely included within the same latent class. Importantly, this approach is suitable for fitting ordinal manifest variables as well as nominal. The Latent Class cluster analysis was implemented using the R package “poLCA” (Haughton et al., 2009; Linzer and Lewis, 2011; Flynt and Dean, 2016). This procedure aims to fit a model in which any confounding between the manifest variables can be explained by a single unobserved “latent” categorical variable. Local independence is assumed to estimate a mixture model of latent multi-way tables.
Following a parsimony criterion, the best clustering solution was considered the one with the best balance between the number of clusters considered and the corresponding fit. Based on previous literature (see Supplementary Table S1), solutions ranging from two to four clusters were considered. BIC, AIC, and entropy were first calculated for each cluster solution and then used to find the greatest change in distance between two cluster solutions. BIC, AIC, and entropy change were calculated as the difference between two cluster solutions starting from the most parsimonious (one cluster) to the less parsimonious (four clusters), thus obtaining three values (2vs1, 3vs2, and 4vs3). The best cluster solution was considered the one with the strongest change and the lower number of clusters. This allowed evaluating the most parsimonious cluster solution presenting the best fit. Such a procedure was performed automatically for the Two-Step cluster analysis and implemented via a custom-made script implemented in R for the Latent Class cluster analysis.
Aiming for a detailed description of the selected clustering solution, the clusters were compared based on clinical and psychosocial functioning using a general linear model on the following continuous variables: severity of psychiatric symptoms (HoNOS and BPRS), side effects of pharmacological treatment (UKU), duration of hospitalization, number of hospitalizations, and quality of life (WhoQoL and WhoDAS). A chi-squared test was used to compare the frequency of diagnosis between the two clusters.
The external validity of the clustering solutions was verified by comparing the clusters (independent variable) on a different set of cognitive tests (dependent variables), including global cognitive functioning (MMSE and CDT), mental flexibility and verbal intelligence (GCA), short-term memory (Digit Span Forward), and working memory (Digit Span Backward). General linear models were used for normally distributed variables (MMSE and CDT). Mann–Whitney tests were used for non-normally distributed variables (GCA and Digit Span Forward and Backward).
The internal validity of the clustering solution was evaluated by dividing the sample according to the diagnosis and running both the Two-Step and Latent Class cluster analysis on each subsample. Cohen’s Kappa statistic was calculated to test the degree of agreement between the cluster assignment for each subject when considered in the cross-diagnostic sample and within the single diagnostic subsample.
Results
The results that emerged from both the Two-Step and the Latent Class cluster analysis reported a two-cluster classification as the optimal solution for the data considered in the present study. That is, following a parsimony criterion (see the Statistical Analysis section), the two-cluster solution presented the greatest BIC, AIC, and entropy change between the two closest clusters at each stage (Figure 1 and Supplementary Table S2). Following the principle of parsimony, the best cluster solution is the one with the highest value of the difference between two indexes of n cluster and n plus one cluster. This way to select the best cluster solution allows evaluating the improvement of homogeneity within each cluster and the heterogeneity between the clusters from one cluster to n cluster by adding one cluster at each step.
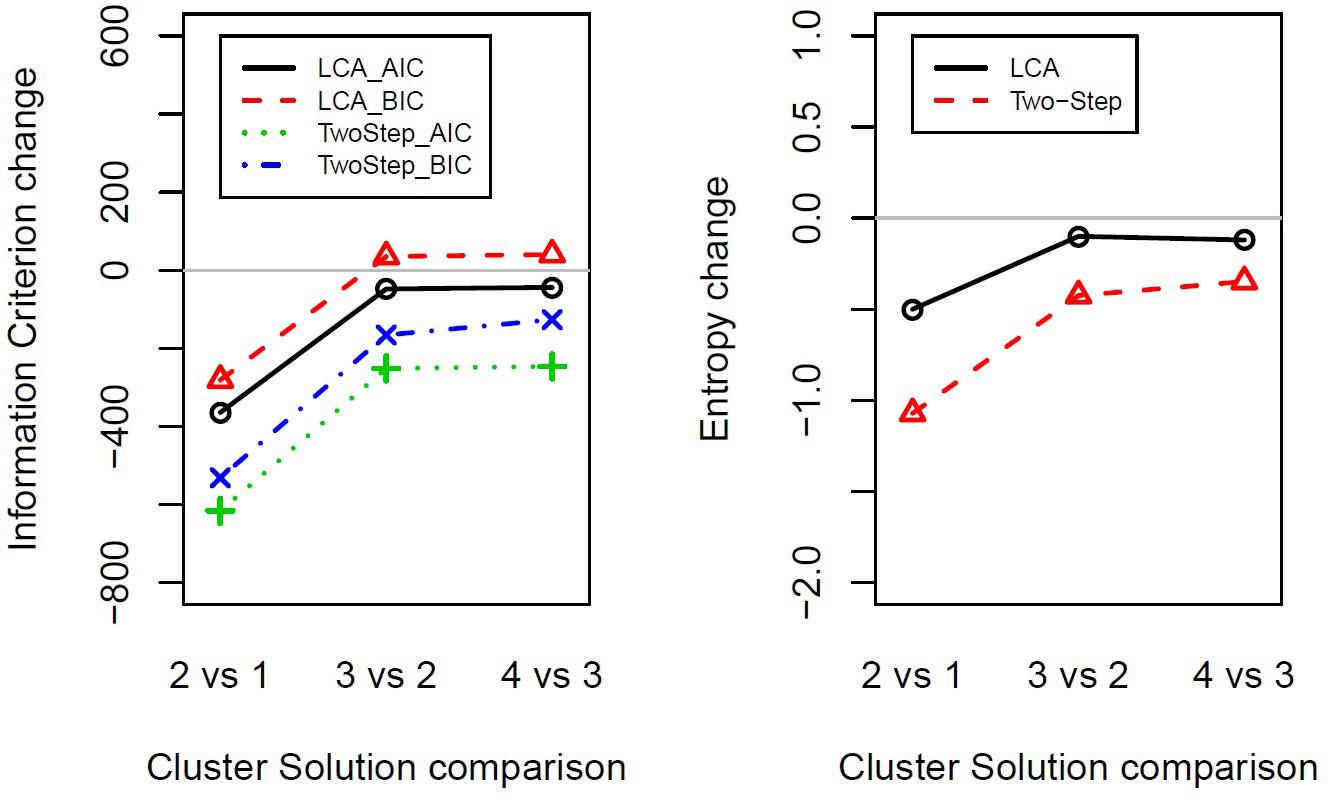
Figure 1. Indexes of fit changes obtained from Latent Class cluster analysis and Two-Step cluster analysis for solutions ranging from one to four clusters. The panels show the change in information criterion (left) or entropy (right) between two close clusters’ solutions (e.g., 2vs1 shows two-cluster solution minus one-cluster solution). LCA, Latent Class cluster analysis; TwoStep, Two-Step cluster analysis; BIC, Bayesian information criterion; AIC, Akaike information criterion.
