Editorial
22 October 2019
Tadahiro Taniguchi
, Emre Ugur
, Tetsuya Ogata
, Takayuki Nagai
and
Yiannis Demiris

In this paper, we propose a hierarchical spatial concept formation method based on the Bayesian generative model with multimodal information e.g., vision, position and word information. Since humans have the ability to select an appropriate level of abstraction according to the situation and describe their position linguistically, e.g., “I am in my home” and “I am in front of the table,” a hierarchical structure of spatial concepts is necessary in order for human support robots to communicate smoothly with users. The proposed method enables a robot to form hierarchical spatial concepts by categorizing multimodal information using hierarchical multimodal latent Dirichlet allocation (hMLDA). Object recognition results using convolutional neural network (CNN), hierarchical k-means clustering result of self-position estimated by Monte Carlo localization (MCL), and a set of location names are used, respectively, as features in vision, position, and word information. Experiments in forming hierarchical spatial concepts and evaluating how the proposed method can predict unobserved location names and position categories are performed using a robot in the real world. Results verify that, relative to comparable baseline methods, the proposed method enables a robot to predict location names and position categories closer to predictions made by humans. As an application example of the proposed method in a home environment, a demonstration in which a human support robot moves to an instructed place based on human speech instructions is achieved based on the formed hierarchical spatial concept.
Humans divide perceived continuous information into segments to facilitate recognition. For example, humans can segment speech waves into recognizable morphemes. Analogously, continuous motions are segmented into recognizable unit actions. People can divide continuous information into segments without using explicit segment points. This capacity for unsupervised segmentation is also useful for robots, because it enables them to flexibly learn languages, gestures, and actions. In this paper, we propose a Gaussian process-hidden semi-Markov model (GP-HSMM) that can divide continuous time series