Editorial
27 May 2020
Sharon M. Crook
, Andrew P. Davison
, Robert A. McDougal
and
Hans Ekkehard Plesser


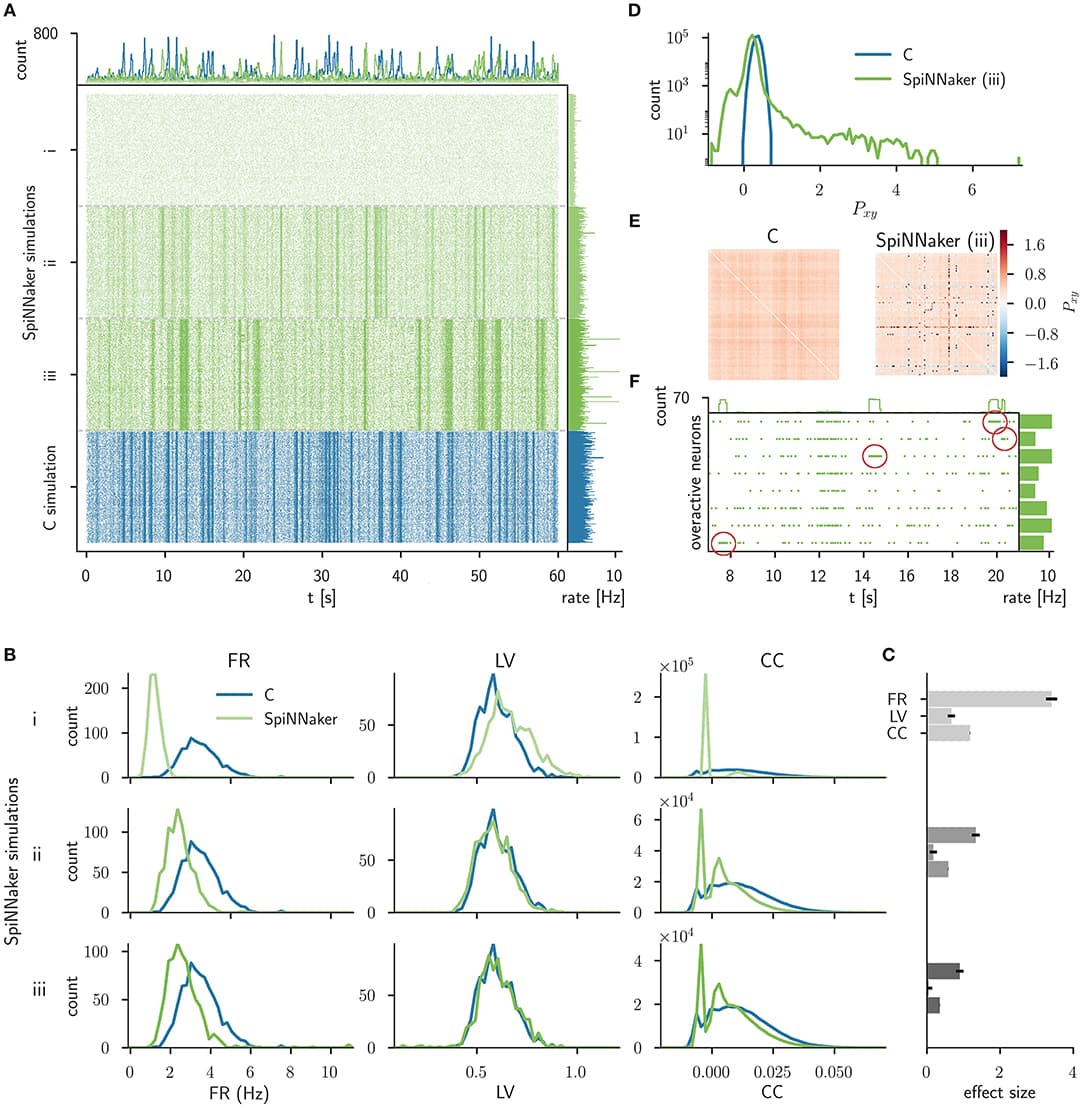
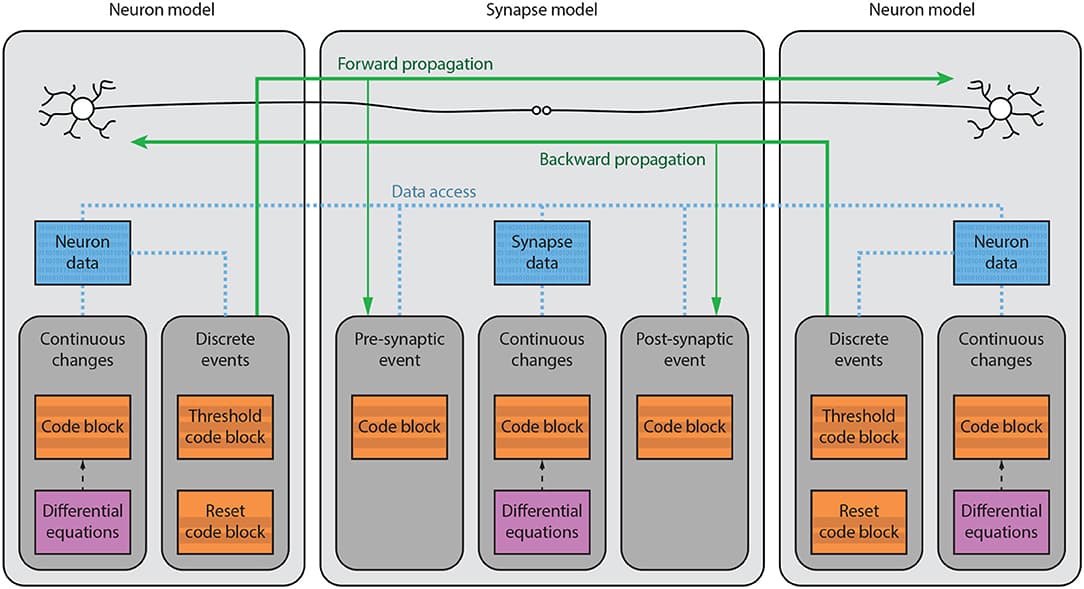
The development of spiking neural network simulation software is a critical component enabling the modeling of neural systems and the development of biologically inspired algorithms. Existing software frameworks support a wide range of neural functionality, software abstraction levels, and hardware devices, yet are typically not suitable for rapid prototyping or application to problems in the domain of machine learning. In this paper, we describe a new Python package for the simulation of spiking neural networks, specifically geared toward machine learning and reinforcement learning. Our software, called BindsNET1, enables rapid building and simulation of spiking networks and features user-friendly, concise syntax. BindsNET is built on the PyTorch deep neural networks library, facilitating the implementation of spiking neural networks on fast CPU and GPU computational platforms. Moreover, the BindsNET framework can be adjusted to utilize other existing computing and hardware backends; e.g., TensorFlow and SpiNNaker. We provide an interface with the OpenAI gym library, allowing for training and evaluation of spiking networks on reinforcement learning environments. We argue that this package facilitates the use of spiking networks for large-scale machine learning problems and show some simple examples by using BindsNET in practice.