The frequency distribution of performances scoring below, within, and above the normative sample for each cognitive test was examined to define the composition of the two clusters (Table 2). The results showed a significantly higher presence of performances classified as “below” in one cluster and “within” or “above” in the other cluster, for both the Two-Step and the Latent Class clustering solutions (Table 2). Consequently, one group was defined as the Low Cognitive Profile cluster (including 48% of subjects for the Two-Step clustering solution and 52% of subjects for the Latent Class clustering solution), and the other group was defined as the High Cognitive Profile cluster. The contribution of each cognitive test to such a clustering solution is represented in Figure 2. For the Latent Class cluster analysis, the major cognitive differences between clusters concerned perseveration and shifting abilities (MCST), fluid intelligence (CPM-47), and selective visual attention (AM), while for the Two-Step cluster analysis, the major cognitive differences between clusters concerned planning abilities and problem-solving (ToL). Since the two clusters reported differences in age (F2,304 = 0.63; p = 0.533; partial η2 = 0.004) and education (F2,304 = 2.64; p = 0.073; partial η2 = 0.017), these two variables were introduced as covariates in all analyses. A general linear model was applied to verify whether the clusters differed in clinical and psychosocial functioning. Although with some discrepancies between the Two-Step and the Latent Class clustering solutions, the Low Cognitive Profile cluster generally reported higher severity of symptoms (HoNOS and BPRS at admission and discharge), higher side effects of pharmacological treatment (UKU), lower improvement in BPRS symptom severity between admission and discharge, and longer duration of hospitalization than the High Cognitive Profile cluster (Table 3). No differences were found on measures of quality of life (WhoQoL and WhoDAS) and the number of hospitalizations (Table 3). The diagnoses were differently represented in the two clusters. Most of the schizophrenia and bipolar disorder patients were similarly distributed between the High and Low Cognitive Profile clusters, while most depressive disorder and personality disorder patients were more represented in the High Cognitive Profile cluster (Table 3).
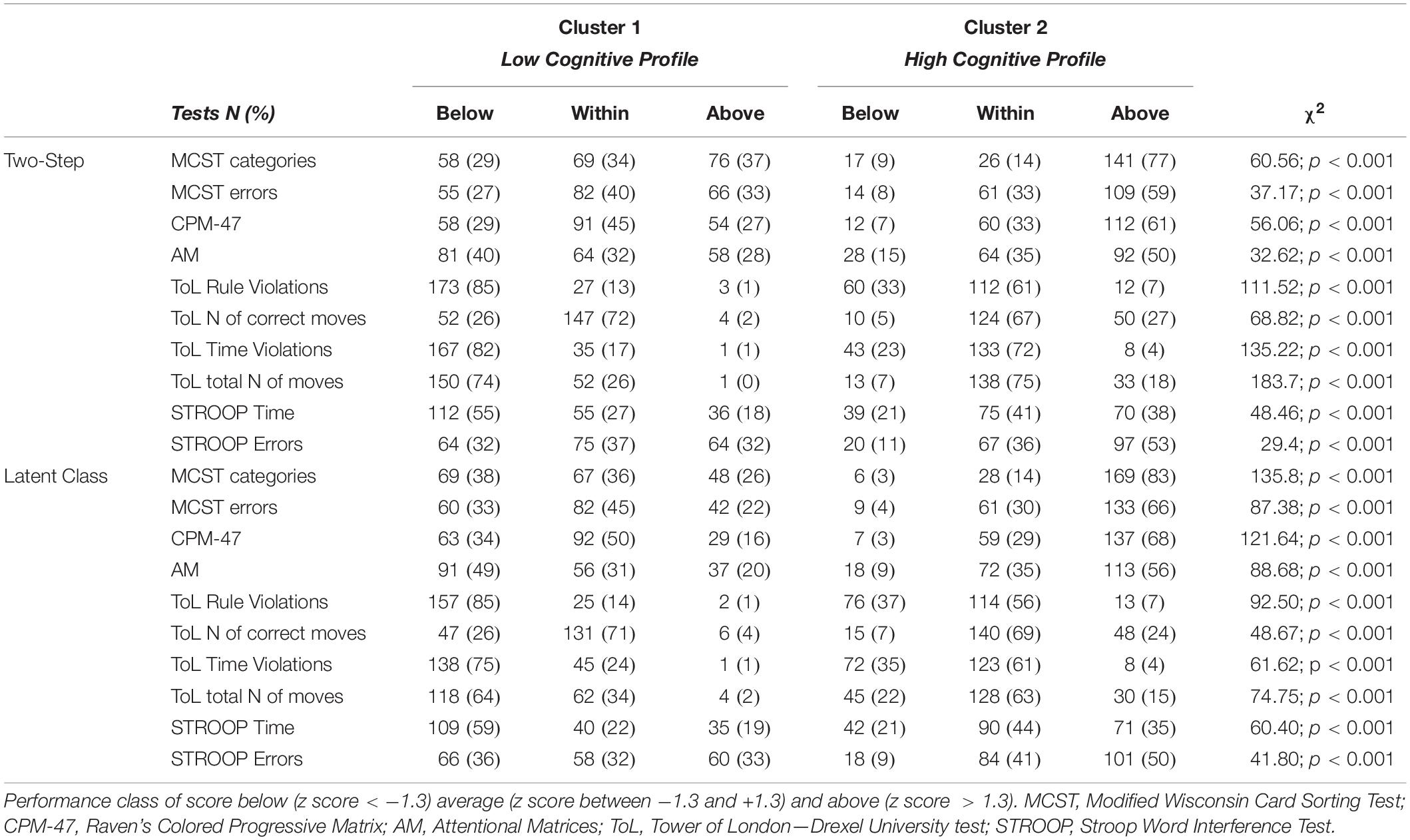
Table 2. Description of the two clusters according to the number and percentage of cases scoring below, within, and above the normative scores for each cognitive test.