data into segments in an unsupervised manner. Our proposed method consists of a generative model based on the hidden semi-Markov model (HSMM), the emission distributions of which are Gaussian processes (GPs). Continuous time series data is generated by connecting segments generated by the GP. Segmentation can be achieved by using forward filtering-backward sampling to estimate the model's parameters, including the lengths and classes of the segments. In an experiment using the CMU motion capture dataset, we tested GP-HSMM with motion capture data containing simple exercise motions; the results of this experiment showed that the proposed GP-HSMM was comparable with other methods. We also conducted an experiment using karate motion capture data, which is more complex than exercise motion capture data; in this experiment, the segmentation accuracy of GP-HSMM was 0.92, which outperformed other methods.
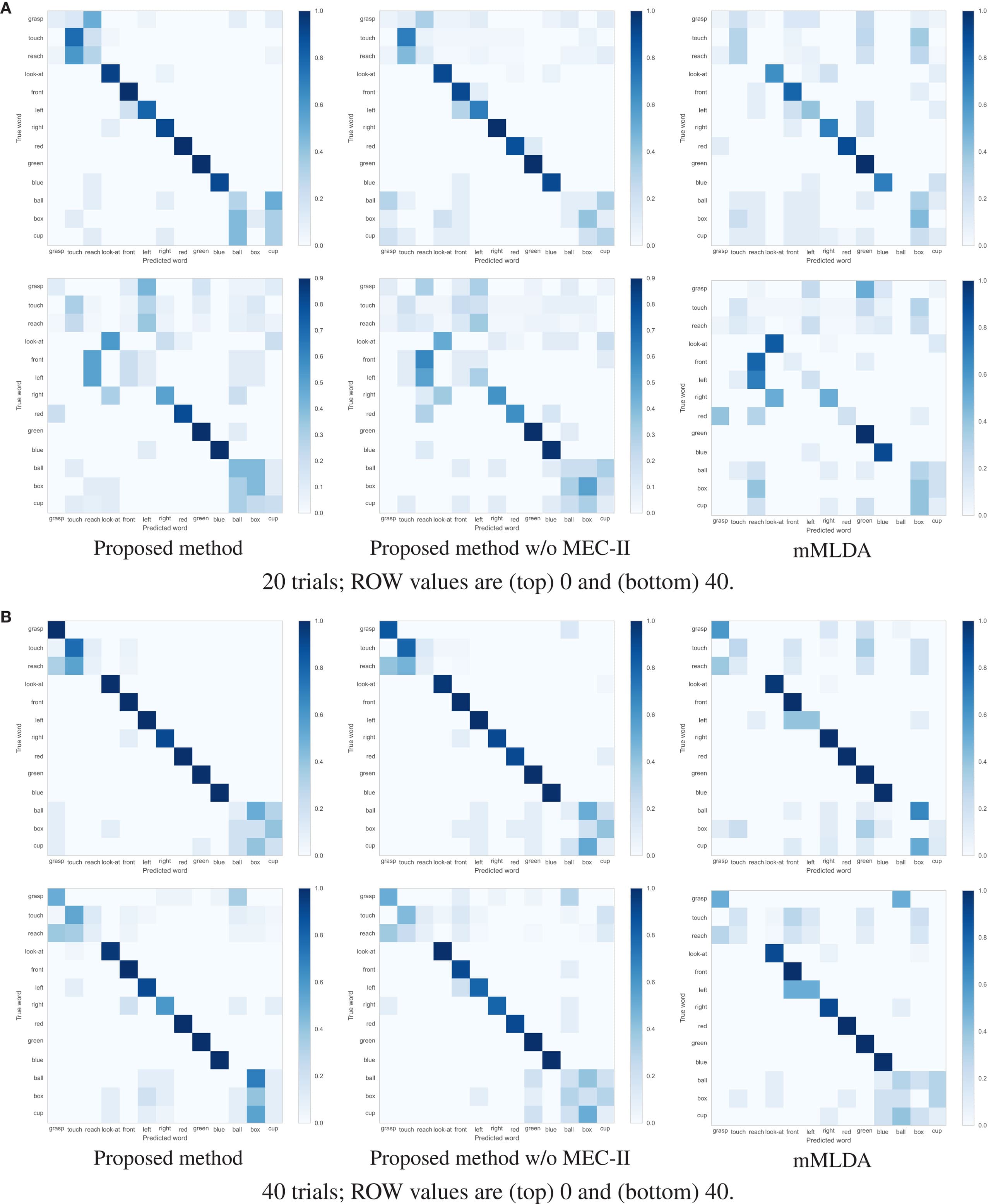
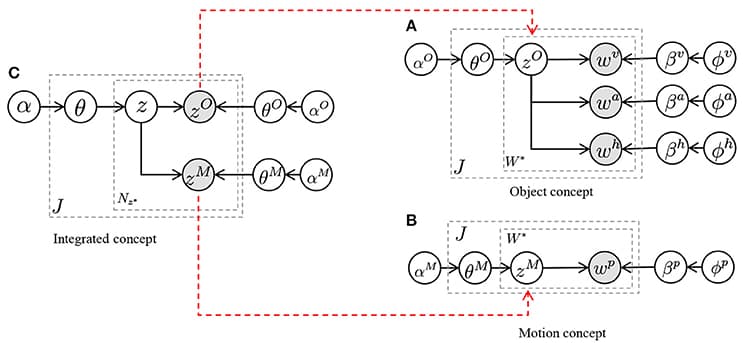
In this paper, we propose a Bayesian generative model that can form multiple categories based on each sensory-channel and can associate words with any of the four sensory-channels (action, position, object, and color). This paper focuses on cross-situational learning using the co-occurrence between words and information of sensory-channels in complex situations rather than conventional situations of cross-situational learning. We conducted a learning scenario using a simulator and a real humanoid iCub robot. In the scenario, a human tutor provided a sentence that describes an object of visual attention and an accompanying action to the robot. The scenario was set as follows: the number of words per sensory-channel was three or four, and the number of trials for learning was 20 and 40 for the simulator and 25 and 40 for the real robot. The experimental results showed that the proposed method was able to estimate the multiple categorizations and to learn the relationships between multiple sensory-channels and words accurately. In addition, we conducted an action generation task and an action description task based on word meanings learned in the cross-situational learning scenario. The experimental results showed that the robot could successfully use the word meanings learned by using the proposed method.