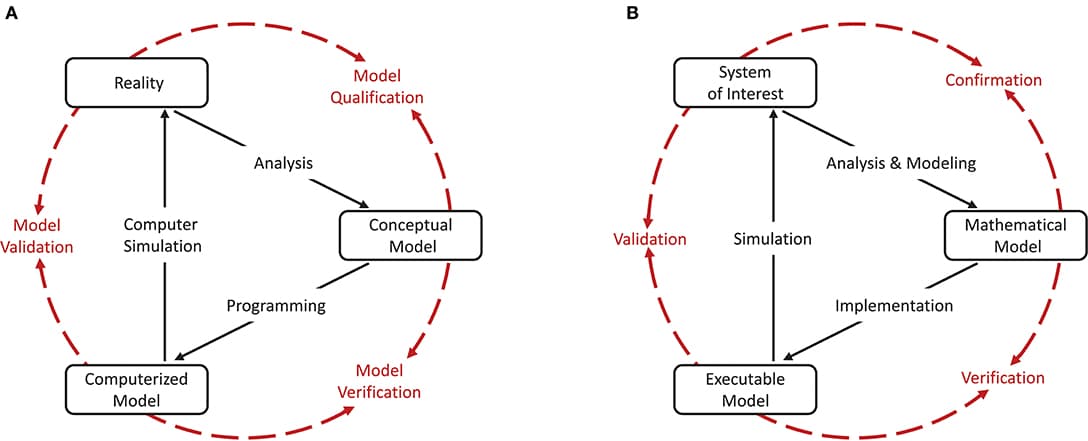
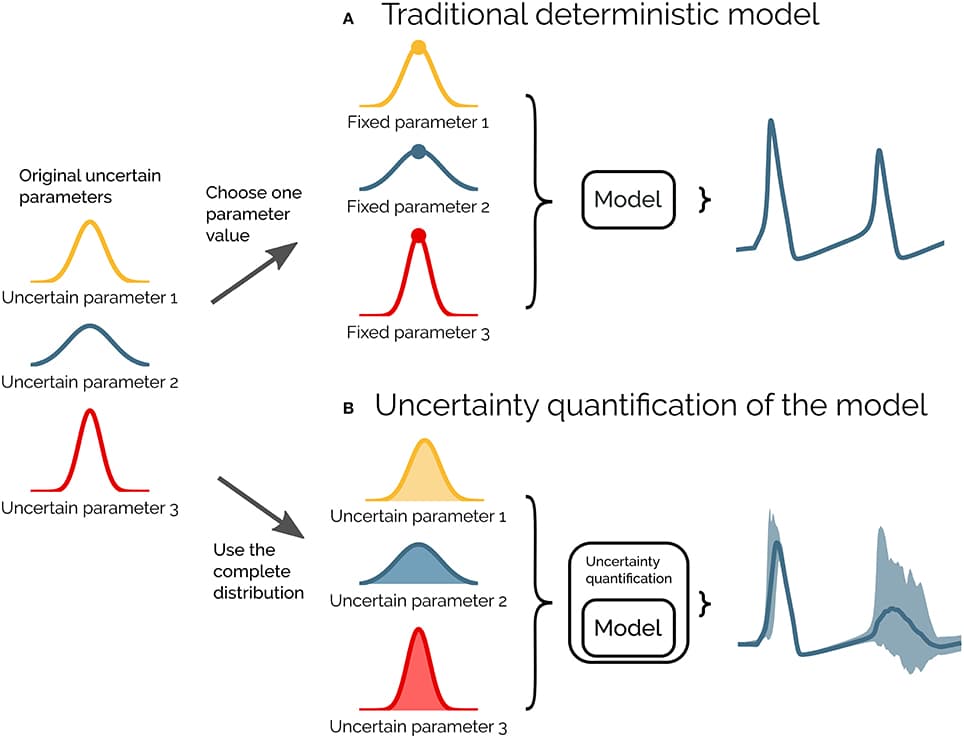
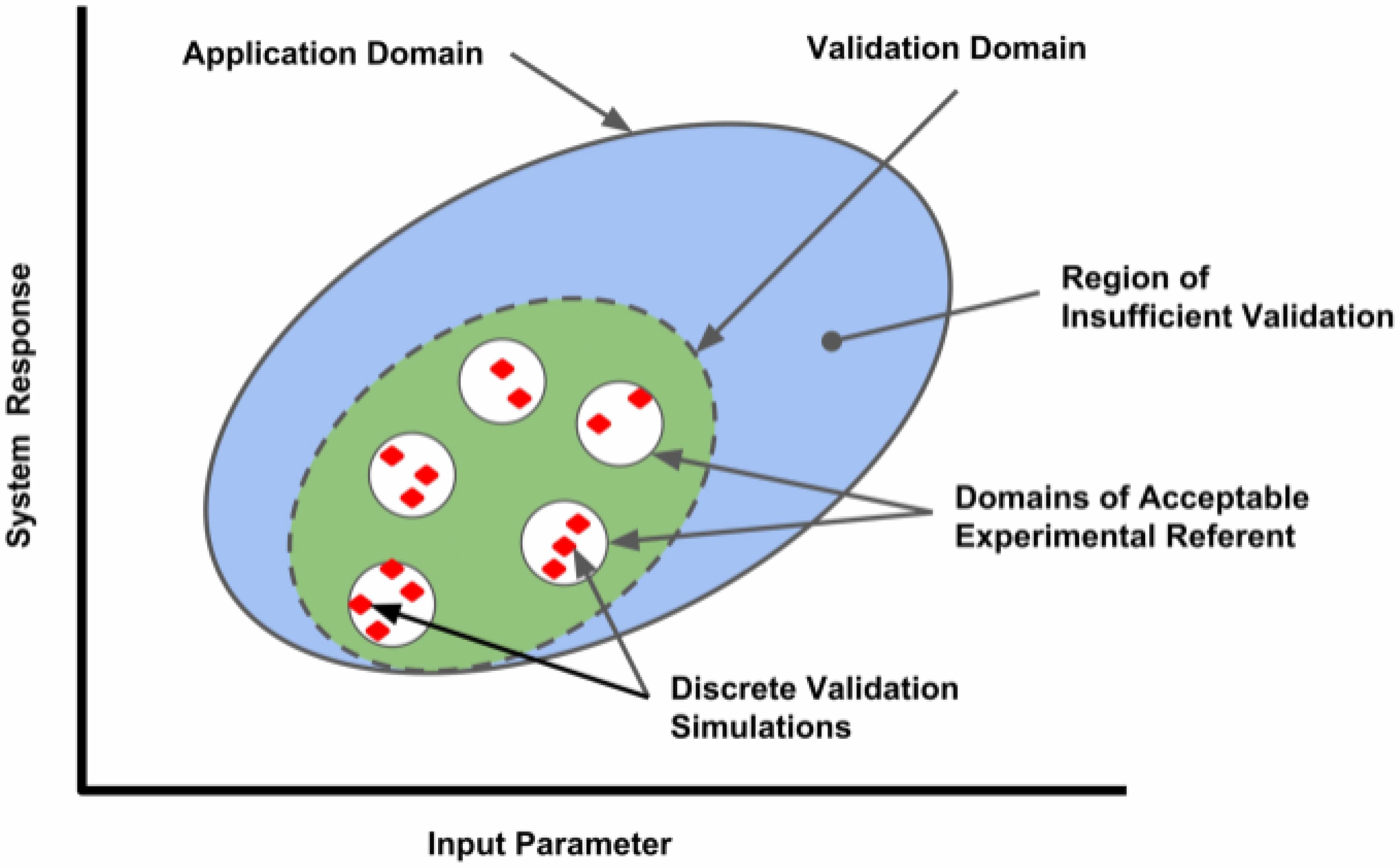
Computational models in neuroscience typically contain many parameters that are poorly constrained by experimental data. Uncertainty quantification and sensitivity analysis provide rigorous procedures to quantify how the model output depends on this parameter uncertainty. Unfortunately, the application of such methods is not yet standard within the field of neuroscience. Here we present Uncertainpy, an open-source Python toolbox, tailored to perform uncertainty quantification and sensitivity analysis of neuroscience models. Uncertainpy aims to make it quick and easy to get started with uncertainty analysis, without any need for detailed prior knowledge. The toolbox allows uncertainty quantification and sensitivity analysis to be performed on already existing models without needing to modify the model equations or model implementation. Uncertainpy bases its analysis on polynomial chaos expansions, which are more efficient than the more standard Monte-Carlo based approaches. Uncertainpy is tailored for neuroscience applications by its built-in capability for calculating characteristic features in the model output. The toolbox does not merely perform a point-to-point comparison of the “raw” model output (e.g., membrane voltage traces), but can also calculate the uncertainty and sensitivity of salient model response features such as spike timing, action potential width, average interspike interval, and other features relevant for various neural and neural network models. Uncertainpy comes with several common models and features built in, and including custom models and new features is easy. The aim of the current paper is to present Uncertainpy to the neuroscience community in a user-oriented manner. To demonstrate its broad applicability, we perform an uncertainty quantification and sensitivity analysis of three case studies relevant for neuroscience: the original Hodgkin-Huxley point-neuron model for action potential generation, a multi-compartmental model of a thalamic interneuron implemented in the NEURON simulator, and a sparsely connected recurrent network model implemented in the NEST simulator.