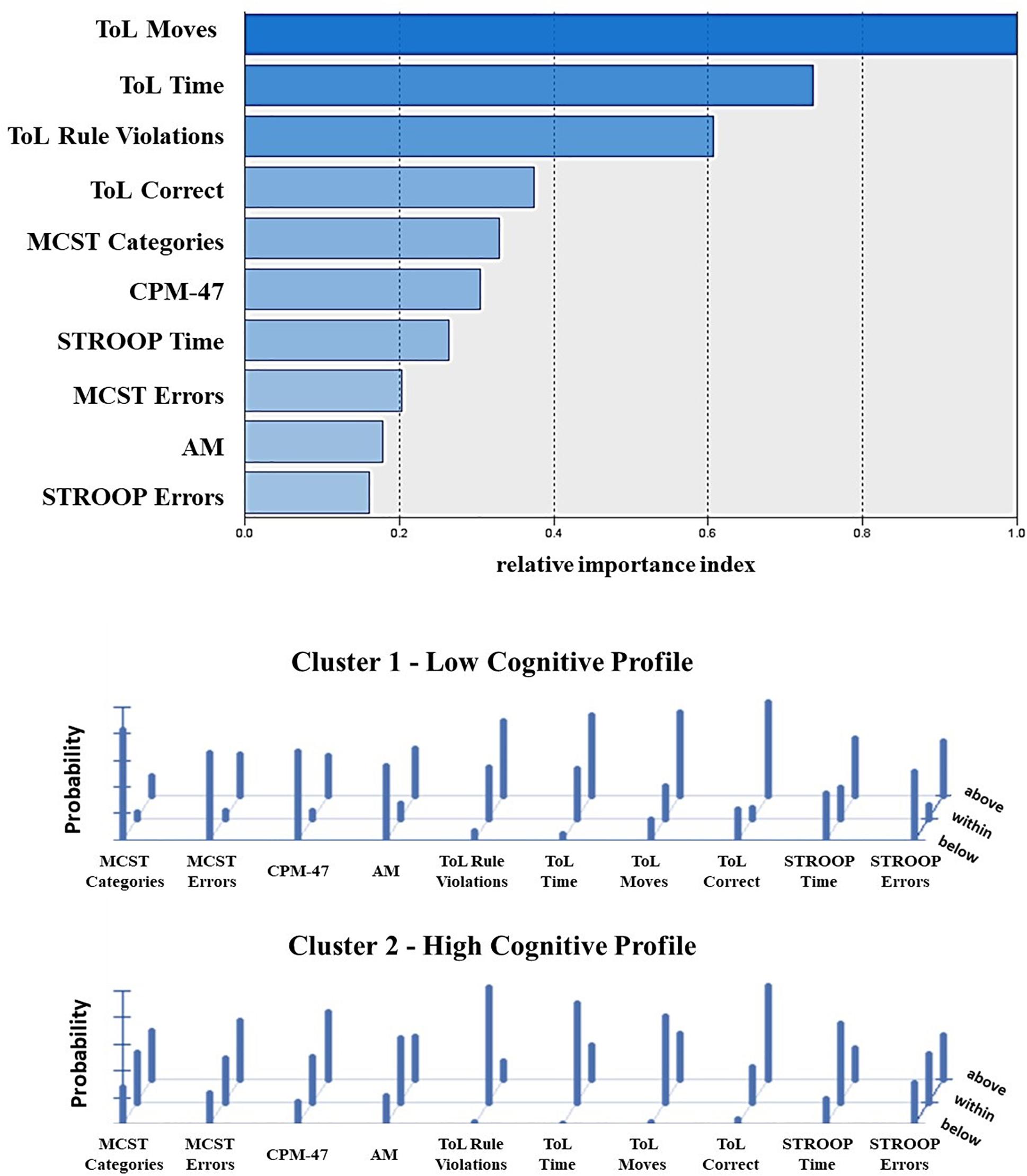
Figure 2. Contribution of the single cognitive tests to the clustering solution as reported from the Two-Step (top) and Latent Class cluster analysis (bottom). The top panel shows the index of relative importance of each cognitive test as identified by the Two-Step cluster analysis. The panel on the bottom shows the conditional item response probabilities for the two clusters identified by the Latent Class cluster analysis. Performance class of score below (z score < –1.3) average (z score between –1.3 and +1.3) and above (z score > 1.3) the normative sample. MCST, Modified Wisconsin Card Sorting Test; CPM-47, Raven’s Colored Progressive Matrix; AM, attentional matrices; ToL, tower of London—Drexel University test; STROOP, Stroop Word Interference Test.
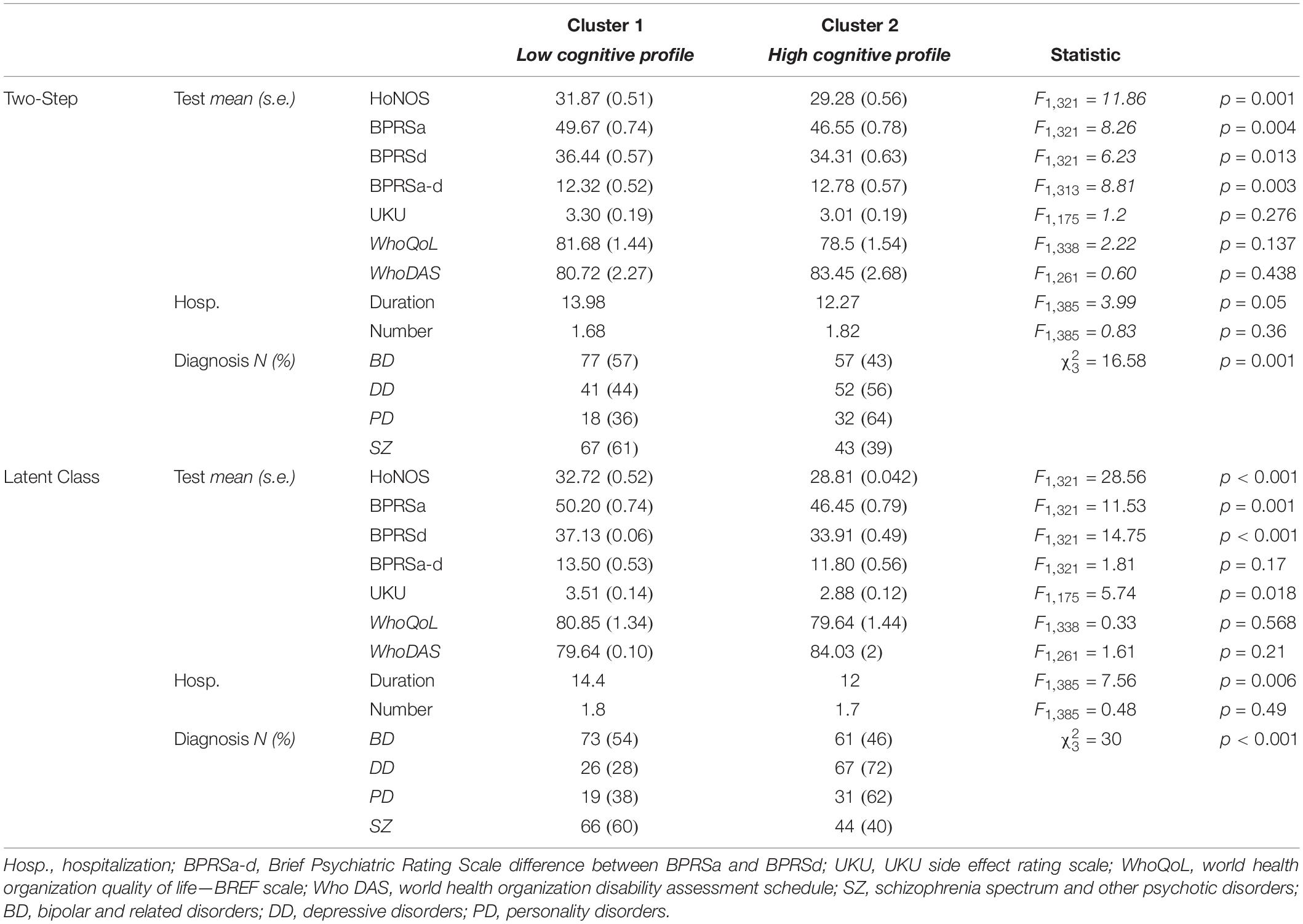
Table 3. Clinical characteristics and distribution of diagnoses in the two clusters.
