 Zhaoyuan Zhang
Zhaoyuan Zhang Jiwei Zhang
Jiwei Zhang Jing Lu1
Jing Lu1- 1Key Laboratory of Applied Statistics of MOE, School of Mathematics and Statistics, Northeast Normal University, Changchun, China
- 2Key Lab of Statistical Modeling and Data Analysis of Yunnan Province, School of Mathematics and Statistics, Yunnan University, Kunming, China
With the increasing demanding for precision of test feedback, cognitive diagnosis models have attracted more and more attention to fine classify students whether has mastered some skills. The purpose of this paper is to propose a highly effective Pólya-Gamma Gibbs sampling algorithm (Polson et al., 2013) based on auxiliary variables to estimate the deterministic inputs, noisy “and” gate model (DINA) model that have been widely used in cognitive diagnosis study. The new algorithm avoids the Metropolis-Hastings algorithm boring adjustment the turning parameters to achieve an appropriate acceptance probability. Four simulation studies are conducted and a detailed analysis of fraction subtraction data is carried out to further illustrate the proposed methodology.
1. Introduction
Modeling the interaction between examinee's latent discrete skills (attributes) and items at the item level for binary response data, cognitive diagnosis models (CDMs) is an important methodology to evaluate whether the examinees have mastered multiple fine-grained skills, and these models have been widely used in a variety of the educational and psychological researches (Tatsuoka, 1984, 2002; Doignon and Falmagne, 1999; Maris, 1999; Junker and Sijtsma, 2001; de la Torre and Douglas, 2004; Templin and Henson, 2006; DiBello et al., 2007; Haberman and von Davier, 2007; de la Torre, 2009, 2011; Henson et al., 2009; von Davier, 2014; Chen et al., 2015). With the increasing complexity of the problems in cognitive psychology research, various specific and general formulations of CDMs have been proposed to deal with the practical problems. There are several specific CDMs, widely known among them, are the deterministic inputs, noisy “and” gate model (DINA; Junker and Sijtsma, 2001; de la Torre and Douglas, 2004; de la Torre, 2009), the noisy inputs, deterministic, “and” gate model (NIDA; Maris, 1999), the deterministic input, noisy “or” gate model (DINO; Templin and Henson, 2006) and the reduced reparameterized unified model (rRUM; Roussos et al., 2007). In parallel with the specific CDMs, the general CDMs have also made great progress, including the general diagnostic model (GDM; von Davier, 2005, 2008), the log-linear CDM (LCDM; Henson et al., 2009), and the generalized DINA (G-DINA; de la Torre, 2011). Parameter estimation has been a major concern in the application of CDMs. In fact, simultaneous estimations of items and examinee's latent discrete skills result in statistical complexities in the estimation task.
Within a fully Bayesian framework, a novel and highly effective Pólya-Gamma Gibbs sampling algorithm (PGGSA; Polson et al., 2013) based on the auxiliary variables is proposed to estimate the commonly used DINA model in this paper. The PGGSA overcomes the disadvantages of Metropolis-Hastings algorithm (Metropolis et al., 1953; Hastings, 1970; Chib and Greenberg, 1995; Chen et al., 2000), which requires to repeatedly adjust the specification of tuning parameters to achieve a certain acceptance probability and thus increases the computational burden. More specifically, the Metropolis–Hasting algorithm depends on the variance (tuning parameter) of the proposal distribution and is sensitive to step size. If the step size is too small, the chain will take longer to traverse the target density. If the step size is too large, there will be inefficiencies due to a high rejection rate. In addition, the Metropolis-Hastings algorithm is relatively difficulty to sample parameters with monotonicity or truncated interval restrictions. Instead, it can improve the accuracy of parameter estimation by employing strong informative prior distributions to avoid violating the restriction conditions (Culpepper, 2016).
The rest of this paper is organized as follows. Section 2 contains a short introductions of DINA model, its reparameterized form, and model identifications. A detailed implementation of PGGSA is shown in section 3. In section 4, four simulations focus on the performance of parameter recovery for the PGGSA, the results of comparing with the Metropolis-Hastings algorithm, the analysis of sensitivity of prior distributions for the PGGSA, the results of comparing with Culpepper (2015)'s Gibbs algorithm on the attribute classification accuracy and the estimation accuracy of class membership probability parameters. In addition, the quality of PGGSA is investigated using a fraction subtraction test data in section 5. We conclude the article with a brief discussion in section 6.
2. Models and Model Identifications
The DINA model focuses on whether the examinee i has mastered the k attribute, where i = 1, …, N, k = 1, …, K. Let αik be a dichotomous latent attribute variable with values of 0 or 1 indicating absence or presence of a attribute, respectively. is a vector of K dimensional latent attributes for the ith examinee. Given the categorical nature of the latent classes, αi belongs to one of C = 2K attribute latent classes. If the ith examinee belongs to the cth classification, the attribute vector can be expressed as Considering a test consisting of J items, each item j is associated with a vector of K dimensional item attributes, , where
Therefore, a Q matrix, Q ={qjk}J × K, can be obtained by the J item attribute vectors. The DINA model is conjunctive. That is, the examinee i must possess all the required attributes to answer the item j correctly. The ideal response pattern ηij can be defined as follows
, where I(·) denotes the indicator function. The parameters for a correct response to item j when given ηij are denoted by sj and gj. The slipping parameter sj and the guessing parameter gj refer to the probability of incorrectly answering the item when ηij = 1 and the probability of correctly guessing the answer when ηij = 0, respectively. Let Yij denote the observed item response for the ith examinee to response jth item, Yij = 1 if the ith examinee correct answer the jth item, 0 otherwise. The parameters sj and gj are formally defined by
The probabilities of observing response given attributes α are represented by
and.
2.1. The Reparameterized DINA Model
To describe the relationship between the attribute vector and the observed response, we can reexpress the DINA model as follow:
where the model discrimination index can be defined as 1 − sj − gj = IDIj (de la Torre, 2008). Based on the traditional DINA model, we reparameterize sj and gj from the probability scale to the logit scale (Henson et al., 2009; DeCarlo, 2011; von Davier, 2014; Zhan et al., 2017). That is,
where logit(x) = log(x/(1 − x)). Therefore, the reparameterized DINA model (DeCarlo, 2011) can be written as
where ςj and βj are the item intercept and interaction parameters, respectively.
2.2. The Likelihood Function of the Reparameterized DINA Model Based on the Latent Class
Suppose that the vector of item responses for the ith examinee can be denoted as Let the vector of intercept and interaction parameters for J items be ς and β, where ς = (ς1, …, ςJ) and β = (β1, …, βJ). Given the categorical nature of the latent classes, αi belongs to one of C = 2K attribute latent classes. For the ith examinee belonging to the cth classification, the attribute vector is expressed as According the Equation (4), the probability of observing Yi that the ith examinee belonging to the cth latent class answers J items can be written as
where αi = αc denotes the examinee i belongs to the cth latent class. p(Yij = 1|αc, ςj, βj) is the probability that the examinee i in class c correctly answers the item j.
Let πc = p(αc) be the probability of examinees for each class c, c = 1, …, C, and π is C dimensional vector of class membership probabilities, where . Therefore, the probability of observing Yi given item parameters ς, β and class membership probabilities π can be written as
The likelihood function based on the latent class can be written as
2.3. Model Identification
The model identification is an important cornerstone for estimating parameters and practical applications. Chen et al. (2015); Xu and Zhang (2016), and Xu (2017) discuss the DINA model identification conditions. Gu and Xu (2019) further provide a set of sufficient and necessary conditions for the identifiability of the DINA model. That is,
Condition 1: (1) The Q-matrix is complete under the DINA model and without loss of generality, we assume the Q-matrix takes the following form:
where is the K × K identify matrix and Q* is a (J − K) × K submarix of Q.
(2) Each of the K attributes is required by at least three items.
