 Dong Gi Seo
Dong Gi Seo Sunho Jung
Sunho Jung
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
BRIEF RESEARCH REPORT article
Front. Psychol. , 28 June 2018
Sec. Quantitative Psychology and Measurement
Volume 9 - 2018 | https://doi.org/10.3389/fpsyg.2018.00681
Arithmetic mean, Harmonic mean, and Jensen equality were applied to marginalize observed standard errors (OSEs) to estimate CAT reliability. Based on different marginalization method, three empirical CAT reliabilities were compared with true reliabilities. Results showed that three empirical CAT reliabilities were underestimated compared to true reliability in short test length (<40), whereas the magnitude of CAT reliabilities was followed by Jensen equality, Harmonic mean, and Arithmetic mean when mean of ability population distribution is zero. Specifically, Jensen equality overestimated true reliability when the number of items is over 40 and mean ability population distribution is zero. However, Jensen equality was recommended for computing reliability estimates because it was closer to true reliability even if small numbers of items was administered regardless of the mean of ability population distribution, and it can be computed easily by using a single test information value at θ = 0. Although CAT is efficient and accurate compared to a fixed-form test, a small fixed number of items is not recommended as a CAT termination criterion for 2PLM, specifically for 3PLM, to maintain high reliability estimates.
Nicewander and Thomasson (1999) applied Arithmetic, Harmonic, and Jensen's inequality methods to marginalize test information for estimating IRT reliability estimates in computerized adaptive testing (CAT). However, the items were drawn from item banks containing an average of 80 items per test, which were longer than practical CAT set up. In addition, many practical assessment programs often used interchangeably three IRT reliabilities (Arithmetic, Harmonic, and Jensen's inequality) in CAT. Therefore, the purpose of this brief report was to compare three methods of calculating marginalizing observed standard error (OSE) that can be expressed by the inverse of the test information function to estimate CAT reliabilities under varied test lengths. True reliability in classical test theory (CTT) is defined as the consistency or reproducibility of test score results, which is equivalent to the squared correlation between the true score (T) and the observed score (X), and the squared correlation between observed scores from two parallel-forms (X and X′), (Crocker and Algina, 1986). Likewise, from the IRT perspective, θs are considered as true scores and s are considered as observed scores. Therefore, true reliability in IRT can be defined as the squared correlation between θs and , . The mathematical form of the three-parameter logistic model (3PLM; Bock and Lieberman, 1970) is written as:
where Pij is the probability of correctly answering item i given θ for examinee j, θj is the latent ability for examinee j, bi is the item difficulty parameter for item i, ai is the item discrimination parameter for item i, ci is the pseudo-guessing parameter for item i. True reliability, however, cannot be computed in practical settings because true θs are unknown. Nevertheless, an empirical IRT reliability estimates, the square of the correlation between observed and true score (), can be derived from the definition of CTT reliability (Lord and Novick, 1968; Green et al., 1984) as
where is the variance of for all examinees and is the mean of squared OSE for .
OSE can be computed by taking inverse of squared root of second derivative of likelihood function whenθ is estimated by MLE or MAP. The OSE is described as
where,
Equation (4) is equal to the test information function . Therefore, variance of OSE can be expressed by the test information function, , as follows:
Based on Equation (5), this report applied three methods of marginalizing the variance of OSE () for each examinee to estimate CAT reliability.
(1) arithmetic mean: was used to approximate CAT reliability as below:
Note that, if is the maximum likelihood estimate for each θ, then will have a normal distribution with mean θ and asymptotical variance, 1/I(θ), where I(θ) is the test information function for each examinee based on IRT model (Samejima, 1994). In CAT, each examinee's θ has been estimated by different item pools so that is described for each examinee as below
and remind that we assume E(e) = 0, and then mean of can be expressed by the mean of 1/ as follows:
As a result, the mean of is actually approximated (Samejima, 1994). As
where g(θ) is a density for the distribution of θ . In Equation (9), can be approximated by 1/I(θ).