The analysis for the external validity confirmed the presence of poorer global functioning, short-term memory, working memory, and mental flexibility and verbal intelligence in the Low Cognitive Profile cluster as compared to the High Cognitive Profile cluster. Such differences were present in both the clustering solutions identified by means of Two-Step cluster analysis (MMSE, F1,297 = 60.72, p < 0.001, partial η2 = 0.170; CDT, F1,123 = 19.21, p < 0.001, partial η2 = 0.135; GCA, U = 6,314.00, p < 0.001; SPAN Forward, U = 8,130.50, p = 0.018; SPAN Backward, U = 7,181.50, p < 0.001) and Latent Class cluster analysis (MMSE, F1,296 = 65.83, p < 0.001, partial η2 = 0.18; CDT, F1,122 = 24.67, p < 0.0001, partial η2 = 0.17; GCA, U = 6,314.00, p < 0.001; SPAN Forward, U = 8,000, p < 0.001; SPAN Backward, U = 7,000, p < 0.001). The Low Cognitive Profile performed worse than the High Cognitive Profile in all the tests: MMSE, Low Cognitive Profile = 26.16 (S.E. = 0.21) vs High Cognitive Profile 28.36 (SE.19); CDT, Low Cognitive Profile = 10.27 (S.E. = 0.39) vs High Cognitive Profile 12.70 (SE.39); GCA, Low Cognitive Profile mean rank = 114.47 vs High Cognitive Profile mean rank = 189.12; SPAN-Forward, Low Cognitive Profile mean rank = 128.04 vs High Cognitive mean rank = 160.50; SPAN Forward mean rank = 120.74 vs high cognitive mean rank = 166.39. These results showed that in all the tests, the Low Cognitive Profile obtained with Two-Step cluster analysis performed worse than the High Cognitive Profile.
The internal validity of the clustering solution was verified by applying the same cluster procedures on each of the four diagnostic groups separately. The results reported the two-cluster classification as the optimal solution within each diagnosis (Supplementary Figure S2 and Supplementary Table S2), thus confirming the result obtained on the cross-diagnostic sample as stable and consistent. Cohen’s Kappa statistics showed a significant agreement between the results of the whole cross-diagnostic sample and those emerging from the single diagnostic subsamples for both the Two-Step (Kappa = 0.66; p < 0.001) and the Latent Class (Kappa = 0.72; p < 0.001) cluster analysis. Patients were re-classified according to the cross-diagnostic solution in 83% of cases for the Two-Step clustering solution and in the 87% of cases for the Latent Class clustering solution. Overall, the two clusters obtained within each diagnosis were confirmed as being characterized by a lower and a higher cognitive profile (Supplementary Tables S3, S4). However, important differences were observed between the diagnoses. Indeed, for both clustering techniques, while schizophrenia and bipolar disorder patients showed a clear-cut separation and a fairly even distribution of subjects between the two clusters, depressive disorder and personality disorder patients were more represented in the High Cognitive Profile cluster (Figure 3; see also Table 3), thus showing lower cognitive heterogeneity.
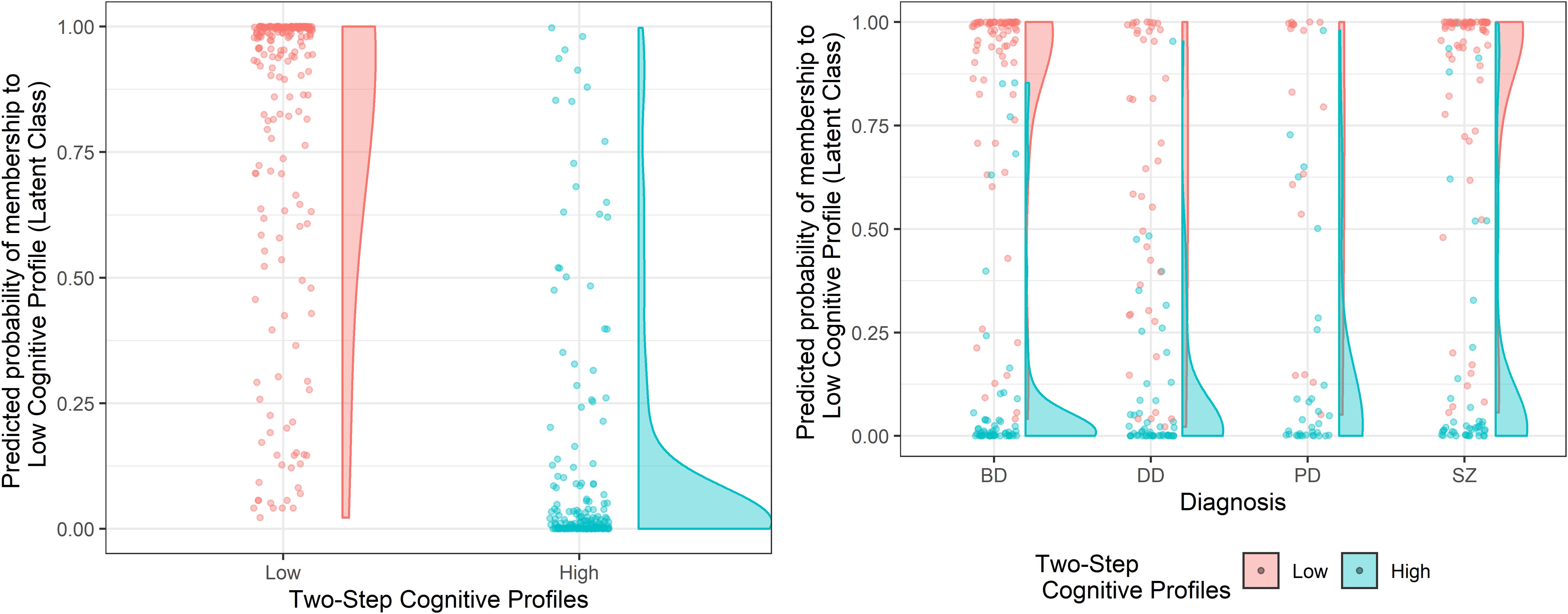
Figure 3. Cluster assignment according to the Two-Step clustering solution as a function of the predicted probability of cluster membership of the Latent Class clustering solution, on the cross-diagnostic sample and within each diagnosis. The left panel represents the clustering solutions obtained on the cross-diagnostic sample. The panel on the right represents the clustering solutions obtained within each diagnosis. SZ, Schizophrenia Spectrum and Other Psychotic Disorders; BD, Bipolar and Related Disorders; DD, Depressive Disorders; PD, Personality Disorders.