Condition 2: Any two different columns of the submatrix Q* in (8) are distinct.
Under the above two conditions, Gu and Xu (2019) give the following identifiability result.
Theorem (Sufficient and Necessary Condition) Conditions 1 and 2 are sufficient and necessary for the identifiability of all the DINA model parameters.
3. Pólya-Gamma Gibbs Sampling Algorithm
Polson et al. (2013) propose a new data augmentation strategy for fully Bayesian inference in logistic regression. The data augmentation approach appeals to a new class of Pólya-Gamma distribution rather than Albert and Chib (1993)'s data augmentation algorithm based on a truncated normal distribution. Next, we introduce the Pólya-Gamma distribution.
Definition: Let is a iid random variable sequences from a Gamma distribution with parameters λ and 1. That is, Tk ~ Gamma (λ, 1). A random variable W follows a Pólya-Gamma distribution with parameters λ > 0 and τ ∈ R, denoted W ~ PG(λ, τ), if
where denotes equality in distribution. In fact, the Pólya-Gamma distribution is an infinite mixture of gamma distributions which provide the plausibility to sample from Gamma distributions.
Based on Polson et al. (2013, p. 1341, Equation 7)'s Theorem 1, the likelihood contribution of the ith examinee to answer the jth item can be expressed as
where p(Wij | 1, 0) is the conditional density of Wij. That is, Wij ~ PG(1, 0). The auxiliary variable Wij follows a Pólya-Gamma distribution with parameters (1, 0). Biane et al. (2001) provide proofs of Equation (10). In addition, Polson et al. (2013) further discuss Equation (10). Therefore, the full conditional distribution of ς, β, α given the auxiliary variables Wij can be written as
where p(ς), p(β), and p(α) are the prior distributions, respectively. The joint posterior distribution based on the latent classes is given by
where p(ς), p(β), and p(π) are the prior distributions, respectively.
Step 1: Sampling the auxiliary variable Wij, given the item intercept and interaction parameters ςj, βj and αi = αc. According to Equation (10), the full conditional posterior distribution of the random auxiliary variable Wij is given by
According to Biane et al. (2001) and Polson et al. (2013; p. 1341), the density function p(Wij|1, 0) can be written as
Therefore, f(Wij | ςj, βj, αi = αc) is proportional to
Finally, the specific form of the full conditional distribution of Wij is as follows
Next, the Gibbs samplers are used to draw the item parameters.
Step 2: Sampling the intercept parameter ςj for each item j. The prior distribution of ςj is assumed to follow a normal distribution, that is, . Given Y, W, β, and α, the fully condition posterior distribution of ςj is given by
where f(Wij | ςj, βj, αi = αc) is equal to the following equation (the details see Polson et al., 2013; p. 1341)
After rearrangement, the full conditional posterior distribution of ςj can be written as follows
Therefore, the fully condition posterior distribution of ςj follow normal distribution with mean
and variance
Step 3: Sampling the interaction parameter βj for each item j. The prior distribution of βj is assumed to follow a truncated normal distribution to satisfy the model identification restriction (Junker and Sijtsma, 2001; Henson et al., 2009; DeCarlo, 2012; Culpepper, 2015). That is, Similarly, given Y, W, ς, and α, the full condition posterior distribution of βj is given by
Therefore, the fully condition posterior distribution of ςj follow the truncated normal distribution with mean
and variance
Step 4: Sampling the attribute vector αi for each examinee i. Given Y, W, ς, and β, we can update the ith examinee's attribute vector αi from the following multinomial distribution
where the probability that the attribute vector αi belongs to the cth(c = 1, …, C) class can be written as
Step 5: Sampling the class membership probabilities π. The prior of π is assumed to follow a Dirichlet distribution. I.e., π = (π1, …, πC) ~Dirichlet(δ0, …, δ0). The full condition posterior distribution of the class membership probabilities π can be written as
4. Simulation Study
4.1. Simulation 1
4.1.1. Simulation Design
In this simulation study, the purpose is to assess the performance of the Pólya-Gamma Gibbs sampling algorithm. Considering the test length is J = 30, and the number of the attribute is set equal to K = 5. The Q-matrix is shown in Table 1, where the design of Q-matrix satisfies Gu and Xu (2019)'s DINA model identification conditions. For the true values of the class membership probabilities, we only consider the most general case that the class membership probabilities are flat though all class, i.e., c = 1, …, C, where C = 2K. Next, two factors and their varied test conditions are simulated. (a) two sample sizes (N = 1000, 2000) are considered; (b) Following Huebner and Wang (2011) and Culpepper (2015), four noise levels are considered to explore the relationship between noise level and recovery by constraining the true values of the item parameters. For each item, (b1) low noise level (LNL) case: sj = gj = 0.1; the corresponding true values of reparameterized parameters are ζj = −2.1972, βj = 4.3945; (b2) high noise level (HNL) case : sj = gj = 0.2; the corresponding true values of reparameterized parameters are ζj = −1.3863, βj = 2.7726; (b3) slipping higher than guessing (SHG) case: sj = 0.2, gj = 0.1; the corresponding true values of reparameterized parameters are ζj = −2.1972, βj = 3.5835; (b4) guessing higher than slipping (GHS) case: sj = 0.1, gj = 0.2; the corresponding true values of reparameterized parameters are ζj = −1.3863, βj = 3.5835. Fully crossing the different levels of these two factors yield 8 conditions.
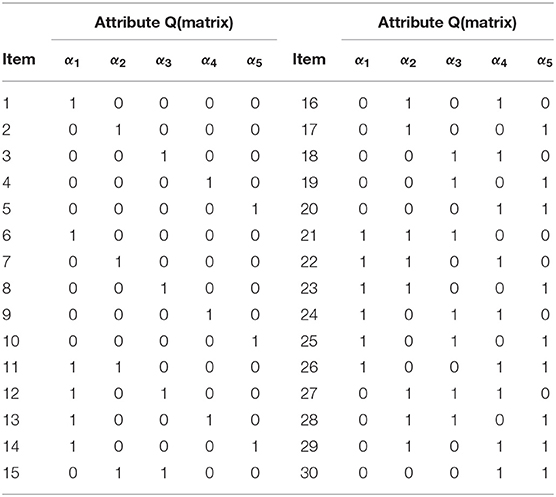
Table 1. The Q matrix design in the simulation study 1.
4.1.2. Priors
Based on the four noise levels, the corresponding four kinds of non-informative prior are used. I.e.,
where the purpose of using non-informative priors is to eliminate the influence of prior uncertainty on posterior inferences. Similarly, the non-informative Dirichlet prior distribution is employed for the class membership probabilities π. I.e., (π1, …, πC) ~ Dirichlet (1, …, 1).
4.1.3. Convergence Diagnostics
As an illustration of the convergence of parameter estimates, we only consider the low noise level (LNL) case and the number of examinees is 1,000. Two methods are used to check the convergence of parameter estimates. One is the “eyeball” method to monitor the convergence by visually inspecting the history plots of the generated sequences (Hung and Wang, 2012; Zhan et al., 2017), and another method is to use the Gelman-Rubin method (Gelman and Rubin, 1992; Brooks and Gelman, 1998) to check the convergence of parameter estimates.
To implement the MCMC sampling algorithm, chains of length 20,000 with an initial burn-in period 10,000 are chosen. Four chains started at overdispersed starting values are run for each replication. The trace plots of Markov Chains for three randomly selected items and class membership probabilities are shown in Figure 1. In addition, the potential scale reduction factor (PSRF; Brooks and Gelman, 1998) values of all parameters are <1.1, which ensures that all chains converge as expected. The trace plots of PSRF values are shown in the simulation 2.