(2) harmonic mean: was used to approximate the mean variance of OSE, the second type of reliability can be approximated as below:
In similar to the first type of approximation, the second type of approximation is also described the test information as below:
and
(3) Jensen's Inequality (see Rao, 1965):
, where is the OSE with , was used to marginalize . As a result, the third type of reliability can be approximated as below:
The item pool was created from the Emergency Medical Technician (EMT) exams administrated from 1/1/2013 to 9/1/2014. Based on the EMT practice analysis, 17~21% items of the test were assigned to Airway, Respiration, and Ventilation (ARV),16~20% items were assigned to Cardiology & Resuscitation (CR), 19~23% items were assigned to Trauma (TRA), 27~31% were assigned to Obstetrics and Gynecology (MOG) content, and 12%~16% were assigned to EMS operations (OPS) contents. The EMT operational item pool was composed of items that were previously calibrated using data from the paper-and-pencil tests and new items that were filed as tested in a previous CAT. The item pool has 1,136 items. The mean of item difficulty parameters for the item pool was 0.969. The item selection algorithm and content-balanced procedure proposed by Kingsbury and Zara (1989) was applied to this study. The CAT algorithm randomly selects the content area during the first 5 items and then content area that is most divergent from targeted percentage is selected next to meet the test plan (Kingsbury and Zara, 1989).
The dichotomous IRT model (Bock and Lieberman, 1970) was applied to generate item responses with three examinee populations [N(0,1), N(1,1), and N(2,1)]. The a-parameters were generated from the mean of 1.0 and SD of 0.2 with D = 1.7, and b-parameter was from the item pool in 2PLM conditions, and c-parameter was set to 0.25 to evaluate the 3PLM conditions. To generate responses for each test, IRT model-based probabilities were compared to random numbers from a uniform distribution to obtain the item responses for each examinee. If the model-based probability was greater than the random number, the response to that item was recorded as correct (1). Otherwise, the item response was recorded as incorrect (0). This process was repeated for each item and examinee to obtain the full item response matrix for each item pool. A total of 1,000 examinees for each pool were generated with true θs following N(0,1), N(1,1), and N(2,1) using D = 1.7. In Figure 1A condition describes 2PL model with θs following N(0,1), (Figure 1B) condition describes 2PL model with θs following N(1,1), (Figure 1C) condition represents 2PL model with θs following N(2,1), and (Figure 1D) condition is designed for 3PL model with θs following N(0,1). For CAT termination, the fixed test length termination criteria were varied from 10 to 60 items within 1,136 item pool. To estimate stable CAT reliability estimates, each pool was replicated 100 times and average empirical reliabilities were calculated for each condition. Then average reliability was plotted as the fixed test length termination criteria were increased from 10 to 60 items. s and OSE of 1,000 examinees were estimated using MLE method. The “true” IRT reliabilities were computed as the squared correlation between the θ sand s(). The three empirical CAT reliabilities were obtained using arithmetic mean, harmonic mean, and Jensen's inequality respectively. Ability estimates were calculated using a Bayesian procedure until at least one item was answered correctly and one item was answered incorrectly. At that point, the ability estimates were calculated using MLE method. The Newton-Raphson procedure identified the maximum of the likelihood using an iterative procedure to estimate θ for MLE method. The Newton-Raphson iterations continued until the incremental change in became less than the criterion of 0.001. Maximum Fisher information(MFI) was used as an item selection method in this study. MFI selects the next item that provides the maximum Fisher information at . All CAT algorithms for this study were implemented by a “catR” package (Magis and Raiche, 2012) in the R program (R Development Core Team, 2008).