To support of the validation of the two cluster solutions obtained with categorical variables, we applied the Two-Step cluster analysis to quantitative data (i.e., standardized scores). Results showed that the two cluster solutions remained the best option according to AIC and BIC changes (see Supplementary Table S5).
Discussion
The main findings here reported responded to our general aim to find reliable and robust cognitive clusters of psychiatric inpatients by comparing Two-Step and Latent Class cluster analysis. To our knowledge, despite the wide use of different cluster analyses in former literature, no study compared different clustering approaches that can handle nominal data on a cross-diagnostic sample of psychiatric inpatients. The two cluster analyses converged on finding the presence of two separate clusters (Low and High) as the most efficient and robust description of the whole sample’s cognitive profile. Importantly, clustering was not dependent on pharmacological treatment side effects, as the two clusters reported comparable levels of iatrogenic effects. Measures of internal and external validity also confirmed the two-cluster classification as the best solution.
The analysis performed within each diagnostic sample showed that while schizophrenia and bipolar disorder were similarly represented in the two clusters, depressive disorder and personality disorder patients were overrepresented in the High Cognitive Profile cluster (Figure 3 and Table 3), thus indicating a higher cognitive heterogeneity in the first two diagnostic categories than in the last two. Crucially, given the known link with biomarkers, etiologies, and clinical factors reported in the literature about cognitive heterogeneity (Burdick et al., 2014; Lewandowski et al., 2014), such differentiation can be informative for clinical practice in terms of both prognosis and treatment planning (Cochrane et al., 2012; Burdick et al., 2014; Lewandowski et al., 2014). Indeed, the two clusters resulted as different in terms of severity and improvement of the symptomatology, side effects of pharmacological treatment, and duration of hospitalization.
The number of clusters here obtained is dissimilar to most of the previous studies using cross-diagnostic samples. A direct comparison between different cluster analytic studies is always problematic, as the clustering solutions are highly sensitive to the input data and the algorithm chosen (Marquand et al., 2016). For example, due to the marked variability of neuropsychological measures used by the previous studies above mentioned, any consideration would be limited by the absence of cluster analytic studies based on the same input data but extended to different cohorts. Nevertheless, we will try to examine the main differences and similarities with previous studies, in the attempt to obtain a more general overview of the currently available evidence (Supplementary Table S1). A recent study from Lee et al. (2017) in schizophrenia and bipolar disorder patients reported two clusters (for a complete overview, see Supplementary Table S1). Conversely, most studies reported either three (Hermens et al., 2011; Lee et al., 2015; Cotrena et al., 2017; Van Rheenen et al., 2017; Crouse et al., 2018) or four clusters (Goldstein and Shelly, 1987; Lewandowski et al., 2014, 2018; Reser et al., 2015). The main reason for obtaining more than two clusters could be attributed to the inclusion of healthy subjects within the cluster analysis and the presence of verbal reasoning tests, which we excluded in favor of a deeper evaluation of executive functions, as classically reported as the most important measures to explain the heterogeneity of cognitive profiles (Goldstein and Shelly, 1987; Hermens et al., 2011; Lewandowski et al., 2014, 2018; Lee et al., 2015, 2017; Reser et al., 2015; Cotrena et al., 2017; Van Rheenen et al., 2017; Crouse et al., 2018). Relatedly, some authors indicated that intermediary clusters could reflect a degree of normal variability across measures of cognitive functioning (Binder et al., 2009) that may underpin different brain abnormalities as far as nature and severity are concerned (Demjaha et al., 2012; Woodward, 2016). However, whether the clusters characterized by selective cognitive impairment represent distinct profiles or only reflect artificial divisions along a continuum of severity is a matter of debate (Wykes and Reeder, 2005). Indeed, the results reported may, at least in part, be confounded by the statistical and methodological limitations of these studies. Indeed, in contrast with previous literature, the robustness of the selected cluster solution was here tested by comparing two clustering techniques, namely Two-Step and Latent Class cluster analysis, that can both handle nominal data and continuous data and are based on optimal BIC and AIC indexes of fit (Chiu et al., 2001; Haughton et al., 2009). These two critical points are the main strengths of the two approaches. Moreover, some specific features of each technique should be mentioned. While the Two-Step cluster analysis is based on a fixed model procedure, in the Latent Class, a probability-based classification is computed for each subject according to the specific model selected by the researcher. Therefore, in the Latent Class cluster analysis, it is possible to obtain the subjective probability membership to each cluster (Figure 3). These aspects already have been discussed in previous literature (Chiu et al., 2001), but no previous study attempted to use them as a validation method for determining the stability of the selected cluster solution. Furthermore, given the known limitations of the cluster analysis, internal and external validation of a clustering solution, as reported in the present study, is always crucial (Marquand et al., 2016). A review by Marquand et al. (2016) has well explained that applying a cluster analysis necessarily entails some heuristics, concerning the choice of algorithm, distance function, and model order, which influence the clustering solution and complicate potential quantitative comparisons between different studies and cohorts. Unfortunately, only a few cross-diagnostic studies provided a validation of the clustering solution obtained (Hermens et al., 2011; Lee et al., 2015; Reser et al., 2015; Van Rheenen et al., 2017; Crouse et al., 2018). The two clusters identified in the present study can be considered as robust since both the external and internal validity of the clustering solution were verified. That is, the Low and High Cognitive Profiles were distinguishable also when compared based on a set of cognitive measures not considered during the cluster analysis and when applying the same cluster procedure on each of the four diagnostic groups separately.
Some limitations of the present study should also be mentioned. Personality Disorder patients are slightly underrepresented in the whole sample. This limitation may have biased the results; therefore, additional studies are needed to better understand if it is possible to find specific cognitive profiles in Personality Disorder patients. Although we attempted to analyze the contribution of pharmacological treatment in the clustering solution, we could only evaluate the iatrogenic effect. Further studies are required to investigate the effect of pharmacological treatment in grouping the cognitive performance of psychiatric patients.