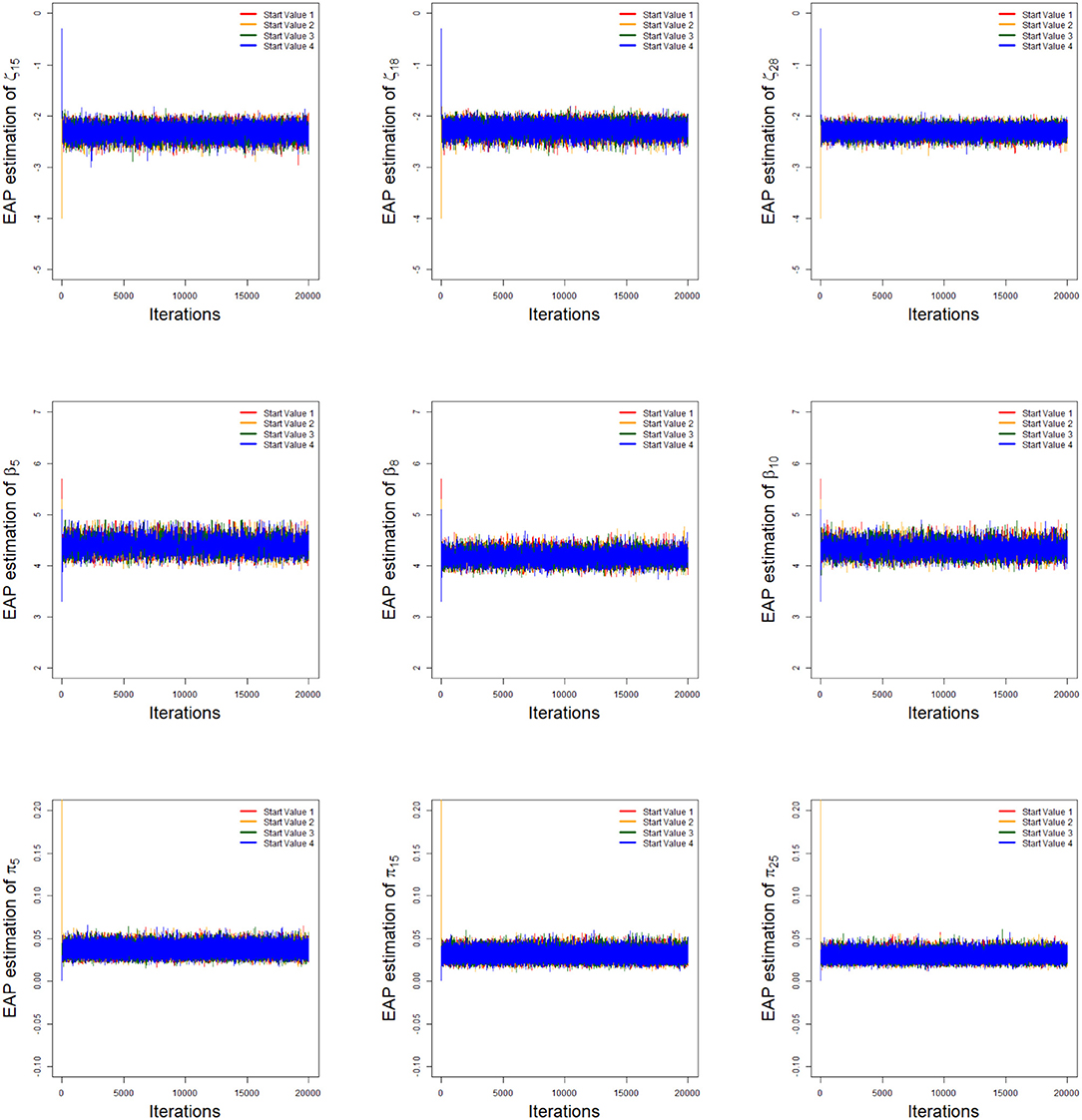
Figure 1. The trace plots of the arbitrarily selected item and class membership probability parameters.
4.1.4. Evaluation Criteria for Convergence and Accuracy of Parameter Estimations
The accuracy of the parameter estimates is measured by two evaluation criteria, i.e., Bias and Mean Squared Error (MSE). Let η be the interested parameter. Assume that M = 25 data sets are generated. Also, let be the posterior mean obtained from the mth simulated data set for m = 1, …, M.
The Bias for parameter is defined as
and the MSE for parameter is defined as
For illustration purposes, we only show the Bias and MSE of ς, β, and π for the four noise levels based on 1,000 sample sizes in Figures 2, 3. In the four noise levels, the Bias of ς, β, and π are near the zero values. However, the MSE of ς and β increase as the number of attributes required by the item increases. In the low noise level, the performances of the recovery for ς and β are well-based on the results of MSE, and the MSE of ς and β are <0.0250. The performances for the high noise level are worst in the four diagnosticity cases. Moreover, we find that when the item tests a attribute, the MSE of ς is not much different from that of β. However, the MSE of β is greater than that of ς when the item requires multiple attributes. The reason is due to a fact that the number of examinees for ηij = 1 is almost equal to that of ηij = 0 when the item tests a attribute, which is accurate for estimating the ς and β. Along with the increase in the attributes required by the item, the number of examinees for ηij = 1 reduces and the number of examinees for ηij = 0 increases, thus resulting in the MSE of β higher than that of ς. Note that the MSE of β is dependent on the number of examinees for ηij = 1.
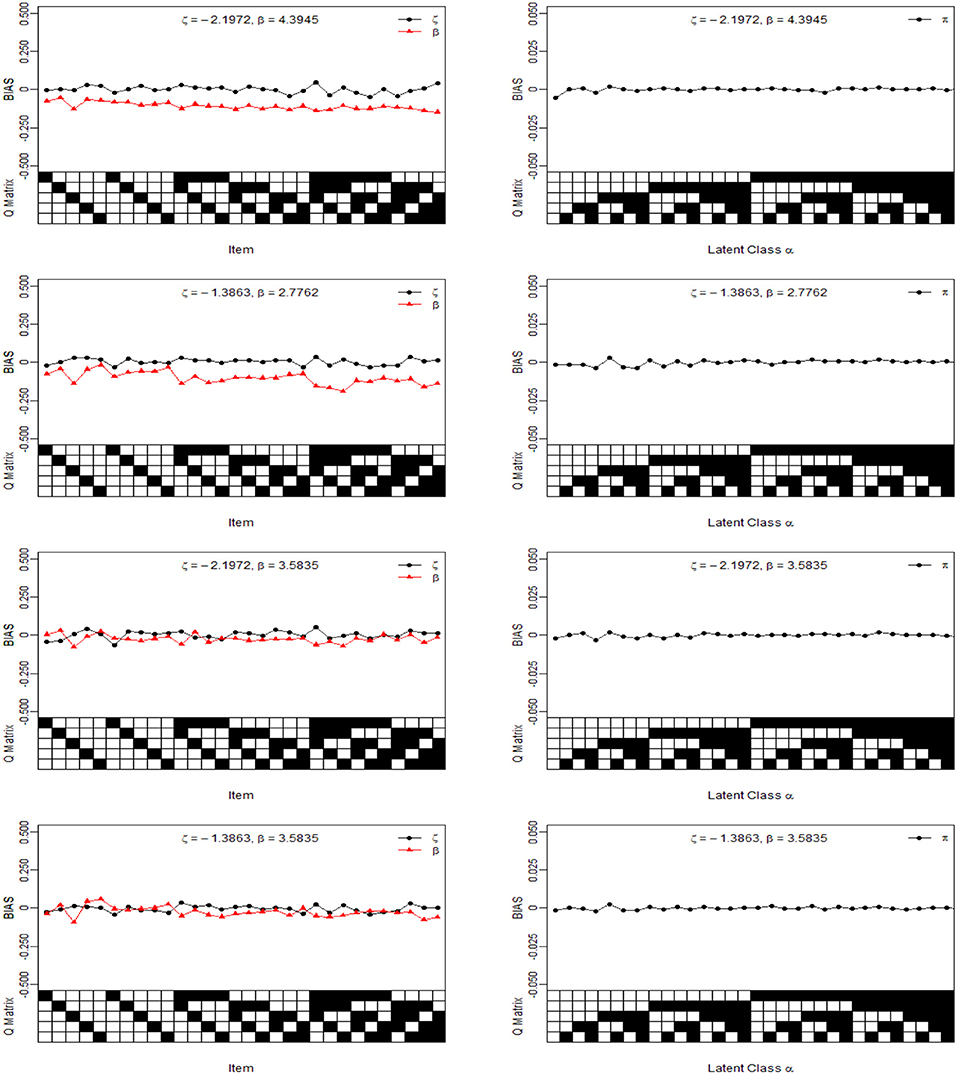
Figure 2. The Bias of intercept, interaction and the latent class parameters under four different noise levels. The Q Matrix denotes the skills required for each item along the x axis, where the black square = “1” and white square = “0.” The αck denotes the examinee who belongs to the cth latent class whether has mastered kth skill, where the black square = “1” for the presence of a skill and white square = “0” for the absence of a skill, . Note the Bias values are estimated from 25 replications.