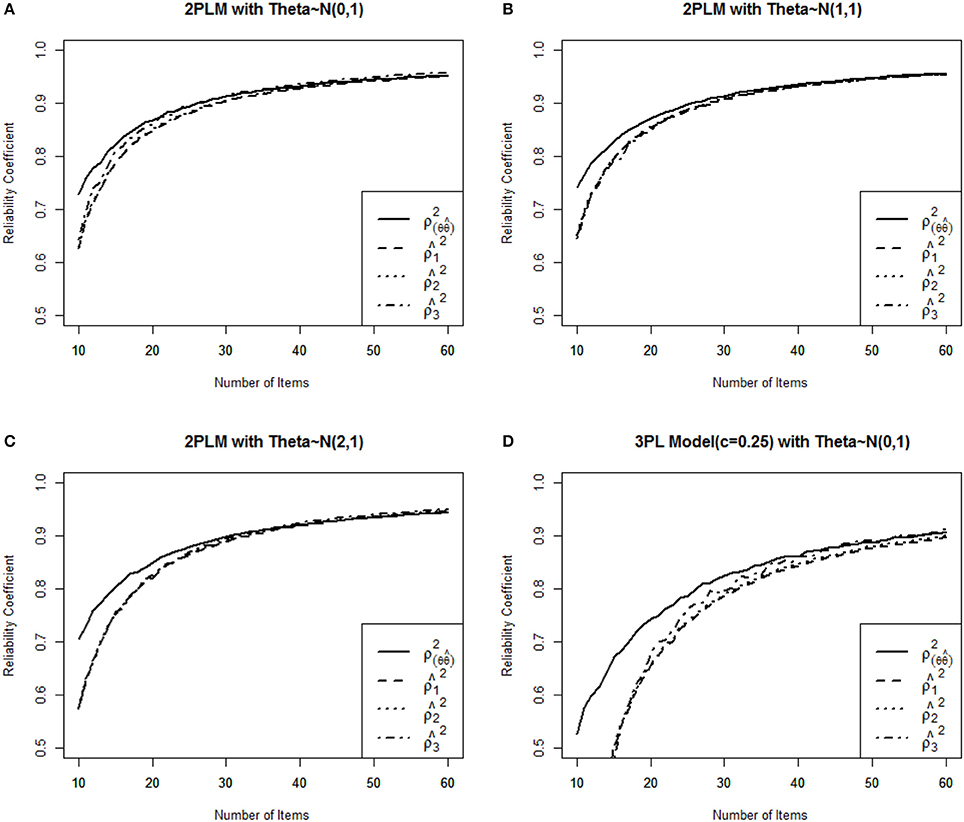
Figure 1. Comparison of three IRT reliability estimates with the true reliability for four different item pools. (A) 2PLM Medium Ability Group, (B) 2PLM High Ability Group, (C) 2PLM Extreme High Ability Group, (D) 3PLM Medium Ability Group.
Figure 1 shows the function of three empirical CAT reliabilities given four different conditions. As expected, CAT reliabilities became greater as the number of items increased as termination criterion, and then this study empirically shows that , as in the Figures 1A,D (If we assume I(θ) is concave and mean of θ is 0). Overall, , , and always underestimated true reliability except that provided larger estimates after more than 30 items were administered for 2PLM and 50 items were administered for 3PLM (Figures 1A,D), and three reliability estimates were not differed to true reliability by more than .01 when the number of items administered was over 30 items for 2PLM. In terms of population ability, three estimates were almost identical to each other and were closer to true reliability when the mean of item difficulty parameters was equal to the mean of group abilities (Figure 1B) compared to two other population groups. , and were close to each other and consistent across all conditions, but showed larger estimates rather than and when mean of θ is 0.0 (Figures 1A,B). Three reliability estimates were consistent across three conditions (Figures 1A–C), under the assumption that the 2PLM is true, which demonstrates the consistent results across different population abilities as an merit of CAT. In 3PLM, however, , , and underestimated true reliability with the small number of items administered, and after more 50 items were administered, these estimates were not differed by more than 0.01 from the true reliability. Specifically, showed larger estimates when only the mean of population was zero (Figures 1A,D), three reliability estimates were identical each other when the mean of population was equal to the mean of item difficulty in the item pool (Figure 1B). These results were not known in a previous research. Nicewander and Thomasson (1999) investigated CAT reliability with only 80 administered items with θ ranging −3 to +3 in 3PLM. However, longer than 50 items is not that in interesting in CAT setting. Table 1 showed that overestimated the true reliability only if more than 50 items were administered in which mean of population ability was zero. This conclusion would hold when data are generated from 3PLM with the population mean of zero as known by Nicewander and Thomasson's study.
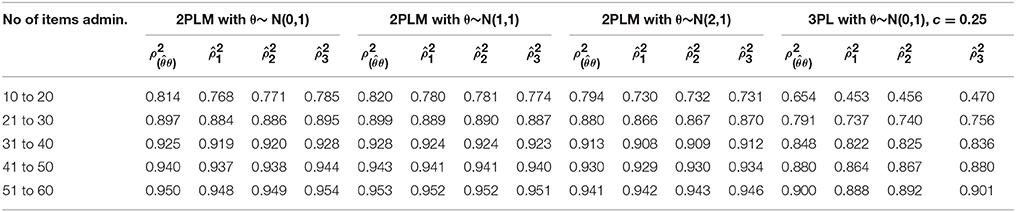
Table 1. Mean of three CAT reliability estimates with the true reliability for four different item pools.