Conclusion
Despite the large variety of solutions proposed by previous literature, the application and comparison of Two-Step and Latent Class cluster analysis on four possible clustering solutions (one to four clusters) allowed confirmation of the robustness of two clusters as the best representation of the cognitive heterogeneity characterizing large cross-diagnostic psychiatric inpatients. The presence of similar solutions obtained with two separate procedures suggests a combined use for future applications to maximize the criteria selection efficiency. These results have also important clinical implications. By clarifying that two subgroups of patients with low or high cognitive abilities can be identified in all the diagnostic groups, we envision the possibility to find specific phenotypes connected to executive functions. These two groups, irrespectively from the diagnosis, present different symptom severity and prognosis (better outcome and lower duration of hospitalization for those patients who are not cognitively impaired as compared to the ones with cognitive deficits). This result informs clinical practice about the fact that specific cognitive training could be proposed to psychiatric patients with low cognitive profile, and suggests that a specific cognitive evaluation could enhance the clinical effectiveness for personalized intervention.
Data Availability Statement
The data supporting the findings of the present study can be found in the Supplementary Material.
Ethics Statement
The studies involving human participants were reviewed and approved by Ausl della Romagna, Ethical Committee. The participants provided their written informed consent to participate in this study.
Author Contributions
MB, SGi, CR, and GP developed the main hypothesis, and all authors contributed to the study design. Patient screening, testing, and the data collection were carried on by FA, RS, RR, GD, and GP. Data analysis was performed by SGa, FA, and MO under the supervision of MB, GP, and SGi. The main text was written by MB, SGa, and FA. All authors approved the final version.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
We are grateful to the patients for their participation. Our thanks go to the Psychiatric Emergency Unit team (U.O. SPDC, AUSL della Romagna, Cesena). Special thanks go to Prof. Roberto Bolzani, for his support in the statistical analysis.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpsyg.2020.01085/full#supplementary-material
References
Allen, D. N., and Goldstein, G. (2013). Cluster Analysis in Neuropsychological Research: Recent Applications. New York, NY: Springer Science & Business Media.
Bacher, J., Wenzig, K., and Vogler, M. (2004). SPSS twostep cluster - a first evaluation. Univ. Erlangennürnb. 1, 1–20.
Berrettini, W. H. (2000). Are schizophrenic and bipolar disorders related? A review of family and molecular studies. Biol. Psychiatry 48, 531–538. doi: 10.1016/S0006-3223(00)00883-0
Binder, L. M., Iverson, G. L., and Brooks, B. L. (2009). To err is human: “abnormal” neuropsychological scores and variability are common in healthy adults. Arch. Clin. Neuropsychol. 24, 31–46. doi: 10.1093/arclin/acn001
Bora, E. (2016). Differences in cognitive impairment between schizophrenia and bipolar disorder: considering the role of heterogeneity. Psychiatry Clin. Neurosci. 70, 424–433. doi: 10.1111/pcn.12410
Burdick, K. E., Russo, M., Frangou, S., Mahon, K., Braga, R. J., Shanahan, M., et al. (2014). Empirical evidence for discrete neurocognitive subgroups in bipolar disorder: clinical implications. Psychol. Med. 44, 3083–3096. doi: 10.1017/S0033291714000439
Caffarra, P., Vezzadini, G., Dieci, F., Zonato, F., and Venneri, A. (2002). A short version of the Stroop test: normative data in an Italian population sample. Nuova Riv. Neurol. 12, 111–115.
Caffarra, P., Vezzadini, G., Dieci, F., Zonato, F., and Venneri, A. (2004). Modified card sorting test: normative data. J. Clin. Exp. Neuropsychol. 26, 246–250. doi: 10.1076/jcen.26.2.246.28087
Chiu, T., Fang, D., Chen, J., Wang, Y., and Jeris, C. (2001). “A robust and scalable clustering algorithm for mixed type attributes in large database environment,” in Proceedings of The Seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining - KDD ’01, (New York, NY: ACM Press), 263–268.
Cochrane, M., Petch, I., and Pickering, A. D. (2012). Aspects of cognitive functioning in schizotypy and schizophrenia: evidence for a continuum model. Psychiatry Res. 196, 230–234. doi: 10.1016/j.psychres.2012.02.010
Cosgrove, V. E., and Suppes, T. (2013). Informing DSM-5: biological boundaries between bipolar I disorder, schizoaffective disorder, and schizophrenia. BMC Med. 11:127. doi: 10.1186/1741-7015-11-127
Cotrena, C., Damiani Branco, L., Ponsoni, A., Milman Shansis, F., and Paz Fonseca, R. (2017). Neuropsychological clustering in bipolar and major depressive disorder. J. Int. Neuropsychol. Soc. 23, 584–593. doi: 10.1017/S1355617717000418
Cross-Disorder Group of the Psychiatric Genomics Consortium (2013). Identification of risk loci with shared effects on five major psychiatric disorders: a genome-wide analysis. Lancet 381, 1371–1379. doi: 10.1016/S0140-6736(12)62129-1
Crouse, J. J., Moustafa, A. A., Bogaty, S. E. R., Hickie, I. B., and Hermens, D. F. (2018). Parcellating cognitive heterogeneity in early psychosis-spectrum illnesses: a cluster analysis. Schizophr. Res. 202, 91–98. doi: 10.1016/j.schres.2018.06.060
Culbertson, W. C., and Zillmer, E. A. (2001). Tower of London-Drexel University (TOLDX). North Tonawada: Multi-Health Systems.
Dawes, S. E., Jeste, D. V., and Palmer, B. W. (2011). Cognitive profiles in persons with chronic schizophrenia. J. Clin. Exp. Neuropsychol. 33, 929–936. doi: 10.1080/13803395.2011.578569
Dell’Osso, B., Berlin, H. A., Serati, M., and Altamura, A. C. (2010). Neuropsychobiological aspects, comorbidity patterns and dimensional models in borderline personality disorder. Neuropsychobiology 61, 169–179. doi: 10.1159/000297734
Demjaha, A., MacCabe, J. H., and Murray, R. M. (2012). How genes and environmental factors determine the different neurodevelopmental trajectories of schizophrenia and bipolar disorder. Schizophr. Bull. 38, 209–214. doi: 10.1093/schbul/sbr100
Dinn, W. M., and Harris, C. L. (2000). Neurocognitive function in antisocial personality disorder. Psychiatry Res. 97, 173–190.