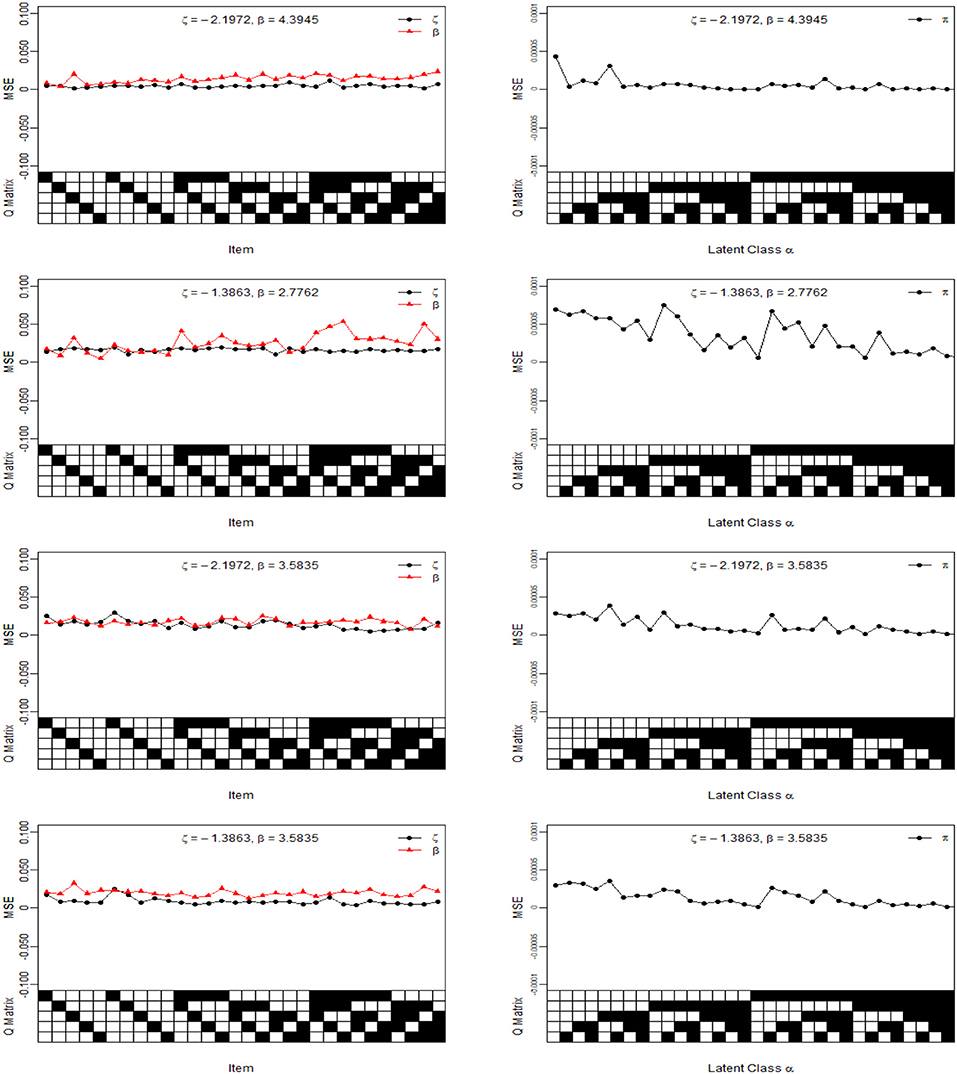
Figure 3. The MSE of intercept, interaction and class membership probability parameters under four different diagnosticity cases. The Q Matrix denotes the skills required for each item along the x axis, where the black square = “1” and white square = “0.” The αck denotes the examinee who belongs to the cth latent class whether has mastered kth skill, where the black square = “1” for the presence of a skill and white square = “0” for the absence of a skill, . Note the MSE values are estimated from 25 replications.
The average Bias and MSE for ς, β, and π based on eight different simulation conditions are shown in Table 2. The following conclusions can be obtained. (1) Given a noise level, when the number of examinees increases from 1,000 to 2,000, the average MSE for ς and β show a decreasing trend. More specifically, when the number of examinees increases from 1,000 to 2,000, in the case of low noise level (LNL), the average MSE of ς decreases from 0.048 to 0.034, the average MSE of β decreases from 0.0141 to 0.0107. In the case of high noise level (HNL), the average MSE of ς decreases from 0.0163 to 0.0117, the average MSE of β decreases from 0.0254 to 0.0239. In the case of the slipping higher than the guessing (SHG), the average MSE of ς decreases from 0.0139 to 0.0078, the average MSE of β decreases from 0.0172 to 0.0159. In the case of the guessing higher than the slipping (GHS), the average MSE of ς decreases from 0.0088 to 0.0041, the average MSE of β decreases from 0.0198 to 0.0181. (2) Given a noise level, when the number of examinees increases from 1,000 to 2,000, In the case of four kinds of noises, the average MSE of π are basically the same and close to 0 under the conditions of four noise levels. (3) Compared with the other three noise level, the average MSE of ς and β are largest at high noise level. In summary, the Bayesian algorithm provides accurate estimates for ς, β, and π in term of various numbers of examinees.
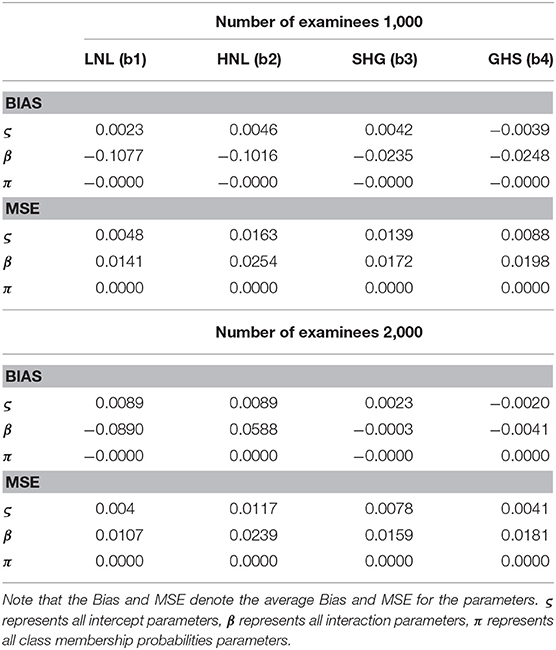
Table 2. The average Bias and MSE for ς, β, and π.