This brief report demonstrated that if the number of items administered was over 30, ,, and provided accurate CAT reliability estimates for 2PLM. However, if the number of items administered in 3PLM was less than around 40 in this study, all three , , and were relatively low. All three , , and would be appropriate to report CAT reliability using all IRT models when over 50 items were administered in this study. However, including c-parameter brings higher OSE of so that does not guarantee accurate reliability estimates when the number of items administered was less than 40 (differed by more than 0.02 from the true reliability). Although the 3PLM fits the data well, it does not accurately estimate person ability because c-parameter could inflate random error variance for examinee scoring (Chiu and Camilli, 2013). As a result, it was not recommended for reporting CAT reliability using 3PLM when a small number of items were administered. Compared with Nicewander and Thomasson (1999)'s study, this study demonstrated that three reliability estimates are appropriate to report CAT reliability regardless of ability population distributions and any IRT models if the number of items were administered from around 40 to 50 in CAT. They were differed within .01 from true reliability.
In summary, although reporting all three reliability estimates would be suggested regardless of any ability population distribution, is recommended for computing CAT reliability when mean of ability population distribution is 0 because was closer to true reliability even if small number of items was administered and it can be computed easily by using a single test information value at θ = 0 in this study. In usual, a CAT was known as efficient and compared to a fixed-form test. However, a small fixed number of items was not suggested as a CAT termination criterion for 2PLM, specifically for 3PLM, in order to maintain high reliability estimates.
As with any research, this study has some limitations. This study examined the accuracy of CAT reliabilities under specific conditions for a medical licensing examination. Thus, there is a limitation to generalize this result to other testing conditions. Future studies would be needed to investigate the accuracy of CAT reliabilities under various conditions such as different ability distributions and item banks with different item parameter conditions.
DS is the first author who conceptualize and write this brief research report and SJ is the corresponding author who manages this research project.
This work is supported by the Hallym University research fund (HRF-201710-002).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Bock, R. D., and Lieberman, M. (1970). Fitting a response model for n dichotomously scored items. Psychometrika 35, 179–197.
Chiu, T., and Camilli, G. (2013). Comments on 3PL IRT adjustment for guessing. Appl. Psychol. Measure. 37, 76–86. doi: 10.1177/0146621612459369
Crocker, L., and Algina, J. (1986). Introduction to Classical and Modern Test Theory. New York, NY: CBS College Publishing.
Green, B. F., Bock, R. D., Humphreys, L. G., Linn, R. L., and Reckase, M. D. (1984). Technical guidelines for assessing computerized adaptive tests. J. Educ. Measure. 21, 347–360.
Kingsbury, G. G., and Zara, A. R. (1989). Procedures for selecting items for computerized adaptive tests. Appl. Measure. Educ. 2, 359–375.
Lord, F. M., and Novick, M. R. (1968). Statistical Theories of Mental Test Scores. Reading, MA: Addison-Welsey.
Magis, D., and Raiche, G. (2012). Random generation of response patterns under computerized adaptive testing with their package catR. J. Statistic. Softw. 48, 1–31. doi: 10.18637/jss.v048.i08
Nicewander, W. A., and Thomasson, G. L. (1999). Some reliability estimates for computerized adaptive tests. Appl. Psychol. Measure. 23, 239–247.
R Development Core Team (2008). R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria. Available online at: http://www.R-project.org
Keywords: reliability, item response theory (IRT), computerized adaptive testing, measurement, classical test theory
Citation: Seo DG and Jung S (2018) A Comparison of Three Empirical Reliability Estimates for Computerized Adaptive Testing (CAT) Using a Medical Licensing Examination. Front. Psychol. 9:681. doi: 10.3389/fpsyg.2018.00681
Received: 03 February 2018; Accepted: 19 April 2018;
Published: 28 June 2018.
Edited by:
Holmes Finch, Ball State University, United StatesReviewed by:
Mark D. Reckase, Michigan State University, United StatesCopyright © 2018 Seo and Jung. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Sunho Jung, c3VuaG8uanVuZ0BraHUuYWMua3I=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.