Fineberg, N. A., Day, G. A., de Koenigswarter, N., Reghunandanan, S., Kolli, S., Jefferies-Sewell, K., et al. (2015). The neuropsychology of obsessive-compulsive personality disorder: a new analysis. CNS Spectr. 20, 490–499. doi: 10.1017/S1092852914000662
First Michael, B., Spitzer Robert, L., Gibbon, M., and Janet, B. W. (1996). Structured Clinical Interview for DSM-IV Axis I Disorders, Clinician Version (SCID-CV). Washington, DC: American Psychiatric Press Inc.
Flynt, A., and Dean, N. (2016). A survey of popular R packages for cluster analysis. J. Educ. Behav. Stat. 41, 205–225. doi: 10.3102/1076998616631743
Folstein, M. F., Folstein, S. E., and McHugh, P. R. (1975). Mini-mental state. A practical method for grading the cognitive state of patients for the clinician. J. Psychiatr. Res. 12, 189–198.
Gandal, M. J., Haney, J. R., Parikshak, N. N., Leppa, V., Ramaswami, G., Hartl, C., et al. (2019). Shared molecular neuropathology across major psychiatric disorders parallels polygenic overlap. Focus 17, 66–72. doi: 10.1176/appi.focus.17103
Gelbard, R., Goldman, O., and Spiegler, I. (2007). Investigating diversity of clustering methods: an empirical comparison. Data Knowl. Eng. 63, 155–166. doi: 10.1016/j.datak.2007.01.002
Goldstein, G., and Shelly, C. (1987). The classification of neuropsychological deficit. J. Psychopathol. Behav. Assess. 9, 183–202. doi: 10.1007/BF00960574
Haughton, D., Legrand, P., and Woolford, S. (2009). Review of three latent class cluster analysis packages: latent gold, poLCA, and MCLUST. Am. Stat. 63, 81–91. doi: 10.1198/tast.2009.0016
Heinrichs, R. W., and Zakzanis, K. K. (1998). Neurocognitive deficit in schizophrenia: a quantitative review of the evidence. Neuropsychology 12, 426–445. doi: 10.1037/0894-4105.12.3.426
Hermens, D. F., Redoblado Hodge, M. A., Naismith, S. L., Kaur, M., Scott, E., and Hickie, I. B. (2011). Neuropsychological clustering highlights cognitive differences in young people presenting with depressive symptoms. J. Int. Neuropsychol. Soc. 17, 267–276. doi: 10.1017/S1355617710001566
Ivleva, E. I., Morris, D. W., Osuji, J., Moates, A. F., Carmody, T. J., Thaker, G. K., et al. (2012). Cognitive endophenotypes of psychosis within dimension and diagnosis. Psychiatry Res. 196, 38–44. doi: 10.1016/j.psychres.2011.08.021
Kent, P., Jensen, R. K., and Kongsted, A. (2014). A comparison of three clustering methods for finding subgroups in MRI, SMS or clinical data: SPSS twostep cluster analysis, latent Gold and SNOB. BMC Med. Res. Methodol. 14:113. doi: 10.1186/1471-2288-14-113
Koch, J., and Exner, C. (2015). Selective attention deficits in obsessive-compulsive disorder: the role of metacognitive processes. Psychiatry Res. 225:550. doi: 10.1016/j.psychres.2014.11.049
Kollmann, B., Yuen, K., Scholz, V., and Wessa, M. (2019). Cognitive variability in bipolar I disorder: a cluster-analytic approach informed by resting-state data. Neuropharmacology 156:107585. doi: 10.1016/j.neuropharm.2019.03.028
Kraus, J. M., Müssel, C., Palm, G., and Kestler, H. A. (2011). Multi-objective selection for collecting cluster alternatives. Comput. Stat. 26, 341–353. doi: 10.1007/s00180-011-0244-6
Lee, J., Rizzo, S., Altshuler, L., Glahn, D. C., Miklowitz, D. J., Sugar, C. A., et al. (2017). Deconstructing bipolar disorder and schizophrenia: a cross-diagnostic cluster analysis of cognitive phenotypes. J. Affect. Disord. 209, 71–79. doi: 10.1016/j.jad.2016.11.030
Lee, R. S. C., Hermens, D. F., Naismith, S. L., Lagopoulos, J., Jones, A., Scott, J., et al. (2015). Neuropsychological and functional outcomes in recent-onset major depression, bipolar disorder and schizophrenia-spectrum disorders: a longitudinal cohort study. Transl. Psychiatry 28:e555. doi: 10.1038/tp.2015.50
Lewandowski, K. E., Baker, J. T., McCarthy, J. M., Norris, L. A., and Öngür, D. (2018). Reproducibility of cognitive profiles in psychosis using cluster analysis. J. Int. Neuropsychol. Soc. 24, 382–390. doi: 10.1017/S1355617717001047
Lewandowski, K. E., Sperry, S. H., Cohen, B. M., and Öngür, D. (2014). Cognitive variability in psychotic disorders: a cross-diagnostic cluster analysis. Psychol. Med. 44, 3239–3248. doi: 10.1017/S0033291714000774
Lingjaerde, O., Ahlfors, U. G., Bech, P., Dencker, S. J., and Elgen, K. (1987). The UKU side effect rating scale. A new comprehensive rating scale for psychotropic drugs and a cross-sectional study of side effects in neuroleptic-treated patients. Acta Psychiatr Scand Suppl 334, 1–100.
Linzer, D. A., and Lewis, J. B. (2011). poLCA: an R package for polytomous variable latent class analysis. J. Stat. Softw. 42, 1–29. doi: 10.18637/jss.v042.i10
Marquand, A. F., Wolfers, T., Mennes, M., Buitelaar, J., and Beckmann, C. F. (2016). Beyond lumping and splitting: a review of computational approaches for stratifying psychiatric disorders. Biol. Psychiatry 1:433. doi: 10.1016/j.bpsc.2016.04.002
McClure, G., Hawes, D. J., and Dadds, M. R. (2016). Borderline personality disorder and neuropsychological measures of executive function: a systematic review. Pers. Ment. Health 10, 43–57. doi: 10.1002/pmh.1320
McLachlan, G., and Peel, D. (2000). “Mixtures of factor analyzers,” in Proc. Seventeenth Int. Conf. Mach. Learn, San Francisco, CA.
Mesholam-Gately, R. I., Giuliano, A. J., Goff, K. P., Faraone, S. V., and Seidman, L. J. (2009). Neurocognition in first-episode schizophrenia: a meta-analytic review. Neuropsychology 23, 315–336. doi: 10.1037/a0014708
Mitrushina, M., Boone, K. B., Razani, J., and D’Elia, L. F. (2005). Handbook of Normative Data for Neuropsychological Assessment. Oxford: Oxford University Press.
Morgan, A. B., and Lilienfeld, S. O. (2000). A meta-analytic review of the relation between antisocial behavior and neuropsychological measures of executive function. Clin. Psychol. Rev. 20, 113–136.