4.2. Simulation 2
In this simulation study, we compare MH algorithm and PGGSA from two aspects: the accuracy and convergence. We consider 1,000 examinees to answer 30 items, and the number of the attribute is set equal to K = 5. The true values of ζj and βj are set equal to −2.1972 and 4.3945 for each item. The corresponding true values of sj and gj are equal to 0.1 for each item. The class membership probabilities are flat though all classes, i.e., c = 1, …, C, where C = 2K. We specify the following non-informative priors to the PGGSA and MH algorithm: and (π1, …, πC) ~ Dirichlet(1, …, 1).
It is known that an improper proposal distribution for MH algorithm can seriously reduce the acceptance probability of sampling. Most of the posterior samples are rejected. Therefore, the low sampling efficiency is usually unavoidable, and the reduction in the number of valid samples may lead to incorrect inference results. In contrast, our PGGSA takes the acceptance probability as 1 to draw the samples from fully condition posterior distributions. The following proposal distributions for the intercept and interaction parameters are considered in the process of implementing MH algorithm. The sampling details of MH algorithm, see Appendix. Note that the class membership probabilities are updated through the same way for the PGGSA and MH algorithms.
• Case 1:
• Case 2:
To compare the convergence of all parameters for the PGGSA and MH algorithm with different proposal distributions, the convergence of item and class membership probability parameters are evaluated by judging whether the values of PSRF are <1.1. From Figure 4, we find that the intercept, interaction and class membership probability parameters have already converged at the 5,000 step iterations for the PGGSA. The fastest convergence is the class membership probability parameters followed by intercept parameters. For the MH algorithm, some parameters do not converge after 5,000 step iterations for the proposal distributions with the variances of 0.1. The convergence of the proposal distributions with the variances of 1 is worse than the convergence of the proposal distributions with the variances of 0.1, even some parameters do not reach convergence at the end of the 10,000 step iterations. Moreover, the Bias and MSE are used to evaluate the performances of the two algorithms in Table 3. It has been proved that the selection of the proposal distribution has an important influence on the accuracy of parameter estimation. The process of finding the proper turning parameter is time consuming. In addition, we investigate the efficiency of the two algorithms from the perspective of the time consumed by implementing them. On a desktop computer [Intel(R) Xeon(R) E5-2695 V2 CPU] with 2.4 GHz dual core processor and 192 GB of RAM memory, PGGSA and MH algorithm, respectively consume 3.6497 and 4.7456 h when Markov chain are run for 20,000 iterations for a replication experiment, where MH algorithm is used to implement the Case 1. In summary, PGGSA is more effective than MH algorithm in estimating model parameters.
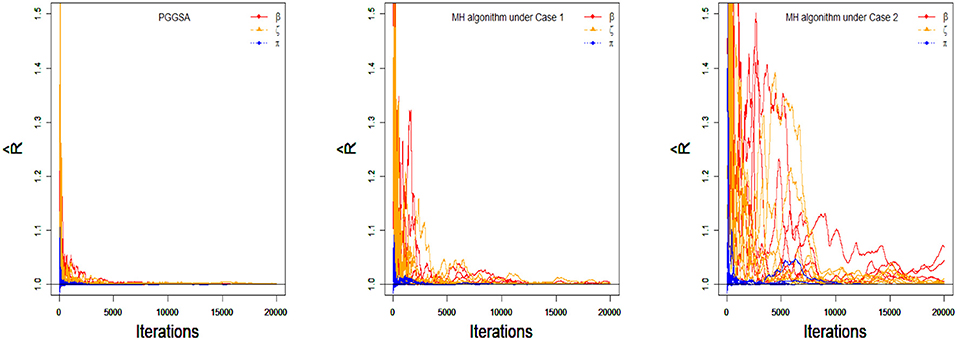
Figure 4. The trace plots of PSRF values for the simulation study 2.
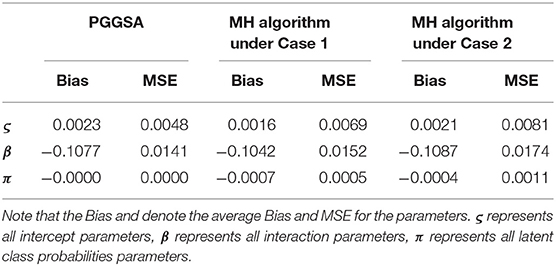
Table 3. Evaluating accuracy of parameter estimation using the two algorithms in the simulation study 2.
4.3. Simulation 3
This simulation study is to show that PGGSA is sufficiently flexible to recover various prior distributions for the item and class membership probability parameters. The simulation design is as follows:
The number of the examinees is N = 1, 000, and the test length is J = 30, and the number of the attributes is set equal to K = 5. The true values of item intercept and interaction parameters are −2.1972 and 4.3945 for each item at low noise level. The class membership probabilities are flat though all classes, i.e., c = 1, …, C, where C = 2K.
The non-informative Dirichlet prior distribution is employed for the class membership probabilities π. I.e., (π1, …, πC) ~ Dirichlet (1, …, 1), and two kinds of prior distributions are considered for the intercept and interaction parameters:
(1) Informative prior: Type I: ζj ~ N(−2.1972, 0.5), βj ~ N(4.3945, 0.5)I(βj > 0); Type II: ζj ~ N(−2.1972, 1), βj ~ N(4.3945, 1) I (βj > 0);
(2) Non-informative prior: Type III: Type IV:
PGGSA is iterated 20,000 times. The first 10,000 iterations are discarded as burn-in period. 25 replications are considered in this simulation study. The PSRF values of all parameters for each simulation condition are <1.1. The Bias and MSE of the ζ, β, and π based on two kinds of prior distributions are shown in Table 4.
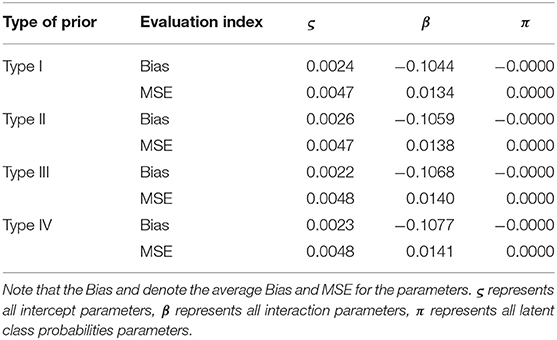
Table 4. Evaluating the accuracy of parameters based on different prior distributions in the simulation study 3.
4.3.1. Result Analysis
From Table 4, we find that the Bias and MSE of ς, β and π are almost the same under different prior distributions. More specifically, the Bias of ς ranges from 0.0022 to 0.026, β ranges from −0.1077 to −0.1044, and the Bias of π under the two kinds of prior distributions is equal to −0.0000. In addition, the MSE of ς ranges from 0.0047 to 0.0048, β ranges from 0.0134 to 0.0141, and the MSE of π under the two kinds of prior distributions is equal to −0.0000. This shows that the accuracy of parameter estimation can be guaranteed by PGGSA, no matter what the informative prior or non-informative distributions are chosen.
4.4. Simulation 4
The main purpose of this simulation study is to compare PGGSA and Culpepper (2015)'s Gibbs sampling algorithm (Geman and Geman, 1984; Tanner and Wong, 1987; Gelfand and Smith, 1990; Albert, 1992; Damien et al., 1999; Béguin and Glas, 2001; Sahu, 2002; Bishop, 2006; Fox, 2010; Chen et al., 2018; Lu et al., 2018) on the attribute classification accuracy and the estimation accuracy of class membership probability parameter (π).
The number of the examinees is N = 1, 000. Considering the test length is J = 30, and the number of the attribute is set equal to K = 5. The Q-matrix is shown in Table 1. Four noise levels are considered in this simulation, i.e., LNL, HNL, SHG, and GHS. The true values of item parameters under the four noise levels, see the simulation study 1. For the true values of the class membership probabilities, we only consider the most general case that the class membership probabilities are flat though all classes, i.e., c = 1, …, C, where C = 2K.