Morosini, P., Gigantesco, A., Mazzarda, A., and Gibaldi, L. (2003). HoNOS-Rome: an expanded, customized, and longitudinally oriented version of the HoNOS. Epidemiol. Psychiatry Sci. 12, 53–62.
Orsini, A., Grossi, D., Capitani, E., Laiacona, M., Papagno, C., and Vallar, G. (1987). Verbal and spatial immediate memory span: normative data from 1355 adults and 1112 children. Ital. J. Neurol. Sci. 8, 539–548.
Owoeye, O., Kingston, T., Scully, P. J., Baldwin, P., Browne, D., Kinsella, A., et al. (2013). Epidemiological and clinical characterization following a first psychotic episode in major depressive disorder: comparisons with schizophrenia and bipolar disorder in the cavan-monaghan first episode psychosis study (CAMFEPS). Schizophr. Bull. 39, 756–765. doi: 10.1093/schbul/sbt075
Pearlson, G. D. (2015). Etiologic, phenomenologic, and endophenotypic overlap of schizophrenia and bipolar disorder. Annu. Rev. Clin. Psychol. 11, 251–281. doi: 10.1146/annurev-clinpsy-032814-112915
Pruneti, C. A., Fenu, A., Freschi, G., Rota, S., Cocci, D., Marchionni, M., et al. (1996). Aggiornamento della standardizzazione italiana del test delle Matrici Progressive Colorate di Raven. Boll. di Psicol. Appl. 217:7.
Reser, M. P., Allott, K. A., Killackey, E., Farhall, J., and Cotton, S. M. (2015). Exploring cognitive heterogeneity in first-episode psychosis: what cluster analysis can reveal. Psychiatry Res. 229, 819–827. doi: 10.1016/j.psychres.2015.07.084
Rosell, D. R., Futterman, S. E., McMaster, A., and Siever, L. J. (2014). Schizotypal personality disorder: a current review. Curr. Psychiatry Rep. 16:452. doi: 10.1007/s11920-014-0452-1
Roux, P., Raust, A., Cannavo, A. S., Aubin, V., Aouizerate, B., Azorin, J. M., et al. (2017). Cognitive profiles in euthymic patients with bipolar disorders: results from the FACE-BD cohort. Bipolar Disord. 19, 146–153. doi: 10.1111/bdi.12485
Sheehan, D. V., Lecrubier, Y., Sheehan, K. H., Amorim, P., Janavs, J., Weiller, E., et al. (1998). The Mini-International Neuropsychiatric Interview (M.I.N.I.): the development and validation of a structured diagnostic psychiatric interview for DSM-IV and ICD-10. J. Clin. Psychiatry 59, 22–57.
Skevington, S. M., Lotfy, M., and O’Connell, K. A. (2004). The World Health Organization’s WHOQOL-BREF quality of life assessment: psychometric properties and results of the international field trial. A Report from the WHOQOL Group. Qual. Life Res. 13, 299–310. doi: 10.1023/B:QURE.0000018486.91360.00
Smith, A. L., and Weissman, M. M. (1992). “Epidemiology,” in Handbook of Affective Disorders, ed. E. S. Paykel (Edinburgh: Churchill-Livingstone), 111–129.
Spinnler, H., and Tognoni, G. (1987). Italian standardization and classification of Neuropsychological tests. Ital. J. Neurol. Sci. 8, 1–120.
Tamminga, C. A., Pearlson, G., Keshavan, M., Sweeney, J., Clementz, B., and Thaker, G. (2014). Bipolar and schizophrenia network for intermediate phenotypes: outcomes across the psychosis continuum. Schizophr. Bull. 40, S131–S137. doi: 10.1093/schbul/sbt179
Üstün, T. B. (2010). World Health Organization. Measuring health and disability: Manual for WHO Disability Assessment Schedule WHODAS 2.0. Genève: World Health Organization.
van Os, J., and Reininghaus, U. (2016). Psychosis as a transdiagnostic and extended phenotype in the general population. World Psychiatry 15, 118–124. doi: 10.1002/wps.20310
Van Rheenen, T. E., Lewandowski, K. E., Tan, E. J., Ospina, L. H., Ongur, D., Neill, E., et al. (2017). Characterizing cognitive heterogeneity on the schizophrenia–bipolar disorder spectrum. Psychol. Med. 47, 1848–1864. doi: 10.1017/S0033291717000307
Ventura, J., Lukoff, D., Nuechterlein, K. H., Liberman, R. P., Green, M., and Shaner, A. (1993). Manual for the expanded brief psychiatric rating scale. Int. J. Methods Psychiatry 3:221.
Vermunt, J. K., and Magidson, J. (2002). Latent class models for clustering: a comparison with K-means. Can. J. Mark. Res. 20, 36–43.
Vermunt, J. K., and Magidson, J. (2009). Latent class cluster analysis. Appl. Latent Cl. Anal. 11, 89–106. doi: 10.1017/cbo9780511499531.004
Watson, Y. I., Arfken, C. L., and Birge, S. J. (1993). Clock completion: an objective screening test for dementia. J. Am. Geriatr. Soc. 41, 1235–1240.
Witt, S. H., Streit, F., Jungkunz, M., Frank, J., Awasthi, S., Reinbold, C. S., et al. (2017). Genome-wide association study of borderline personality disorder reveals genetic overlap with bipolar disorder, major depression and schizophrenia. Transl. Psychiatry 7:e1155. doi: 10.1038/tp.2017.115
Woodward, N. D. (2016). The course of neuropsychological impairment and brain structure abnormalities in psychotic disorders. Neurosci. Res. 102, 39–46. doi: 10.1016/j.neures.2014.08.006
Keywords: two-step cluster analysis, latent class cluster analysis, cognitive functioning, psychiatric inpatients, cluster analyses
Citation: Benassi M, Garofalo S, Ambrosini F, Sant’Angelo RP, Raggini R, De Paoli G, Ravani C, Giovagnoli S, Orsoni M and Piraccini G (2020) Using Two-Step Cluster Analysis and Latent Class Cluster Analysis to Classify the Cognitive Heterogeneity of Cross-Diagnostic Psychiatric Inpatients. Front. Psychol. 11:1085. doi: 10.3389/fpsyg.2020.01085
Received: 30 November 2019; Accepted: 28 April 2020;
Published: 10 June 2020.
Edited by:
Jason C. Immekus, University of Louisville, United StatesReviewed by:
Andrea Rose Zammit, Albert Einstein College of Medicine, United StatesAna Maria Hernandez Baeza, University of Valencia, Spain
Copyright © 2020 Benassi, Garofalo, Ambrosini, Sant’Angelo, Raggini, De Paoli, Ravani, Giovagnoli, Orsoni and Piraccini. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Sara Garofalo, c2FyYS5nYXJvZmFsb0B1bmliby5pdA==