For the prior distributions of the two algorithms, we use the non-informative prior distributions to eliminate the influence of the prior distributions on the posterior inference. The non-informative Dirichlet prior distribution is employed for the class membership probabilities π. I.e., (π1, …, πC) ~ Dirichlet (1, …, 1), and the non-informative prior distributions of item parameters under the two algorithms based on the four noise levels are set as follows
• (LNL case): PGGSA: v.s. Gibbs algorithm: sj ~ Beta(1, 1), gj ~ Beta(1, 1) I (gj < 1 − sj);
• (HNL case): PGGSA: v.s. Gibbs algorithm: sj ~ Beta(1, 1), gj ~ Beta(1, 1) I (gj < 1 − sj);
• (SHG case): PGGSA: v.s. Gibbs algorithm: sj ~ Beta(1, 1), gj ~ Beta(1, 1) I (gj < 1 − sj);
• (GHS case): PGGSA: v.s. Gibbs algorithm: sj ~ Beta(1, 1), gj ~ Beta(1, 1) I (gj < 1 − sj).
PGGSA and Gibbs algorithm are iterated 20,000 times. The first 10,000 iterations are discarded as burn-in period for the two algorithms. Twenty-five replications are considered for the two algorithms in this simulation study. The PSRF values of all parameters for each simulation condition are <1.1. Culpepper's the R “dina” package is used to implement the Gibbs sampling.
The correct pattern classification rate (CPCR), the average attribute match rate (AAMR) are used as the evaluation criteria to evaluate the attributes. These statistics are defined as
where represents examinee i′s estimated attribute patterns. Next, the evaluation results of the accuracy of the two algorithms for attribute patterns and class membership probability parameters are shown in Table 5.
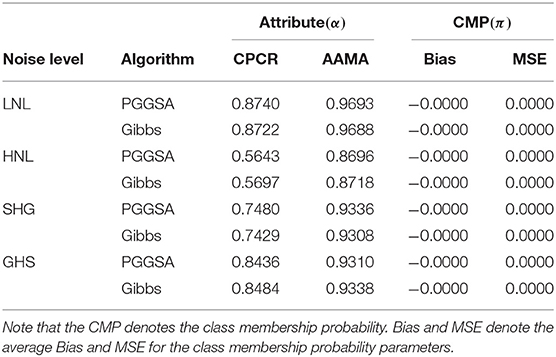
Table 5. Evaluating accuracy of attribute and class membership probability parameter estimations using PGGSA and Gibbs algorithm in the simulation study 4.
In Table 5, we find that the results of the attributes classification accuracy (CPCR and AAMA criteria) are basically the same for PGGSA and Gibbs algorithm under four kinds of noise levels. More specifically, the values of CPCR and AAMA for two algorithms under the HNL case are lowest. At the LNL case, the values of CPCR and AAMA for two algorithms are the highest. In addition, the CPCR value for the SHG case is lower than the CPCR value for the GHS, while the corresponding AAMA values are basically the same for the SHG case and GHS case. This indicates that slipping parameters (s) have important influence on the CPCR. In term of the two algorithms, the Bias and MSE of the classification membership parameters (π) are basically the same and close to zero under the four noise levels.
5. Empirical Example
In this example, a fraction subtraction test data is analyzed based on Tatsuoka (1990), Tatsuoka (2002), and de la Torre and Douglas (2004). The middle school students of 2,144 take part in this test to response 15 fraction subtraction items, where five attributes are measured, including subtract basic fractions, reduce and simplify, separate whole from fraction, borrow from whole, and convert whole to fraction. We choose 536 of 2,144 students in this study. These students are divided into 25 latent classes based on the five attributes. The reparameterized DINA model is used to analyze the cognitive response data.
The priors of parameters are also the same as the simulation 1. I.e., the non-informative priors are used in this empirical example analysis. To implement PGGSA, chains of length 20,000 with an initial burn-in period 10,000 are chosen. The PSRF is used to evaluate the convergence of each parameters. The trace plots of PSRF values for all parameters is shown in Figure 5. We find that the values of PSRF are <1.1.
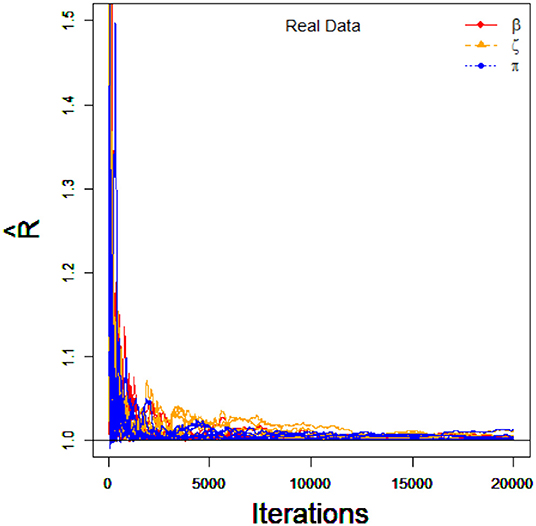
Figure 5. The trace plots of PSRF values for the real data.
The Q matrix, the expected a posteriori (EAP) estimators of the item parameters, the corresponding standard deviation (SD), and 95% highest posterior density intervals (HPDIs) of these item parameters are shown in Table 6. Based on the Table 6, we transform intercept and interaction parameters into traditional slipping and guessing parameters to analyze item characteristics. We find that the expected a posteriori (EAP) estimations of the five items with the lowest slipping are item 3, item 8, item 9, item 10, and item 11 in turn. The EAP estimations of slipping parameters for the five items are 0.0461, 0.0585, 0.0708, 0.0754, and 0.1039. This shows that these items are not easy to slipping compared with the other ten items. In addition, the EAP estimations of five items with the highest guessing are item 3, item 2, item 8, item 10, and item 11 in turn. The EAP estimations of guessing parameters for the five items are 0.2271, 0.2143, 0.2069, 0.1790, and 0.1441. Furthermore, we find that items 3, 8, 10, and 11 have low slipping parameters and high guessing parameters, which indicates that these items are more likely to be guessed correctly.
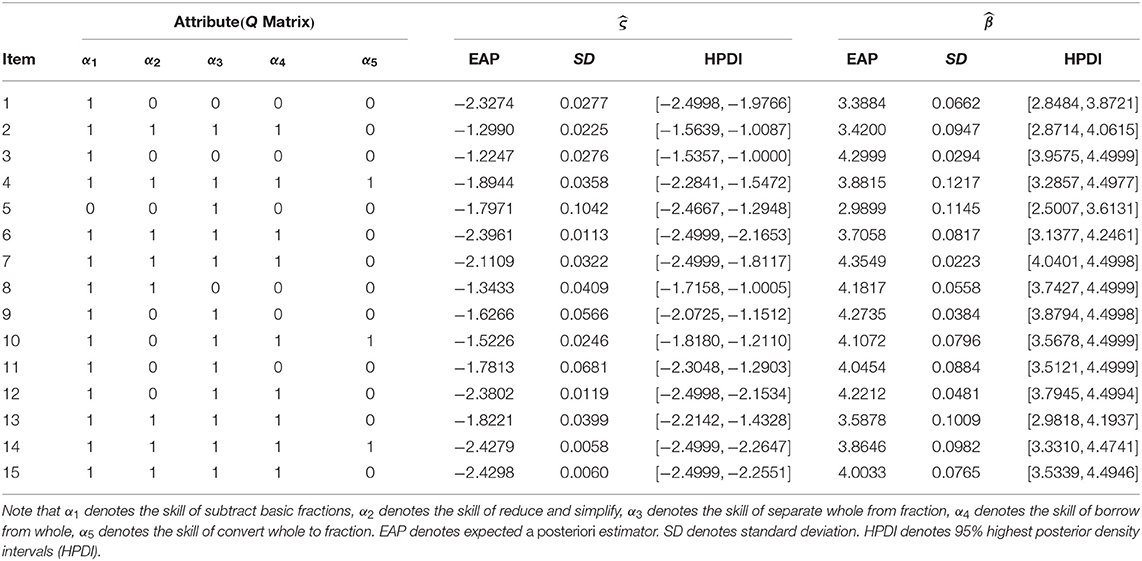
Table 6. The Q matrix design and MCMC estimations of ς and β.
The EAP estimations of the class membership probabilities, , c = 1, …, 32, and the corresponding SD and 95% HPDI are reported in Table 7. The top five classes that the majority of examinees are classified into these classes are respectively “11111,”“11101,”“11100,”“11110,” and “00010.”The estimation results show that 34.142% of the examinees have mastered all the five skills, and 11.119% of the examinees have mastered the four skills except the skill of borrow from whole, and the examinees who only have mastered the three skills of subtract basic fractions, reduce and simplify, separate whole from fraction account for 10.146%, and 9.680% of the examinees have mastered the four skills except the skill of convert whole to fraction, and the examinees who only have mastered a skill of skill of borrow from whole account for 2.001%. In addition, among the thirty-two classes, the class with the lowest number of the examinees is 0.429%. I.e., when the examinees have mastered the skills of subtract basic fractions, separate whole from fraction, borrow from whole, and convert whole to fraction, the proportion of examinees who do not master the skill of reduce and simplify is very low. According to the 1.743% and 0.429%, we find that the skill of reduce and simplify is easier to master than the other four skills.
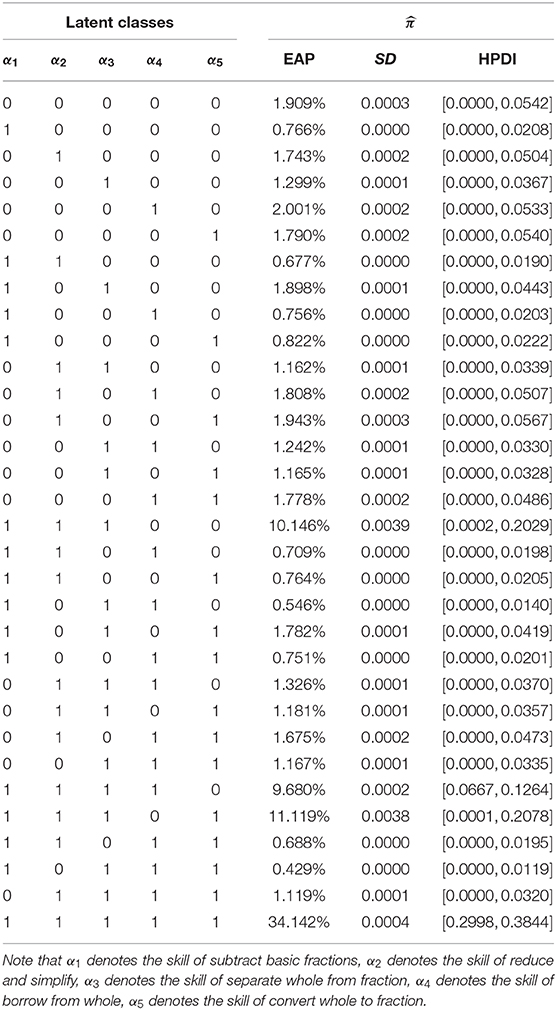
Table 7. The posterior probability distribution of the latent class parameters for the Fraction Subtraction Test.
6. Conclusion
In this paper, a novel and effective PGGSA based on auxiliary variables is proposed to estimate the widely applied DINA model. PGGSA overcomes the disadvantages of MH algorithm, which requires to repeatedly adjust the specification of tuning parameters to achieve a certain acceptance probability and thus increases the computational burden. However, the computational burden of the PGGSA becomes intensive especially as the CDMs become more complex, when a large number of examinees or the items is considered, or a large number of the MCMC sample size is used. Therefore, it is desirable to develop a standing-alone R package associated with C++ or Fortran software for more extensive CDMs and large-scale cognitive assessment tests.
In addition, Pólya-Gamma Gibbs sampling algorithm can be used to estimate many cognitive diagnosis models, which is not limited to the DINA model. These cognitive diagnostic models include DINO (Templin and Henson, 2006), Compensatory RUM (Hartz, 2002; Henson et al., 2009), and log-linear CDM (LCDM; von Davier, 2005; Henson et al., 2009) and so on. More specifically, first of all, the parameters of these cognitive diagnosis models are reparameterized, and then the logit link function is used to link these parameters with the response. Further, we can use Pólya-Gamma Gibbs sampling algorithm to estimate these reparameterized cognitive diagnosis models. Discussions of the reparameterized cognitive diagnosis models based on logit link function, see Henson et al. (2009).
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found here: https://cran.r-project.org/web/packages/CDM/index.html.
Author Contributions
JZ completed the writing of the article. ZZ and JZ provided article revisions. JZ, JL, and ZZ provided the key technical support. JT provided the original thoughts.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpsyg.2020.00384/full#supplementary-material
References
Albert, J. H. (1992). Bayesian estimation of normal ogive item response curves using Gibb sampling. J. Educ. Stat. 17, 251–269. doi: 10.3102/10769986017003251
Albert, J. H., and Chib, S. (1993). Bayesian analysis of binary and polychotomous response data. J am Stat Assoc. 88, 669–679. doi: 10.2307/2290350
Béguin, A. A., and Glas, C. A. W. (2001). MCMC estimation and some model-fit analysis of multidimensional IRT models. Psychometrika 66, 541–561. doi: 10.1007/BF02296195
Biane, P., Pitman, J., and Yor, M. (2001). Probability laws related to the Jacobi theta and Riemann zeta Functions, and Brownian Excursions. B Am Math Soc. 38, 435–465.
Bishop, C. M. (2006). “Slice sampling,” in Pattern Recognition and Machine Learning. New York, NY: Springer, 546.
Brooks, S. P., and Gelman, A. (1998). Alternative methods for monitoring convergence of iterative simulations. J. Comput. Graph. Statist. 7, 434–455. doi: 10.1080/10618600.1998.10474787
Chen, M.-H., Shao, Q.-M., and Ibrahim, J. G. (2000). Monte Carlo Methods in Bayesian Computation. New York, NY: Springer.
Chen, Y., Culpepper, S. A., Chen, Y., and Douglas, J. A. (2018). Bayesian estimation of the DINA Q matrix. Psychometrika 83, 89–108. doi: 10.1007/s11336-017-9579-4
Chen, Y., Liu, J., Xu, G., and Ying, Z. (2015). Statistical analysis of Q-matrix based diagnostic classification models. J. Am. Stat. Assoc. 110, 850–866. doi: 10.1080/01621459.2014.934827
Chib, S., and Greenberg, E. (1995). Understanding the Metropolis-Hastings algorithm. Am. Stat. 49, 327–335. doi: 10.1080/00031305.1995.10476177
Culpepper, S. A. (2015). Bayesian estimation of the DINA model with Gibbs sampling. J. Educ. Behav. Stat. 40, 454–476. doi: 10.3102/1076998615595403
Culpepper, S. A. (2016). Revisiting the 4-parameter item response model: Bayesian estimation and application. Psychometrika 81, 1142–1163. doi: 10.1007/s11336-015-9477-6
Damien, P., Wakefield, J., and Walker, S. (1999). Gibbs sampling for Bayesian non-conjugate and hierarchical models by auxiliary variables. J. R. Stat. Soc. B 61, 331–344. doi: 10.1111/1467-9868.00179
de la Torre, J. (2008). An empirically based method of Q-matrix validation for the DINA model: Development and applications. J. Educ. Meas., 45, 343–362. doi: 10.1111/j.1745-3984.2008.00069.x
de la Torre, J. (2009). DINA model and parameter estimation: a didactic. J. Educ. Behav. Stat. 34, 115–130. doi: 10.3102/1076998607309474
de la Torre, J. (2011). The generalized DINA model framework. Psychometrika. 76, 179–199. doi: 10.1007/s11336-011-9207-7
de la Torre, J., and Douglas, J. (2004). Higher-order latent trait models for cognitive diagnosis. Psychometrika. 69, 333–353. doi: 10.1007/BF02295640
DeCarlo, L. T. (2011). On the analysis of fraction subtraction data: the DINA model, classification, latent class sizes, and the Q-matrix. Appl Psychol Meas. 35, 8–26. doi: 10.1177/0146621610377081
DeCarlo, L. T. (2012). Recognizing uncertainty in the Q-matrix via a Bayesian extension of the DINA model. Appl. Psychol. Meas. 36, 447–468. doi: 10.1177/0146621612449069
DiBello, L. V., Roussos, L. A., and Stout, W. F. (2007). “Review of cognitively diagnostic assessment and a summary of psychometric models,” in Handbook of Statistics, Psychometrics, Vol. 26, eds C. R. Rao and S. Sinharay (Amsterdam: Elsevier), 979–1030.
Fox, J.-P. (2010). Bayesian Item Response Modeling: Theory and Applications. New York, NY: Springer.
Gelfand, A. E., and Smith, A. F. M. (1990). Sampling-based approaches to calculating marginal densities. J. Am. Stat. Assoc. 85, 398–409. doi: 10.1080/01621459.1990.10476213
Gelman, A., and Rubin, D. B. (1992). Inference from iterative simulation using multiple sequences. Stat. Sci. 7, 457–472. doi: 10.1214/ss/1177011136
Geman, S., and Geman, D. (1984). Stochastic relaxation, Gibbs distributions and the Bayesian restoration of images. IEEE Trans. Pattern Anal. Mach. Intell. 6, 721–741. doi: 10.1109/TPAMI.1984.4767596
Gu, Y., and Xu, G. (2019). The sufficient and necessary condition for the identifiability and estimability of the DINA model. Psychometrika 84, 468–483. doi: 10.1007/s11336-018-9619-8
Haberman, S. J., and von Davier, M. (2007). “Some notes on models for cognitively based skill diagnosis,” in Handbook of Statistics, Psychometrics, Vol. 26, eds C. R. Rao and S. Sinharay (Amsterdam: Elsevier), 1031–1038.
Hartz, S. M. (2002). A Bayesian framework for the unifified model for assessing cognitive abilities: blending theory with practicality (Unpublished doctoral dissertation), University of Illinois at Urbana-Champaign, Champaign, IL, United States.
Hastings, W. K. (1970). Monte Carlo sampling methods using Markov chains and their applications. Biometrika 57, 97–109. doi: 10.1093/biomet/57.1.97
Henson, R. A., Templin, J. L., and Willse, J. T. (2009). Defining a family of cognitive diagnosis models using log-linear models with latent variables. Psychometrika 74, 191–210. doi: 10.1007/s11336-008-9089-5
Huebner, A., and Wang, C. (2011). A note on comparing examinee classification methods for cognitive diagnosis models. Educ. Psychol. Meas. 71, 407–419. doi: 10.1177/0013164410388832
Hung, L.-F., and Wang, W.-C. (2012). The generalized multilevel facets model for longitudinal data. J. Educ. Behav. Stat. 37, 231–255. doi: 10.3102/1076998611402503
Junker, B. W., and Sijtsma, K. (2001). Cognitive assessment models with few assumptions, and connections with nonparametric item response theory. Appl. Psychol. Meas. 25, 258–272. doi: 10.1177/01466210122032064
Lu, J., Zhang, J. W., and Tao, J. (2018). Slice-Gibbs sampling algorithm for estimating the parameters of a multilevel item response model. J. Math. Psychol. 82, 12–25. doi: 10.1016/j.jmp.2017.10.005
Maris, E. (1999). Estimating multiple classification latent class models. Psychometrika 64, 187–212. doi: 10.1007/BF02294535
Metropolis, N., Rosenbluth, A. W., Rosenbluth, M. N., Teller, A. H., and Teller, E. (1953). Equations of state calculations by fast computing machines. J. Chem. Phys. 21, 1087–1092. doi: 10.1063/1.1699114
Polson, N. G., Scott, J. G., and Windle, J. (2013). Bayesian inference for logistic models using Pólya–Gamma latent variables. J. Am. Stat. Assoc. 108, 1339–1349. doi: 10.1080/01621459.2013.829001
Roussos, L. A., DiBello, L. V., Stout, W., Hartz, S. M., Henson, R. A., and Templin, J. L. (2007). “The fusion model skills diagnosis system,” in Cognitive Diagnostic Assessment for Education: Theory and Applications, eds J. P. Leighton and M. J. Gierl (Cambridge: Cambridge University Press), 275–318.
Sahu, S. K. (2002). Bayesian estimation and model choice in item response models. J. Stat. Comput. Simul. 72, 217–232. doi: 10.1080/00949650212387
Tanner, M. A., and Wong, W. H. (1987). The calculation of posterior distributions by data augmentation. J. Am. Stat. Assoc. 82, 528–550. doi: 10.1080/01621459.1987.10478458
Tatsuoka, C. (2002). Data analytic methods for latent partially ordered classification models. J. R. Stat. Soc. C Appl. Stat. 51, 337–350. doi: 10.1111/1467-9876.00272
Tatsuoka, K. K. (1984). Analysis of Errors in Fraction Addition and Subtraction Problems. Champaign, IL: Computer-Based Education Research Laboratory, University of Illinois at Urbana-Champaign.
Tatsuoka, K. K. (1990). “Toward an integration of item-response theory and cognitive error diagnosis.” in Diagnostic monitoring of skill and knowledge acquisition. eds N. Frederiksen, R. Glaser, A. Lesgold, and M. Shafto (Hillsdale, NJ: Erlbaum) 453–488.
Templin, J. L., and Henson, R. A. (2006). Measurement of psychological disorders using cognitive diagnosis models. Psychol. Methods 11, 287–305. doi: 10.1037/1082-989X.11.3.287
von Davier, M. (2005). A General Diagnostic Model Applied to Language Testing Data. Research report no. RR-05-16. Princeton, NJ: Educational Testing Service.
von Davier, M. (2008). A general diagnostic model applied to language testing data. Br. J. Math. Stat. Psychol. 61, 287–301. doi: 10.1348/000711007X193957
von Davier, M. (2014). The DINA model as a constrained general diagnostic model: two variants of a model equivalency. Br. J. Math. Stat. Psychol. 67, 49–71. doi: 10.1111/bmsp.12003
Xu, G. (2017). Identifiability of restricted latent class models with binary responses. Ann. Stat. 45, 675–707. doi: 10.1214/16-AOS1464
Xu, G., and Zhang, S. (2016). Identifiability of diagnostic classification models. Psychometrika 81, 625–649. doi: 10.1007/s11336-015-9471-z
Keywords: Bayesian estimation, cognitive diagnosis models, DINA model, Pólya-Gamma Gibbs sampling algorithm, Metropolis-Hastings algorithm, potential scale reduction factor
Citation: Zhang Z, Zhang J, Lu J and Tao J (2020) Bayesian Estimation of the DINA Model With Pólya-Gamma Gibbs Sampling. Front. Psychol. 11:384. doi: 10.3389/fpsyg.2020.00384
Received: 08 January 2020; Accepted: 19 February 2020;
Published: 10 March 2020.
Edited by:
Peida Zhan, Zhejiang Normal University, ChinaReviewed by:
Gongjun Xu, University of Michigan, United StatesYinghan Chen, University of Nevada, Reno, United States
Copyright © 2020 Zhang, Zhang, Lu and Tao. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jiwei Zhang, emhhbmdqdzcxMyYjeDAwMDQwO25lbnUuZWR1LmNu